First, we will carry out a correlation analysis, which will allow us to analyze the tightness of the relationship between the target variable “q6”, which concerns the benefits of participating in the academic mobility program for further subsequent employment of the students, and the rest of the questions of the questionnaire. This question of the benefit of the respondent’s participation in the academic mobility program was determined as the dependent variable in the logit model. In the case where the pair correlation is calculated between two dichotomous variables, it is possible to calculate the “phi” coefficient, Kramer’s V, since their values coincide. Statistically significant correlation coefficients are marked with two asterisks (**), indicating 99% confidence, or one asterisk (*), indicating 95% confidence. Correlation coefficients can take on values from 1 to −1. Values close to zero show no relationship. If the correlation coefficient is positive, then the relationship between variables is directly proportional; that is, the dependent variable also increases with the increase of the independent variable. In addition, vice versa, if the correlation coefficient is negative, then the relationship between variables is inversely proportional, that is, the values of the dependent variable decrease as the values of the independent variable increase. The following table shows the correlation coefficients themselves, among which the largest values of positive correlation coefficients are identified. The greatest positive relationship was found between the dependent variable and such categories of responses as “Creation of offices under Government at the labor market”, “employment within 1 year”, “Reference level”, “Academic mobility affected the development of abilities in research activity” and “Educational level and university ranking”.
4.2. Building a Prognostic Model Based on Logistic Regression
The use of binary logistic regression will show whether it is possible to predict the values of the dependent variable depending on the values of one or more selected independent variables. The model has the form of an equation that contains the values of the regression coefficients.
The equation of the model is presented in the form of a logistic function, which has the following form:
Logistic regression calculates the probability of an event occurring; in our case, the probability that participation in an academic mobility program positively affected employment.
The decision was reached in six steps, each of which added a statistically significant variable to the model.
The most important result of modeling is the table with the calculated regression coefficients, which were selected by the program. For the selection of significant variables, the following selection method was used: direct step-by-step (conditional). As a result, this algorithm selected variables that have a statistically significant effect on the probability that participation in the academic mobility program helped respondents find employment. For the selected variables, regression coefficients were calculated, with the help of which it is possible to calculate the expected probability.
Regression coefficients with statistically significant variables are presented in
Table 4.
Thus, the algorithm for selecting statistically significant variables stopped at a six-factor model. Five of six regression coefficients have a positive sign, suggesting a directly proportional relationship. Those respondents who noted that academic mobility was beneficial for their employment also noted the importance of the reference level; the extension of terms of academic mobility; developing an educational program based on the needs of the labor market; expanding the significance of those methods that form practical skills for analyzing information; and the creation of offices under the Government in the labor market. At the same time, although the support for entrepreneurial initiatives of young people has a statistically significant effect on the dependent variable, it has an adverse effect; that is, respondents who were helped by academic mobility in finding employment note that the support for entrepreneurial initiatives of young people is not important for employment. Perhaps the respondents do not perceive entrepreneurship as one of the types of employment.
The role of this assessment is to show by example how the probability of an affirmative answer to the benefits of participation in the academic mobility program is calculated, for what purpose logistic regression coefficients are calculated, and how they are used.
Let us make a forecast using the resulting model. The predicted value is determined by substituting the corresponding values of independent variables into the regression equation. The equation below shows the number of questions; their semantic meaning is given in Table
If we take the values of six independent variables for the resulting model for the first respondent from our database and substitute them into the resulting model, then we obtain:
The Y value will be −5.123 given the values of the independent variables.
This value must be substituted into the logistic function.
Let us substitute the resulting value into the formula:
The result is 0.00593. This value indicates the probability that participation in the academic mobility program helped in finding a job. In this case, the forecasting results coincided with the actual value indicated by the respondent, namely, that the academic mobility program helped the respondent find a job.
The quality of the built model and its predictive power can be judged by several of the following indicators:
R-square for model are presented in
Table 5.
Measures of certainty are one of the indicators of the quality of the built model: Cox–Snell R-square and Nagelkirk R-square, which are R-squared counterparts of linear regression models. They also indicate the percentage of dependent variable variation that the model can clarify. At the same time, the indicator of Nagelkirk R-square is more perfect, which indicates that the model can clarify the behavior of the dependent variable by 78.7%.
The following classification table can also be called a measure of the quality of the built model. It shows the number and percentage of correctly predicted dependent variable values. The percentage of correctly predicted values was 90% for the resulting model.
Model classification table are presented in
Table 6.
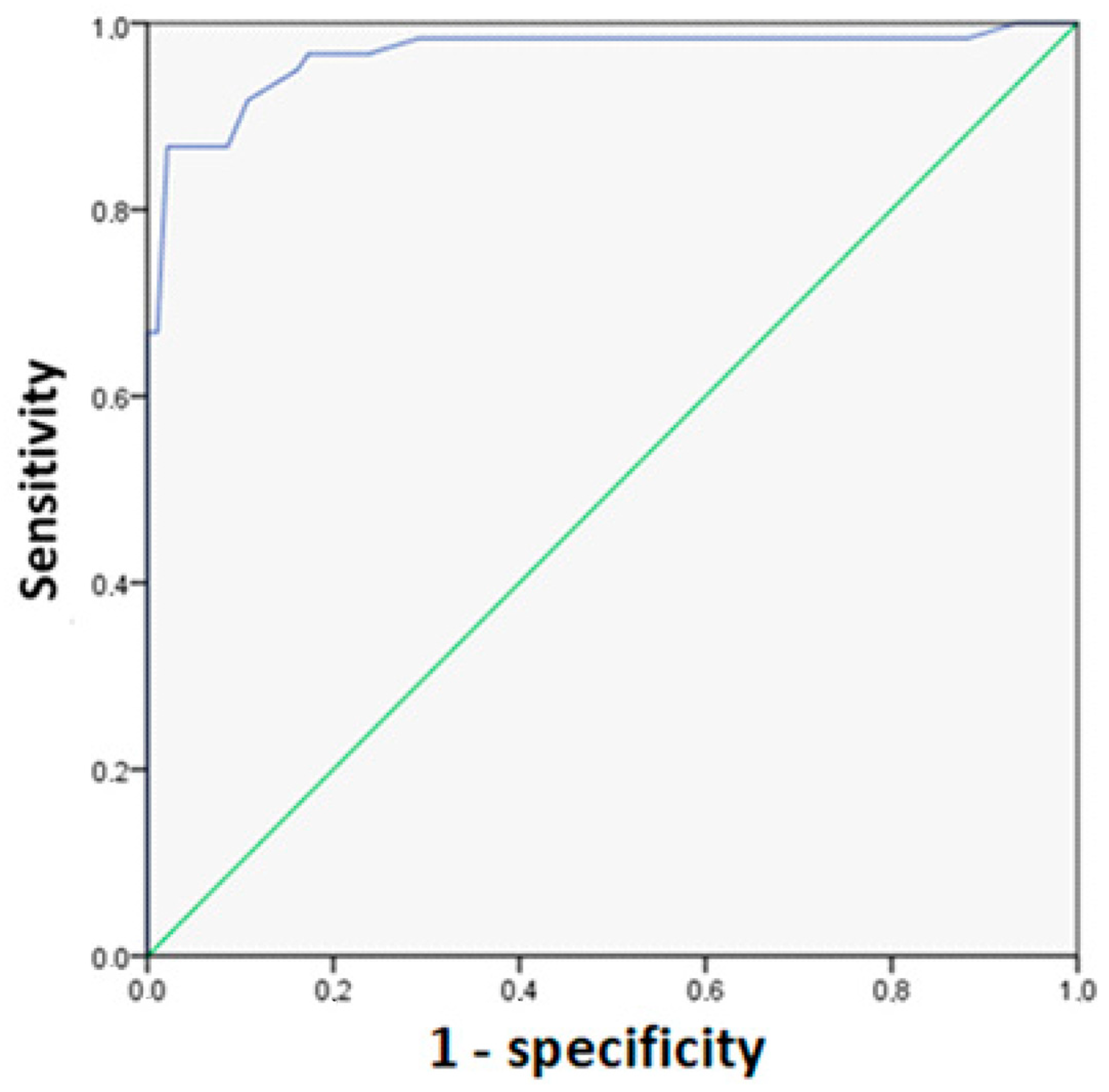
There is another indicator that can be used to evaluate the discriminatory power of logistic regression. The ROC curve (Eng. receiver operating characteristic) allows us to evaluate the efficiency of a binary classifier and select the optimal cutoff threshold. It represents a curve of the ratios of correct and false detections of students who noted the usefulness of academic mobility, obtained by varying the cutoff point of the probability of occurrence. It will be recalled that the cutoff value is 0.5 by default. The same value was set by default when building the logistic regression. The cutoff point does not affect the values of the regression coefficients.
The ROC curve plot is constructed as follows: False positive cases (FPCc) are plotted along the x-axis of the ROC curve (1 − specificity). True positive cases (TPCs) are plotted along the y-axis of the ROC curve (sensitivity). The ROC curve plot passes through the upper left corner in the case of perfect classification. In this case, the proportion of true positive cases is 100%, and the proportion of false positive cases will be 0%. Therefore, the closer the curve is to the upper left corner, the higher the discriminative power of the model. In addition, vice versa, the smaller the bend in the curve and the closer it is to the diagonal line (corresponding to the useless classifier), the model is less efficient.
An optimal model should have 100% sensitivity and 100% specificity, but this is impossible to achieve. In practice, an ROC curve is constructed—a curve of the ratio of true positive cases (sensitivity) and false positive cases (1 − specificity) for various cut-off thresholds—and such a cut-off threshold is chosen that gives optimal sensitivity and specificity values.
The plots show that the curve deviates from the diagonal line, which indicates good discriminative power of models. An indicator of this power is the area under the ROC curve, which is 0.5 for a model with zero predictive power and 1 for a model with the highest predictive power. The model resulted in a value equal to 0.965, which allows rejecting the null hypothesis that the area under the ROC curve does not differ from 0.5 and that the model has low predictive power and accepting an alternative hypothesis, according to which the model well clarifies the variation of the dependent variable and has good predictive power.
Area under curve is presented in
Table 7.
The following table lists the values for “Sensitivity” and “1 − Specificity”. The default cut-off points of 0.5 was chosen in our logistic regression model. The value of sensitivity or TPCs with it is 0.89; that is, 89% of respondents who indicated that academic mobility helped them in employment were correctly predicted by the model; however, 8.6% of respondents who indicated that academic mobility did not help them in employment were mistakenly identified as persons whom it, on the contrary, helped in employment.
Area under ROC Curve are presented in
Table 8.
Sensitivity is the number of true positive cases divided by the total number of positive cases in the sample. Sensitivity is also called completeness. It is measured according to the formula:
where TPCs are true positive cases and FPCs are false positive cases.
In our example, sensitivity is the power of the model to correctly detect cases where respondents positively assessed the impact of academic mobility on student employment. A model with high sensitivity maximizes the proportion of correctly classified cases.
1 − specificity (one minus specificity) is the number of false positive cases (FPCs) divided by the total number of true negative cases (TNCs) in the sample and is calculated according to the formula:
or
In our example, 1 − specificity characterizes the level of “false responses” of the model when persons who have been helped by academic mobility in employment are classified as persons whom it has not helped in employment.
Thus, calculating the correlation coefficients and performing the chi-square test given above showed the existence of a relationship between the dependent variable and other questions of the questionnaire. After the detection of pairwise relationships, a multidimensional logistic model was built that included statistically significant categories of responses. The model showed good predictive properties. Accordingly, this model can be used to predict the probability that participation in the academic mobility program helped in finding a job.

 ,
, 

{kind=link}