
Robust Intrusion Detection System Using an Improved Hybrid Deep Learning Model for Binary and Multi-Class Classification in IoT Networks



Abstract
1. Introduction
- Development of a robust intrusion detection system leveraging an advanced hybrid CNN-MLP architecture, wherein the CNN layers intricately extract high-dimensional feature representations from input data, while the MLP layers execute refined classification, ensuring precise anomaly and intrusion detection.
- Mitigating class imbalance by employing advanced hybrid ADASYN-SMOTE for binary classification, advanced ADASYN for multi-class classification, alongside ENN for noise reduction and class weights to ensure balanced model performance.
- Utilizing enhanced Z-score method to remove outliers improves dataset quality and model performance, allowing the model to focus on relevant data and enhancing its ability to accurately classify attacks.
- Utilizing the IoT-23 and NF-BoT-IoT-v2 datasets, this study substantiates the superior efficacy of the suggested approach, exceeding the performance of existing cutting-edge techniques in intrusion detection.
2. Related Literature
2.1. Binary Classification
2.2. Multi-Class Classification
2.3. Challenges
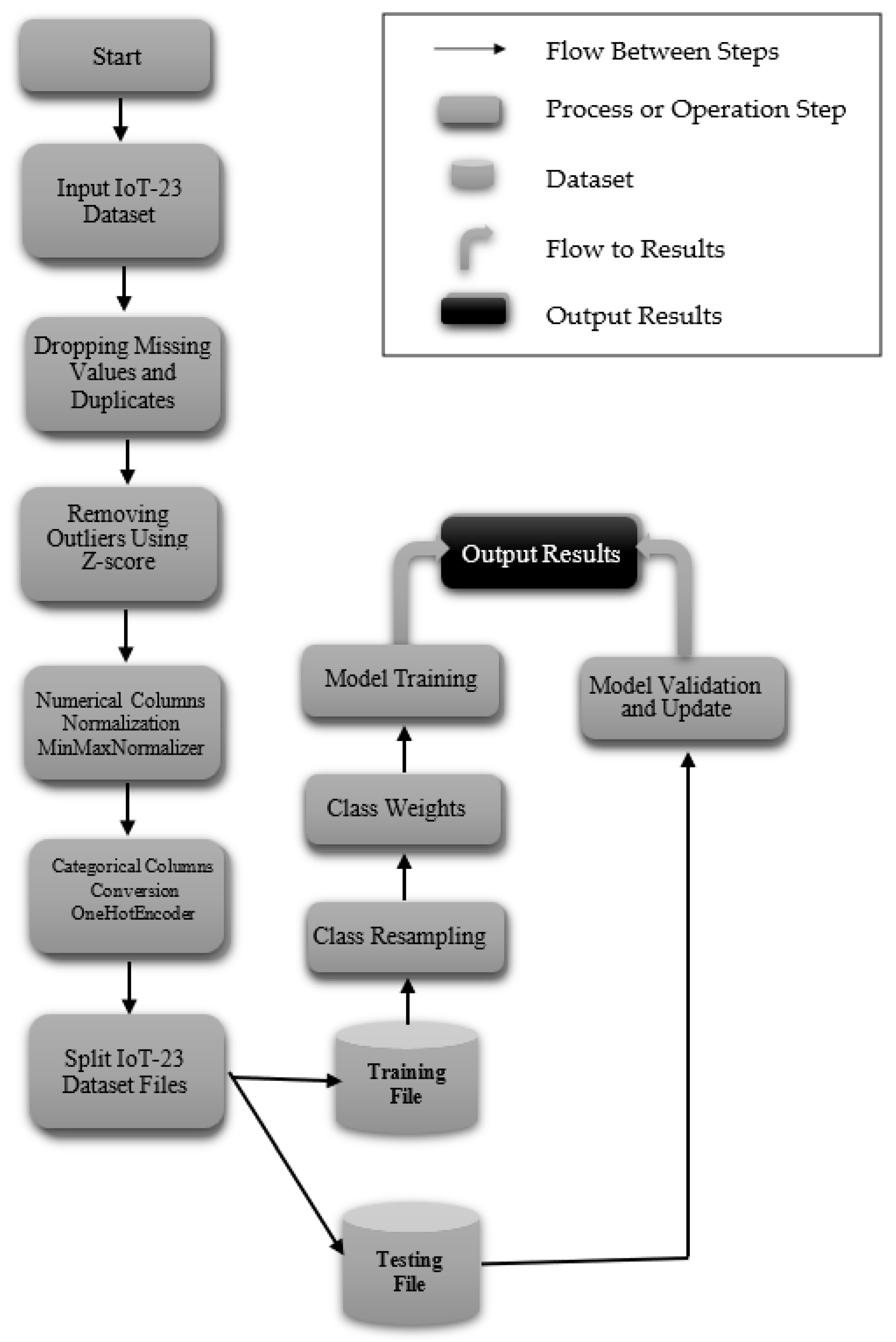
3. Proposed Approach
3.1. Dataset Description
3.2. Data Preprocessing
3.2.1. Removing Outliers Using Z-Score
3.2.2. Normalization
3.2.3. Encoding
3.2.4. Splitting Dataset for Training and Evaluation
3.2.5. Class Balancing
- 1.
- Hybrid ADASYN-SMOTE
- 2.
- ADASYN
- 3.
- ENN
- 4.
- Class Weights
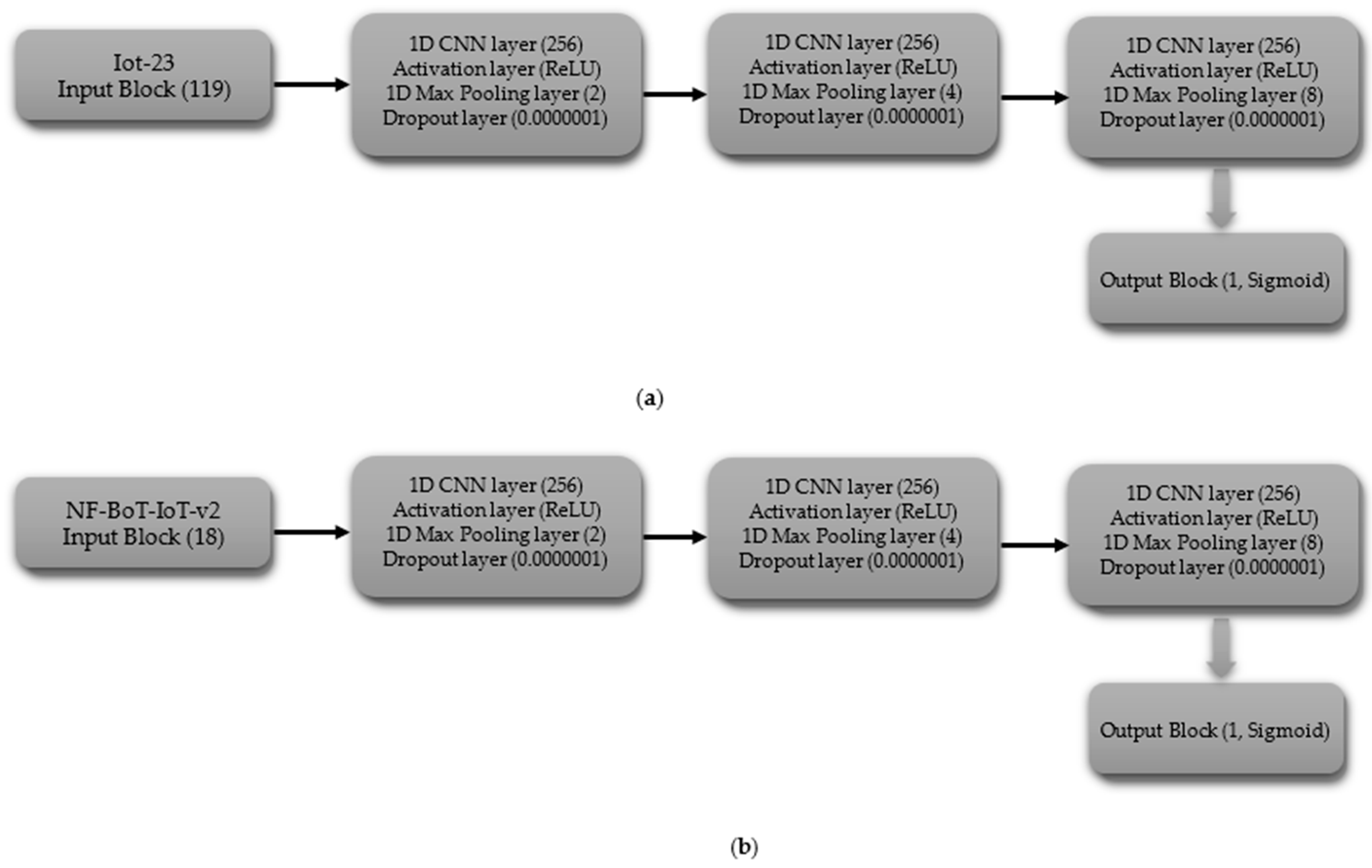
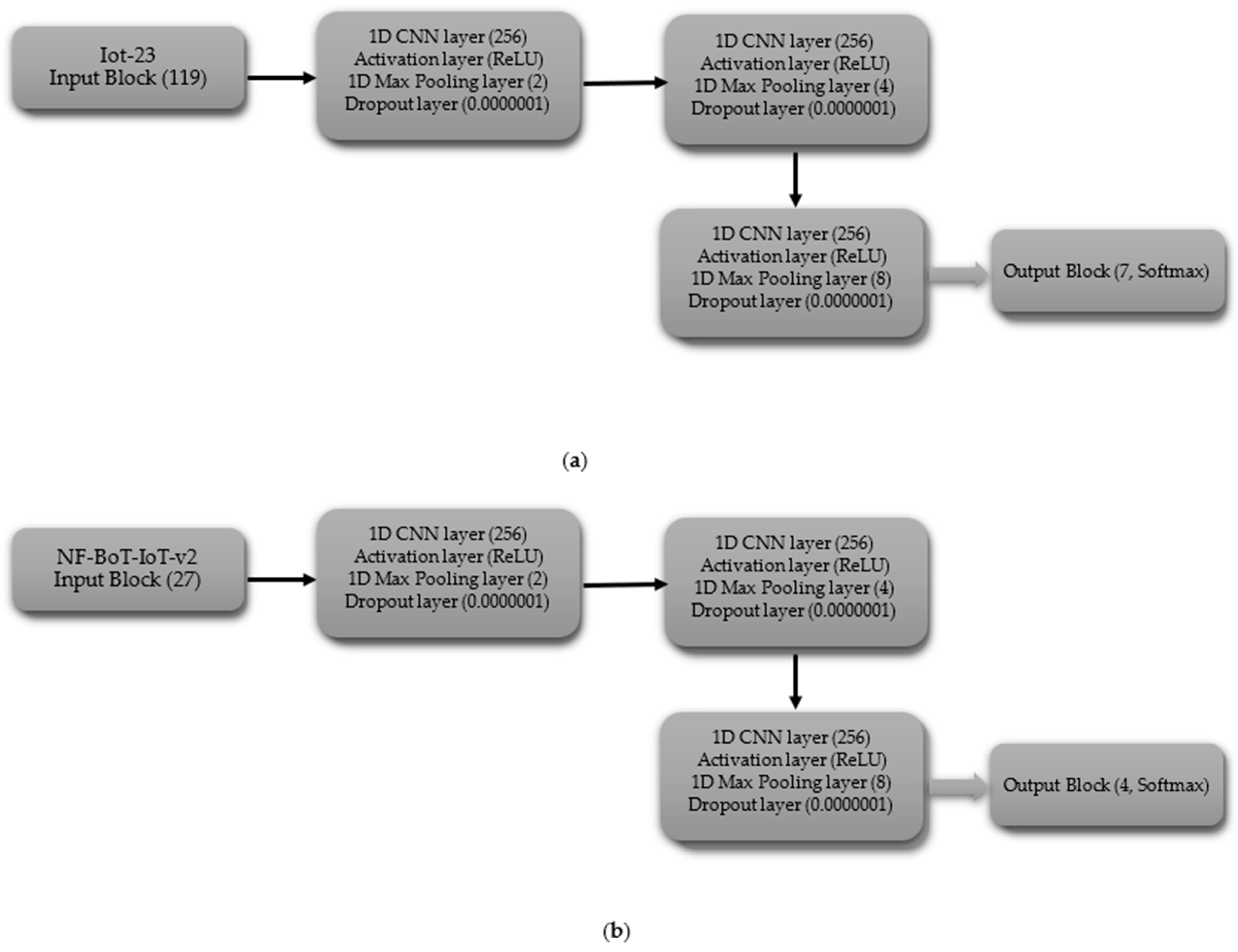
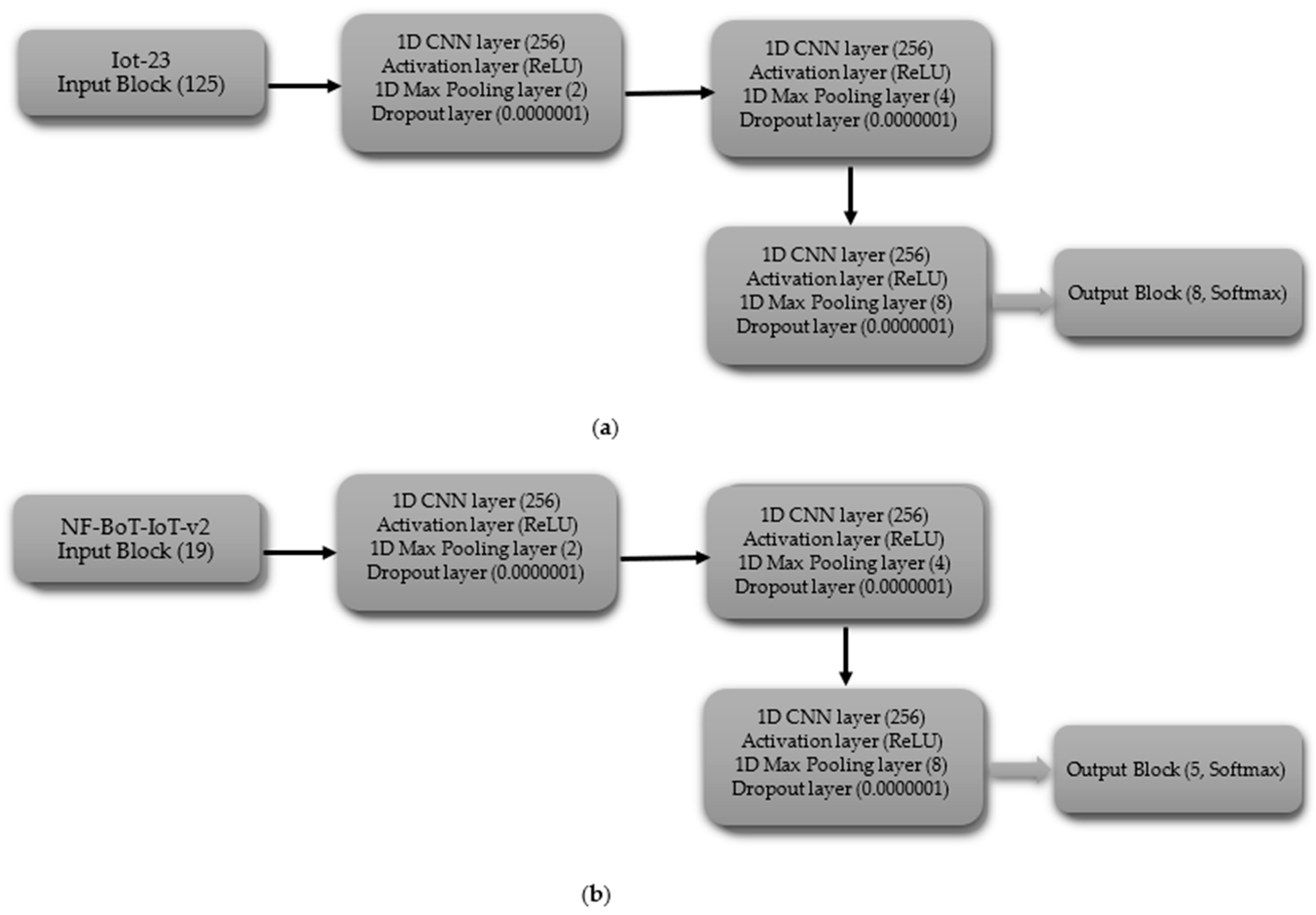
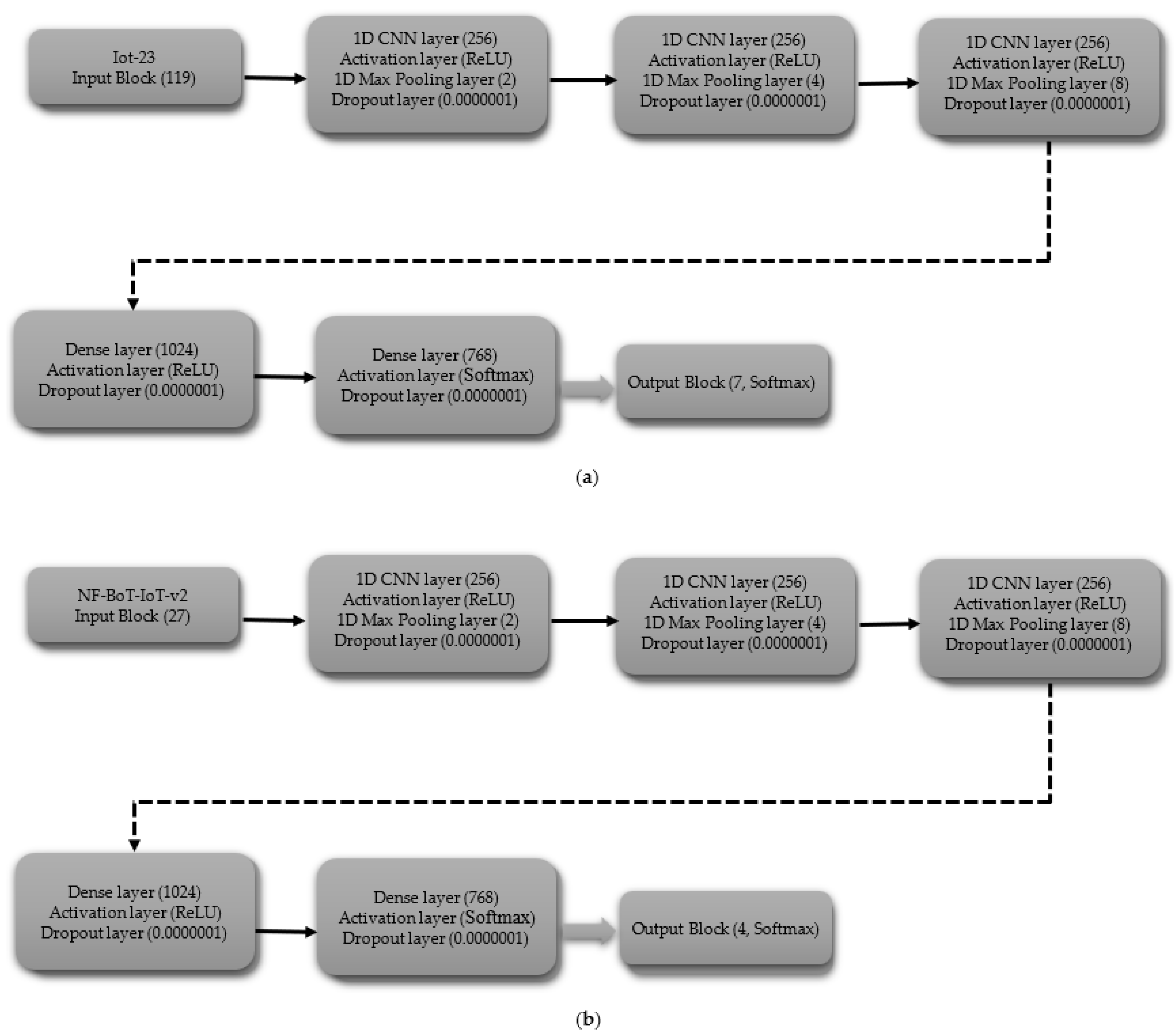
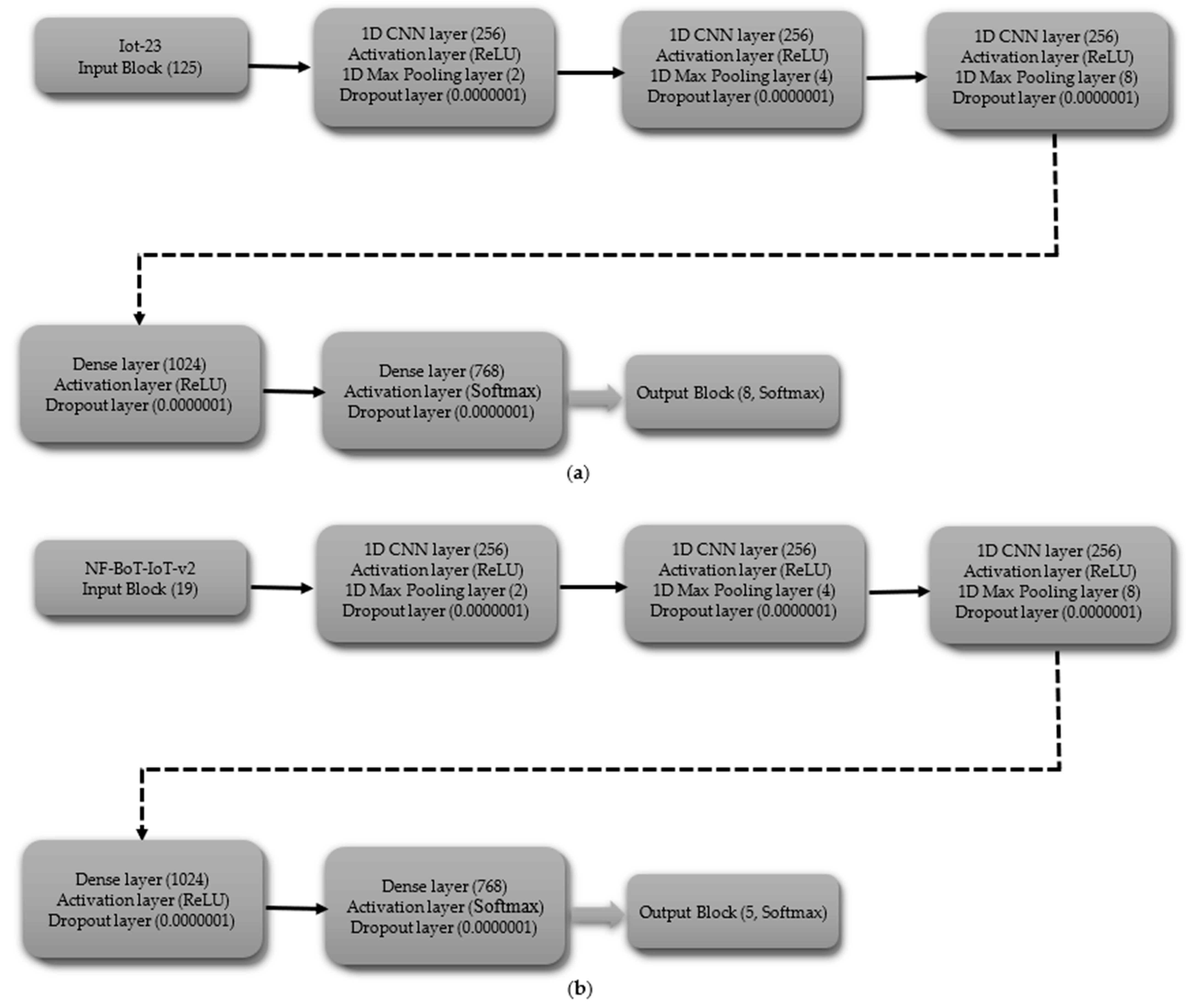
3.3. Architectures of Models
3.3.1. Convolutional Neural Networks (CNN)
- (i)
- Binary Classification
- (ii)
- Multi-Class Classification excluding Normal Class
- (iii)
- Multi-Class Classification including Normal Class
- (iv)
- Hyperparameters for the CNN Model
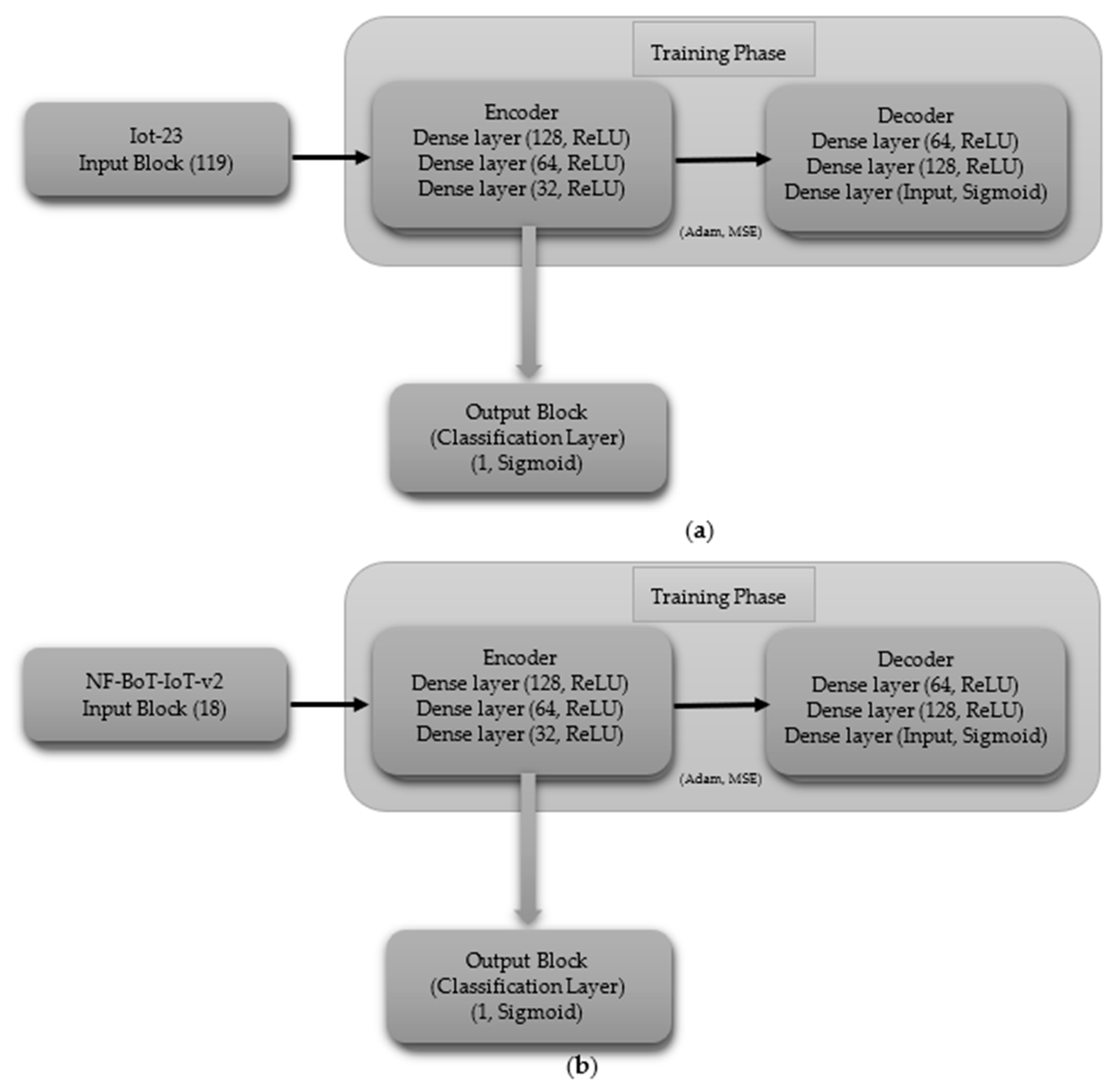
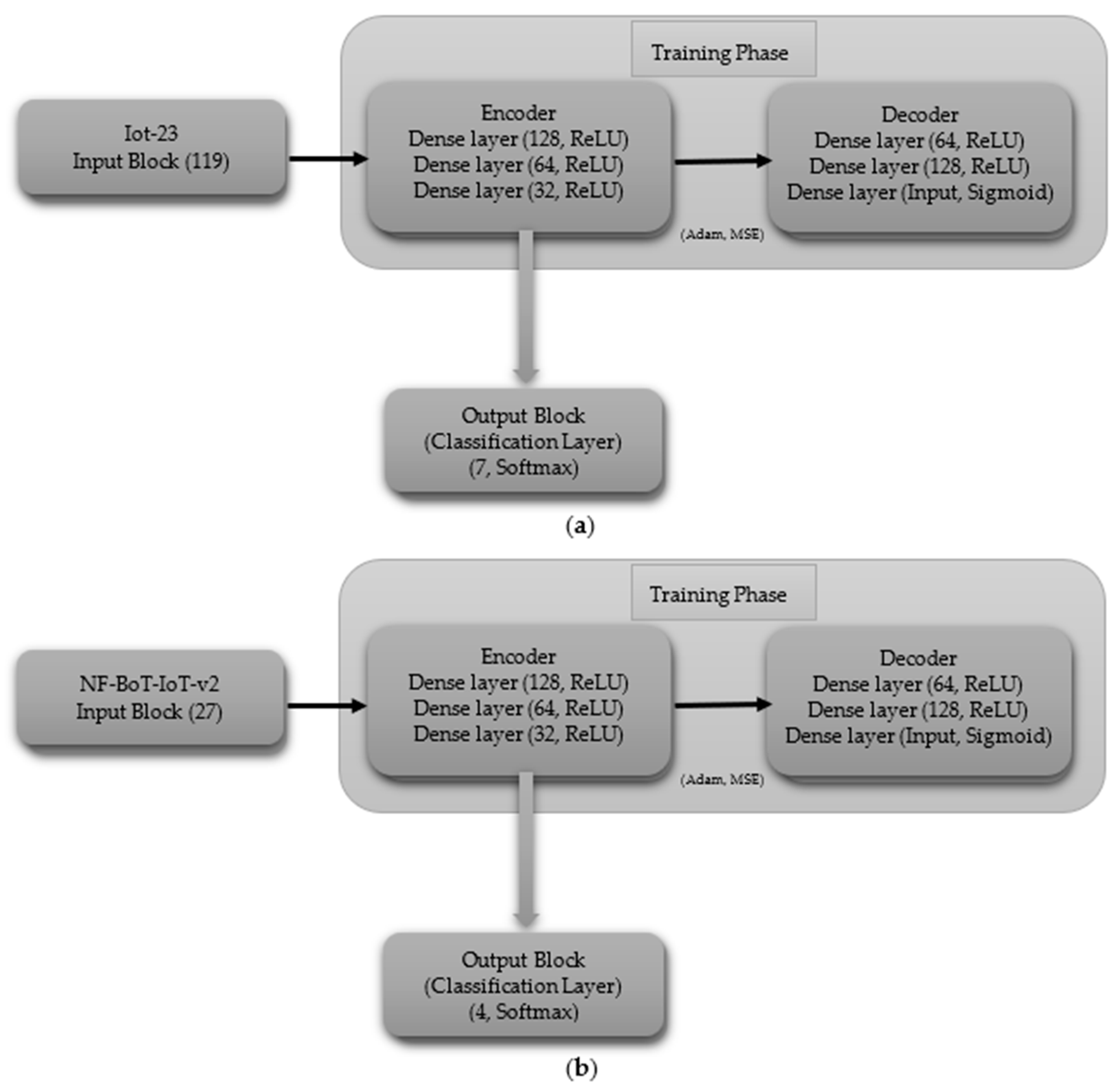
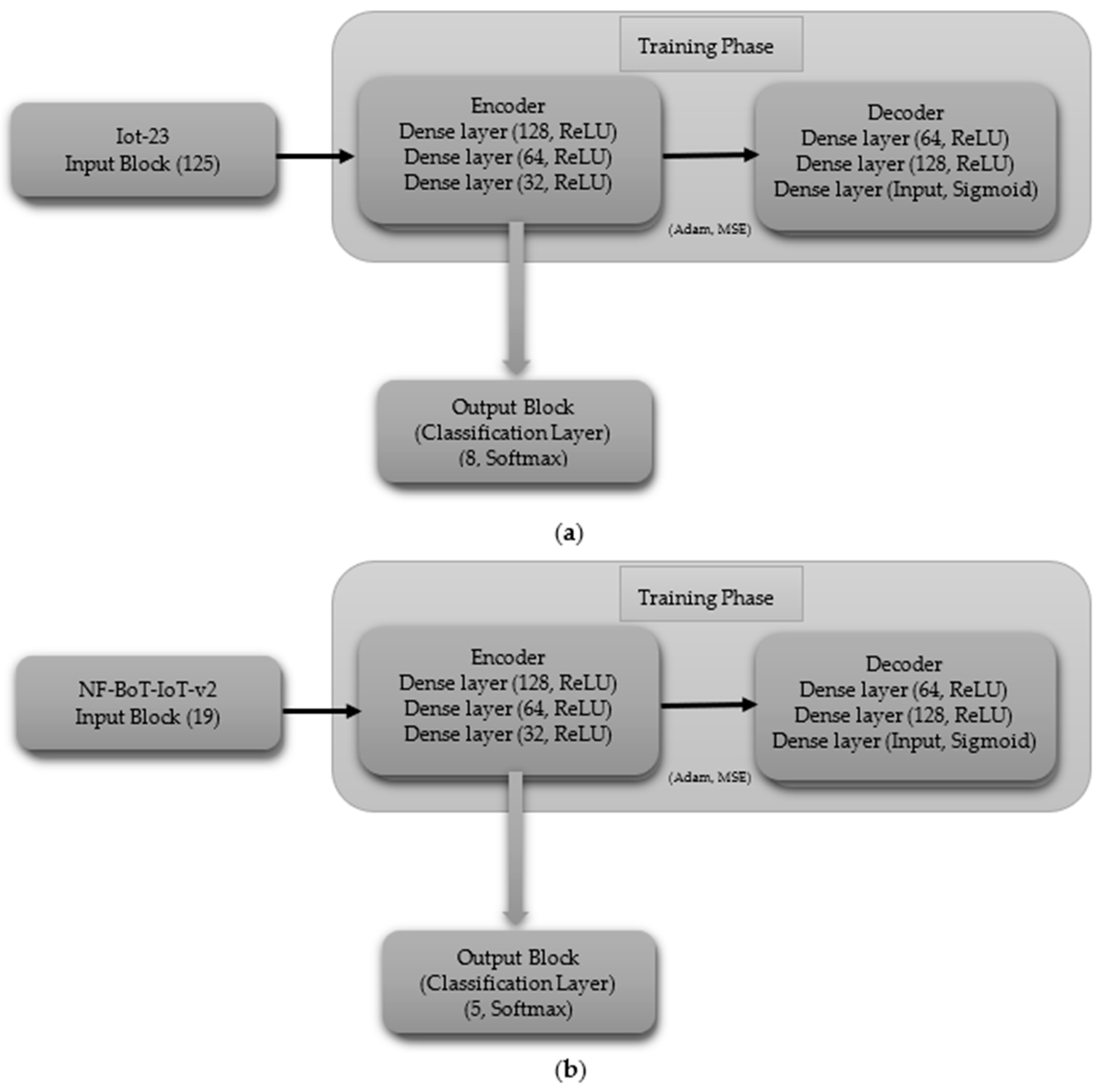
3.3.2. Autoencoder (AE)
- (i)
- Binary Classification
- (ii)
- Multi-Class Classification excluding Normal Class
- (iii)
- Multi-Class Classification including Normal Class
- (iv)
- Autoencoder Model Hyperparameter Specifications
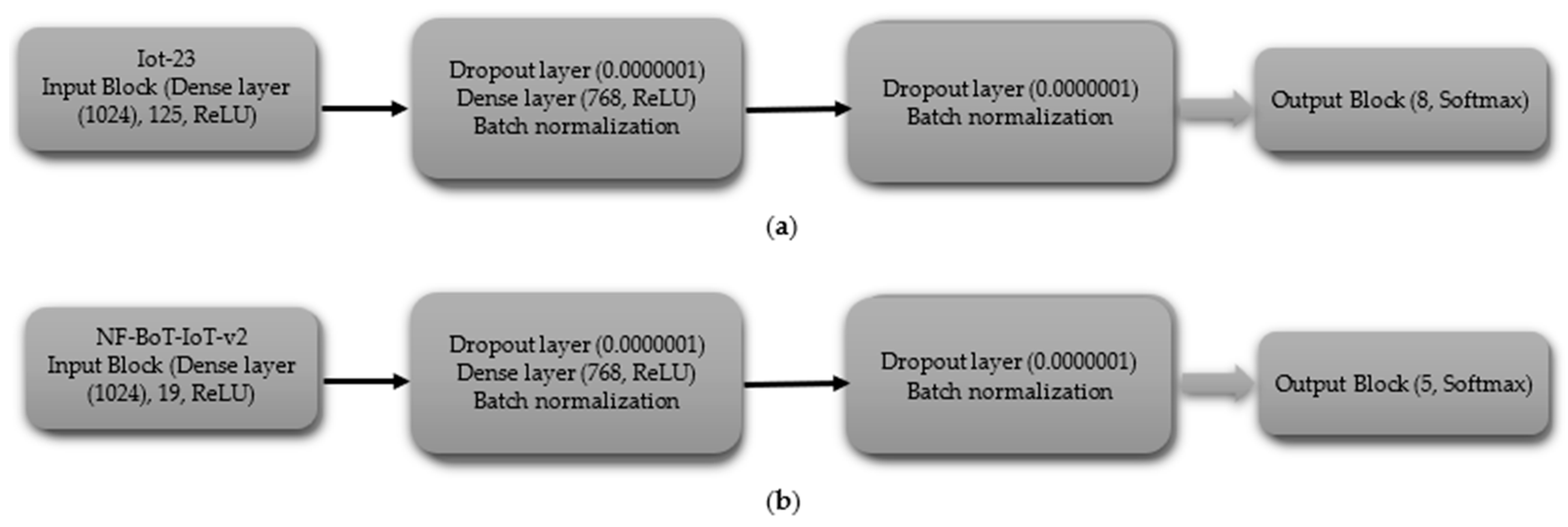
3.3.3. Deep Neural Network (DNN)
- (i)
- Binary Classification
- (ii)
- Multi-Class Classification excluding Normal Class
- (iii)
- Multi-Class Classification including Normal Class
- (iv)
- DNN Model Hyperparameter Specifications
3.3.4. Convolutional Neural Network-Multilayer Perceptron (CNN-MLP)
- (i)
- Binary Classification
- (ii)
- Multi-Class Classification excluding Normal Class
- (iii)
- Multi-Class Classification including Normal Class
- (iv)
- CNN-MLP Model Hyperparameter Specifications
4. Results and Experiments
4.1. Description of Dataset and Preprocessing Overview
4.1.1. IoT-23 Dataset
4.1.2. NF-BoT-IoT-v2 Dataset
4.2. Experiment’s Establishment
4.3. Setting up the Experiment
- True Positive (TP): Instances where the model accurately predicts the positive class, correctly identifying the presence of the target condition or event.
- False Negative (FN): Cases where the model incorrectly predicts a positive instance as negative, failing to identify the presence of the target condition or event.
- True Negative (TN): Instances where the model accurately predicts the negative class, correctly recognizing the absence of the target condition or event.
- False Positive (FP): Cases where the model erroneously classifies a negative instance as positive, mistakenly identifying the absence of the target condition or event as its presence.
4.4. Results
- (i)
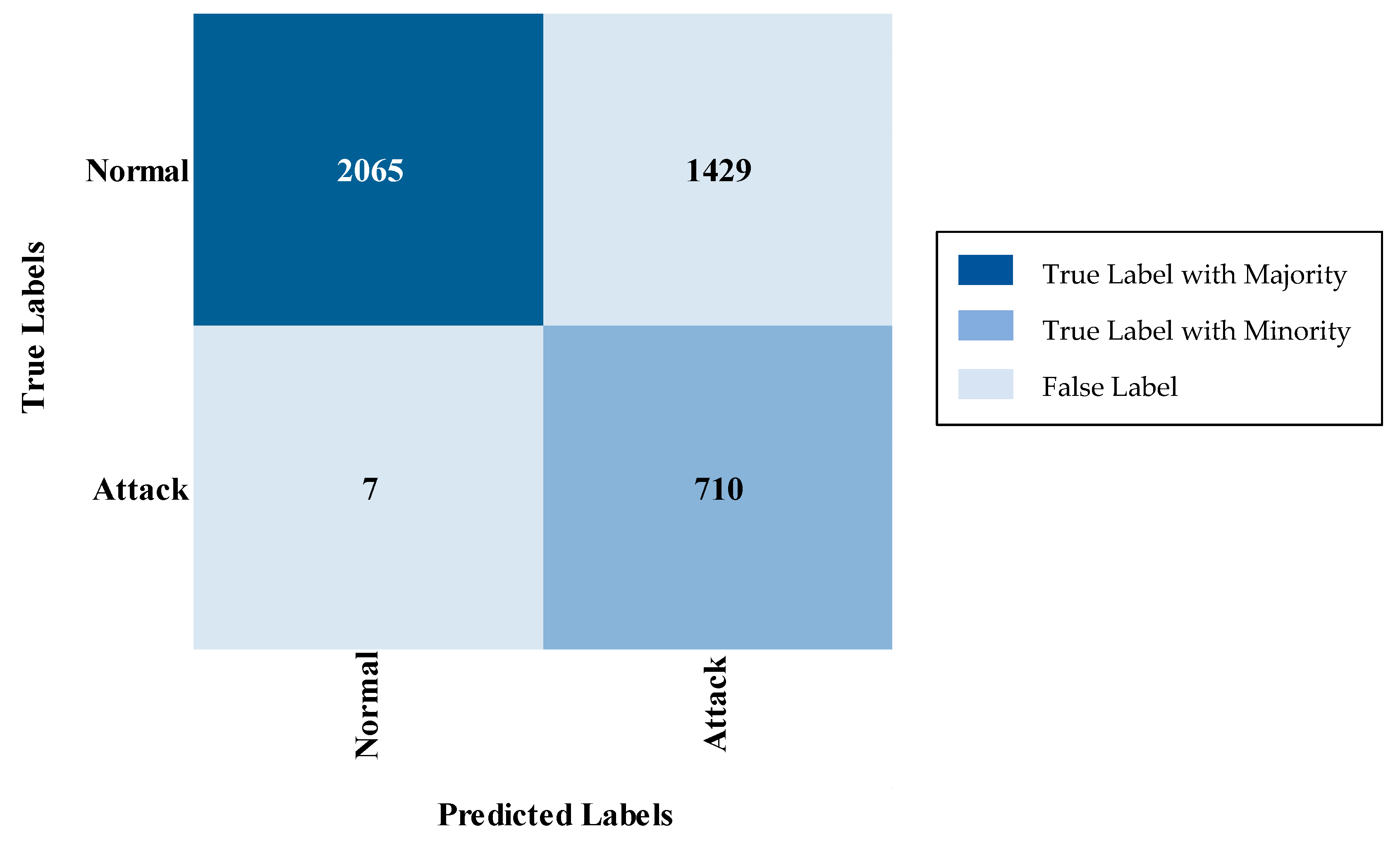
- Binary Classification
- (ii)
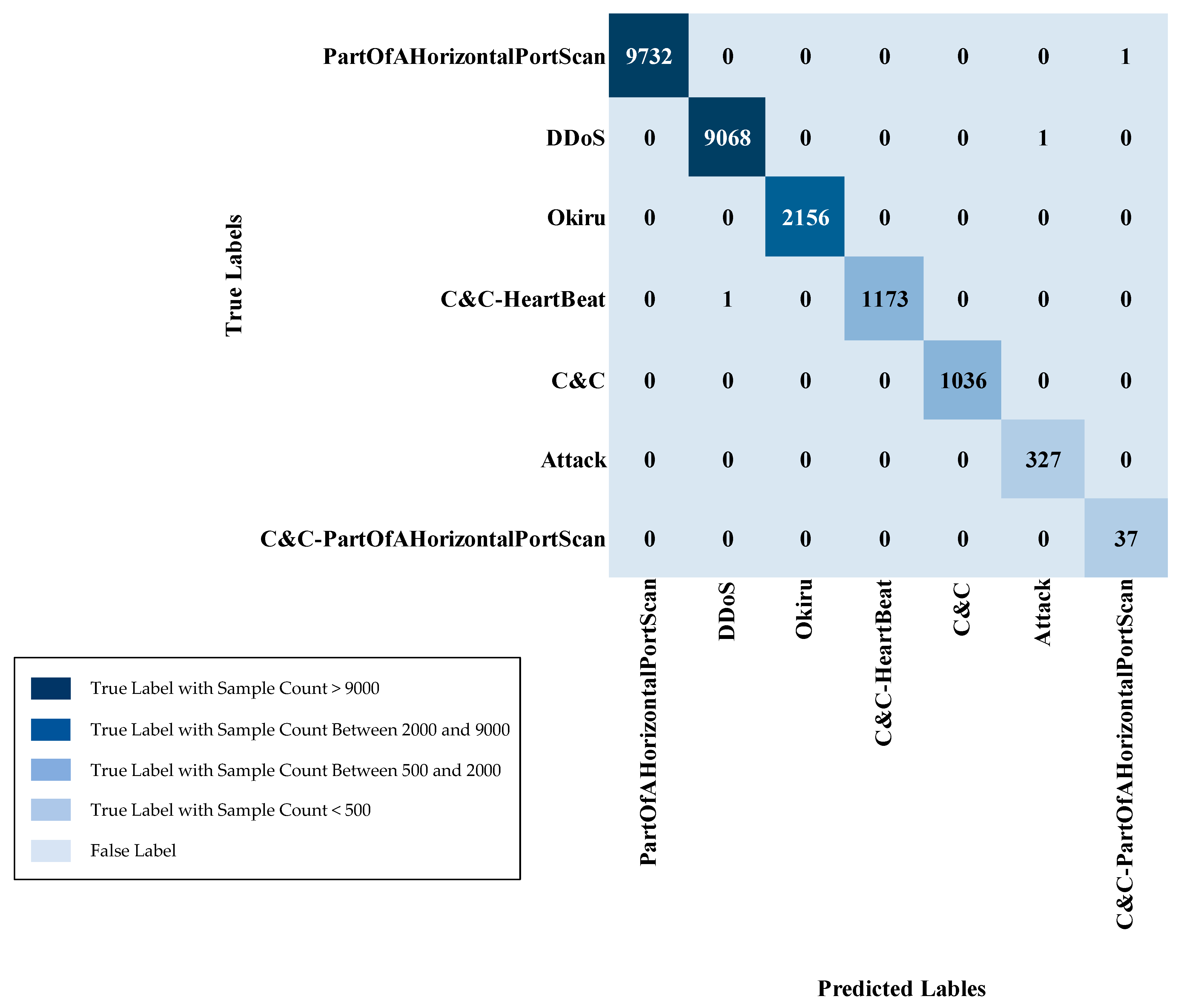
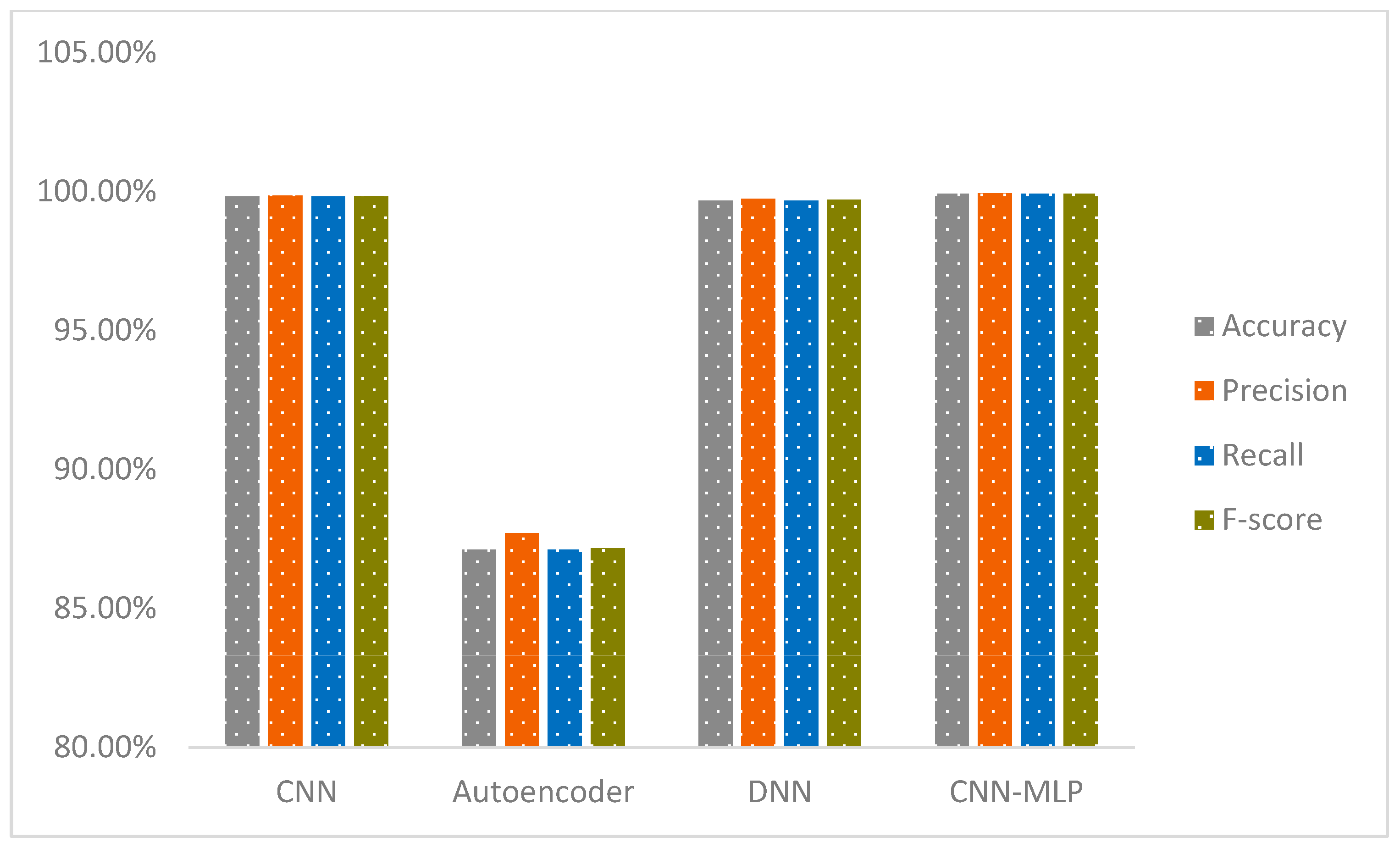
- Multi-Class Classification excluding Normal Class
- (iii)
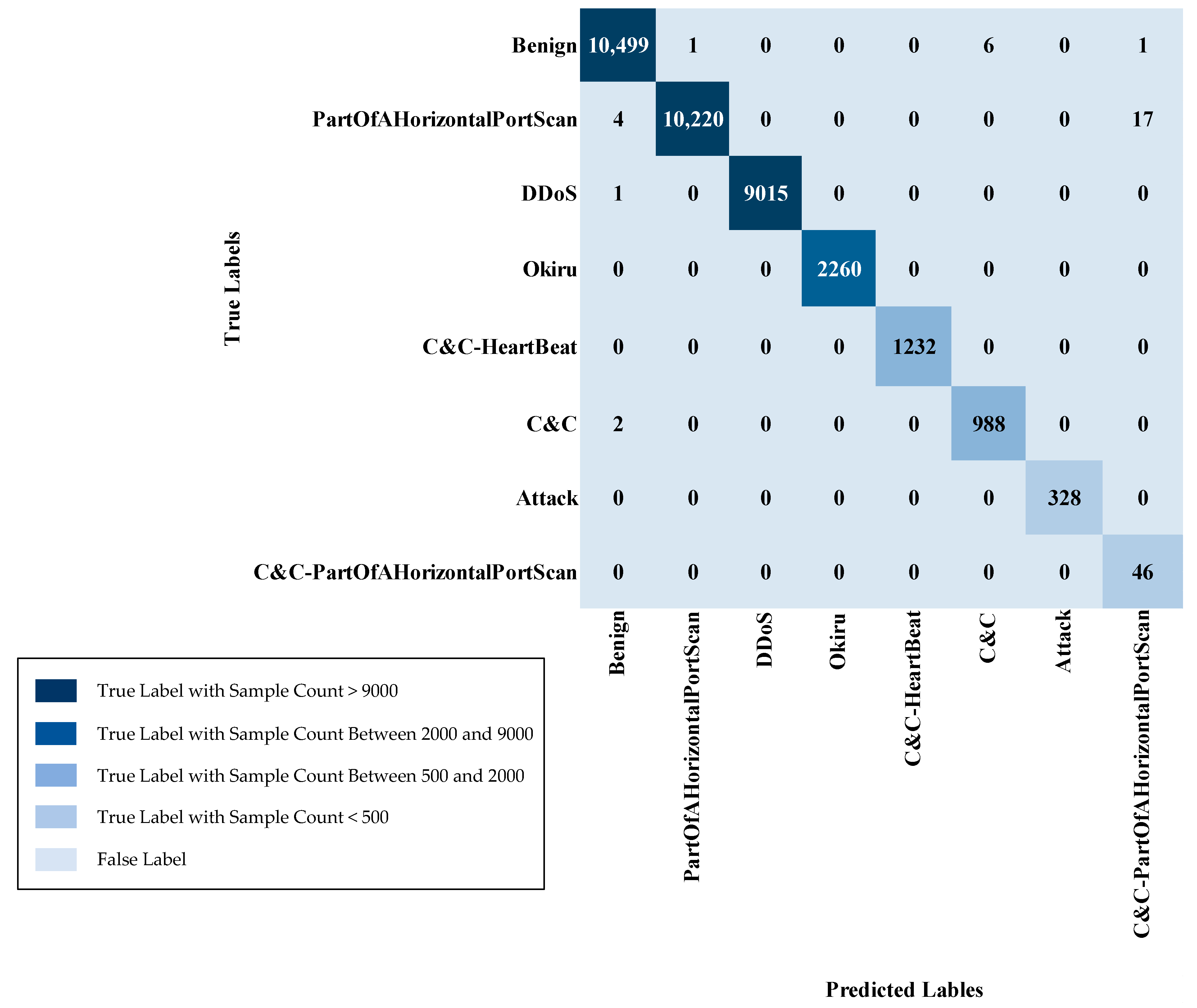
- Multi-Class Classification including Normal Class
4.5. Time, Memory, and Enegry for CNN-MLP Model
- (i)
- Training time
- (ii)
- Inference time
- (iii)
- Memory consumption
- (iv)
- Energy efficiency
5. Discussion
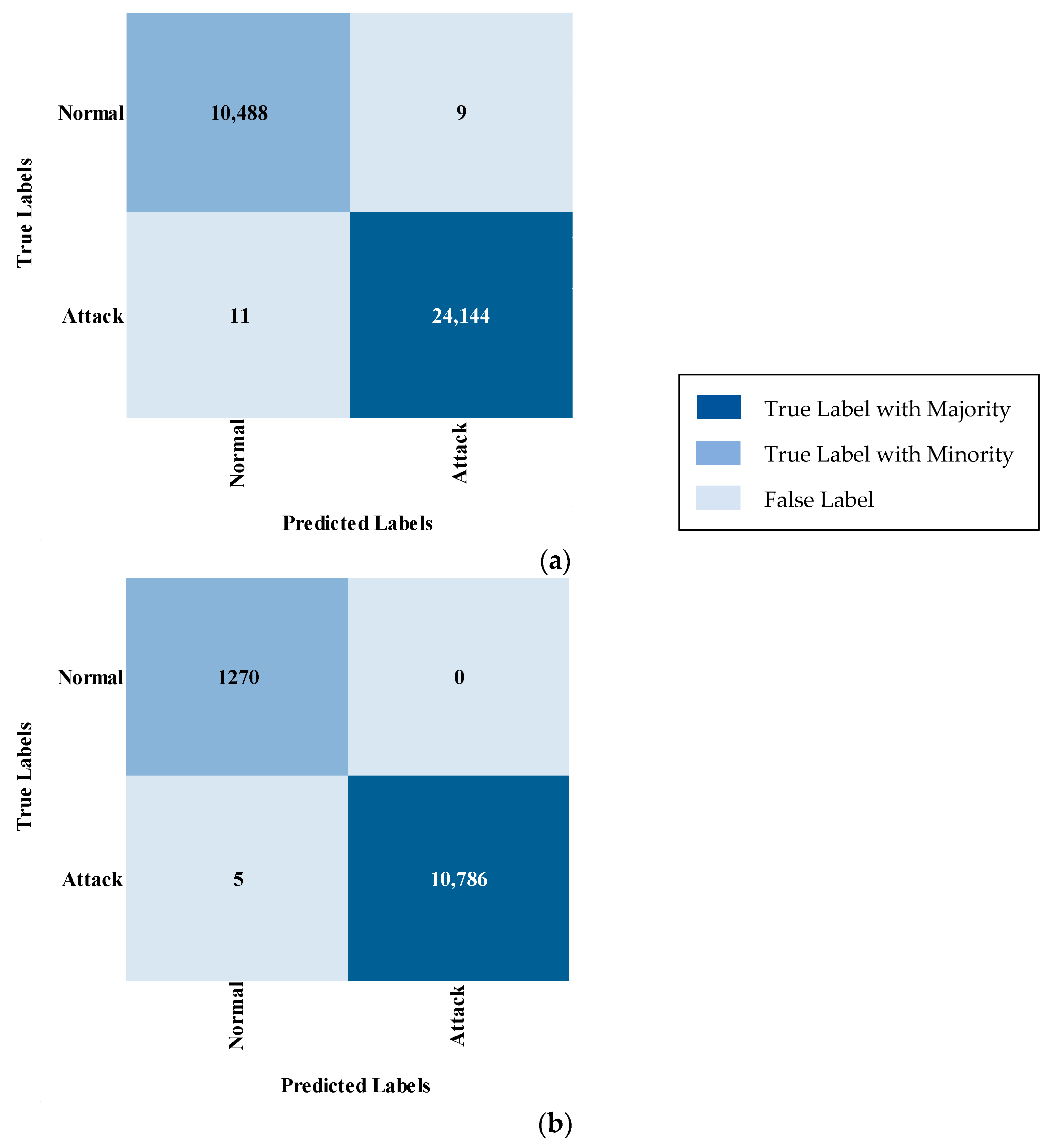
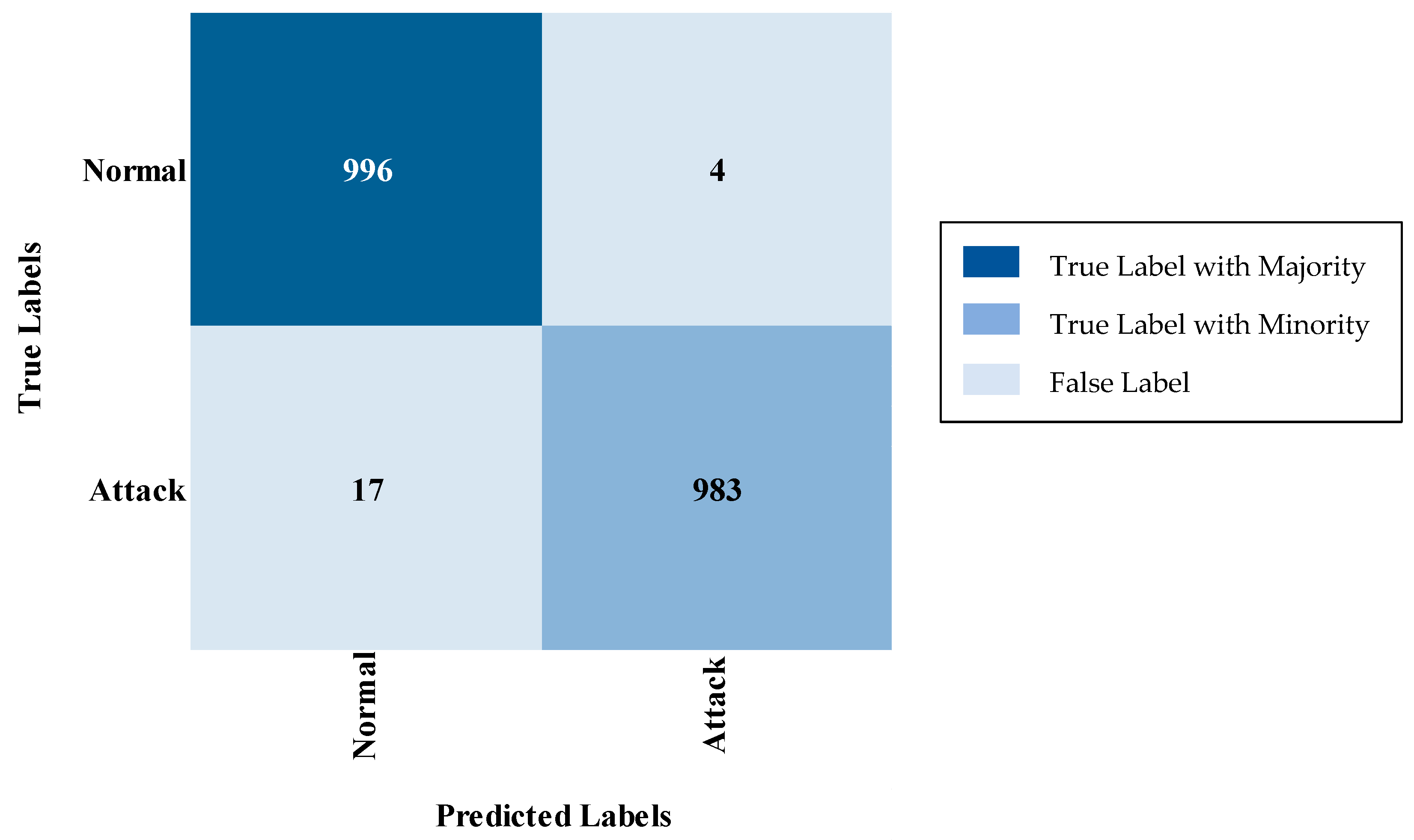
5.1. Binary Classification
5.2. Multi-Class Classification Excluding Normal Class
5.3. Multi-Class Classification Including Normal Class
5.4. Advantages and Trade-Offs of Two-Stage and Single-Phase Classification
5.5. Effect of Data Resampling and Class Weights on CNN-MLP Model Performance
5.6. Case Study for Zero-Day Attack
5.7. Case Study for Detecting Zero-Day Attack for Fully Synthetic Data
5.8. Strategies for Minimizing False Positives and Negatives
6. Limitations
- Scalability: As datasets expand or the intricacy of network traffic intensifies, the computational requirements of the model are likely to rise substantially. This increase may have a considerable effect on the model’s performance, limiting its ability to process extensive datasets or adjust to changing network environments.
- Generalization: Despite the CNN-MLP model’s remarkable outcomes on the IoT-23 and NF-BoT-IoT-v2 datasets, its ability to generalize across a broad range of network traffic variations or respond to novel attack strategies has yet to be fully proven. To thoroughly evaluate the model’s robustness and its ability to generalize, it is essential to apply it to a diverse set of datasets, including established ones like KDDCup99 and NSL-KDD, alongside newer datasets such as ToN-IoT and CSE-CIC-IDS2018. This broader evaluation will help determine the model’s effectiveness in diverse and evolving network environments.
- Data Preprocessing: Effective data preprocessing is crucial for optimizing model performance across various datasets. This workflow entails handling absent values, converting categorical data into suitable representations, adjusting numerical features for uniformity, and eliminating unnecessary or irrelevant data. The success of the CNN-MLP model is closely tied to the quality and thoroughness of these preprocessing steps, which can significantly influence the model’s overall accuracy and reliability.
- Model Adaptation: Adjusting the model for various datasets requires an iterative process of hyperparameter tuning. This step is vital for refining the model, allowing it to align more precisely with the unique patterns and subtleties inherent in unfamiliar datasets. Effective adaptation involves systematically experimenting with different hyperparameters to enhance the model’s performance and ensure its alignment with the specific attributes of each dataset.
7. Conclusions
8. Future Work
- Broader Dataset Evaluation: Upcoming research should shift focus to evaluating the CNN-MLP model on an expanded selection of datasets, incorporating both classic datasets such as KDDCup99 and NSL-KDD, and contemporary ones like ToN-IoT and CSE-CIC-IDS2018. This broader evaluation will provide insights into the model’s robustness, generalizability, and effectiveness in identifying and mitigating emerging attack vectors, ensuring that it remains effective in diverse and evolving network environments.
- Data Preprocessing Refinement: Further refinement and customization of data preprocessing techniques are essential for optimizing model performance across various datasets. This involves experimenting with and fine-tuning preprocessing methods to better align with the characteristics of each dataset and to understand their impact on the model’s effectiveness. A comprehensive analysis of these preprocessing strategies and their implications for model performance is detailed in Section 3.2 and Section 4.1 of the manuscript.
- Model Adaptation and Hyperparameter Optimization: Continuous exploration of strategies for fine-tuning the model is of utmost importance, particularly in refining hyperparameter tuning for various datasets. This requires a comprehensive and systematic evaluation to identify the optimal strategies for customizing the model to fit varying data landscapes. An in-depth exploration of these adaptation techniques and hyperparameter optimization processes are presented in Section 3, with a focus on Section 3.3.4.
- Scalability and Computational Efficiency: Improving the model’s processing capability and expandability is essential, enabling it to effectively handle extensive datasets and adjust to progressively intricate network traffic environments. This involves optimizing the model’s architecture and processing capabilities to ensure robust performance and adaptability as data volume and complexity increase.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Makhdoom, I.; Abolhasan, M.; Lipman, J.; Liu, R.P.; Ni, W. Anatomy of Threats to the Internet of Things. IEEE Commun. Surv. Tutorials 2018, 21, 1636–1675. [Google Scholar] [CrossRef]
- Tawalbeh, L.; Muheidat, F.; Tawalbeh, M.; Quwaider, M. IoT Privacy and Security: Challenges and Solutions. Appl. Sci. 2020, 10, 4102. [Google Scholar] [CrossRef]
- Donnell, L.O. IoT Device Takeovers Surge 100 Percent in 2020. 2020. Available online: https://threatpost.com/iot-devicetakeovers-surge/160504 (accessed on 20 May 2021).
- Alzain, M.A.; Soni, S. A Comprehensive Survey on Intrusion Detection Systems in IoT. IEEE Access 2020, 8, 114786–114804. [Google Scholar]
- Gao, J.; Wang, Y.; Liu, Y. Deep Learning-Based Network Intrusion Detection for IoT Devices. In Proceedings of the 2019 IEEE 24th Pacific Rim International Symposium on Dependable Computing (PRDC), Kyoto, Japan, 1–3 December 2019; Volume 8, pp. 10112–10122. [Google Scholar]
- Ansam, K.; Alazab, A. A critical review of intrusion detection systems in the internet of things: Techniques, deployment strategy, validation strategy, attacks, public datasets and challenges. Cybersecurity 2021, 4, 1–27. [Google Scholar]
- Zhang, X.; Xie, J.; Huang, L. Real-Time Intrusion Detection Using Deep Learning Techniques. J. Netw. Comput. Appl. 2020, 140, 45–53. [Google Scholar]
- Kumar, S.; Kumar, R. A Review of Real-Time Intrusion Detection Systems Using Machine Learning Approaches. Comput. Secur. 2020, 95, 101944. [Google Scholar]
- Smith, A.; Jones, B.; Taylor, C. Enhancing Network Security with Real-Time Intrusion Detection Systems. Int. J. Inf. Secur. 2021, 21, 123–135. [Google Scholar]
- Anderson, J.P. Computer security threat monitoring and surveillance. In Technical Report; James P. Anderson Company: Washington, DC, USA, 1980. [Google Scholar]
- Mahalingam, A.; Perumal, G.; Subburayalu, G.; Albathan, M.; Altameem, A.; Almakki, R.S.; Hussain, A.; Abbas, Q. ROAST-IoT: A novel range-optimized attention convolutional scattered technique for intrusion detection in IoT networks. Sensors 2023, 23, 8044. [Google Scholar] [CrossRef] [PubMed]
- ElKashlan, M.; Elsayed, M.S.; Jurcut, A.D.; Azer, M. A machine learning-based intrusion detection system for iot electric vehicle charging stations (evcss). Electronics 2023, 12, 1044. [Google Scholar] [CrossRef]
- Vitorino, J.; Praça, I.; Maia, E. Towards adversarial realism and robust learning for IoT intrusion detection and classification. Ann. Telecommun. 2023, 78, 401–412. [Google Scholar] [CrossRef]
- Othman, T.S.; Abdullah, S.M. An intelligent intrusion detection system for internet of things attack detection and identification using machine learning. Aro-Sci. J. Koya Univ. 2023, 11, 126–137. [Google Scholar] [CrossRef]
- Gad, A.R.; Nashat, A.A.; Barkat, T.M. Barkat. Intrusion detection system using machine learning for vehicular ad hoc networks based on ToN-IoT dataset. IEEE Access 2021, 9, 142206–142217. [Google Scholar] [CrossRef]
- Yaras, S.; Dener, M. IoT-Based Intrusion Detection System Using New Hybrid Deep Learning Algorithm. Electronics 2024, 13, 1053. [Google Scholar] [CrossRef]
- Faker, O.; Dogdu, E. Intrusion detection using big data and deep learning techniques. In Proceedings of the 2019 ACM Southeast Conference, Kennesaw, GA, USA, 18–20 April 2019; pp. 86–93. [Google Scholar]
- Vinayakumar, R.; Alazab, M.; Soman, K.P.; Poornachandran, P.; Al-Nemrat, A.; Venkatraman, S. Deep learning approach for intelligent intrusion detection system. IEEE Access 2019, 7, 41525–41550. [Google Scholar] [CrossRef]
- Farhana, K.; Rahman, M.; Ahmed, M.T. An intrusion detection system for packet and flow based networks using deep neural network approach. Int. J. Electr. Comput. Eng. 2020, 10, 2088–8708. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, Y.; Meng, Y.; Ruan, F.; Chen, R.; Li, Y.; Yang, Y. A novel framework design of network intrusion detection based on machine learning techniques. Secur. Commun. Netw. 2021, 2021, 6610675. [Google Scholar] [CrossRef]
- Alsharaiah, M.A.; Abualhaj, M.; Baniata, L.H.; Al-Saaidah, A.; Kharma, Q.M.; Al-Zyoud, M.M. An innovative network intrusion detection system (NIDS): Hierarchical deep learning model based on Unsw-Nb15 dataset. Int. J. Data Netw. Sci. 2024, 8, 709–722. [Google Scholar] [CrossRef]
- Jouhari, M.; Benaddi, H.; Ibrahimi, K. Efficient Intrusion Detection: Combining X2 Feature Selection with CNN-BiLSTM on the UNSW-NB15 Dataset. arXiv 2024, arXiv:2407.14945. [Google Scholar]
- Türk, F. Analysis of intrusion detection systems in UNSW-NB15 and NSL-KDD datasets with machine learning algorithms. Bitlis Eren Üniversitesi Fen. Bilim. Derg. 2023, 12, 465–477. [Google Scholar] [CrossRef]
- Muhuri, P.S.; Chatterjee, P.; Yuan, X.; Roy, K.; Esterline, A. Using a long short-term memory recurrent neural network (lstm-rnn) to classify network attacks. Information 2020, 11, 243. [Google Scholar] [CrossRef]
- Fu, Y.; Du, Y.; Cao, Z.; Li, Q.; Xiang, W. A deep learning model for network intrusion detection with imbalanced data. Electronics 2022, 11, 898. [Google Scholar] [CrossRef]
- Yin, Y.; Jang-Jaccard, J.; Xu, W.; Singh, A.; Zhu, J.; Sabrina, F.; Kwak, J. IGRF-RFE: A hybrid feature selection method for MLP-based network intrusion detection on UNSW-NB15 dataset. J. Big Data 2023, 10, 15. [Google Scholar] [CrossRef]
- Yoo, J.; Min, B.; Kim, S.; Shin, D.; Shin, D. Study on network intrusion detection method using discrete pre-processing method and convolution neural network. IEEE Access 2021, 9, 142348–142361. [Google Scholar] [CrossRef]
- Alzughaibi, S.; El Khediri, S. A cloud intrusion detection systems based on dnn using backpropagation and pso on the cse-cic-ids2018 dataset. Appl. Sci. 2023, 13, 2276. [Google Scholar] [CrossRef]
- Basnet, R.B.; Shash, R.; Johnson, C.; Walgren, L.; Doleck, T. Towards Detecting and Classifying Network Intrusion Traffic Using Deep Learning Frameworks. J. Internet Serv. Inf. Secur. 2019, 9, 1–17. [Google Scholar]
- Thilagam, T.; Aruna, R. Intrusion detection for network based cloud computing by custom RC-NN and optimization. ICT Express 2021, 7, 512–520. [Google Scholar] [CrossRef]
- Farahnakian, F.; Jukka, H. A deep auto-encoder based approach for intrusion detection system. In Proceedings of the 2018 20th International Conference on Advanced Communication Technology (ICACT), Chuncheon, Republic of Korea, 11–14 February 2018; pp. 178–183. [Google Scholar]
- Mahmood, H.A.; Hashem, S.H.H. Network intrusion detection system (NIDS) in cloud environment based on hid-den Naïve Bayes multiclass classifier. Al-Mustansiriyah J. Sci. 2018, 28, 134–142. [Google Scholar] [CrossRef]
- Baig, M.M.; Awais, M.M.; El-Alfy, E.S.M. A multiclass cascade of artificial neural network for network intrusion detection. J. Intell. Fuzzy Syst. 2017, 32, 2875–2883. [Google Scholar] [CrossRef]
- Stoian, N.A. Machine Learning for Anomaly Detection in Iot Networks: Malware Analysis on the Iot-23 Data Set. Bachelor’s Thesis, University of Twente, Enschede, The Netherlands, 2020. [Google Scholar]
- Susilo, B.; Sari, R.F. Intrusion detection in IoT networks using deep learning algorithm. Information 2020, 11, 279. [Google Scholar] [CrossRef]
- Szczepański, M.; Pawlicki, M.; Kozik, R.; Choraś, M. The application of deep learning imputation and other advanced methods for handling missing values in network intrusion detection. J. Comput. Sci. 2023, 10, 1–23. [Google Scholar] [CrossRef]
- Kumar, P.; Bagga, H.; Netam, B.S.; Uduthalapally, V. Sad-iot: Security analysis of ddos attacks in iot networks. Wirel. Pers. Commun. 2022, 122, 87–108. [Google Scholar] [CrossRef]
- Sarhan, M.; Siamak, L.; Marius, P. Feature analysis for machine learning-based IoT intrusion detection. arXiv 2021, arXiv:2108.12732. [Google Scholar]
- Ferrag, M.A.; Friha, O.; Hamouda, D.; Maglaras, L.; Janicke, H. Edge-IIoTset: A new comprehensive realistic cyber security dataset of IoT and IIoT applications for centralized and federated learning. IEEE Access 2022, 10, 40281–40306. [Google Scholar] [CrossRef]
- Abdulhammed, R.; Faezipour, M.; Musafer, H.; Abuzneid, A. Efficient network intrusion detection using PCA-based dimensionality reduction of features. In Proceedings of the 2019 International Symposium on Networks, Computers and Communications (ISNCC), Istanbul, Turkey, 18–20 June 2019; pp. 1–6. [Google Scholar]
- Aleesa, A.; Younis, M.O.H.A.M.M.E.D.; Mohammed, A.A.; Sahar, N. Deep-intrusion detection system with en-hanced UNSW-NB15 dataset based on deep learning techniques. J. Eng. Sci. Technol. 2021, 16, 711–727. [Google Scholar]
- Ahmad, M.; Riaz, Q.; Zeeshan, M.; Tahir, H.; Haider, S.A.; Khan, M.S. Intrusion detection in internet of things using supervised machine learning based on application and transport layer features using UNSW-NB15 data-set. EURASIP J. Wirel. Commun. Netw. 2021, 2021, 10. [Google Scholar] [CrossRef]
- Mohammed, B.; Gbashi, E.K. Intrusion detection system for NSL-KDD dataset based on deep learning and recursive feature elimination. Eng. Technol. J. 2021, 39, 1069–1079. [Google Scholar] [CrossRef]
- Umair, M.B.; Iqbal, Z.; Faraz, M.A.; Khan, M.A.; Zhang, Y.-D.; Razmjooy, N.; Kadry, S. A network intrusion detection system using hybrid multilayer deep learning model. Big Data 2022, 12, 367–376. [Google Scholar] [CrossRef]
- Choobdar, P.; Naderan, M.; Naderan, M. Detection and multi-class classification of intrusion in software defined networks using stacked auto-encoders and CICIDS2017 dataset. Wirel. Pers. Commun. 2022, 123, 437–471. [Google Scholar] [CrossRef]
- Dong, S.; Xia, Y.; Peng, T. Network abnormal traffic detection model based on semi-supervised deep reinforcement learning. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4197–4212. [Google Scholar] [CrossRef]
- Farhan, B.I.; Jasim, A.D. Performance analysis of intrusion detection for deep learning model based on CSE-CIC-IDS2018 dataset. Indones. J. Electr. Eng. Comput. Sci. 2022, 26, 1165–1172. [Google Scholar] [CrossRef]
- Farhan, R.I.; Maolood, A.T.; Hassan, N. Performance analysis of flow-based attacks detection on CSE-CIC-IDS2018 dataset using deep learning. Indones. J. Electr. Eng. Comput. Sci. 2020, 20, 1413–1418. [Google Scholar] [CrossRef]
- Lin, P.; Ye, K.; Xu, C.Z. Dynamic network anomaly detection system by using deep learning techniques. In Proceedings of the Cloud Computing–CLOUD 2019: 12th International Conference, Held as Part of the Services Conference Federation, SCF 2019, San Diego, CA, USA, 25–30 June 2019; Proceedings 12. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 161–176. [Google Scholar]
- Liu, G.; Zhang, J. CNID: Research of network intrusion detection based on convolutional neural network. Discret. Dyn. Nat. Soc. 2020, 2020, 4705982. [Google Scholar] [CrossRef]
- Di Mauro, M.; Galatro, G.; Liotta, A. Experimental review of neural-based approaches for network intrusion management. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2480–2495. [Google Scholar] [CrossRef]
- Jahangir, M.T.; Wakeel, M.; Asif, H.; Ateeq, A. Systematic Approach to Analyze The Avast IOT-23 Challenge Dataset For Malware Detection Using Machine Learning. In Proceedings of the 2023 18th International Conference on Emerging Technologies (ICET), Peshawar, Pakistan, 6–7 November 2023; pp. 234–239. [Google Scholar]
- Balaji, R.; Deepajothi, S.; Prabaharan, G.; Daniya, T.; Karthikeyan, P.; Velliangiri, S. Survey on intrusions detection system using deep learning in iot environment. In Proceedings of the 2022 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 7–9 April 2022; pp. 195–199. [Google Scholar]
- Garcia, S.; Parmisano, A.; Erquiaga, M.J. IoT-23: A Labeled Dataset with Malicious and Benign IoT Network Traffic. Zenodo. 2021. Available online: https://zenodo.org/records/4743746 (accessed on 20 February 2024).
- Abdalgawad, N.; Sajun, A.; Kaddoura, Y.; Zualkernan, I.A.; Aloul, F. Generative deep learning to detect cyberattacks for the IoT-23 dataset. IEEE Access 2021, 10, 6430–6441. [Google Scholar] [CrossRef]
- Patro, S.G.; Sahu, D.-K.K. Normalization: A preprocessing stage. Int. Adv. Res. J. Sci. Eng. Technol. 2015, 2, 20–22. [Google Scholar] [CrossRef]
- Rodríguez, P.; Bautista, M.A.; Gonzalez, J.; Escalera, S. Beyond one-hot encoding: Lower dimensional target embedding. Image Vis. Comput. 2018, 75, 21–31. [Google Scholar] [CrossRef]
- Jie, L.; Jiahao, C.; Xueqin, Z.; Yue, Z.; Jiajun, L. One-hot encoding and convolutional neural network based anomaly detection. J. Tsinghua Univ. Sci. Technol. 2019, 59, 523–529. [Google Scholar]
- Elmasry, W.; Akbulut, A.; Zaim, A.H. Empirical study on multiclass classifcation-based network intrusion detection. Comput. Intell. 2019, 35, 919–954. [Google Scholar] [CrossRef]
- Bagui, S.; Li, K. Resampling imbalanced data for network intrusion detection datasets. J. Big Data. 2021, 8, 1–41. [Google Scholar] [CrossRef]
- Mbow, M.; Koide, H.; Sakurai, K. Handling class imbalance problem in intrusion detection system based on deep learning. Int. J. Netw. Comput. 2022, 12, 467–492. [Google Scholar] [CrossRef]
- EL-Habil, B.Y.; Abu-naser, S.S. Global climate prediction using deep learning. J. Theor. Appl. Inf. Technol. 2022, 100, 24. [Google Scholar]
- Zhendong, S.; Jinping, M. Deep learning-driven MIMO: Data encoding and processing mechanism. Phys. Commun. 2022, 57, 101976. [Google Scholar] [CrossRef]
- Xin, Z.; Chunjiang, Z.; Jun, S.; Kunshan, Y.; Min, X. Detection of lead content in oilseed rape leaves and roots based on deep transfer learning and hyperspectral imaging technology. Spectroch Acta Part. A Mol. Biomol. Spectrosc. 2022, 290, 122288. [Google Scholar] [CrossRef]
- Hesham, K.; Mashaly, M. Advanced Hybrid Transformer-CNN Deep Learning Model for Effective Intrusion Detec-tion Systems with Class Imbalance Mitigation Using Resampling Techniques. Future Internet 2024, 16, 481. [Google Scholar] [CrossRef]
- Novaria, K.Y.; Nurmaini, S.; Stiawan, D.; Zarkasi, A. Automatic features extraction using autoencoder in intrusion detection system. In Proceedings of the 2018 International Conference on Electrical Engineering and Computer Science (ICECOS), Pangkal, Indonesia, 2–4 October 2018; pp. 219–224. [Google Scholar]
- Hesham, K.; Mashaly, M. Enhanced Hybrid Deep Learning Models-Based Anomaly Detection Method for Two-Stage Binary and Multi-Class Classification of Attacks in Intrusion Detection Systems. Algorithms 2025, 18, 69. [Google Scholar] [CrossRef]
- Anupriya, G.; Majumdar, A. Discriminative autoencoder for feature extraction: Application to character recognition. Neural Process. Lett. 2019, 49, 1723–1735. [Google Scholar]
- Chen, X.; Ma, L.; Yang, X. Stacked denoise autoencoder based feature extraction and classification for hyperspectral images. J. Sens. 2016, 2016, 3632943. [Google Scholar]
- Sarhan, M.; Layeghy, S.; Portmann, M. Towards a standard feature set for network intrusion detection system datasets. Mob. Netw. Appl. 2022, 27, 357–370. [Google Scholar] [CrossRef]
- Veeramreddy, J.; Prasad, K. Anomaly-Based Intrusion Detection System. In Computer and Network Security; Alexandrov, A.A., Ed.; IntechOpen: Rijeka, Croatia, 2019. [Google Scholar] [CrossRef]
- Chen, C.; Song, Y.; Yue, S.; Xu, X.; Zhou, L.; Lv, Q.; Yang, L. FCNN-SE: An Intrusion Detection Model Based on a Fusion CNN and Stacked Ensemble. Appl. Sci. 2022, 12, 8601. [Google Scholar] [CrossRef]
- Ahmed, A.; Mashaly, M. Addressing the class imbalance problem in network intrusion detection systems using data resampling and deep learning. J. Supercomput. 2023, 79, 10611–10644. [Google Scholar]
- Powers, D.M.W. Evaluation: From Precision, Recall, and F-Measure to ROC, Informedness, Markedness & Correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Hesham, K.; Mashaly, M. Improving Anomaly Detection in IDS with Hybrid Auto Encoder-SVM and Auto Encoder-LSTM Models Using Resampling Methods. In Proceedings of the 2024 6th Novel Intelligent and Leading Emerging Sciences Conference (NILES), Giza, Egypt, 19–21 October 2024; pp. 34–39. [Google Scholar]
- Tamer, A.A.; Mostafa, Y.; El-khaleq, A.A.; Mashaly, M. Anomaly-based intrusion detection system using one-dimensional convolutional neural network. Procedia Comput. Sci. 2023, 220, 78–85. [Google Scholar]
- Khalid, M.H.; Awad, A.I.; Khashaba, M.M.; Mohamed, E.R. New improved multi-objective gorilla troops algorithm for dependent tasks offloading problem in multi-access edge computing. J. Grid Comput. 2023, 21, 21. [Google Scholar]
- Vanessa, M.; Schacht, S.; Lanquillon, C. Towards energy-efficient deep learning: An overview of energy-efficient approaches along the deep learning lifecycle. arXiv 2023, arXiv:2303.01980. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Dataset | Year | Utilized Technique | Accuracy | Contribution | Limitations |
|---|---|---|---|---|---|---|
| Anandaraj Mahalingam et al. [11] | IoT-23 | 2023 | ROAST-IoT | 99.15% | This research unveils ROAST-IoT, an intelligent AI-powered architecture meticulously crafted to fortify intrusion detection mechanisms within the intricate landscape of IoT environments. The framework leverages a sophisticated multi-modal architecture to intricately decipher and encapsulate the nuanced interdependencies embedded within diverse network traffic patterns. Intelligent sensors continuously scrutinize system dynamics, transmitting behavioral telemetry to a cloud-based repository for in-depth analytical processing. The framework’s efficacy is rigorously validated using reference datasets of established significance, such as IoT-23, Edge-IIoT, ToN-IoT, and UNSW-NB15, ensuring comprehensive evaluation and assessment. |
|
| Mohamed ElKashlan et al. [12] | IoT-23 | 2023 | Filtered classifier | 99.2% | This study unveils a precision-engineered classification paradigm, leveraging advanced machine learning methodologies to meticulously dissect and identify nefarious traffic patterns within the intricate and dynamic fabric of IoT ecosystems. The proposed system utilizes a genuine IoT dataset based on real IoT traffic, and various classification algorithms are assessed for performance. |
|
| João Vitorino et al. [13] | IoT-23 | 2023 | RF, XGB, LGBM, and IFOR | 99% | This research intricately defines the essential parameters for crafting a truly authentic adversarial cyber intrusion, emphasizing the need for an attack of unparalleled realism. It further introduces a comprehensive methodology for executing a robust analysis of system defenses, leveraging a nuanced adversarial evasion strategy engineered to seamlessly bypass security measures. The methodology put forth was meticulously applied to probe the fortitude of three prominent supervised learning models: RF, XGB, and LGBM, combined with the autonomous IFOR mechanism to rigorously assess their durability in complex and high-stress environments. |
|
| Trifa S. Othman and Saman M. Abdullah [14] | IoT-23 | 2023 | ANN | 99% | This research unveils a triad of advanced computational intelligence paradigms, meticulously architected for dual-phase classification encompassing both binary and multi-class categorization. These methodologies serve as the cornerstone of an intrusion detection mechanism, meticulously engineered to fortify the intricate and ever-evolving landscape of interconnected IoT infrastructures. These methodologies are strategically harnessed to identify a spectrum of cyber intrusions targeting IoT ecosystems, facilitating precise differentiation and categorization of their distinctive attack typologies. By harnessing the state-of-the-art IoT-23 dataset, the research develops an advanced intelligent IDS capable of identifying malicious activities and categorizing attack vectors in real-time, enhancing security for IoT networks. |
|
| Abdallah R. Gad et al. [15] | ToN-IoT | 2020 | XGBoost | 98.2% | This work confronts the challenge by unveiling an innovative, data-centric IoT/IIoT dataset, meticulously structured with annotated ground truth to distinctly delineate normal and attack classes, thereby refining the precision of intrusion detection mechanisms. Additionally, it incorporates a type attribute that categorically identifies various attack sub-classes, thereby facilitating the execution of multi-class classification and enriching the depth of threat analysis. The TON_IoT dataset encompasses an extensive spectrum of telemetry insights, meticulously extracted from IoT and IIoT infrastructures, integrating system-generated System-generated event records and complex network communication flows, providing a rich and multifaceted foundation for analysis. This corpus of data emerges from a meticulously orchestrated emulation of an intermediate-scale network infrastructure, conducted within the state-of-the-art Cyber Range and IoT Research Facilities at UNSW Canberra, Australia. |
|
| Sami Yaras and Murat Dener [16] | ToN-IoT | 2024 | CNN-LSTM | 98.75% | This research was executed within the Colab environment, leveraging the power of PySpark and Apache Spark framework, in conjunction with the Keras deep learning suite and the Scikit-Learn machine learning toolkit. The ‘CICIoT2023’ and ‘TON_IoT’ datasets functioned as the critical resources for both training and evaluating the model’s performance. Feature reduction was performed using the correlation method to ensure only the most relevant features were included. The scholars engineered a synergistic deep learning paradigm, seamlessly fusing a 1D-CNN with a LSTM architecture to elevate predictive efficacy and optimize model robustness |
|
| João Vitorino et al. [13] | ToN-IoT | 2023 | RF, XGB, LGBM, and IFOR | 85% | This research meticulously delineates the core underpinnings constraints necessary to craft a sophisticated malicious cyber-attack of unparalleled realism, and concurrently proposes a methodical framework for executing a thorough robustness analysis through the strategic application of a targeted distortion, grounded in practical execution. This strategy was meticulously executed to rigorously examine the fortitude of three eminent supervised learning paradigms, RF, XGB, and LGBM, along with the unsupervised IFOR model, systematically assessing their resilience when subjected to formidable adversarial conditions. |
|
| Osama Faker and Erdogan Dogdu [17] | CICIDS2017 | 2019 | DNN | 99.9% | This research pioneers a transformative leap in intrusion detection by intricately synthesizing advanced deep learning frameworks with comprehensive big data analytical frameworks, harnessing the capabilities of RF, GBT, and a DFFNN to significantly refine detection performance and operational efficacy. It rigorously assesses feature importance, performs comprehensive assessments on the UNSW-NB15 and CICIDS2017 datasets through a rigorous 5-fold cross-validation framework, intricately fuses Keras with Apache Spark, and strategically leverages ensemble learning techniques to amplify predictive efficacy. |
|
| R. Vinayakumar et al. [18] | CICIDS2017 | 2019 | DNN | 93.1% | This research explores the application of DNNs to create an adaptable IDS for identifying and categorizing emerging cyber threats, while assessing their performance against conventional machine learning classifiers using standard benchmark datasets |
|
| Kaniz Farhana et al. [19] | CICIDS2017 | 2020 | DNN | 99% | This work unveils an IDS powered by DNN, meticulously developed within the Keras framework, operating seamlessly within the TensorFlow ecosystem. The model was implemented on a contemporary, significantly imbalanced dataset comprising 79 distinct features. The dataset contains details at the granular level of network packets, statistics based on flow, and supplementary data, with some classes notably having limited representation. |
|
| Chongzhen Zhang et al. [20] | CICIDS2017 | 2021 | SAE | 99.92% | This study unveils a comprehensive and resilient IDS architecture, carefully structured into five fundamental components: data preprocessing, AE processing, database integration, classification, and dynamic feedback. AE performs data compression, meanwhile, the classification component generates the outcomes of the detection process. The database proficiently retains the compacted features, streamlining future assessments and model refinement. |
|
| Mohammad A. Alsharaiah et al. [21] | UNSW-NB15 | 2024 | AT-LSTM | 92.2% | This work presents a new NIDS approach that leverages LSTM and attention mechanisms to analyze both the time-dependent and spatial patterns within network data. The UNSW-NB15 dataset is utilized, with varied segmentations meticulously assigned for both the training and evaluation stages to ensure comprehensive model assessment and robustness |
|
| Mohammed Jouhari et al. [22] | UNSW-NB15 | 2024 | CNN-BiLSTM | 97.90% | This investigation unveils a highly efficient IDS model that intricately merges BiLSTM with a compact CNN and employs dimensionality reduction techniques to optimize the model’s structure and performance |
|
| Fuat Turk [23] | UNSW-NB15 | 2023 | RF | 98.6% | In this research, a comprehensive intrusion identification evaluation was carried out on the UNSW-NB15 dataset, reaching an impressive 98.6% accuracy for two-class classification and 98.3% for multi-category classification, facilitated by the deployment of advanced machine learning and deep learning techniques. |
|
| Osama Faker and Erdogan Dogdu [17] | UNSW-NB15 | 2019 | DNN | 99.16% | This study undertakes a thorough analysis of machine learning methodologies through the application of 5-fold cross-validation, utilizes ensemble techniques enhanced by Apache Spark, and seamlessly combines the capabilities of deep learning by linking Apache Spark with Keras |
|
| Pramita Sree Muhuri et al. [24] | NSL KDD | 2020 | LSTM-RNN | 96.51% | This paper introduces an innovative intrusion detection strategy by combining RNN with LSTM and utilizing a genetic algorithm to identify the most optimal features. It reveals that LSTM-RNN categorization algorithms, when equipped with the appropriate features, improve intrusion detection on the NSL-KDD dataset. |
|
| Yanfang Fu et al. [25] | NSL KDD | 2022 | CNN and BiLSTMs | 90.73% | This study unveils DLNID, an advanced framework designed to identify irregularities in network traffic, which leverages the synergy of an attention mechanism integrated with Bi-LSTM, thereby significantly enhancing the precision of anomaly detection. The model harnesses CNN for effective feature extraction, incorporates attention mechanisms to optimize channel weights, and employs Bi-LSTM to learn sequential features, thereby refining its ability to detect anomalies. |
|
| WEN XU et al. [26] | NSL KDD | 2021 | Autoencoder | 90.61% | This work presents an innovative 5-layer autoencoder model for network anomaly detection, supported by a thorough assessment of its performance indicators. |
|
| Jihoon Yoo et al. [27] | NSL KDD | 2021 | CNN | 83% | This investigation delves into a CNN-based classifier designed to tackle the issue of class imbalance in network traffic datasets. The technique involves preparing and transforming data prior to analysis, including steps such as data cleaning, feature engineering, and restructuring, to optimize the model’s performance and accuracy. |
|
| Saud Alzughaibi and Salim El Khediri [28] | CSE-CIC-IDS2018 | 2023 | MLP-BP, MLP-PSO | 98.97% | This work studies cloud IDS advancement via two new deep neural nets. One uses MLP with BP, the other PSO. These models seek to boost IDS efficacy, improving intrusion detection and response, while ensuring adaptive, fast action. |
|
| Ram B. Basnet et al. [29] | CSE-CIC-IDS2018 | 2019 | MLP | 98.68% | This study performs a detailed evaluation of deep learning models for intrusion detection. It systematically compares frameworks such as Keras, TensorFlow, Theano, fast.ai, and PyTorch, employing the CSE-CIC-IDS2018 dataset to achieve a solid empirical analysis. |
|
| T. Thilagam and R. Aruna [30] | CSE-CIC-IDS2018 | 2021 | RC-NN-IDS | 94% | This research unveils a highly intricate IDS, architected with a meticulously tailored RC-NN framework, synergistically fine-tuned via the ALO algorithm to profoundly amplify detection precision and operational efficacy. |
|
| Fahimeh Farahnakian and Jukka Heikkonen [31] | KDD-CUP’99 | 2018 | DAE | 96.53% | This study introduces a novel IDS, rooted in the DAE framework, to tackle this critical issue. The model’s core strength lies in its sequential, layer-wise training strategy, meticulously designed to minimize overfitting and navigate past local optima. This refined training process fundamentally enhances the system’s robustness and significantly improves its capacity for accurate and effective intrusion detection. |
|
| Hafza A. Mahmood and Soukaena H. Hashem [32] | KDD-CUP’99 | 2017 | HNB | 97% | This research suggests employing an HNB Classifier to tackle DoS attacks. The HNB model, an advanced data mining technique, relaxes the conditional independence constraint of the NB classifier. It integrates HNB with discretization and feature selection to enhance performance and minimize processing time by optimizing feature relevance. |
|
| Mirza M. Baig et al. [33] | KDD-CUP’99 | 2017 | ANNs | 98.25% | This work pioneers a methodology for developing a highly durable classifier, leveraging a cascading architecture of boosting-reinforced neural networks, and rigorously demonstrates its performance using two distinct intrusion detection data repositories. This strategy, resembling the one-vs-rest approach but augmented with additional filtering of examples, leads to improved classifier effectiveness. |
|
| Author | Dataset | Year | Utilized Technique | Accuracy | Contribution | Limitations |
|---|---|---|---|---|---|---|
| Mohamed ElKashlan et al. [12] | IoT-23 | 2023 | Filtered classifier | 99.2% | This research pioneers a sophisticated machine learning-based framework, engineered for the precise identification of malicious traffic within the complex landscape of IoT networks. It employs a uniquely curated, highly representative dataset, meticulously designed to mirror authentic, real-world IoT traffic dynamics, and subsequently conducts a comprehensive, comparative performance assessment across a diverse spectrum of state-of-the-art classification algorithms. |
|
| Nicolas-Alin Stoian [34] | IoT-23 | 2020 | RF | 99.5% | This research delves into the critical area of IoT network security, meticulously evaluating the capacity of machine learning algorithms to discern anomalous patterns within intricate network data streams, thereby enhancing network resilience. It evaluates various ML algorithms that have demonstrated success in comparable contexts and performs a comparative analysis based on multiple parameters and methodologies. |
|
| Bambang Susilo and Riri Fitri Sari [35] | IoT-23 | 2020 | CNN | 91.24% | This investigation examines diverse machine learning and deep learning strategies, paired with conventional datasets, to fortify the security of IoT systems. An algorithm specifically designed for detecting DoS attacks has been developed using DL methods. |
|
| Mateusz Szczepański et al. [36] | IoT-23 | 2022 | RF | 96.30% | This research confronts the problem of effectively managing absent or incomplete data in real-world applications of computational intelligence. It presents two experimental studies that evaluate various methods for imputing missing values in Random Forest classifiers, which were trained using contemporary cyber security benchmark datasets, this includes the use of CICIDS2017 and IoT-23 datasets. |
|
| Abdallah R. Gad et al. [15] | ToN-IoT | 2020 | XGBoost | 97.8% | This work innovates by delivering a highly detailed, data-centric IoT/IIoT dataset, meticulously annotated with ground truth labels for precise normal/attack differentiation. It further incorporates attack subtype categorization, enabling nuanced multi-class analysis. The TON_IoT dataset aggregates telemetry from real-world IoT/IIoT services, system logs, and network traffic, all captured from a genuine, medium-scale network at UNSW Canberra’s Cyber Range and IoT Labs |
|
| Prahlad Kumar et al. [37] | Bot-IOT | 2021 | DT, RF, KNN, NB, and ANN | 99.6% | This research conducts a rigorous, dual-pronged investigation into DoS and DDoS attack vectors, employing both Machine Learning and Deep Learning paradigms. The study’s primary training data is the Bot-IoT dataset, originating from the UNSW Canberra Cyber Centre. To achieve granular feature extraction from UNSW dataset’s pcap files, the ARGUS software was deployed. This process facilitates an in-depth dissection of attack signatures, enabling precise identification and hierarchical classification of malicious actions within IoT environments. |
|
| Prabhat Kumar et al. [37]. | ToN-IoT | 2021 | ANN | 99.44% | This study pioneers a groundbreaking P2IDF, specifically engineered for Software-Defined IoT-Fog architectures, implementing a SAE to encode data into a form that effectively neutralizes inference-driven malicious intrusions. This study rigorously scrutinizes the operational effectiveness of an ANN driven intrusion detection paradigm, employing the ToN-IoT dataset, via a comparative analysis of its performance across both the unaltered and modified data configurations. The framework demonstrates a robust ability to detect attacks while maintaining stringent information confidentiality. |
|
| Mohanad Sarhan et al. [38] | ToN-IoT | 2022 | DFF, RF | 96.10%, 97.35% | This study meticulously scrutinizes the salience of attributes across six Network Intrusion Detection System (NIDS) data repositories, applying three divergent attribute selection techniques: Chi-squared, Mutual Information, and interrelation analysis. The chosen attribute subsets were then rigorously evaluated via Deep Feedforward Neural Networks and Random Forest classification algorithms, culminating in 414 comprehensive experimental runs. A pivotal revelation indicates that a diminished attribute subset can equal, or even surpass, the detection efficacy of the complete attribute set, thus highlighting the profound effectiveness of attribute selection in optimizing NIDS operational efficiency and diagnostic accuracy. |
|
| Mohamed Amine Ferrag et al. [39] | Edge-IIoT | 2022 | DNN | 94.67% | This work unveils Edge-IIoTset, a comprehensive cyber security dataset for the application of machine learning-based intrusion detection systems in IoT and IIoT contexts. Designed with a customized IoT/IIoT testbed, featuring a diverse array of devices, sensors, protocols, and cloud/edge setups, it supports both centralized and federated learning models, ensuring its relevance and applicability in real-world environments. |
|
| Osama Faker and Erdogan Dogdu [17]. | CICIDS2017 | 2019 | DNN | 99.56% | This study advances the field of intrusion detection by harnessing the synergy between Big Data analytics and Deep Learning methodologies, deploying Gradient Boosted Trees, Random Forest ensembles, and Deep Feed-Forward Neural Networks to fortify detection capabilities. It examines features using a homogeneity measure and performs evaluations utilizing the UNSW-NB15 and CICIDS2017 data repositories through a five-segment cross-validation methodology, employing Apache Spark and Keras. |
|
| R. Vinayakumar et al. [18] | CICIDS2017 | 2019 | DNN | 95.6% | This research endeavors to engineer a supremely adaptable IDS, leveraging deep neural network architectures to discern and categorize dynamic cybernetic assaults. It evaluates diverse data repositories and algorithmic methodologies, contrasting Deep Neural Networks with traditional classification paradigms across standardized malware benchmarks to pinpoint the optimal technique for emergent threat recognition |
|
| Kaniz Farhana et al. [19]. | CICIDS2017 | 2020 | DNN | 99% | This study fabricates an IDS predicated upon a deep neural network topology, authenticated against a modern, non-uniform dataset comprising 79 unique descriptors. Assembled utilizing the Keras and TensorFlow computational libraries, the model examines data at the packet level, flow-derived metrics, and pertinent supplementary information. |
|
| Razan Abdulhammed et al. [40]. | CICIDS2017 | 2019 | PCA, RF, LDA and QDA | 99.6% | This study applies PCA for feature dimensionality reduction, followed by utilizing the reduced features to train multiple classifiers, including RF, LDA, and QDA, for an IDS. |
|
| Osama Faker and Erdogan Dogdu [17]. | UNSW-NB15 | 2019 | DNN | 97.01% | This investigation performs a valuation of machine learning paradigms via a quintuple-partition cross-validation procedure, merging Keras with Apache Spark for deep learning execution, and employing Apache Spark MLlib for ensemble-based algorithmic frameworks. |
|
| A. M. ALEESA et al. [41] | UNSW-NB15 | 2021 | ANN | 99.59% | This investigation appraised the operational proficiency of deep learning paradigms for both dual-class and multi-categorical classification through the utilization of a reformed data compilation, integrating all data into one file and forming new multi-class labels derived from attack families. |
|
| Muhammad Ahmad et al. [42] | UNSW-NB15 | 2021 | RF | 97.37% | This research posits the utilization of attribute agglomerations associated with Flow, TCP, and MQTT within the UNSW-NB15 dataset to alleviate predicaments such as category imbalance, excessive dimensionality, and model overfitting, concurrently implementing ANN, SVM, and RF for classification objectives. |
|
| Fuat Turk [23]. | UNSW-NB15 | 2023 | RF | 98.3% | This work employs advanced computational learning and deep neural network methods to discern security violations within the UNSW-NB15 and NSL-KDD data repositories, attaining 98.6% correctness in binary categorization and 98.3% accuracy in poly-class labeling on the UNSW-NB15 data compilation. |
|
| Bilal Mohammed, Ekhlas K. Gbashi [43]. | NSL KDD | 2021 | RNN | 94% | The study uses RFE to select features and applies both DNN and RNN for categorization, attaining 94% accuracy across five distinct categories using the RNN learning model. |
|
| Muhammad Basit Umair et al. [44] | NSL KDD | 2022 | Multilayer CNN-LSTM | 99.5% | In response to the shortcomings of traditional techniques, this work introduces a data-driven method for detecting unauthorized activities. It involves the process of extracting relevant features, classification through a multi-layered CNN with softmax, followed by additional classification using a multi-layered DNN. |
|
| Padideh Choobdar et al. [45] | NSL KDD | 2021 | Sparse Stacked Auto-Encoders | 98.5% | This study outlines the creation of a controller component tailored for an intrusion detection system based on SDN principles, incorporating an initial pre-training phase using sparse stacking autoencoders, followed by training with a softmax classifier, and concludes with the fine-tuning of parameters to optimize performance. |
|
| Shi Dong et al. [46] | NSL KDD | 2021 | SSDDQN | 79.43% | This study presents a semi-supervised optimization method for network anomaly traffic detection, based on a DDQN approach, which is a prominent technique in Deep Reinforcement Learning. In the proposed SSDDQN model, the current network utilizes an autoencoder to reconstruct traffic features, followed by a deep neural network classifier. The target network, on the other hand, first applies the unsupervised K-Means clustering algorithm and then employs a deep neural network for prediction. |
|
| Ram B. Basnet et al. [29] | CSE-CIC-IDS2018 | 2019 | MLP | 98.31% | This investigation scrutinizes a broad assortment of deep neural network methodologies for network security breach recognition, evaluating numerous computational platforms, including Keras, TensorFlow, Theano, fast.ai, and PyTorch, while leveraging the CSE-CIC-IDS2018 data compilation for assessment purposes |
|
| Baraa Ismael Farhan and Ammar D. Jasim [47] | CSE-CIC-IDS2018 | 2022 | LSTM | 99% | This study recognizes the intensifying imperative for robust digital protective measures, consequently the necessity for efficient network surveillance becomes paramount. This investigation utilizes deep learning algorithms upon the CSE-CIC-IDS2018 data repository, achieving 99% detection accuracy via a LSTM paradigm for discerning network security breaches |
|
| Rawaa Ismael Farhan et al. [48] | CSE-CIC-IDS2018 | 2020 | DNN | 90% | This research comprehensively assesses their DNN construct, which has attained a remarkable detection correctness of roughly 90%, exhibiting substantial capacity for subsequent refinement and operational enhancement |
|
| Peng Lin et al. [49] | CSE-CIC-IDS2018 | 2019 | LSTM | 96.2% | In order to fortify cyber defense, we have designed an adaptive anomaly detection framework utilizing advanced deep learning approaches. This construct implements a LSTM deep neural network system, bolstered by an AM to heighten its overall efficiency. Moreover, the SMOTE, fused with an improved loss criterion, is utilized to effectively mitigate the distributional disparity present within the CSE-CIC-IDS2018 data repository. |
|
| Mirza M. Baig et al. [33] | KDD-CUP’99 | 2017 | ANNs | 99.36% | This research proposes a methodology that deploys a succession of augmentation-based artificial neural network frameworks to develop a vigorous classification model. Validated on two intrusion recognition data repositories, this method enhances the one-against-remaining strategy through the inclusion of additional instance screening to improve fidelity |
|
| R. Vinayakumar et al. [18] | KDD-CUP’99 | 2019 | DNN | 93% | The researchers have designed a DNN-driven intrusion detection system that reaches 93% accuracy in identifying and categorizing novel cyberattacks by analyzing both fixed and evolving datasets. |
|
| Guojie Liu and Jianbiao Zhang [50] | KDD-CUP’99 | 2020 | CNN | 98.2% | This research executed network security penetration detection across diverse categorizations employing the KDD-CUP 99 and NSL-KDD data repositories. The CNN architecture accomplished an outstanding accuracy of 98.2%, illustrating its skill in effectively recognizing diverse network attack variations. |
|
| Mario Di Mauro et al. [51] | CICIDS2017 | 2020 | MLP | 88.92% | In this paper, the authors present an experimental-based review of various neural network-based methods applied to IDS. They specifically highlight the performance of MLP, a prominent type of neural network-based method, which achieved an accuracy of 88.92% in multi-class classification for detecting intrusions |
|
| Attack Type | Samples Counts | Description |
|---|---|---|
| benign | 70,000 | A general label for traffic captures deemed non-suspicious. |
| PartOfAHorizontalPortScan | 69,198 | It involves collecting information from a device by scanning multiple ports to identify open or vulnerable ports. This information is gathered to facilitate planning and execution of future attacks. |
| DDoS | 65,000 | An attack where the compromised device is used to participate in a distributed denial-of-service, overwhelming a target system or network with excessive traffic to disrupt its normal operations. |
| Okiru | 14,942 | An attack carried out by the Okiru botnet, a more advanced and sophisticated variant of the Mirai botnet. This network is designed to exploit IoT devices for malicious purposes, extending the capabilities of earlier botnet versions. |
| C&C-HeartBeat | 10,239 | A method where the server controlling the infected device sends regular messages to monitor the status of the compromised device. These periodic communications are detected by identifying small data packets sent at regular intervals from a suspicious source. |
| C&C | 8939 | A type of attack in which an attacker gains control over a device and establishes a command channel to issue instructions. This allows the attacker to direct the device to perform various malicious actions or attacks at their discretion in the future. |
| Attack | 3396 | A general label applied to anomalies that cannot be specifically identified or classified. This designation is used when a detected issue falls into an undefined category of malicious activity or remains unclassified due to insufficient details. |
| C&C-PartOfAHorizontalPortScan | 327 | A scenario where the network sends data packets to perform a horizontal port scan, collecting information about open ports and vulnerabilities on multiple devices. This data gathering is aimed at identifying potential targets for future attacks. |
| Attribute | Description |
|---|---|
| ts | The time at which the capture occurred, represented in Unix time format. |
| uid | A unique identifier assigned to the capture, serving as a distinct reference for each data entry. |
| id_orig.h | The IP address of the originating source where the attack occurred, which can be either in IPv4 or IPv6 format. |
| id_orig.p | The port number utilized by the originating source in the communication process. |
| id_resp.h | The IP address of the device that received the capture, indicating the destination of the network traffic. |
| id_resp.p | The port number used for the response from the device where the capture took place, indicating the communication endpoint on the receiving device. |
| proto | The network protocol employed for the data packet transmission, specifying the method of communication used for the data exchange. |
| service | The application-level protocol used for the communication, defining the specific type of service or application interacting over the network. |
| duration | The total amount of time that data was exchanged between the device and the attacker, representing the period of active communication. |
| orig_bytes | The volume of data transmitted to the device from the source, indicating the total amount of incoming data. |
| resp_bytes | The volume of data sent by the device in response, representing the total amount of outbound data transmitted from the device. |
| conn_state | The current status of the connection, reflecting the connection’s operational state or phase at the time of the data capture. |
| local_orig | Indicates whether the connection was initiated locally from within the same network or system. |
| local_resp | Indicates whether the response was generated locally within the same network or system. |
| missed_bytes | The count of bytes that were not captured or were lost within a message transmission, indicating gaps in the data recorded. |
| history | The record of changes or transitions in the connection’s state over time, detailing the evolution and previous statuses of the connection. |
| orig_pkts | The total count of packets transmitted to the device from the source, reflecting the volume of incoming network traffic directed towards it. |
| orig_ip_bytes | The total number of bytes transmitted to the device over the IP network, indicating the volume of data received by the device. |
| resp_pkts | The total count of packets sent from the device, representing the volume of outbound network traffic originating from it. |
| resp_ip_bytes | The total number of bytes transmitted from the device over the IP network, reflecting the volume of data sent out by the device. |
| labels | The classification of the capture, denoting whether it is benign, normal, or malicious. |
| detailed_label | When the capture is identified as malicious, this field specifies the type of malicious activity, as described in the detailed classifications provided above. |
| Class Type | Train | Test |
|---|---|---|
| Normal | 58,997 | 10,497 |
| Attack | 137,358 | 24,155 |
| Class Type | Train | Test |
|---|---|---|
| PartOfAHorizontalPortScan | 54,762 | 9733 |
| DDoS | 51,048 | 9069 |
| Okiru | 12,777 | 2156 |
| C&C-HeartBeat | 6965 | 1174 |
| C&C | 5756 | 1036 |
| Attack | 1814 | 327 |
| C&C-PartOfAHorizontalPortScan | 225 | 37 |
| Class Type | Train | Test |
|---|---|---|
| benign | 58,964 | 10,507 |
| PartOfAHorizontalPortScan | 58,901 | 10,241 |
| DDoS | 51,026 | 9016 |
| Okiru | 12,675 | 2260 |
| C&C-HeartBeat | 6863 | 1232 |
| C&C | 5697 | 990 |
| Attack | 1825 | 328 |
| C&C-PartOfAHorizontalPortScan | 227 | 46 |
| Category Label | Pre-Resampling Sample Count (ADASYN-SMOTE) | Post-Resampling Sample Count (ADASYN-SMOTE) |
|---|---|---|
| Normal | 58,997 | 140,815 |
| Attack | 137,358 | 140,815 |
| Category Label | Pre-Resampling Sample Count (ADASYN-SMOTE) | Post-Resampling Sample Count (ADASYN-SMOTE) |
|---|---|---|
| PartOfAHorizontalPortScan | 54,762 | 54,762 |
| DDoS | 51,048 | 51,048 |
| Okiru | 12,777 | 12,777 |
| C&C-HeartBeat | 6965 | 6965 |
| C&C | 5756 | 5756 |
| Attack | 1814 | 54,762 |
| C&C-PartOfAHorizontalPortScan | 225 | 54,761 |
| Category Label | Pre-Resampling Sample Count (ADASYN-SMOTE) | Post-Resampling Sample Count (ADASYN-SMOTE) |
|---|---|---|
| benign | 58,964 | 58,964 |
| PartOfAHorizontalPortScan | 58,901 | 58,901 |
| DDoS | 51,026 | 51,026 |
| Okiru | 12,675 | 12,675 |
| C&C-HeartBeat | 6863 | 6863 |
| C&C | 5697 | 5697 |
| Attack | 1825 | 58,962 |
| C&C-PartOfAHorizontalPortScan | 227 | 58,924 |
| Category Label | Pre-Resampling Sample Count (ENN) | Post-Resampling Sample Count (ENN) |
|---|---|---|
| Normal | 140,815 | 140,815 |
| Attack | 140,815 | 115,850 |
| Category Label | Pre-Resampling Sample Count (ENN) | Post-Resampling Sample Count (ENN) |
|---|---|---|
| PartOfAHorizontalPortScan | 54,762 | 54,491 |
| DDoS | 51,048 | 51,043 |
| Okiru | 12,777 | 12,777 |
| C&C-HeartBeat | 6965 | 6957 |
| C&C | 5756 | 5756 |
| Attack | 54,762 | 54,761 |
| C&C-PartOfAHorizontalPortScan | 54,761 | 54,761 |
| Category Label | Pre-Resampling Sample Count (ENN) | Post-Resampling Sample Count (ENN) |
|---|---|---|
| benign | 58,964 | 48,622 |
| PartOfAHorizontalPortScan | 58,901 | 42,206 |
| DDoS | 51,026 | 51,020 |
| Okiru | 12,675 | 12,675 |
| C&C-HeartBeat | 6863 | 6861 |
| C&C | 5697 | 5697 |
| Attack | 58,962 | 58,962 |
| C&C-PartOfAHorizontalPortScan | 58,924 | 58,923 |
| Class Type | Weight Using Class Weights |
|---|---|
| Normal | 0.9114 |
| Attack | 1.1077 |
| Class Type | Weight Using Class Weights |
|---|---|
| PartOfAHorizontalPortScan | 0.6306 |
| DDoS | 0.6732 |
| Okiru | 2.6895 |
| C&C-HeartBeat | 4.9394 |
| C&C | 5.9701 |
| Attack | 0.6275 |
| C&C-PartOfAHorizontalPortScan | 0.6275 |
| Class Type | Weight Using Class Weights |
|---|---|
| benign | 0.7326 |
| PartOfAHorizontalPortScan | 0.8440 |
| DDoS | 0.6982 |
| Okiru | 2.8103 |
| C&C-HeartBeat | 5.1918 |
| C&C | 6.2525 |
| Attack | 0.6041 |
| C&C-PartOfAHorizontalPortScan | 0.6045 |
| Parameter | Binary Classifier | Multi-Class Classifier |
|---|---|---|
| Batch size | 128 | 128 |
| Learning rate | Scheduled: Starting Value = 0.001, Factor = 0.5, Min = 1 × 10−5 (ReduceLROnPlateau) | Scheduled: Starting Value = 0.001, Factor = 0.5, Min = 1 × 10−5 (ReduceLROnPlateau) |
| Optimizer | Adam | Adam |
| Loss function | Binary cross-entropy | Categorical cross-entropy |
| Metric | Accuracy | Accuracy |
| Parameter | Binary Classifier | Multi-Class Classifier |
| Batch size | 128 | 128 |
| Learning rate | Scheduled: Starting Value = 0.001, Factor = 0.5, Min = 1 × 10−5 (ReduceLROnPlateau) | Scheduled: Starting Value = 0.001, Factor = 0.5, Min = 1 × 10−5 (ReduceLROnPlateau) |
| Optimizer | Adam | Adam |
| Loss function | Binary cross-entropy | Categorical cross-entropy |
| Metric | Accuracy | Accuracy |
| Parameter | Binary Classifier | Multi-Class Classifier |
| Batch size | 128 | 128 |
| Learning rate | Scheduled: Starting Value = 0.0003, Factor = 0.9, Decay Steps = 10,000 (Exponential Decay) | Scheduled: Starting Value = 0.0003, Factor = 0.9, Decay Steps = 10,000 (Exponential Decay) |
| Optimizer | Adam | Adam |
| Loss function | Binary cross-entropy | Categorical cross-entropy |
| Metric | Accuracy | Accuracy |
| Parameter | Binary Classifier | Multi-Class Classifier |
| Batch size | 128 | 128 |
| Learning rate | Scheduled: Starting Value = 0.001, Factor = 0.5, Min = 1 × 10−5 (ReduceLROnPlateau) | Scheduled: Starting Value = 0.001, Factor = 0.5, Min = 1 × 10−5 (ReduceLROnPlateau) |
| Optimizer | Adam | Adam |
| Loss function | Binary cross-entropy | Categorical cross-entropy |
| Metric | Accuracy | Accuracy |
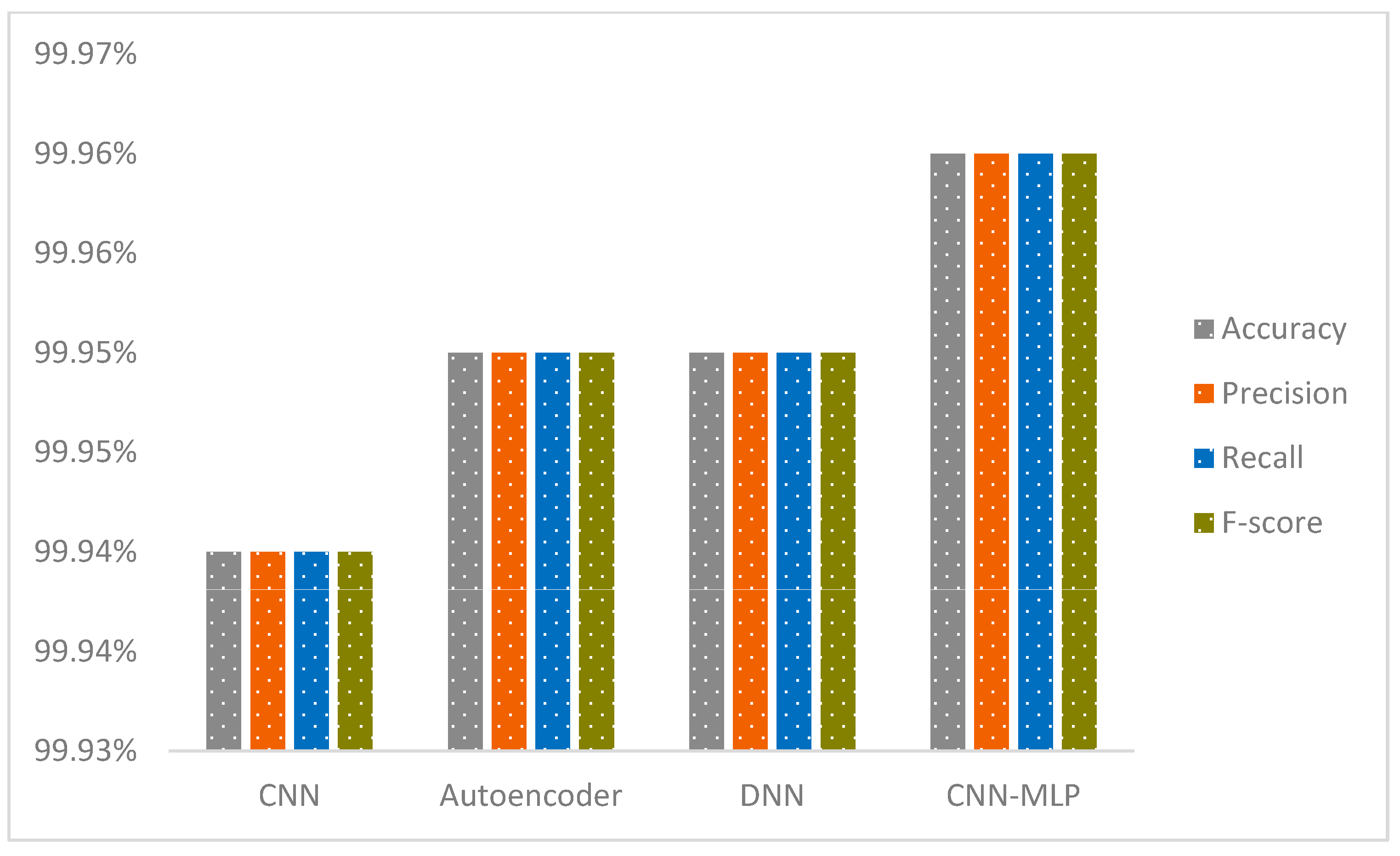
| Dataset | Metric | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| IoT-23 | CNN | 99.92% | 99.92% | 99.92% | 99.92% |
| Autoencoder | 84.02% | 89.34% | 84.02% | 84.64% | |
| DNN | 99.24% | 99.25% | 99.24% | 99.24% | |
| CNN-MLP | 99.94% | 99.94% | 99.94% | 99.94% | |
| NF-BoT-IoT-v2 | CNN | 99.94% | 99.94% | 99.94% | 99.94% |
| Autoencoder | 99.95% | 99.95% | 99.95% | 99.95% | |
| DNN | 99.95% | 99.95% | 99.95% | 99.95% | |
| CNN-MLP | 99.96% | 99.96% | 99.96% | 99.96% |
| Dataset | Metric | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| IoT-23 | CNN | 99.97% | 99.98% | 99.97% | 99.97% |
| Autoencoder | 99.57% | 99.60% | 99.57% | 99.57% | |
| DNN | 99.94% | 99.94% | 99.94% | 99.94% | |
| CNN-MLP | 99.99% | 99.99% | 99.99% | 99.99% | |
| NF-BoT-IoT-v2 | CNN | 97.99% | 98.04% | 97.99% | 97.99% |
| Autoencoder | 98.01% | 98.06% | 98.01% | 98.00% | |
| DNN | 97.92% | 97.99% | 97.92% | 97.92% | |
| CNN-MLP | 98.02% | 98.07% | 98.02% | 98.02% |
| Dataset | Metric | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| IoT-23 | CNN | 99.81% | 99.84% | 99.81% | 99.82% |
| Autoencoder | 87.12% | 87.70% | 87.12% | 87.16% | |
| DNN | 99.67% | 99.73% | 99.67% | 99.69% | |
| CNN-MLP | 99.91% | 99.92% | 99.91% | 99.91% | |
| NF-BoT-IoT-v2 | CNN | 98.04% | 98.04% | 98.04% | 98.04% |
| Autoencoder | 98.08% | 98.12% | 98.08% | 98.07% | |
| DNN | 97.89% | 97.92% | 97.89% | 97.88% | |
| CNN-MLP | 98.11% | 98.17% | 98.11% | 98.11% |
| Dataset | Classification Type | Training Time per Batch (Seconds) | Training Time per Sample (Milliseconds) |
|---|---|---|---|
| IoT-23 | Binary classification | 0.0688 | 0.54 |
| Multi-class classification excluding normal class | 0.0824 | 0.64 | |
| Multi-class classification including normal class | 0.0870 | 0.68 | |
| NF-BoT-IoT-v2 | Binary classification | 0.0579 | 0.45 |
| Multi-class classification excluding normal class | 0.0680 | 0.53 | |
| Multi-class classification including normal class | 0.0747 | 0.58 |
| Dataset | Classification Type | Inference Time per Batch (Seconds) | Inference Time per Sample (Milliseconds) |
|---|---|---|---|
| IoT-23 | Binary classification | 0.0575 | 0.45 |
| Multi-class classification excluding normal class | 0.0613 | 0.48 | |
| Multi-class classification including normal class | 0.0674 | 0.53 | |
| NF-BoT-IoT-v2 | Binary classification | 0.0570 | 0.45 |
| Multi-class classification excluding normal class | 0.0634 | 0.50 | |
| Multi-class classification including normal class | 0.0687 | 0.54 |
| Dataset | Classification Type | Memory consumption (MB) |
|---|---|---|
| IoT-23 | Binary classification | 111.63 |
| Multi-class classification excluding normal class | 119.70 | |
| Multi-class classification including normal class | 123.84 | |
| NF-BoT-IoT-v2 | Binary classification | 15.54 |
| Multi-class classification excluding normal class | 23.99 | |
| Multi-class classification including normal class | 25.69 |
| Label | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| Normal | 99.91% | 99.90% | 99.91% | 99.90% |
| Attack | 99.95% | 99.96% | 99.95% | 99.96% |
| Label | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| Normal | 100% | 99.61% | 100% | 99.80% |
| Attack | 99.95% | 100% | 99.95% | 99.98% |
| Class | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| PartOfAHorizontalPortScan | 99.99% | 100% | 99.99% | 99.99% |
| DDoS | 99.99% | 99.99% | 99.99% | 99.99% |
| Okiru | 100% | 100% | 100% | 100% |
| C&C-HeartBeat | 99.91% | 100% | 99.91% | 99.96% |
| C&C | 100% | 100% | 100% | 100% |
| Attack | 100% | 99.70% | 100% | 99.85% |
| C&C-PartOfAHorizontalPortScan | 100% | 97.37% | 100% | 98.67% |
| Class | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| Reconnaissance | 94.72% | 99.27% | 94.72% | 96.94% |
| DDoS | 99.41% | 99.53% | 99.41% | 99.47% |
| DoS | 98.93% | 95.43% | 98.93% | 97.15% |
| Theft | 98.18% | 96.43% | 98.18% | 97.30% |
| Class | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| Benign | 99.92% | 99.93% | 99.92% | 99.93% |
| PartOfAHorizontalPortScan | 99.79% | 99.99% | 99.79% | 99.89% |
| DDoS | 99.99% | 100% | 99.99% | 99.99% |
| Okiru | 100% | 100% | 100% | 100% |
| C&C-HeartBeat | 100% | 100% | 100% | 100% |
| C&C | 99.80% | 99.40% | 99.80% | 99.60% |
| Attack | 100% | 100% | 100% | 100% |
| C&C-PartOfAHorizontalPortScan | 100% | 71.88% | 100% | 83.64% |
| Class | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| Benign | 100% | 99% | 100% | 99.50% |
| Reconnaissance | 94.47% | 99.85% | 94.47% | 97.09% |
| DDoS | 99.18% | 99.30% | 99.18% | 99.24% |
| DoS | 99.05% | 95.19% | 99.05% | 97.08% |
| Theft | 100% | 98.04% | 100% | 99.01% |
| Data Handling Strategy | Classification Type | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| Without Resampling and Class Weights | Binary classification | 99.38% | 99.39% | 99.38% | 99.38% |
| Multi-class classification excluding normal class | 99.96% | 99.96% | 99.96% | 99.96% | |
| Multi-class classification including normal class | 99.84% | 99.84% | 99.84% | 99.80% | |
| With Resampling and Class Weights | Binary classification | 99.94% | 99.94% | 99.94% | 99.94% |
| Multi-class classification excluding normal class | 99.99% | 99.99% | 99.99% | 99.99% | |
| Multi-class classification including normal class | 99.91% | 99.92% | 99.91% | 99.91% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kamal, H.; Mashaly, M. Robust Intrusion Detection System Using an Improved Hybrid Deep Learning Model for Binary and Multi-Class Classification in IoT Networks. Technologies 2025, 13, 102. https://doi.org/10.3390/technologies13030102
Kamal H, Mashaly M. Robust Intrusion Detection System Using an Improved Hybrid Deep Learning Model for Binary and Multi-Class Classification in IoT Networks. Technologies. 2025; 13(3):102. https://doi.org/10.3390/technologies13030102
Chicago/Turabian StyleKamal, Hesham, and Maggie Mashaly. 2025. "Robust Intrusion Detection System Using an Improved Hybrid Deep Learning Model for Binary and Multi-Class Classification in IoT Networks" Technologies 13, no. 3: 102. https://doi.org/10.3390/technologies13030102
APA StyleKamal, H., & Mashaly, M. (2025). Robust Intrusion Detection System Using an Improved Hybrid Deep Learning Model for Binary and Multi-Class Classification in IoT Networks. Technologies, 13(3), 102. https://doi.org/10.3390/technologies13030102