Abstract
This study introduces an Artificial Intelligence framework based on the Deep Learning model Bidirectional Encoder Representations from Transformers framework trained on a dataset from 2000–2023. The AI tool categorizes articles into six classes: Contactology, Low Vision, Refractive Surgery, Pediatrics, Myopia, and Dry Eye, with supervised learning enhancing classification accuracy, achieving F1-Scores averaging 86.4%, AUC at 0.98, Precision at 87%, and Accuracy at 86.8% via one-shot training, while Epoch training showed 85.9% Accuracy and 92.8% Precision. Utilizing the Artificial Intelligence model outputs, the Autoregressive Integrated Moving Average model provides forecasts from all classes through 2030, predicting decreases in research interest for Contactology, Low Vision, and Refractive Surgery but increases for Myopia and Dry Eye due to rising prevalence and lifestyle changes. Stability is expected in pediatric research, highlighting its focus on early detection and intervention. This study demonstrates the effectiveness of AI in enhancing diagnostic precision and strategic planning in optometry, with potential implications for broader clinical applications and improved accessibility to eye care.
1. Introduction
Optometry is rapidly evolving from a discipline centered on diagnosing and correcting visual impairments to a sophisticated, technology-driven field. Advanced technologies such as Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) have become essential tools. Research shows that good eye care depends on more than just a doctor’s experience, it also relies on using patient data and electronic health records (EHRs), running systematic tests, and applying digital tools to improve outcomes [1,2].
Interestingly, there are parallels between optometry and other fields of medicine. For example, Natural Language Processing (NLP),a branch of AI, has been used in healthcare to identify patterns and to guide research. Researchers believe that these techniques can be adapted to optometry to make more accurate and efficient clinical decisions [3,4]. AI models, such as the Bidirectional Encoder Representations from Transformers (BERT), analyze large amounts of data, including electronic health records, which can be used for diagnostics. Regarding the analyzing of diagnostic images using convolutional neural networks (CNNs), they have become faster and more reliable. These systems can help identify early warning signs of eye diseases, improve preventative care, and create personalized treatment plans for patients [5,6,7,8].
One area with huge potential is NLP. It’s already being used to sift through medical literature and classify information, which saves time and supports collaboration between researchers. In optometry, it can help doctors quickly analyze patient records or pull actionable insights from clinical data. This type of real-time guidance could make it easier for doctors to keep up with new treatments and make informed decisions for their patients [9,10]. In addition, AI-powered diagnostic tools are opening new possibilities for rural and underserved areas. Portable devices equipped with AI can detect conditions such as early diabetic retinopathy, even in remote locations. This type of accessibility is a game-changer for global eye care [11,12].
With the development of these technologies, AI has rapidly evolved into a transformative tool in clinical practice, enabling significant advancements in diagnostic and healthcare management. In ophthalmology, deep learning models have achieved remarkable success in identifying diabetic retinopathy, glaucoma, and age-related macular degeneration (AMD) using fundus images and Optical Coherence Tomography (OCT), attaining accuracy levels comparable to, or even exceeding, those of human experts [13,14,15]. These systems have proven particularly effective in enhancing early detection and intervention, critical for preventing irreversible vision loss. Furthermore, AI-driven OCT platforms have demonstrated substantial efficiency in primary care by reducing specialists’ workloads and expediting referrals for urgent cases, achieving high efficiency improvements in clinical workflows [15]. AI’s impact extends beyond ophthalmology into other medical specialties. In dermatology, CNNs have matched dermatologists in classifying malignant skin lesions, while in radiology, AI models have accurately detected tumors in mammograms and other imaging modalities [16,17]. In histopathology, AI systems have facilitated the quantification of biomarkers such as PD-L1, pivotal for personalized oncology treatments, and uncovered complex biological patterns associated with patient survival [16]. These innovations highlight AI’s potential not only for improving diagnostic accuracy but also for driving advancements in precision medicine.
Additionally, the integration of AI with telemedicine has expanded access to high-quality diagnostic services in underserved regions. AI-powered platforms leveraging cloud computing and OCT imaging have demonstrated high sensitivity and specificity in real-world settings, enabling remote detection of retinal diseases [17]. These advancements address systemic healthcare challenges, including workforce shortages and disparities in access to care, while promising to enhance global health equity. As research progresses, the development of explainable and robust AI systems will further transform clinical practice, offering improved patient outcomes and more efficient workflows worldwide.
AI has shown significant promise in the field of optometry, with several studies demonstrating its varied applications. For instance, Ho et al. [1] utilized evidence-based AI practices to systematically enhance ocular care by applying clinical guidelines. In another study, Alam et al. [18] employed NLP classification models to efficiently categorize large datasets of medical literature within both oncology and optometry. Their work demonstrated the potential of AI to handle vast amounts of data. Kalyan and Sangeetha [5] developed a BERT-based model that demonstrated superior accuracy in medical text normalization, showing how AI can be adapted to understand and process user-generated texts and electronic health records with high precision.
Another exciting development is the use of predictive analytics. Using ML models or statistical tools such as Autoregressive Integrated Moving Average (ARIMA), experts can predict trends in eye health, like disease spikes or seasonal changes. This helps public health officials prepare better and ensure that resources are allocated where they are most needed [19,20,21]. However, these tools are not just useful in the clinical practice. They are also helping educators update optometry training programs to focus on emerging technologies and areas of need [22,23,24].
Ultimately, the future of optometry depends on combining together technology and traditional clinical skills. Tools such as AI and NLP help doctors, streamline diagnoses, and reach more patients. They make eye care faster, smarter, and more accessible for everyone. This combination of innovation and evidence-based care is changing how optometry works [25,26,27].
Although the utilization of ML, DL, and AI is not particularly new in the field of optometry, there remains a persistent need to continually develop and implement new and more effective solutions. The dynamic nature of ocular diseases and visual impairments demands that optometric practices keep pace with technological advancements in order to enhance diagnostic accuracy and therapeutic outcomes. The integration of AI-driven technologies can lead to significant improvements in patient care by enabling the earlier detection of conditions, personalized treatment plans, and more efficient management of ocular health. Table 1 provides a comprehensive summary of several studies that have investigated AI applications in optometry, illustrating the breadth of research and the potential impact of these technologies on the field.

Table 1.
Comparison of Studies on AI Applications in Optometry.
The objectives of the present study are:
- Design of the Optometry BERT (O-BERT) DL model tailored for optometry data interpretation and classification.
- Use O-BERT to classify and diagnose different areas of optometry.
- Use the O-BERT output to forecast each class until 2030 using the ARIMA fortecast model.
The objectives outlined above form the cornerstone of the novelty this study. By achieving these objectives, this study aims to establish a comprehensive pipeline that bridges the gap between AI models trained in academic literature and their application to real-world medical data. The primary focus of this study is to develop the data pipeline and enable AI agents to seamlessly integrate and cross-reference real medical data with published academic research. This integration represents a critical step toward creating AI systems capable of leveraging both empirical clinical data and theoretical advancements to enhance decision-making and foster more robust medical insights.
This paper is organized as follows: In Section 2 is where the main literature is reviewed, Section 3 is Materials and Methods, where the theoretical framework of described, in the Section 4 the Results are presented, in Section 5 there is a Discussion on the given results, and finally in Section 6 where the Conclusions are outlined.
2. Literature Review
Optometry, a fundamental discipline in ocular health, has seen significant diversification into subspecialties aimed at enhancing specific aspects of vision and ocular wellbeing. Research in optometry is not only crucial for developing more effective treatments but also for a better understanding of how various genetic and environmental factors affect visual health throughout life [1]. Tools such as ML, NLP, and DL are essential not only for organizing, classifying, and predicting future trends in optometric research, facilitating better collaboration between researchers and clinicians, and improving access to specialized knowledge but also aid in the process of diagnostics.
A crucial aspect of optometric research is its capacity to directly influence the prevention, diagnosis, and treatment of ocular disorders, which affect millions of people worldwide. For instance, advancements in the understanding of visual development and the factors affecting children’s ocular health can lead to earlier and more effective interventions, potentially safeguarding the vision of future generations. Ho et al. [1] and Twa MD [2] highlighted the importance of systematic, evidence-based assessments in delivering ocular care, a practice that could be analogously applied in optometry to prevent serious vision issues before they worsen.
DL is a branch of ML, is the main driver of AI. AI and NLP revolutionize the way optometric literature is organized and classified. These tools not only allow for better management of the growing volume of publications and data, but also enable the discovery of patterns and trends that might go unnoticed without computational analysis. Alam et al. [18] demonstrated the effectiveness of these technologies in classifying medical articles in oncology, a method that could be equally valuable in optometry for prioritizing urgent research areas and optimizing resources; however, they proved that these models can be trained to understand information.
The adoption of advanced natural language processing (NLP) techniques has led to the discovery of emerging trends in various medical fields. A significant study by Jensen et al. [3] used NLP to analyze the literature on cardiovascular diseases and identify research patterns and potential future directions, which could be adapted to better understand optometry trends [4]. Applying these methodologies could provide similar insights and better direct future research towards areas of urgent clinical and scientific needs.
NLP techniques have revolutionized medical analysis. Jensen et al. [3] applied NLP to electronic health records to identify the emerging trends in cardiovascular research. This approach can be transfered to optometry, in which similar methodologies can be used to uncover research patterns and guide future investigations. The potential of NLP to provide meaningful insights from vast datasets underscores its importance for biomedical informatics. For example, NLP can be used to analyze patient records and extract relevant information for diagnosing conditions, such as keratoconus or refractive errors.
Beyond its traditional applications, NLP has the potential to transform patient interaction and clinical documentation into optometry. Automated transcription services powered by NLP can convert spoken interactions between optometrists and patients into structured EHRs, thereby saving time and ensuring the accuracy of patient records, which is essential for ongoing patient care and legal compliance. NLP can enhance patient education and communication. Chatbots and virtual assistants using NLP can provide patients with instant answers to common eye care questions, reminders for medication, and guidance on managing their conditions, improving patient engagement and adherence to treatment plans, which is particularly beneficial for managing chronic conditions, such as glaucoma or diabetic retinopathy [3].
Moreover, the NLP can facilitate large-scale epidemiological optometry studies. By analyzing vast amounts of unstructured data from EHRs, research articles, and patient forums, NLP can identify trends in disease prevalence, treatment outcomes, and patient experience. This information can guide public health initiatives and inform clinical guidelines, ultimately leading to improved eye-care policies and practices. Advanced NLP models, such as those based on transformers, can also be used to predict patient outcomes by analyzing clinical notes and other textual data. For example, these models can identify subtle cues in patient records, which may indicate a higher risk of disease progression, thus enabling early intervention and personalized care strategies. This predictive capability is a powerful tool in preventive medicine, helping reduce the incidence of severe ocular conditions through timely treatment [5].
The integration of NLP into optometric research also facilitates interdisciplinary collaborations. By harmonizing terminologies and standardizing data across different specialties, NLP ensures that optometric research findings are more easily accessible and interpretable by professionals in related fields such as neurology and endocrinology. This interdisciplinary approach can lead to more comprehensive care of patients with complex health needs. Furthermore, NLP technologies can assist in regulatory compliance and reporting. Automated systems can scan clinical documents to ensure that they meet regulatory standards, generate reports for health authorities, reduce the administrative burden on optometrists, and allow them to focus more on patient care [3,5].
Effective document classification can directly influence education and training in optometry. Research like that of Ren et al. [22] explored how automatic classification models can inform and enhance medical curricula, ensuring that content is relevant and up-to-date. This approach can be adapted to optometric education by optimizing the preparation of future professionals to respond to changes in visual treatment and diagnosis.
The most important task AI can perform is optometry for disease diagnosis. ML and DL have the potential to detect early signs of ocular problems faster than human-made diagnostics but also more precisely. Another important aspect is the accessibility. An online model can be accessed by every optometry technician, and at a moment, a pre-diagnostic given by DL can be made, bypassing the lack of ophthalmologists in remote regions with fewer resources and democratizing access to corrective ophthalmologic treatments and corrections. The use of these types of AI tools has revolutionized the way diagnostics are made, namely in medicine, where the use of AI in image analysis, identification of disease outbreaks, and diagnosis is already a reality [12].
Recent advancements in AI have demonstrated substantial potential for improving medical diagnostics and treatment outcomes across various domains, including optometry. One of the most significant advancements is the development and application of the BERT models. The use of AI in image analysis has led to improved accuracy in detecting and diagnosing ocular diseases, thereby enhancing the efficacy of traditional methods [7].
Furthermore, advancements in the BERT models have been extended to various medical applications. For example, the BertMCN model, which combines BERT and highway networks, has shown improved performance in mapping colloquial phrases to standard medical concepts, outperforming the existing methods on standard datasets [5]. This model leverages the context-sensitive nature of BERT to accurately normalize medical concepts, which is crucial for the effective analysis of user-generated clinical texts, such as tweets, reviews, and blog posts. Another study demonstrated the use of transformers to extract breast cancer information from Spanish clinical samples and achieved high F-scores using BERT-based models [9]. This study highlights the application of BERT in a multilingual context, demonstrating its adaptability and efficiency in extracting detailed medical information from electronic health records. Chari et al. [10] highlighted the benefits of risk prediction models using BERT and SciBERT to improve the clinical assessment of type-2 diabetes. This emphasizes the importance of providing contextual explanations that allow medical professionals to understand and trust AI-generated predictions, thereby enhancing the integration of AI tools into clinical settings. In addition, Kalyan and Sangeetha [5] demonstrated BERT’s capability to map colloquial medical phrases to standard concepts, which is a critical feature for analyzing user-generated content and electronic health records in multiple languages. This adaptability renders BERT an invaluable tool for optometry research, enabling precise classification and trend analysis.
Perhaps the primary focus of AI in optometry is the development of models that can assist in early detection and accurate diagnosis of ocular conditions. AI’s ability to process and analyze large volumes of data with high precision makes it an invaluable tool in this field. A significant advancement is the use of CNNs for image analyses. CNNs have proven to be highly effective in interpreting retinal images and diagnosing conditions, such as diabetic retinopathy, glaucoma, and AMD. Gulshan et al. [6] demonstrated that a deep learning algorithm could achieve a sensitivity and specificity comparable to those of human ophthalmologists in detecting diabetic retinopathy from retinal photographs.
In addition to CNNs, other DL models, such as recurrent neural networks (RNNs) and generative adversarial networks (GANs) have been explored for optometric applications. RNNs are particularly useful for sequential data analysis, making them suitable for monitoring the progression of ocular disease over time. However, GANs have shown promise in generating synthetic data to augment training datasets, thereby improving the robustness and accuracy of diagnostic models [28,29].
Beyond commonly used CNNs, other innovative AI techniques are also being employed. For example, ensemble learning, which combines multiple models to improve overall performance, is increasingly being applied to enhance diagnostic accuracy. This approach can be particularly useful in optometry, where the combination of different AI models can lead to better predictions and insights [30].
AI’s role in optometric diagnostics also extends to improving the accessibility of eye-care services. For instance, mobile AI-powered applications can be used for the remote screening of ocular conditions, providing preliminary diagnostics in underserved and rural areas. This democratization of eye care ensures that patients who do not have easy access to ophthalmologists receive timely assessments and interventions [11]. Moreover, AI has been integrated into advanced imaging devices used in optometric applications. OCT machines equipped with AI can now provide detailed analyses of the retinal layers, assisting in the early detection of conditions, such as macular edema and retinal detachment. The integration of AI with these devices not only accelerates the diagnostic process, but also increases the accuracy of the results, thereby improving patient outcomes [25,31].
The continuous learning capabilities of AI models play a significant role in optometric diagnostics because these models are exposed to more data over time, their diagnostic capabilities have been refined and improved. This iterative learning process ensures that AI systems remain up-to-date with the latest clinical findings and treatment protocols, making them reliable tools for ongoing patient care [32]. Furthermore, AI can aid in disease management by predicting disease progression and treatment response. Personalized treatment plans can be developed based on AI analyses to optimize patient care and resource allocation. For instance, AI models can predict which patients are more likely to benefit from specific treatments such as anti-VEGF injections for AMD, thus tailoring interventions to individual patient needs [33].
The application of AI to optometric diagnostics is a critical area of development. Studies by Haug and Drazen [12] emphasized AI’s role of AI in enhancing diagnostic accuracy and early disease detection. In optometry, AI models can identify early signs of ocular conditions with greater speed and precision than traditional methods, thereby democratizing access to eye care, particularly in underserved areas. For instance, AI-driven tools can be integrated into portable devices to perform preliminary screening in rural areas, thereby allowing early intervention and treatment. The portability of AI-driven diagnostic tools is another significant advantage. Portable fundus cameras equipped with AI capabilities can be used for eye screening in community health programs and rural clinics. These devices can capture retinal images and provide immediate analysis, enabling healthcare providers to identify at-risk individuals and refer them for further treatment. This approach is particularly beneficial in low-resource settings, where access to comprehensive eye care is limited [11]. AI’s application extends beyond diagnostics to monitoring disease progression. For patients with chronic conditions such as glaucoma, AI algorithms can analyze trends in intraocular pressure measurements and visual field test results over time. By detecting subtle changes that may indicate disease progression, these tools can help clinicians proactively adjust treatment plans, potentially preventing vision loss [33].
AI’s capabilities in early detection are particularly transformative in the diagnosis of diseases such as diabetic retinopathy, glaucoma, and AMD. Traditional screening methods often rely on subjective assessments and manual interpretations, which can lead to diagnostic variability. However, AI algorithms provide consistent and objective analysis, reducing the likelihood of misdiagnosis and ensuring that patients receive timely and appropriate care [11]. One notable example of AI’s impact is in the use of DL algorithms for analyzing retinal images. These algorithms are trained on vast datasets of retinal photographs to recognize patterns indicative of various eye diseases. Once integrated into diagnostic tools, such as fundus cameras and OCT devices, these AI systems can automatically detect abnormalities with high accuracy. This integration not only speeds up the diagnostic process but also makes advanced eye care accessible in settings where specialized ophthalmologists may not be available [25].
AI-driven tools are also being developed to enhance the screening process for pediatric eye conditions. The early detection of amblyopia (lazy eye) and strabismus (crossed eyes) is crucial for effective treatment. AI models can analyze images and videos of children’s eyes to identify signs of these conditions, enabling early intervention and improving long-term visual outcomes [32]. The potential of AI in telemedicine is noteworthy. Teleoptometry platforms can incorporate AI algorithms to provide remote consultation and diagnostic services. Patients can upload images of their eyes with their smartphones or home-monitoring devices, and AI can provide preliminary assessments. This not only increases convenience for patients, but also ensures continuous monitoring and follow-up care, which is essential for managing conditions such as diabetic retinopathy [31]. Furthermore, AI can assist in the screening of rare genetic eye diseases. AI models can identify biomarkers associated with these conditions by analyzing genetic data and clinical images. This approach enhances the ability to diagnose and manage rare diseases that might otherwise go undetected until they cause significant visual impairment [28].
Another high-societal-impact field, in which these technologies are in great development is the aerospace ecosystem. For example, ML and NLP are used to classify human-factors related causes from aircraft incident/accident reports [34]. Another critical ML application in the aerospace field is the prediction of accidents involving victims based on accident reports [4,35]. These advancements demonstrate the importance of continuous innovation and adaptation of research methodologies to leverage the full potential of AI. The incorporation of such cutting-edge technologies into optometry can lead to more precise diagnostics, personalized treatment plans, and, ultimately, better patient outcomes. By continually refining these models and incorporating more specialized training data, the future of optometric diagnostics and treatment is promising.
The ability to anticipate future trends through data analysis is invaluable in strategic planning. A study by Wang et al. [26] explored how advanced data analysis techniques can predict emerging trends in neuroscience, providing critical guidance for directing research and funding towards areas of great potential. Implementing similar techniques in optometry could ensure that research and resources align with the emerging needs and innovation opportunities.
The use of ML/DL for fuel AI can be accomplished using forecasting tools. The ARIMA model is a robust statistical tool for forecasting time-series data that can be effectively applied to predict trends [19,20]. Trends in optometry, including the prevalence of eye diseases. Its utility stems from its capacity to analyze ongoing trends and seasonal variations, which are particularly relevant for conditions that show seasonal fluctuations, such as allergic conjunctivitis. Moreover, ARIMA can evaluate the impact of health policies and facilitate the assessment of interventions such as vision screening programs. Such predictions are vital for optimizing resource allocation and ensuring that healthcare providers can anticipate and meet the demands of treatment and specialized care. Additionally, the model aids in planning preventive strategies, enabling earlier interventions, such as diabetic retinopathy, for conditions predicted to increase. The flexibility of ARIMA in incorporating new corporate adjustments and adjustments to changing disease patterns makes it indispensable for guiding research directions, prioritizing funding, and enhancing overall strategic planning in public health related to optometry [21].
The ARIMA model has proven to be effective in predicting disease prevalence and research trends. Wang et al. [26] highlighted the use of advanced data analysis techniques to anticipate trends in neuroscience that could be similarly applied to optometry. ARIMA models facilitate strategic planning and resource optimization by forecasting trends in myopia and dry eye research, ensuring that the emerging needs are met efficiently. Predictive models such as screening programs and resource allocation are crucial for managing public health initiatives, especially in regions with limited access to eye care services.
There are several other applications of the ARIMA models. For instance, they can be used to predict the incidence of seasonal eye conditions such as allergic conjunctivitis, which typically spikes during certain times of the year. By analyzing historical data on allergy seasons and environmental factors, ARIMA models can help optometrists prepare for patient surges and ensure an adequate stock of necessary medications and resources [19]. In addition to ARIMA, other predictive modeling techniques, such as ML algorithms, including decision trees, support vector machines (SVMs), and ensemble methods such as random forests, are being explored for their applications in optometry. These models can handle complex, non-linear relationships within data, making them ideal for predicting multifactorial conditions, such as glaucoma, where genetic, lifestyle, and environmental factors interact. The use of these advanced models enhances the predictive accuracy and helps identify high-risk patients who might benefit from early interventions [27].
Predictive modeling also plays a significant role in personalized medicine in optometry. By analyzing individual patent data such as genetic markers, lifestyle habits, and previous ocular health records, predictive models can predict the likelihood of developing specific eye conditions. This allows for the creation of tailored treatment plans that address each patient’s unique risk profile and improve outcomes and patient satisfaction [26]. In addition to disease prediction, predictive models are valuable for anticipating future needs of optometric services. For example, demographic shifts and aging populations are expected to increase the demand for age-related eye care services, such as cataract surgery and AMD treatment. Predictive models can help healthcare providers and policymakers plan for these changes by forecasting the required number of eye care professionals, infrastructure, and potential budget allocations [27].
The integration of AI-based predictions with teleoptometry services is another promising approach. Teleoptometry leverages remote consultation and diagnostics, services, and predictive models, and these services can become more proactive. For instance, AI can analyze data from wearable devices that monitor eye health indicators and predict potential issues before they become critical, prompting timely virtual consultations or visits to eye care professionals [19]. Moreover, predictive models can assist in the optimization of clinical trials for optometry. By identifying patient populations most likely to benefit from new treatments or interventions, these models can enhance the efficiency and effectiveness of clinical research. This targeted approach reduces costs, shortens treatment duration, and increases the likelihood of successful outcomes, ultimately accelerating the availability of new therapies for patients [28].
The use of predictive analytics in public health has been extended to include both educational and preventive measures. For instance, models predicting an increase in myopia prevalence among children can lead to initiatives that promote outdoor activities and proper lighting conditions during study hours. These preventive strategies can significantly reduce the incidence of myopia and the burden on healthcare systems in the long term [26]. Predictive modeling and forecasting in optometry encompass a broad range of applications, from disease prediction and personalized treatment to resource planning and public health initiatives. The adoption of advanced predictive models, such as ARIMA and ML algorithms, is transforming the delivery of optometric care, making it more proactive, personalized, and efficient. As these technologies continue to evolve, their impact on optometry increases, leading to better patient outcomes and more sustainable healthcare practices [26,27,28].
When analyzing the most suitable and effective tool for predictive analytics, it is useful to recognize that ARIMA models often excel with data exhibiting clear linear trends and seasonality, as is common in certain medical contexts, whereas RNNs and LSTM models are frequently preferred for data that exhibit non-linear patterns or abrupt changes, such as stock-market behaviors, commodity price fluctuations, or epidemics. The literature is not entirely unanimous in its comparisons: for instance, [16] found ARIMA to outperform LSTMs in predicting monkeypox, while [36] noted that LSTM captured trends more accurately for diabetes even though ARIMA provided greater predictive accuracy for actual values. A similar observation emerged from [37], who reported that LSTM offered slightly better forecasts for blood pressure time-series yet did not substantially outperform ARIMA. RNNs and LSTMs clearly outperform ARIMA when there are many variables, but like in the present study, where only two variables are involved, ARIMA usually performs better than more sophisticated methods.
The use of AI for document classification in medical education has significant implications in optometry. Civaner et al. [23] explored how automatic classification models can inform and enhance medical curricula, ensuring that the content remains relevant and current. This approach can be adapted for optometric education by optimizing the preparation of future professionals in response to advancements in visual treatment and diagnosis. AI-driven document classification can streamline the research process, making it easier for practitioners and researchers to remain informed about the latest developments in their fields.
AI’s role in document classification extends to the organization and retrieval of vast amounts of medical literature and clinical guidelines. By employing NLP techniques, AI systems can categorize and summarize research articles, clinical studies, and patient records. This capability is particularly valuable in optometry, where staying abreast of the latest research is crucial for effective patient care. AI can automatically index and sort documents based on their relevance and content, enabling optometrists to quickly find pertinent information without manual sifting through extensive databases [24].
Furthermore, AI-driven document classification systems can identify gaps in existing literature and highlight emerging trends in optometric research. This proactive approach allows educators and curriculum developers to incorporate relevant topics into their teaching materials. For example, if AI identifies a surge in research related to new treatments for myopia, optometry programs can adjust their curricula to include these advancements, ensuring that students are well-prepared to implement the latest clinical practices upon graduation [38].
In addition to enhancing curricula, AI can support the continuous professional development of optometrists. By analyzing the latest publications and clinical guidelines, AI can create personalized learning paths and recommend relevant articles, courses, and seminars based on an individual’s areas of interest and practice needs. This targeted approach to continuing education helps optometrists stay current with advancements in the field, ultimately improving patient outcomes [39]. AI-driven document classification plays a crucial role in clinical decision-support systems (CDSS). These systems integrate vast amounts of medical knowledge and patient data to assist optometrists in making informed clinical decisions. By providing real-time access to the latest research and clinical guidelines, the CDSS can enhance diagnostic and treatment processes. For instance, an AI system might alert an optometrist to a new study suggesting a more effective treatment protocol for dry eye disease, enabling them to offer their patients the best possible care [40]. AI can also facilitate the standardization and quality control of educational materials. By ensuring that all training documents adhere to the latest evidence-based practices, AI helps maintain a high standard of education across different institutions. This standardization is essential for producing competent and well prepared optometrists who can deliver high-quality care in various settings [41]. The integration of AI into medical education supports interdisciplinary learning and collaboration. AI can cross-reference documents from related fields such as neurology, endocrinology, and general medicine, highlighting the interconnectedness of these disciplines. This holistic approach to education prepares optometry students to collaborate effectively with other healthcare professionals and to promote comprehensive patient care [24].
Additionally, AI-driven systems can provide insights into the effectiveness of educational programs by analyzing performance data and feedback from students. This data-driven approach allows educators to continually refine and improve their curricula, ensuring that it meets the evolving needs of both students and the optometrics profession. AI’s capability to handle multilingual documents further broadens its applicability to global optometric education. By translating and classifying documents from various languages, AI ensures that educational resources are accessible to diverse student population, thereby fostering a more inclusive learning environment [40].
3. Materials and Methods
The O-BERT process inputs through a tokenization mechanism. Each input sequence x is represented as a series of tokens which are first converted into vectors using an embedding layer. The input embedding is the sum of the token embeddings, segmentation embeddings (such as distinguishing different information), and position embeddings, which indicate the token position in structured data.
Let be tokens of any piece of data. The input embeddings are denoted by Equation (1) as:
where and represent token, segment, and position embeddings, respectively.
O-BERT model uses a Transformers Encoder, which is a deep learning model, based on self-attention mechanisms that compute the response at a position in a sequence by attending to all positions and taking their weighted average in an embedding space. The self-attention mechanism in the transformer allows the model to weigh the influence of different words. It uses query Q, keys K, and values V matrices derived from the input embeddings given by Equation (1) and is given by Equation (2):
where are the weight matrices learned during training. The output of attention layer, , is computed using Equation (3):
where is the dimension of the key vectors and the softmax function is applied to normalize the weights.
O-BERT extends the self-attention mechanism by employing multi-head attention, allowing the model to aggregate information from different representation subspaces at different positions. This methodology enables O-BERT for fine-tuning and multi-tasking, a key component in the time for use at the Optometry level, which consists of different classification classes. If h is the number of heads, the multi-head attention output is calculated using Equations (4) and (5):
where and are parameter matrices specific to each head.
Both the Original BERT and O-BERT have multiple layers, and each layer in both BERT and O-BERT contains a fully connected feed-forward, which is applied to each position separately and identically. This consists of the linear transformations given by Equation (6):
where and are layer parameters.
Each sublayer in O-BERT, including the attention and feed-forward layers, employs a residual connection around it, which is then normalized to the function described by Equation (7).
where Sublayer(x) is the function implemented by the sublayer to perform its optimization.
The embedding output from O-BERT encode the semantic information of optometry data, which can then be used as features for further classification tasks, such as the LLM, or to feed into other models such as the ARIMA model for forecasting trends in the data. Each embedding , is associated with one or more categories based on the classification performed by O-BERT. For instance, these categories may include areas such as Myopia, Dry Eye, and Refractive Surgery. To prepare the data for the ARIMA model, these embeddings were aggregated over each category to form a time series.
It is defined that represents the embedding of any piece of data in class k at time t.
To fine-tune the O-BERT model, it is necessary to perform hyperparameterization to optimize various aspects of the performance of the algorithm. This process involves adjusting parameters that govern the model’s architecture and learning process, such as the number of tokens each text input can accommodate and the regularization strength in the regression models. Proper hyperparameterization enhances the model’s ability to generalize from training data to unseen data, thus improving the accuracy and robustness in practical applications. By meticulously selecting these parameters, the designed model can effectively capture the contextual nuances of optometric data, thereby ensuring precise and reliable classification outcomes. These adjustments are crucial for adapting the pre-trained BERT framework to the specific lexical and syntactic characteristics of the optometric domain, enabling the model to perform its tasks with the expected level of precision and efficiency. Table 2 provides an overview of the main hyperparameters of the O-BERT Model.
Table 2.
Hyperparameters in O-BERT Model and Classifiers.
In order to be able to perform a forecast, the time series data can now be used as input for the ARIMA model because the data has been transformed in a time series configuration. The ARIMA model analyzes the time series to forecast future trends based on historical data patterns. This helps in understanding how certain classes evolve over time and predicting future interests and directions in optometry. To operationalize this transformation, techniques such as Principal Component Analysis (PCA) can be applied to embedding to extract relevant features that are most indicative of data trends. This quantification step is crucial for accurately capturing the essence of the research focus within the high-dimensional space of O-BERT embeddings.
The O-BERT model processes and classifies the optometric data by outputting categorical data over time. This output serves as input for the ARIMA model, which forecasts future trends based on the historical data patterns observed in each defined class. represents the time-series data for category k at time t, derived from O-BERT classifications, such as the number of any particular data class. The ARIMA model is applied for each class k. Where in the ARIMA model is denoted as , where p is the number of autoregressive terms, d is the number of nonseasonal differences needed for stationarity, and q is the number of lagged forecast errors in the prediction equation.
The ARIMA model for the time series used together with O-BERT is given by Equation (9):
where L is the lag operator, are the parameters of the autoregressive part, are the parameters of the moving average part, and is data noise.
The parameters and q are selected based on the Bayesian Information Criterion (BIC) to optimize the fit to the historical data, which is based on the likelihood function. This is given by Equation (10).
where n is the number of observations or sample size, k is the number of parameters in the model, is the maximum value of the likelihood function of the model. Once the model parameters have been estimated, the ARIMA model can forecast future values of for each class k in Equation (9). These forecasts provide insights into the expected trends in optometry data.
Dataset
For the development of AI software, the BERT model was selected as the primary DL architecture owing to its robustness in NLP tasks [42]. Although BERT is pre-trained, it does not inherently possess training specific to optometry-related terminology. To address this limitation, the model underwent further training using a dataset comprised of 32,485 academic articles from the field of Optometry, sourced from the Web of Science and spanning from 2000 to 2023. These academic articles used for training were all peer-reviewed, thus the training data quality is ensured. Table 3 presents the number of academic articles published in each year.
Table 3.
Collected Optometry Related Papers from Web of Science.
To avoid data imbalance in the AI model, DL supervised training was carefully conducted with a similar number of articles for each labeled dataset, and the ML metrics were closely monitored. From all the dataset, 951 articles were used in supervised training to enhance the optometry knowledge of the model. The retrained BERT model, O-BERT, was configured to classify articles into six distinct classes relevant to optometry: Contactology, Low Vision, Refractive Surgery, Pediatrics, Myopia, and Dry Eye. This classification was based on the content and focus of each article, facilitating a more nuanced understanding and processing of the optometric literature using an AI tool. The use of supervised learning allowed the model to refine its classification accuracy by learning directly from the labeled examples provided in the training set. Table 4 lists the supervised training data for each labeled dataset.
Table 4.
Supervised Training Data.
Hyperparameter Tuning is performed to fine-tune the AI model. The objective function quantifies the performance of a model given a set of hyperparameters. For a regression model, this is often the mean squared error (MSE), and for classification, it might be an accuracy or log loss. This is given by Equation (11) where represents the parameters of the model, n is the number of samples in the dataset, is the actual value of the output and is the model’s prediction for input .
Regarding the classification, the cross-entropy loss was used to determine the optimal solution by adjusting the calculated weights for the DL model, which are given by applying Equation (12).
The search space for the best-fit solution is defined as the set of all possible values for the hyperparameters. For hyperparameter , this may be represented, for example, as given in Equation (13). In addition, the best-fit solution search strategy is dynamic to best adapt to current model hyperparameters. A grid search systematically explored this space by training and evaluating the model for each combination of hyperparameters. For example, if a grid search is used for C parameter, the process follows the framework given in Equation (14).
Cross-validation was performed to evaluate the model configuration. In k-fold cross-validation, the training set is split into k smaller sets. The performance measure reported by k-fold cross-validation was the average of the performance measured on each fold. Here, the cross-validation score S, the mean model probability to provide corect outputs, can be computed using (15).
The performance measured using Equation (15) fuels the model’s general performance. Thus, its generalization across different datasets is better assessed, reducing the risk of overfitting and ensuring a more reliable estimate of the real-world performance. This approach helps ensure that the model’s performance assessment is robust and less sensitive to the specific split of the training and testing data, which can provide a more reliable measure of how well the model is likely to perform on unseen data.
Figure 1 illustrates the general architecture of O-BERT in a graphical format. The process commences with data collection, wherein academic optometry articles from ScienceDirect are extracted in Excel format for the years 2000 to 2023. Articles from 2024 were excluded due to incomplete data. The retrieved Excel data are subsequently processed and engineered to serve as input for the O-BERT model. Preprocessing involves the elimination of incomplete data, while data engineering provides the initial labeling necessary for the initial training phase. Subsequently, the DL model processes the data using one-shot learning and epoch-based methods, providing, when applicable, learning metrics for each class and overall performance. A statistical analysis of the learning capabilities is conducted to evaluate the model’s performance, which subsequently feeds into the ARIMA model for forecasting. The DL model also supplies input to the AI component, enabling the classification of symptoms and the performance of diagnostics based on the training data. The current version of O-BERT utilizes only public data.
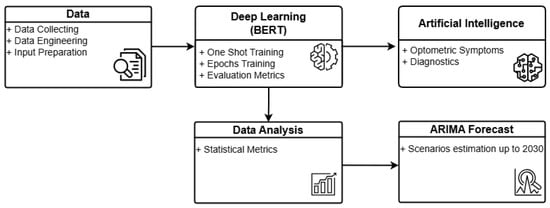
Figure 1.
O-BERT Process Overview.
4. Results
The O-BERT performance metrics for various classes are listed in Table 5, and presented an average of 86.4% in the F1-Score, 0.98 in AUC, 87% in Precision, and 86.8% in Accuracy. The F1-Score, which represents the harmonic mean of the precision and recall, equally weighs these metrics to provide a balanced measure of the accuracy of a classification model. An F1-Score above 90% is considered ‘Very Good’, scores between 80% and 90% are rated as ‘Good’, those between 50% and 80% are seen as ‘OK’, and scores under 50% are deemed ‘Not Good’.
Table 5.
Performance Indicators from the O-BERT AI Model by One-Shot Training.
The Receiver Operating Characteristic (ROC) curve is a graphical representation used in ML/DL to assess the diagnostic ability of a binary classifier system as its discrimination threshold. The ROC curve plots two parameters: the True Positive Rate (TPR), also known as sensitivity or recall, and the False Positive Rate (FPR). Each point on the ROC curve represents a sensitivity/specificity pair corresponding to a particular decision threshold. The TPR is calculated by dividing the number of true positives by the sum of true positives and false negatives, indicating the model’s ability to correctly identify positive instances. Conversely, the FPR is calculated by dividing the number of false positives by the sum of false positives and true negatives, representing the proportion of negative instances incorrectly classified as positive. Specificity measures the ability of a model to identify negative cases correctly. This is also called the true negative rate (TNR). Specificity is calculated by dividing the true negatives by the sum of true negatives and false positives.
The ROC curve provided several insights into the performance of the classification model. Primarily, it illustrates the trade-off between sensitivity and specificity: a higher sensitivity results in a lower specificity, and vice versa.
The Area Under the Curve (AUC) is another critical indicator of model efficacy that measures the ability to distinguish between categories at various threshold levels. An AUC value of 0.5 implies performance no better than random chance, below 0.5 indicates underperformance, and an AUC of 1.0 reflects perfect model calibration.
Precision measures the accuracy of positive class predictions, and is calculated as the ratio of true positives to all positive predictions (true and false positives combined). This metric is vital to understanding the predictive reliability of a model. Finally, Accuracy is the proportion of correct predictions made by the model compared to the total predictions, indicating how often the model predicts correctly.
The ROC curve depicted in Figure 2 reflects the analysis from the O-BERT model and demonstrates the exceptionally high performance of the classification models across various optometry-related classes, each denoted by an AUC value near perfection. The ’Low Vision’ class achieved a perfect AUC of 1.00, indicating flawless discrimination between positive and negative instances, as evidenced by the curve reaching the top left corner of the plot, which signifies 100% sensitivity with a 0% false positive rate. The other labels, including Contactology, Dry Eye, Myopia, Pediatric, and Refractive Surgery, exhibited similarly high AUC values (0.98), underscoring nearly perfect classification capabilities. These curves closely approached the left border and top of the ROC space, reflecting minimal differences in the ability of the O-BERT models’ to discriminate between classes. This uniformity in performance across the O-BERT model highlights its robustness and reliability, making it a potentially valuable tool in clinical settings, where precise and dependable classification is critical for effective diagnosis and treatment planning.
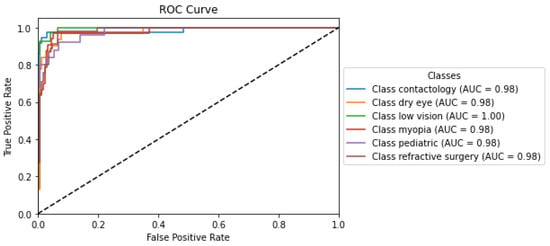
Figure 2.
O-BERT ROC Curve and AUC Values for the depicted classes.
Another graphical indicator is the precision-recall curve. This graphical representation was used to evaluate the performance of the binary classifier as the decision threshold varied. Unlike the ROC curve, which plots the true positive rate against the false positive rate, the precision-recall curve focuses on the relationship between precision (positive predictive value) and recall (sensitivity). Precision is defined as the ratio of true positive outcomes to all predicted positives (i.e., the sum of true positives and false positives), and measures the accuracy of the classifier in identifying only relevant instances.
The precision-recall curve presented in Figure 3 illustrates the performance of the developed model across the labels within the optometry domain. Each curve corresponds to a distinct class: Contactology, Dry Eye, Low Vision, Myopia, Pediatric, and Refractive Surgery, providing a visual representation of the trade-off between precision and recall for each classification. Notably, classes such as Contactology, Dry Eye, and Refractive Surgery maintain relatively high precision even when the recall approaches 1, suggesting that the O-BERT model is particularly robust in it’s ability to correctly identify positive cases without incurring many false positives. The classes Low Vision, Myopia, and Pediatric show a small decline in precision at lower recall levels, which may indicate challenges in maintaining a very high accuracy when attempting to capture a larger fraction of positive instances; however, even with this, it still presents notably high accuracy. The overall high performance in the initial segments of each curve underscores the capability of the model to accurately classify cases with fewer false positives, which is crucial in clinical settings where precision is highly valued to avoid unnecessary treatments or intervention.
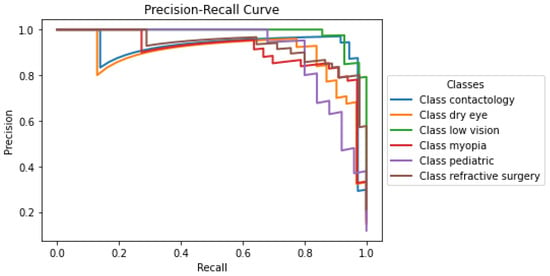
Figure 3.
O-BERT Precision-Recall Curve for the depicted classes.
In ML/DL, a confusion matrix is a specific table layout that allows visualization of the performance of an algorithm, typically in supervised learning. Each row of the matrix represents the instances in a predicted label and each column represents the instances in an actual label. It is particularly useful for measuring the Recall, Precision and Accuracy.
The confusion matrix depicted in Figure 4 provides a detailed view of the class classification performance from the trained data. The numbers on the diagonal (31, 28, 39, 27, 19, and 40) indicate the count of correct predictions for each respective class, suggesting a high degree of accuracy across most categories. This level of accuracy across diverse classes underscores the model’s robustness in correctly identifying various conditions. However, the off-diagonal entries in the confusion matrix reveal instances of misclassification that are worth further discussion. These entries, where the model incorrectly predicts the class, highlight specific areas where the model’s performance could be improved. One way to improve the misclassifications, and bring any model close to the 100% accuracy benchmark, is in enhancing the feature recognition capabilities to better differentiate between classes that are frequently misclassified. This could involve refining the internal embeddings or adjusting the attention mechanisms specifically to target distinguishing characteristics.
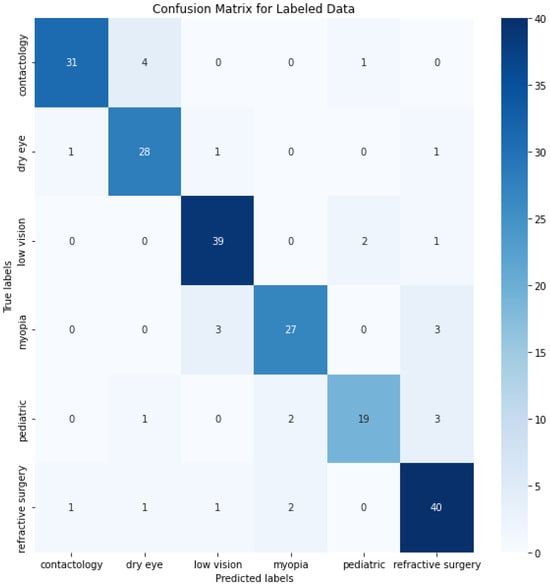
Figure 4.
O-BERT Confusion Matrix for the depicted classes.
All of the above metrics were obtained using an approach of “one-shot” training, which involves presenting the entire dataset to the model at once, allowing the model to adjust its weights based on this singular exposure. This method can be efficient in terms of computational speed and simplicity, however in some models, there exists the possibility of a lower degree of performance, mainly because they can fail to capture the complexity of the data, potentially leading to underfitting if the model is not exposed to sufficient variations of the data to generalize effectively. The opposite approach trains the model in several epochs involving multiple iterations over the entire dataset, thereby allowing the model to learn incrementally and refine its parameters through repeated exposure to the data. Each epoch represents a complete pass through the training dataset, followed by an update of model parameters. Thus, although training in epochs can be more computationally intensive and time-consuming than “one-shot” training, it typically results in more robust and accurate models, particularly in scenarios involving large and complex datasets.
The confusion matrix depicted in Figure 5 obtained from multiple epochs of training exhibits strong class-specific performance, evidenced by high diagonal counts of correctly classified samples in categories such as contactology, dry eye, low vision, myopia, pediatric, and refractive surgery. These figures suggest that repeated passes over the training data also provides a model’s that has the ability to identify and learn nuanced patterns associated with distinct conditions in the data.
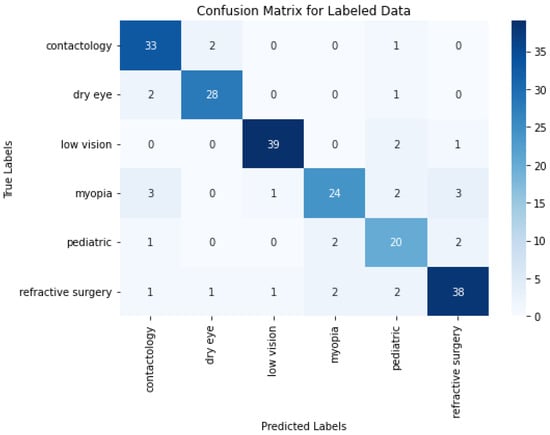
Figure 5.
O-BERT Confusion Matrix using Epochs Training for the Labeled Data.
When comparing the results from Figure 5 and the ones derived from one-shot training depicted in Figure 4, it appears that some classes, such as contactology and pediatric, benefit notably from the multi-epoch approach by improving from 31 to 33 correct predictions and from 19 to 20 correct predictions, respectively. In contrast, others like myopia and refractive surgery experience slight declines, where correct predictions decrease from 27 to 24 and from 40 to 38. These findings indicate a balanced and similar results between both approaches.
The performance metrics of the model over 500 epochs, as shown in Figure 6 and Table 6, demonstrated substantial improvement and stabilization in various metrics, specifically, Accuracy, AUC, Precision, and Recall. Initially, the accuracy increased rapidly to approximately 0.8585 within the first few epochs, indicating that the model adapted rapidly to the training data. Similarly, the AUC, which assesses the model’s ability to differentiate between classes, quickly reached an impressive score of 0.9834, thus underscoring the model’s effective classification capabilities at various thresholds.
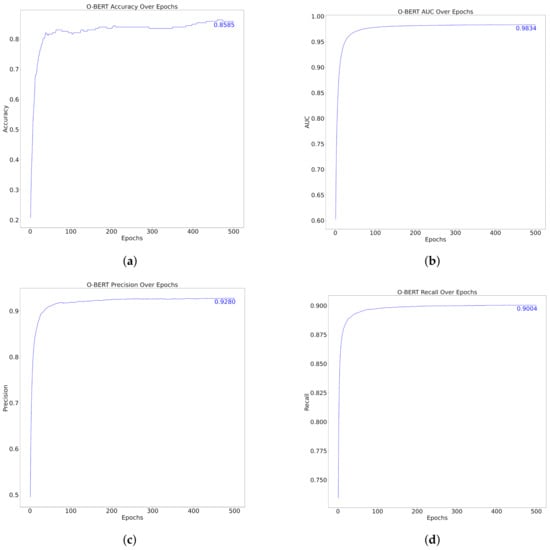
Figure 6.
O-BERT Performance over Epochs. (a) Top Left: Accuracy (b) Top Right: AUC (c) Bottom Left: Precision (d) Bottom Right: Recall.
Table 6.
Performance Indicators from the O-BERT AI Model by Epochs Training.
Precision, which measures the accuracy of the model’s positive predictions, increased to 0.9280, indicating that the model was highly reliable in terms of its positive classifications. The recall metric, which indicates the model’s ability to identify all relevant instances, also exhibited a rapid increase, reaching a peak of 0.9004. This suggests that the model can capture a high proportion of positive cases, thereby reducing the likelihood of false-negatives.
Across the epochs, after the initial rapid improvements, all metrics displayed a plateau, indicating that the model reached a point of diminishing returns, where further training did not significantly enhance the performance and could be said to lie down to approximately 100 epochs. This plateau typically indicates that the model has effectively learned the underlying patterns in the dataset and that additional training epochs may not yield meaningful improvement, potentially leading to overfitting if excessively continued. Compared with the “one-shot” method, the performance metrics over the epochs did not excel the first one. Applying training over several epochs did not generally increase the O-BERT performance, therefore, it can be said that training over epochs, like the one presented in the present study, it’s not resourcefully efficient.
Regarding the class-imbalance analysis, crucial for multi-class studies, both the One-Shot trained O-BERT and the Epoch trained O-BERT exhibit relatively similar and high AUC values across different classes. An examination of the Precision-Recall curve for the One-Shot trained O-BERT, as presented in Figure 3, reveals relatively high precision across varying levels of recall. This observation generally indicates effective handling of class imbalance, as precision remains high even as recall increases. It suggests that the model is correctly identifying positive cases without a substantial number of false positives across all classes. Similarly, an analysis of Figure 6d, which depicts the recall for the Epoch trained O-BERT, allows us to draw the same conclusion. This uniformly high performance across metrics could imply a balanced dataset or that any initial class imbalances were effectively addressed during the training process.
In the overhaul, O-BERT performance reflects a well-tuned learning process in which the model achieves high performance across all key metrics, affirming its efficacy and robustness in processing and classifying the data as intended. Altogether, these results offer a comprehensive view of the performance excellence of the developed AI O-BERT-based model compared with the original BERT developed by Google, which reported a Precision of 87.07% and an F1-Score of 93.2% [42].
Table 7 provides a clear O-BERT trained by one-shot and epochs method comparison between the original BERT [42] and several authors [5,6,9,25,28,29,32] that have used the BERT or similar DL in medical applications. With the exception of the original BERT, which was trained in a broader context, the remaining authors used BERT and DL methods with a very specific objective, such as the diagnosis of a specific medical condition, which can theoretically increase the model’s metrics. Both one-shot and epoch trained BERT were trained in the general context of optometry but were general enough to be able to detect any specific context or pathology in the optometry field. In this manner, it can be seen from Table 7 that both models obtain higher classification metrics than most tailored task-specific models.
Table 7.
Developed Models comparison between the original BERT [42] and other BERT/DL Methods [5,6,9,25,28,29,32] in the medical diagnosis.
Regarding the data forecast, Table 8 illustrates the forecast trends concerning the prevalence of various optometry-related classes in academic articles from 2025 to 2030. These trends were analyzed using an O-BERT classifier and projected from 2025 to 2030 using an ARIMA forecasting model. For instance, and considering the data history given in Table 8, showed distinct trends over time. Historical data indicate fluctuations in interest and research focuses. Notably, after 2020, a sharp decline in articles on Contactology was observed, whereas Dry Eye stabilized in recent years after earlier volatility. Forecasts from 2025 to 2030 suggest varying future trends across all the labels. These projections are instrumental for academic institutions and researchers in prioritizing future research areas and understanding evolving trends in optometry. The use of ARIMA in predicting these trends demonstrate its utility in extrapolating future directions based on historical patterns, thus providing a strategic tool for academic planning and resource allocation in optometry.
Table 8.
ARIMA Forecasted Data.
5. Discussion
The developed O-BERT model demonstrated a strong performance across various optometry-related categories, achieving F1-Scores above 80% for all classifications. This high performance indicates the ability of the model to accurately interpret and classify a diverse range of optometric areas, highlighting its potential to significantly aid in the literature review and knowledge dissemination within the field of optometry.
ROC curve analysis and near-perfect AUC values further validated the efficacy of the model, demonstrating its exceptional capability to distinguish between different categories with high accuracy. This capability is crucial for clinical applications, where precise classification can lead to improved diagnostic and treatment outcomes. These findings align with those of previous studies that highlighted the effectiveness of AI in medical classification tasks. Gulshan et al. [6] demonstrated that an AI system could achieve recall and specificity comparable to those in ophthalmologists on detecting diabetic retinopathy. De Fauw et al. [25] showed that DL algorithms can accurately diagnose and recommend treatments for more than 50 different eye diseases. These examples suggest that the methodology used in this study is robust and transferable to several medical fields. The application of the ARIMA model to forecasting optometric research trends from 2025 to 2030 can provide valuable insights for strategic planning. The ability to forecast future research directions and disease prevalence helps prioritize funding and resources in areas with the highest potential impact. Projections for different classes, such as Contactology, Dry Eye, Low Vision, Myopia, Pediatrics, and Refractive Surgery, show varying trends. This predictive capability aligns with the findings of Wang et al. [12], who used similar techniques to forecast neuroscience trends, thereby supporting the utility of ARIMA models in medical research planning. By understanding these trends, academic institutions and researchers can better align their efforts with emerging needs, thereby ensuring that optometric research is relevant and impactful.
Detailed results indicate that research interest in Contactology, Low Vision, and Refractive Surgery is projected to decrease. This could reflect the stabilization in these areas owing to technological advancements and established treatment protocols. For example, recent advancements in contact lens materials and surgical techniques may have reached a point where major breakthroughs are less frequent, thereby reducing the volume of novel research in these fields. Studies have shown similar trends where technological maturation leads to a plateau in research interest [43,44].
Conversely, the research focus on Myopia and Dry Eye is expected to rise, likely driven by the increasing prevalence of these conditions, particularly in younger populations with myopia due to lifestyle factors such as prolonged screen use. The growing concern regarding the global myopia epidemic, especially in East Asia, has spurred significant research efforts aimed at understanding its etiology and identifying effective interventions [45,46]. Similarly, the increase in dry eye research is associated with the increasing use of digital devices, which has been identified as a significant risk factor for dry eye syndrome [47].
The Pediatrics category shows a relatively stable trend, indicating a consistent interest in ensuring early detection and intervention in children’s eye health. This stability might be due to the ongoing need to address various pediatric eye conditions that can have long-term effects if not treated early. Research in pediatric optometry remains critical, as early intervention can prevent serious visual impairment later in life [43]. This study also underscores the potential of AI to enhance the diagnostic accuracy in optometry. The high F1-Scores and AUC values indicate that the AI model is highly reliable for classifying various optometric conditions. This is particularly important for conditions such as myopia and pediatric eye disorders, where early detection can significantly improve treatment outcomes. The potential of AI in diagnostics is further evidenced by studies such as De Fauw et al. [25], who demonstrated the high diagnostic accuracy of deep learning algorithms in identifying retinal diseases. The use of AI to understand the optometric literature has significant implications for education and training. By automating the classification of research articles, these technologies ensure that the educational content remains current and relevant. This approach can help future optometrists to respond to the latest advancements in the field, thereby ensuring a well-informed and capable workforce. Ren et al. [26] highlighted the benefits of automatic classification models in enhancing medical curricula, which can be adapted for optometric education to incorporate up-to-date knowledge and practices. This can lead to a more informed and capable workforce, better equipped to handle the complexities of modern optometry.
One of the most transformative aspects of AI in optometry is its potential to democratize eye care access. This capability is crucial for addressing disparities in healthcare accessibility and ensuring that all individuals receive timely and accurate eye care, regardless of location. Ting et al. [31] demonstrated the effectiveness of AI in primary care settings for screening diabetic retinopathy, underscoring the potential of AI to extend healthcare services to underserved populations. By leveraging AI, optometry can overcome geographical and resource barriers, and provide high-quality care to a broader population.
Although the results are promising regarding the use of O-BERT for data labeling and analysis, several challenges remain. Ensuring the quality and representativeness of the training data is critical for maintaining the accuracy and reliability of the AI models. Continuous validation and refinement of these models in real-world clinical settings is necessary to ensure their effectiveness across diverse populations. Ethical considerations, particularly those related to patient privacy and data security, must also be addressed. The integration of AI in healthcare requires robust frameworks to protect patient information and to prevent bias in AI algorithms. Future research should focus on expanding the training datasets to include more diverse and comprehensive data to enhance the generalizability of the models.
6. Conclusions
The O-BERT AI model architecture was developed to enhance understanding and classification of optometry-related topics. This model demonstrates significant improvements in learning and classifying diverse arrays of optometric content across several classes. Furthermore, forecasts generated for the period 2025–2030 using the ARIMA model based on data previously classified by the AI model, confirmed the model’s robust predictive capability in the field of optometry. The potential applications of the model extend beyond academic research, offering a basis for further development that could bring substantial benefits in clinical settings, particularly in the diagnosis of various eye-related diseases. It can predict the occurrence and potential severity of specific diseases, thus serving as a vital tool for both diagnostics and resource allocation, particularly in regions with limited resources. This capability underscores the model’s potential utility as a practical aid for healthcare delivery and strategic planning. However, it is important to acknowledge that the model does not achieve 100% accuracy, which is a theoretical benchmark that is often sought in medical applications. To enhance the Accuracy and Reliability, further research is necessary, particularly in incorporating real diagnostic data from clinical environments. This approach refines the training dataset of a model and improves its applicability.
Despite the metrics achieved by the O-BERT model, its limitation lies in the nature of its training dataset, which consists solely of academic publications. Although this makes O-BERT highly effective for tasks such as data labeling and data engineering, its applicability and effectiveness in clinical settings remain unproven. Despite that in medicine, or more specifically in optometry, there are no major difference between the published data and the clinical data, the use of public available data in the training may limit model’s ability to capture diverse and nuanced scenarios, as public datasets may not fully represent the variability and specificity of conditions found in clinical settings. This could potentially impact the model’s generalizability and accuracy when applied to clinical settings. In addition, despite being a reliable tool for forecasting, the ARIMA is highly dependent on historical trends, which might not always capture future shifts influenced by changes.
Future research should focus on overcoming current training limitations by incorporating real clinical data into the training process. Additionally, exploring the integration of new deep learning and machine learning models into the existing optometry AI framework is essential for enhancing its diagnostic accuracy and applicability. To further this aim, the development of O2-BERT, which will integrate real clinical data alongside the published data utilized by O-BERT. This approach will not only refine the model’s accuracy but also enhance its robustness and applicability. Moreover, an emphasis on rigorous validation in clinical settings and adherence to ethical approaches in data handling and algorithm deployment is crucial, regarding this, the incorporation of the Ethics Committee for future developments must be addressed. The current lack of validation in real clinical scenarios notably limits the practical applicability of the study. Therefore, O2-BERT should include an experimental phase that involves collaboration with healthcare professionals and engagement with patients, ensuring that the model’s utility in clinical environments.
Author Contributions
L.F.F.M.S.: Deep Learning and Artificial Intelligence Model Development, Theoretical Formulation, Conceptualization, Original Draft, Visualization, Formal Analysis. C.M.-P.: Data Management, Conceptualization, Visualization, Original Draft, Methodology, Formal Analysis. M.Á.S.-T.: Validation, Formal Analysis, Review. J.-M.S.-G.: Validation, Formal Analysis, Review. C.A.-P.: Validation, Formal Analysis, Review. All authors have read and agreed to the published version of the manuscript.
Funding
The present work was performed under the scope of activities at the Aeronautics and Astronautics Research Center (AEROG) of the Laboratório Associado em Energia, Transportes e Aeroespacial (LAETA), and was supported by the Fundação para a Ciência e Tecnologia (Project Nos. UIDB/50022/2020, UIDP/50022/2020 and LA/P/0079/2020).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All the historical data used to develop the Machine Learning and Artificial Intelligence Model are publicly available.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| AMD | Age-related Macular Degeneration |
| ARIMA | Autoregressive Integrated Moving Average |
| AUC | Area Under the Curve |
| BERT | Bidirectional Encoder Representations from Transformers |
| BIC | Bayesian Information Criterion |
| CDSS | Clinical Decision-Support Systems |
| CNN | Convolutional Neural Networks |
| DL | Deep Learning |
| EHR | Electronic Health Records |
| FPR | False Positive Rate |
| GAN | Generative Adversarial Networks |
| LLM | Large Language Model |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| MSE | Mean Squared Error |
| NLP | Natural Language Processing |
| O-BERT | Optometry BERT |
| OCT | Optical Coherence Tomography |
| PCA | Principal Component Analysis |
| RNN | Recurrent Neural Networks |
| ROC | Receiver Operating Characteristic |
| SVM | Support Vector Machines |
| TNR | True Negative Rate |
| TPR | True Positive Rate |
References
- Ho, K.; Stapleton, F.; Wiles, L.; Hibbert, P.; Alkhawajah, S.; White, A.; Jalbert, I. Systematic review of the appropriateness of eye care delivery in eye care practice. BMC Health Serv. Res. 2019, 19, 646. [Google Scholar] [CrossRef]
- Twa, M. Evidence-based reviews: Systematic reviews and meta-analyses. Optom. Vis. Sci. 2022, 99, 1–2. [Google Scholar] [CrossRef] [PubMed]
- Jensen, P.; Jensen, L.; Brunak, S. Mining electronic health records: Towards better research applications and clinical care. Nat. Rev. Genet. 2012, 13, 395–405. [Google Scholar] [CrossRef]
- Lázaro, F.L.; Nogueira, R.P.; Melicio, R.; Valério, D.; Santos, L.F. Human Factors as Predictor of Fatalities in Aviation Accidents: A Neural Network Analysis. Appl. Sci. 2024, 14, 640. [Google Scholar] [CrossRef]
- Kalyan, K.; Sangeetha, S. BertMCN: Mapping colloquial phrases to standard medical concepts using BERT and highway network. Artif. Intell. Med. 2021, 112, 102008. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 2016, 316, 2402. [Google Scholar] [CrossRef]
- Wada, S.; Takeda, T.; Okada, K.; Manabe, S.; Konishi, S.; Kamohara, J.; Matsumura, Y. Oversampling effect in pretraining for bidirectional encoder representations from transformers (BERT) to localize medical BERT and enhance biomedical BERT. Artif. Intell. Med. 2024, 153, 102889. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Li, W.; Li, B.; Yuan, Y. MRM: Masked Relation Modeling for Medical Image Pre-Training with Genetics. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 21395–21405. [Google Scholar] [CrossRef]
- Solarte-Pabón, O.; Montenegro, O.; García-Barragán, A.; Torrente, M.; Provencio, M.; Menasalvas, E.; Robles, V. Transformers for extracting breast cancer information from Spanish clinical narratives. Artif. Intell. Med. 2023, 143, 102625. [Google Scholar] [CrossRef]
- Chari, S.; Acharya, P.; Gruen, D.; Zhang, O.; Eyigoz, E.; Ghalwash, M.; Seneviratne, O.; Saiz, F.; Meyer, P.; Chakraborty, P.; et al. Informing clinical assessment by contextualizing post-hoc explanations of risk prediction models in type-2 diabetes. Artif. Intell. Med. 2023, 137, 102498. [Google Scholar] [CrossRef] [PubMed]
- Abràmoff, M.; Lavin, P.; Birch, M.; Shah, N.; Folk, J. Pivotal Trial of an Autonomous AI-Based Diagnostic System for Detection of Diabetic Retinopathy in Primary Care Offices. NPJ Digit. Med. 2018, 1, 39. [Google Scholar] [CrossRef] [PubMed]
- Haug, C.; Drazen, J. Artificial Intelligence and Machine Learning in Clinical Medicine. N. Engl. J. Med. 2023, 388, 1201–1208. [Google Scholar] [CrossRef] [PubMed]
- Jin, K.; Ye, J. Artificial intelligence and deep learning in ophthalmology: Current status and future perspectives. Adv. Ophthalmol. Pract. Res. 2022, 2, 100078. [Google Scholar] [CrossRef] [PubMed]
- Ting, D.S.; Peng, L.; Varadarajan, A.V. Deep learning in ophthalmology: The technical and clinical considerations. Prog. Retin. Eye Res. 2019, 72, 100759. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Zhao, C.; Wang, L. Evaluation of an OCT-AI–Based Telemedicine Platform for Retinal Disease Screening and Referral in a Primary Care Setting. Transl. Vis. Sci. Technol. 2022, 11, 4. [Google Scholar] [CrossRef]
- Esteva, A.; Robicquet, A.; Ramsundar, B. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. Briefings Bioinform. 2017, 19, 1236–1246. [Google Scholar] [CrossRef] [PubMed]
- Alam, T.M.; Shaukat, K.; Mahboob, H.; Sarwar, M.U.; Iqbal, F.; Nasir, A.; Hameed, I.A.; Luo, S. A Machine Learning Approach for Identification of Malignant Mesothelioma Etiological Factors in an Imbalanced Dataset. Comput. J. 2022, 65, 1740–1751. [Google Scholar] [CrossRef]
- Amaral, Y.; Santos, L.F.F.M.; Valério, D.; Melicio, R.; Barqueira, A. Probabilistic and Statistical Analysis of Aviation Accidents. J. Phys. Conf. Ser. 2023, 2526, 012107. [Google Scholar] [CrossRef]
- Samarra, J.; Santos, L.F.; Barqueira, A.; Melicio, R.; Valério, D. Uncovering the Hidden Correlations between Socioeconomic Indicators and Aviation Accidents in the United States. Appl. Sci. 2023, 13, 7997. [Google Scholar] [CrossRef]
- Sánchez-Tena, M.; Martinez-Perez, C.; Villa-Collar, C.; González-Pérez, M.; González-Abad, A.; Alvarez-Peregrina, C. Prevalence and Estimation of the Evolution of Myopia in Spanish Children. J. Clin. Med. 2024, 13, 1800. [Google Scholar] [CrossRef]
- Ren, C.; Sun, Z.; Li, X.; Fan, G.; Huo, C.; Cheng, L. Research on Quantitative Method of Power Network Risk Assessment Based on Improved K-Means Clustering Algorithm. In Proceedings of the 2020 Asia Energy and Electrical Engineering Symposium (AEEES), Chengdu, China, 29–31 May 2020; pp. 652–657. [Google Scholar] [CrossRef]
- Civaner, M.; Uncu, Y.; Bulut, F.; Chalil, E.; Tatli, A. Artificial intelligence in medical education: A cross-sectional needs assessment. BMC Med. Educ. 2022, 22, 772. [Google Scholar] [CrossRef]
- Li, Q.; Qin, Y. AI in medical education: Medical student perception, curriculum recommendations and design suggestions. BMC Med. Educ. 2023, 23, 852. [Google Scholar] [CrossRef]
- Fauw, J.D.; Ledsam, J.; Romera-Paredes, B.; Nikolov, S.; Tomasev, N.; Blackwell, S.; Askham, H.; Glorot, X.; O’Donoghue, B.; Visentin, D.; et al. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nat. Med. 2018, 24, 1342–1350. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Liu, L.; Wang, C. Trends in using deep learning algorithms in biomedical prediction systems. Front. Neurosci. 2023, 17, 1256351. [Google Scholar] [CrossRef] [PubMed]
- Kass, M.; Heuer, D.; Higginbotham, E.; Johnson, C.; Keltner, J.; Miller, J.; Parrish, R.; Wilson, M.; Gordon, M. The Ocular Hypertension Treatment Study: A randomized trial determines that topical hypotensive medication delays or prevents the onset of primary open-angle glaucoma. Am. J. Ophthalmol. 2016, 121, 212–225. [Google Scholar] [CrossRef] [PubMed]
- Ching, T.; Himmelstein, D.; Beaulieu-Jones, B.; Kalinin, A.; Do, B.; Way, G.; Ferrero, E.; Agapow, P.; Zietz, M.; Hoffman, M.; et al. Opportunities and obstacles for deep learning in biology and medicine. J. R. Soc. Interface 2018, 15, 20170387. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45. [Google Scholar] [CrossRef]
- Ting, D.; Cheung, C.; Lim, G.; Tan, G.; Quang, N.; Gan, A.; Hamzah, H.; Garcia-Franco, R.; San Yeo, I.Y.; Lee, S.Y.; et al. Development and Validation of a Deep Learning System for Diabetic Retinopathy and Related Eye Diseases Using Retinal Images from Multiethnic Populations with Diabetes. JAMA 2017, 318, 2211. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Kuprel, B.; Novoa, R.; Ko, J.; Swetter, S.; Blau, H.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Grassmann, F.; Mengelkamp, J.; Brandl, C.; Harsch, S.; Zimmermann, M.; Linkohr, B.; Peters, A.; Heid, I.; Weber, B. A Deep Learning Algorithm for Prediction of Age-Related Eye Disease Study Severity Scale for Age-Related Macular Degeneration From Color Fundus Photography. Ophthalmology 2018, 125, 1410–1420. [Google Scholar] [CrossRef]
- Madeira, T.; Melício, R.; Valério, D.; Santos, L. Machine Learning and Natural Language Processing for Prediction of Human Factors in Aviation Incident Reports. Aerospace 2021, 8, 47. [Google Scholar] [CrossRef]
- Nogueira, R.; Melicio, R.; Valério, D.; Santos, L. Learning Methods and Predictive Modeling to Identify Failure by Human Factors in the Aviation Industry. Appl. Sci. 2023, 13, 4069. [Google Scholar] [CrossRef]
- Shah, K.; Rasal, N.; Mhatre, S. Demand Forecasting in Retail for Diabetes Medicine. In Proceedings of the 2023 International Conference on Data Science and Network Security (ICDSNS), Tiptur, India, 28–29 July 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Niako, N.; Melgarejo, J.D.; Maestre, G.E.; Vatcheva, K.P. Effects of missing data imputation methods on univariate blood pressure time series data analysis and forecasting with ARIMA and LSTM. BMC Med. Res. Methodol. 2024, 24, 320. [Google Scholar] [CrossRef] [PubMed]
- Sridharan, K.; Sequeira, R. Artificial intelligence and medical education: Application in classroom instruction and student assessment using a pharmacology & therapeutics case study. BMC Med. Educ. 2024, 24, 431. [Google Scholar] [CrossRef]
- Çalışkan, S.; Demir, K.; Karaca, O. Artificial intelligence in medical education curriculum: An e-Delphi study for competencies. PLoS ONE 2022, 17, e0271872. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.; Chen, C.; Fu, C.; Chaou, C.; Wu, Y.; Hsu, C.; Chang, C.; Chung, I.; Hsieh, C.; Hsieh, M.; et al. Artificial intelligence-based education assists medical students’ interpretation of hip fracture. Insights Imaging 2020, 11, 119. [Google Scholar] [CrossRef] [PubMed]
- Rampton, V.; Mittelman, M.; Goldhahn, J. Implications of artificial intelligence for medical education. Lancet Digit. Health 2020, 2, e111–e112. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Stapleton, F.; Tan, J. Impact of Contact Lens Material, Design, and Fitting on Discomfort. Eye Contact Lens 2017, 43, 32–39. [Google Scholar] [CrossRef] [PubMed]
- Efron, N.; Morgan, P. Rethinking contact lens aftercare. Clin. Exp. Optom. 2017, 100, 411–431. [Google Scholar] [CrossRef] [PubMed]
- Holden, B.; Fricke, T.; Wilson, D.; Jong, M.; Naidoo, K.; Sankaridurg, P.; Wong, T.Y.; Naduvilath, T.J.; Resnikoff, S. Global Prevalence of Myopia and High Myopia and Temporal Trends from 2000 through 2050. Ophthalmology 2016, 123, 1036–1042. [Google Scholar] [CrossRef]
- Morgan, I.; Ohno-Matsui, K.; Saw, S. Myopia. Lancet 2012, 379, 1739–1748. [Google Scholar] [CrossRef]
- Craig, J.; Nelson, J.; Azar, D.; Belmonte, C.; Bron, A.; Chauhan, S.; de Paiva, C.; Gomes, J.A.; Hammitt, K.M.; Jones, L.; et al. TFOS DEWS II Report Executive Summary. Ocul. Surf. 2017, 15, 802–812. [Google Scholar] [CrossRef] [PubMed]
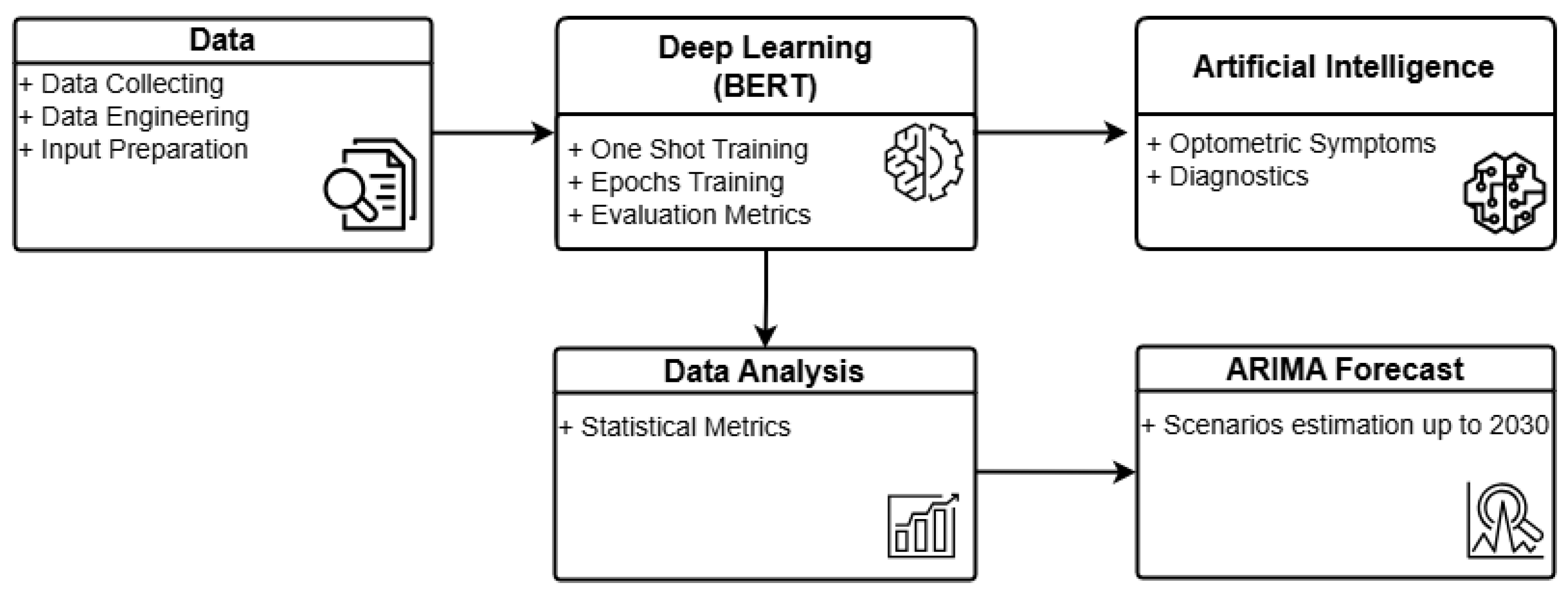
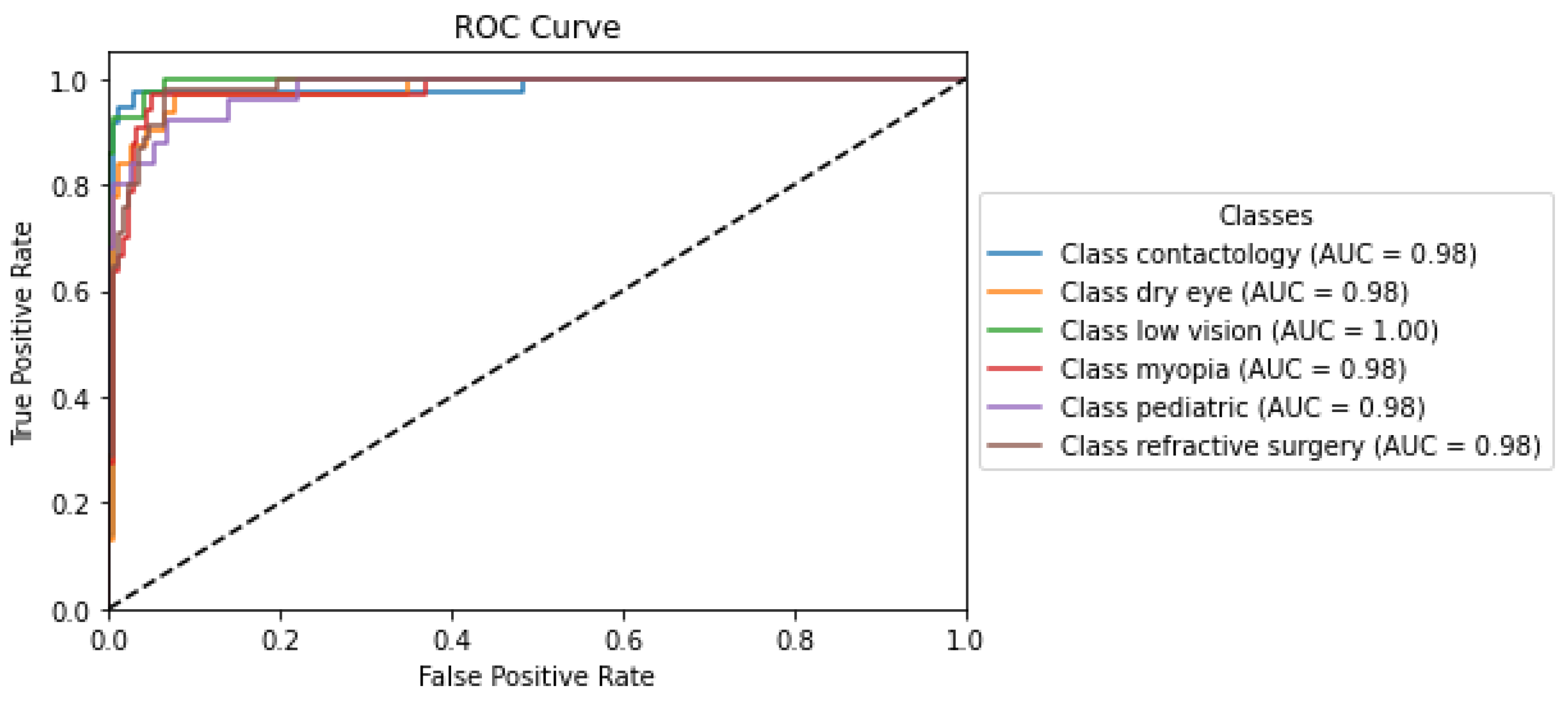
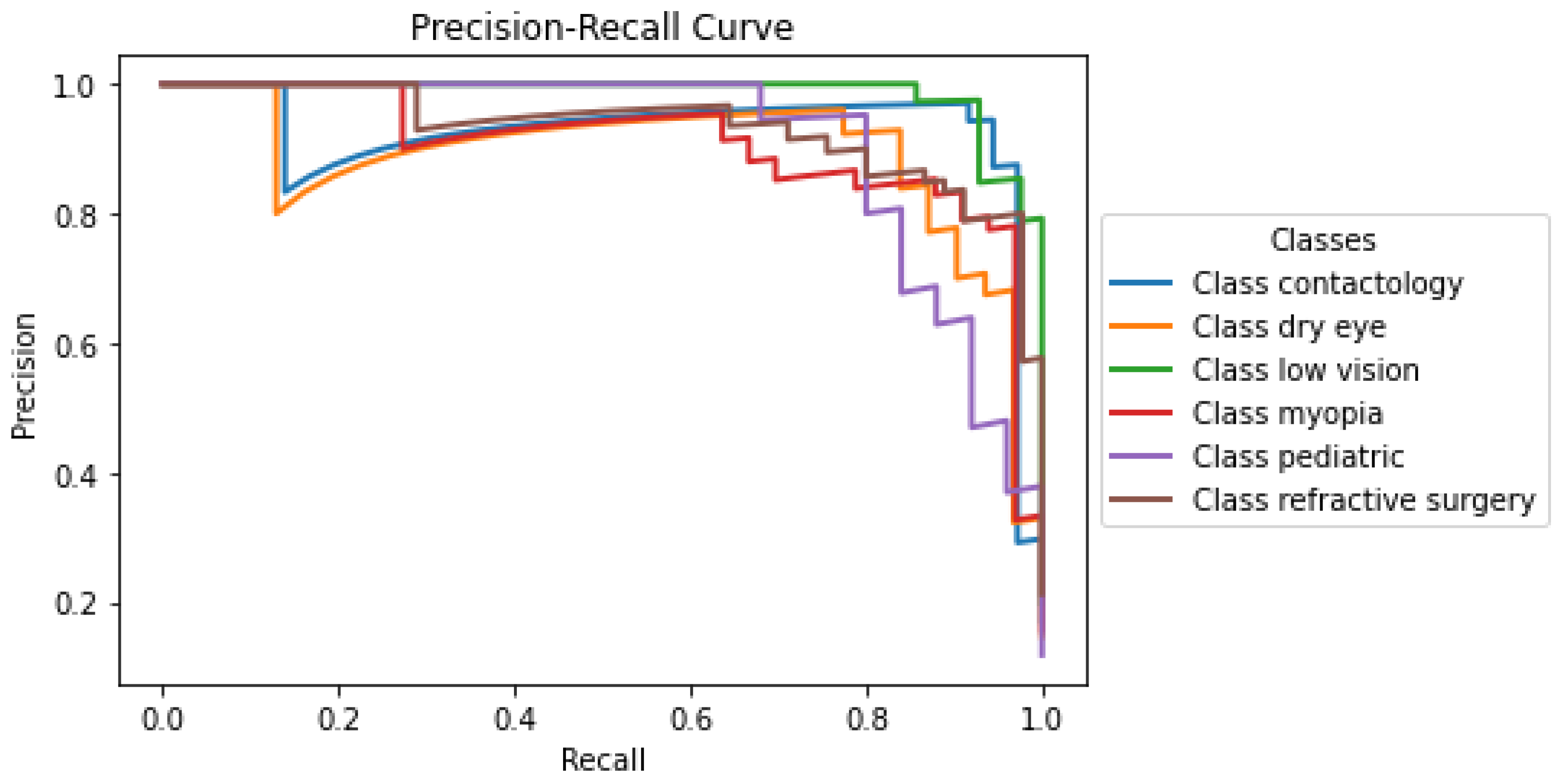
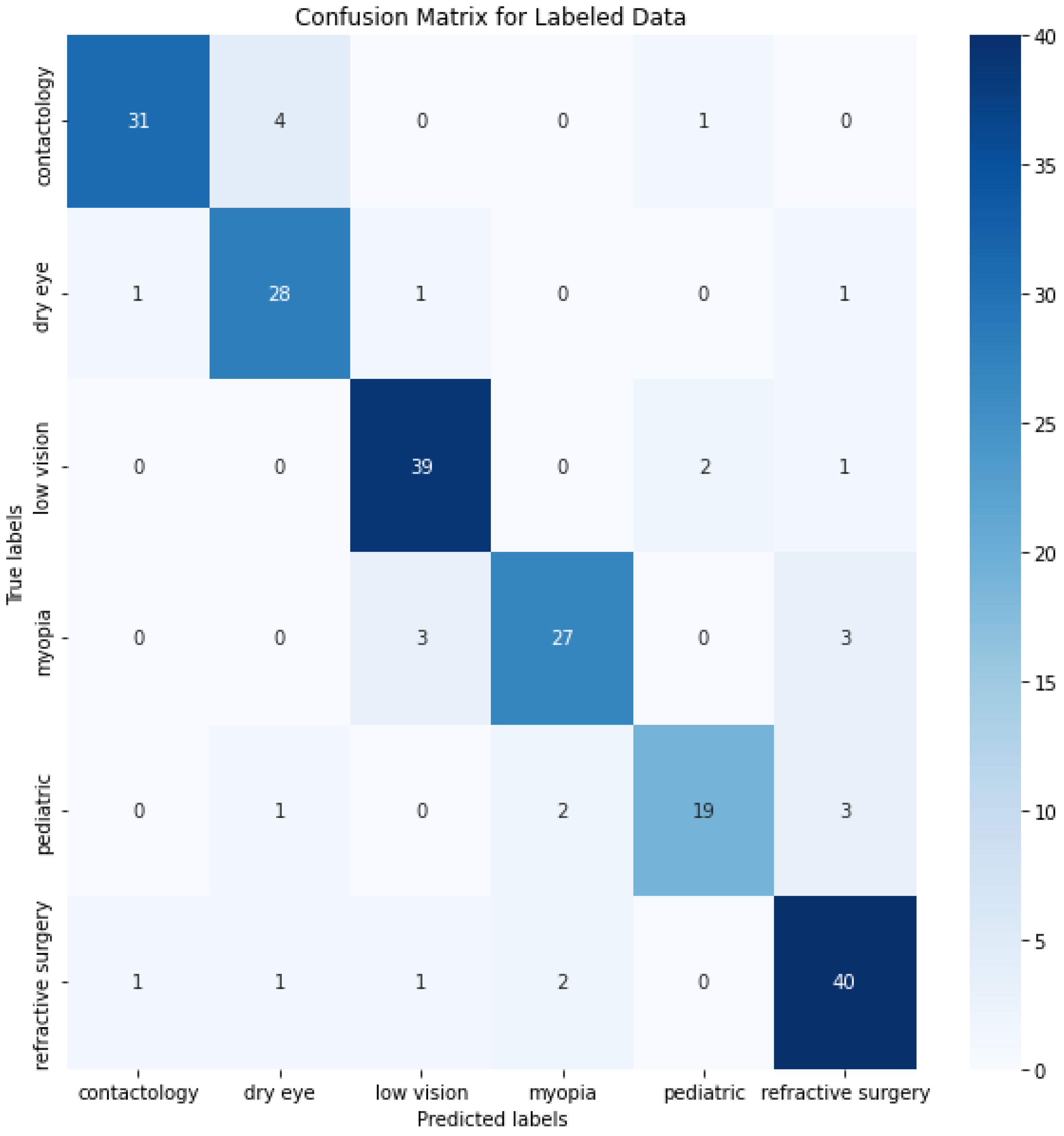
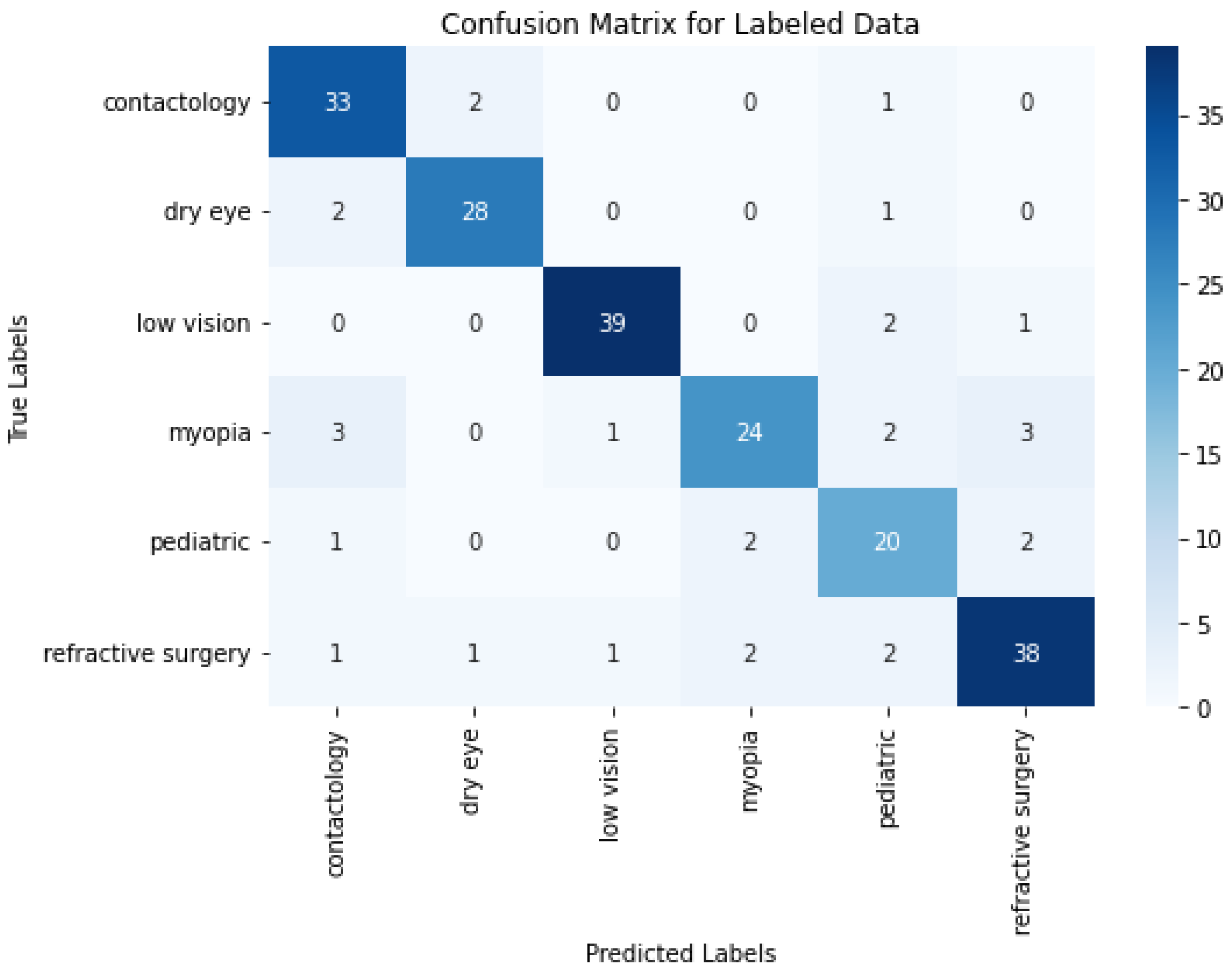
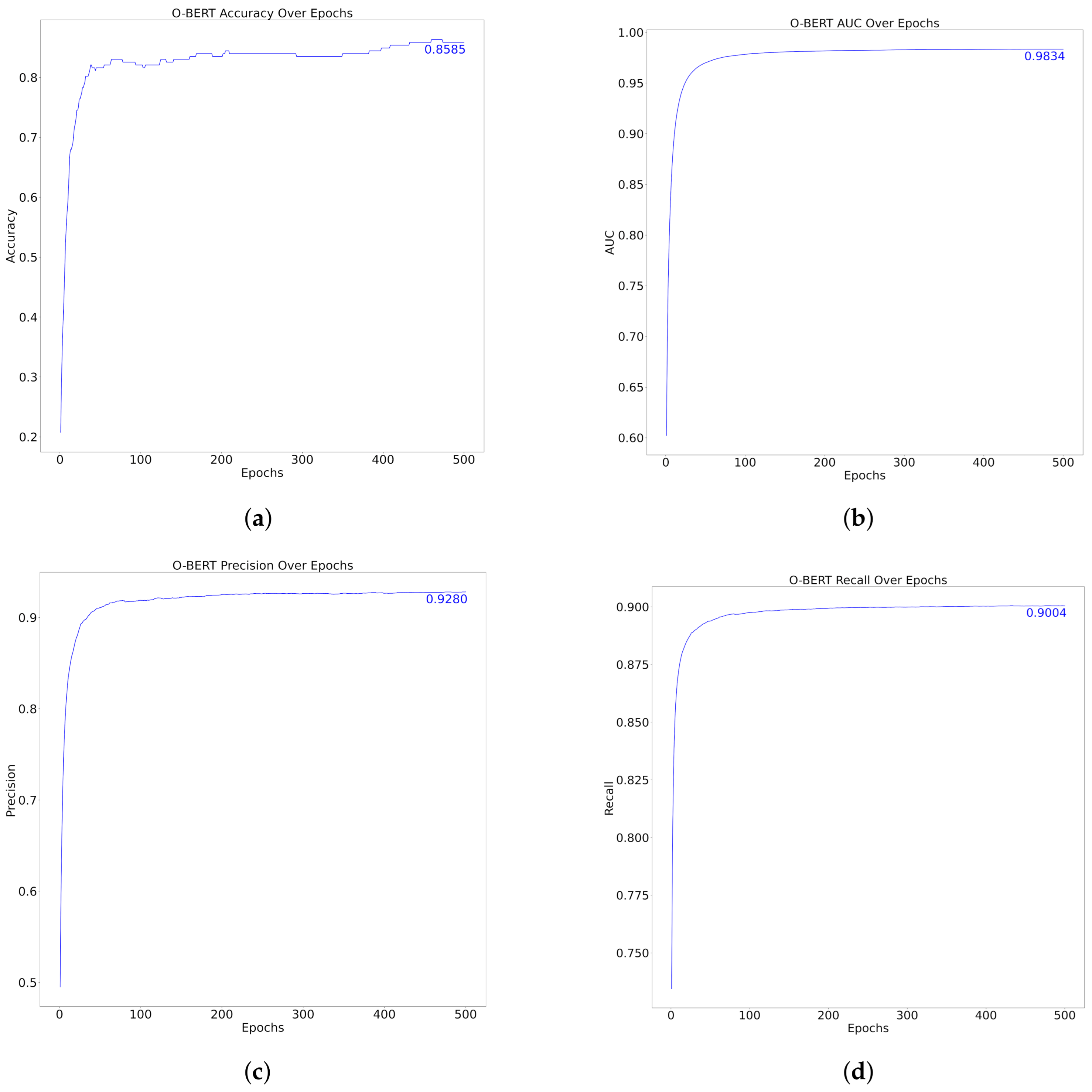
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).