3.5. Testing the System
Multiple experiments were conducted using historical and real-time data. Special attention was paid to trading liquid companies and SPY, the trust that owns stocks in the same proportion as that represented by the SP500 stock index.
CONTROL PERIODS. The most systematic historical testing was for the period 2006/01/01–2007/04/13. More exactly, five 4 month control periods (out-of-sample!) were taken:
Period 1: 2006/01/01–2006/04/30, Period 2: 2006/04/01–2006/07/30,
Period 3: 2006/07/01–2006/10/30, Period 4: 2006/10/01–2007/01/30,
Period 5: 2007/01/01–2007/04/13.
The last period was a little shorter.
The historical testing consisted of
- (i)
optimization during the 12 month optimization period taken backward from the beginning of the control period,
- (ii)
“trading from scratch” during the next 4 month control period with closing all positions at the end of the period.
Note that the control periods overlap (1 month), to simulate continuous trading, without closing all open positions at the ends of periods; this is how the system really works. The optimization periods and the corresponding control periods do not overlap of course. The system was used in the pro-trend variant in this test.
We evaluate the
AVERAGE 4 MONTH RETURN for five 4 month
control periods by the formula:
where 88 is the average number of business days in 4 months, RET
, NUM
, and LNGTH
are the corresponding
RET, NUM, LNGTH, the average return per position, the number of positions, and the average length (duration in business days) of one position during the corresponding 4 month period.
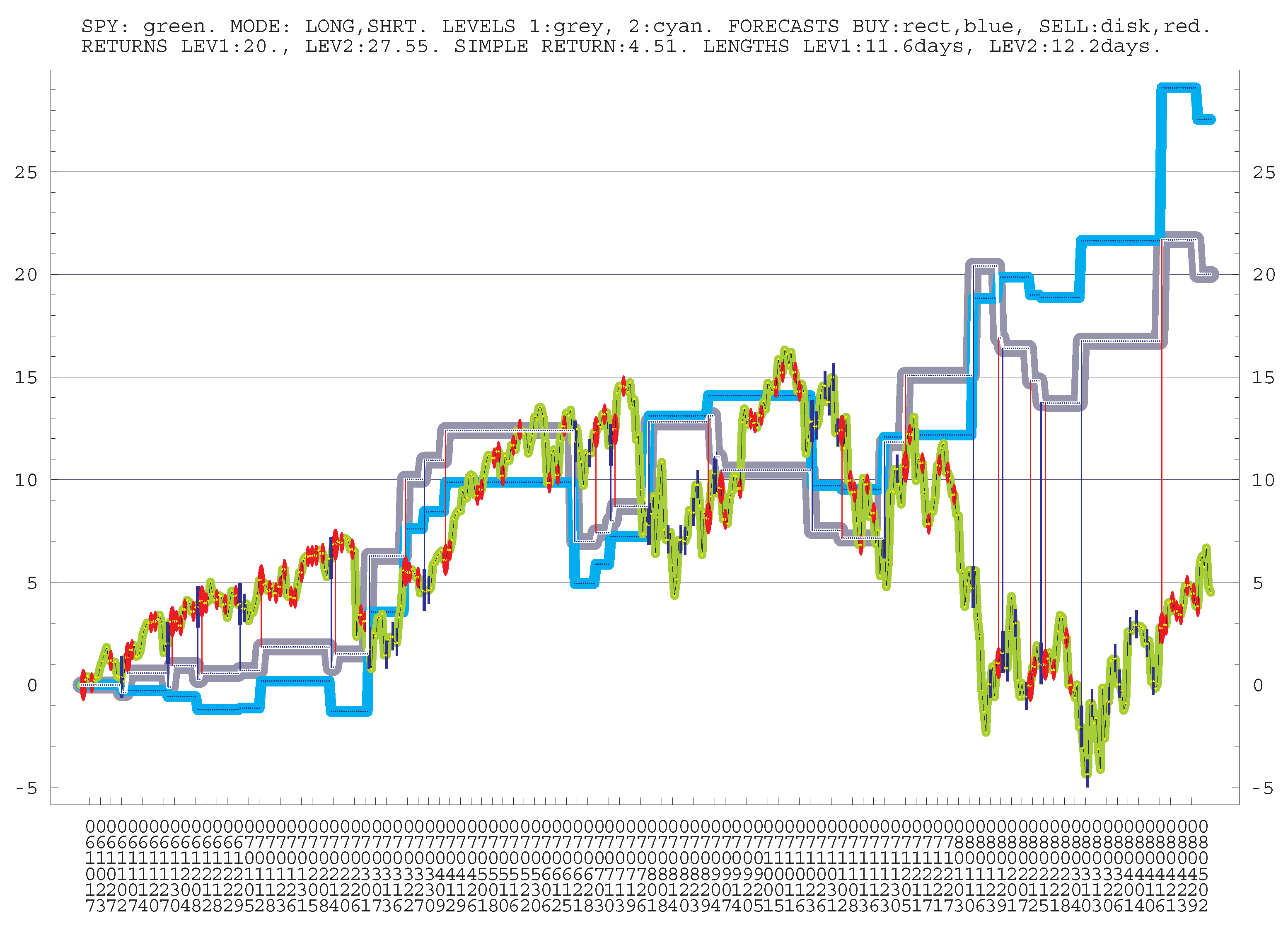
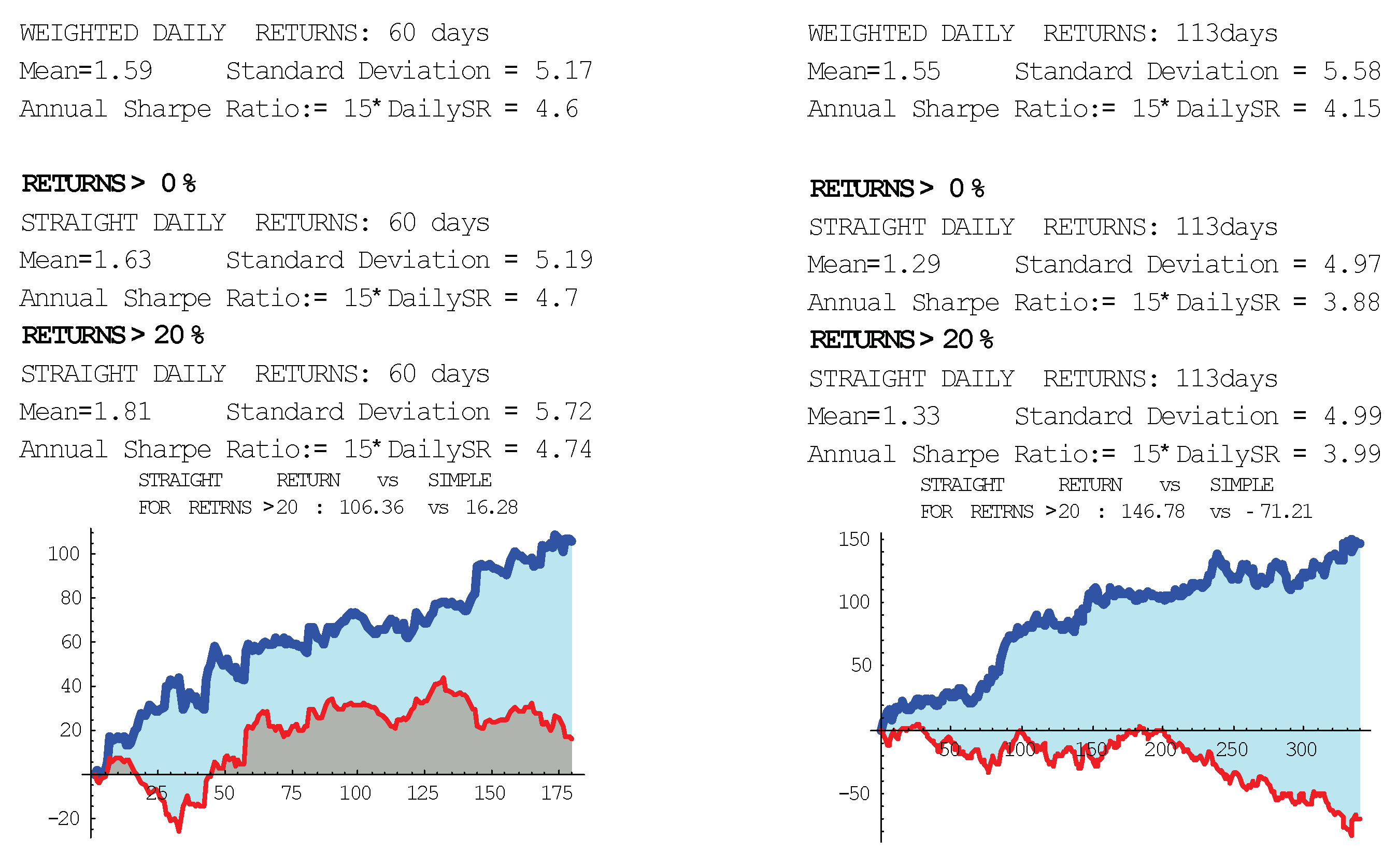
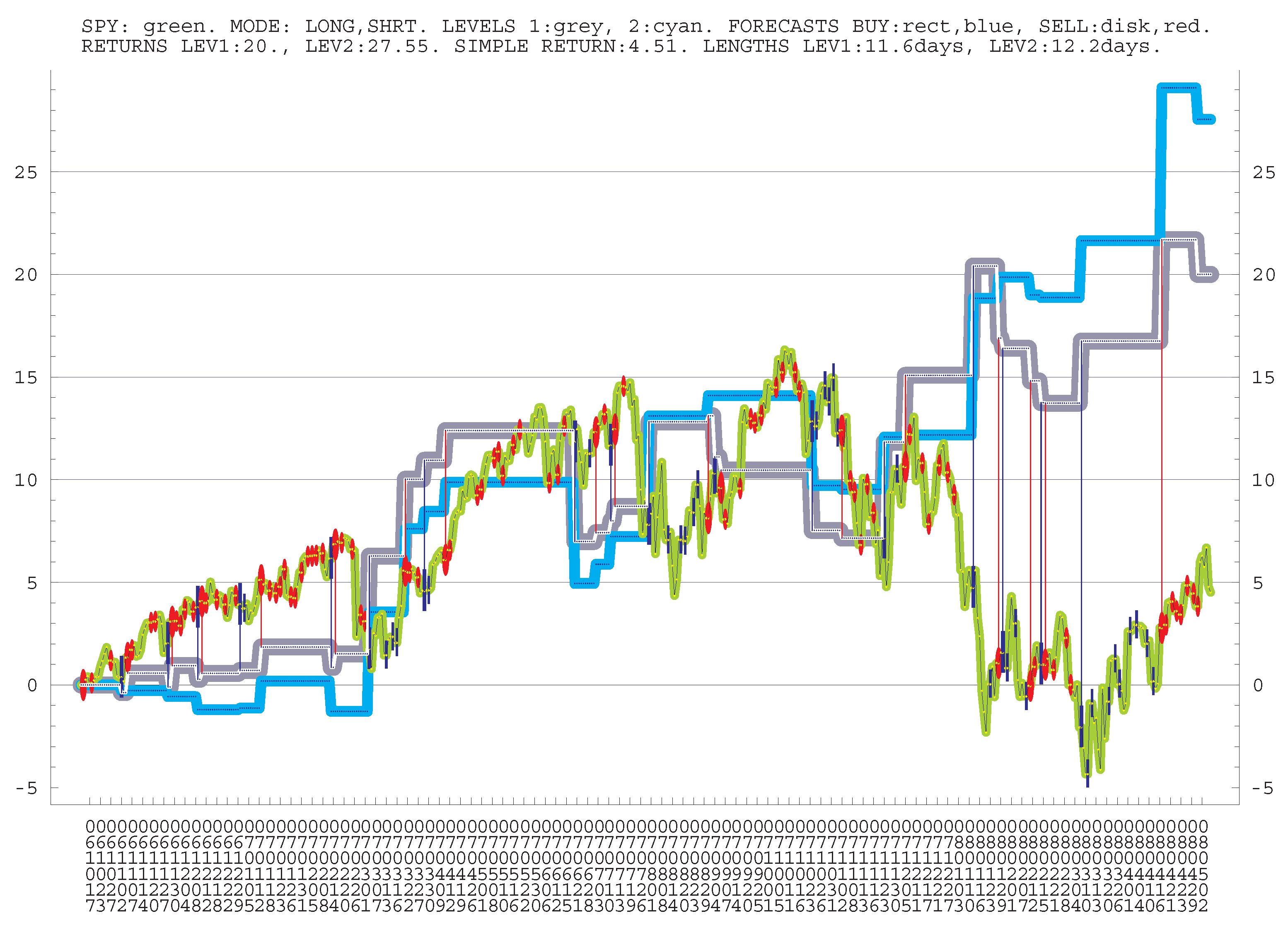
TRADING SPY (LONG ONLY). Let us provide the results of control “trading” SPY , without short positions and in the pro-trend regime. Generally, trading SPY is quite a challenge; see, e.g., (
Fouque et al. 2003) concerning some aspects of its fluctuations. Mathematically, long and short trading are on equal grounds; addressing possible negative developments is part of any risk-managements, which is quite universal.
The results for the signals of 4 levels are presented separately. By num, ret, lngth we denote the number of (long only) positions, the returns per position, and their durations for each level. The number in is the corresponding standard deviation. The averages for all 5 periods, RETURN, LNGTH, and AVR CHANGE are provided. We mention that RETURN becomes in the (well-tested) variant with LNGTH d, instead of d, which can be more suitable for end-users; the duration can be made even longer, but this can reduce profitability.
TRADING SPY (LONG ONLY)
AVERAGE POSITION LNGTH: 3.0 d;
AVERAGE 4 MONTH RETURN: 14.9%;
AVR SPY 4 MONTH CHANGE: 4.80%.
PERIOD: 20060101-20060430, SPY CHANGE=4.6%
NUM=18 RET=0.72(0.37) LNGTH=3.0d ALL
num=10 ret=0.58(0.38) lngth=3.1d lev=1
num=4 ret=0.87(0.23) lngth=4.0d lev=2
num=2 ret=0.79(0.19) lngth=3.1d lev=3
num=2 ret=1.1(0.15) lngth=0.5d lev=4
PERIOD: 20060401-20060730, SPY CHANGE=-1.0%
NUM=13 RET=0.45(1.26) LNGTH=5.2d ALL
num=4 ret=-0.23(1.15) lngth=7.0d lev=1
num=3 ret=0.17(1.05) lngth=6.3d lev=2
num=3 ret=0.97(1.12) lngth=3.7d lev=3
num=3 ret=1.11(1.19) lngth=3.3d lev=4
PERIOD: 20060701-20061030, SPY CHANGE=9.0%
NUM=23 RET=0.56(0.43) LNGTH=2.2d ALL
num=13 ret=0.44(0.42) lngth=2.1d lev=1
num=5 ret=0.44(0.26) lngth=2.2d lev=2
num=3 ret=0.8(0.15) lngth=2.9d lev=3
num=2 ret=1.28(0.22) lngth=2.0d lev=4
PERIOD: 20061001-20070130, SPY CHANGE=8.5%
NUM=12 RET=0.59(0.35) LNGTH=2.2d ALL
num=8 ret=0.46(0.33) lngth=2.4d lev=1
num=3 ret=0.89(0.12) lngth=2.3d lev=2
num=1 ret=0.8(0.09) lngth=0.8d lev=3
PERIOD: 20070101-20070413, SPY CHANGE=2.0%
NUM=17 RET=0.1(1.47) LNGTH=2.4d ALL
num=8 ret=0.08(1.58) lngth=2.4d lev=1
num=5 ret=0.22(1.7) lngth=2.2d lev=2
num=3 ret=0.31(0.52) lngth=2.2d lev=3
num=1 ret=-0.94(0.02) lngth=3.1d lev=4.
Short trading with a market that essentially goes up is quite a challenge for any trading system. Short trading here provides some “insurance” for the periods when SPY goes down. Some losses can be acceptable when it goes up, but the system actually remains profitable. Let us demonstrate this for the same periods and data. As we wrote, the bid-ask spread is not counted, not too high for liquid assets.
TRADING SPY (SHRT ONLY)
AVERAGE POSITION LNGTH: 3.2 d;
AVERAGE 4 MONTH RETURN: 3.15%;
AVR SPY 4 MONTH CHANGE: 4.80%.
PERIOD: 20060101-20060430, SPY CHANGE=4.6%
NUM=33 RET=0.02(0.72) LNGTH=3.7d ALL
num=14 ret=-0.06(0.81) lngth=3.5d lev=1
num=10 ret=0.19(0.69) lngth=3.2d lev=2
num=5 ret=-0.11(0.51) lngth=4.6d lev=3
num=4 ret=0.(0.62) lngth=4.5d lev=4
PERIOD: 20060401-20060730, SPY CHANGE=-1.0%
NUM=46 RET=0.5(0.61) LNGTH=2.7d ALL
num=18 ret=0.31(0.65) lngth=2.8d lev=1
num=13 ret=0.6(0.58) lngth=2.8d lev=2
num=8 ret=0.65(0.49) lngth=2.7d lev=3
num=7 ret=0.64(0.53) lngth=2.0d lev=4
PERIOD: 20060701-20071030, SPY CHANGE=9.0%
NUM=66 RET=0.04(0.77) LNGTH=2.9d ALL
num=24 ret=0.01(0.83) lngth=2.7d lev=1
num=15 ret=0.03(0.75) lngth=3.4d lev=2
num=14 ret=0.04(0.75) lngth=3.1d lev=3
num=13 ret=0.09(0.65) lngth=2.6d lev=4
PERIOD: 20061001-20070130, SPY CHANGE=8.5%
NUM=42 RET=0.05(0.64) LNGTH=4.4d ALL
num=14 ret=-0.18(0.7) lngth=4.5d lev=1
num=12 ret=0.11(0.56) lngth=4.4d lev=2
num=10 ret=0.21(0.62) lngth=4.0d lev=3
num=6 ret=0.18(0.49) lngth=4.8d lev=4
PERIOD: 20070101-20070413, SPY CHANGE=2.0%
NUM=68 RET=0.(0.93) LNGTH=2.5d ALL
num=31 ret=0.09(0.96) lngth=2.0d lev=1
num=17 ret=0.06(1.08) lngth=2.6d lev=2
num=11 ret=-0.17(0.68) lngth=2.8d lev=3
num=9 ret=-0.22(0.7) lngth=3.2d lev=4.
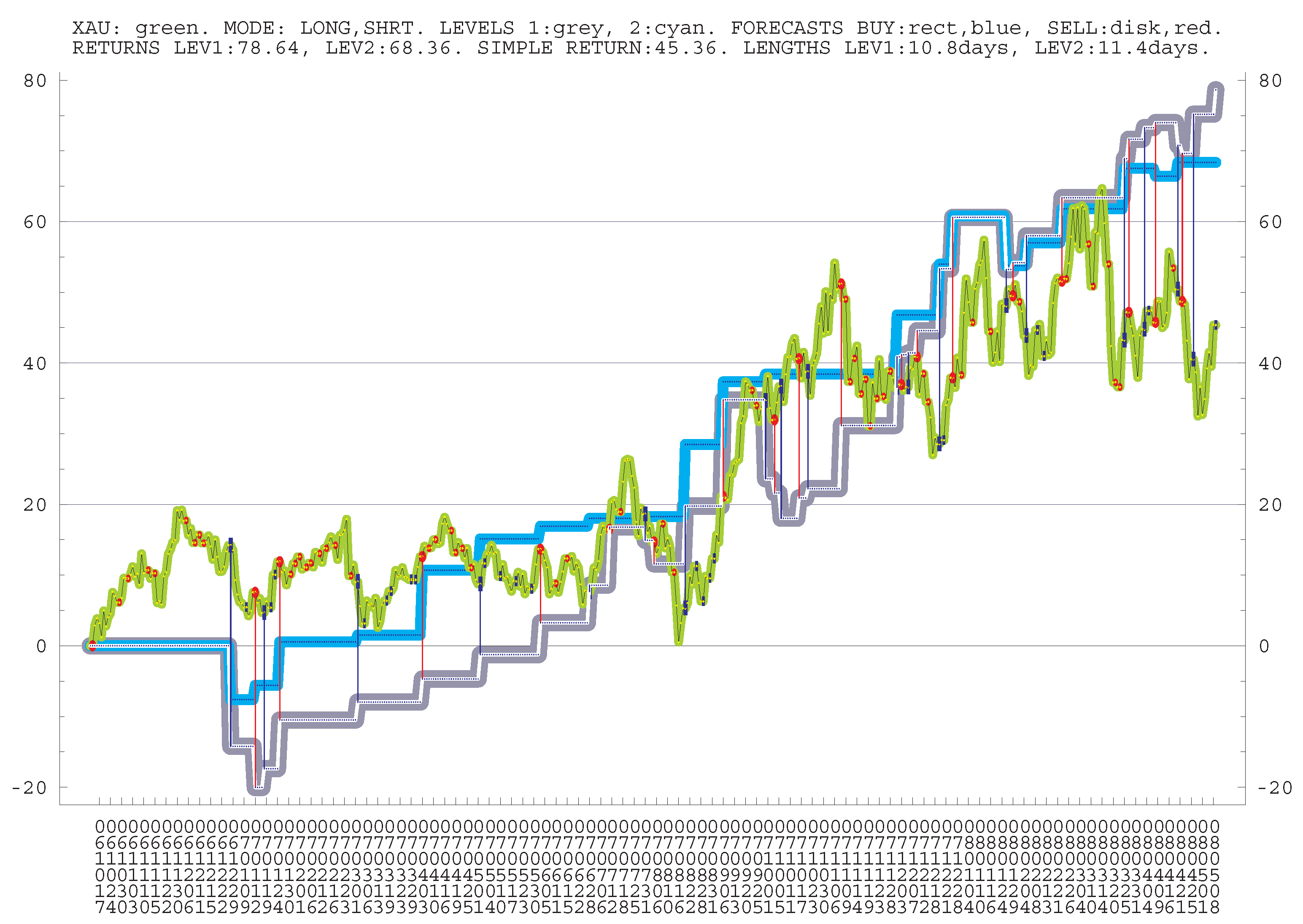
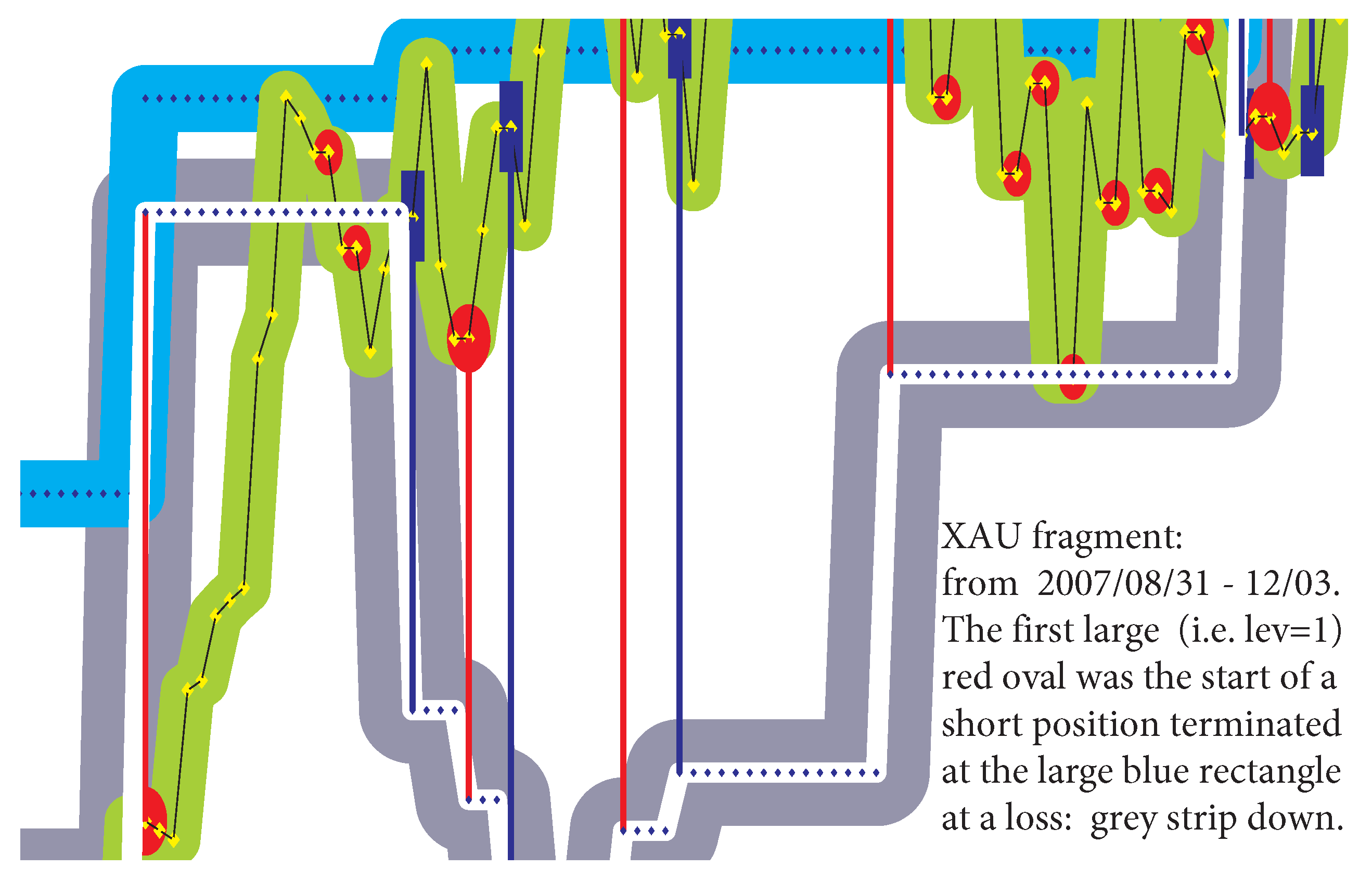
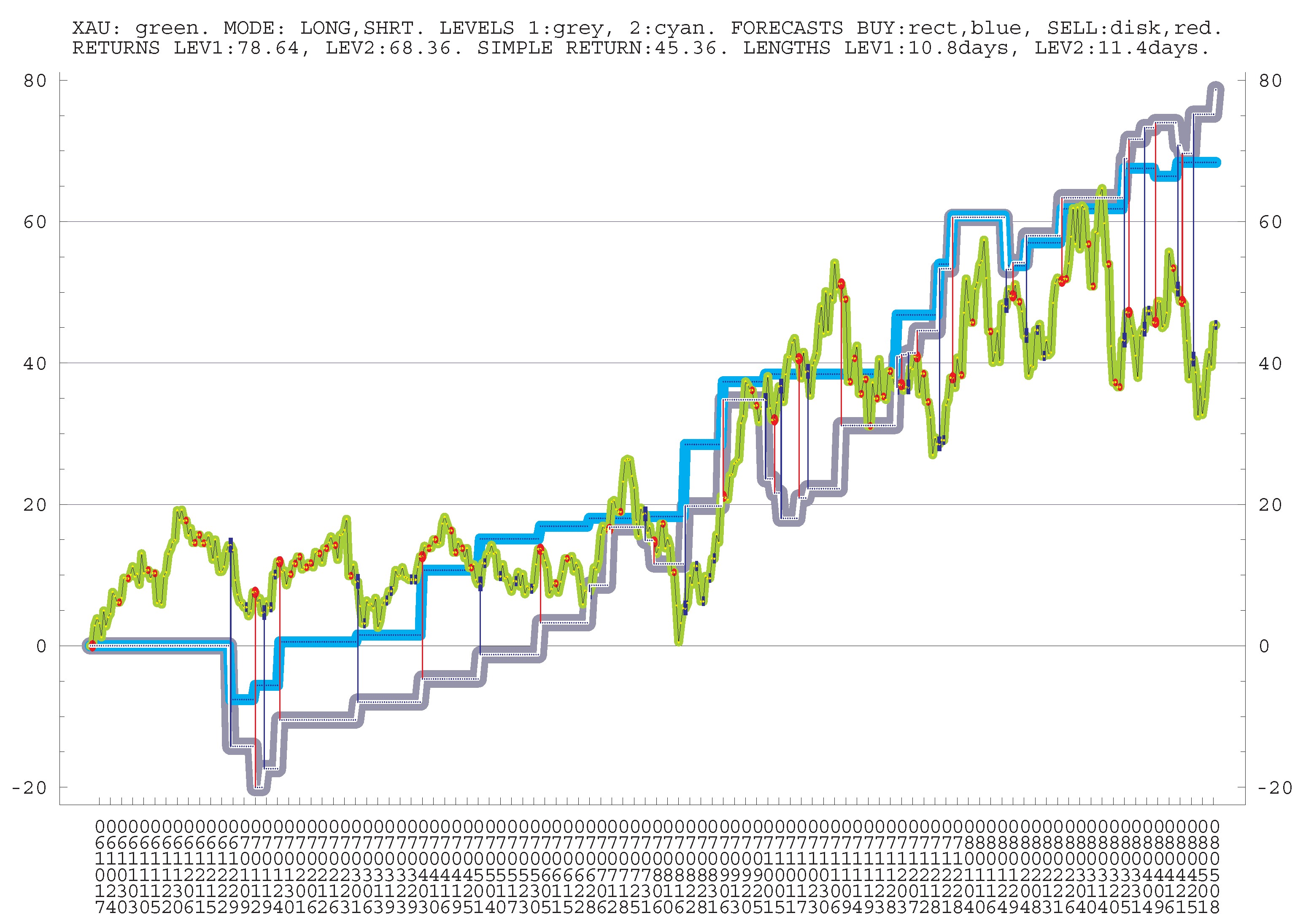
TRADING LIQUID COMPANIES. For the same periods, let us present data for “trading” of 165 stocks, mostly liquid. It is for longs and shorts and pro-trend, i.e., essentially under the mean reversion trading. The AVERAGE LNGTH and RETURN are the averages over all five periods; NUM and num are the numbers of positions.
AVERAGE POSITION LNGTH: 5.0 d;
AVERAGE 4 MONTH RETURN: 9.56%;
AVR SPY 4 MONTH CHANGE: 4.80%.
PERIOD: 20060101-20060430, SPY CHANGE=4.6%
NUM=2236 RET=0.64(3.4) LNGTH=5.2d ALL
num=1105 ret=0.55(3.57) lngth=5.4d lev=1
num=602 ret=0.68(3.25) lngth=5.2d lev=2
num=344 ret=0.81(3.31) lngth=5.1d lev=3
num=185 ret=0.79(2.89) lngth=4.7d lev=4
PERIOD: 20060401-20060730, SPY CHANGE=-1.0%
NUM=2433 RET=0.14(4.08) LNGTH=5.4d ALL
num=1169 ret=0.13(4.19) lngth=5.3d lev=1
num=628 ret=0.16(4.12) lngth=5.6d lev=2
num=394 ret=0.09(3.89) lngth=5.4d lev=3
num=242 ret=0.25(3.78) lngth=4.9d lev=4
PERIOD: 20060701-20071030, SPY CHANGE=9.0%
NUM=2401 RET=0.66(3.93) LNGTH=4.5d ALL
num=1248 ret=0.64(3.92) lngth=4.4d lev=1
num=619 ret=0.74(3.91) lngth=4.5d lev=2
num=344 ret=0.53(3.98) lngth=4.5d lev=3
num=190 ret=0.7(3.99) lngth=4.2d lev=4
PERIOD: 20061001-20070130, SPY CHANGE=8.5%
NUM=2174 RET=0.71(3.67) LNGTH=5.2d ALL
num=1101 ret=0.67(3.73) lngth=5.2d lev=1
num=566 ret=0.77(3.66) lngth=5.2d lev=2
num=324 ret=0.74(3.54) lngth=5.d lev=3
num=183 ret=0.73(3.62) lngth=5.2d lev=4
PERIOD: 20070101-20070413, SPY CHANGE=2.0%
NUM=1812 RET=0.65(3.05) LNGTH=5.d ALL
num=934 ret=0.56(3.1) lngth=5.1d lev=1
num=476 ret=0.79(3.05) lngth=5.d lev=2
num=257 ret=0.71(3.06) lngth=4.9d lev=3
num=145 ret=0.62(2.63) lngth=4.9d lev=4.
The list of stock symbols of these companies is as follows:
"AA", "AAP", "AAPL", "ABC", "ABT", "ACAS", "ADBE", "ADM", "ADP", "ADSK",
"AIG", "AIV", "ALL", "AMAT", "AMGN", "AMTD", "AMZN", "ANF", "ANN", "APA",
"APC", "ATI", "AVP", "AXP", "BA", "BAC", "BBBY", "BBY", "BEAS", "BEN",
"BHI", "BJS", "BMET", "BMY", "BNI", "BP", "BRCM", "BSC", "C", "CAL", "CAT",
"CCU", "CELG", "CEPH", "CFC", "CHK", "CHRW", "CHS", "CMCSA", "CMCSK", "CMI",
"COF", "COP", "COST", "CSCO", "CTSH", "CVS", "CVX", "D", "DE", "DELL",
"DO", "DVN", "EBAY", "EK", "EOG", "EQR", "ERTS", "ESRX", "FD", "FDO",
"FDX", "FNM", "FPL", "FRE", "GE", "GENZ", "GG", "GILD", "GLW", "GM", "GPS",
"GRMN", "GS", "GSF", "HD", "HON", "HPQ", "IBM", "INTC", "IP", "ITG", "ITW",
"JCP", "JNJ", "JPM", "JWN", "KLAC", "KO", "KR", "KSS", "LEH", "LLY", "LMT",
"LNCR", "LOW", "LRCX", "MCD", "MER", "MET", "MIL", "MMM", "MO", "MON",
"MOT", "MRO", "MRVL", "MSFT", "MXIM", "NBR", "NE", "NEM", "NKE", "NOV",
"NSC", "NUE", "ORCL", "OXY", "PEP", "PFE", "PG", "POT", "PRU", "QCOM",
"RIG", "ROK", "SBUX", "SLB", "SNDK", "SPG", "STN", "SU", "SUN", "SUNW",
"SYMC", "TEVA", "TGT", "TWX", "TXN", "UNH", "UNP", "UTX", "VLO", "VNO",
"VZ", "WAG", "WB", "WFMI", "WMT", "WYE", "X", "XLNX", "XOM", "XTO", "YHOO".
Let us combine all five control intervals in one period (avoiding terminations of the ends of the intervals) and show all levels and the corresponding numbers of positions taken, NUM for all and num for levels; the lengths are the average durations of the positions. One has:
Period: FROM 1/1/2006 TO 4/13/2007
NUM=9332 RET=0.6 LNGTH=5.5d ALL
num=4143 ret=0.52 lngth=5.6 lev=1
num=2228 ret=0.67 lngth=5.4 lev=2
num=1285 ret=0.63 lngth=5.3 lev=3
num=735 ret=0.69 lngth=5.1 lev=4
num=416 ret=0.76 lngth=5.3 lev=5
num=237 ret=0.6 lngth=5.6 lev=6
num=131 ret=0.55 lngth=5.7 lev=7
num=76 ret=0.57 lngth=5.5 lev=8
num=54 ret=0.99 lngth=4.9 lev=9
num=27 ret=0.52 lngth=5. lev=10.
A simplified optimization was performed here, with only two fixed categories () and a reduced number of iterations. For this period, 24 stocks (from 165) performed negatively, including INTC, DELL, EBAY. Trading such “heavy-weighters” generally requires full optimization and at least three categories. However here we made the optimization fully uniform for all companies and fast, aiming at thousands of companies. The optimization for INTC or similar, if this is the objective, must be done more thoroughly. The following 24 companies had negative returns:
ADBE num= 90 ret=-0.29% lngth=3.9
AMGN num= 49 ret=-0.48% lngth=9.1
APA num= 66 ret=-0.25% lngth=5.6
BJS num= 68 ret=-0.88% lngth=6.9
CHK num= 58 ret=-0.7% lngth=8.1
CHS num= 74 ret=-0.4% lngth=6.1
COF num= 49 ret=-0.05% lngth=6.4
COP num= 45 ret=-0.51% lngth=9.2
DELL num= 88 ret=-0.32% lngth=4.8
EBAY num= 101 ret=-0.51% lngth=4.3
EOG num= 82 ret=-0.64% lngth=5.4
HD num= 47 ret=-0.05% lngth=8.5
INTC num= 89 ret=-0.53% lngth=7.1
JNJ num= 26 ret=-0.94% lngth=11.6
MMM num= 50 ret=-0.53% lngth=7.2
MOT num= 67 ret=-0.86% lngth=5.3
NBR num= 80 ret=-0.99% lngth=5.3
NOV num= 87 ret=-0.66% lngth=5.1
SNDK num= 90 ret=-0.73% lngth=2.8
SUN num= 79 ret=-1.04% lngth=3.8
SYMC num= 83 ret=-0.69% lngth=4.2
TEVA num= 80 ret=-0.15% lngth=4.2
TWX num= 46 ret=-0.27% lngth=10.4
XLNX num= 82 ret=-0.16% lngth=5.5.
Here and above only signals of levels no greater than 4 were used for trading. We invested a symbolic $100 in every position, so multiple signals in one direction increased this amount up to $400, which resembles trading on margin. The first signal in the opposite direction (for this stock) results in the termination of all positions. This regime can significantly improve profitability. Higher levels are more frequent for actively traded companies, so this is some kind of leverage.
We do not use weights here. Let us just mention that investing only in 100 companies from 165 above with the best optimization results constantly improves the performance of the systems; which is a variant of using weights. However, some companies with solid optimization returns, i.e., suitable for our system, performed just so-so during the control periods. This is the nature of stock markets, discussed well in the literature; see, e.g., (
Yang and Zhang 2019).
Let us now provide some auto-generated results of real-time trading simulation with 170 companies, similar to those listed above, under long and short with 4 levels (L1, L2, L3, L4), and for 3 “production lines” (A,B,C). The lines were with different “opti-parameters” and/or different entry points; “B” was counter-trend. The first half, “no weights”, describes the uniform trading of all companies, the second half is for the 100 companies with the best returns during the optimization:
TRADING FROM 2007, 2, 20 TO 2007, 6, 4; ALL, NO WEIGHTS:
RET AVR A: RETL1=0.68 RETL2=0.76 RETL3=0.89 RETL4=1.04
RET AVR B: RETL1=0.67 RETL2=0.7 RETL3=0.86 RETL4=0.84
RET AVR C: RETL1=0.61 RETL2=0.7 RETL3=0.75 RETL4=0.75
TRADING FROM 2007, 2, 20 TO 2007, 6, 4; FOR 100 FROM 170:
RET AVR A: RETL1=0.57 RETL2=0.79 RETL3=1.16 RETL4=1.4
RET AVR B: RETL1=0.96 RETL2=1.04 RETL3=1.23 RETL4=1.23
RET AVR C: RETL1=1.08 RETL2=1.11 RETL3=1.19 RETL4=1.17.
The returns here are per position; the average position lasted about 5 days; SPY increased 5.5% during 2007/02/20–2007/06/04. Actually, about 1000 companies were traded for this period combined in groups based on trading volumes, with about 170 in each. Every company was traded in 12 different “lines“, so the total was 72 lines. The average return was about 0.7% per position; the average position was about 5 days. The results above are for 3 lines only.
The optimization procedure is based on the gradient method and is actually not far from the methods used in
networks; see (
Borovykh et al. 2019;
Horel and Giesecke 2019). It was almost always with solid returns for any equities and “learning periods” in spite of using very few parameters. This alone is some discovery. However, predicting the future is, of course, much more subtle and much less certain, in spite of the fact that risk-taking preferences of investors are quite conservative. In our approach, we only try to predict the ways investors react to news, but not the news itself! See here, e.g., (
Chinthalapati and Tsang 2019) for various algorithms used in financial mathematics.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}