Abstract
In this paper, a dynamic mixture copula model is used to estimate the marginal expected shortfall in the South African insurance sector. We also employ the generalized autoregressive score model (GAS) to capture the dynamic asymmetric dependence between the insurers’ returns and the stock market returns. Furthermore, the paper implements a ranking framework that expresses to what extent individual insurers are systemically important in the South African economy. We use the daily stock return of five South African insurers listed on the Johannesburg Stock Exchange from November 2007 to June 2020. We find that Sanlam and Discovery contribute the most to systemic risk, and Santam turns out to be the least systemically risky insurance company in the South African insurance sector. Our findings defy common belief whereby only banks are systemically risky financial institutions in South Africa and should undergo stricter regulatory measures. However, our results indicate that stricter regulations such as higher capital and loss absorbency requirements should be required for systemically risky insurers in South Africa.
1. Introduction
The insurance sector (life and non-life) plays a significant role in the economy and is viewed as crucial in the financial system. The European Central Bank (ECB 2013) states that insurance companies are essential for the stability of the financial system due to their investment ability, their growing links to banks, and their ability to safeguard the financial stability of households and firms by insuring their risks. In line with ECB, the National Treasury of South Africa (2011) argues that the insurance sector is a pillar of the South African financial system by being the guardian of the stability of the whole system. In addition, according to the Insurance Institute of South Africa (IISA 2016), the insurance sector (short-term and long-term insurance) accounted for 23% of total financial assets in South Africa in 2016 and contributed to R 18 billion to the country’s revenue based in 2015, implying that the insurance sector is a driver of the South African economy. Thus, a failure of one or more insurers could disrupt the insurance sector and lead to systemic risk.
Nevertheless, the International Monetary Fund (IMF 2009) has defined systemic risk as “the risk of extensive disturbance to the delivery of financial services caused by an impairment of all or parts of the financial system, which can bring about severe adverse effects on the economy”.
The 2007–2009 Global Financial Crisis (GFC) is a typical example of systemic risk. The crisis began in the United States (U.S.) real estate sector and spread to the financial system with a negative impact on economic activities across the world.
The GFC has revealed that the insurance sector was partly responsible for the crisis with American International Group (AIG) becoming the first example of an insurer in the U.S. that received federal assistance to prevent bankruptcy due to it being considered systemically risky. Thus, concerns have been raised about whether the insurance sector is a significant contributor to systemic risk. The answer to this question is capital for regulators, policymakers, investors, and academics. Hence, many studies have focused on the extent to which the insurance sector contributes to systemic risk.
For example, Grace (2011) uses granger-causality to assess the systemic risk of 12 major insurance companies in the U.S. from 2000 to 2010. The main results indicate that the insurance sector does not contribute to systemic risk because the period between its assets and liabilities is closely equaled.
Drakos and Kouretas (2015) apply the conditional value at risk (CoVaR), and the marginal conditional value at risk (ΔCoVaR) to measure systemic risk in the banking sector, insurance sector, and other financial services sectors for the U.S., and the United Kingdom (UK) between 2000 and 2012. They find that the banking sector contributes relatively more to systemic risk than the insurance sector or the other financial services in the U.S. and UK. Furthermore, based on the ΔCoVaR measures, Drakos and Kouretas (2015) argue that there is a significant increase in the contribution to systemic risk for all sectors in both countries since 2008.
Acharya and Richardson (2014) use the Credit Default Swaps Marginal Expected Shortfall (CDS-MES) as a measure of systemic risk to provide a ranking for 20 insurance companies in the U.S. with respect to their contribution to systemic risk. Their results reveal that Genworth Financial Inc., AMBAC Financial Group Inc., MBIA Inc., and AIG are the most systemically risky insurers, respectively, during the sample period, while AETNA Inc., CIGNA Corp, and Marsh & McLennan Cos. Inc. are the least systemically risky insurance companies, with CDS MESs being negative. The authors further contend that the insurance sector may cause systemic risk as the sector is moving away from its traditional activities by offering financial products with non-diversifiable risk which is more prone to run.
Dungey et al. (2014) assess systemic risk through the interconnectedness of the banking sector, insurance sector, and real economy firms in the U.S. by applying eigenvector centrality measures. The results show that while the banks are the most consistently systemically risky financial institutions in the economy, insurers are becoming an identifiable group exhibiting substantial systemic risk via interconnectedness with the financial sector and the real economy.
Bernal et al. (2014) employ ΔCoVaR and the Kolmogorov-Smirnov test to provide a ranking of commercial banks, insurance companies, and other financial services for their contribution to systemic risk in the Eurozone and the U.S. during the period of the 2007–2009 financial crisis and the European sovereign debt crisis. They find that in the Eurozone, the other financial services sector contributes relatively the most to systemic risk at times of distress affecting this sector. In turn, the banking sector appears to contribute more to systemic risk than the insurance sector. By contrast, the insurance sector is the systemically riskiest financial sector in the U.S. for the same period, while the banking sector contributes the least to systemic risk. In addition, Bernal et al. (2014) argue that beyond this ranking, the three financial sectors of interest are found to contribute significantly to systemic risk, both in the Eurozone and in the U.S.
Weiß and Muhlnickel (2014) examine systemic risk for 89 U.S. insurers during the period of the 2007–2009 financial crisis using ΔCoVaR, MES, and SRISK as systemic risk measures. Their findings reveal that size is the main driver of insurers’ exposure and contribution to systemic risk in the U.S., and the exposure to systemic risk additionally depends on non-traditional and non-insurance activities such as CDS writing. Similarly, Berdin and Sottocornola (2015) apply the linear Granger causality test, ΔCoVaR, and MES to assess systemic risk in the banking sector, insurance sector, and non-financial sectors in Europe. Their results show that the insurance sector shows a persistent systemic relevance over time and plays a subordinate role in causing systemic risk compared to the banking sector. Moreover, their findings indicate that insurance companies that engage more in non-traditional and non-insurance activities tend to pose more systemic risk and size is also a significant driver of systemic risk in the banking sector and the insurance sector in Europe.
Furthermore, Bierth et al. (2015) employ ΔCoVaR, MES, and SRISK as measures of systemic risk to study the exposure and contribution of 253 life and non-life insurers across the world to systemic risk between 2000 and 2012. They find that the interconnectedness of large insurers with the insurance sector to be a significant driver of the insurers’ exposure to systemic risk. In addition, Bierth et al (2015) argue that the contribution of insurers to systemic risk appears to be principally driven by the insurers’ leverage.
Kaserer and Klein (2019) utilize CDS-implied systemic risk measure to investigate how insurance companies contribute to systemic risk in the global financial system represented by 201 major banks and insurers from 2004 to 2014. They find that the insurance sector contributes relatively little to the aggregate systemic risk. However, at the institution level, several multi-line and life insurers appear to be as systemically risky as the riskiest banks. They conclude that some insurers are systemically important and indicate that insurers’ level of systemic risk varies by line of business.
More details on the review of literature in the insurance sector can be found in (Eling and Pankoke 2016).
Our study contributes to the increasing literature analyzing systemic risk in the insurance sector. Despite many methodologies used to identify and evaluate systemic risk in the insurance sector, no studies have investigated the dynamic and asymmetric dependence between insurance companies and the market.
Cerrato et al. (2015) argue that the dynamic and asymmetric dependence between financial institutions is one of the primary factors causing systemic risk. They describe dynamic and asymmetric dependence as a situation whereby financial institutions present greater correlation during market declines than market expansions. Thus, modeling the dynamic and asymmetric dependence could help to identify potential systemic risk.
Moreover, the majority of studies analyzing systemic risk in the insurance sector have been done on developed countries. However, research on measuring systemic risk in the insurance sector is still scarce in emerging economies such as South Africa.
Therefore, it is essential to investigate the asymmetric dependence between insurers and the market and how their correlation evolves over time. Thus, this study is of paramount importance for South African regulators and risk managers to understand the dynamic and asymmetric dependence in the insurance sector and appropriately manage systemic risk in the South African insurance sector. For this reason, our study analyzes the dynamic and asymmetric dependence between the market and five insurance companies in South Africa by employing copula models.
By definition, a copula model enables us to assess the dependence structure between random variables, and it provides more information on the dependence structure of the variables than linear correlation.
The main objective of this study is to implement a ranking that expresses to what extent individual insurers are systemically important in South Africa. In other words, which one of the insurers would pose a systemic threat to the stability of the financial system in South Africa?
To achieve our objective, we use a Dynamic Mixture Copula model to estimate the Marginal Expected Shortfall (DMC-MES), a model proposed by Eckernkemper (2018). Our choice for the dynamic mixture copula is that it is flexible as it can capture dynamic, symmetric, and asymmetric dependence altogether in one framework. More specifically, we opt for two dynamic mixture copula models, a combination of Rotated Clayton and Clayton (RC&C) and a combination of Rotated Gumbel and Gumbel (RG&G). The Clayton and Rotated Gumbel copulas allow for lower tail dependence, whereas the Gumbel and Rotated Clayton allow for upper tail dependence. In addition, we use the Generalized Autoregressive Score (GAS) developed by Creal et al. (2013) to model the dynamic parameters of our dynamic mixture copula models.
We also apply the time-varying symmetrized Joe-Clayton copula to measure the dynamic and asymmetric dependence as this copula model presents similar attributes like the RC&C and RG&G. We then compare the different copula models based on the Log-Likelihood estimates.
Finally, we analyze systemic risk using five insurers listed on the Johannesburg Stock Exchange, Discovery Limited, Liberty Holdings Limited, Momentum Metropolitan Holdings, Sanlam Limited, and Santam Limited. We cover the period from November 2007 to June 2020. We use the DMC-MES to analyze the systemic risk contribution of the five insurers. Our results show that Sanlam is the biggest contributor to systemic risk, followed by Discovery. However, the results indicate that Santam is the least systemically risky insurer in our analysis. Our findings show that insurers’ contribution to systemic risk might be related to the size of the insurers, as Sanlam and Discovery are among the largest insurers in South Africa. Therefore, insurers could present different threats to the insurance sector and the economy at large. Hence, stricter regulatory measures such as higher capital and loss absorbency requirements are required for systemically risky insurers to ensure financial stability in the South African economy.
2. Methodology
The first part of this section explains the Marginal Expected Shortfall (MES) used to measure systemic risk and how it is derived. The second part briefly discusses the copula models used in this study. Finally, we provide the steps involved in estimating the DMC-MES proposed by Eckernkemper (2018).
2.1. Marginal Expected Shortfall (MES)
The Marginal Expected Shortfall (MES) measures an institution’s expected return when the return of the market is below or equal to a certain level over a given horizon.
Expected Shortfall (ES)
Let us consider the bivariate time series process where represents the market’s return of the entire market at time and denotes an institution return, also at time .
The return of the market is expressed as follows,
where represents the weight of institution .
The expected shortfall (ES) of the market is then described as with threshold being the value at risk (VaR) of the market return and in our analysis, we chose to be equal to 0.05. Plugging into yields
The MES for an institution at time is obtained by partially differentiating Equation (1) with respect to ,
From Equation (2), the MES, besides measuring the expected return of institution conditional to the market’s return being below or equal to a certain level , provides information on an institution’s systemic risk contribution and its significance for the market under consideration (Eckernkemper 2018).
2.2. Dynamic Mixture Copula-Marginal Expected Shortfall (DMC-MES)
This section aims to describe the DMC-MES model. We firstly provide an overview of a copula model. Secondly, we show a step-by-step analysis of how to derive the DMC-MES model. Finally, we present the estimation technique of the DMC-MES model and briefly discuss the Symmetrized Joe-Clayton Copula.
2.2.1. Copula
A copula model is used to describe the dependence between random variables. Hence, it couples the marginal distribution together to form a joint distribution. Let us consider two random variables which are respectively the institution and market innovation. These two variables are assumed to be separately independent and identically distributed () and represents the joint distribution of the two random variables . The marginal distributions are denoted by and . Sklar’s theorem (Sklar 1959) states that any joint distribution can be written in terms of univariate marginal distribution, and , linked via a copula function , that is
Equation (3) can be solved for
where , , is the dynamic copula parameter and and are the respective quantile functions. However, Eckernkemper (2018) argues that Equation (4) can be improved by using a mixture copula as a mixture copula can bring together different dependence features inducing higher flexibility of the model. Thus, a mixture of N copula functions is defined as
with
where represents the th copula, is the weight and denotes the dynamic parameter. Therefore, under the above framework, one can select different copula families with different properties as the combination of their individual properties within the copula function is feasible.
Lastly, we can obtain a conditional expectation based on Equation (4) as a function of the copula ,
We can also obtain a conditional expectation for the mixture copula as specified by Equation (5) as
where . The foundation of the DMC-MES is embodied in the conditional expectation given by Equation (7).
2.2.2. Construction of the DMC-MES
We model the conditional marginal distributions of an institution and market return processes as
where and represent the volatility of the market and an institution , respectively. In this analysis, we show that the conditional standard deviations follow a univariate GJR-GARCH model developed by Glosten et al. (1993).
Below are the general assumptions we made for this study:
- and are each independent and identically distributed (i.i.d) with unspecified, static distribution and
- , and
- with dynamic copula parameter .
By substituting and in Equation (2) gives
with .
Applying Equation (6), we get the MES in Equation (9) as
where is the quantile function, represents the copula of the market and institution innovation and is the dynamic copula parameter. Note that the DC-MES stands for dynamic copula to estimate the marginal expected shortfall. It is the basis of the dynamic mixture copula.
Similarly, we obtain a mixture of two dynamic copulas with static weights by using Equation (7) for . The MES in Equation (9) is given as
where the copula weight is denoted by .
2.3. Estimation Technique of the DMC-MES
In this section, we discuss the estimation technique of the DMC-MES as shown in Eckernkemper (2018).
- Step 1
To allow for the model to capture conditional heteroscedasticity and autocorrelation of each series, we begin by running a group of GARCH models as candidates. We found that the return of the market and insurers follow independent AR(1)-GJR-GARCH(1,1) specifications. The particularity of this model is that it accounts for leverage effect, that is, bad news about an insurer increases its future volatility more than good news. Let denote the model for the market and insurer return.
where represents the Hadamard product and the th elements of and are given by
where .
- Step 2
The Generalized Autoregressive Score (GAS) model is used to model the dynamic copula parameters and . The main advantage of the GAS model is that it allows the use of the score function as the driver of time-variation in the parameters of a wide class of nonlinear models. The specification of the model is as follows:
The joint cdf for and is specified as
where represents the set of information at period .
We specified our GAS (1,1) as in Creal et al. (2013) with the score function, a scaling matrix, the gradient, a vector of constants and , represent two matrices of parameters, which are supposed to be diagonal. For more details on the GAS model, one can read Blasques et al. (2014a, 2014b).
- Step 3
To combine the parameters of the copula to the GAS model, we apply the changes and to limit the range of the Gumbel and rotated Gumbel parameters and the changes and are also applied to limit the range of the Clayton and rotated Clayton parameters as in Eckernkemper (2018). Lastly, we employ the maximum likelihood to evaluate the parameters in , , and . The maximization problem is as follows:
2.4. The Symmetrized Joe-Clayton (SJC) Copula
The Symmetrized Joe-Clayton is an Archimedean copula, which is an adaptation of the Joe-Clayton Copula. It can measure both the upper and lower tail dependence. The expression of (SJC) copula is given by:
where and and denote the upper and lower tail dependence coefficients, respectively, and is the Joe-Clayton copula. is expressed as follows:
2.5. Robustness Test
We use the bivariate Clayton and Gumbel copula to double-check the dependence between the systemically riskiest insurer, Sanlam, and the market and the rest of the insurers. Finally, to explain the relationship among the insurers, we use the Vector Autoregressive (VAR) model through the impulse response function and give an overview of the relationship of the South African insurance sector.
2.5.1. Clayton Copula
The Clayton copula is mostly used to model asymmetric dependence and correlated risks because of their ability to capture lower tail dependence. The closed-form of the bivariate Clayton copula is given by:
where .
2.5.2. Gumbel Copula
As the Clayton copula, the Gumbel copula is used to model asymmetric dependence. However, it is famous for its ability to capture strong upper tail dependence. If outcomes are expected to be strongly correlated at high values but less correlated at low values, then the Gumbel copula is an appropriate choice. The bivariate Gumbel copula is given by:
where .
2.5.3. Vector Autoregressive Model and Impulse Responses
Vector Autoregression (VAR) is an econometric model which represents the correlations among a set of variables, it is often used to analyze certain aspects of the relationships between the variables of interest. It is a multi-equation system where all the variables are treated as endogenous (dependent). The VAR (p) model is given by:
where:
- : an vector of time series variables;
- an vector of intercepts;
- an coefficient matrices;
- an vector of unobservable zero mean error term.
The Impulse Response Function enables us to know the response of one variable to an impulse in another variable in a system that involves several variables as well.
3. Empirical Analysis
3.1. Data
Due to data availability, our analysis is on five insurance companies listed on the Johannesburg stock exchange that have data covering our entire sample period. For this study, we use daily stock price data from 13 November 2007 to 15 June 2020, and it is easily accessible from I-net BFA Database. The stock prices are converted to log returns multiplied by 100. We also estimate the marginal distributions and using the kernel estimator to transform the standardized innovations (residuals) to the copula scale. All our estimations are done with Matlab software.
Table 1 provides the list of the insurers that constitutes the South African insurance companies in our analysis.

Table 1.
List of the Five South African Insurance Companies.
Table 2 below presents the results of the descriptive statistics. We can see from the table that the skewness of the insurers’ returns is nonzero while the kurtosis of the insurers’ returns are all above 3, implying that the empirical distributions of the returns exhibit fat tail distribution with means around zero. Hence, our series presents the properties of financial time series.
Table 2.
Descriptive Statistics.
In addition, when performing the Jarque–Bera test for normality at 5% confidence level, the results show that the null hypothesis of the normality test is rejected for all series, at 5% confidence level indicating that the series is not normally distributed.
3.2. Marginal Distributions
We considered a group of GARCH models as candidates and find that the AR(1)-GJRGARCH(1,1) model developed by Glosten et al. (1993) is a suitable model for the marginal returns distributions based on the diagnostic tests for model adequacy (ARCH LM test and Ljung–Box test). Moreover, given the presence of large kurtosis in tails, we model the shock dynamics in both tails of each conditional distribution with a skewed student’s t distribution introduced by Hansen (1994). Thus, our choice is justified as the skewed Student’s t distribution can capture skewness and high kurtosis of series.
Table 3 below exhibits the results for the diagnostic tests for model adequacy.
Table 3.
Diagnostic Tests for Model Adequacy.
Table 3 shows that the null hypothesis of no autocorrelation for the Ljung–Box test up to lag 30 is not rejected at 5% statistical level of significance because the p-values are greater than 0.05. As for the ARCH LM test up to lag 10, the null hypothesis of no heteroscedasticity is not rejected at 5% statistical level of significance because the p-values are greater than 0.05. Thus, the AR(1) GJR-GARCH (1,1) is a suitable model for our data.
Table 4 reports the parameters estimates from the AR(1) GJR-GARCH (1,1) model. We find that the sum of the GJR-GARCH parameters and is close to unity for all insurers indicating highly persistent volatilities. Moreover, we can see from the table that the leverage effect parameter is significant and positive at 5% confidence level for Discovery, Liberty, Sanlam, and Santam, except for Momentum, where it is negative and significant at 10%. A positive leverage effect implies that a negative return on the series increases volatility more than a positive return with the same magnitude.
Table 4.
Estimates of AR(1) GJR-GARCH (1,1) for Each Series.
Overall, the diagnostic test confirms that the marginal distribution used for this study is well-specified. Therefore, we can use the AR(1) GJR-GARCH (1,1) and the skewed t distribution alongside copulas to model the dependence structure.
3.3. Estimation of the Copula Models
This section focuses on the dependence between the market and the insurers. We first plot the scatter plots of the marginals between the market and each of the insurers. Figure 1 displays the joint behavior of extreme values between the marginals.
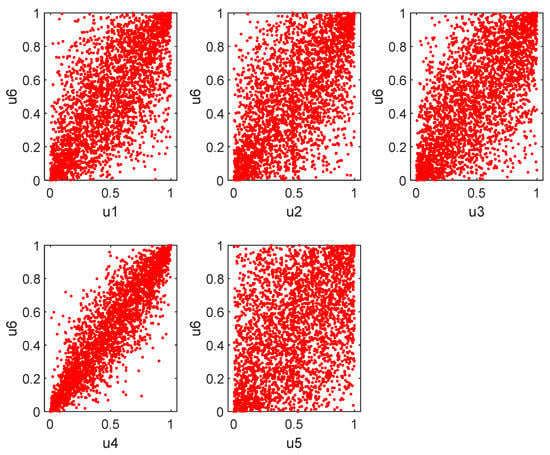
Figure 1.
Scatter plots of the marginals. Note that the horizontal axis represents the marginal of the insurers, while the vertical axis represents the marginal of the market.
From the figure, there seems to be lower and upper tail dependence between the marginals. Hence, copula models that can account for both upper and lower tail dependence may be appropriate for the data.
In what follows, we estimate the dynamic mixture copula, namely the Rotated Clayton and Clayton (RC&C) and the Rotated Gumbel and Gumbel (RG&G), for each series, and the results of the estimations are reported in Table 5 and Table 6.
Table 5.
Estimation Results of the Dynamic Mixture Copula of the Rotated Clayton and Clayton (RC&C): Between Market and Insurers.
Table 6.
Estimation Results of Dynamic Mixture Copula of the Rotated Gumbel and Gumbel (RG&G): Between Markets and Insurers.
We can observe from Table 5 and Table 6 that the copula weights are between 0.392 and 0.485 for the RC&C (see Table 5) and between 0.555 and 0.696 for the RG&G (see Table 6). This provides strong evidence for an asymmetric dependence structure between insurers and the market.
Furthermore, we consider the symmetrized Joe-Clayton copula, which is a modification of the Joe-Clayton copula. Our interest in the symmetrized Joe-Clayton copula is its ability to measures the dependence in both the lower and upper tail. Hence, it possesses similar characteristics as the RC&C and RG&G copula models. Table 7 presents the estimation outputs of the bivariate time-varying Joe-Clayton copula between the market and each of the insurers.
Table 7.
Estimation Output of the Time-Varying SJC copula.
Table 7 shows that the coefficient of the lower tail dependence is significantly higher than the one of upper tail dependence for three insurers except for Liberty and Santam. This behavior may suggest a lower tail dependence between Discovery, Momentum, Sanlam, and the market and an upper tail dependence between Liberty, Santam, and the market. Overall, the results display a dynamic and asymmetric dependence between the market and insurers.
Table 8 below shows the results of the log-likelihood function to select the best copula model.
Table 8.
Log-Likelihood Estimates.
Table 8 reports the estimated likelihood values for the tvSJC copula, the RC&C, and the RG&G. We can see that the mixture of the RG&G model has the lowest log-likelihood estimates for all insurers. Hence, it is a suitable copula model for the series than the other two copula models. Therefore, we use the RG&G to estimate the marginal expected shortfall of the five insurers.
3.4. Estimation of the DMC-MES
In this section, we use the estimates of the DMC-MES to establish a ranking for the contribution to systemic risk of the five insurers.
Table 9 provides the ranking of the five insurers based on the average DMC-MES. At the top of the list is Sanlam, the biggest insurer in South Africa, whose systemic risk measure is as high as 1.942, making Sanlam the systemically riskiest insurer in the South African insurance sector. Discovery which is among the biggest insurers in South Africa is the second-largest contributor to systemic risk with an average DMC-MES of 0.983. According to the literature, this might imply that Sanlam and Discovery are engaged in non-traditional business activities such as the issuance of Credit Default Swaps and securities lending, etc. In addition, our results indicate that financial institutions tend to be as systemically important as they are large.
Table 9.
Summary Statistics for DMC-MES for All Insurers Based on RG&G.
Momentum Metropolitan and Liberty are next in the ranking, with an average DMC-MES of 0.805 and 0.583, respectively. On the other hand, Santam is the least systemically risky insurer in South Africa, with an average DMC-MES being negative −0.007. This implies that Santam is relatively resilient when the insurance market is in distress. This might indicate that Santam is still probably involved in traditional insurance business activities.
3.5. Robustness Test
3.5.1. Bivariate Copula
After filtering the data using AR(1)-GJRGARCH(1,1) models, the obtained pair of innovations (standardized residuals) was transformed to uniforms using the estimated skew Student-t distributions. The uniform series will be used as input for the bivariate Clayton and Gumbel copula to get an insight into the dependence structure between the largest contributor to systemic risk, Sanlam, and the market, and the other insurers.
The estimated parameters corresponding to each copula, the confidence interval (CI), the Akaike Information Criteria (AIC), and the Bayesian Information Criteria (BIC) values are reported in Table 10.
Table 10.
Parameters for the Copulas and Their 95% Confidence Intervals between Sanlam and the Market, and Sanlam and the Other Insurers.
First, we can notice from the table that the Gumbel copula provides the best fit to the data between Sanlam, and Discovery, and Sanlam and Santam, since it has the lowest values for the AIC criteria. This indicates a greater dependence in the positive tail than in the negative. In other words, large gains from Sanlam and Discover; and Sanlam and Santam are more likely to occur simultaneously than large losses.
On the other hand, according to the AIC criteria, Table 10 tells us that the Clayton copula provides the best fit to the data between Sanlam and Liberty, Sanlam and Momentum Metropolitan, and Sanlam and the market, exhibiting greater dependence in the negative tail than in the positive. This means that large losses from Sanlam and Liberty, Sanlam and Momentum Metropolitan, and Sanlam and the market are more likely to happen simultaneously than a large gain. This finding is in line with our previous results as we expect a left tail dependence between Sanlam and the market.
3.5.2. Impulse Response Function
In this section, we estimate a bivariate VAR model to determine the effect of a shock to Sanlam on the market and the other insurers; and to also determine the effect of a shock to the market on the five insurers. We use the Cholesky decomposition to orthogonalize the innovation shocks.
Figure 2 exhibits the impulse response of Sanlam to the market and the other insurers, while Figure 3 shows the impulse response of the market to the five insurers.
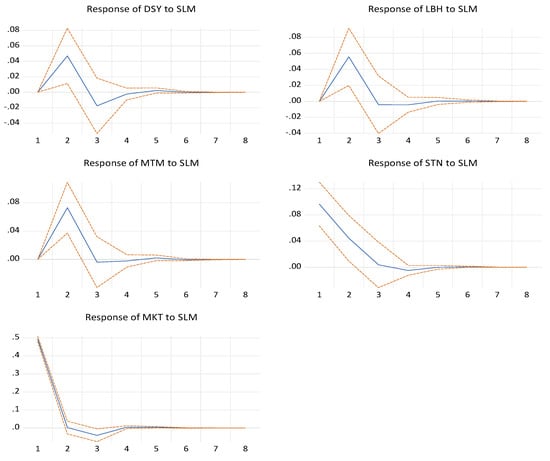
Figure 2.
Impulse response function: Response of the market and other insurers to Sanlam shock.
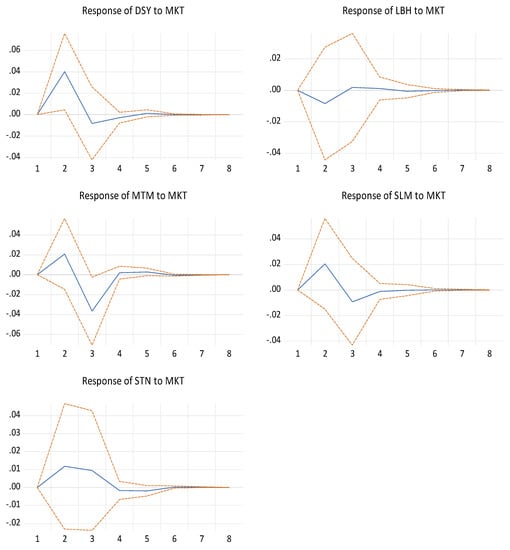
Figure 3.
Impulse response function: Response of each insurer to the market shock.
From Figure 2, we can first notice an initial increase from periods 1 to 2 of Discovery, Liberty, and Momentum Metropolitan to a one standard deviation shock (innovation) to Sanlam. Afterward, between periods 2 and 3, there is a sharp decline in their responses; they become negative and increase from the negative region to the positive region until they hit the steady-state. Conversely, we can see a sharp decline of Santam and market to a one standard deviation shock (innovation) to Sanlam. They become negative and increase gradually until they reach the steady-state.
In conclusion, this result confirms our previous findings as we expect a shock to Sanlam to have an adverse effect on the market and the insurers in the short run.
From Figure 3, we can first observe an initial increase from periods 1 to 2 of Discovery, Momentum Metropolitan, Sanlam, and Santam to a one standard deviation shock (innovation) to the market. Afterward, between period 2 and 3, there is a sharp decline in their responses, they become negative and increases from the negative region to the positive region until they hit their steady-state, except for Santam, where, between period 2 to 3, there is a slight decline in the positive region and from period 3 to 4 it declines into the negative region. Afterward, it reaches the steady-state between period 4 and 5, and gradually increases and hit again the steady-state in the long run. Finally, we can see a decline of Liberty to the negative region from periods 1 to 2 to a one standard deviation shock (innovation) to the market. It gradually increases between periods 2 and 3 until the positive region where it reaches the steady-state in the long run.
In conclusion, our result support our previous findings as we expect a shock to the market to have a negative impact on the insurance companies in the short run except for Santam.
4. Conclusions
In this paper, a Dynamic Mixture Copula Marginal Expected Shortfall (DMC-MES) is applied to measure systemic risk for five insurance companies in South Africa. Many studies argue that a primary factor causing systemic risk is the dynamic and asymmetric dependence between financial institutions. For this reason, we employed three copula models that can measure dynamic and asymmetric dependence. We used two dynamic mixture copula models, namely the Rotated Clayton and Clayton and the Rotated Gumbel and Gumbel, and the time-varying Symmetrized Joe-Clayton copula. Then, we compared the goodness of fit of the different copula models based on their log-likelihood estimates. We found that the Rotated Gumbel and Gumbel had the lowest log-likelihood estimates for all the pair of series, making it a suitable copula model for our data.
Finally, we used the Rotated Gumbel and Gumbel to estimate the marginal expected shortfall of the five insurers. The main findings showed that Sanlam is the largest contributor to systemic risk over the sample period, followed by Discovery, and Santam turns out to be the least systemically risky insurer. Our findings may imply that Sanlam and Discovery are more likely to be involved in non-traditional insurance activities such as financial securities, Credit Default Swap, derivatives, and many others.
In addition, our results revealed that the contribution of insurers to systemic risk in South Africa is linked to the size of the insurer, as Sanlam and Discovery are among the largest insurers in South Africa. This may indicate that instability in the insurance sector is more likely to occur if one of these two insurers is in financial difficulty. Thus, our results confirm the assumption that “no financial institution should be too big to fail (TBTF)”. Therefore, our findings could help South African regulators to have a better understanding of the dynamic and asymmetric dependence between insurers and the market in order to handle adequately systemic risk in the insurance sector by taking stricter regulatory measures in the form of higher capital and loss absorbency requirements for systemically risky insurers.
Due to data availability, we could not use all of the South African insurance companies listed on the Johannesburg Stock Exchange in our analysis. A possible extension of our study would be to include more copula models as well as other segments of the financial system such as the banking sector, the hedge funds market, and the real estate market so that one can have a broader picture of the systemically riskiest financial sector in South Africa.
One could also be interested in conducting more research on non-core activities of insurers in South Africa and their systemic impact.
Author Contributions
The contribution of each author is as follows: Conceptualization, J.W.M.M.; methodology, J.W.M.M., and E.S.E.F.A.; software, E.S.E.F.A.; validation, J.W.M.M.; formal analysis, E.S.E.F.A.; investigation, J.W.M.M., and E.S.E.F.A.; resources, E.S.E.F.A.; data curation, E.S.E.F.A.; writing—original draft preparation, E.S.E.F.A.; writing—review and editing, J.W.M.M.; visualization, E.S.E.F.A.; supervision, J.W.M.M.; project administration, E.S.E.F.A.; funding acquisition, Not Applicable. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The dataset consisting of daily stock prices is taken from the I-net BFA Database available at: http://research.mcgregorbfa.com/Default.aspx. (accessed on 15 June 2020).
Conflicts of Interest
The authors declare no conflict of interest. The authors certify that they have no affiliations with or involvement in any organization or entity with any financial or non-financial interest in the subject matter or materials discussed in this manuscript.
References
- Acharya, Viral V., and Matthew Richardson. 2014. Is the Insurance Industry Systemically Risky? In Modernizing Insurance Regulation. Edited by John H. Biggs and Matthew P. Richardson. New York: John Wiley & Sons, pp. 151–79. [Google Scholar]
- Berdin, Elia, and Matteo Sottocornola. 2015. Insurance Activities and Systemic Risk. SAFE Working Paper No.121. Frankfurt: Goethe University. [Google Scholar]
- Bernal, Oscar, Jean-Yves Gnabo, and Gregory Guilmin. 2014. Assessing the Contribution of Banks, Insurance, and Other Financial Services to Systemic Risk. Journal of Banking and Finance 47: 270–87. [Google Scholar] [CrossRef]
- Bierth, Christopher, Felix Irresberger, and Gregor N. F. Weiß. 2015. Systemic Risk of Insurers Around the Globe. Journal of Banking and Finance 55: 232–45. [Google Scholar] [CrossRef]
- Blasques, Francisco, Siem Jan Koopman, and Andre Lucas. 2014a. Maximum Likelihood Estimation for Generalized Autoregressive Score Models. Tinbergen Institute Discussion Paper. Amsterdam: VU University Amsterdam and Tinbergen Institute. [Google Scholar]
- Blasques, Francisco, Siem Jan Koopman, and Andre Lucas. 2014b. Stationarity and Ergodicity of Univariate Generalized Autoregressive Score Processes. Electronic Journal of Statistics 8: 1088–112. [Google Scholar] [CrossRef]
- Cerrato, Mario, John Crosby, Minjoo Kim, and Yang Zhao. 2015. Correlated Defaults of UK Banks: Dynamics and Asymmetries. Working paper 2015-24. Glasgow: Business School-Economics, University of Glasgow. [Google Scholar]
- Creal, Drew, Siem Jan Koopman, and Andre Lucas. 2013. Generalized Autoregressive Score Models with Applications. Journal of Applied Econometrics 28: 777–95. [Google Scholar] [CrossRef]
- Drakos, Anastassios A, and Georgios Kouretas. 2015. Bank Ownership, Financial Segments, and the Measurement of Systemic Risk: An Application of CoVaR. International Review of Economics and Finance 40: 127–40. [Google Scholar] [CrossRef]
- Dungey, Mardi, Matteo Luciani, and David Veredas. 2014. The Emergence of Systemically Important Insurers. Econometric Modeling: Capital Markets Risk eJournal. [Google Scholar] [CrossRef]
- Eckernkemper, Tobias. 2018. Modeling Systemic Risk: Time-Varying Tail Dependence when Forecasting Marginal Expected Shortfall. Journal of Financial Econometrics 16: 63–117. [Google Scholar] [CrossRef]
- Eling, Martin, and David Antonius Pankoke. 2016. Systemic Risk in the Insurance Sector: A review and Direction for Future Research. Risk Management and Insurance Review 19: 249–84. [Google Scholar] [CrossRef]
- ECB, European Central Bank. 2013. Financial Stability Review. Frankfurt: European Central Bank. [Google Scholar]
- Glosten, Lawrence. R., Ravi Jagannathan, and David E. Runkle. 1993. On the Relation Between the Expected Value and the Volatility of Nominal Excess Return on Stocks. Journal of Finance 48: 1779–801. [Google Scholar] [CrossRef]
- Grace, Martin F. 2011. The Insurance Industry and Systemic Risk: Evidence and Discussion. Working Paper. Atlanta: Georgia State University. [Google Scholar]
- Hansen, Bruce E. 1994. Autoregressive Conditional Density Estimation. International Economic Review 35: 705–30. [Google Scholar] [CrossRef]
- IMF, International Monetary Fund. 2009. Global Financial Stability Report. Washington: International Monetary Fund. [Google Scholar]
- IISA, Insurance Institute of South Africa. 2016. Business unusual. Paper presented at 43rd Annual Insurance Conference, Rustenburg, South Africa, July 2016. [Google Scholar]
- Kaserer, Christoph, and Christian Klein. 2019. Systemic Risk in Financial Markets: How Systemically Important Are Insurers? Journal of Risk and Insurance 86: 729–59. [Google Scholar] [CrossRef]
- National Treasury of South Africa. 2011. A Safer Financial Sector to Serve South Africa Better. Pretoria: National Treasury. [Google Scholar]
- Sklar, A. 1959. Fonctions de Repartition a n Dimensions et Leurs Marges. Paris: Publications de l’Institut de Statistique de l’Universite de Paris, vol. 8, pp. 229–31. [Google Scholar]
- Weiß, Gregor N.F, and Janina Muhlnickel. 2014. Why do Some Insurers Become Systemically Relevant? Journal of Financial Stability 13: 95–117. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).