Stock Market Analysis: A Review and Taxonomy of Prediction Techniques



Abstract
1. Introduction
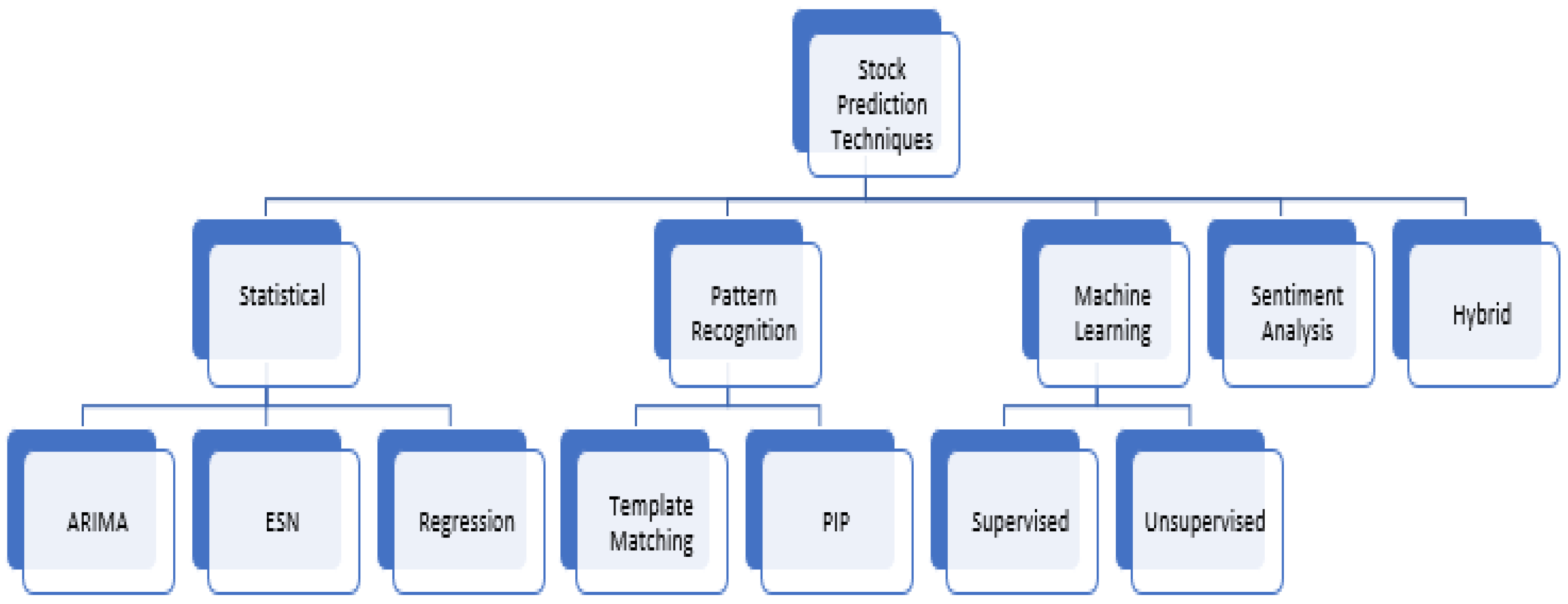
2. Taxonomy of Stock Market Analysis Approaches
3. Literature Survey
3.1. Statistical Approach
3.2. Pattern Recognition
3.3. Machine Learning
3.3.1. Supervised Learning
3.3.2. Unsupervised Learning
3.4. Sentiment Analysis
3.5. Hybrid Approach
4. Discussion
4.1. Statistical
4.2. Pattern Recognition
4.3. Machine Learning
4.3.1. Supervised Learning
4.3.2. Unsupervised Learning
4.4. Sentiment Analysis
4.5. Hybrid
5. Challenges and Open Problems
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Abu-Mostafa, Yaser S., and Amir F. Atiya. 1996. Introduction to financial forecasting. Applied Intelligence 6: 205–13. [Google Scholar] [CrossRef]
- Arévalo, Rubén, Jorge García, Francisco Guijarro, and Alfred Peris. 2017. A dynamic trading rule based on filtered flag pattern recognition for stock market price forecasting. Expert Systems with Applications 81: 177–92. [Google Scholar] [CrossRef]
- Ariyo, Adebiyi A., Adewumi O. Adewumi, and Charles K. Ayo. 2014. Stock Price Prediction Using the Arima Model. Paper presented at the 2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation (UKSim), Cambridge, UK, March 26–28. [Google Scholar]
- Babu, M. Suresh, N. Geethanjali, and B. Satyanarayana. 2012. Clustering Approach to Stock Market Prediction. International Journal of Advanced Networking and Applications 3: 1281. [Google Scholar]
- Ballings, Michel, Dirk Van den Poel, Nathalie Hespeels, and Ruben Gryp. 2015. Evaluating multiple classifiers for stock price direction prediction. Expert Systems with Applications 42: 7046–56. [Google Scholar] [CrossRef]
- Bao, Wei, Jun Yue, and Yulei Rao. 2017. A deep learning framework for financial time series using stacked autoencoders and long-short term memory. PLoS ONE 12: e0180944. [Google Scholar] [CrossRef] [PubMed]
- Bernal, Armando, Sam Fok, and Rohit Pidaparthi. 2012. Financial Market Time Series Prediction with Recurrent Neural Networks. State College: Citeseer. [Google Scholar]
- Bhardwaj, Aditya, Yogendra Narayan, and Maitreyee Dutta. 2015. Sentiment analysis for Indian stock market prediction using Sensex and nifty. Procedia Computer Science 70: 85–91. [Google Scholar] [CrossRef]
- Bhuriya, Dinesh, Girish Kausha, Ashish Sharma, and Upendra Singh. 2017. Stock Market Prediction Using a Linear Regression. Paper presented at the 2017 International Conference of Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, April 20–22, vol. 2. [Google Scholar]
- Billah, Baki, Maxwell L. King, Ralph D. Snyder, and Anne B. Koehler. 2006. Exponential Smoothing Model Selection for Forecasting. International Journal of Forecasting 22: 239–47. [Google Scholar] [CrossRef]
- Bollen, Johan, Huina Mao, and Xiaojun Zeng. 2011. Twitter Mood Predicts the Stock Market. Journal of Computational Science 2: 1–8. [Google Scholar] [CrossRef]
- Box, George E. P., Gwilym M. Jenkins, Gregory C. Reinsel, and Greta M. Ljung. 2015. Time Series Analysis: Forecasting and Control. Hoboken: John Wiley & Sons. [Google Scholar]
- Cakra, Yahya Eru, and Bayu Distiawan Trisedya. 2015. Stock Price Prediction Using Linear Regression Based on Sentiment Analysis. Paper presented at the 2015 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Depok, Indonesia, October 10–11. [Google Scholar]
- Cervelló-Royo, Roberto, Francisco Guijarro, and Karolina Michniuk. 2015. Stock market trading rule based on pattern recognition and technical analysis: Forecasting the DJIA index with intraday data. Expert Systems with Applications 42: 5963–75. [Google Scholar] [CrossRef]
- Chen, Tai-Liang. 2011. Forecasting the Taiwan Stock Market with a Stock Trend Recognition Model Based on the Characteristic Matrix of a Bull Market. African Journal of Business Management 5: 9947–60. [Google Scholar]
- Chen, Tai-liang, and Feng-yu Chen. 2016. An intelligent pattern recognition model for supporting investment decisions in stock market. Information Sciences 346: 261–74. [Google Scholar] [CrossRef]
- Cheng, Ching-Hsue, Tai-Liang Chen, and Liang-Ying Wei. 2010. A hybrid model based on rough sets theory and genetic algorithms for stock price forecasting. Information Sciences 180: 1610–29. [Google Scholar] [CrossRef]
- Chong, Eunsuk, Chulwoo Han, and Frank C. Park. 2017. Deep learning networks for stock market analysis and prediction: Methodology, data representations, and case studies. Expert Systems with Applications 83: 187–205. [Google Scholar] [CrossRef]
- Creighton, Jonathan, and Farhana H. Zulkernine. 2017. Towards Building a Hybrid Model for Predicting Stock Indexes. Paper presented at the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, December 11–14. [Google Scholar]
- De Faria, E. L., Marcelo P. Albuquerque, J. L. Gonzalez, J. T. P. Cavalcante, and Marcio P. Albuquerque. 2009. Predicting the Brazilian Stock Market through Neural Networks and Adaptive Exponential Smoothing Methods. Expert Systems with Applications 36: 12506–9. [Google Scholar] [CrossRef]
- Devi, B. Uma, D. Sundar, and P. Alli. 2013. An Effective Time Series Analysis for Stock Trend Prediction Using Arima Model for Nifty Midcap-50. International Journal of Data Mining & Knowledge Management Process 3: 65. [Google Scholar]
- Dey, Shubharthi, Yash Kumar, Snehanshu Saha, and Suryoday Basak. 2016. Forecasting to Classification: Predicting the Direction of Stock Market Price Using Xtreme Gradient Boosting. Working Paper. [Google Scholar] [CrossRef]
- Di Persio, Luca, and Oleksandr Honchar. 2017. Recurrent Neural Networks Approach to the Financial Forecast of Google Assets. International Journal of Mathematics and Computers in simulation 11: 7–13. [Google Scholar]
- Diamond, Peter A. 2000. What Stock Market Returns to Expect for the Future. Social Security Bulletin 63: 38. [Google Scholar]
- Ding, Xiao, Yue Zhang, Ting Liu, and Junwen Duan. 2015. Deep Learning for Event-Driven Stock Prediction. Paper presented at the 24th International Conference on Artificial Intelligence (IJCAI), Buenos Aires, Argentina, July 25–31. [Google Scholar]
- Dutta, Avijan, Gautam Bandopadhyay, and Suchismita Sengupta. 2012. Prediction of Stock Performance in Indian Stock Market Using Logistic Regression. International Journal of Business and Information 7: 105–36. [Google Scholar]
- Efron, Bradley, and Robert J. Tibshirani. 1994. An Introduction to the Bootstrap. Boca Raton: CRC Press. [Google Scholar]
- Fama, Eugene F. 1970. Efficient Capital Markets: A Review of Theory and Empirical Work. The Journal of Finance 25: 383–417. [Google Scholar] [CrossRef]
- Fama, Eugene F. 1995. Random walks in stock market prices. Financial Analysts Journal 51: 75–80. [Google Scholar] [CrossRef]
- Fu, King Sun, and Tzay Y. Young. 1986. Handbook of Pattern Recognition and Image Processing. Cambridge: Academic Press. [Google Scholar]
- Fu, Tak-chung, Fu-lai Chung, Robert Luk, and Chak-man Ng. 2005. Preventing Meaningless Stock Time Series Pattern Discovery by Changing Perceptually Important Point Detection. Paper presented at the International Conference on Fuzzy Systems and Knowledge Discovery, Changsha, China, August 27–29. [Google Scholar]
- Gordon, Myron J. 1959. Dividends, Earnings, and Stock Prices. The Review of Economics and Statistics 41: 99–105. [Google Scholar] [CrossRef]
- Gordon, Myron J., and Eli Shapiro. 1956. Capital Equipment Analysis: The Required Rate of Profit. Management Science 3: 102–10. [Google Scholar] [CrossRef]
- Hiransha, M., E. A. Gopalakrishnan, Vijay Krishna Menon, and Soman Kp. 2018. NSE stock market prediction using deep-learning models. Procedia Computer Science 132: 1351–62. [Google Scholar]
- Hossain, Mohammad Asiful, Rezaul Karim, Ruppa K. Thulasiram, Neil D. B. Bruce, and Yang Wang. 2018. Hybrid Deep Learning Model for Stock Price Prediction. Paper presented at the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, November 18–21. [Google Scholar]
- Hu, Yong, Kang Liu, Xiangzhou Zhang, Lijun Su, E. W. T. Ngai, and Mei Liu. 2015. Application of evolutionary computation for rule discovery in stock algorithmic trading: A literature review. Applied Soft Computing 36: 534–51. [Google Scholar] [CrossRef]
- Imam, Shahed, Richard Barker, and Colin Clubb. 2008. The Use of Valuation Models by Uk Investment Analysts. European Accounting Review 17: 503–35. [Google Scholar] [CrossRef]
- Kalyanaraman, Vaanchitha, Sarah Kazi, Rohan Tondulkar, and Sangeeta Oswal. 2014. Sentiment Analysis on News Articles for Stocks. Paper presented at the 2014 8th Asia Modelling Symposium (AMS), Taipei, Taiwan, September 23–25. [Google Scholar]
- Kim, Sang, Hee Soo Lee, Hanjun Ko, Seung Hwan Jeong, Hyun Woo Byun, and Kyong Joo Oh. 2018. Pattern Matching Trading System Based on the Dynamic Time Warping Algorithm. Sustainability 10: 4641. [Google Scholar] [CrossRef]
- Lee, Heeyoung, Mihai Surdeanu, Bill MacCartney, and Dan Jurafsky. 2014. On the Importance of Text Analysis for Stock Price Prediction. Paper presented at the 9th International Conference on Language Resources and Evaluation, LREC 2014, Reykjavik, Iceland, May 26–31. [Google Scholar]
- Leigh, William, Naval Modani, Russell Purvis, and Tom Roberts. 2002. Stock market trading rule discovery using technical charting heuristics. Expert Systems with Applications 23: 155–59. [Google Scholar] [CrossRef]
- Leigh, William, Cheryl J. Frohlich, Steven Hornik, Russell L. Purvis, and Tom L. Roberts. 2008. Trading with a Stock Chart Heuristic. IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans 38: 93–104. [Google Scholar] [CrossRef]
- Lv, Dongdong, Shuhan Yuan, Meizi Li, and Yang Xiang. 2019. An Empirical Study of Machine Learning Algorithms for Stock Daily Trading Strategy. Mathematical Problems in Engineering. [Google Scholar] [CrossRef]
- Markowska-Kaczmar, Urszula, and Maciej Dziedzic. 2008. Discovery of Technical Analysis Patterns. Paper presented at the International Multiconference on Computer Science and Information Technology, 2008, IMCSIT 2008, Wisia, Poland, October 20–22. [Google Scholar]
- Milosevic, Nikola. 2016. Equity Forecast: Predicting Long Term Stock Price Movement Using Machine Learning. arXiv arXiv:1603.00751. [Google Scholar]
- Mittal, Anshul, and Arpit Goel. 2012. Stock Prediction Using Twitter Sentiment Analysis. Standford University, CS229. Available online: http://cs229.stanford.edu/proj2011/GoelMittal-StockMarketPredictionUsingTwitterSentimentAnalysis.pdf (accessed on 3 March 2019).
- Naseer, Mehwish, and Yasir bin Tariq. 2015. The efficient market hypothesis: A critical review of the literature. IUP Journal of Financial Risk Management 12: 48–63. [Google Scholar]
- Nesbitt, Keith V., and Stephen Barrass. 2004. Finding trading patterns in stock market data. IEEE Computer Graphics and Applications 24: 45–55. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, Thien Hai, Kiyoaki Shirai, and Julien Velcin. 2015. Sentiment Analysis on Social Media for Stock Movement Prediction. Expert Systems with Applications 42: 9603–11. [Google Scholar] [CrossRef]
- Pagolu, Venkata Sasank, Kamal Nayan Reddy, Ganapati Panda, and Babita Majhi. 2016. Sentiment Analysis of Twitter Data for Predicting Stock Market Movements. Paper presented at the 2016 International Conference on Signal Processing, Communication, Power and Embedded System (SCOPES), Paralakhemundi, India, October 3–5. [Google Scholar]
- Park, Cheol-Ho, and Scott H. Irwin. 2007. What do we know about the profitability of technical analysis? Journal of Economic Surveys 21: 786–826. [Google Scholar] [CrossRef]
- Parracho, Paulo, Rui Neves, and Nuno Horta. 2010. Trading in Financial Markets Using Pattern Recognition Optimized by Genetic Algorithms. Paper presented at the 12th Annual Conference Companion on Genetic and Evolutionary Computation, Portland, OR, USA, July 7–11. [Google Scholar]
- Patel, Jigar, Sahil Shah, Priyank Thakkar, and K. Kotecha. 2015. Predicting stock market index using fusion of machine learning techniques. Expert Systems with Applications 42: 2162–72. [Google Scholar] [CrossRef]
- Peachavanish, Ratchata. 2016. Stock selection and trading based on cluster analysis of trend and momentum indicators. Paper presented at the International MultiConference of Engineers and Computer Scientists, Hong Kong, China, March 16–18. [Google Scholar]
- Phetchanchai, Chawalsak, Ali Selamat, Amjad Rehman, and Tanzila Saba. 2010. Index Financial Time Series Based on Zigzag-Perceptually Important Points. Journal of Computer Science 6: 1389–95. [Google Scholar]
- Powell, Nicole, Simon Y. Foo, and Mark Weatherspoon. 2008. Supervised and Unsupervised Methods for Stock Trend Forecasting. Paper presented at the 40th Southeastern Symposium on System Theory (SSST 2008), New Orleans, LA, USA, March 16–18. [Google Scholar]
- Rather, Akhter Mohiuddin, Arun Agarwal, and V. N. Sastry. 2015. Recurrent Neural Network and a Hybrid Model for Prediction of Stock Returns. Expert Systems with Applications 42: 3234–41. [Google Scholar] [CrossRef]
- Roondiwala, Murtaza, Harshal Patel, and Shraddha Varma. 2017. Predicting Stock Prices Using Lstm. International Journal of Science and Research (IJSR) 6: 1754–56. [Google Scholar]
- Schumaker, Robert P., and Hsinchun Chen. 2009. Textual Analysis of Stock Market Prediction Using Breaking Financial News: The Azfin Text System. ACM Transactions on Information Systems (TOIS) 27: 12. [Google Scholar] [CrossRef]
- Seng, Jia-Lang, and Hsiao-Fang Yang. 2017. The association between stock price volatility and financial news—A sentiment analysis approach. Kybernetes 46: 1341–65. [Google Scholar] [CrossRef]
- Shah, Dev, Campbell Wesley, and Zulkernine Farhana. 2018. A Comparative Study of LSTM and DNN for Stock Market Forecasting. Paper presented at the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, December 10–13. [Google Scholar]
- Shen, Shunrong, Haomiao Jiang, and Tongda Zhang. 2012. Stock Market Forecasting Using Machine Learning Algorithms. Stanford: Department of Electrical Engineering, Stanford University, pp. 1–5. [Google Scholar]
- Shiller, Robert J. 1980. Do Stock Prices Move Too Much to Be Justified by Subsequent Changes in Dividends? Cambridge: National Bureau of Economic Research. [Google Scholar]
- Shiller, Robert C. 2000. Irrational Exuberance. Philosophy & Public Policy Quarterly 20: 18–23. [Google Scholar]
- Tiwari, Shweta, Rekha Pandit, and Vineet Richhariya. 2010. Predicting Future Trends in Stock Market by Decision Tree Rough-Set Based Hybrid System with Hhmm. International Journal of Electronics and Computer Science Engineering 1: 1578–87. [Google Scholar]
- Velay, Marc, and Fabrice Daniel. 2018. Stock Chart Pattern recognition with Deep Learning. arXiv arXiv:1808.00418. [Google Scholar]
- Wang, Jar-Long, and Shu-Hui Chan. 2007. Stock Market Trading Rule Discovery Using Pattern Recognition and Technical Analysis. Expert Systems with Applications 33: 304–15. [Google Scholar] [CrossRef]
- Wang, Ju-Jie, Jian-Zhou Wang, Zhe-George Zhang, and Shu-Po Guo. 2012. Stock Index Forecasting Based on a Hybrid Model. Omega 40: 758–66. [Google Scholar] [CrossRef]
- Wu, Kuo-Ping, Yung-Piao Wu, and Hahn-Ming Lee. 2014. Stock Trend Prediction by Using K-Means and Aprioriall Algorithm for Sequential Chart Pattern Mining. Journal of Information Science and Engineering 30: 669–86. [Google Scholar]
- Xu, Yumo, and Shay B. Cohen. 2018. Stock movement prediction from tweets and historical prices. Paper Presented at the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, July 15–20. [Google Scholar]
- Yang, Bing, Zi-Jia Gong, and Wenqi Yang. 2017. Stock Market Index Prediction Using Deep Neural Network Ensemble. Paper Presented at the 2017 36th Chinese Control Conference (CCC), Dalian, China, July 26–28. [Google Scholar]
- Yoshihara, Akira, Kazuki Fujikawa, Kazuhiro Seki, and Kuniaki Uehara. 2014. Predicting Stock Market Trends by Recurrent Deep Neural Networks. Paper presented at the Pacific RIM International Conference on Artificial Intelligence, Gold Coast, Australia, December 1–5. [Google Scholar]
- Zhang, Jing, Shicheng Cui, Yan Xu, Qianmu Li, and Tao Li. 2018. A novel data-driven stock price trend prediction system. Expert Systems with Applications 97: 60–69. [Google Scholar] [CrossRef]
- Zhong, Xiao, and David Enke. 2017. Forecasting daily stock market return using dimensionality reduction. Expert Systems with Applications 67: 126–39. [Google Scholar] [CrossRef]
| 1 |


{kind=link}
| Paper | Dataset | Features | Technique | Prediction Type | Metrics | Results |
|---|---|---|---|---|---|---|
| Leigh et al. (2008) | NYSE | Price | Template Matching | Daily | Average profits | 3.1–4.59% |
| Bernal et al. (2012) | S&P 500 | Price, MA, volume | ESN RNN | Daily | Test Error | 0.0027 |
| Milosevic (2016) | 1700+ individual stocks | Price, 10 financial ratios | Random Forest vs. SVM vs. NB vs. Logistic Regression | Classification (good vs. bad) | Precision, Recall and F-score | 0.751 (Random Forest) |
| Dey et al. (2016) | Apple, Yahoo | Technical indicators | XGBoost vs. SVM vs. ANN | Daily | Accuracy | 85–99% (XGBoost) |
| Di Persio and Honchar (2017) | Google Stock | OHLCV | RNN vs. LSTM vs. GRU | Daily, Weekly | Log loss, accuracy | 72%, 5 day (LSTM) |
| Yang et al. (2017) | Shanghai composite index | OHLCV | Ensemble of DNN’s | Daily | Accuracy, relative error | 71.34% |
| Zhang et al. (2018) | Shenzhen GE Market | Price trends | Random Forest | Classification (up, down, flat, and unknown) | Return per trade | 75.1% |
| Paper | Dataset | Technique | Prediction Type | Metrics | Results |
|---|---|---|---|---|---|
| Schumaker and Chen (2009) | News articles, S&P 500 | Bag of words vs. noun phrases vs. noun entities → SVM | Daily | Returns, DA | 2.57% (Noun phrases) |
| Bollen et al. (2011) | DJIA, Twitter data | Mood Indicators → SOFNN | Daily | Accuracy | 87.14% |
| Lee et al. (2014) | 8-K Reports, Stock prices, volatility | Ngram → Random Forest | Daily, long term | Accuracy | >10% (Increase in accuracy) |
| Kalyanaraman et al. (2014) | News articles (Bing API) | Dictionary approach → Linear Regression | Daily | Accuracy | 81.82% |
| Pagolu et al. (2016) | MSFT price, Twitter data | Ngram + word vec → Random Forest | Daily | Accuracy | 70.1% |
| Paper | Dataset | Features | Technique | Prediction Type | Metrics | Results |
|---|---|---|---|---|---|---|
| Wang et al. (2012) | DJIA and SJI Index | Price | ESM + BPNN + ARIMA | Weekly | Directional Accuracy | 70.16% |
| Tiwari et al. (2010) | Sensex + 3 stocks | Price, EPS and DPS | HHMM + Decision Trees | Daily | Accuracy | 92.1% |
| Shen et al. (2012) | Indices, commodities | Asset prices | Auto, cross correlation + SVM | Daily, monthly | Accuracy | 77.6% |
| Rather et al. (2015) | NSE stocks | Price, mean, SD | ARIMA + ESM + RNN + GA | Daily | Avg MSE, MAE | 0.0009, 0.0127 |
| Yoshihara et al. (2014) | Nikkei stocks, news articles | Word vectors | Bag of Words → DBN + RNN-RBM vs. SVM vs. DBN | Long term | Test error rates | 39% (Lowest) |
| Ding et al. (2015) | S&P 500 | Historical events | NN (event embeddings) + CNN | Weekly, Monthly | Accuracy & MCC | 64.21% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah, D.; Isah, H.; Zulkernine, F. Stock Market Analysis: A Review and Taxonomy of Prediction Techniques. Int. J. Financial Stud. 2019, 7, 26. https://doi.org/10.3390/ijfs7020026
Shah D, Isah H, Zulkernine F. Stock Market Analysis: A Review and Taxonomy of Prediction Techniques. International Journal of Financial Studies. 2019; 7(2):26. https://doi.org/10.3390/ijfs7020026
Chicago/Turabian StyleShah, Dev, Haruna Isah, and Farhana Zulkernine. 2019. "Stock Market Analysis: A Review and Taxonomy of Prediction Techniques" International Journal of Financial Studies 7, no. 2: 26. https://doi.org/10.3390/ijfs7020026
APA StyleShah, D., Isah, H., & Zulkernine, F. (2019). Stock Market Analysis: A Review and Taxonomy of Prediction Techniques. International Journal of Financial Studies, 7(2), 26. https://doi.org/10.3390/ijfs7020026