
A Soft Intelligent Risk Evaluation Model for Credit Scoring Classification

Abstract
:1. Introduction
- Improving cash flows;
- Insuring proper credit collections;
- Reducing possible credit losses;
- Reducing cost of credit analysis, enabling credit decision almost instantaneously;
- Allowing to offer credit products geared to different risk levels;
- Analyzing the purchasing behavior of existing customers.
2. Formulation of the Proposed Hybrid Model
3. The Australian Credit Data Sets
Australian Credit Data Set

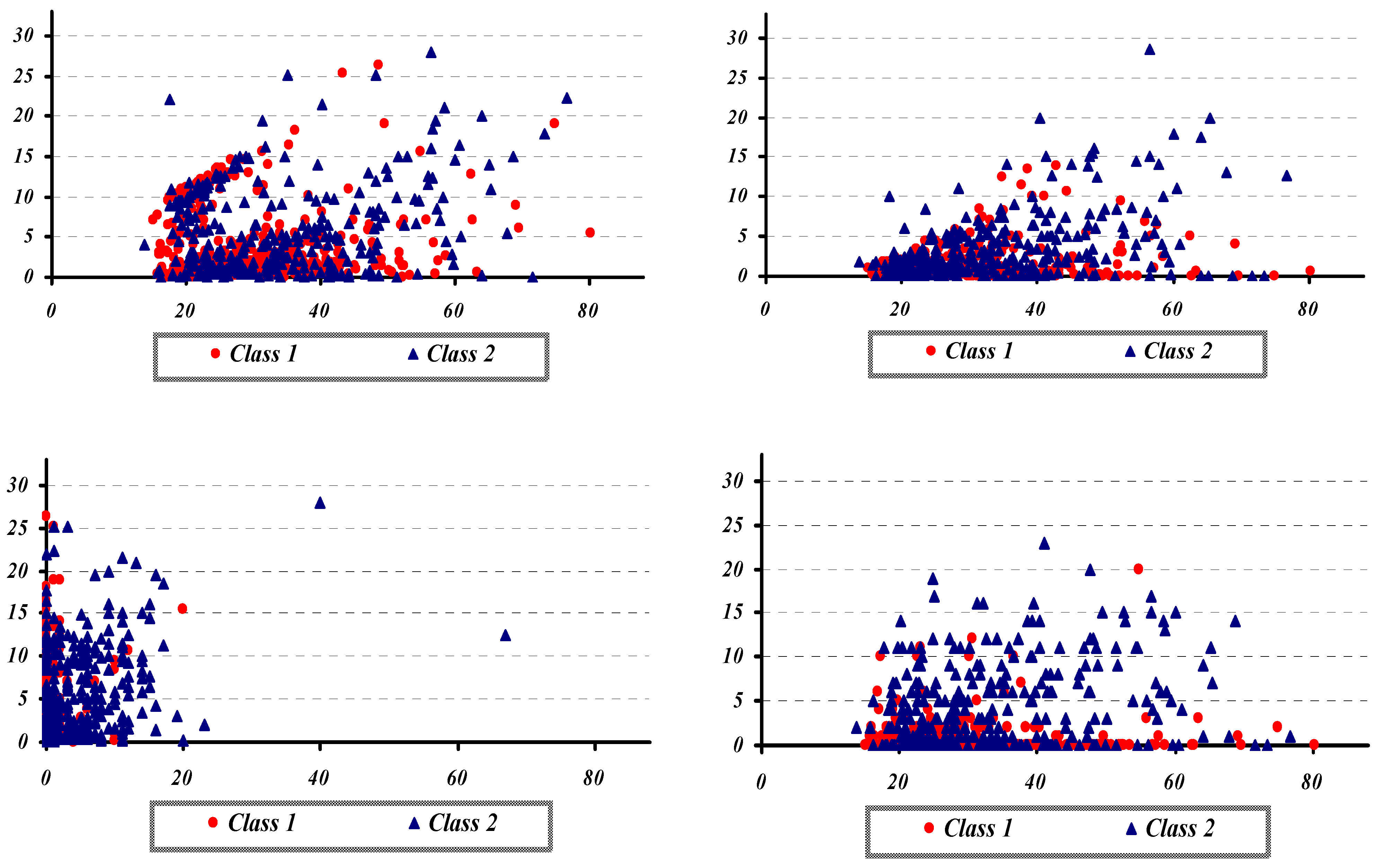{kind=link}
| Attributes | Type | Values | Values (Formerly) |
|---|---|---|---|
| Attribute 1 | Discrete | 0,1 | a,b |
| Attribute 2 | Continuous | 13.75−80.25 | 13.75−80.25 |
| Attribute 3 | Continuous | 0−28 | 0−28 |
| Attribute 4 | Discrete | 1,2,3 | p,g,gg |
| Attribute 5 | Discrete | 1,2,3,…,14 | ff,d,i,k,j,aa,m,c,w,e,q,r,cc,x |
| Attribute 6 | Discrete | 1,2,3,…,9 | ff,dd,j,bb,v,n,o,h,z |
| Attribute 7 | Continuous | 0−28.5 | 0−28.5 |
| Attribute 8 | Discrete | 0,1 | t,f |
| Attribute 9 | Discrete | 0,1 | t,f |
| Attribute 10 | Continuous | 0−67 | 0−67 |
| Attribute 11 | Discrete | 0,1 | t,f |
| Attribute12 | Discrete | 1,2,3 | s,g,p |
| Attribute13 | Continuous | 0−2000 | 0−2000 |
| Attribute14 | Continuous | 0−100,000 | 0−100,000 |
| Class | Discrete | 0,1 | −,+ |
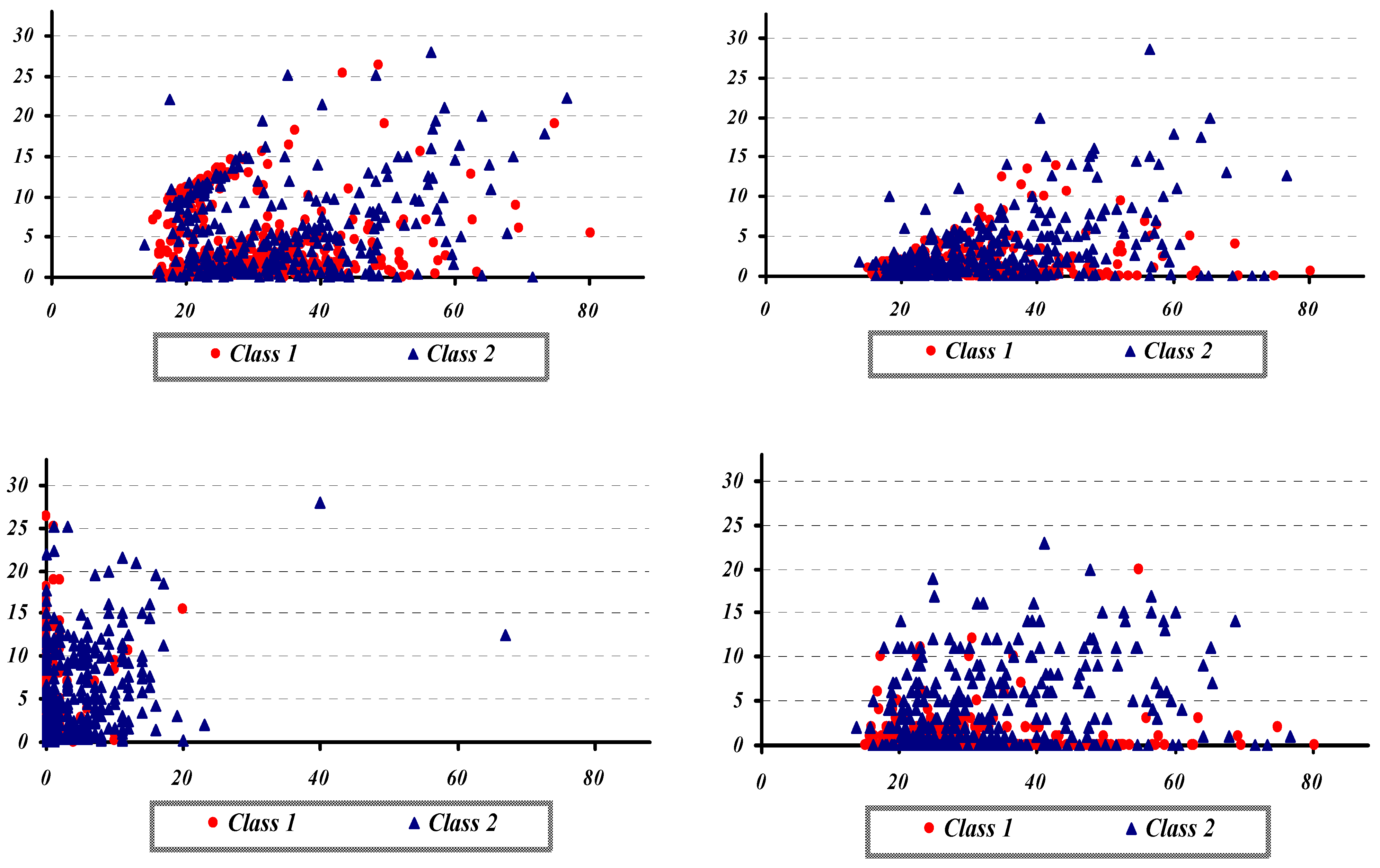
4. Application the Proposed Hybrid Model to Australian Credit Scoring
| Model | Classification Error (%) |
|---|---|
| Test Data | |
| Linear Discriminant Analysis (LDA) | 14.0 |
| Quadratic Discriminant Analysis (QDA) | 19.9 |
| K-Nearest Neighbor (KNN) | 14.2 |
| Support Vector Machines (SVM) | 22.5 |
| Artificial Neural Networks (ANN) | 12.3 |
| Proposed Hybrid Model | 10.9 |
| Model | Improvement (%) |
|---|---|
| Test Data | |
| Linear Discriminant Analysis (LDA) | 22.14 |
| Quadratic Discriminant Analysis (QDA) | 45.23 |
| K-Nearest Neighbor (KNN) | 23.24 |
| Support Vector Machines (SVM) | 51.56 |
| Artificial Neural Networks (ANN) | 11.38 |
Comparison with Other Classifiers
5. Conclusions
Author Contributions
Conflicts of Interest
References
- E.M. Lewis. An Introduction to Credit Scoring. San Rafael, CA, USA: Athena Press, 1992. [Google Scholar]
- D. West. “Neural network credit scoring models.” Comput. Oper. Res. 27 (2000): 1131–1152. [Google Scholar] [CrossRef]
- K. Lee, D. Booth, and P. Alam. “A comparison of supervised and unsupervised neural networks in predicting bankruptcy of Korean firms.” Expert Syst. Appl. 29 (2005): 1–16. [Google Scholar] [CrossRef]
- D. Durand. Risk Elements in Consumer Instalment Financing. New York, NY, USA: National Bureau of Economic Research, 1941. [Google Scholar]
- T. Harris. “Credit scoring using the clustered support vector machine.” Expert Syst. Appl. 42 (2015): 741–750. [Google Scholar] [CrossRef] [Green Version]
- H.A. Abdou, and J. Pointon. “Credit Scoring, Statistical Techniques and Evaluation Criteria: A Review of the Literature.” Intell. Syst. Account. Financ. Manag. 18 (2011): 59–88. [Google Scholar] [CrossRef]
- D. Lando. Credit risk modeling: Theory and applications. Princeton Series in Finance; Princeton, NJ, USA: Princeton University Press, 2004. [Google Scholar]
- L.C. Thomas, D.B. Edelman, and J.N. Crook. Credit Scoring and its Applications. SIAM Monographs on Mathematical Modeling and Computation; Philadelphia, PA, USA: SIAM, 2002. [Google Scholar]
- C. Bolton. “Logistic Regression and its Application in Credit Scoring.” MSc Dissertation, University of Pretoria, Pretoria, South Africa, 2009. [Google Scholar]
- J.C. Wiginton. “A note on the comparison of logit and discriminant models of consumer credit behaviour.” J. Financ. Quant. Anal. 15 (1980): 757–770. [Google Scholar] [CrossRef]
- G. Lee, T.K. Sung, and N. Chang. “Dynamics of modeling in data mining: Interpretive approach to bankruptcy prediction.” J. Manag. Inform. Syst. 16 (1999): 63–85. [Google Scholar]
- T.S. Lee, and I.F. Chen. “A two-stage hybrid credit scoring model using artificial neural networks and multivariate adaptive regression splines.” Expert Syst. Appl. 28 (2005): 743–752. [Google Scholar] [CrossRef]
- T. Bellotti, and J. Crook. “Support vector machines for credit scoring and discovery of significant features.” Expert Syst. Appl. 36 (2008): 3302–3308. [Google Scholar] [CrossRef]
- B.J. Grablowsky, and W.K. Talley. “Probit and discriminant functions for classifying credit applicants: A comparison.” J. Econ. Bus. 33 (1981): 254–261. [Google Scholar]
- W.E. Henley, and D.J. Hand. “Nearest neighbor analysis in credit scoring.” Statistician 45 (1996): 77–95. [Google Scholar] [CrossRef]
- B. Baesens, M. Egmont-Petersen, R. Castelo, and J. Vanthienen. “Learning Bayesian network classifiers for credit scoring using Markov chain Monte Carlo search.” In Proceedings of the 16th International Conference on Pattern Recognition (ICPR’02), Quebec, Canada, 2002; Volume 3, p. 30049.
- T. Pavlenko, and O. Chernyak. “Credit risk modeling using Bayesian networks.” Int. J. Intell. Syst. 25 (2010): 326–344. [Google Scholar] [CrossRef]
- M. Paliwal, and U.A. Kumar. “Neural networks and statistical techniques: A review of applications.” Expert Syst. Appl. 36 (2009): 2–17. [Google Scholar] [CrossRef]
- M. Khashei, M. Bijari, and G.A. Raissi. “Improvement of auto-regressive integrated moving average models using fuzzy logic and artificial neural networks (ANNs).” Neurocomputing 72 (2009): 956–967. [Google Scholar] [CrossRef]
- A. Celikyilmaz, and I.B. Turksen. “Uncertainty modeling of improved fuzzy functions with evolutionary systems.” IEEE Trans. Syst. Man Cybern. 38 (2008): 1098–1110. [Google Scholar] [CrossRef] [PubMed]
- M. Khashei, M. Bijari, and S.R. Hejazi. “Combining seasonal ARIMA models with computational intelligence techniques for time series forecasting.” Soft Comput. 16 (2012): 1091–1105. [Google Scholar] [CrossRef]
- M. Khashei, A.Z. Hamadani, and M. Bijari. “A novel hybrid classification model of artificial neural networks and multiple linear regression models.” Expert Syst. Appl. 39 (2012): 2606–2620. [Google Scholar] [CrossRef]
- T.S. Lee, C.C. Chiu, C.J. Lu, and I.F. Chen. “Credit scoring using the hybrid neural discriminant technique.” Expert Syst. Appl. 23 (2002): 245–254. [Google Scholar] [CrossRef]
- N.-C. Hsieh. “Hybrid mining approach in the design of credit scoring models.” Expert Syst. Appl. 28 (2005): 655–665. [Google Scholar] [CrossRef]
- S.-T. Luo, B.-W. Cheng, and C.-H. Hsieh. “Prediction model building with clustering-launched classification and support vector machines in credit scoring.” Expert Syst. Appl. 36 (2009): 7562–7566. [Google Scholar] [CrossRef]
- C.L. Hung, M.C. Chen, and C.J. Wang. “Credit scoring with a data mining approach based on support vector machines.” Expert Syst. Appl. 33 (2007): 847–856. [Google Scholar] [CrossRef]
- J. Li, L. Wei, G. Li, and W. Xu. “An evolution strategy-based multiple kernels multi-criteria programming approach: The case of credit decision making.” Decis. Support Syst. 51 (2011): 292–298. [Google Scholar] [CrossRef]
- F.-L. Chen, and F.-C. Li. “Combination of feature selection approaches with SVM in credit scoring.” Expert Syst. Appl. 37 (2010): 4902–4909. [Google Scholar] [CrossRef]
- K. Bijak, and L.C. Thomas. “Does segmentation always improve model performance in credit scoring.” Expert Syst. Appl. 39 (2012): 2433–2442. [Google Scholar] [CrossRef]
- B.-W. Chi, and C.-C. Hsu. “A hybrid approach to integrate genetic algorithm into dual scoring model in enhancing the performance of credit scoring model.” Expert Syst. Appl. 39 (2012): 2650–2661. [Google Scholar] [CrossRef]
- Y. Ping, and L. Yongheng. “Neighborhood rough set and SVM based hybrid credit scoring classifier.” Expert Syst. Appl. 38 (2011): 11300–11304. [Google Scholar] [CrossRef]
- K.S. Kim, and I. Han. “The cluster-indexing method for case based reasoning using self-organizing maps and learning vector quantization for bond rating cases.” Expert Syst. Appl. 21 (2001): 147–156. [Google Scholar] [CrossRef]
- C. Park, and I. Han. “A case-based reasoning with the feature weights derived by analytic hierarchy process for bankruptcy prediction.” Expert Syst. Appl. 23 (2002): 255–264. [Google Scholar] [CrossRef]
- H. Ahn, and K.-J. Kim. “Bankruptcy prediction modeling with hybrid case-based reasoning and genetic algorithms approach.” Appl. Soft Comput. 9 (2009): 599–607. [Google Scholar] [CrossRef]
- A. Capotorti, and E. Barbanera. “Credit scoring analysis using a fuzzy probabilistic rough set model.” Comput. Stat. Data Anal. 56 (2012): 981–994. [Google Scholar] [CrossRef]
- S. Akkoc. “An empirical comparison of conventional techniques, neural networks and the three stage hybrid Adaptive Neuro Fuzzy Inference System (ANFIS) model for credit scoring analysis: The case of Turkish credit card data.” Eur. J. Oper. Res. 222 (2012): 168–178. [Google Scholar] [CrossRef]
- A. Laha. “Building contextual classifiers by integrating fuzzy rule based classification technique and k-NN method for credit scoring.” Adv. Eng. Inform. 21 (2007): 281–291. [Google Scholar] [CrossRef]
- P. Yao. “Hybrid fuzzy SVM model using CART and MARS for credit scoring.” In Proceedings of the International Conference on Intelligent Human-Machine Systems and Cybernetics, IHMSC’09, Hangzhou, China, 26–27 August 2009; pp. 392–395.
- M. Khashei, and M. Bijari. “An artificial neural network (p, d, q) model for time series forecasting.” Expert Syst. Appl. 37 (2010): 479–489. [Google Scholar] [CrossRef]
- M. Khashei, S.R. Hejazi, and M. Bijari. “A new hybrid artificial neural networks and fuzzy regression model for time series forecasting.” Fuzzy Sets Syst. 159 (2008): 769–786. [Google Scholar] [CrossRef]
- M. Khashei. “Forecasting the Isfahan Steel Company Production Price in Tehran Metals Exchange Using Artificial Neural Networks (ANNs).” Master of Science Thesis, Isfahan University of Technology, Isfahan, Iran, 2005. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khashei, M.; Mirahmadi, A. A Soft Intelligent Risk Evaluation Model for Credit Scoring Classification. Int. J. Financial Stud. 2015, 3, 411-422. https://doi.org/10.3390/ijfs3030411
Khashei M, Mirahmadi A. A Soft Intelligent Risk Evaluation Model for Credit Scoring Classification. International Journal of Financial Studies. 2015; 3(3):411-422. https://doi.org/10.3390/ijfs3030411
Chicago/Turabian StyleKhashei, Mehdi, and Akram Mirahmadi. 2015. "A Soft Intelligent Risk Evaluation Model for Credit Scoring Classification" International Journal of Financial Studies 3, no. 3: 411-422. https://doi.org/10.3390/ijfs3030411
APA StyleKhashei, M., & Mirahmadi, A. (2015). A Soft Intelligent Risk Evaluation Model for Credit Scoring Classification. International Journal of Financial Studies, 3(3), 411-422. https://doi.org/10.3390/ijfs3030411