A Hybrid of Box-Jenkins ARIMA Model and Neural Networks for Forecasting South African Crude Oil Prices


Abstract
1. Introduction
2. Literature Review
3. Methodology
3.1. ARIMA Model
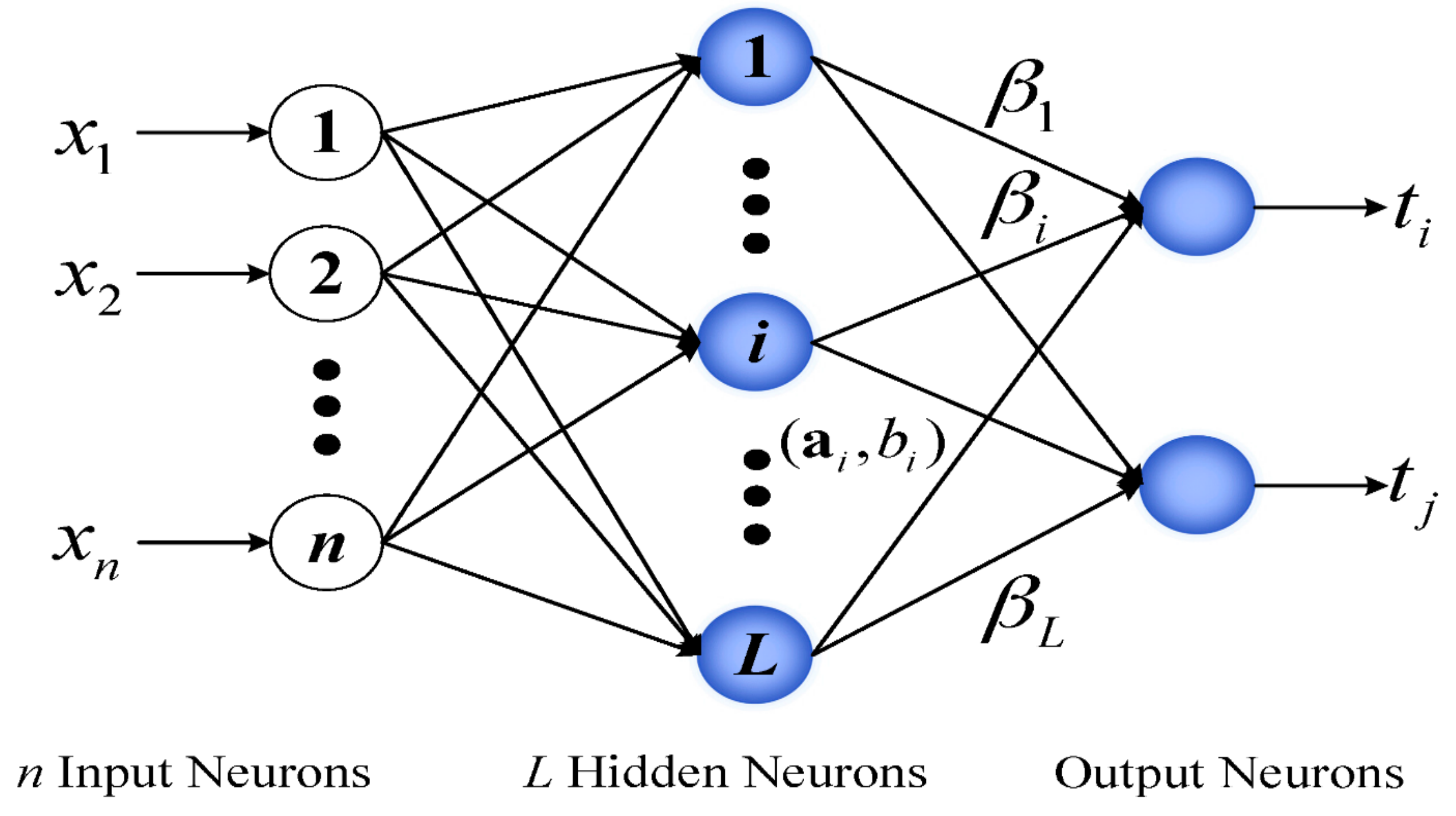
3.2. Hybridisation of ARIMA-ANN-Based ELM
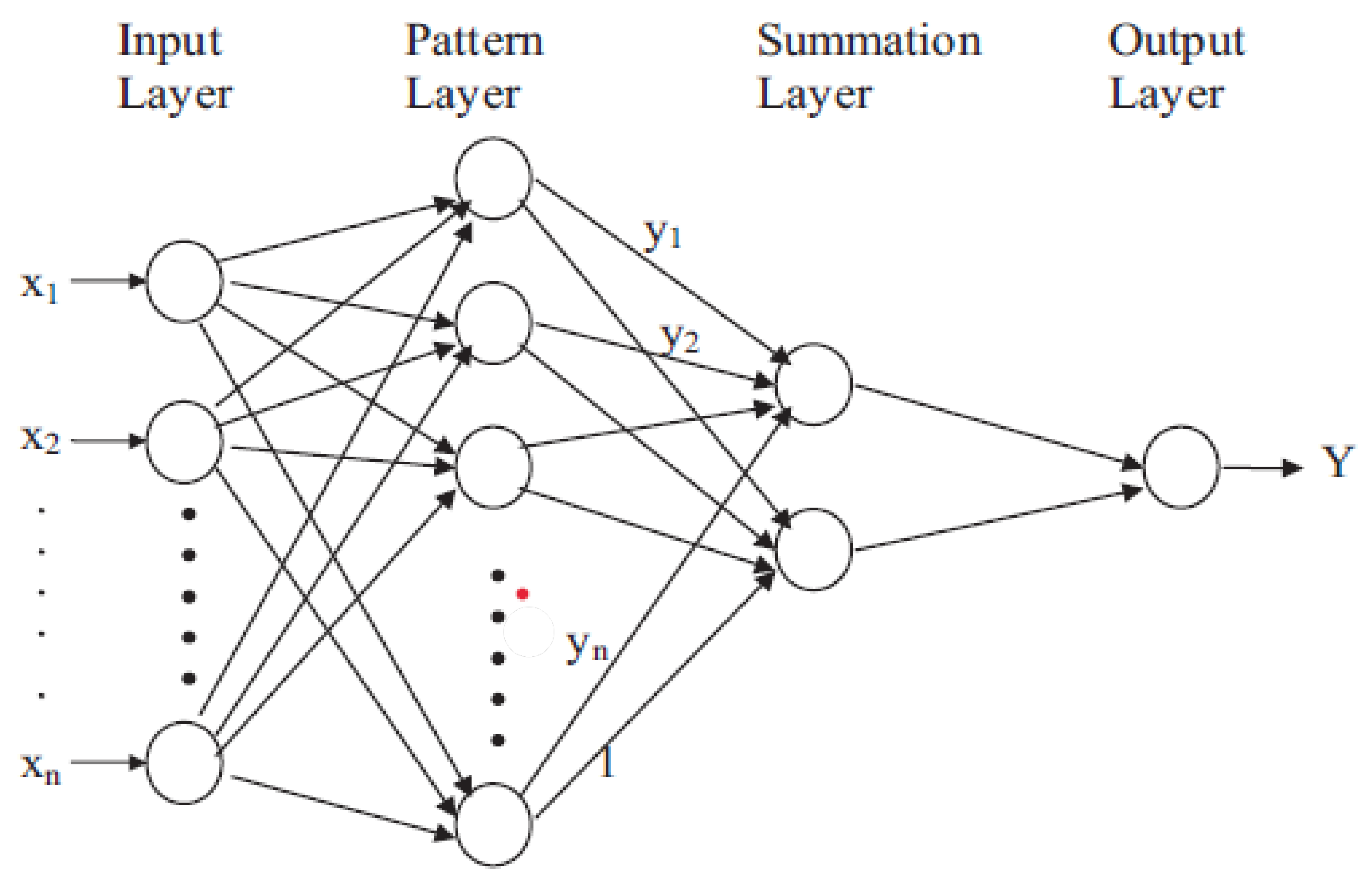
3.3. Hybridisation of ARIMA-GRNN
3.4. Assessment of the Models’ Forecasting Performance
4. Discussion of Findings
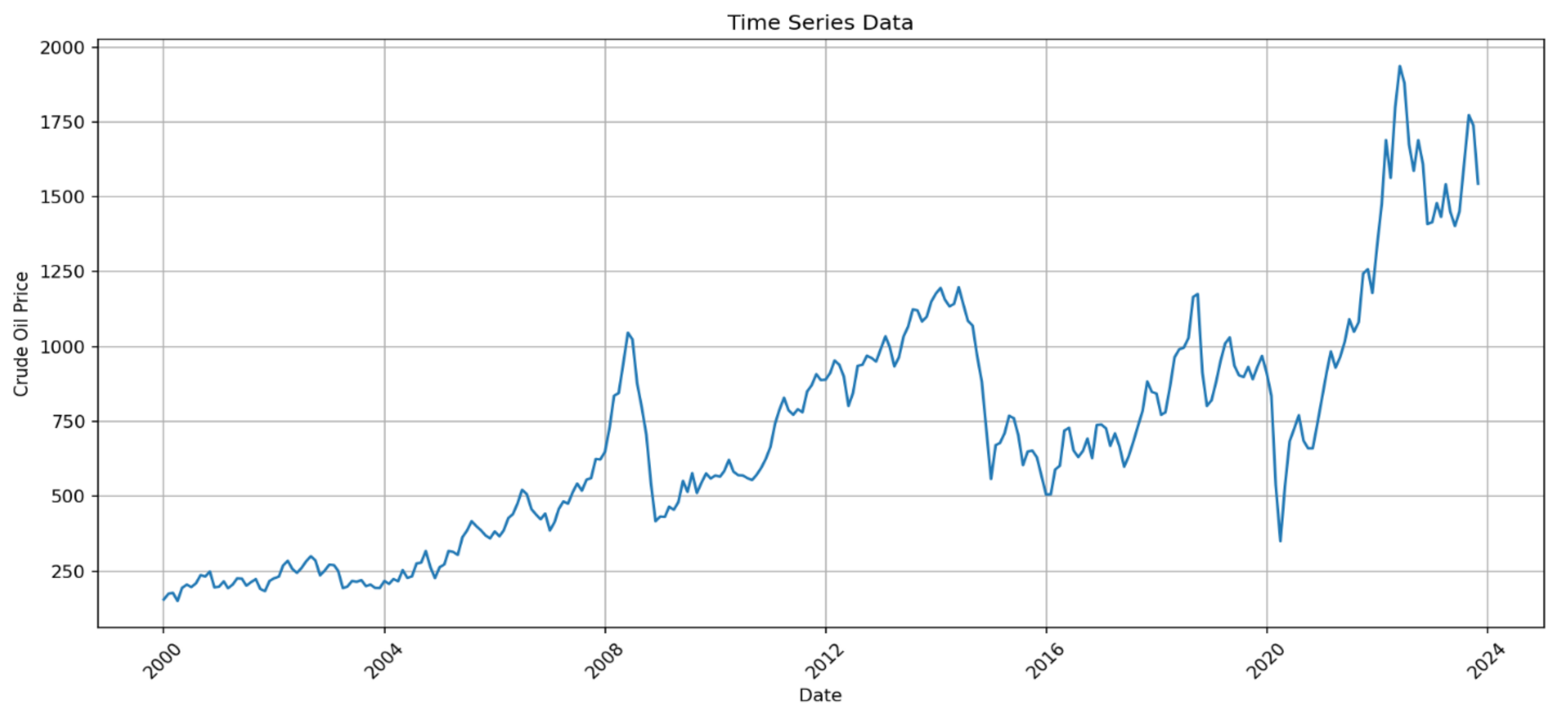
4.1. Exploratory Data Analysis (EDA)
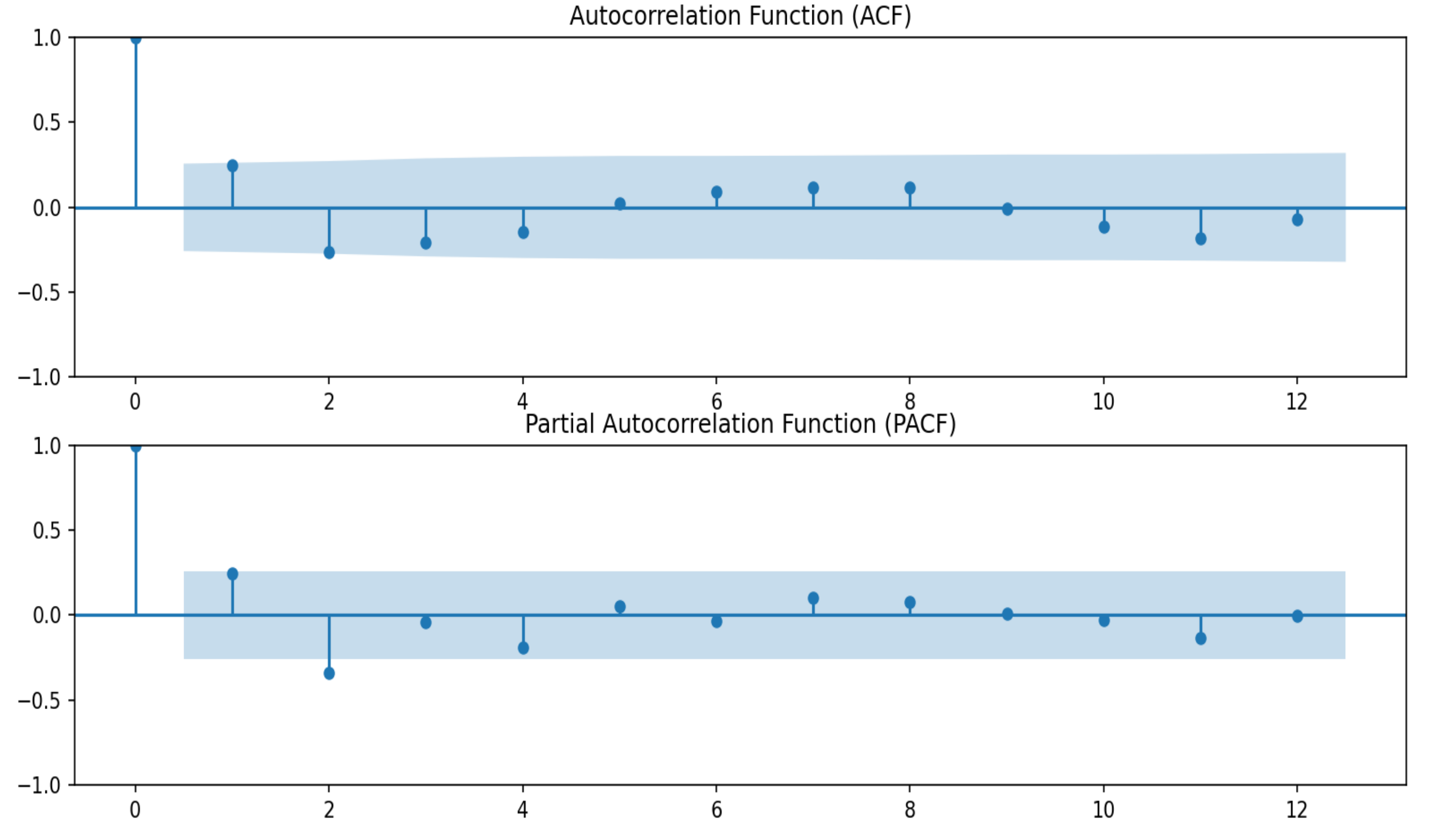
4.2. Results of the ARIMA Model
4.3. Comparison of Forecasting Accuracy Between Hybrid ARIMA and NN Models
5. Conclusions and Recommendations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aggarwal, Vaibhav, Sudhi Sharma, and Adesh Doifode. 2023. Artificial Neural Network and Forecasting Major Electricity Markets. In Applications of Big Data and Artificial Intelligence in Smart Energy Systems. Aalborg: River Publishers, pp. 193–214. [Google Scholar]
- Al-Gounmeein, Remal Shaher, and Mohd Tahir Ismail. 2021. Comparing the performances of artificial neural networks models based on autoregressive fractionally integrated moving average models. IAENG International Journal of Computer Science 48: 266–76. [Google Scholar]
- Bărbulescu, Alina, Cristian Stefan Dumitriu, Iulia Ilie, and Sebastian-Barbu Barbeş. 2022. Influence of anomalies on the models for nitrogen oxides and ozone series. Atmosphere 13: 558. [Google Scholar]
- Box, George E. P., Gwilym M. Jenkins, Gregory C. Reinsel, and Greta M. Ljung. 2015. Time Series Analysis: Forecasting and Control. Hoboken: John Wiley & Sons. [Google Scholar]
- Breiman, Leo. 2001. Random forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef]
- Buliali, Joko Lianto, Victor Hariadi, Ahmad Saikhu, and Saprina Mamase. 2016. Generalized Regression Neural Network for predicting traffic flow. Paper presented at the 2016 International Conference on Information & Communication Technology and Systems (ICTS), Surabaya, Indonesia, October 12. [Google Scholar]
- Chen, Tianqi, and Carlos Guestrin. 2016. Xgboost: A scalable tree boosting system. Paper presented at the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13–17; pp. 785–94. [Google Scholar]
- Chong, Edwin K., and Stanislaw H. Żak. 2013. An Introduction to Optimization. Hoboken: John Wiley & Sons. [Google Scholar]
- Cigizoglu, Hikmet Kerem. 2005. Generalized regression neural network in monthly flow forecasting. Civil Engineering and Environmental Systems 22: 71–81. [Google Scholar]
- Cihan, Pınar. 2024. Comparative performance analysis of deep learning, classical, and hybrid time series models in ecological footprint forecasting. Applied Sciences 14: 1479. [Google Scholar]
- Dickey, David A., and Wayne A. Fuller. 1979. Distribution of the estimators for autoregressive time series with a unit root. Journal of the American Statistical Association 74: 427–31. [Google Scholar]
- Feng, Yu, Ningbo Cui, Qingwen Zhang, Lu Zhao, and Daozhi Gong. 2017. Comparison of artificial intelligence and empirical models for estimation of daily diffuse solar radiation in North China Plain. International Journal of Hydrogen Energy 42: 14418–28. [Google Scholar]
- Goswami, Kakoli, and Aditya Bihar Kandali. 2020. Electricity demand prediction using data driven forecasting scheme: ARIMA and SARIMA for real-time load data of Assam. Paper presented at the 2020 International Conference on Computational Performance Evaluation (ComPE), Shillong, India, July 2–4. [Google Scholar]
- Hu, Rui, Shiping Wen, Zhigang Zeng, and Tingwen Huang. 2017. A short-term power load forecasting model based on the generalized regression neural network with decreasing step fruit fly optimization algorithm. Neurocomputing 221: 24–31. [Google Scholar]
- Huang, Guang-Bin, Qin-Yu Zhu, and Chee-Kheong Siew. 2014. Extreme learning machine: A new learning scheme of feedforward neural networks. Paper presented at the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No. 04CH37541), Budapest, Hungary, July 25–29. [Google Scholar]
- Jagan, J., Pijush Samui, and Dookie Kim. 2019. Reliability analysis of simply supported beam using GRNN, ELM and GPR. Structural Engineering and Mechanics 71: 739–49. [Google Scholar]
- Jenkins, Gwilym M., and George E. P. Box. 1976. Time Series Analysis: Forecasting and Control. Holden-Day Series in Time Series Analysis; Hoboken: John Wiley & Sons. [Google Scholar]
- Karimuzzaman, Md, Sabrina Afroz, Md Moyazzem Hossain, and Azizur Rahman. 2020. Forecasting the COVID-19 pandemic with climate variables for top five burdening and three south asian countries. medRxiv. [Google Scholar] [CrossRef]
- Kim, Byungwhan, Duk Woo Lee, Kyung Young Park, Serk Rim Choi, and Seongjin Choi. 2004. Prediction of plasma etching using a randomized generalized regression neural network. Vacuum 76: 37–43. [Google Scholar]
- Kwiatkowski, Denis, Peter C. B. Phillips, Peter Schmidt, and Yongcheol Shin. 1992. Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series have a unit root? Journal of Econometrics 54: 159–78. [Google Scholar]
- Li, Zhongqi, Zhizhong Wang, Huan Song, Qiao Liu, Biyu He, Peiyi Shi, Ye Ji, Dian Xu, and Jianming Wang. 2019. Application of a hybrid model in predicting the incidence of tuberculosis in a Chinese population. Infection and Drug Resistance 12: 1011–20. [Google Scholar] [PubMed]
- Moseane, Onalenna, Johannes Tshepiso Tsoku, and Daniel Metsileng. 2024. Hybrid time series and ANN-based ELM model on JSE/FTSE closing stock prices. Frontiers in Applied Mathematics and Statistics 10: 1454595. [Google Scholar]
- Peng, Yi, Kang He, and Qing Yu. 2021. Stock Index Prediction Method based on ARIMA-ELM Combination Model. Paper presented at the 2021 4th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), Changsha, China, March 26–28. [Google Scholar]
- Sha, Wei, Shuai Qiu, Wenjun Yuan, and Zhangrong Qin. 2019. Hybrid Model of Time Series Prediction Model for Railway Passenger Flow. Paper presented at the Data Science: 5th International Conference of Pioneering Computer Scientists, Engineers and Educators (ICPCSEE 2019), Guilin, China, September 20–23. Proceedings, Part II 5. [Google Scholar]
- Shao, Xiuli, Doudou Ma, Yiwei Liu, and Quan Yin. 2017. Short-term forecast of stock price of multi-branch LSTM based on K-means. Paper presented at the 2017 4th International Conference on Systems and Informatics (ICSAI), Hangzhou, China, November 11–13. [Google Scholar]
- Shelatkar, Tejas, Stephen Tondale, Swaraj Yadav, and Sheetal Ahir. 2020. Web traffic time series forecasting using ARIMA and LSTM RNN. Paper presented at the ITM Web of Conferences, Nerul, Navi Mumbai, India, June 27–28. [Google Scholar]
- Singh, Rampal, and S. Balasundaram. 2007. Application of extreme learning machine method for time series analysis. International Journal of Computer and Information Engineering 1: 3407–13. [Google Scholar]
- Siripanich, Pongsiri, Ninkorn Pranee, and S. Tragantalerngsak. 2007. Time Series Forecasting Using a Combined ARIMA and Artificial Neural Network Model. Nakorn Pathom: Independent Studies of Mathematics and Information Technology, Faculty of Science, Silpakorn University. [Google Scholar]
- Specht, Donald F. 1991. A general regression neural network. IEEE Transactions on Neural Networks 2: 568–76. [Google Scholar]
- Tsoku, Johannes Tshepiso, Nonofo Phukuntsi, and Daniel Metsileng. 2017. Gold sales forecasting: The Box–Jenkins methodology. Risk Governance & Control: Financial Markets & Institutions 7: 54–60. [Google Scholar]
- Vapnik, Vladimir. 2013. The Nature of Statistical Learning Theory. Edited by Michael Jordan, Jerald F. Lawless, Steffen L. Lauritzen and Vijay Nair. Springer: New York. [Google Scholar] [CrossRef]
- Wang, Eric, Tomislav Galjanic, and Raymond Johnson. 2012. Short-term electric load forecasting at Southern California Edison. Paper presented at the 2012 IEEE Power and Energy Society General Meeting, Diego, CA, USA, July 22–26. [Google Scholar]
- Wang, Jianzhou, and Jianming Hu. 2015. A robust combination approach for short-term wind speed forecasting and analysis–Combination of the ARIMA (Autoregressive Integrated Moving Average), ELM (Extreme Learning Machine), SVM (Support Vector Machine) and LSSVM (Least Square SVM) forecasts using a GPR (Gaussian Process Regression) model. Energy 93: 41–56. [Google Scholar]
- Wei, Wudi, Junjun Jiang, Lian Gao, Bingyu Liang, Jiegang Huang, Ning Zang, Chuanyi Ning, Yanyan Liao, Jingzhen Lai, and Jun Yu. 2017. A new hybrid model using an autoregressive integrated moving average and a generalized regression neural network for the incidence of tuberculosis in Heng County, China. The American Journal of Tropical Medicine and Hygiene 97: 799. [Google Scholar]
- Wu, Don Chi Wai, Lei Ji, Kaijian He, and Kwok Fai Geoffrey Tso. 2021. Forecasting tourist daily arrivals with a hybrid Sarima–Lstm approach. Journal of Hospitality & Tourism Research 45: 52–67. [Google Scholar]
- Yu, He, Li Jing Ming, Ruan Sumei, and Zhao Shuping. 2020. A hybrid model for financial time series forecasting—Integration of EWT, ARIMA with the improved ABC optimized ELM. IEEE Access 8: 84501–18. [Google Scholar]
- Zhang, Jie, Wendong Xiao, Sen Zhang, and Shoudong Huang. 2017. Device-free localization via an extreme learning machine with parameterized geometrical feature extraction. Sensors 17: 879. [Google Scholar] [PubMed]
- Zheng, Jian, Cencen Xu, Ziang Zhang, and Xiaohua Li. 2017. Electric load forecasting in smart grids using long-short-term-memory based recurrent neural network. Paper presented at the 2017 51st Annual conference on information sciences and systems (CISS), Baltimore, MD, USA, March 22–24. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Observations | Mean | Median | Mode | Variance | Standard Deviation | Min | Max |
|---|---|---|---|---|---|---|---|
| 287 | 702.651 | 660.490 | 416.890 | 154137.133 | 392.603 | 150.470 | 1936.560 |
| Test | Test Statistic | Probability (p-Value) |
|---|---|---|
| ADF test results at level | −1.173 | 0.685 |
| KPSS test results at level | 1.962 | 0.010 |
| ADF test results at first difference | −6.551 | 0.000 |
| KPSS test results at first difference | 0.057 | 0.100 |
| Variables | Coefficient | Standard Error | Z | P > |z| |
|---|---|---|---|---|
| Intercept | 0.0009 | 0.001 | 1.726 | 0.084 |
| AR1 | 0.2093 | 0.077 | 2.703 | 0.007 |
| AR2 | 0.6634 | 0.087 | 7.601 | 0.000 |
| MA1 | −0.0793 | 0.058 | −1.363 | 0.173 |
| MA2 | −0.8785 | 0.062 | −14.237 | 0.000 |
| Sigma2 | 0.0088 | 0.001 | 17.261 | 0.000 |
| Test | Test Statistic | Probability (p-Value) |
|---|---|---|
| JB Test | 151.50 | 0.000 |
| Ljung–Box (LB) Q | 0.750 | 0.390 |
| ARIMA | ARIMA-GRNN | ARIMA-ANN-ELM | |
|---|---|---|---|
| Pre-COVID-19 | |||
| RMSE | 0.085 | 0.632 | 30.911 |
| MAE | 0.066 | 0.606 | 30.842 |
| During COVID-19 | |||
| RMSE | 0.176 | 0.687 | 3.677 |
| MAE | 0.161 | 0.621 | 3.700 |
| Post-COVID-19 | |||
| RMSE | 0.118 | 0.734 | 3.188 |
| MAE | 0.099 | 0.624 | 3.143 |
| Overall sample | |||
| RMSE | 0.126 | 0.490 | 0.033 |
| MAE | 0.087 | 0.486 | 0.028 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsoku, J.T.; Metsileng, D.; Botlhoko, T. A Hybrid of Box-Jenkins ARIMA Model and Neural Networks for Forecasting South African Crude Oil Prices. Int. J. Financial Stud. 2024, 12, 118. https://doi.org/10.3390/ijfs12040118
Tsoku JT, Metsileng D, Botlhoko T. A Hybrid of Box-Jenkins ARIMA Model and Neural Networks for Forecasting South African Crude Oil Prices. International Journal of Financial Studies. 2024; 12(4):118. https://doi.org/10.3390/ijfs12040118
Chicago/Turabian StyleTsoku, Johannes Tshepiso, Daniel Metsileng, and Tshegofatso Botlhoko. 2024. "A Hybrid of Box-Jenkins ARIMA Model and Neural Networks for Forecasting South African Crude Oil Prices" International Journal of Financial Studies 12, no. 4: 118. https://doi.org/10.3390/ijfs12040118
APA StyleTsoku, J. T., Metsileng, D., & Botlhoko, T. (2024). A Hybrid of Box-Jenkins ARIMA Model and Neural Networks for Forecasting South African Crude Oil Prices. International Journal of Financial Studies, 12(4), 118. https://doi.org/10.3390/ijfs12040118