1. Introduction
In recent years, deep learning has made significant strides in stock prediction. The powerful capabilities of deep learning models allow for the extraction of complex features from vast amounts of historical data, enabling highly accurate predictions. Combined models of Convolutional Neural Networks (CNNs) and Long Short-Term Memory networks (LSTM) have been particularly successful in time series forecasting. For instance,
Zhang et al. (
2023) used the CNN-LSTM model to capture spatial and temporal features in stock market data, demonstrating superior performance over traditional machine learning methods. Similarly,
Wu et al. (
2023) implemented a CNN-LSTM model for predicting stock prices, highlighting its ability to handle the volatility and noise inherent in financial time series.
CNN can extract local features, such as trends and patterns in stock prices (
Cavalli and Amoretti 2021), while LSTM captures long-term dependencies and sequential patterns, making it effective for time series forecasting (
Zheng et al. 2021). Combining CNN and bidirectional LSTM (BiLSTM) models leverages the strengths of both architectures, leading to improved predictive performance (
Chen et al. 2021;
Lu et al. 2021). However, these models often struggle with the imbalanced number of different types of prediction errors, for example, false positives and false negatives that are common in stock market predictions. This is where cost-sensitive learning becomes essential for this application. Cost-sensitive learning can enhance the model’s ability to handle imbalanced datasets by introducing different costs for various prediction errors, leading to more reliable and robust predictions (
Mienye and Sun 2021). Although significant progress has been made in applying deep learning techniques to stock prediction, integrating cost-sensitive learning into these models has not been sufficiently explored.
Our previous research (
Zhao et al. 2023) introduced the cost-sensitive mechanism into model training and proposed the cost-harmonization loss function (CHL). CHL was combined with the gradient-boosting decision tree (GBDT) algorithm to predict the stock market. GBDT combined with CHL has very good performance for a fixed dataset. However, since GBDT-based models cannot change adaptively with new data (e.g., in the case of stock market analysis), to preserve historical information in one model, it is necessary to investigate the capability of deep learning models, and this is the main purpose of the current work.
To address these challenges, implementing a generalized loss function with a CNN-BiLSTM model can significantly enhance the model’s performance in stock prediction. The generalized loss function includes three critical factors: the class balancing factor (), the data difficulty factor (), and the error type factor (). These factors address data imbalance and prediction difficulty. Specifically, the class balancing factor helps to balance the class distribution during training, the data difficulty factor accounts for the varying difficulty of predicting different instances, and the error-type factor differentiates between various prediction errors. This research proposes the generalized loss function by adding adjustable parameters to the factors. The generalized loss function makes the model more adaptive and responsive to the complexities of stock market data, ultimately improving the accuracy and robustness of predictions.
The experimental design of this research involves model comparison and practical application in stock markets. We have selected data from the Shanghai, Hong Kong, and NASDAQ Stock Exchanges for our experiments. We compare the performance of the CNN-BiLSTM model using the cost-sensitive loss function with traditional models using the binary cross entropy loss function. The objective is to evaluate the effectiveness of the generalized loss function in handling data imbalance and complex time series forecasting. The experiments demonstrate that the model with the generalized loss function significantly outperforms the traditional models in terms of predictive accuracy and handling difficult data.
The experimental results show that the CNN-BiLSTM model with the generalization loss function performs exceptionally well on the Shanghai, Hong Kong, and NASDAQ and Stock Exchange data. Compared to traditional models using the BCE loss function, the model with the generalized loss function exhibits substantial improvements in predictive accuracy and robustness. Additionally, by adjusting different cost factors, the model can better adapt to various market conditions, enhancing the practical applicability of the predictions. These results validate the effectiveness of the generalized loss function in stock prediction, providing valuable insights for future research and applications.
The main contributions of this research include proposing a new generalized loss function (GLoss) with an adjustable balance factor as a hyperparameter and setting adjustable exponents for factors related to error type and difficulty of the instance. This approach enhances the model’s fitting and generalization capabilities by optimizing these hyperparameters. Implementing the generalized loss function with a CNN-BiLSTM model significantly improves its performance in stock prediction, demonstrating its practical utility.
This paper is organized as follows.
Section 2 reviews related works and situates the current study within the existing literature.
Section 3 and
Section 4 outline the methodology, including the model architecture and the proposed generalized loss function.
Section 5 and
Section 6 present the experimental setup, including data collection and preprocessing.
Section 7 discusses the experiments’ results, comparing the proposed model’s performance with traditional approaches. Finally,
Section 8 concludes the paper, summarizing the key findings and suggesting directions for future research.
Table 1 shows the explanation of abbreviations in this paper.
2. Related Works
2.1. Deep Learning
Deep learning, a subset of machine learning algorithms, employs a cascade of multiple layers of nonlinear processing units for feature extraction and transformation. Each successive layer processes the output from the previous layer as its input. It can operate in both supervised modes (such as classification) and unsupervised modes (such as pattern analysis) and can model different levels of abstraction in a hierarchical structure. Despite its self-learning capabilities, some manual tuning, such as adjusting the number or the size of layers, is often necessary to achieve the desired levels of abstraction (
Avci et al. 2021;
Jiang 2021).
Most modern deep learning models are built on neural networks. They can also include deep generative models with layers of propositional formulas or latent variables, such as nodes in deep belief networks and Boltzmann machines. The deep learning process is fundamentally about learning deep enough to determine optimal feature placement at various levels of abstraction autonomously (
Linzen and Baroni 2021).
Chong et al. (
2017) analyzed deep learning networks for stock market prediction, highlighting its potential for high-frequency prediction due to its ability to extract features from large raw data without relying on prior knowledge of predictors.
Zhou et al. (
2023) compared deep neural network (DNN) models with ordinary least squares (OLS) and historical average (HA) models for forecasting equity premiums. The DNN models consistently outperformed OLS and HA models in in-sample and out-of-sample tests and asset allocation exercises.
2.2. Convolutional Neural Network (CNN)
A prominent model in deep learning, particularly in computer vision, is the Convolutional Neural Network (CNN). CNN is also applied in areas like acoustic modeling for automated speech recognition and is inspired by biological processes, specifically the organization of the visual cortex in animals. CNN models the connectivity patterns between neurons. They excel in applications such as image and video recognition, recommendation systems, image classification, medical image analysis, and natural language processing, particularly because of their proficiency in processing time-based flowing data (
Shi et al. 2022).
CNN is characterized by its ability to process multichannel input data, making it ideal for handling various time series data. However, research into its efficacy in modeling and forecasting complex time series data is still developing. One of the main strengths of CNN is its local perception and weight sharing, which significantly reduces the number of parameters, thereby enhancing the efficiency of the learning process. Structurally, CNN mainly comprises convolutional layers and pooling layers. The convolutional layers utilize several convolutional kernels to extract important features, which are subsequently managed by integration layers that reduce feature dimensionality to ease the training burden (
Shah et al. 2022).
2.3. Long Short-Term Memory (LSTM)
Another well-known deep neural network model is the Long Short-Term Memory (LSTM), a recurrent neural network designed to improve upon traditional RNNs by better handling sequence information. LSTMs are particularly suited for classifying, processing, and making predictions based on time series data due to their structure, which includes components like input, forget, and output gates. These gates regulate the flow of information, allowing the model to maintain or discard information over time, making it highly effective for tasks requiring the analysis and modeling of time series data (
Dubey et al. 2021).
LSTM and CNN models are useful for investigating complex and unknown patterns in large and varied datasets. There is a growing trend to combine these models into an ensemble to harness each model’s strengths in capturing intricate data trends (
Chen et al. 2021).
2.4. CNN and LSTM for Financial Time Series Prediction
The dynamic, nonparametric, and noisy financial market challenges traditional econometric analysis. Recent developments in machine learning, particularly neural networks, have emerged as effective alternatives for financial forecasting. These models can extract features from vast raw data without prior knowledge, making them particularly suited for predicting stock market indices and other financial indicators (
Widiputra et al. 2021).
Hybrid machine learning models, including those that integrate CNN and LSTM, have shown promise in enhancing the accuracy of financial time series predictions (
Durairaj and Mohan 2022). These models leverage the feature extraction capability of CNN and the sequence modeling proficiency of LSTM to forecast financial trends more reliably. Additionally, ensemble models that combine multiple deep learning approaches have been found to improve prediction accuracy further, offering a robust solution for financial forecasting by integrating multivariate time series analysis. This approach allows for the simultaneous prediction of multiple related financial time series, enhancing the model’s ability to account for correlations between different series (
Mehtab and Sen 2022).
3. Generalized Loss Function for Deep Learning
In this section, we introduce the generalized loss function (GLoss) with a cost-sensitive mechanism to deep learning and further improve it to be more adaptable for different applications.
3.1. Cost-Sensitive Learning
There are many approaches for cost-sensitive problems. At the data-level approach, the distribution of classes is changed using oversampling or undersampling within the training dataset (
Wang et al. 2021). At the algorithmic level approach, we are incorporating cost-sensitive capabilities into existing cost-insensitive learning methods to be biased toward classes with high misclassification costs. At the decision level approach, the decision threshold is adjusted after modeling a classifier to minimize the misclassification costs.
Cost-sensitive learning (CSL) is the ML method that considers the cost of incorrect classification during model training. Misclassifying specific instances can be more costly than others in many real-world scenarios. The processing methods of CSL can be categorized into two types: instance dependent and class dependent. Instance-dependent CSL is a technique that calculates the cost of misclassification based on each instance’s specific characteristics. In contrast, class-dependent CSL involves assigning a cost to each class label rather than to individual instances (
Xiaosong and Qiangfu 2021;
Zhao and Liu 2022). This approach assumes that misclassification costs are the same for all instances of a given class (
Zelenkov 2019).
For binary classification problems, the cost matrix represents the costs associated with different types of errors. The matrix rows represent the actual class labels (positive and negative), while the columns represent the predicted class labels. The matrix elements represent the cost of making each type of error.
Table 2 shows a typical binary classification cost matrix, where
represents the cost of false positive and
represents the cost of false negative. We can adjust classification decisions to minimize expected misclassification costs by incorporating
and
into the learning algorithm.
The method for calculating the cost matrix depends on the specific application in the field of CSL. To predict the return on stock investment, we use to represent investment loss and to represent profit loss resulting from missed investment opportunities. Investment loss is caused by a decline in the stock price, while profit loss represents the return missed due to a rise in the stock price. Each instance involves these two costs in the binary instance-dependent cost matrix, and the choice of these costs is determined by the outcome of misclassification.
To address the problem of CSL, a cost-sensitive loss function can be created to minimize classification cost by optimizing cost-sensitive risk (
Li et al. 2023). Given the misclassification cost matrix
C, the prediction loss is calculated using a cost-sensitive loss function
. The cost-sensitive decision function
is obtained by optimizing the cost-sensitive expected loss
in the data space:
3.2. Generalized Loss Function
The generalized loss function is defined as follows:
Generally speaking, where and are, respectively, the data difficulty factor and the error type factor (cost factor) of the i-th instance, is the true label, and is the predicted probability of the positive class.
For an imbalanced binary classification problem,
is a class balancing factor, and it is calculated as follows:
where
is a hyperparameter (
), which penalizes the majority class for balancing class distribution during training.
The difficulty factor
is defined by
If the ground truth is 1 (positive), a small predicted probability implies a more difficult instance. On the other hand, if the ground truth is 0 (negative), a large predicted probability implies a difficult instance.
Finally, the error type factor
is given by
where
and
are given in
Table 2. Substituting Equation (
4) to Equation (
2), we obtain
If we define
as follows:
To improve the training and fitting effects of error type and difficulty factors, we introduce two hyperparameters (
and
) to perform exponential operations on the factors to enhance the cost and difficulty differences of instances for different datasets. Based on Equation (
8), the generalized loss function is formed as follows:
The above loss function is a more generalized version of the cost-harmonization loss (CHL) we proposed earlier (
Zhao et al. 2023). It can be converted to binary cross entropy (BCE) when
is set to 1, and
and
are set to 0. It can be converted to CHL when
,
, and
are set to 1.
The improved GLoss integrates multiple functions, such as class balancing, cost sensitivity, and difficulty awareness. Through hyperparameter optimization, the impact of the class balancing factor can be more precise. Differences in instance cost or difficulty can be more significant, and the model’s awareness can be further enhanced. Therefore, GLoss can better adapt to the characteristics of the dataset, which helps improve the model’s fitting and generalization capabilities. In this research, as the number of classes is balanced, we set the class balancing factor as 1.
3.3. Implementation of Generalized Loss Function for PyTorch
The design of the loss function and the computation of its gradients are critical to the successful application of deep learning models. Deep learning frameworks like PyTorch allow the design of custom loss functions. This is particularly useful when the standard loss functions do not meet the specific criteria of a training scenario or when optimizing for particular model properties. The gradient of the loss function is fundamental in the neural network training process, primarily through gradient descent or its variants like Adam (an optimizer).
To create the generalized loss function in PyTorch, we can inherit the torch.nn.Module class. This method provides better integration with PyTorch’s model-building API and allows the loss function to behave like any other layer. Once the loss function is defined, use it in a training loop, just like a built-in loss function. In PyTorch, it is straightforward to implement loss calculations and backward passes due to its auto-gradient mechanism. The algorithm of the generalized loss function for PyTorch is shown in Algorithm 1.
| Algorithm 1 Generalized loss function for PyTorch. |
Input: : prediction : correct labels : hyperparameter of class balancing factor : hyperparameter of error type factor : hyperparameter of difficulty factor : cost weight of instances
Output: : GLoss() Function at(true) if alpha is None return ones_like(true) return where(true, 1, alpha) Function pt(true, pred) pred←clamp(pred, 1 × 10−15, 1 − 1 × 10−15) return where(true, pred, 1 − pred) Function forward(pred, true, costw) at←at(true) pt←pt(true, pred) loss← - at * costw ** beta * (1 - pt) ** gamma * log(pt) loss←mean(loss) return loss
|
4. Generalized Loss CNN-BiLSTM
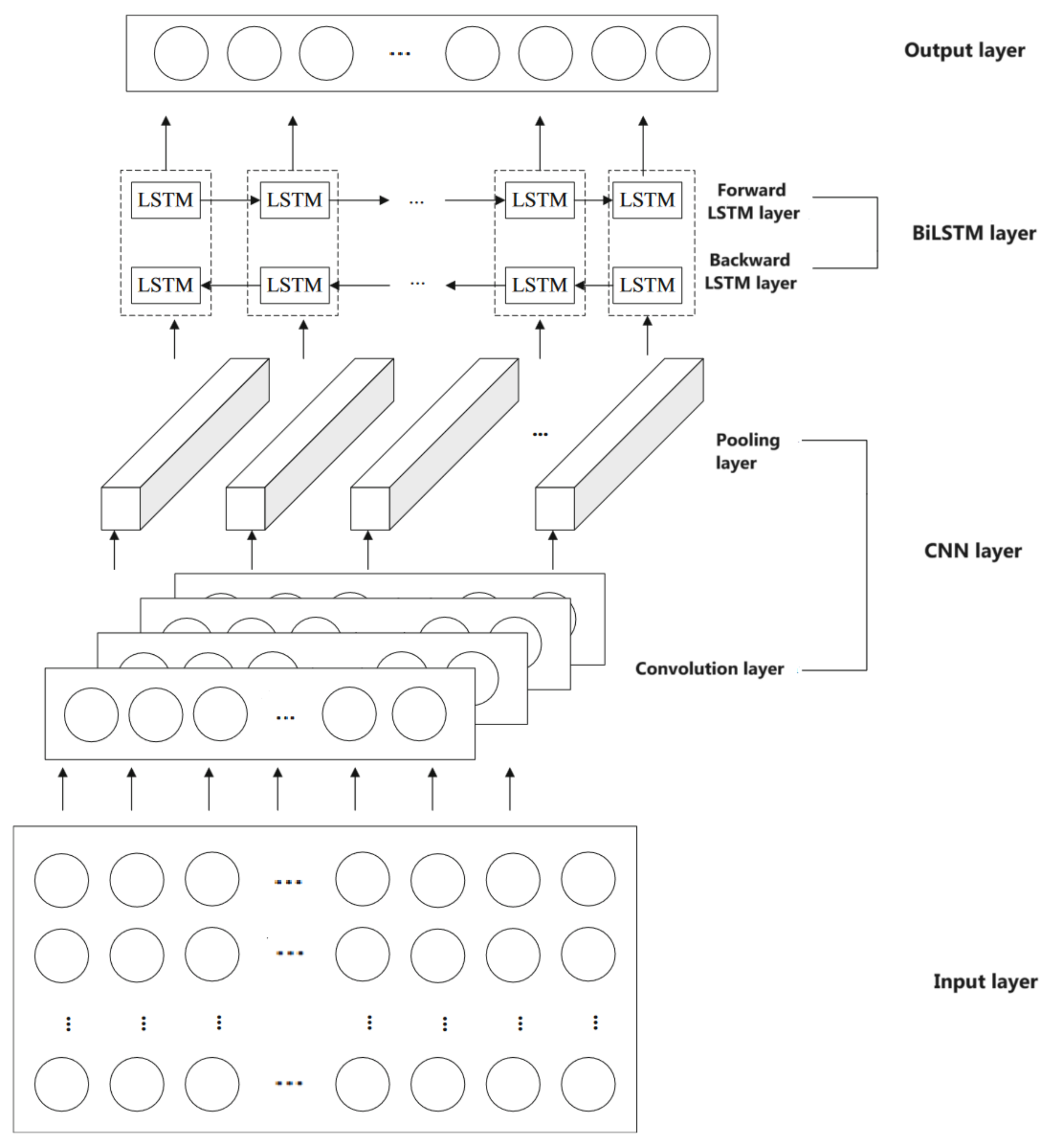
Convolutional Neural Network (CNN) is commonly used in feature engineering because it emphasizes the most prominent features in the field of view. The bidirectional LSTM (BiLSTM) network is widely utilized in time series analysis because it expands based on the time sequence. To extract features and improve cost awareness and prediction accuracy, we combine CNN and BiLSTM networks into a unified framework and combine it with the generalized loss function (GLoss) to propose a new time series prediction network model, GLoss CNN-BiLSTM (GL-CNN-BiLSTM). The proposed model can automatically learn and extract local features and long memory features in time series by making full use of data information to minimize the complexity of the model and maximize the model’s ability to perceive instance cost and difficulty.
Figure 1 shows the model structure diagram. The main structures are CNN and BiLSTM, including the input layer, CNN layer (one-dimensional convolution layer and pooling layer), BiLSTM layer (forward LSTM layer and backward LSTM layer), and output layer.
4.1. CNN
CNN is a network model proposed by (
LeCun et al. 1998). It is a feed-forward neural network that performs well in image and natural language processing (NLP). It can be effectively applied to time series prediction (
Qin et al. 2018). The local perception and weight sharing of CNN can greatly reduce the number of parameters, thus improving the efficiency of learning models. CNN mainly comprises the convolution, pooling, and full connection layers (
Hao and Gao 2020). Each convolution layer contains a plurality of convolution kernels, and its calculation is shown in Equation (
10). After the convolution operation of the convolution layer, the data features are extracted. However, the extracted feature dimensions are very high. So, to solve this problem and reduce the cost of training the network, a pooling layer is added after the convolution layer to reduce the feature dimensions (
Kamalov 2020):
where
is the output value after convolution,
is the activation function,
is the input vector,
is the weight of the convolution kernel, and
is the bias of the convolution kernel.
4.2. LSTM
Long Short-Term Memory (LSTM) (
Hochreiter and Schmidhuber 1997) is a type of recurrent neural network (RNN) aimed at dealing with the long-standing problems of gradient explosion and gradient disappearance in traditional RNNs (
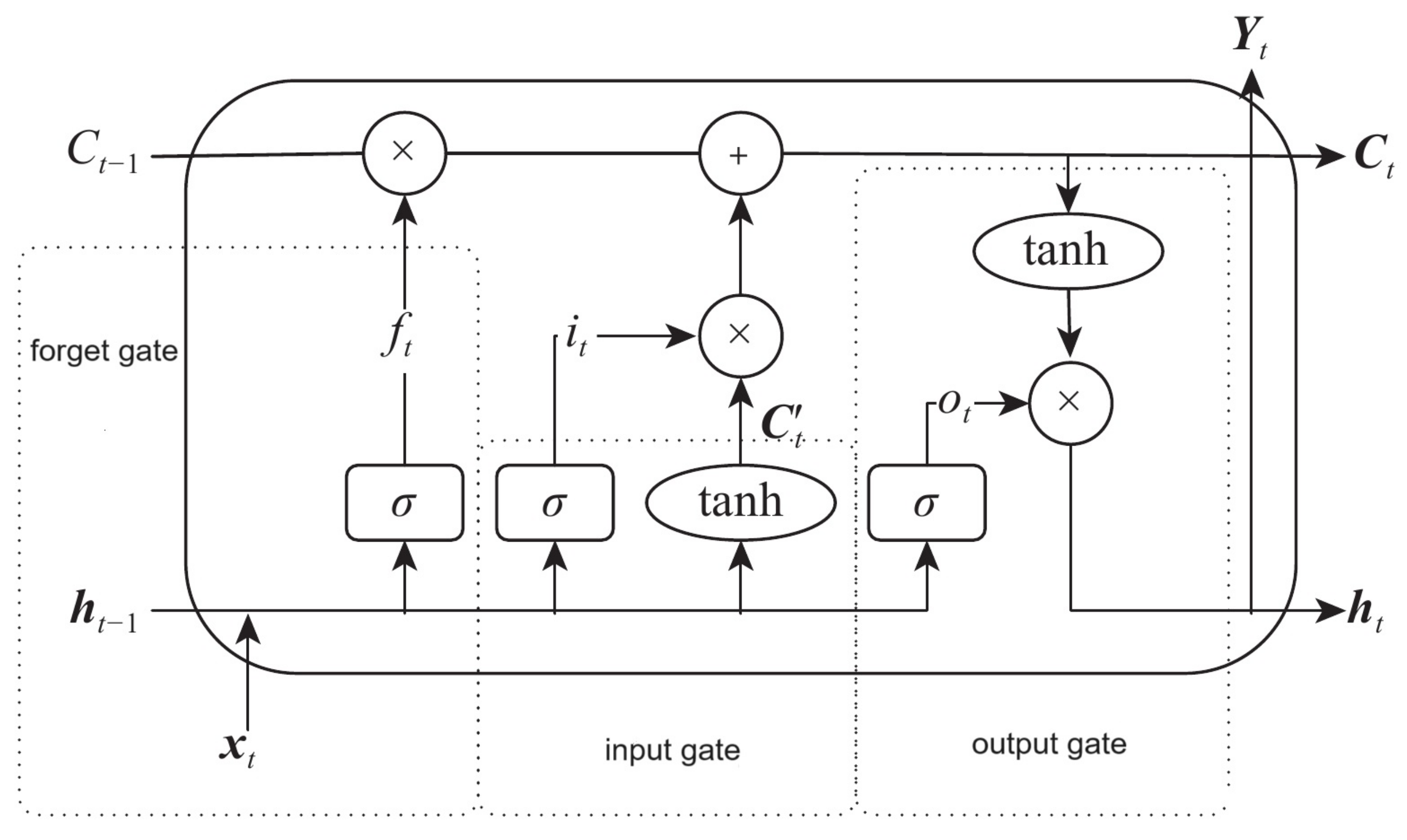
Ta et al. 2020). Its advantage over other RNNs, hidden Markov models, and other sequence learning methods is its relative insensitivity to gap length. It aims to provide a short-term memory for RNN that can last thousands of time steps. The LSTM memory cell consists of three parts—the forget gate, the input gate, and the output gate—as shown in
Figure 2. The model utilizes a gate control mechanism to adjust information flow and systematically determines the amount of incoming information retained in each time step.
In
Figure 2,
is the cell state of the previous moment,
is the final output value of the LSTM neuronal unit at the last moment,
is the input for the current moment,
is the activation function,
is the output of the forget gate at the current moment,
is the input gate output for the current moment,
is the candidate cell status at the current moment,
is the output value of the output gate,
is the cell state at the current moment, and
is the output of the current moment. The working of LSTM is as follows.
Forget Gate
The information that is no longer useful in the cell state is removed with the forget gate. Two inputs,
(input at the particular time) and
(previous cell output), are fed to the gate and multiplied with weight matrices followed by the addition of bias. The result is passed through an activation function, which gives a binary output. If, for a particular cell state, the output is 0, the piece of information is forgotten, and for output 1, the information is retained for future use. The equation for the forget gate is as shown in Equation (
11):
where the value range of
is from 0 to 1,
represents the weight matrix associated with the forget gate,
is the bias of the forget gate, and
denotes the concatenation of the current input and the previous hidden state.
Input gate
The input gate adds useful information to the cell state. First, the information is regulated using the sigmoid function and filters the values to be remembered, similar to the forget gate using inputs
and
. Then, a vector is created using the
function that gives an output from −1 to +1, which contains all the possible values from
and
. Finally, the vector and the regulated values are multiplied to obtain useful information. The equation for the input gate is as shown in Equation (
12):
where the value range of
is from 0 to 1,
is the weight of the input gate,
is the bias of the input gate,
is the weight of the candidate input gate, and
is the bias of the candidate input gate.
Multiply the previous state by
, disregarding the information previously chosen to ignore. Next, include
. This represents the updated candidate values, adjusted for the amount chosen to update each state value as shown in Equation (
13):
where the value range of
is from 0 to 1, and ⊙ is the Hadamard (element-wise) product operator.
Output gate
The task of extracting useful information from the current cell state to be presented as output is performed by the output gate. First, a vector is generated by applying the
function on the cell. Then, the information is regulated using the sigmoid function and filtered by the values to be remembered using inputs
and
. Finally, the vector and the regulated values are multiplied to be sent as an output and input to the next cell. The equation for the output gate is shown in Equation (
14):
where the value range of
is from 0 to 1,
is the weight of the output gate, and
is the bias of the output gate.
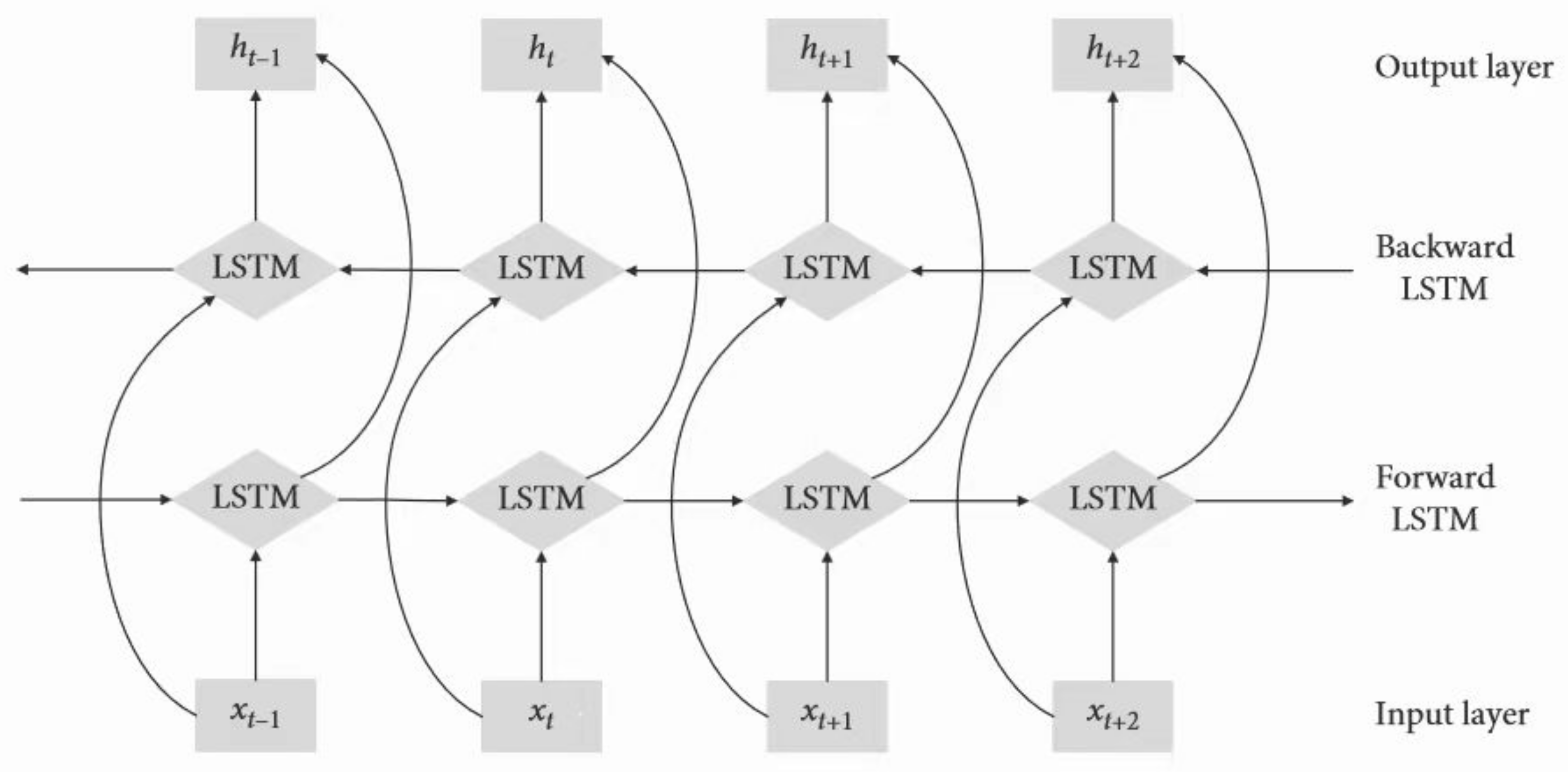
4.3. Bidirectional LSTM
The bidirectional LSTM (BiLSTM) network, which acts as forward and backward LSTM networks for each training sequence, is employed to build a more accurate prediction model. The two LSTM networks are connected to the same output layer to provide complete context information to each sequence point.
Figure 3 shows the structure of BiLSTM.
5. Preprocessing for Data from Three Stock Markets
Data used in the simulation were selected from three stock markets: the Shanghai, Hong Kong, and NASDAQ Stock Exchanges. The effectiveness of the prediction model may be affected by the state of the market (
Mehtab and Sen 2022). To address this, incorporating data from various market conditions could resolve this issue. The data used in this thesis were taken from the Tushare data platform (
https://tushare.pro, accessed on 29 February 2024). Tushare provides a free data interface, including stock, financial statement data, indexes, funds, futures, macroeconomic data, etc.
We obtained the daily historical data of individual stocks in three stock markets from the platform from 2014 to 2021. This includes the historical data of 1655 stocks (main board) in the Shanghai market, 2071 in the Hong Kong market, and 2131 in the NASDAQ market. We also selected the historical data of the Shanghai Stock Exchange Composite Index (SSE Composite Index), Hang Seng Index (HSI), and NASDAQ Composite Index (IXIC).
5.1. Data Preprocessing
Financial data hvae been proven to be noisy and contain a lot of outliers and missing values, which can negatively affect the performance of machine learning models. However, machine learning algorithms require high-quality, relevant, well-structured data to produce accurate predictions. That means the data-processing section is an essential step for this research (
Haq et al. 2021). To complete data processing, we removed the missing value, and then the z-score was implemented to detect the outliers and standardization.
The z-score is a statistical method used to determine how many standard deviations a particular data point is from the mean of a dataset. To calculate the z-score, subtract the mean of the dataset from the data point and then divide by the standard deviation of the dataset. A high z-score indicates that the data point deviates significantly from the mean of the dataset and is likely an anomaly. The z-score method is commonly used for data normalization, which involves transforming the data to have a mean of zero and a standard deviation of one. Normalizing the data makes it easier to compare data points measured on different scales and identify patterns and relationships between variables.
5.2. Feature Selection
Feature engineering is creating new features from raw data to improve the model’s predictive performance. This process includes feature extraction, feature selection, and data denoising. We selected three different sets of features, which are OHLC indicators, financial indicators, and technical indicators (
Zhang et al. 2014). OHLC indicators are the daily open price, high price, low price, and close price.
Technical indicators are based on historical price and volume data, and are used to analyze patterns and trends in the market. We used the TA-Lib tool (
https://ta-lib.github.io/ta-lib-python/index.html, accessed on 26 May 2024) to extract technical indicators related to short-term investment, including overlap studies, momentum, volume, cycle, and volatility indicators (
Vargas et al. 2018). For indicators with time parameters, we set the “timeperiod” to 5 days and 10 days, respectively. In this way, we extracted more than 40 technical indicators. It has been proved that these features effectively identify patterns and relationships that may influence future stock prices (
Zhai et al. 2007). Part of the technical indicators that have been put into use are shown in
Table 3. We also selected market indices and financial indicators. The financial indicators include the p/e ratio, p/b ratio, and price–sales ratio.
Four filtering methods were used to remove irrelevant features:
- (1)
- (2)
- (3)
Filter the features with high correlation with other features (
Tang et al. 2014);
- (4)
We computed the Pearson correlation coefficient while filtering the highly correlated features to determine the interrelationships between the features (
Liu et al. 2020). It was observed that highly correlated features were associated with computational inefficiencies and a propensity for overfitting. Consequently, variables displaying a correlation of
were eliminated from the dataset. Finally, features demonstrating minor importance were eliminated, as they were deemed to have no discernible impact on the model. After data processing and feature selection, we generated 39 features as input variables.
5.3. Data Labeling
In stock market prediction, a common approach for classification involves assigning labels to examples based on the changes in the closing price of stocks. Specifically, two classes are typically employed: “up” and “down”. An example is classified as “up” if the closing price of a stock rises the following day, while it is labeled as “down” if the price decreases. However, this conventional labeling method overlooks the impact of transaction charges associated with market activities. Consequently, examples that incur losses may be mistakenly labeled as profitable if the investment gains fail to cover the transaction costs, such as stamp duty.
This research introduces the labeling scheme incorporating a threshold value denoted as
to address this limitation. This threshold is determined based on the stock’s return rate (
R). Specifically, if the return rate
R exceeds the predefined threshold
, the corresponding example is categorized as belonging to the profit class. Conversely, the example is classified as a loss if
R is less than or equal to
. Notably, throughout the experiment analysis, a uniform value of
is employed as the threshold:
The return rate of the stock is calculated according to the following formula:
where
is the stock closing price, and
is the stock closing price the next day.
By adopting the return label strategy, we can ensure that the labeling strategy does not influence the potential loss incurred through stock trading. This separation of losses from labeling decisions maintains the integrity of the evaluation process.
5.4. Dataset Splitting
In data analysis contests, reserving a test set and making it unknown to all participants is common practice. On the other hand, to increase the generalization ability, the participants often divide the training data into several parts, obtain a model for each part, and use the averaged output of all models to make decisions for the test set. Specifically,
Table 4 presents the dataset splitting for the stock market prediction analysis. The table outlines data division into training and testing datasets. The training dataset contains three folds from 1 January 2014 to 31 December 2020, representing seven years of historical data. Each fold contains 5 years of historical data. These datasets are utilized to train the model. The corresponding testing dataset covers 2021, from 1 January to 31 December. It is an independent dataset to evaluate the model’s performance and assess its ability to make correct investment decisions for that particular year. The final predicted probability is calculated as the average of the model predictions from training on three data folds.
6. Experiment Setting
This section details the PyTorch platform, hyperparameter optimization, model implementation, backtesting, and performance measurement. All the experiments were conducted under the running environment of an Intel i9-9900K 5.0 GHz, 64 GB of RAM, a graphics card RTX-4090, and Windows 11 Pro.
6.1. PyTorch Platform
PyTorch is an open-source machine learning library developed by Facebook’s AI Research Lab (FAIR) (
Paszke et al. 2019). It provides a flexible, user-friendly platform for building and training deep neural networks. PyTorch was designed to be fast, reliable, and scalable, with features such as dynamic computational graphs, memory management automation, and support for CPU and GPU. It is widely used in research and industry for tasks such as image and text classification, object detection, and generative modeling.
6.2. Hyperparameter Optimization
To improve the model further, we utilized the Optuna (
Akiba et al. 2019) framework for hyperparameter optimization. Optuna is a tool that automatically searches for the best hyperparameters for a given machine learning model. It employs Bayesian optimization, which selects hyperparameters based on their expected improvement in the objective function.
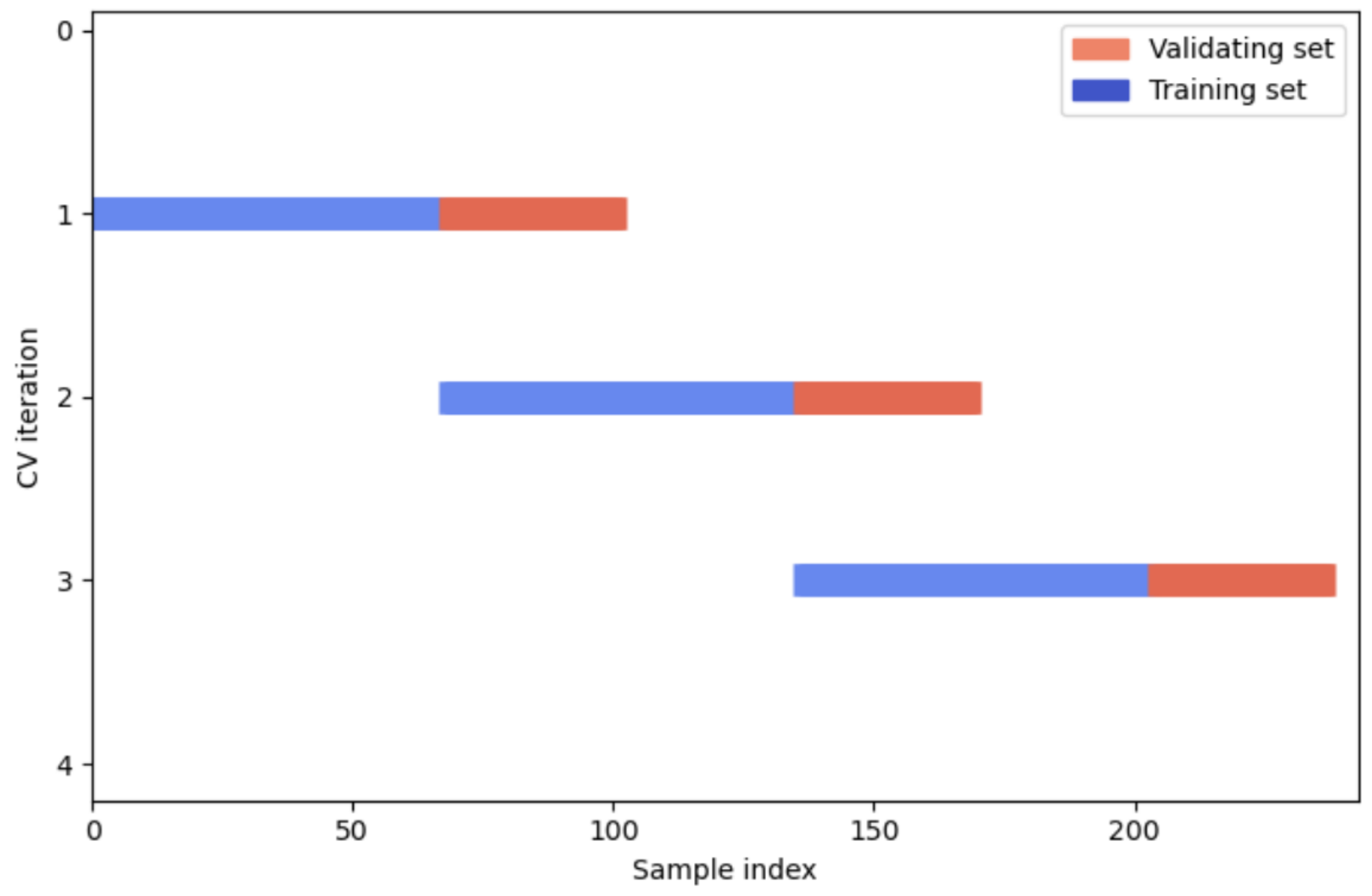
We optimize model hyperparameters using blocking time series cross-validation (
Zhao and Liu 2022). In this process, we chronologically divide the entire training dataset into three blocks. Each block comprises a training set and a validating set. Starting from the second block, the training set’s start date aligns with the validation set’s start date from the preceding block as illustrated in
Figure 4.
The hyperparameters include ‘batch_size’, ‘hidden_size’, ‘num_layer’, and ‘dropout’ of LSTM, ‘’, and ‘’ of GLoss.
6.3. Model Implementation
To prove GLoss CNN-BiLSTM (GL-CNN-BiLSTM)’s effectiveness, it is compared with binary cross entropy LSTM (BCE-LSTM), GL-LSTM, BCE-CNN-LSTM, GL-CNN-LSTM, BCE-BiLSTM, GL-BiLSTM, BCE-CNN-BiLSTM, and GL-CNN-BiLSTM using the same training set and testing set data under the same operating environment. All methods are implemented in Python and Pytorch. GLoss and BCE are used as the evaluation criteria for the methods to evaluate the prediction effect of GL-CNN-BiLSTM.
In addition, since the cost-harmonization loss (CHL) is a special case of GLoss, we simultaneously designed CHL-CNN-LSTM and CHL-CNN-BiLSTM models.
Table 5 shows the parameter settings of the GL-CNN-BiLSTM model for the experiment. In the experiment, all the method training parameters are the same: the epoch is 10, the loss functions are BCE, GLoss, and CHL, the optimizer chooses Adamax, the batch size is 256, the time step is 10, and the learning rate is 0.001.
6.4. Backtesting
Backtesting involves building models that simulate trading strategies using historical data aimed to evaluate the performance of the model (
Olorunnimbe and Viktor 2023). In this research, the backtesting is based on the prediction results from the classifier; the stocks predicted to be profitable for the next day can participate in simulated trading. The specific steps of the backtesting are as follows.
We first determine the total investment amount and the investment ratio of one stock. Secondly, stocks classified as profitable are sorted in descending order of their predicted probabilities. Finally, the selected stocks are simulated until the total investment is reduced to the limit or all the selected stocks are traded.
Backtesting follows a defined investment strategy. This research focuses on investing over a short period, aiming to generate investment income while maintaining asset liquidity. Drawing on the short-term investment methodology used in the work of
Xiaosong and Qiangfu (
2021), our longest holding period is five trading days. Therefore, all inventory will be sold within this time frame.
6.5. Performance Measurement
We discuss the measurement of the model in three different aspects: predictive accuracy, profitability, and risk control ability.
(1) AUC
AUC (Area Under Curve) is the area under the receiver operating characteristic curve and is an important measure of classifier performance. Its calculation formula is as follows:
where
is the false positive rate.
(2) Accuracy
Accuracy measures the proportion of correctly classified examples by the classifier, and its calculation formula is as follows:
where
is true positive,
is true negative,
is false positive, and
is false negative.
(3) Precision
Precision measures the ability of the classifier to predict positive examples correctly, and its calculation formula is as follows:
(4) F score
The F score is a weighted average of precision and recall, with a weight biased towards recall, making it suitable for imbalanced datasets. Its calculation formula is as follows:
where
,
is typically set to 2 to emphasize the importance of recall.
(5) Rate Of Return
The rate of return (ROR) measures the percentage change in the value of an investment over a specific period. It can be calculated using the following formula:
where
is the initial value of the investment, and
is the final value of the investment.
(6) Winning Rate
The winning rate (WR) measures the percentage of successful trades from all trades made by the model. It can be calculated using the following formula:
where
is the number of successful trades, and
is the total number of trades.
(7) Sharpe Ratio
The Sharpe ratio (SR) measures an investment’s excess return per unit of risk. It can be calculated using the following formula:
where
is the portfolio’s expected return,
is the risk-free rate, and
is the portfolio’s standard deviation.
(8) Annual Volatility
The annual volatility (AV) measures the variability of a portfolio’s returns over a year. It can be calculated using the following formula:
where
is the portfolio’s standard deviation, and
N is the number of trading days in a year.
7. Experimental Results
The Shanghai, Hong Kong, and NASDAQ stock market datasets from 2014 to 2020 are chosen for three-fold cross-training. The final predicted probability for 2021 equals the average of the corresponding model predictions after training on three data folds. The proposed model’s performance is evaluated based on predictive accuracy, profitability, and risk control capabilities.
Table 6,
Table 7 and
Table 8 present the performance comparison of different methods, including three groups of methods, on predicting stock market trends. The evaluation metrics used in the analysis are AUC, Accuracy, Precision, F2, ROR, WR, SR, and AV. The test dataset includes data from 2021 for Shanghai, Hong Kong, and NASDAQ stock markets. The results show that the GL-CNN-LSTM and GL-CNN-BiLSTM, including CHL-CNN-LSTM and CHL-CNN-BiLSTM, methods outperformed the other methods in F2, ROR, SR, and AV.
The experimental results of Group-3 are quoted from our early research (
Zhao et al. (
2023)). By comparison, we can observe that LightGBM may outperform LSTM when dealing with large datasets.
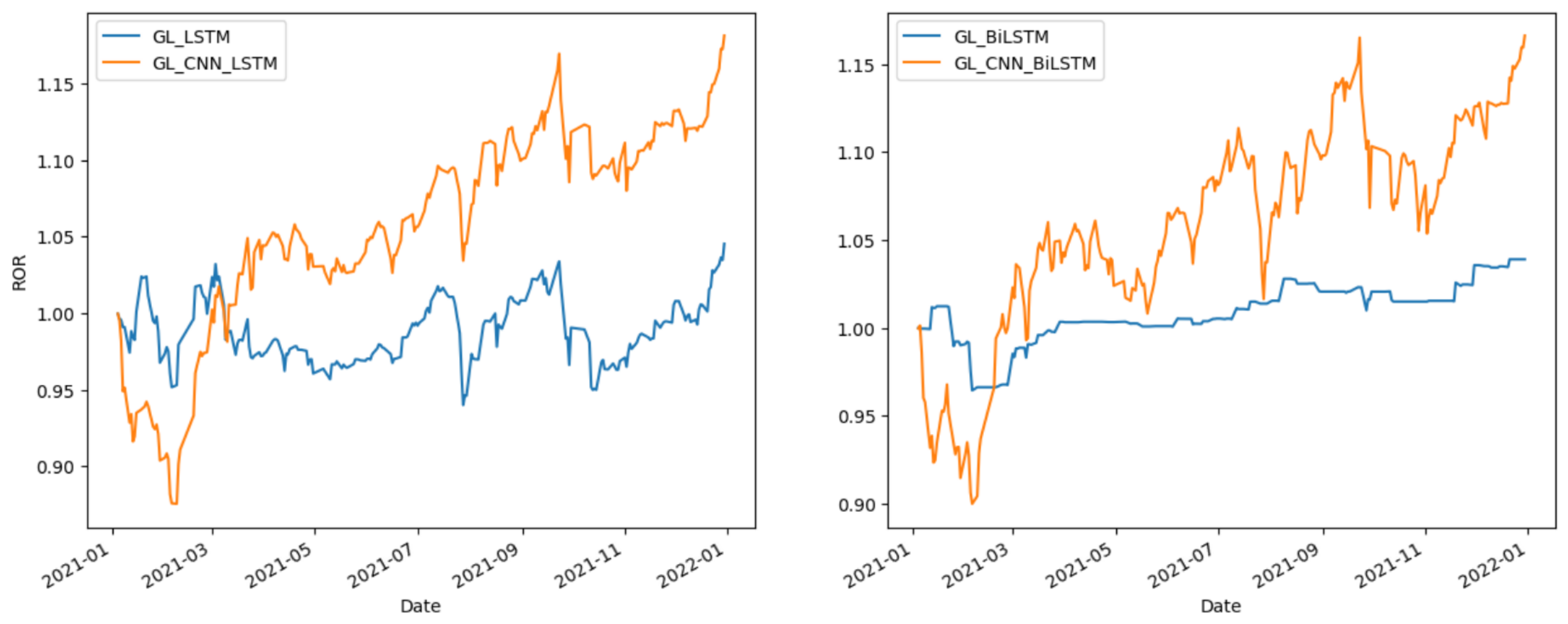
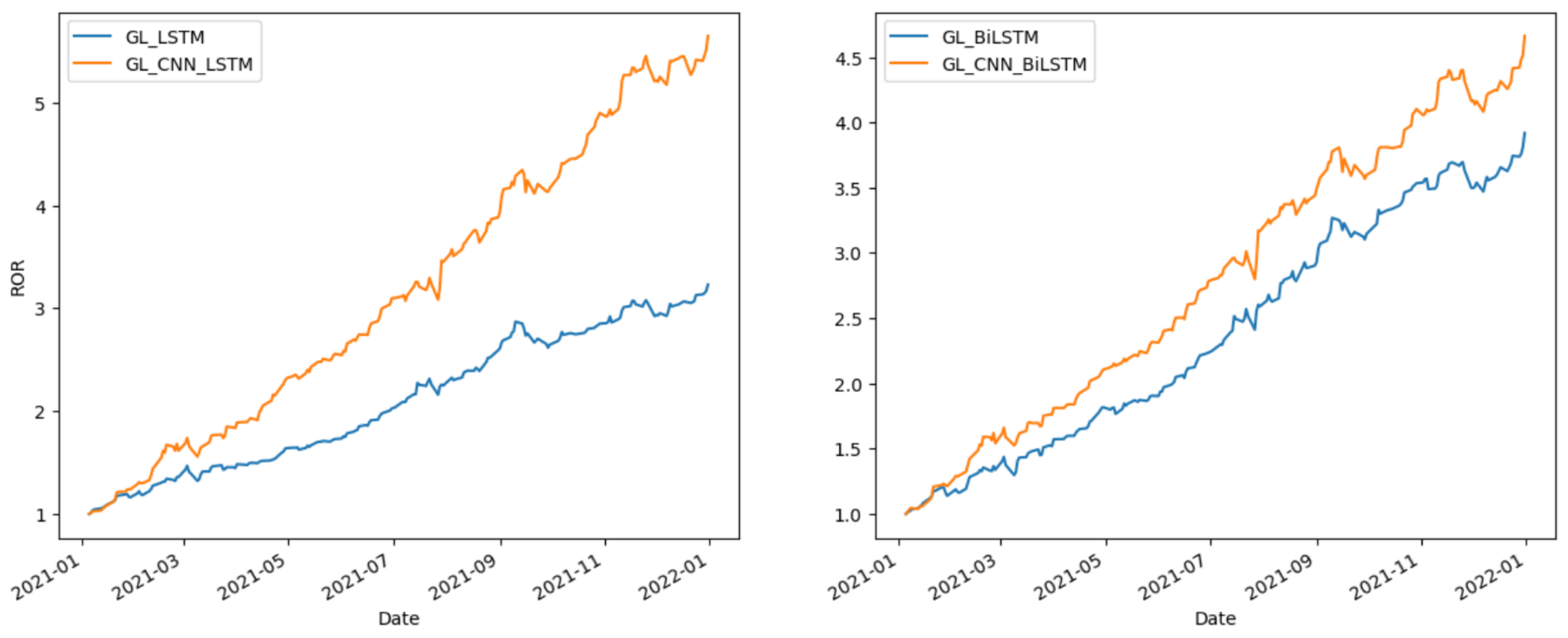
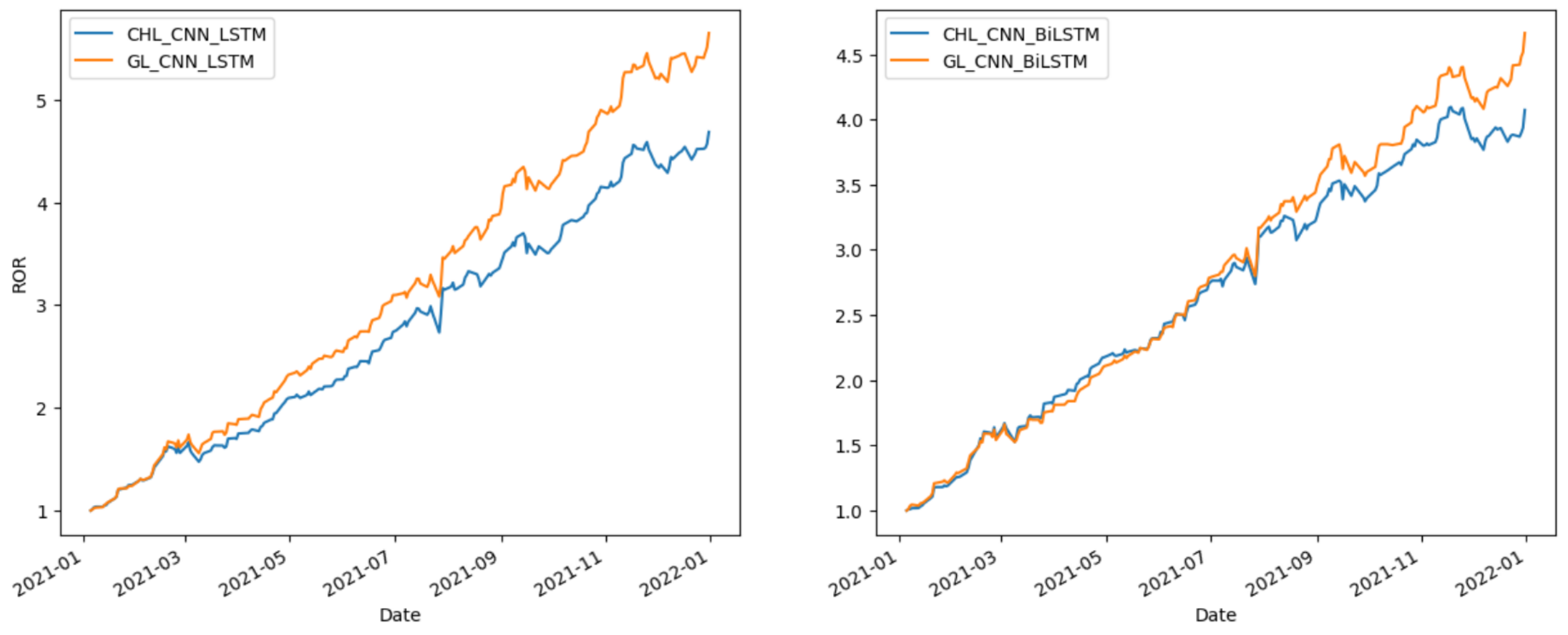
Figure 5,
Figure 6 and
Figure 7 provide the comparative analysis of the methods related to CNN-LSTM and CNN-BiLSTM in different markets during 2021. This shows that GL-CNN-LSTM and GL-CNN-BiLSTM consistently demonstrate excellent performance in terms of ROR. These observations indicate that utilizing GLoss, CNN-LSTM, or CNN-BiLSTM can significantly enhance stock returns in stock prediction.
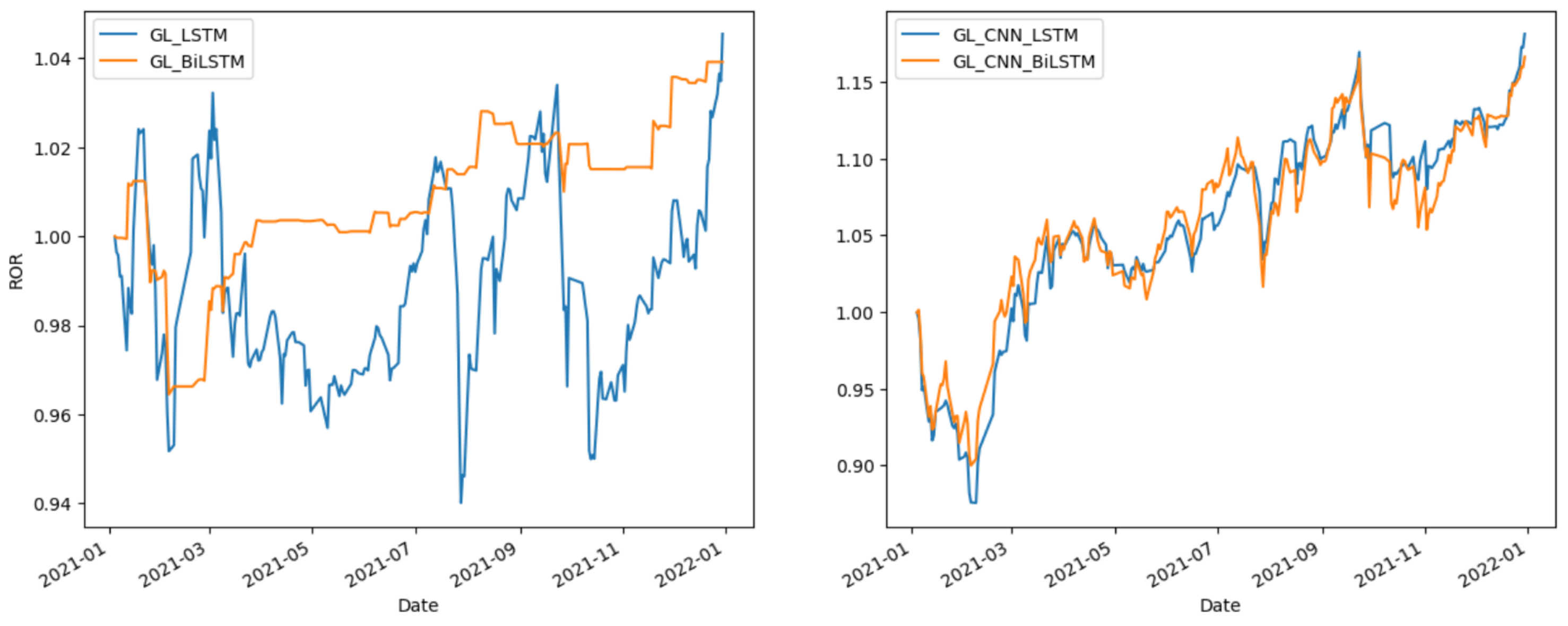
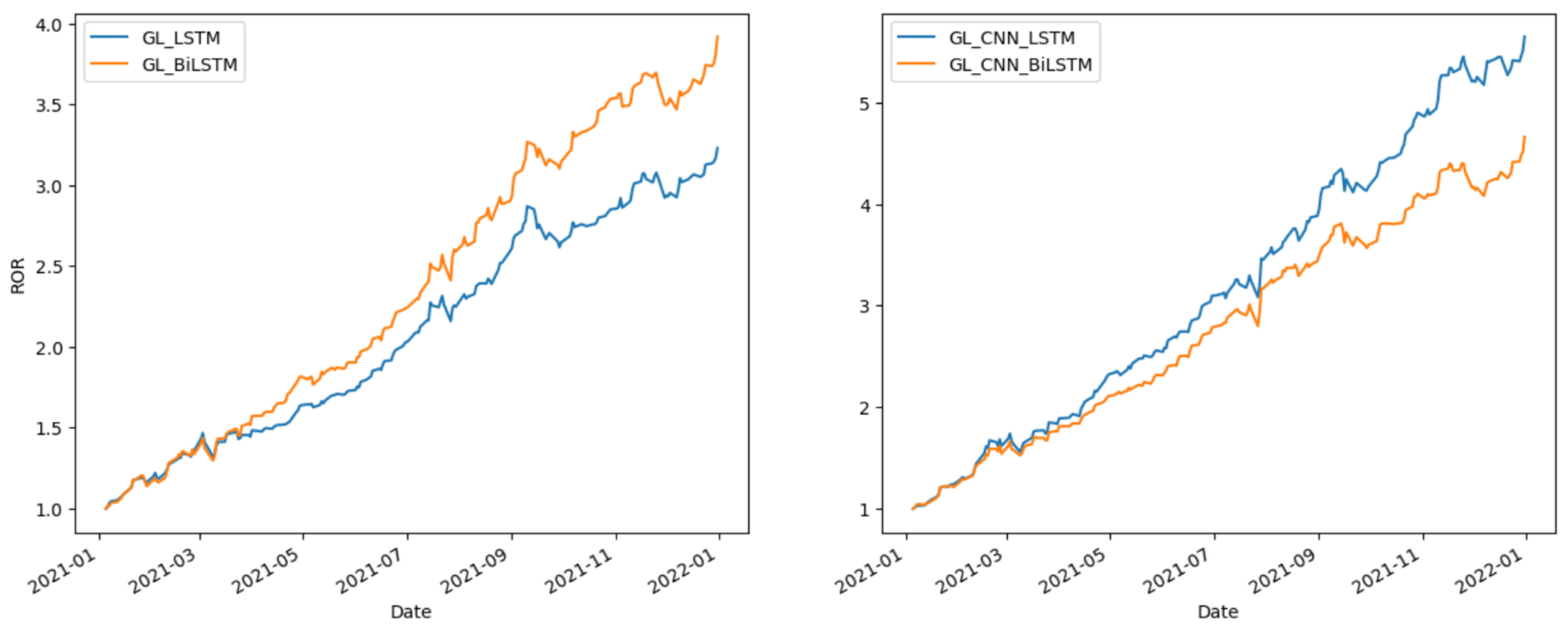
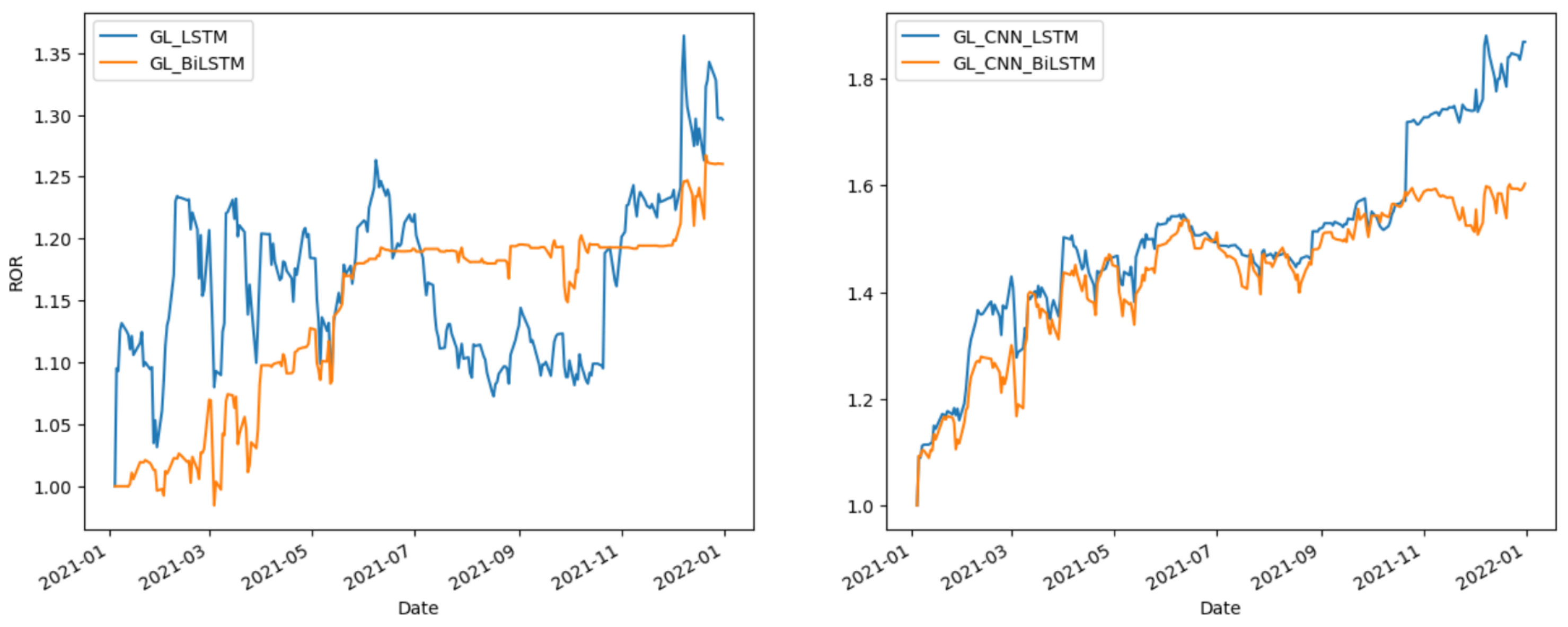
Figure 8,
Figure 9 and
Figure 10 compare the effects of LSTM and BiLSTM. The results indicate that BiLSTM outperforms LSTM in terms of investment return stability.
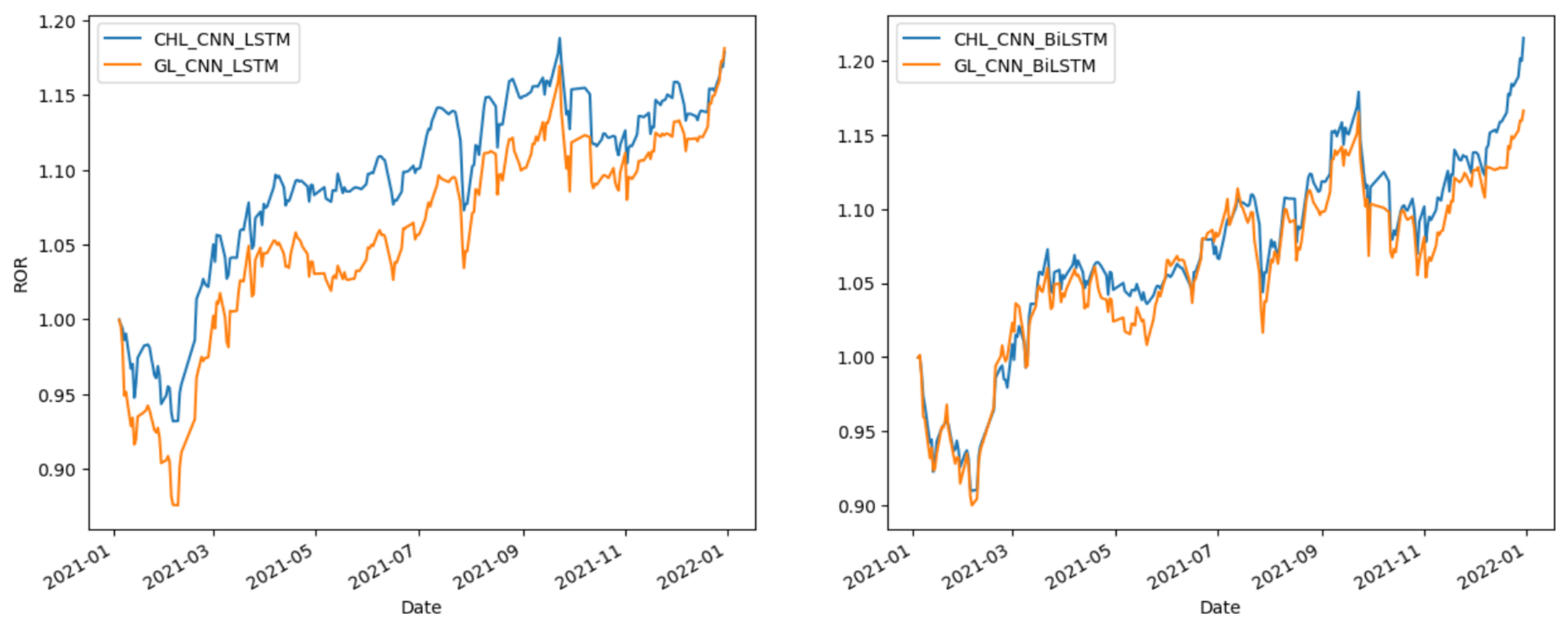
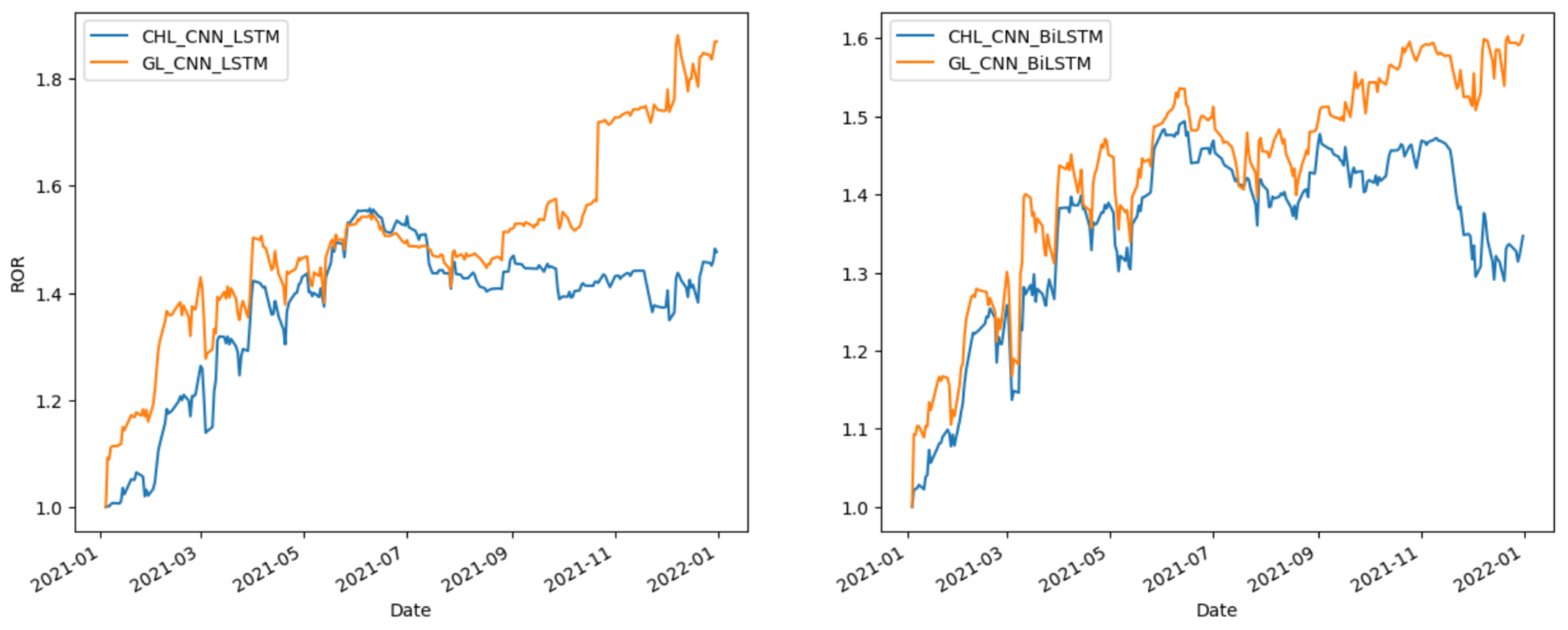
Figure 11,
Figure 12 and
Figure 13 compare the effects of CHL and GLoss. As a special case of Gloss, CHL has the same performance as Gloss. On some occasions, CHL performs particularly well, for example, in the Shanghai stock market.
From the predictive accuracy perspective, the evaluation metrics of the proposed models differ by less than from those of other models and show the same results in the three stock markets. However, the ROR of the proposed models differs significantly from that of other models. The Hong Kong stock market outperforms the other two.
The proposed models show better risk control than others, with a higher Sharpe ratio and lower annual volatility. The Hong Kong stock market has the highest Sharpe ratio and the lowest annual volatility among the three stock markets.
Based on the above observations, the proposed model has similar accuracy metrics to others, but the ROR and Sharpe ratios differ significantly. We can explain the reason from the internal principle of the proposed model. GLoss introduces the cost-sensitive mechanism into the CNN-LSTM model. Under the joint effect of the error type factor (cost factor) and the difficulty factor, the model pays more attention to instances with high cost and difficulty during the training process, and the prediction of such instances should be more accurate. Therefore, compared with other models, the prediction results should be a small cost in the False Positive (FP) instances and a large cost in the True Positive (TP) instances. In this way, when conducting transaction backtesting, the proposed models may manage risk better and predict large gains with low frequency; that is, even fewer transactions can bring higher returns and lower annual volatility, resulting in higher Sharpe ratios. Therefore, the level of return and Sharpe ratio have a low correlation with accuracy.
8. Conclusions
The experimental results indicate that the CNN-LSTM model with the generalized loss function performs exceptionally well when applied to the Shanghai, Hong Kong, and NASDAQ Stock Exchange data. Compared to traditional models using the BCE loss function, the model with the generalized loss function demonstrates significant improvements in predictive accuracy and robustness. Moreover, by adjusting different cost factors, the model can better adapt to various market conditions, thereby enhancing the practical applicability of the predictions. These results validate the effectiveness of the generalized loss function in stock prediction, offering valuable insights for future research and applications.
The GL-CNN-BiLSTM and GL-CNN-LSTM models demonstrate favorable investment returns and risk control capabilities as evidenced by their lower annual volatility. They also exhibit good risk-adjusted returns and a high Sharpe ratio.
Our goal in introducing cost-sensitive mechanisms into machine learning is to develop a set of cost-aware algorithms that use machine learning to learn from historical data and continuously improve the cost-minimization strategies, adjust the strategies based on real-time market conditions (such as volatility and liquidity), and slow down or speed up transactions to minimize costs. In future research, we will incorporate practical considerations such as transaction costs and improve cost-aware algorithms. This will help to enhance the performance and feasibility of stock market prediction models, enabling traders and investors to align their strategies with real-world trading environments and improve their risk-adjusted returns.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}