1. Introduction
Geopolitical conflicts significantly impact the level of risk associated with commodity market volatility. Several events, such as the COVID-19 pandemic, the conflict between Russia and Ukraine, and the war between Israel and Hamas, have already caused significant economic and financial disruptions. These disruptions have led to a sharp increase in commodity prices (
Fang and Shao 2022). However, the latest Israel–Hamas war has had a limited but noticeable impact on specific commodity prices, particularly energy and agricultural commodities, while impacting Gold and Cocoa Futures differently (
Kim and Fortner 2023;
Mintec.com 2023). Research on commodity futures markets like cocoa suggests that speculators react quickly to new information, leading to efficient price discovery mechanisms (
Nardella 2006). In contrast, even earlier studies on armed conflicts like the Israeli military offensive in Gaza show that conflicts can affect capital markets negatively, causing declines in asset prices during escalations in violence (
Kollias et al. 2010). Therefore, while the efficiency of price discovery in cocoa market prices remains intact despite speculator activity, armed conflicts like the Israel–Hamas war can lead to adverse effects on asset prices in capital markets, including gold prices (
Baur and McDermott 2010,
2012), due to increased uncertainty and risk aversion among investors.
Modeling volatility is a crucial aspect of assessing risk management strategies. Given the highly volatile environment following recent conflicts, it is necessary to determine the volatility of commodities compared to financial stock markets. Commodity prices have shown significant fluctuations over the last few years, and their behavior is raising concerns about overall economic market stability. For example, according to research by
Baur and McDermott (
2010), gold prices exhibit unique behavior; unlike other asset classes, gold prices tend to respond positively to negative market shocks. This finding significantly contributes to understanding commodity markets and raises additional questions in forecasting their volatility.
In traditional econometric methods, the growth of volatility models has been a significant area of development since the initial study by
Engle (
1982), which introduced the autoregressive conditional heteroscedastic (ARCH) class of models. Building on Engle’s earlier work,
Bollerslev (
1986) presented the generalized autoregressive conditional heteroscedastic (GARCH) model. Over time, GARCH models have emerged as the most commonly used method for estimating volatility. According to the literature, various authors have utilized different GARCH models to assess the volatility of financial markets and cryptocurrencies (see
Alfeus and Nikitopoulos 2022;
Ampountolas 2022,
2023;
Bakas and Triantafyllou 2019;
Iftikhar et al. 2023;
Mensi et al. 2022;
Nguyen and Walther 2020;
Takaishi 2020). Therefore, it is crucial to identify the most suitable technique for predicting the volatility of commodities and overall financial assets. This question is becoming increasingly vital as predicting the future volatility of the commodities marketplace greatly influences managing price risk for both commodity producers and consumers.
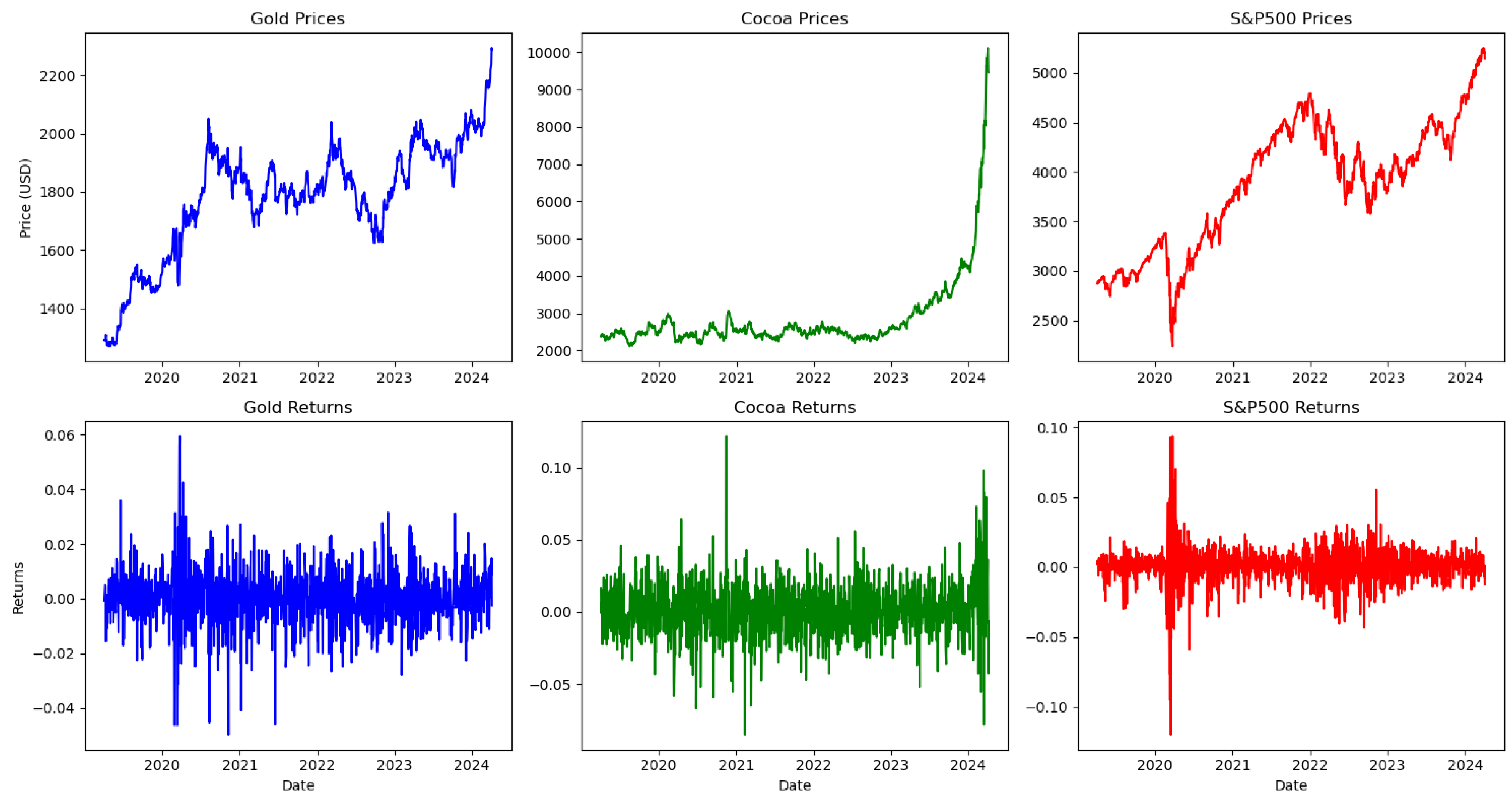
Therefore, our focus has shifted towards the commodity markets due to their recent increasing importance in financial and economic news. Specifically, we are paying attention to gold and cocoa, which have experienced substantial price increases over the past few months. Of particular note is cocoa, which has seen a significant fivefold rise from 2023 to 2024, as presented in
Figure 1. Our research contributes to the growing literature in several ways. While building on previous studies, we distinguish our work by examining the significance of capturing the volatility of commodity markets during periods of conflict. Our primary aim is to explore the importance of volatility in the daily dynamics of commodity markets by employing various GARCH models such as standard GARCH, eGARCH, and gjrGARCH, as well as long memory models like FIGARCH. Additionally, our study provides an empirical analysis of price forecasts by considering five forecasting models, including the Support Vector Regression (SVR) model and the GARCH family models, to determine the preferred method for price forecasting in the commodities market. Thus, we aim to evaluate the accuracy of predicting commodities market volatility dynamics beyond the observed data sample at various future time horizons. Furthermore, this study investigates the reliability of conditional heteroscedasticity models and distributional assumptions to effectively describe commodities’ price volatility. We use the Diebold and Mariano test (
Diebold and Mariano 1995) to conduct pairwise model comparisons and determine the best set of models. Our evaluation of the models is based on three loss functions: mean absolute error (MAE), mean square error (MSE), and the root mean square error (RMSE). Finally, the Value-at-Risk (VaR) model estimates market risk. To be more precise, a Cornish–Fisher expansion (CFVaR), which is a four-moment modified VaR, is used to consider both mean and variance and skewness and kurtosis. The two-moment VaR is considered less accurate than the CFVaR approach (
Ali et al. 2021;
Favre and Galeano 2002).
The following section briefly summarizes the relevant literature, and
Section 3 highlights the employed techniques and analyzes the data. Finally,
Section 4 examines the study’s findings, emphasizing the methods used, and
Section 5 summarizes the paper’s conclusions and directions for future research.
2. Research Background
The commodity price forecasting literature has advanced significantly in recent years. Recent studies have drawn attention to the importance of commodity assets for asset allocation and portfolio diversification (
Alfeus and Nikitopoulos 2022;
Degiannakis and Filis 2018;
Gkillas et al. 2020;
Klein 2017). Additionally, research has affirmed the potential of commodity assets to act as safe havens and hedges (
Rubbaniy et al. 2022). Authors have emphasized the significant influence of macroeconomic news (
Smales 2017,
2022), macroeconomic factors, such as industrial production and inflation (
Bakas and Triantafyllou 2019;
Karali and Power 2013), economic uncertainty (
Bakas and Triantafyllou 2019;
Fang et al. 2019), and financial drivers like the VIX measure (
Baur and Smales 2020), the default return spread, bond markets, and the Treasury–Eurodollar spread (
Prokopczuk et al. 2017), in forecasting commodity prices.
Gargano and Timmermann (
2014) study utilized a broad array of commodity prices to evaluate the out-of-sample predictability of commodity prices based on financial and macroeconomic variables. Commodity currencies were found to be able to predict short-term forecast horizons, while economic growth and the investment-capital ratio were found to have the ability to predict relatively longer horizons.
Other research has utilized a Bayesian method to create stochastic models. For example,
Kostrzewski and Kostrzewska (
2019) compared the Bayesian approach with non-Bayesian individual autoregressive models and three averaging methods for predicting spot prices. They determined that the Bayesian stochastic volatility model outperformed the others because it takes into account time-varying parameters, latent volatility, and jumps.
The
Foroutan and Lahmiri (
2024) study examined the connectedness between the ten most traded cryptocurrencies and the gold and crude oil markets before and during the COVID-19 pandemic. The authors utilized various statistical techniques, such as cointegration tests, vector error correction models, vector autoregressive models, Granger causality analyses, and the autoregressive distributed lag models, to investigate the relationship between these markets and to evaluate the safe haven properties of gold and crude oil for cryptocurrencies. The results indicate that during the COVID-19 pandemic, gold serves as a solid safe haven for Bitcoin, Litecoin, and Monero while showing a weaker safe haven potential for Bitcoin Cash, EOS, Chainlink, and Cardano. In contrast, gold only demonstrates a robust safe haven characteristic for Litecoin and Monero before the pandemic.
Alfeus and Nikitopoulos (
2022) investigated the fluctuations in volatility within commodity markets using three standard long memory models: the fractional integrated generalized autoregressive conditional heteroscedastic (FIGARCH), fractional stochastic volatility (FSV), and heterogeneous autoregressive (HAR) models. The results indicated that commodity market volatility is characterized by roughness, with volatility components across different time frames being economically and statistically significant. Anti-persistent long memory was observed across all commodities, with weekly volatility prevailing in most commodity markets and daily volatility dominating the oil and gold markets. Moreover, HAR models demonstrated superior forecasting performance for short time frames compared to the other two, while fractional volatility models produced comparatively more accurate forecasts over more extended time frames.
Nguyen and Walther (
2020) examined the changing volatility patterns of major commodities and the potential factors influencing their long-term volatility. The study utilizes a recently developed approach that combines generalized autoregressive conditional heteroscedasticity with mixed data sampling (GARCH-MIDAS). The research used commodity futures for crude oil (WTI and Brent), gold, silver, platinum, and a commodity index. The findings highlight the importance of distinguishing between short-term and long-term components when modeling and predicting commodity volatility. They also suggest that long-term volatility is significantly influenced by real global economic activity, changes in consumer sentiment, industrial production, and monetary policy uncertainty.
The use of traditional time series models for forecasting commodity prices has been widespread for a long time. For example, in their study,
Dooley and Lenihan (
2005) employed a time series ARIMA model and lagged-forward price modeling to predict future metals prices, demonstrating the high effectiveness of the ARIMA model. However, recent studies have proposed adopting stochastic models for price forecasting (
Lee et al. 2017). According to
Ben Ameur et al. (
2023), a stochastic model with time-varying specificity and non-Gaussian distribution can account for the time dependency of commodity markets. They discovered that its asymmetric distribution could outperform traditional time series models. The study of
Idilbi-Bayaa and Qadan (
2021) examined the effectiveness of the yield curve on US government bonds in predicting the future movements in the prices of commodities. They analyzed the monthly prices of nine commodities over more than 30 years. Their results suggest that the predictive power changes over time. In the earlier years, the yield curve effectively forecasted monthly changes in commodity prices, but this effectiveness declined in the subsequent period.
In addition, during the last decade, the literature on forecasting commodity prices has focused on utilizing operational research tools such as artificial intelligence (AI), machine learning (ML), and deep learning (DL) systems.
Panella et al. (
2012) used an ML approach, specifically neural networks, to forecast crude oil, coal, natural gas, and electricity prices. They found that a mixture of Gaussian neural network algorithms was optimal and could be identified using a hierarchical constructive procedure.
Narayan et al. (
2013) showed that their proposed model for predicting future oil prices was simple and accurate. It was based on a regime-switching framework and used hidden Markov filtering algorithms. However, only some studies have utilized DL models for commodity price forecasting. For example,
Kamdem et al. (
2020) applied DL models, specifically the Long Short-Term Memory (LSTM) model, to forecast commodity prices during the COVID-19 pandemic crisis. Their results showed that the LSTM model accurately predicted commodity prices.
As such, various studies have demonstrated that both traditional time series models and modern machine learning techniques, including Bayesian and deep learning approaches, offer valuable insights for forecasting. Moreover, the research highlights the significant roles of macroeconomic factors, financial drivers, and advanced stochastic models in predicting commodity prices. The evolving methodologies and findings underscore the dynamic nature of commodity markets and the continual need for robust forecasting models to navigate economic uncertainties and market volatilities effectively.
4. Results and Discussions
This study aims to analyze the volatility dynamics of commodities’ returns such as gold, cocoa, and the financial market index S&P500 by applying different GARCH models, namely sGARCH, eGARCH, gjrGARCH, and FIGARCH. We used the Akaike information criterion (AIC) to determine the best model. In addition, we optimized each model with the Skewed Generalized Error Distribution (SGED), and the autoregressive parameters of the mean model are GC=F: ARFIMA (0, 0, 0), CC=F: ARFIMA (1, 0, 0), and GSPC: ARFIMA (3, 0, 2), respectively.
More specifically, for Gold Futures (GC=F), the study’s findings are presented in
Table 2, which includes the maximum likelihood estimates of these models. Among the GARCH models considered for modeling Gold Futures (GC=F) returns, the sGARCH model appears to have generated better results based on Akaike’s information criterion (AIC) and the overall pattern of parameter estimates. The sGARCH model exhibits the lowest AIC value (−6.4802), indicating a favorable balance between model fit and complexity compared to the other models. Additionally, the parameter estimates in the sGARCH model suggest significant volatility clustering, as evidenced by the relatively high value of
(0.057106) and the corresponding low value of
(0.883539). This implies that past volatility shocks persistently impact current volatility levels, a characteristic often observed in financial time series data. The skewness parameter (Skew) is estimated at 0.929098, indicating a slight positive skewness in the return distribution.
While the eGARCH model also demonstrates volatility clustering, its AIC value is slightly higher (−6.4793) than that of the sGARCH model, suggesting a somewhat inferior fit. In the eGARCH model, the estimated parameters show a similar pattern of volatility persistence, with (0.038442) and (0.965718), indicating significant volatility clustering. The gjrGARCH model, which incorporates asymmetry in volatility responses to positive and negative shocks, does not show substantial evidence of asymmetry based on the estimated parameter (−0.054843). The other parameters and suggest similar levels of volatility persistence compared to the sGARCH and eGARCH models.
Lastly, the FIGARCH model, which accounts for long memory dependence in volatility, indicates strong evidence of long memory effects based on the estimated fractional integration parameter (0.999998), which is close to 1. However, the FIGARCH model’s AIC value (−6.4678) is higher than the sGARCH model’s, indicating a less favorable trade-off between model fit and complexity. Therefore, considering the lower AIC value and the favorable pattern of parameter estimates indicating volatility clustering, the sGARCH model is likely to have generated better results for modeling Gold Futures returns.
Table 3 presents the maximum likelihood estimates of the study’s GARCH models for Cocoa Futures and compares the performance in estimating the volatility dynamics. The results indicate that the sGARCH model has limitations in accurately capturing these dynamics, as evidenced by its lower log-likelihood value of
and AIC value of
compared to other models. Moreover, while the estimated parameters are statistically significant, they may not fully account for the asymmetry and leverage effects present in the data. Finally, the absence of fractional integration may limit its ability to capture long-memory properties related to volatility.
The eGARCH model attempts to address volatility’s asymmetric response to shocks. However, its performance seems subpar compared to other models, with a log-likelihood value of and an AIC value of . Although some model parameters are statistically significant, the presence of relatively high standard errors and the negative estimate for the constant term () raise concerns about the model’s stability and reliability in capturing Cocoa Futures’ volatility dynamics. The gjrGARCH model incorporates a leverage effect, enabling asymmetric responses to positive and negative shocks. However, its performance, with a log-likelihood value of and an AIC value of , is similar to that of the sGARCH and eGARCH models. Notably, the estimated parameters for the gjrGARCH model include (standard error ), (standard error ), and (standard error ). While some parameters are statistically significant, the absence of fractional integration might limit its ability to capture long memory effects in volatility, potentially leading to suboptimal model fit.
In contrast, the FIGARCH model is the most promising model for estimating Cocoa Futures’ volatility dynamics. It achieves the highest log-likelihood value of
and the lowest AIC value of
among all models, indicating superior model fit. These findings confirm the results shown in the study by
Alfeus and Nikitopoulos (
2022), where the FIGARCH model successfully detected the long-memory characteristics of commodity markets. The statistically significant parameter estimates, including the fractional differencing parameter (
),
(standard error
), suggest that the model effectively captures the autocorrelation and volatility clustering in Cocoa Futures’ returns. Additionally, including skewness and shape parameters enhances the model’s ability to capture the distributional characteristics of the data.
Table 4 presents the evaluation results of GARCH models for the S&P500 financial index. Regarding model fit, the eGARCH model demonstrates superior performance, boasting the highest log-likelihood value and the lowest AIC value among all models. The eGARCH’s log-likelihood value of
and AIC value of
suggest it best compromises between model complexity and goodness of fit. This implies that the eGARCH model effectively captures the volatility dynamics of the GSPC index compared to the other analyzed models. Furthermore, the parameter estimates for the eGARCH model, including
,
, and
, indicate robustness and reliability in estimation.
Despite the eGARCH model’s superiority, the gjrGARCH model also demonstrates strong performance in model fit, with log-likelihood and AIC values comparable to those of the eGARCH model. The gjrGARCH model’s log-likelihood value of and AIC value of suggest that it captures the volatility dynamics of the GSPC index effectively, albeit slightly less optimally than the eGARCH model. The parameter estimates for the gjrGARCH model, including , , and , further reinforce its robustness and reliability in estimation. Conversely, while the sGARCH model provides some insights into the volatility dynamics of the GSPC index, its limitations become apparent regarding model fit. The sGARCH model’s log-likelihood value of and AIC value of indicate that it captures volatility dynamics less effectively than the eGARCH and gjrGARCH models. Additionally, the sGARCH model’s parameter estimates, including , , and , suggest limitations in capturing asymmetry and long memory effects in volatility.
Finally, the FIGARCH model exhibits promising performance in log-likelihood but faces challenges related to estimation precision. Although the FiGARCH model’s log-likelihood value of suggests that it captures volatility dynamics reasonably well, its relatively higher AIC value of compared to the eGARCH and gjrGARCH models raises concerns. Moreover, the FIGARCH model’s parameter estimates, particularly the relatively high standard errors for some parameters (e.g., and ), indicate potential issues with estimation precision, which could affect the reliability of the model’s predictions.
The study presents experimental results in
Table 5 analyzing
h-step-ahead forecasting performance for gold, cocoa, and S&P500 using sGARCH (1,1), eGARCH (1,1), GJR-GARCH (1,1), FIGARCH (1,1), and the SVR model. For a robust comparison, we applied three loss functions and adaptive forecasting with a 252 market days rolling window for testing over a recursive one. This approach was more robust to time-varying parameters. To evaluate the sensitivity of their volatility prediction for financial assets time series return data, we investigated three horizons (
h) of 1, 5, and 20 market days, covering both short-term and long-term intervals. As demonstrated in
Table 5, the forecasting performance depends on the horizon, with significantly reduced forecast losses under each metric over longer forecast horizons for all assets. The GARCH-type models, particularly sGARCH, eGARCH, and GJR-GARCH, show effective volatility forecasting capabilities across different assets and forecast horizons according to the loss function analysis. However, the SVR model displays relatively lower accuracy.
More specifically, across all forecasting horizons, the accuracy of the gold performance was measured using GARCH models, particularly the sGARCH and grjGARCH models, which consistently demonstrated superior forecasting accuracy compared to the support vector regression (SVR) model. In the short term (1-day horizon), the sGARCH model exhibited the lowest MAE, MSE, and RMSE values (MAE: 0.003863, MSE: 0.000015, and RMSE: 0.003863), indicating its ability to provide more accurate forecasts of Gold Futures prices. The SVR model showed promising results at longer horizons with considerable improvement compared to the 1-day horizon. Thus, the SVR model consistently outperforms the others in terms of forecasting accuracy for 5 and 20 trading days. The SVR demonstrates the lowest accuracy measures, indicating advanced predictive capability compared to traditional GARCH-based models, suggesting that SVR effectively captures the underlying patterns and dynamics in asset returns. Finally, the grjGARCH, followed by the eGARCH model, exhibited moderate accuracy in all horizons. Overall, the results highlight the potential of SVR as a superior alternative to traditional GARCH-based models for accurate and reliable asset return forecasting over extended time horizons.
Table 5 also provides a comprehensive overview of the accuracy metrics for Cocoa Futures (CC=F), confirming the superior performance of the Support Vector Regression (SVR) model over traditional GARCH-based models. Across all three forecasting horizons, SVR consistently outperforms the GARCH models, as evidenced by the accuracy metrics. For example, for the 1-day horizon, SVR yields an MAE of approximately 0.023759, significantly lower than the values obtained by the GARCH models, which range from 0.036262 to 0.037242. Similarly, SVR consistently demonstrates superior accuracy for the 5-day and 20-day horizons, with lower MAE, MSE, and RMSE values than the GARCH models. As such, these results highlight SVR’s capability to capture the underlying dynamics of Cocoa Futures returns more effectively than traditional GARCH models. However, these findings differ somewhat from those observed in gold forecasting, where SVR exhibited greater accuracy over longer horizons than shorter ones. Despite this discrepancy, SVR remains the preferred choice for Cocoa Futures forecasting, offering precise predictions across various forecasting horizons. Finally, while SVR consistently demonstrates superior accuracy, the performance of the grjGARCH and FIGARCH models also deserves attention. These traditional GARCH-based models exhibit competitive results, especially for shorter forecasting horizons. However, as the forecasting horizon extends, the performance gap between the SVR and the GARCH models becomes more pronounced. Despite some variability, the grjGARCH and FIGARCH models may still offer viable alternatives to SVR. Nevertheless, according to the results, the SVR’s consistently superior performance makes it the preferred choice for capturing the intricate dynamics of Cocoa Futures returns across different forecasting horizons.
The analysis of various forecasting models for the S&P500 Index (GSPC) shows that Support Vector Regression (SVR) outperforms traditional GARCH-based models by a significant margin. At a 1-day forecast horizon, SVR exhibits remarkable accuracy with a low mean absolute error (MAE) of around 0.002960, which is substantially lower compared to the MAE values obtained by the sGARCH (MAE: 0.005662), eGARCH (MAE: 0.006091), grjGARCH (MAE: 0.005364), and FIGARCH (MAE: 0.005437) models. This substantial difference in MAE values confirms SVR’s superior capability in short-term forecasting, similar to cocoa forecasting. As the forecast horizon extends to 5 days, SVR maintains its dominance, although with a slight increase in error metrics. Even in this scenario, SVR (MAE: 0.003775) outperforms traditional GARCH models, including sGARCH (MAE: 0.010252), eGARCH (MAE: 0.010534), grjGARCH (MAE: 0.009940), and FIGARCH (MAE: 0.010081), by a significant margin. Similarly, at the 20-day horizon, SVR exhibits better accuracy, although with a slightly higher MAE compared to the shorter horizons. Nonetheless, SVR’s MAE, MSE, and RMSE values remain significantly lower than those of the GARCH models across all forecasting horizons, reaffirming its consistent performance superiority. These results highlight SVR’s reliability and effectiveness as a forecasting tool for the S&P500 Index. In addition, traditional GARCH models may need help to capture the index’s intricate volatility dynamics over longer timeframes. Therefore, the study underlines the importance of using advanced modeling approaches like SVR to improve forecasting accuracy and reliability in financial markets.
The Diebold–Mariano test results from
Table 6 present the comparative forecast accuracy of various forecasting models for Gold Futures (GC=F), Cocoa Futures (CC=F), and the S&P500 index (GSPC). Overall, significant differences in forecast accuracy are observed across different sets of comparisons. Based on the results in Set 1, the sGARCH model does not perform as well as the eGARCH, gjrGARCH, and FIGARCH models for Gold Futures. However, its performance varies for Cocoa Futures and the S&P500 index. In Set 2, the eGARCH model outperforms the gjrGARCH model for Gold Futures but falls short compared to the FIGARCH model for the same asset. In addition, for the S&P500 index, the eGARCH model does not perform as well as the FIGARCH model. Moving on to Set 3, the gjrGARCH model consistently outperforms the FIGARCH model across all assets, indicating its superior forecast accuracy. Lastly, Set 4 demonstrates that the FIGARCH model outperforms the SVR model significantly for all assets, highlighting the effectiveness of the FIGARCH model in forecasting.
Table 7 displays estimations of Value at Risk (VaR) and Cornish–Fisher expansion (CFVaR) for various financial instruments over the period spanning 4 April 2019 to 4 April 2024. VaR represents the maximum potential loss at a specific confidence level, while CFVaR offers a modified VaR considering higher moments of the return distribution. For Gold Futures (GC=F), the VaR and CFVaR estimates increase as the confidence level increases, indicating more significant potential losses. Similar patterns are observed for Cocoa Futures (CC=F), with both VaR and CFVaR estimates showing an upward trend as the confidence level rises. However, it is worth noting that the CFVaR estimates tend to be slightly lower than the VaR estimates for Cocoa Futures across all confidence levels, suggesting a potential smoothing effect introduced by the Cornish–Fisher expansion. For the S&P500 index (GSPC), the VaR and CFVaR estimates show more variability than the other instruments, particularly at higher confidence levels. Interestingly, at the 90% confidence level, the CFVaR estimate for the S&P500 index is notably higher than the corresponding VaR estimate, indicating a more conservative risk assessment considering higher moments of the return distribution.
5. Conclusions
This study aims to provide a better understanding of the volatility patterns in commodity returns such as gold and cocoa, as well as the financial market index S&P500. We employed various GARCH models to achieve this and evaluated their effectiveness using Akaike’s information criterion (AIC) and maximum likelihood estimates. The study found that these findings could have significant implications for financial practitioners and researchers. To develop accurate forecasting models, we must understand the underlying dynamics of commodity returns.
Therefore, the study provides an overview of each model’s effectiveness in capturing volatility clustering, asymmetry, and long-term memory effects in the respective asset returns. By employing models like sGARCH, eGARCH, gjrGARCH, and FIGARCH, researchers gain a nuanced understanding of how volatility evolves over time and its impact on asset returns. Moreover, incorporating Skewed Generalized Error Distribution (SGED) in model optimization underscores the significance of capturing asymmetry and fat-tailedness in return distributions, standard features in financial data.
The analysis reveals several key findings regarding the performance of GARCH models in modeling the volatility of different assets. For Gold Futures (GC=F), the sGARCH model emerges as the preferred choice due to its lower AIC value and favorable parameter estimates, indicating significant volatility clustering and a slight positive skewness in return distribution. Conversely, while other models like eGARCH, gjrGARCH, and FIGARCH exhibit some strengths in capturing certain aspects of volatility dynamics, they generally show inferior performance compared to sGARCH in model fit and complexity.
Similarly, for Cocoa Futures (CC=F), the FIGARCH model demonstrates the best performance in capturing volatility dynamics, as evidenced by its higher log-likelihood value and lower AIC value than other models. The results suggest that the FIGARCH model effectively captures long-memory effects in Cocoa Futures returns, providing more reliable forecasts over various forecasting horizons.
In the case of the S&P500 Index (GSPC), the eGARCH model stands out as the most effective in modeling volatility dynamics, exhibiting superior performance in both log-likelihood and AIC values compared to other models. The eGARCH model’s ability to capture asymmetry in volatility responses contributes to its robust forecasting capabilities for the S&P500 Index.
Overall, identifying superior modeling approaches, such as the FIGARCH model for capturing long memory effects in volatility, can enhance risk management strategies by providing more accurate estimates of Value-at-Risk (VaR) and Expected Shortfall (ES).
Furthermore, the out-of-sample evaluation of forecasting models reveals that Support Vector Regression (SVR) outperforms traditional GARCH models, particularly for short-term forecasting horizons, across all analyzed assets. SVR consistently accurately predicts asset returns, indicating its potential as an alternative forecasting tool in financial markets.
Limitations and Future Research
While the study provides valuable insights into volatility modeling and forecasting accuracy in financial markets and, more specifically, in commodities, several limitations should be considered when interpreting the results, similar to many other studies. It is essential to acknowledge that several factors may limit the generalization of the findings. Firstly, the analysis is primarily focused on specific assets, so it may not be possible to extrapolate the results to other asset classes or different market conditions. Different assets may exhibit unique volatility dynamics influenced by factors such as sector-specific news, geopolitical events, or macroeconomic trends, which are not fully captured in the study’s analysis. Moreover, the study’s comparison of forecasting accuracy between GARCH models and SVR may be subject to methodological biases. For example, selecting specific SVR parameters or kernel functions could influence the comparative performance results.




{kind=link}