1. Introduction
Forecasting stock market returns relies on advanced financial time series analysis, with probability distributions serving as fundamental components in statistical modeling (
Taylor 2008). The fitting of parametric distributions to the statistical characteristics of stock indices returns is integral to econometrics, and holds practical implications for effective risk management. The identification of an accurate distribution for stock indices returns establishes a critical benchmark for evaluating investment success, given that decision-making often hinges on empirical data assessments.
Within the domain of financial economics, a nuanced understanding of stock market return behavior is pivotal. The interplay between stock prices and returns is instrumental in determining potential profits for investors. As a result, the financial literature incorporates sophisticated analytical models that accommodate the non-linear dynamics inherent in stock price fluctuations (
Pokharel et al. 2022). Researchers spanning academia and trading circles exhibit a pronounced interest in the statistical modeling of financial asset returns. The initial step in any predictive analysis of significance involves the meticulous determination of the statistical distribution characterizing the phenomenon under scrutiny. While historical suggestions favor normal variance models for stock market return distributions (
Praetz 1972), such models often fall short, given the distinctive features of stock returns—displaying a higher peak and heavier tails than what the Gaussian probability distribution predicts.
Some challenges within stock index research revolves around the volatility and it has attracted attention of many scholars who have explored them through the Barndorff-Nielsen and Shephard (BN-S) model. Both the conventional BN-S model and its generalizations have proven instrumental in addressing diverse phenomena such as jumps, stochastic fluctuations, and leverage effects. Interested readers are referred to the pioneering works by
Shephard and Barndorff-Nielsen (
2001),
Kallsen et al. (
2011), and
SenGupta (
2016).
Furthermore,
Durham (
2007) emphasizes the critical understanding of volatility dynamics and return distribution shapes in finance, proposing the stochastic volatility model (SV-mix model) as a discrete mixture of normals to capture the conditional distribution. This approach provides enhanced insight into return distribution tails and demonstrates empirical superiority over competing models like the single-factor volatility model. In empirical finance, conditional distributions of financial returns are often established through standardized error distributions within GARCH-type models.
Chen (
2015) introduced the maximum entropy (MaxEnt) approach, presenting a method for moment combination and selection to tackle this distribution-building challenge. This framework proves valuable in unifying and comparing existing distribution specifications, crafting more fitting distribution specifications, and illuminating the significance of various moments in the distribution-building process. This proposition is validated through an empirical investigation on stock index returns. Nevertheless, amidst these efforts, there remains a significant quest for precision for uncovering the exact distribution of returns for stock indices. Finding the exact distribution of returns of stock indices could provide a useful benchmark to measure the success of investment, since stock investment decisions always rely on assessments of the distribution of expected stock returns, which could be obtained from empirical data. Thus, establishing an accurate distribution of stock index returns stands not only as a scholarly pursuit, but also as a practical necessity for investors seeking to make informed decisions.
The Laplace and related distributions are obvious candidates to replace Gaussian models and processes in modeling financial asset returns, because traditional Gaussian distribution models are frequently not supported by real-world data due to fat tails and asymmetry prominent in financial data (
Franczak et al. 2013). Laplace distributions are used to fit the marginal distribution function, which will then be employed in a copula function because they can account for leptokurtic and skewed data (
Kotz et al. 2001). Compared to the Gaussian distribution, it typically better describes stock return behavior while capturing the greater peak and heavy tails (
Nadaf et al. 2022). Recognizing the rarity of stock market data adhering strictly to a standard Laplace distribution, introducing the generalized Laplace distribution enhances flexibility for modeling real-life data.
Empirical research underscores the appropriateness of the skew Laplace distribution in modeling asset returns data, offering a parametric solution to control skewness (
Aryal and Nadarajah 2005). The Kumaraswamy Laplace distribution finds application across diverse fields, including medicine, environmental science, economics, engineering, and finance, among others, due to its adaptability (
Aryal and Zhang 2016). The asymmetric Laplace distribution exhibits general asymmetry, high peaks, and heavier tails than the normal distribution, is used to model data, and has applications in communication, economics, engineering, and finance (
Kotz et al. 2012). The class of asymmetric Laplace distributions is well suited for modeling phenomena where the variable of interest is the result of a significant number of independent, random observations, and the empirical distribution appears to be asymmetric, with a steep peak and heavier tails than those permitted by the normal distribution (
Jayakumar and Kuttykrishnan 2007).
The four-parameter Variance-Gamma (V-G) distribution, proposed by
Madan and Seneta (
1990), occupies a prominent position in finance literature as a potent model for stock returns. The V-G is a continuous statistical distribution, referred to as the generalized Laplace or Bessel function distribution. The V-G distribution’s significant characteristic is that its tails decelerate more slowly than the normal distribution. As a result, it is thought to be exceptionally well-suited for simulating returns on financial assets and turbulent wind speeds.
This article delves into the potential of probability distributions within the Laplace family for modeling stock return predictions, supported by empirical evidence derived from real market data spanning various indices. Acknowledging the absence of a universal probability distribution applicable to all financial data types, our objective is to discern the most suitable distribution for predictive modeling of stock returns. Evaluating the performance of the Variance-Gamma distribution against four-parameter distributions like Kumaraswamy Laplace across eleven S&P 500 business sectors and the index as a whole, our study, based on log-likelihood and AIC criteria, reveals Kumaraswamy Laplace as a superior alternative to Variance-Gamma for modeling stock index returns in eleven out of twelve indices, including the S&P 500 index. The Variance-Gamma distribution marginally performs better than the Kumaraswamy Laplace distribution in fitting the Consumer Discretionary index. Our research suggests that Kumaraswamy Laplace is a potent alternative substitute for Variance-Gamma distribution when modeling stock index returns. This significant finding not only encourages further exploration, but also sparks discussion within the realm of applied finance.
The remaining part of the manuscript is organized as follows.
Section 2 describes various generalizations of Laplace distributions, which are used to model the stock return data.
Section 3 discusses the data description and methodology used to derive the conclusion.
Section 4 discusses the analysis of data. This section is further divided into eleven subsections: each subsection is dedicated to individual business sectors of S&P 500 index and the index itself.
Section 5 outlines the ranking of distributions for modeling stock returns, while
Section 6 explores exceedance probability and return level prediction.
Section 7 includes parallel inferences and some discussions, and
Section 8 offers concluding remarks.
2. Generalization of Laplace Distribution
It is of great interest to many investors, portfolio managers, and others to model the returns of their investments, especially stocks. Like any financial modeling problem, fitting a model to stock returns (daily, weekly, or monthly) is difficult, as the returns patterns can drastically change due to many internal and external influences on the stock price or the market more generally. Probability distribution plays a key role in describing and predicting real-world phenomena. Probabilistic modeling and statistical analysis of the behavior of stock market returns are important in finance and economics for assessing risk analysis and providing a means to identify the pattern from the existing data. There are hundreds of discrete and continuous probability distributions in the literature. The data under study may guide us in the choice of distribution among parametric distributions. For example, choice among symmetric versus asymmetric distribution, long-tailed vs. short-tailed distribution, distribution with threshold parameter, among others. Among the prominent probability distributions, the Laplace distribution holds a special place in the modeling financial data.
The Laplace family distribution, with its heavier tails compared to the normal distribution, better captures extreme events such as market crashes or sudden spikes in stock market that influence stock returns. Its robustness to outliers, such as corporate scandals or geopolitical events, enhances modeling reliability. Additionally, its symmetry around the mean accommodates both positive and negative returns without assuming skewness, unlike some traditional distributions. With flexibility in modeling various parameters, it can tailor distributions to fit specific data characteristics. In this article, we will explore the statistical modeling of stock index data using Laplace and some generalized distributions that are derived using the genesis of Laplace distribution.
2.1. Laplace Distribution
The Laplace distribution is named after the French astronomer, mathematician, and physicist Marquis Pierre Simon de Laplace (1749–1827), and is one of the earliest distributions introduced in the probability theory. Laplace distribution is also known as double-exponential distribution, as well as the two-tailed distribution. It is a symmetric distribution whose tails fall off less sharply than the Gaussian distribution and has a cusp, discontinuous first derivative at the mean. The Laplace distribution has been quite commonly used as an alternative to the normal distribution in robustness studies, including the stock returns. An in-depth study of the Laplace distribution, including various properties and applications, is provided in
Kotz et al. (
2012).
The Laplace distribution has the probability density function (pdf) given by
where
,
and
. The expected value,
, and the variance,
, of a Laplace random variable respectively given by
It should be noted that the median and the mode of the Laplace distribution are the same as its mean
. Since the generalized distribution allows more flexibility to model real-world data, there has been a growing interest in developing a generalized class of distribution by inducting one or more additional parameter(s). Several asymmetry forms of Laplace distribution have appeared in the literature, including those introduced by
McGill (
1962),
Holla and Bhattacharya (
1968),
Lingappaiah (
1988),
Poiraud-Casanova and Thomas-Agnan (
2000),
Kozubowski and Podgorski (
2000),
Gupta et al. (
2002),
Kozubowski and Nadarajah (
2008), and
Cordeiro and Lemonte (
2011), to name a few. A comprehensive review of variations of the univariate Laplace distribution is provided in
Kozubowski and Nadarajah (
2010).
2.2. Asymmetric Laplace Distribution
A random variable X is said to have an asymmetric Laplace distribution (ALD) with location parameter
, scale parameter
, and skewness parameter
, if its probability density function (pdf) is given by
where
is the loss function, with
denoting the usual indicator function. The support of the random variable X is the real line and the loss function
assigns weight
p or
to the observations greater or, respectively, less than
and that
. Therefore, the distribution splits along the scale parameter into two parts, one with probability
p to the left, and one with probability
to the right. Note that the ALD is skewed to the left when
, and skewed to the right when
. It should be noted that for
, the ALD reduces to double exponential distribution with its pdf
The expected value,
, and the variance,
, of X are respectively given by
Readers are referred to
Yu and Zhang (
2005) for details.
2.3. Skew Laplace Distribution
A random variable X is said to have the skew-Laplace distribution if its probability density function is
, where
and
are the pdf and cdf of the Laplace distribution and
is the skewness parameter. One can consider the case of
, as the corresponding results for
can be obtained using the fact that
has the pdf given by
. When
, the pdf of skew Laplace distribution is given by
Note that the additional shape parameter
regulates the skewness, allowing for continuous variation from symmetric to non-symmetric. The expected value,
, and the variance,
of X are respectively given by
Readers are referred to
Aryal and Nadarajah (
2005) and references therein for details.
2.4. Kumaraswamy Laplace Distribution
A random variable
X is said to have Kumaraswamy Laplace (Kum-Laplace) distribution if its pdf is given by
, where
and
are the pdf and cdf of Laplace distribution and
and
are two additional shape parameters. The pdf of Kum-Laplace (
) distribution is given by
The Kum-Laplace distribution has a limiting property of
Readers are referred to
Nassar (
2016) and
Aryal and Zhang (
2016) and references therein for details.
2.5. Variance-Gamma Distribution
The Variance-Gamma distribution is a continuous probability distribution that is defined as the normal variance-mean mixture where the mixing density is the gamma distribution. The tails of the distribution decrease more slowly than the normal distribution. It is, therefore, suitable to model phenomena where numerically large values are more probable than is the case for the normal distribution. The pdf of VG distribution is given by
with
c (location),
(spread),
(asymmetry) and
(shape) parameters.
is the modified Bessel function of the third kind of order
. The expected value,
, and the variance,
of a Variance-Gamma distribution are given by
Readers are referred to
Kotz et al. (
2012),
Madan and Seneta (
1990), and
Seneta (
2004) for more details.
3. Data Description and Methodology
Investing in stocks is influenced by various factors, including investor risk profiles, investment duration, size, asset class characteristics, and the economic foundation of the stock markets. However, the primary goal remains consistent: optimizing returns. Achieving optimal returns requires a comprehensive assessment of return behaviors across different asset classes, investment durations, and market types. This study aims to identify the most suitable probability distribution to model returns across various asset classes, durations, and market conditions. The S&P 500 index, consisting of the 500 largest publicly traded US companies, offers immediate diversification across sectors and historically strong long-term returns. It provides high liquidity and serves as a benchmark for portfolio performance, accessible through diverse investment vehicles like mutual funds, ETFs, and index funds (
Cooper and Woglom 2002). Thus, for the illustration purpose, we focused our study on benchmark S&P 500 index and its eleven business sector indices dataset. These eleven sectors, which are considered to be constituent business segments of the S&P 500, are Information Technology, Health Care, Financials, Consumer Discretionary, Communication Services, Industrials, Consumer Staples, Energy, Utilities, Real State, and Materials. Each of these business sectors has their own index. Changes in the price of individual stocks within a sector can influence both the overall performance of that sector index and its market-capitalization-weight within the S&P 500 index, as sector performance directly impacts its representation in the broader index (
Pokharel and Tsokos 2022). To broaden the scope of our empirical study, we also fit the chosen distributions for return datasets from international stock market indices such as IBOVESPA from the emerging market economy and KOSPI from the developed market economy, along with the 20+ Years Treasury Bond ETFs and individual stocks across various time horizons, drawing parallel conclusions.
Inspired by Laplace and its generalized forms, known for capturing the heavy-tailed and asymmetric characteristics of stock index return data, along with robustness to outliers and empirical backing, we explore the Laplace family as a potential alternative distribution for modeling stock index returns. Our goal is to identify the optimal probability distribution within the Laplace family.
Our imperial analysis is based on the raw data obtained from yahoofinance.com for S&P 500 index and its 11 constituent business segments. The weekly closing price of the indices from January 2010 to May 2022 are used to calculate the index return and formally, the stock return is defined as follows.
where
is the weekly return and
and
represent the closing price of a stock at time
t and previous week price, respectively.
In many statistical applications, the interest is centered on estimating the parameters and evaluating the goodness-of-fit of the model to analyze the data on hand. Using the method of maximum likelihood procedure, we estimated the parameters of each distribution. That is, if
are observations on X, then the parameters of each distribution are the values maximizing the likelihood function
or the log likelihood function
where
is a vector of parameters specifying the pdf
of a distribution. We can use the
optim function in R (
R Core Team 2023) software for direct numerical maximization of the log-likelihood function. Throughout this article, we will use the Nelder-Mead optimization method using the
AdequacyModel library of the R-package written by Marinho et al. (
Marinho et al. 2022) to estimate the parameters. Our calculations also makes use of the R packages
ald (for Asymmetric Laplace distribution) by
Galarza and Lachos (
2021) and
VarianceGamma (for Variance-Gamma distribution) by
Scott and Dong (
2023).
The standard errors of the of the estimated parameters were computed by approximating the covariance matrix of the estimated parameters by the inverse of observed information matrix. This means, if
denote the maximum likelihood estimate of
, then the standard errors are computed by approximating the covariance matrix of
by the inverse of observed information matrix, i.e.,
To compare the fit of different distributions, one can consider the goodness-of-fit statistics, namely the Akaike information criterion (AIC), Bayesian information criterion (BIC), Hannan-Quinn information criterion (HQIC), corrected Akaike information criterion (AICc), consistent Akaike information criterion (CAIC) and Kolmogorov–Smirnov (KS) test statistics (D), among others. These statistics are given by
and
respectively, where
p is the number of parameters,
n is the sample size, and the values
’s are the
ordered observations. The smaller these statistics are, the better the fit to the given data.
Once the values of the parameters are estimated, we can calculate the value of the log-likelihood statistic, which can then be used to determine the measures of goodness-of-fit statistic, including the Akaike information criterion (AIC). One can employ the likelihood ratio (LR) test statistic to check the superiority of a distribution over the other competing distributions. For example,
The LR test statistic for testing
versus
is
where
and
are the MLEs under
and
, respectively. The statistic
is asymptotically distributed as
, where
k is the length of the parameter vector of interest. In this particular comparison,
, the Kumaraswamy Laplace distribution has four parameters, and the Laplace distribution has only two parameters. We will also provide the value of the Kolmogorov–Smirnov test statistic and the corresponding
p-value for the test.
4. Data Analysis
The weekly closing price of the indices from eleven different business sectors of S&P 500 and S&P 500 itself from January 2010 to May 2022 are collected from Yahoo Finance. The weekly returns of the indices are calculated using Equation (6). A numerical summary of the returns data for each sector and S&P 500 is provided in
Table 1.
Based on the skewness and kurtosis of the financial data, we can descriptively comment on the shape of the distribution. Negative skewness implies that the tail on the left side of the distribution is longer or fatter than the tail on the right side, whereas positive skewness is when the tail on the right side of the distribution is longer or fatter than the left side. Generally, the data distribution is fairly symmetrical if the skewness is between −0.5 and 0.5. The data are moderately skewed if the skewness is between −1 and −0.5 (negatively skewed) or between 0.5 and 1 (positively skewed). If the skewness is less than −1 (negatively skewed) or greater than 1 (positively skewed), the data are highly skewed. We can see from
Table 1 that the distribution of the return data for all indices is either negatively or highly negatively skewed, resulting in a longer or fatter tail on the left side of the distribution.
Likewise, kurtosis is a statistical measure used to describe the degree to which scores cluster in the tails or the peak of a frequency distribution. High kurtosis in a data set is an indicator that data has heavy tails. A kurtosis measure equal to 3 implies that the distribution is mesokurtic, which is the same as the normal distribution. Negative excess values of kurtosis (<3) indicate that the distribution is flat and has thin tails. Platykurtic distributions have negative kurtosis values. Positive excess values of kurtosis (>3) indicate that the distribution is peaked and possesses thick tails. Leptokurtic distributions have positive kurtosis values. The kurtosis value presented in
Table 1 shows that index returns have leptokurtic distribution with high peaks and thick tails. This observation also supports our conclusion that Gaussian probability distribution is not suitable for modeling financial asset returns.
Further, the Shapiro–Wilk test of normality across all the business sectors of S&P 500 and S&P 500 itself is conducted. In other words, we have performed the following hypothesis:
The corresponding W-statistic and
p-value from the Shapiro–Wilk test of normality are presented in
Table 2. The
p-values are extremely small, indicating that stock/index returns data does not support Gaussian probability distribution.
Once we established the fact that index returns do not follow normality, we evaluated the distributions listed in
Section 2 through a goodness-of-fit test using Kolmogorov–Smirnov test (KS-test). The KS-test is used to identify the goodness-of-fit of the data towards the specified distribution.
Next, we present the findings concerning each of the eleven business sectors within the S&P 500. Specifically, we outline the estimated parameters, likelihood statistics, and the goodness-of-fit metrics for the selected distributions described in
Section 2.
4.1. Communication Service Sector
The Communication Services Sector includes telecommunication service providers, such as Wireless Telecom Networks, Media and Entertainment Companies, older radio and television companies, Newer Interactive Media, and Internet Companies. Examples of large communication services companies include Alphabet (GOOG) and AT&T (T). The Communication Services Sector granted a 4.42% annualized return in the last 10 years and is known as the worst performer sector of S&P 500 over the past 10 years (
Lazy Portfolio 2023).
The estimated parameters and the goodness-of-fit statistics, including the KS-test statistics (D) for the Communication Sector data, are provided in
Table 3. The number in the parenthesis in the KS-test column is the
p-value of the test. The plots comparing all five distributions described in
Section 2 are given in
Figure 1. It is evident that the Kumaraswamy Laplace distribution fits better than any of the other competing distributions for the subject data. Specifically, Kumaraswamy Laplace also outperforms the Variance-Gamma distribution for the subject data.
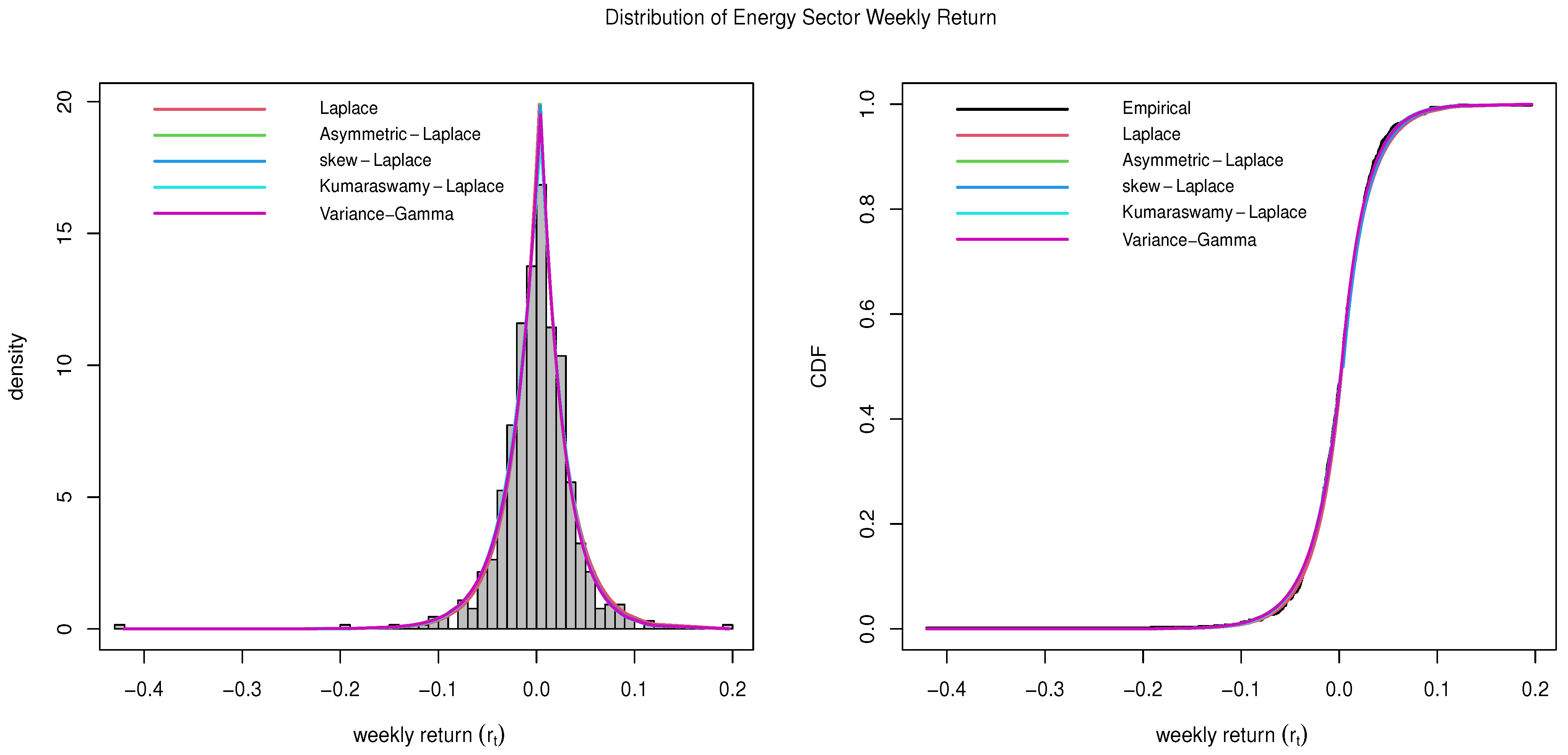
4.2. Energy Sector
The Energy Sector comprises businesses involved in the exploration, production, refining, and sale of energy resources, including oil and natural gas, as well as companies that service these industries. The energy sector includes some of the largest energy companies in the world, such as Exxon Mobil (XOM) and Chevron (CVX). The Energy Sector achieved a 5.95% annualized return in the last 10 years, and it is known as the best performer sector of S&P 500 in the years 2021 and 2022 (
Lazy Portfolio 2023).
The estimated parameters and the goodness-of-fit statistics, including the KS-test statistics (D) for the Energy Sector data, are provided in
Table 4. The number in the parenthesis in the KS-test column is the
p-value of the test. The plots comparing all five distributions described in
Section 2 are given in
Figure 2. It is evident that all five distributions fit well with the subject data. Specifically, Kumaraswamy Laplace also has a slight edge over the Variance-Gamma distribution for the subject data.
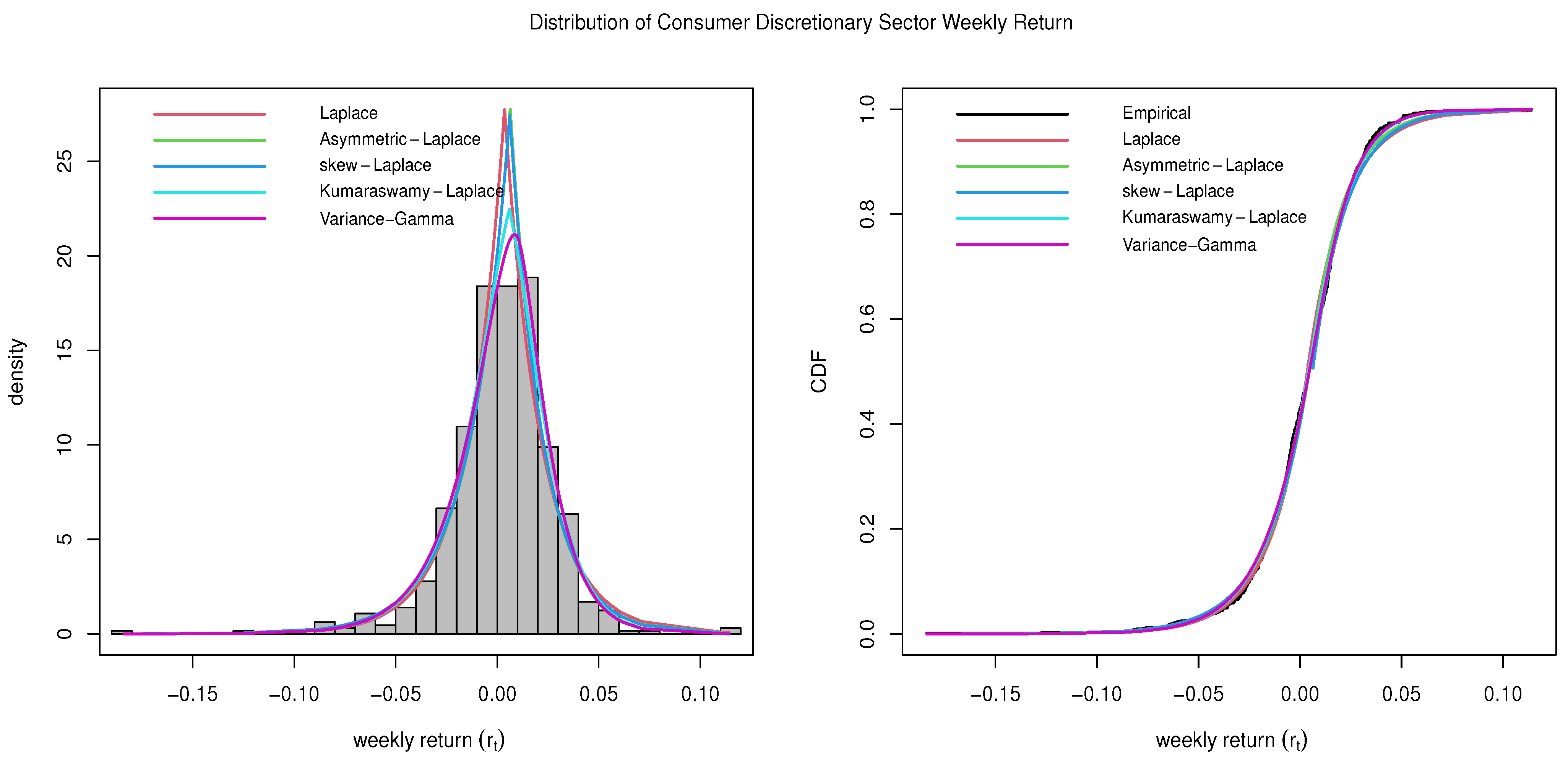
4.3. Consumer Discretionary Sector
The Consumer Discretionary Sector, also known as consumer cyclical, encompasses companies engaged in retail, eCommerce, hotel, luxury goods, leisure, and travel industries. Unlike consumer staples, these goods and services are often considered non-essential or discretionary purchases. Some of the major players within this sector include Amazon (AMZN), Tesla (TSLA), and Home Depot (HD). Over the last decade, the Consumer Discretionary Sector has delivered an impressive annualized return of 11.91% in the last 10 years (
Lazy Portfolio 2023), showcasing its resilience and growth potential in the market. This sector’s performance underscores its importance in reflecting consumer sentiment, economic trends, and evolving consumer preferences. As consumer behavior continues to evolve, driven by technological advancements and changing lifestyles, the Consumer Discretionary Sector remains dynamic and poised for further growth opportunities.
The estimated parameters and the goodness-of-fit statistics, including the KS-test statistics (D) for the Consumer Discretionary Sector data, are provided in
Table 5. The number in the parenthesis in the KS-test column is the
p-value of the test. The plots comparing all five distributions described in
Section 2 are given in
Figure 3.
It can be observed that Variance-Gamma seems to be a slightly better fit than other distributions. However, the Kumaraswamy Laplace distribution also fits equally well.
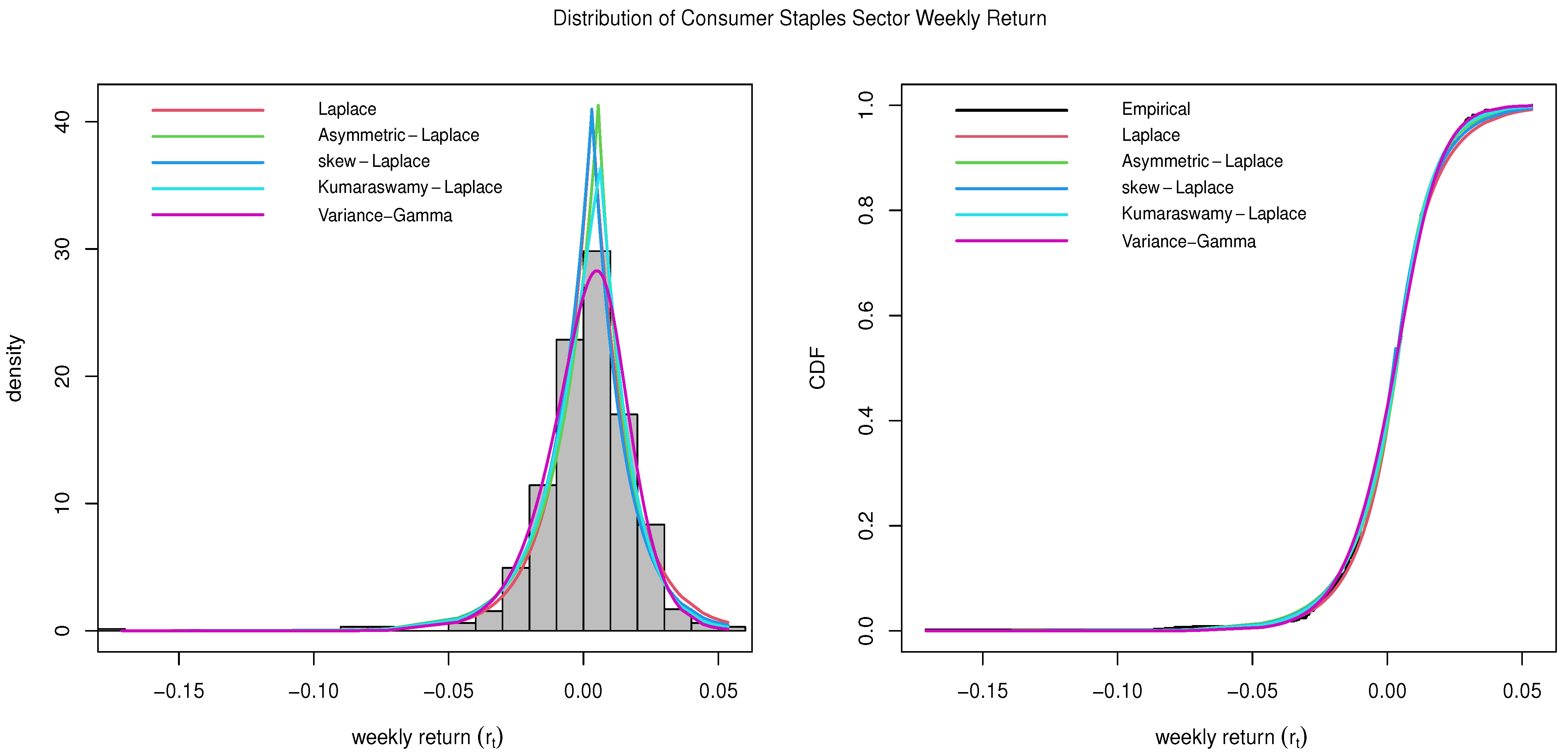
4.4. Consumer Staples Sector
The Consumer Staples Sector includes companies involved in food, beverages, and tobacco, as well as the producers of household goods and personal products. Since these are goods and services that consumers need, regardless of their current financial condition, consumer staples are considered to be a defensive sector (i.e., recession-proof industries). The largest Consumer Staples companies include Walmart (WMT), Procter & Gamble (PG), and The Coca-Cola Company (KO). The Consumer Staples Sector delivered a 10.76% annualized return in the last 10 years (
Lazy Portfolio 2023).
The estimated parameters and the goodness-of-fit statistics, including the KS-test statistics (D) for the Consumer Staples sector data, are provided in
Table 6. The number in the parenthesis in the KS-test column is the
p-value of the test. The plots comparing all five distributions described in
Section 2 are given in
Figure 4. Specifically, Kumaraswamy Laplace also outperforms the Variance-Gamma distribution for the subject data.
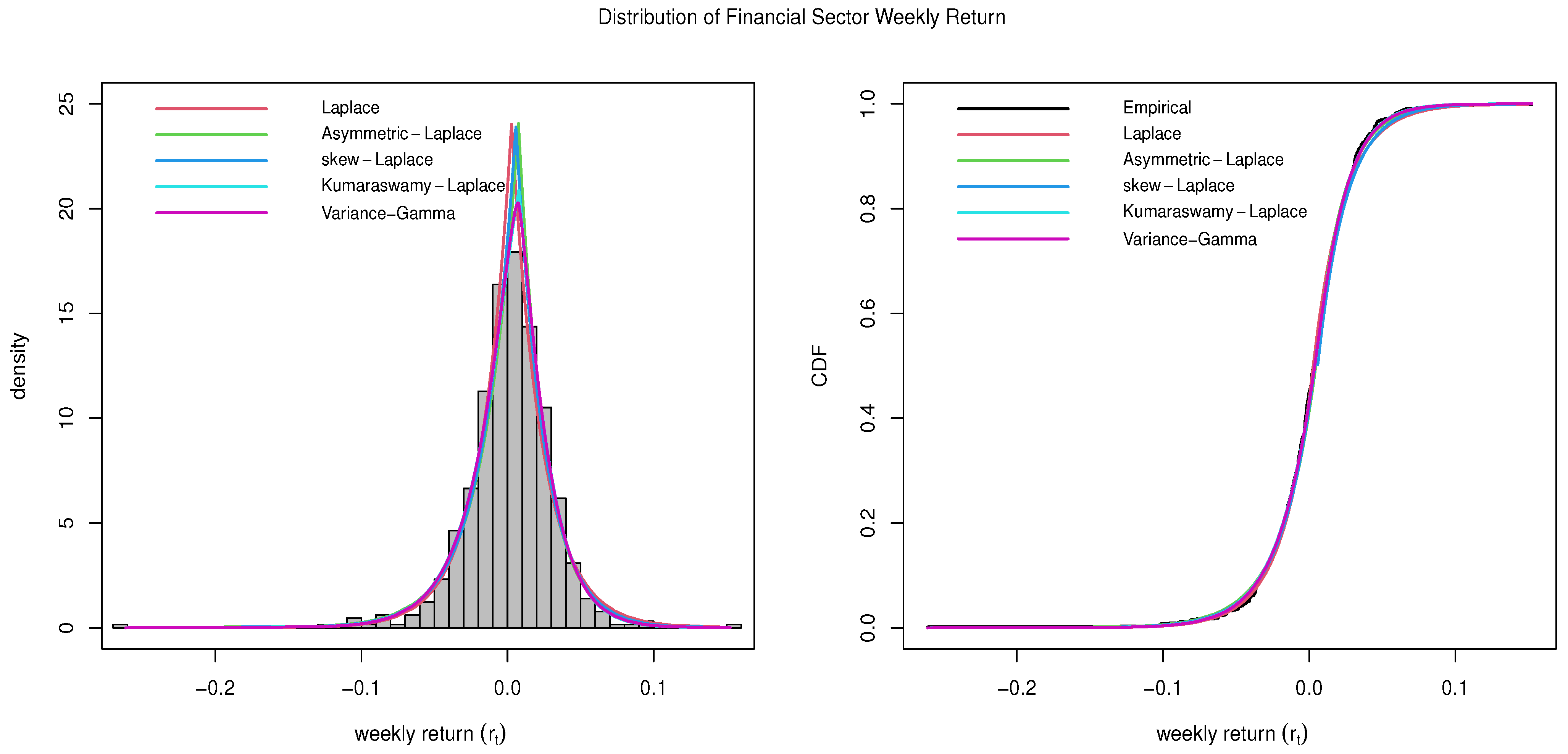
4.5. Financial Sector
The financial sector includes a wide range of financial companies, including investment banks, commercial banks, insurance companies, financial service providers, asset management companies, financial brokers, etc. The financial sector includes some of the largest financial companies in the world like Visa (V), JPMorgan Chase (JPM), and Bank of America (BAC). The Financial Sector delivered a 12.01% annualized return in the last 10 years (
Lazy Portfolio 2023).
The estimated parameters and the goodness-of-fit statistics, including the KS-test statistics (D) for the Financial Sector data, are provided in
Table 7. The number in the parenthesis in the KS-test column is the
p-value of the test. The plots comparing all five distributions described in
Section 2 are given in
Figure 5. The Kumaraswamy Laplace distributions outperform the other generalized Laplace distributions. It also has a slight edge over the Variance-Gamma distribution for the subject data.
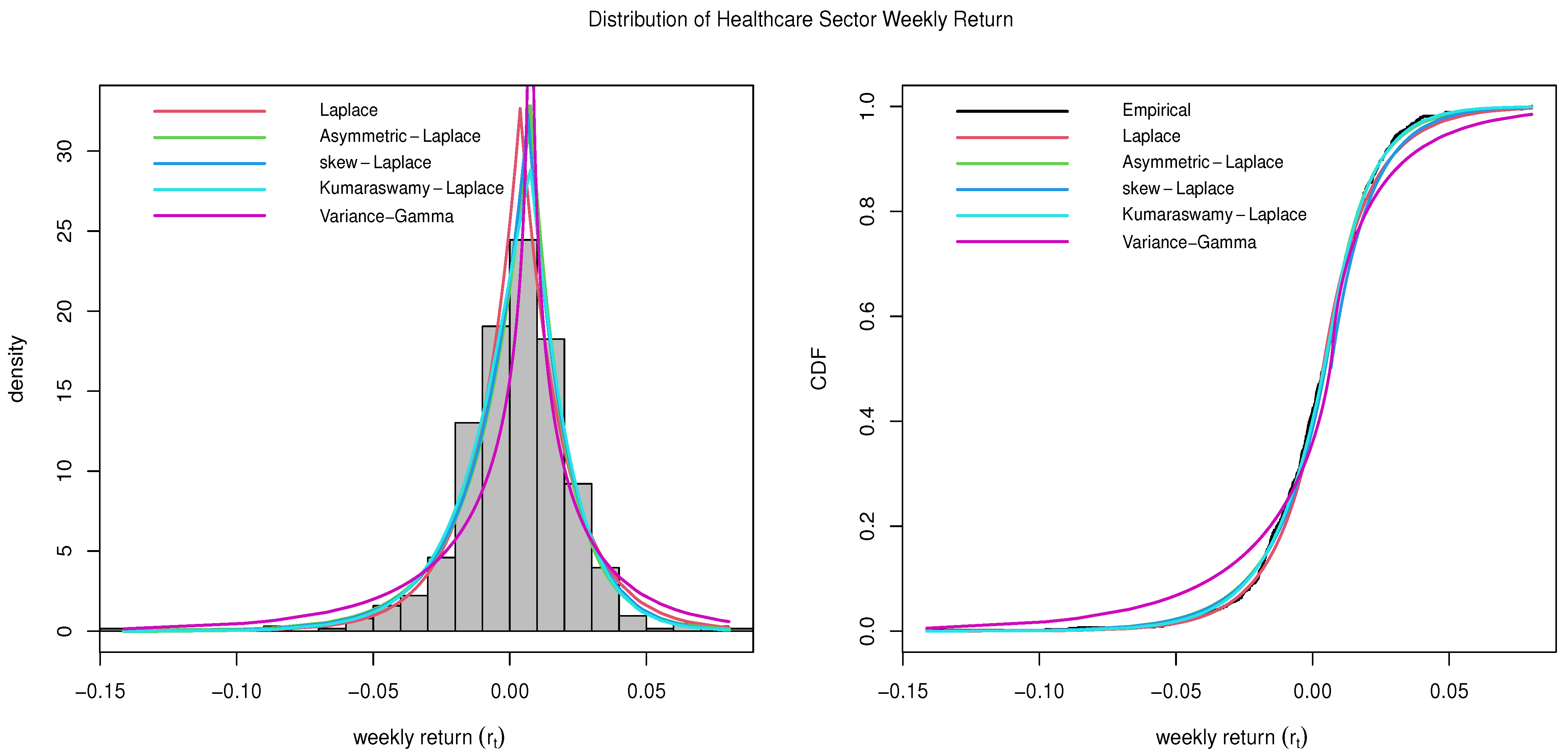
4.6. Healthcare Sector
The Healthcare Sector consists of the stocks of companies involved in a range of health-related industries, including but not limited to pharmaceutical producers, medical devices, healthcare service providers, biotech stocks, insurance companies, etc. Examples of large healthcare companies include UnitedHealth Group (UNH) and Pfizer (PFE). The Healthcare Sector delivered a 14.85% annualized return in the last 10 years, and is known as the second-best performer sector of S&P 500 only after the Information Technology Sector (
Lazy Portfolio 2023).
The estimated parameters and the goodness-of-fit statistics, including the KS-test statistics (D) for the Healthcare Sector data, are provided in
Table 8. The number in the parenthesis in the KS-test column is the
p-value of the test. The plots comparing all five distributions described in
Section 2 are given in
Figure 6. It can be observed that the Kumaraswamy Laplace distribution outperforms all other generalizations of the Laplace family. It also outperforms the Variance-Gamma distribution for the subject data.
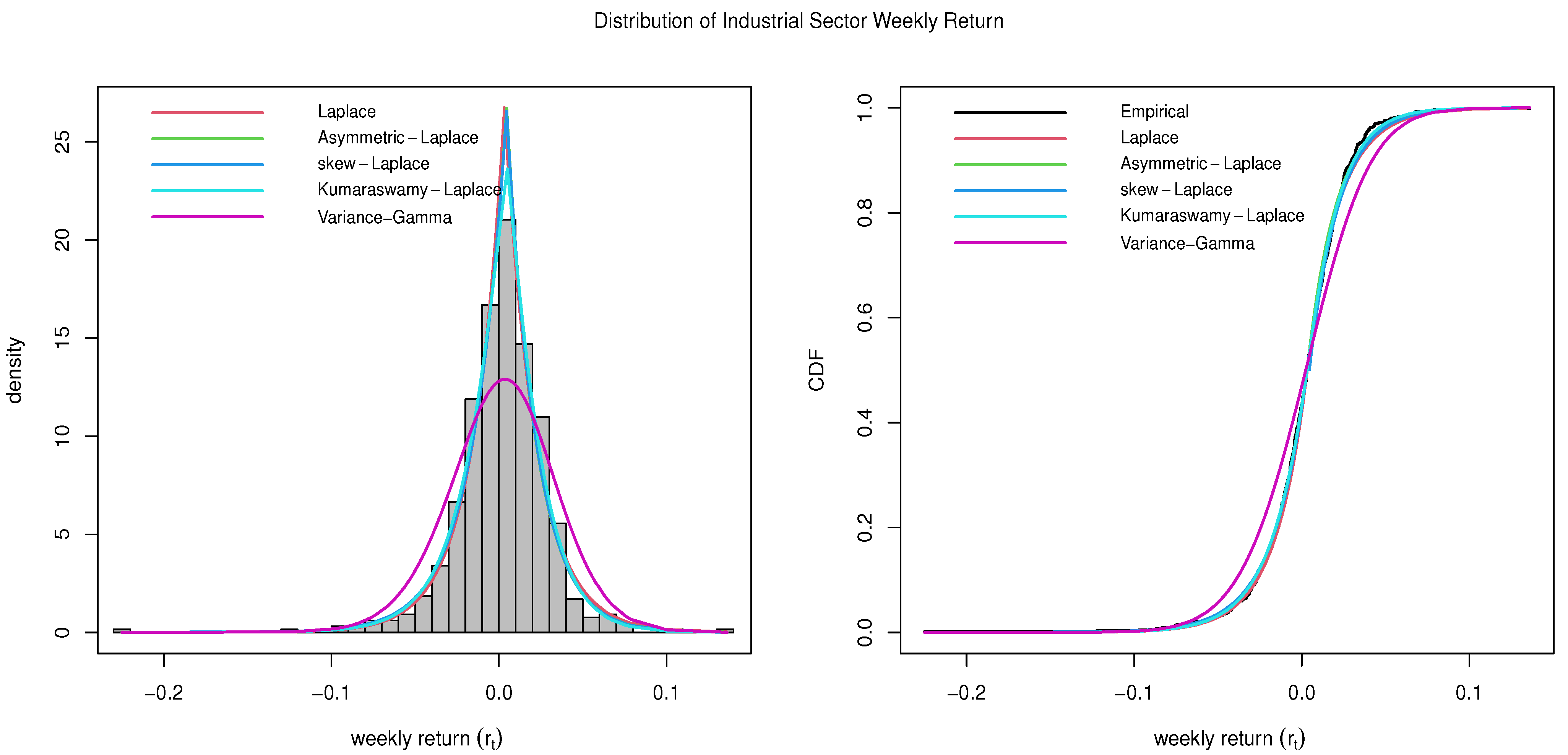
4.7. Industrials Sector
The Industrials Sector may include businesses that are involved in a wide range of industries, including industrial machinery construction and engineering, aerospace and defense, electrical equipment, etc. Some of the largest industrial companies in the world include Boeing (BA), Honeywell (HON), and Union Pacific (UNP). The Industrials Sector delivered a 12.11% annualized return in the last 10 years (
Lazy Portfolio 2023).
The estimated parameters and the goodness-of-fit statistics, including the KS-test statistics (D) for the Industrial Sector data, are provided in
Table 9. The number in the parenthesis in the KS-test column is the
p-value of the test. The plots comparing all five distributions described in
Section 2 are given in
Figure 7. It can be observed that the Kumaraswamy Laplace distribution outperforms all other generalizations of the Laplace distribution. It also outperforms the Variance-Gamma distribution for the subject data.
4.8. Information Technology Sector
The Information Technology (IT) Sector includes multiple sub-sectors and industries, from semiconductor producers to software and hardware providers, as well as internet stocks and cloud computing. The sector includes companies with some of the largest market capitalizations in the world, such as Apple (AAPL), Microsoft (MSFT), Accenture Plc (ACN), Meta Platforms, Inc (META), etc. It had a 17.46% annualized return in the last 10 years, and is known as the best performer sector of S&P 500 over the past 10 years (
Lazy Portfolio 2023).
The estimated parameters and the goodness-of-fit statistics, including the KS-test statistics (D) for the Information Technology Sector data, are provided in
Table 10. The number in the parenthesis in the KS-test column is the
p-value of the test. The plots comparing all five distributions described in
Section 2 are given in
Figure 8. Note that the Kumaraswamy Laplace distribution fits the data better than other generalizations of Laplace distribution. It also outperforms the Variance-Gamma distribution for the subject data.
4.9. Materials Sector
The Materials Sector includes businesses involved in the manufacture of construction materials, chemicals, paper, glass, companies specializing in making paper and forest products metals, and mining companies. Some of the largest materials companies in the world include DuPont (DD) and The Sherwin-Williams Company (SHW). The Materials Sector delivered a 9.78% annualized return in the last 10 years (
Lazy Portfolio 2023).
The estimated parameters and the goodness-of-fit statistics, including the KS-test statistics (D) for the Materials Sector data, are provided in
Table 11. The plots comparing all five distributions described in
Section 2 are given in
Figure 9. Note that Laplace distribution and its generalizations fit better than the Variance-Gamma distribution for the Materials Sector data. The Kumaraswamy Laplace outperforms the rest of the other distributions within the Laplace family.
4.10. Real Estate Sector
The Real Estate Sector includes companies that develop or manage real estate property. This sector also includes real estate investment trusts (REITS), which are companies that purchase multiple income-producing assets, such as office buildings and hotels. Some of the largest real estate companies include American Tower Corp. (AMT) and Simon Property Group (SPG). The Real Estate Sector delivered a 7.42% annualized return in the last 10 years (
Lazy Portfolio 2023).
The estimated parameters and the goodness-of-fit statistics, including the KS-test statistics (D) for the Real Estate Sector data, are provided in
Table 12. The plots comparing all five distributions described in
Section 2 are given in
Figure 10. It can be observed that the Laplace distribution and its generalizations fit better than the Variance-Gamma distribution for the Real Estate Sector data. The Kumaraswamy Laplace outperforms the rest of the other distributions within the Laplace family.
4.11. Utilities Sector
The Utilities Sector includes companies that provide customers with utility services, such as water, electricity, and gas. Since utilities are considered to be essentials for daily living, the utility sector is also generally seen as a defensive sector. Some of the largest utility companies include NextEra Energy (NEE), Duke (DUK), and The Southern Company (SO). The Utility Sector delivered a 10.87% annualized return in the last 10 years (
Lazy Portfolio 2023).
The estimated parameters and the goodness-of-fit statistics, including the KS-test statistics (D) for the Utilities Sector data, are provided in
Table 13. The plots comparing all five distributions described in
Section 2 are given in
Figure 11. It can be observed that the Laplace distribution and its generalizations fit better than the Variance-Gamma distribution for the Utilities Sector data. In particular, the Kumaraswamy Laplace outperforms the other competing distributions.
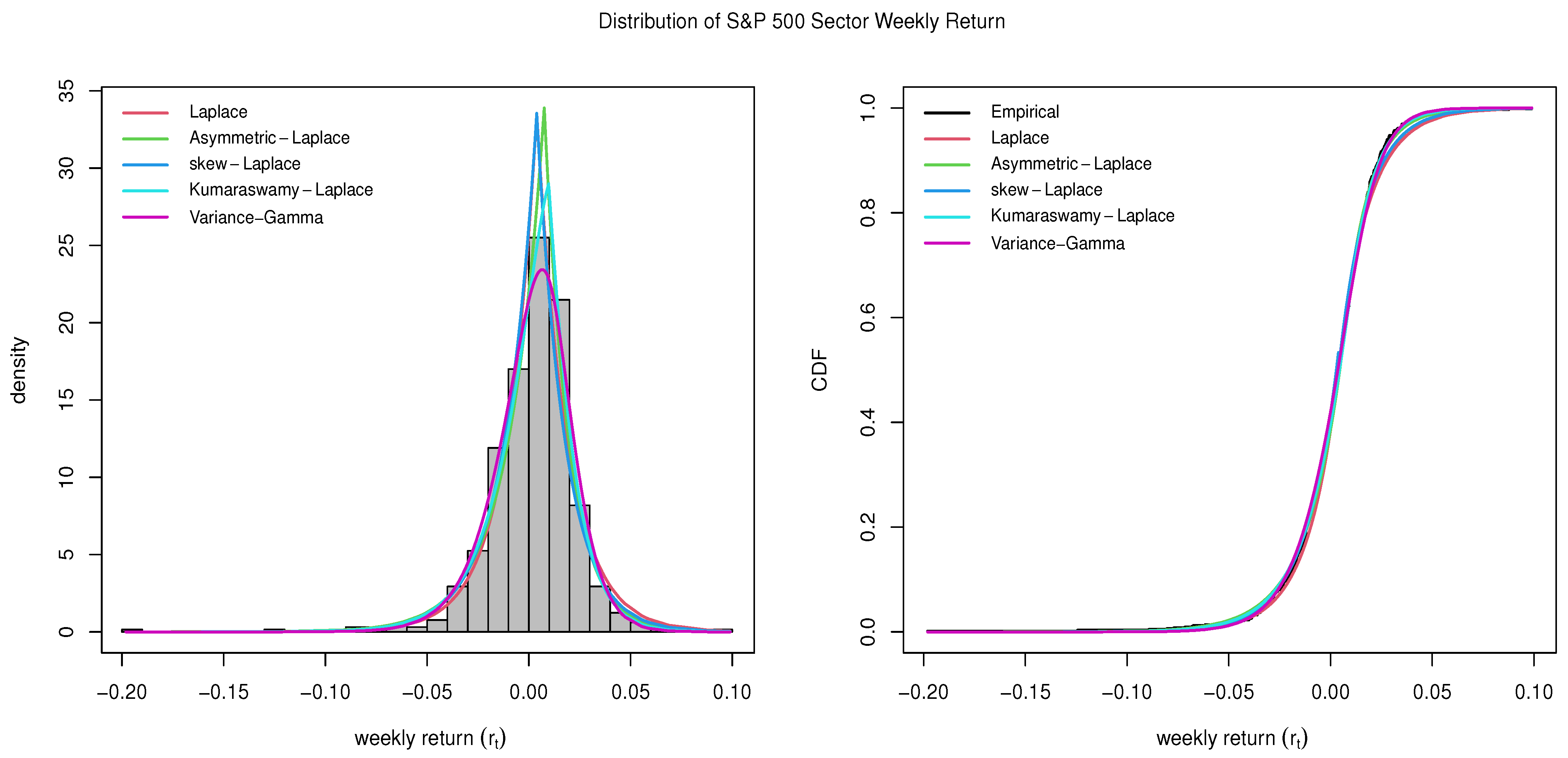
4.12. S&P 500 Index
The first S&P Index was launched in 1923 as a joint project by the Standard Statistical Bureau and Poor’s Publishing. The original index covered 233 companies in 26 different industries. The two companies merged in 1941 to become Standard and Poor’s. The Standard and Poor’s 500, or simply the S&P 500, is a stock market index tracking the stock performance of 500 large companies listed on stock exchanges in the United States. It is one of the most commonly followed equity indices in the world. As of 31 December 2021, more than USD 7.1 trillion was invested in assets tied to the performance of the index. The S&P 500 index delivered a 12.46% annualized return in the last 10 years (
Lazy Portfolio 2023).
The estimated parameters and the goodness-of-fit statistics for the S&P 500 Index data are provided in
Table 14. The plots comparing all five distributions described in
Section 2 are given in
Figure 12. It can be observed that a generalized Laplace distribution fits better than the Variance-Gamma distribution to model the S& P Index data.
5. Ranking Probability Distributions for Modeling Stock Returns
It would be ideal if one could discover the probability distribution that universally fits all types of asset returns. However, practically, it is hard to find such one universal distribution that can explain the probabilistic characteristics of various types of asset returns. In this empirical study, we examined the goodness-of-fit of the five popular Laplace family probability distributions among various stock indices of S&P 500 based on
p-value criteria. We discovered that out of five distributions, only two of them, namely, Laplace (two parameters) and the Kumaraswamy Laplace (four parameters) distributions, fit the returns data from all eleven indices, including the benchmark index S&P 500. Our main objective of this study is to compare the performance of the four-parameter probability distributions: the popular Variance-Gamma with Laplace distribution and its generalizations. It is interesting to note that in eleven out of twelve indices, Kumaraswamy Laplace (Kum-Laplace) outperforms the VG distribution, except for the Consumer Discretionary index.
Table 15 and
Table 16 provide the ranking of the most appropriate distribution to model index returns data based on Kolmogorov–Smirnov (K-S)
p-value criteria. The null hypothesis of the subject of study is that the returns data follows a specified distribution, whereas the alternative hypothesis says otherwise.
The rank of the specified distribution is 1 through 5, where Rank 1 refers to the most appropriate and Rank 5 is the least appropriate distribution for index returns modeling. The distributions without rank are not appropriate for modeling returns datasets from the specified index in a given period. It is found that Kumaraswamy Laplace distribution is the number one probability distribution among the Laplace family of distributions, and the Variance-Gamma distribution fails measurably, especially for Communication Services, Healthcare, Industrial, Information Technology, Materials, Real Estate, and Utilities sectors of S&P 500. The rank of the distributions provides very useful information for financial analysts concerning their application in modeling returns, while the correct choice of the distribution for modeling leads to excellence in prediction.
6. Exceedance Probability Prediction
The exceedance probability is the probability of a random variable exceeding a certain threshold. The complement of exceedance probability is often called the non-exceedance probability. Based on the choice of probability distribution, we may obtain a different exceedance probability. In
Table 17, we present the exceedance probability at different return levels of the S&P data using the distributions discussed in
Section 2.
We can see from
Table 17 that Kumaraswamy Laplace has a low bias as compared to the Variance-Gamma distribution while predicting the exceedance probability of different return levels of S&P 500. These findings also attest that Kum-Laplace outperforms VG distribution while fitting returns data. One can compute the exceedance probability of all eleven business segments.
7. Parallel Inferences and Discussions
We expanded our empirical investigations to assess the goodness-of-fit of all five chosen probability distributions on returns from stock indices across both emerging and developed markets. Our analysis focused on the IBOVESPA from Brazil and the KOSPI from Korea, spanning from January 2010 to May 2022 and encompassing daily, weekly, and monthly stock returns data. Consistently, our findings underscore the superior fit of the Kumaraswamy Laplace distribution compared to the other distributions examined. This trend persisted when the distribution was applied to various assets, such as the 20+ Year Treasury Bond ETF (TLT), as well as prominent individual stocks like Amazon and Apple. Specifically, when examining the KOSPI index on a daily, weekly, and monthly basis, we found KS statistics p-values of 0.6130, 0.8885, and 0.9687, respectively. Likewise, for the IBOVESPA index, the p-values for KS statistics were 0.6308, 0.5577, and 0.9448, corresponding to the daily, weekly, and monthly stock index returns dataset, respectively. Similarly, for individual stocks Amazon and Apple, the p-values over daily, weekly, and monthly were (0.5327 and 0.1848), (0.8096 and 0.7015), and (0.8084 and 0.2919), respectively. For the 20+ Year Treasury Bond ETF (TLT), based on available weekly and monthly data, KS statistics p-values were 0.2965 and 0.3228. Additionally, our study involved calculating log-likelihood functions and goodness-of-fit statistics, consistently favoring the Kumaraswamy Laplace distribution over other competitive distributions considered.
The empirical evidence across diverse markets, asset classes, and timeframes reaffirms the superiority of the Kumaraswamy Laplace distribution in modeling stock returns data. Consequently, it emerges as a robust alternative to other Laplace family distributions, including the Variance-Gamma distribution.
Probability distributions play a pivotal role in modeling potential returns within asset portfolios. The Kumaraswamy Laplace distribution (Kum-Laplace) offers a powerful tool for enhancing portfolio construction and risk analysis. By employing this distribution, investors can effectively model the distribution of portfolio returns, amalgamating individual asset return distributions for comprehensive evaluations of expected returns and inherent variability (risk). Furthermore, the Kum-Laplace distribution facilitates the computation of various risk metrics, including standard deviation, value-at-risk (VaR), and conditional value-at-risk (CVaR), thereby providing valuable insights into portfolio downside risk exposure across a spectrum of probability scenarios.
Furthermore, probability distributions seamlessly integrate into portfolio optimization models, allowing for the creation of portfolios that maximize returns while maintaining predetermined risk levels or minimize risk while targeting specific return levels. Modern portfolio theory serves as a prime example, leveraging probability distributions to identify optimal asset allocations within portfolios. Consequently, the Kum-Laplace probability distribution offers a robust framework for understanding uncertainty in financial markets, empowering investors to make informed decisions regarding portfolio construction and risk management.
8. Concluding Remarks
Modeling and predicting stock returns are pivotal tasks in the financial market, offering investors valuable guidance to mitigate risks in their portfolio management. The Laplace distribution has emerged as a favored alternative to the normal variance model, owing to its adept fit with financial data and its effective portrayal of underlying behaviors. However, the quest for a universal distribution capable of fitting all forms of financial data proves virtually unattainable, particularly when dealing with complex natural phenomena like stock returns. In this context, both Laplace and generalized Laplace probability distributions play crucial roles in modeling asset returns. The four-parameter Variance-Gamma distribution stands out as the preferred choice for modeling stock returns, extensively examined in finance and economics literature.
In this article, we conducted an empirical investigation using real market data from the S&P 500 index and its eleven business sector indices, employing Laplace distributions and their generalized forms, which encompass both the four-parameter Variance Gamma and the Kumaraswamy Laplace distribution. Additionally, we evaluated the goodness-of-fit of these distributions on returns across various assets class, investment durations, and market types, including 20+ Years Treasury Bond ETFs, individual stocks, and international stock indices such as IBOVESPA and KOSPI.
Our analysis indicates that the Kumaraswamy Laplace distribution is the only distribution consistently fitting stock/index returns data across diverse assets class, investment durations, and market types. Given the compelling evidence presented, the superior performance of the Kumaraswamy Laplace distribution over other choices establishes, it as a robust alternative for practitioners aiming for precise return predictions and efficient risk mitigation in their investments.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}