Abstract
The landscape of financial credit risk models is changing rapidly. This study takes a brief look into the future of predictive modelling by considering some factors that influence financial credit risk modelling. The first factor is machine learning. As machine learning expands, it becomes necessary to understand how these techniques work and how they can be applied. The second factor is financial crises. Where predictive models view the future as a reflection of the past, financial crises can violate this assumption. This creates a new field of research on how to adjust predictive models to incorporate forward-looking conditions, which include future expected financial crises. The third factor considers the impact of financial technology (Fintech) on the future of predictive modelling. Fintech creates new applications for predictive modelling and therefore broadens the possibilities in the financial predictive modelling field. This changing landscape causes some challenges but also creates a wealth of opportunities. One way of exploiting these opportunities and managing the associated risks is via industry collaboration. Academics should join hands with industry to create industry-focused training and industry-focused research. In summary, this study made three novel contributions to the field of financial credit risk models. Firstly, it conducts an investigation and provides a comprehensive discussion on three factors that contribute to rapid changes in the credit risk predictive models’ landscape. Secondly, it presents a unique discussion of the challenges and opportunities arising from these factors. Lastly, it proposes an innovative solution, specifically collaboration between academic and industry partners, to effectively manage the challenges and take advantage of the opportunities for mutual benefits.
1. Introduction and Motivation
Predictive modelling is a mathematical process used to predict future events or outcomes by analysing patterns in each set of input data (Lawton et al. 2022). As shown in Figure 1, many predictive models are used in the financial industry, ranging from regulatory models (Basel and IFRS 9) for credit risk, fraud detection models, customer retention models, collection strategies models, and market risk models. Yet these predictive models are not only restricted to the financial industry—the ability to predict the future is a goal for all organisations (De Jongh et al. 2017). The focus of this article is on traditional credit risk prediction modelling, which has seen a lot of change in recent years. These changes result in many opportunities to enrich predictive models within the financial credit field, but at the same time, they can also create some challenges.
Figure 1.
Examples of predictive models in the financial industry.
This gives rise to the research objectives of this study. Firstly, to investigate and discuss the factors causing rapid changes in the landscape of credit risk predictive models by specifically focusing on three pertinent factors, namely: machine learning, financial crises, and Fintech. Secondly, to explore and discuss the challenges and opportunities that are caused by the changes brought forward by the above. Lastly, to propose a possible innovative solution for utilising these challenges and opportunities in such a manner that both academic and industry partners will benefit from them.
In this study, we discuss machine learning, financial crises, and Fintech as factors that are changing the predictive modelling landscape. The discussion will point out the changes brought forward by these factors as well as make academics and their industry partners aware that they might have to make some adjustments to adapt to these changes going forward. We will show that these factors create a wealth of opportunities along with the additional challenges that arise. These opportunities and challenges drive this study not only to stimulate people’s interest in the changing landscape of predictive models but also to warn them about the related risks. We also exploit the rising opportunities and simultaneously address these challenges. In summary, this study investigates the changing landscape of predictive modelling by considering three factors that influence financial credit risk predictive modelling (see Figure 2): machine learning (Section 2), financial crises (Section 3), and Fintech (Section 4), followed by providing a unique discussion of the resulting challenges and opportunities (Section 5) and it suggests one possible original solution to make use of these opportunities and challenges in such a way that will benefit academic and industry partners alike namely industry collaboration (Section 6). In Section 7, a discussion in the form of a conclusion is provided. Note that many of the opportunities and challenges that arise are also applicable to other risk areas, e.g., market risk.

Figure 2.
Three factors influencing financial credit risk predictive modelling.
2. Machine Learning
2.1. Role and Impact
Machine learning is influencing and will continue to influence predictive modelling. Machine learning is the science of using computers to learn and act similarly to humans (Fagella 2020). Many machine-learning techniques are successfully applied within the predictive modelling field of finance. In some cases, it even achieves better results than traditional models (Shi et al. 2022). Lessmann et al. (2015) compared 41 machine-learning techniques on eight retail credit scoring datasets. The results showed that several of the machine-learning techniques predicted credit risk significantly more accurately than the industry standard of logistic regression. One specific example is a publication by Verster et al. (2021) which showed that bagging and boosting techniques outperformed logistic regression when predicting take-up rates of home loans in cases where banks offered different interest rates. Meaning in the future, more machine learning techniques will be used in financial credit risk predictive modelling.
2.2. Challenges and Opportunities
Many challenges and opportunities will arise within the world of machine learning should these techniques be applied in the context of internal ratings-based (IRB) models to calculate regulatory capital for credit risk (EBA 2021). Although machine-learning models can outperform more traditional techniques such as regression analysis or simple decision trees, they are often more complex and less ‘transparent.’ In addition, machine-learning models need to comply with the standard industry practice of transparency and interpretability (Yurcan 2022). One of the most significant challenges is to explain why a model produces given outcomes. Several techniques have been developed to address this challenge. Some of the more widely used techniques include graphical tools, Shapley values, and local explanations (EBA 2021).
According to SAS Institute Inc. (2015), many people think machine learning means magically finding hidden nuggets of information without having to formulate the problem and with no regard for the structure or content of data. This is an unfortunate misconception. The rapid expansion in the technological development of fast computers and software that can perform machine-learning techniques within seconds creates an opportunity to build machine-learning models quickly and easily. However, the related risk is the possibility of obtaining nonsensical results when models are built by non-experts. The analyst still needs to understand the underlying data, the business problem, and the underlying statistical foundation (Efron and Hastie 2016). In our opinion, the future of success in predictive modelling lies in where statistics and machine learning come together.
2.3. Overlap
When considering the impact that machine learning has on predictive models, it is important to discuss the overlap between machine learning and statistics. Visually this overlap is presented in Figure 3, and this overlap could be seen as “predictive modelling.” Predictive modelling can be viewed as a synonym for machine learning but only when referring to machine-learning techniques used for future prediction. Hastie et al. (2009) purposefully rebranded the intersection between machine learning using classical statistical modelling called “statistical learning.” Most machine-learning techniques used in the predictive modelling context relate directly to statistics.
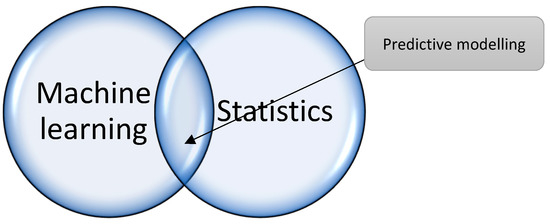
Figure 3.
Overlap between machine learning and statistics.
One example is ensemble-based models, such as bagging (Maldonado et al. 2014), random forests (Yiu 2019), and boosting (Verster et al. 2021). For all three of these ensemble machine-learning techniques (random forest, bagging, and boosting), the underlying technique is a statistical technique called CART (classification and regression tree) developed by Breiman et al. (1984).
Another popular machine-learning technique used in the predictive modelling context is neural networks (IBM Cloud Education 2020). A neural network can be thought of as a regression model on a set of derived inputs called hidden units. In turn, these hidden units can be thought of as regressions on the original inputs (SAS Institute Inc. 2015). Therefore, the core statistical underlying technique of a neural network is linear regression.
These are just two examples of machine-learning techniques used in predictive models that are based on statistics. In fact, hardly any difference is observed where statistics are used to build predictive models and where machine learning is used for building predictive models. However, terminology differs, e.g., “weights” will be used in machine learning and “estimates” in statistics. In another example, the process of obtaining values for these estimates/weights in machine learning is called “training a model,” whereas, in statistics, this is known as “fitting a model.” Machine learning will typically refer to a “supervised application,” whereas statisticians will refer to a “predictive model” or a “classification technique.”
The main difference between statistics and machine learning is the aim of the analysis. Statisticians are interested in the values and significance of the estimates. In machine-learning applications, however, the actual values of the estimates are less important than the success of the model in predicting new cases (ActEd 2020). The pertinent question here is: which are the most important? Efron and Hastie (2016) state that a hopeful scenario for the future is one of an increasing overlap that puts data science—which includes machine learning (2U Inc. 2020)—on a solid footing while leading to a broader general formulation of statistical inference.
3. Financial Crises
3.1. Role and Impact
The second factor influencing predictive modelling is financial crises; some examples are listed in Figure 4. Where predictive models view the future as a reflection of the past, financial crises can violate this assumption. This creates a new research field on how to adjust predictive models to incorporate extreme forward-looking conditions, which include future expected financial crises. The credit crisis of 2007/2008 provoked concerns about the use of models in finance (De Jongh et al. 2017). Many examples can be found in the literature on the effect that this credit crisis had on financial credit risk predictive models (Breed et al. 2019), (Dendramis et al. 2018), and (Skoglund 2014). Generally, financial credit risk predictive models break down in a financial crisis (Saliba et al. 2023).

Figure 4.
Examples of financial crises.
3.2. Challenges and Opportunities
Historical financial crises created a new research field in predictive modelling: investigating how to adjust predictive models to incorporate forward-looking macroeconomic conditions (e.g., financial crises) as specified by IFRS 9 (Bellini 2019). IFRS 9 requires models to accommodate the influence of the current and forecasted macroeconomic conditions on default rates (IFRS 2014, 2020). Typically, macroeconomic variables might pick up a more long-term crisis ahead of time, such as the 2007/2008 financial crisis, and could be used to predict similar future crises. However, macroeconomic variables will lag when a more abrupt type of crisis arises (e.g., COVID-19) and will be less useful in predicting abrupt financial crises; thus, the inclusion of these variables in credit risk models needs to be an ongoing focus of researchers.
One example of a relatively new financial crisis is climate change, another long-term crisis that manifests gradually over time. Climate change is one of the greatest challenges facing humankind this century (Alogoskoufis et al. 2021). Climate risk is generally broken down into transition risk and physical risk. Transition risk refers to the negative impact that the introduction of climate policies to reduce CO2 emissions could have on certain high-emission industries (Bell and van Vuuren 2022). These affected industries could face a sharp fall in profits and higher production costs. The physical risk refers to the economic impact stemming from the expected increase in the frequency and magnitude of natural disasters. The damage caused by these disasters could interrupt the production process in the short term and lead to business failure in the long term. To quantify the impact of both these risks on banks’ credit risk, the changes in the PD (probability of default) and LGD (loss given default) of banks’ loan books are derived under different climate scenarios (Bell and van Vuuren 2022).
The exact way in which these predictive models in the financial industry need to be adjusted to mitigate the impact of climate risk is still unclear and will be a future influence that impacts financial credit risk predictive models, which creates both challenges and opportunities within financial predictive models.
4. Financial Technology
4.1. Role and Impact
The third factor is the impact of Fintech on the future of predictive modelling. Fintech describes any new technology that seeks to improve and automate the delivery and use of financial services. Examples (Howat 2020) include crowdfunding platforms (e.g., GoFundMe or Kickstarter), blockchain, cryptocurrency (e.g., Bitcoin), mobile payments, Fintech lending, robo-advising, and stock-trading apps (e.g., Acron) as depicted in Figure 5. These innovations in Fintech have had a huge impact on traditional bank lending, thereby causing competition. Fintech lending also increases financial inclusion (Bazarbash 2019), especially in low-income and emerging countries which were not included in traditional credit risk models and thus violate the assumption that the future will be similar to the past.
Figure 5.
Examples of Fintech.
4.2. Challenges and Opportunities
The first cryptocurrency, Bitcoin, came into existence in 2009, and in the years that followed, other cryptocurrencies were introduced as well. Many predictive models were developed and will continue to be developed in the context of cryptocurrencies (Gandal and Halaburda 2016). Some of the challenges associated with cryptocurrencies are their unregulated nature and extreme volatility. These need to be taken into account when developing credit risk models seeing that they can increase counterparty credit risk.
As mentioned previously, the ability to predict the future is a goal for any organisation, from financial management to marketing and even oncology. Everyone would like to have a glimpse into the future to be better prepared and to seize upcoming opportunities. According to Brooke (2018), blockchain can offer solutions to make predictive models more accessible, whereas blockchain can offer viable solutions to the typical challenges of predictive models. Blockchain is most commonly defined as a “distributed ledger of transactions” (Halaburda 2017). The technology of blockchain can be used to predict price movements for cryptocurrencies and other financial markets. If predictive models are built using the decentralised approach offered by blockchain, more organisations can jump on the bandwagon and take advantage (Brooke 2018) of using predictive models. Blockchain technologies will have a big impact on many industries, which are not limited to only finance (Halaburda 2017).
Another example of Fintech credit is crowdfunding. Crowdfunding is the use of small amounts of capital from many individuals to finance a new business venture (Smith 2022). Predictive models can be built to forecast the success of crowdfunding. For example, Kao (2021) employed machine-learning techniques to develop a model that successfully predicted the crowdfunding outcome from a dataset containing more than 25,000 crowdfunding projects on Kickstarter. App-based avatars (another example of Fintech) are listed, amongst others (De Almeida Filho et al. 2010), as a future suggestion of an innovative way to enhance collection strategies (Blaschczok et al. 2018).
Fintech credit is growing rapidly, and potential benefits include access to alternative funding for previously excluded customers. Some challenges might include a possible lower lending standard, and Fintech credit poses challenges to the regulatory monitoring of credit activity (CGFS 2017). While Fintech credit has the potential to enhance financial inclusion and outperform traditional credit scoring, some caution should be given to ensure data relevance, especially in situations when a deep structural change occurs or where information asymmetry exists (Bazarbash 2019).
The interest and investment in Fintech grew significantly in many regions around the world, and its scope broadened well beyond its early definition (Ruddenklau 2022). This expanding landscape is expected to maintain growth and create more opportunities in which to apply predictive models within Fintech.
5. Summary of Challenges and Opportunities
This changing landscape (machine learning, financial crises, and Fintech) presents many opportunities, but new threats are also emerging. Table 1, Table 2 and Table 3 provide novel summaries of the challenges and opportunities associated with each of these three factors. It is interesting to note that most of these are both a challenge as well as an opportunity and apply to both practitioners as well as for academics. One possible way of taking advantage of these opportunities and managing the associated risks is to provide young graduates with relevant industry-focused training and to ensure that universities apply industry-focused research.

Table 1.
Challenges and opportunities of machine learning.
Table 2.
Challenges and opportunities of financial crises.
Table 3.
Challenges and opportunities of Fintech.
Table 1 presents condensed overviews of the challenges and opportunities linked to machine learning.
6. Industry Collaboration
Yurcan (2022) suggests that financial institutions should consider partnerships with think tanks, universities, and research institutions to bring together credit providers from around the world.
Many predictive models are built within the financial industry, and simultaneously many universities conduct research within the field of predictive modelling. Academics have several obligations, such as training students and contributing to current research within their field of knowledge. Therefore, the challenge is to maintain a balance. Industry, however, does not always have the time and specialised knowledge to find the best solution to a specific problem. The solution to both these challenges is industry collaboration.
Synergy exists where academics join hands with industry to solve these real-world problems. This can be seen in many successful industry collaborations in the past. The Centre for Business Mathematics and Informatics (BMI) at North-West University in South Africa (Centre for BMI 2022), the Master’s in Business Analytics at Vrije Universiteit in Amsterdam (VU 2022), the Master of Science in Analytics at North Carolina State University (NCSU 2022), as well as the New York University Stern Business School (NYU Stern 2022) are four examples of successful collaborations. In this study, we discuss two types of industry collaboration: industry-focused training and industry-focused research.
6.1. Industry-Focused Training
De Jongh and Erasmus (2014) instituted a framework for designing and implementing career-orientated training programmes and industry-directed research programmes with a statistical science core. To illustrate their design concept, they used a Venn diagram consisting of three overlapping circles depicting a set of training, research, and industry activities. The heart of the programme is considered to be the set of activities labelled Industry-focused training, where all three circles overlap, as shown in Figure 6.
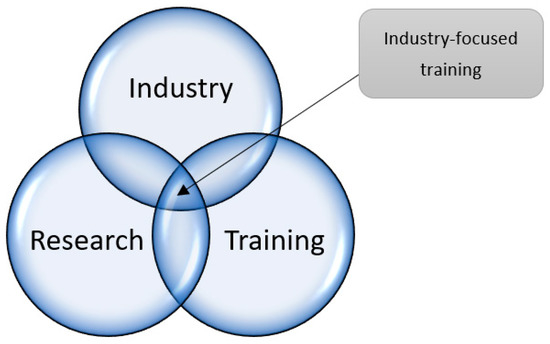
Figure 6.
The design concept for industry-focused training (Adapted from (De Jongh and Erasmus 2014)).
The basic idea is that all MSc students in the programme are required to complete an individual, six-month industry-directed research project under the guidance of an industry mentor (responsible for the business success of the project) and an academic supervisor (responsible for the academic/technical quality of the project). The project should be carefully chosen via role-player collaboration to ensure that the student solves a specific real-world problem while simultaneously encompassing the requisite academic content. Slightly different applications of this model can be found at other academic institutions. The NYU Stern Master of Science in Business Analytics (MSBA) is based on a blended learning approach combining in-person classroom time and independent study (NYU Stern 2022). The MSBA Capstone is an integrative year-long team project that allows students to demonstrate an understanding of the core competencies taught throughout the programme and apply them to real business concerns. The Master of Science in Analytics at North Carolina State University has at its core the Practicum: a team-based learning experience that allows students to conduct real-world analytics projects using data from sponsoring organisations. The Practicum spans eight months and culminates with an executive-level report and presentation to the sponsor (NCSU 2022). Students work in teams of five to understand the business problem and then clean and analyse data. Each stage of the project is managed by the Institute. The Master’s in Business Analytics at the Vrije Universiteit Amsterdam is a two-year programme divided into four semesters (VU 2022). In the fourth semester, students spend six months doing an internship at a business or research institute, gaining first-hand experience in the world of work.
This type of industry collaboration (industry-focused training) benefits both the academic partner and the industry partner. For the industry partner, a real-world problem is solved, and for the academic partner, an MSc student is produced. Often, the research conducted in these kinds of projects feeds back into the content of postgraduate modules, and newfound industry knowledge enhances the teaching of other modules, resulting in better-equipped new young professionals.
6.2. Example of Such an Industry-Focused Training
For example, one such industry project resulted in a peer-reviewed article on a fraud scorecard that was developed for telecommunications (Human et al. 2021). In this instance, a South African telecommunication operator developed two internal fraud scorecards to mitigate future risks of fraud events. The scorecards aim to predict the likelihood of an application being fraudulent by identifying fraud at the time of application, thereby surprising fraudsters before they have a chance to initiate a scam. Figure 7a graphically illustrates how the three main components of the predictive model (Rajalingham 2005) were applied.
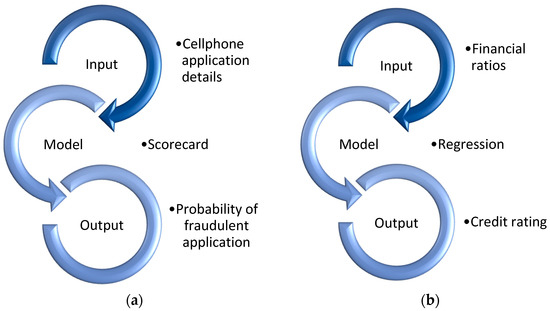
Figure 7.
Example of industry-focused training (a) and industry-focused research (b).
6.3. Opportunities and Possible Future Impact of Industry-Focused Training
This collaboration between the industry and the university led to a model that, in the future, would save the telecommunication operator money and also lead to research outputs for the university. Many examples of such industry-focused training are found in the machine-learning context, but some have not yet been published.
6.4. Industry-Focused Research
Industry-focused research is another form of industry collaboration (De Jongh and Erasmus 2014). With this type of industry collaboration, staff at a university tackle a specific problem posed by industry to generate income for the university. The benefit to industry is that a real-world problem is solved; the benefit to academia is fund generation as well as the opportunity for academic staff to perform focused research on industry-relevant topics.
6.5. Example of Industry-Focused Research
For example, university staff completed an applied research project where research was conducted on the risk grading of provincial governments, which eventually became a springboard for a Ph.D. topic. One of the four research studies published from this, Fourie et al. (2016) developed a generic, quantitative credit rating methodology for rating the Department of Health and the Department of Education of South Africa. To summarise how these three main components of predictive modelling were used in this project, we visually illustrate these three components in Figure 7b.
6.6. Opportunities and Possible Future Impact of Industry-Focused Research
Industry collaboration has been a success factor in many universities, and our opinion is that industry collaboration is the future route to success. The applications of predictive modelling are only limited by the user’s imagination, and an industry partnership can provide many more areas of application for research and collaboration. There already are many more examples of industry-focused research within the context of machine learning, Fintech, and financial crises, and even more, will arise in the future. Thus, proving that by joining hands, industry and academics can tackle the challenges and utilise the opportunities that are caused by the changing landscape of financial credit risk models in such a manner that benefits both.
7. Conclusions and Future Recommendations
This study took a brief look into the future of predictive modelling by considering three factors that will enrich and influence the landscape of financial credit risk predictive modelling, as well as suggest one possible solution to exploit the challenges and opportunities associated with the changing landscape.
The first factor discussed was machine learning. Many machine-learning techniques are used for predictive modelling, and this trend will continue in the future. There is a need for guidelines to use machine-learning techniques in regulatory models, as well as a need for techniques that explain and interpret machine-learning models. Statistical inference and a statistical foundation for machine-learning techniques need to be researched. Machine learning can be equated to a gun: in the wrong hands, it is terrifying, but in the right hands, it is a powerful tool. When machine learning is used in predictive modelling, it should be combined with a statistical basis and business knowledge. This will ensure that machine learning becomes a powerful tool.
The second factor that was discussed was financial crises. Any financial crisis results in the need to adjust predictive models, which creates many areas of enrichment in the financial predictive modelling field.
The third factor considered was the impact of Fintech on the future of predictive modelling. Fintech creates new applications for predictive modelling, again creating an enriched environment for financial credit risk predictive models.
Finally, industry collaboration was proposed as we looked at how the synergy of industry collaboration could enrich and benefit both the industry and the academic institution. We outlined how industry-focused training and industry-focused research could take advantage of any opportunities and address the challenges that arise in this changing landscape.
One aspect that remains untouched until now is the policy implications of this study which is similar to other studies (e.g., Athari et al. 2021). First, looking at machine learning and how it affects financial credit risk models holds crucial policy implications for policymakers and regulators striving to safeguard consumers of machine learning models (EBA 2021). While machine learning algorithms enhance the convenience and accessibility of financial services, they also introduce new risks. However, the emphasis on the explainability of machine learning models can effectively enhance the comprehension of factors influencing financial risks (Yurcan 2022), which in turn may have an influence on policymaking. Second, moving on to financial crises. IFRS (2020) states that although financial crises present numerous challenges and opportunities to shape policies, there are still unexplored areas where further policy research would be beneficial. These areas encompass competition policy for a stable financial system, approaches to consumer protection in financial services, and the political economy of financial regulation, financial openness, and financial crises (Claessens et al. 2010). Third, the current study holds important implications for policymakers to reinforce credit risk assessment and foster financial inclusion in the context of Fintech. Howat (2020) also commented on this. The regulatory framework must support Fintech lending and promote collaboration between Fintech lenders and traditional banks (CGFS 2017).
The focus of this study was on credit risk, but most of the opportunities and challenges that arise are also applicable to other risk areas. For example, machine learning is used in market risk models, e.g., the use of neural networks used to predict interest rates (Joseph et al. 2011). The effect of financial crises is prominent in market risk, as can be seen, for example, by how COVID-19 affected interest rates (Rizwan et al. 2020). Fintech also has a big influence on market risk, e.g., on interest rates (Hodula 2023). As with credit risk, all three of these factors lead to opportunities and threads that can be capitalised on by industry-focused training and research. The same argument can be followed for operational risk. In similar ways, machine learning (e.g., Pena et al. 2021), financial crises (e.g., Andersen et al. 2012), and Fintech (e.g., Cheng 2023) have created opportunities and challenges in the operational risk realm that could be addressed by more industry-focused activities within universities, e.g., (Human et al. 2021).
These three factors were summarised separately in this study, but these factors influence each other as well. For example, the impact of the COVID-19 pandemic (an example of a financial crisis) on cryptocurrencies (an example of Fintech) is described in Karagiannopoulou et al. (2023). Their findings can be utilised in the credit, market, and operational risk domains.
Therefore, this study’s first unique contribution to the field of financial credit risk models is the investigation and discussion of the factors causing rapid changes in the landscape of credit risk predictive models (with a special focus on three pertinent factors: machine learning, financial crises, and Fintech). This not only makes academics and industry partners aware of these changes but also makes them aware that they will need to make some changes going forward to adjust to the changing landscape. The second unique contribution is the documentation of the challenges and opportunities that arise from the changes brought forward by the discussed factors. The last contribution to the field is the suggested solution, i.e., collaborations between academic and industry partners, to utilise these challenges and opportunities in a multi-beneficial way.
That being said, these three factors are not the only factors that will change the landscape of financial credit risk predictive models in the future, and no one can predict exactly what will happen in the future. The factors listed in this study are just the beginning. In the time it took to read this study, innovations, and new technologies would have been developed. One thing we are convinced of is that the future of predictive modelling includes a wealth of exciting opportunities. As Albert Einstein said, “Learn from yesterday, live for today, and hope for tomorrow. The important thing is not to stop questioning”.
Author Contributions
T.V.: Conceptualization; Investigation; Methodology; Writing—original draft. E.F.: Writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This work is based on the research supported wholly/in part by the National Research Foundation of South Africa (Grant Number 126885). This work is based on research supported in part by the Department of Science and Innovation (DSI) of South Africa. The grant holder acknowledges that opinions, findings, and conclusions or recommendations expressed in any publication generated by DSI-supported research are those of the authors and that the DSI accepts no liability whatsoever in this regard.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The author declares no conflict of interest.
References
- 2U Inc. 2020. Data Science vs. Machine Learning. Masters in Data Science. Available online: https://www.mastersindatascience.org/learning/data-science-vs-machine-learning/ (accessed on 13 January 2022).
- ActEd. 2020. Subject CS2 Course Notes: Combined Materials Pack. London: The Actuarial Education Company. [Google Scholar]
- Alogoskoufis, Spyros, Nepomuk Dunz, Tina Emambakhsh, Tristan Hennig, Michiel Kaijser, Charalampos Kouratzoglou, Manuel Muñoz, Laura Parisi, and Carmelo Salleo. 2021. ECB Economy-Wide Climate Stress Test. Occasional Paper Series, No. 281: European Central Bank. Available online: https://www.ecb.europa.eu/pub/pdf/scpops/ecb.op281~05a7735b1c.en.pdf (accessed on 25 July 2022).
- Andersen, Lasse Berg, David Häger, Svein Maberg, Nils Bjørn Næss, and Morten Tungland. 2012. The financial crisis in an operational risk management context—A review of causes and influencing factors. Reliability Engineering & System Safety 105: 3–12. [Google Scholar] [CrossRef]
- Athari, Seyed Alireza, Dervis Kirikkaleli, Isah Wada, and Tomiwa Sunday Adebayo. 2021. Examining the Sectoral Credit-Growth Nexus in Australia: A Time and Frequency Dynamic Analysis. Economic Computation and Economic Cybernetics Studies and Research. Available online: https://ssrn.com/abstract=3993479 (accessed on 21 June 2023).
- Bazarbash, Majid. 2019. FinTech in Financial Inclusion: Machine Learning Applications in Assessing Credit Risk. Retrieved from International Monetary Fund (IMF) Working Paper WP/19/109. Available online: https://www.imf.org/~/media/Files/Publications/WP/2019/WPIEA2019109.ashx (accessed on 25 February 2023).
- Bell, Francesca, and Gary van Vuuren. 2022. The impact of climate risk on corporate credit risk. Cogent Economics & Finance 10: 1. [Google Scholar] [CrossRef]
- Bellini, Tiziano. 2019. IFRS 9 and CECL Credit Risk Modelling and Validation: A Practical Guide with Examples Worked in R and SAS, 1st ed. London: Elsevier. [Google Scholar]
- Blaschczok, Vinzent, Tanja Verster, and Alan Broderick. 2018. Review of innovations in the South African collection industry. South African Journal of Science 114: 25–33. [Google Scholar] [CrossRef] [PubMed]
- Breed, Douw Gerbrand, Tanja Verster, Willem Daniel Schutte, and Naeem Siddiqi. 2019. Developing an Impairment Loss Given Default Model Using Weighted Logistic Regression Illustrated on a Secured Retail Bank Portfolio. Risks 7: 123. [Google Scholar] [CrossRef]
- Breiman, Leo, Jerome Friedman, Richard Olsen, and Charles Stone. 1984. Classification and Regression Trees. Wadsworth: Pacific Grove. [Google Scholar]
- Brooke, Sophia. 2018. How Will Blockchain Make Predictive Analytics Accessible? Towards Data Science. Available online: https://towardsdatascience.com/how-will-blockchain-make-predictive-analytics-accessible-d256d543081d (accessed on 16 August 2022).
- Centre for BMI. 2022. Centre for Business Mathematics and Informatics. Available online: https://natural-sciences.nwu.ac.za/bmi (accessed on 16 August 2022).
- CGFS. 2017. FinTech Credit Market Structure, Business Models and Financial Stability Implications Report on FinTech Credit Market Structure, Business Models and Financial Stability Implications. Committee on the Global Financial System (CGFS) and the Financial Stability Board (FSB). Available online: https://www.bis.org/publ/cgfs_fsb1.pdf (accessed on 25 February 2023).
- Cheng, Aijun. 2023. Evaluating Fintech Industry’s Risks: A Preliminary Analysis Based on CRISP-DM Framework. Finance Research Letters 55, Pt B: 103966. [Google Scholar] [CrossRef]
- Claessens, Stijn, Luc Laeven, Deniz Igan, and Giovanni Dell’Ariccia. 2010. Lessons and Policy Implications From the Global Financial Crisis. IMF Working Papers. Washington, DC: International Monetary Fund, vol. 2010, pp. 1–40. [Google Scholar] [CrossRef]
- De Almeida Filho, Adiel Teixeira, Christophe Mues, and Lyn Thomas. 2010. Optimizing the Collections Process in Consumer Debt. Productions and Operations Management Society 19: 698–708. [Google Scholar] [CrossRef]
- De Jongh, Pieter Juriaan, and Cornelius Marthinus Erasmus. 2014. Industry-directed training and research programmes: The BMI experience. South African Journal of Science 110: 1–8. [Google Scholar] [CrossRef][Green Version]
- De Jongh, Pieter Juriaan, Janette Larney, Eben Mare, Gary van Vuuren, and Tanja Verster. 2017. A proposed best practice model validation framework for banks. South African Journal of Economic and Management Sciences 20: 1–15. [Google Scholar] [CrossRef]
- Dendramis, Yiannis, Elias Tzavalis, and Georgios Adraktas. 2018. Credit risk modelling under recessionary and financially distressed conditions. Journal of Banking and Finance 91: 160–75. [Google Scholar] [CrossRef]
- EBA. 2021. EBA Discussion Paper on Machine Learning for IRB Models. European Banking Authority. Available online: https://www.eba.europa.eu/sites/default/documents/files/document_library/Publications/Discussions/2022/Discussion%20on%20machine%20learning%20for%20IRB%20models/1023883/Discussion%20paper%20on%20machine%20learning%20for%20IRB%20models.pdf (accessed on 22 July 2022).
- Efron, Bradley, and Trevor Hastie. 2016. Computer Age Statistical Inference: Algorithms, Evidence, and Data Science (Institute of Mathematical Statistics Monographs). Cambridge: Cambridge University Press. [Google Scholar] [CrossRef]
- Fagella, Daniel. 2020. EMERJ: The AI Research and Advisory Company—What Is Machine Learning? Available online: https://emerj.com/ai-glossary-terms/what-is-machine-learning/#:~:text=*%20%E2%80%9CMachine%20Learning%20is%20the%20science,and%20real%2Dworld%20interactions.%E2%80%9D (accessed on 28 October 2022).
- Fourie, Erika, Tanja Verster, and Gary van Vuuren. 2016. A proposed quantitative credit rating methodology for South African provincial departments. d quantitative credit rating methodology for South African provincial departments. SAJEMS (South African Journal of Economic and Management Sciences) 19: 192–214. [Google Scholar] [CrossRef]
- Gandal, Neil, and Hanna Halaburda. 2016. Can we predict the winner in a market with network effects? Competition in cryptocurrency market. Games 7: 16. [Google Scholar] [CrossRef]
- Halaburda, Hanna. 2017. Blockchain Revolution without the Blockchain? Communications of CACM 61: 7. [Google Scholar] [CrossRef]
- Hastie, Trevor, Rrobert Tibshirani, and Jermone Friedman. 2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed. New York: Springer. [Google Scholar]
- Hodula, Martin. 2023. Interest rates as a finance battleground? The rise of Fintech and big tech credit providers and bank interest margin. Finance Research Letters 53: 103685. [Google Scholar] [CrossRef]
- Howat, Evelyn. 2020. What Is Fintech? Fintech Magazine. Available online: https://fintechmagazine.com/venture-capital/what-is-fintech (accessed on 23 November 2022).
- Human, Ansoné, Nantes Kirsten, Tanja Verster, and Willem Daniel Schutte. 2021. Surprise fraudsters before they surprise you: A South African telecommunications case study. Southern African Journal of Accountability and Auditing Research 23: 1. [Google Scholar] [CrossRef]
- IBM Cloud Education. 2020. Neural Networks. Available online: https://www.ibm.com/cloud/learn/neural-networks (accessed on 22 July 2022).
- IFRS. 2014. IRFS9 Financial Instruments: Project Summary. Available online: http://www.ifrs.org/Current-Projects/IASB-Projects/Financial-Instruments-A-Replacement-of-IAS-39-Financial-Instruments-Recognitio/Documents/IFRS-9-Project-Summary-July-2014.pdf (accessed on 31 January 2016).
- IFRS. 2020. IFRS 9 and COVID-19. Available online: https://www.ifrs.org/content/dam/ifrs/supporting-implementation/ifrs-9/ifrs-9-ecl-and-coronavirus.pdf (accessed on 25 November 2021).
- Joseph, Anthony, Maurice Larrain, and Eshwar Singh. 2011. Predictive Ability of the Interest Rate Spread Using Neural Networks. Procedia Computer Science 6: 207–12. [Google Scholar] [CrossRef][Green Version]
- Kao, Shu-Chen. 2021. A crowdfunding prediction model: A data-driven approach. In The 8th Multidisciplinary International Social Networks Conference (MISNC2021). New York: ACM. [Google Scholar] [CrossRef]
- Karagiannopoulou, Sofia, Konstantina Rgazou, Ioannis Passas, Alexandros Garefalakis, and Nikolaos Sariannidis. 2023. The Impact of the COVID-19 Pandemic on the Volatility of Cryptocurrencies. International Journal of Financial Studies 11: 50. [Google Scholar] [CrossRef]
- Lawton, George, Joseph Michael Carew, and Ed Burns. 2022. What Is Predictive Modelling? TechTarget. Available online: https://www.techtarget.com/searchenterpriseai/definition/predictive-modeling (accessed on 28 November 2022).
- Lessmann, Stefan, Bart Baesens, Hsin-Vonn Seow, and Lyn Thomas. 2015. Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research. European Journal of Operational Research 247: 124–36. [Google Scholar] [CrossRef]
- Maldonado, Miguel, Jared Dean, Wendy Czika, and Susan Haller. 2014. Leveraging Ensemble Models in SAS Enterprise Miner. Paper SAS133-2014. Charlotte: SAS Institute Inc. [Google Scholar]
- NCSU. 2022. Institute of Advanced Analytics: MSA Curriculum. Retrieved from North Carolina State University. Available online: https://analytics.ncsu.edu/?page_id=2874 (accessed on 13 January 2022).
- NYU Stern. 2022. NYU Stern Master of Science in Business Analytics. Available online: https://www.stern.nyu.edu/programs-admissions/ms-business-analytics/academics/blended-learning-capstone (accessed on 26 November 2022).
- Pena, Alejandro, Alejandro Patino, Francisco Chiclana, Fabio Caraffini, Mario Gongora, Juan David Gonzalez-Ruiz, and Eduardo Duque-Grisales. 2021. Fuzzy convolutional deep-learning model to estimate the operational risk capital using multi-source risk events. Applied Soft Computing 107: 107381. [Google Scholar] [CrossRef]
- Rajalingham, Kamalasen. 2005. A revised classification of spreadsheet errors. In 2. EuSpRIG Conference Proceedings, July 7–8. London: University of Greenwich. [Google Scholar]
- Rizwan, Muhammad Suhail, Ghufran Ahmad, and Dawood Ashraf. 2020. Systemic risk: The impact of COVID-19. Finance Research Letters 36: 101682. [Google Scholar] [CrossRef]
- Ruddenklau, Anton. 2022. Pulse of Fintech H2 21. Available online: https://assets.kpmg/content/dam/kpmg/xx/pdf/2022/02/pulse-of-fintech-h2-21.pdf (accessed on 20 July 2022).
- Saliba, Chafic, Panteha Farmanesh, and Seyed Alireza Athari. 2023. Does country risk impact the banking sectors’ non-performing loans? Evidence from BRICS emerging economies. Financial Innovation 9: 86. [Google Scholar] [CrossRef]
- SAS Institute Inc. 2015. Applied Analytics Using SAS Enterprise Miner (SAS Institute Course Notes). Charlotte: SAS Institute Inc. [Google Scholar]
- Shi, Si, Rita Tse, Wuman Luo, Stefano D’Addona, and Giovanni Pau. 2022. Machine learning-driven credit risk: A systemic review. Neural Computing and Applications 34: 14327–39. [Google Scholar] [CrossRef]
- Skoglund, Jimmy. 2014. Credit risk term-structures for lifetime impairment forecasting: A practical guide. Journal of Risk Management in Financial Institutions 10: 177–95. Available online: https://www.econbiz.de/Record/credit-risk-term-structures-for-lifetime-impairment-forecasting-a-practical-guide-skoglund-jimmy/10011670671 (accessed on 16 August 2022). [CrossRef]
- Smith, Tim. 2022. Investopedia. Available online: https://www.investopedia.com/terms/c/crowdfunding.asp (accessed on 20 October 2022).
- Verster, Tanja, Samistha Harcharan, Lizette Bezuidenhout, and Bart Baesens. 2021. Predicting take-up of home loan offers using tree-based ensemble models: A South African case study. South African Journal of Science 117: 1–8. [Google Scholar] [CrossRef] [PubMed]
- VU. 2022. Solve Today’s Complex Business Problems: From Data to Answers. Available online: https://vu.nl/en/education/master/business-analytics/curriculum (accessed on 13 January 2022).
- Yiu, Tony. 2019. Towards data science: Understanding random forests. Available online: https://towardsdatascience.com/understanding-random-forest-58381e0602d2 (accessed on 16 August 2022).
- Yurcan, Bryan. 2022. How Banks Can Shed Light on the ‘Black Box’ of AI Decision-Making. Available online: https://thefinancialbrand.com/news/data-analytics-banking/artificial-intelligence-banking/how-banks-can-shed-light-on-the-black-box-of-ai-decision-making-147960/ (accessed on 25 February 2023).







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).