
A Deep Learning Approach to Dynamic Interbank Network Link Prediction


Abstract
:1. Introduction
- Inspired by Chen et al. (2021), the model is proposed to combine the advantages of the Graph convolutional network (GCN), which obtains valuable information and learns the internal representations of the network snapshots, with the benefits of the Long short-term memory model (LSTM), which is effective at identifying and modeling short and long-term temporal relationships embedded in the sequence of data.
- To handle the network sparsity and the fact that we care more about the existing links than nonexisting links; we design a loss function that adds a penalty to nonexisting links.
- On test data, the proposed model is assessed and compared with two traditional statistical baseline models using the metrics Area Under the ROC Curve (AUC) and Precision–Recall Curve (PRAUC). They are the Discrete autoregressive model and Dynamic latent space model. The findings indicate that our proposed model beats the two models in predicting future links in both precrisis and crisis periods for the top 100 Italian trading dataset and European core countries dataset.
2. Literature Review
2.1. Financial Contagion
2.2. Interconnectedness Network Models
3. Materials and Methods
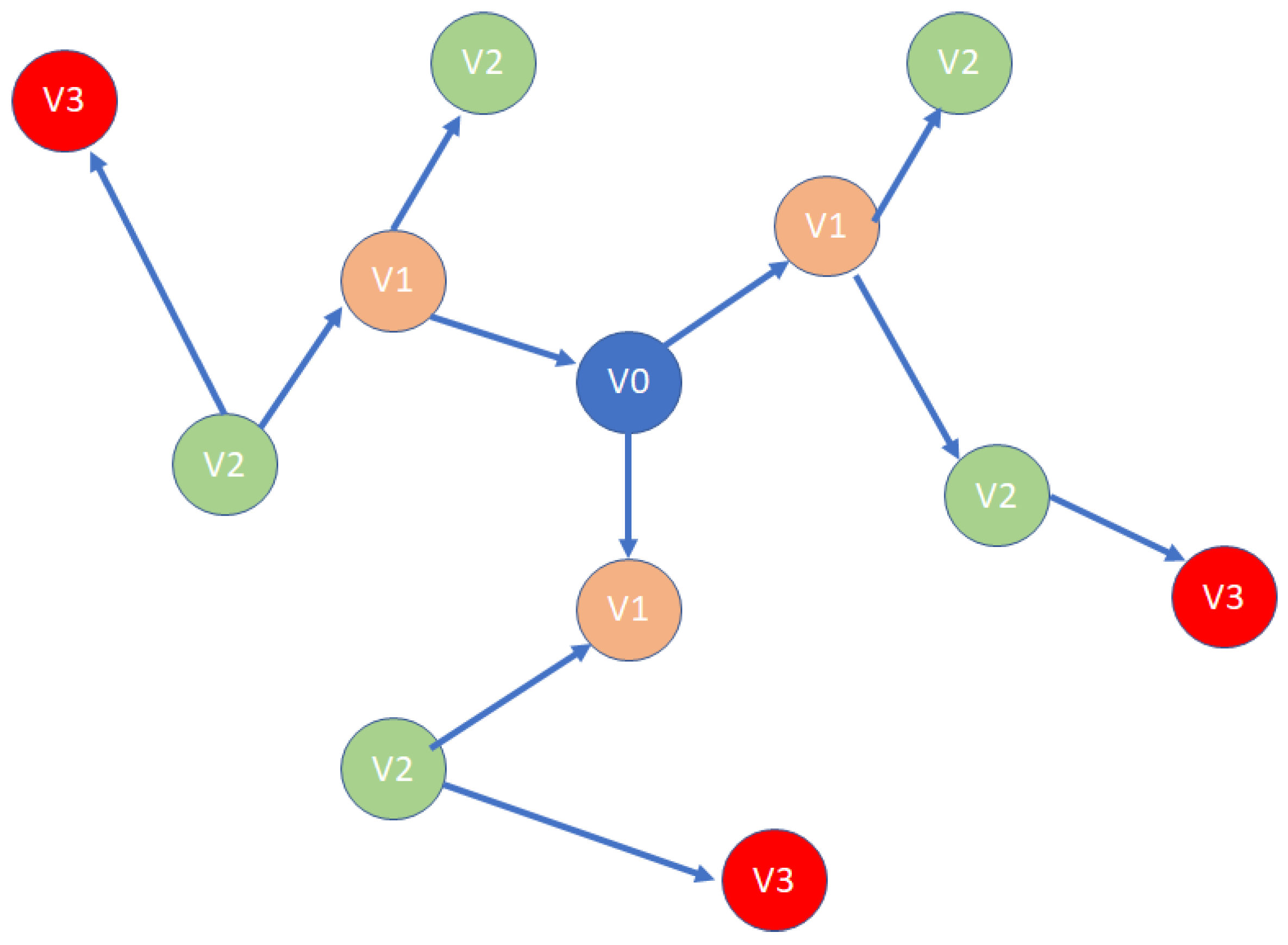
3.1. Problem Definition
3.2. GC–LSTM Framework
3.2.1. Graph Convolutional Network
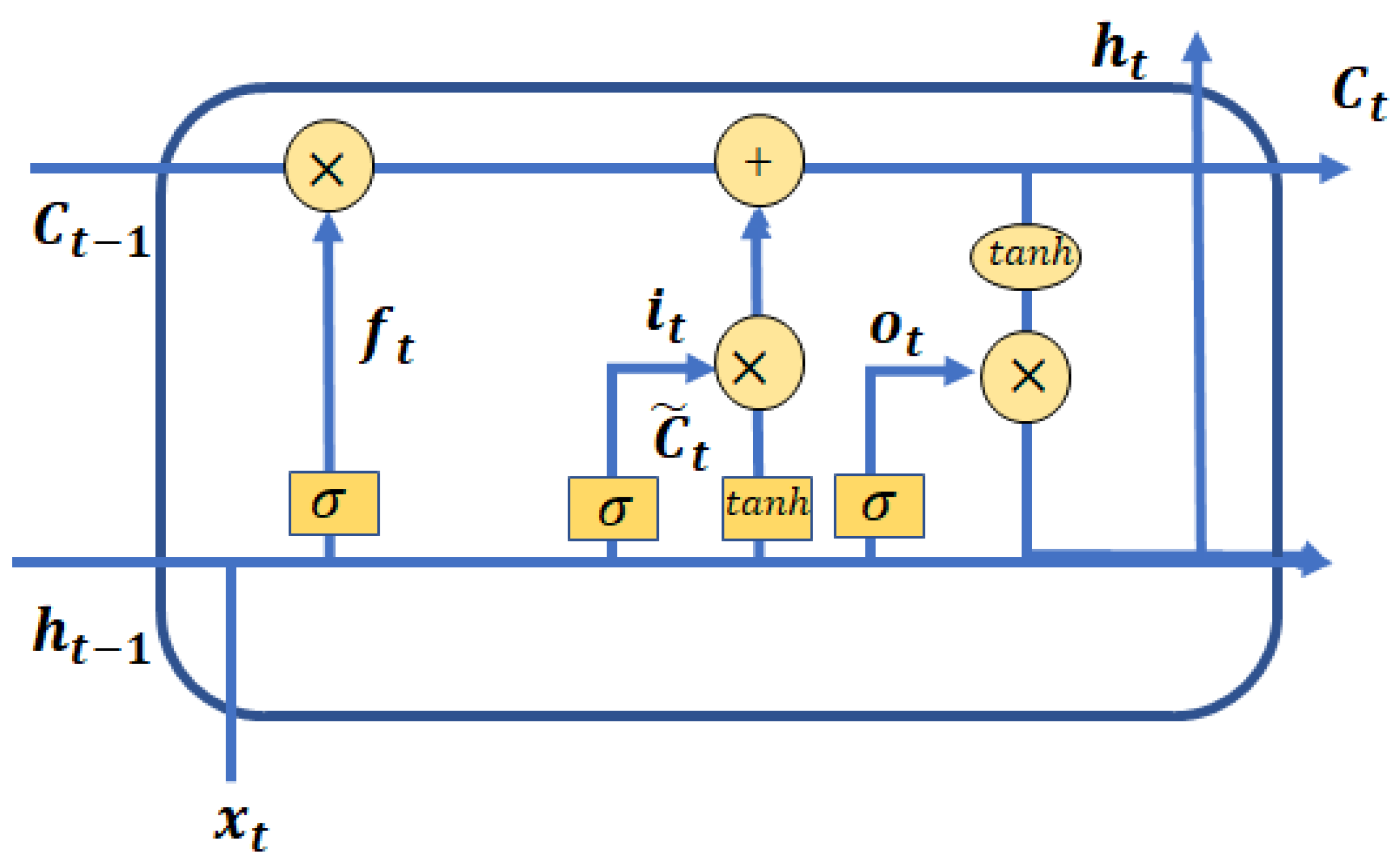
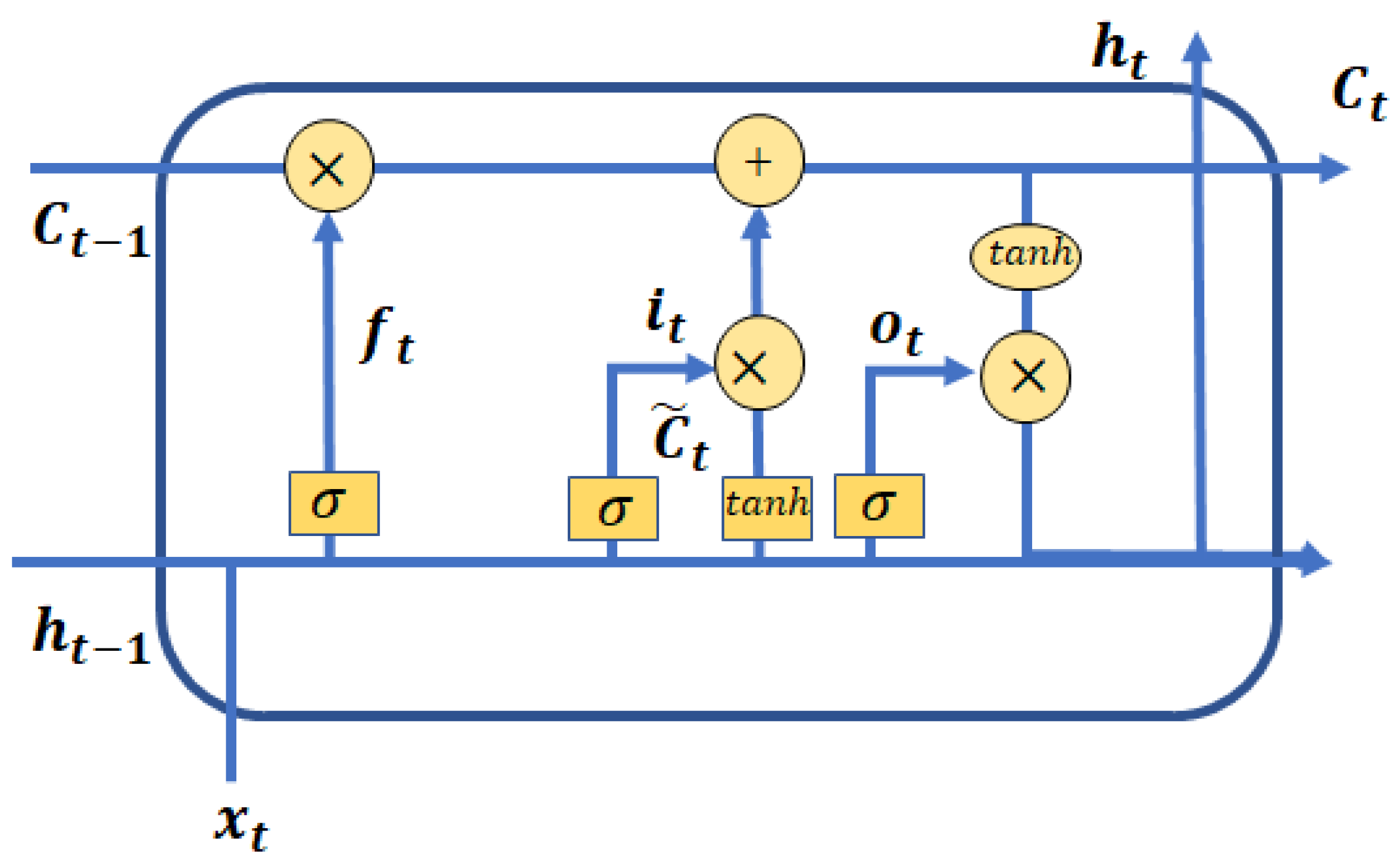
3.2.2. Long Short-Term Memory
- Forget Gate: The forget gate decides what information should be kept or removed from the cell state.
- Input gate: The input gate decides what information should be added to the cell state.
- Output gate: The output gate decides what the next hidden state should be.
3.2.3. GC–LSTM Model
3.2.4. Decoder Model
3.3. Loss Function and Model Training
4. Experiments and Results
4.1. e-MID Dataset
- Degree: The degree of the network is defined as the number of connections as a proportion of all possible links inside the network (Boss et al. 2004). A low value of the degree might indicate a low level of liquidity in the e-MID interbank market.
- Clustering coefficient: The clustering coefficient is a measure of how closely nodes in a network cluster together (Soramäki et al. 2007).
- Centrality: In this part, we introduce three kinds of centrality, which are degree, betweenness, and Eigen centrality. For the degree centrality, it is defined as the number of links incident upon a node (Temizsoy et al. 2017). Since only the node’s immediate ties are considered when calculating degree centrality, it is a local centrality measure. For between centrality, which is introduced by Freeman (1978), it is defined as the number of times a node functions as a bridge along the shortest path between two other nodes, since it focuses on a node’s distance from all other nodes in the network and is a measure of global centrality in this sense. The last centrality measure we introduce is Eigen centrality (Negre et al. 2018). Eigen centrality calculates a node’s centrality based on its neighbors’ centrality, which is a measure of the influence of a node in a network. The score of the Eigen centrality of a bank is between 0 to 1, where higher values indicate more essential banks for interconnection.
- Largest strongest connected component: A strongly connected component is the portion of a directed graph where each vertex has a route to another vertex. The fraction of banks connected to other banks via directed edges on the network scaled by the total number of banks in the network is defined as the largest strongest connected component of the graph. If the value of the largest strongest connected component is close to 1, it means that the network is highly connected, and if the value is close to zero, the network is much more fragmented.
4.2. Baseline Methods
- Dynamic latent space model: Dynamic latent space model is a model based on the distance idea in social networks (Hoff et al. 2002). The model assumes that the link probability between any two nodes depends on the distance between the latent position of the two nodes. A dynamic latent space model is proposed by Sewell and Chen (2015) and is used on the interbank network model by Linardi et al. (2020).
- Discrete autoregressive model: To avoid systemic risk, the information of the counterparty plays an important role to decide who to trade with. The past trading relationship, which is also seen as link persistence, is documented in the paper Papadopoulos and Kleineberg (2019). The relationship is defined as preferential trading and allows banks to ensure liquidity risk in the presence of market frictions such as information and transaction cost (Cocco et al. 2009; Giraitis et al. 2012). Based on the preferential trading theory, the link formation strategy of the Discrete autoregressive model (Jacobs and Lewis 1978) is that the value of a link between bank i and bank j at time t is determined by past value at time and the ability to create new links. Therefore, the model could be described as follow:where and . indicates Bernoulli distribution. The link formation strategy of the Discrete autoregressive model is that the value of a link between bank i and bank j at time t is determined by past value at time and the ability to create new links.
4.3. Evaluation Metrics
4.4. Parameter Sensitivity
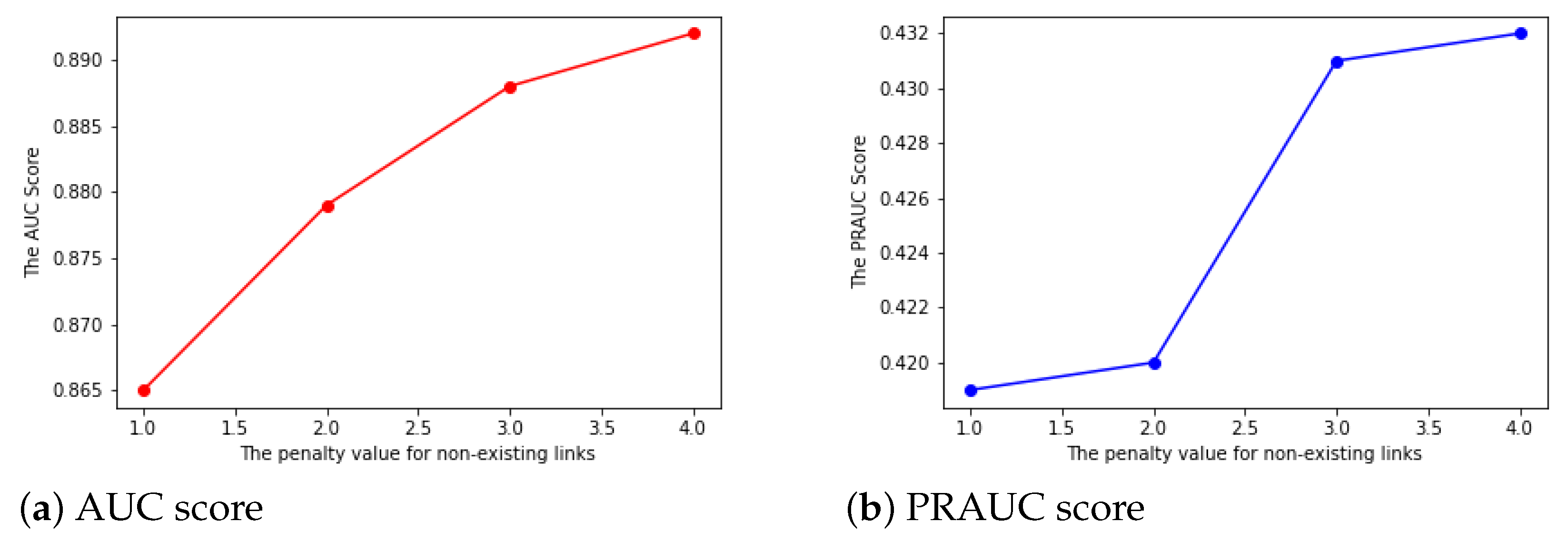
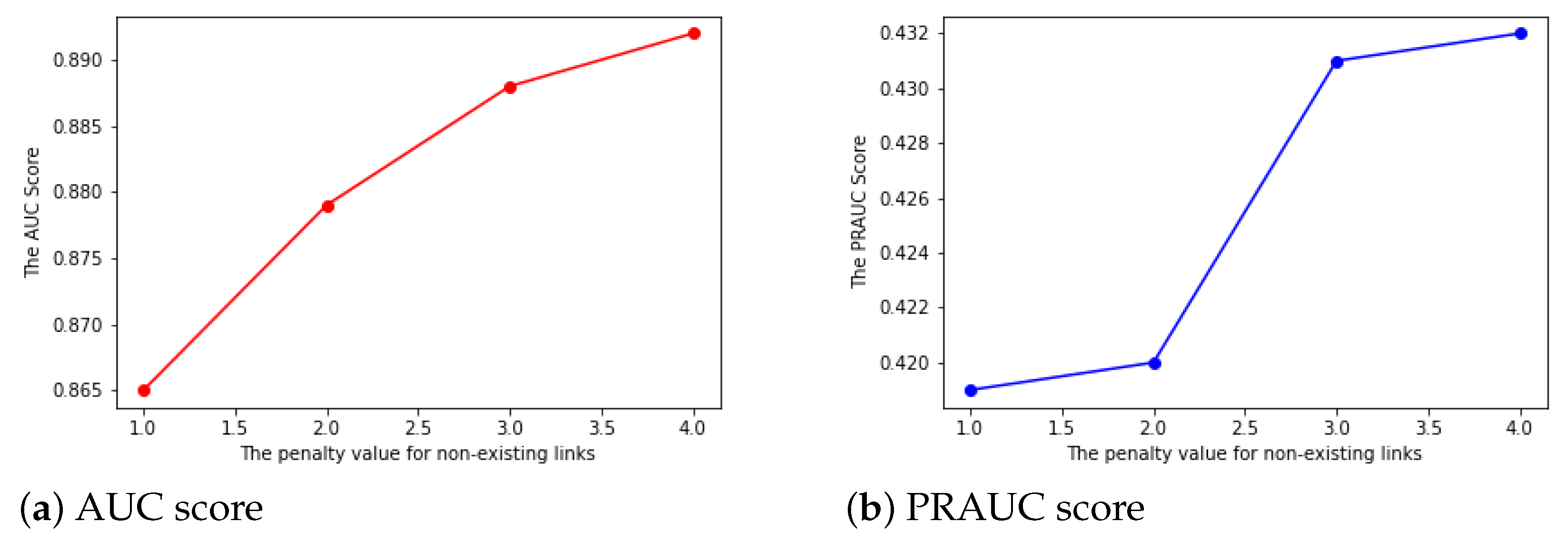
- The penalty index: As exiting links are much more important than the nonexisting links, we add a penalty to the nonexisting links with a different from 1 to 4. Additionally, we set the value for the existing links to be 1. If the penalty value is the same for both the existing links and nonexisting links, then we treat the two kinds of links with no difference. The results shown in Figure 3 indicate that a larger penalty could lead to slightly larger AUC and PRAUC. This suggests we choose a higher penalty score for nonexisting links in the following model parameter settings.
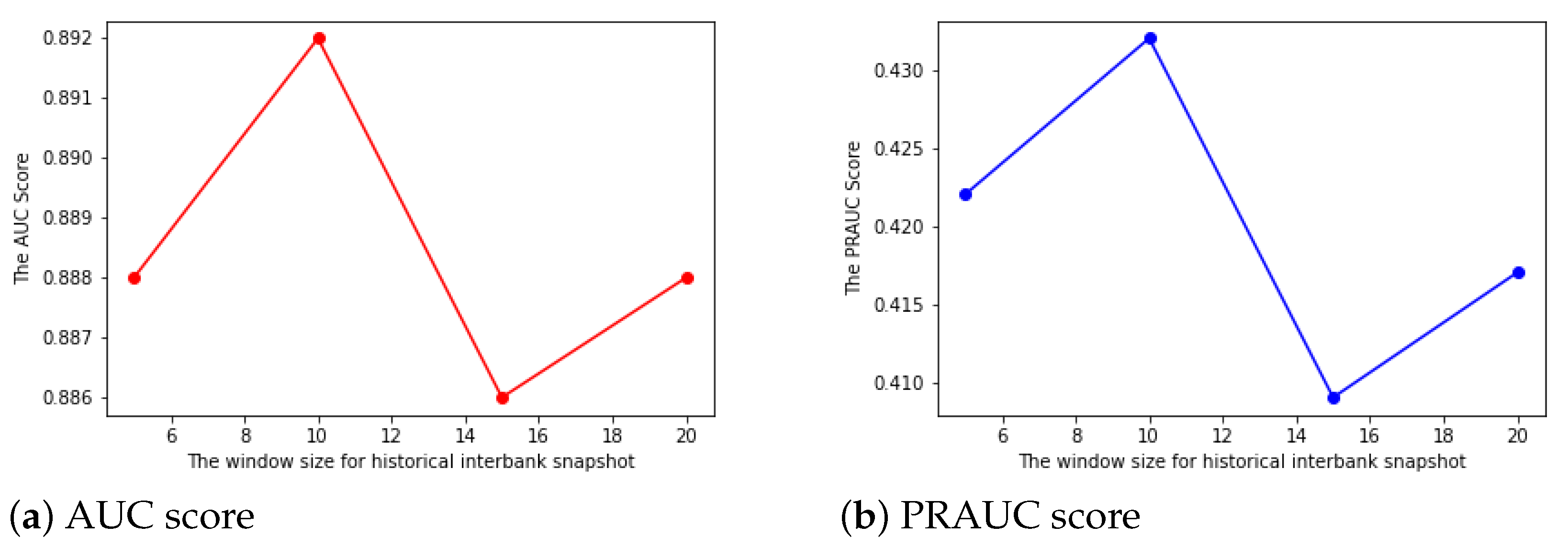
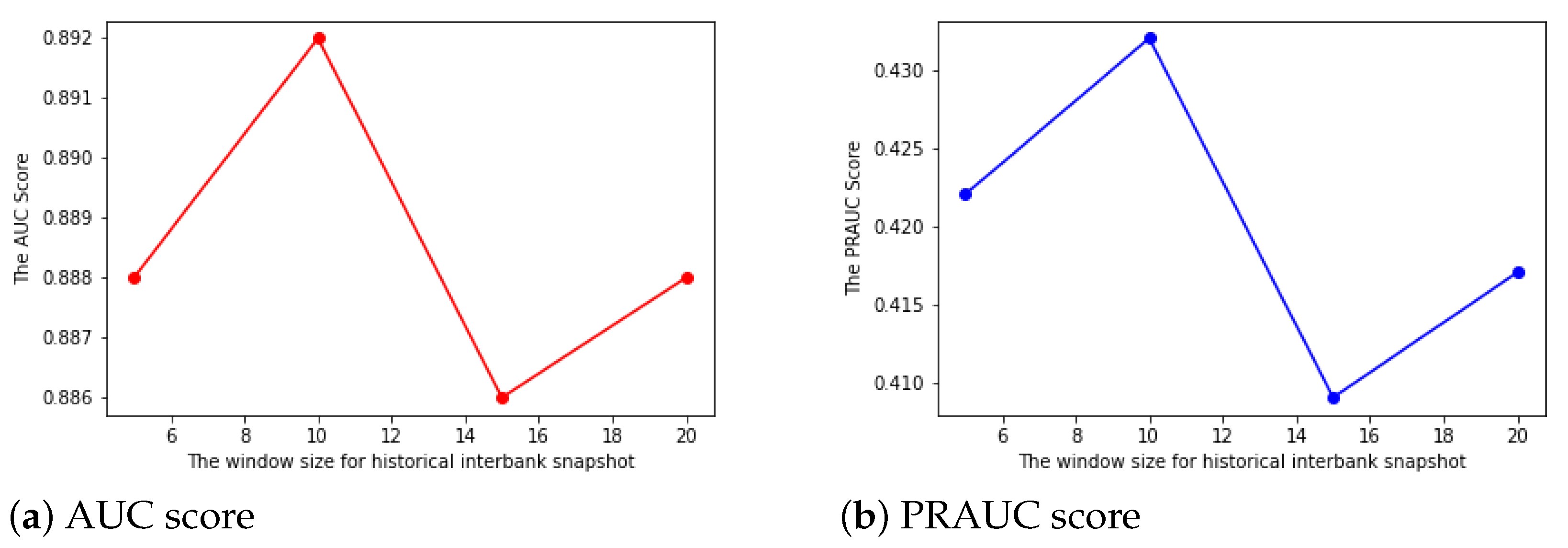
- The window sizel: In most cases, a larger historical interbank network snapshots input might improve the performance in link prediction. In our case, we use a range of window sizes from 5 to 20 with a regular interval of 5, and the results for both AUC and PRAUC follow a similar pattern. By choosing the window size to be 10, we could achieve both the highest AUC and PRAUC. The results are shown in Figure 4.
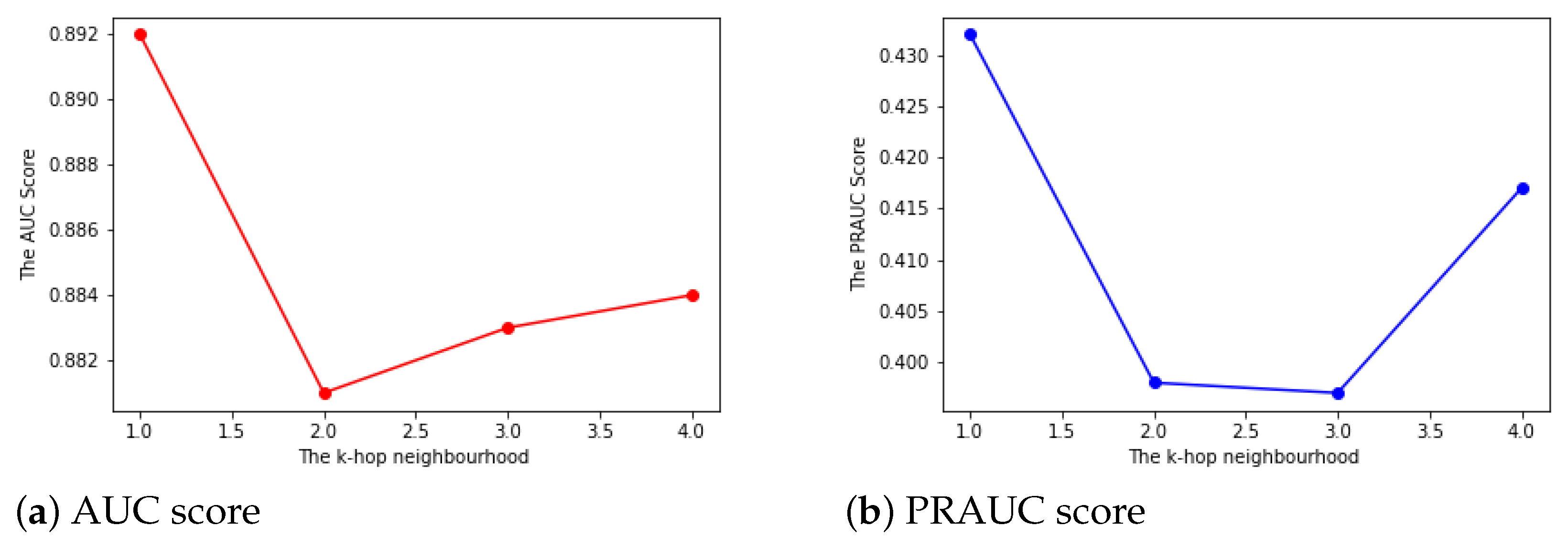
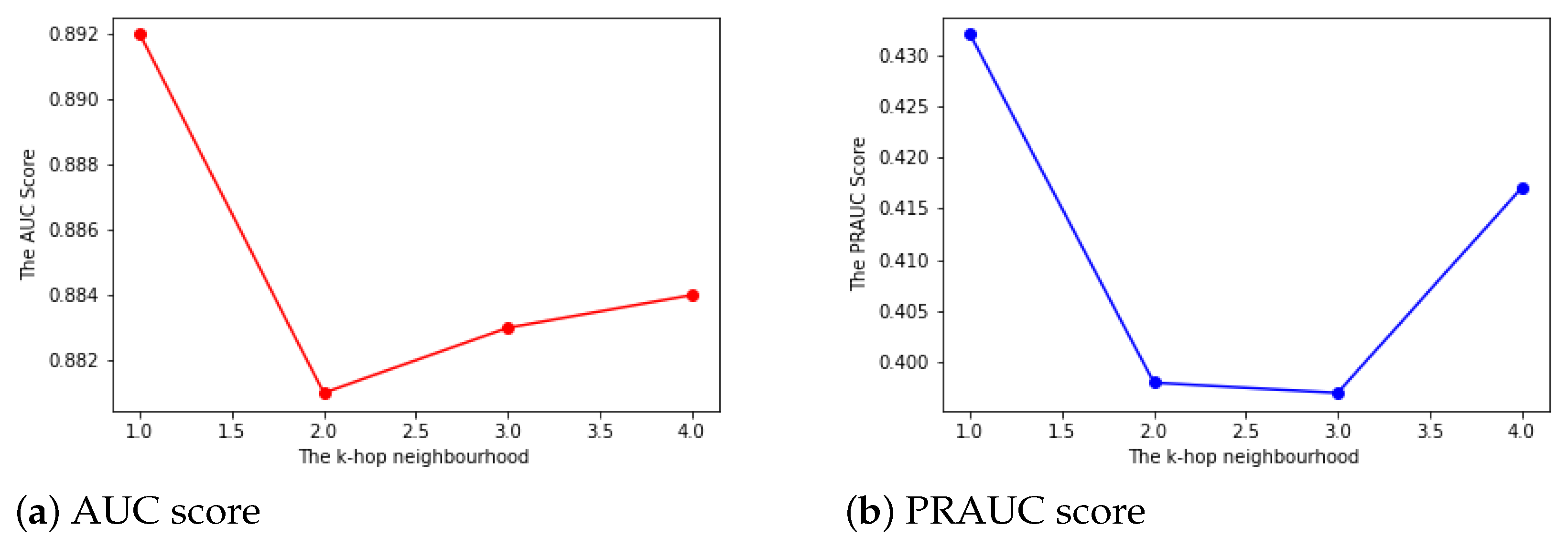
- TheK-hop neighborhood: The K-hop neighborhood idea comes from social network analysis. The larger the size of K, the more information a node utilizes from its neighborhood. In our interbank network, a larger K does not help in link prediction. It means that if a bank i trades with another bank j, even if bank j has a close relationship to bank z, bank i will not preferentially trade with bank z. The results are shown in Figure 5.
4.5. Link Prediction
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Allen, Franklin, and Douglas Gale. 2000. Financial contagion. Journal of Political Economy 108: 1–33. [Google Scholar] [CrossRef]
- Betancourt, Brenda, Abel Rodríguez, and Naomi Boyd. 2017. Bayesian fused lasso regression for dynamic binary networks. Journal of Computational and Graphical Statistics 26: 840–50. [Google Scholar] [CrossRef]
- Boss, Michael, Helmut Elsinger, Martin Summer, and Stefan Thurner 4. 2004. Network topology of the interbank market. Quantitative Finance 4: 677–84. [Google Scholar] [CrossRef]
- Bräuning, Falk, and Falko Fecht. 2012. Relationship Lending and Peer Monitoring: Evidence from Interbank Payment Data. Working Paper. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2020171 (accessed on 13 March 2012).
- Bräuning, Falk, and Siem Jan Koopman. 2020. The dynamic factor network model with an application to international trade. Journal of Econometrics 216: 494–515. [Google Scholar] [CrossRef]
- Brunetti, Celso, Jeffrey H. Harris, Shawn Mankad, and George Michailidis. 2019. Interconnectedness in the interbank market. Journal of Financial Economics 133: 520–38. [Google Scholar] [CrossRef] [Green Version]
- Cassola, Nuno, Cornelia Holthausen, and Marco Lo Duca. 2010. The 2007/2009 turmoil: A challenge for the integration of the euro area money market. Paper presented at ECB Workshop on Challenges to Monetary Policy Implementation beyond the Financial Market Turbulence, Frankfurt am Main, Germany, November 30–December 1. [Google Scholar]
- Chen, Jinyin, Xueke Wang, and Xuanheng Xu. 2021. Gc-lstm: Graph convolution embedded lstm for dynamic network link prediction. Applied Intelligence 52: 7513–28. [Google Scholar] [CrossRef]
- Cocco, Joao F., Francisco J. Gomes, and Nuno C. Martins. 2009. Lending relationships in the interbank market. Journal of Financial Intermediation 18: 24–48. [Google Scholar] [CrossRef]
- Denbee, Edward, Christian Julliard, Ye Li, and Kathy Yuan. 2021. Network risk and key players: A structural analysis of interbank liquidity. Journal of Financial Economics 141: 831–59. [Google Scholar] [CrossRef]
- Durante, Daniele, and David B. Dunson. 2016. Locally adaptive dynamic networks. The Annals of Applied Statistics 10: 2203–32. [Google Scholar] [CrossRef]
- Elliott, Matthew, Benjamin Golub, and Matthew O. Jackson. 2014. Financial networks and contagion. American Economic Review 104: 3115–53. [Google Scholar] [CrossRef] [Green Version]
- Freeman, Linton C. 1978. Centrality in social networks conceptual clarification. Social Networks 1: 215–39. [Google Scholar] [CrossRef] [Green Version]
- Freixas, Xavier, Bruno M. Parigi, and Jean-Charles Rochet. 2000. Systemic risk, interbank relations, and liquidity provision by the central bank. Journal of Money, Credit and Banking 32: 611–38. [Google Scholar] [CrossRef] [Green Version]
- Gai, Prasanna, Andrew Haldane, and Sujit Kapadia. 2011. Complexity, concentration and contagion. Journal of Monetary Economics 58: 453–70. [Google Scholar] [CrossRef]
- Gai, Prasanna, and Sujit Kapadia. 2010. Contagion in financial networks. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences 466: 2401–23. [Google Scholar] [CrossRef] [Green Version]
- Gers, Felix A., Jürgen Schmidhuber, and Fred Cummins. 2000. Learning to forget: Continual prediction with lstm. Neural Computation 12: 2451–71. [Google Scholar] [CrossRef]
- Giraitis, Liudas, George Kapetanios, Anne Wetherilt, and Filip Žikeš. 2012. Estimating the dynamics and persistence of financial networks, with an application to the sterling money market. Journal of Applied Econometrics 31: 58–84. [Google Scholar] [CrossRef]
- Hatzopoulos, Vasilis, Giulia Iori, Rosario N. Mantegna, Salvatore Micciche, and Michele Tumminello. 2015. Quantifying preferential trading in the e-mid interbank market. Quantitative Finance 15: 693–710. [Google Scholar] [CrossRef]
- Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. Long short-term memory. Neural Computation 9: 1735–80. [Google Scholar] [CrossRef]
- Hoff, Peter D., Adrian E. Raftery, and Mark S. Handcock. 2002. Latent space approaches to social network analysis. Journal of the American Statistical Association 97: 1090–98. [Google Scholar] [CrossRef]
- Jacobs, Patricia A., and Peter A. W. Lewis. 1978. Discrete time series generated by mixtures. I: Correlational and runs properties. Journal of the Royal Statistical Society: Series B (Methodological) 40: 94–105. [Google Scholar] [CrossRef]
- Kipf, Thomas N., and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. arXiv arXiv:1609.02907. [Google Scholar]
- Leventides, John, Kalliopi Loukaki, and Vassilios G. Papavassiliou. 2019. Simulating financial contagion dynamics in random interbank networks. Journal of Economic Behavior & Organization 158: 500–25. [Google Scholar]
- Linardi, Fernando, Cees Diks, Marco van der Leij, and Iuri Lazier. 2020. Dynamic interbank network analysis using latent space models. Journal of Economic Dynamics and Control 112: 103792. [Google Scholar] [CrossRef] [Green Version]
- Mazzarisi, Piero, Paolo Barucca, Fabrizio Lillo, and Daniele Tantari. 2019. A dynamic network model with persistent links and node-specific latent variables, with an application to the interbank market. European Journal of Operational Research 281: 50–65. [Google Scholar] [CrossRef] [Green Version]
- Negre, Christian F. A., Uriel N. Morzan, Heidi P. Hendrickson, Rhitankar Pal, George P. Lisi, J. Patrick Loria, Ivan Rivalta, Junming Ho, and Victor S. Batista. 2018. Eigenvector centrality for characterization of protein allosteric pathways. Proceedings of the National Academy of Sciences USA 115: E12201–E12208. [Google Scholar] [CrossRef] [Green Version]
- Nier, Erlend, Jing Yang, Tanju Yorulmazer, and Amadeo Alentorn. 2007. Network models and financial stability. Journal of Economic Dynamics and Control 31: 2033–60. [Google Scholar] [CrossRef]
- Papadopoulos, Fragkiskos, and Kaj-Kolja Kleineberg. 2019. Link persistence and conditional distances in multiplex networks. Physical Review 99: 012322. [Google Scholar] [CrossRef] [Green Version]
- Polson, Nicholas G., James G. Scott, and Jesse Windle. 2013. Bayesian inference for logistic models using pólya–gamma latent variables. Journal of the American statistical Association 108: 1339–49. [Google Scholar] [CrossRef] [Green Version]
- Sarkar, Purnamrita, and Andrew Moore. 2005. Dynamic social network analysis using latent space models. Advances in Neural Information Processing Systems 18: 1145. [Google Scholar] [CrossRef]
- Sarkar, Purnamrita, Deepayan Chakrabarti, and Michael Jordan. 2012. Nonparametric link prediction in dynamic networks. arXiv arXiv:1206.6394. [Google Scholar]
- Sewell, Daniel K., and Yuguo Chen. 2015. Latent space models for dynamic networks. Journal of the American Statistical Association 110: 1646–57. [Google Scholar] [CrossRef]
- Soramäki, Kimmo, Morten L. Bech, Jeffrey Arnold, Robert J. Glass, and Walter E. Beyeler. 2007. The topology of interbank payment flows. Physica A: Statistical Mechanics and Its Applications 379: 317–33. [Google Scholar] [CrossRef] [Green Version]
- Temizsoy, Asena, Giulia Iori, and Gabriel Montes-Rojas. 2017. Network centrality and funding rates in the e-mid interbank market. Journal of Financial Stability 33: 346–65. [Google Scholar] [CrossRef]
- Upper, Christian. 2011. Simulation methods to assess the danger of contagion in interbank markets. Journal of Financial Stability 7: 111–25. [Google Scholar] [CrossRef]
- Zhou, Shuheng, John Lafferty, and Larry Wasserman. 2010. Time varying undirected graphs. Machine Learning 80: 295–319. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| the adjacency matrix of the interbank network snapshot at time t | |
| l | the window size for prediction |
| N | the number of banks (nodes) in the network |
| d | the number of hidden layers in the GC–LSTM model |
| Chebyshev polynomial function | |
| the output probability matrix at time t | |
| , , , | the bias terms in gate function |
| , , , | the weight terms in gate function |
| the graph convolutional operation | |
| penalty parameter in Equation (9) |
| Time Period | Interconnectedness Statistics | Mean | Standard Deviation |
|---|---|---|---|
| All data results | Degree | 0.0670 | 0.0090 |
| Clustering coefficient | 0.1157 | 0.0296 | |
| Betweenness centrality | 0.0045 | 0.0024 | |
| Eigen centrality | 0.0506 | 0.0039 | |
| Degree centrality | 0.1340 | 0.0180 | |
| Largest strongest connected component | 0.1892 | 0.1241 | |
| Precrisis | Degree | 0.0682 | 0.0081 |
| Clustering coefficient | 0.1207 | 0.0269 | |
| Betweenness centrality | 0.0048 | 0.0023 | |
| Eigen centrality | 0.0508 | 0.039 | |
| Degree centrality | 0.1365 | 0.0162 | |
| Largest strongest connected component | 0.2006 | 0.1229 | |
| Crisis | Degree | *** | 0.0058 |
| Clustering coefficient | *** | 0.0248 | |
| Betweenness centrality | *** | 0.0015 | |
| Eigen centrality | * | 0.0036 | |
| Degree centrality | *** | 0.0115 | |
| Largest strongest connected component | ** | 0.1085 |
| Time Period | Methods | Mean AUC | Standard Deviation |
|---|---|---|---|
| All data results | DAR | *** | 0.036 |
| Latent Space Model | *** | 0.023 | |
| GC–LSTM | 0.895 | 0.016 | |
| Precrisis | DAR | *** | 0.034 |
| Latent Space Model | *** | 0.018 | |
| GC–LSTM | 0.893 | 0.016 | |
| Crisis | DAR | *** | 0.018 |
| Latent Space Model | *** | 0.019 | |
| GC–LSTM | 0.905 | 0.013 |
| Time Period | Methods | Mean PRAUC | Standard Deviation |
|---|---|---|---|
| All data results | DAR | *** | 0.054 |
| Latent Space Model | *** | 0.021 | |
| GC–LSTM | 0.431 | 0.038 | |
| Precrisis | DAR | *** | 0.049 |
| Latent Space Model | *** | 0.017 | |
| GC–LSTM | 0.432 | 0.038 | |
| Crisis | DAR | *** | 0.032 |
| Latent Space Model | *** | 0.017 | |
| GC–LSTM | 0.426 | 0.035 |
| Time Period | Methods | Mean AUC | Standard Deviation |
|---|---|---|---|
| All data results | DAR | *** | 0.051 |
| Latent Space Model | *** | 0.095 | |
| GC–LSTM | 0.782 | 0.054 | |
| Precrisis | DAR | *** | 0.048 |
| Latent Space Model | *** | 0.039 | |
| GC–LSTM | 0.779 | 0.056 | |
| Crisis | DAR | *** | 0.057 |
| Latent Space Model | *** | 0.025 | |
| GC–LSTM | 0.795 | 0.042 |
| Time Period | Methods | Mean PRAUC | Standard Deviation |
|---|---|---|---|
| All data results | DAR | *** | 0.040 |
| Latent Space Model | *** | 0.023 | |
| GC–LSTM | 0.275 | 0.074 | |
| Precrisis | DAR | *** | 0.042 |
| Latent Space Model | *** | 0.024 | |
| GC–LSTM | 0.432 | 0.075 | |
| Crisis | DAR | *** | 0.030 |
| Latent Space Model | *** | 0.013 | |
| GC–LSTM | 0.426 | 0.065 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H. A Deep Learning Approach to Dynamic Interbank Network Link Prediction. Int. J. Financial Stud. 2022, 10, 54. https://doi.org/10.3390/ijfs10030054
Zhang H. A Deep Learning Approach to Dynamic Interbank Network Link Prediction. International Journal of Financial Studies. 2022; 10(3):54. https://doi.org/10.3390/ijfs10030054
Chicago/Turabian StyleZhang, Haici. 2022. "A Deep Learning Approach to Dynamic Interbank Network Link Prediction" International Journal of Financial Studies 10, no. 3: 54. https://doi.org/10.3390/ijfs10030054
APA StyleZhang, H. (2022). A Deep Learning Approach to Dynamic Interbank Network Link Prediction. International Journal of Financial Studies, 10(3), 54. https://doi.org/10.3390/ijfs10030054