
Hyperspectral Imaging and Machine Learning for Diagnosing Rice Bacterial Blight Symptoms Caused by Xanthomonas oryzae pv. oryzae, Pantoea ananatis and Enterobacter asburiae

 , and
, and
Abstract
1. Introduction
2. Results
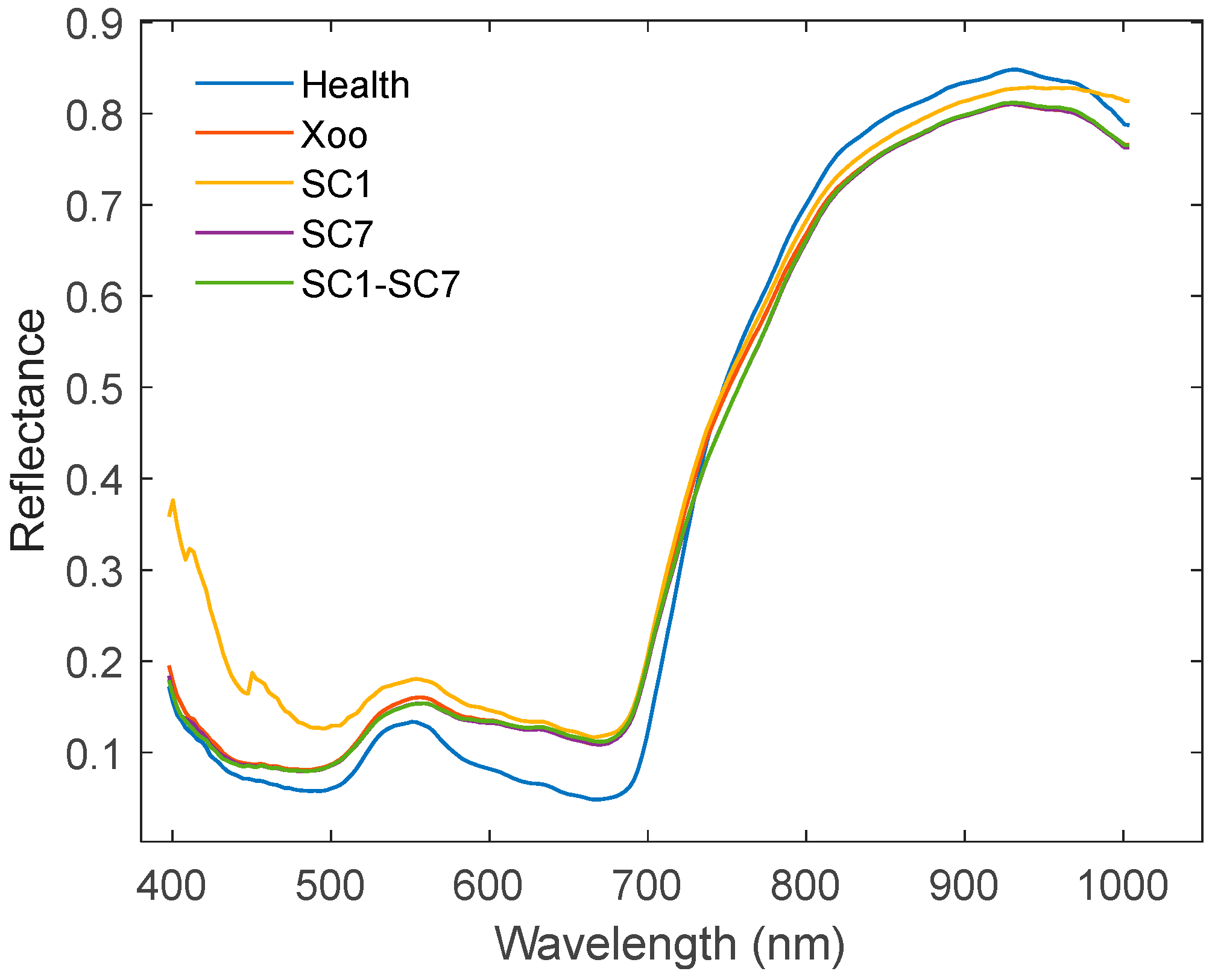
2.1. Spectral Characteristics
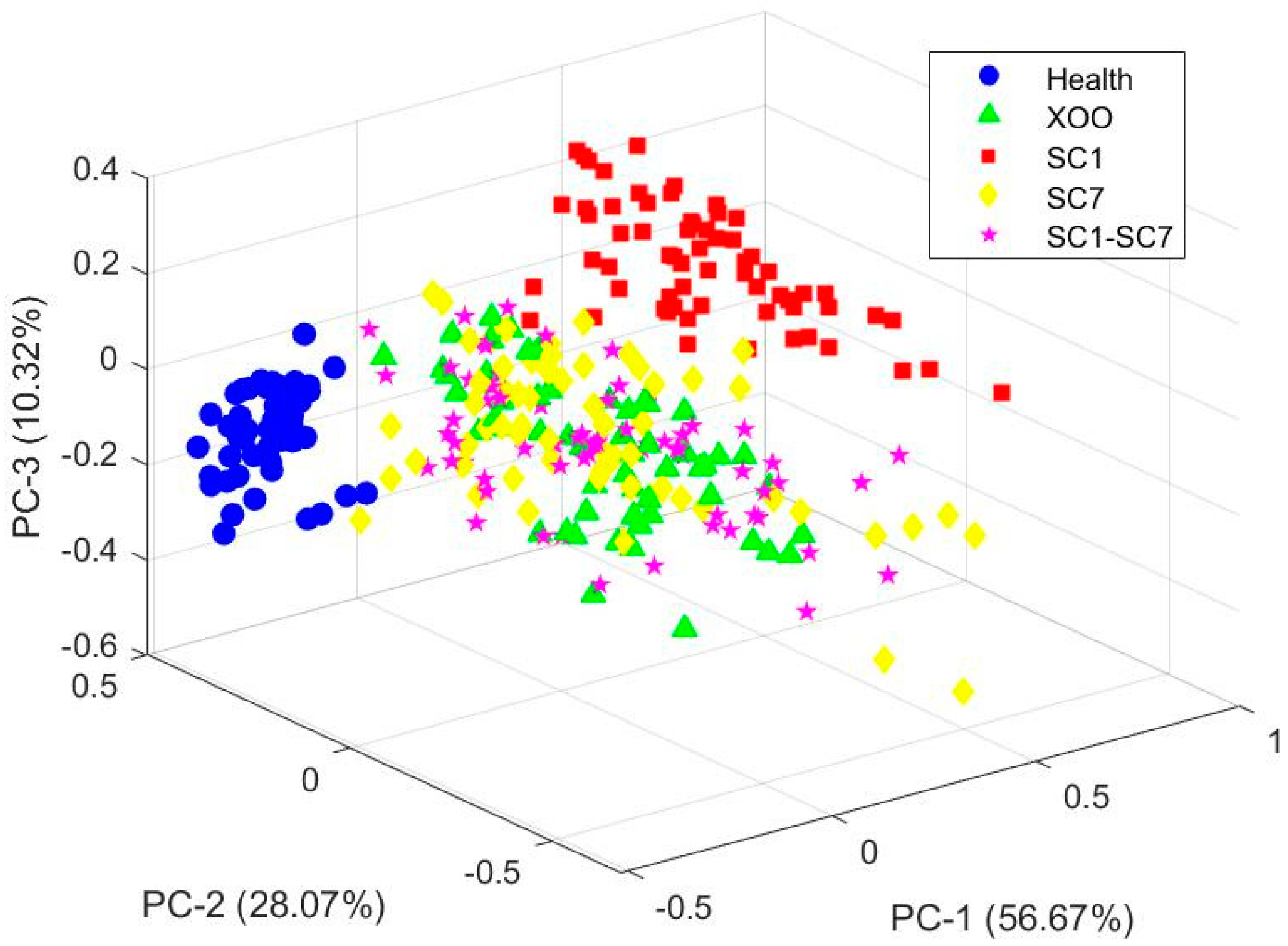
2.2. PCA Explanatory
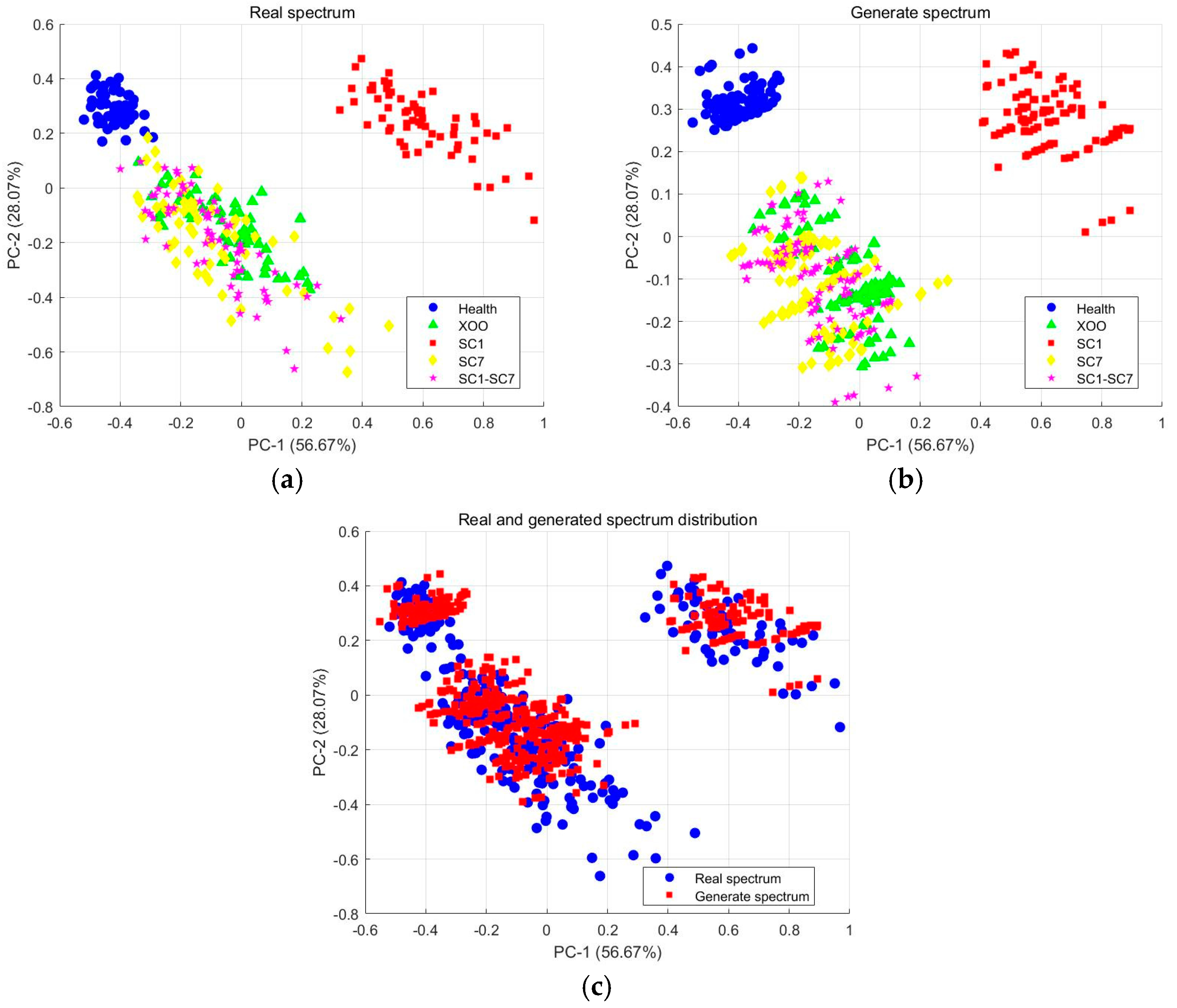
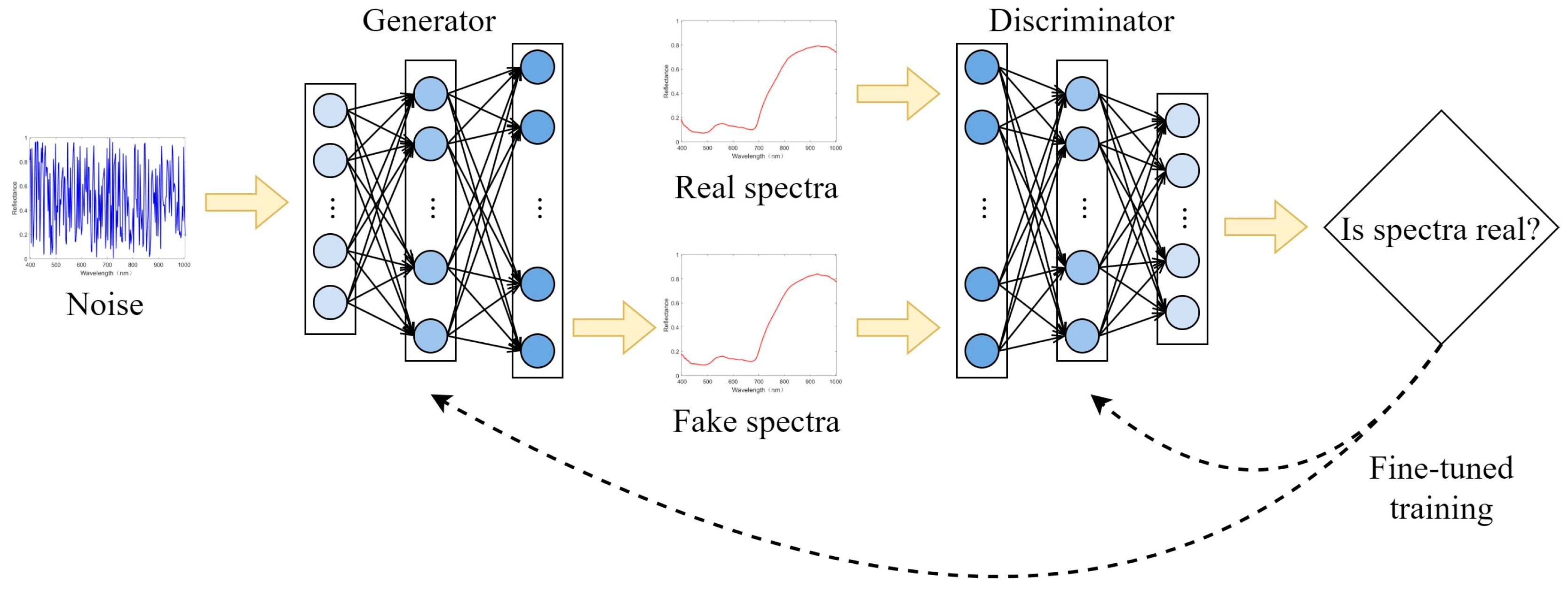
2.3. Data Augmentation and Evaluation
2.4. Adulteration Detection Based on Full Spectra
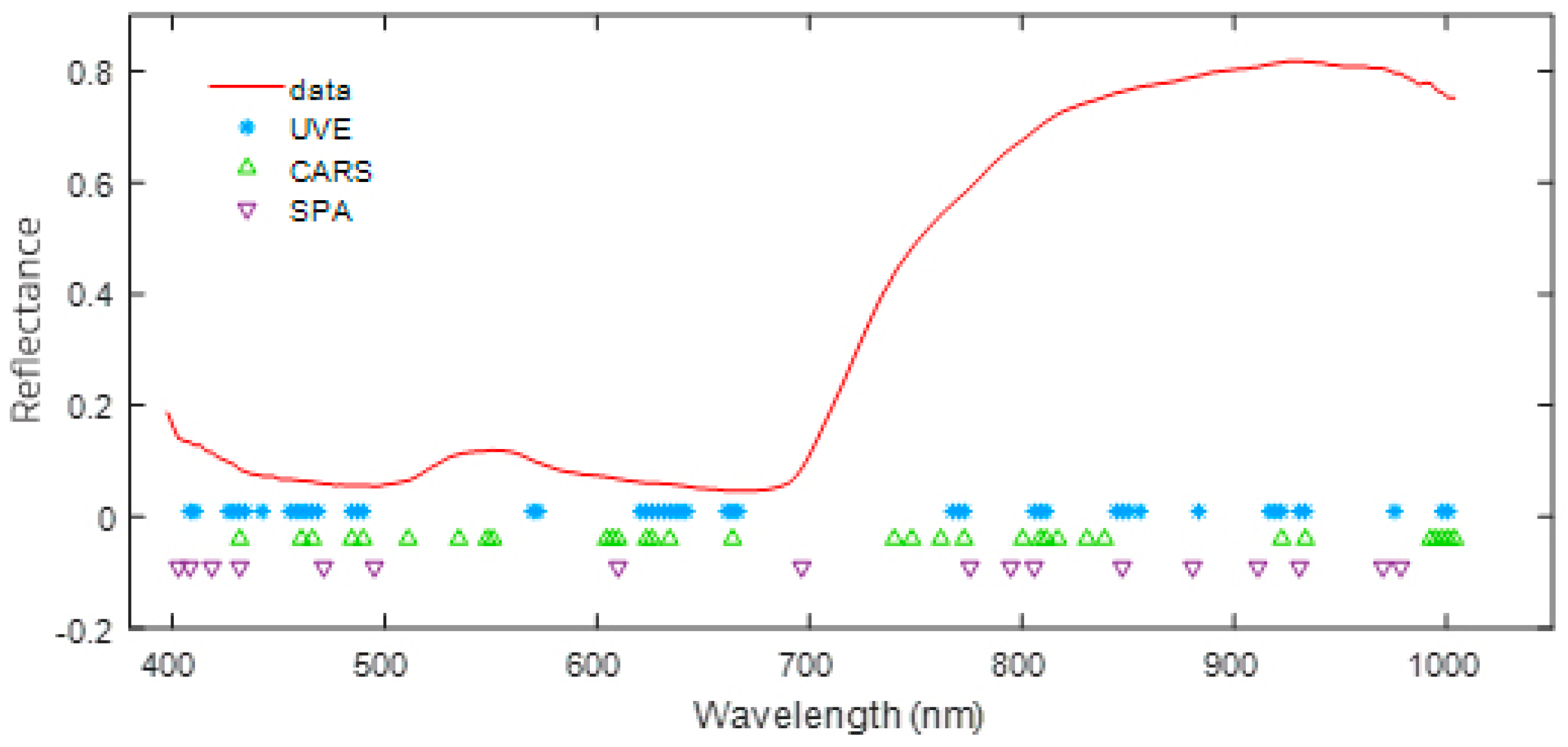
2.5. Identification of Important Wavelengths
2.6. Identification of Important Wavelengths (Without Mixed Bacteria)
3. Discussion
4. Materials and Methods
4.1. Sample Preparation
4.2. HIS System and Spectra Acquisition
4.2.1. HSI System
4.2.2. Spectra Extraction and Data Split
4.3. Data Enhancement
4.4. Principal Component Analysis
4.5. Spectral Preprocessing
4.6. Characteristic Wavelengths Selection
4.7. Modeling Algorithm
4.8. Model Evaluation
4.9. Computational Environment
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Xoo | Xanthomonas oryzae pv. oryzae |
| P. ananatis | Pantoea ananatis |
| E. asburiae | Enterobacter asburiae |
| PCR | Polymerase chain reaction |
| HSI | Hyperspectral imaging |
| PLSDA | Partial least squares discriminant analysis |
| PCA | Principal component analysis |
| KNN | K-nearest neighbors |
| RF | Random forest |
| 1DCNN | One-dimensional convolutional neural networks |
| GAN | Generative Adversarial Networks |
| SG | Savitzky–Golay filter |
| NOR | Normalization |
| BASE | Baseline correction |
| SNV | Standard normal variate |
| MSC | Multiplicative scatter correction |
| UVE | Uninformative variable elimination |
| CARS | Competitive adaptive reweighted sampling |
| SPA | Successive projections algorithm |
| ROI | Region of interest |
| Conv | Convolutional |
| BN | Batch normalization |
| FC | Fully connected |
| TP | True positive |
| TN | True negative |
| FP | False positive |
| FN | False negative |
References
- Peng, S.; Tang, Q.; Zou, Y. Current Status and Challenges of Rice Production in China. Plant Prod. Sci. 2009, 12, 3–8. [Google Scholar] [CrossRef]
- Wang, Y.; Xue, Y.; Li, J. Towards molecular breeding and improvement of rice in China. Trends Plant Sci. 2005, 10, 610–614. [Google Scholar] [CrossRef] [PubMed]
- Mondal, K.K.; Mani, C.; Singh, J.; Kim, J.G.; Mudgett, M.B. A new leaf blight of rice caused by Pantoea ananatis in India. Plant Dis. 2011, 95, 1582. [Google Scholar] [CrossRef]
- Kini, K.; Agnimonhan, R.; Afolabi, O.; Soglonou, B.; Silué, D.; Koebnik, R. First Report of a New Bacterial Leaf Blight of Rice Caused by Pantoea ananatis and Pantoea stewartii in Togo. Plant Dis. 2017, 101, 241. [Google Scholar] [CrossRef]
- Egorova, M.; Mazurin, E.; Ignatov, A.N. First report of Pantoea ananatis causing grain discolouration and leaf blight of rice in Russia. New Dis. Rep. 2015, 32, 21. [Google Scholar] [CrossRef]
- Toh, W.K.; Loh, P.C.; Wong, H.L. First Report of Leaf Blight of Rice Caused by Pantoea ananatis and Pantoea dispersa in Malaysia. Plant Dis. 2019, 103, 1764. [Google Scholar] [CrossRef]
- Luna, E.; Lang, J.; McClung, A.; Wamishe, Y.; Jia, Y.; Leach, J.E. First Report of Rice Bacterial Leaf Blight Disease Caused by Pantoea ananatis in the United States. Plant Dis. 2023, 107, 2214. [Google Scholar] [CrossRef]
- Wang, Q. Isolation and Identiifcation of a New Pathogen Pantoea ananatis Causing Rice Leaf Blight. Master’s Thesis, Anhui Agricultural University, Hefei, China, 2018. [Google Scholar]
- Yu, L.; Yang, C.; Ji, Z.; Zeng, Y.; Liang, Y.; Hou, Y. Complete Genomic Data of Pantoea ananatis Strain TZ39 Associated with New Bacterial Blight of Rice in China. Plant Dis. 2022, 106, 751–753. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Laborda, P.; Li, C.; Zhao, Y.; Liu, F. First Report of Bacterial Leaf Blight Caused by Enterobacter asburiae on Sorghum in Jiangsu Province, China. Plant Dis. 2023, 107, 4017. [Google Scholar] [CrossRef]
- Yu, L.; Yang, C.; Ji, Z.; Zeng, Y.; Liang, Y.; Hou, Y. First Report of New Bacterial Leaf Blight of Rice Caused by Pantoea ananatis in Southeast China. Plant Dis. 2022, 106, 310. [Google Scholar] [CrossRef]
- Xue, Y.; Hu, M.; Chen, S.; Hu, A.; Li, S.; Han, H.; Lu, G.; Zeng, L.; Zhou, J. Enterobacter asburiae and Pantoea ananatis Causing Rice Bacterial Blight in China. Plant Dis. 2021, 105, 2078–2088. [Google Scholar] [CrossRef] [PubMed]
- Aksoy, H.M.; Boluk, E.; Kaya, Y.; Marakli, S. The effect of leaf blight disease of rice caused by Pantoea ananatis on Nikita, Osr30 and RIRE1 retrotransposons’ movements. J. Plant Pathol. 2023, 105, 1629–1636. [Google Scholar] [CrossRef]
- Doni, F.; Ishak, M.N.; Suhaimi, N.S.M.; Syaputri, Y.; Han, L.; Mohamed, Z.; Mispan, M.S. Leaf blight disease of rice caused by Pantoea: Profile of an increasingly damaging disease in rice. Trop. Plant Pathol. 2023, 48, 1–10. [Google Scholar] [CrossRef]
- Hou, Y.; Yu, L.; Li, Y.; Chen, J. Indoor bacteriostatic effects of 16 fungicides against three pathogenic bacteria from rice. China Rice 2023, 29, 28–32. [Google Scholar] [CrossRef]
- Xu, H.; Yang, X.; Zang, Y.; Pan, R.; Gu, C. Development and application of a duplex PCR assay for the detection of Xanthomonas oryzae pv. oryzae and Pantoea ananatis. Plant Prot. 2023, 49, 194–200. [Google Scholar] [CrossRef]
- Wang, A.; Luo, J.; Wang, C.; Hou, Y.; Yang, B.; Tang, J.; Liu, S. Establishment and application of the Recombinase-Aided Amplification-Lateral Flow Dipstick detection method for Pantoea ananatis on rice. Australas. Plant Pathol. 2023, 52, 283–291. [Google Scholar] [CrossRef]
- Liao, J.; Tao, W.; Zang, Y.; Zeng, H.; Wang, P.; Luo, X. Research progress and prospect of key technologies in crop disease and insect pest monitoring. Trans. Chin. Soc. Agric. Mach. 2023, 54, 1–19. [Google Scholar] [CrossRef]
- Chen, Z.; Ren, J.; Tang, H.; Shi, Y.; Leng, P.; Liu, J.; Wang, L.; Wu, W.; Yao, Y.; Hasiyuya. Progress and perspectives on agricultural remote sensing research and applications in China. J. Remote Sens. 2016, 20, 748–767. [Google Scholar] [CrossRef]
- Zhao, C. Advances of research and application in remote sensing for agriculture. Trans. Chin. Soc. Agric. Mach. 2014, 45, 277–293. [Google Scholar] [CrossRef]
- Weng, H.; Cen, H.; He, Y. Hyperspectral model transfer for citrus canker detection based on direct standardization algorithm. Spectrosc. Spectr. Anal. 2018, 38, 235–239. [Google Scholar] [CrossRef]
- Mohd Asaari, M.S.; Mertens, S.; Verbraeken, L.; Dhondt, S.; Inzé, D.; Bikram, K.; Scheunders, P. Non-destructive analysis of plant physiological traits using hyperspectral imaging: A case study on drought stress. Comput. Electron. Agric. 2022, 195, 106806. [Google Scholar] [CrossRef]
- Ugarte Fajardo, J.; Bayona Andrade, O.; Criollo Bonilla, R.; Cevallos-Cevallos, J.; Mariduena-Zavala, M.; Ochoa Donoso, D.; Vicente Villardon, J.L. Early detection of black Sigatoka in banana leaves using hyperspectral images. Appl. Plant Sci. 2020, 8, e11383. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Ehsani, R.; Shi, Y.; de Castro, A.I.; Wang, S. Detection of multi-tomato leaf diseases (late blight, target and bacterial spots) in different stages by using a spectral-based sensor. Sci. Rep. 2018, 8, 2793. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, Q.; Lin, F.; Yin, X.; Gu, C.; Qiao, H. Development and Evaluation of a New Spectral Disease Index to Detect Wheat Fusarium Head Blight Using Hyperspectral Imaging. Sensors 2020, 20, 2260. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Cao, Y.; Xu, T.; Yu, F.; Zhao, D.; Zhang, G. Rice Leaf Blast Classification Method Based on Fused Features and One-Dimensional Deep Convolutional Neural Network. Remote Sens. 2021, 13, 3207. [Google Scholar] [CrossRef]
- Feng, L.; Wu, B.; He, Y.; Zhang, C. Hyperspectral Imaging Combined With Deep Transfer Learning for Rice Disease Detection. Front. Plant Sci. 2021, 12, 693521. [Google Scholar] [CrossRef]
- Wan, L.; Li, H.; Li, C.; Wang, A.; Yang, Y.; Wang, P. Hyperspectral Sensing of Plant Diseases: Principle and Methods. Agronomy 2022, 12, 1451. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, X.; Wu, Q.; Yang, G.; Tao, M.; Yang, Y.; He, Y. Rice bacterial blight resistant cultivar selection based on visible/near-infrared spectrum and deep learning. Plant Methods 2022, 18, 49. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Nie, Q.; Ji, H.; Wang, Y.; Wei, Y.; An, D. Hyperspectral imaging combined with generative adversarial network (GAN)-based data augmentation to identify haploid maize kernels. J. Food Compos. Anal. 2022, 106, 104346. [Google Scholar] [CrossRef]
- Li, H.; Zhang, L.; Sun, H.; Rao, Z.; Ji, H. Discrimination of unsound wheat kernels based on deep convolutional generative adversarial network and near-infrared hyperspectral imaging technology. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 268, 120722. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Li, P.; Tang, S.; Chen, S.; Tian, X.; Zhong, N. Hyperspectral imaging combined with convolutional neural network for accurately detecting adulteration in Atlantic salmon. Food Control 2023, 147, 109573. [Google Scholar] [CrossRef]
- Demilie, W.B. Plant disease detection and classification techniques: A comparative study of the performances. J. Big Data 2024, 11, 5. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, S.; Liu, J.; Wei, Y.; An, D.; Wu, J. Maize seed variety identification using hyperspectral imaging and self-supervised learning: A two-stage training approach without spectral preprocessing. Expert Syst. Appl. 2024, 238, 122113. [Google Scholar] [CrossRef]
- Danilov, R.; Kremneva, O.; Sereda, I.; Gasiyan, K.; Zimin, M.; Istomin, D.; Pachkin, A. Study of the Spectral Characteristics of Crops of Winter Wheat Varieties Infected with Pathogens of Leaf Diseases. Plants 2024, 13, 1892. [Google Scholar] [CrossRef] [PubMed]
- Lespinats, S.; Colange, B.; Dutykh, D. Nonlinear Dimensionality Reduction Techniques; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Xuan, G.; Li, Q.; Shao, Y.; Shi, Y. Early diagnosis and pathogenesis monitoring of wheat powdery mildew caused by blumeria graminis using hyperspectral imaging. Comput. Electron. Agric. 2022, 197, 106921. [Google Scholar] [CrossRef]
- Khan, A.; Vibhute, A.D.; Mali, S.; Patil, C.H. A systematic review on hyperspectral imaging technology with a machine and deep learning methodology for agricultural applications. Ecol. Inform. 2022, 69, 101678. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameter | Preprocessing Methods | Identification Accuracy | |
|---|---|---|---|---|
| Training Set | Testing Set | |||
| PLSDA | PCs = 10 | UVE | 0.8530 | 0.7824 |
| PCs = 10 | CARS | 0.8581 | 0.7731 | |
| PCs = 4 | SPA | 0.8429 | 0.7500 | |
| KNN | k = 2 | UVE | 0.8125 | 0.7824 |
| k = 2 | CARS | 0.8192 | 0.7824 | |
| k = 2 | SPA | 0.8378 | 0.7917 | |
| RF | n = 50, depth = 5 | UVE | 0.8125 | 0.7361 |
| n = 50, depth = 6 | CARS | 0.8057 | 0.7454 | |
| n = 50, depth = 5 | SPA | 0.8311 | 0.7639 | |
| 1DCNN | / | UVE | 0.9088 | 0.8611 |
| CARS | 0.8902 | 0.8287 | ||
| SPA | 0.9037 | 0.8472 | ||
| Label | Index | PLSDA | KNN | RF | 1DCNN |
|---|---|---|---|---|---|
| Health | Precision | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Recall | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| F1 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| Xoo | Precision | 0.7250 | 0.7234 | 0.7209 | 0.8409 |
| Recall | 0.7073 | 0.8293 | 0.7561 | 0.9024 | |
| F1 | 0.7160 | 0.7727 | 0.7381 | 0.8706 | |
| SC1 | Precision | 0.9730 | 0.8889 | 0.8409 | 1.0000 |
| Recall | 0.8000 | 0.8333 | 0.8222 | 0.9556 | |
| F1 | 0.8780 | 0.8602 | 0.8315 | 0.9773 | |
| SC7 | Precision | 0.6458 | 0.6170 | 0.6275 | 0.7509 |
| Recall | 0.7209 | 0.6744 | 0.7442 | 0.8372 | |
| F1 | 0.6813 | 0.6444 | 0.6809 | 0.7660 | |
| SC1–SC7 | Precision | 0.6400 | 0.6923 | 0.6486 | 0.7838 |
| Recall | 0.6956 | 0.5870 | 0.5217 | 0.6304 | |
| F1 | 0.6667 | 0.6353 | 0.5783 | 0.6988 |
| Label | Index | PLSDA | KNN | RF | 1DCNN |
|---|---|---|---|---|---|
| Health | Precision | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Recall | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| F1 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| Xoo | Precision | 0.9000 | 0.7917 | 0.8605 | 0.9286 |
| Recall | 0.8780 | 0.9268 | 0.9024 | 0.9512 | |
| F1 | 0.8889 | 0.8539 | 0.8810 | 0.9398 | |
| SC1 | Precision | 0.9773 | 0.9524 | 1.0000 | 1.0000 |
| Recall | 0.9556 | 0.8889 | 0.9111 | 1.0000 | |
| F1 | 0.9663 | 0.9195 | 0.9535 | 1.0000 | |
| SC7 | Precision | 0.8667 | 0.8974 | 0.8444 | 0.9524 |
| Recall | 0.9070 | 0.8140 | 0.8837 | 0.9302 | |
| F1 | 0.8864 | 0.8537 | 0.8636 | 0.9412 |
| Label | Raw Data | Training Set | Testing Set | |
|---|---|---|---|---|
| Raw Data | Enhanced Data | |||
| Health | 58 | 17 | 117 | 41 |
| Xoo | 58 | 17 | 117 | 41 |
| SC1 | 64 | 19 | 119 | 45 |
| SC7 | 62 | 19 | 119 | 43 |
| SC1–SC7 | 66 | 20 | 120 | 46 |
| Total | 308 | 92 | 592 | 216 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Tang, S.; Lin, C.; Lin, Z.; Zhang, L.; Dong, W.; Zhong, N. Hyperspectral Imaging and Machine Learning for Diagnosing Rice Bacterial Blight Symptoms Caused by Xanthomonas oryzae pv. oryzae, Pantoea ananatis and Enterobacter asburiae. Plants 2025, 14, 733. https://doi.org/10.3390/plants14050733
Zhang M, Tang S, Lin C, Lin Z, Zhang L, Dong W, Zhong N. Hyperspectral Imaging and Machine Learning for Diagnosing Rice Bacterial Blight Symptoms Caused by Xanthomonas oryzae pv. oryzae, Pantoea ananatis and Enterobacter asburiae. Plants. 2025; 14(5):733. https://doi.org/10.3390/plants14050733
Chicago/Turabian StyleZhang, Meng, Shuqi Tang, Chenjie Lin, Zichao Lin, Liping Zhang, Wei Dong, and Nan Zhong. 2025. "Hyperspectral Imaging and Machine Learning for Diagnosing Rice Bacterial Blight Symptoms Caused by Xanthomonas oryzae pv. oryzae, Pantoea ananatis and Enterobacter asburiae" Plants 14, no. 5: 733. https://doi.org/10.3390/plants14050733
APA StyleZhang, M., Tang, S., Lin, C., Lin, Z., Zhang, L., Dong, W., & Zhong, N. (2025). Hyperspectral Imaging and Machine Learning for Diagnosing Rice Bacterial Blight Symptoms Caused by Xanthomonas oryzae pv. oryzae, Pantoea ananatis and Enterobacter asburiae. Plants, 14(5), 733. https://doi.org/10.3390/plants14050733