
GWAS Identifies SNP Markers and Candidate Genes for Off-Flavours and Protein Content in Faba Bean (Vicia faba L.)

 , , , , ,
, , , , ,
Abstract
1. Introduction
2. Results
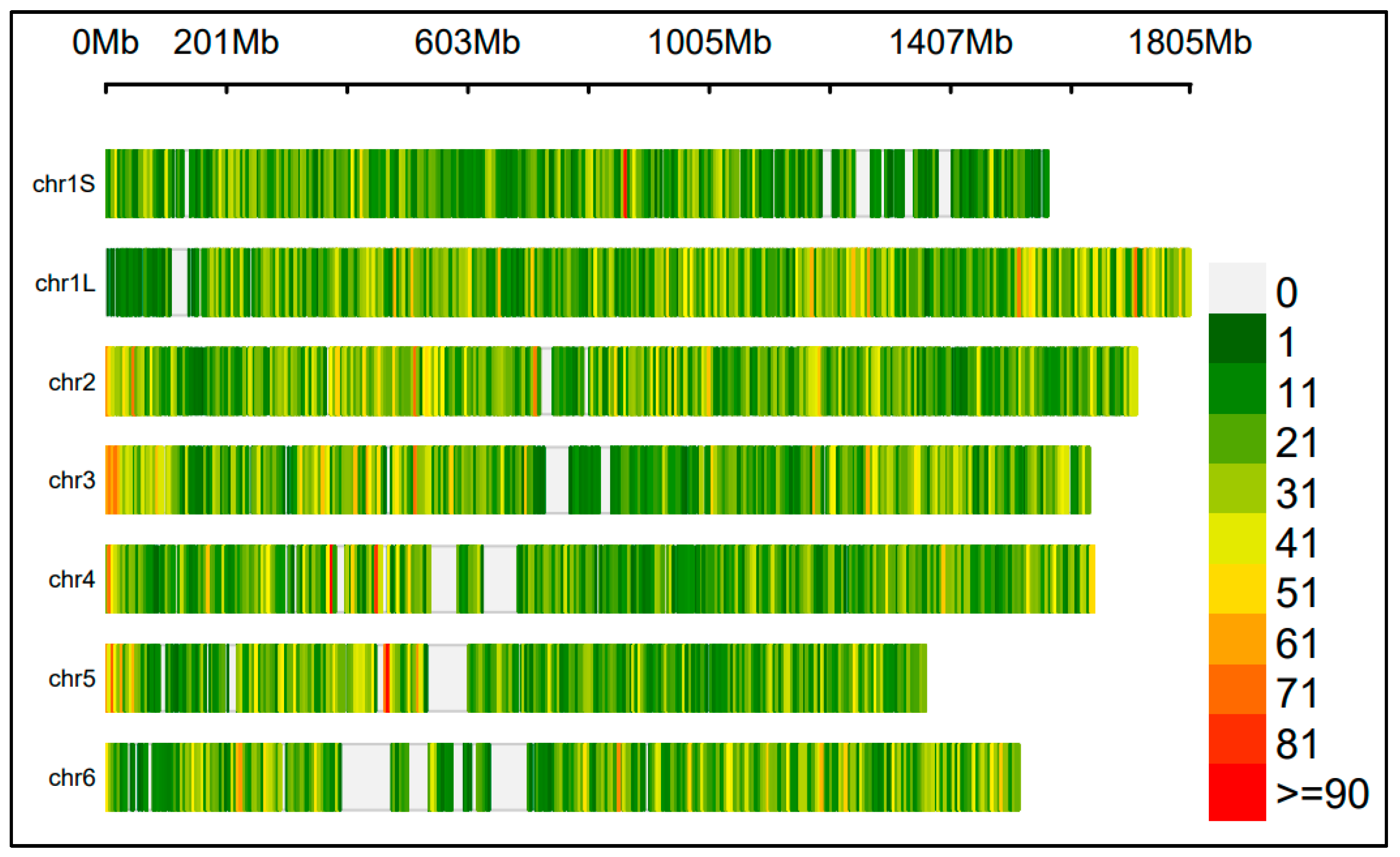
2.1. A Large SNP Panel for GWAS
2.2. Reliable NIRS Prediction Models
2.3. Large Phenotypic Variability
2.4. Trait-Specific Genotype-by-Year Interaction (GxY)
2.5. High Heritability (h2) for Oil, Fatty Acids, Protein, and Tannins
2.6. Specific Type-A Additive Genetic Correlations (ρtype-A) Between Traits
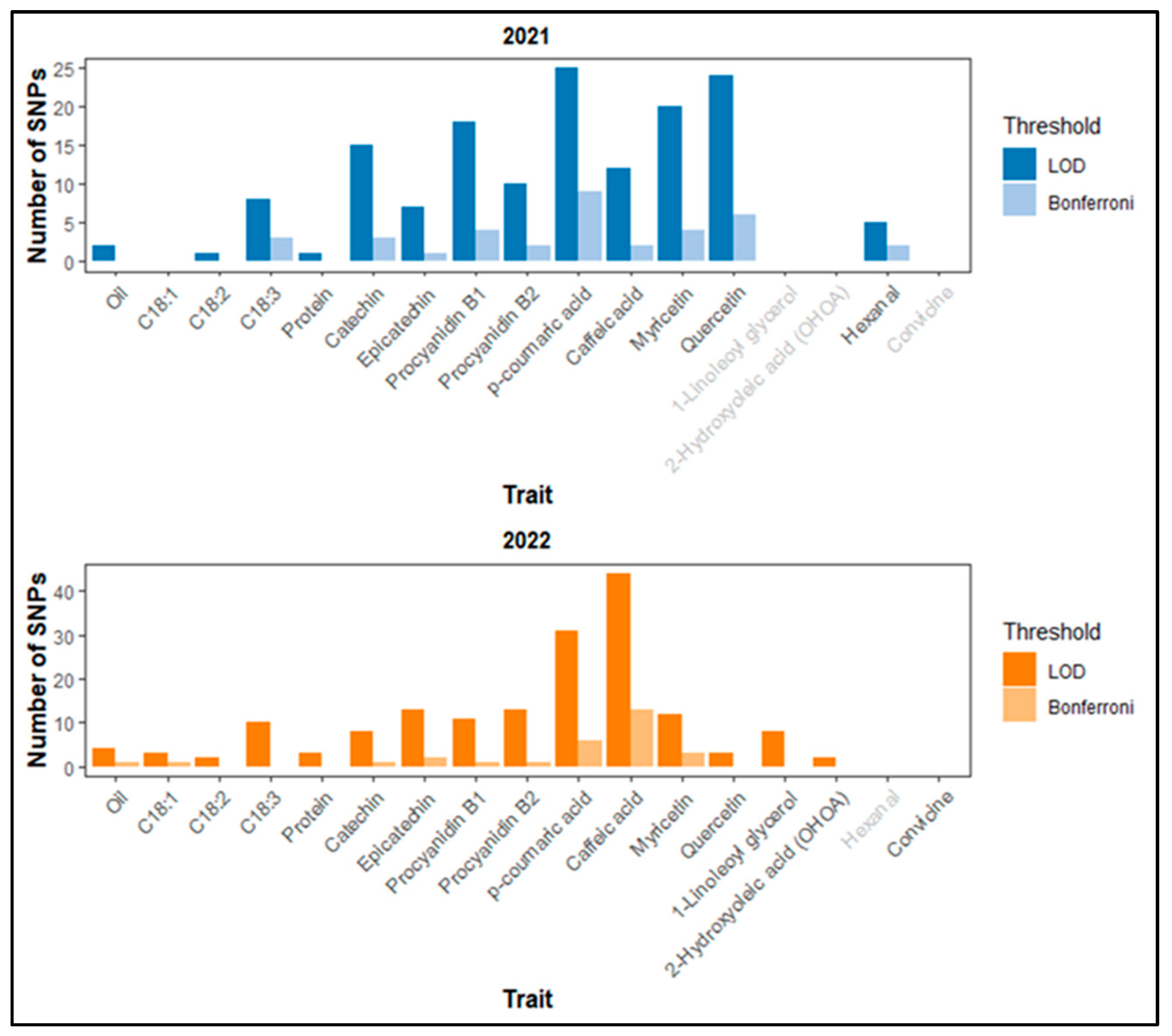
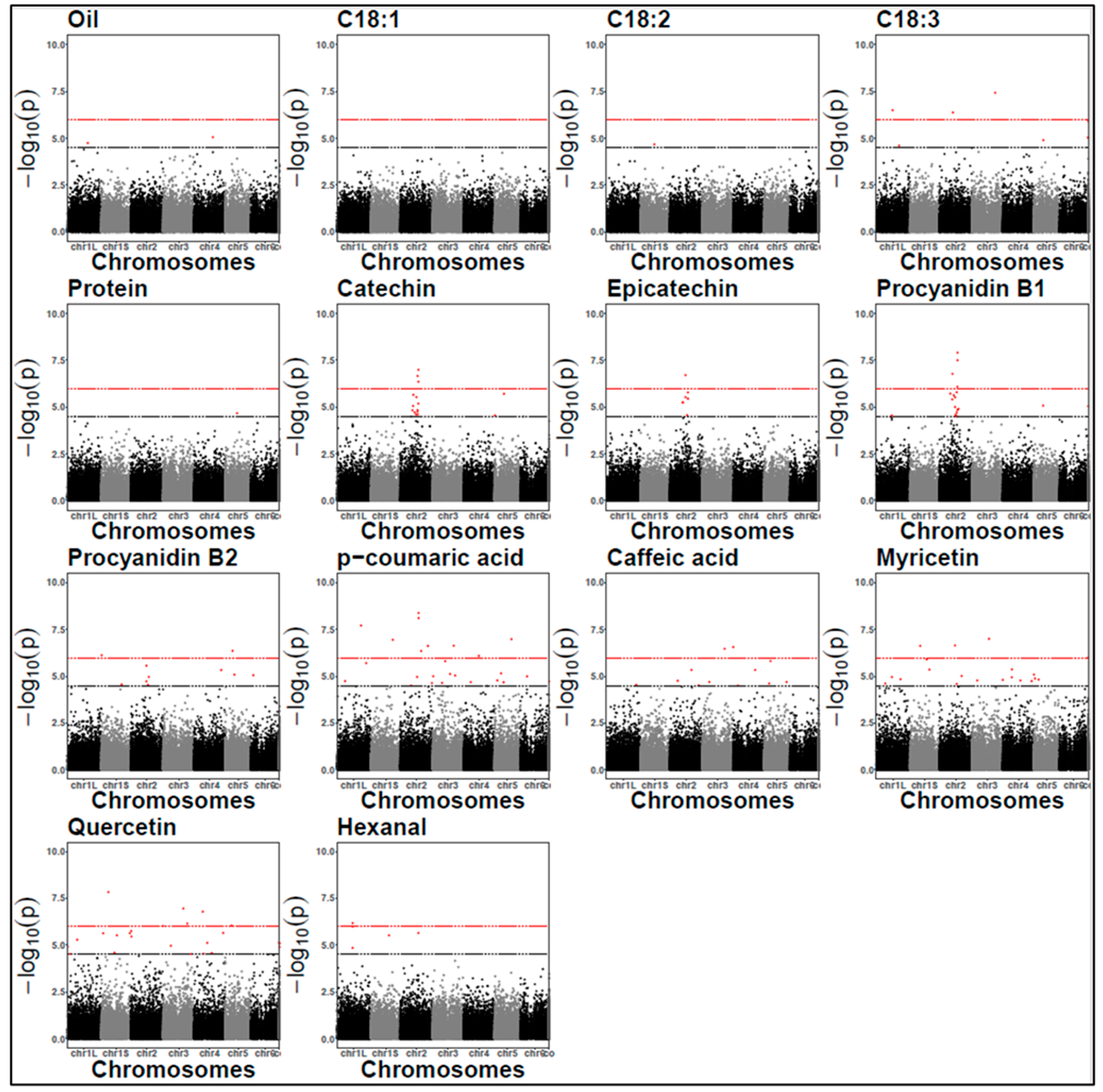
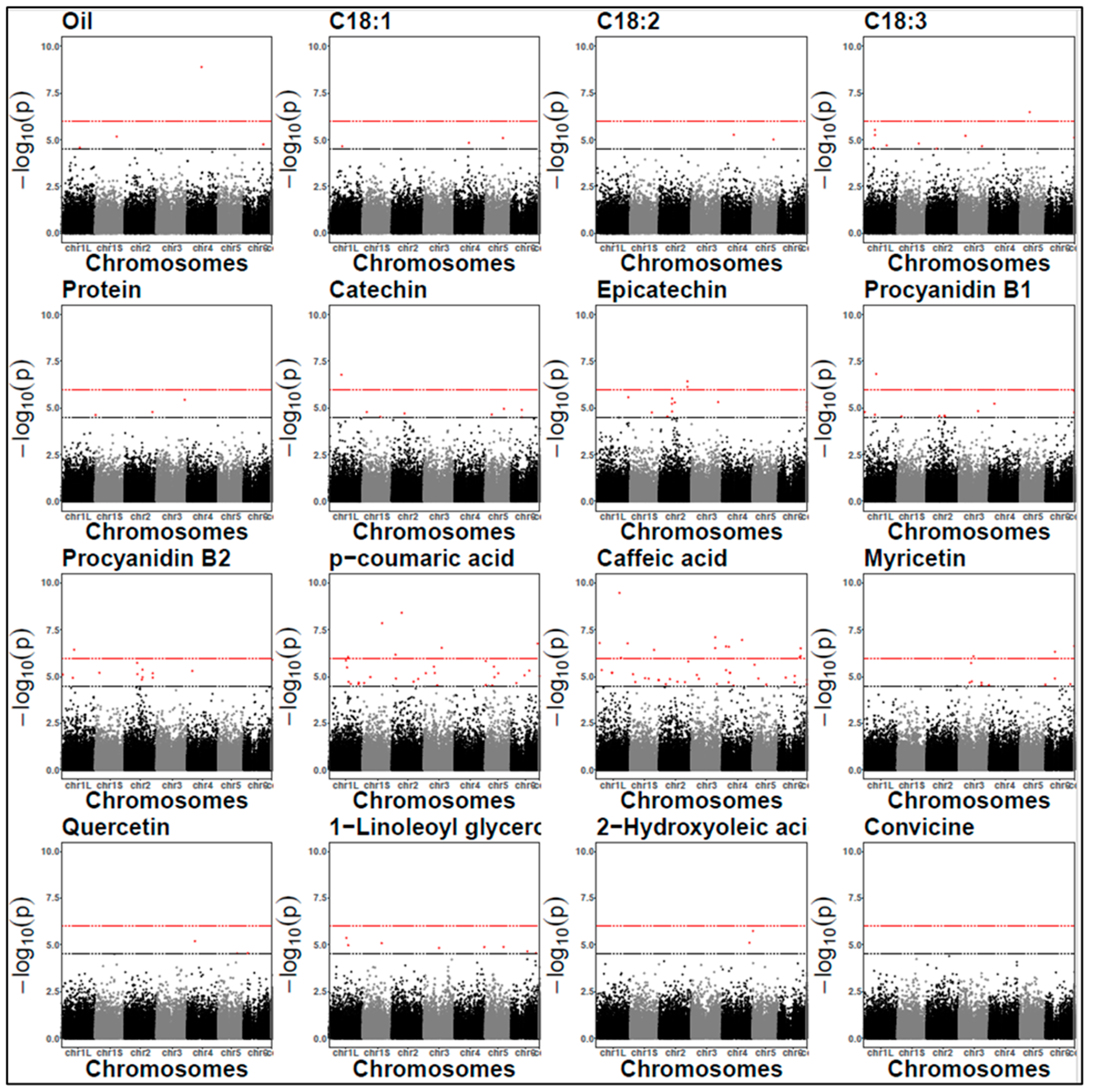
2.7. Identification of SNPs via GWAS
2.8. Candidate Genes
3. Discussion
Novel QTLs and Candidate Genes
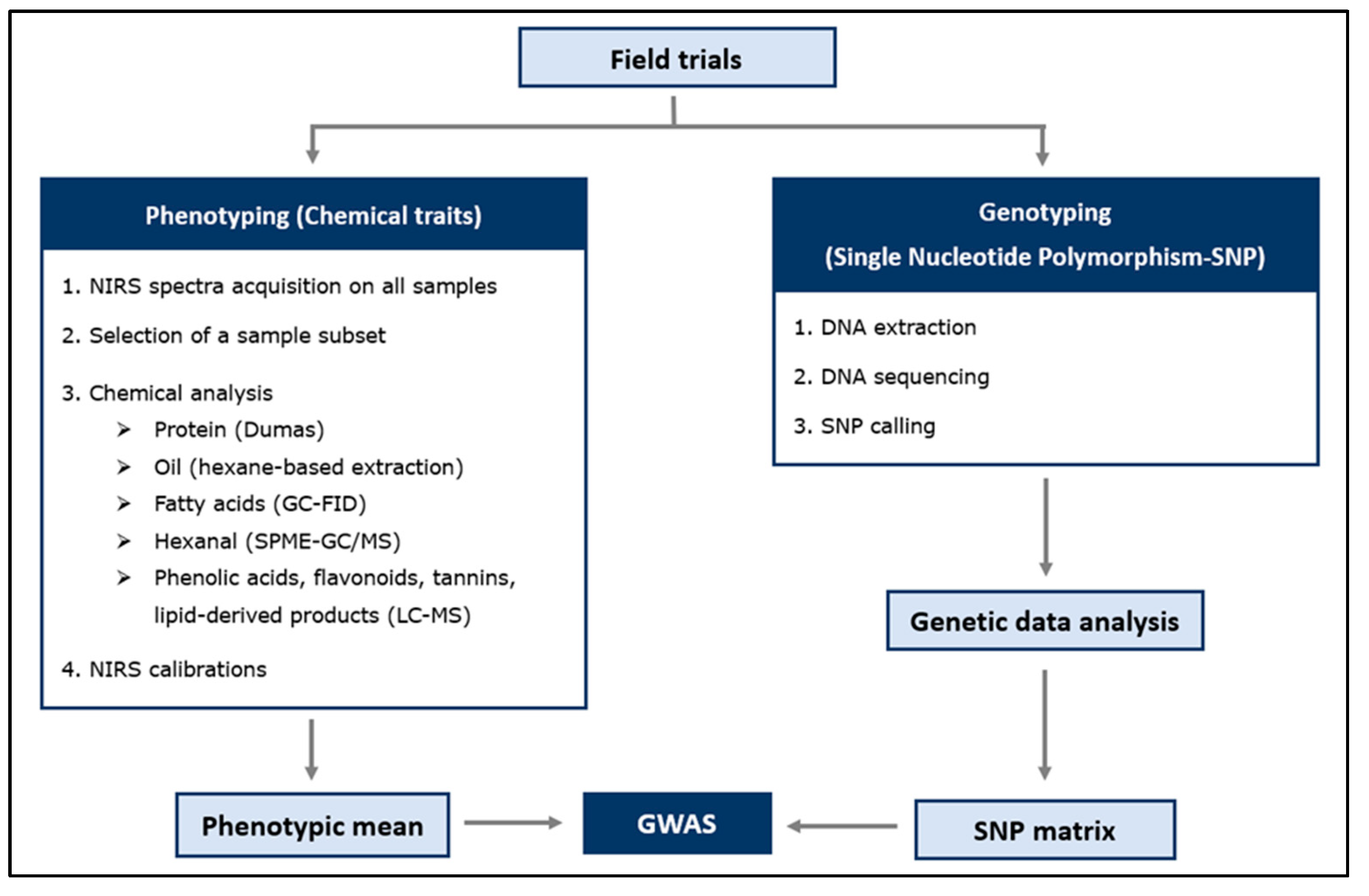
4. Material and Methods
4.1. Plant Material and Experimental Design
4.2. Phenotyping: NIRS (Near-Infrared Spectroscopy) and Chemical Analysis
4.2.1. NIRS Spectra Acquisition
4.2.2. Sub-Sample Sample Selection (Training Set)
4.2.3. Chemical Analysis of Protein, Oil, and Fatty Acids
4.2.4. Gas Chromatography-Mass Spectrometry (GC-MS) Measurements of Volatile Compounds (VOCs)
4.2.5. Liquid Chromatography-Mass Spectrometry (LC-MS) of Non VOCs
4.2.6. Predictive Models Based on NIRS
4.3. Genetic and Phenotypic Data Analysis
4.3.1. DNA Extraction, Sequencing, and SNP Typing
4.3.2. Genomic Relationship Matrix (G) and Principal Component Analysis (PCA)
4.3.3. Field Trial Analysis: Adjusted Mean, Heritability, Type-B, and Type-A Additive Genetic Correlations
4.3.4. Linkage Disequilibrium Decay
4.3.5. Genome-Wide Association Study (GWAS)
4.3.6. Candidate Gene Identification and Putative SNP Effects
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Field Trial Analysis: Adjusted Mean, Heritability, Type-B and Type-A Additive Genetic Correlations
References
- Ciani, M.; Lippolis, A.; Fava, F.; Rodolfi, L.; Niccolai, A.; Tredici, M.R. Microbes: Food for the Future. Foods 2021, 10, 971. [Google Scholar] [CrossRef] [PubMed]
- McClements, D.J.; Grossmann, L. A brief review of the science behind the design of healthy and sustainable plant-based foods. NPJ Sci. Food 2021, 5, 17. [Google Scholar] [CrossRef] [PubMed]
- Possidónio, C.; Prada, M.; Graça, J.; Piazza, J. Consumer perceptions of conventional and alternative protein sources: A mixed-methods approach with meal and product framing. Appetite 2021, 156, 104860. [Google Scholar] [CrossRef] [PubMed]
- Andersson, J.; Hannah, K. To What Extent EU Regulations and Consumer Behavior Have Affected the Expansion of Alternative Proteins: A Comparison of the Plant-Based and Cell-Based Meat Markets. Master’s Thesis, Uppsala Univeristy, Uppsala, Sweden, 2023. [Google Scholar]
- Martineau-Côté, D.; L’Hocine, L.; Tuccillo, F.; Wanasundara, J.P.; Stoddard, F.L. Faba Bean as a Sustainable Plant Protein Source. In Sustainable Protein Sources; Elsevier: Amsterdam, The Netherlands, 2024; pp. 163–184. [Google Scholar] [CrossRef]
- Coda, R.; Varis, J.; Verni, M.; Rizzello, C.G.; Katina, K. Improvement of the protein quality of wheat bread through faba bean sourdough addition. LWT—Food Sci. Technol. 2017, 82, 296–302. [Google Scholar] [CrossRef]
- Le Roux, L.; Mejean, S.; Chacon, R.; Lopez, C.; Dupont, D.; Deglaire, A.; Nau, F.; Jeantet, R. Plant proteins partially replacing dairy proteins greatly influence infant formula functionalities. LWT 2020, 120, 108891. [Google Scholar] [CrossRef]
- Chan, C.K.Y.; Fabek, H.; Mollard, R.C.; Jones, P.J.H.; Tulbek, M.C.; Chibbar, R.N.; Gangola, M.P.; Ramadoss, B.R.; Sanchez-Hernandez, D.; Anderson, G.H. Faba bean protein flours added to pasta reduce post-ingestion glycaemia, and increase satiety, protein content and quality. Food Funct. 2019, 10, 7476–7488. [Google Scholar] [CrossRef]
- do Carmo, C.S.; Knutsen, S.H.; Malizia, G.; Dessev, T.; Geny, A.; Zobel, H.; Myhrer, K.S.; Varela, P.; Sahlstrøm, S. Meat analogues from a faba bean concentrate can be generated by high moisture extrusion. Future Foods 2021, 3, 100014. [Google Scholar] [CrossRef]
- Ferawati, F.; Zahari, I.; Barman, M.; Hefni, M.; Ahlström, C.; Witthöft, C.; Östbring, K. High-moisture meat analogues produced from yellow pea and faba bean protein isolates/concentrate: Effect of raw material composition and extrusion parameters on texture properties. Foods 2021, 10, 843. [Google Scholar] [CrossRef]
- Wang, Y.; Tuccillo, F.; Lampi, A.M.; Knaapila, A.; Pulkkinen, M.; Kariluoto, S.; Coda, R.; Edelmann, M.; Jouppila, K.; Sandell, M.; et al. Flavor challenges in extruded plant-based meat alternatives: A review. Compr. Rev. Food Sci. Food Saf. 2022, 21, 2898–2929. [Google Scholar] [CrossRef]
- Roland, W.S.; Pouvreau, L.; Curran, J.; van de Velde, F.; de Kok, P.M. Flavor aspects of pulse ingredients. Cereal Chem. 2017, 94, 58–65. [Google Scholar] [CrossRef]
- Seidel, U. Sensorische und Gaschromatographische Untersuchungen zum Off-Flavour von Ackerbohnensamen und-proteinisolat: Ein Beitrag zur “Subjektiven Gustometrie und Olfaktometrie” und zur Reaktionskinetik Sensorischer Veränderungen. Ph.D. Thesis, Humboldt University of Berlin, Berlin, Germany, 1976. [Google Scholar]
- Schultz, M.; Hoppe, K.; Schmandke, H. Off-flavour reduction in Vicia faba bean protein isolate. Food Chem. 1988, 30, 129–135. [Google Scholar] [CrossRef]
- Fereidoon, S.; Abrehem, A. Lipid-derived flavours and off-flavours in food. In Encyclopedia of Food Chemistry; Elsevier: Amsterdam, The Netherlands, 2018; pp. 182–192. [Google Scholar] [CrossRef]
- Glaser, P.; Dawid, C.; Meister, S.; Bader-Mittermaier, S.; Schott, M.; Eisner, P.; Hofmann, T. Molecularization of Bitter Off-Taste Compounds in Pea-Protein Isolates (Pisum sativum L.). J. Agric. Food Chem. 2020, 68, 10374–10387. [Google Scholar] [CrossRef] [PubMed]
- Drewnowski, A.; Gomez-Carneros, C. Bitter taste, phytonutrients, and the consumer: A review. Am. J. Clin. Nutr. 2000, 72, 1424–1435. [Google Scholar] [CrossRef]
- de Camargo, A.C.; Schwember, A.R. Phenolic-driven sensory changes in functional foods. J. Food Bioact. 2019, 5, 6–7. [Google Scholar] [CrossRef]
- Iwaniak, A.; Hrynkiewicz, M.; Bucholska, J.; Minkiewicz, P.; Darewicz, M. Understanding the nature of bitter-taste di- and tripeptides derived from food proteins based on chemometric analysis. J. Food Biochem. 2019, 43, e12500. [Google Scholar] [CrossRef]
- Peleg, H.; Gacon, K.; Schlich, P.; Noble, A.C. Bitterness and astringency of flavan-3-ol monomers, dimers and trimers. J. Sci. Food Agric. 1999, 79, 1123–1128. [Google Scholar] [CrossRef]
- Soares, S.; Brandao, E.; Guerreiro, C.; Soares, S.; Mateus, N.; De Freitas, V. Tannins in Food: Insights into the Molecular Perception of Astringency and Bitter Taste. Molecules 2020, 25, 2590. [Google Scholar] [CrossRef]
- Karolkowski, A.; Belloir, C.; Lucchi, G.; Martin, C.; Bouzidi, E.; Levavasseur, L.; Salles, C.; Briand, L. Activation of bitter taste receptors by saponins and alkaloids identified in faba beans (Vicia faba L. minor). Food Chem. 2023, 426, 136548. [Google Scholar] [CrossRef]
- Lippolis, A.; Roland, W.S.U.; Bocova, O.; Pouvreau, L.; Trindade, L.M. The challenge of breeding for reduced off-flavor in faba bean ingredients. Front. Plant Sci. 2023, 14, 1286803. [Google Scholar] [CrossRef]
- Akkad, R.; Kharraz, E.; Han, J.; House, J.D.; Curtis, J.M. Characterisation of the volatile flavour compounds in low and high tannin faba beans (Vicia faba var. minor) grown in Alberta, Canada. Food Res. Int. 2019, 120, 285–294. [Google Scholar] [CrossRef]
- Johnson, J.B.; Skylas, D.J.; Mani, J.S.; Xiang, J.; Walsh, K.B.; Naiker, M. Phenolic Profiles of Ten Australian Faba Bean Varieties. Molecules 2021, 26, 4642. [Google Scholar] [CrossRef] [PubMed]
- Choi, Y.-M.; Yoon, H.; Shin, M.-J.; Lee, S.; Yi, J.; Jeon, Y.-a.; Wang, X.; Desta, K.T. Nutrient Levels, Bioactive Metabolite Contents, and Antioxidant Capacities of Faba Beans as Affected by Dehulling. Foods 2023, 12, 4063. [Google Scholar] [CrossRef] [PubMed]
- De Angelis, D.; Pasqualone, A.; Costantini, M.; Ricciardi, L.; Lotti, C.; Pavan, S.; Summo, C. Data on the proximate composition, bioactive compounds, physicochemical and functional properties of a collection of faba beans (Vicia faba L.) and lentils (Lens culinaris Medik.). Data Brief. 2021, 34, 106660. [Google Scholar] [CrossRef] [PubMed]
- Zhao, N.; Xue, D.; Miao, Y.; Wang, Y.; Zhou, E.; Zhou, Y.; Yao, M.; Gu, C.; Wang, K.; Li, B.; et al. Construction of a high-density genetic map for faba bean (Vicia faba L.) and quantitative trait loci mapping of seed-related traits. Front. Plant Sci. 2023, 14, 1201103. [Google Scholar] [CrossRef] [PubMed]
- Ohm, H.; Åstrand, J.; Ceplitis, A.; Bengtsson, D.; Hammenhag, C.; Chawade, A.; Grimberg, Å. Novel SNP markers for flowering and seed quality traits in faba bean (Vicia faba L.): Characterization and GWAS of a diversity panel. Front. Plant Sci. 2023, 15, 1348014. [Google Scholar] [CrossRef]
- Gutierrez, N.; Torres, A.M. Characterization and diagnostic marker for TTG1 regulating tannin and anthocyanin biosynthesis in faba bean. Sci. Rep. 2019, 9, 16174. [Google Scholar] [CrossRef]
- Gutierrez, N.; Avila, C.M.; Torres, A.M. The bHLH transcription factor VfTT8 underlies zt2, the locus determining zero tannin content in faba bean (Vicia faba L.). Sci. Rep. 2020, 10, 14299. [Google Scholar] [CrossRef]
- Gutierrez, N.; Avila, C.M.; Rodriguez-Suarez, C.; Moreno, M.T.; Torres, A.M. Development of SCAR markers linked to a gene controlling absence of tannins in faba bean. Mol. Breed. 2006, 19, 305–314. [Google Scholar] [CrossRef]
- Gutierrez, N.; Avila, C.M.; Duc, G.; Marget, P.; Suso, M.J.; Moreno, M.T.; Torres, A.M. CAPs markers to assist selection for low vicine and convicine contents in faba bean (Vicia faba L.). Theor. Appl. Genet. 2006, 114, 59–66. [Google Scholar] [CrossRef]
- Tacke, R.; Ecke, W.; Höfer, M.; Sass, O.; Link, W. Fine-mapping of the major locus for vicine and convicine in faba bean (Vicia faba) and marker-assisted breeding of a novel, low vicine and convicine winter faba bean population. Plant Breed. 2022, 141, 644–657. [Google Scholar] [CrossRef]
- Bjornsdotter, E.; Nadzieja, M.; Chang, W.; Escobar-Herrera, L.; Mancinotti, D.; Angra, D.; Xia, X.; Tacke, R.; Khazaei, H.; Crocoll, C.; et al. VC1 catalyses a key step in the biosynthesis of vicine in faba bean. Nat. Plants 2021, 7, 923–931. [Google Scholar] [CrossRef] [PubMed]
- Blanco, M.; Castillo, M.; Peinado, A.; Beneyto, R. Determination of low analyte concentrations by near-infrared spectroscopy: Effect of spectral pretreatments and estimation of multivariate detection limits. Anal. Chim. Acta 2007, 581, 318–323. [Google Scholar] [CrossRef] [PubMed]
- Lippolis, A.; Gezan, S.A.; Zuidgeest, J.; Cafaro, V.; Dinter, B.-J.; Elzes, G.; Paulo, M.-J.; Trindade, L.M. Targeted genotyping (90K-SPET) facilitates genome-wide association studies and the prediction of yield-related traits in faba bean (Vicia faba L.). Res. Sq. 2024. [Google Scholar] [CrossRef]
- Welch, R.W.; Wynne Griffiths, D. Variation in the oil content and fatty acid composition of field beans (Vicia faba) and peas (Pisum spp.). J. Sci. Food Agric. 2006, 35, 1282–1289. [Google Scholar] [CrossRef]
- Yoshida, H.; Saiki, M.; Yoshida, N.; Tomiyama, Y.; Mizushina, Y. Fatty acid distribution in triacylglycerols and phospholipids of broad beans (Vicia faba). Food Chem. 2009, 112, 924–928. [Google Scholar] [CrossRef]
- Loizzo, M.R.; Bonesi, M.; Leporini, M.; Falco, T.; Sicari, V.; Tundis, R. Chemical Profile and In Vitro Bioactivity of Vicia faba Beans and Pods. Proceedings 2021, 70, 45. [Google Scholar] [CrossRef]
- Turco, I.; Ferretti, G.; Bacchetti, T. Review of the health benefits of Faba bean (Vicia faba L.) polyphenols. J. Food Nutr. Res. 2016, 55, 283–293. [Google Scholar]
- Glaser, P.; Mittermeier-Klessinger, V.K.; Spaccasassi, A.; Hofmann, T.; Dawid, C. Quantification and Bitter Taste Contribution of Lipids and Their Oxidation Products in Pea-Protein Isolates (Pisum sativum L.). J. Agric. Food Chem. 2021, 69, 8768–8776. [Google Scholar] [CrossRef]
- Koyama, T.; Inada, T.; Kuwabara, C.; Arakawa, K.; Fujikawa, S. Anti-ice nucleating activity of polyphenol compounds against silver iodide. Cryobiology 2014, 69, 223–228. [Google Scholar] [CrossRef]
- Shomali, A.; Das, S.; Arif, N.; Sarraf, M.; Zahra, N.; Yadav, V.; Aliniaeifard, S.; Chauhan, D.K.; Hasanuzzaman, M. Diverse physiological roles of flavonoids in plant environmental stress responses and tolerance. Plants 2022, 11, 3158. [Google Scholar] [CrossRef]
- Oomah, B.D.; Razafindrainibe, M.; Drover, J.C. Headspace volatile components of Canadian grown low-tannin faba bean (Vicia faba L.) genotypes. J. Sci. Food Agric. 2014, 94, 473–481. [Google Scholar] [CrossRef] [PubMed]
- Fenn, D.; Wang, N.; Maximiuk, L. Effect of variety, growing location and year on composition, certain antinutritional factors, and functionality of faba beans (Vicia faba) grown in Canada. Cereal Chem. 2024, 101, 1020–1031. [Google Scholar] [CrossRef]
- Oomah, B.D.; Luc, G.; Leprelle, C.; Drover, J.C.; Harrison, J.E.; Olson, M. Phenolics, phytic acid, and phytase in Canadian-grown low-tannin faba bean (Vicia faba L.) genotypes. J. Agric. Food Chem. 2011, 59, 3763–3771. [Google Scholar] [CrossRef] [PubMed]
- Mora, J.; Pott, D.M.; Osorio, S.; Vallarino, J.G. Regulation of plant tannin synthesis in crop species. Front. Genet. 2022, 13, 870976. [Google Scholar] [CrossRef] [PubMed]
- Walter, S.; Zehring, J.; Mink, K.; Ramminger, S.; Quendt, U.; Zocher, K.; Rohn, S. Analysis and correlations of the protein content and selected ‘antinutrients’ of faba beans (Vicia faba) in a German sample set of the cultivation years 2016, 2017, and 2018. J. Sci. Food Agric. 2023, 103, 729–737. [Google Scholar] [CrossRef]
- Hong, H.; Yoosefzadeh-Najafabadi, M.; Rajcan, I. Correlations between soybean seed quality traits using a genome-wide association study panel grown in Canadian and Ukrainian mega-environments. Can. J. Plant Sci. 2022, 102, 1040–1052. [Google Scholar] [CrossRef]
- Diers, B.W.; Specht, J.E.; Graef, G.L.; Song, Q.; Rainey, K.M.; Ramasubramanian, V.; Liu, X.; Myers, C.L.; Stupar, R.M.; An, Y.Q.C. Genetic architecture of protein and oil content in soybean seed and meal. Plant Genome 2023, 16, e20308. [Google Scholar] [CrossRef]
- Yao, X.; Nie, J.; Bai, R.; Sui, X. Amino acid transporters in plants: Identification and function. Plants 2020, 9, 972. [Google Scholar] [CrossRef]
- Miranda, M.; Borisjuk, L.; Tewes, A.; Heim, U.; Sauer, N.; Wobus, U.; Weber, H. Amino acid permeases in developing seeds of Vicia faba L.: Expression precedes storage protein synthesis and is regulated by amino acid supply. Plant J. 2001, 28, 61–71. [Google Scholar] [CrossRef]
- Angelovici, R.; Batushansky, A.; Deason, N.; Gonzalez-Jorge, S.; Gore, M.A.; Fait, A.; DellaPenna, D. Network-guided GWAS improves identification of genes affecting free amino acids. Plant Physiol. 2017, 173, 872–886. [Google Scholar] [CrossRef]
- Lutkewitte, A.J.; Finck, B.N. Regulation of signaling and metabolism by lipin-mediated phosphatidic acid phosphohydrolase activity. Biomolecules 2020, 10, 1386. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, V.C.; Nakamura, Y. Distinctly localized lipid phosphate phosphatases mediate endoplasmic reticulum glycerolipid metabolism in Arabidopsis. Plant Cell 2023, 35, 1548–1571. [Google Scholar] [CrossRef] [PubMed]
- Li-Beisson, Y.; Shorrosh, B.; Beisson, F.; Andersson, M.X.; Arondel, V.; Bates, P.D.; Baud, S.; Bird, D.; DeBono, A.; Durrett, T.P. Acyl-lipid metabolism. Arab. Book Am. Soc. Plant Biol. 2013, 11, e0161. [Google Scholar] [CrossRef]
- Yuan, J.; Zhong, S.; Long, Y.; Guo, J.; Yu, Y.; Liu, J. Shikimate kinase plays important roles in anthocyanin synthesis in Petunia. Int. J. Mol. Sci. 2022, 23, 15964. [Google Scholar] [CrossRef]
- Dong, N.Q.; Lin, H.X. Contribution of phenylpropanoid metabolism to plant development and plant–environment interactions. J. Integr. Plant Biol. 2021, 63, 180–209. [Google Scholar] [CrossRef]
- Jin, S.-W.; Rahim, M.A.; Afrin, K.S.; Park, J.-I.; Kang, J.-G.; Nou, I.-S. Transcriptome profiling of two contrasting ornamental cabbage (Brassica oleracea var. acephala) lines provides insights into purple and white inner leaf pigmentation. BMC Genom. 2018, 19, 797. [Google Scholar] [CrossRef]
- Kodama, M.; Brinch-Pedersen, H.; Sharma, S.; Holme, I.B.; Joernsgaard, B.; Dzhanfezova, T.; Amby, D.B.; Vieira, F.G.; Liu, S.; Gilbert, M.T.P. Identification of transcription factor genes involved in anthocyanin biosynthesis in carrot (Daucus carota L.) using RNA-Seq. BMC Genom. 2018, 19, 811. [Google Scholar] [CrossRef]
- Murillo, D.A.; Gezan, S.A.; Heilman, A.M.; Walk, T.C.; Aparicio, J.S.; Horsley, R.D. FielDHub: A shiny app for design of experiments in life sciences. J. Open Source Softw. 2021, 6, 3122. [Google Scholar] [CrossRef]
- Lippolis, A.; Polo, P.V.; de Sousa, G.; Dechesne, A.; Pouvreau, L.; Trindade, L.M. High-throughput seed quality analysis in faba bean: Leveraging Near-InfraRed spectroscopy (NIRS) data and statistical methods. Food Chem. X 2024, 23, 101583. [Google Scholar] [CrossRef]
- Shenk, J.S.; Westerhaus, M.O. Populations Structuring of Near Infrared Spectra and Modified Partial Least Squares Regression. Crop Sci. 1991, 31, 1548–1555. [Google Scholar] [CrossRef]
- Stekhoven, D.J.; Stekhoven, M.D.J. Package ‘missForest’. R Package Version 2013, 1, 21. [Google Scholar]
- Nazzicari, N.; Biscarini, F.; Cozzi, P.; Brummer, E.C.; Annicchiarico, P. Marker imputation efficiency for genotyping-by-sequencing data in rice (Oryza sativa) and alfalfa (Medicago sativa). Mol. Breed. 2016, 36, 69. [Google Scholar] [CrossRef]
- Amadeu, R.R.; Garcia, A.A.F.; Munoz, P.R.; Ferrão, L.F.V. AGHmatrix: Genetic relationship matrices in R. Bioinformatics 2023, 39, btad445. [Google Scholar] [CrossRef] [PubMed]
- Butler, D.; Cullis, B.; Gilmour, A.; Gogel, B.; Thompson, R. ASReml-R Reference Manual Version 4; VSN Int. Ltd.: Hemel Hempstead, UK, 2017. [Google Scholar]
- Burdon, R.D. Genetic Correlation as a Concept for Studying Genotype-Environment Interaction in Forest Tree Breeding. Silvae Genet. 1977, 26, 168–175. [Google Scholar]
- Cullis, B.R.; Smith, A.B.; Coombes, N.E. On the design of early generation variety trials with correlated data. J. Agric. Biol. Environ. Stat. 2006, 11, 381–393. [Google Scholar] [CrossRef]
- Kendall, M.G.; Stuart, A. The Advanced Theory of Statistics. Vol. 3. Biometrics 1969, 25, 435. [Google Scholar] [CrossRef]
- van Rossum, B.-J.; Kruijer, W.; van Eeuwijk, F.; Boer, M.; Malosetti, M.; Bustos-Korts, D.; Millet, E. Package ‘statgenGWAS’; R Package Version; R Foundation: Vienna, Austria, 2022. [Google Scholar]
- Kang, H.M.; Zaitlen, N.A.; Wade, C.M.; Kirby, A.; Heckerman, D.; Daly, M.J.; Eskin, E. Efficient control of population structure in model organism association mapping. Genetics 2008, 178, 1709–1723. [Google Scholar] [CrossRef]
- Cingolani, P.; Platts, A.; Wang, L.L.; Coon, M.; Nguyen, T.; Wang, L.; Land, S.J.; Lu, X.; Ruden, D.M. A program for annotating and predicting the effects of single nucleotide polymorphisms, SnpEff: SNPs in the genome of Drosophila melanogaster strain w1118; iso-2; iso-3. Fly 2012, 6, 80–92. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trait a | Cross-Validation | |
|---|---|---|
| Tuning Parameter LVs b | rcv c | |
| Protein 2021–2022 | 12 | 0.99 |
| Oil 2021–2022 | 10 | 0.97 |
| C18:1 2021–2022 | 11 | 0.87 |
| C18:2 2021–2022 | 11 | 0.82 |
| C18:3 2021–2022 | 11 | 0.94 |
| Catechin 2021 | 6 | 0.78 |
| Catechin 2022 | 5 | 0.80 |
| Epicatechin 2021 | 5 | 0.76 |
| Epicatechin 2022 | 5 | 0.81 |
| Procyanidin B1 2021 | 6 | 0.86 |
| Procyanidin B1 2022 | 5 | 0.84 |
| Procyanidin B2 2021 | 5 | 0.72 |
| Procyanidin B2 2022 | 5 | 0.82 |
| 2021 | 2022 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Chemical Class | Trait a | Min | Mean | Max | CV% | Min | Mean | Max | CV% |
| Oil | Oil | 1.37 | 1.69 | 2.14 | 7.93 | 1.23 | 1.49 | 1.84 | 7.07 |
| Protein | Protein | 18.70 | 25.14 | 30.66 | 7.91 | 22.02 | 29.29 | 35.15 | 7.04 |
| Fatty acid | C18:1 | 15.74 | 21.17 | 27.11 | 11.19 | 14.81 | 20.05 | 25.12 | 9.23 |
| C18:2 | 48.68 | 52.73 | 56.60 | 2.77 | 48.51 | 52.97 | 58.83 | 2.88 | |
| C18:3 | 2.50 | 4.79 | 7.37 | 15.15 | 2.57 | 5.20 | 7.40 | 12.60 | |
| Tannin | Catechin | 1.04 | 41.93 | 80.17 | 38.28 | 0.28 | 7.22 | 15.51 | 42.20 |
| Epicatechin | 0.15 | 37.04 | 70.01 | 39.69 | 1.23 | 11.76 | 21.63 | 37.58 | |
| Procyanidin B1 | 1.81 | 77.85 | 121.08 | 33.10 | 0.51 | 16.14 | 31.10 | 37.33 | |
| Procyanidin B2 | 0.22 | 90.60 | 224.26 | 32.37 | 1.42 | 32.20 | 60.16 | 37.16 | |
| Phenolic acid | p-coumaric acid | 0.05 | 7.16 | 27.45 | 71.03 | 0.01 | 0.06 | 0.17 | 53.00 |
| Caffeic acid | 0.04 | 1.46 | 5.58 | 72.98 | 0.02 | 0.56 | 1.97 | 61.30 | |
| Ferulic acid | 0.12 | 5.01 | 8.64 | 34.36 | - | - | - | - | |
| Flavonoid | Myricetin | 0.01 | 14.98 | 62.09 | 96.12 | 0.06 | 4.92 | 18.84 | 86.01 |
| Quercetin | 0.13 | 6.19 | 32.00 | 90.06 | 0.30 | 2.63 | 6.62 | 55.37 | |
| Lipid oxidation product | Hexanal | 16.67 | 984.70 | 2797.92 | 62.36 | - | - | - | - |
| 1-Linoleoyl glycerol | - | - | - | - | 0.01 | 0.19 | 0.62 | 65.84 | |
| 2-Hydroxyoleic acid (OHOA) | - | - | - | 2.37 | 7.18 | 10.87 | 27.08 | ||
| Alkaloid | Convicine | - | - | - | - | 2.31 | 16.67 | 28.42 | 27.90 |
| 2021 | 2022 | ||
|---|---|---|---|
| Trait | ρtype-B a | h2 PEV b | h2 PEV |
| Oil | 0.74 (0.06) | 0.65 | 0.77 |
| C18:1 | 0.81 (0.05) | 0.74 | 0.78 |
| C18:2 | 0.73 (0.08) | 0.60 | 0.70 |
| C18:3 | 0.87 (0.04) | 0.74 | 0.82 |
| Protein | 0.5 (0.12) | 0.45 | 0.70 |
| Catechin | 0.64 (0.07) | 0.68 | 0.80 |
| Epicatechin | 0.81 (0.04) | 0.72 | 0.87 |
| Procyanidin B1 | 0.74 (0.05) | 0.75 | 0.84 |
| Procyanidin B2 | 0.55 (0.06) | 0.75 | 0.84 |
| p-coumaric acid | 0.34 (0.13) | 0.43 | 0.41 |
| Caffeic acid | 0.53 (0.10) | 0.48 | 0.43 |
| Ferulic acid | - | 0.07 | - |
| Myricetin | 0.44 (0.10) | 0.43 | 0.48 |
| Quercetin | 0.82 (0.14) | 0.49 | 0.19 |
| Hexanal | - | 0.33 | - |
| 1-Linoleoyl glycerol | - | - | 0.26 |
| 2-Hydroxyoleic acid (OHOA) | - | - | 0.39 |
| Convicine | - | - | 0.42 |
| Compound Class | Trait | Year | SNP ID a | allFreq | p Value | Bonf | Effect | Variance (%) | SNP Location | Protein Impact | Candidate Gene Annotation b |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Lipid | Oil C18:3 | 2022 | chr1S 1143102257 | 0.93 | 6.77 × 10−6 1.59 × 10−5 | no | −0.09 0.44 | 7.11 4.8 | Intergenic region | Modifier | Cytochrome p450 |
| Oil C18:1 | 2022 | chr4 755718730 | 0.91 | 1.27 × 10−9 1.46 × 10−5 | yes | −0.11 −1.18 | 15.11 6 | Synonymous variant | Low | Cytochrome p450 | |
| C18:1 | 2022 | chr1L 713263969 | 0.94 | 2.25 × 10−5 | no | −1.31 | 5.38 | Synonymous variant | Low | Tryptophan aminotransferase protein Lipase in LD (~227.7 kbp) | |
| C18:3 | 2021/ 2022 | chr1L 1230530421 | 0.94 | 2.46 × 10−5/ 2.02 × 10−5 | no | −0.57/−0.43 | 5.1/4.1 | Missense variant | Moderate | GDT protein 1 chloroplastic | |
| C18:3 | 2021/ 2022 | chr3 1234617141 | 0.96 | 3.70 × 10−8/ 2.2 × 10−5 | yes | −0.76/−0.49 | 8.3/4 | Upstream gene variant | Modifier | Ras protein rab | |
| C18:3 | 2021/ 2022 | chr5 505151579 | 0.94 | 1.27 × 10−5/ 3.28 × 10−7 | no | 0.55/0.53 | 6.4/7.1 | Missense variant | Moderate | Protein plastid movement impaired Lipid phosphate phosphatase (LPP) in LD (~61.8 kbp) | |
| C18:3 | 2021/ 2022 | contig 7845 77914 | 0.96 | 1.23 × 10−6/ 7.65 × 10−6 | no | −0.6/−0.47 | 6/3.98 | Synonymous variant | Low | Unknown | |
| C18:3 | 2022 | chr1L 607096754 | 0.94 | 5.57 × 10−6 | no | 0.60 | 4.85 | Intron variant | Modifier | Reticulon protein b21 1-acyl-sn-glycerol−3-phosphate acyltransferase (ATS2) in LD (~188 kbp) | |
| C18:3 | 2022 | chr3 353865653 | 0.96 | 6.14 × 10−6 | no | 0.55 | 4.84 | Intron variant | Modifier | 3-oxoacyl-[acyl carrier protein]-synthase (KAS) | |
| Lipid- derived | Hexanal | 2021 | chr1L 841732900 | 0.94 | 1.01 × 10−6 | yes | −818 | 21.6 | Missense variant | Moderate | Pentatricopeptide repeat containing protein |
| 1-Linoleoyl glycerol | 2022 | chr1L 1034384645 | 0.86 | 1.05 × 10−5 | no | −0.12 | 22.77 | Downstream gene variant | Modifier | Phosphopantetheine adenylyltransferase isoform | |
| 2- Hydroxyoleic acid (OHOA) | 2022 | chr4 1463710346 | 0.78 | 7.78 × 10−6 | no | 1.51 | 19.13 | Missense variant | Moderate | Rab gap tbc domain containing protein | |
| Phenolic acid | p-coumaric acid | 2021 | chr2 964372547 | 0.94 | 7.81 × 10−9 | yes | −9.54 | 27.8 | Intron variant | Modifier | Quality protein dual specificity protein phosphatase phs Helix-loop-helix transcription factor (bHLH) 137-LIKE in LD (~450.5 kbp) |
| p-coumaric acid | 2022 | chr1S 1040083079 | 0.93 | 1.40 × 10−8 | yes | −0.04 | 27.23 | Missense variant | Moderate | Protein kinase domain containing protein Transcription factor (MYB) in LD (~141.6 kbp) | |
| Caffeic acid | 2021 | chr4 6021087 | 0.96 | 2.75 × 10−7 | yes | −2.11 | 28.2 | Downstream gene variant | Modifier | oxygen evolving enhancer protein 3 1 chloroplastic Transcription factor (MYB) in LD (~120 kbp) | |
| Caffeic acid | 2022 | chr6 1188716500 | 0.95 | 7.98 × 10−7 | yes | −0.61 | 24.92 | Missense variant | Moderate | Shikimate kinase | |
| Flavonoid | Quercetin Myricetin | 2021 | chr4 935741377 | 0.91 | 2.66 × 10−5 1.68 × 10−5 | no | −6.33 −16.5 | 16.7 17.4 | Synonymous variant | Low | Beta amylase |
| Tannin | Catechin Epicatechin Procyanidin B1 | 2021/ 2022 | chr2 671378841 | 0.94 | 8.7 × 10−6/ 1.9 × 10−5 5.6 × 10−6/ 5.9 × 10−6 3.8 × 10−6/ 2.6 × 10−5 | no | 14.4/2.5 11.9/3.4 22/4.7 | 8.9/8 10.4/8.5 10.1/7.1 | Missense variant | Moderate | Unknown protein |
| Epicatechin | 2021/ 2022 | chr2 826275103 | 0.92 | 5.06 × 10−6/ 1.96 × 10−7 | no | 13.7/3.7 | 13.29/14.9 | Upstream gene variant | Modifier | Auxin responsive protein saur | |
| Procyanidin B1 | 2021/ 2022 | chr2 953872991 | 0.89 | 1.22 × 10−8/ 2.75 × 10−5 | no | 21.4/3.5 | 17.9/8.4 | Synonymous variant | Low | Calcium binding mitochondrial carrier protein scamc | |
| Procyanidin B1 Procyanidin B2 | 2022 | chr2 953899416 | 0.93 | 3.14 × 10−8 2.59 × 10−5 | no | 4.1 8.5 | 8.15 8.5 | Intron variant | Modifier | Carbonyl reductase [nadph] | |
| Catechin Procyanidin B1 Procyanidin B2 | 2022 | chr1L 672262213 | 0.95 | 1.65 × 10−7 1.51 × 10−7 3.6 × 10−7 | yes | 3.1 5.9 11.3 | 10.3 9.7 8.8 | Intron variant | Modifier | Cathepsin | |
| Epicatechin | 2022 | chr2 1501542265 | 0.94 | 3.72 × 10−7 | yes | 3.58 | 7.27 | Synonymous variant | Low | Cytochrome p450 | |
| Protein | Protein | 2021 | chr5 632641479 | 0.57 | 2.13 × 10−5 | no | −0.87 | 10.7 | Missense variant | Moderate | 50s ribosomal protein l25 Cationic amino acid transporter 4 (CAT4) in LD (~136.8 kbp) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lippolis, A.; Hollebrands, B.; Acierno, V.; de Jong, C.; Pouvreau, L.; Paulo, J.; Gezan, S.A.; Trindade, L.M. GWAS Identifies SNP Markers and Candidate Genes for Off-Flavours and Protein Content in Faba Bean (Vicia faba L.). Plants 2025, 14, 193. https://doi.org/10.3390/plants14020193
Lippolis A, Hollebrands B, Acierno V, de Jong C, Pouvreau L, Paulo J, Gezan SA, Trindade LM. GWAS Identifies SNP Markers and Candidate Genes for Off-Flavours and Protein Content in Faba Bean (Vicia faba L.). Plants. 2025; 14(2):193. https://doi.org/10.3390/plants14020193
Chicago/Turabian StyleLippolis, Antonio, Boudewijn Hollebrands, Valentina Acierno, Catrienus de Jong, Laurice Pouvreau, João Paulo, Salvador A. Gezan, and Luisa M. Trindade. 2025. "GWAS Identifies SNP Markers and Candidate Genes for Off-Flavours and Protein Content in Faba Bean (Vicia faba L.)" Plants 14, no. 2: 193. https://doi.org/10.3390/plants14020193
APA StyleLippolis, A., Hollebrands, B., Acierno, V., de Jong, C., Pouvreau, L., Paulo, J., Gezan, S. A., & Trindade, L. M. (2025). GWAS Identifies SNP Markers and Candidate Genes for Off-Flavours and Protein Content in Faba Bean (Vicia faba L.). Plants, 14(2), 193. https://doi.org/10.3390/plants14020193