
UAV-Based Automatic Detection of Missing Rice Seedlings Using the PCERT-DETR Model
 ,
,
Abstract
1. Introduction
2. Related Work
2.1. Traditional Image Processing-Based Methods
2.2. Deep Learning-Based Methods
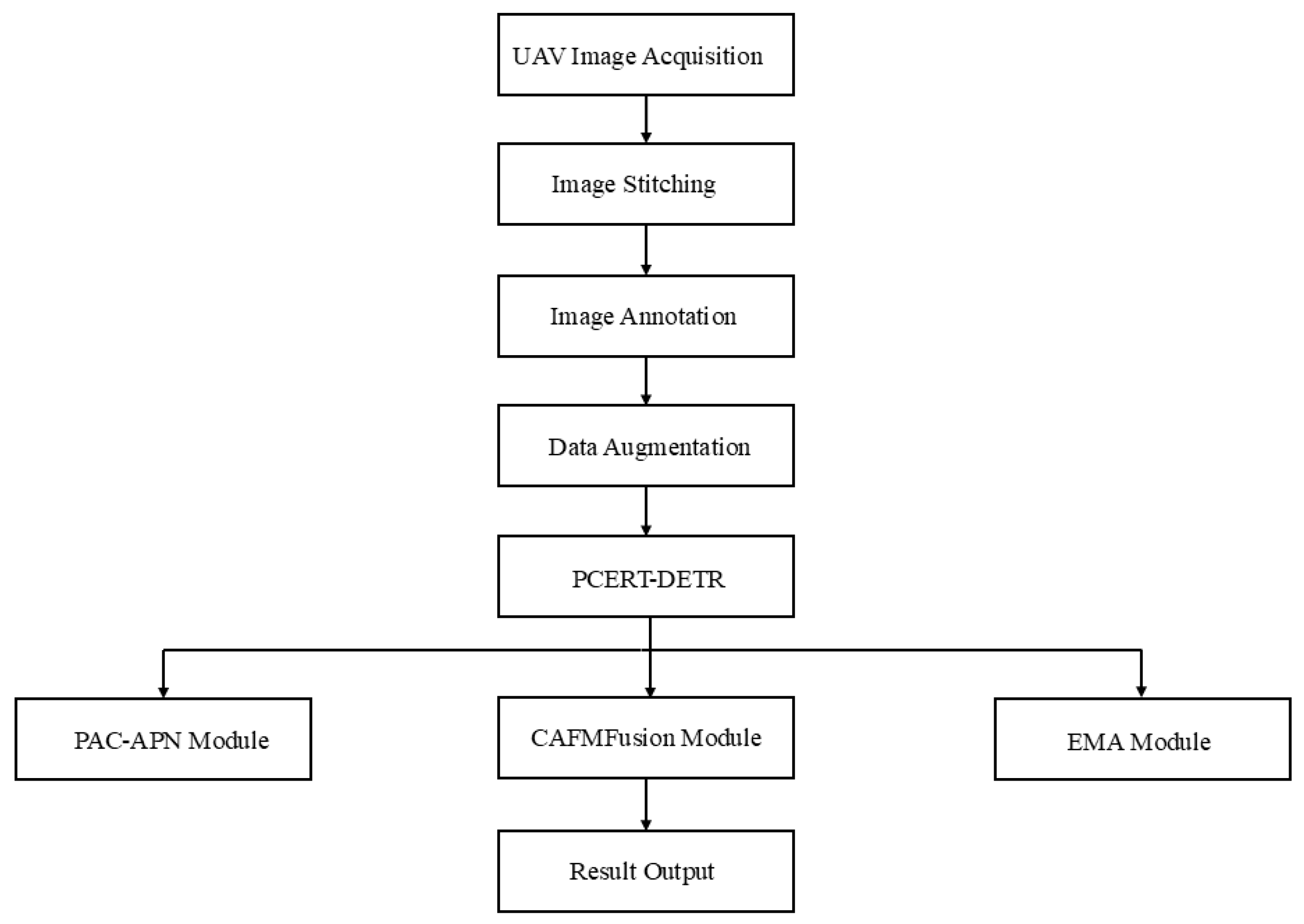
3. Materials and Methods
3.1. Image Acquisition
3.2. Image Stitching
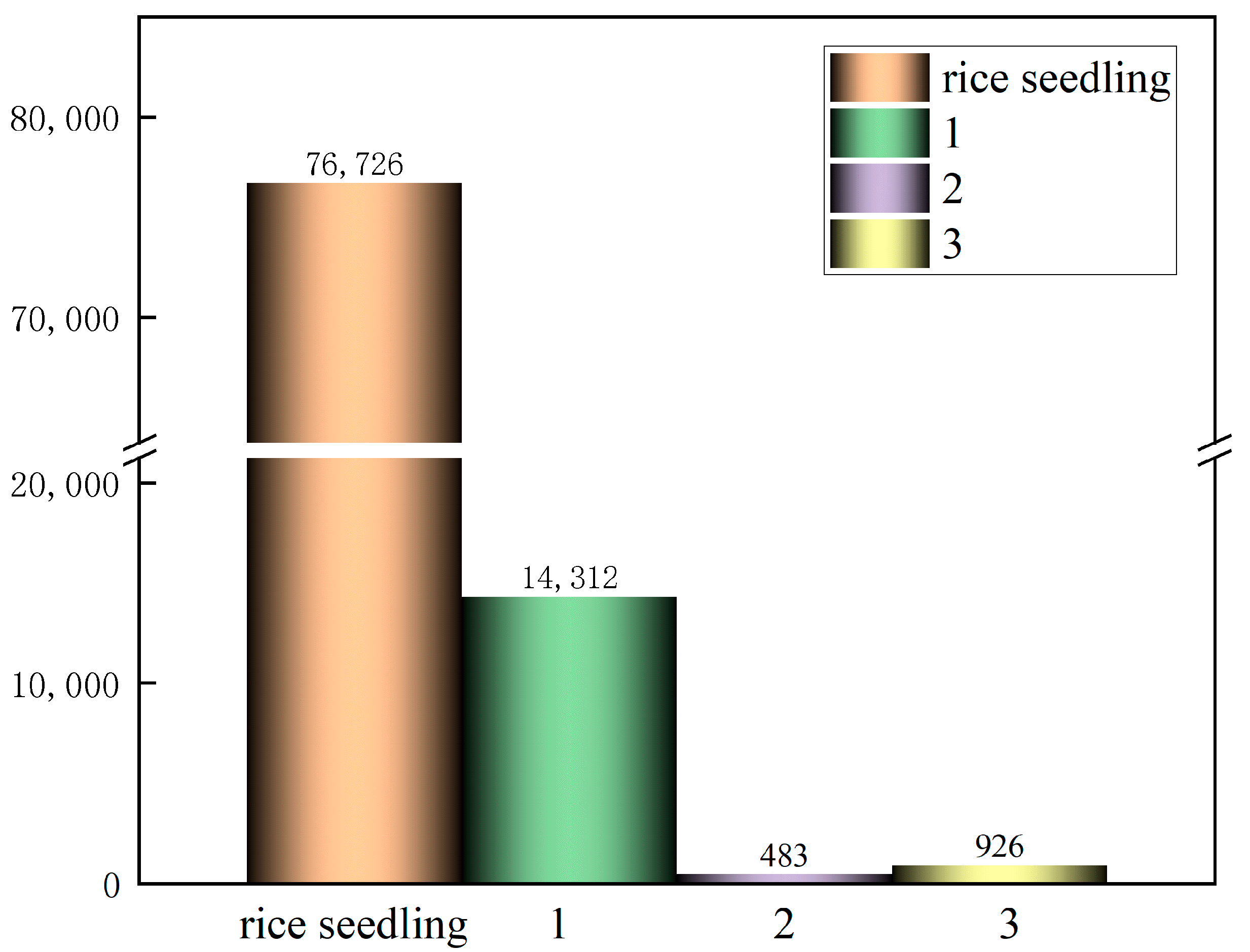
3.3. Data Annotation and Partitioning
3.4. Data Augmentation
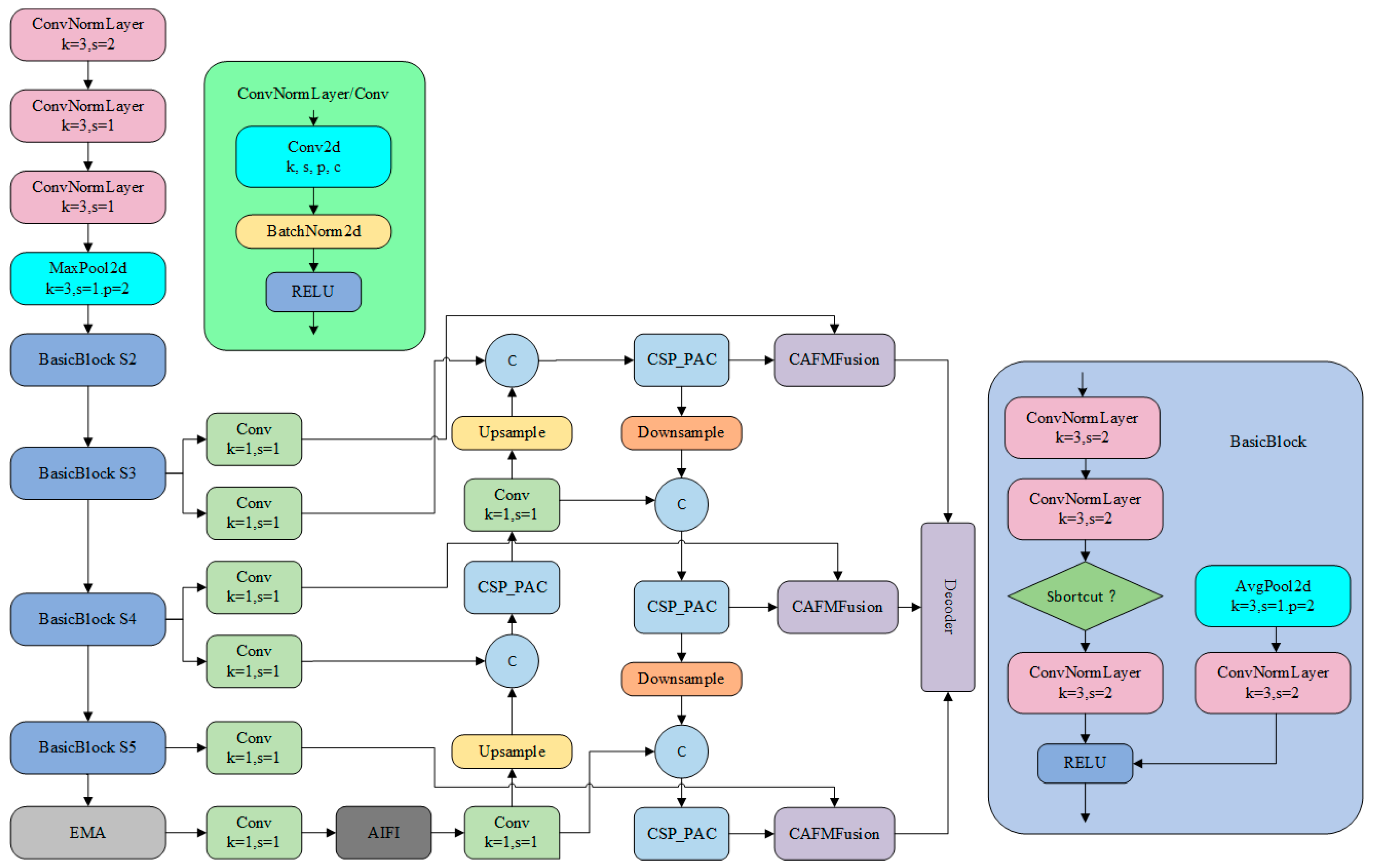
3.5. Construction of the PCERT-DETR Model
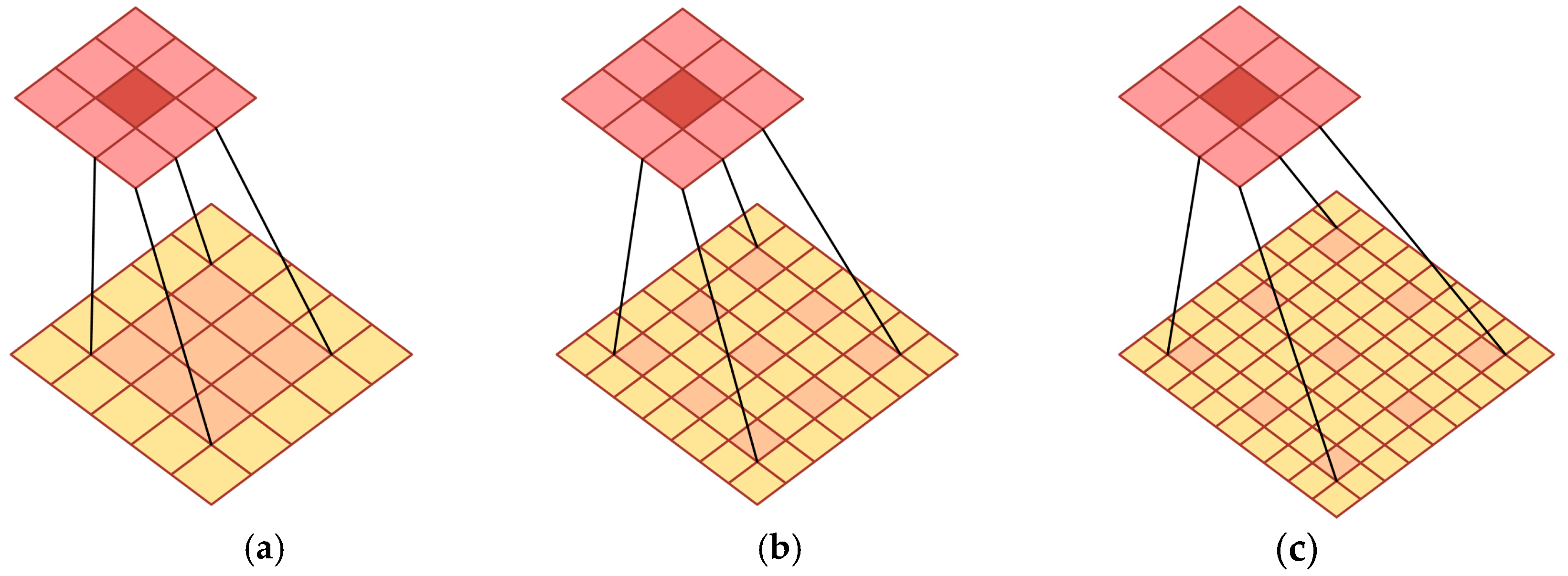
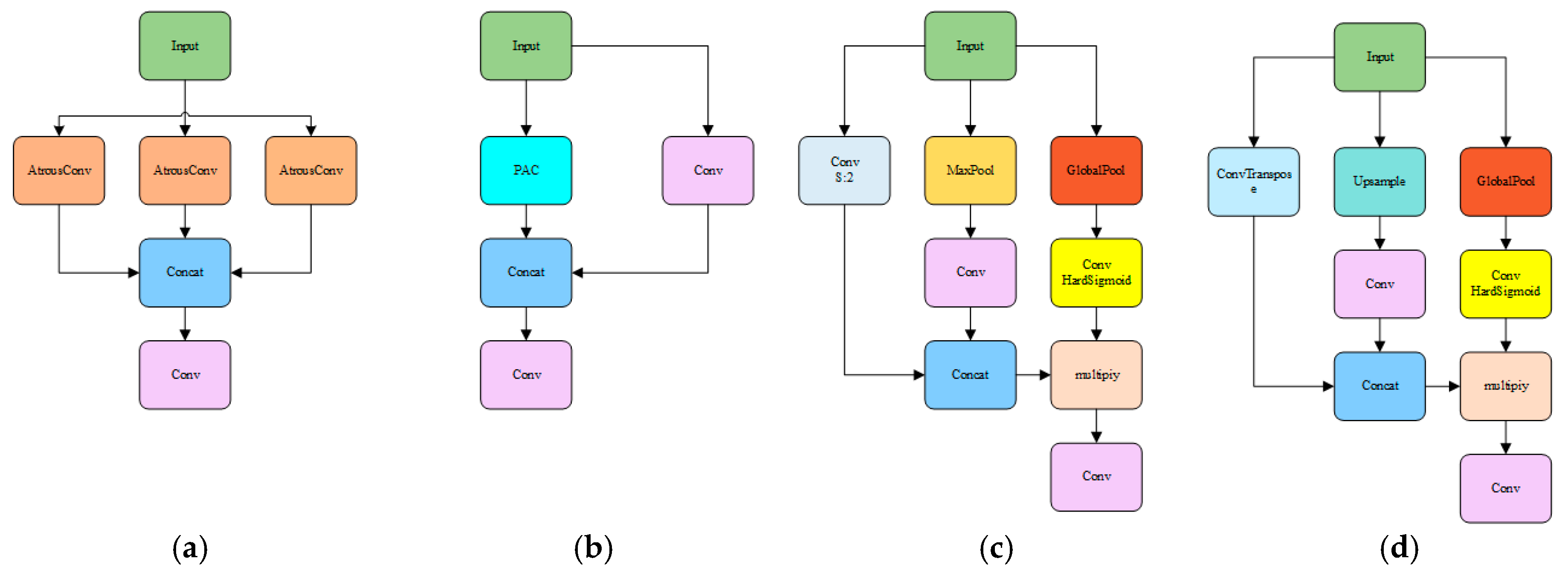
3.5.1. Construction of the PAC-APN Module
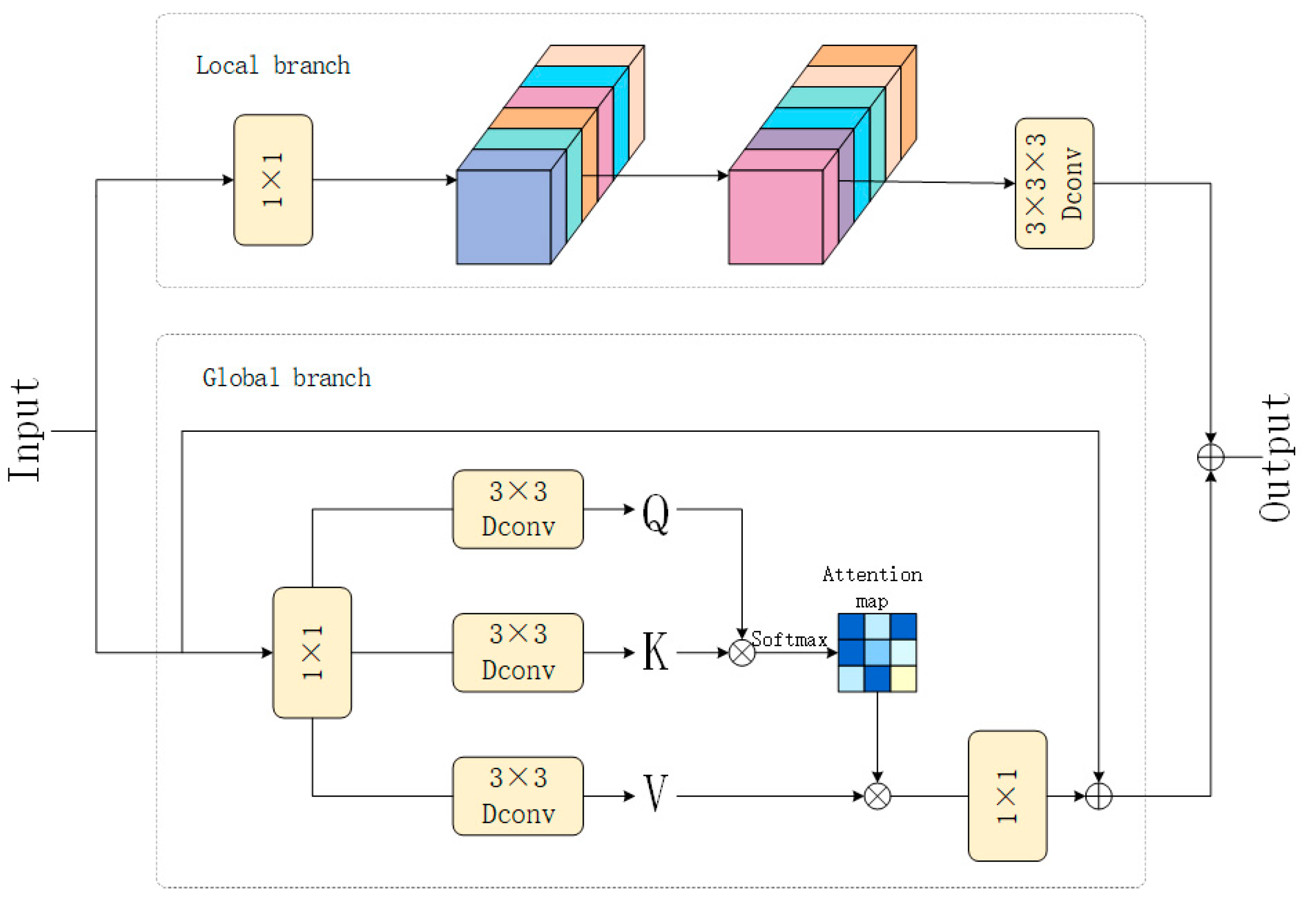
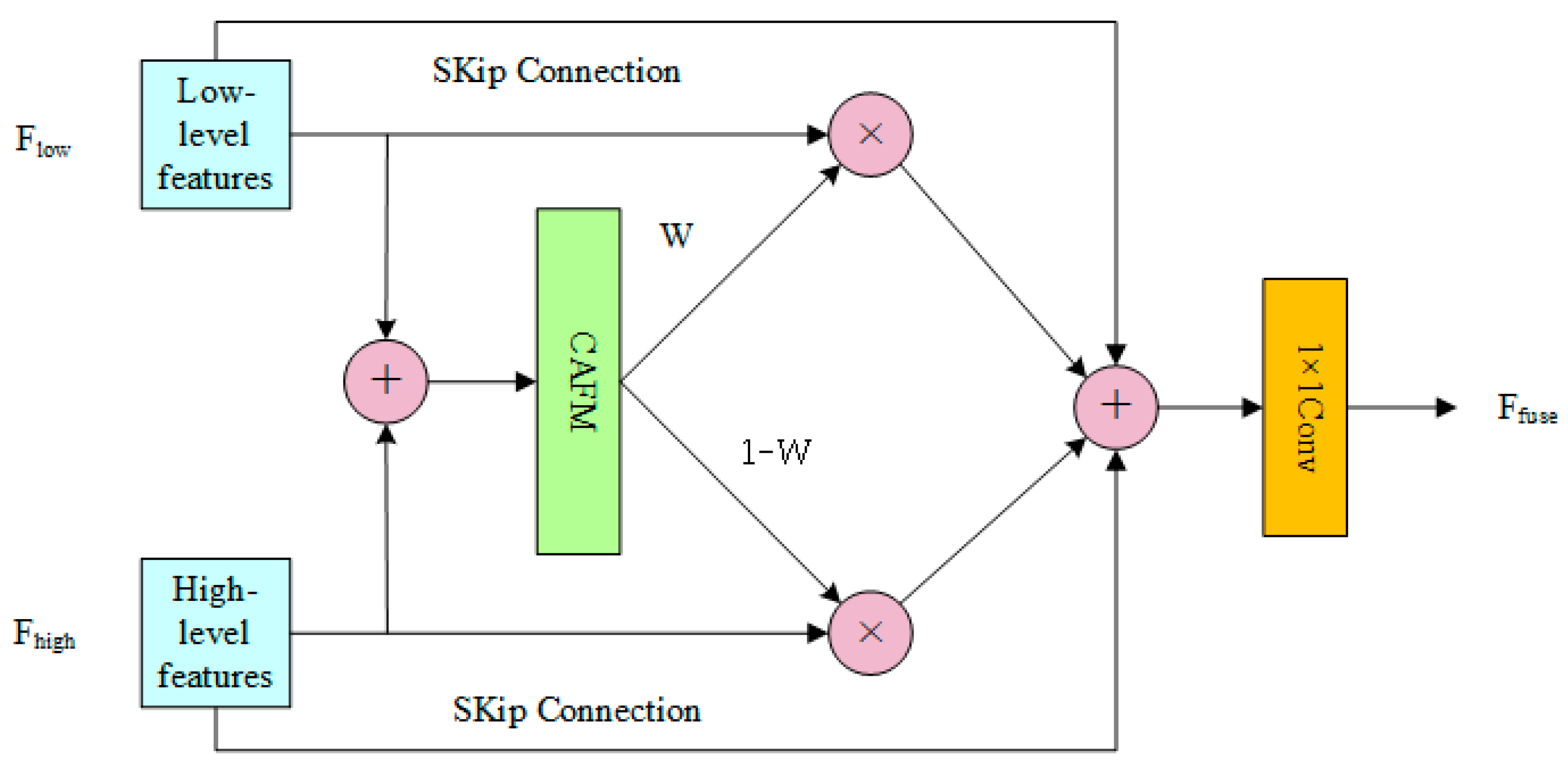
3.5.2. Design of the CAFM
3.5.3. The Efficient Multi-Scale Attention Mechanism
4. Results and Analysis
4.1. Experimental Environment
4.2. Model Evaluation Index
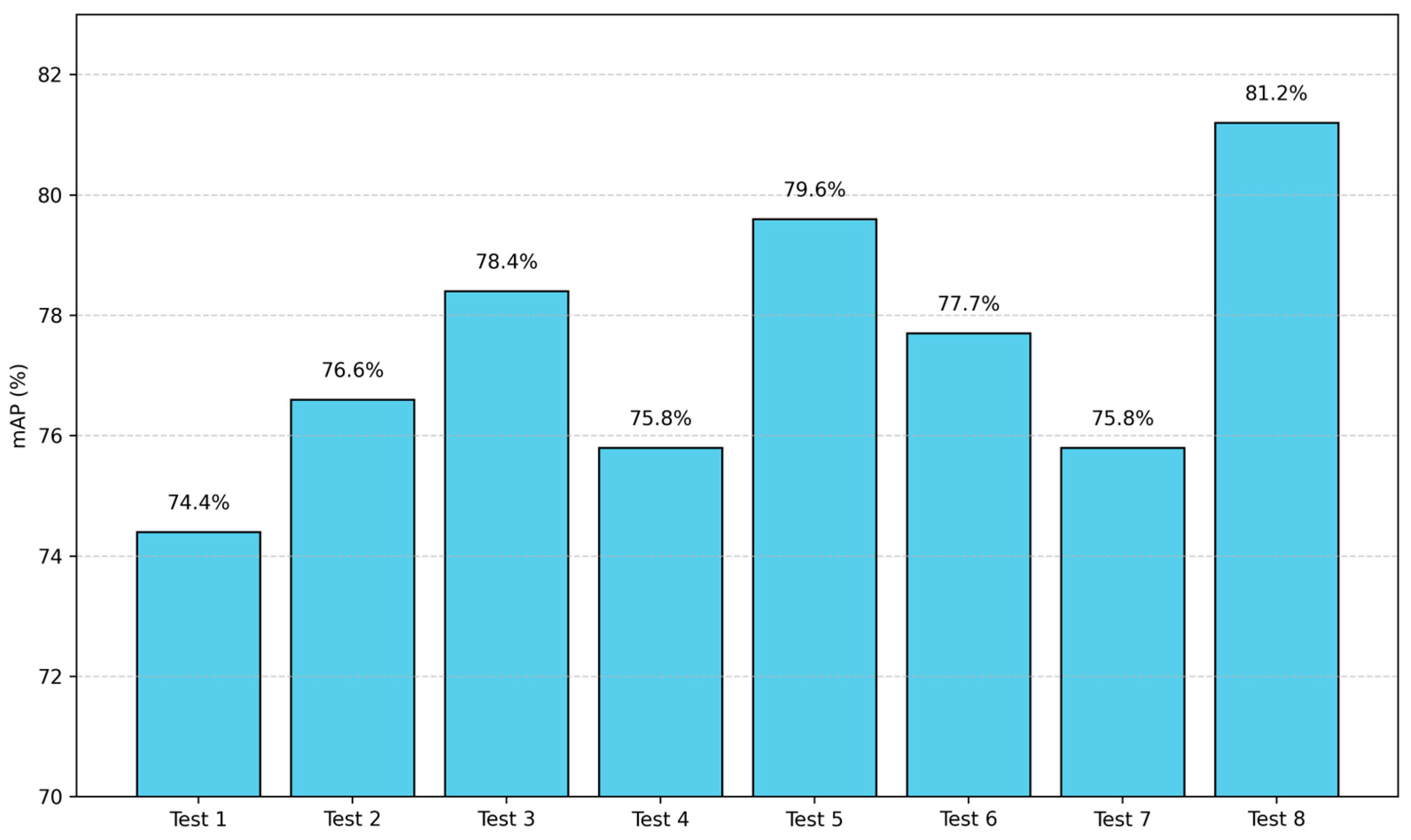
4.3. Ablation Test Results
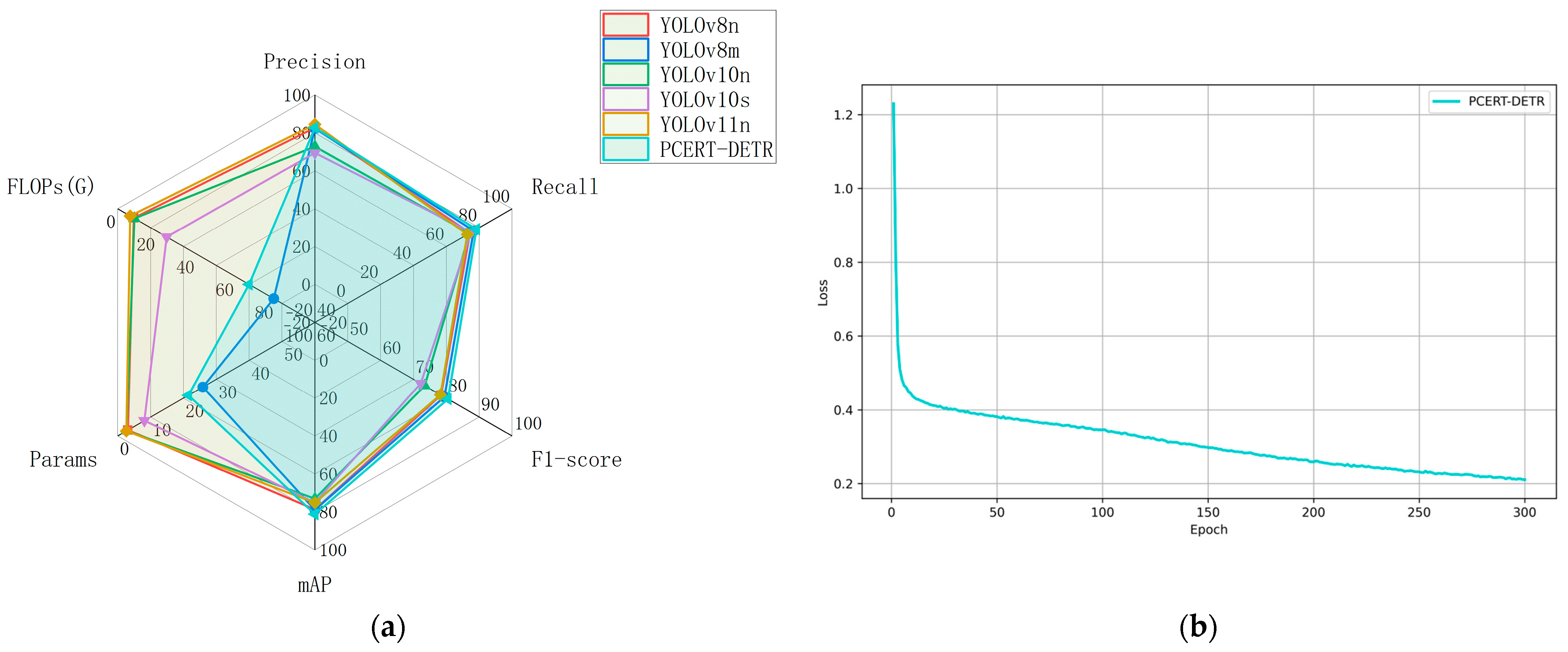
4.4. Detection Model Comparison Test
4.5. Simulation Test
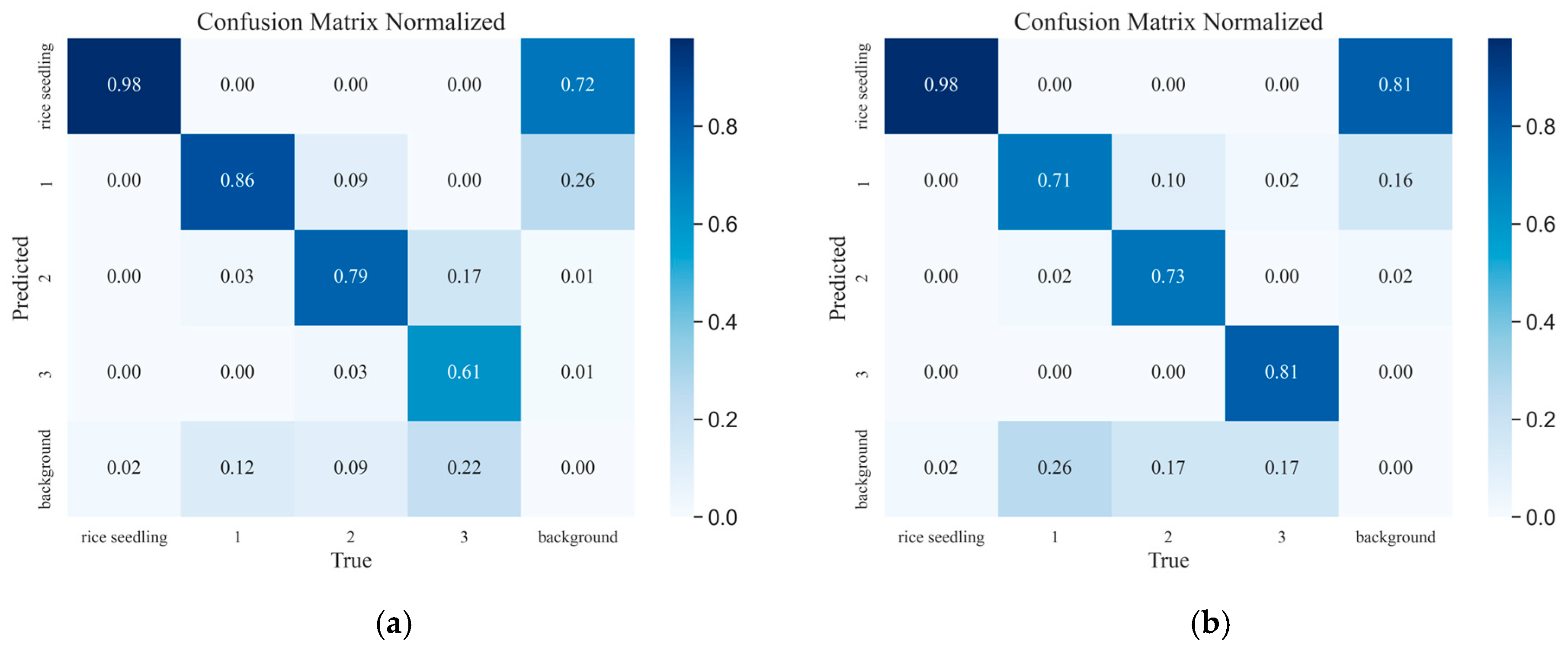
4.6. Feature Visual Analysis
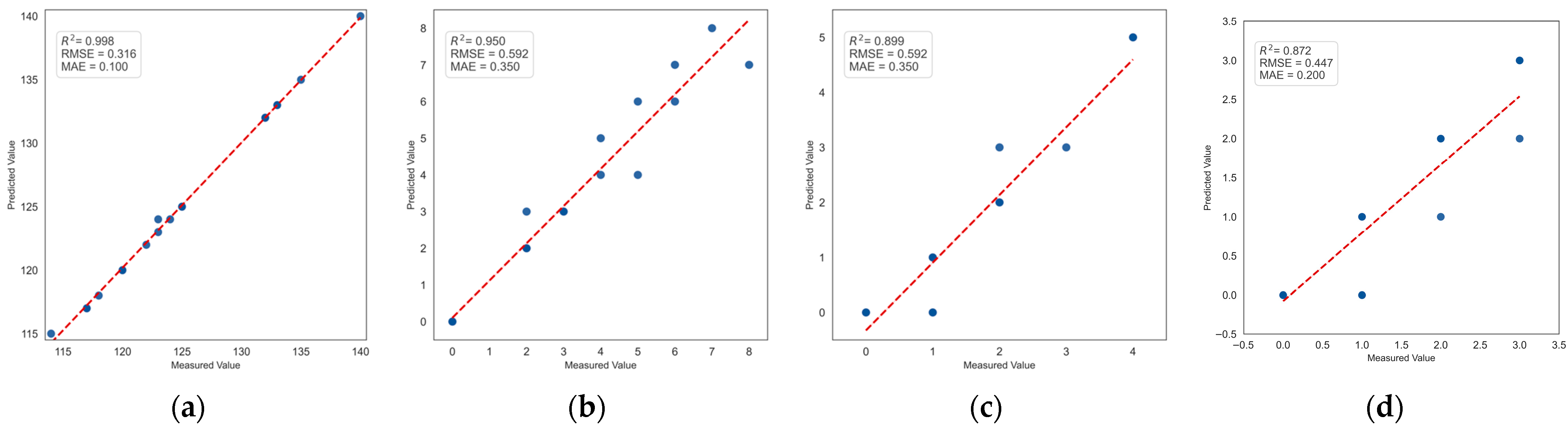
4.7. Correlation Study of Seedling Leakage Count
5. Discussion
5.1. Model Performance
5.2. Practical Implications and Deployment Considerations
5.3. Limitations and Solutions
- (1)
- The mAP of the PCERT-DETR model proposed in this study is 81.2%, indicating the presence of a detection error. The primary reason for this is the relatively small number of missing seedling samples in the training dataset, which hinders the model’s ability to fully learn and extract key features of missing seedlings during the training process. This may result in the insufficient generalization ability of the model when detecting missing seedlings, thereby reducing the accuracy and robustness of detection. Secondly, the discrepancy between missing and non-missing seedling areas is minimal, thereby impeding the model’s capacity to discern distinctive features during the learning process and consequently affecting the accuracy of detection. Thirdly, human factors, subjective judgment biases, and limitations in the data quality during the manual data annotation process can result in issues such as missing or mislabeled data. These annotation errors can lead to the model learning inaccurate features during training, resulting in detection errors in specific cases. To address this issue, the authors plan to further consider increasing the size of the sample dataset to expand the number of missing seedling samples, adopting more advanced feature extraction methods to enhance the model’s ability to perceive subtle features, and introducing a multi-round manual review mechanism where multiple annotators cross-check the same data to improve the accuracy and consistency of annotations.
- (2)
- The PCERT-DETR model contains 21.4 M parameters and 66.6 G FLOPs, which may result in an increased model inference time. The RT-DETR model utilizes a Transformer architecture, which inherently involves a greater number of parameters and computational costs. Conversely, the results of the ablation experiments suggest that the designed CAFMFusion module adds additional parameters and computational loads. To effectively reduce the number of parameters and computational costs of the RT-DETR model and improve its applicability in resource-constrained environments, future work will consider adopting lighter backbone networks, such as MobileNet, EfficientNet [29], or ShuffleNet [30], to reduce the computational overhead while maintaining strong feature extraction capabilities. Furthermore, the exploration of model compression and acceleration techniques, such as pruning [31], quantization [32], and knowledge distillation, will be undertaken to further optimize the model structure, reduce the computational complexity, and lessen the dependence on high-performance hardware. Additionally, methods like sparse computation, operator fusion, and model architecture optimization will be combined to further reduce the computational cost during model inference and improve the computational efficiency.
- (3)
- The proposed methodology has thus far been evaluated exclusively on a dataset from the early growth stage of rice. Following the training phase of the model, its efficacy was assessed on a dataset comprising 1070 test images. The results indicated that the mAP attained 81.2%, thereby substantiating the proposed methodology’s efficacy for this particular task. Nevertheless, the applicability of this methodology for target detection tasks in the early growth stage of rice remains to be further investigated. In future iterations, the dataset may be expanded to include images from the middle and late growth stages of rice, with the aim of enhancing the model’s capacity to recognize missing seedling areas and improve its adaptability across different growth stages.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AP | Average Precision |
| CAFM | Convolution and Attention Fusion Module |
| EMA | Efficient Multi-scale Attention |
| mAP | Mean Average Precision |
| UAV | Unmanned Aerial Vehicle |
References
- Abdo, A.I.; Tian, M.; Shi, Z.; Sun, D.; Abdel-Fattah, M.K.; Zhang, J.; Wei, H.; Abdeen, M.A. Carbon footprint of global rice production and consumption. J. Clean. Prod. 2024, 474, 143560. [Google Scholar] [CrossRef]
- Wang, X.; Tang, Q.; Chen, Z.; Luo, Y.; Fu, H.; Li, X. Estimating and evaluating the rice cluster distribution uniformity with UAV-based images. Sci. Rep. 2021, 11, 21442. [Google Scholar] [CrossRef]
- Kong, S.; Li, J.; Zhai, Y.; Gao, Z.; Zhou, Y.; Xu, Y. Real-Time Detection of Crops with Dense Planting Using Deep Learning at Seedling Stage. Agronomy 2023, 13, 1503. [Google Scholar] [CrossRef]
- Li, D.; Zhao, H.; Zhao, X.; Gao, Q.; Xu, L. Cucumber Detection Based on Texture and Color in Greenhouse. Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1754016. [Google Scholar] [CrossRef]
- Li, H.; Lee, W.S.; Wang, K. Immature green citrus fruit detection and counting based on fast normalized cross correlation (FNCC) using natural outdoor colour images. Precis. Agric. 2016, 17, 678–697. [Google Scholar] [CrossRef]
- Dorj, U.-O.; Lee, M.; Yun, S.-S. An yield estimation in citrus orchards via fruit detection and counting using image processing. Comput. Electron. Agric. 2017, 140, 103–112. [Google Scholar] [CrossRef]
- Fu, L.; Duan, J.; Zou, X.; Lin, G.; Song, S.; Ji, B.; Yang, Z. Banana detection based on color and texture features in the natural environment. Comput. Electron. Agric. 2019, 167, 105057. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, D.; Jia, W.; Ji, W.; Sun, Y. A Detection Method for Apple Fruits Based on Color and Shape Features. IEEE Access 2019, 7, 67923–67933. [Google Scholar] [CrossRef]
- Liu, T.; Wu, W.; Chen, W.; Sun, C.; Zhu, X.; Guo, W. Automated image-processing for counting seedlings in a wheat field. Precis. Agric. 2015, 17, 392–406. [Google Scholar] [CrossRef]
- Wang, X.; Yang, W.; Lv, Q.; Huang, C.; Liang, X.; Chen, G.; Xiong, L.; Duan, L. Field rice panicle detection and counting based on deep learning. Front. Plant Sci. 2022, 13, 966495. [Google Scholar] [CrossRef]
- Li, Y.; Qian, M.; Liu, P.; Cai, Q.; Li, X.; Guo, J.; Yan, H.; Yu, F.; Yuan, K.; Yu, J.; et al. The recognition of rice images by UAV based on capsule network. Clust. Comput. 2018, 22, 9515–9524. [Google Scholar] [CrossRef]
- Liao, J.; Wang, Y.; Yin, J.; Liu, L.; Zhang, S.; Zhu, D. Segmentation of Rice Seedlings Using the YCrCb Color Space and an Improved Otsu Method. Agronomy 2018, 8, 269. [Google Scholar] [CrossRef]
- Anuar, M.M.; Halin, A.A.; Perumal, T.; Kalantar, B. Aerial Imagery Paddy Seedlings Inspection Using Deep Learning. Remote Sens. 2022, 14, 274. [Google Scholar] [CrossRef]
- Ma, N.; Wu, Y.; Bo, Y.; Yan, H. Chili Pepper Object Detection Method Based on Improved YOLOv8n. Plants 2024, 13, 2402. [Google Scholar] [CrossRef]
- Li, J.; Zhu, Z.; Liu, H.; Su, Y.; Deng, L. Strawberry R-CNN: Recognition and counting model of strawberry based on improved faster R-CNN. Ecol. Inform. 2023, 77, 102210. [Google Scholar] [CrossRef]
- Tsai, F.-T.; Nguyen, V.-T.; Duong, T.-P.; Phan, Q.-H.; Lien, C.-H. Tomato Fruit Detection Using Modified Yolov5m Model with Convolutional Neural Networks. Plants 2023, 12, 3067. [Google Scholar] [CrossRef] [PubMed]
- Yan, H.; Cai, S.; Li, Q.; Tian, F.; Kan, S.; Wang, M. Study on the Detection Method for Daylily Based on YOLOv5 under Complex Field Environments. Plants 2023, 12, 1769. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Rong, Q.; Hu, C. Ripe Tomato Detection Algorithm Based on Improved YOLOv9. Plants 2024, 13, 3253. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, D.; Guo, X.; Yang, H. Lightweight Algorithm for Apple Detection Based on an Improved YOLOv5 Model. Plants 2023, 12, 3032. [Google Scholar] [CrossRef]
- Liu, Q.; Lv, J.; Zhang, C. MAE-YOLOv8-based small object detection of green crisp plum in real complex orchard environments. Comput. Electron. Agric. 2024, 226, 109458. [Google Scholar] [CrossRef]
- Hu, S.; Gao, F.; Zhou, X.; Dong, J.; Du, Q. Hybrid Convolutional and Attention Network for Hyperspectral Image Denoising. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5504005. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); IEEE: New York, NY, USA, 2023. [Google Scholar]
- Ashish, V.; Noam, S.; Niki, P.; Jakob, U.; Llion, J.; Aidan, N.G.; Lukasz, K.; Illia, P. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2015/hash/ae0eb3eed39d2bcef4622b2499a05fe6-Abstract.html (accessed on 7 July 2025).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Yeh, J.-F.; Lin, K.-M.; Yuan, L.-C.; Hsu, J.-M.J.E. Automatic counting and location labeling of rice seedlings from unmanned aerial vehicle images. Electronics 2024, 13, 273. [Google Scholar] [CrossRef]
- Tseng, H.-H.; Yang, M.-D.; Saminathan, R.; Hsu, Y.-C.; Yang, C.-Y.; Wu, D.-H. Rice Seedling Detection in UAV Images Using Transfer Learning and Machine Learning. Remote Sens. 2022, 14, 2837. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both weights and connections for efficient neural network. In Proceedings of the NIPS’15: Neural Information Processing Systems Montreal Canada, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.-P. Binaryconnect: Training deep neural networks with binary weights during propagations. In Proceedings of the NIPS’15: Neural Information Processing Systems Montreal Canada, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Method | Description | Average Precision |
|---|---|---|---|
| [13] | EfficienDet-D1 EfficientNet | Several deep convolutional neural network (DCNN) models were explored. The EfficientDet-D1 EficientNet model performed best in the detection of defective rice seedlings using aerial images. | 0.83 |
| [14] | The improved YOLOv8n | This study proposes a lightweight YOLOv8n-based model with HGNetV2 and attention-enhanced modules for robust pepper detection under occlusion and complex backgrounds. | 96.3% |
| [15] | Strawberry R-CNN | A strawberry R-CNN model is proposed. This model can accurately detect and count strawberries and support automatic harvesting and yield estimation. | 99.1%, 73.7% |
| [16] | Yolov5m + BoTNet model | Three CNN models were proposed for the automatic detection of three types of tomato fruits on vines, namely ripe, unripe, and damaged. The modified-Yolov5m-BoTNet model had a high value in the range of 94–96%. | 94% |
| [17] | The optimized YOLOv5s model | This study improves YOLOv5s with optimized network settings and lightweight backbones for accurate, real-time daylily detection across growth stages in complex field conditions, achieving strong performance and robustness. | 78.1% |
| [18] | An enhanced YOLOv9-C model | An improved YOLOv9-C model is proposed for the rapid and accurate detection of mature tomatoes, achieving a mAP of 98%, and has strong applicability to real-world picking tasks. | 98% |
| [19] | YOLOv5-CS mode | A lightweight YOLOv5-CS model is proposed for the rapid and accurate detection of mature apples, which has strong potential in the real-time application of agricultural robots. | 99.10% |
| [20] | MAE-YOLOv8 model | The MAE-YOLOv8 model was proposed for accurate and real-time detection of green and crisp plums, achieving intelligent robot picking in complex orchard environments. | 87.5% |
| Configuration | Argument |
|---|---|
| CPU | Intel(R) Xeon(R) Platinum 8352 V CPU @ 2.10 GHz |
| GPU | NVIDIA GeForce RTX3080 × 2 (20 GB) |
| Operating system | Ubuntu 20.04 |
| Accelerating environment | Cuda11.3 |
| Development platform | PyCharm |
| Other | Numpy1.17.0 Opencv4.1.0 |
| Test | Baseline | PACAPN | CAFM Fusion | EMA | P (%) | R (%) | F1-Score (%) | mAP (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | ✓ | 67.8 | 77.1 | 72.0 | 74.4 | 19.9 | 57.0 | |||
| 2 | ✓ | ✓ | 82.9 | 71.2 | 76.6 | 76.6 | 19.9 | 58.2 | ||
| 3 | ✓ | ✓ | ✓ | 84.5 | 76.2 | 80.1 | 78.4 | 21.4 | 66.4 | |
| 4 | ✓ | ✓ | 80.1 | 73.7 | 76.8 | 75.8 | 21.4 | 65.1 | ||
| 5 | ✓ | ✓ | 82.7 | 75.0 | 78.7 | 79.6 | 19.9 | 57.2 | ||
| 6 | ✓ | ✓ | ✓ | 75.6 | 78.5 | 77.0 | 77.7 | 21.5 | 65.4 | |
| 7 | ✓ | ✓ | ✓ | 78.8 | 78.3 | 78.5 | 75.8 | 19.9 | 58.4 | |
| 8 | ✓ | ✓ | ✓ | ✓ | 82.8 | 78.3 | 80.5 | 81.2 | 21.4 | 66.6 |
| Model | P (%) | R (%) | F1-Score (%) | mAP (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|
| YOLOv8n | 82.8 | 74.4 | 78.4 | 78.7 | 3.1 | 8.1 |
| YOLOv8m | 82.4 | 76.7 | 79.4 | 78.9 | 25.9 | 79.1 |
| YOLOv10n | 72.8 | 74.1 | 73.4 | 73.0 | 2.7 | 8.4 |
| YOLOv10s | 69.5 | 75.0 | 72.2 | 75.1 | 8.1 | 24.8 |
| YOLOv11n | 84.5 | 72.8 | 78.2 | 75.2 | 2.6 | 6.3 |
| PCERT-DETR | 82.8 | 78.3 | 80.5 | 81.2 | 21.4 | 66.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, J.; Tan, F.; Hou, Z.; Li, X.; Feng, A.; Li, J.; Bi, F. UAV-Based Automatic Detection of Missing Rice Seedlings Using the PCERT-DETR Model. Plants 2025, 14, 2156. https://doi.org/10.3390/plants14142156
Gao J, Tan F, Hou Z, Li X, Feng A, Li J, Bi F. UAV-Based Automatic Detection of Missing Rice Seedlings Using the PCERT-DETR Model. Plants. 2025; 14(14):2156. https://doi.org/10.3390/plants14142156
Chicago/Turabian StyleGao, Jiaxin, Feng Tan, Zhaolong Hou, Xiaohui Li, Ailin Feng, Jiaxin Li, and Feiyu Bi. 2025. "UAV-Based Automatic Detection of Missing Rice Seedlings Using the PCERT-DETR Model" Plants 14, no. 14: 2156. https://doi.org/10.3390/plants14142156
APA StyleGao, J., Tan, F., Hou, Z., Li, X., Feng, A., Li, J., & Bi, F. (2025). UAV-Based Automatic Detection of Missing Rice Seedlings Using the PCERT-DETR Model. Plants, 14(14), 2156. https://doi.org/10.3390/plants14142156