
Rice Ear Counting Based on Image Segmentation and Establishment of a Dataset


Abstract
:1. Introduction
2. Materials and Methods
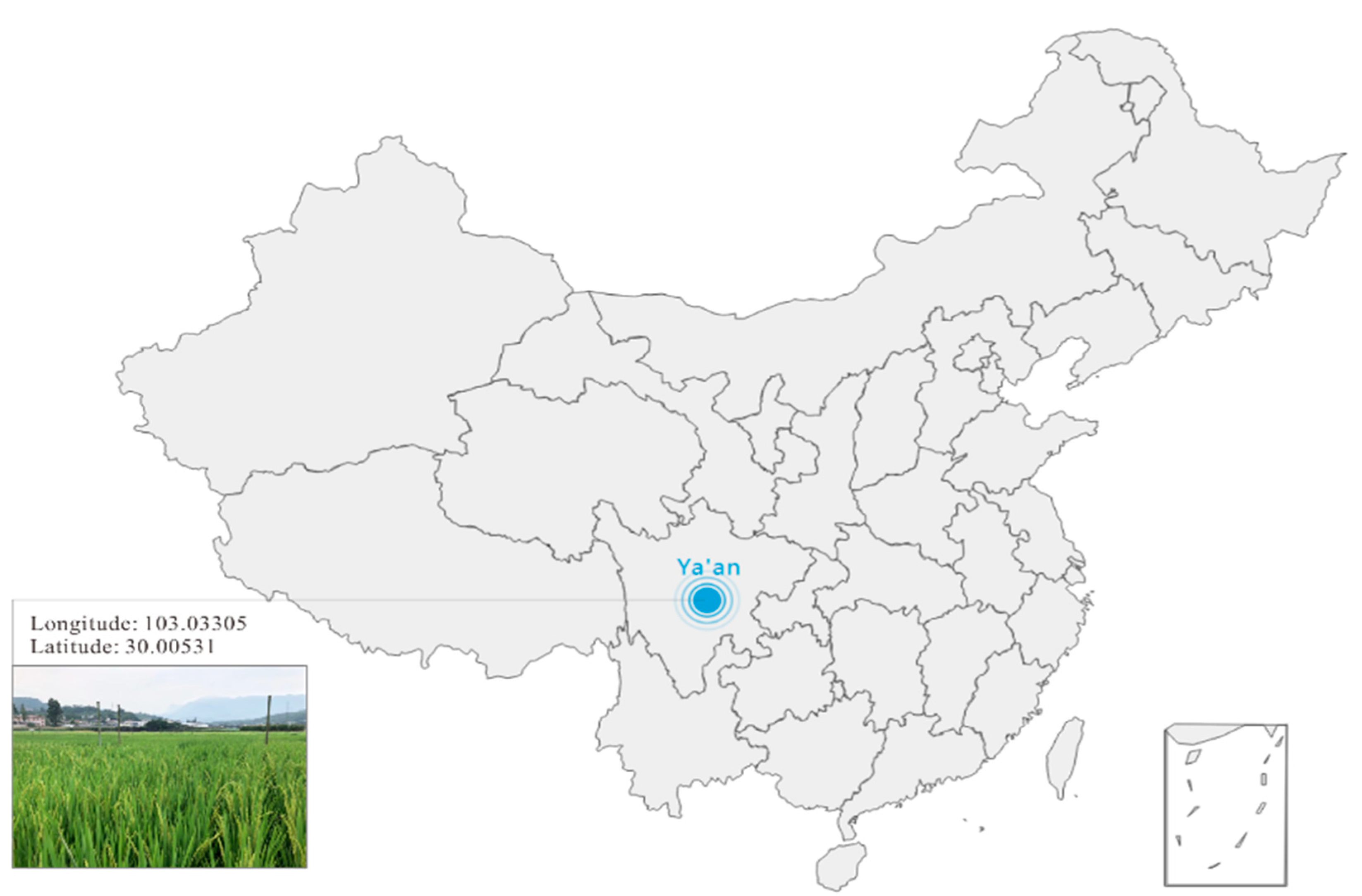
2.1. Experiment Field and Data Acquisition
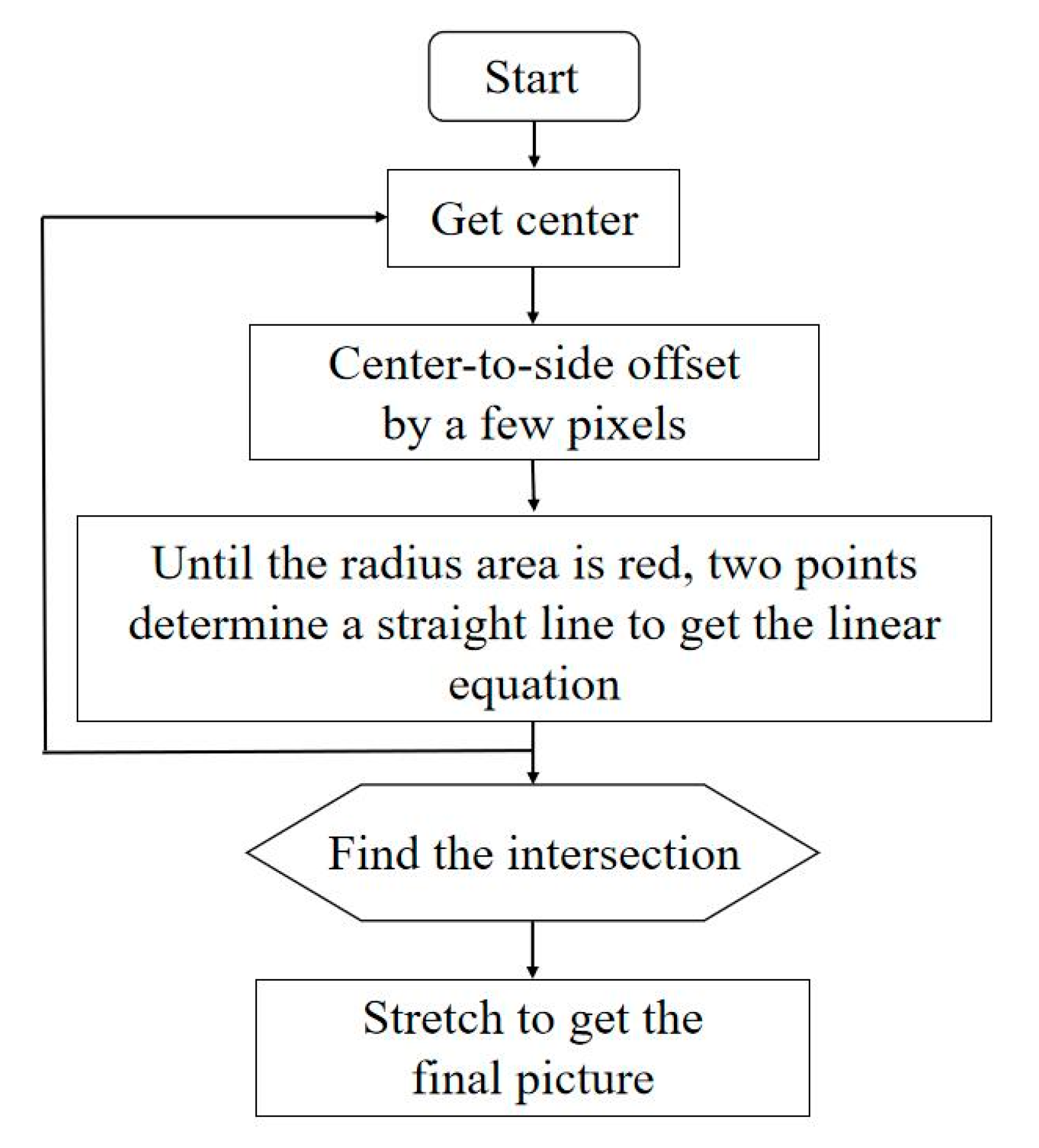
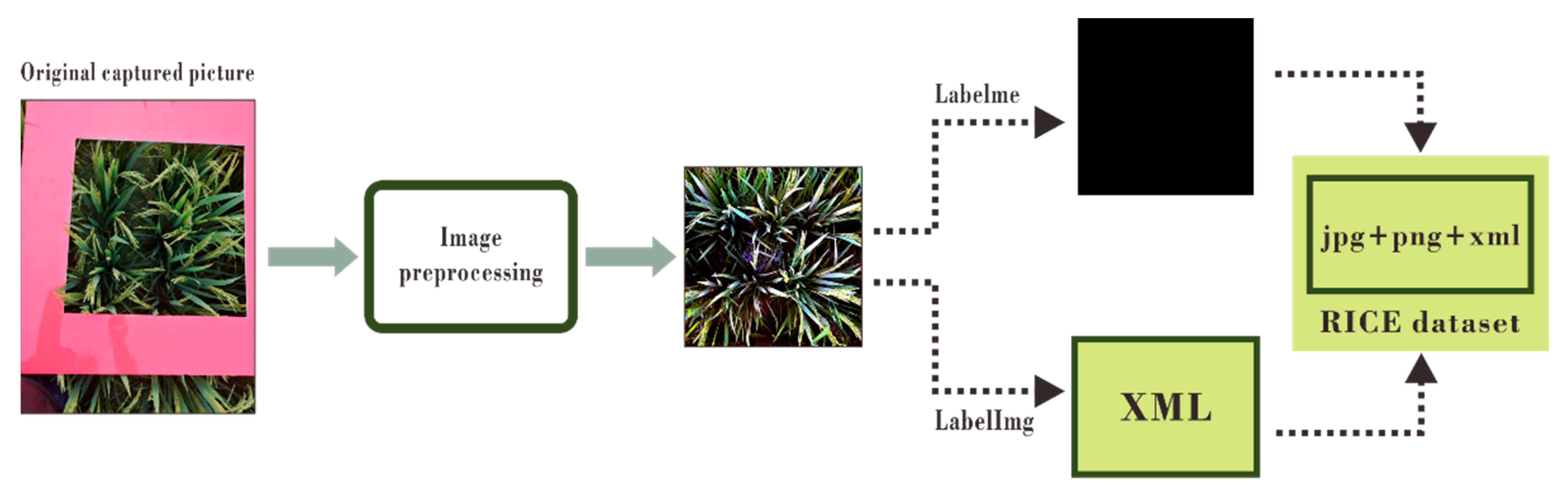
2.2. Image Preprocessing
2.3. Dataset Creation
2.4. LC-FCN Algorithm
2.5. Implementation and Evaluation Index
3. Results
3.1. Data Augmentation
3.2. Comparison of Different Backbones
3.3. Comparison with Machine Learning
3.4. With Object Detection
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gebbers, R.; Adamchuk, V.I. Precision agriculture and food security. Science 2010, 327, 828–831. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Wang, M.; Wang, N. Precision agriculture—A worldwide overview. Comput. Electron. Agric. 2002, 36, 113–132. [Google Scholar] [CrossRef]
- Stafford, J.V. Implementing Precision Agriculture in the 21st Century. J. Agric. Eng. Res. 2000, 76, 267–275. [Google Scholar] [CrossRef] [Green Version]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Ma, C.; Zhang, J.; Chen, X.; Zhu, D. Research and application of deep learning methods in agriculture. Ningxia Agric. For. Sci. Technol. 2020, 61, 35–37, 42, 63. [Google Scholar]
- Zhang, S.; Zhang, C.; Ding, J. Forecast model of winter jujube diseases and insect pests in greenhouses based on improved deep confidence network. J. Agric. Eng. 2017, 33, 202–208. (In Chinese) [Google Scholar] [CrossRef]
- An, Q.; Zhang, F.; Li, Z.; Zhang, Y. Image recognition of plant diseases and insect pests based on deep learning. Agric. Eng. 2018, 8, 48–50. (In Chinese) [Google Scholar]
- Wang, X.; Zhang, C.; Zhang, S.; Zhu, Y. Cotton disease and insect pest prediction based on adaptive discriminant deep confidence network. J. Agric. Eng. 2018, 34, 157–164. (In Chinese) [Google Scholar] [CrossRef]
- Xiong, X. Field Rice Ear Segmentation and Non-Destructive Yield Estimation Based on Deep Learning; Huazhong University of Science and Technology: Wuhan, China, 2018. [Google Scholar]
- Duan, L.; Xiong, X.; Liu, Q.; Yang, W.; Huang, C. Field rice ear segmentation based on deep full convolutional neural network. Trans. Chin. Soc. Agric. Eng. 2018, 34, 210–217. (In Chinese) [Google Scholar]
- Tri, N.C.; Duong, H.N.; Hoai, T.V.; Hoa, T.V.; Nguyen, V.H.; Toan, N.T.; Snase, V. A novel approach based on deep learning techniques and UAVs to yield assessment of paddy fields. In Proceedings of the 2017 9th International Conference on Knowledge and Systems Engineering (KSE), Hue, Vietnam, 19–21 October 2017. [Google Scholar]
- Wang, P.; Luo, X.W.; Zhou, Z.Y.; Zang, Y.; Hu, L. Key technology for remote sensing information acquisition based on micro UAV. Trans. CSAE 2014, 30, 1–12. [Google Scholar]
- Xiang, H.T.; Tian, L. Development of a low-cost agricultural re-mote sensing system based on an autonomous unmanned aerialvehicle (UAV). Biosyst. Eng. 2011, 108, 174–190. [Google Scholar] [CrossRef]
- Bai, Y.L.; Yang, L.P.; Wang, L.; Lu, Y.L.; Wang, H. Theagricul turelow-altitude remote sensing technology and its application pro-spect. Agric. Netw. Inf. 2010, 1, 5–7. [Google Scholar]
- Chosa, T.; Miyagawa, K.; Tamura, S.; Yamazaki, K.; Iiyoshi, S.; Furuhata, M.; Kota, M. Monitoring rice growth over a produc-tion region using an unmanned aerial vehicle: Preliminary trial for establishing a regional rice strain. IFAC Proc. Vol. 2010, 43, 178–183. [Google Scholar] [CrossRef]
- Reza, M.N.; Na, I.S.; Baek, S.W.; Lee, K.-H. Rice yield estimation based on K-means clustering with graph-cut segmentation using low-altitude UAV images. Biosyst. Eng. 2019, 177, 109–121. [Google Scholar] [CrossRef]
- Laradji, I.; Rostamzadeh, N.; Pinheiro, P.O.; Vazquez, D.; Schmidt, M. Where are the blobs: Counting by localization with point supervision. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, IEEE Computer Society, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Number | Characteristics |
|---|---|---|
| A | 596 | The color difference is relatively large, the effect is the clearest and easiest to identify. |
| B | 935 | The effect is general, the noise is large, and the distinction is obvious. |
| C | 130 | The effect is the worst, the picture is reddish and the most difficult to recognize. |
| Backbone | Augmentation | Dataset Size | MAE | RMSE | nRMSE (%) | Acc-Rate (%) |
|---|---|---|---|---|---|---|
| VGG16 | / | 1100 | 8.88 | 11.72 | 17.76 | 61.70 |
| Flip | 2200 | 5.07 | 8.14 | 11.62 | 82.82 | |
| Flip + Rotation | 3300 | 3.96 | 5.93 | 8.72 | 87.48 | |
| ResNet50 | / | 1100 | 8.48 | 12.19 | 18.20 | 61.78 |
| Flip | 2200 | 4.05 | 7.63 | 11.22 | 84.90 | |
| Flip + Rotation | 3300 | 2.99 | 5.40 | 7.01 | 89.88 |
| Method | MAE | RMSE | Accuracy |
|---|---|---|---|
| SSD | 13.62 | 15.79 | 54.14% |
| ResFCN | 9.27 | 13.14 | 56.29% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, H.; Tang, R.; Lei, Y.; Mu, J.; Guan, Y.; Xiang, Y. Rice Ear Counting Based on Image Segmentation and Establishment of a Dataset. Plants 2021, 10, 1625. https://doi.org/10.3390/plants10081625
Shao H, Tang R, Lei Y, Mu J, Guan Y, Xiang Y. Rice Ear Counting Based on Image Segmentation and Establishment of a Dataset. Plants. 2021; 10(8):1625. https://doi.org/10.3390/plants10081625
Chicago/Turabian StyleShao, Hongmin, Rong Tang, Yujie Lei, Jiong Mu, Yan Guan, and Ying Xiang. 2021. "Rice Ear Counting Based on Image Segmentation and Establishment of a Dataset" Plants 10, no. 8: 1625. https://doi.org/10.3390/plants10081625
APA StyleShao, H., Tang, R., Lei, Y., Mu, J., Guan, Y., & Xiang, Y. (2021). Rice Ear Counting Based on Image Segmentation and Establishment of a Dataset. Plants, 10(8), 1625. https://doi.org/10.3390/plants10081625