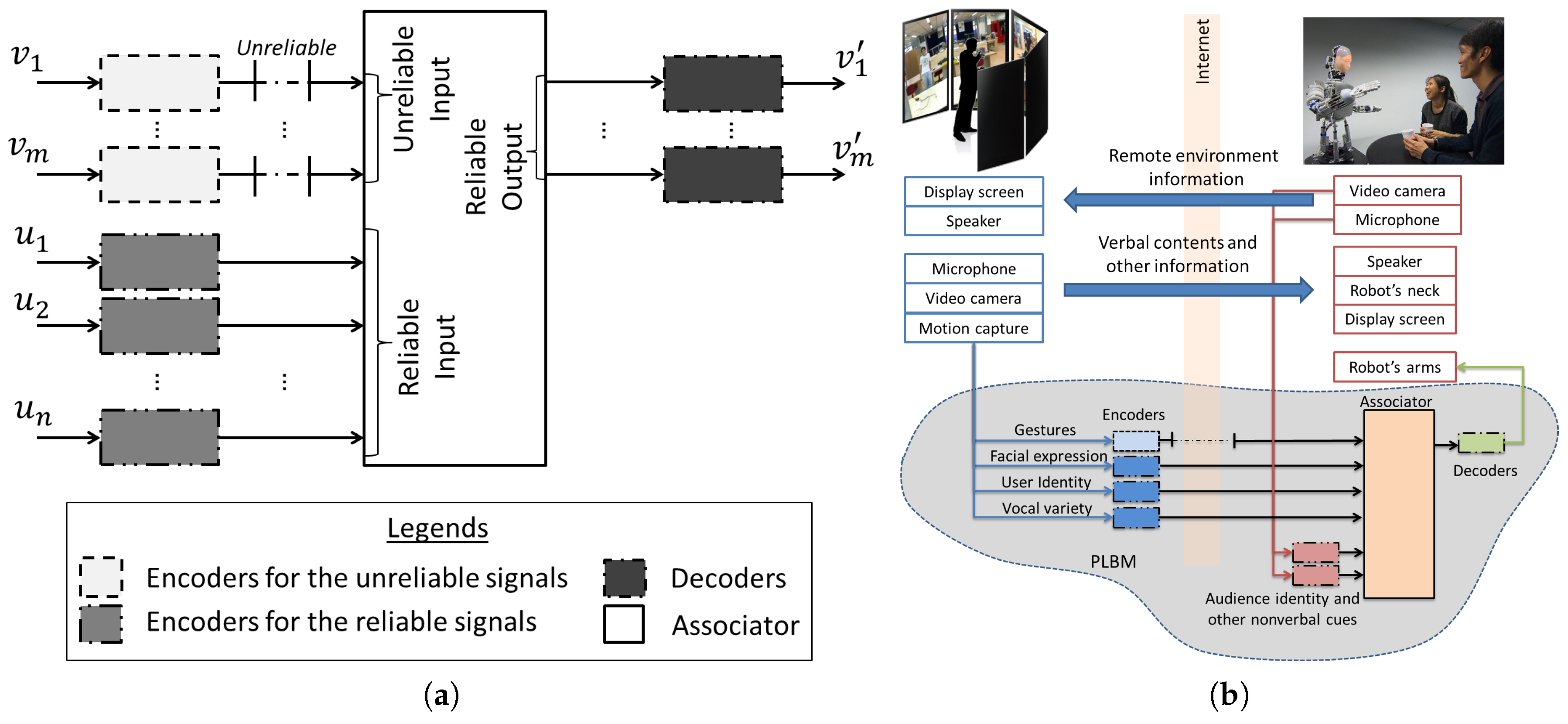
3.1. Perception-Link Behavior Model
The name of this model is the perception-link behavior model (PLBM) because the conversation partners might react according to what they see during a conversation, and this is the concept behind role negotiation [
15] and the chameleon effect [
16]. Alternatively, the perception-link behavior model (PLBM) is also an online associative multimodal model with encoding and decoding capability (
Figure 3a). It can be implemented into a CATR’s framework to associate multiple modalities, as shown in
Figure 3b. Primarily, it has three components: encoders, decoders and associator.
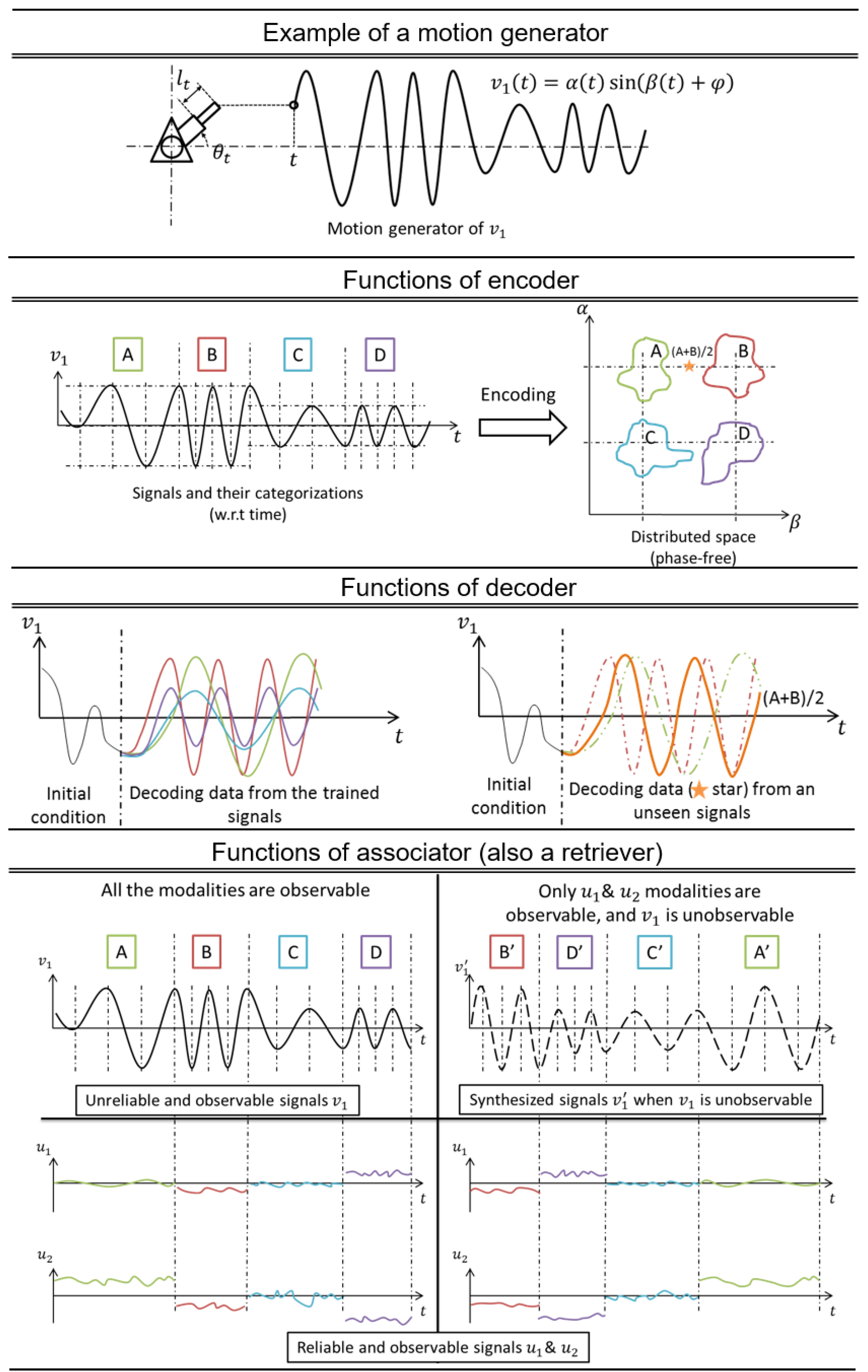
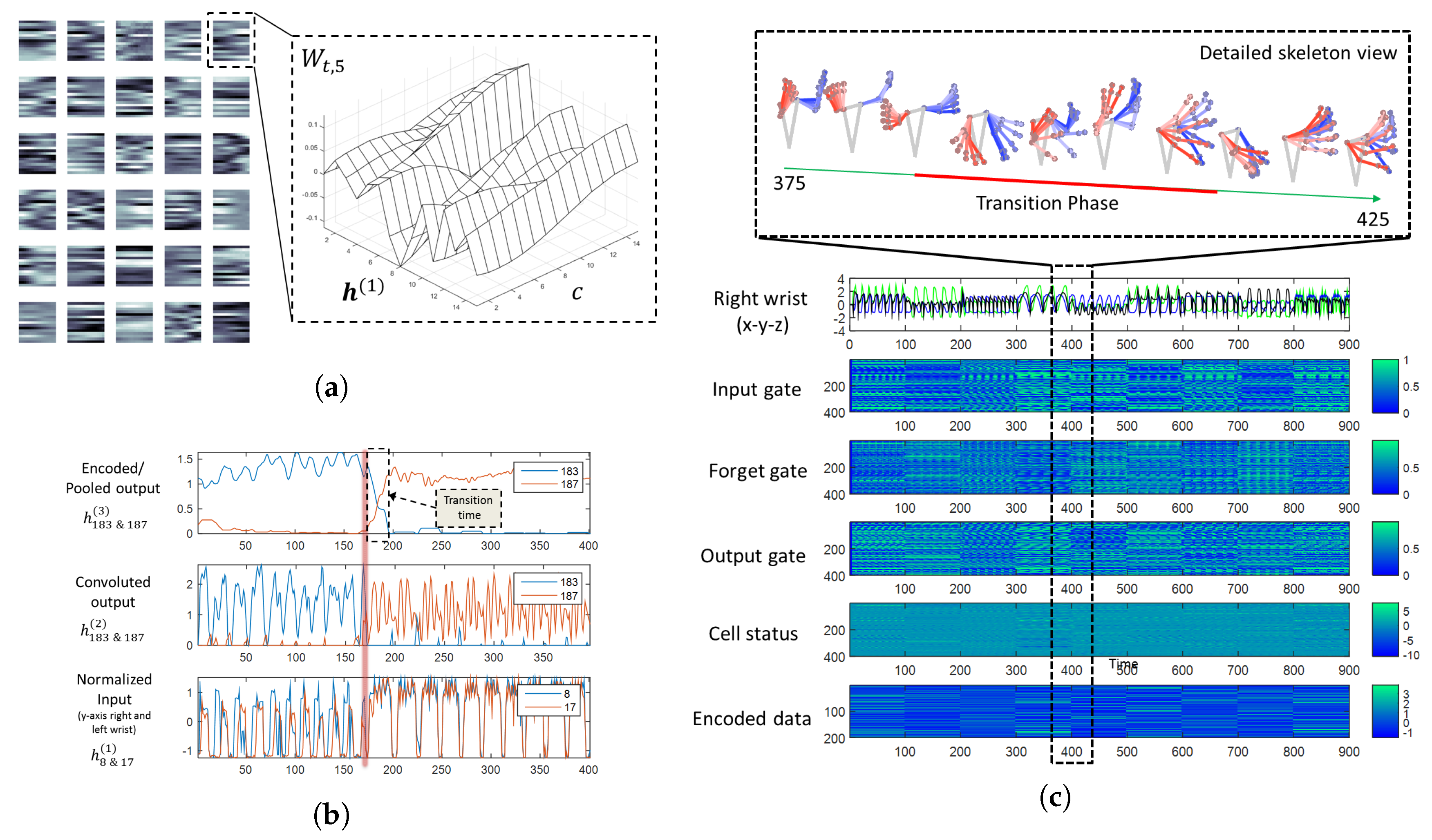
The following descriptions are the function of each component with a simple example. The encoder transforms the input signal into distributed output, and it groups similar signals nearer to each other. For example, let us assume that there exists a motion generator (
Figure 4, Row 1) with two degrees of freedom: linear
and rotation
. During the training process, the motion generator only generated four signals, A, B, C and D, by varying
and
. The encoder should learn the distributed features
and
using the training signals. Subsequently, the encoder can map any signal, including
, into the new space, as shown in
Figure 4, Row 2, where the signals with similar dynamics are grouped nearer to each other. From the distributed output, the decoder should extrapolate the gesture motion without losing its expressiveness. Once the encoder has mapped a signal to its distributed output, the decoder can take the distributed output and transform it back to its originals dynamic (
Figure 4, Row 3). Lastly, the associator can learn relationships between multiple modalities. If necessary, it can retrieve the missing signal from its knowledge base.
Figure 4, Row 4, left, shows the relationship of a motion
and the two other signals
and
. If these relationships are consistent, then the associator can leverage this knowledge and create a list of rules of these relationships. In a different situation (
Figure 4, Row 4, right), if there were a missing channel
, the associator could exploit the knowledge base and retrieve a synthesized signal
given the observable signals
and
.
With the above functions, the framework with PLBM can obtain the first objective of the paper, because it adopts an unsupervised learning model and a contextual generative model. The encoder utilizes an unsupervised learning model so that the extracted features are more thorough and comprehensive. In an unsupervised approach, e.g., Fourier transformation, the distributed features are the amplitude
and angular frequency
(
Figure 4). However, there is no assurance of the completeness of the features if they are manually selected. Secondly, the model produces distributed features. The distributed representation encompasses more information given the same amount of memory size. For a memory size of
N capacity, a system with the distributed binary representation can hold up to
classes. On the other hand, the local representation can only group up to
N classes. Lastly, the decoder is a contextual generative model that reconstructs the signals given a contextual information, e.g., encoded data. A decoder model predicts a sequence of future time steps
given the encoded data
and the boundary conditions
. With extensive training, the decoder model should figure out the intrinsic dynamics encompassed in the encoded data
, and it should be capable of generating output
similar to the training data
. In short, the framework with the PLBM can imitate the operator’s personal gestures because the encoding process preserves expressiveness, and the decoding process is capable of generating personal gestures given the encoded data.
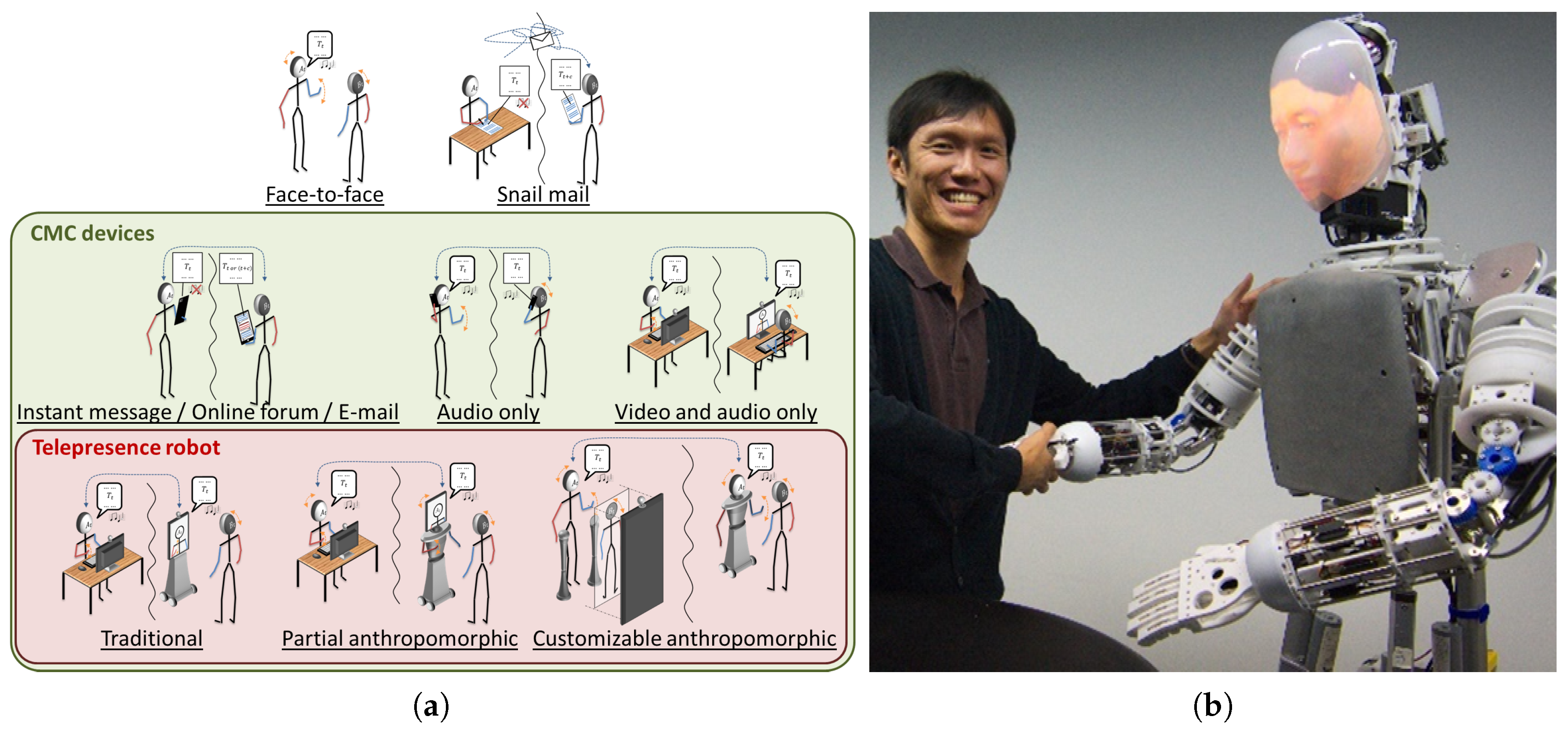
From the review, the framework with the PLBM and natural interface (NI) should result in minimum cognitive load and be easier for the operator to use because they require minimal remapping and less memorization. The NI is the user interface that directly acquires the conversational gesture. For example, Hasegawa [
10] chose the NI, instead of the passive model controller [
5], because it could capture both conscious and subconscious gestures. From the review, the NI can capture the subconscious gesture because it does not require much remapping. Secondly, the NI also requires less memorization. For our case, we chose the NI because any operator can just make his/her gestures as if it were a face-to-face conversation. Furthermore, all of the modules in the PLBM are automatic. The encoder will automatically encode the user gesture to its distributed output. Next, the system will transmit all of the data to the remote system. Upon reaching the remote system, the associator will update its parameters. Concurrently, the decoder will synthesize the current poses. In summary, all of the processes require minimal human intervention, except for the gesticulation process.
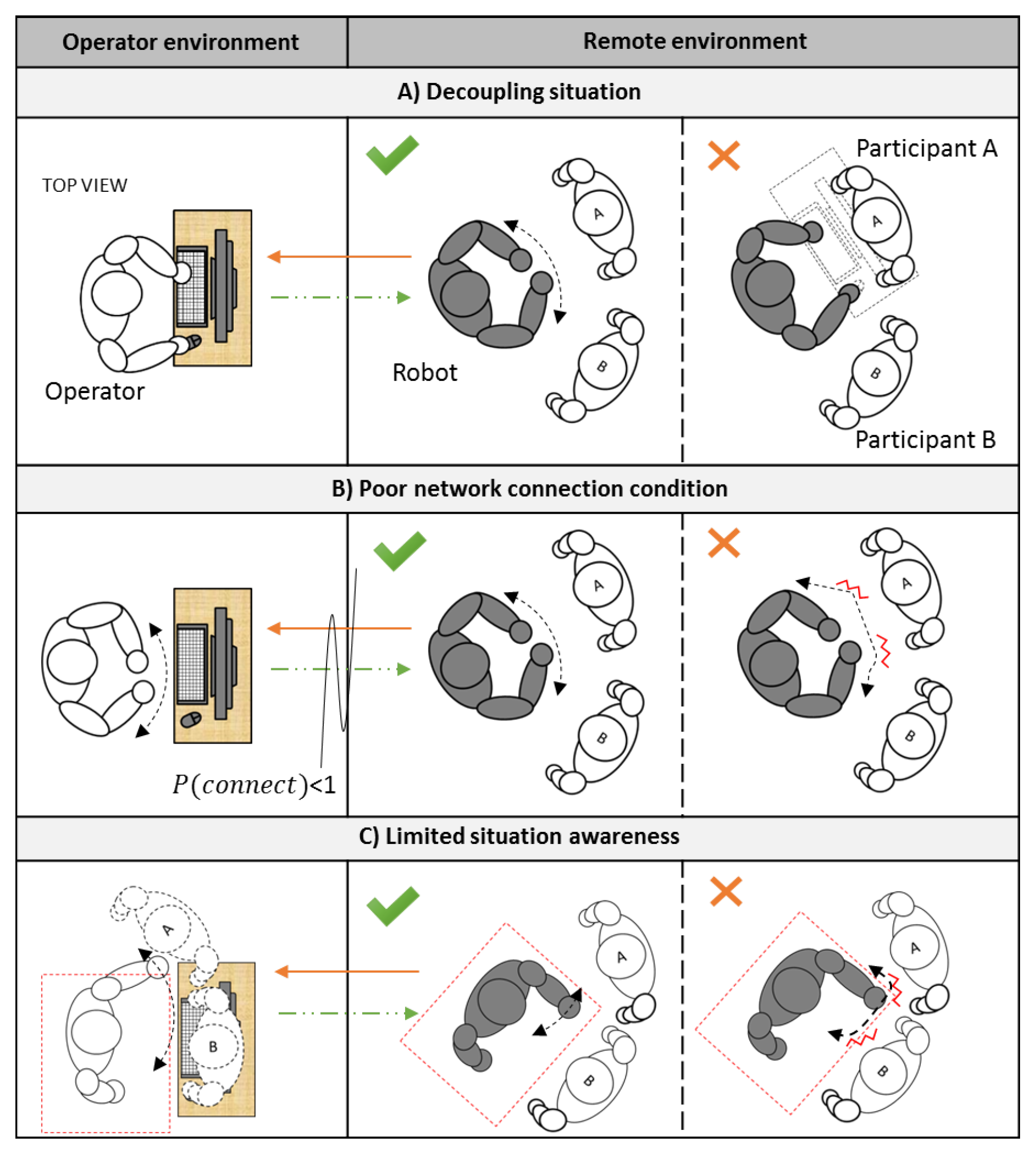
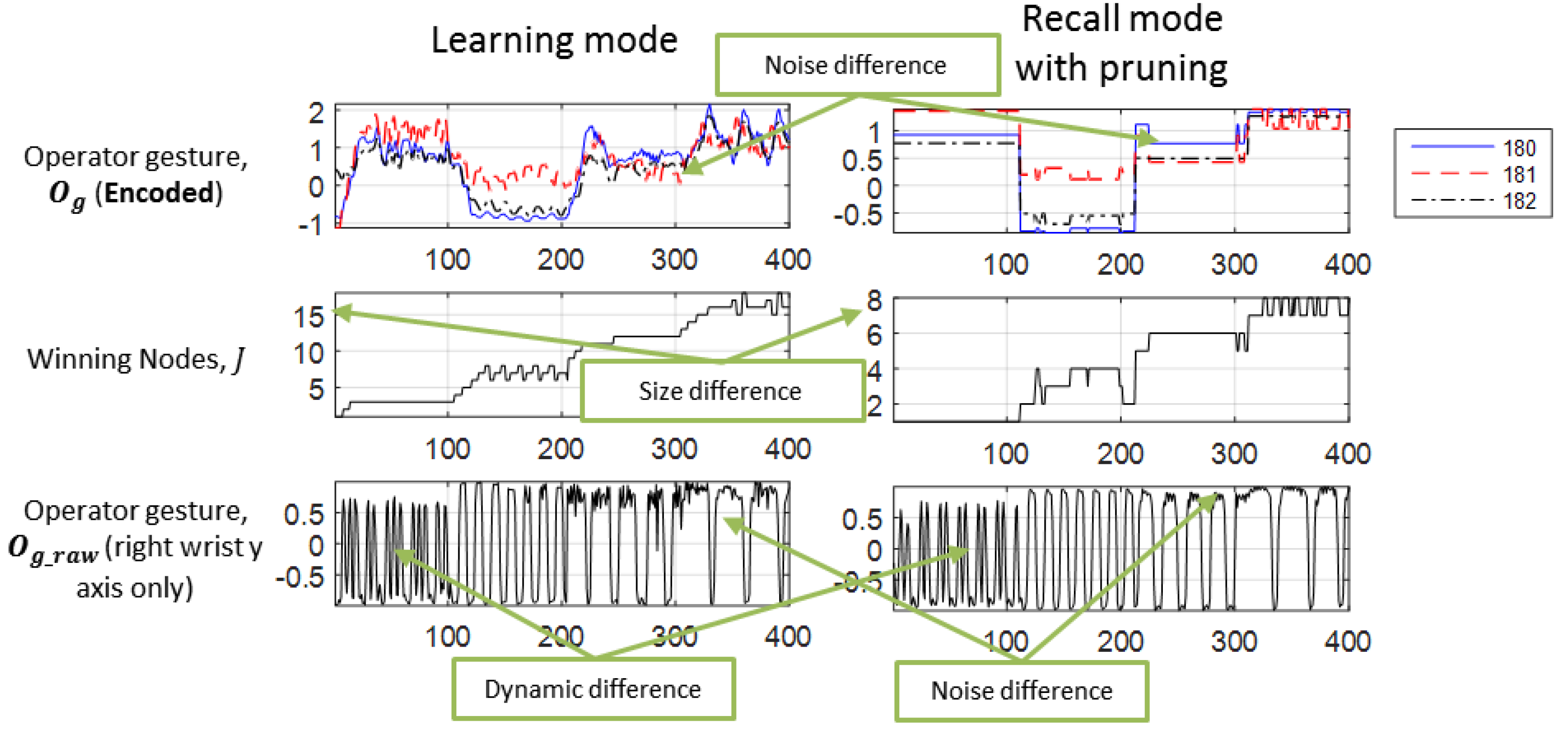
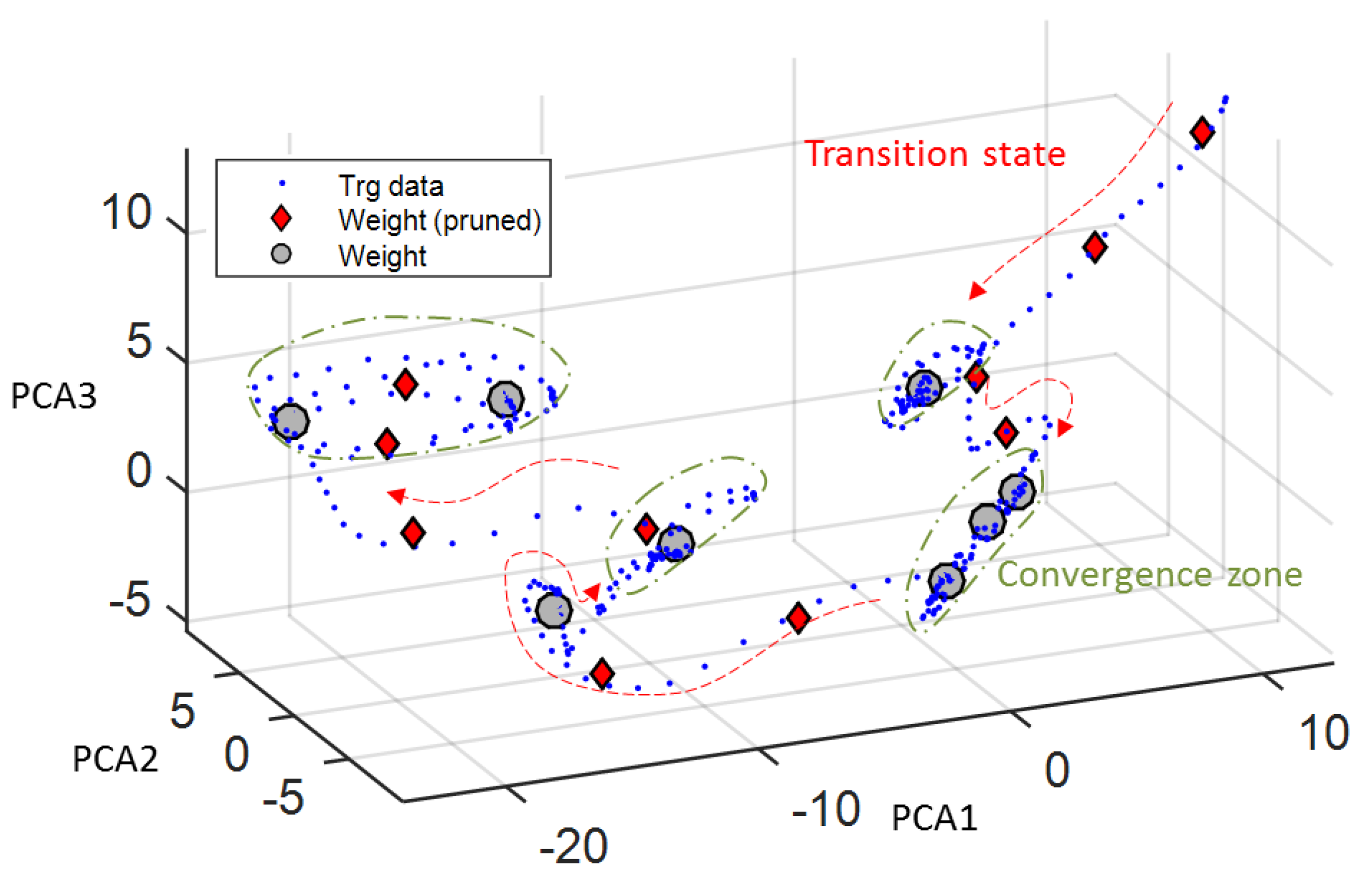
Finally, the PLBM can be incorporated into the CATR’s framework to handle the three teleoperation issues (
Figure 2). In the first scenario, the PLBM can conceal and replace the unwanted user gesture because of the intrinsic properties of the feature space and the proposed algorithms in the associator. Firstly, each modality should be encoded to its space so that the signals with the same dynamics are grouped closer together. When talking, if the operator and audience react consistently, then some clusters, which capture co-occurrence of the modalities, might emerge. At every time step, the associator updates its knowledge base. This update process ensures that the clusters’ parameters, e.g., mean and hit-rate, are up to date. In the recall mode, the associator can clean up its knowledge base. For instance, it can remove low hit-rate clusters, which might be outliers or transition data points. Subsequently, the associator will receive remaining modalities less the concealed modalities. From the unobservable channels, the associator can look up its knowledge base to find the closest cluster based on their parameters, e.g., mean. Once the associator finds it, the associator then evokes the missing data and passes it to the decoder. In conclusion, the PLBM can associate multiple modalities and retrieve corresponding missing data because of the feature space and the learning model in the associator.
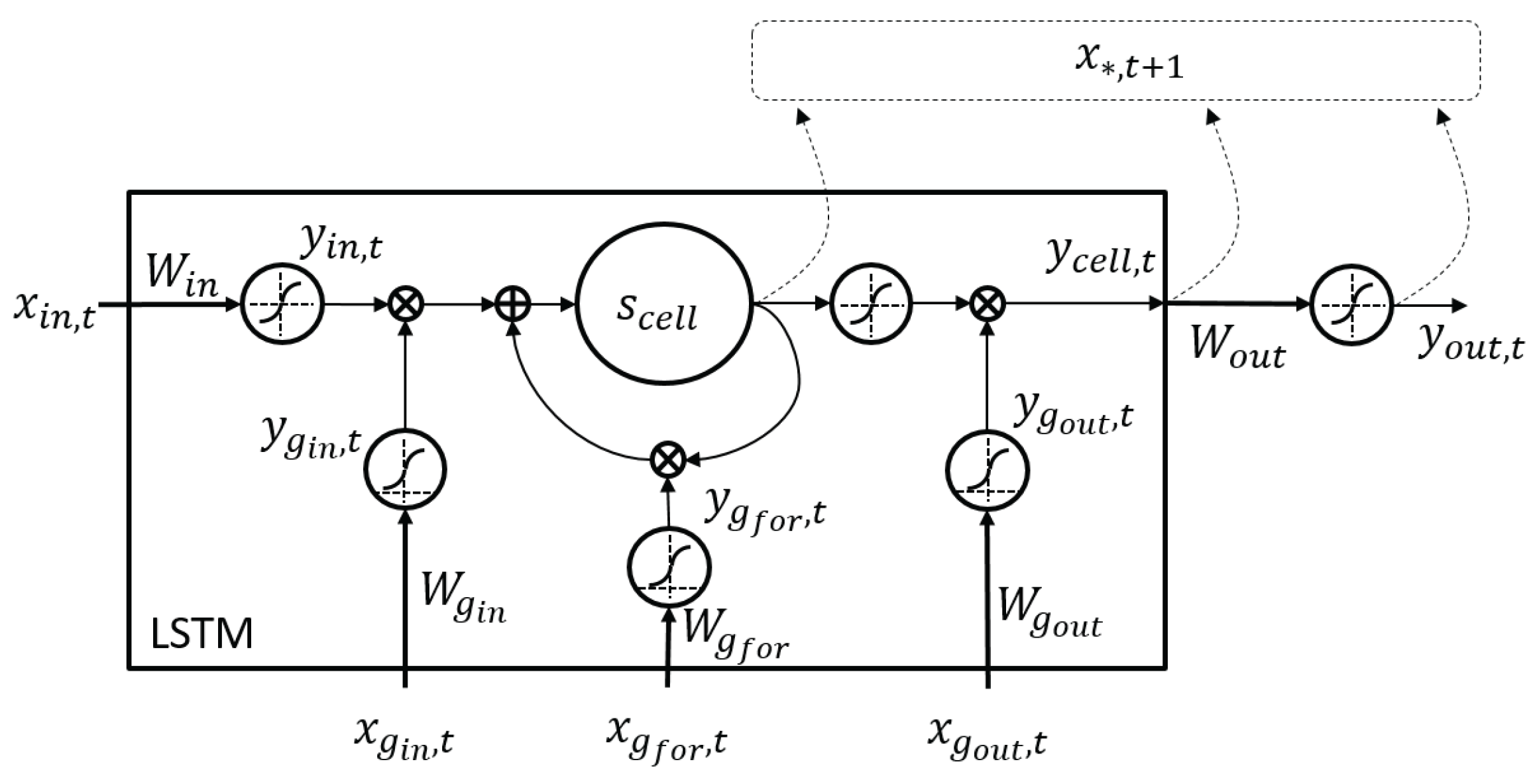
For the second scenario, the PLBM can insert similar data when there is a poor network connection, which results in packet loss, because the encoded data encompass the spatiotemporal information. When network disruption or congestion occurred, the incoming data might be dropped to reduce latency. For this instance, the framework can feed the last received data, e.g., and , to the decoder. The lost data can be replaced by the last known data because the last known data encapsulate the gesture style, and , rather than the pose information, . With the gesture style, the decoder can infer the next pose, . In brief, the PLBM should be capable of reconstructing a smooth and expressive gesture even when the packets are lost.
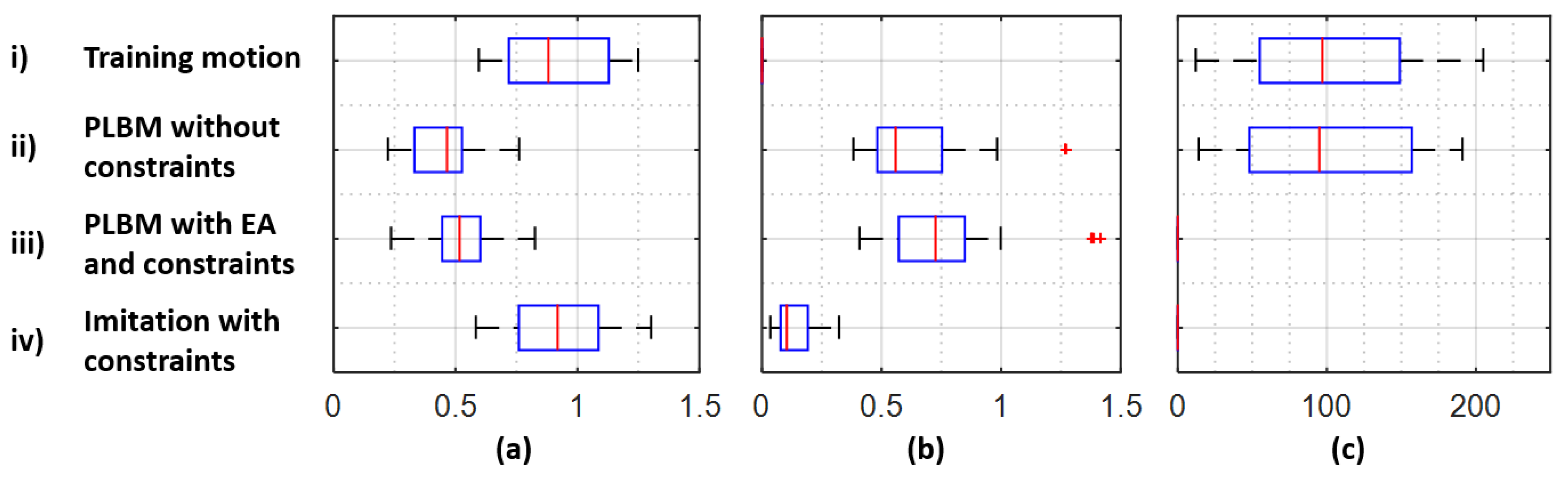
For the last scenario, the CATR can deliberatively and smoothly avoid a collision because of the intrinsic properties of the feature space. Since the encoded data with similar dynamics are close to one another, a searching algorithm can find a good candidate in that region. A list of criteria can be chosen to measure the fitness of the candidate depending on the problem. In our case, the searching algorithm, e.g., the evolutionary algorithm, can be activated when the decoder projects a collision trajectory given the original encoded data. It starts by generating a group of candidates using the seeds. The seeds can be the original encoded data for the first iteration or a list of the highest scoring candidates for the subsequent iteration. Next, the candidates will undergo the evaluation processes to determine their fitness; for example, a collision criterion measuring the number of points that lie outside the desirable boundary or a similarity criterion measuring the degree of similarity between the original’s and the candidate’s projected trajectory. The algorithm then selects a list of the candidates and continues the above processes. It will continue until it finds a good candidate. In short, the PLBM with a searching algorithm exploits the inherit properties from the encoder to find a good candidate, which is collision-free and expressive.
In conclusion, the framework with PLBM and NI should meet the objectives of the paper. First of all, the encoder can remap any gesture into its features space without losing its expressiveness because the features are comprehensive and distributed. The decoder can reconstruct the personal gesture onto the CATR because it can generate the desired gesture given the encoded data. Next, a framework with NI and PLBM is preferred because they require minimal human intervention, remapping and memorization. Lastly, the PLBM can handle the teleoperating issues because of the intrinsic properties of the features space. In the following sections, we will provide the implementation for each component.
3.2. Model for the Encoder
Inspired by the vector space model, the restricted Boltzmann machine [
17,
18] and the convolution neural network, the concept of the encoder model is to remap a non-stationary signal into a distributed and phase-free vector space.
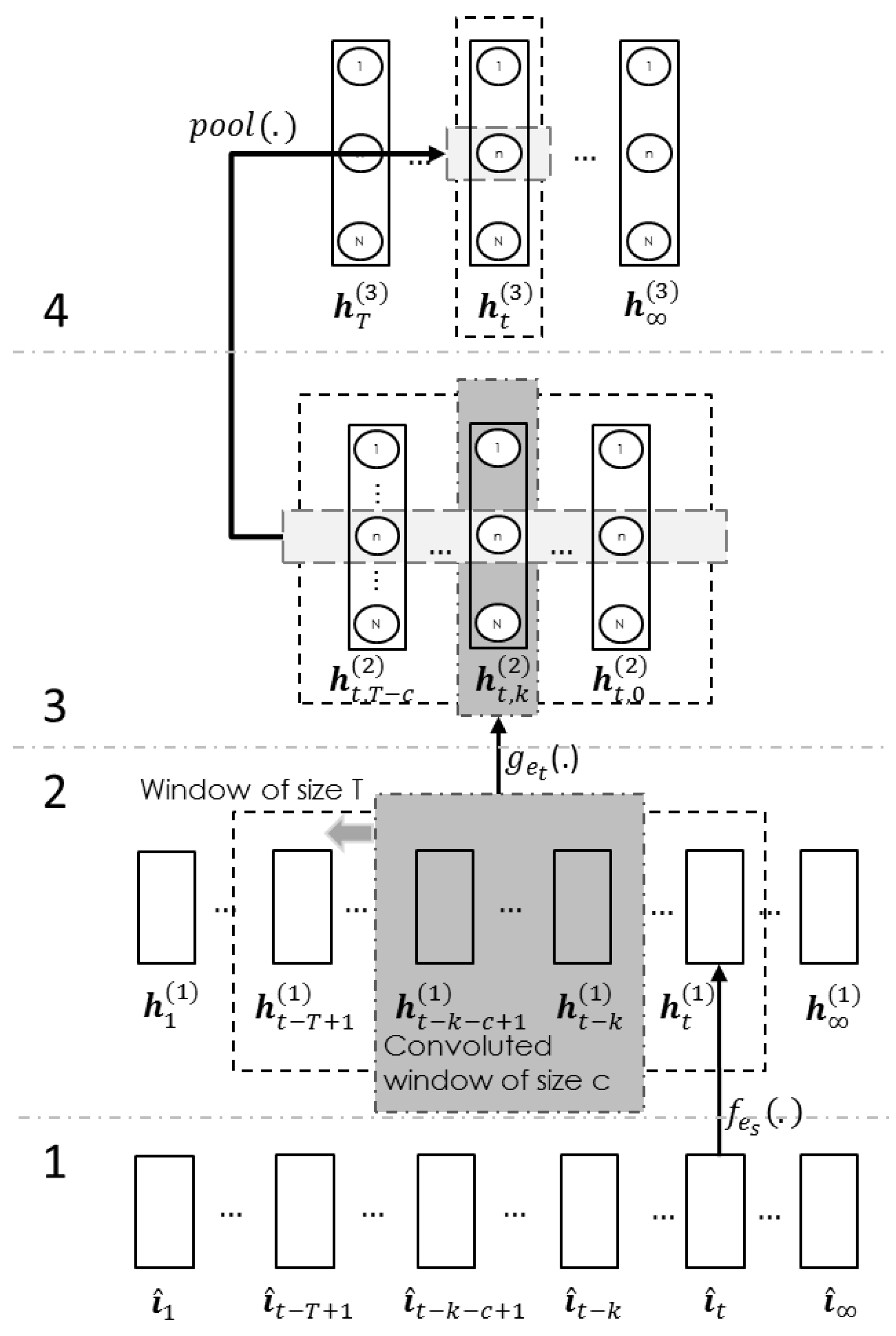
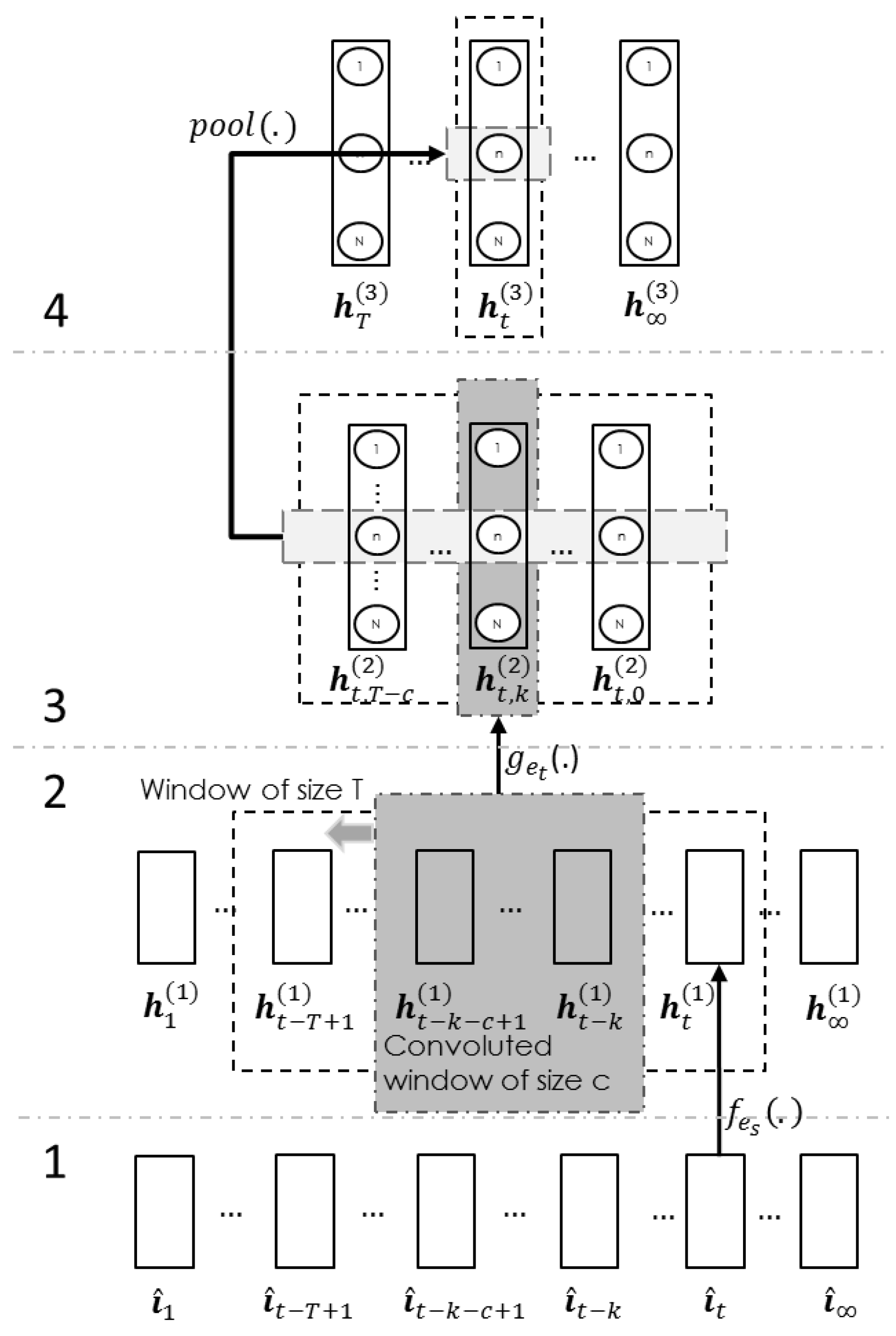
The proposed encoder model (
Figure 5) has four layers. The first layer is the input layer, and the data are a list of unit upper-limb vectors
from (
27). Next, the second layer is the spatial transformation layer, which is optional. It transforms the data of the joints
into the distributed spatial data:
where
are the model parameters, which were trained using contrastive divergence [
19], and
is the number of feature maps in the second layer. The third layer is the convolution layer. Initially, this layer pulls out a
T sequence of spatial data
. Sequentially, it pulls out a subset of
c size from the above sequence for every
k step, and
k ranges from
. In each
k step, the model calculates the convoluted output:
where
are the parameters, which were also trained using contrastive divergence [
19], and
is a rectified function [
20]. The last layer is the element-wise pooling layer. This layer merges the sequence from the previous layer
to form:
where the
can either be the
or max operation. To simplify the encoding process from (
1) to (
3), the encoder function is reduced to:
Once the encoder can transform the input signal into the new vector/gesture space, the next step is to find a decoder to extrapolate the future joint states given the boundary condition and the encoded data .
3.4. Model for Associator
The associator is a modified multi-channel adaptive resonance associative map (ARAM) [
26], which is an extension of the adaptive resonance theory (ART) model [
27]. In the PLBM, the channels of the associator are the encoded nonverbal cues from the operator and the audiences. Ideally, the associator forms rules across the different channels for future querying. For better illustration, the following paragraphs will explain the learning and recalling process using three features, and they are the user’s face feature, the audience’s face feature and the user’s gesture feature.
The learning process has four steps. The function for each step is: (1) preparing the input; (2) computing the choice activation; (3) finding the best activation; and (4) updating the weight through fast or slow learning. The first step only assembles the input features. Some existing ART models [
28] have its input
ranging within
, but our approach intrinsically restricts the range by using the encoder. As a result, the input is:
where
,
and
are the encoded data of the user’s face feature, the audience’s face feature and the user’s gesture feature, respectively. Because the encoded data have no precise limit, there is also no known upper limit to the distance between two data. Therefore, we proposed a new choice activation function:
where
is the closeness index between input
and weight
,
is the
i-th element in the
j-th node of the
k-th channel,
is the number of elements in the
k-th channel and
. The third step finds the best activation index
J. This process considers the results from all of the channels by:
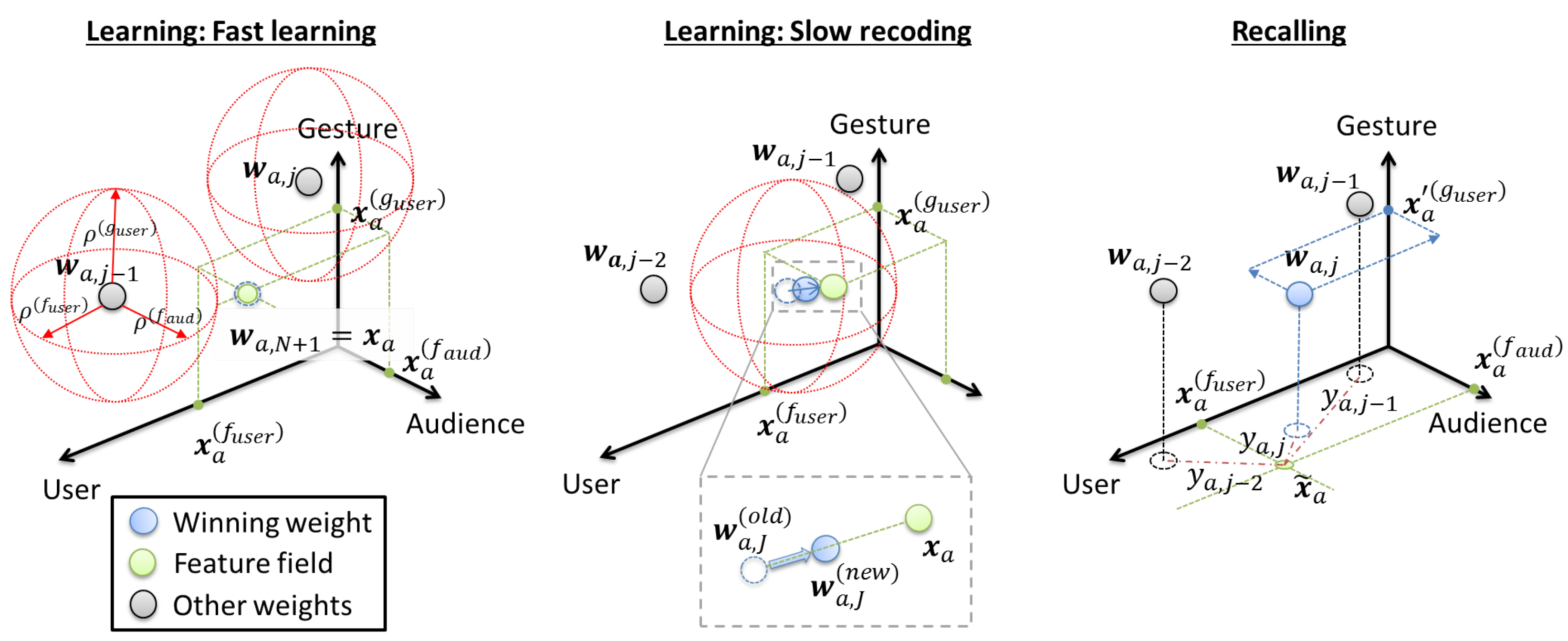
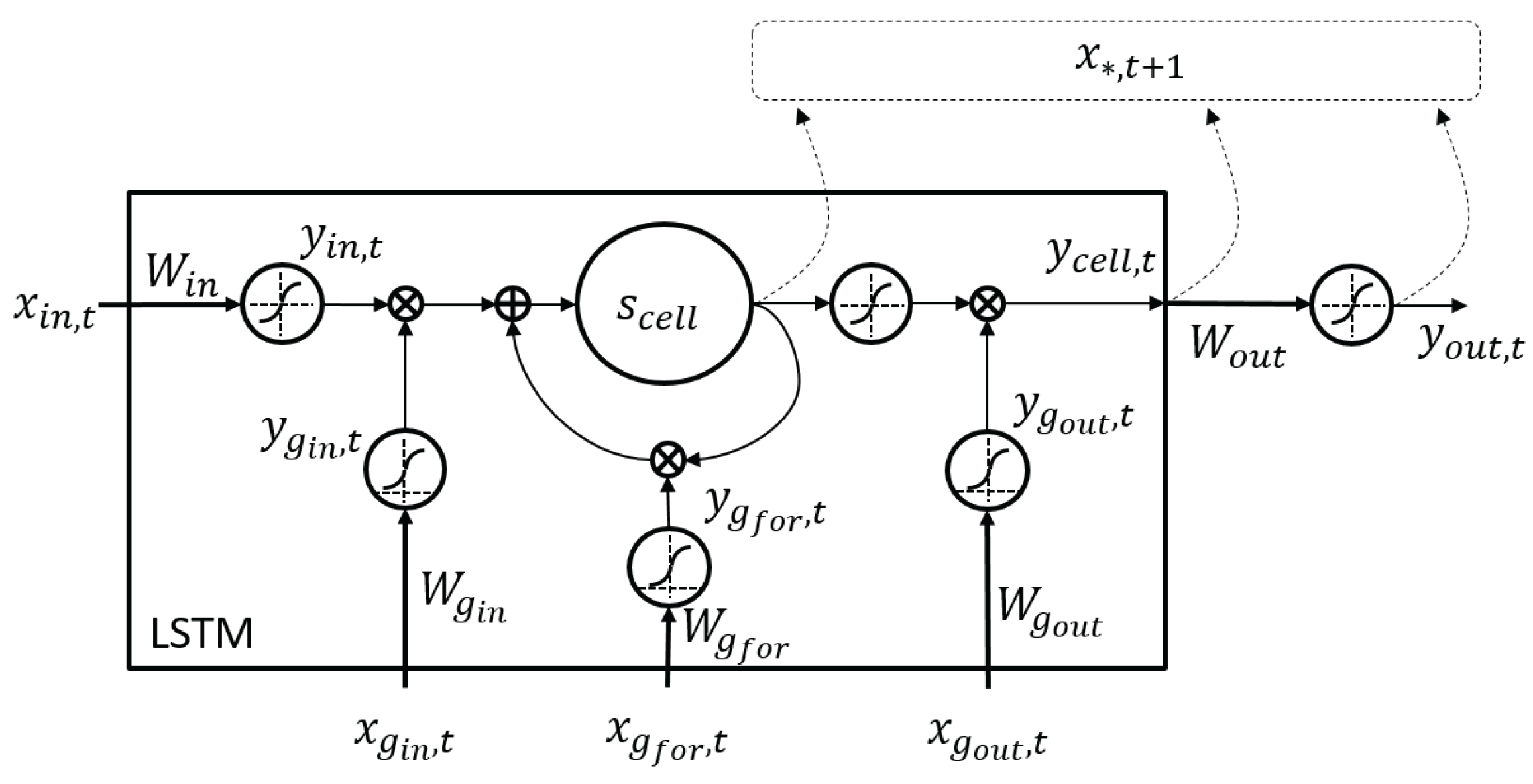
Lastly, there are two update methods, and they are known as the fast learner and slow recoder (
Figure 8). The associator executes the faster learner:
if
there
such that
, where
is the vigilance threshold of the
k-th channel. On the other hand, if there
such that
satisfy
, then the slow recoding function updates the winner node
by:
where
is an adaptive learning rate, which decreases as the weight occurrence
increases. In short, the associator will regularly create or update the relationships among all of the modalities. This process will come to a pause when there is a need to recall or replace one of the modalities.
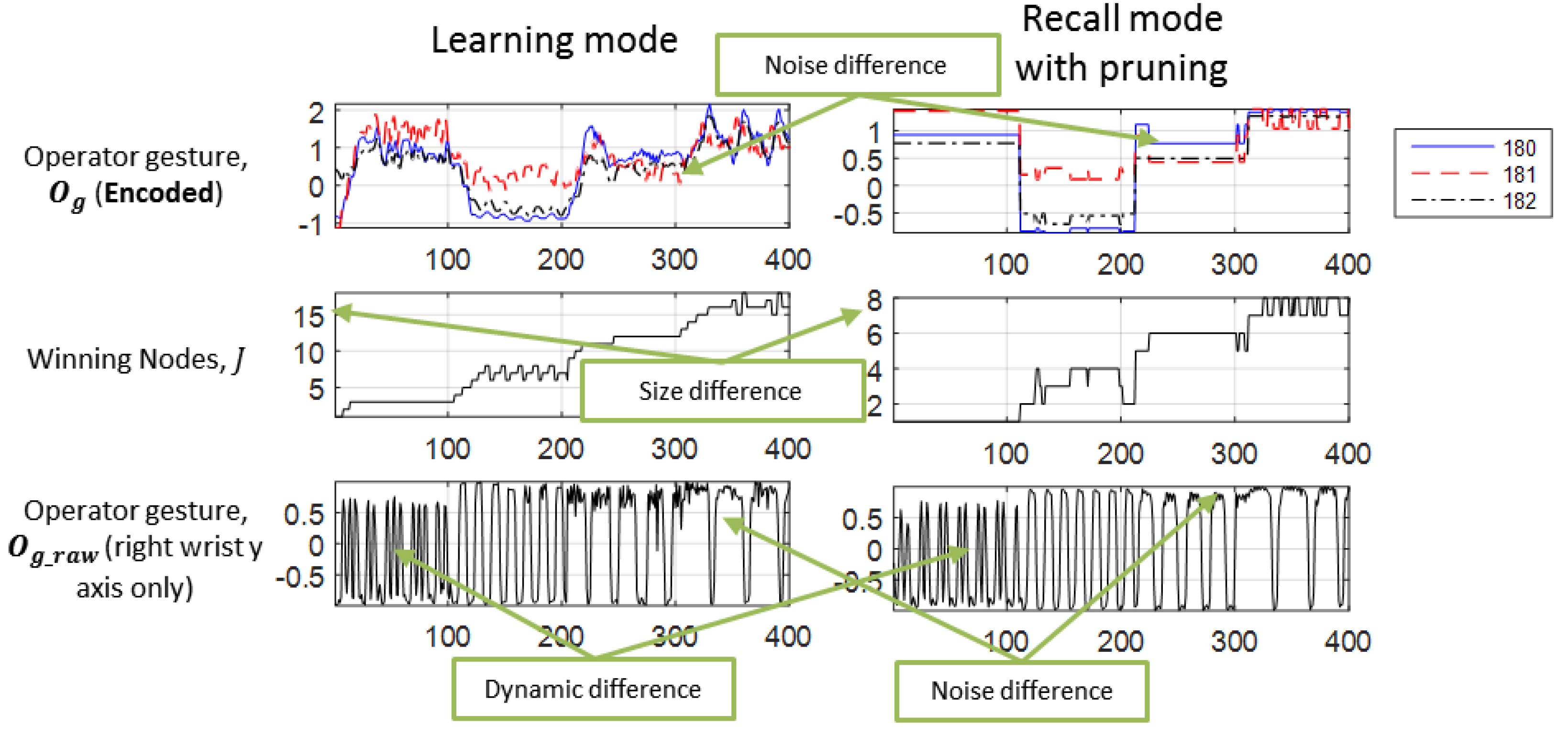
The associator will switch to the recall mode (
Figure 8) when there is one or more missing modalities. For this case, the following explanation assumes that the user’s gesture feature
is missing. Hence, there is a newer and shorter input:
During the initialization, the associator discards any weight
if its frequency
, where
is the pruning threshold. Next, the associator computes the choice activation using (
18) on the observable feature fields
and
. It then finds the best activation:
From the best weight
, the associator can infer the gesture style:
The last process decodes the encoded data
using the decoder function
from (
13) to estimate next joint state:
where
is the
p number of previous upper-limb states. As a whole, this recalling strategy can retrieve associated data given a partial context.
In theory, the proposed framework can handle the teleoperating issues using its three components, and they are the encoders, decoders and associator. The next section will discuss the processes applied to the data to train each component.
3.5. Data and Its Preprocesses
The encoder and decoder should be trained with a diversified dataset because the diversified dataset can produce a generalized predictor. Therefore, the proposed gesture dataset is a combination of three datasets. The first source is the Microsoft action gesture [
29]. It has three sets of 12 gaming gestures from ten people. However, only nine out of the 12 gestures were selected because they have more expressive upper-limb motion. The second source is the 3D iconic gesture dataset [
30]. These gestures are speech-dependent, and the speech-dependent gesture is useful for our application. Furthermore, this dataset covers 29 subjects gesturing 20 different virtual objects. The last dataset is an in-house dataset, and it consists of deictic gestures and a few speech-dependent gestures (refer to
Supplementary Material 4 for the description). It was noticed that all of the gesture styles in [
29,
30] are periodic gestures. Hence, a set of nonperiodic gestures, which are primary deictic gestures, were acquired and stored in the in-house dataset. In addition, the action and the iconic gestures are very intensive and dynamic. As a result, the in-house data also have waving and beating gestures, for which only a few of the joints are moving. Lastly, the combined dataset underwent a mirroring operation to double up the number of training data to 268,296, where each datum has five frames of poses. In conclusion, the final dataset has a high variety of gestures, and the next process is to normalize the data.
There is a series of processes to normalize the skeleton data. The first operation normalizes pose data so that the poses
are independent of the torso’s movement. Subsequently, the second process computes the upper-limb orientations:
where
is the relatively unit vector. The relative vector is
, where
is a list of poses from the skeleton data. The last operation is feature-rescaling, also known as standardization. Standardization scales all of the features, so that they are zero-mean and unit variance. As a result, the normalized data are:
where
is the mean of the gesture data and
is the standard deviation of the gesture data. Up to this point, the encoder can be trained using the normalized dataset, but more steps are required to train a decoder.
For training a decoder, there are two additional processes. The first process transforms the gesture signal into their gesture style
using the encoder function at (
4). Subsequently, the encoded data
go through the standardization process. The second step then aligns the encoded data
with the corresponding normalized data
. In this paper, the encoded data
have
frames (5 FPS) of information, and the number of previous data is
. As a result, the initial condition is
. During training, the decoder will generate the remaining
frames, which is
. In short, the encoding and alignment processes are the two addition steps for training a decoder. The next step is to add other modalities so that the associator can be trained and evaluated.
For the associator, there are two simulated datasets. Both the simulated datasets have three channels, and they are the operator’s facial channel, the audience’s facial channel and the operator’s gesture channel. The facial channels acquired their facial data from a facial expression dataset, the CK+dataset [
31], while the gesture channel obtained its data from the above gesture dataset. The first set of data, the identity dataset (
Figure 9, left), simulates a situation where an operator is talking to three different characters in a row. In each sequence, the operator and the audiences only display the neutral facial expression, but the operator motions different gesture styles towards each audience. In the second set, the expression dataset (
Figure 9, right) simulates the operator talking to the same person. Each sequence has four parts, and each part has a unique gesture style. In terms of facial expression, the first part has the operator and audience making a neutral expression. The second and third have one of them displaying an arbitrary expression, while the others stay neutral. The last covers both expressing a random expression. In short, these two simulated datasets have three modalities so that we can observe the learning and recall process in the associator. With the availability of data for each component, the next section will present the evaluation criterion for training and evaluating the system.
3.6. Training and Evaluation Criteria
First of all, the objective function to evaluate the temporal parameters
for the encoder is:
The first item in the function is the ratio between intra-distance to inter-distance . It describes the cluster distributions within the new vector space. The intra-distance measures the distance from all of the data to the cluster center within the same style, while the inter-distance measures the distance between the cluster centers of different styles. Next, the similarity function measures the error between and , where is the reconstruction of . Lastly, the is the sparsity function. It measures the number non-zero elements in the encoded data , and this promotes a more biased model. In short, the above criteria generate a vector space where similar gesture styles are closer to one another. Furthermore, the encoder with the sparse and distributed parameters can also transform unknown data.
Secondly, the evaluation function for the parameters of the decoder
is:
where
is the aligned decoded signals and
is the training signals. The following steps compute the aligned decoded signals
. The first step generates the decoded signal
using (
13) and the encoded data
. The next process arranges the decoded signal
into the aligned decoded signals
using the dynamic time warping (DTW) algorithm. Lastly, the similarity function measures the error between the aligned signals
to the original signals
. In conclusion, the goal is to find a suitable parameter
for the decoder so that the decoder can generate the specific gesture signal given a gesture style.
For the associator, the objective primarily focuses on reconstructing the user’s gestures given the user’s and audiences’ facial features. Hence, the initial step learns the relationship between these modalities using (
17) to (
21). These operations compute the knowledge-based
, which is parameterized by
. Subsequently, the associator retrieves the missing modalities, that is the encoded gesture
using (
22) to (
24). Using (
25), it generates the decoded signals
, and it is aligned to form
. Similar to (
29), the aim is to find the best parameters:
that minimize the error between the aligned decoded signal
and the original signal
.
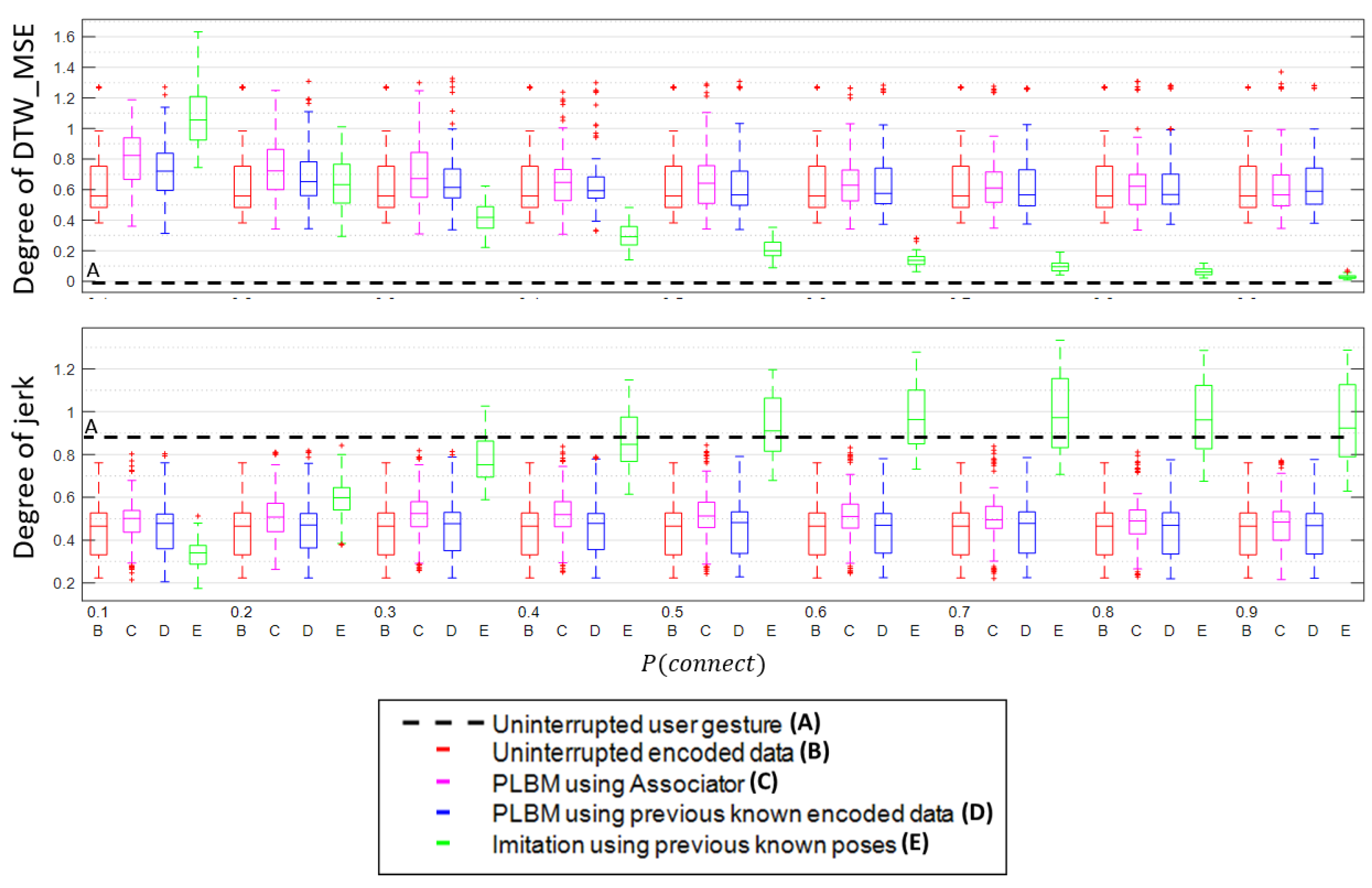
Besides evaluating the components, there are also functions to test the framework for the different scenarios. The first evaluation function measures the smoothness in a multivariate signal. The jerky index:
is the average jerk measurement across a feature, where
is the magnitude of the
m feature at
t time. The second evaluation function measures the total points outside the boundaries. The collision function is:
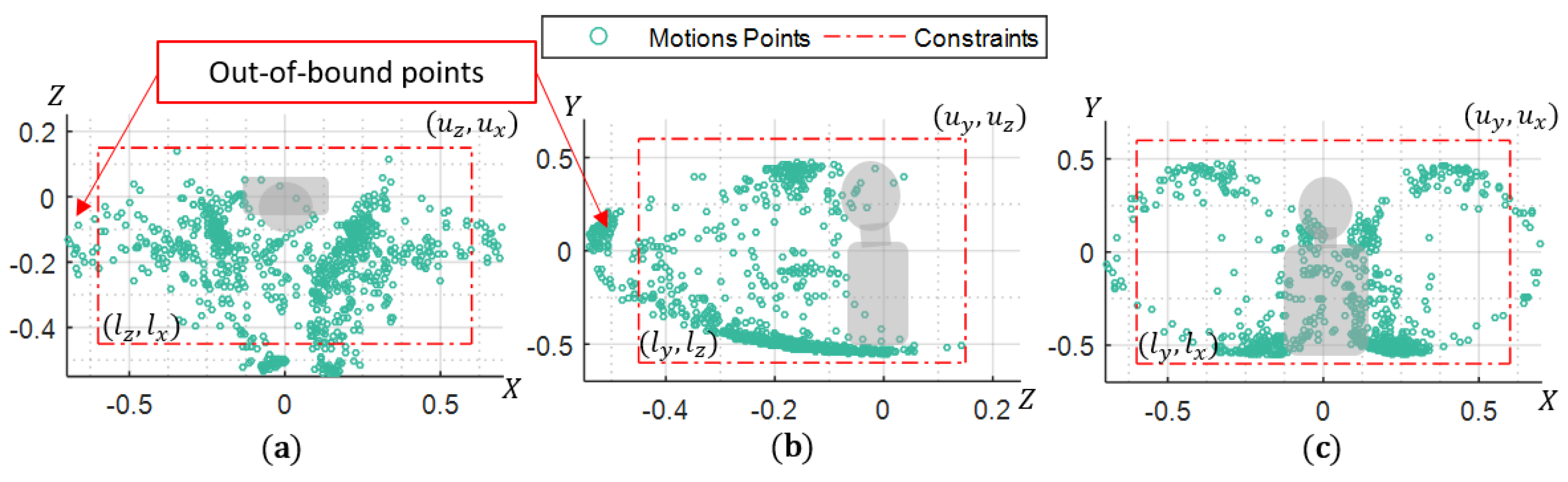
where
and
are the total points outside the upper limit
or lower limit
at the
i axis (
Figure 10). The
is the corresponding skeleton indexes with respect to the axis. Lastly, the similarity function
, which measures the accuracy between two signals, can also measure the degree of expressivity between the generated signal with respect to the original signal. In this paper, the similarity function
is the mean square error function:
where
.
In summary, this section has presented a list of procedures and a list of evaluation functions to achieve the overall goals. The following section will show the different experiments and their results in term of these criteria.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}