Automated Assembly Using 3D and 2D Cameras

Abstract
:1. Introduction
2. Preliminaries
3. Approach
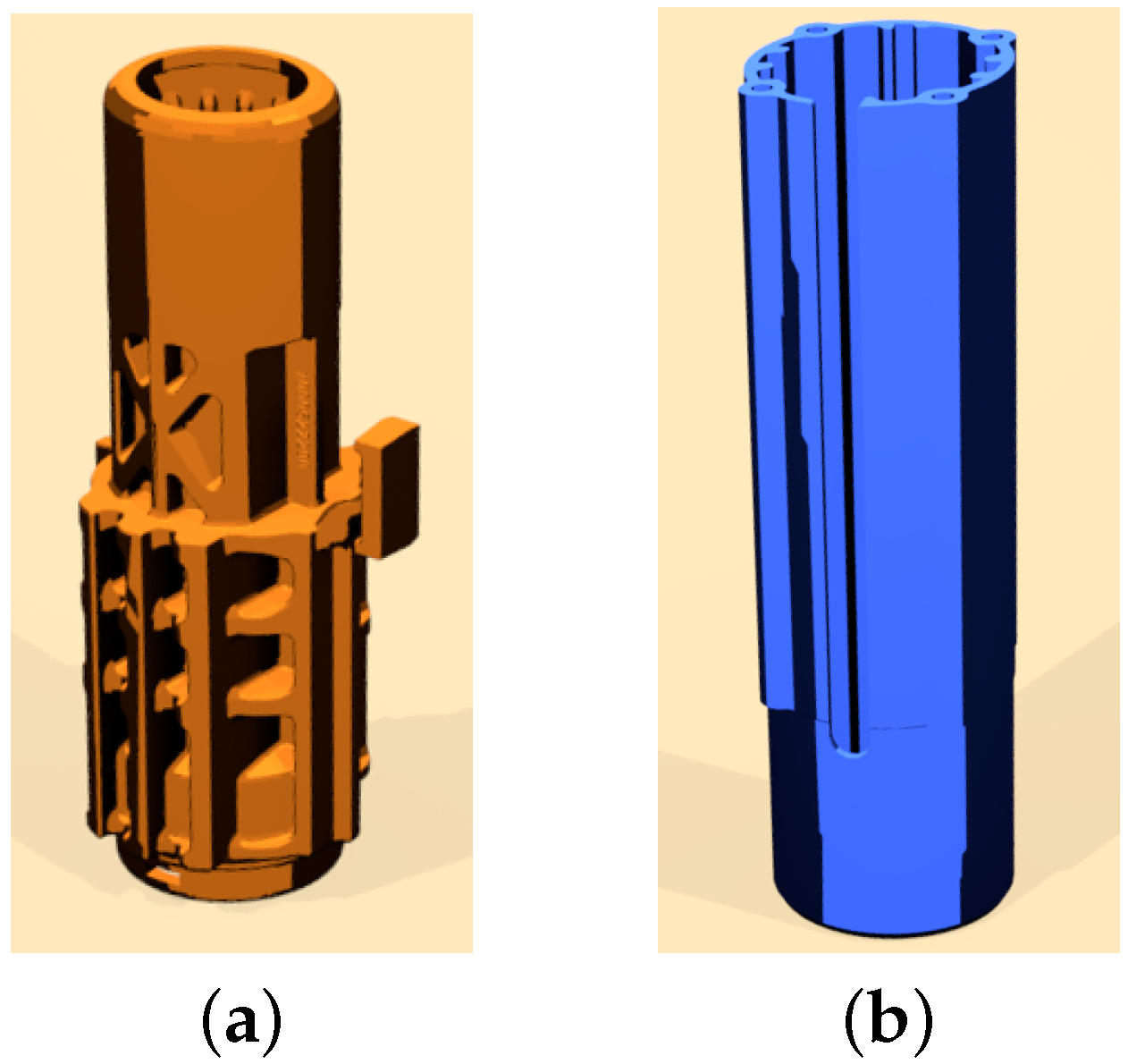
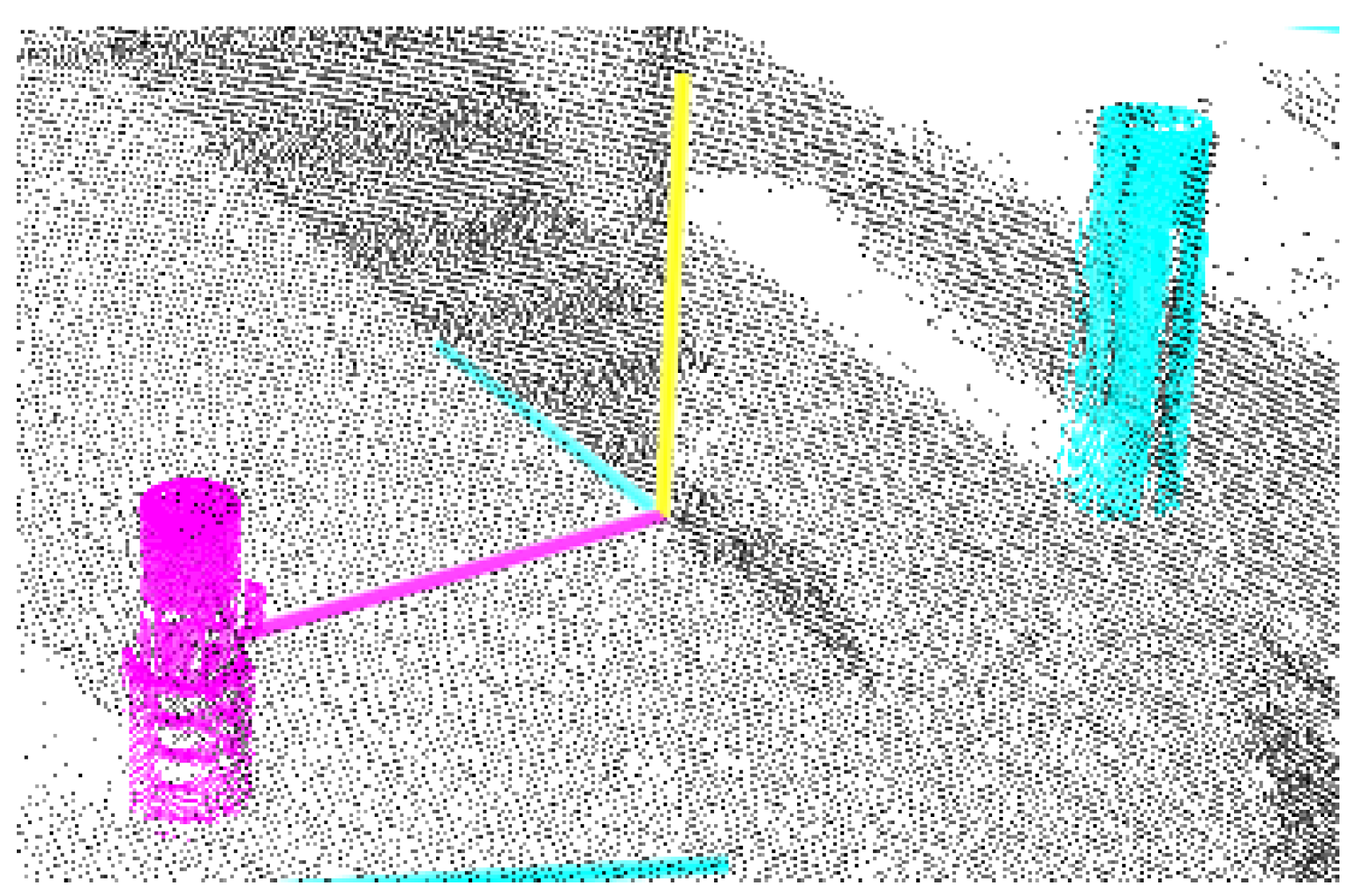
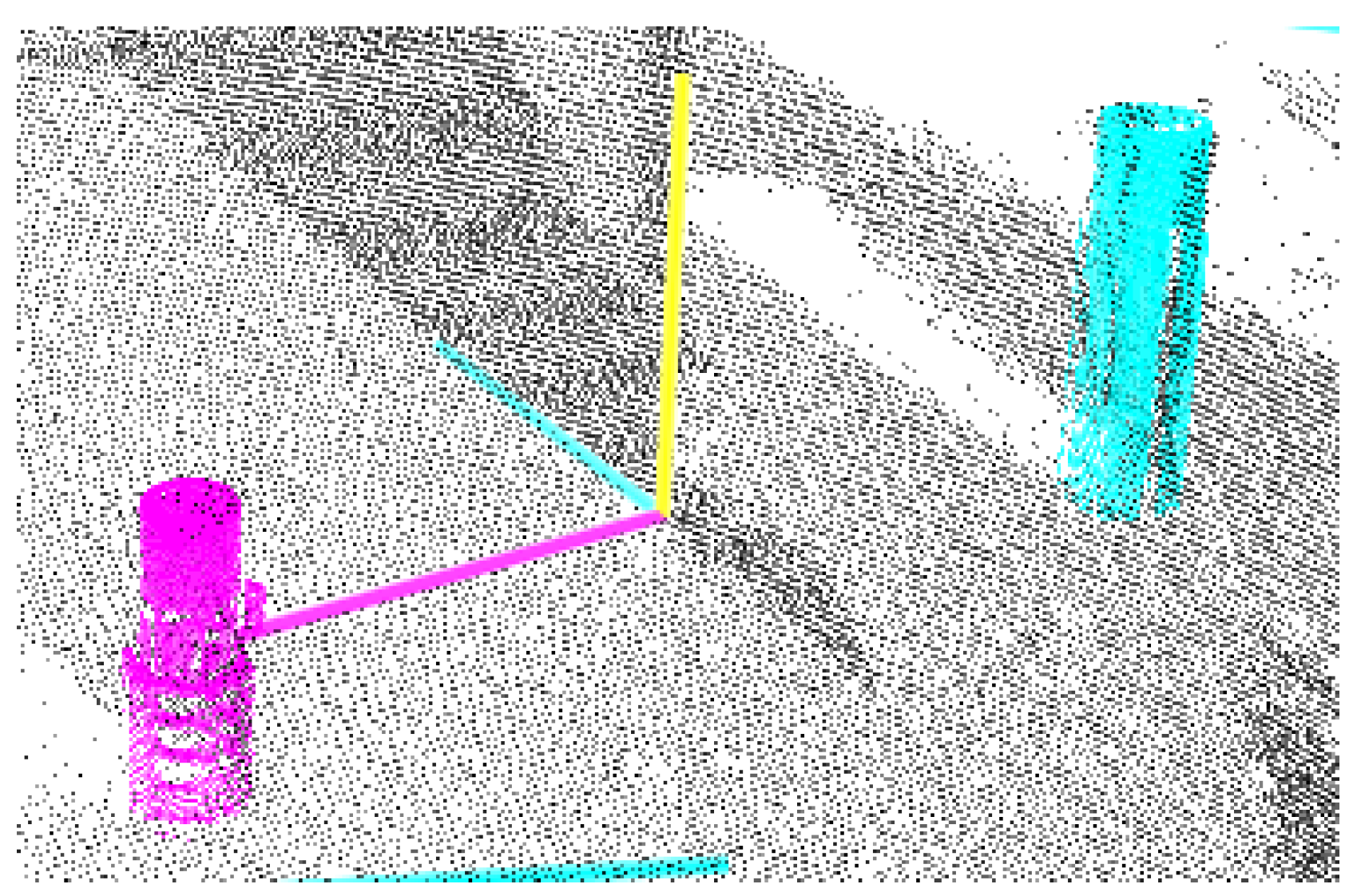
3.1. 3D Object Detection
3.1.1. Viewpoint Sampling
3.1.2. Removing Unqualified Points
3.1.3. Object Detection
3.1.4. Object Alignment
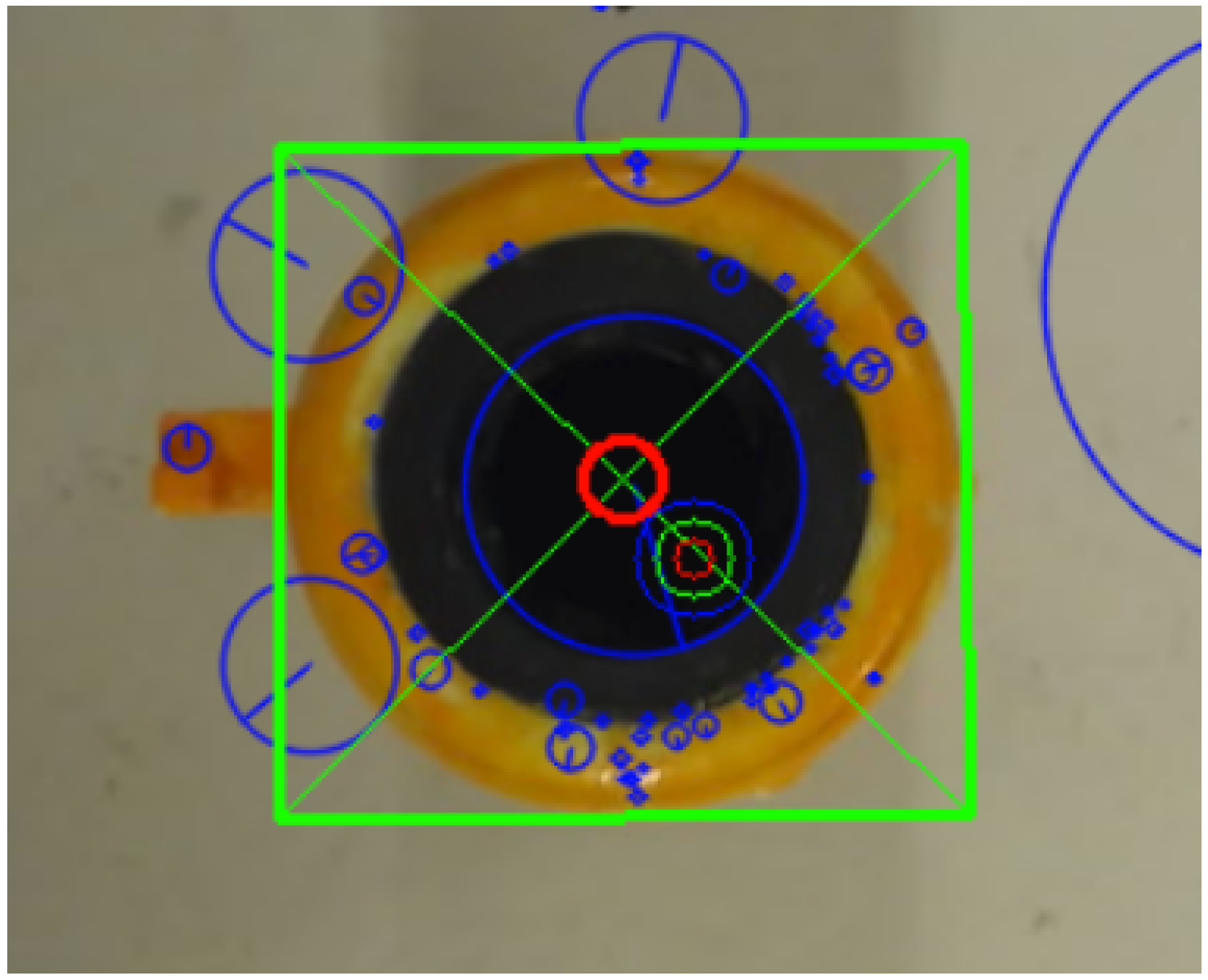
3.2. 2D Object Alignment
4. Experiments and Results
4.1. Setup
- Two KUKA KR 6 R900 sixx (KR AGILUS) six-axis robotic manipulators (Augsburg, Germany).
- Microsoft Kinect™ One 3D depth sensor (Redmond, WA, USA).
- Logitech C930e web camera (Lausanne, Switzerland).
- Schunck PSH 22-1 linear pneumatic gripper (Lauffen, Germany).
- Ubuntu 14.04 (Canonical, London, United Kindom).
- Point Cloud Library 1.7 (Willow Garage, Menlo Park, CA, USA).
- OpenCV 3.1 (Intel Corpiration, Santa Clara, CA, USA).
- Robot Operating System (ROS) Indigo (Willow Garage, Menlo Park, CA, USA).
4.2. Experiment 1: 3D Accuracy
4.2.1. Results
4.3. Experiment 2: 2D Stability
4.3.1. Results
4.4. Experiment 3: Full Assembly
- Place the two objects to be assembled at random positions and orientations on the table.
- Run the initial 3D alignment described in described in Section 3.
- Perform the final 2D alignment by moving the robot in position above the part found in the initial alignment.
- Move the robotic manipulator with the gripper to the estimated position of the first part, and pick it up. The manipulator then moved the part to the estimated pose of the second part to assemble the two parts.
4.4.1. Results
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Dietz, T.; Schneider, U. Programming System for Efficient Use of Industrial Robots for Deburring in SME Environments. In Proceedings of the 7th German Conference on Robotics ROBOTIK 2012, Munich, Germany, 21–22 May 2012; pp. 428–433. [Google Scholar]
- Freeman, W.T. Where computer vision needs help from computer science. In Proceedings of the ACM-SIAM Symposium on Discrete Algorithms (SODA), San Francisco, CA, USA, 23–25 January 2011; pp. 814–819. [Google Scholar]
- Blake, A.; Brelstaff, G. Geometry from Specularities. In Proceedings of the Second International Conference on Computer Vision, Tampa, FL, USA, 5–8 December 1988. [Google Scholar]
- Chaumette, F.; Hutchinson, S.A. Visual Servo Control, Part II: Advanced Approaches. IEEE Robot. Autom. Mag. 2007, 14, 109–118. [Google Scholar] [CrossRef]
- Campbell, R.J.; Flynn, P.J. A Survey of Free-Form Object Representation and Recognition Techniques. Comput. Vis. Image Underst. 2001, 210, 166–210. [Google Scholar] [CrossRef]
- Khoshelham, K. Accuracy Analysis of Kinect Depth Data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, XXXVIII-5, 133–138. [Google Scholar] [CrossRef]
- Nguyen, D.D.; Ko, J.P.; Jeon, J.W. Determination of 3D object pose in point cloud with CAD model. In Proceedings of the 2015 21st Korea-Japan Joint Workshop on Frontiers of Computer Vision, Mokpo, Korea, 28–30 January 2015. [Google Scholar]
- Luo, R.C.; Kuo, C.W.; Chung, Y.T. Model-based 3D Object Recognition and Fetching by a 7-DoF Robot with Online Obstacle Avoidance for Factory Automation. In Proceedings of the IEEE International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015; Volume 106, pp. 2647–2652. [Google Scholar]
- Lutz, M.; Stampfer, D.; Schlegel, C. Probabilistic object recognition and pose estimation by fusing multiple algorithms. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 4244–4249. [Google Scholar]
- Rennie, C.; Shome, R.; Bekris, K.E.; De Souza, A.F. A Dataset for Improved RGBD-Based Object Detection and Pose Estimation for Warehouse Pick-and-Place. IEEE Robot. Autom. Lett. 2016, 1, 1179–1185. [Google Scholar] [CrossRef]
- Aldoma, A.; Vincze, M.; Blodow, N.; Gossow, D.; Gedikli, S.; Rusu, R.B.; Bradski, G. CAD-model recognition and 6DOF pose estimation using 3D cues. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 585–592. [Google Scholar]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for point-cloud shape detection. Comput. Graph. Forum 2007, 26, 214–226. [Google Scholar] [CrossRef]
- Chen, Y.; Medioni, G. Object modeling by registration of multiple range images. In Proceedings of the 1991 IEEE International Conference on Robotics and Automation, Sacramento, CA, USA, 9–11 April 1991; Volume 10, pp. 2724–2729. [Google Scholar]
- Besl, P.; McKay, N. A Method for Registration of 3-D Shapes. Int. Soc. Opt. Photonics 1992, 586–606. [Google Scholar] [CrossRef]
- Arun, K.S.; Huang, T.S.; Blostein, S.D. Least-squares fitting of two 3-D point sets. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 5, 698–700. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast Point Feature Histograms (FPFH) for 3D registration. In Proceedings of the IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006. [Google Scholar]
- Kleppe, A.L.; Bjørkedal, A.; Larsen, K.; Egeland, O. Website of NTNU MTP Production Group. Available online: https://github.com/ps-mtp-ntnu/Automated-Assembly-using-3D-and-2D-Cameras/ (accessed on 31 March 2017).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Min/Max Recorded Values | |
|---|---|
| Max [cm] | 1.46 |
| Max [cm] | 1.56 |
| Min [cm] | 0.43 |
| Min [cm] | 0.08 |
| Actual | Measured | Absolute | |||
|---|---|---|---|---|---|
| X | Y | X | Y | ||
| −5 | 5 | −6.18 | 5.4 | 1.18 | 0.4 |
| −5 | 10 | −6.25 | 10.55 | 1.25 | 0.55 |
| −5 | 15 | −6.28 | 16.11 | 1.28 | 1.11 |
| −5 | 20 | −5.17 | 21.56 | 1.28 | 1.56 |
| −10 | 5 | −11.12 | 5.08 | 1.12 | 0.08 |
| −10 | 10 | −10.83 | 10.43 | 0.83 | 0.43 |
| −10 | 15 | −10.98 | 15.92 | 0.98 | 0.92 |
| −10 | 20 | −11.46 | 20.85 | 1.46 | 0.85 |
| −15 | 5 | −15.89 | 5.2 | 0.89 | 0.2 |
| −15 | 10 | −15.81 | 10.56 | 0.81 | 0.56 |
| −15 | 15 | −15.97 | 15.77 | 0.97 | 0.77 |
| −15 | 20 | −16.18 | 21.01 | 1.18 | 1.01 |
| −20 | 5 | −20.43 | 5.4 | 0.43 | 0.4 |
| −20 | 10 | −20.68 | 10.72 | 0.68 | 0.72 |
| −20 | 15 | −20.72 | 16.27 | 0.72 | 1.27 |
| −20 | 20 | −21.18 | 21.38 | 1.18 | 1.38 |
| Min/Max Recorded Values | |
|---|---|
| Max [cm] | 1.43 |
| Max [cm] | 1.96 |
| Min [cm] | 0.1 |
| Min [cm] | 0.06 |
| Actual | Measured | Absolute | |||
|---|---|---|---|---|---|
| X | Y | X | Y | ||
| −5 | 5 | −5.76 | 5.16 | 0.76 | 0.16 |
| −5 | 10 | −6.12 | 10.8 | 1.12 | 0.8 |
| −5 | 15 | −5.98 | 15.94 | 0.98 | 0.94 |
| −5 | 20 | −6.17 | 20.88 | 1.17 | 0.88 |
| −10 | 5 | −10.65 | 5.47 | 0.65 | 0.47 |
| −10 | 10 | −10.62 | 10.21 | 0.62 | 0.21 |
| −10 | 15 | −10.73 | 15.81 | 0.73 | 0.81 |
| −10 | 20 | −10.91 | 20.79 | 0.91 | 0.79 |
| −15 | 5 | −15.22 | 5.46 | 0.22 | 0.46 |
| −15 | 10 | −15.46 | 10.62 | 0.46 | 0.62 |
| −15 | 15 | −15.71 | 16.2 | 0.71 | 1.2 |
| −15 | 20 | −15.85 | 21.14 | 0.85 | 1.14 |
| −20 | 5 | −20.1 | 5.43 | 0.1 | 0.43 |
| −20 | 10 | −20.73 | 10.06 | 0.73 | 0.06 |
| −20 | 15 | −20.26 | 16.35 | 0.26 | 1.35 |
| −20 | 20 | −21.43 | 21.96 | 1.43 | 1.96 |
| 0 Degrees | −90 Degrees | ||
|---|---|---|---|
| SIFT | SIFT/SURF | SIFT | SIFT/SURF |
| 1.7469 | 5.4994 | 1.1102 | 7.9095 |
| 0 Ddegree | −90 Degrees | ||
|---|---|---|---|
| SIFT | SURF | SIFT | SURF |
| 0.07888 | 0.2041 | 0.1721 | 0.1379 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kleppe, A.L.; Bjørkedal, A.; Larsen, K.; Egeland, O. Automated Assembly Using 3D and 2D Cameras. Robotics 2017, 6, 14. https://doi.org/10.3390/robotics6030014
Kleppe AL, Bjørkedal A, Larsen K, Egeland O. Automated Assembly Using 3D and 2D Cameras. Robotics. 2017; 6(3):14. https://doi.org/10.3390/robotics6030014
Chicago/Turabian StyleKleppe, Adam Leon, Asgeir Bjørkedal, Kristoffer Larsen, and Olav Egeland. 2017. "Automated Assembly Using 3D and 2D Cameras" Robotics 6, no. 3: 14. https://doi.org/10.3390/robotics6030014
APA StyleKleppe, A. L., Bjørkedal, A., Larsen, K., & Egeland, O. (2017). Automated Assembly Using 3D and 2D Cameras. Robotics, 6(3), 14. https://doi.org/10.3390/robotics6030014