
Extracting Semantic Information from Visual Data: A Survey



Abstract
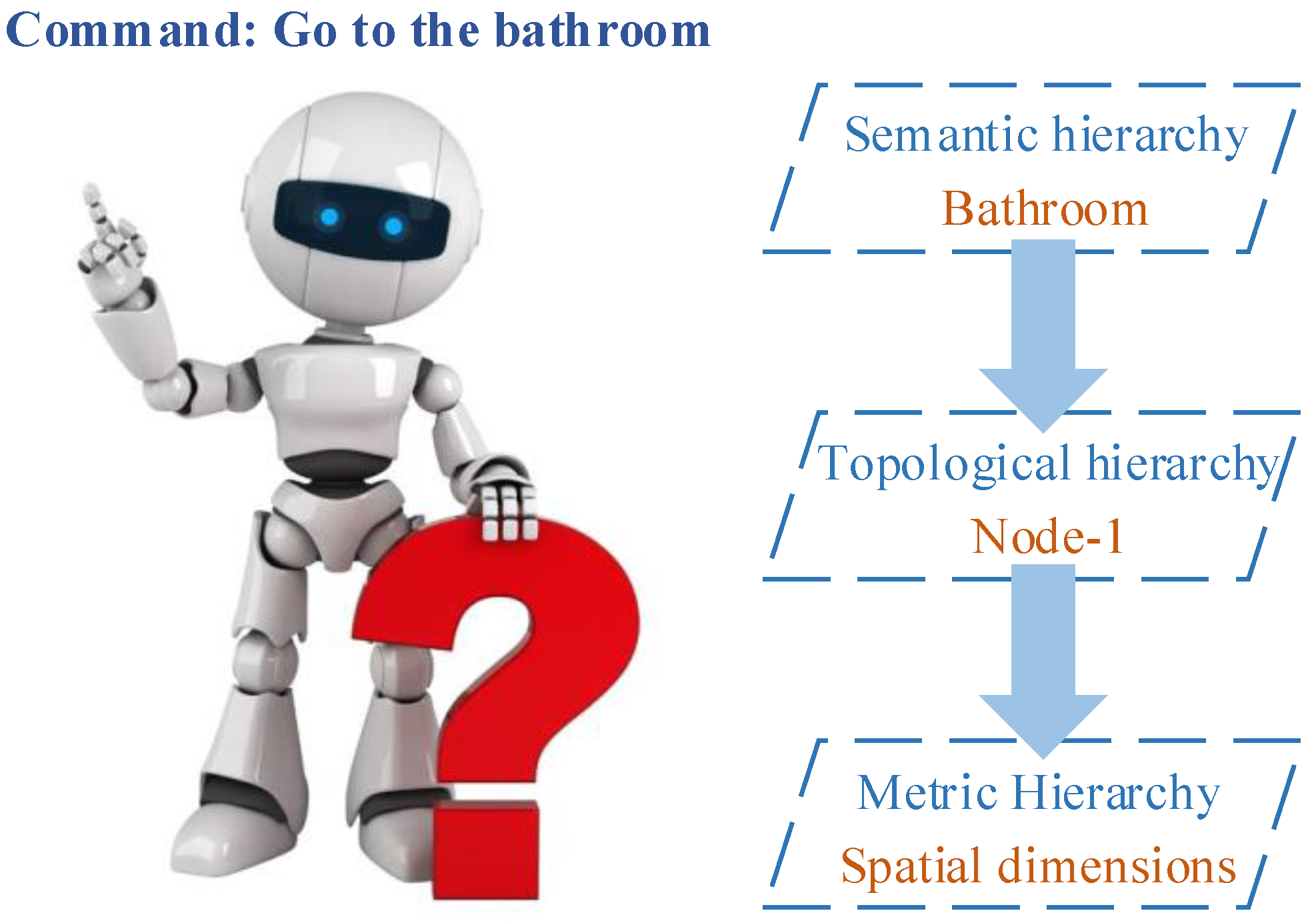
:1. Introduction
2. Overview of Visual-Based Approaches to Semantic Mapping
2.1. General Process for Semantic Mapping
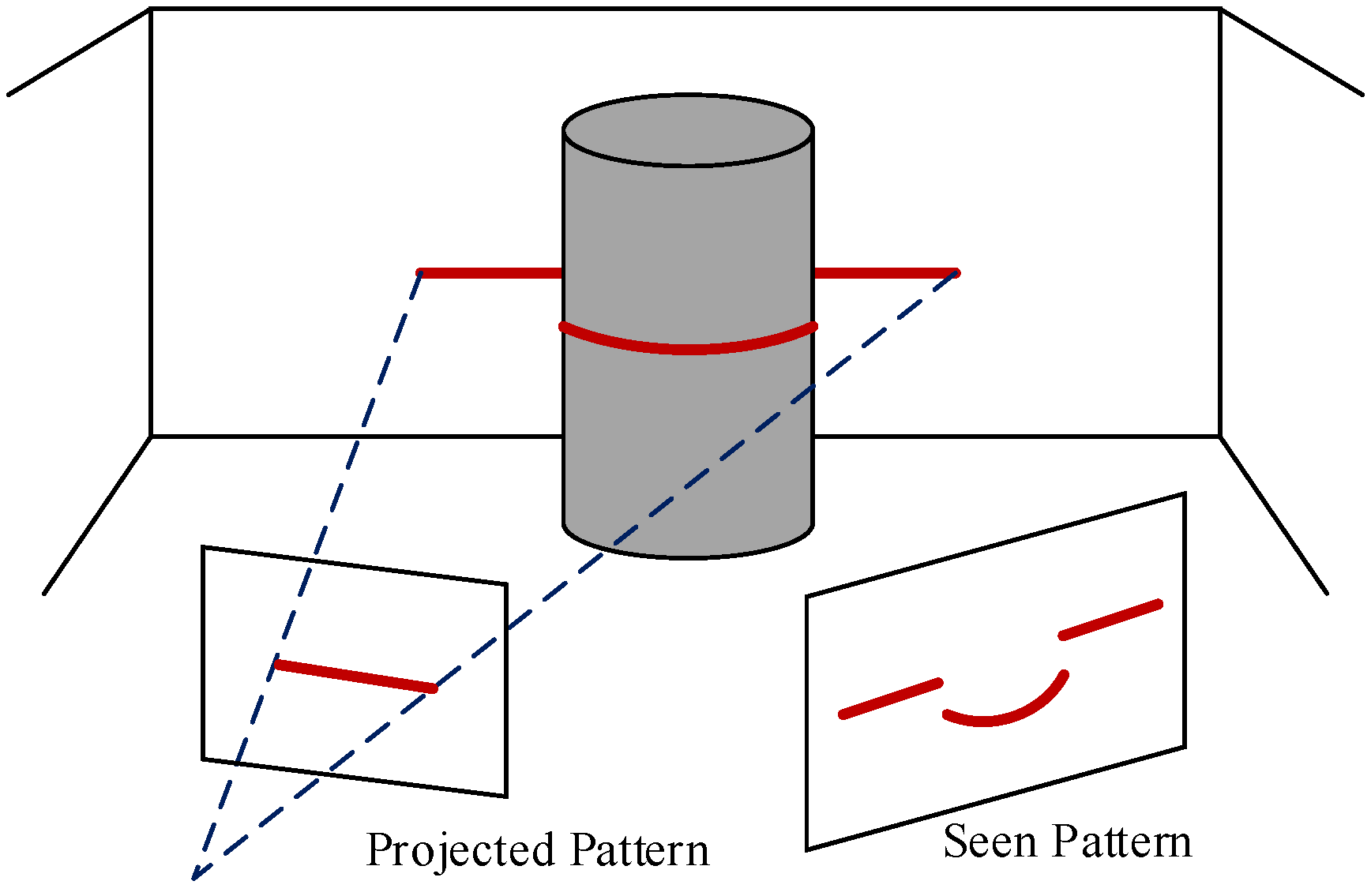
2.2. Use of Conventional Cameras
2.3. Use of RGB-D Cameras
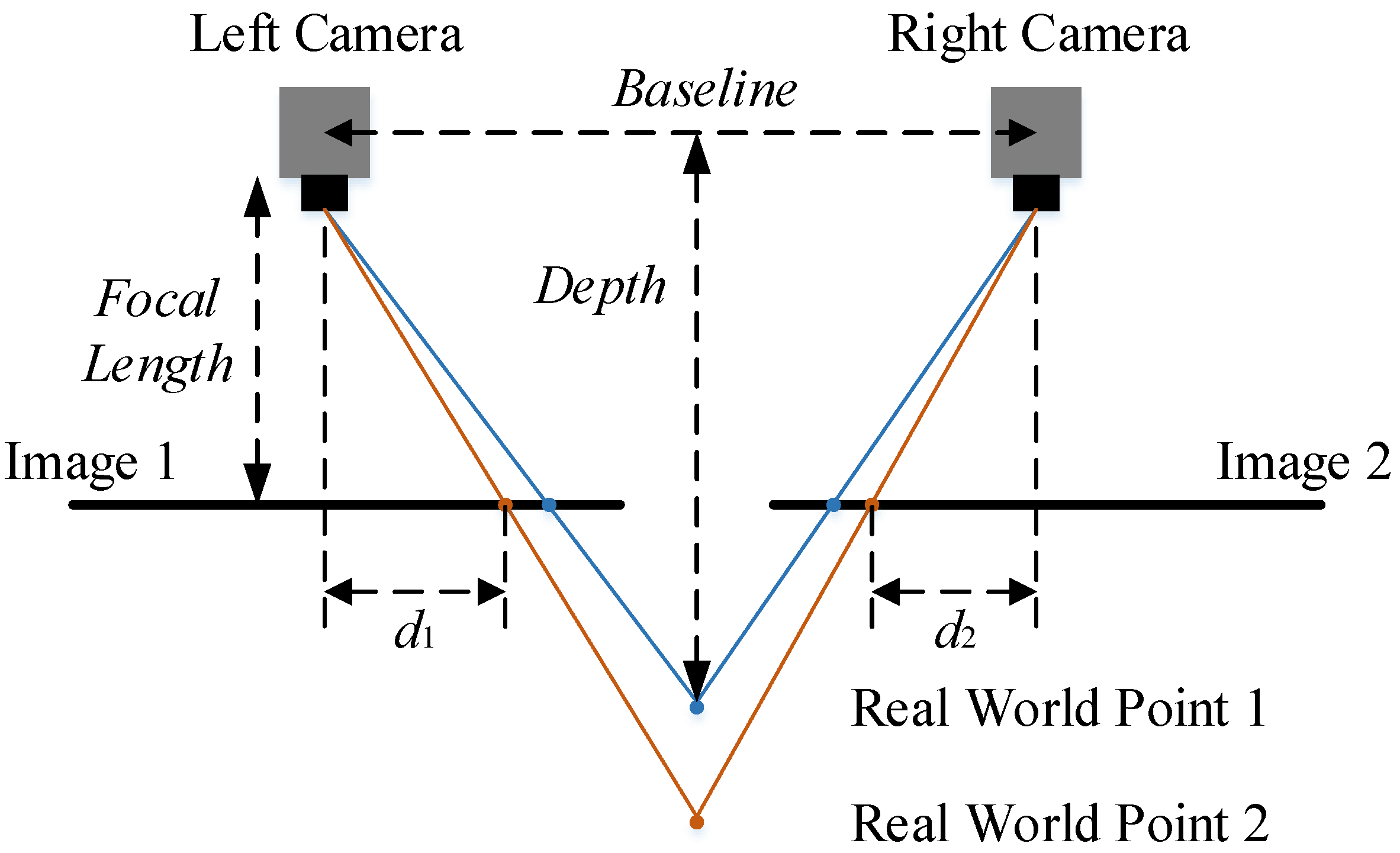
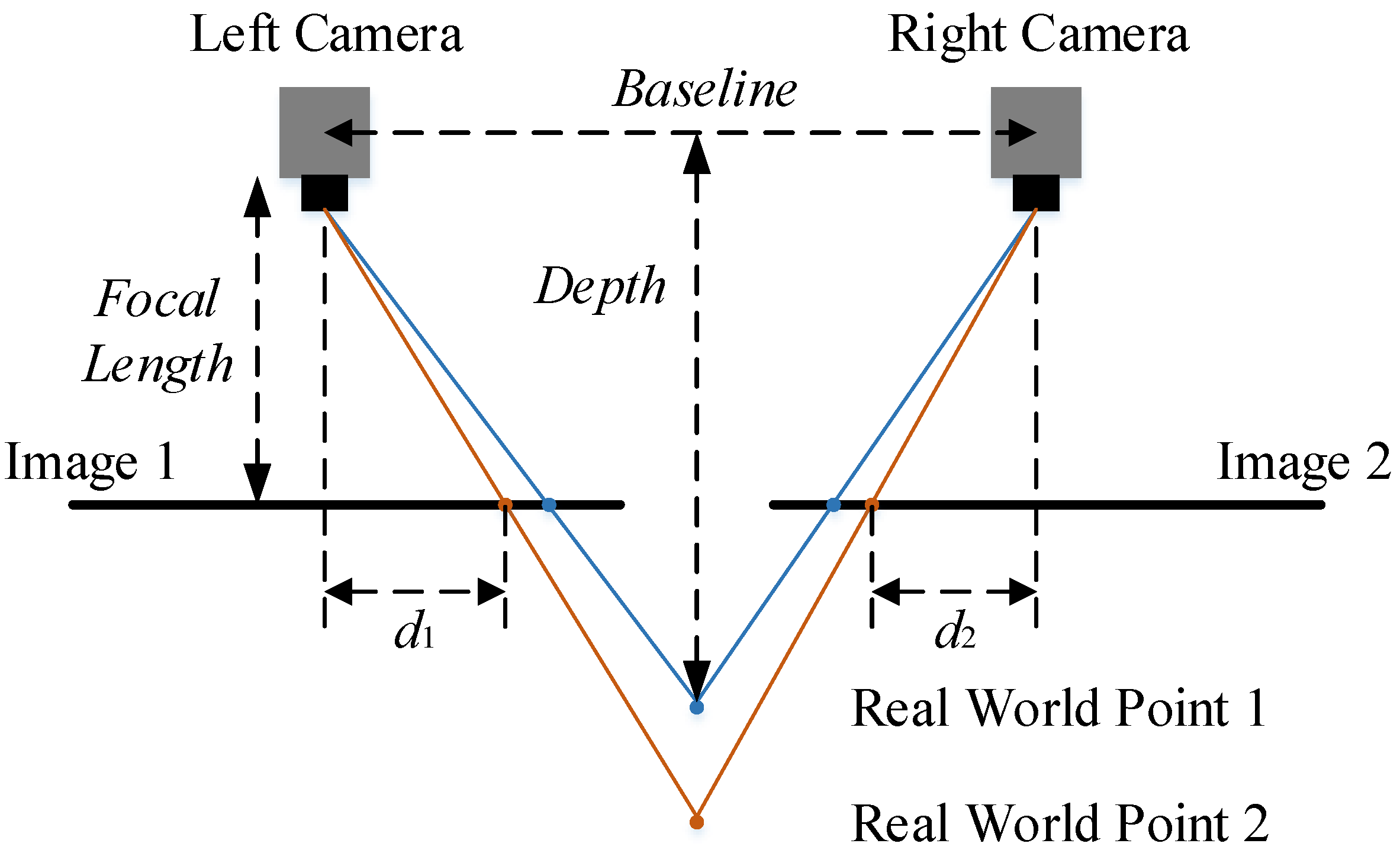
2.4. Use of Stereo Cameras
3. Visual Features Applied in Semantic Mapping Systems
3.1. Global Features
3.2. Local Features
3.2.1. Edge-Based Approaches
3.2.2. Corner-Based Approaches
3.2.3. Blob-Based Approaches
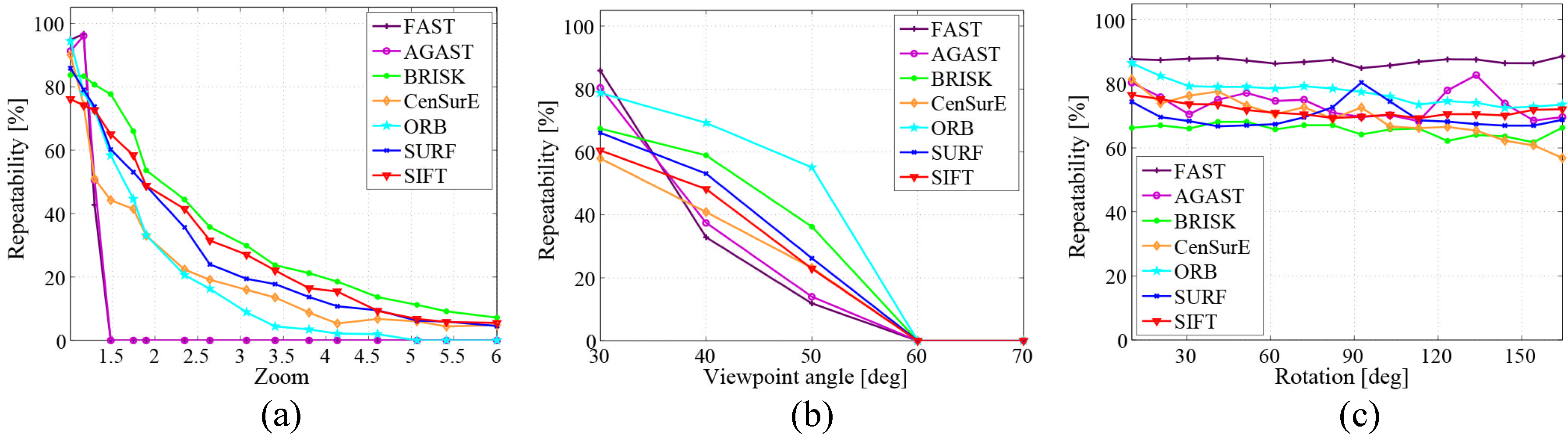
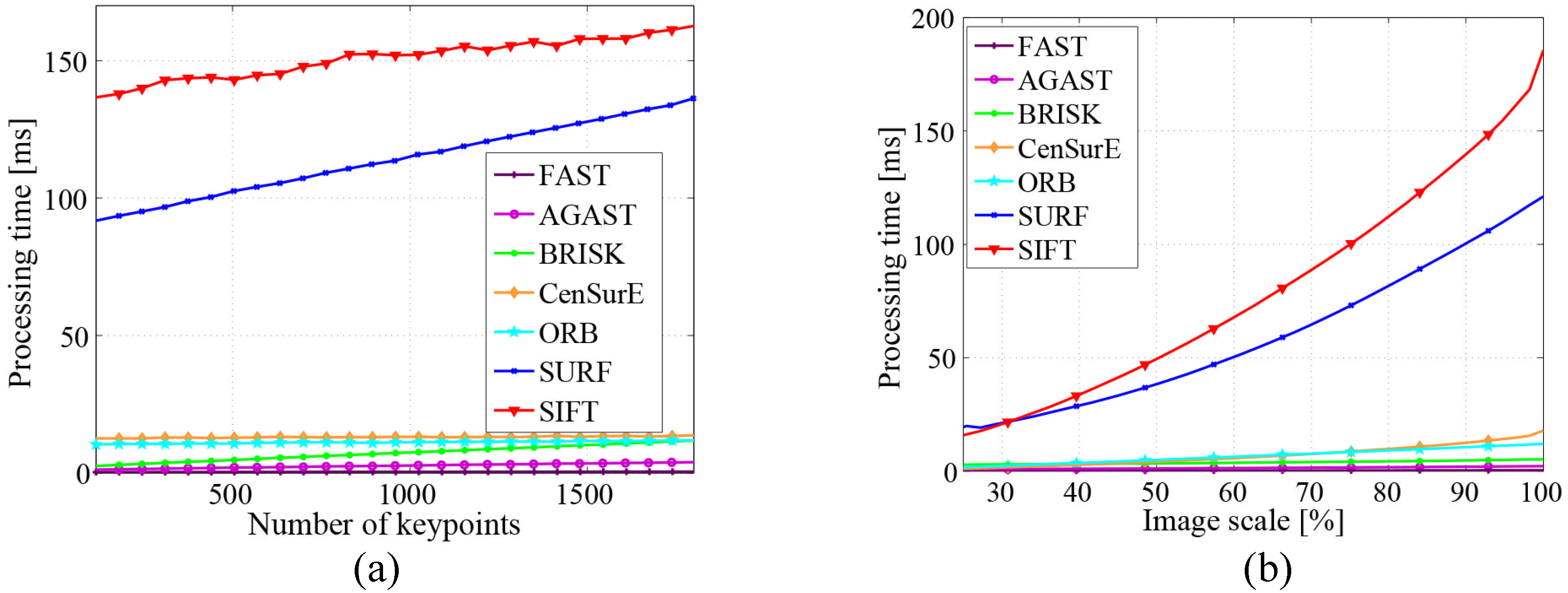
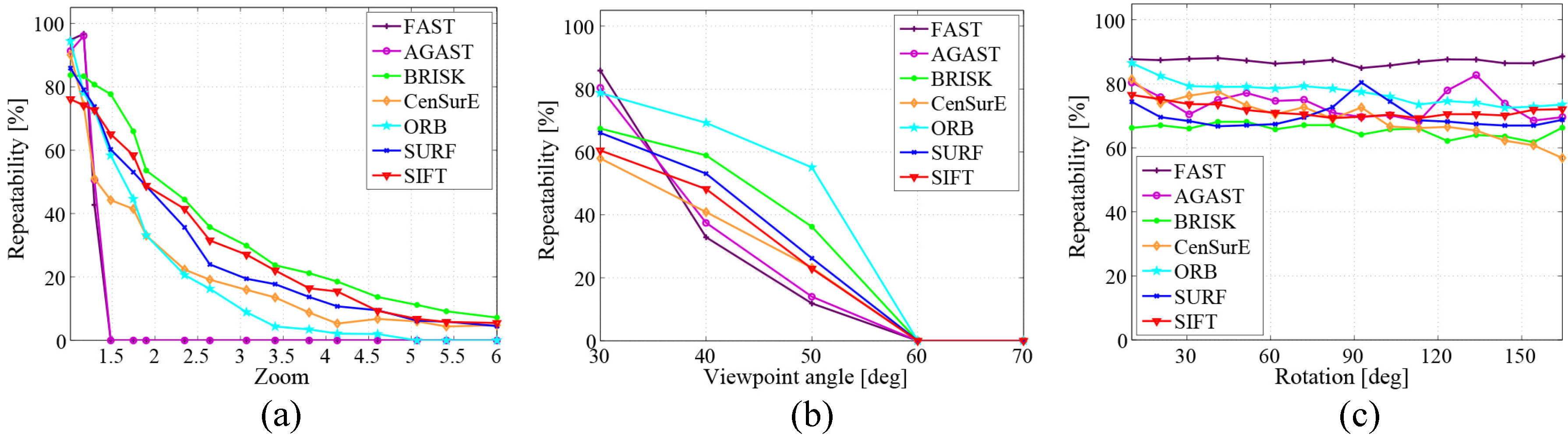
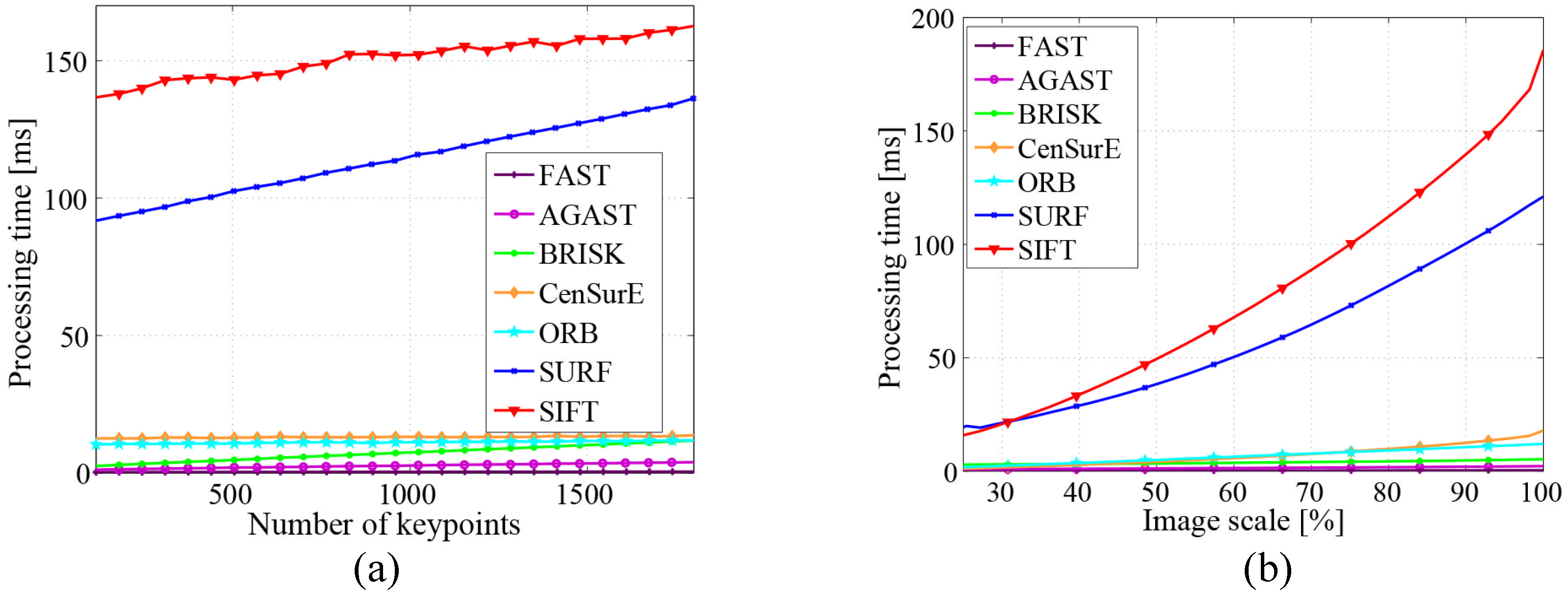
3.2.4. Discussion
4. Recognition Approaches
4.1. Global Approaches
4.2. Local Approaches
4.3. Hybrid Approaches
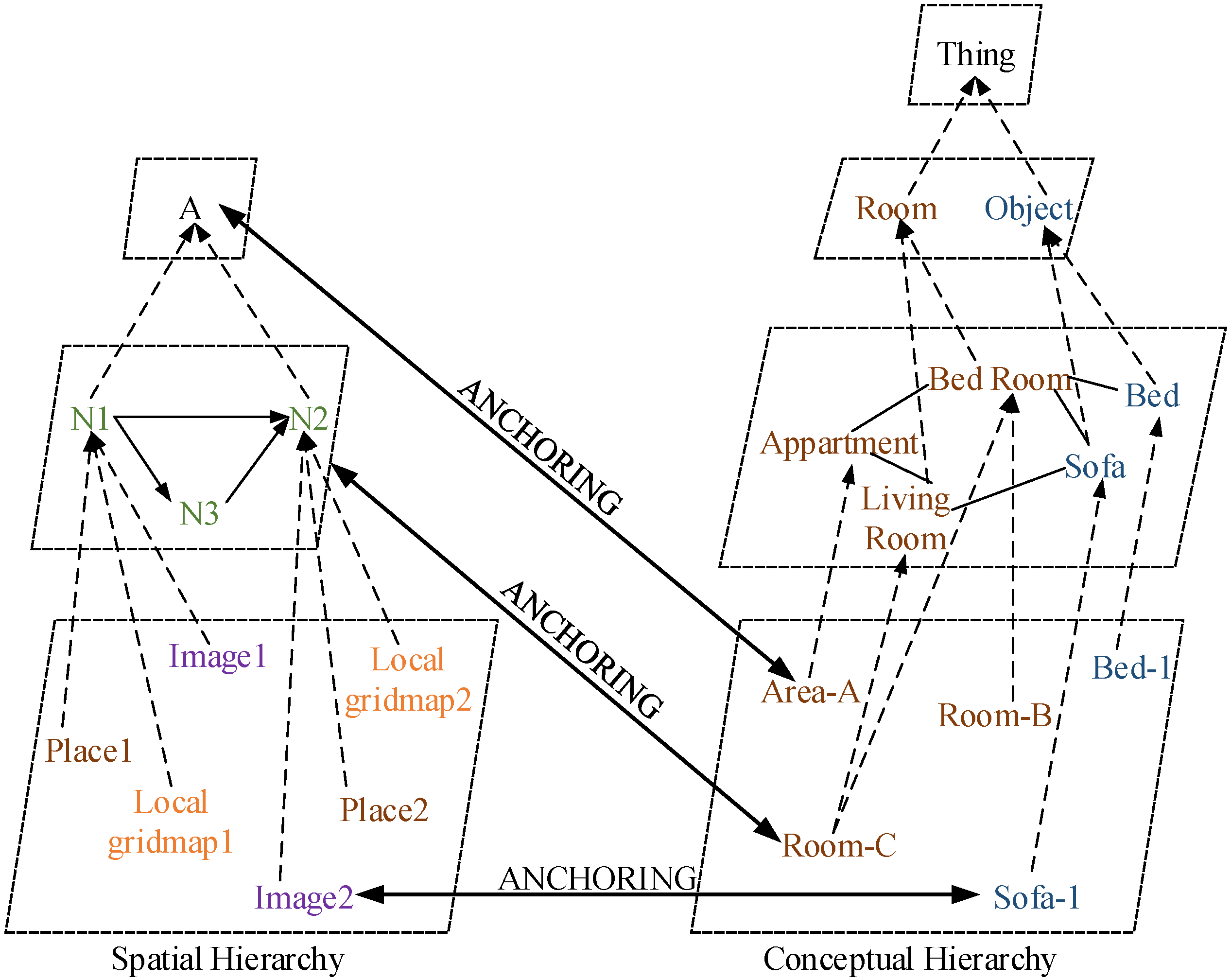
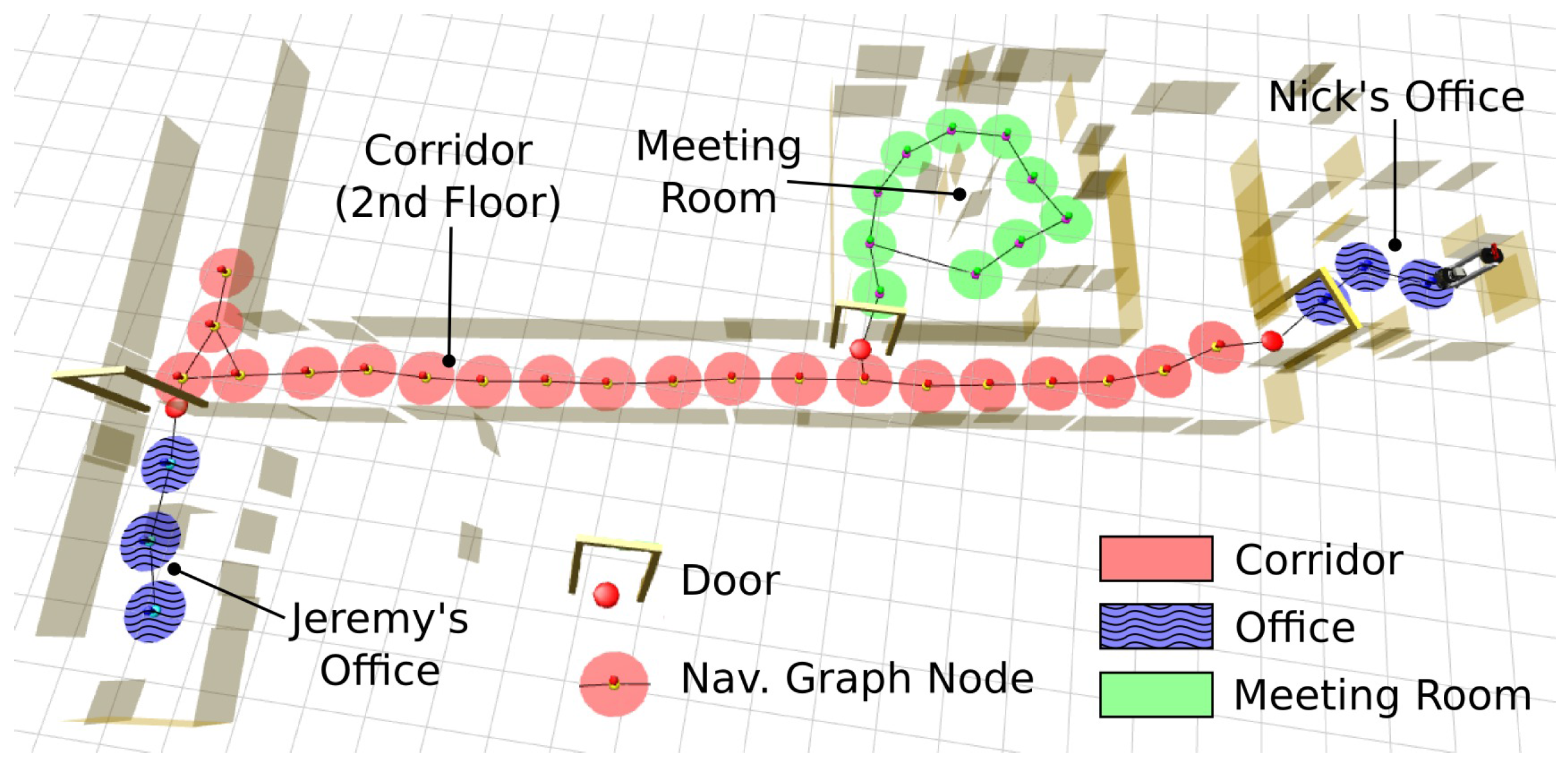
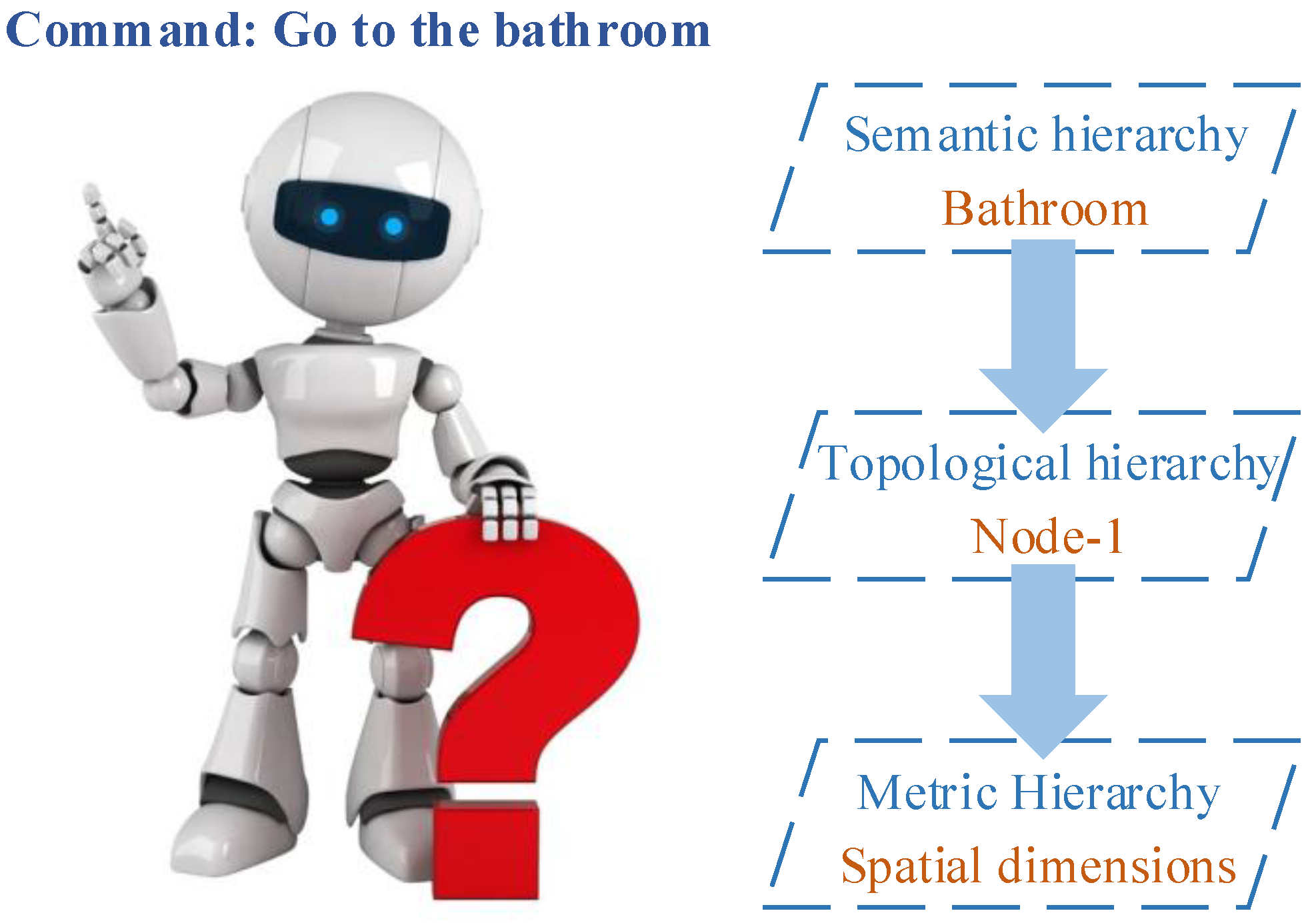
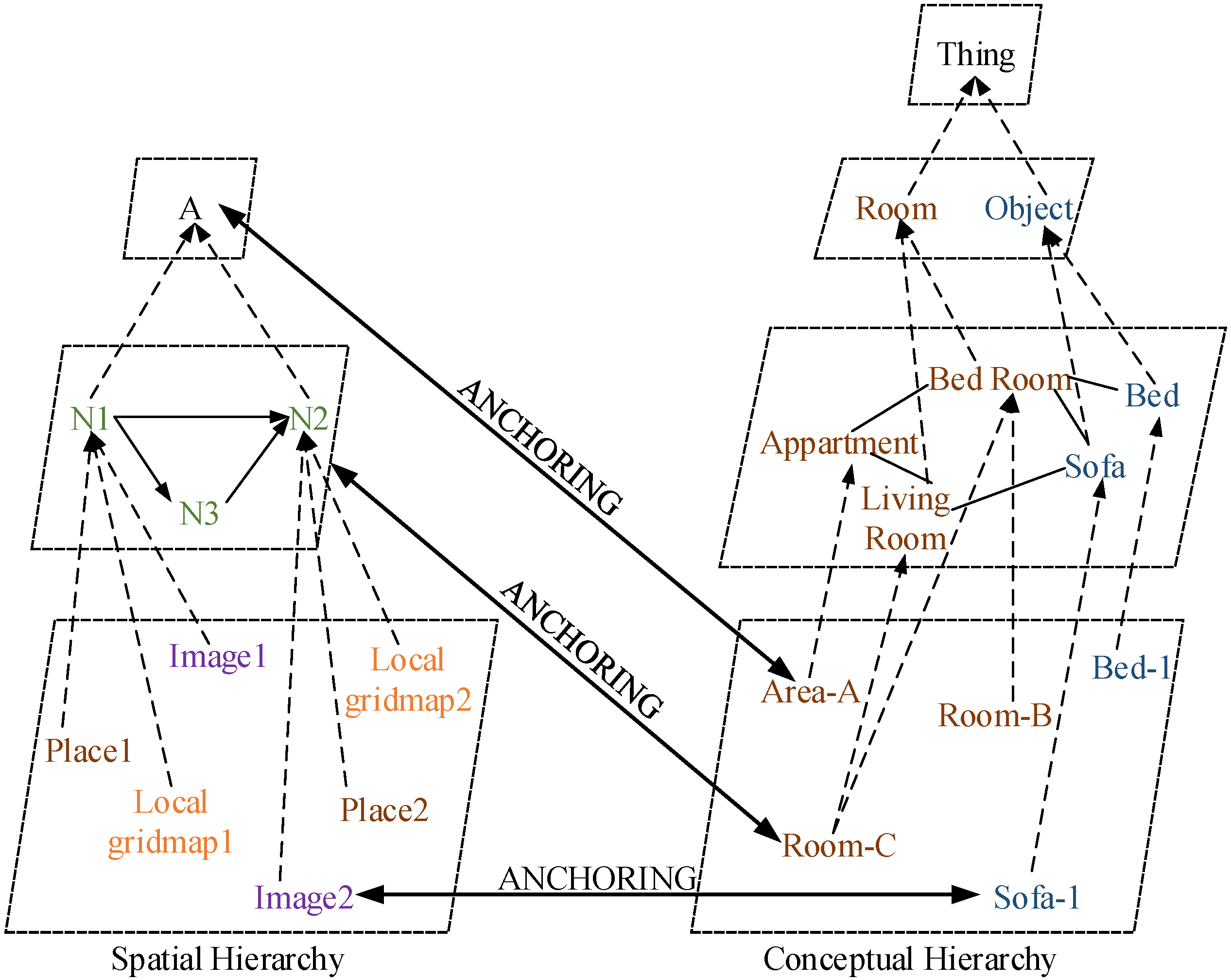
5. Semantic Representation
6. Typical Applications
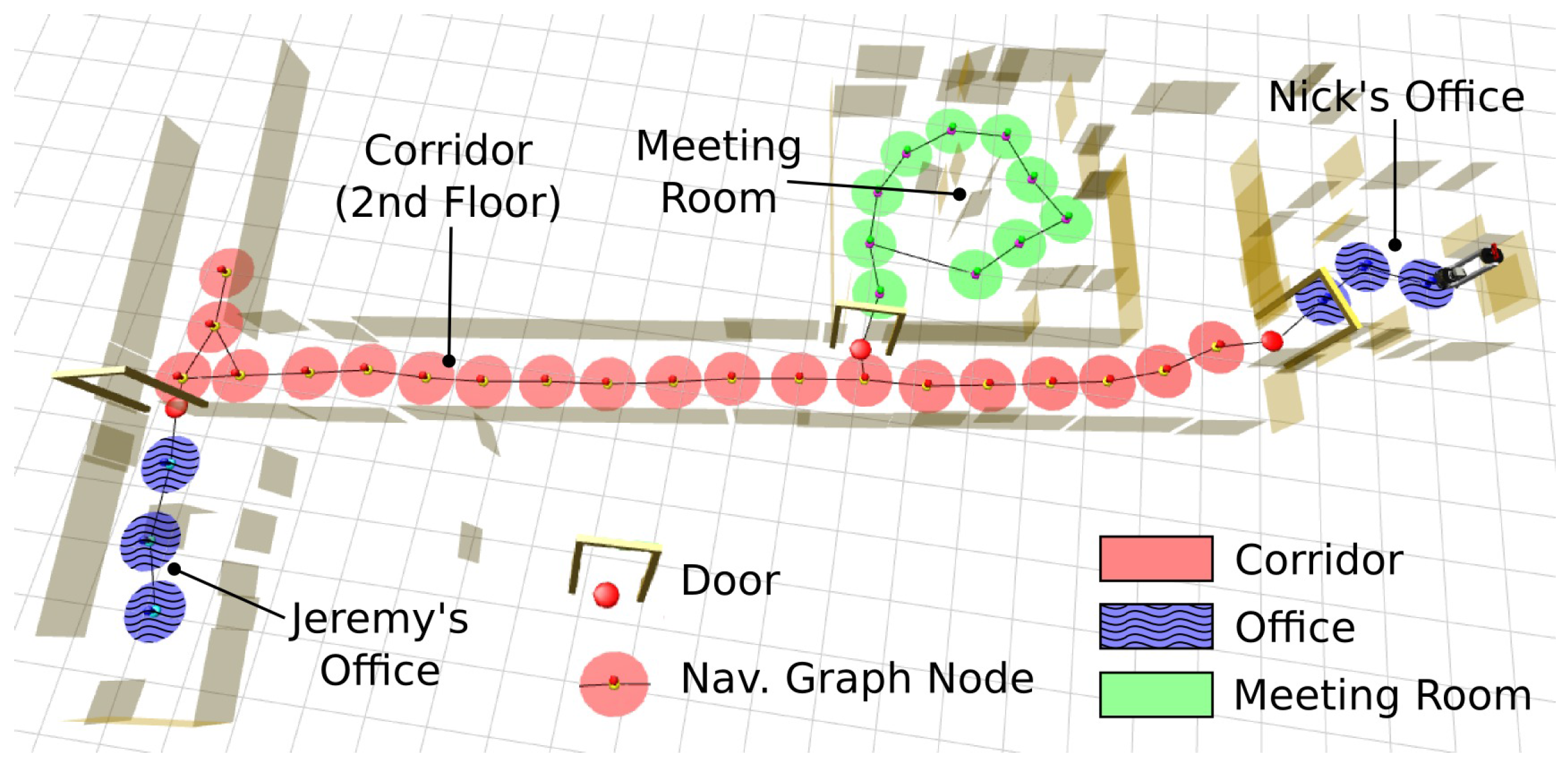
6.1. Indoor Applications
6.2. Outdoor Applications
7. Conclusion and Discussion
- A 3D visual sensor with high accuracy and resolution is needed for abstracting semantic information, since a 2D camera is not adequate for the recognition of a wider range of objects and places. Furthermore, the blurred images produced by low accuracy and resolution 3D cameras cannot be used for a robot to recognize objects in the real world. Apart from the improvement of hardware, several software methodologies, such as super-resolution or data fusion, could be deployed for accurate semantic mapping. Super-resolution is a class of techniques that enhances the resolution of an imaging system. Data fusion is a process of integrating multiple data and knowledge representing the same scene in order to produce an accurate output.
- The current feature detectors and descriptors need to be extended in semantic mapping systems. Although local visual features are robust to geometric transformations and illumination changes, the features are quite limited to the appearance of objects, such as edges, corners and their relations. Extracting the semantic inherent characteristic of objects might be a solution, e.g., the legs of a chair, the keyboard and display of a laptop, etc. Another solution is to abstract the text information that can normally be found on the packaging of products. The text is quite easy to distinguish between a bottle of shampoo and conditioner by their labels.
- Classifiers should be adaptive to the dynamic changes in the real world. The current semantic mapping systems need pre-training and can only recognize the trained objects or certain scenes. However, the real-world environments are changing dynamically, and object appearances are changing all the time. Any semantic mapping algorithms need the ability of self-learning to adapt these changes and recognize new objects. Solutions might be found in deep learning algorithms.
- Semantic mapping systems should be able to detect novelty and learn novel concepts about the environment continuously and in real time. The conceptual definitions that are initially encoded by using common sense knowledge should only be used for bootstrapping, which should be updated or extended based on new experience. For instance, a robot operating in a home environment should link its actions to rooms and objects in order to bridge the gap between the metric map and semantic knowledge. Moreover, this conceptual learning performance opens new possibilities in terms of truly autonomous semantic mapping and navigation. Thus, an incremental adaptive learning model should be built by using machine learning algorithms.
Acknowledgements
Author Contributions
Conflicts of Interest
References
- Thrun, S. Robotic Mapping: A Survey. In Exploring Artificial Intelligence in the New Millennium; Morgan Kaufmann: San Francisco, CA, USA, 2002; pp. 1–35. [Google Scholar]
- Wolf, D.F.; Sukhatme, G.S. Semantic Mapping Using Mobile Robots. IEEE Trans. Robot. 2008, 24, 245–258. [Google Scholar] [CrossRef]
- Vasudevan, S.; Gächter, S.; Nguyen, V.; Siegwart, R. Cognitive Maps for Mobile Robots—An Object Based Approach. Robot. Auton. Syst. 2007, 55, 359–371. [Google Scholar] [CrossRef]
- Nüchter, A.; Hertzberg, J. Towards Semantic Maps for Mobile Robots. Robot. Auton. Syst. 2008, 56, 915–926. [Google Scholar] [CrossRef]
- Kostavelis, I.; Gasteratos, A. Semantic Mapping for Mobile Robotics Tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar] [CrossRef]
- Harmandas, V.; Sanderson, M.; Dunlop, M. Image Retrieval by Hypertext Links. In Proceedings of the 20th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Philadelphia, PA, USA, 27–31 July 1997; pp. 296–303.
- Zhuge, H. Retrieve Images by Understanding Semantic Links and Clustering Image Fragments. J. Syst. Softw. 2004, 73, 455–466. [Google Scholar] [CrossRef]
- Flint, A.; Mei, C.; Murray, D.; Reid, I. A Dynamic Programming Approach to Reconstructing Building Interiors. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Crete, Greece, 5–11 September 2010; pp. 394–407.
- Coughlan, J.M.; Yuille, A.L. Manhattan World: Compass Direction from a Single Image by Bayesian Inference. In Proceedings of the 7th IEEE International Conference on Computer Vision (ICCV), Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 941–947.
- Anguelov, D.; Koller, D.; Parker, E.; Thrun, S. Detecting and Modeling Doors with Mobile Robots. In Proceedings of the 2004 IEEE International Conference on Robotics and Automation (ICRA), New Orleans, LA, USA, 26 April–1 May 2004; Volume 4, pp. 3777–3784.
- Tian, Y.; Yang, X.; Arditi, A. Computer Vision-Based Door Detection for Accessibility of Unfamiliar Environments to Blind Persons. In Proceedings of the 12th International Conference on Computers Helping People with Special Needs (ICCHP), Vienna, Austria, 14–16 July 2010; pp. 263–270.
- Wu, J.; Christensen, H.; Rehg, J.M. Visual Place Categorization: Problem, Dataset, and Algorithm. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), St. Louis, MO, USA, 11–15 October 2009; pp. 4763–4770.
- Neves dos Santos, F.; Costa, P.; Moreira, A.P. A Visual Place Recognition Procedure with a Markov Chain Based Filter. In Proceedings of the 2014 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Espinho, Portugal, 14–15 May 2014; pp. 333–338.
- Civera, J.; Gálvez-López, D.; Riazuelo, L.; Tardós, J.D.; Montiel, J. Towards Semantic SLAM Using a Monocular Camera. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011; pp. 1277–1284.
- Riazuelo, L.; Tenorth, M.; Di Marco, D.; Salas, M.; Gálvez-López, D.; Mosenlechner, L.; Kunze, L.; Beetz, M.; Tardos, J.D.; Montano, L.; et al. RoboEarth Semantic Mapping: A Cloud Enabled Knowledge-Based Approach. IEEE Trans. Autom. Sci. Eng. 2015, 12, 432–443. [Google Scholar] [CrossRef]
- Rusu, R.B. Semantic 3D Object Maps for Everyday Manipulation in Human Living Environments. KI-Künstliche Intell. 2010, 24, 345–348. [Google Scholar] [CrossRef]
- Sarbolandi, H.; Lefloch, D.; Kolb, A. Kinect Range Sensing: Structured-Light versus Time-of-Flight Kinect. Comput. Vis. Image Underst. 2015, 139, 1–20. [Google Scholar] [CrossRef]
- Jain, R.; Kasturi, R.; Schunck, B.G. Machine Vision; McGraw-Hill: New York, NY, USA, 1995. [Google Scholar]
- Theobalt, C.; Bos, J.; Chapman, T.; Espinosa-Romero, A.; Fraser, M.; Hayes, G.; Klein, E.; Oka, T.; Reeve, R. Talking to Godot: Dialogue with a Mobile Robot. In Proceedings of the 2002 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), EPFL, Lausanne, Switzerland, 30 September–4 October 2002; Volume 2, pp. 1338–1343.
- Skubic, M.; Perzanowski, D.; Blisard, S.; Schultz, A.; Adams, W.; Bugajska, M.; Brock, D. Spatial Language for Human-Robot Dialogs. IEEE Trans. Syst. Man Cybern. 2004, 34, 154–167. [Google Scholar] [CrossRef]
- Galindo, C.; Saffiotti, A.; Coradeschi, S.; Buschka, P.; Fernández-Madrigal, J.A.; Gonzalez, J. Multi-Hierarchical Semantic Maps for Mobile Robotics. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Edmonton, AB, Canada, 2–6 August 2005; pp. 2278–2283.
- Canclini, A.; Cesana, M.; Redondi, A.; Tagliasacchi, M.; Ascenso, J.; Cilla, R. Evaluation of Low-Complexity Visual Feature Detectors and Descriptors. In Proceedings of the 2013 18th IEEE International Conference on Digital Signal Processing (DSP), Fira, Santorini, Greece, 1–3 July 2013; pp. 1–7.
- Siagian, C.; Itti, L. Biologically Inspired Mobile Robot Vision Localization. IEEE Trans. Robot. 2009, 25, 861–873. [Google Scholar] [CrossRef]
- Lisin, D.A.; Mattar, M.; Blaschko, M.B.; Learned-Miller, E.G.; Benfield, M.C. Combining Local and Global Image Features for Object Class Recognition. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 47–47.
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A General Framework for Object Detection. In Proceedings of the 6th IEEE International Conference on Computer Vision (ICCV), Bombay, India, 7 January 1998; pp. 555–562.
- Swain, M.J.; Ballard, D.H. Color Indexing. Int. J. Comput. Vis. (IJCV) 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893.
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Fua, P.; Navab, N. Dominant Orientation Templates for Real-Time Detection of Texture-Less Objects. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2257–2264.
- Pronobis, A.; Caputo, B.; Jensfelt, P.; Christensen, H.I. A Discriminative Approach to Robust Visual Place Recognition. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Beijing, China, 9–15 October 2006; pp. 3829–3836.
- Murphy, K.; Torralba, A.; Freeman, W. Using the Forest to See the Trees: A Graphical Model Relating Features, Objects and Scenes. Adv. Neural Inf. Process. Syst. (NIPS) 2003, 16, 1499–1506. [Google Scholar]
- Mozos, O.M.; Triebel, R.; Jensfelt, P.; Rottmann, A.; Burgard, W. Supervised Semantic Labeling of Places Using Information Extracted from Sensor Data. Robot. Auton. Syst. 2007, 55, 391–402. [Google Scholar] [CrossRef]
- Ulrich, I.; Nourbakhsh, I. Appearance-Based Place Recognition for Topological Localization. In Proceedings of the 2000 IEEE International Conference on Robotics and Automation (ICRA), San Francisco, CA, USA, 24–28 April 2000; Volume 2, pp. 1023–1029.
- Filliat, D.; Battesti, E.; Bazeille, S.; Duceux, G.; Gepperth, A.; Harrath, L.; Jebari, I.; Pereira, R.; Tapus, A.; Meyer, C.; et al. RGBD Object Recognition and Visual Texture Classification for Indoor Semantic Mapping. In Proceedings of the 2012 IEEE International Conference on Technologies for Practical Robot Applications (TePRA), Woburn, MA, USA, 23–24 April 2012; pp. 127–132.
- Grimmett, H.; Buerki, M.; Paz, L.; Pinies, P.; Furgale, P.; Posner, I.; Newman, P. Integrating Metric and Semantic Maps for Vision-Only Automated Parking. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 2159–2166.
- Matignon, L.; Jeanpierre, L.; Mouaddib, A.I. Decentralized Multi-Robot Planning to Explore and Perceive. Acta Polytech. 2015, 55, 169–176. [Google Scholar] [CrossRef]
- Siagian, C.; Itti, L. Rapid Biologically-Inspired Scene Classification Using Features Shared with Visual Attention. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 300–312. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Meng, M.Q.H. Indoor Scene Recognition via Probabilistic Semantic Map. In Proceedings of the 2012 IEEE International Conference on Automation and Logistics (ICAL), Zhengzhou, China, 15–17 August 2012; pp. 352–357.
- Hinterstoisser, S.; Holzer, S.; Cagniart, C.; Ilic, S.; Konolige, K.; Navab, N.; Lepetit, V. Multimodal Templates for Real-Time Detection of Texture-Less Objects in Heavily Cluttered Scenes. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 858–865.
- Li, Y.; Wang, S.; Tian, Q.; Ding, X. A Survey of Recent Advances in Visual Feature Detection. Neurocomputing 2015, 149, 736–751. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef] [PubMed]
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the 4th Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; Volume 15, p. 50.
- Tomasi, C.; Kanade, T. Detection and Tracking of Point Features. Int. J. Comput. Vis. (IJCV) 1991, 9, 137–154. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Proceedings of the 9th European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 430–443.
- Mair, E.; Hager, G.D.; Burschka, D.; Suppa, M.; Hirzinger, G. Adaptive and Generic Corner Detection Based on the Accelerated Segment Test. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Crete, Greece, 5–11 September 2010; pp. 183–196.
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; pp. 778–792.
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. (IJCV) 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Proceedings of the 9th European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 404–417.
- Agrawal, M.; Konolige, K.; Blas, M.R. CenSurE: Center Surround Extremas for Realtime Feature Detection and Matching. In Proceedings of the 10th European Conference on Computer Vision (ECCV), Marseille, France, 12–18 October 2008; pp. 102–115.
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571.
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust Invariant Scalable Keypoints. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2548–2555.
- Alahi, A.; Ortiz, R.; Vandergheynst, P. FREAK: Fast Retina Keypoint. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 510–517.
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust Wide-Baseline Stereo from Maximally Stable Extremal Regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Basu, M. Gaussian-Based Edge-Detection Methods—A Survey. IEEE Trans. Syst. Man Cybern. 2002, 32, 252–260. [Google Scholar] [CrossRef]
- Ranganathan, A.; Dellaert, F. Semantic Modeling of Places Using Objects. In Proceedings of the 2007 Robotics: Science and Systems Conference, Atlanta, GA, USA, 27–30 June 2007; Volume 3, pp. 27–30.
- Kim, S.; Shim, M.S. Biologically Motivated Novel Localization Paradigm by High-Level Multiple Object Recognition in Panoramic Images. Sci. World J. 2015, 2015. [Google Scholar] [CrossRef] [PubMed]
- Tsai, G.; Kuipers, B. Dynamic Visual Understanding of the Local Environment for an Indoor Navigating Robot. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Algarve, Portugal, 7–12 October 2012; pp. 4695–4701.
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGB-D Mapping: Using Kinect-Style Depth Cameras for Dense 3D Modeling of Indoor Environments. Int. J. Robot. Res. (IJRR) 2012, 31, 647–663. [Google Scholar] [CrossRef]
- Gálvez-López, D.; Tardós, J.D. Bags of Binary Words for Fast Place Recognition in Image Sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Rosten, E.; Porter, R.; Drummond, T. Faster and Better: A Machine Learning Approach to Corner Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 105–119. [Google Scholar] [CrossRef] [PubMed]
- Meger, D.; Forssén, P.E.; Lai, K.; Helmer, S.; McCann, S.; Southey, T.; Baumann, M.; Little, J.J.; Lowe, D.G. Curious George: An Attentive Semantic Robot. Robot. Auton. Syst. 2008, 56, 503–511. [Google Scholar] [CrossRef]
- Zender, H.; Mozos, O.M.; Jensfelt, P.; Kruijff, G.J.; Burgard, W. Conceptual Spatial Representations for Indoor Mobile Robots. Robot. Auton. Syst. 2008, 56, 493–502. [Google Scholar] [CrossRef]
- Kostavelis, I.; Charalampous, K.; Gasteratos, A.; Tsotsos, J.K. Robot Navigation via Spatial and Temporal Coherent Semantic Maps. Eng. Appl. Artif. Intell. 2016, 48, 173–187. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Schmid, C. A Performance Evaluation of Local Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed]
- Morisset, B.; Rusu, R.B.; Sundaresan, A.; Hauser, K.; Agrawal, M.; Latombe, J.C.; Beetz, M. Leaving Flatland: Toward Real-Time 3D Navigation. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009; pp. 3786–3793.
- Kostavelis, I.; Gasteratos, A. Learning Spatially Semantic Representations for Cognitive Robot Navigation. Robot. Auton. Syst. 2013, 61, 1460–1475. [Google Scholar] [CrossRef]
- Waibel, M.; Beetz, M.; Civera, J.; dâĂŹAndrea, R.; Elfring, J.; Galvez-Lopez, D.; Haussermann, K.; Janssen, R.; Montiel, J.; Perzylo, A.; et al. A World Wide Web for Robots. IEEE Robot. Autom. Mag. 2011, 18, 69–82. [Google Scholar] [CrossRef]
- Yousif, K.; Bab-Hadiashar, A.; Hoseinnezhad, R. A Real-Time RGB-D Registration and Mapping Approach by Heuristically Switching between Photometric and Geometric Information. In Proceedings of the 17th International Conference on Information Fusion (FUSION), Salamanca, Spain, 7–10 July 2014; pp. 1–8.
- Grimmett, H.; Buerki, M.; Paz, L.; Pinies, P.; Furgale, P.; Posner, I.; Newman, P. Integrating Metric and Semantic Maps for Vision-Only Automated Parking. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 2159–2166.
- Zhang, L.; Mistry, K.; Jiang, M.; Neoh, S.C.; Hossain, M.A. Adaptive Facial Point Detection and Emotion Recognition for a Humanoid Robot. Comput. Vis. Image Underst. 2015, 140, 93–114. [Google Scholar] [CrossRef]
- Sun, H.; Wang, C.; El-Sheimy, N. Automatic Traffic Lane Detection for Mobile Mapping Systems. In Proceedings of the 2011 International Workshop on Multi-Platform/Multi-Sensor Remote Sensing and Mapping (M2RSM), Xiamen, China, 10–12 January 2011; pp. 1–5.
- Schmid, C.; Mohr, R.; Bauckhage, C. Evaluation of Interest Point Detectors. Int. J. Comput. Vis. (IJCV) 2000, 37, 151–172. [Google Scholar] [CrossRef]
- Salas-Moreno, R.F. Dense Semantic SLAM. PhD Thesis, Imperial College, London, UK, 2014. [Google Scholar]
- Torralba, A.; Murphy, K.P.; Freeman, W.T.; Rubin, M. Context-Based Vision System for Place and Object Recognition. In Proceedings of the 10th IEEE International Conference on Computer Vision (ICCV), Madison, WI, USA, 16–22 June 2003; pp. 273–280.
- Lienhart, R.; Kuranov, A.; Pisarevsky, V. Empirical Analysis of Detection Cascades of Boosted Classifiers for Rapid Object Detection. Pattern Recognit. 2003, 2781, 297–304. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Belongie, S.; Fowlkes, C.; Chung, F.; Malik, J. Spectral Partitioning with Indefinite Kernels Using the Nyström Extension. In Proceedings of the 7th European Conference on Computer Vision (ECCV), Copenhagen, Denmark, 28–31 May 2002; pp. 531–542.
- Taylor, S.; Drummond, T. Multiple Target Localisation at over 100 FPS. In Proceedings of the 2009 British Machine Vision Conference (BMVC), London, UK, 7–10 September 2009; pp. 1–11.
- Anati, R.; Scaramuzza, D.; Derpanis, K.G.; Daniilidis, K. Robot Localization Using Soft Object Detection. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), St Paul, MN, USA, 14–18 May 2012; pp. 4992–4999.
- Stückler, J.; Biresev, N.; Behnke, S. Semantic Mapping Using Object-Class Segmentation of RGB-D Images. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Algarve, Portugal, 7–12 October 2012; pp. 3005–3010.
- Bosch, A.; Zisserman, A.; Munoz, X. Image Classification Using Random Forests and Ferns. In Proceedings of the 11th IEEE International Conference on Computer Vision (ICCV), Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8.
- Filliat, D. A Visual Bag of Words Method for Interactive Qualitative Localization and Mapping. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation (ICRA), Roma, Italy, 10–14 April 2007; pp. 3921–3926.
- Martínez-Gómez, J.; Morell, V.; Cazorla, M.; García-Varea, I. Semantic Localization in the PCL Library. Robot. Auton. Syst. 2016, 75, 641–648. [Google Scholar] [CrossRef]
- Sivic, J.; Zisserman, A. Video Google: A Text Retrieval Approach to Object Matching in Videos. In Proceedings of the 9th IEEE International Conference on Computer Vision (ICCV), Nice, France, 13–16 October 2003; pp. 1470–1477.
- Leung, T.; Malik, J. Representing and Recognizing the Visual Appearance of Materials Using Three-Dimensional Textons. Int. J. Comput. Vis. (IJCV) 2001, 43, 29–44. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178.
- Case, C.; Suresh, B.; Coates, A.; Ng, A.Y. Autonomous Sign Reading for Semantic Mapping. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 3297–3303.
- Sami, M.; Ayaz, Y.; Jamil, M.; Gilani, S.O.; Naveed, M. Text Detection and Recognition for Semantic Mapping in Indoor Navigation. In Proceedings of the 2015 5th International Conference on IT Convergence and Security (ICITCS), Kuala Lumpur, Malaysia, 25–27 August 2015; pp. 1–4.
- Wyss, M.; Corke, P.I. Active Text Perception for Mobile Robots. QUT EPrints. 2012, unpublished. [Google Scholar]
- Galindo, C.; Fernández-Madrigal, J.A.; González, J.; Saffiotti, A. Robot Task Planning Using Semantic Maps. Robot. Auton. Syst. 2008, 56, 955–966. [Google Scholar] [CrossRef]
- Baader, F. The Description Logic Handbook: Theory, Implementation, and Applications; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Coradeschi, S.; Saffiotti, A. An Introduction to the Anchoring Problem. Robot. Auton. Syst. 2003, 43, 85–96. [Google Scholar] [CrossRef]
- Vasudevan, S.; Siegwart, R. Bayesian Space Conceptualization and Place Classification for Semantic Maps in Mobile Robotics. Robot. Auton. Syst. 2008, 56, 522–537. [Google Scholar] [CrossRef]
- Viswanathan, P.; Meger, D.; Southey, T.; Little, J.J.; Mackworth, A. Automated Spatial-Semantic Modeling with Applications to Place Labeling and Informed Search. In Proceedings of the 6th Canadian Conference on Computer and Robot Vision (CRV), Kelowna, BC, Canada, 25–27 May 2009; pp. 284–291.
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. (IJCV) 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Capobianco, R.; Serafin, J.; Dichtl, J.; Grisetti, G.; Iocchi, L.; Nardi, D. A Proposal for Semantic Map Representation and Evaluation. In Proceedings of the 2015 European Conference on Mobile Robots (ECMR), Lincoln, UK, 2–4 September 2015; pp. 1–6.
- Pronobis, A.; Mozos, O.M.; Caputo, B.; Jensfelt, P. Multi-Modal Semantic Place Classification. Int. J. Robot. Res. (IJRR) 2009, 29, 298–320. [Google Scholar] [CrossRef]
- Galindo, C.; González, J.; Fernández-Madrigal, J.A.; Saffiotti, A. Robots that change their world: Inferring Goals from Semantic Knowledge. In Proceedings of the 5th European Conference on Mobile Robots (ECMR), Örebro, Sweden, 7–9 September 2011; pp. 1–6.
- Crespo Herrero, J.; Barber Castano, R.I.; Martinez Mozos, O. An Inferring Semantic System Based on Relational Models for Mobile Robotics. In Proceedings of the 2015 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Vila Real, Portugal, 8–10 April 2015; pp. 83–88.
- Blodow, N.; Goron, L.C.; Marton, Z.C.; Pangercic, D.; Rühr, T.; Tenorth, M.; Beetz, M. Autonomous Semantic Mapping for Robots Performing Everyday Manipulation Tasks in Kitchen Environments. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011; pp. 4263–4270.
- Ko, D.W.; Yi, C.; Suh, I.H. Semantic Mapping and Navigation: A Bayesian Approach. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 2630–2636.
- Boularias, A.; Duvallet, F.; Oh, J.; Stentz, A. Grounding Spatial Relations for Outdoor Robot Navigation. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1976–1982.
- Bernuy, F.; Solar, J. Semantic Mapping of Large-Scale Outdoor Scenes for Autonomous Off-Road Driving. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 11–12 December 2015; pp. 35–41.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Classification | Performance |
|---|---|---|
| Haar-like [25] | Texture | Robust to illumination changes |
| Colour histograms [26] | Colour | Robust to viewing angles |
| HOG [27] | Template | Robust to illumination and shadowing changes, sensitive to object orientations |
| DOT [28] | Template | Computationally efficient, robust to small shifting and deformations |
| High dimensional composed receptive field histograms [29] | Combination | Robust to illumination and minor scene changes |
| GIST [30] | Combination | Robust to occlusion and viewpoint changes; noise in isolated regions is ignored |
| Category | Classification | Feature | Performance |
|---|---|---|---|
| Edge based | Differentiation based | Sobel | Computationally efficient, high error rate |
| Canny [40] | High accuracy, computationally expensive | ||
| Corner based | Gradient based | Harris [41] | Sensitive to noise, computationally expensive |
| KLT [42] | Computationally efficient, sensitive to noise | ||
| Corner based | Template based | FAST [43] | Computationally efficient, low level of generality |
| AGAST [44] | High level of generality, computationally efficient | ||
| BRIEF [45] | Computationally efficient, sensitive to viewpoint rotations | ||
| Blob based (keypoint) | PDE based | SIFT [46] | Robust to scale and transformation changes, computationally expensive |
| SURF [47] | Robust to scale and transformation changes, computationally efficient | ||
| CenSurE [48] | High accuracy, computationally efficient | ||
| Blob based (keypoint) | Template based | ORB [49] | Computationally efficient, robust to viewpoint rotations |
| BRISK [50] | Robust to scale changes, computationally efficient | ||
| FREAK [51] | Computationally efficient, robust to scale changes | ||
| Blob based (region) | Intensity based | MSER [52] | Robust to affine transformations, computationally efficient |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Li, R.; Hu, H.; Gu, D. Extracting Semantic Information from Visual Data: A Survey. Robotics 2016, 5, 8. https://doi.org/10.3390/robotics5010008
Liu Q, Li R, Hu H, Gu D. Extracting Semantic Information from Visual Data: A Survey. Robotics. 2016; 5(1):8. https://doi.org/10.3390/robotics5010008
Chicago/Turabian StyleLiu, Qiang, Ruihao Li, Huosheng Hu, and Dongbing Gu. 2016. "Extracting Semantic Information from Visual Data: A Survey" Robotics 5, no. 1: 8. https://doi.org/10.3390/robotics5010008
APA StyleLiu, Q., Li, R., Hu, H., & Gu, D. (2016). Extracting Semantic Information from Visual Data: A Survey. Robotics, 5(1), 8. https://doi.org/10.3390/robotics5010008