
MM-EMOG: Multi-Label Emotion Graph Representation for Mental Health Classification on Social Media †


Abstract
1. Introduction
- We propose a new multi-label emotion representation for mental health classification using only social media textual posts.
- To our knowledge, no other studies have utilised Graph Convolutional Neural Network [8] (GCN) in a purely textual capacity for multi-label emotion representation and social media mental health classification tasks. We are the first to apply multi-label and graph-based textual emotion representation.
- Our proposed model, MM-EMOG, achieved the highest performance on three publicly available social media mental health classification datasets.
2. Related Works
2.1. Social Media Mental Health Classification
2.2. Graph Convolutional Networks
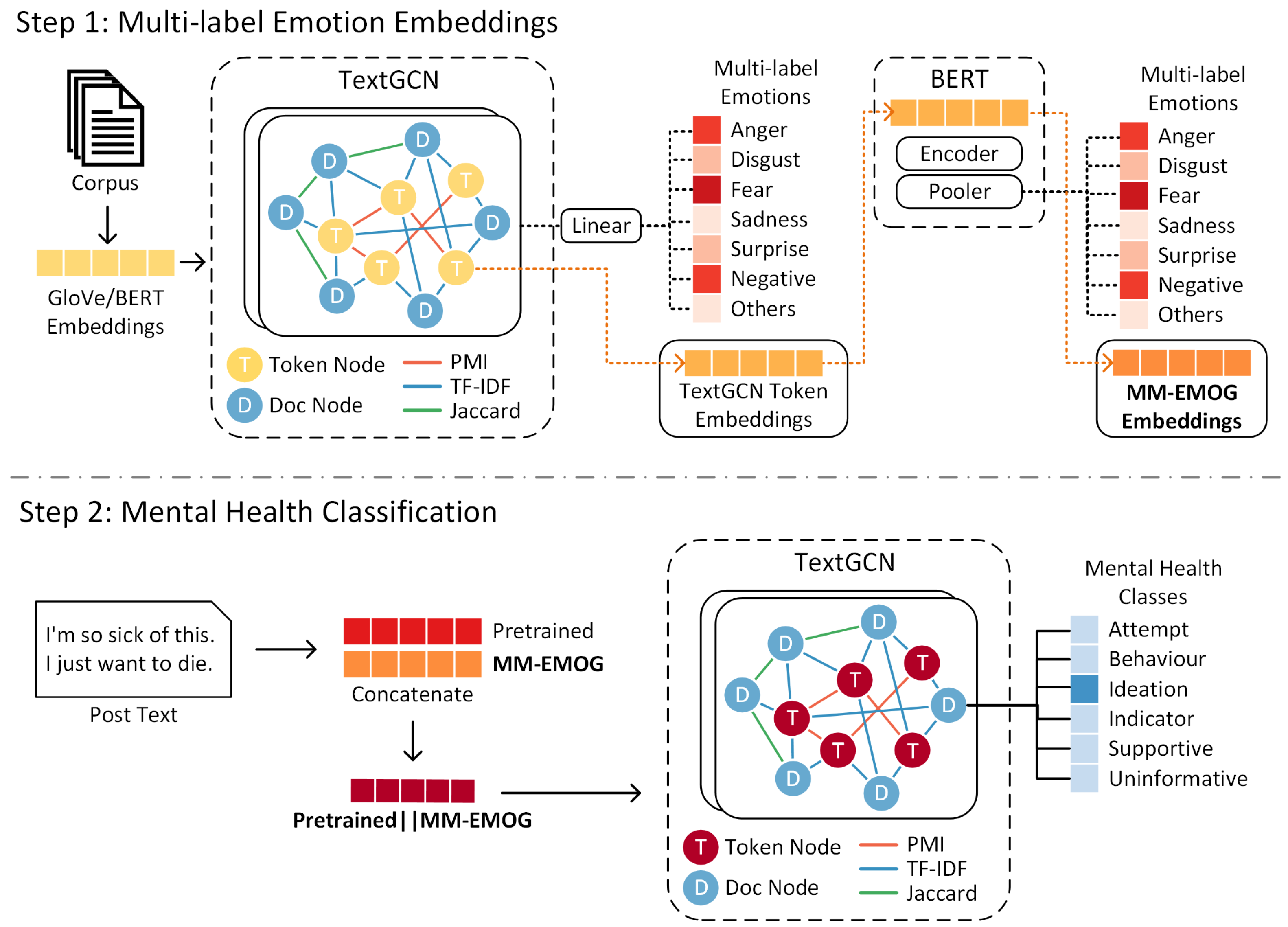
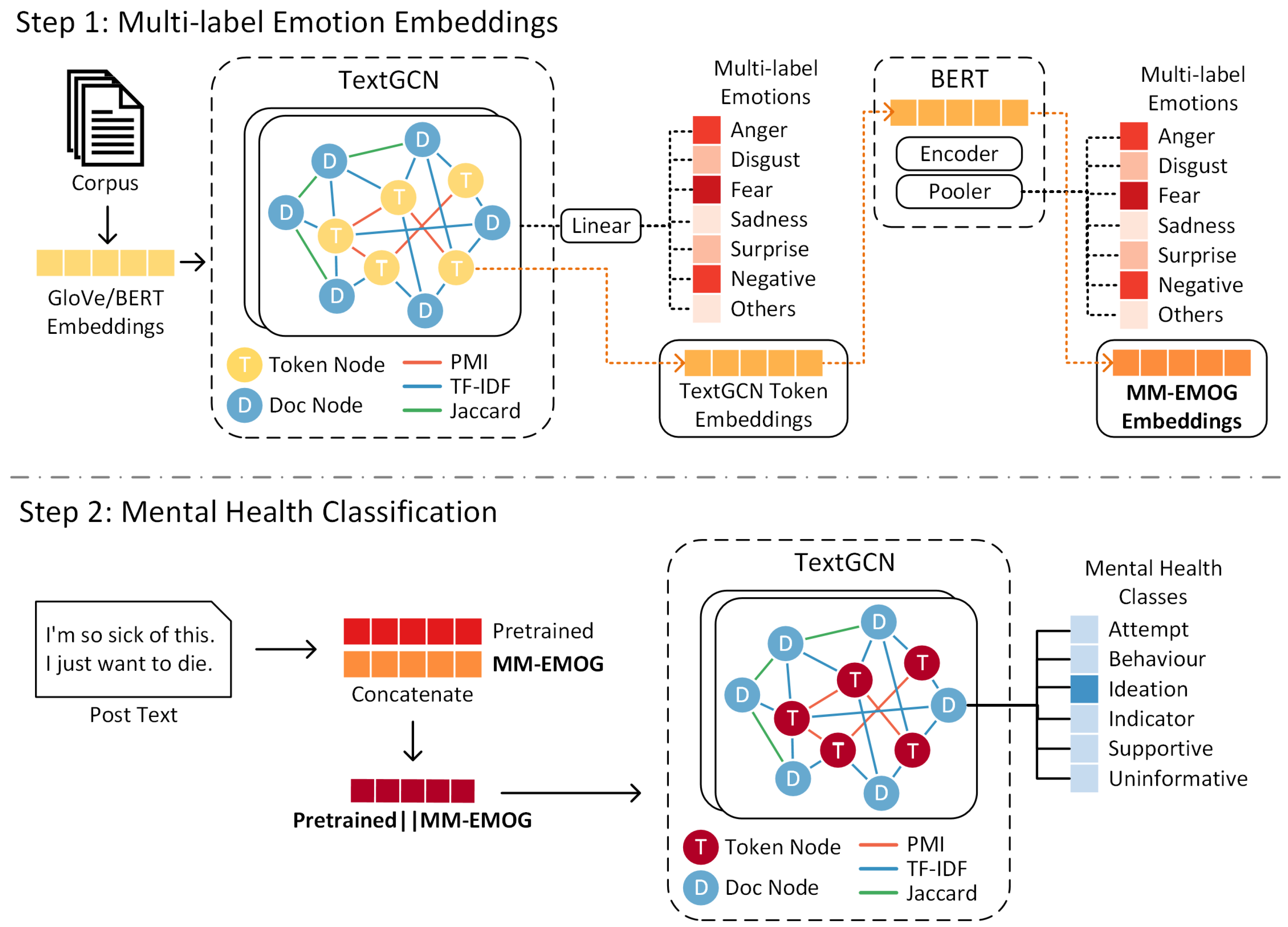
3. MM-EMOG
3.1. MM-EMOG Construction
3.1.1. Node Construction
3.1.2. Edge Construction
3.2. MM-EMOG Learning
3.2.1. Multi-Label Document Emotions
3.2.2. Multi-Label Emotion Training
3.3. Mental Health Post Classification
4. Experimental Setup
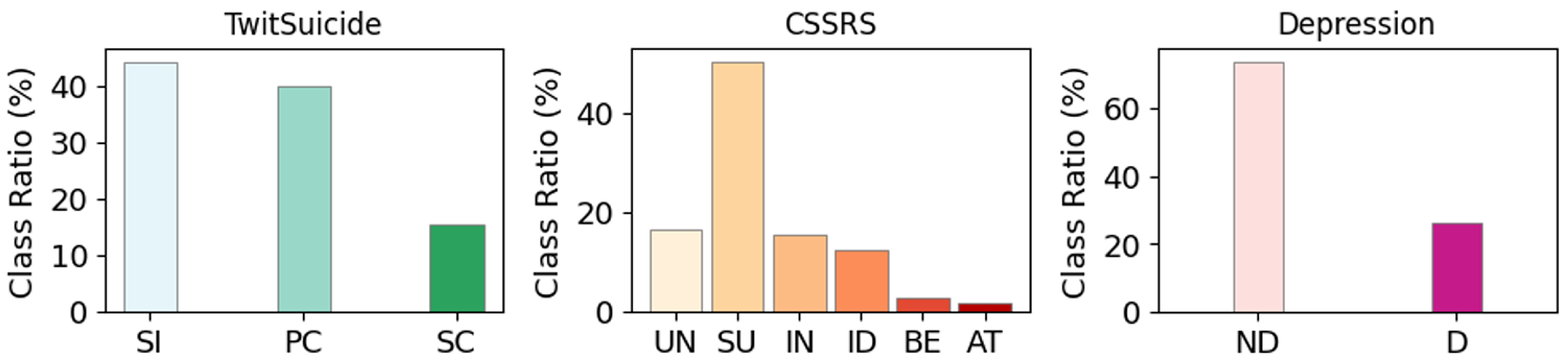
4.1. Datasets
4.2. Emotion Lexicons
4.3. Baselines and Metrics
4.4. Implementation Details
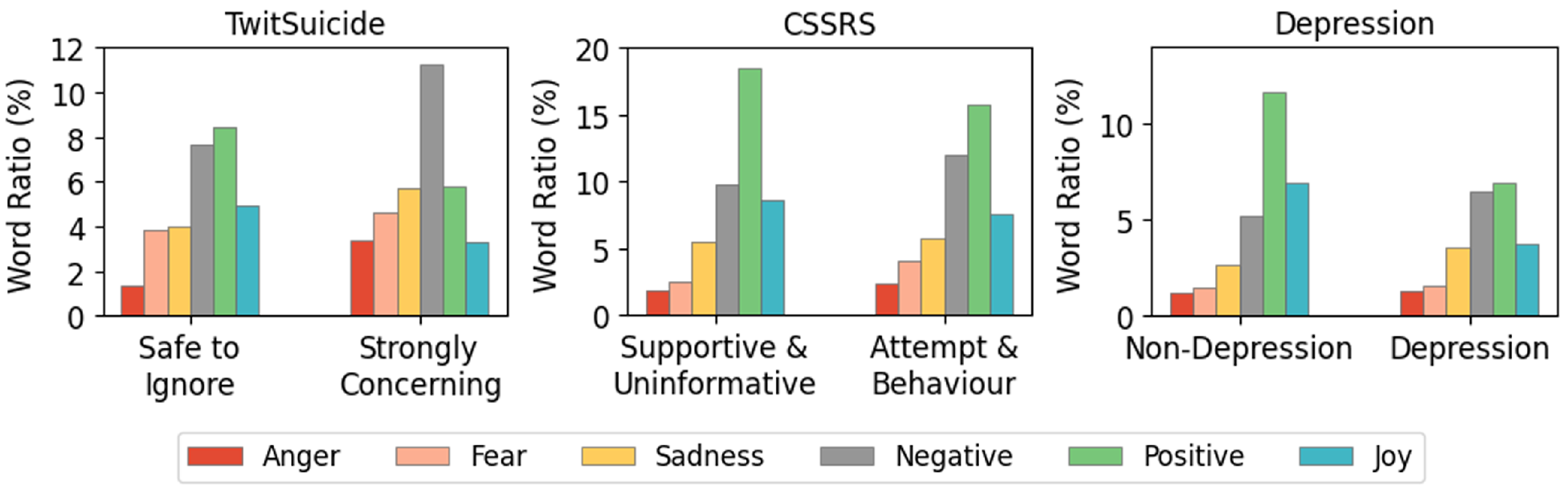
5. Emotion Analysis
6. Results
6.1. Overall Performance
6.2. Ablation Results
6.3. Case Studies
7. Ethical Considerations
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| WHO | World Health Organization |
| MM-EMOG | Multi-label Mental Health Emotion Graph representations |
| NLP | Natural Language Processing |
| GCN | Graph Convolutional Neural Network |
| BERT | Bidirectional Encoder Representations from Transformers |
| RoBERTa | Robustly Optimized BERT Pretraining Approach |
| GloVe | Global Vectors for Word Representation |
| PMI | Pointwise Mutual Information |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| ReLu | Rectified Linear Unit |
| CV | Cross Validation |
| SC | Strongly Concerning |
| PC | Possibly Concerning |
| SI | Safe to Ignore |
| AT | Actual Attempt |
| BE | Suicidal Behaviour |
| ID | Suicidal Ideation |
| IN | Suicidal Indicator |
| SU | Supportive |
| UN | Uninformative |
| D | Depression |
| ND | Non-Depression |
| Acc | Accuracy |
| F1w | Weighted F1-score |
| EW | EmoWord representation |
| EWP | EmoWordPiece representation |
Appendix A. Hyperparameter Search

{kind=link}
{kind=link}
{kind=link}
| TwitSuicide | CSSRS | Depression | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Emo | TEC | Sen | Emo | TEC | Sen | Emo | TEC | Sen | |
| EW1 | |||||||||
| dropout | 0.5 | 0.01 | 0.5 | 0.01 | 0.1 | 0.05 | 0.01 | 0.1 | 0.05 |
| num layers | 4 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| num hidden | 200 | 400 | 400 | 300 | 200 | 500 | 200 | 200 | 200 |
| learning rate | 0.01 | 0.03 | 0.04 | 0.05 | 0.03 | 0.03 | 0.05 | 0.02 | 0.05 |
| weight decay | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| EW2 | |||||||||
| dropout | 0.5 | 0.01 | 0.01 | 0.01 | 0.01 | 0.05 | 0.01 | 0.5 | 0.05 |
| num layers | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| num hidden | 200 | 200 | 400 | 300 | 400 | 200 | 200 | 200 | 200 |
| learning rate | 0.02 | 0.05 | 0.01 | 0.03 | 0.05 | 0.04 | 0.05 | 0.03 | 0.01 |
| weight decay | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| EWP1 | |||||||||
| dropout | 0.5 | 0.01 | 0.1 | 0.01 | 0.1 | 0.5 | 0.1 | 0.5 | 0.1 |
| num layers | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| num hidden | 100 | 100 | 200 | 200 | 200 | 400 | 200 | 200 | 200 |
| learning rate | 0.05 | 0.01 | 0.04 | 0.04 | 0.04 | 0.05 | 0.01 | 0.02 | 0.05 |
| weight decay | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| EWP2 | |||||||||
| dropout | 0.5 | 0.5 | 0.1 | 0.01 | 0.5 | 0.05 | 0.05 | 0.1 | 0.01 |
| num layers | 2 | 2 | 5 | 2 | 2 | 2 | 2 | 2 | 2 |
| num hidden | 200 | 500 | 300 | 200 | 500 | 200 | 200 | 200 | 200 |
| learning rate | 0.02 | 0.04 | 0.04 | 0.04 | 0.04 | 0.05 | 0.04 | 0.05 | 0.02 |
| weight decay | 0 | 0 | 0.005 | 0 | 0 | 0 | 0 | 0 | 0 |
Appendix B. Limitations
References
- World Health Organization. One in 100 Deaths is by Suicide. World Health Organization News Release, 17 June 2021. Available online: https://www.who.int/news/item/17-06-2021-one-in-100-deaths-is-by-suicide (accessed on 17 March 2024).
- World Health Organization. Mental Disorders. 2022. Available online: https://www.who.int/news-room/fact-sheets/detail/mental-disorders (accessed on 17 March 2024).
- Lara, J.S.; Aragón, M.E.; González, F.A.; Montes-y Gómez, M. Deep Bag-of-Sub-Emotions for Depression Detection in Social Media. In Proceedings of the Text, Speech, and Dialogue: 24th International Conference, TSD 2021, Olomouc, Czech Republic, 6–9 September 2021; Springer: Cham, Switzerland, 2021; pp. 60–72. [Google Scholar] [CrossRef]
- Sawhney, R.; Joshi, H.; Shah, R.R.; Flek, L. Suicide Ideation Detection via Social and Temporal User Representations using Hyperbolic Learning. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Virtual, 6–11 June 2021; pp. 2176–2190. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. Proc. AAAI Conf. Artif. Intell. 2019, 33, 7370–7377. [Google Scholar] [CrossRef]
- Liu, X.; You, X.; Zhang, X.; Wu, J.; Lv, P. Tensor Graph Convolutional Networks for Text Classification. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8409–8416. [Google Scholar] [CrossRef]
- Wang, K.; Han, S.C.; Long, S.; Poon, J. ME-GCN: Multi-dimensional Edge-Embedded Graph Convolutional Networks for Semi-supervised Text Classification. arXiv 2022, arXiv:2204.04618. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Buddhitha, P.; Inkpen, D. Multi-task learning to detect suicide ideation and mental disorders among social media users. Front. Res. Metr. Anal. 2023, 8, 1152535. [Google Scholar] [CrossRef]
- Cao, L.; Zhang, H.; Feng, L. Building and Using Personal Knowledge Graph to Improve Suicidal Ideation Detection on Social Media. IEEE Trans. Multimed. 2022, 24, 87–102. [Google Scholar] [CrossRef]
- Cao, L.; Zhang, H.; Feng, L.; Wei, Z.; Wang, X.; Li, N.; He, X. Latent Suicide Risk Detection on Microblog via Suicide-Oriented Word Embeddings and Layered Attention. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1718–1728. [Google Scholar] [CrossRef]
- Mathur, P.; Sawhney, R.; Chopra, S.; Leekha, M.; Ratn Shah, R. Utilizing Temporal Psycholinguistic Cues for Suicidal Intent Estimation. In Proceedings of the Advances in Information Retrieval, Lisbon, Portugal, 14–17 April 2020; Jose, J.M., Yilmaz, E., Magalhães, J., Castells, P., Ferro, N., Silva, M.J., Martins, F., Eds.; Springer: Cham, Switzerland, 2020; pp. 265–271. [Google Scholar] [CrossRef]
- Sawhney, R.; Joshi, H.; Flek, L.; Shah, R.R. PHASE: Learning Emotional Phase-aware Representations for Suicide Ideation Detection on Social Media. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Virtual, 19–23 April 2021; pp. 2415–2428. [Google Scholar] [CrossRef]
- Sawhney, R.; Joshi, H.; Gandhi, S.; Jin, D.; Shah, R.R. Robust suicide risk assessment on social media via deep adversarial learning. J. Am. Med. Inform. Assoc. 2021, 28, 1497–1506. [Google Scholar] [CrossRef] [PubMed]
- Sawhney, R.; Joshi, H.; Gandhi, S.; Shah, R.R. A Time-Aware Transformer Based Model for Suicide Ideation Detection on Social Media. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual, 16–20 November 2020; pp. 7685–7697. [Google Scholar] [CrossRef]
- Shing, H.C.; Nair, S.; Zirikly, A.; Friedenberg, M.; Daumé, H., III; Resnik, P. Expert, Crowdsourced, and Machine Assessment of Suicide Risk via Online Postings. In Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, New Orleans, LA, USA, 5 June 2018; pp. 25–36. [Google Scholar] [CrossRef]
- Sinha, P.P.; Mishra, R.; Sawhney, R.; Mahata, D.; Shah, R.R.; Liu, H. #suicidal—A Multipronged Approach to Identify and Explore Suicidal Ideation in Twitter. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM ’19, New York, NY, USA, 3–7 November 2019; pp. 941–950. [Google Scholar] [CrossRef]
- Zogan, H.; Razzak, I.; Jameel, S.; Xu, G. Hierarchical Convolutional Attention Network for Depression Detection on Social Media and Its Impact during Pandemic. IEEE J. Biomed. Health Inform. 2023, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Sawhney, R.; Joshi, H.; Gandhi, S.; Shah, R.R. Towards Ordinal Suicide Ideation Detection on Social Media. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, WSDM ’21, New York, NY, USA, 8–12 March 2021; pp. 22–30. [Google Scholar] [CrossRef]
- Mishra, R.; Prakhar Sinha, P.; Sawhney, R.; Mahata, D.; Mathur, P.; Ratn Shah, R. SNAP-BATNET: Cascading Author Profiling and Social Network Graphs for Suicide Ideation Detection on Social Media. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop, Minneapolis, MN, USA, 2–7 June 2019; pp. 147–156. [Google Scholar] [CrossRef]
- Aragón, M.E.; López-Monroy, A.P.; González-Gurrola, L.C.; Montes-y Gómez, M. Detecting Depression in Social Media using Fine-Grained Emotions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; Volume 1 (Long and Short Papers), pp. 1481–1486. [Google Scholar] [CrossRef]
- Gaur, M.; Alambo, A.; Sain, J.P.; Kursuncu, U.; Thirunarayan, K.; Kavuluru, R.; Sheth, A.; Welton, R.; Pathak, J. Knowledge-Aware Assessment of Severity of Suicide Risk for Early Intervention. In Proceedings of the World Wide Web Conference, WWW ’19, New York, NY, USA, 13–17 May 2019; pp. 514–525. [Google Scholar] [CrossRef]
- Mowery, D.L.; Park, A.; Bryan, C.; Conway, M. Towards Automatically Classifying Depressive Symptoms from Twitter Data for Population Health. In Proceedings of the Workshop on Computational Modeling of People’s Opinions, Personality, and Emotions in Social Media (PEOPLES), Osaka, Japan, 12 December 2016; pp. 182–191. [Google Scholar]
- Uban, A.S.; Chulvi, B.; Rosso, P. An emotion and cognitive based analysis of mental health disorders from social media data. Future Gener. Comput. Syst. 2021, 124, 480–494. [Google Scholar] [CrossRef]
- Zogan, H.; Razzak, I.; Wang, X.; Jameel, S.; Xu, G. Explainable depression detection with multi-aspect features using a hybrid deep learning model on social media. World Wide Web 2022, 25, 281–304. [Google Scholar] [CrossRef] [PubMed]
- Ren, L.; Lin, H.; Xu, B.; Zhang, S.; Yang, L.; Sun, S. Depression Detection on Reddit with an Emotion-Based Attention Network: Algorithm Development and Validation. JMIR Med Inf. 2021, 9, e28754. [Google Scholar] [CrossRef]
- Abdul-Mageed, M.; Ungar, L. EmoNet: Fine-Grained Emotion Detection with Gated Recurrent Neural Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Barzilay, R., Kan, M.Y., Eds.; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; Volume 1: Long Papers, pp. 718–728. [Google Scholar] [CrossRef]
- Linmei, H.; Yang, T.; Shi, C.; Ji, H.; Li, X. Heterogeneous Graph Attention Networks for Semi-supervised Short Text Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4821–4830. [Google Scholar] [CrossRef]
- Liu, T.; Hu, Y.; Wang, B.; Sun, Y.; Gao, J.; Yin, B. Hierarchical Graph Convolutional Networks for Structured Long Document Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 1–15. [Google Scholar] [CrossRef]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl.-Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Tang, H.; Ji, D.; Li, C.; Zhou, Q. Dependency Graph Enhanced Dual-transformer Structure for Aspect-based Sentiment Classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 5–10 July 2020; pp. 6578–6588. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Q.; Song, D. Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks. arXiv 2019, arXiv:cs.CL/1909.03477. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, X.; Cui, Z.; Wu, S.; Wen, Z.; Wang, L. Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks. arXiv 2020, arXiv:2004.13826. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Han, S.C.; Yuan, Z.; Wang, K.; Long, S.; Poon, J. Understanding Graph Convolutional Networks for Text Classification. arXiv 2022, arXiv:2203.16060. [Google Scholar]
- Church, K.W.; Hanks, P. Word Association Norms, Mutual Information, and Lexicography. Comput. Linguist. 1990, 16, 22–29. [Google Scholar]
- Long, S.; Cabral, R.; Poon, J.; Han, S.C. A Quantitative and Qualitative Analysis of Suicide Ideation Detection using Deep Learning. arXiv 2022, arXiv:2206.08673. [Google Scholar] [CrossRef]
- O’Dea, B.; Wan, S.; Batterham, P.J.; Calear, A.L.; Paris, C.; Christensen, H. Detecting suicidality on Twitter. Internet Interv. 2015, 2, 183–188. [Google Scholar] [CrossRef]
- Posner, K.; Brent, D.; Lucas, C.; Gould, M.; Stanley, B.; Brown, G.; Fisher, P.; Zelazny, J.; Burke, A.; Oquendo, M.; et al. Columbia-Suicide Severity Rating Scale (C-SSRS); Columbia University Medical Center: New York, NY, USA, 2008; Volume 10, p. 2008. [Google Scholar]
- MacAvaney, S.; Mittu, A.; Coppersmith, G.; Leintz, J.; Resnik, P. Community-level Research on Suicidality Prediction in a Secure Environment: Overview of the CLPsych 2021 Shared Task. In Proceedings of the Seventh Workshop on Computational Linguistics and Clinical Psychology: Improving Access, Virtual, 11 June 2021; pp. 70–80. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Turney, P.D. Crowdsourcing a word–emotion association lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Kiritchenko, S. Using Hashtags to Capture Fine Emotion Categories from Tweets. Comput. Intell. 2015, 31, 301–326. [Google Scholar] [CrossRef]
- Cambria, E.; Liu, Q.; Decherchi, S.; Xing, F.; Kwok, K. SenticNet 7: A Commonsense-based Neurosymbolic AI Framework for Explainable Sentiment Analysis. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; Calzolari, N., Béchet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., et al., Eds.; European Language Resources Association: Luxemburg, 2022; pp. 3829–3839. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Ji, S.; Zhang, T.; Ansari, L.; Fu, J.; Tiwari, P.; Cambria, E. MentalBERT: Publicly Available Pretrained Language Models for Mental Healthcare. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; Calzolari, N., Béchet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., et al., Eds.; European Language Resources Association: Luxemburg, 2022; pp. 7184–7190. [Google Scholar]
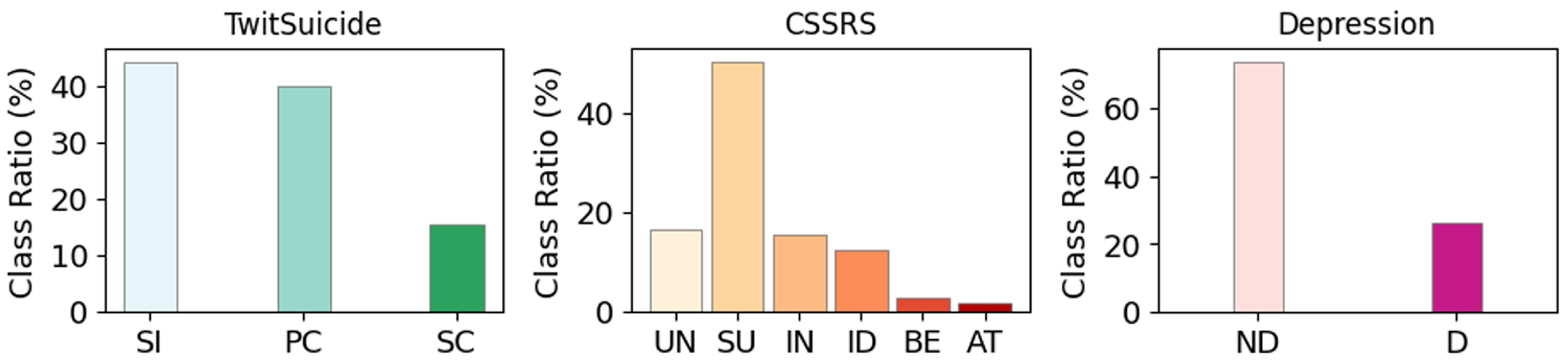
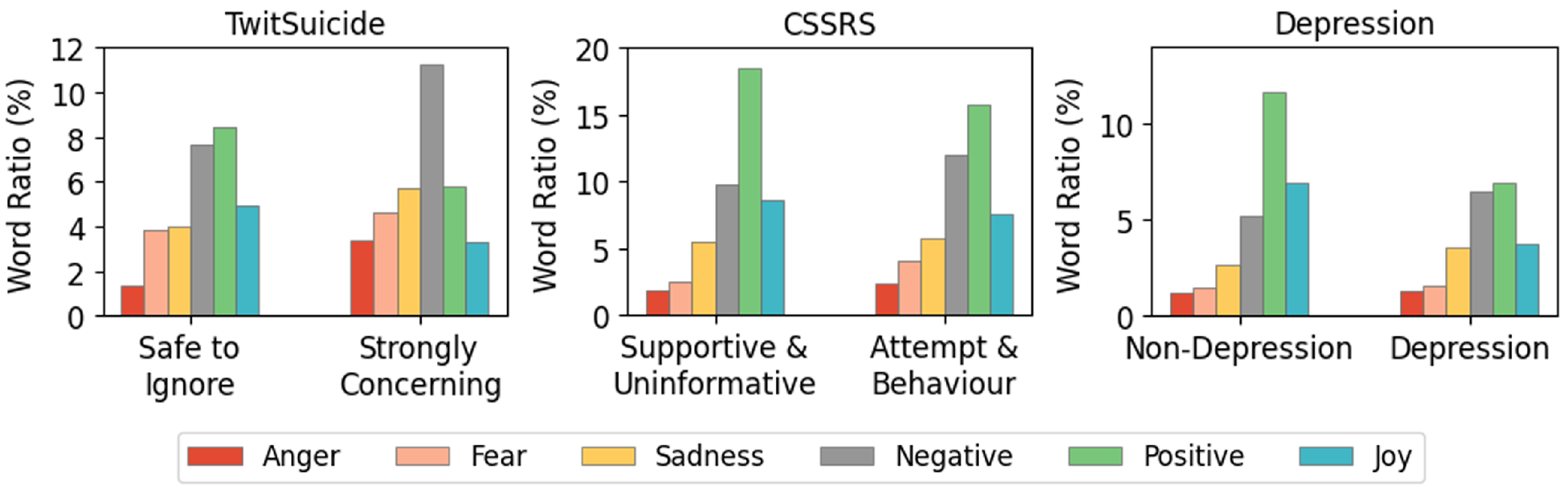
| TwitSuicide | CSSRS | Depression | |
|---|---|---|---|
| Platform | |||
| Total Posts | 660 | 2680 | 3200 |
| Total Users | 645 | 375 | - |
| Number of Classes | 3 | 6 | 2 |
| Evaluation Method | 10 CV | 5 CV | 80/20 |
| Length | 13–147 | 2–6221 | 6–374 |
| Average Length | 90.32 | 451.67 | 90.08 |
| Word Count | 3–31 | 1–1051 | 1–77 |
| Average Word Count | 16.85 | 85.51 | 17.43 |
| Lexicon | Description | Emotion Types |
|---|---|---|
| EmoLex [42] | Crowdsourced word–emotion and word–polarity pairings | Anger, Anticipation *, Disgust, Fear, Joy *, Sadness, Surprise, Trust *, Positive *, Negative |
| TEC [43] | Automatic annotation from emotion-related hashtags on Twitter | Anger, Anticipation *, Disgust, Fear, Joy *, Sadness, Surprise, Trust * |
| SenticNet [44] | Concepts from common sense knowledge graphs associated with emotions through similarity prediction | Anger, Calmness *, Disgust, Eagerness *, Fear, Joy *, Pleasantness *, Sadness, Positive *, Negative |
| Class F1-Scores | ||||
|---|---|---|---|---|
| TwitSuicide | Acc | F1w | (SC) | (SI) |
| BERT | 55.15 | 54.25 | 33.96 | 61.49 |
| RoBERTa | 45.00 | 38.86 | 00.00 | 60.43 |
| MentalBERT | 63.33 | 63.29 | 48.00 | 71.23 |
| MentalRoBERTa | 45.75 | 44.02 | 24.46 | 53.22 |
| Ours (EW2-EmoLex) | 67.97 | 65.26 | 28.06 | 75.96 |
| Ours (EW2-TEC) | 71.86 | 71.03 | 52.64 | 78.03 |
| Ours (EW2-SenticNet) | 70.12 | 68.80 | 44.09 | 76.84 |
| CSSRS | Acc | F1w | (A,B,I) | (UN) |
| BERT | 53.02 | 44.38 | 16.75 | 22.59 |
| RoBERTa | 28.66 | 25.86 | 00.00 | 23.38 |
| MentalBERT | 51.75 | 50.02 | 28.84 | 35.16 |
| MentalRoBERTa | 36.04 | 30.92 | 00.00 | 21.75 |
| Ours (EWP1-EmoLex) | 73.07 | 70.79 | 43.82 | 72.71 |
| Ours (EWP1-TEC) | 72.34 | 69.79 | 41.54 | 72.09 |
| Ours (EWP1-SenticNet) | 70.07 | 67.41 | 37.86 | 71.14 |
| Depression | Acc | F1w | (D) | (ND) |
| BERT | 73.59 | 62.40 | 00.00 | 84.79 |
| RoBERTa | 73.59 | 62.40 | 00.00 | 84.79 |
| MentalBERT | 73.59 | 62.40 | 00.00 | 84.79 |
| MentalRoBERTa | 73.59 | 62.40 | 00.00 | 84.79 |
| Ours (EWP2-EmoLex) | 77.56 | 76.61 | 52.31 | 85.33 |
| Ours (EWP2-TEC) | 77.64 | 76.61 | 49.40 | 85.61 |
| Ours (EWP2-SenticNet) | 78.16 | 76.20 | 48.51 | 86.13 |
| Dataset (Lexicon) | EW1 | EW2 | EWP1 | EWP2 | ||||
|---|---|---|---|---|---|---|---|---|
| Acc | F1w | Acc | F1w | Acc | F1w | Acc | F1w | |
| TwitSuicide (TEC) | 69.24 | 67.01 | 71.86 | 71.03 | 67.52 | 64.81 | 68.09 | 65.73 |
| CSSRS (EmoLex) | 70.30 | 66.99 | 72.33 | 69.81 | 73.07 | 70.79 | 72.59 | 70.28 |
| Depression (SenticNet) | 76.06 | 66.46 | 77.45 | 66.22 | 77.27 | 68.83 | 78.16 | 76.20 |
| Dataset | Setup | Lexicon | Embedding | Acc | F1w |
|---|---|---|---|---|---|
| TwitSuicide | EW2 | TEC | BERT | 71.86 | 71.03 |
| MentalBERT | 70.55 | 69.44 | |||
| CSSRS | EWP1 | EmoLex | BERT | 73.07 | 70.79 |
| MentalBERT | 72.02 | 69.47 | |||
| Depression | EWP2 | SenticNet | BERT | 78.16 | 76.20 |
| MentalBERT | 77.48 | 76.20 |
| Example | Actual | Ours | BERT | MentalBERT |
|---|---|---|---|---|
| TwitSuicide | ||||
| i’m SO fucking tired i want to die. *** adrenal exhaustion *** since surgery, I have not been well *** | SC | SC | PC | PC |
| *** tired, *** foot hurts *** do not want to be here | PC | PC | SC | SC |
| *** victim of a failed suicide attempt *** I dont wet-shave my neck. Ouch | SI | SI | PC | SC |
| CSSRS | ||||
| Aannnnnnnd I failed… again. *** pills *** stomach Muscle cramp and Common cold chills… | AT | AT | SU | IN |
| *** VA hospital for three months *** awesome. | BE | BE | SU | BE |
| I know what you mean. I think about blowing my brains *** the immensely sweet relief *** constant Anxiety and Fear no longer exist. All of my issues will disappear, and thats all that matters. Why is suicide bad, again? *** why should I continue? *** | ID | ID | SU | SU |
| *** Im still sad that I had to go trough my life, sometimes bit angry to fate, *** nothing to show of my life. *** no longer bitter and *** that I was/am bad and deserved this. *** | IN | IN | SU | ID |
| *** you didnt study the right way:) Things change *** so dont give up! I thought I wouldnt make it *** but then I changed majors *** | SU | SU | IN | UN |
| *** dressed in some of my finer casual *** made myself some coffee. *** today is better *** | UN | UN | SU | AT |
| Depression | ||||
| *** scares get re opened *** pooring salt in them. I hate this feeling. *** pain im in again | D | D | ND | ND |
| *** so revolting, yet so irresistible *** I must have it | ND | ND | ND | ND |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cabral, R.C.; Han, S.C.; Poon, J.; Nenadic, G. MM-EMOG: Multi-Label Emotion Graph Representation for Mental Health Classification on Social Media. Robotics 2024, 13, 53. https://doi.org/10.3390/robotics13030053
Cabral RC, Han SC, Poon J, Nenadic G. MM-EMOG: Multi-Label Emotion Graph Representation for Mental Health Classification on Social Media. Robotics. 2024; 13(3):53. https://doi.org/10.3390/robotics13030053
Chicago/Turabian StyleCabral, Rina Carines, Soyeon Caren Han, Josiah Poon, and Goran Nenadic. 2024. "MM-EMOG: Multi-Label Emotion Graph Representation for Mental Health Classification on Social Media" Robotics 13, no. 3: 53. https://doi.org/10.3390/robotics13030053
APA StyleCabral, R. C., Han, S. C., Poon, J., & Nenadic, G. (2024). MM-EMOG: Multi-Label Emotion Graph Representation for Mental Health Classification on Social Media. Robotics, 13(3), 53. https://doi.org/10.3390/robotics13030053