
Improved Visual SLAM Using Semantic Segmentation and Layout Estimation


Abstract
:1. Introduction
- Does the human brain perform SLAM?
- How does the human brain solve navigation tasks?
- What landmarks and semantic information could form human brain spatial maps?
- What is the brain spatial mapping process?
1.1. Human Navigation Strategies
1.2. Mapping and Navigation Tasks in the Human Brain
- The human brain builds short-term, high-resolution body-referenced visual maps (egocentric) to be used with the motor sensors’ motion predictions to solve the immediate navigational tasks; however, these maps fade with time and when navigating in large spaces (environmental spaces). These maps are the equivalent of the local maps that VO and VSLAM systems use in pose estimation.
- Alongside the egocentric maps, the human brain forms a more general representation that integrates visual and motor sensors over time, generating allocentric environmental models. The allocentric maps are referenced outside the human body to a distinct point or a landmark in the environment. This type of model is equivalent to the global maps in SLAM systems.
- Unlike SLAM systems in the literature, the human brain depends on the environment’s geometry and layout to recognise and map the visited places.
- The brain mainly tracks the surrounding objects for pose estimation. It does not depend on feature points unless they are essential for describing the space layout or belong to a distinct landmark. Alternatively, the brain abstracts all the background points into colour and shade information.
2. Related Work
2.1. Layout Estimation
2.2. Semantic SLAM
2.2.1. Semantics for Loop Closing
2.2.2. Semantics for Handling Dynamic Environments
2.2.3. Semantic Reasoning within an Unknown Environment
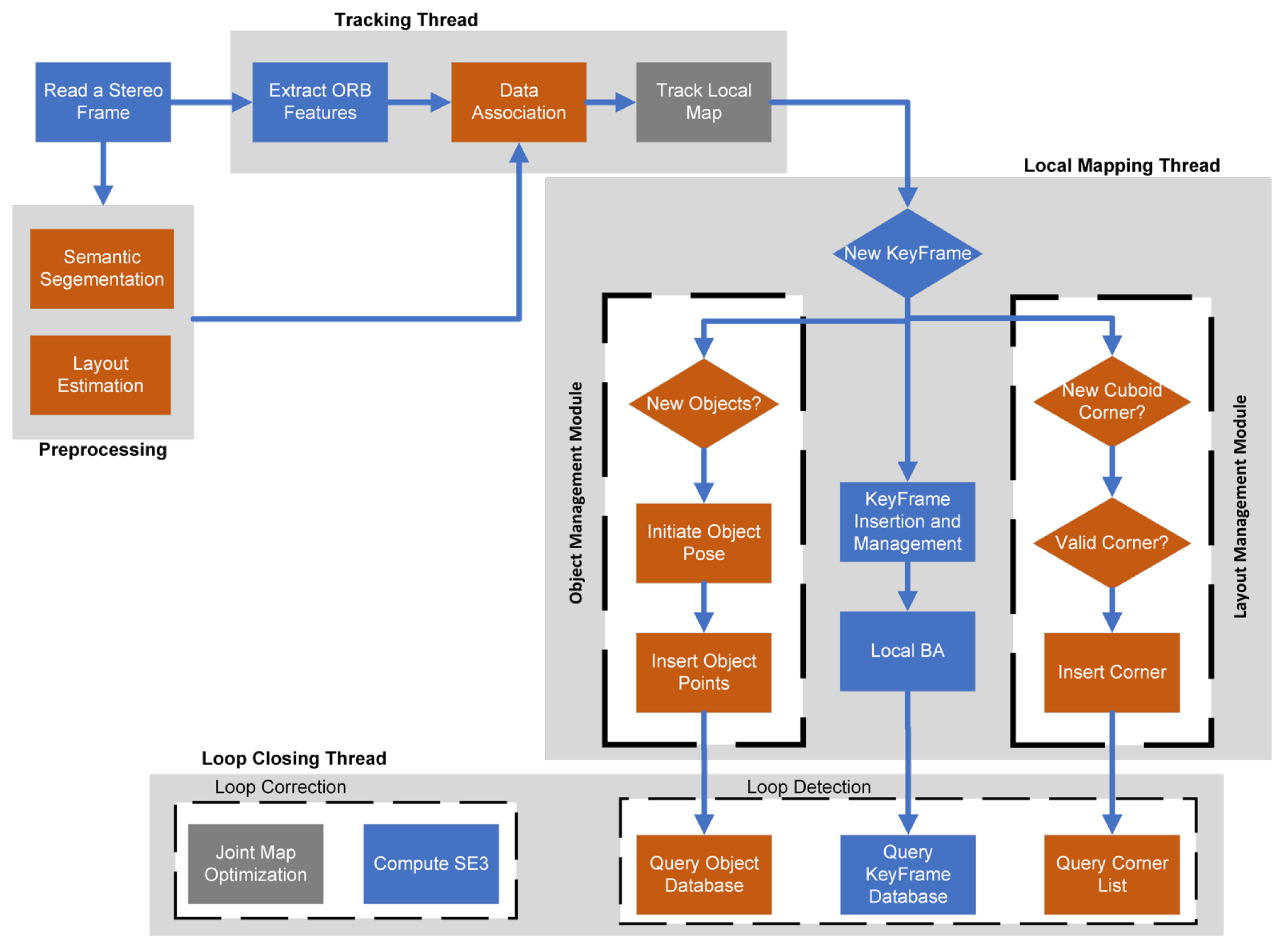
3. Proposed System
- A complete visual SLAM system tracks and maps geometric and semantic structures in indoor environments. The system was built on ORB-SLAM2 as its SLAM backbone and redesigned its threads to utilise semantic observations throughout the tracking, mapping and loop closing tasks.
- The system also uses an offline created object model database to provide a point of view independent object tracking and provide the physical relationship between the object points as a set of constraints that anchor the odometry positional drifts.
- Because background feature points are hard to precisely re-detect and match, the proposed system is configured to allow object points to be more influential in pose optimisations.
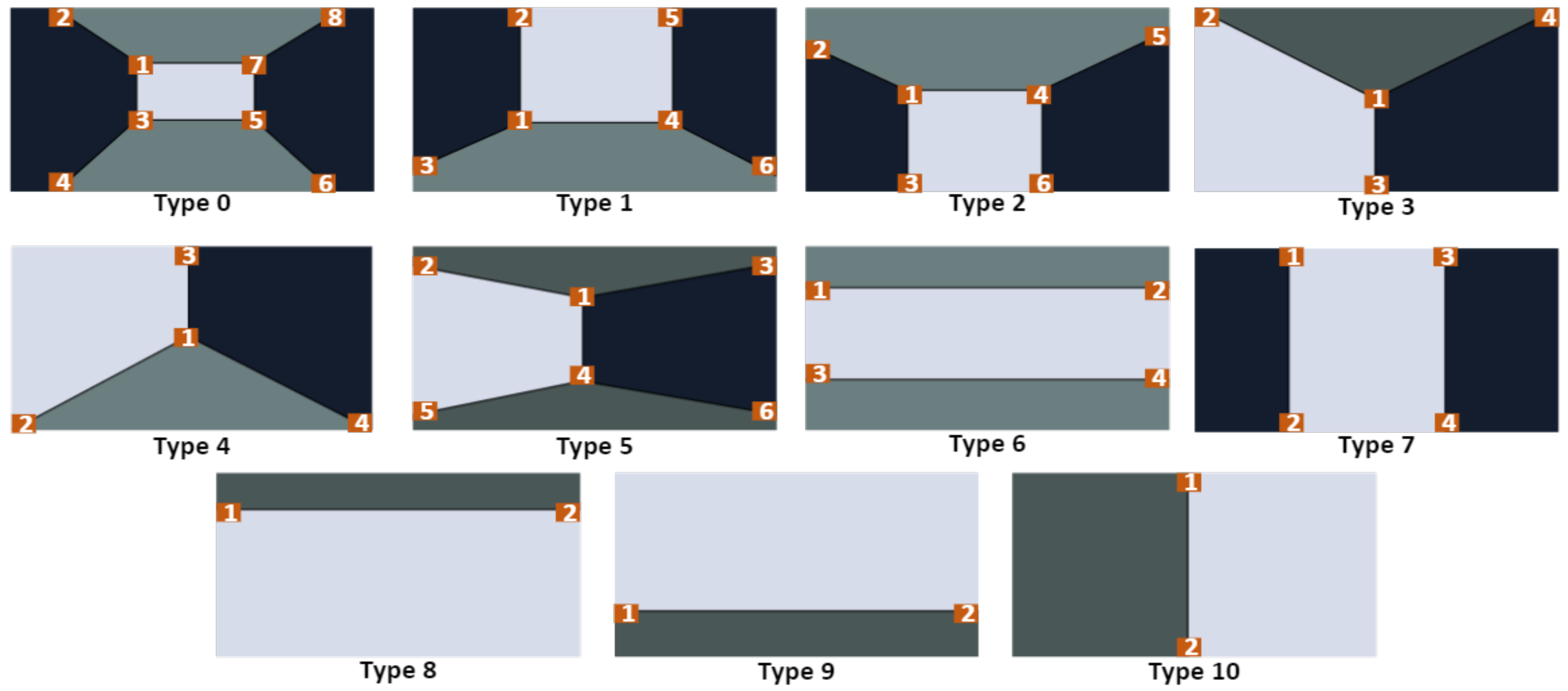
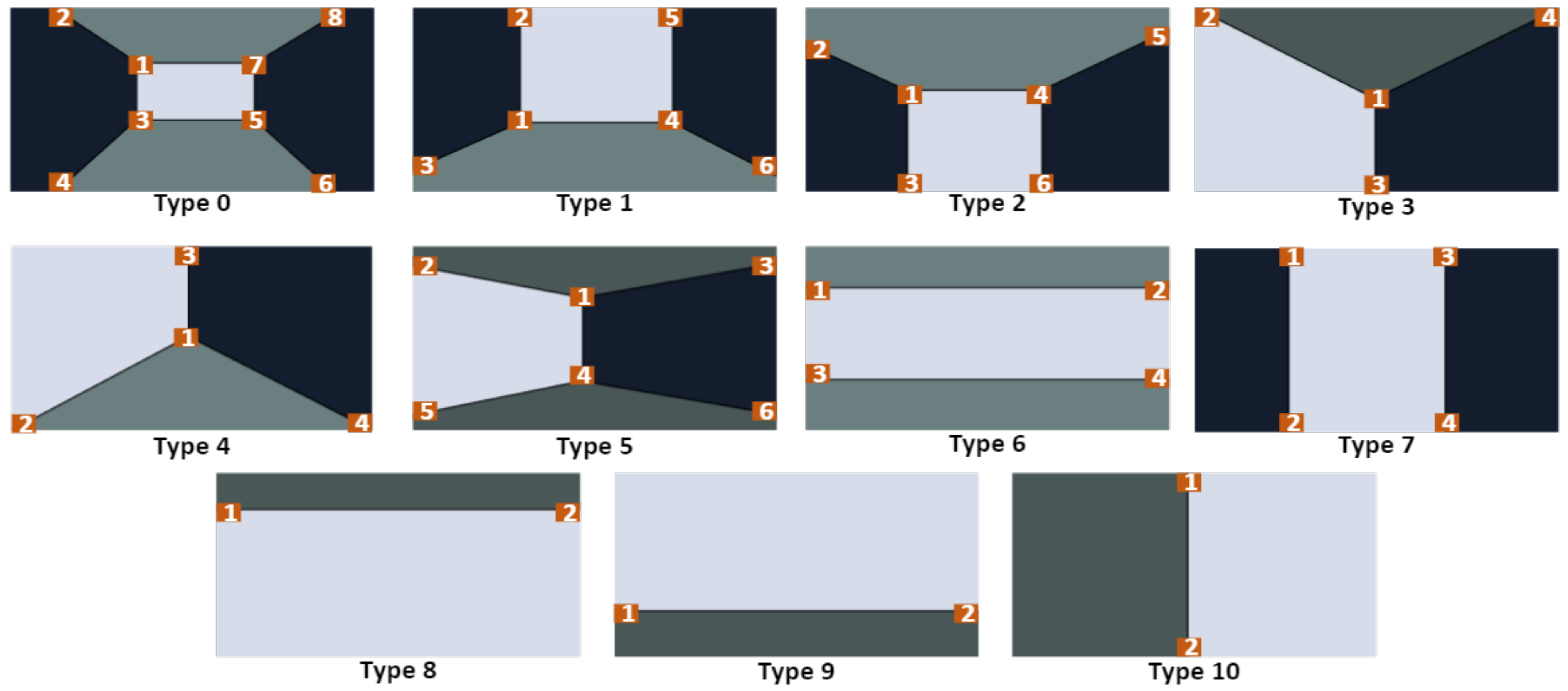
- With most of the images in the tracked sequences containing at least one cuboid corner, tracking and mapping threads are modified to detect and track cuboid corners and include them in the map optimisation process.
- The proposed system introduces the idea of slicing the map into multiple geometrical links. Each link represents keyframes connecting two environment corners and exploits the geometric relationship between these corners as map optimisation constraints.
- Two modifications are introduced to the loop closure thread: first, the local map is queried for objects and cuboid points to verify loop detections before accepting it. The second modification introduces a new loop closure approach by detecting all the cuboid corners of the traversed space. Four cuboid corners allow the system to optimise the four edges defining the space limits.
4. System Description
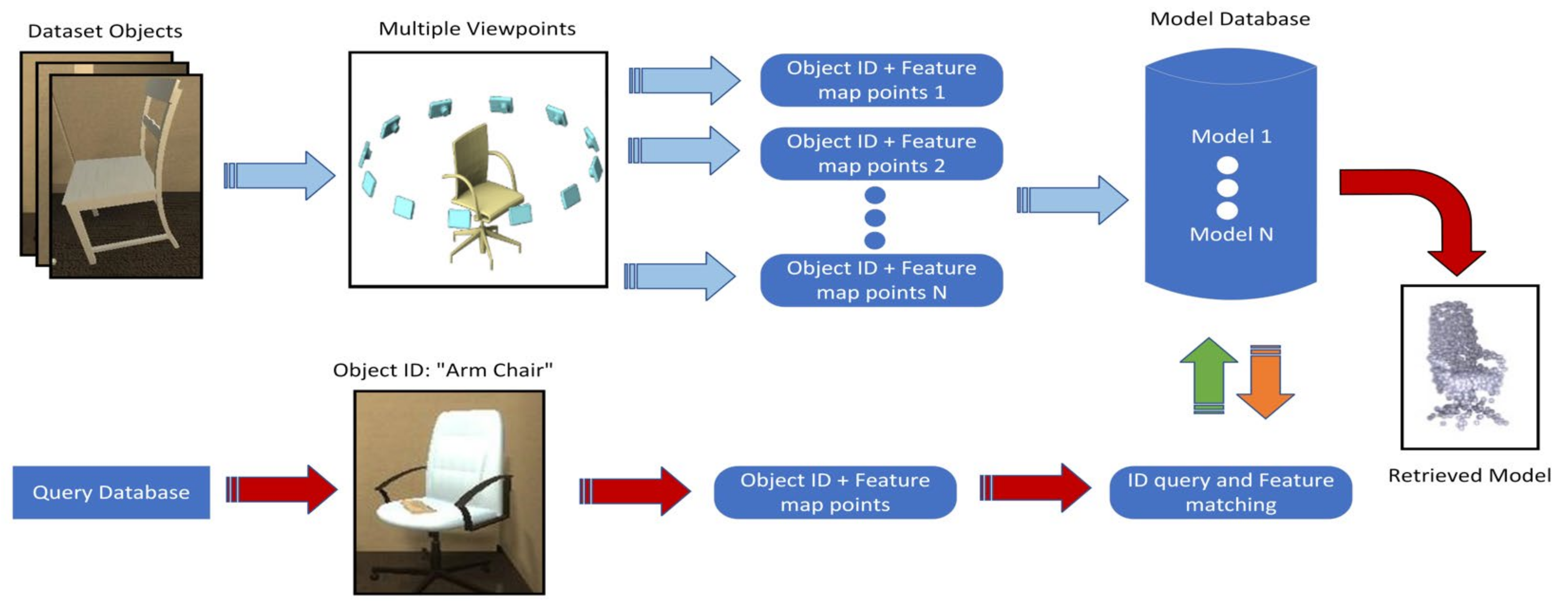
4.1. Object Model Database
4.2. Frame Preprocessing
4.3. System Threads
4.3.1. Tracking Thread
- After extracting ORB features from the current frame, all detected features are annotated using the semantic segmentation input data.
- The previous frame is searched for matches; the encoded semantic annotations guide the search, limiting the mismatches and the number of match candidates. An initial estimate of the pose is then optimised using the found correspondences.
- Once an initial pose is acquired and we have an initial set of matches, we project the local map points into the current frame; this includes observed feature points, object points, and layout corner points. If the point projection lies inside the image bounds and with a viewing angle less than 60° we search the still unmatched features in the current frame and associate the map point to the best match.
- Finally, the camera pose is optimised with motion-only bundle adjustment, a variant of the generic BA described in Chapter 2, where the camera pose in the world frame () is optimised to minimise the reprojection error between the 3D map points matched to the current frame’s 2D keypoints :
4.3.2. Local Mapping Thread
4.3.3. Loop Closure Thread
5. Experiments and Analysis
5.1. Test Data
5.2. Evaluation Metrics
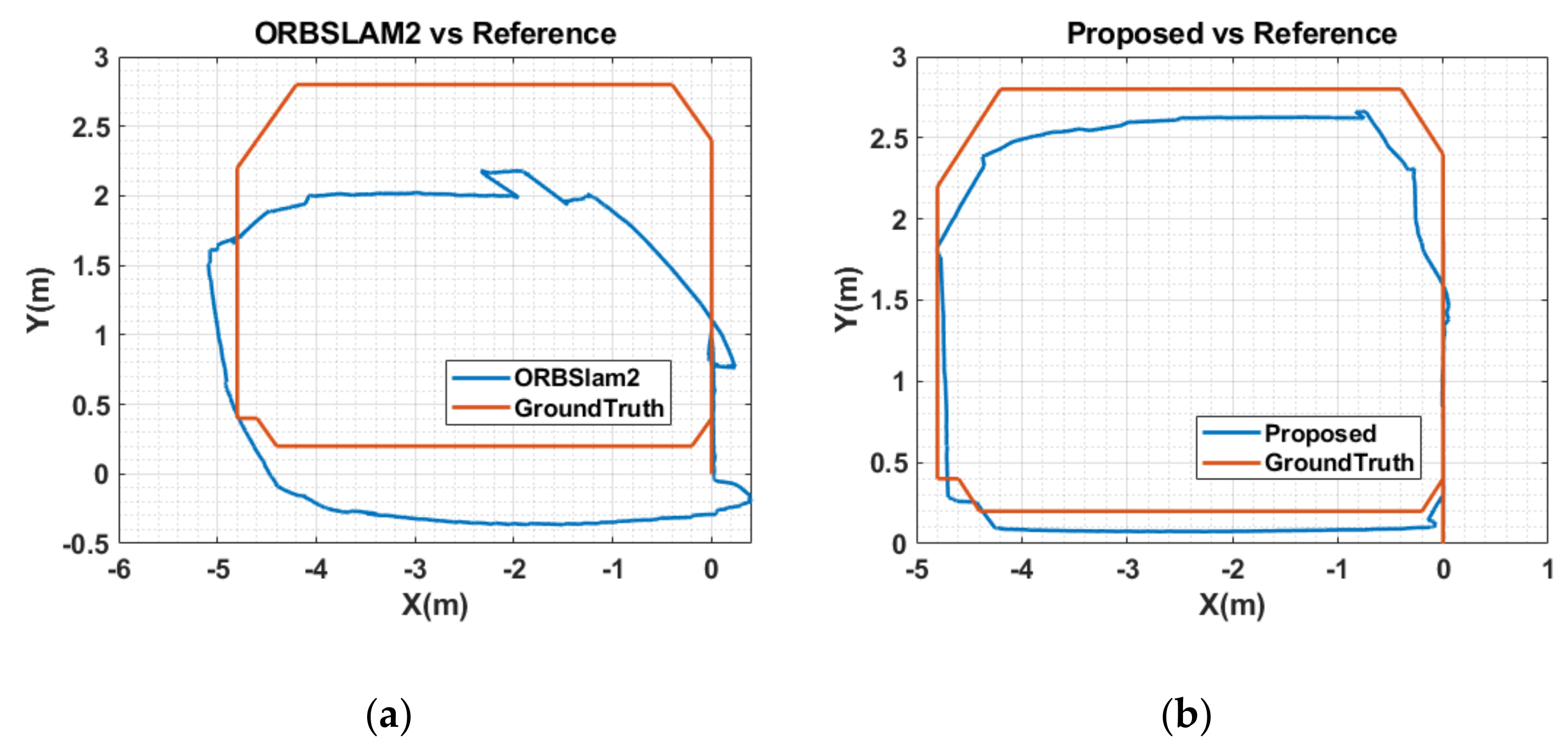
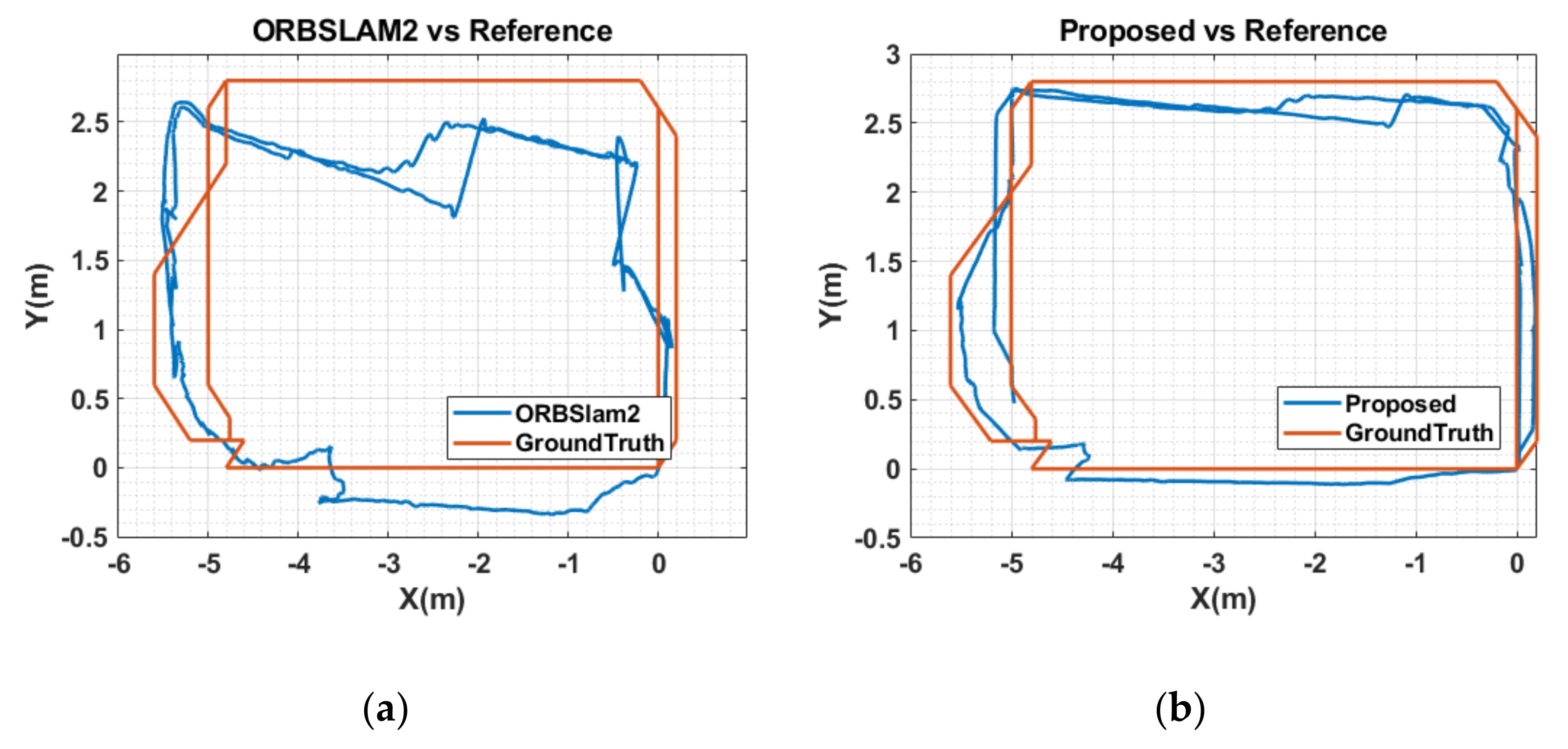
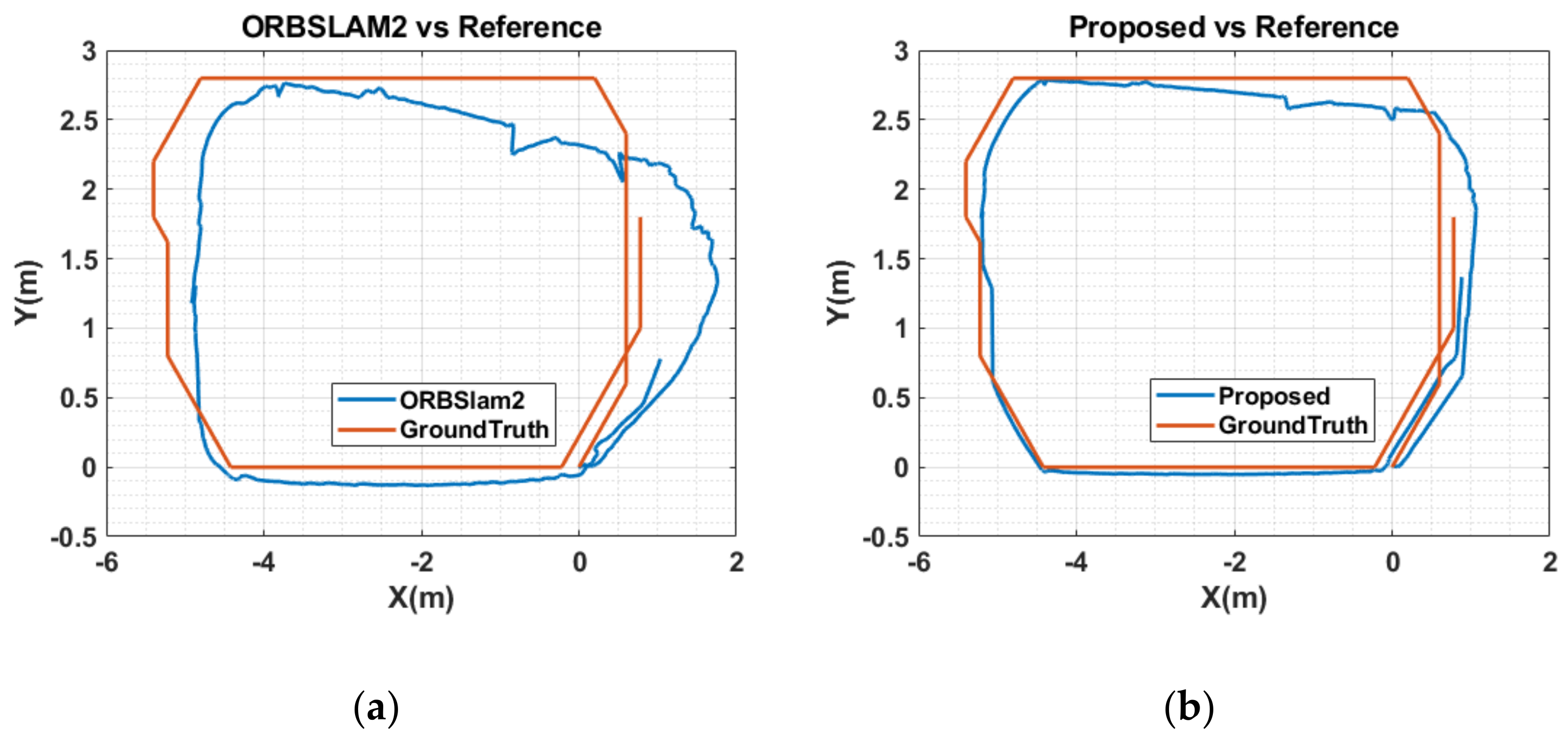
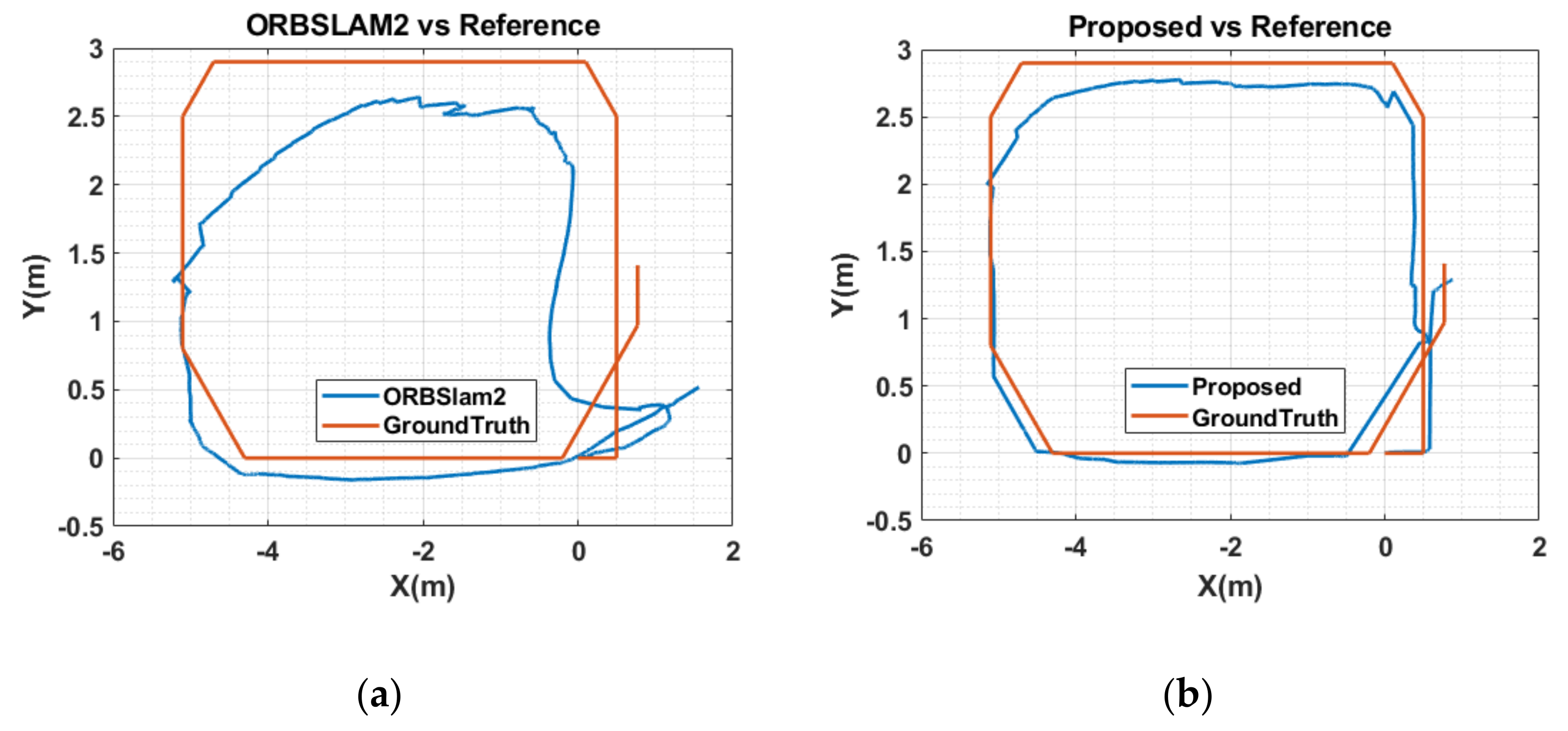
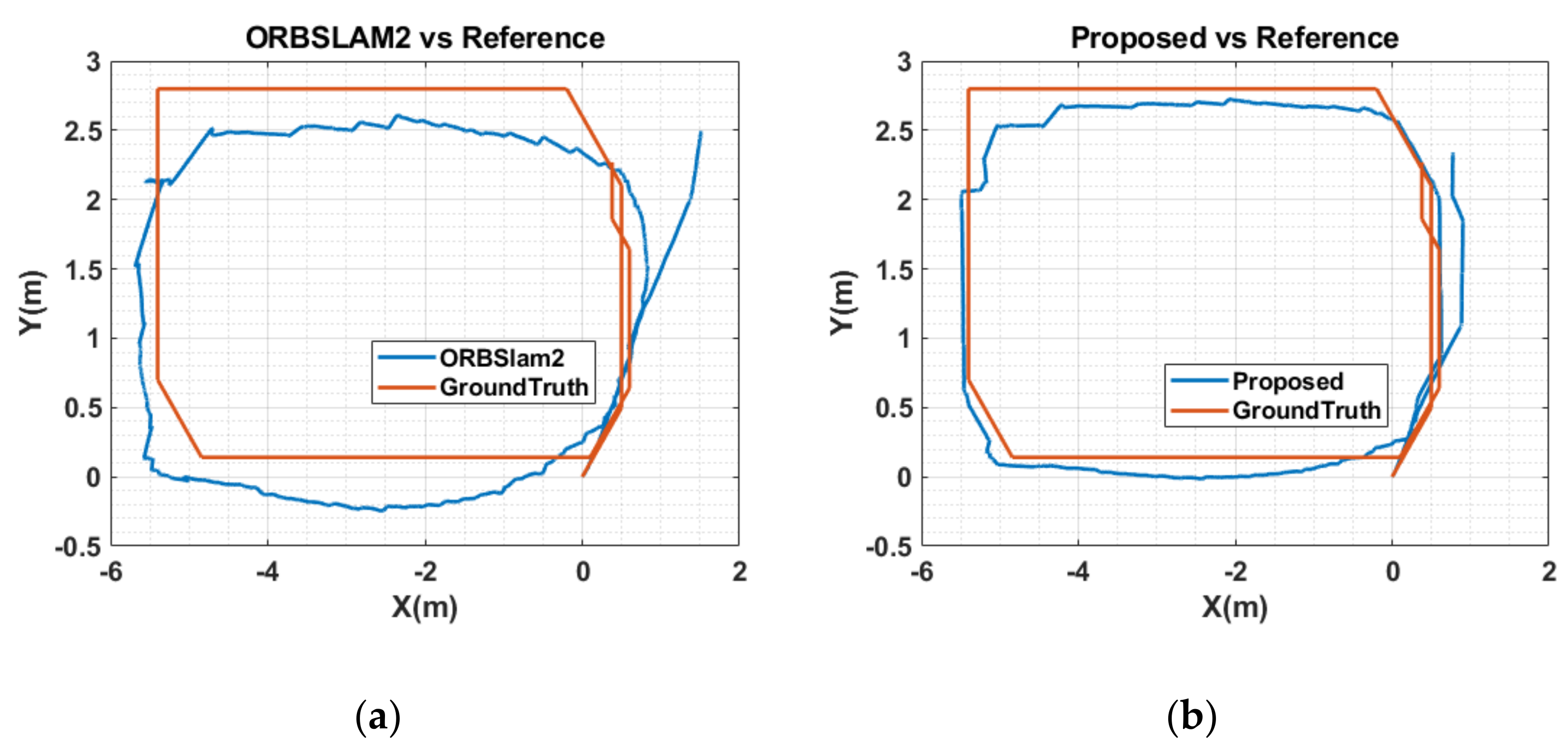
5.3. Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Herweg, N.A.; Kahana, M.J. Spatial Representations in the Human Brain. Front. Hum. Neurosci. 2018, 12, 297. [Google Scholar] [CrossRef] [PubMed]
- Ekstrom, A.D. Why vision is important to how we navigate. Hippocampus 2015, 25, 731–735. [Google Scholar] [CrossRef] [PubMed]
- Widrow, B.; Aragon, J.C. Cognitive memory. Neural Netw. 2013, 41, 3–14. [Google Scholar] [CrossRef] [PubMed]
- Ekstrom, A.D.; Isham, E.A. Human spatial navigation: Representations across dimensions and scales. Curr. Opin. Behav. Sci. 2017, 17, 84–89. [Google Scholar] [CrossRef]
- Burgess, N.; Recce, M.; O’Keefe, J. A model of hippocampal function. Neural Netw. 1994, 7, 1065–1081. [Google Scholar] [CrossRef]
- Fyhn, M. Spatial Representation in the Entorhinal Cortex. Science 2004, 305, 1258–1264. [Google Scholar] [CrossRef]
- Sargolini, F.; Fyhn, M.; Hafting, T.; McNaughton, B.L.; Witter, M.P.; Moser, M.-B.; Moser, E.I. Conjunctive Representation of Position, Direction, and Velocity in Entorhinal Cortex. Science 2006, 312, 758–762. [Google Scholar] [CrossRef]
- Morris, R.G.M.; Garrud, P.; Rawlins, J.N.P.; O’Keefe, J. Place navigation impaired in rats with hippocampal lesions. Nature 1982, 297, 681–683. [Google Scholar] [CrossRef]
- Burgess, N.; Jackson, A.; Hartley, T.; O’Keefe, J. Predictions derived from modelling the hippocampal role in navigation. Biol. Cybern. 2000, 83, 301–312. [Google Scholar] [CrossRef]
- Maguire, E.A.; Burgess, N.; O’Keefe, J. Human spatial navigation: Cognitive maps, sexual dimorphism, and neural substrates. Curr. Opin. Neurobiol. 1999, 9, 171–177. [Google Scholar] [CrossRef]
- Ishikawa, T.; Montello, D. Spatial knowledge acquisition from direct experience in the environment: Individual differences in the development of metric knowledge and the integration of separately learned places. Cognit. Psychol. 2006, 52, 93–129. [Google Scholar] [CrossRef]
- Török, Á.; Peter Nguyen, T.; Kolozsvári, O.; Buchanan, R.J.; Nadasdy, Z. Reference frames in virtual spatial navigation are viewpoint dependent. Front. Hum. Neurosci. 2014, 8, 646. [Google Scholar]
- Gramann, K.; Müller, H.J.; Eick, E.-M.; Schönebeck, B. Evidence of Separable Spatial Representations in a Virtual Navigation Task. J. Exp. Psychol. Hum. Percept. Perform. 2005, 31, 1199–1223. [Google Scholar] [CrossRef]
- Li, X.; Mou, W.; McNamara, T.P. Retrieving enduring spatial representations after disorientation. Cognition 2012, 124, 143–155. [Google Scholar] [CrossRef]
- Siegel, A.W.; White, S.H. The Development of Spatial Representations of Large-Scale Environments. In Advances in Child Development and Behavior; Elsevier: Amsterdam, The Netherlands, 1975; Volume 10, pp. 9–55. ISBN 978-0-12-009710-4. [Google Scholar]
- Tolman, E.C. Cognitive maps in rats and men. Psychol. Rev. 1948, 55, 189–208. [Google Scholar] [CrossRef]
- McNaughton, B.L.; Chen, L.L.; Markus, E.J. “Dead Reckoning,” Landmark Learning, and the Sense of Direction: A Neurophysiological and Computational Hypothesis. J. Cogn. Neurosci. 1991, 3, 190–202. [Google Scholar] [CrossRef]
- Worsley, C. Path integration following temporal lobectomy in humans. Neuropsychologia 2001, 39, 452–464. [Google Scholar] [CrossRef]
- Appleyard, D. Styles and methods of structuring a city. Environ. Behav. 1970, 2, 100–117. [Google Scholar] [CrossRef]
- Chapman, E.H.; Lynch, K. The Image of the City. J. Aesthet. Art Crit. 1962, 21, 91. [Google Scholar] [CrossRef]
- Zhang, H.; Zherdeva, K.; Ekstrom, A.D. Different “routes” to a cognitive map: Dissociable forms of spatial knowledge derived from route and cartographic map learning. Mem. Cognit. 2014, 42, 1106–1117. [Google Scholar] [CrossRef]
- Ekstrom, A.D.; Arnold, A.E.G.F.; Iaria, G. A critical review of the allocentric spatial representation and its neural underpinnings: Toward a network-based perspective. Front. Hum. Neurosci. 2014, 8, 803. [Google Scholar] [CrossRef] [Green Version]
- Thorndyke, P.W.; Hayes-Roth, B. Differences in spatial knowledge acquired from maps and navigation. Cognit. Psychol. 1982, 14, 560–589. [Google Scholar] [CrossRef]
- Rieser, J.J. Access to Knowledge of Spatial Structure at Novel Points of Observation. J. Exp. Psychol. Learn. Mem. Cogn. 1989, 15, 1157. [Google Scholar] [CrossRef]
- Shelton, A.L.; McNamara, T.P. Systems of Spatial Reference in Human Memory. Cognit. Psychol. 2001, 43, 274–310. [Google Scholar] [CrossRef]
- Waller, D.; Hodgson, E. Transient and enduring spatial representations under disorientation and self-rotation. J. Exp. Psychol. Learn. Mem. Cogn. 2006, 32, 867. [Google Scholar] [CrossRef]
- O’keefe, J.; Nadel, L. Précis of O’Keefe & Nadel’s The hippocampus as a cognitive map. Behav. Brain Sci. 1979, 2, 487–494. [Google Scholar]
- Klatzky, R.L. Allocentric and Egocentric Spatial Representations: Definitions, Distinctions, and Interconnections; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Richard, L.; Waller, D. Toward a definition of intrinsic axes: The effect of orthogonality and symmetry on the preferred direction of spatial memory. J. Exp. Psychol. Learn. Mem. Cogn. 2013, 39, 1914–1929. [Google Scholar] [CrossRef]
- McNamara, T.P.; Rump, B.; Werner, S. Egocentric and geocentric frames of reference in memory of large-scale space. Psychon. Bull. Rev. 2003, 10, 589–595. [Google Scholar] [CrossRef]
- Mou, W.; Zhao, M.; McNamara, T.P. Layout geometry in the selection of intrinsic frames of reference from multiple viewpoints. J. Exp. Psychol. Learn. Mem. Cogn. 2007, 33, 145–154. [Google Scholar] [CrossRef]
- Chan, E.; Baumann, O.; Bellgrove, M.A.; Mattingley, J.B. Reference frames in allocentric representations are invariant across static and active encoding. Front. Psychol. 2013, 4, 565. [Google Scholar] [CrossRef]
- Frankenstein, J.; Mohler, B.J.; Bülthoff, H.H.; Meilinger, T. Is the map in our head oriented north? Psychol. Sci. 2012, 23, 120–125. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.F.; Spelke, E.S. Updating egocentric representations in human navigation. Cognition 2000, 77, 215–250. [Google Scholar] [CrossRef]
- Diwadkar, V.A.; McNamara, T.P. Viewpoint dependence in scene recognition. Psychol. Sci. 1997, 8, 302–307. [Google Scholar] [CrossRef]
- Holmes, C.A.; Marchette, S.A.; Newcombe, N.S. Multiple views of space: Continuous visual flow enhances small-scale spatial learning. J. Exp. Psychol. Learn. Mem. Cogn. 2017, 43, 851. [Google Scholar] [CrossRef]
- Mittelstaedt, M.L.; Mittelstaedt, H. Homing by path integration in a mammal. Naturwissenschaften 1980, 67, 566–567. [Google Scholar] [CrossRef]
- Souman, J.L.; Frissen, I.; Sreenivasa, M.N.; Ernst, M.O. Walking Straight into Circles. Curr. Biol. 2009, 19, 1538–1542. [Google Scholar] [CrossRef]
- Morris, R.G.M.; Hagan, J.J.; Rawlins, J.N.P. Allocentric Spatial Learning by Hippocampectomised Rats: A Further Test of the “Spatial Mapping” and “Working Memory” Theories of Hippocampal Function. Q. J. Exp. Psychol. Sect. B 1986, 38, 365–395. [Google Scholar]
- Waller, D.; Lippa, Y. Landmarks as beacons and associative cues: Their role in route learning. Mem. Cognit. 2007, 35, 910–924. [Google Scholar] [CrossRef]
- Packard, M.G.; Hirsh, R.; White, N.M. Differential effects of fornix and caudate nucleus lesions on two radial maze tasks: Evidence for multiple memory systems. J. Neurosci. 1989, 9, 1465–1472. [Google Scholar] [CrossRef]
- Packard, M.G.; Knowlton, B.J. Learning and memory functions of the basal ganglia. Annu. Rev. Neurosci. 2002, 25, 563–593. [Google Scholar] [CrossRef]
- White, N.M.; McDonald, R.J. Multiple parallel memory systems in the brain of the rat. Neurobiol. Learn. Mem. 2002, 77, 125–184. [Google Scholar] [CrossRef]
- Dasgupta, S.; Fang, K.; Chen, K.; Savarese, S. DeLay: Robust Spatial Layout Estimation for Cluttered Indoor Scenes. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 616–624. [Google Scholar]
- Mathew, B.P.; Dharan, S. Review on Room Layout Estimation from a Single Image. Int. J. Eng. Res. 2020, 9, 1068–1073. [Google Scholar]
- Mohan, N.; Kumar, M. Room layout estimation in indoor environment: A review. Multimed. Tools Appl. 2022, 81, 1921–1951. [Google Scholar] [CrossRef]
- Lee, C.-Y.; Badrinarayanan, V.; Malisiewicz, T.; Rabinovich, A. RoomNet: End-to-End Room Layout Estimation. arXiv 2017, arXiv:1703.06241. [Google Scholar]
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop 2016. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Coughlan, J.M.; Yuille, A.L. The manhattan world assumption: Regularities in scene statistics which enable Bayesian inference. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 9–11 May 2001. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human pose estimation with iterative error feedback. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Pfister, T.; Charles, J.; Zisserman, A. Flowing ConvNets for Human Pose Estimation in Videos 2015. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Tompson, J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. In Proceedings of the Advances in Neural Information Processing Systems, Bangkok, Thailand, 18–20 November 2014; Volume 2. [Google Scholar]
- Wu, J.; Xue, T.; Lim, J.J.; Tian, Y.; Tenenbaum, J.B.; Torralba, A.; Freeman, W.T. Single image 3D interpreter network. In Proceedings of the European Conference on Computer Vision (ECCV), Amesterdam, The Netherlands, 8–16 October 2016; Volume 9910 LNCS. [Google Scholar]
- Sualeh, M.; Kim, G.W. Simultaneous Localization and Mapping in the Epoch of Semantics: A Survey. Int. J. Control Autom. Syst. 2019, 17, 729–742. [Google Scholar] [CrossRef]
- Bowman, S.L.; Atanasov, N.; Daniilidis, K.; Pappas, G.J. Probabilistic data association for semantic SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017. [Google Scholar]
- Schonberger, J.L.; Pollefeys, M.; Geiger, A.; Sattler, T. Semantic Visual Localization. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Gaalvez-Lopez, D.; Juan, D.T. Bags of Binary Words for Fast Place Recognition in Image Sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Kaneko, M.; Iwami, K.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Mask-SLAM: Robust feature-based monocular SLAM by masking using semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.-J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: Madrid, Spain, 2018; pp. 1168–1174. [Google Scholar]
- Li, S.; Li, G.; Wang, L.; Qin, Y. SLAM integrated mobile mapping system in complex urban environments. ISPRS J. Photogramm. Remote Sens. 2020, 166, 316–332. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, S. SaD-SLAM: A Visual SLAM Based on Semantic and Depth Information. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; IEEE: Las Vegas, NV, USA, 2020; pp. 4930–4935. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Y.; Wang, C.; Wang, W.; Henein, M.; Scherer, S. AirDOS: Dynamic SLAM benefits from Articulated Objects. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Philadelphia, PA, USA, 2022; pp. 8047–8053. [Google Scholar]
- Casser, V.; Pirk, S.; Mahjourian, R.; Angelova, A. Depth prediction without the sensors: Leveraging structure for unsupervised learning from monocular videos. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Nicholson, L.; Milford, M.; Sunderhauf, N. QuadricSLAM: Dual quadrics from object detections as landmarks in object-oriented SLAM. IEEE Robot. Autom. Lett. 2019, 4, 1–8. [Google Scholar] [CrossRef]
- Hosseinzadeh, M.; Latif, Y.; Pham, T.; Suenderhauf, N.; Reid, I. Structure Aware SLAM Using Quadrics and Planes. In Proceedings of the 14th Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2018; Volume 11363 LNCS. [Google Scholar]
- Runz, M.; Buffier, M.; Agapito, L. MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality, ISMAR 2018, Munich, Germany, 16–20 October 2018. [Google Scholar]
- McCormac, J.; Clark, R.; Bloesch, M.; Davison, A.; Leutenegger, S. Fusion++: Volumetric object-level SLAM. In Proceedings of the 2018 International Conference on 3D Vision, 3DV 2018, Verona, Italy, 5–8 September 2018. [Google Scholar]
- Wang, Y.; Zell, A. Improving Feature-based Visual SLAM by Semantics. In Proceedings of the IEEE 3rd International Conference on Image Processing, Applications and Systems, IPAS 2018, Sophia Antipolis, France, 12–14 December 2018. [Google Scholar]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016-December. [Google Scholar]
- Deitke, M.; Han, W.; Herrasti, A.; Kembhavi, A.; Kolve, E.; Mottaghi, R.; Salvador, J.; Schwenk, D.; VanderBilt, E.; Wallingford, M.; et al. RoboTHOR: An Open Simulation-to-Real Embodied AI Platform. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 3161–3171. [Google Scholar]
- Ehsani, K.; Han, W.; Herrasti, A.; VanderBilt, E.; Weihs, L.; Kolve, E.; Kembhavi, A.; Mottaghi, R. ManipulaTHOR: A Framework for Visual Object Manipulation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Nashville, TN, USA, 2021; pp. 4495–4504. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequences | ORB-SLAM2 | Proposed | Improvements | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | |
| Floor10_1 | 4.299 | 3.472 | 3.662 | 2.537 | 2.567 | 2.086 | 2.208 | 1.496 | 40.29% | 39.92% | 39.71% | 41.01% |
| Floor10_2 | 1.501 | 1.246 | 1.367 | 0.839 | 0.753 | 0.609 | 0.630 | 0.443 | 49.86% | 51.11% | 53.89% | 47.21% |
| Floor10_3 | 1.395 | 0.936 | 0.728 | 1.035 | 0.798 | 0.648 | 0.639 | 0.467 | 75.88% | 24.94% | 53.66% | 62.66% |
| Floor10_4 | 3.604 | 2.570 | 1.493 | 2.528 | 2.107 | 1.533 | 0.979 | 1.446 | 41.55% | 40.37% | 34.41% | 42.79% |
| Floor10_5 | 3.699 | 3.231 | 3.092 | 1.799 | 2.431 | 2.126 | 2.128 | 1.179 | 34.27% | 34.20% | 31.19% | 34.48% |
| Sequences | ORB-SLAM2 | Proposed | Improvements | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | |
| Floor10_1 | 0.0036 | 0.095 | 0.064 | 0.164 | 0.0004 | 0.032 | 0.020 | 0.058 | 87.77% | 68.55% | 66.28% | 64.62% |
| Floor10_2 | 0.0035 | 0.153 | 0.144 | 0.109 | 0.0009 | 0.063 | 0.038 | 0.072 | 73.79% | 58.52% | 73.42% | 33.74% |
| Floor10_3 | 0.0014 | 0.058 | 0.035 | 0.103 | 0.0003 | 0.043 | 0.016 | 0.038 | 75.88% | 24.94% | 53.66% | 62.66% |
| Floor10_4 | 0.0038 | 0.105 | 0.076 | 0.165 | 0.0016 | 0.098 | 0.075 | 0.083 | 56.89% | 7.193% | 1.594% | 49.48% |
| Floor10_5 | 0.0004 | 0.045 | 0.030 | 0.047 | 0.0003 | 0.041 | 0.012 | 0.045 | 11.26% | 7.752% | 60.60% | 4.074% |
| Sequences | ORB-SLAM2 | Proposed | Improvements | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | RMSE | MEAN | Median | S.D. | |
| Floor10_1 | 0.696 | 0.552 | 0.504 | 0.424 | 0.23 | 0.181 | 0.158 | 0.142 | 66.96% | 67.25% | 68.66% | 66.47% |
| Floor10_2 | 0.367 | 0.334 | 0.353 | 0.152 | 0.15 | 0.138 | 0.145 | 0.061 | 58.97% | 58.74% | 58.92% | 60.08% |
| Floor10_3 | 1.170 | 0.188 | 0.157 | 1.156 | 0.36 | 0.013 | 0.079 | 0.359 | 69.36% | 92.96% | 49.72% | 68.98% |
| Floor10_4 | 0.752 | 0.655 | 0.643 | 0.369 | 0.15 | 0.132 | 0.130 | 0.075 | 79.83% | 79.85% | 79.79% | 79.76% |
| Floor10_5 | 0.717 | 0.514 | 0.478 | 0.499 | 0.261 | 0.176 | 0.162 | 0.193 | 63.53% | 65.77% | 66.11% | 61.29% |
| RGB-D | Stereo | |
|---|---|---|
| ORB-SLAM2 | 23 fps | 10 fps |
| Proposed | 17 fps | 8 fps |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmoud, A.; Atia, M. Improved Visual SLAM Using Semantic Segmentation and Layout Estimation. Robotics 2022, 11, 91. https://doi.org/10.3390/robotics11050091
Mahmoud A, Atia M. Improved Visual SLAM Using Semantic Segmentation and Layout Estimation. Robotics. 2022; 11(5):91. https://doi.org/10.3390/robotics11050091
Chicago/Turabian StyleMahmoud, Ahmed, and Mohamed Atia. 2022. "Improved Visual SLAM Using Semantic Segmentation and Layout Estimation" Robotics 11, no. 5: 91. https://doi.org/10.3390/robotics11050091
APA StyleMahmoud, A., & Atia, M. (2022). Improved Visual SLAM Using Semantic Segmentation and Layout Estimation. Robotics, 11(5), 91. https://doi.org/10.3390/robotics11050091