
Shelf Replenishment Based on Object Arrangement Detection and Collapse Prediction for Bimanual Manipulation

 ,
,  , , ,
, , ,  and
and 
Abstract
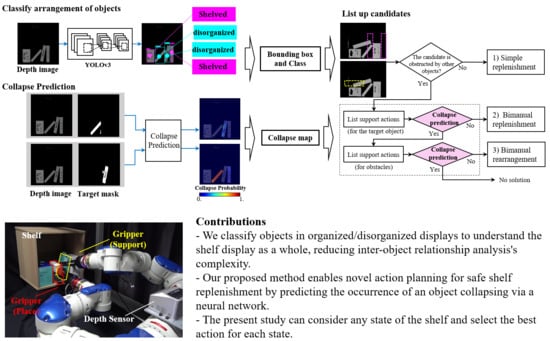
1. Introduction
- We classify objects in organized/disorganized displays to understand the shelf display as a whole, which reduces the complexity of inter-object relationship analysis and allows the manipulation of a group of objects as a unit instead of single objects.
- Our method enables novel action planning with a bimanual robot for shelf replenishment by predicting the occurrence of an object collapsing via a neural network. In particular, our method can consider any state of the shelf, and select the best action for each state, including single-arm or bimanual manipulation.
2. Materials and Methods
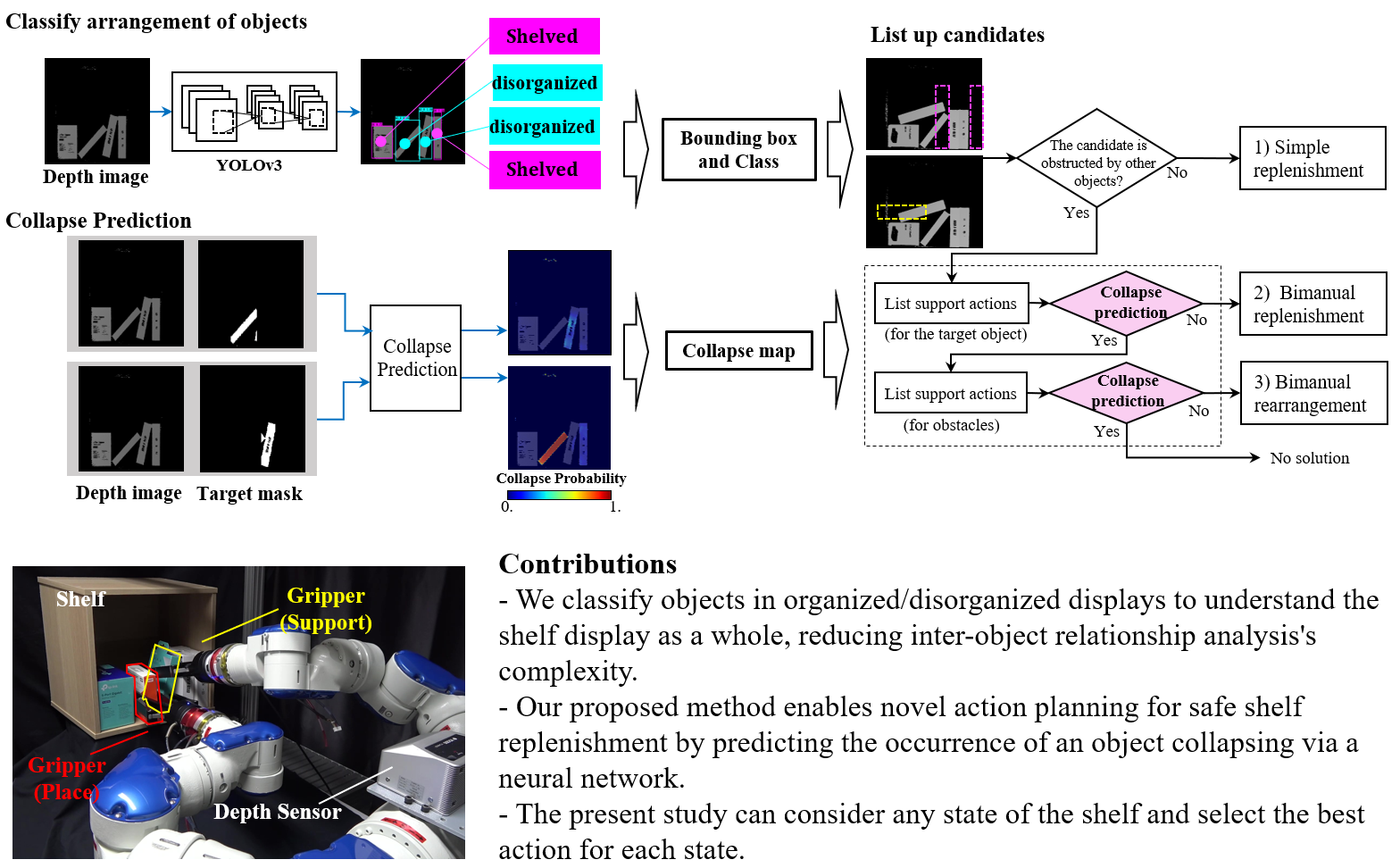
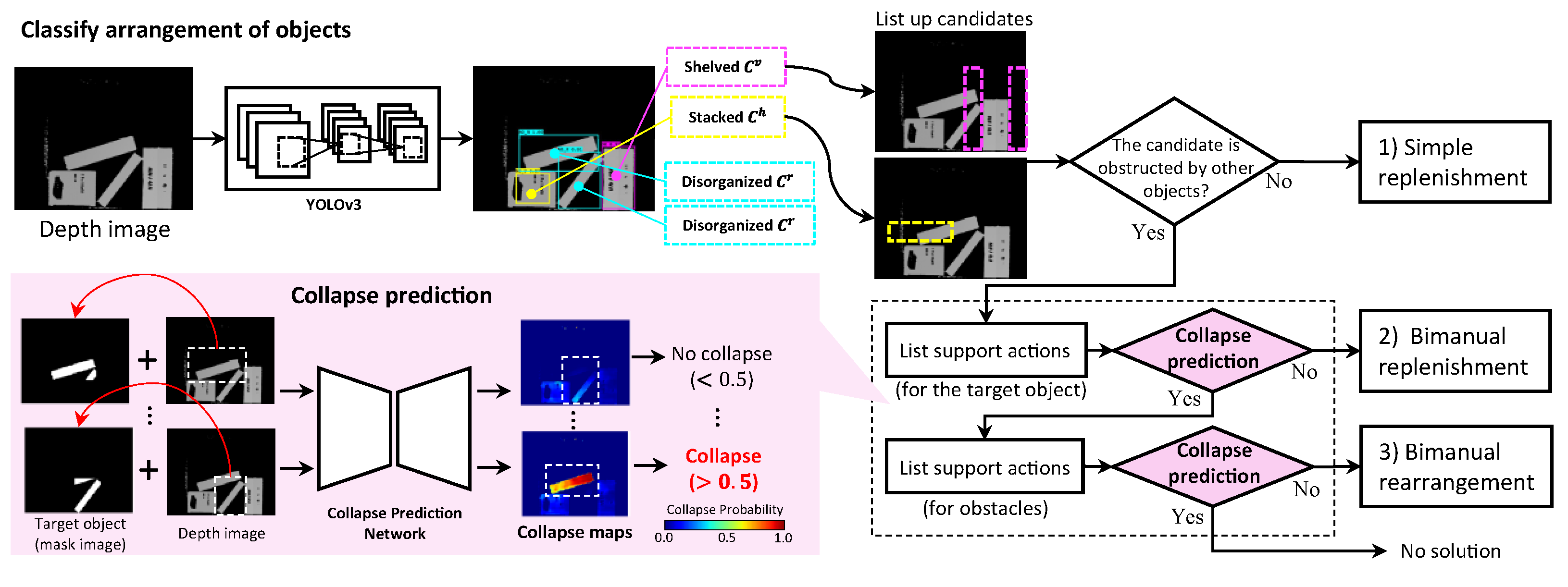
2.1. Objects Arrangement Classification
2.2. Collapse Map
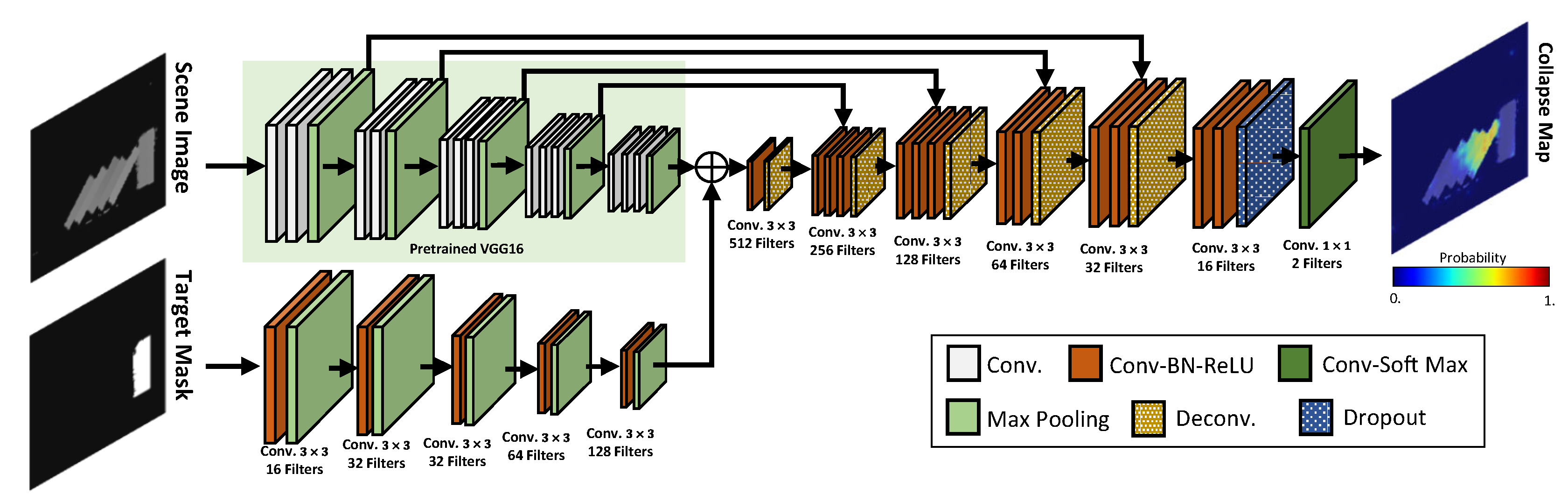
2.2.1. Network Architecture
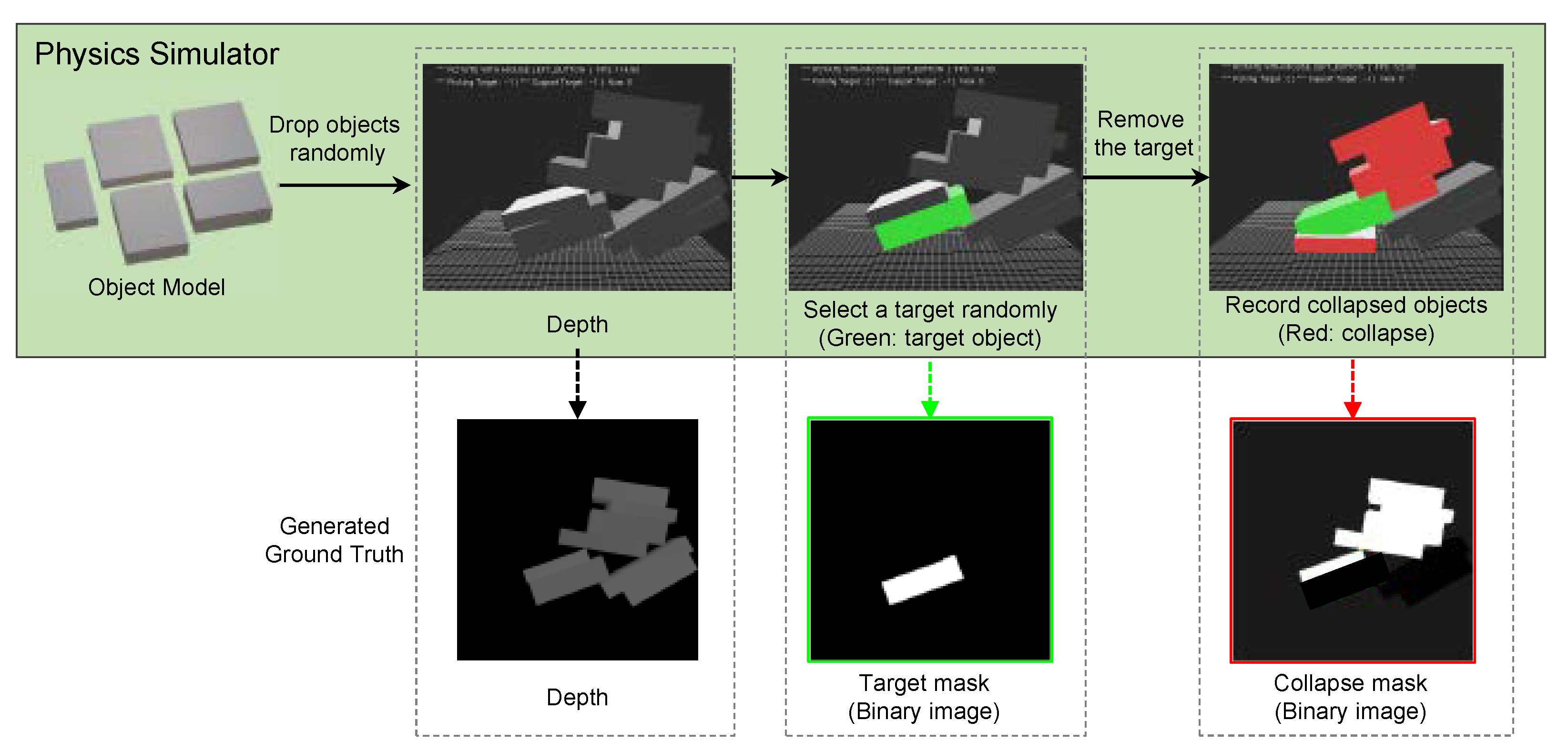
2.2.2. Dataset
2.2.3. Implementation Details
2.3. Shelf Replenishment
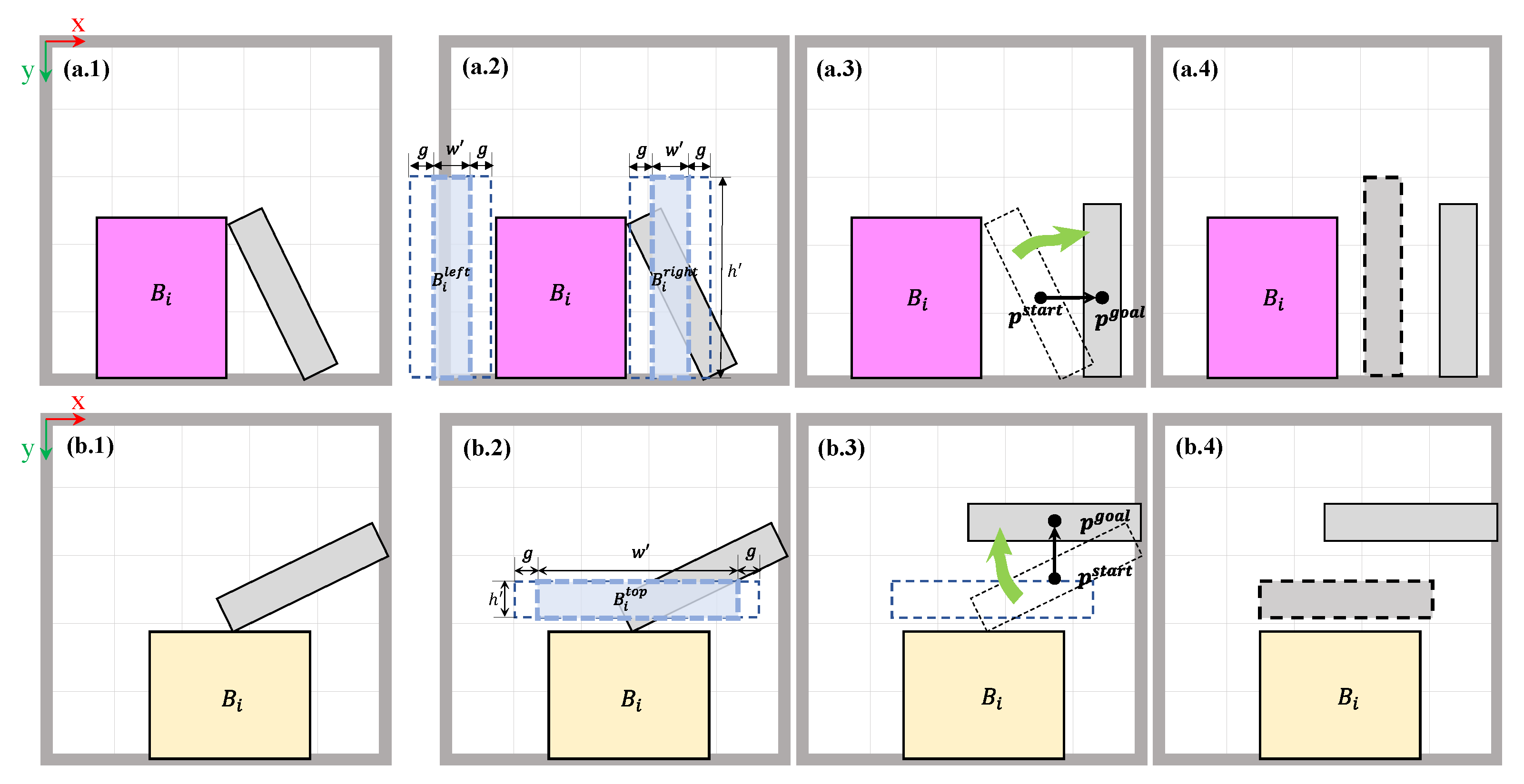
2.3.1. Simple Replenishment
2.3.2. Bimanual Replenishment
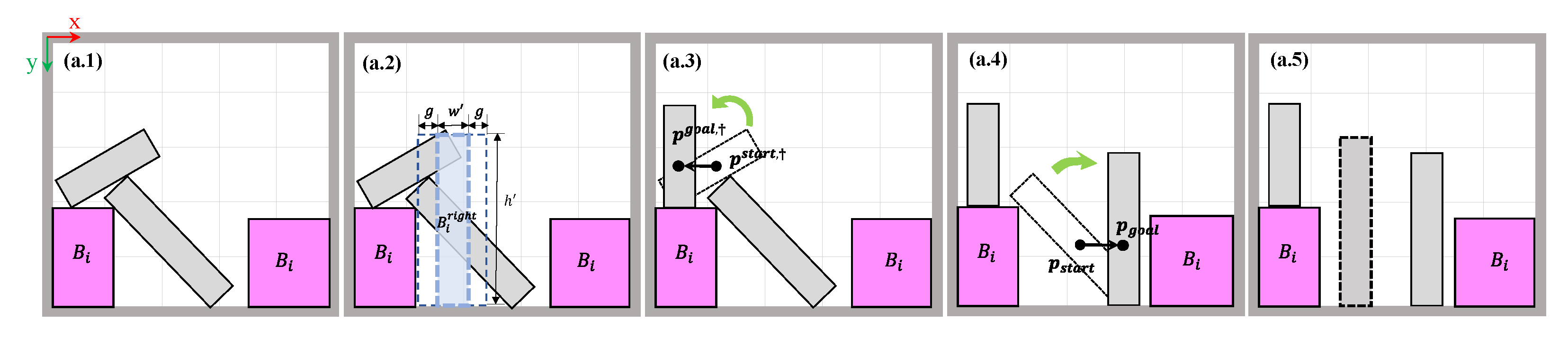
2.3.3. Bimanual Rearrangement
3. Experiments and Results
3.1. Predicting the Collapse Map
3.2. Robotic Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fujita, M.; Domae, Y.; Noda, A.; Garcia Ricardez, G.A.; Nagatani, T.; Zeng, A.; Song, S.; Rodriguez, A.; Causo, A.; Chen, I.M.; et al. What are the important technologies for bin picking? Technology analysis of robots in competitions based on a set of performance metrics. Adv. Robot. 2019, 34, 560–574. [Google Scholar] [CrossRef]
- Billard, A.; Kragic, D. Trends and challenges in robot manipulation. Science 2019, 364, eaat8414. [Google Scholar] [CrossRef] [PubMed]
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Ojea, J.A.; Goldberg, K. Dex-Net 2.0: Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics. arXiv 2017, arXiv:1703.09312. [Google Scholar]
- Zhang, H.; Lan, X.; Zhou, X.; Tian, Z.; Zhang, Y.; Zheng, N. Visual Manipulation Relationship Network for Autonomous Robotics. In Proceedings of the 2018 IEEE-RAS 18th International Conference on Humanoid Robots (Humanoids), Beijing, China, 6–9 November 2018; pp. 118–125. [Google Scholar]
- Li, J.K.; Hsu, D.; Lee, W.S. Act to see and see to act: POMDP planning for objects search in clutter. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 5701–5707. [Google Scholar]
- Eppner, C.; Höberfer, S.; Jonschkowski, R.; Martín-Martxixn, R.; Sieverling, A.; Wall, V.; Brock, O. Four aspects of building robotic systems: Lessons from the Amazon Picking Challenge 2015. Auton. Robot. 2018, 42, 1459–1475. [Google Scholar] [CrossRef]
- Zhu, H.; Kok, Y.Y.; Causo, A.; Chee, K.J.; Zou, Y.; Al-Jufry, S.O.K.; Liang, C.; Chen, I.; Cheah, C.C.; Low, K.H. Strategy-based robotic item picking from shelves. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 2263–2270. [Google Scholar]
- Lenz, I.; Lee, H.; Saxena, A. Deep learning for detecting robotic grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef]
- Schwarz, M.; Lenz, C.; García, G.M.; Koo, S.; Periyasamy, A.S.; Schreiber, M.; Behnke, S. Fast Object Learning and Dual-arm Coordination for Cluttered Stowing, Picking, and Packing. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3347–3354. [Google Scholar]
- Zeng, A.; Song, S.; Yu, K.T.; Donlon, E.; Hogan, F.R.; Bauza, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3750–3757. [Google Scholar]
- Costanzo, M.; Stelter, S.; Natale, C.; Pirozzi, S.; Bartels, G.; Maldonado, A.; Beetz, M. Manipulation Planning and Control for Shelf Replenishment. IEEE Robot. Autom. Lett. 2021, 5, 1595–1601. [Google Scholar] [CrossRef]
- Winkler, J.; Balint-Benczedi, F.; Wiedemeyer, T.; Beetz, M.; Vaskevicius, N.; Mueller, C.A.; Fromm, T.; Birk, A. Knowledge-Enabled Robotic Agents for Shelf Replenishment in Cluttered Retail Environments. In Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems (AAMAS), Singapore, 9–13 May 2016; pp. 1421–1422. [Google Scholar]
- Domae, Y.; Okuda, H.; Taguchi, Y.; Sumi, K.; Hirai, T. Fast graspability evaluation on single depth maps for bin picking with general grippers. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1997–2004. [Google Scholar]
- Harada, K.; Wan, W.; Tsuji, T.; Kikuchi, K.; Nagata, K.; Onda, H. Initial experiments on learning-based randomized bin-picking allowing finger contact with neighboring objects. In Proceedings of the 2016 IEEE International Conference on Automation Science and Engineering (CASE), Fort Worth, TX, USA, 21–25 August 2016; pp. 1196–1202. [Google Scholar]
- Dogar, M.R.; Hsiao, K.; Ciocarlie, M.T.; Srinivasa, S.S. Physics-Based Grasp Planning through Clutter; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Lee, J.; Cho, Y.; Nam, C.; Park, J.; Kim, C. Efficient Obstacle Rearrangement for Object Manipulation Tasks in Cluttered Environments. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 183–189. [Google Scholar]
- Nam, C.; Lee, J.; Cheong, S.H.; Cho, B.Y.; Kim, C. Fast and resilient manipulation planning for target retrieval in clutter. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 3777–3783. [Google Scholar]
- Nagata, K.; Nishi, T. Modeling object arrangement patterns and picking arranged objects. Adv. Robot. 2021, 35, 981–994. [Google Scholar] [CrossRef]
- Grauman, K.; Leibe, B. Visual object recognition, Synthesis Lectures on Artificial Intelligence and Machine Learning; Morgan & Claypool Publishers: San Rafael, CA, USA, 2011. [Google Scholar]
- Goldman, E.; Herzig, R.; Eisenschtat, A.; Goldberger, J.; Hassner, T. Precise detection in densely packed scenes. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5227–5236. [Google Scholar]
- Asaoka, T.; Nagata, K.; Nishi, T.; Mizuuchi, I. Detection of object arrangement patterns using images for robot picking. Robomech J. 2018, 5, 23. [Google Scholar] [CrossRef]
- Rosman, B.; Ramamoorthy, S. Learning spatial relationships between objects. Int. J. Robot. Res. 2011, 30, 1328–1342. [Google Scholar] [CrossRef]
- Panda, S.; Hafez, A.H.A.; Jawahar, C.V. Learning support order for manipulation in clutter. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 809–815. [Google Scholar]
- Mojtahedzadeh, R.; Bouguerra, A.; Schaffernicht, E.; Lilienthal, A.J. Support relation analysis and decision making for safe robotic manipulation tasks. Robot. Auton. Syst. 2015, 71, 99–117. [Google Scholar] [CrossRef]
- Grotz, M.; Sippel, D.; Asfour, T. Active vision for extraction of physically plausible support relations. In Proceedings of the 2019 IEEE-RAS 19th International Conference on Humanoid Robots (Humanoids), Toronto, ON, Canada, 15–17 October 2019; pp. 439–445. [Google Scholar]
- Zhang, H.; Lan, X.; Bai, S.; Wan, L.; Yang, C.; Zheng, N. A Multi-task Convolutional Neural Network for Autonomous Robotic Grasping in Object Stacking Scenes. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 6435–6442. [Google Scholar]
- Temstsin, S.; Degami, A. Decision-making algorithms for safe robotic disassembling of randomly piled objects. Adv. Robot. 2017, 31, 1281–1295. [Google Scholar] [CrossRef]
- Ornan, O.; Degani, A. Toward autonomous disassembling of randomly piled objects with minimal perturbation. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 4983–4989. [Google Scholar]
- Xu, Z.; He, Z.; Wu, J.; Song, S. Learning 3D Dynamic Scene Representations for Robot Manipulation. In Proceedings of the 4th Conference on Robot Learning (CoRL), Cambridge, MA, USA, 16–18 November 2020; pp. 1–17. [Google Scholar]
- Magassouba, A.; Sugiura, K.; Nakayama, A.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H.; Kawai, H. Predicting and attending to damaging collisions for placing everyday objects in photo-realistic simulations. Adv. Robot. 2021, 35, 787–799. [Google Scholar] [CrossRef]
- Janner, M.; Levine, S.; Freeman, W.T.; Tenenbaum, J.B.; Finn, C.; Wu, J. Reasoning about physical interactions with object-oriented prediction and planning. In Proceedings of the 7th International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019; pp. 1–12. [Google Scholar]
- Motoda, T.; Petit, D.; Wan, W.; Harada, K. Bimanual Shelf Picking Planner Based on Collapse Prediction. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 510–515. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 240–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- NVIDIA DEVELOPER. Available online: https://developer.nvidia.com/physx-sdk (accessed on 7 September 2022).
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Industrial Robots & Robot Automation Tech | Yaskawa Motoman. Available online: https://www.motoman.com/en-us/products/robots/industrial/assembly-handling/sda-series/sda5f (accessed on 7 September 2022).
- Choreonoid Official Site. Available online: https://choreonoid.org/en/ (accessed on 7 September 2022).
- graspPlugin for Choreonoid. Available online: http://www.hlab.sys.es.osaka-u.ac.jp/grasp/en/ (accessed on 7 September 2022).
- Robotiq: Start Production Faster. Available online: https://robotiq.com (accessed on 7 September 2022).
- YOODS Co. Ltd. Available online: https://www.yoods.co.jp/products/ycam.html (accessed on 7 September 2022).
- Mahler, J.; Matl, M.; Satish, V.; Danielczuk, M.; DeRose, B.; McKinley, S.; Goldberg, K. Learning ambidextrous robot grasping policies. Sci. Robot. 2019, 4, eaau4984. [Google Scholar] [CrossRef] [PubMed]
- Avigal, Y.; Berscheid, L.; Asfour, T.; Kräger, T.; Goldberg, K. SpeedFolding: Learning Efficient Bimanual Folding of Garments. arXiv 2022, arXiv:2208.10552. [Google Scholar]
- Kartmann, R.; Paus, F.; Grotz, M.; Asfour, T. Extraction of Physically Plausible Support Relations to Predict and Validate Manipulation Action Effects. IEEE Robot. Autom. Lett. 2018, 3, 3991–3998. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PA * | IoU ** |
|---|---|---|
| FCN-8s-based | 0.941 | 0.461 |
| Ours (Batch size = 32) | 0.982 | 0.668 |
| Ours (Batch size = 16) | 0.981 | 0.662 |
| Ours (fine-tuned, Batch size = 16) | 0.980 | 0.640 |
| Ours (fine-tuned, Batch size = 32) | 0.957 | 0.545 |
| Stacked | Shelved | Random | Total | |
|---|---|---|---|---|
| Success w/ Collapse Prediction | 23/40 (57.5%) | 42/50 (84.0%) |
3/10 (30.0%) | 68/100 (68.0%) |
| Success w/o Collapse Prediction | 5/10 (50.0%) | 6/10 (60.0%) |
0/5 (0.0%) | 11/25 (44.0%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Motoda, T.; Petit, D.; Nishi, T.; Nagata, K.; Wan, W.; Harada, K. Shelf Replenishment Based on Object Arrangement Detection and Collapse Prediction for Bimanual Manipulation. Robotics 2022, 11, 104. https://doi.org/10.3390/robotics11050104
Motoda T, Petit D, Nishi T, Nagata K, Wan W, Harada K. Shelf Replenishment Based on Object Arrangement Detection and Collapse Prediction for Bimanual Manipulation. Robotics. 2022; 11(5):104. https://doi.org/10.3390/robotics11050104
Chicago/Turabian StyleMotoda, Tomohiro, Damien Petit, Takao Nishi, Kazuyuki Nagata, Weiwei Wan, and Kensuke Harada. 2022. "Shelf Replenishment Based on Object Arrangement Detection and Collapse Prediction for Bimanual Manipulation" Robotics 11, no. 5: 104. https://doi.org/10.3390/robotics11050104
APA StyleMotoda, T., Petit, D., Nishi, T., Nagata, K., Wan, W., & Harada, K. (2022). Shelf Replenishment Based on Object Arrangement Detection and Collapse Prediction for Bimanual Manipulation. Robotics, 11(5), 104. https://doi.org/10.3390/robotics11050104