
Multirobot Confidence and Behavior Modeling: An Evaluation of Semiautonomous Task Performance and Efficiency


Abstract
1. Introduction
2. Background
2.1. Robot Confidence
2.2. Human Interaction with Multiple Robots
2.3. Understanding the User’s Intent
2.4. Eye Tracking for Human–Robot Interaction
2.5. Augmented Reality for Human–Robot Interfaces
3. Materials and Methods
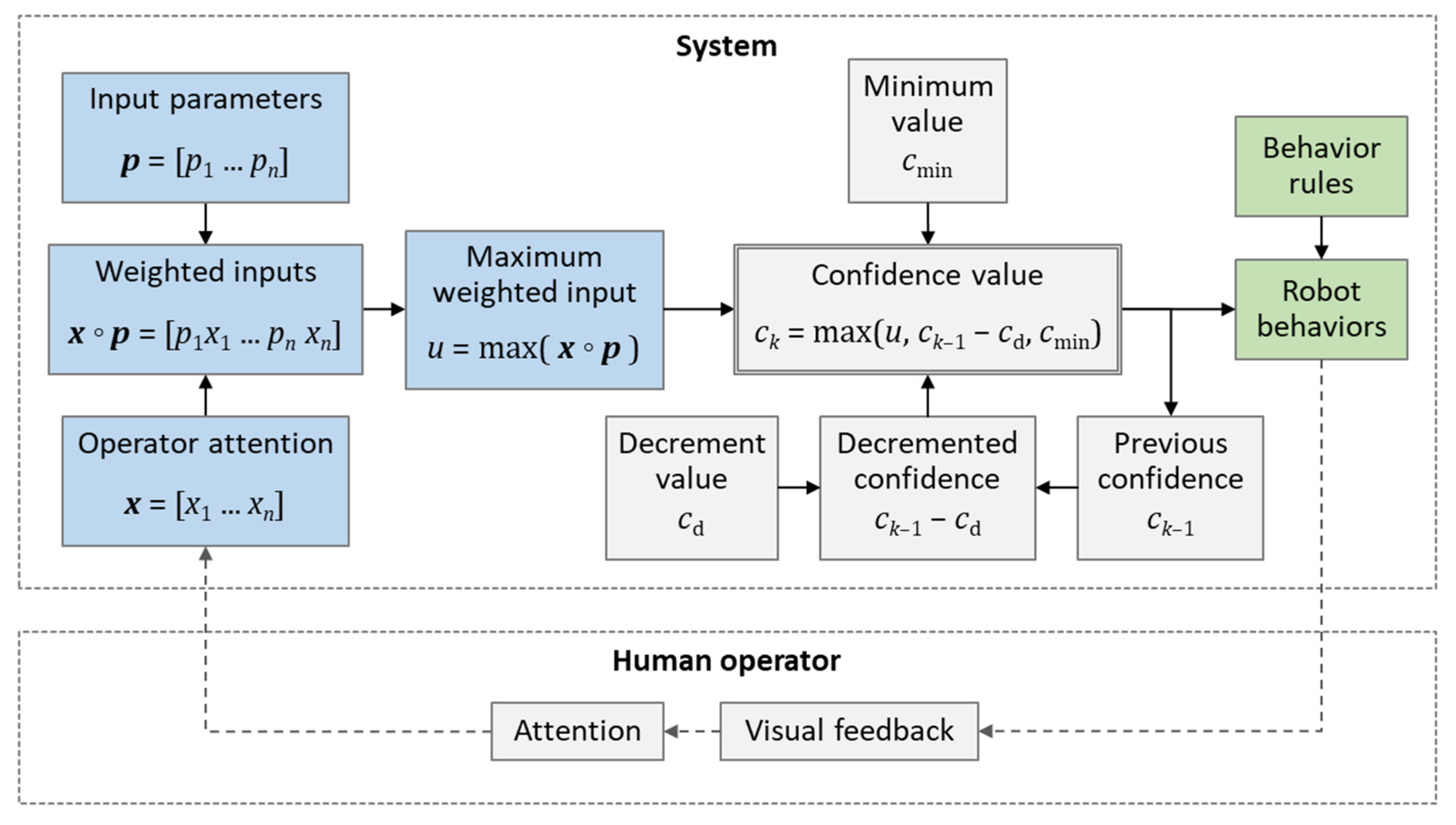
3.1. Robot Confidence Model
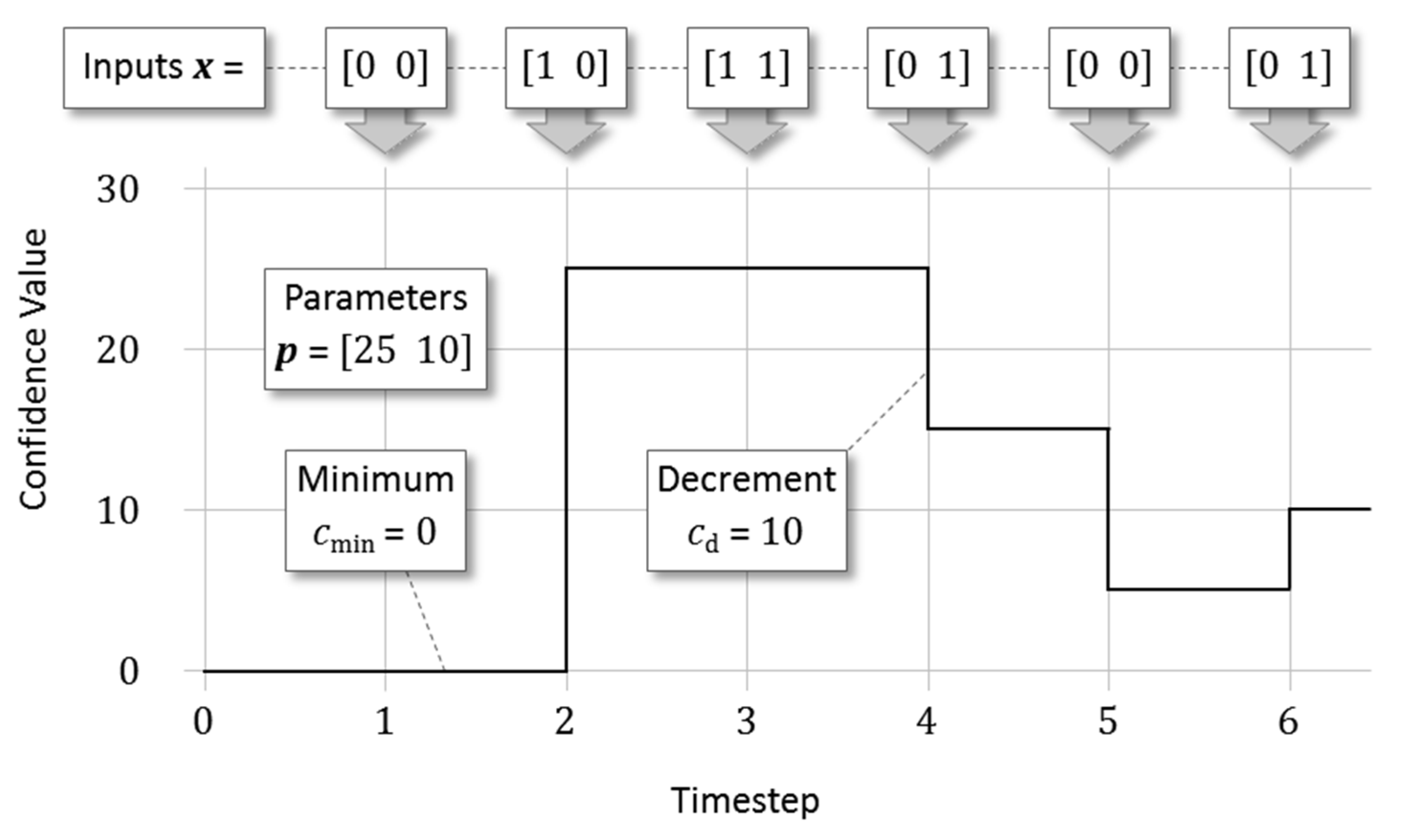
- At timestep , Equation (3) with model input results in a maximum confidence input of . Equation (4) then yields robot confidence . Here, we see the maximum value prevents confidence values below .
- At timestep , input results in and robot confidence .
- At timestep , input results in and robot confidence . Note that multiple instances of the same input at consecutive timesteps sustain confidence but do not increase it.
- At timestep , input results in and robot confidence . Here, we see the new confidence value is the decremented value because this is still greater than the weighted sum .
- At timestep , input results in and robot confidence .
- At timestep , input results in and robot confidence . Note that confidence does not increase by the value of the maximum weighted input (). Instead, it only increases by to reach a value of .
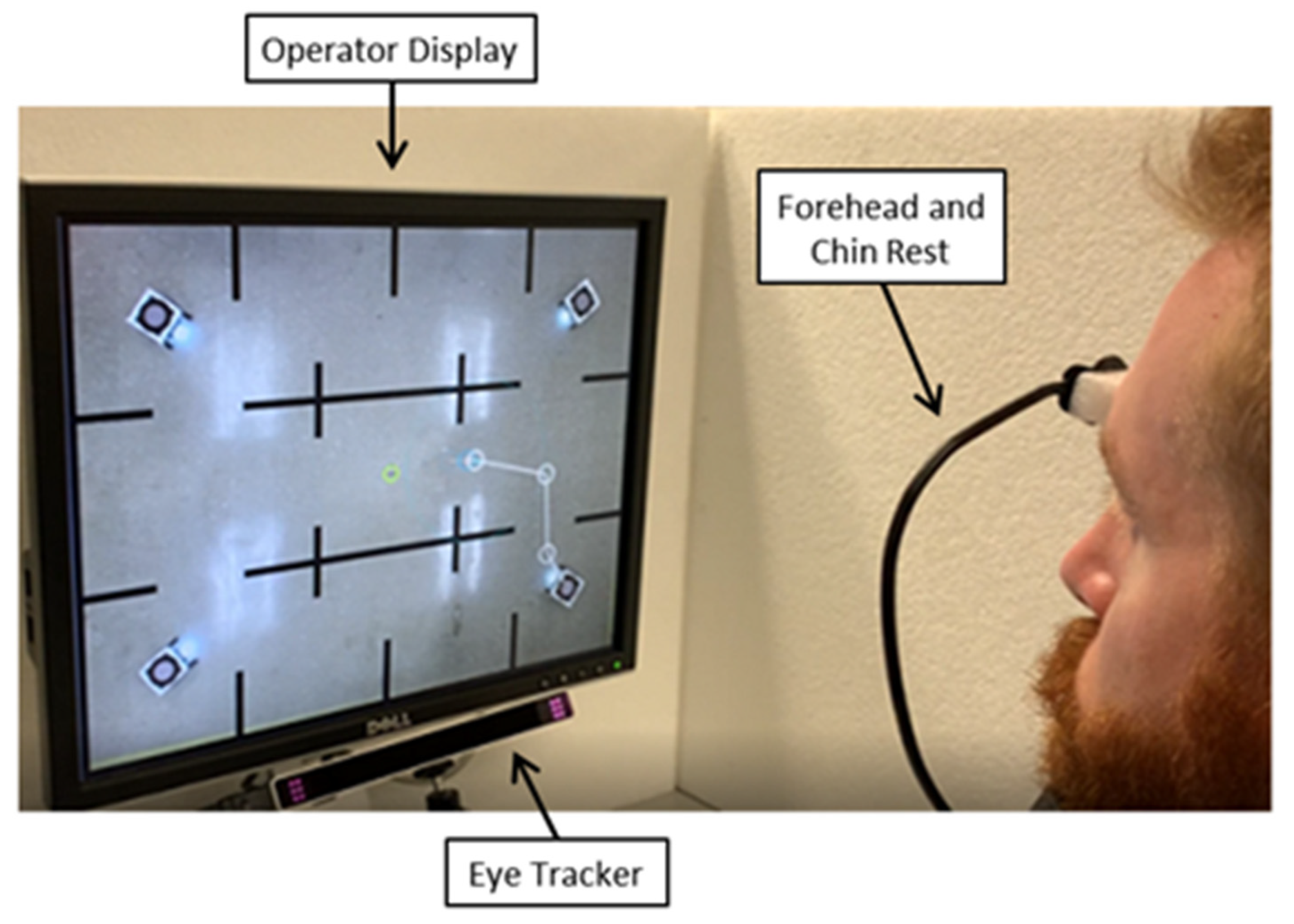
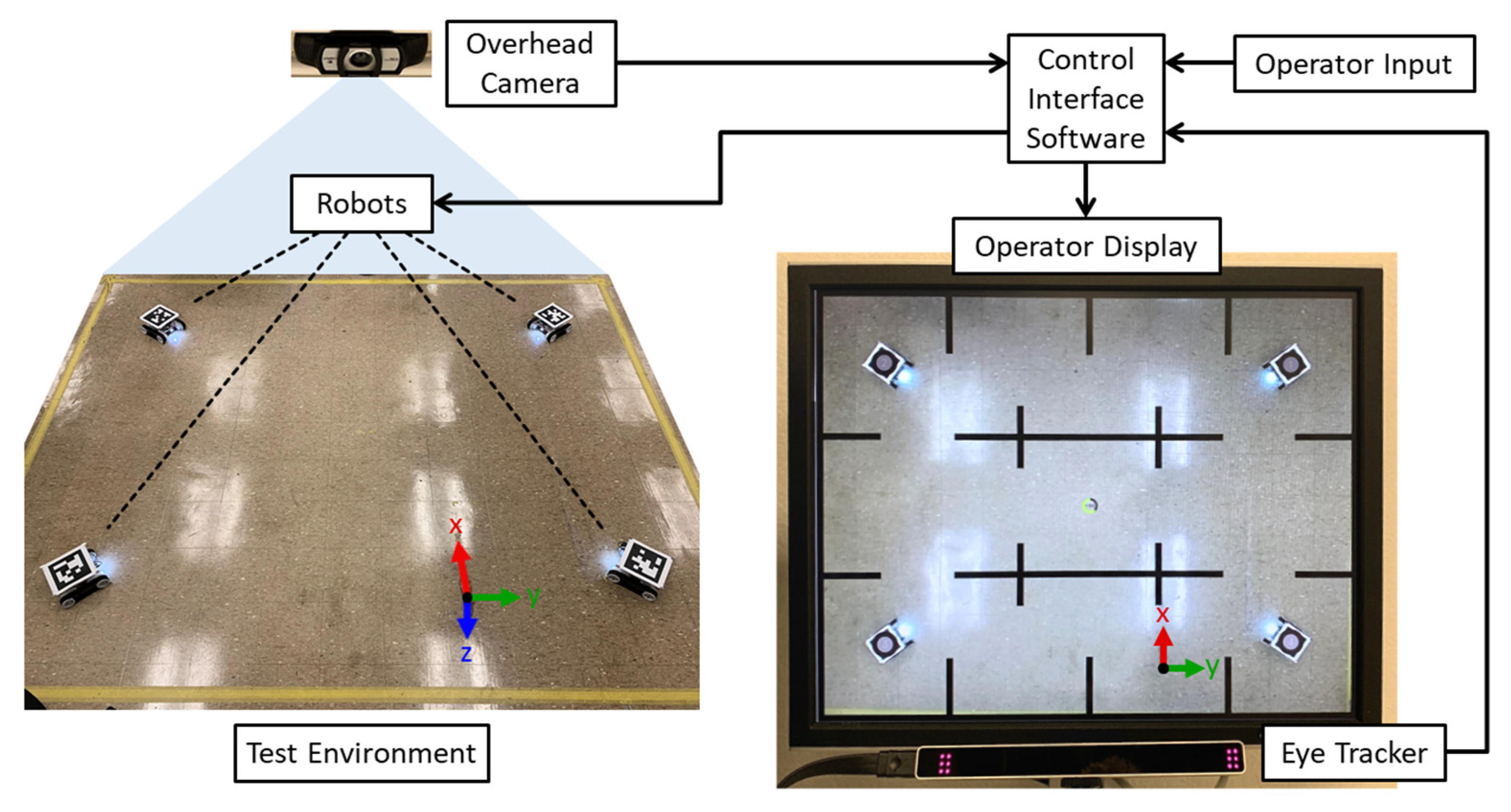
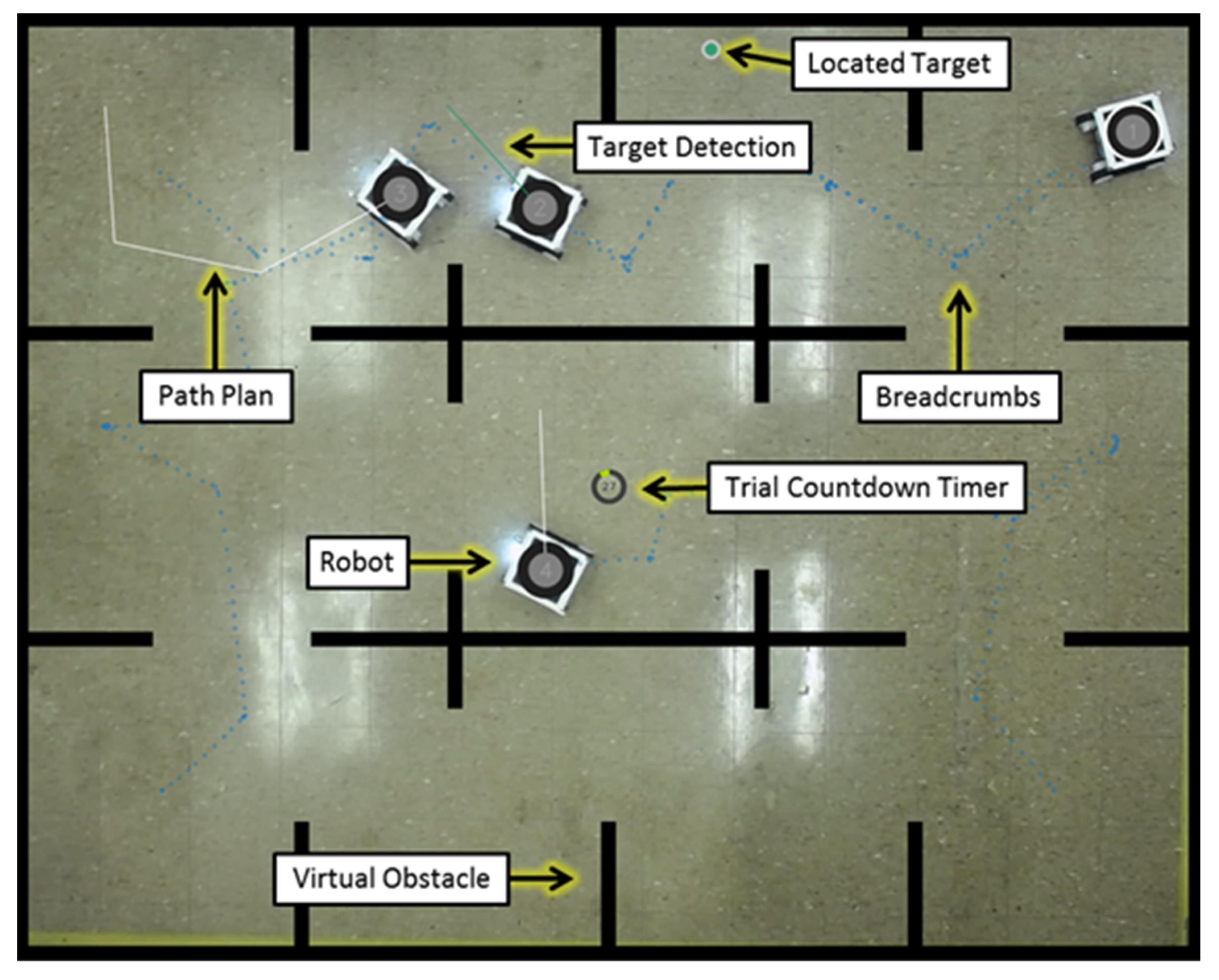
3.2. Multirobot Test Platform with Eye Tracking
- Velocity boost;
- Velocity drop;
- Constant velocity (control).
3.3. Experiment
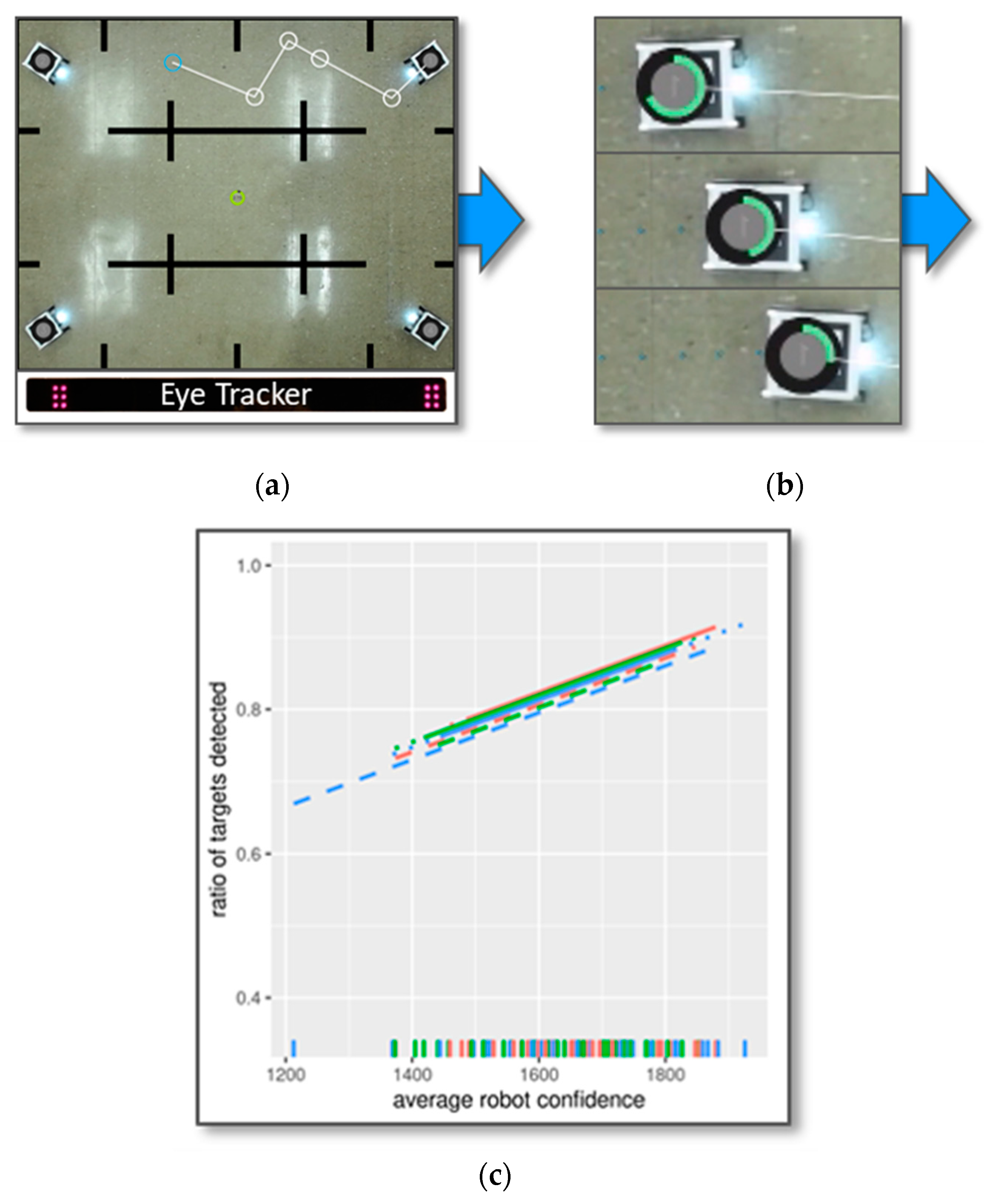
3.4. Data Analysis
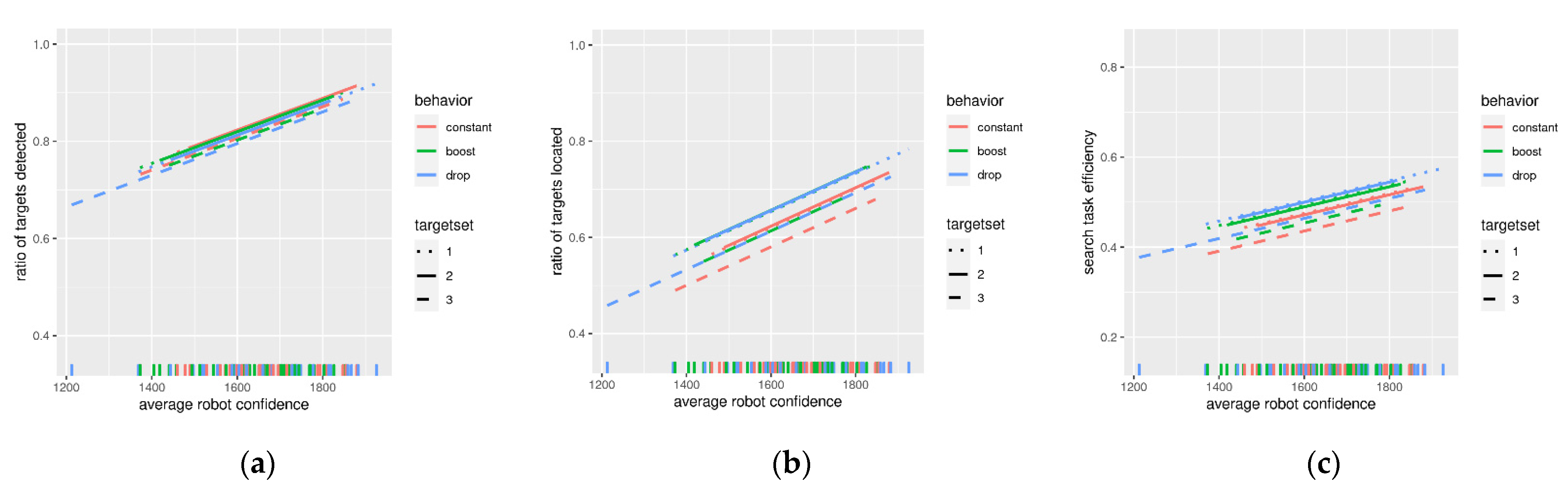
- Ratio of targets detected;
- Ratio of targets located;
- Search task efficiency.
4. Results
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dudek, G.; Jenkin, M.R.M.; Milios, E.; Wilkes, D. A taxonomy for multi-agent robotics. Auton. Robot. 1996, 3, 375–397. [Google Scholar] [CrossRef]
- Farinelli, A.; Iocchi, L.; Nardi, D. Multirobot systems: A classification focused on coordination. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2004, 34, 2015–2028. [Google Scholar] [CrossRef]
- Arai, T.; Pagello, E.; Parker, L.E. Guest editorial advances in multirobot systems. Robot. Autom. IEEE Trans. 2002, 18, 655–661. [Google Scholar] [CrossRef]
- Parker, L.E. Current research in multirobot systems. Artif. Life Robot. 2003, 7, 1–5. [Google Scholar] [CrossRef]
- Lucas, N.P.; Pandya, A.K.; Ellis, R.D. Review of multi-robot taxonomy, trends, and applications for defense and space. In Proceedings of SPIE 8387, Unmanned Systems Technology XIV; International Society for Optics and Photonics: Baltimore, MD, USA, 2012. [Google Scholar] [CrossRef]
- Parker, L.E. Heterogeneous Multi-Robot Cooperation. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1994. [Google Scholar]
- Parker, L.E. ALLIANCE: An architecture for fault tolerant multirobot cooperation. Robot. Autom. IEEE Trans. 1998, 14, 220–240. [Google Scholar] [CrossRef]
- Mataric, M.J. Reinforcement learning in the multi-robot domain. Auton. Robot. 1997, 4, 73–83. [Google Scholar] [CrossRef]
- Stone, P.; Veloso, M. Multiagent systems: A survey from a machine learning perspective. Auton. Robot. 2000, 8, 345–383. [Google Scholar] [CrossRef]
- Dias, M.B.; Zlot, R.; Kalra, N.; Stentz, A. Market-based multirobot coordination: A survey and analysis. Proc. IEEE 2006, 94, 1257–1270. [Google Scholar] [CrossRef]
- Burgard, W.; Moors, M.; Stachniss, C.; Schneider, F.E. Coordinated multi-robot exploration. IEEE Trans. Robot. 2005, 21, 376–386. [Google Scholar] [CrossRef]
- Fox, D.; Burgard, W.; Kruppa, H.; Thrun, S. A probabilistic approach to collaborative multi-robot localization. Auton. Robot. 2000, 8, 325–344. [Google Scholar] [CrossRef]
- Rosenfeld, A.; Agmon, N.; Maksimov, O.; Kraus, S. Intelligent agent supporting human–multi-robot team collaboration. Artif. Intell. 2017, 252, 211–231. [Google Scholar] [CrossRef]
- Kruijff, G.-J.M.; Janíček, M.; Keshavdas, S.; Larochelle, B.; Zender, H.; Smets, N.J.; Mioch, T.; Neerincx, M.A.; Diggelen, J.; Colas, F. Experience in system design for human-robot teaming in urban search and rescue. In Field and Service Robotics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 111–125. [Google Scholar] [CrossRef]
- Zadorozhny, V.; Lewis, M. Information fusion based on collective intelligence for multi-robot search and rescue missions. In Proceedings of the 2013 IEEE 14th International Conference on Mobile Data Management, Milan, Italy, 3–6 June 2013; pp. 275–278. [Google Scholar] [CrossRef]
- Lewis, M.; Wang, H.; Chien, S.Y.; Velagapudi, P.; Scerri, P.; Sycara, K. Choosing autonomy modes for multirobot search. Hum. Factors 2010, 52, 225–233. [Google Scholar] [CrossRef]
- Kruijff-Korbayová, I.; Colas, F.; Gianni, M.; Pirri, F.; Greeff, J.; Hindriks, K.; Neerincx, M.; Ögren, P.; Svoboda, T.; Worst, R. TRADR project: Long-term human-robot teaming for robot assisted disaster response. Ki-Künstliche Intell. 2015, 29, 193–201. [Google Scholar] [CrossRef]
- Gregory, J.; Fink, J.; Stump, E.; Twigg, J.; Rogers, J.; Baran, D.; Fung, N.; Young, S. Application of multi-robot systems to disaster-relief scenarios with limited communication. In Field and Service Robotics; Springer: Cham, Switzerland, 2016; pp. 639–653. [Google Scholar] [CrossRef]
- Dawson, S.; Crawford, C.; Dillon, E.; Anderson, M. Affecting operator trust in intelligent multirobot surveillance systems. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 3298–3304. [Google Scholar] [CrossRef]
- Leitner, J. Multi-robot cooperation in space: A survey. In 2009 Advanced Technologies for Enhanced Quality of Life; IEEE: New Jersey, NJ, USA, 2009; pp. 144–151. [Google Scholar] [CrossRef]
- Thangavelautham, J.; Law, K.; Fu, T.; El Samid, N.A.; Smith, A.D.; D’Eleuterio, G.M. Autonomous multirobot excavation for lunar applications. Robotica 2017, 35, 2330–2362. [Google Scholar] [CrossRef]
- Stroupe, A.; Huntsberger, T.; Okon, A.; Aghazarian, H.; Robinson, M. Behavior-based multi-robot collaboration for autonomous construction tasks. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 1495–1500. [Google Scholar] [CrossRef]
- Simmons, R.; Singh, S.; Heger, F.; Hiatt, L.M.; Koterba, S.; Melchior, N.; Sellner, B. Human-robot teams for large-scale assembly. In Proceedings of the NASA Science Technology Conference, College Park, MD, USA, 19–21 June 2007. [Google Scholar]
- Boning, P.; Dubowsky, S. The coordinated control of space robot teams for the on-orbit construction of large flexible space structures. Adv. Robot. 2010, 24, 303–323. [Google Scholar] [CrossRef]
- Ueno, H.; Nishimaki, T.; Oda, M.; Inaba, N. Autonomous cooperative robots for space structure assembly and maintenance. In Proceedings of the 7th International Symposium on Artificial Intelligence, Robotics, and Automation in Space, Nara, Japan, 19–23 May 2003. [Google Scholar]
- Huntsberger, T.; Pirjanian, P.; Trebi-Ollennu, A.; Nayar, H.D.; Aghazarian, H.; Ganino, A.; Garrett, M.; Joshi, S.; Schenker, P. CAMPOUT: A control architecture for tightly coupled coordination of multirobot systems for planetary surface exploration. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2003, 33, 550–559. [Google Scholar] [CrossRef]
- Chen, J.Y.; Haas, E.C.; Barnes, M.J. Human performance issues and user interface design for teleoperated robots. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2007, 37, 1231–1245. [Google Scholar] [CrossRef]
- Crandall, J.W.; Goodrich, M.A.; Olsen, D.R., Jr.; Nielsen, C.W. Validating human-robot interaction schemes in multitasking environments. Syst. Man Cybern. Part A Syst. Hum. IEEE Trans. 2005, 35, 438–449. [Google Scholar] [CrossRef]
- Cummings, M.; Nehme, C.; Crandall, J.; Mitchell, P. Predicting operator capacity for supervisory control of multiple UAVs. In Innovations in Intelligent Machines-1; Springer: Berlin/Heidelberg, Germany, 2007; Volume 70, pp. 11–37. [Google Scholar] [CrossRef]
- Olsen, D.R., Jr.; Wood, S.B. Fan-out: Measuring human control of multiple robots. In Proceedings of the SIGCHI Conf. on Human Factors in Computer Systems, Vienna, Austria, 24–29 April 2004; pp. 231–238. [Google Scholar] [CrossRef]
- Olsen, D.R.; Goodrich, M.A. Metrics for evaluating human-robot interactions. In Proceedings of the PerMIS, Gaithersburg, MD, USA, 16–18 August 2003. [Google Scholar]
- Goodrich, M.A.; Olsen, D.R., Jr. Seven principles of efficient human robot interaction. In Proceedings of the SMC’03 2003 IEEE International Conference on Systems, Man and Cybernetics. Conference Theme-System Security and Assurance (Cat. No.03CH37483), Washington, DC, USA, 8 October 2003; Volume 4, pp. 3942–3948. [Google Scholar] [CrossRef]
- Crandall, J.W.; Cummings, M.L. Identifying predictive metrics for supervisory control of multiple robots. Robot. IEEE Trans. 2007, 23, 942–951. [Google Scholar] [CrossRef]
- Lee, S.Y.-S. An Augmented Reality Interface for Multi-Robot Tele-Operation and Control; Wayne State University Dissertations: Detroit, MI, USA, 2011; Available online: https://digitalcommons.wayne.edu/oa_dissertations/381 (accessed on 15 March 2021).
- Lee, S.; Lucas, N.P.; Ellis, R.D.; Pandya, A. Development and human factors analysis of an augmented reality interface for multi-robot tele-operation and control. In Proceedings of the SPIE 8387, Unmanned Systems Technology XIV, 83870N, Baltimore, MD, USA, 25 May 2012. [Google Scholar] [CrossRef]
- Wright, J.L.; Chen, J.Y.; Lakhmani, S.G. Agent transparency and reliability in human–robot interaction: The influence on user confidence and perceived reliability. IEEE Trans. Hum.Mach. Syst. 2020, 50, 254–263. [Google Scholar] [CrossRef]
- Saeidi, H.; Wang, Y. Incorporating Trust and Self-Confidence Analysis in the Guidance and Control of (Semi) Autonomous Mobile Robotic Systems. IEEE Robot. Autom. Lett. 2019, 4, 239–246. [Google Scholar] [CrossRef]
- Desai, M.; Kaniarasu, P.; Medvedev, M.; Steinfeld, A.; Yanco, H. Impact of robot failures and feedback on real-time trust. In Proceedings of the 8th ACM/IEEE International Conference on Human-Robot Interaction, Tokyo, Japan, 3–6 March 2013; pp. 251–258. [Google Scholar] [CrossRef]
- Sanders, D.A.; Sanders, B.J.; Gegov, A.; Ndzi, D. Using confidence factors to share control between a mobile robot tele-operater and ultrasonic sensors. In Proceedings of the 2017 Intelligent Systems Conference (IntelliSys), London, UK, 7–8 September 2017; pp. 1026–1033. [Google Scholar] [CrossRef]
- Chernova, S.; Veloso, M. Confidence-based multi-robot learning from demonstration. Int. J. Soc. Robot. 2010, 2, 195–215. [Google Scholar] [CrossRef]
- Chernova, S. Confidence-Based Robot Policy Learning from Demonstration. Master’s Thesis, Carnegie-Mellon University Pittsburgh Pa School of Computer Science, Pittsburgh, PA, USA, 5 March 2009. [Google Scholar]
- Chernova, S.; Veloso, M. Teaching collaborative multi-robot tasks through demonstration. In Proceedings of the Humanoids 2008—8th IEEE-RAS International Conference on Humanoid Robots, Daejeon, Korea, 1–3 December 2008; pp. 385–390. [Google Scholar] [CrossRef]
- Tran, A. Robot Confidence Modeling and Role Change In Physical Human-Robot Collaboration. Master’s Thesis, University of Technology Sydney, Ultimo, Australia, March 2019. [Google Scholar]
- Fisac, J.F.; Bajcsy, A.; Herbert, S.L.; Fridovich-Keil, D.; Wang, S.; Tomlin, C.J.; Dragan, A.D. Probabilistically safe robot planning with confidence-based human predictions. In Proceedings of the Robotics: Science and Systems, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar] [CrossRef]
- Pronobis, A.; Caputo, B. Confidence-based cue integration for visual place recognition. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 2394–2401. [Google Scholar] [CrossRef]
- Belkaid, M.; Cuperlier, N.; Gaussier, P. Autonomous cognitive robots need emotional modulations: Introducing the eMODUL model. IEEE Trans. Syst. ManCybern. Syst. 2018, 49, 206–215. [Google Scholar] [CrossRef]
- Schillaci, G.; Pico Villalpando, A.; Hafner, V.V.; Hanappe, P.; Colliaux, D.; Wintz, T. Intrinsic motivation and episodic memories for robot exploration of high-dimensional sensory spaces. Adapt. Behav. 2020. [Google Scholar] [CrossRef]
- Huang, X.; Weng, J. Novelty and Reinforcement Learning in the Value System of Developmental Robots; Computer Science and Engineering Department Michigan State University: East Lansing, MI, USA, 2002. [Google Scholar]
- Belkaid, M.; Cuperlier, N.; Gaussier, P. Emotional metacontrol of attention: Top-down modulation of sensorimotor processes in a robotic visual search task. PLoS ONE 2017, 12, e0184960. [Google Scholar] [CrossRef] [PubMed]
- Oudeyer, P.-Y.; Kaplan, F.; Hafner, V.V. Intrinsic motivation systems for autonomous mental development. IEEE Trans. Evol. Comput. 2007, 11, 265–286. [Google Scholar] [CrossRef]
- Wickens, C.D.; Gordon, S.E.; Liu, Y. An Introduction to Human Factors Engineering; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2004. [Google Scholar]
- Chien, S.-Y.; Lin, Y.-L.; Lee, P.-J.; Han, S.; Lewis, M.; Sycara, K. Attention allocation for human multi-robot control: Cognitive analysis based on behavior data and hidden states. Int. J. Hum. Comput. Stud. 2018, 117, 30–44. [Google Scholar] [CrossRef]
- Lewis, M. Human Interaction With Multiple Remote Robots. Rev. Hum. Factors Ergon. 2013, 9, 131–174. [Google Scholar] [CrossRef]
- Chien, S.-Y.; Lewis, M.; Mehrotra, S.; Brooks, N.; Sycara, K. Scheduling operator attention for multi-robot control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 473–479. [Google Scholar] [CrossRef]
- Crandall, J.W.; Cummings, M.L.; Della Penna, M.; de Jong, P.M. Computing the effects of operator attention allocation in human control of multiple robots. Syst. Man Cybern. Part A Syst. Hum. IEEE Trans. 2011, 41, 385–397. [Google Scholar] [CrossRef]
- Payton, D.; Daily, M.; Estowski, R.; Howard, M.; Lee, C. Pheromone robotics. Auton. Robot. 2001, 11, 319–324. [Google Scholar] [CrossRef]
- Daily, M.; Cho, Y.; Martin, K.; Payton, D. World embedded interfaces for human-robot interaction. In Proceedings of the 36th Annual Hawaii International Conference on System Sciences, 2003, Big Island, HI, USA, 6–9 January 2003. [Google Scholar] [CrossRef]
- Dragan, A.; Lee, K.C.T.; Srinivasa, S. Teleoperation with Intelligent and Customizable Interfaces. J. Hum. Robot Interact. 2013, 2, 33–57. [Google Scholar] [CrossRef]
- Kwok, K.-W.; Sun, L.-W.; Mylonas, G.P.; James, D.R.C.; Orihuela-Espina, F.; Yang, G.-Z. Collaborative Gaze Channelling for Improved Cooperation During Robotic Assisted Surgery. Ann. Biomed. Eng. 2012, 40, 2156–2167. [Google Scholar] [CrossRef]
- Goldberg, J.H.; Schryver, J.C. Eye-gaze-contingent control of the computer interface: Methodology and example for zoom detection. Behav. Res. MethodsInstrum. Comput. 1995, 27, 338–350. [Google Scholar] [CrossRef]
- Ali, S.M.; Reisner, L.A.; King, B.; Cao, A.; Auner, G.; Klein, M.; Pandya, A.K. Eye gaze tracking for endoscopic camera positioning: An application of a hardware/software interface developed to automate Aesop. Stud. Health Technol. Inform. 2007, 132, 4–7. [Google Scholar]
- Latif, H.O.; Sherkat, N.; Lotfi, A. TeleGaze: Teleoperation through eye gaze. In Proceedings of the 2008 7th IEEE International Conference on Cybernetic Intelligent Systems, London, UK, 9–10 September 2008; pp. 1–6. [Google Scholar]
- Latif, H.O.; Sherkat, N.; Lotfi, A. Teleoperation through eye gaze (TeleGaze): A multimodal approach. In Proceedings of the 2009 IEEE International Conference on Robotics and Biomimetics (ROBIO), Guilin, China, 19–23 December 2009; pp. 711–716. [Google Scholar]
- Zhu, D.; Gedeon, T.; Taylor, K. “Moving to the centre”: A gaze-driven remote camera control for teleoperation. Interact. Comput. 2011, 23, 85–95. [Google Scholar] [CrossRef]
- Steinfeld, A.; Fong, T.; Kaber, D.; Lewis, M.; Scholtz, J.; Schultz, A.; Goodrich, M. Common metrics for human-robot interaction. In Proceedings of the 1st ACM SIGCHI/SIGART Conference on HRI, Salt Lake City, UT, USA, 2–4 March 2006; pp. 33–40. [Google Scholar] [CrossRef]
- Yanco, H.A.; Drury, J.L.; Scholtz, J. Beyond usability evaluation: Analysis of human-robot interaction at a major robotics competition. Hum. Comput. Interact. 2004, 19, 117–149. [Google Scholar]
- Endsley, M.R. Toward a theory of situation awareness in dynamic systems. Hum. Factors J. Hum. Factors Ergon. Soc. 1995, 37, 32–64. [Google Scholar] [CrossRef]
- Endsley, M.R. Situation awareness global assessment technique (SAGAT). In Proceedings of the IEEE 1988 National Aerospace and Electronics Conference, Dayton, OH, USA, 23–27 May 1988; pp. 789–795. [Google Scholar] [CrossRef]
- Endsley, M.R. Measurement of situation awareness in dynamic systems. Hum. Factors J. Hum. Factors Ergon. Soc. 1995, 37, 65–84. [Google Scholar] [CrossRef]
- Stein, E.S. Air Traffic Controller Workload: An Examination of Workload Probe; DOT/FAA/CT-TN84/24; U.S. Department of Transportation, Federal Aviation Administration: Atlantic City Airport, NJ, USA, 1985.
- Rubio, S.; Díaz, E.; Martín, J.; Puente, J.M. Evaluation of Subjective Mental Workload: A Comparison of SWAT, NASA-TLX, and Workload Profile Methods. Appl. Psychol. 2004, 53, 61–86. [Google Scholar] [CrossRef]
- Hart, S.G.; Staveland, L.E. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research. Hum. Ment. Work. 1988, 1, 139–183. [Google Scholar]
- Hart, S.G. NASA-task load index (NASA-TLX); 20 years later. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, San Francisco, CA, USA, 16–20 October 2006; Volume 50, pp. 904–908. [Google Scholar] [CrossRef]
- NASA Human Systems Integration Division. NASA TLX Publications/Instruction Manual. Available online: http://humansystems.arc.nasa.gov/groups/TLX/tlxpublications.html (accessed on 18 October 2014).
- Veltman, J.; Gaillard, A. Physiological workload reactions to increasing levels of task difficulty. Ergonomics 1998, 41, 656–669. [Google Scholar] [CrossRef]
- Kramer, A.F. Physiological Metrics of Mental Workload: A Review of Recent Progress; University of Illinois at Urbana-Champaign: Champaign, IL, USA, 1990. [Google Scholar]
- Ware, C.; Mikaelian, H.H. An evaluation of an eye tracker as a device for computer input. In Proceedings of the ACM SIGCHI Bulletin, Toronto, ON, Canada, 5–9 April 1987; pp. 183–188. [Google Scholar] [CrossRef]
- Jacob, R.J. Eye movement-based human-computer interaction techniques: Toward non-command interfaces. Adv. Hum. Comput. Interact. 1993, 4, 151–190. [Google Scholar]
- Sibert, L.E.; Jacob, R.J. Evaluation of eye gaze interaction. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, The Hague, The Netherlands, 1–6 April 2000; pp. 281–288. [Google Scholar] [CrossRef]
- Gartenberg, D.; Breslow, L.A.; Park, J.; McCurry, J.M.; Trafton, J.G. Adaptive automation and cue invocation: The effect of cue timing on operator error. In Proceedings of the 2013 ACM Annual Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 3121–3130. [Google Scholar] [CrossRef]
- Breslow, L.A.; Gartenberg, D.; Malcolm McCurry, J.; Gregory Trafton, J. Dynamic Operator Overload: A Model for Predicting Workload During Supervisory Control. IEEE Trans. Hum. Mach. Syst. 2014, 44, 30–40. [Google Scholar] [CrossRef]
- Duchowski, A.T. A breadth-first survey of eye-tracking applications. Behav. Res. MethodsInstrum. Comput. 2002, 34, 455–470. [Google Scholar] [CrossRef]
- Just, M.A.; Carpenter, P.A. A theory of reading: From eye fixations to comprehension. Psychol. Rev. 1980, 87, 329. [Google Scholar] [CrossRef] [PubMed]
- Hyrskykari, A. Utilizing eye movements: Overcoming inaccuracy while tracking the focus of attention during reading. Comput. Hum. Behav. 2006, 22, 657–671. [Google Scholar] [CrossRef]
- Rayner, K. Eye movements in reading and information processing: 20 years of research. Psychol. Bull. 1998, 124, 372. [Google Scholar] [CrossRef]
- Jacob, R.J. What you look at is what you get: Eye movement-based interaction techniques. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Seattle, WA, USA, 1–5 April 1990; pp. 11–18. [Google Scholar] [CrossRef]
- Jacob, R.J. The use of eye movements in human-computer interaction techniques: What you look at is what you get. ACM Trans. Inf. Syst. (TOIS) 1991, 9, 152–169. [Google Scholar] [CrossRef]
- Goldberg, J.H.; Schryver, J.C. Eye-gaze determination of user intent at the computer interface. Stud. Vis. Inf. Process. 1995, 6, 491–502. [Google Scholar]
- Goldberg, J.H.; Schryver, J.C. Eye-gaze control of the computer interface: Discrimination of zoom intent. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Seattle, WA, USA, 11–15 October 1993; pp. 1370–1374. [Google Scholar]
- Goldberg, J.H.; Kotval, X.P. Computer interface evaluation using eye movements: Methods and constructs. Int. J. Ind. Ergon. 1999, 24, 631–645. [Google Scholar] [CrossRef]
- Morimoto, C.H.; Mimica, M.R. Eye gaze tracking techniques for interactive applications. Comput. Vis. Image Underst. 2005, 98, 4–24. [Google Scholar] [CrossRef]
- Hansen, D.W.; Ji, Q. In the eye of the beholder: A survey of models for eyes and gaze. Pattern Anal. Mach. Intell. IEEE Trans. 2010, 32, 478–500. [Google Scholar] [CrossRef] [PubMed]
- Salvucci, D.D.; Goldberg, J.H. Identifying fixations and saccades in eye-tracking protocols. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications, Palm Beach Gardens, FL, USA, 6–8 November 2000; pp. 71–78. [Google Scholar] [CrossRef]
- Jacob, R.J.; Karn, K.S. Eye Tracking in Human-Computer Interaction and Usability Research: Ready to Deliver the Promises. In The Mind’s Eye: Cognitive and Applied Aspects of Eye Movement Research; Hyönä, J., Radach, R., Deubel, H., Eds.; North-Holland: Amsterdam, The Netherlands, 2003; pp. 573–605. [Google Scholar] [CrossRef]
- Fono, D.; Vertegaal, R. EyeWindows: Evaluation of eye-controlled zooming windows for focus selection. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Portland, OR, USA, 2–7 April 2005; pp. 151–160. [Google Scholar] [CrossRef]
- Hutchinson, T.E.; White Jr, K.P.; Martin, W.N.; Reichert, K.C.; Frey, L.A. Human-computer interaction using eye-gaze input. Syst. Man Cybern. IEEE Trans. 1989, 19, 1527–1534. [Google Scholar] [CrossRef]
- Hansen, D.W.; Skovsgaard, H.H.; Hansen, J.P.; Møllenbach, E. Noise Tolerant Selection by Gaze-Controlled Pan and Zoom in 3D. In Proceedings of the 2008 Symposium on Eye Tracking Research and Applications, Savannah, GA, USA, 26–28 March 2008; pp. 205–212. [Google Scholar] [CrossRef]
- Kotus, J.; Kunka, B.; Czyzewski, A.; Szczuko, P.; Dalka, P.; Rybacki, R. Gaze-tracking and Acoustic Vector Sensors Technologies for PTZ Camera Steering and Acoustic Event Detection. In Proceedings of the 2010 Workshop on Database and Expert Systems Applications (DEXA), Bilbao, Spain, 30 August–3 September 2010; pp. 276–280. [Google Scholar] [CrossRef]
- Pandya, A.; Reisner, L.A.; King, B.; Lucas, N.; Composto, A.; Klein, M.; Ellis, R.D. A Review of Camera Viewpoint Automation in Robotic and Laparoscopic Surgery. Robotics 2014, 3, 310–329. [Google Scholar] [CrossRef]
- Doshi, A.; Trivedi, M.M. On the Roles of Eye Gaze and Head Dynamics in Predicting Driver’s Intent to Change Lanes. Intell. Transp. Syst. IEEE Trans. 2009, 10, 453–462. [Google Scholar] [CrossRef]
- McCall, J.C.; Wipf, D.P.; Trivedi, M.M.; Rao, B.D. Lane change intent analysis using robust operators and sparse Bayesian learning. Intell. Transp. Syst. IEEE Trans. 2007, 8, 431–440. [Google Scholar] [CrossRef]
- Trivedi, M.M.; Cheng, S.Y. Holistic sensing and active displays for intelligent driver support systems. Computer 2007, 40, 60–68. [Google Scholar] [CrossRef]
- Poitschke, T.; Laquai, F.; Stamboliev, S.; Rigoll, G. Gaze-based interaction on multiple displays in an automotive environment. In Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Anchorage, AK, USA, 9–12 October 2011; pp. 543–548. [Google Scholar] [CrossRef]
- Gartenberg, D.; McCurry, M.; Trafton, G. Situation awareness reacquisition in a supervisory control task. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Las Vegas, NV, USA, 19–23 September 2011; pp. 355–359. [Google Scholar] [CrossRef]
- Ratwani, R.M.; McCurry, J.M.; Trafton, J.G. Single operator, multiple robots: An eye movement based theoretic model of operator situation awareness. In Proceedings of the HRI ’10, Osaka, Japan, 2–5 March 2010; pp. 235–242. [Google Scholar] [CrossRef]
- Di Stasi, L.L.; McCamy, M.B.; Catena, A.; Macknik, S.L.; Cañas, J.J.; Martinez-Conde, S. Microsaccade and drift dynamics reflect mental fatigue. Eur. J. Neurosci. 2013, 38, 2389–2398. [Google Scholar] [CrossRef]
- Ahlstrom, U.; Friedman-Berg, F.J. Using eye movement activity as a correlate of cognitive workload. Int. J. Ind. Ergon. 2006, 36, 623–636. [Google Scholar] [CrossRef]
- Beatty, J. Task-evoked pupillary responses, processing load, and the structure of processing resources. Psychol. Bull. 1982, 91, 276. [Google Scholar] [CrossRef]
- Klingner, J.; Kumar, R.; Hanrahan, P. Measuring the task-evoked pupillary response with a remote eye tracker. In Proceedings of the 2008 Symposium on Eye Tracking Research & Applications, Savannah, GA, USA, 26–28 March 2008; pp. 69–72. [Google Scholar] [CrossRef]
- Iqbal, S.T.; Zheng, X.S.; Bailey, B.P. Task-evoked pupillary response to mental workload in human-computer interaction. In Proceedings of the CHI’04 Extended Abstracts on Human Factors in Computing Systems, Vienna, Austria, 24–29 April 2004; pp. 1477–1480. [Google Scholar] [CrossRef]
- Azuma, R.T. A survey of augmented reality. Presence Teleoperators Virtual Environ. 1997, 6, 355–385. [Google Scholar] [CrossRef]
- Azuma, R.; Baillot, Y.; Behringer, R.; Feiner, S.; Julier, S.; MacIntyre, B. Recent advances in augmented reality. Comput. Graph. Appl. IEEE 2001, 21, 34–47. [Google Scholar] [CrossRef]
- Chintamani, K.; Cao, A.; Ellis, R.D.; Pandya, A.K. Improved telemanipulator navigation during display-control misalignments using augmented reality cues. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2010, 40, 29–39. [Google Scholar] [CrossRef]
- Pandya, A.; Siadat, M.-R.; Auner, G.; Kalash, M.; Ellis, R.D. Development and human factors analysis of neuronavigation vs. augmented reality. In Studies in Health Technology and Informatics; IOS Press: Amsterdam, The Netherlands, 2004; Volume 98, pp. 291–297. [Google Scholar] [CrossRef]
- Olson, E. AprilTag: A robust and flexible visual fiducial system. In Proceedings of the 2011 IEEE International Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 3400–3407. [Google Scholar] [CrossRef]
- Wang, J.; Olson, E. AprilTag 2: Efficient and robust fiducial detection. In Proceedings of the 2016 IEEE/RSJ Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4193–4198. [Google Scholar] [CrossRef]
- Chen, J.Y.C. Effects of operator spatial ability on UAV-guided ground navigation. In Proceedings of the 2010 5th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Osaka, Japan, 2–5 March 2010; pp. 139–140. [Google Scholar]
- Chen, J.Y.C.; Barnes, M.J. Robotics operator performance in a military multi-tasking environment. In Proceedings of the 3rd ACM/IEEE International Conference on Human-Robot Interaction, Amsterdam, The Netherlands, 12–15 March 2008; pp. 279–286. [Google Scholar] [CrossRef]
- Chen, J.Y.C. Concurrent performance of military tasks and robotics tasks: Effects of automation unreliability and individual differences. In Proceedings of the 4th ACM/IEEE International Conference on Human-Robot Interaction, La Jolla, CA, USA, 11–13 March 2009; pp. 181–188. [Google Scholar] [CrossRef]
- Bolker, B.M.; Brooks, M.E.; Clark, C.J.; Geange, S.W.; Poulsen, J.R.; Stevens, M.H.H.; White, J.-S.S. Generalized linear mixed models: A practical guide for ecology and evolution. Trends Ecol. Evol. 2009, 24, 127–135. [Google Scholar] [CrossRef]
- Barr, D.J.; Levy, R.; Scheepers, C.; Tily, H.J. Random effects structure for confirmatory hypothesis testing: Keep it maximal. J. Mem. Lang. 2013, 68, 255–278. [Google Scholar] [CrossRef]
- Baayen, R.H.; Davidson, D.J.; Bates, D.M. Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. 2008, 59, 390–412. [Google Scholar] [CrossRef]
- Bates, D.; Kliegl, R.; Vasishth, S.; Baayen, H. Parsimonious mixed models. arXiv 2015, arXiv:1506.04967. Available online: https://arxiv.org/abs/1506.04967 (accessed on 1 January 2021).
- Bolker, B.M.; Brooks, M.E.; Clark, C.J.; Geange, S.W.; Poulsen, J.R.; Stevens, M.H.H.; White, J.-S.S. GLMMs in Action: Gene-by-Environment Interaction in Total Fruit Production Wild Populations of Arabidopsis thaliana, Revised Version, Part 1; Corrected Supplemental Material Originally Published with https://doi.org/10.1016/j.tree.2008.10.008. Available online: http://glmm.wdfiles.com/local--files/examples/Banta_2011_part1.pdf (accessed on 1 January 2018).
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 7 October 2019).
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Halekoh, U.; Højsgaard, S. A kenward-roger approximation and parametric bootstrap methods for tests in linear mixed models–the R package pbkrtest. J. Stat. Softw. 2014, 59, 1–30. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, C.; Shi, B.E.; Liu, M. Robot navigation in crowds by graph convolutional networks with attention learned from human gaze. IEEE Robot. Autom. Lett. 2020, 5, 2754–2761. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term | Targets Detected | Targets Located | Search Efficiency | |||
|---|---|---|---|---|---|---|
| behavior | 0.25 | p = 0.89 | 2.26 | p = 0.35 | 2.83 | p = 0.32 |
| confidence | 10.53 | p = 0.0033 ** | 12.66 | p = 0.0014 ** | 7.32 | p = 0.013 * |
| target set | 0.83 | p = 0.68 | 3.63 | p = 0.18 | 5.48 | p = 0.074 |
| time | 2.34 | p = 0.18 | 1.53 | p = 0.27 | 0.060 | p = 0.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lucas, N.; Pandya, A. Multirobot Confidence and Behavior Modeling: An Evaluation of Semiautonomous Task Performance and Efficiency. Robotics 2021, 10, 71. https://doi.org/10.3390/robotics10020071
Lucas N, Pandya A. Multirobot Confidence and Behavior Modeling: An Evaluation of Semiautonomous Task Performance and Efficiency. Robotics. 2021; 10(2):71. https://doi.org/10.3390/robotics10020071
Chicago/Turabian StyleLucas, Nathan, and Abhilash Pandya. 2021. "Multirobot Confidence and Behavior Modeling: An Evaluation of Semiautonomous Task Performance and Efficiency" Robotics 10, no. 2: 71. https://doi.org/10.3390/robotics10020071
APA StyleLucas, N., & Pandya, A. (2021). Multirobot Confidence and Behavior Modeling: An Evaluation of Semiautonomous Task Performance and Efficiency. Robotics, 10(2), 71. https://doi.org/10.3390/robotics10020071