Abstract
Software requirements are primarily classified into functional and non-functional requirements. While research has explored automated multiclass classification of non-functional requirements, functional requirements remain largely unexplored. This study addressed that gap by introducing a comprehensive dataset comprising 9529 functional requirements from 315 diverse projects. The requirements are classified into five categories: ubiquitous, event-driven, state-driven, unwanted behavior, and optional capabilities. Natural Language Processing (NLP), machine learning (ML), and deep learning (DL) techniques are employed to enable automated classification. All software requirements underwent several procedures, including normalization and feature extraction techniques such as TF-IDF. A series of Machine learning (ML) and deep learning (DL) experiments were conducted to classify subcategories of functional requirements. Among the trained models, the convolutional neural network achieved the highest performance, with an accuracy of 93, followed by the long short-term memory network with an accuracy of 92, outperforming traditional decision-tree-based methods. This work offers a foundation for precise requirement classification tools by providing both the dataset and an automated classification approach.
1. Introduction
Natural language processing (NLP) has a long history of being widely applied in diverse domains, from digital humanities, social sciences, education, and bibliometrics to commercial content utilization. The software requirements present a unique challenge, unlike general text. The software requirements incorporate domain-specific terms, implicit constraints, semi-structured natural language, and specific behavior specification. Further, software requirements have critical importance for successful software project development because these serve as a key input to software design, implementation, test cases, and user manuals. The ambiguities, incompleteness, and variability due to the specification of requirements in natural language demand specialized NLP techniques. This makes requirement engineering a distinct subfield of applying NLP. The requirement classification using NLP is the most commonly researched area of requirement engineering in recent times [1].
Requirement engineering is the most critical phase of the software development life cycle (SDLC). It involves elicitation, specification, analysis, verification, validation, and management of software requirements. Every software development organization needs to build quality software products that satisfy stakeholder requirements. There are different types of software requirements, including business, user, and software requirements. Software requirements are the needs or conditions that a system must meet to achieve business and/or user objectives. They are categorized into functional requirements (FR) and non-functional requirements (NFR) [2,3].
FR defines the behavior, actions, and services that a system offers. Functional requirements are product features or functions that a developer must implement for users to fulfill their tasks. As a result, making them explicit for both the development team and the stakeholders is crucial. In general, functional requirements define how a system operates under specific conditions. NFR defines the qualities of a software product, such as performance, availability, security, privacy, usability, and constraints on the application development process [4].
Software requirement classification is the process of deciding which category software requirements belong to which category [5]. The ability to classify textual content based on attributes and features inherent to each text is text categorization. This is achieved through a supervised learning (SL) task, which is defined as detecting new document or statement classes based on the likelihood given by a training dataset of previously labeled texts [6].
The ever-increasing role of software products in all aspects of life has presented key challenges in managing their complexity and quality. This involves considerable effort to elicit, specify, and review the requirements of multiple stakeholders. The requirements are often expressed in inherently imprecise and unconstrained natural language. This leads to ambiguity and vagueness in requirements, which impacts project management (e.g., scheduling, budget) and technical management (e.g., translating requirements into design, code, test cases, and user manuals). Some experts have proposed non-textual formal modeling approaches such as Petri-nets and mclr2. These approaches require translation from natural language requirements, which entails training overhead, and they can also result in specification errors due to their complexity. Issues with natural language specifications, such as ambiguity, vagueness, and wordiness, can be mitigated through semi-formal specifications that utilize structural rules. The most used semi-formal specification method is EARS (easy approach to requirements syntax), which categorizes functional requirements into five classes: state-driven, event-driven, ubiquitous, unwanted behavior, and optional requirements [7,8,9].
Multiple research studies have proposed various datasets, including PURE, Promise, the Tera Promise repository, DOORS, CCHIT, and Aurora. These datasets lack background information such as project duration, source SRS documents, and diversity of projects across technical domains like artificial intelligence, mobile applications, and web applications. Additionally, the sizes of the datasets range from a few hundred to fewer than two thousand functional requirements. These publicly available datasets categorize software requirements into functional and non-functional types and further classify non-functional requirements. However, the subclasses of functional requirements are not explored within these datasets either [1,2].
The classification of software requirements into functional (FRs) and non-functional requirements (NFRs), as well as the subcategories of FRs and NFRs, faces challenges of disagreement among stakeholders and experts, who utilize various sentence structures for different classes and use different terminologies [7]. Furthermore, manually classifying requirements consumes a chunk of project time and effort, especially when working with large projects. The automatic software requirements classification saves effort and cost while improving accuracy. Many supervised machine learning (ML) techniques, e.g., random forest (RF), logistic regression (LR), naïve Bayes (NB), and deep learning (DL) techniques, e.g., short-term memory network (LSTM) and convolutional neural network (CNN), have been used for FRs and NFR classifications [10,11,12,13,14,15,16,17,18,19,20,21,22].
The automatic requirement classification supports the concept of human-machine collaboration through the utilization of the strengths of both humans and machines. The human strengths include the ability to engage with diverse stakeholders, careful interpretation of subtle customer behaviors, and taking small details into account during the requirement elicitation. However, the specified requirements may suffer from vagueness, ambiguity, and misclassification due to varying experience levels and complexities of natural language specification. Furthermore, the ergonomics variability also impacts their requirements engineering activities. For example, the ability of the users to effectively interact with the computer systems depends on their ability to make mental effort to process the information and take actions, their physical and organizational settings, e.g., working environment, product’s time to market, team size, workload load etc. In this context, machines help in mitigating these factors and support assurance of consistency (e.g., requirement specification and classification), saving manual effort, and overcoming human limitations. Therefore, human-machine collaboration supports in efficiency and effectiveness of the requirement classification process [23].
Automated requirement classification can be very useful in creating architectural components, e.g., ubiquitous requirements can identify global system behavior, such as system-wide services, event-driven requirements can be used to model behavior triggered due to external events, such as event handlers, input interfaces, service endpoints, etc. The state-driven requirements can be useful in identifying components responsible for the internal state of the system, such as workflow engines and session managers. The unwanted behavior requirements can be used to model exception handling and design safe mechanisms. The optional requirements can support the modeling of features such as plugins and plugin managers. The automated requirements classification can feed into automated test case generation because of the consistent syntax of EARS requirements. The NLP techniques can be used to extract entities using name entity recognition (NER) and condition-action pairs for automated testing. The use of EARS for architectural components identification can also help identification of components, services, and modules that require testing. It can also help prioritization of test cases, e.g., components implementing ubiquitous requirements will always be tested based on any change, the event-driven requirement will be used for testing based on API changes, and unwanted behavior will be used to test fault-injection testing. This traceability of requirements in software architecture, implementation, and testing can be effectively managed through CI/CD pipelines [24,25].
Therefore, this paper aims to classify software functional requirements using machine learning and deep learning techniques. The fundamental goal of this research is to:
- Create the largest benchmark dataset of 9529 functional requirements from 315 projects of different domains.
- Exploring five sub-classes of functional requirements using EARS and pre-processing using natural language processing techniques.
- Performing ML and DL experiments to explore the best model according to evaluation measures.
2. Related Work
Multiple studies have performed classification of software requirements using machine learning and deep learning models [2,17,19,26,27,28,29,30,31,32,33]. This section briefly discusses a few of the related studies. It is observed that functional requirements are not further classified, such as EARS classification, to the best of our knowledge.
Shred et al. used the public requirement document PURE, which contains 1846 requirement sentences. All the requirements are written in the natural English language [10]. They classified software requirements. They used different NLP and ML techniques. They used supervised ML algorithms such as LR, SVM, and NB. To consider a state-of-the-art classifier, they used a CNN. They used different evaluation measures: precision, recall, and F1-score. They achieved an accuracy of 84% to 87% using the statistical vectorization methods, and applying a word embedding semantic approach, they obtained a higher accuracy of 88% to 92%.
Quba et al. used PROMISE datasets of requirements [11]. They employed different natural language preprocessing approaches, such as case folding, tokenization, stop word removal, stemming, and feature selection approaches such as bag of words. Support vector machine (SVM) algorithm and k-nearest neighbor (KNN) algorithm are used to train ML models. SVM performed better for binary classification with precision, recall, and f1-score of 0.90, 0.90, and 0.90, followed by KNN with precision, recall, and f1-score of 0.80, 0.80, and 0.80. The subcategories of NFRs were classified with precision, recall, and f1-score of 0.68, 0.67, and 0.66, respectively, and followed by KNN with precision, recall, and f1-score of 0.56, 0.48, and 0.49, respectively.
Rahimi et al. used the PROMISE dataset to classify software requirements and used several NLP techniques, such as data pre-processing techniques, tokenization, lemmatization, and deep learning models such as LSTM, GRU, BiLSTM, and a CNN to categorize the software needs [12]. The binary categorization phase of the two-phase classification system had 95.7 percent accuracy, and the non-functional and functional requirements multiclass classification phase had 93.4 percent accuracy.
Younas et al. used the PROMISE and CCHIT datasets to classify non-functional requirements [13]. The PROMISE dataset contains 625 requirements, 255 were FRs, and 370 were NFRs, and CCHIT contains 306 requirements, 228 were FRs, and 78 were NFRs, and others. All these requirements were cleaned through preprocessing techniques like stop word removal, removing punctuation mark tokenization, and lemmatization will be applied. They used Semi-supervised learning for classifying requirements. Precision, recall, and f-measure were 75%, 59%, and 64%, respectively, for the PROMISE dataset; on the other hand, the recall value was larger than the PROMISE dataset, and the precision value of CCHIT was smaller than the PROMISE dataset.
Winkler et al. used the DOORS database, which contains all the required documents of their company [33]. In total, 89 documents are selected from the database, and the quality of the dataset is improved with the help of text clustering and removing stop words. A deep learning model, i.e., the convolutional neural network model, is trained on the dataset. The model achieved a precision of 0.73 and a recall of 0.89.
Merugu et al. employed supervised machine learning algorithms to automatically classify software quality requirements [34]. They used applications of deep learning with supervised learning techniques for feature extraction in this study. They employed the Aurora 2 dataset, which contains raw data files, and the MATLAB 2017 program for this [35]. Over learning tasks, deep learning models produce more desirable performance results. SVM, a convolutional neural network model, and a multilayer perceptron model were employed. CNN model achieved the higher precision, recall, and F1 score of 0.879, 0.939, and 0.909, respectively.
Mavin et al. discussed ambiguity in three forms, i.e., lexical, referential, and syntactical, which occur due to varying ergonomics of requirement engineers [7]. Lexical ambiguity suffers from multiple interpretations of a requirement due to the use of a phrase or word that may have more than one meaning. Referential ambiguity involves confusion caused by referring to two things. Syntactic ambiguity could be caused because of the structure of the sentence. Another challenge of natural language specification is to ensure the number of details in the requirements and a high probability of either missing the key details or duplicating one requirement in multiple instances. The lack of language proficiency also causes wordiness [36]. The issues due to the ergonomics variability of humans induce a lack of verifiability, inappropriate implementations, and the attainment of the requirements. The semi-formal specification of requirements using EARS and requirements preprocessing using NLP techniques, and automatic classification of requirements, mitigates the discussed limitations through reduction in variability, improvement in clarity, and consistent formulation of requirements [37].
3. Dataset Construction
We compiled software Requirement Specification documents of final year projects (FYPs) for Bachelor of Science in Computer Science and Bachelor of Science in Software Engineering students. These projects were completed between 2017 and 2020 at COMSATS University Islamabad, Lahore campus, Pakistan. The purpose of creating the dataset is to create a benchmark of functional requirements in the EARS format that reflects an extended behavioral viewpoint of functional requirements. Each FYP report is created using a template document that contains a requirement analysis chapter and specifies functional and non-functional requirements. Figure 1a represents the structure of the requirement analysis chapter. Each FYP document is revised by students based on midterm evaluations and faculty review. The students study the requirements engineering concepts and the software development life cycle, along with programming courses, before starting the FYP project. The students defend their project report and product in front of the software engineering and computer science faculty and external reviewers from either the software industry or senior faculty members of other universities.

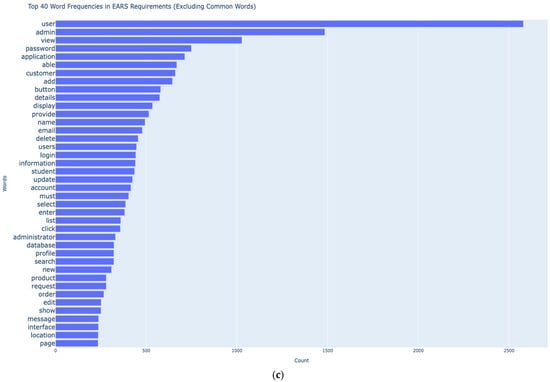
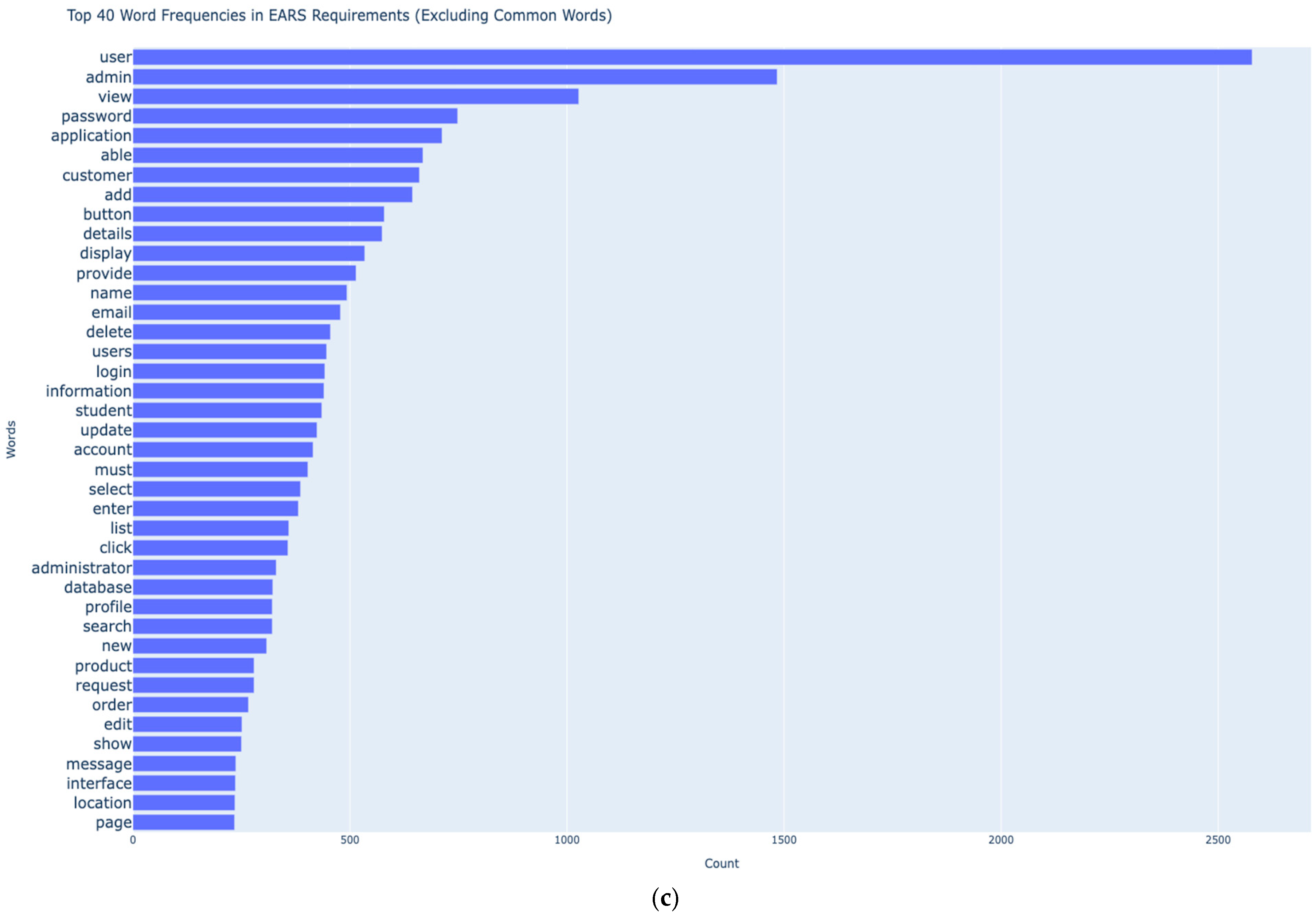
Figure 1.
(a) Structure of Requirements Analysis Chapter. (b) Word Cloud of EARS Requirements. (c) Frequency of top 40 keywords [tokens] in the dataset.
The guidelines in chapter 1 of the SWEBOK (Software Engineering Body of Knowledge) and ISO/IEC/IEEE 29148:2018 are used to validate each raw functional requirement statement [38]. According to ISO/IEC/IEEE 29148:2018, “A functional requirement is a statement that translates or expresses a need and its associated constraints and conditions. A requirement can be written in the form of a natural language or some other form of language. If expressed in the form of a natural language, the statement should include a subject and a verb, together with other elements necessary to adequately express the information content of the requirement. A requirement shall state the subject of the requirement (e.g., the system, the software, etc.), what shall be done (e.g., operate at a power level, provide a field for), or a constraint on the system.”
3.1. Dataset Description
The proposed dataset contains 9529 functional requirements, which are extracted from 315 software requirement specifications (SRS) documents of completed BS (CS) and BS (SE) final year projects (FYP) of CUI, Lahore. Raw software requirements from the SRS document were extracted into an MS Excel file. The guidelines of the EARs template are used to identify the type of functional requirements and apply its boilerplate. EARS was created by Alistair Mavin and others from Rolls-Royce PLC and presented at the 2009 requirement engineering (RE09) conference. EARS distinguishes 5 different types of requirements: state-driven, event-driven, ubiquitous, optional, and unwanted behavior.
This functional requirement dataset includes 5 types of requirements, and these five are ubiquitous, event-driven, state-driven, optional, and unwanted behavior. The total number of ubiquitous requirement instances in the dataset is 4615, event-driven requirement instances are 1415, state-driven requirement instances are 3150, optional feature requirement instances are 108, and unwanted behavior requirement instances are 252. EARS template reduced the obvious wordiness problem of raw requirements. The average number of words in the smallest requirement before applying the EARS boilerplate was 4. The average number of words in the smallest requirement after applying the EARS boilerplate was 8.
Table 1 presents the metadata of the proposed dataset. In this dataset requirement, types of requirements, SDLC models, programming language, areas, and domains are explained. This dataset contains the requirements of projects that were completed during the years 2017, 2018, 2019, and 2020.

Table 1.
Functional Requirement Dataset Description.
3.2. Validity Threats
The dataset comprises more than 9000 requirements spanning across more than 16 software application domains in 315 software development projects. This poses a threat to the validity of requirements because of the ergonomic variabilities of requirement engineers, such as their software engineering background, experience, and expertise in requirement engineering. These variabilities may induce syntactical and lexical ambiguities across the requirements statements [7]. This threat is mitigated because all the requirements are specified by the undergraduates of software engineering and computer science who have studied (more than 130 credit hours) and applied the requirement engineering process. Furthermore, these requirements are rigorously verified and validated by project members, supervisors, and external reviewers throughout the software development life cycle. All the projects are completed, and the final set of requirements in the SRS reflects the behavior of actual software. The raw requirements are verified according to the guidelines in chapter 1 of the SWEBOK (Software Engineering Body of Knowledge) and ISO/IEC/IEEE 29148:2018. In addition, there is another validity threat of misclassification when raw requirements are transformed into EARS types. The dataset provides raw requirements along with their EAR types to ensure transparency and future corrections, if any. The task of requirements transformation is distributed between the two annotators/authors of this study, and each author verified the type of transformed requirements by the other annotator. Eventually, two other authors verified all the annotated EARS requirements.
In the future, we will explore the role of reinforcement learning (RL) in the annotation of EARS requirements. We will investigate the role of RL for an adaptive and dynamic annotation process. We can train RL agents to annotate the EARS requirements using an environment that treats requirements as states, labels as requirement types (e.g., ubiquitous), and rewards based on human-machine agreements on correct annotation [39,40,41].
4. Multiclass Classification Methodology
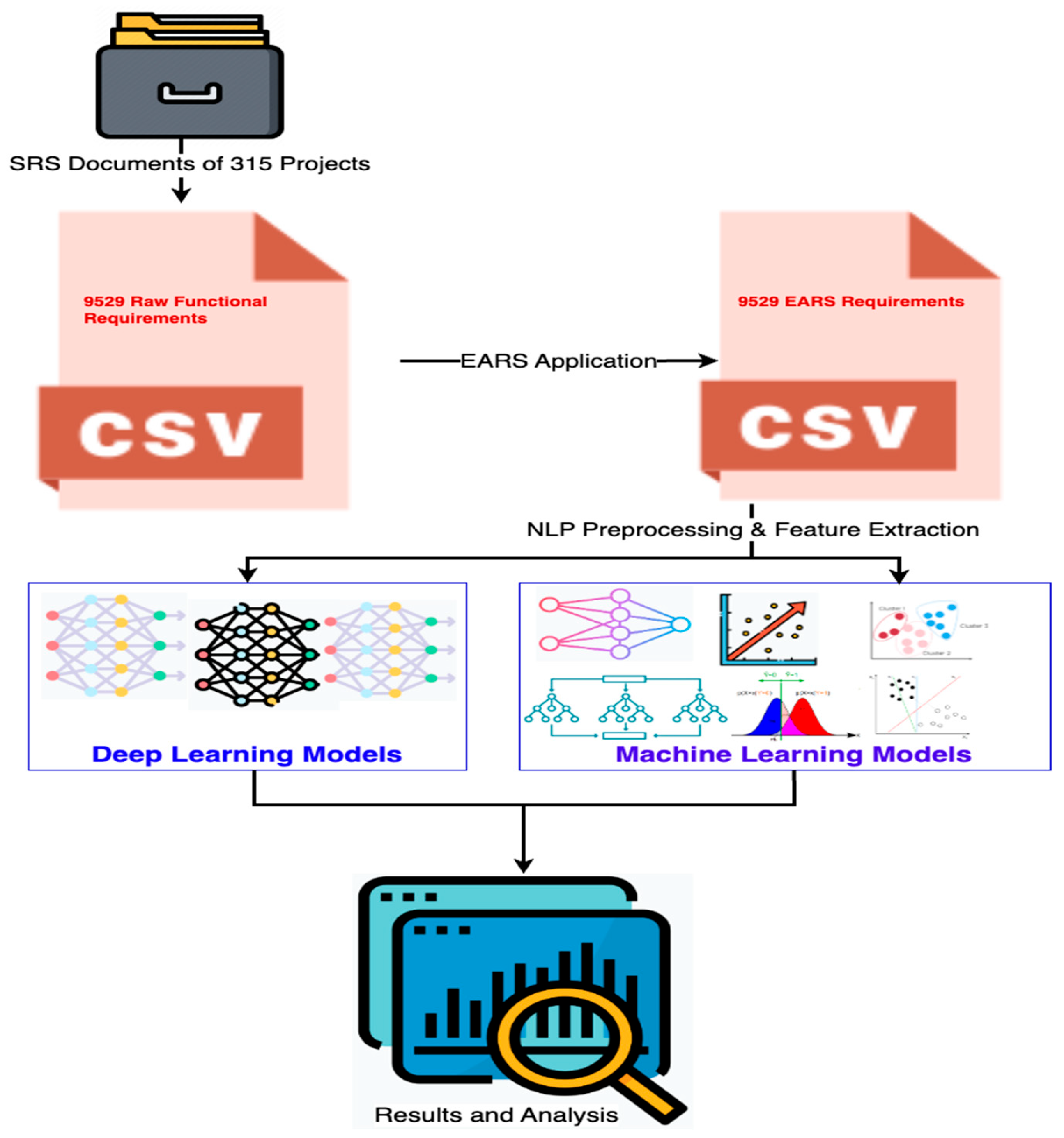
The overall approach of requirements classification is highlighted below in Figure 2. The following sections provide a detailed discussion of each step in the classification approach.
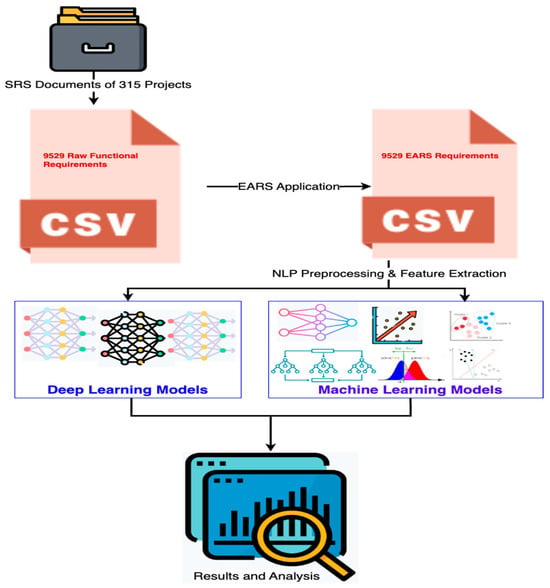
Figure 2.
Proposed Approach of Multiclass Classification of EARS Requirements.
- EARS Application
- EARS Examples
- NLP Pre-processing
- Feature Extraction
- Classification Models and Evaluation Methods
- Results and Analysis
4.1. EARS Application
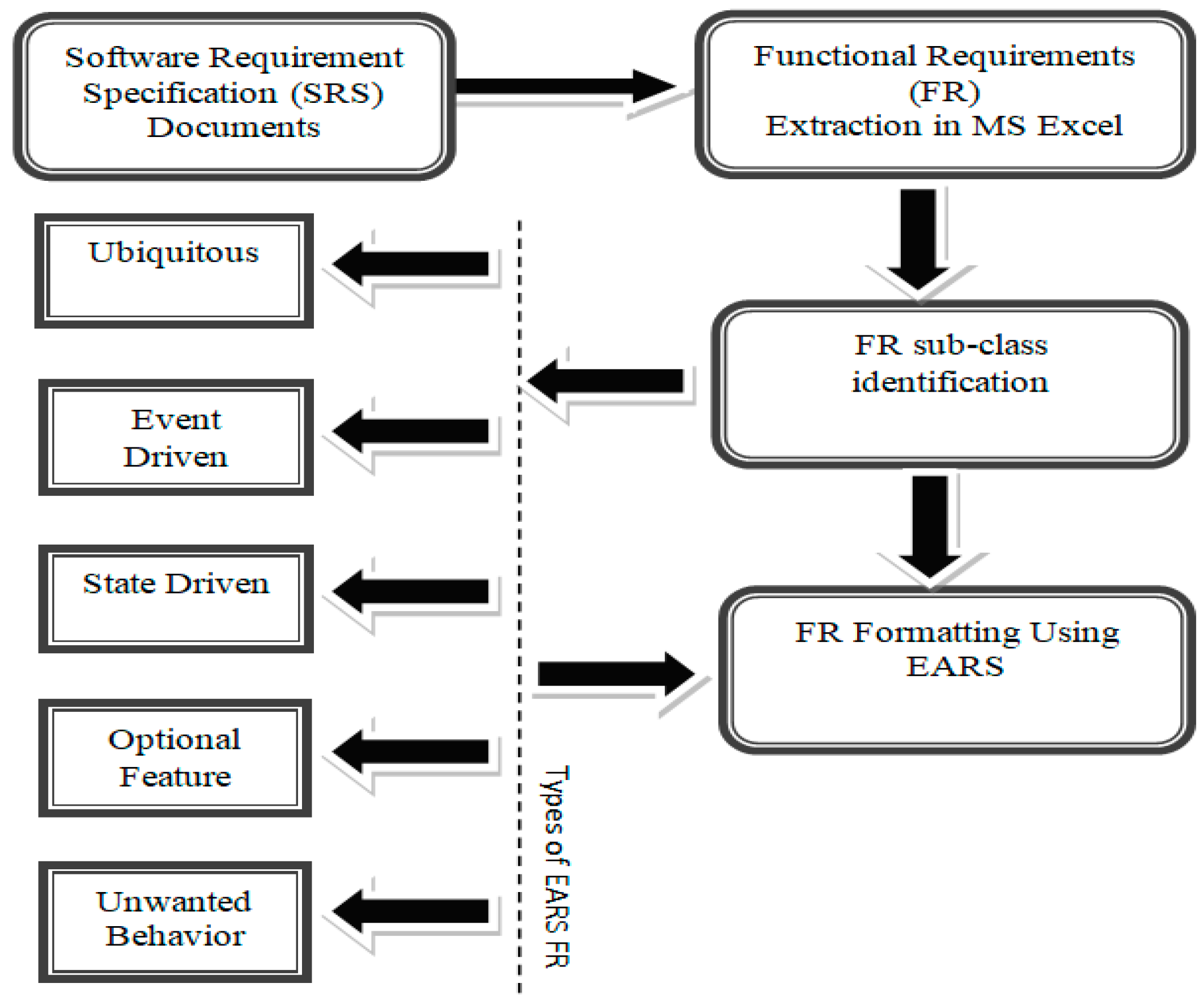
The raw requirements extracted from SRSs are first formatted using the EARS boilerplate. Figure 3 illustrates the EARS application process.
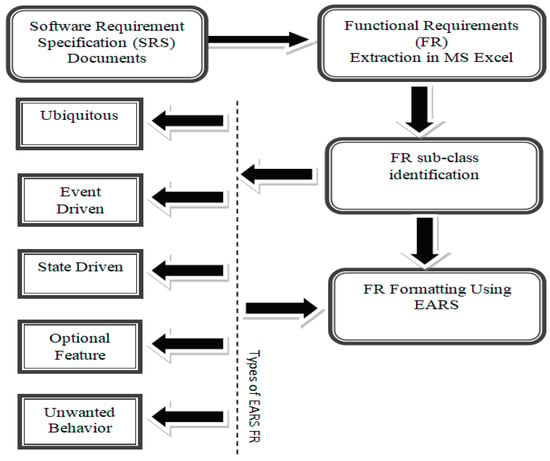
Figure 3.
EARS Boilerplate Application Process.
Here are some examples of functional requirement types, i.e., ubiquitous, event-driven, state-driven, optional, and unwanted behavior.
4.2. Examples
We took different examples of standardized requirements, which are formatted using EARS.
Ubiquitous:
Syntax: The <system name> shall <system response>
Raw Requirement: Admin must verify new brands.
Standardized Requirement: The system shall allow the admin to verify new brands.
Event-driven:
Syntax: WHEN <optional preconditions> <trigger> the <system name> shall <system response>
Raw Requirement: The package request will be sent to the selected driver, and the rider will be notified after the driver has accepted the package request.
Standardized Requirement: When the driver has accepted the package request, the system shall send the package request to the selected driver, and the rider will be notified.
State-driven:
Syntax: WHILE < in a specific state> the <system name> shall <system response>
Raw Requirement: The teacher can upload the assignment along with the solution along samples.
Standardized Requirement: While the teacher is logged in, the system shall allow the teacher to upload the assignment along with the solution.
Unwanted behavior:
Syntax: IF <optional preconditions> <trigger>, THEN the <system name> shall <system response>
Raw Requirement: The application shall display an error message if the email and password are incorrect.
Standardized Requirement: If the email and password are incorrect, the system shall display an error message.
Optional Feature:
Syntax: WHERE <feature is included> the <system name>shall <system response>
Raw Requirement: The bake my day shall enable the customer to select the payment method (credit card, debit card, master card, Visa card, or cash on delivery).
Standardized Requirement: Where credit card, debit card, master, Visa card, or cash on delivery are available, the system shall allow the customer to select the payment method.
4.3. NLP Pre-Processing
It aims to clean, normalize, and format data because it influences the prediction power of machine learning and deep learning models. The requirements (text) are first transformed to lowercase, followed by removing null values and stop words. These are sentence elements that have a detrimental impact on multi-classification issues. Prepositions, pronouns, adverbs, and conjunctions are examples of stop words. Later, tokenization is performed, which is a process of splitting or converting sentences, words, paragraphs, or documents (text) into tokens of words. Later, we used the lemmatization procedure. This method was chosen since it outperforms stemming in terms of converting individual words to their origin and finding the appropriate the right base word.
4.4. Feature Extraction
TF-IDF (Frequency-Inverse Document Frequency) calculates the importance of each word in all the software requirements of the whole dataset. The TF-IDF values of all the words are arranged as features in the matrix. Each TF-IDF value combines two concepts, i.e., TF (term frequency) and IDF (inverse document frequency). TF is the number of occurrences of a word among multiple instances. IDF is several instances containing the word. Each example of a requirement is represented as a vector in the matrix. The TF-IDF for each word is calculated as follows:
where: t refers to ‘terms’ and i refers to ‘instances of requirements’. ft,i refers to the raw count of terms in an instance.
TF-IDF (t, i) = TF (t, i) * IDF(t)
TF (t, i) = log (1 + ft,i)
IDF(t) = log [n/DF(t)] + 1
4.5. Classification Models and Evaluation Methods
The vectorized data was then utilized for training and performance testing by using machine and deep learning algorithms, for example, k-nearest neighbor, SVC, multinomial naïve Bayes, GNB, Bernoulli naïve Bayes, RF, logistic regression, LSTM, and convolutional neural network etc.
Multiple evaluation measures are used to understand the performance of classifiers in deep learning and machine learning tasks.
4.5.1. Accuracy
The degree of proximity to actual values is known as accuracy. One of the most essential evaluation metrics is accuracy, which shows a classifier’s overall performance. These evaluation measures are based on a confusion matrix. The is based on the count of true positives (tp), false positives (fp), true negatives (tn), and false negatives (fn).
Accuracy = True Positives + True Negatives/True Positives + True Negatives + False Positive + False Negative
4.5.2. Precision
The precision is calculated as the sum of all positive prediction values.
Precision = True Positives/True Positives + False Positives
4.5.3. Recall
The recall is a true positive rate, i.e.,
Recall = True Positives/True Positives + False Negatives
4.5.4. F1-Score
The F1 score is a recall and precision relationship metric. Only if both recall and precision are high can it be high.
F1-score = 2 × (Precision × Recall/Precision + Recall)
4.5.5. Loss
The difference between predicted and true values was calculated using loss. “Sparse categorical cross-entropy” was utilized in the instance where each input belonged to one of the numerous categories. This calculation is simplified using the following formula, where S stands for samples, C for classes, and (SC) for samples belonging to the C class.
Loss = −log p(SC)
4.5.6. ROC Curve
The performance metrics, such as precision, recall, and F1-score, use confusion metrics and are sensitive to the class skewness [10,23,24]. These performance metrics depend on the distribution of instances in a dataset. The number of instances for each of the five classes of functional requirements is different, which will cause machine learning models to make biased predictions. Therefore, the Receiver Operating Characteristic (ROC) graph is used that measure the algorithm’s performance, being insensitive to class skewness and unequal classification error costs. The true positive rate is depicted on the Y axis, while the false positive rate is represented on the X axis. The two-dimensional area under the entire ROC curve from axis (0, 0) to (1, 1) is called the area under the curve (AUC). The coverage of a higher amount of AUC represents less effect of dataset limitations on the prediction performance.
4.5.7. Hyperparameter Analysis
The LSTM and CNN models were trained with the aim of hyperparameter tuning. The LSTM model was tuned to improve temporal feature learning. The maximum vocabulary size (MVS) was set to 1500, and maximum sequence length (MSL) was set to 200, and the maximum embedding dimensions (MED) were set to 300. The optimum unit size (OUS) was explored between 32 to 128. The use of dense layer with 64 neurons and ReLU activation was used for non-linear transformation. The higher rates of dropout rates were tested, and a lower dropout rate of 0.1 was applied. The CNN model was improved using hyperparameter tuning by setting MVS between 10,000 and 15,000 to keep a balance between expressiveness and overfitting. The MSL was set to 200 based on the dataset size and structure of the functional requirements. The embedding dimension is set between 100 and 300 to make more sense of semantic details. Adjustments are made in CNN architecture, pooling strategies, filter sizes, and kernel sizes were adjusted with Conv1D layers on 64 and 128 filters and sequence reduction through MaxPooling1D layers. Dropout is set to 0.1 to avoid overfitting after exploring it up to 0.5. The CNN model is trained up to 8 epochs. The hyperparameter tuning is continuously refined based on loss trend and validation accuracy.
5. Results and Analysis
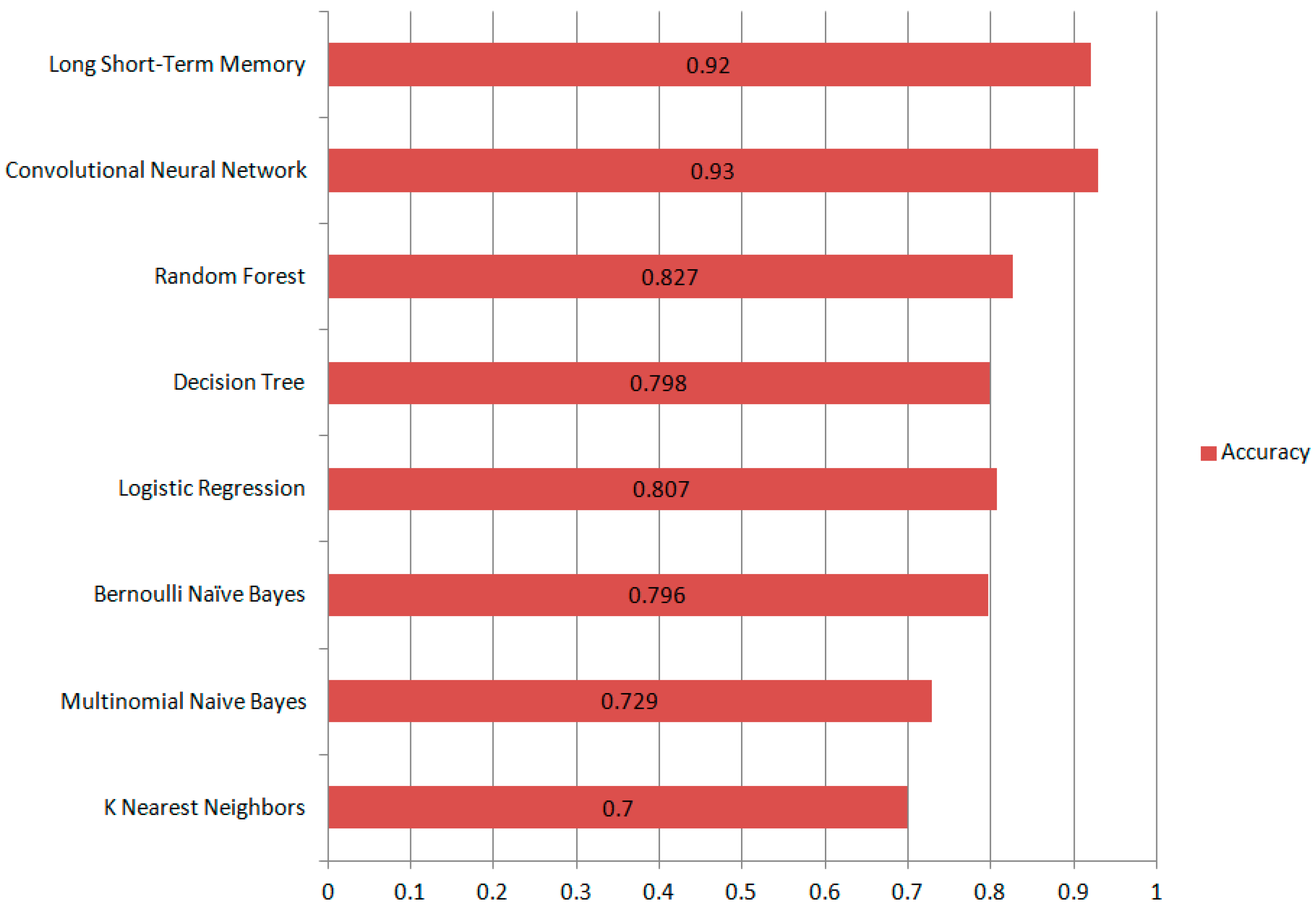
This section analyzes the performance of machine learning and deep learning models. Figure 4 presents the accuracy of all the deep learning and machine learning models. CNN, Long Short-Term Memory, BNB, Random Forest, DT, and Logistic Regression showed higher results. Selecting the appropriate machine learning algorithm is often the most challenging aspect of achieving accurate results. When machine learning features are manually extracted, the risk of classification errors increases.
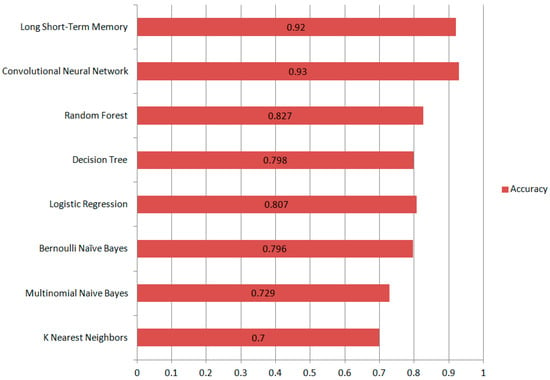
Figure 4.
Accuracy Measures of ML and DL models.
Most machine learning methods perform well when class distributions are balanced, as they are typically designed to maximize accuracy while minimizing errors. In our case, the imbalanced data can significantly reduce the accuracy of our model. Because our dataset is skewed, the outcomes of machine learning approaches are lower. However, this is the challenge that comes with large real-time data.
Deep learning models perform well on both binary and multiclass classification problems due to their hierarchical representation learning, which automatically captures both high-level and low-level features simultaneously. Furthermore, deep learning models such as Long Short-Term Memory (LSTM) networks learn features dynamically during each iteration of the classification process. Generally, the hidden layers play a crucial role; deeper models can learn more complex patterns, leading to better performance. Due to the large architecture of deep learning models, they contain a vast number of parameters known as weights and biases. These parameters are adjusted during training, allowing the models to handle even imbalanced data effectively. As a result, deep learning models often outperform traditional machine learning models. More hidden layers enable deep learning models to effectively distinguish between complex and non-linearly separable data. The weights among hidden layers are adjusted to form non-linear decision boundaries that effectively discriminate between training examples. As a result, misclassifications are significantly reduced, and deep learning models have much better accuracy than traditional machine learning algorithms.
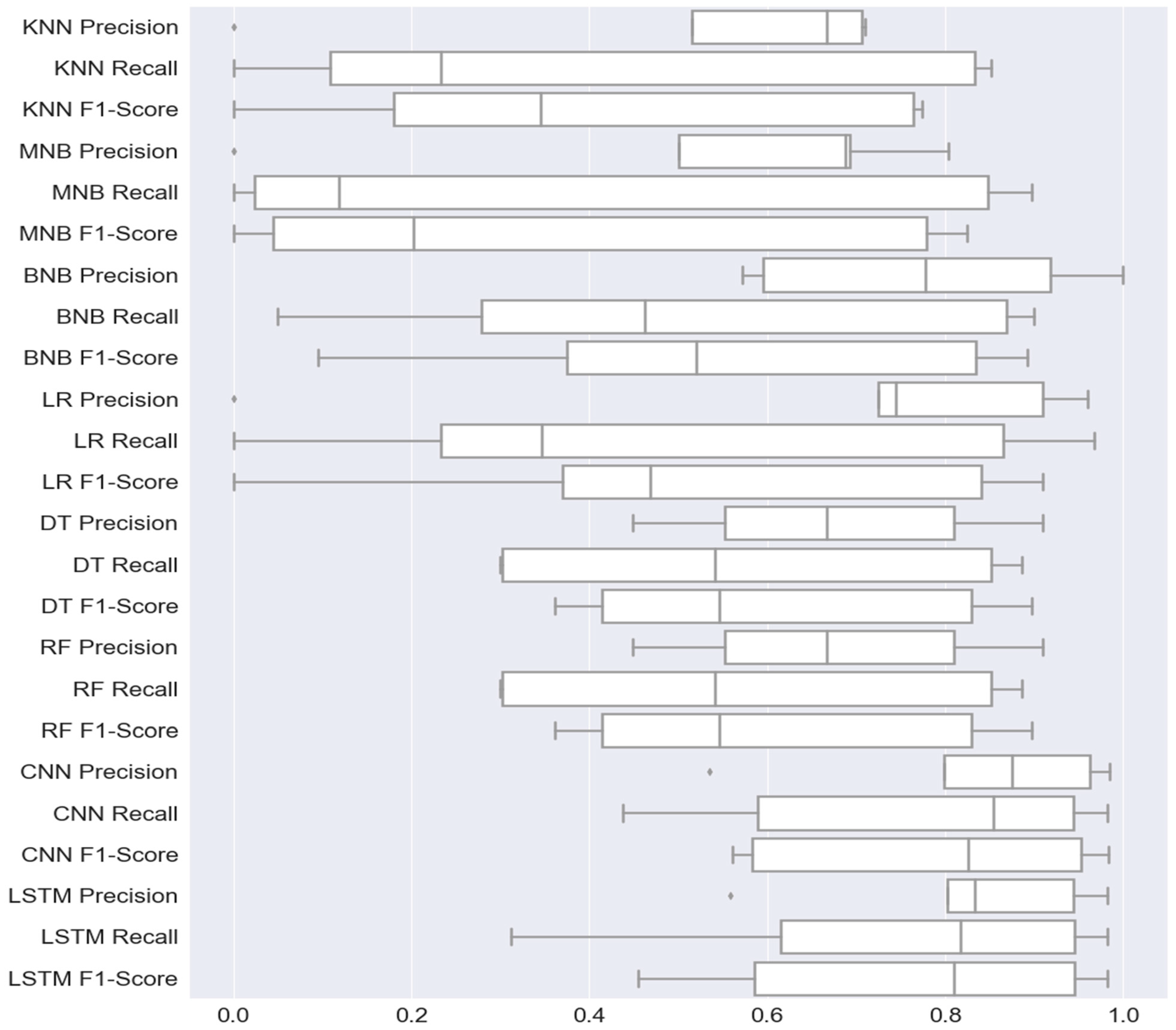
Figure 5 shows the box plot that depicts the minimum, first quartile (Q1), median, third quartile (Q3), and maximum values of multiple ML and DL models. It can give you information about your outliers and their values. The figure shows the precision, recall, and F1 score of DL and ML models. The CNN model achieved the highest F1 score because the CNN model with maximum precision, recall, and F1 score is 0.99, 0.98, and 0.99, respectively. The random forest model performs best among ML models with a maximum precision, recall, and F1 score of 0.99, 0.98, and 0.99, respectively.
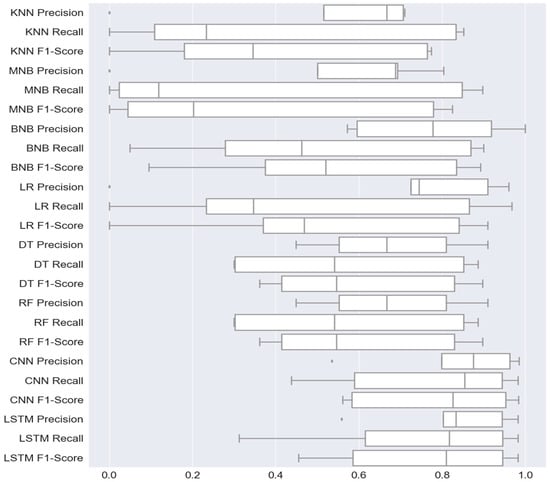
Figure 5.
Boxplot of Functional Requirements Classification Models.
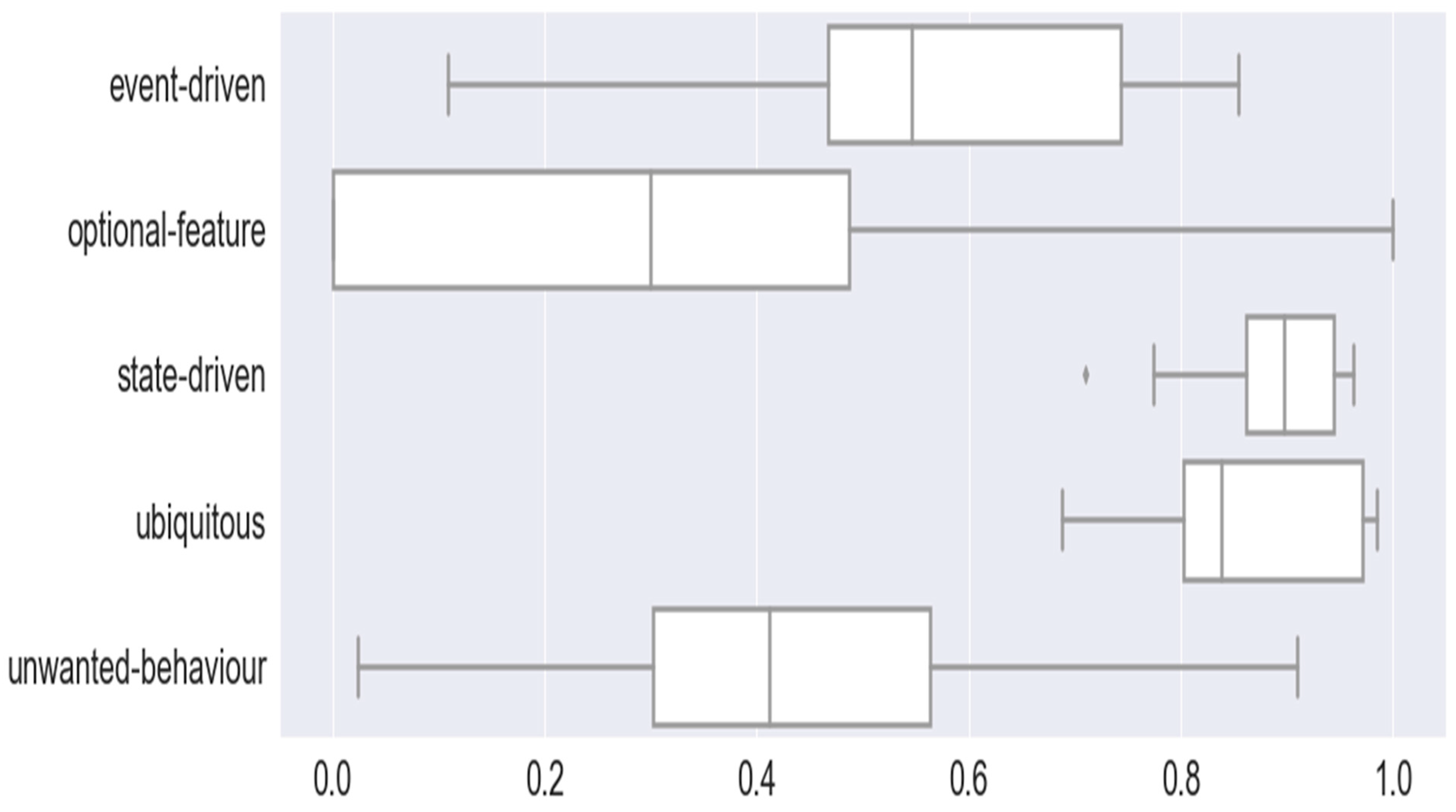
Figure 6 represents the box plot of F1-scores of EARS classification based on all the trained ML and DL models. The event-driven and ubiquitous classes are predicted closely by all the models. The optional features and unwanted behavior classes are generally predicted at lower F1-scores. The median and maximum F1-scores of event-driven class prediction are 0.55 and 0.83. The median and maximum F1-scores of the optional-feature class prediction are 0.3 and 1. The median and maximum F1-scores of state-driven class prediction are 0.90 and 0.98. The median and maximum F1-scores of ubiquitous class prediction are 0.70 and 0.99. The median and maximum F1-scores of unwanted-behavior class prediction are 0.4 and 0.9.
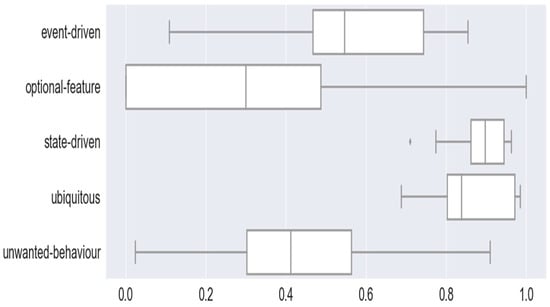
Figure 6.
Box Plots of Multiclass Classifications of EARS Functional Requirements.
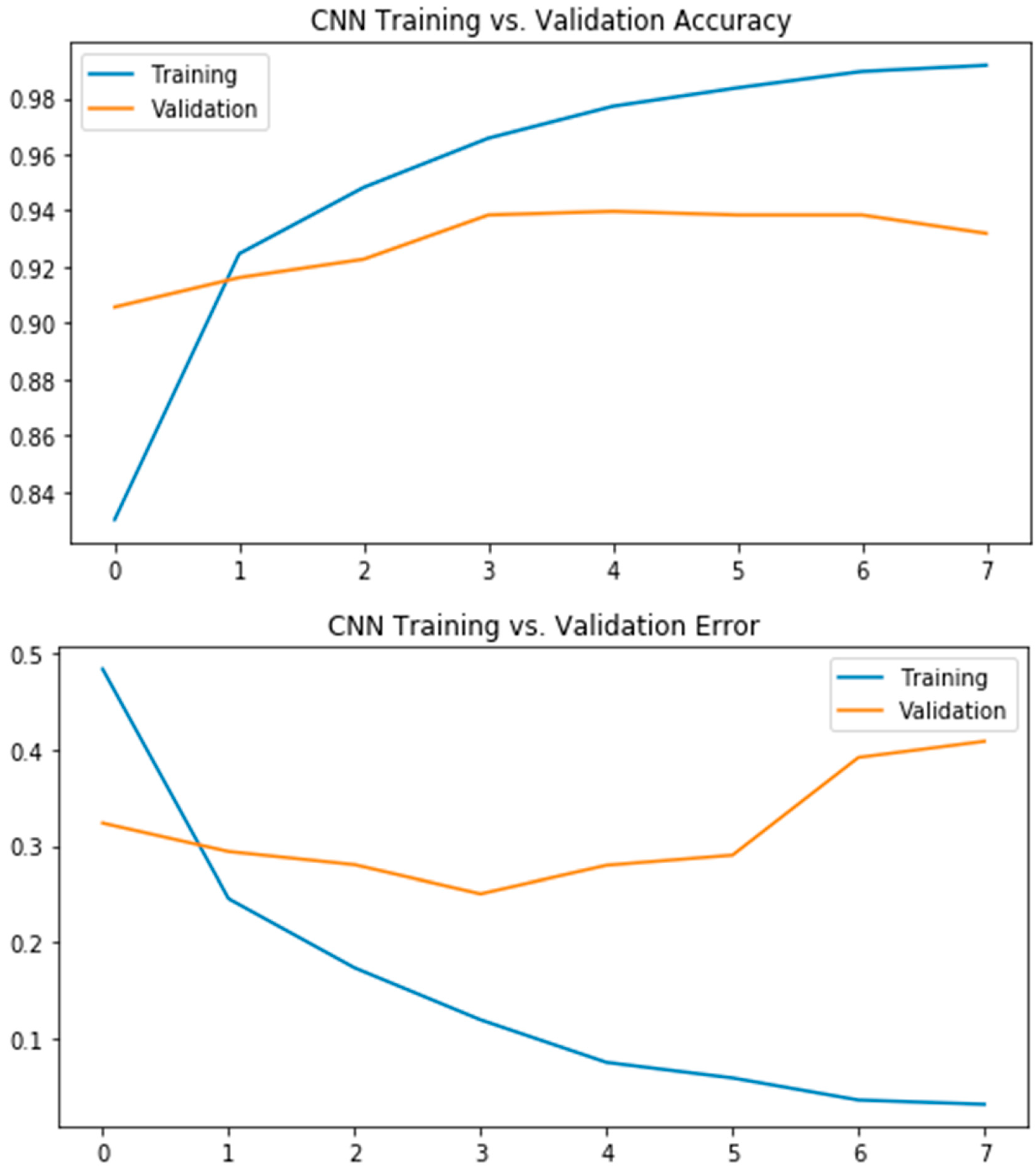
Figure 7 represents the line graph of training and validation accuracies of the convolutional neural network (CNN) model. The model is run for 8 epochs, and the training and validation accuracies against each epoch are plotted using the line plot. The graph shows that the training accuracy starts at 84% in the first epoch and keeps on increasing until the last epoch, where it almost converges to the training set and achieves an accuracy of more than 99%. The validation accuracy starts at around 91% and finishes at around 92% accuracy on the validation set. The graph represents the error of the convolutional neural network (CNN) for the training and validation sets. The model is run for 8 epochs, and the errors for each epoch are calculated and plotted against each epoch. The training error starts at around 0.5 and keeps on decreasing for the next epochs until the last epoch, for which the error is nearly zero and the model almost converges to the training set. While for the validation set, the error starts at nearly 0.3 and ends at around 0.4. The validation error reduces for the first three epochs and then starts increasing a little bit.
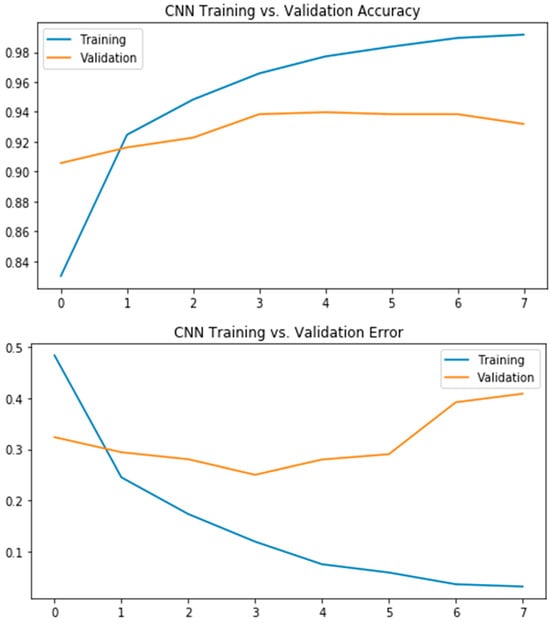
Figure 7.
Accuracy-Error Curve for CNN Model.
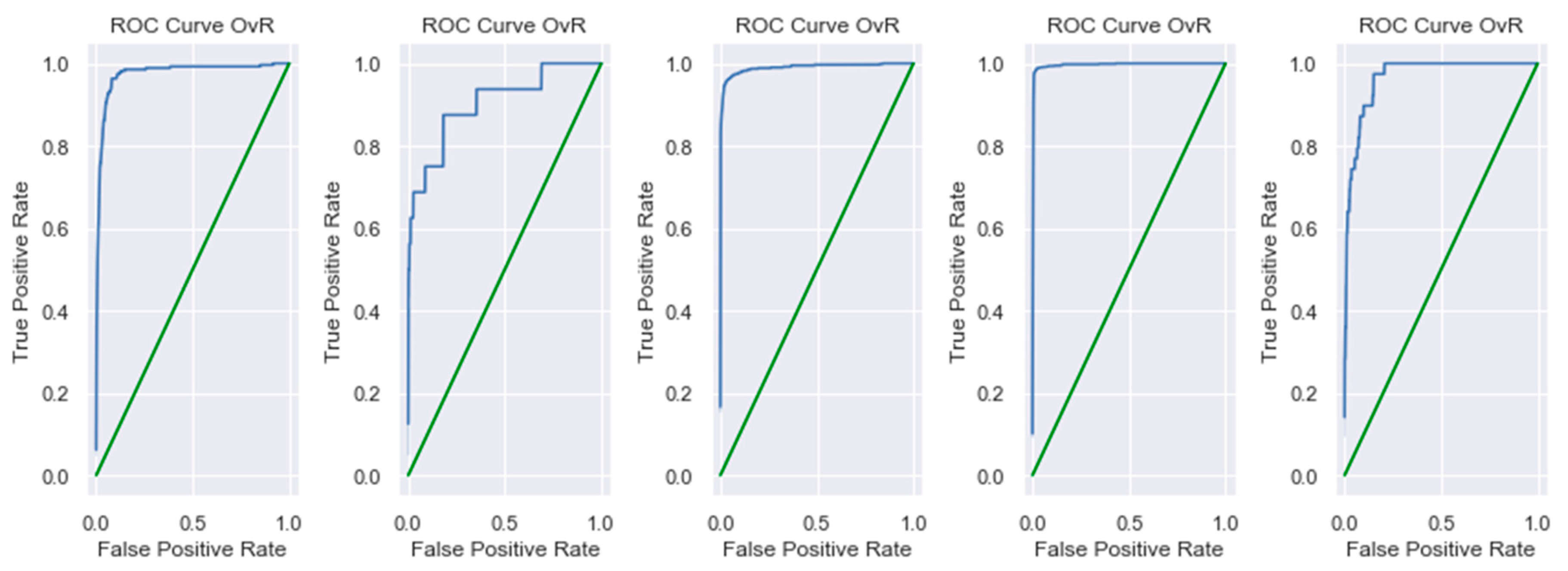
Figure 8 represents ROC and AUC statistics based on the CNN model. The ROC-AUC is a widely used metric for evaluating the performance of classification models, particularly in assessing their ability to distinguish between classes. A higher AUC value indicates better class separation and, consequently, a more effective model. AUC-ROC curves are frequently used to illustrate the relationship and trade-off between sensitivity and specificity for each possible cut-off for a test or a collection of tests. The area under the ROC curve shows how effective the test is at solving the underlying problem. The ROC curve depicts the ratio of true positives to false positives, emphasizing the sensitivity of the classifier model. The average ROC AUC OvR is 0.97, which reflects how well the classifier was in predicting each class.
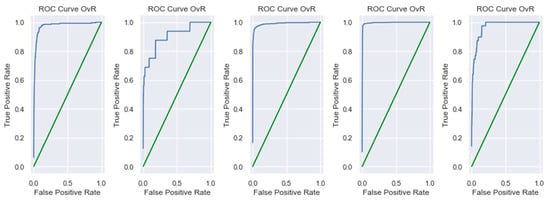
Figure 8.
ROC Curve 0vR.
The ROC curves for CNN and LSTM validate that both models performed without bias. It is also important to analyze their complexity and interpretability. The LSTM models are more complex than CNN in terms of architecture (sequential vs. parallel), training speed (slower vs. faster), memory usage (higher vs. lower), and patterns exploration (long-term dependencies vs. local patterns). The requirement engineering datasets are smaller in size compared to other text-based datasets used in plagiarism, sentiment analysis, user reviews, etc. CNNs are more interpretable based on understanding the feature mapping and pattern matching, as compared to the consideration of the temporal internal state in LSTM models.
The human factors and ergonomic design may significantly impact the input and output of the training models. The quality of the dataset plays a vital role in the performance of the training models; therefore, the validity threats of datasets and mitigating factors are discussed in the dataset description section. The deep learning models have shown better performance because of hierarchical feature extraction. The CNN models recognize local patterns, and LSTM models recognize the contextual dependencies, which can adjust to syntactical and semantic variations in the requirements due to human and ergonomics factors and diverse software application domains. The requirement engineering is a human-centered domain, and the CNN model has better interpretation than LSTM due to clearer feature mapping, and it offers better traceability of model working and feedback for decision making in project management.
6. Conclusions
Requirement classification is a popular machine learning problem that straddles the natural language processing and artificial intelligence disciplines. Functional requirements classification into its subcategories has not gained attention. No state-of-the-art discussed the classification of functional requirements subcategories such as ubiquitous requirements, event-driven, unwanted behavior, optional, and state-driven requirements. Furthermore, previously used datasets were very small and not formatted in standard syntax. It was made to fill this research gap with the help of this research study by creating a large-scale software functional requirement dataset from many domains and reducing the natural language problem by using the EARS (Easy Approach to Requirement Syntax) boilerplate.
In this research, a larger dataset of 9529 FRs is proposed. This dataset is constructed through functional requirements extraction from different software requirements specification documents of 315 projects of heterogeneous domains like education, game, law, broadcasting, online shopping, etc. Requirements were originally written in natural language. Often, unstructured natural language requirements can be ambiguous, incomplete, and repetitive. So, the EARS boilerplate is used to write the requirements with the help of syntax to reduce the above issues. The dataset was evaluated with the help of experiments based on state-of-the-art NLP techniques and multiple classical machine learning (ML) and deep learning models (DL). Several ML models (Bernoulli Naive Bayes, Multinomial Naïve Bayes, SVM, Logistic Regression, Random Forest, Decision Tree, KNN) are explored along with DL models such as CNN, and LSTM for software functional requirement classification tasks. DL models of CNN and LSTM performed overall better than classical ML models. These CNN classifiers got the highest accuracy of 0.93, and the LSTM classifier achieved an accuracy of 0.92 on multiclass classification tasks. This dataset can be further extended with more requirements. This study encourages existing function requirements datasets to be transformed into EARS categories of requirements and further creation of the EARS dataset. It will enable deeper analysis of functional requirements.
This research addresses a key research gap in the classification of subcategories of functional requirements. In addition, it promotes clear and consistent requirements specification using the EARS approach. The standardization of requirements formulation and automated classification improves the communication between stakeholders and software professionals and reduces the need for experts for requirement classification. It supports computer-aided requirement engineering practices, which aim to ensure reusability, traceability, and effective management of software requirements. The use of semi-formal specification, NLP, and training models enables interdisciplinary collaboration among software engineers, domain experts, AI practitioners, and human factor specialists. This study encourages the transformation of requirements corpora into forms such as EARS to promote inclusive, scalable, and intelligent requirement engineering processes.
In future work, we will explore reinforcement learning (RL) for adaptive annotation of EARS requirements by training agents to label requirements as EARS types using a reward-driven framework based on human-machine agreement.
Author Contributions
Conceptualization, T.T.; Methodology, B.H.; Validation, B.H.; Formal analysis, B.H.; Resources, T.T.; Writing—original draft, K.T.; Writing—review & editing, T.T. and H.J.; Project administration, H.J. and B.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original data presented in the study are openly available in Zenodo at https://doi.org/10.5281/zenodo.15834954.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhao, L.; Alhoshan, W.; Ferrari, A.; Letsholo, K.J.; Ajagbe, M.A.; Chioasca, E.-V.; Batista-Navarro, R.T. Natural Language Processing for Requirements Engineering. ACM Comput. Surv. 2021, 54, 55. [Google Scholar] [CrossRef]
- Rahimi, N.; Eassa, F.; Elrefaei, L. An Ensemble Machine Learning Technique for Functional Requirement Classification. Symmetry 2020, 12, 1601. [Google Scholar] [CrossRef]
- Pandey, D.; Suman, U.; Ramani, A.K. An Effective Requirement Engineering Process Model for Software Development and Requirements Management. In Proceedings of the 2010 International Conference on Advances in Recent Technologies in Communication and Computing, Kottayam, India, 16–17 October 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 287–291. [Google Scholar] [CrossRef]
- Cleland-Huang, J.; Settimi, R.; Zou, X.; Solc, P. Automated classification of non-functional requirements. Requir. Eng. 2007, 12, 103–120. [Google Scholar] [CrossRef]
- Zubcoff, J.; Garrigós, I.; Casteleyn, S.; Mazón, J.-N.; Aguilar, J.-A.; Gomariz-Castillo, F. Evaluating different i*-based approaches for selecting functional requirements while balancing and optimizing non-functional requirements: A controlled experiment. Inf. Softw. Technol. 2019, 106, 68–84. [Google Scholar] [CrossRef]
- Lima, M.; Valle, V.; Costa, E.; Lira, F.; Gadelha, B. Software Engineering Repositories: Expanding the PROMISE Database. In Proceedings of the XXXIII Brazilian Symposium on Software Engineering, Salvador, Brazil, 23–27 September 2019; ACM: New York, NY, USA, 2019; pp. 427–436. [Google Scholar] [CrossRef]
- Mavin, A.; Wilkinson, P.; Harwood, A.; Novak, M. Easy Approach to Requirements Syntax (EARS). In Proceedings of the 2009 17th IEEE International Requirements Engineering Conference, Atlanta, GA, USA, 31 August–4 October 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 317–322. [Google Scholar] [CrossRef]
- Reisig, W. Petri Nets: An Introduction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Groote, J.F.; Mathijssen, A.; Reniers, M.; Usenko, Y.; van Weerdenburg, M. The Formal Specification Language mCRL2. In Methods for Modelling Software Systems (MMOSS); Brinksma, E., Harel, D., Mader, A., Stevens, P., Wieringa, R., Eds.; Dagstuhl Seminar Proceedings (DagSemProc); Schloss Dagstuhl—Leibniz-Zentrum für Informatik: Dagstuhl, Germany, 2007; Volume 6351, pp. 1–34. [Google Scholar] [CrossRef]
- Shreda, Q.A.; Hanani, A.A. Identifying Non-functional Requirements from Unconstrained Documents using Natural Language Processing and Machine Learning Approaches. IEEE Access 2016, 4, 22. [Google Scholar] [CrossRef]
- Quba, G.Y.; Al Qaisi, H.; Althunibat, A.; AlZu’bi, S. Software Requirements Classification using Machine Learning algorithm’s. In Proceedings of the 2021 International Conference on Information Technology (ICIT), Amman, Jordan, 14–15 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 685–690. [Google Scholar] [CrossRef]
- Rahimi, N.; Eassa, F.; Elrefaei, L. One- and Two-Phase Software Requirement Classification Using Ensemble Deep Learning. Entropy 2021, 23, 1264. [Google Scholar] [CrossRef] [PubMed]
- Younas, M.; Jawawi, D.N.A.; Ghani, I.; Shah, M.A. Extraction of non-functional requirement using semantic similarity distance. Neural Comput. Appl. 2020, 32, 7383–7397. [Google Scholar] [CrossRef]
- Halim, F.; Siahaan, D. Detecting Non-Atomic Requirements in Software Requirements Specifications Using Classification Methods. In Proceedings of the 2019 1st International Conference on Cybernetics and Intelligent System (ICORIS), Denpasar, Indonesia, 22–23 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 269–273. [Google Scholar] [CrossRef]
- Navarro-Almanza, R.; Juarez-Ramirez, R.; Licea, G. Towards Supporting Software Engineering Using Deep Learning: A Case of Software Requirements Classification. In Proceedings of the 2017 5th International Conference in Software Engineering Research and Innovation (CONISOFT), Mérida, Mexico, 25–27 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 116–120. [Google Scholar] [CrossRef]
- Slankas, J.; Williams, L. Automated extraction of non-functional requirements in available documentation. In Proceedings of the 2013 1st International Workshop on Natural Language Analysis in Software Engineering (NaturaLiSE), San Francisco, CA, USA, 18–26 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 9–16. [Google Scholar] [CrossRef]
- Kurtanovic, Z.; Maalej, W. Automatically Classifying Functional and Non-functional Requirements Using Supervised Machine Learning. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference (RE), Lisbon, Portugal, 4–8 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 490–495. [Google Scholar] [CrossRef]
- Singh, P.; Singh, D.; Sharma, A. Rule-based system for automated classification of non-functional requirements from requirement specifications. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 620–626. [Google Scholar] [CrossRef]
- Taj, S.; Arain, Q.; Memon, I.; Zubedi, A. To apply Data Mining for Classification of Crowd sourced Software Requirements. In Proceedings of the 2019 8th International Conference on Software and Information Engineering, Cairo, Egypt, 9–12 April 2019; ACM: New York, NY, USA, 2019; pp. 42–46. [Google Scholar] [CrossRef]
- Dalpiaz, F.; Dell’Anna, D.; Aydemir, F.B.; Cevikol, S. Requirements Classification with Interpretable Machine Learning and Dependency Parsing. In Proceedings of the 2019 IEEE 27th International Requirements Engineering Conference (RE), Jeju, Republic of Korea, 23–27 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 142–152. [Google Scholar] [CrossRef]
- Baker, C.; Deng, L.; Chakraborty, S.; Dehlinger, J. Automatic Multi-class Non-Functional Software Requirements Classification Using Neural Networks. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 610–615. [Google Scholar] [CrossRef]
- Parra, E.; Dimou, C.; Llorens, J.; Moreno, V.; Fraga, A. A methodology for the classification of quality of requirements using machine learning techniques. Inf. Softw. Technol. 2015, 67, 180–195. [Google Scholar] [CrossRef]
- Lilleberg, J.; Zhu, Y.; Zhang, Y. Support vector machines and Word2vec for text classification with semantic features. In Proceedings of the 2015 IEEE 14th International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), Beijing, China, 6–8 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 136–140. [Google Scholar] [CrossRef]
- Chen, J.Y.C.; Barnes, M.J. Human–Agent Teaming for Multirobot Control: A Review of Human Factors Issues. IEEE Trans. Hum.-Mach. Syst. 2014, 44, 13–29. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, S.; Tan, C.W. From Code Generation to Software Testing: AI Copilot with Context-Based Retrieval-Augmented Generation. IEEE Softw. 2025, 42, 34–42. [Google Scholar] [CrossRef]
- Dekhtyar, A.; Fong, V. RE Data Challenge: Requirements Identification with Word2Vec and TensorFlow. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference (RE), Lisbon, Portugal, 4–8 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 484–489. [Google Scholar] [CrossRef]
- Canedo, E.D.; Mendes, B.C. Software Requirements Classification Using Machine Learning Algorithms. Entropy 2020, 22, 1057. [Google Scholar] [CrossRef] [PubMed]
- Raharja, I.M.S.; Siahaan, D.O. Classification of Non-Functional Requirements Using Fuzzy Similarity KNN Based on ISO/IEC 25010. In Proceedings of the 2019 12th International Conference on Information & Communication Technology and System (ICTS), Surabaya, Indonesia, 18 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 264–269. [Google Scholar] [CrossRef]
- Mahmoud, M. Software Requirements Classification using Natural Language Processing and SVD. IJCA 2017, 164, 7–12. [Google Scholar] [CrossRef]
- Abad, Z.S.H.; Karras, O.; Ghazi, P.; Glinz, M.; Ruhe, G.; Schneider, K. What Works Better? A Study of Classifying Requirements. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference (RE), Lisbon, Portugal, 4–8 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 496–501. [Google Scholar] [CrossRef]
- Hakim, L.; Rochimah, S. Oversampling Imbalance Data: Case Study on Functional and Non Functional Requirement. In Proceedings of the 2018 Electrical Power, Electronics, Communications, Controls and Informatics Seminar (EECCIS), Batu, Indonesia, 9–11 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 315–319. [Google Scholar] [CrossRef]
- Rashwan, A.; Ormandjieva, O.; Witte, R. Ontology-Based Classification of Non-functional Requirements in Software Specifications: A New Corpus and SVM-Based Classifier. In Proceedings of the 2013 IEEE 37th Annual Computer Software and Applications Conference, Kyoto, Japan, 22–26 July 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 381–386. [Google Scholar] [CrossRef]
- Chatterjee, R.; Ahmed, A.; Anish, P.R. Identification and Classification of Architecturally Significant Functional Requirements. In Proceedings of the 2020 IEEE Seventh International Workshop on Artificial Intelligence for Requirements Engineering (AIRE), Zurich, Switzerland, 1 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 9–17. [Google Scholar] [CrossRef]
- Winkler, J.; Vogelsang, A. Automatic Classification of Requirements Based on Convolutional Neural Networks. In Proceedings of the 2016 IEEE 24th International Requirements Engineering Conference Workshops (REW), Beijing, China, 12–16 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 39–45. [Google Scholar] [CrossRef]
- Merugu, R.R.R.; Chinnam, S.R. Automated cloud service based quality requirement classification for software requirement specification. Evol. Intel. 2021, 14, 389–394. [Google Scholar] [CrossRef]
- Hirsch, H.-G.; Pearce, D. the aurora experimental framework for the performance evaluation of speech recognition systems under noisy conditions. In Proceedings of the 6th International Conference on Spoken Language Processing (ICSLP 2000), Beijing, China, 16–20 October 2000; p. 8. [Google Scholar]
- Håkansson, E.; Bjarnason, E. Including Human Factors and Ergonomics in Requirements Engineering for Digital Work Environments. In Proceedings of the 2020 IEEE First International Workshop on Requirements Engineering for Well-Being, Aging, and Health (REWBAH), Zurich, Switzerland, 31 August 2020; pp. 57–66. [Google Scholar] [CrossRef]
- ISO/IEC/IEEE 29148:2018; Systems and Software Engineering—Life Cycle Processes—Requirements Engineering. International Organization for Standardization. International Electrotechnical Commission; IEEE: Geneva, Switzerland, 2018.
- Hidellaarachchi, D.; Grundy, J.; Hoda, R.; Madampe, K. The Effects of Human Aspects on the Requirements Engineering Process: A Systematic Literature Review. IEEE Trans. Softw. Eng. 2022, 48, 2105–2127. [Google Scholar] [CrossRef]
- Christiano, P.F.; Leike, J.; Brown, T.B.; Martic, M.; Legg, S.; Amodei, D. Deep Reinforcement Learning from Human Preferences. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; in NIPS’17. Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4302–4310. [Google Scholar]
- Wong, M.F.; Tan, C.W. Aligning Crowd-Sourced Human Feedback for Reinforcement Learning on Code Generation by Large Language Models. IEEE Trans. Big Data 2024, 1–12. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).