1. Introduction
Autonomous driving can significantly improve the traffic efficiency and safety of roads. Autonomous vehicles (AVs) perceive the surrounding road environment through sensors and predict future situations based on the perceived information [
1,
2]. The trajectory prediction of traffic participation around target vehicles is a crucial step in achieving autonomous driving [
3,
4]. Trajectory prediction is an uncertainty issue, so multi-modal trajectory prediction is also highly valued by people [
3,
5].
In general, trajectory prediction is a time series forecasting problem, the goal of which is to extract features from past trajectories within a certain period and then use these features to predict future trajectories. Historical trajectory data are commonly in the form of time series data, so some sequence models, such as RNN, transformer, etc., are used for trajectory prediction [
6]. However, in the real world, the traffic environment in which vehicles operate is very complex. There are often multiple types of traffic participants, such as pedestrians, electric vehicles, bicycles, etc. When predicting trajectories, it is necessary to consider the impact of surrounding traffic participants on the target vehicle being predicted. This introduces a spatial dimension on top of the time dimension, making it challenging for some sequence models to handle this type of structured data.
Therefore, spatial–temporal models and spatial–temporal data have become research hotpotS, leading to the development of deep learning models based on spatial–temporal data. In the spatial dimension, it is necessary to consider the relationships between different traffic entities in various regions and then aggregate information features from the traffic entities. But the inherent graph structure in space could limit information propagation along the edges [
7]. In other words, when performing feature fusion between nodes, they can only propagate based on the edges, which makes it difficult for some nodes to have comprehensive interaction, and is like an attention mechanism with natural biases to nodes. In the time dimension, various sequence models can be utilized, such as the RNN model.
However, most of these spatial–temporal models separate time and space, with fewer models considering the coupled features of time and space. Hence, it is necessary to simultaneously couple spatial and temporal features and utilize them for downstream tasks. Spatial–temporal data have a similar structure to image data. We can treat the spatial dimension of spatial–temporal data as the channel dimension of image and use some 2D convolutional kernels to extract features from different spatial nodes simultaneously, combining them into a feature map.
Due to the strong performance of the transformer in large language models, the transformer has also been applied in vision tasks, leading to the development of the Vision Transformer (ViT) [
8,
9]. ViT divides images into patches, converts these patches into token sequences using a certain tokenize method, and then fuses them using a transformer. Therefore, ViT can be used to extract the correlations between different spatial features of image and output the fused features from different image patches. An earlier precursor to ViT is SENet [
10], which globally pools the feature maps into scalars, calculates the importance of each feature map channel using fully connected layers and sigmoid, aggregates information from different patches, and achieves a good feature extraction ability while having fewer parameters.
Considering that some existing research has overlooked the spatial–temporal coupling features of traffic participant and some deficiencies in spatial feature information aggregation and transmission, this paper proposes a trajectory prediction model that couples spatial–temporal data of surrounding vehicles in the target area. This model can simultaneously fuse the feature in the time and space dimensions, addressing existing shortcomings. Therefore, the main contributions of this paper are as follows:
Spatial–temporal coupling features of trajectory spatial–temporal data are extracted using 2D convolutional kernels, capturing the feature relationships of different nodes and periods.
2D feature maps of different spatial–temporal segments are fused using ViT and SENet, obtaining a fusion feature map between different periods and spaces.
By integrating the aforementioned advantages, an end-to-end vehicle trajectory model, the Vit-Traj model, was proposed and experimentally demonstrated to exhibit good performance.
3. Preliminary
3.1. SENet
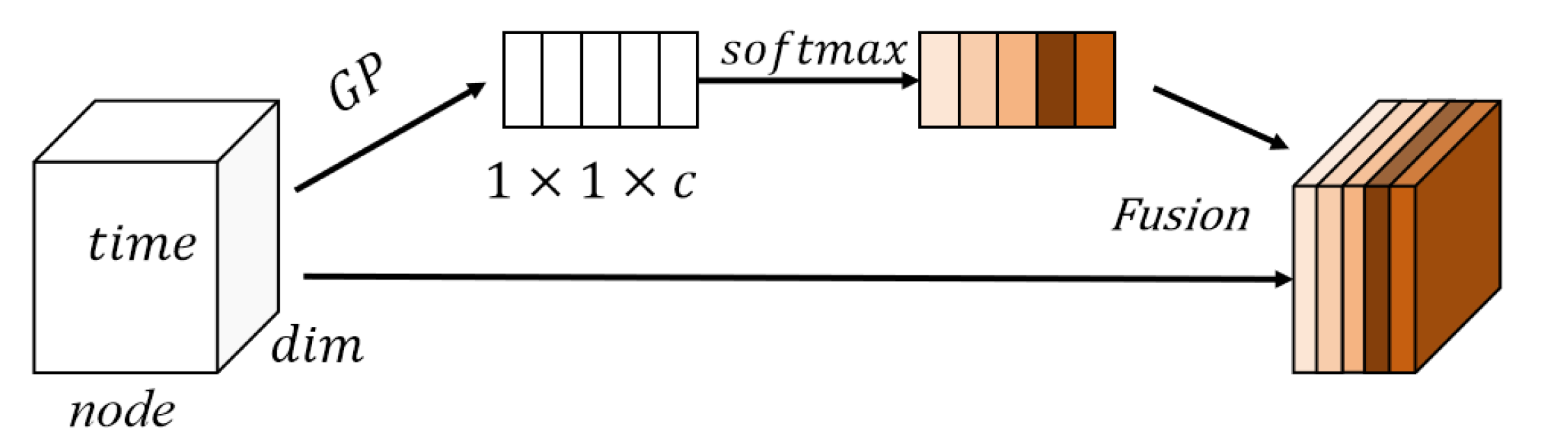
SENet (Squeeze-and-Excitation Network) is an attention mechanism used to enhance the performance of deep convolutional neural networks (CNNs). It adaptively adjusts the correlations between channels by learning the weights for each channel, thereby improving the expressive power of the model.
The core idea of SENet is to weight the feature maps of CNNs using an attention mechanism called the “Squeeze-and-Excitation” module. This module consists of two main operations, namely Squeeze and Excitation, as shown in
Figure 1. SENet first squeezes the channel dimension by global pooling, then calculates the importance of each channel, and finally expands it to its original shape.
In the Squeeze operation, SENet compresses the feature maps of each channel into a single value by using global average pooling. This represents each channel as a global feature that reflects its importance to the overall feature, as shown in Formula (1), where
is a channel,
is squeeze value of channel
,
and
are the height and width of the feature map, respectively.
In the Excitation operation, SENet learns the weights for each channel through two fully connected layers. The first layer maps the global feature to a smaller dimension and applies a nonlinear transformation using an activation function like ReLU. The second layer maps this smaller dimension back to the original number of channels and generates weights between 0 and 1 using a sigmoid function. This weight vector is then applied to each channel of the original feature maps to adjust their importance. The formula for the Excitation operation is shown in Formula (2), where
,
, and
represent the learnable parameter. In the process of gradient descent, the model can automatically determine the optimal weight values between the channels.
By introducing the SENet module, CNNs can learn the weights for each channel adaptively, enhancing important feature channels while suppressing less important ones. This attention mechanism improves the model’s expressive power and generalization ability, thereby enhancing its performance.
In this paper, SENet is used to fuse features between different feature channels (feature maps). Specifically, each feature map represents different aspects of features, which clearly have certain relationships, and SENet can perfectly extract this relationship.
3.2. Vision Transformer
Figure 2 outlines the architecture of a transformer-based model for spatial–temporal data extraction. The shape of the spatiotemporal data is
. The matrix formed by the
and
dimensions can be divided into a grid patch from left to right and from top to bottom. Subsequently, each grid can be flattened and then subjected to positional encoding. The division of spatial–temporal data is as shown in Formula (3a), and the flattening of each patch is as shown in Formula (3b).
The model begins with a Vision Transformer that generates a fusion spatial–temporal representation through an MLP head and a Transformer Encoder. The input is processed via Patch-Position Embedding before being fed into the Linear Projection of Flattened Patches. The core mechanism of the Transformer Encoder is the attention mechanism, which is specifically formulated as follows (3c). Firstly, the scaled dot product correlation coefficient between the token
and
is calculated, and then the coefficient is normalized using softmax.
is the exponential function.
The model then proceeds to multiple stages of encoding and processing. Each stage consists of an Encoder Block, which includes Multi-Head Attention, Dropout, Layer Norm, and Linear layers. This is followed by an MLP Block containing GELU activation functions and additional Dropout and Linear layers. The overall structure suggests a deep learning approach designed for efficient handling of complex spatial–temporal information.
In this paper, Vit is used to fuse information from different spatial–temporal blocks, enabling the model to obtain global and spatial–temporal coupling features, enhancing the model’s feature extraction ability and robustness.
4. Methodology
4.1. Problem Definition
We consider trajectory prediction as a time series forecasting problem. However, based on the time dimension, we have also considered the space dimension here, so the input data are spatial–temporal, which have a data shape of
. In addition,
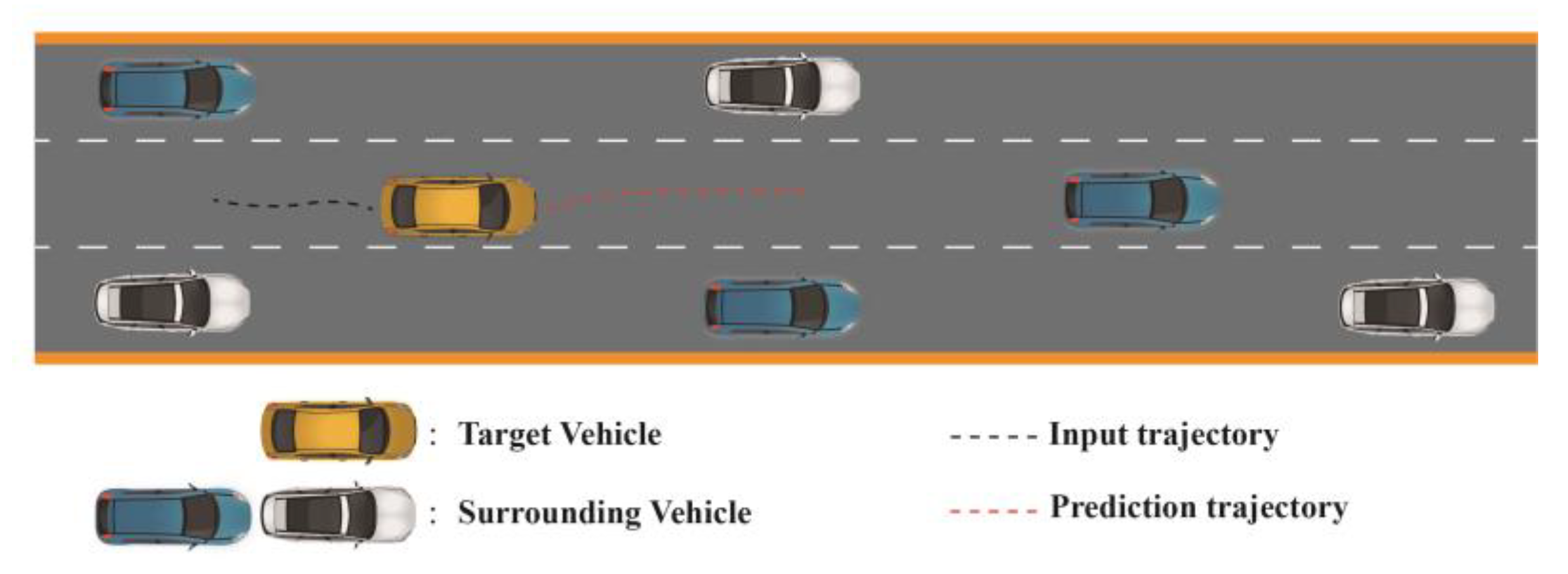
Figure 3 shows the specific research scenario. We considered the impact of vehicles in eight directions around the target vehicle.
In this paper, the vehicle trajectory prediction problem is expressed as predicting the future trajectory of the target vehicle based on the observed historical trajectory of the target vehicle and its surrounding vehicles. At the time step , the spatial–temporal historical state of the region can be described as , it representing the state of a total of vehicles at the current moment. The state of the vehicle includes the coordinates and , relative to the origin. Here, the superscript represents the time step, and the subscript represents the car number.
If considering the time dimension, the input can be represented as , where represents the number of vehicles, represents the historical time step length, and 2 represents the three variables and .
For the output, was used to represent the predicted horizons. The future trajectory of the target vehicle can be represented as , where represents the coordinates at a time point , so , and 2 represents the two variables , .
To sum up, the trajectory prediction problem in this article can be represented as Formula (4):
where
represents the proposed model, and
is the parameters of the model, which can be continuously optimized through the gradient descent algorithm.
4.2. Model Structure
The overall model structure is shown in
Figure 4. It is an end-to-end model with spatial–temporal data as input and a matrix of 2-variate time series as output. In addition, the feature extraction structure is based on the CNNs, SENet, and Vit.
In the first stage of processing spatial–temporal data, we employ 2D convolutional kernels to extract stereoscopic features from different spatial–temporal segments. This process involves increasing the number of channels progressively, enabling the model to learn diverse semantic features that capture both local and global patterns within the data. By stacking multiple convolutional network layers, the receptive fields of the extracted features expand, leading to more abstract representations. These higher-level features represent complex spatial–temporal blocked structures that encapsulate intricate relationships between temporal sequences and spatial distributions. To enhance the expressiveness of these features, we integrate SENet for channel-wise feature fusion. This mechanism allows the model to recalibrate channel-wise feature responses by modeling interdependencies between channels, thereby emphasizing informative features and suppressing less useful ones. Additionally, for intra-channel feature fusion, we utilize Vision Transformers (Vit) to facilitate feature exchange across different parts of a single channel. This approach ensures comprehensive coupling of spatial–temporal features, creating a robust representation that integrates both global and local information.
Following the feature extraction backbone, the next step is to prepare these fused features for input into a Multi-Layer Perceptron (MLP) to feature space mapping and function fitting. To achieve this, we flatten the spatial–temporal fused features into a one-dimensional vector. This transformation simplifies the feature representation while preserving the rich information captured during the earlier stages of processing. The flattened features are then passed through an MLP, which performs nonlinear transformations to map the input features into a higher-dimensional space. This process enables the model to learn complex mappings between the input spatial–temporal data and the desired output. Ultimately, the MLP outputs a future time series matrix, which represents the predicted evolution of spatial–temporal patterns over time. This architecture not only captures the inherent complexity of spatial–temporal data but also provides a flexible framework for forecasting and analysis in various domains, such as weather prediction, traffic flow estimation, and video understanding.
4.3. Stereoscopic Feature Extraction Module
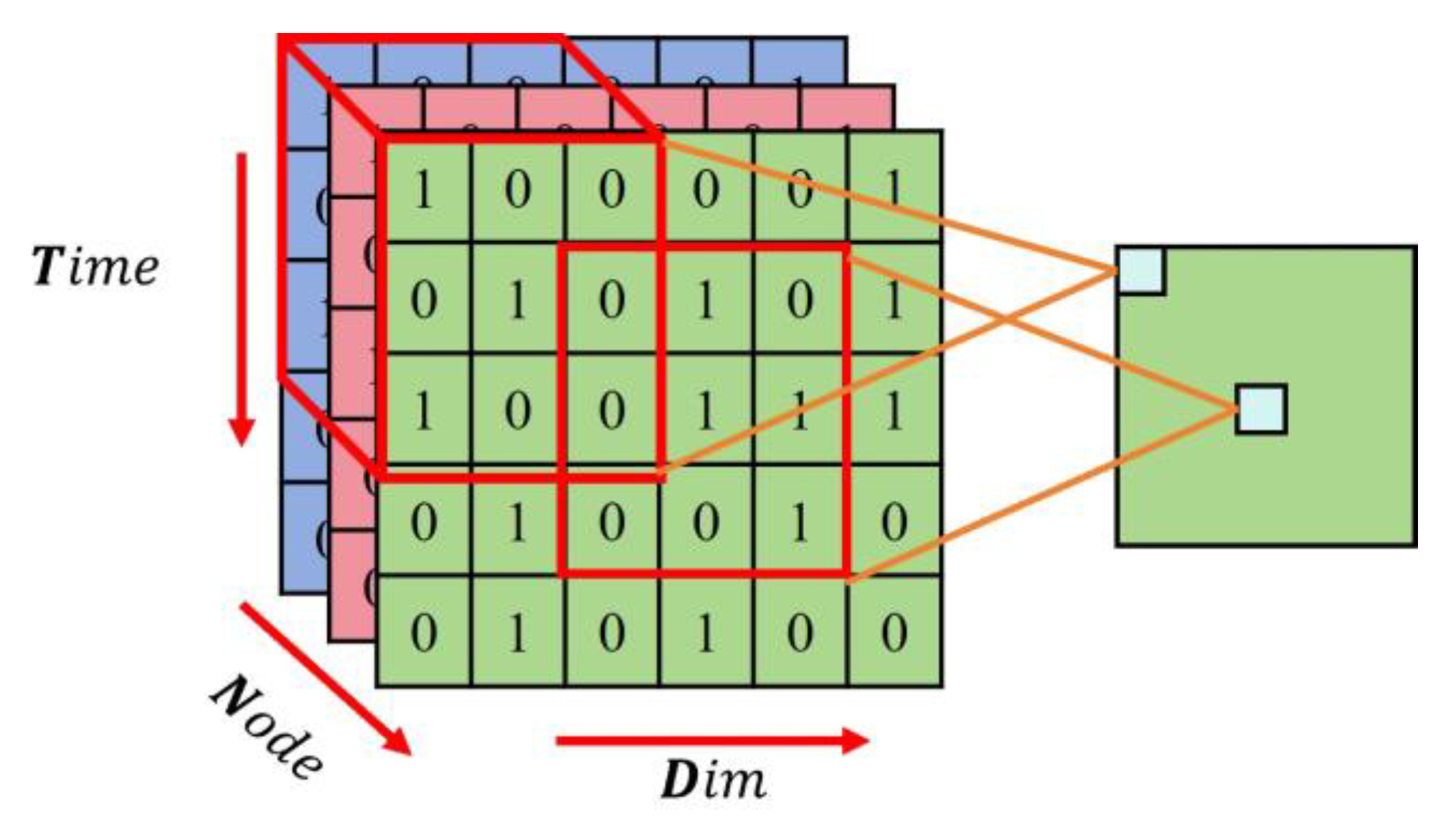
For spatial–temporal data, the spatial dimension is the number of nodes (which can be viewed as the number of channels of image data), the temporal dimension, and the feature dimension, which can be viewed as a time series matrix.
In
Figure 5, we show how 2D convolutional kernels extract the stereoscopic features of the spatial–temporal segment. On the one hand, each convolutional kernel in 2D convolutional can extract features from many nodes at the same time. On the other hand, the convolutional kernel within the time series matrix of each node with the shape (time, dim) can extract features from both the temporal dimension and the feature dimension, thereby handling the associations between different variables in multivariate time series and aligning different variables. Therefore, 2D convolutional kernels can be utilized to extract stereoscopic features from the same spatial–temporal segment.
The calculation formula for each convolutional kernel
is as follows (5). Kernel size is
,
is the kernel weight, and
is an input with time length
and variable number
. The kernel performs the same operation on each node and then obtains the features of all nodes within time
and dimension
. As the convolution kernel continuously slides in two directions in
, it extracts features between different time and feature dimensions in all regions, and then obtains a feature map, that is, a channel. Each value of each two-dimensional feature map channel is calculated by a convolution kernel, as shown in Formula (6), where
is nonlinear activation function, and
is the shape of the feature map.
4.4. Loss Function
RMSE (root mean squared error) using squared penalization terms can effectively narrow the error between predicted and true values. Therefore, this paper uses RMSE loss functions. The formula for RMSE is shown in Formula (7).
where
has the physical meaning of the accumulated error between the predicted positions in the prediction time domain and the actual positions.
is maximum prediction horizon.
For the input, we fill the data with 0 if there is no vehicle to ensure the matching of tensor dimensions and finally obtain the input tensor with a shape of .
We use some convolutional neural network layers to extract stereoscopic spatial–temporal block features and set a feasible number of output channels. Therefore, we can obtain some feature map tensors with a shape of , which is derived from the shape of . For each feature map, we divide it into some patches, then convert each patch into sequential tokens and use Vit to extract and fusion features from different spatial–temporal blocks. For all feature maps, we globally pool them into a scalar and finally form a one-dimensional tensor. Then, we use a dense attention mechanism to fuse features between different feature maps, which are derived from SENet. For fully connected layer MLP, we output the reshape as the shape of the label, with a loss function of a RMSE.
5. Experiments and Results
5.1. Datasets and Setting
5.1.1. Datasets Introduction
The HighD Dataset is a large-scale natural vehicle trajectory dataset from German highways, including 11.5 h of measurements from six locations and 110,000 vehicles. The total traveled distance of the measured vehicles is 45,000 km, with a positioning error typically less than ten centimeters using State-of-the-Art computer vision algorithms. Therefore, it can be used for trajectory prediction research [
47].
The HighD Dataset coordinate system is as shown in
Figure 6, where the horizontal axis to the right represents the positive direction of
, and the vertical axis downward represents the positive direction of
, with the origin at the top left corner. In the HighD Dataset, the FPS is 25, while some of the literature has changed it to 5 FPS. This can reduce the tensor dimension of the labels
and improve the prediction effect. In this paper, 75 historical time steps (3 s) are used as input, and the output is the future two-dimensional trajectory coordinates of the target vehicle.
We conducted experiments using publicly available NGSIM datasets I-80 and US-101, which are in show
Figure 7. Each sub-dataset consists of real highway traffic trajectories captured at a frequency of 10 Hz within 45 min. We divided the dataset into a training set and a testing set. We used one-quarter of the trajectories from each of the three subsets of the US-101 and I-80 datasets in the test set. We divide the trajectory into 8 s segments, Where we use a 3 s trajectory history and a 5 s prediction range. These 8 s segments are sampled at a 10 Hz dataset sampling rate.
5.1.2. Datasets Preprocessing
Based on the problem definition and the data format of the HighD Dataset and NGSIM, we create the corresponding samples here. As it needs to consider spatial features, we select a central vehicle (target vehicle) and assume that its movement is influenced by vehicles in the surrounding eight directions, such as front, back, left, right, and the four corners. We padd the data with 0 if no vehicle is present there. We select the
coordinate and the
coordinate time series of each vehicle as features. For each vehicle in the study region (a total of nine vehicles), we perform min–max normalization on each feature along the time dimension. The formula for min–max normalization is as follows (Formula (8)):
where
and
represent the maximum and minimum values in the feature,
represents the original value, and
represents the normalized value. Finally, we use 80% of the samples for training and 20% for testing with two datasets. In addition, we calculate the error metrics after normalizing the predicted values.
5.2. Baseline Models
The baselines models are as follows. These models are all from the latest work in recent years. The summary of the baseline models is listed below.
1. CS-LSTM: A Convolutional Social Pooling model was proposed by Deo [
48]. This model integrates long short-term memory networks (LSTM) with convolutional neural networks (CNN) to capture interactions among individuals.
2. NLS-LSTM: A Non-local Social Pooling model introduced by Messaoud [
30]. This model extends the idea of social pooling by incorporating non-local dependencies to better understand the context and interactions within a scene.
3. I2T: An intent-based model developed by Zhou [
47]. This model focuses on understanding the intentions behind actions or movements, which can be crucial for predicting future behavior accurately.
4. MHA-LSTM: An LSTM model enhanced with Multi-Head Attention mechanism proposed by Messaoud [
49]. The addition of multi-head attention allows the model to focus on different parts of the input sequence simultaneously, improving its ability to handle complex patterns.
5. MS-STGCN: A Multi-Scale Spatial–Temporal Graph Convolutional Network was created by Tang [
50]. This model captures both spatial and temporal dynamics at multiple scales, making it particularly useful for tasks involving sequences of actions over time.
6. EA-NET: The Environment-Attention based model was designed by Cai [
44] in 2021. This model considers the environment’s influence on behavior or events, making it suitable for scenarios where environmental factors play a significant role.
5.3. Comparison of Results on HighD
We use 80% of the data for model training and 20% for model testing. We infer future trajectories for each of the 20% samples using the model and then perform denormalization. The input time step is fixed at 3 s, and the output horizon ranges from 1 s to 5 s. So, the tensor shape of the input samples is , where 9 represents the nine vehicles in the research scenario, 75 represents a total of 75 time points for the past 3 s (at 25 Hz), and 2 represents the coordinates of the corresponding vehicle. The output tensor form is , where can be represented as 25, 50, 75, 100, 125.
Table 2 shows the results of the proposed model. This table presents the performance of different models across various prediction horizons, ranging from 1 s to 5 s. The metric used is RMSE, where a small RMSE value indicates better predictive performance. In addition, all metrics were calculated at a sampling frequency of 25 Hz.
From
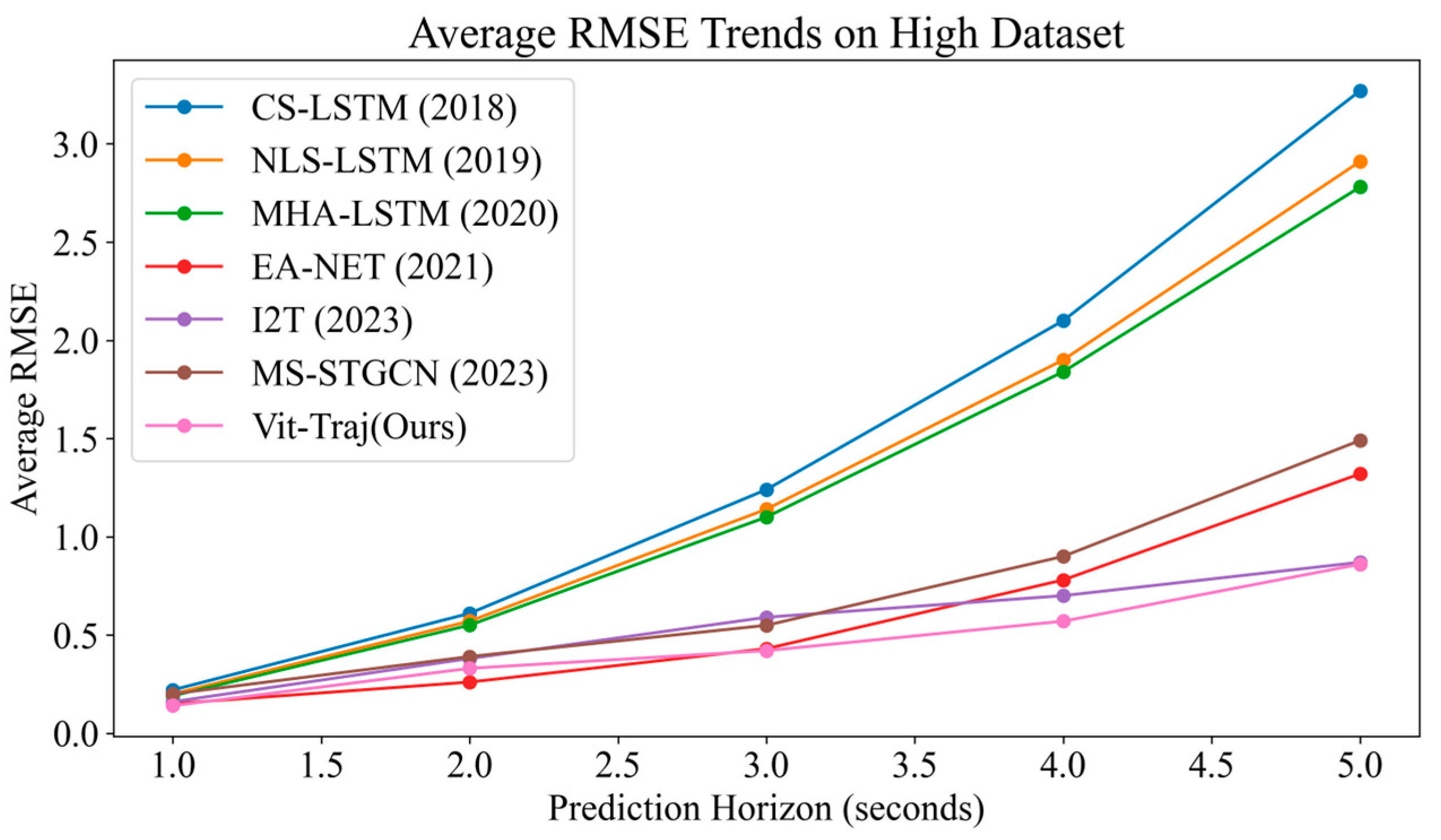
Table 2, it can be seen that our model has achieved the best predictive performance compared to existing works. Compared to the GCN based model, our model performs better. The Vit-Traj demonstrates superior performance across all prediction horizons compared to the baseline models, showcasing a significant enhancement in predictive accuracy. Notably, at the shortest prediction horizon of 1 s, Vit-Traj achieves an error value of 0.14, representing a 6.7% reduction from the closest competitor, EA-NET. As the prediction horizon extends, Vit-Traj maintains its lead with relatively stable improvements over longer durations. For instance, at a 5 s prediction horizon, Vit-Traj’s error value stands at 0.86, reflecting a 36.7% improvement over EA-NET’s error of 1.32 and a remarkable 73.7% reduction compared to the baseline CS-LSTM model, which has an error of 3.27 at the same interval. This consistent outperformance underscores the robustness and efficiency of the Vit-Traj architecture in handling complex temporal dynamics.
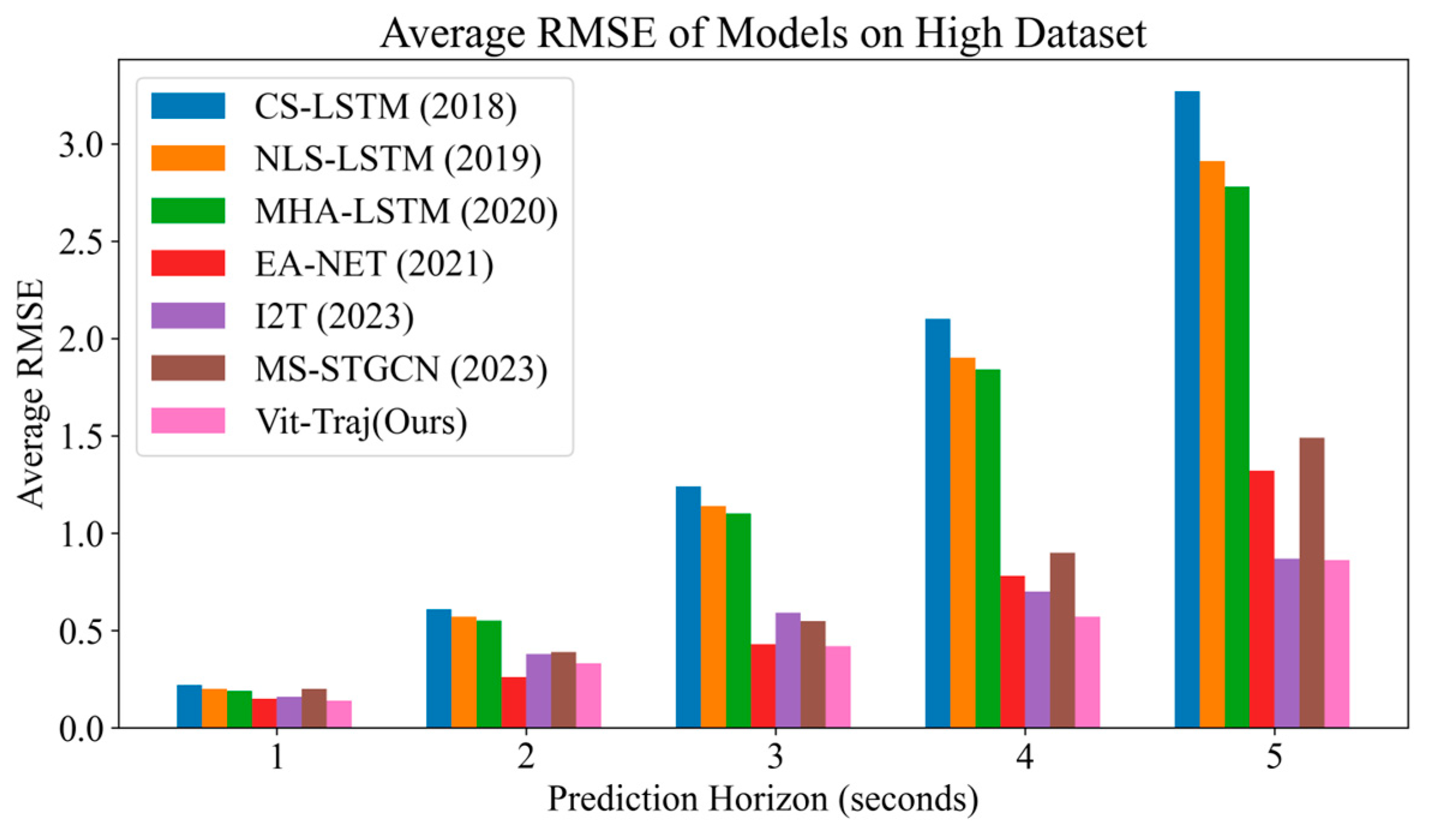
Figure 8’s bar chart presents the average root mean square error (RMSE) of various models on a HighD dataset, with prediction horizon ranging from 1 to 5 s. It can be observed that the performance of the models deteriorates as the prediction horizon increases, with higher RMSE values indicating lower accuracy. Among the models, Vit-Traj (ours) consistently exhibits the lowest RMSE values across all prediction horizons, suggesting superior performance compared to others. In contrast, CS-LSTM displays the highest RMSE values, indicating its inferior effectiveness.
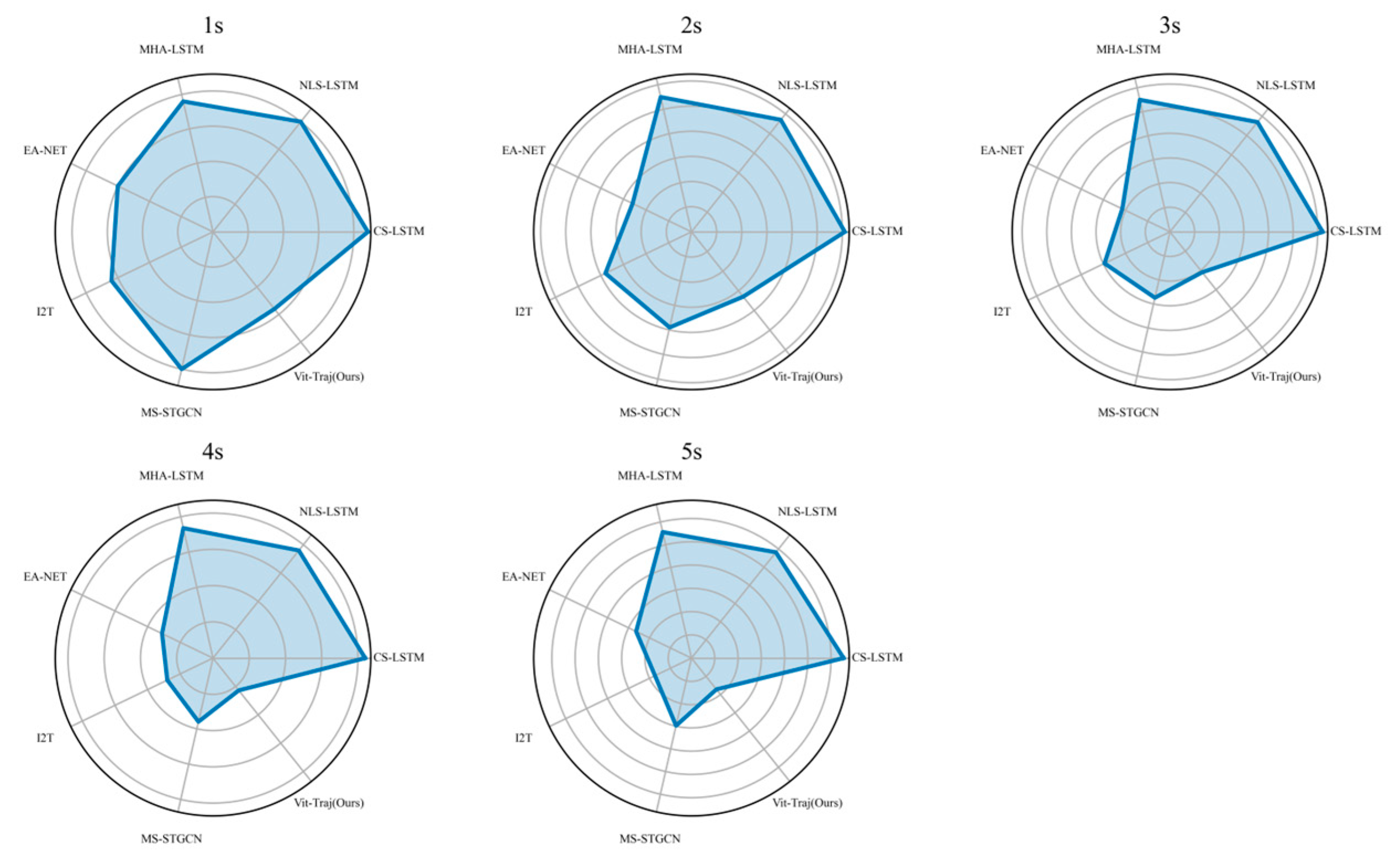
Figure 9 shows the RMSE radar graph of different models with different prediction steps, which provides a more intuitive view of the errors of different models. In the radar images with prediction steps of 1, 3, 4, and 5, our model achieved the lowest RMSE.
Figure 9 presents the average RMSE trends for various models on a HighD dataset, with the x-axis representing the prediction horizon in seconds and the y-axis showing the RMSE values. From the chart, it is evident that the Vit-Traj model (represented by the pink line) consistently outperforms other models, such as CS-LSTM, NLS-LSTM, MHA-LSTM, EA-NET, I2T, MS-STGCN, and others. The Vit-Traj model exhibits lower RMSE values across all prediction horizons compared to its counterparts. The performance improvement of the Vit-Traj model can be attributed to its ability to effectively capture complex patterns and dependencies within the data, which results in more accurate predictions. This superior performance suggests that the Vit-Traj model might be better suited for tasks involving HighD datasets in which precision and accuracy are crucial factors.
5.4. Comparison of Results on NGSIM
We also use 80% of the data for model training and 20% for model testing. The input time step is fixed at 3 s, and the output horizon ranges from 1 s to 5 s. But because the frequency if different, the tensor shape of the input samples is , where 9 represents the nine vehicles, 30 represents a total of 30 time points for the past 3 s (at 10 Hz), and 2 represents the coordinates of the corresponding vehicle. The output tensor form is , where can be represented as 10, 20, 30, 40, 50.
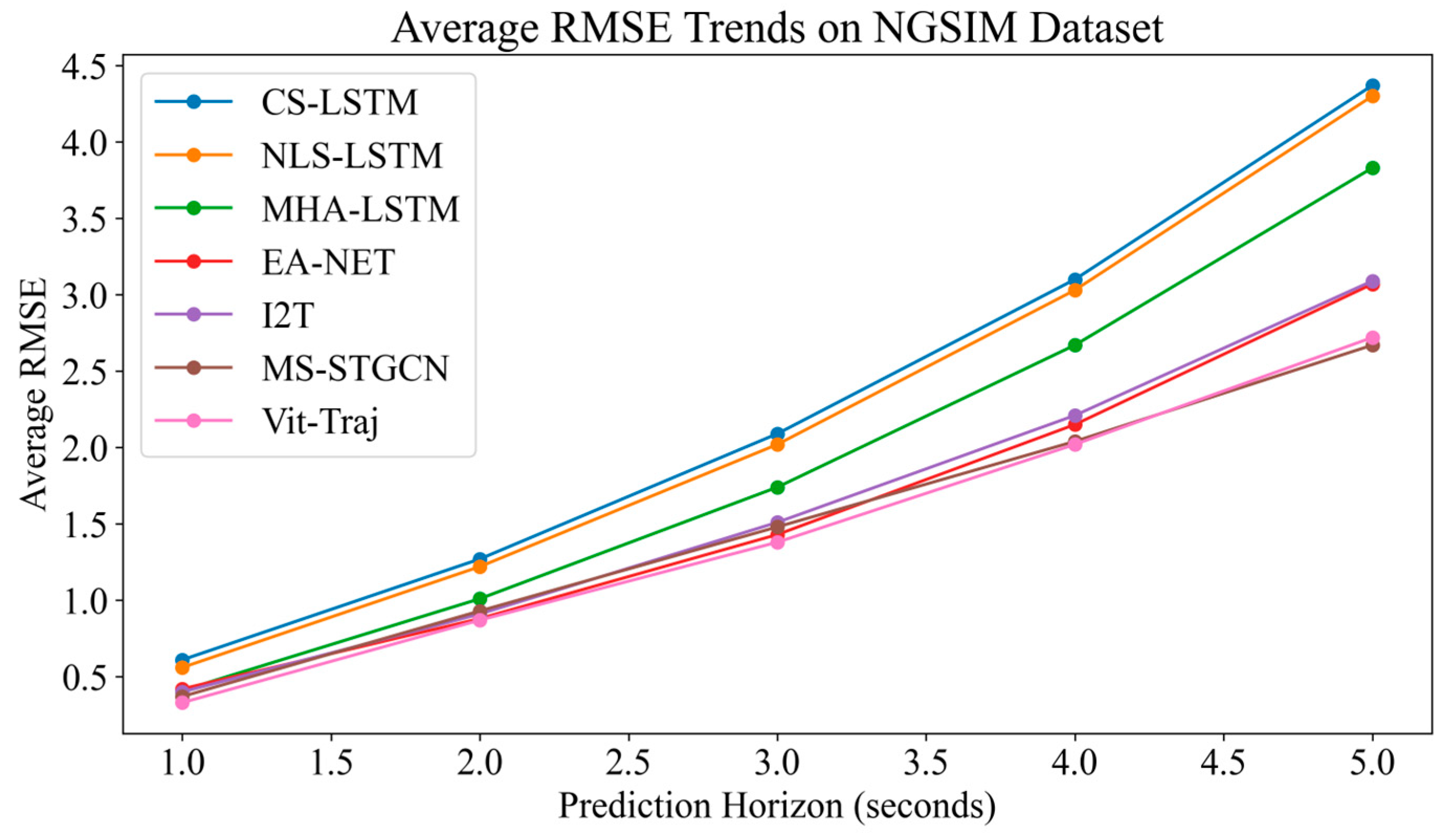
Table 3 compares the average root mean squared error (RMSE) for different models predicting vehicle trajectories on the NGSIM dataset over various prediction horizons from 1 to 5 s, and its sample frequency is 10 Hz. The summary of the model performance are as follows. CS-LSTM shows a steady increase in error as the prediction horizon increases, with an RMSE of 0.61 at 1 s and rising to 4.37 at 5 s. NLS-LSTM has a slight improvement over CS-LSTM, with lower RMSE values across all horizons, such as 0.56 at 1 s and 4.30 at 5 s. MHA-LSTM performs significantly better than the previous two, with RMSE values like 0.41 at 1 s and 3.83 at 5 s. EA-NET is an another improvement, with RMSE values such as 0.42 at 1 s and 3.07 at 5 s. I2T model has a competitive performance with EA-NET, with RMSE values close to EA-NET but slightly higher at longer horizons, like 0.40 at 1 s and 3.09 at 5 s. The MS-STGCN model stands out with relatively low RMSE values, which are particularly noticeable at the longer horizons, such as 0.37 at 1 s and 2.67 at 5 s. The Vit-Traj model (ours) appears to have the best performance overall, showing the lowest RMSE values across all prediction horizons, ranging from 0.33 at 1 s to 2.72 at 5 s.
In summary, Vit-Traj is performing the best among the listed models, suggesting that it is more accurate in predicting future trajectories on the NGSIM dataset compared to the other models mentioned.
Figure 10 displays the average RMSE of various models on the NGSIM dataset, showcasing the RMSE metrics of models. These models have been evaluated within a prediction range of 1 to 5 s. As the prediction range increases, the RMSE of most models also increases, indicating an increased difficulty in making accurate predictions over longer periods of time. However, at many points, the Vit-Traj model consistently exhibited the lowest RMSE, indicating outstanding performance in this task. From
Figure 11 and
Figure 12, it can be seen that our model achieved good accuracy at step sizes of 1, 2, 3, and 4. However, its performance was inferior to MS-TGCN at a prediction step size of 5, which may be due to MS-TGCN, considering multiple scales. Overall, although our proposed spatial–temporal feature fusion model did not specifically process features from both temporal and spatial perspectives, the results show that the spatial–temporal mixer has a very significant effect.
5.5. Spatial–Temporal Prediction Results
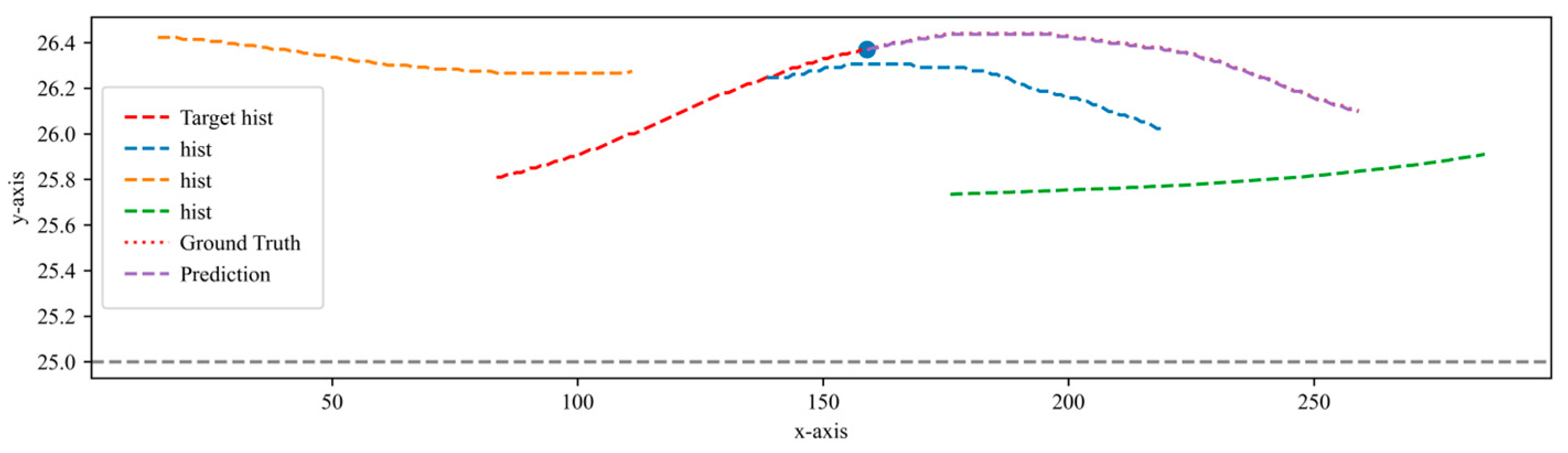
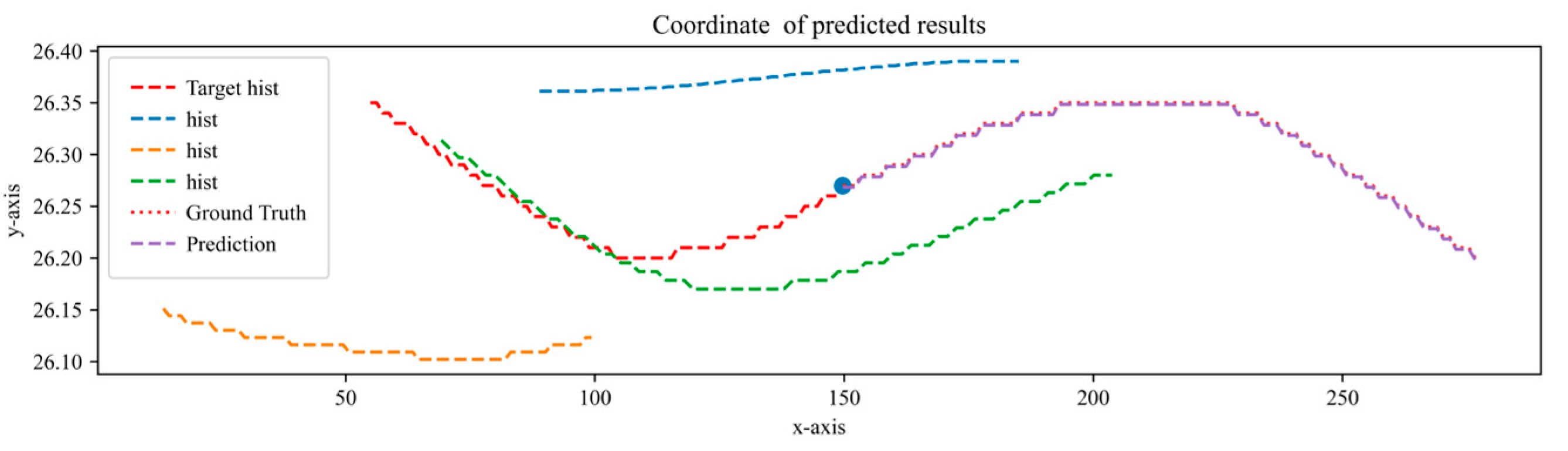
To qualitatively evaluate the performance of the model, we visualize the predicted results as shown in
Figure 13. This graph not only displays the historical trajectories of surrounding vehicles and target vehicles but also shows the future trajectory of the target vehicle and its actual future trajectory. The corresponding horizon is 75. It is evident from
Figure 14 that our model performs well in predicting future trajectories for different traffic flow densities.
Figure 15 shows a vehicle sample in the NGSIM dataset, displaying the historical trajectories of the target vehicle and surrounding vehicles. Based on these spatial–temporal trajectories, the future trajectory of the target vehicle is predicted. The figure shows the predicted trajectory and the true trajectory, and it can be observed that the predicted values almost coincide with the true values. The model can not only predict the straight trajectory, but also the lane changing trajectory.
5.6. Ablation Experiment
Due to the use of a combination of SENet and Vit for spatial–temporal feature extraction and fusion, we will now demonstrate the results of the experiments conducted, in which we used only one spatial–temporal fusion method to explore the performance of both modules. All experiments were tested on the HighD dataset with a prediction horizon size of 1–5 s.
- (a)
Only Vision Transformer
We removed the SENet residual branch from the model for experimentation, while keeping all other experimental parameters consistent with the original experiment and only modifying the necessary tensor transformation network layers.
- (b)
Only SENet
We excludede the mainstream Vit in the model and only retained the channel spatial–temporal mixer SENet flow for experimentation.
From
Table 4 and
Figure 16, it can be seen that the results of the ablation experiment show that the performance of the Vit stream and the SENet stream is significantly lower than that of the complete model, and the effectiveness of the SENet stream alone is also lower than that of the Vit stream alone.
This indicates that SENet uses global pooling of feature maps to fuse relationships between different feature maps. This has drawbacks, mainly due to the loss of important information caused by global pooling. The Vit stream fuses different spatial–temporal blocks of each feature map, avoiding the drawbacks of global pooling. Fortunately, the proposed Vit-Traj model integrates these two advantages, further improving predictive performance.
6. Conclusions
In this paper, the vision Transformer is applied to vehicle trajectory prediction of spatiotemporal data. The proposed Vit-Traj model significantly improves the prediction accuracy through spatiotemporal feature coupling, which may be an initial attempt. The model can simultaneously extract coupled features of time and space, making time and space compatible with each other rather than separated. Experiments on the HighD dataset and NGSIM dataset show that, compared to State-of-the-Art models, the proposed model exhibits better performance, proving the feasibility of using CNN and ViT for modeling spatial–temporal data and indicating that Vit is a good feature extraction structure for spatial–temporal data. In the future, its applicability to other spatiotemporal data scenarios can be further studied.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}