
Panoramic Video Synopsis on Constrained Devices for Security Surveillance



Abstract
1. Introduction
- This study is the first to construct a synopsis from a panoramic view for resource-constrained devices. The crucial part of the PVSF is the panoramic stitching model, which efficiently stitches the parallax view obtained from multiple images and outperforms traditional stitching techniques. A customized dataset of parallax images is created because the current standard dataset is too small to train the model.
- The detector used in the PVSF is trained on a sizable dataset consisting of images of weapons, such as guns and knives. The detector inferences only the abnormal object using the resource-constrained device. Thus, the PVSF can easily extract and shift only abnormal tubes in the space and time domains, stitching them to create a synopsis video.
- The PVSF constructs a synopsis that is not vulnerable to noise or distortion, as the quality enhancement model helps blend and enhance the quality of the foreground objects and background, smoothing the stitched frames.
2. Problem Definition
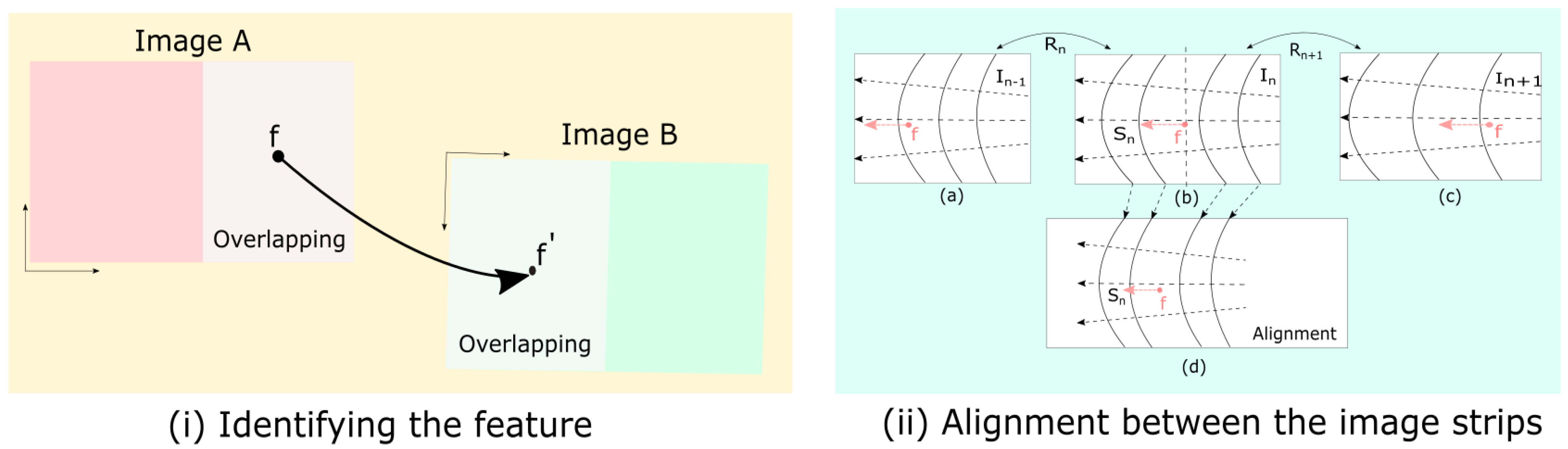
- Wide viewpoint and significant deviation: In real-life scenarios, cameras tend to shoot images casually where the variability in the scene does not change the camera setting (i.e., the surveillance cameras are fixed for monitoring). Thus, the acquired footage is exposed to a wide baseline, significant deviation, and illumination changes. The existing techniques suffer when dealing with the wide baseline problem; thus, adopting a feature enhancement model can significantly solve this problem and increase the stitching quality.
- Minimum features in the overlapping region: Significant proportions of the background features are infused in the scene, causing background clutter. Background clutter is observed in low-texture regions and images of landscapes in a natural scene (e.g., forests, lakes, and sky).
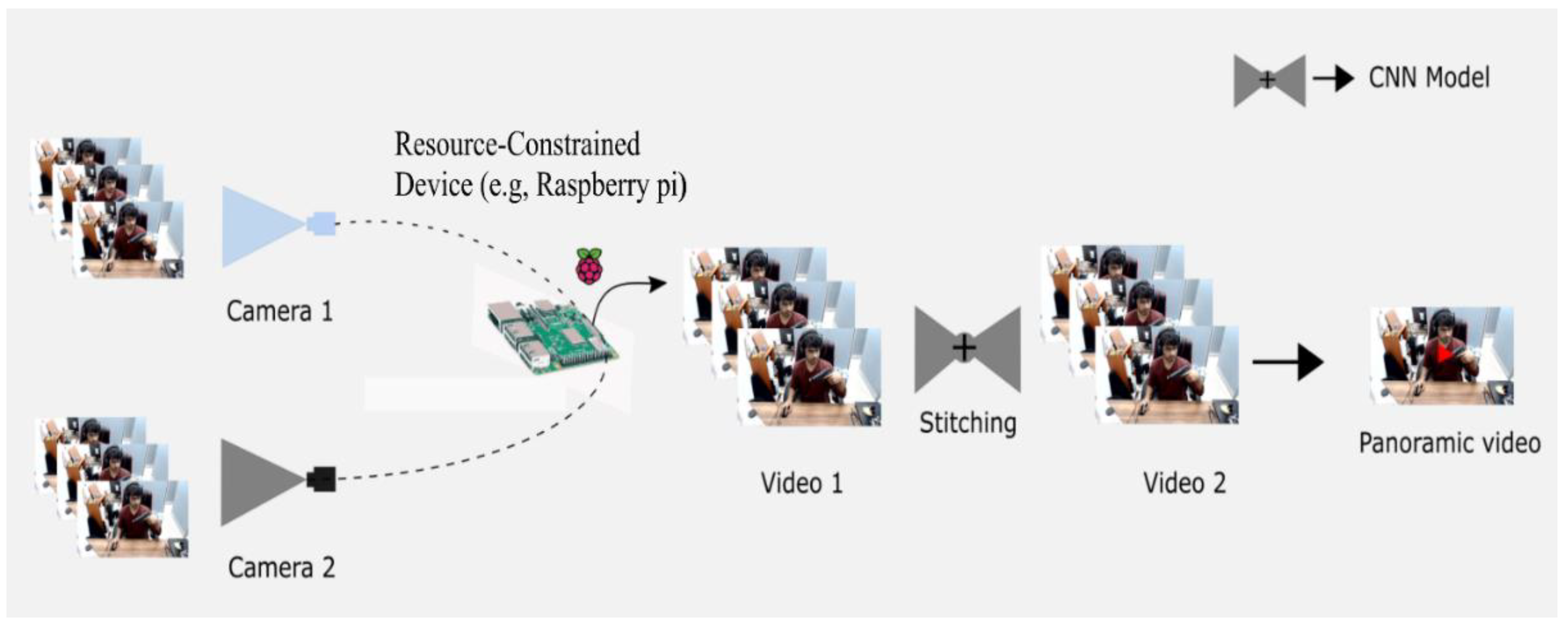
- Node synopsis: Advancements in technology have made next-generation cameras marginally more computationally efficient. A synopsis can be processed on end-node devices using edge/fog computing. The present synopsis technique cannot create an end-node solution.
3. Related Work
3.1. Traditional Synopsis Techniques
3.2. Traditional Panoramic Techniques
3.3. Feature Enhancement Techniques
4. Panoramic Video Synopsis
4.1. System Structure of PVSF
4.2. Process Structure of PVSF
4.3. Panoramic Stitching
4.3.1. Model Training
4.3.2. Discriminator
4.3.3. Generator Loss
4.3.4. Discriminator Loss
4.4. Object Detector
4.5. Feature Enhancement
5. Experimental Results
5.1. Evaluation of the Panoramic Model
5.2. Evaluation of the Object Detector
5.3. Evaluation of the Feature Enhancement Model
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Reinsel, D.; Gantz, J.; Rydning, J. Data Age 2025: The Evolution of Data to Life-Critical. Don’t Focus on Big Data; Focus on the Data That’s Big; International Data Corporation (IDC) White Paper; IDC: Needham, MA, USA, 2017. [Google Scholar]
- United Nations Office on Drugs and Crime (UNODC). Global Study on Homicide 2019. Data: UNODC Homicide Statistics 2019. Available online: https://www.unodc.org/documents/data-and-analysis/gsh/Booklet_5.pdf (accessed on 1 March 2022).
- Namitha, K.; Narayanan, A. Video synopsis: State-of-the-art and research challenges. In Proceedings of the 2018 International Conference on Circuits and Systems in Digital Enterprise Technology (ICCSDET), Kottayam, India, 21–22 December 2018; pp. 1–10. [Google Scholar]
- Ingle, P.; Kim, Y. Video Synopsis Algorithms and Framework: A Survey and Comparative Evaluation. Systems 2023, 11, 108. [Google Scholar] [CrossRef]
- Li, X.; Wang, Z.; Lu, X. Video synopsis in complex situations. IEEE Trans. Image Process. 2018, 27, 3798–3812. [Google Scholar] [CrossRef] [PubMed]
- K, N.; Narayanan, A. Preserving interactions among moving objects in surveillance video synopsis. Multimed. Tools Appl. 2020, 79, 32331–32360. [Google Scholar] [CrossRef]
- Yang, Y.; Kim, H.; Choi, H.; Chae, S.; Kim, I. Scene adaptive online surveillance video synopsis via dynamic tube rearrangement using octree. IEEE Trans. Image Process. 2021, 30, 8318–8331. [Google Scholar] [CrossRef] [PubMed]
- Priyadharshini, S.; Mahapatra, A. PanoSyn: Immersive video synopsis for spherical surveillance video. Sādhanā 2022, 47, 167. [Google Scholar] [CrossRef]
- Pritch, Y.; Rav-Acha, A.; Peleg, S. Nonchronological video synopsis and indexing. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1971–1984. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Chung, P.; Yang, D.; Chen, H.; Huang, G. Maximum a posteriori probability estimation for online surveillance video synopsis. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1417–1429. [Google Scholar] [CrossRef]
- He, Y.; Gao, C.; Sang, N.; Qu, Z.; Han, J. Graph coloring based surveillance video synopsis. Neurocomputing 2017, 225, 64–79. [Google Scholar] [CrossRef]
- Nie, Y.; Li, Z.; Zhang, Z.; Zhang, Q.; Ma, T.; Sun, H. Collision-free video synopsis incorporating object speed and size changes. IEEE Trans. Image Process. 2019, 29, 1465–1478. [Google Scholar] [CrossRef]
- Ruan, T.; Wei, S.; Li, J.; Zhao, Y. Rearranging online tubes for streaming video synopsis: A dynamic graph coloring approach. IEEE Trans. Image Process. 2019, 28, 3873–3884. [Google Scholar] [CrossRef]
- Ghatak, S.; Rup, S.; Majhi, B.; Swamy, M. HSAJAYA: An improved optimization scheme for consumer surveillance video synopsis generation. IEEE Trans. Consum. Electron. 2020, 66, 144–152. [Google Scholar] [CrossRef]
- Moussa, M.M.; Shoitan, R. Object-based video synopsis approach using particle swarm optimization. Signal Image Video Process. 2021, 15, 761–768. [Google Scholar] [CrossRef]
- Ghatak, S.; Rup, S.; Behera, A.; Majhi, B.; Swamy, M. An improved tube rearrangement strategy for choice-based surveillance video synopsis generation. Digit. Signal Process. 2022, 132, 103817. [Google Scholar] [CrossRef]
- Zhu, J.; Liao, S.; Li, S.Z. Multicamera joint video synopsis. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 1058–1069. [Google Scholar] [CrossRef]
- Panagiotakis, C.; Doulamis, A.; Tziritas, G. Equivalent key frames selection based on iso-content principles. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 447–451. [Google Scholar] [CrossRef]
- Yeung, M.M.; Yeo, B.L. Video visualization for compact presentation and fast browsing of pictorial content. IEEE Trans. Circuits Syst. Video Technol. 1997, 7, 771–785. [Google Scholar] [CrossRef]
- Sun, W.; Xie, Y. Evaluation of the Geographic Video Synopsis Effect Based on Eye Movement Data. In Proceedings of the 2023 4th International Symposium on Computer Engineering and Intelligent Communications (ISCEIC), Nanjing, China, 18–20 August 2023; pp. 33–37. [Google Scholar]
- Zhang, Y.; Zhu, P.; Zheng, T.; Yu, P.; Wang, J. Surveillance video synopsis framework base on tube set. J. Vis. Commun. Image Represent. 2024, 98, 104057. [Google Scholar] [CrossRef]
- Ingle, P.Y.; Kim, Y.; Kim, Y.G. Dvs: A drone video synopsis towards storing and analyzing drone surveillance data in smart cities. Systems 2022, 10, 170. [Google Scholar] [CrossRef]
- Ingle, P.Y.; Kim, Y.G. Real-time abnormal object detection for video surveillance in smart cities. Sensors 2022, 22, 3862. [Google Scholar] [CrossRef] [PubMed]
- Ingle, P.; Kim, Y. Multiview abnormal video synopsis in real-time. Eng. Appl. Artif. Intell. 2023, 123, 106406. [Google Scholar] [CrossRef]
- Parab, M.; Ingle, P. Innovative Method for Camouflaged Wildlife Segmentation in Agricultural Practices. In Proceedings of the 2024 2nd International Conference on Advancement in Computation & Computer Technologies (InCACCT), Gharuan, India, 2–3 May 2024; IEEE: Piscataway, NJ, USA; pp. 76–81. [Google Scholar]
- Ingle, P.; Kim, Y.G. Integrated Interoperability Based Panoramic Video Synopsis Framework. In Proceedings of the 39th ACM/SIGAPP Symposium on Applied Computing, Avila, Spain, 8–12 April 2024; pp. 584–591. [Google Scholar]
- Zhang, T.; Zhao, R.; Chen, Z. Application of migration image registration algorithm based on improved SURF in remote sensing image mosaic. IEEE Access 2020, 8, 163637–163645. [Google Scholar] [CrossRef]
- Parab, M.; Bhanushali, A.; Ingle, P.; Pavan Kumar, B.N. Image enhancement and exposure correction using convolutional neural network. SN Comput. Sci. 2023, 4, 20. [Google Scholar] [CrossRef]
- Setiawan, A.; Yunmar, R.A.; Tantriawan, H. Comparison of speeded-up robust feature (SURF) and oriented FAST and rotated BRIEF (ORB) methods in identifying museum objects using Low light intensity images. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2020; Volume 537, p. 012025. [Google Scholar]
- Bhanushali, A.; Parab, M.; Kumar, B.P.; Ingle, P. Adversarial Attack on 3D Fused Sensory Data in Drone Surveillance. In Proceedings of the 2024 2nd International Conference on Advancement in Computation & Computer Technologies (InCACCT), Gharuan, India, 2–3 May 2024; IEEE: Piscataway, NJ, USA; pp. 70–75. [Google Scholar]
- Zhu, J.; Gong, C.; Zhao, M.; Wang, L.; Luo, Y. Image mosaic algorithm based on PCA-ORB feature matching. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 42, 83–89. [Google Scholar] [CrossRef]
- Caparas, A.; Fajardo, A.; Medina, D. Feature-based Automatic Image Stitching Using SIFT, KNN and RANSAC. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 96–101. [Google Scholar] [CrossRef]
- Hoang, V.; Tran, D.; Nhu, N.; Pham, T.; Pham, V. Deep feature extraction for panoramic image stitching. In Asian Conference on Intelligent Information and Database Systems; Springer: Cham, Switzerland, 2020; pp. 141–151. [Google Scholar]
- Wang, M.; Niu, S.; Yang, X. A novel panoramic image stitching algorithm based on ORB. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017; pp. 818–821. [Google Scholar]
- Win, K.; Kitjaidure, Y. Biomedical images stitching using orb feature based approach. In Proceedings of the 2018 International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Bangkok, Thailand, 21–24 October 2018; Volume 3, pp. 221–225. [Google Scholar]
- Delphin, D.; Bhatt, M.; Thiripurasundari, D. Holoentropy measures for image stitching of scenes acquired under CAMERA unknown or arbitrary positions. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 1096–1107. [Google Scholar] [CrossRef]
- Li, J.; Liu, D. March. SIFT Feature Image Stitching Based on Improved Cuckoo Algorithm. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2020; Volume 782, p. 032100. [Google Scholar]
- Brown, M.; Lowe, D.G. Automatic panoramic image stitching using invariant features. Int. J. Comput. Vis. 2007, 74, 59–73. [Google Scholar] [CrossRef]
- Zaragoza, J.; Chin, T.; Brown, M.; Suter, D. As-projective-as-possible image stitching with moving DLT. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2339–2346. [Google Scholar]
- He, X.; He, L.; Li, X. Image Stitching via Convolutional Neural Network. In Proceedings of the 2021 7th International Conference on Computer and Communications (ICCC), Chengdu, China, 10–13 December 2021; pp. 709–713. [Google Scholar]
- Shen, C.; Ji, X.; Miao, C. Real-time image stitching with convolutional neural networks. In Proceedings of the 2019 IEEE International Conference on Real-time Computing and Robotics (RCAR), Irkutsk, Russia, 4–9 August 2019; pp. 192–197. [Google Scholar]
- Jia, Q.; Li, Z.; Fan, X.; Zhao, H.; Teng, S.; Ye, X.; Latecki, L. Leveraging line-point consistence to preserve structures for wide parallax image stitching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12186–12195. [Google Scholar]
- Nie, L.; Lin, C.; Liao, K.; Liu, S.; Zhao, Y. 2023, Parallax-Tolerant Unsupervised Deep Image Stitching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 7399–7408. [Google Scholar]
- Li, J.; Wang, Z.; Lai, S.; Zhai, Y.; Zhang, M. Parallax-tolerant image stitching based on robust elastic warping. IEEE Trans. Multimed. 2017, 20, 1672–1687. [Google Scholar] [CrossRef]
- Du, P.; Ning, J.; Cui, J.; Huang, S.; Wang, X.; Wang, J. Geometric structure preserving warp for natural image stitching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3688–3696. [Google Scholar]
- Jia, Y.; Li, Z.; Zhang, L.; Song, B.; Song, R. Semantic Aware Stitching for Panorama. Sensors 2024, 24, 3512. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.; Kim, J.; Kwon, J.; Kim, T. Depth-controllable very deep super-resolution network. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super Resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Schulter, S.; Leistner, C.; Bischof, H. Fast and accurate image upscaling with super-resolution forests. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3791–3799. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Fan, Y.; Shi, H.; Yu, J.; Liu, D.; Han, W.; Yu, H.; Wang, Z.; Wang, X.; Huang, T. Balanced two-stage residual networks for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 161–168. [Google Scholar]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Cheng, P.; Tang, X.; Liang, W.; Li, Y.; Cong, W.; Zang, C. Tiny-YOLOv7: Tiny Object Detection Model for Drone Imagery. In International Conference on Image and Graphics; Springer: Cham, Switzerland, 2023; pp. 53–65. [Google Scholar]
- Kiran, R.; Kumar, P.; Bhasker, B. DNNRec: A novel deep learning based hybrid recommender system. Expert Syst. Appl. 2020, 144, 113054. [Google Scholar]
- Tiwari, S.; Jain, A.; Sapra, V.; Koundal, D.; Alenezi, F.; Polat, K.; Alhudhaif, A.; Nour, M. A smart decision support system to diagnose arrhythymia using ensembled ConvNet and ConvNet-LSTM model. Expert Syst. Appl. 2023, 213, 118933. [Google Scholar] [CrossRef]
- Ingle, P.; Parab, M.; Lendave, P.; Bhanushali, A.; Bn, P.K. A Comprehensive Study on LLM Agent Challenges. Available online: https://aair-lab.github.io/aia2024/papers/ingle_aia24.pdf (accessed on 1 March 2022).
- Charbonnier, P.; Blanc-Feraud, L.; Aubert, G.; Barlaud, M. Two deterministic half-quadratic regularization algorithms for computed imaging. In Proceedings of the 1st International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; IEEE: Piscataway, NJ, USA; Volume 2, pp. 168–172. [Google Scholar]
- Yamanaka, J.; Kuwashima, S.; Kurita, T. Fast and accurate image super resolution by deep CNN with skip connection and network in network. In Neural Information Processing: 24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017, Proceedings, Part II 24; Springer: Cham, Switzerland, 2017; pp. 217–225. [Google Scholar]
- Abbadi, N.K.E.; Al Hassani, S.A.; Abdulkhaleq, A.H. September. A review over panoramic image stitching techniques. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; Volume 1999, p. 012115. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 2287–2318. [Google Scholar]
- Gu, Y.; Liao, X.; Qin, X. YouTube-GDD: A challenging gun detection dataset with rich contextual information. arXiv 2022, arXiv:2203.04129. [Google Scholar]
- Shenoy, R.; Yadav, D.; Lakhotiya, H.; Sisodia, J. An Intelligent Framework for Crime Prediction Using Behavioural Tracking and Motion Analysis. In Proceedings of the 2022 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 9–11 March 2022; pp. 1–6. [Google Scholar]
- Kinga, D.; Adam, J. A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; Volume 5, p. 6. [Google Scholar]
- Liu, H.; Ruan, Z.; Zhao, P.; Dong, C.; Shang, F.; Liu, Y.; Yang, L.; Timofte, R. Video super-resolution based on deep learning: A comprehensive survey. Artif. Intell. Rev. 2022, 55, 5981–6035. [Google Scholar] [CrossRef]
- Benito-Picazo, J.; Dominguez, E.; Palomo, E.J.; Lopez-Rubio, E. Deep learning-based video surveillance system managed by low cost hardware and panoramic cameras. Integr. Comput.-Aided Eng. 2020, 27, 373–387. [Google Scholar] [CrossRef]
- Peronikolis, M.; Panagiotakis, C. Personalized Video Summarization: A Comprehensive Survey of Methods and Datasets. Appl. Sci. 2024, 14, 4400. [Google Scholar] [CrossRef]
- Apostolidis, E.; Adamantidou, E.; Metsai, A.I.; Mezaris, V.; Patras, I. Video summarization using deep neural networks: A survey. Proc. IEEE 2021, 109, 1838–1863. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sr.No | Image Stitching Techniques | Accuracy Matching Rate (%) |
|---|---|---|
| 1 | SURF | 90.9 |
| 2 | FAST | 50.7 |
| 3 | PCA-ORB | 91.9 |
| 4 | SIFT-KNN | 92.4 |
| 5 | AKAZE | 89.6 |
| 6 | OFAST | 82.5 |
| 7 | FAST-BRIEF | 87.2 |
| 8 | VSGV | 88.1 |
| 9 | SIFT-CUCKOO | 90.7 |
| 10 | Proposed | 98.7 |
| PSNR ↑ | SSIM ↑ | |||||||
|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Average | Easy | Moderate | Hard | Average | |
| Pano-GAN | 10.9 | 8.8 | 8.1 | 9.3 | 0.5 | 0.3 | 0.2 | 0.3 |
| APAP | 10.6 | 8.1 | 7.4 | 8.6 | 0.4 | 0.2 | 0.1 | 0.2 |
| Autostitch | 9.9 | 7.5 | 6.8 | 8.0 | 0.3 | 0.1 | 0.0 | 0.1 |
| FMM-CNN | 11.1 | 9.1 | 8.4 | 9.9 | 0.7 | 0.6 | 0.5 | 0.6 |
| LPC | 13.3 | 9.1 | 8.4 | 9.9 | 0.8 | 0.7 | 0.6 | 0.7 |
| PTUS | 15.0 | 11.5 | 10.8 | 12.2 | 0.9 | 0.8 | 0.7 | 0.7 |
| Ours | 16.2 | 12.1 | 11.4 | 12.9 | 0.9 | 0.8 | 0.7 | 0.8 |
| Gradient | Entropy | |||
|---|---|---|---|---|
| Street | Parallax | Street | Parallax | |
| ELA | 6.9222 | 7.1042 | 7.1380 | 7.6456 |
| GES-GSP | 8.0001 | 7.6984 | 7.5543 | 8.1284 |
| SASP | 8.5120 | 7.2342 | 7.3247 | 7.8962 |
| Ours | 9.1024 | 8.9654 | 8.4297 | 8.7659 |
| Dataset (Scale = 2) | Bicubic | FSRCNN | c-DCSCN | Proposed |
|---|---|---|---|---|
| Set5 | 33.65/0.93 | 37.00/0.95 | 37.15/0.95 | 37.40/0.96 |
| Set14 | 30.24/0.88 | 32.63/0.90 | 32.74/0.91 | 33.09/0.92 |
| BSD100 | 29.57/0.84 | 31.53/0.89 | 31.61/0.89 | 32.21/0.90 |
| Video | Original Video (t) | Number of Objects | Number of Abnormal Object | Panoramic Video Synopsis (t) |
|---|---|---|---|---|
| V1 | 3.24 min | 3 | 2 | 1.24 min |
| V2 | ||||
| V3 | 5.24 min | 2 | 1 | 2.20 min |
| V4 | ||||
| V5 | 6.28 min | 3 | 2 | 2.14 min |
| V6 | ||||
| V7 | 2.35 min | 2 | 1 | 1.16 min |
| V8 |
| Video | Namitha et al. [3] | Pritch et al. [9] | Proposed | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Original Time (t) | FR | FCR | Synopsis Video (t) | FR | FCR | Synopsis Video (t) | Accuracy Matching Rate (%) | F1 (%) | FR | FCR | Synopsis Video (t) | |
| V1 | 3.24 min | 0.21 | 0.14 | 2.12 min | 0.23 | 0.09 | 2.58 min | 96 | 95 | 0.18 | 0.18 | 1.24 min |
| V2 | 0.21 | 0.11 | 2.14 min | 0.24 | 0.08 | 2.36 min | 96 | 96 | 0.18 | 0.19 | ||
| V3 | 5.24 min | 0.19 | 0.08 | 4.36 min | 0.20 | 0.06 | 5.01 min | 97 | 96 | 0.17 | 0.15 | 2.20 min |
| V4 | 0.19 | 0.09 | 4.22 min | 0.21 | 0.06 | 4.45 min | 97 | 96 | 0.17 | 0.15 | ||
| V5 | 6.28 min | 0.24 | 0.16 | 5.12 min | 0.27 | 0.10 | 5.46 min | 98 | 95 | 0.21 | 0.20 | 2.14 min |
| V6 | 0.24 | 0.17 | 5.18 min | 0.29 | 0.11 | 5.40 min | 98 | 94 | 0.21 | 0.21 | ||
| V7 | 2.35 min | 0.18 | 0.11 | 1.55 min | 0.21 | 0.08 | 2.05 min | 97 | 95 | 0.16 | 0.16 | 1.16 min |
| V8 | 0.18 | 0.12 | 1.43 min | 0.21 | 0.08 | 2.08 min | 97 | 95 | 0.16 | 0.18 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ingle, P.Y.; Kim, Y.-G. Panoramic Video Synopsis on Constrained Devices for Security Surveillance. Systems 2025, 13, 110. https://doi.org/10.3390/systems13020110
Ingle PY, Kim Y-G. Panoramic Video Synopsis on Constrained Devices for Security Surveillance. Systems. 2025; 13(2):110. https://doi.org/10.3390/systems13020110
Chicago/Turabian StyleIngle, Palash Yuvraj, and Young-Gab Kim. 2025. "Panoramic Video Synopsis on Constrained Devices for Security Surveillance" Systems 13, no. 2: 110. https://doi.org/10.3390/systems13020110
APA StyleIngle, P. Y., & Kim, Y.-G. (2025). Panoramic Video Synopsis on Constrained Devices for Security Surveillance. Systems, 13(2), 110. https://doi.org/10.3390/systems13020110