1.2. Inductive Reasoning
Intelligence research often employs tests of inductive reasoning which is considered a marker of ‘fluid intelligence’ [
14,
15]. According to [
16,
17], it is central to the concept of intelligence testing. Inductive reasoning involves generating and testing hypotheses and generalisation of findings from a set of predefined instances [
18]. Similarly, Spearman [
10] defined inductive reasoning as a process consisting of perception of units, logical induction of correspondences between these units and application of the identified rules to other units. It is typically measured by series completion tasks, which form a common part of many standardised intelligence test batteries [
19,
20,
21].
Series completion tasks are usually based on schemes which define the succession and enable identification of consecutive elements. Such schemes were first introduced by Simon and Kotovsky [
22], who developed the theory and descriptive language applied to letter series problems. Holzman, Pellegrino and Glaser [
23] extended their classical scheme to incorporate number series and further emphasised the cognitive mechanisms rather than the problem features of the series. They proposed that the number series completion task should be based on (1) relations detection, (2) discovery of periodicity, (3) pattern description and (4) extrapolation.
Identification of relation detection is based on respondents scanning the number series and postulating hypotheses about the relationships between the elements. Research indicates that the difficulty of detecting a relationship in the number series task is dependent on the arithmetic operations involved [
23] and the initial practice that participants had with structural relations [
24]. However, it is not limited to these reasons as a source of explanation. The emphasis is about hypothesising how the elements in the series are related to one another. Discovery of periodicity is the ability to detect the elements which constitute one complete cycle of the pattern. The relationship of the elements is based on adjacent positions until proved otherwise. At this stage, either the participants assume that a new period is introduced, or they have identified an incorrect pattern of cycle. The number series task is conceived to be harder if the participant’s pattern prediction is wrong [
25]. Pattern description identifies the relationship governing the remaining positions within the period and defines the rule for the sequence which is then extrapolated to its missing elements [
23]. Participants are able to integrate the previously formed hypotheses to deduce the rules that govern the number series and extrapolate the rules to complete the number series by filling in the missing elements [
26]. Extrapolation is the means by which the numbers are generated to complete the sequence based on the previous three components.
By definition, the three cognitive determinants proposed by Holzman et al. [
23] are necessary in order to solve a series completion task. However, there is little systematic guidance regarding the development of new number series item models. Arendasy and Sommer [
26] proposed four generative components for number series, that is, rule span, number of rules, rule complexity and periodicity. These four rules focused more on the problem features and did not necessarily represent or explain how participants use different cognitive domains to solve the number series problems. Moreover, individual differences in working-memory capacity and overall performance on the number series were found only with children and not with adults [
23]. While these findings provide a preliminary understanding of the performance of series completion tasks, they are inadequate in providing a more detailed account of the cognitive processes involved in solving the number series items in the adult population.
1.3. Automatic Number Series Item Generator
The creation of an Automatic Number Series Item Generator (ANSIG), based on the four cognitive determinants proposed by Holzman et al. [
23], has several important advantages. First, systematic design of number series items will allow researchers to carefully manipulate important item parameters which may contribute to the performance of the tasks. Second, a clear and detailed account of item difficulty variance may allow researchers to better understand how individual differences play a role in number series tests. Third, in longitudinal assessment of cognitive functioning studies, researchers may employ item variants rather than the same set of items across different time points in order to evaluate cognitive ability, reducing the possibility of practice effect and minimising item exposure [
27,
28]. Fourth, in cases where adaptive testing is not feasible as part of a larger suite of psychological test battery, using efficient methods such as genetic algorithm for item selection strategy can be adopted to select a subset of items from an item bank created by the AIG [
29]. Fifth, the administration of an on-the-fly, adaptive test with calibrated item models serves as an alternative cost-effective approach to testing [
30].
Empirical information to build a complete cognitive model is often unavailable during the test design phase. While schemas provided by the subject matter experts may be a good starting point, these predictions of item difficulty are often inaccurate [
31,
32]. Therefore, this study employs the model-based (or strong-theory) approach [
33] in which the manipulation of the item features is based on a model of hypothesised cognitive operators. Following this approach enables the development of items with psychometric attributes to be theoretically predictable.
In this study, we propose five cognitive operators (i.e., the rules) which individuals (adults) may employ to solve the number series items within the item model: (1) apprehension of succession (AOS), which detects a single coherent number series without involving any arithmetic operation; (2) identification of parallel sequences (PS), where two parallel number series are present; (3) object cluster formation (CF), which identifies clusters of numbers embedded in the series; (4) identification of non-progressive coefficient patterns (NPCP), where the missing value is determined solely by the preceding elements; and (5) identification of complex progressive relationships with a change in the coefficients (PCP), which requires identification of the pattern in the increments of the consecutive values. Example items are shown in
Table 1. Individuals use at least one of these 5 cognitive operators to reason logically and identify the correct answer(s) in the number series task.
These five cognitive operators map onto the four determinants proposed by Holzman et al. [
23] with variant levels of weights. As indicated in
Table 1, the first cognitive operator, apprehension of succession serves as a baseline. Building on this, items with parallel sequences poses more processing demand on the discovery of periodicity, as respondents need to realise the existence of two rather than one series in the item, through detecting inconsistent patterns between conjunctive numbers. Identifying object clusters formation within the number series requires a high level of relation detection, because it requires respondents to identify groups of elements that are linearly sequential rather than a single element establishing a (parallel) relation with the adjacent element. Respondents, therefore, must form a hypothesis based on the relations of the elements and the discovery a cycle of pattern until an element contradicts this presumption [
23,
34]. At this point, respondents either begin forming new hypothesis or have miscalculated. In the next phase, respondents integrate their hypothesis with the completion of pattern description to deduce the rules that govern the number series. The inferred rules are then extrapolated to find the missing element(s) of the number series. The last two cognitive operators adopt the identification of simple and complex arithmetic operations respectively, exhibiting increasing weights on the pattern description and extrapolation. Therefore, the increased dependency on the processing stages of the cognitive determinants in relation to the five cognitive variables lead to varying levels of impact on item difficulty.
1.4. ANSIG Item Models
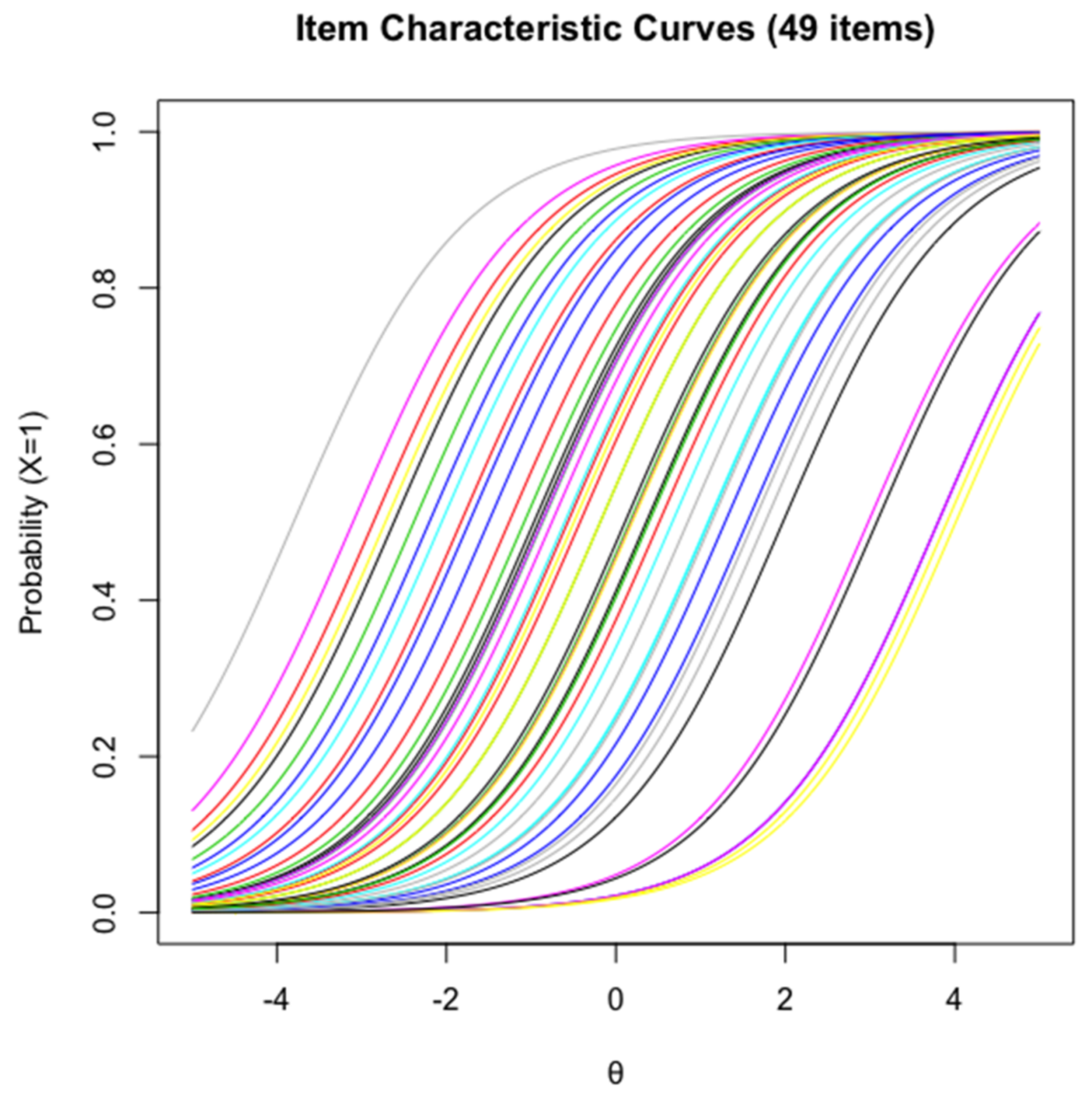
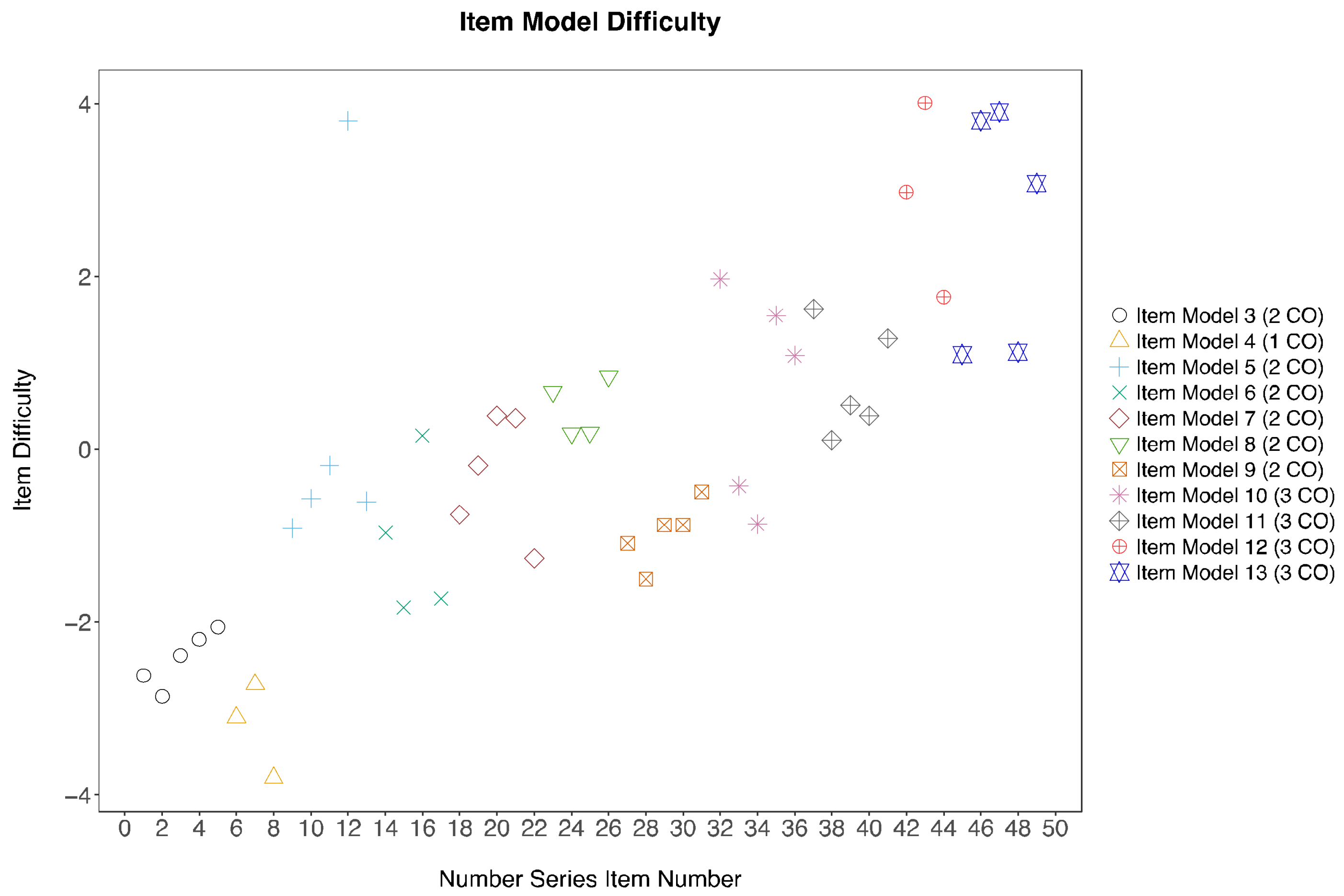
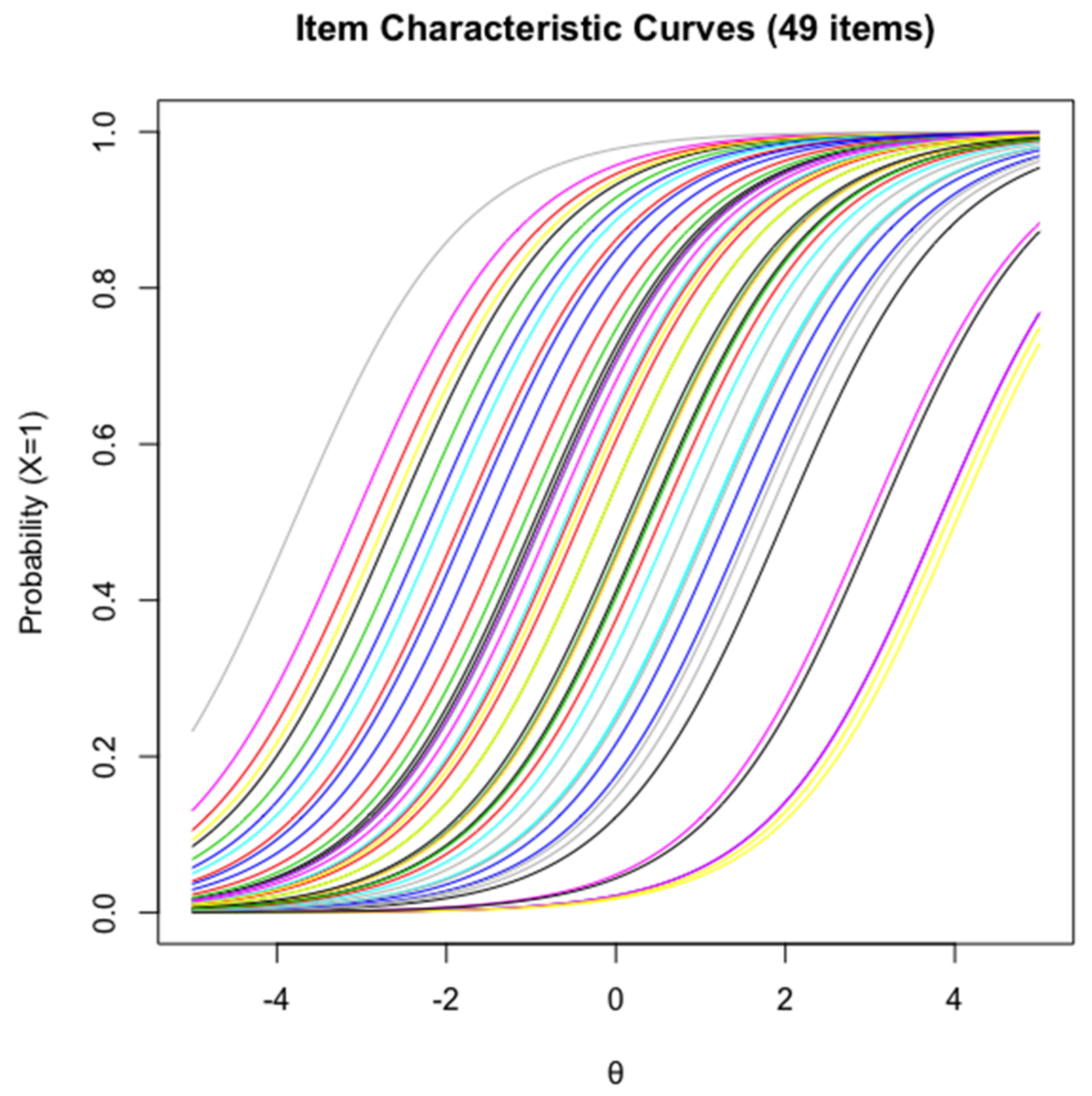
Thirteen item models were designed based on a non-arbitrary combination of the 5 cognitive operators. The generation of the items from each model is an integration of the item cloning approach and the item attribute approach [
35]. Following the item cloning procedure described by Glas and van der Linden [
36], attributes from the parent item can be filled in by specified substitution sets [
37,
38]. In this study, the numeric values in the number series are the substitution sets within each item family, allowing the ability to clone large number of items while maintaining the same item templates. Simple mathematical arithmetic operators were involved in the generation of the items but were not considered substantial to impact difficulty levels significantly and were therefore, not treated as substitution sets. Furthermore, based on the attribute approach proposed by Freund, Hofer and Holling [
39] and Holling, Bertling and Zeuch [
40], the structural variants of the item templates are created based on elementary operators [
41], which in this case, is the combination of the five cognitive operators.
A description of the item models can be found in
Table 2. A design matrix (Q-matrix) was created to account for these five cognitive operators. Following a theoretical cognitive model reduces the chances of having to revise our proposed item logic. Furthermore, using fixed item logic extends our understanding of how the cognitive mechanisms affect the item model difficulty. Therefore, the rules employed to develop an item model were not merely operational in its workings but rather designed to investigate individual differences in inductive reasoning.
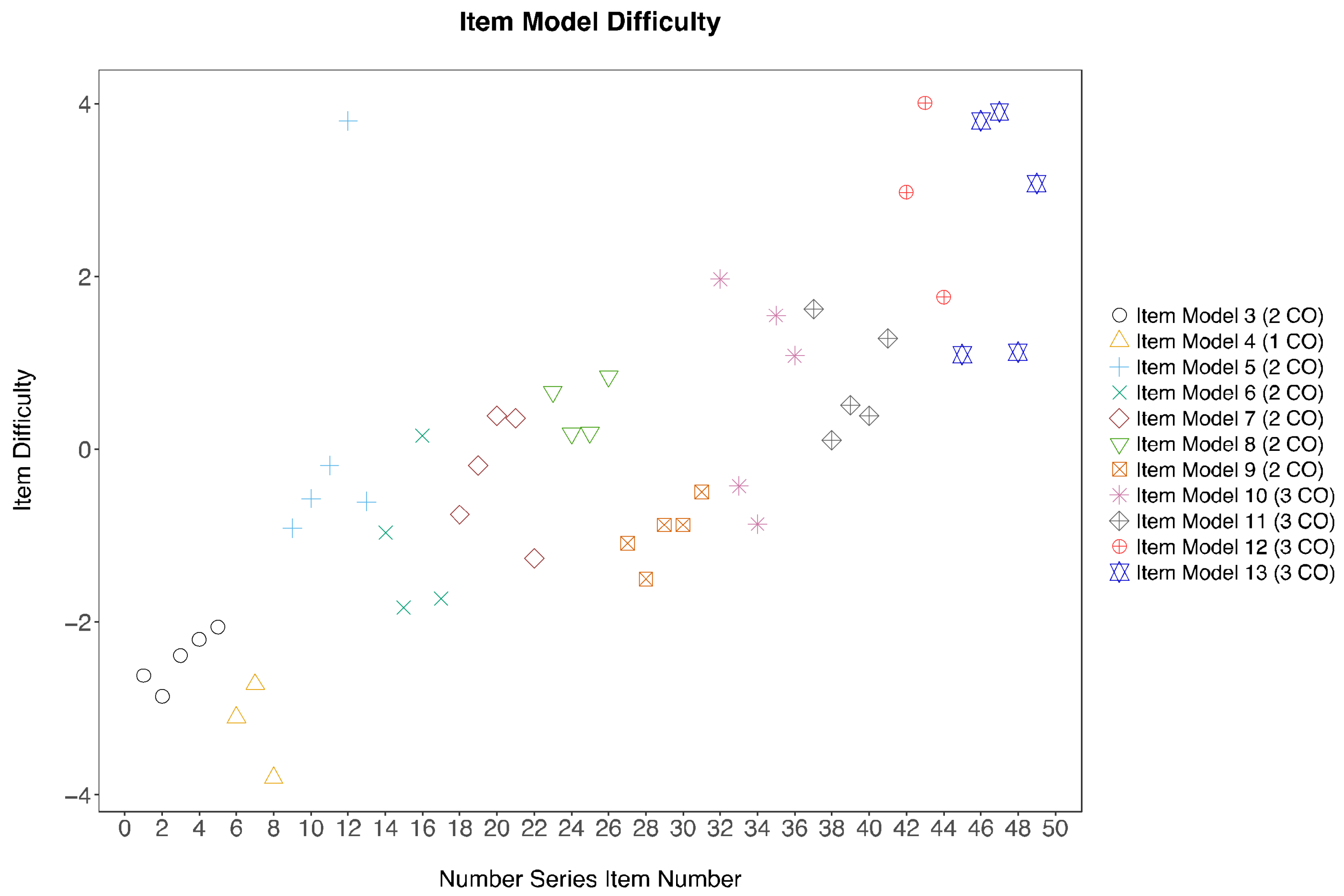
The item difficulty of each item model is largely dependent on the combination of cognitive operations that individuals employ while trying to solve the problems. Carpenter, Just & Shell [
42] argued that the most difficult problems in Raven Progressive Matrices are those that place a heavy burden on the working memory. These authors proposed that the amount of information, which one could maintain in the working memory, is an important indicator of the individual’s reasoning ability. Furthermore, they suggested that performance is not only based on the number of rules that are required to solve each problem but are also attributable to differences in the way one utilises the rules. Their argument was supported through a thorough item analysis of the Raven Progressive Matrices. Difficult items are those that require a large number of rules held in the working memory and that require the use of more difficult rules in order to solve the items [
42]. Babcock [
43] also supported the notion that the difficulty of Raven Matrices is due to the processing resources in the working memory available to the participants. Therefore, in accordance with the theory of individual differences in working memory, we propose that items from different item models may exhibit different item difficulty levels, as the cognitive operators underlying the item models require variable amount of working memory and involve different mental processes. Moreover, the item difficulty in each item model increases when individuals employ more cognitive operators to solve an item. This is due to a heavy burden in the information processing resources when more than one cognitive operators are held in the working memory when the individual is attempting to solve the item. Thus, item models designed to involve more cognitive operators will be more difficult than those that use fewer cognitive operators.
1.5. numGen R Package
It may be of interest to readers to understand how the number series generator was created. Hence, a written description of the numGen R package item generator is provided in this section. The numGen R package [
44] was developed based on the proposed cognitive operators, which led to the creation of 13 R functions corresponding to each item model. Each function can generate many items that can be considered to be an item clone of one another. Constraints were not employed in the generator to allow more flexibility in the item generation.
Item model 1 is based on the first operator only. The starting value of the number sequence could begin from any value, while the following values are of ordered constant of 1, 10 or 100 (e.g., 1 2 3 4 (5)). The sequence length is fixed at 5. Given a fixed sequence length, a starting value and a specific constant, a large number of items could be generated.
Item model 2 is designed based on the third cognitive operator only, which is the understanding of object clusters. The order of sequential numbers is not important but it is essential to recognise that the sequence of values is clustered in groups. Thus, it is critical that there is an equal length of repetitive numbers in each group. For example, in the number series 1 1 1 23 23 (23), there are 2 clustered groups. The first being ‘1’, while the second being ‘23’. Each of this value is repeated three times, with a fixed length of 6 sequences. Thus, random numbers could be used as a representation of the clustered groups.
Item model 3 is designed based on the first and the fourth cognitive operator. The values of the numbers increase sequentially based on a mathematical operator performing on the previous value. Unlike the first item model, the increasing values are not constant. Hence, basic mathematical operators such as addition, subtraction, multiplication and division could be used to increase the order of the values. A large number of similar number sequence type questions could be generated (e.g., 1 2 4 8 16 (32)) given a starting value, a fixed length, an arithmetic operator and a numeric value.
Item model 4 is designed based on the second cognitive operator only. The logic consists of an alternating pattern of sub-sequences. Two individual sequences could first be generated: 1 2 3 4 (5) and 2 4 6 8 (10); then both sequences are combined by alternating the input of the two sequences one at a time, resulting in a final sequence of 1 2 2 4 3 6 4 8 (5) (10). In order to compute a large number of items based on item model 4, random sequences could first be generated before combining the sequences into one.
Item model 5 is designed based on the second and fourth cognitive operators. One of the two sequences is first designed based on the second cognitive operator (item model 4), before combining them to form the parallel sub-sequences within a sequence. Furthermore, there is no constraint on the pattern of the second sequence. Therefore, in practice, this could be any form of number sequence pattern.
Item models 6 and 7 are created following the theoretical models of the first and the fifth cognitive operator. The creation of this sequence requires a higher level of abstraction between the paired numbers because the abstract value that results in the change of the preceding number to the next number is not invariant. For example, in the sequence 1 2 4 7 (11), the abstract value increases in the value by 1 between each paired number. In other words, the difference between 1 and 2 is 1, while the difference between 2 and 4 is 2, so on and so forth until the desired fixed length is reached. In the above example, we showed that there is an increasing value of 1 regardless of the starting abstract value but that value need not be fixed to 1. For item model 7, an item would be 3 10 24 52 108 (220), where the abstract value begins from 7 and changes by a value of 3 instead of 1. The change in the abstract value can be randomly generated using different arithmetic operators. The R function that generates items following Item model 7 is restricted to only the use of addition and multiplication operator to calculate the abstract value in the R package. Thus, the main difference between the two item models is a change in the abstract value which consequently changes the value between the preceding and the following number in the sequence.
Item model 8 is a combination of the third and fourth cognitive operators. First, the generation of these items is based on grouping the numbers into pairs or triads (third cognitive operator), with each group not necessarily having a relationship with the preceding group of numbers. However, each group needs to have the same set of numbers. For example, in the sequence 2 5 8 11 89 (92), there are 3 groups of paired numbers. The difference between the paired numbers in each group is the same (3), adhering to the fourth cognitive model but there is no relationship between each pair of numbers.
Item models 9 and 11 follows the theoretical model of the first, third and fourth cognitive operators. An example of item model 9 is 1 1 2 3 5 8 (13), where the value of a number in the sequence is based on the addition (fourth cognitive operator) of the two preceding numbers (first and third cognitive operators). This way of generating items follow the Fibonacci sequence approach. An example of item model 11 is the sequence 1 7 14 20 40 46 (92) (98), the items are first grouped in pairs (1–7) (14–20) (40–46) (92–98), with a difference of 6 in each pair of numbers (third and fourth cognitive operator). The starting value of the first number in the pair is the multiplication of the second number in the preceding pair by 2 (first cognitive operator).
The design of item model 10 is a combination of the second and fifth cognitive operators. For example, the sequence 2 15 4 17 7 19 11 21 16 (23) (22) can be broken up into two individual sequences 2 4 7 11 16 (22) and 15 17 19 21 (23) (second cognitive operator). The logic of the fifth cognitive operator is applied to at least one of the sequences, where the next value progressively evolves from the preceding value.
Finally, item model 12 and item model 13 is a combination of the second, third and fourth cognitive operators. An instance of item model 12 is as follows: 1 22 44 2 66 88 3 (110) (132). Parallel sequencing (second cognitive operator) follows between each pair of numbers in the item, where 1 2 (3) is a sequence and (22 44) (66 88) (110) (132) is another sequence of paired numbers (third cognitive operator). The difference between the pair of numbers in each group is 22 and the difference between the second paired number of the preceding group and the first paired number of the next group is 22. The value (i.e., 22) that differentiates within the pair of numbers and between the paired groups do not need to be the same, allowing more items to be generated. For item model 13, the sequence is similar to item model 12 (e.g., 1 5 8 3 209 212 5 41 (44) (7)), with the difference being that the pair of numbers within the sequence (5 8) (209 212) (41 44) are not connected to one another.
It is possible that some item models (e.g., item models 3 and 8) were given the flexibility to change certain parameters (e.g., arithmetic operators) in the R package. However, this flexibility is part of the functional design of the generator as it is not yet intended to be used in an automated item banking system. The items in this research were, therefore, selected from a larger pool of generated items to ensure that the group of items from each item model were logically similar but appeared distinct from one another. The four arithmetic operators were not systematically controlled to generate the items and thus, mathematically ability was not included as a cognitive operator. Given the first iteration of the generator, constraints were not introduced and should thus, be considered as a separate component of the generator. Please refer to the technical manual for more details regarding the numGen R package.
1.7. Construct Validity
An important aspect of AIG development is construct validity. Whitely [
51] proposed two aspects of construct validation that stem from different types of supporting research, namely, construct representation and nomothetic span. Construct representation is concerned with recognising the theoretical concepts that influence item responses and is mostly related to the processes, strategies and knowledge structures that are involved in solving the item [
51]. That is, elements within the items are manipulated to vary cognitive demands. Mathematical modelling of item difficulty has often been a chief approach in understanding construct representation because it can be used to identify cognitive processes, develop item models and empirically evaluate generated items [
52]. Thus, item difficulty indirectly affects the construct representation through the cognitive processing ability of the individual. Individuals may engage in various processes simultaneously if the tasks are deemed complex. Often, the processes that are most important within a set of items determine which dimension is being measured. Even though the item features vary, the parameters of the items should vary in a predictable fashion depending on the patterns of cognitive complexity [
1]. Thus, the proposed cognitive model should be accountable for all significant sources of variance in item difficulty.
Nomothetic span is concerned with the external correlates of test scores to other related measures [
51]. The focus is on assessing the utility of the test for measuring individual differences. Individual differences on a test should have frequent and strong correlations with other related tests measuring the same construct. It is not unusual to have a well-supported, constructed representation but relatively low correlations with other measures [
53]. In contrast, nomothetic span of general intelligence tests is often strong but construct representation remains a continuous academic discourse [
54]. Therefore, the generated number series items must be evaluated for aspects of nomothetic span, allowing specific predictions about external correlates of scores to be made from reference tests measuring similar constructs. The 16-item International Cognitive Ability Resource (ICAR) short form test [
55] was used as an external measure of the nomothetic span. A four-factor solution was previously identified to be the optimal solution with different item types representing different factors [
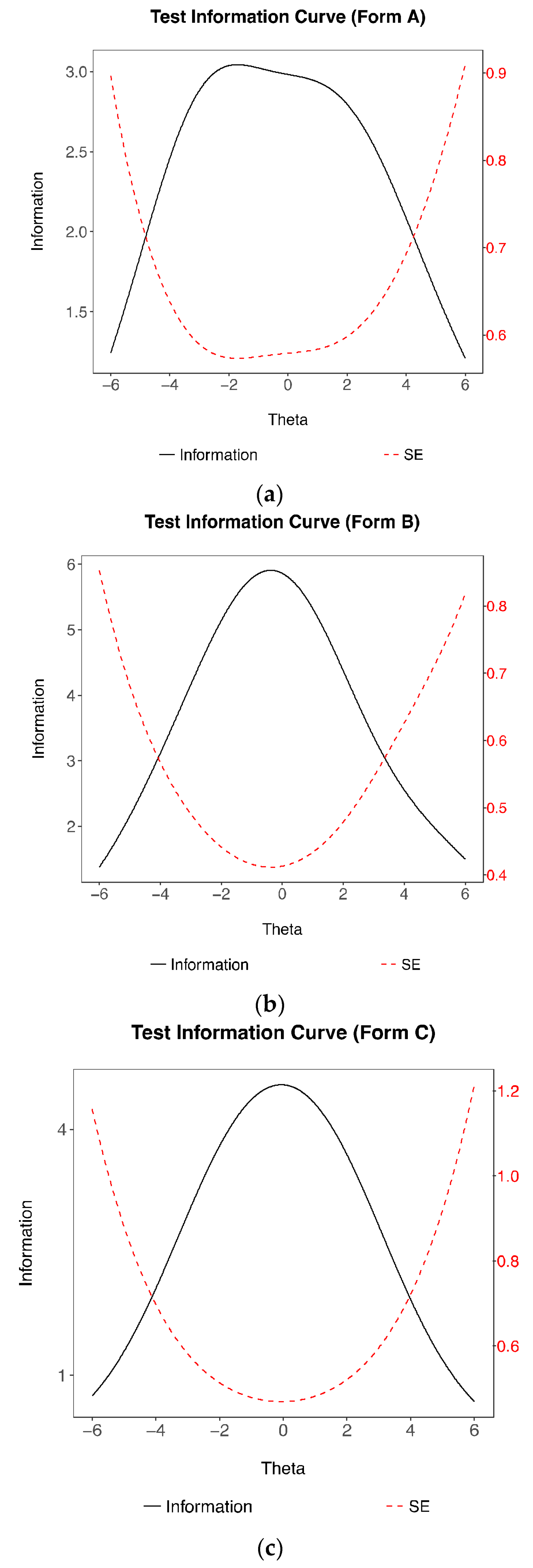
55]. With these goals in mind, this study examines the item properties to better understand the shared variance of the item difficulties and cognitive operators, as well as the construct and criterion validity of the newly developed automatic number series item generator.




{kind=link}
{kind=link}
{kind=link}