Explaining the Validity of the ASVAB for Job-Relevant Multitasking Performance: The Role of Placekeeping Ability



Abstract
:1. Introduction
2. Present Study
3. Method
3.1. Participants
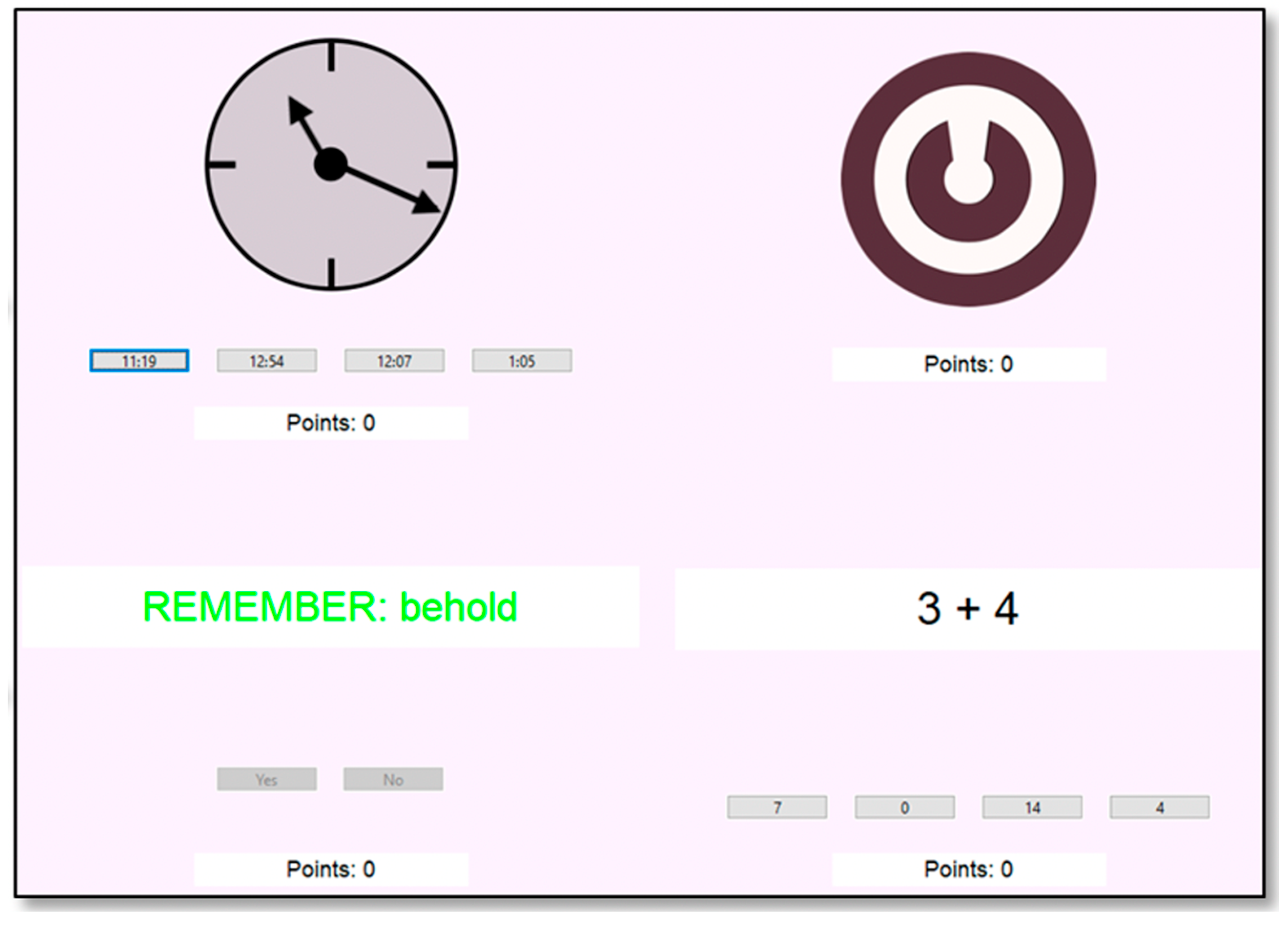
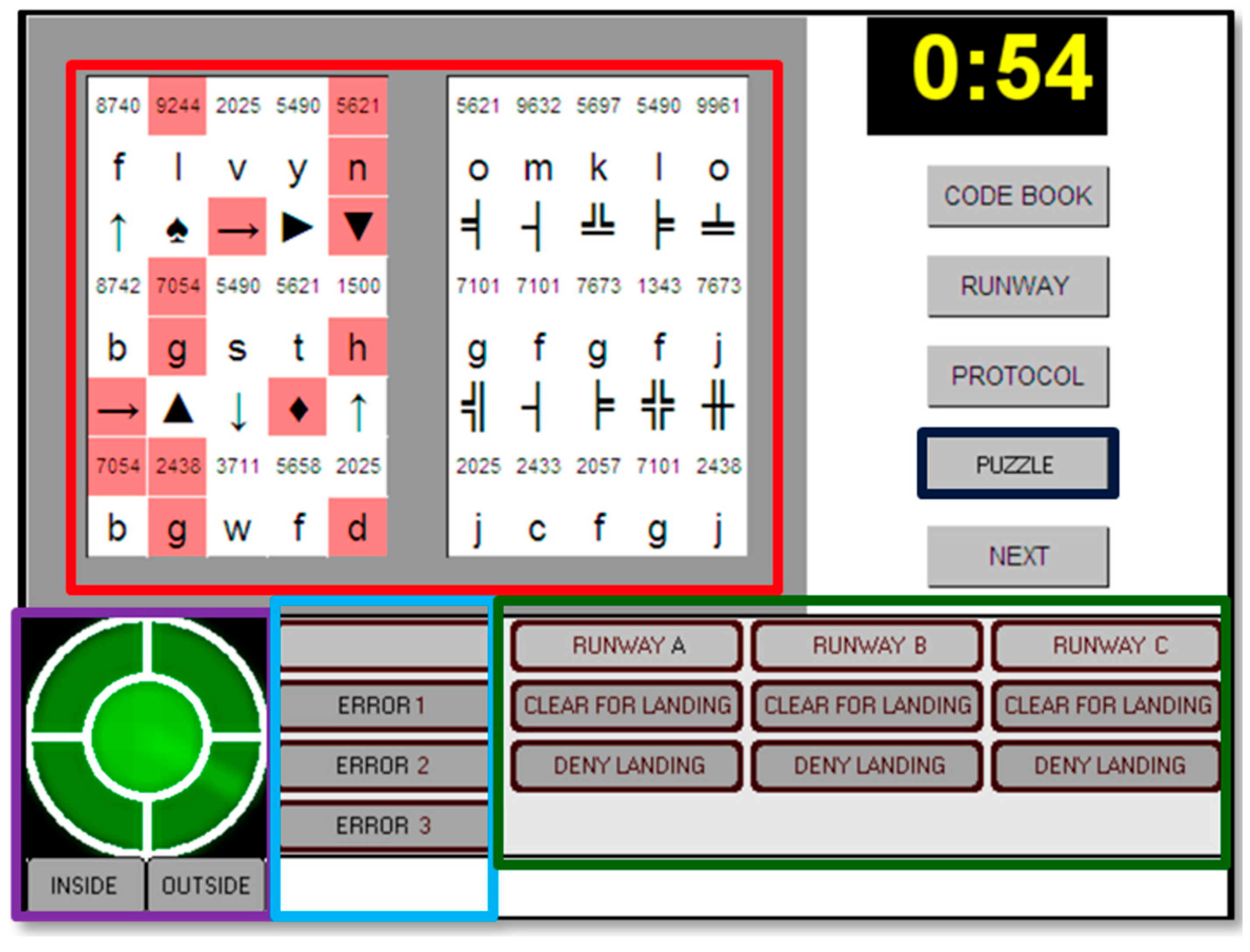
3.2. Procedure and Materials
3.3. Data Preparation
3.4. Composite Variables
3.5. Power Analyses
4. Results
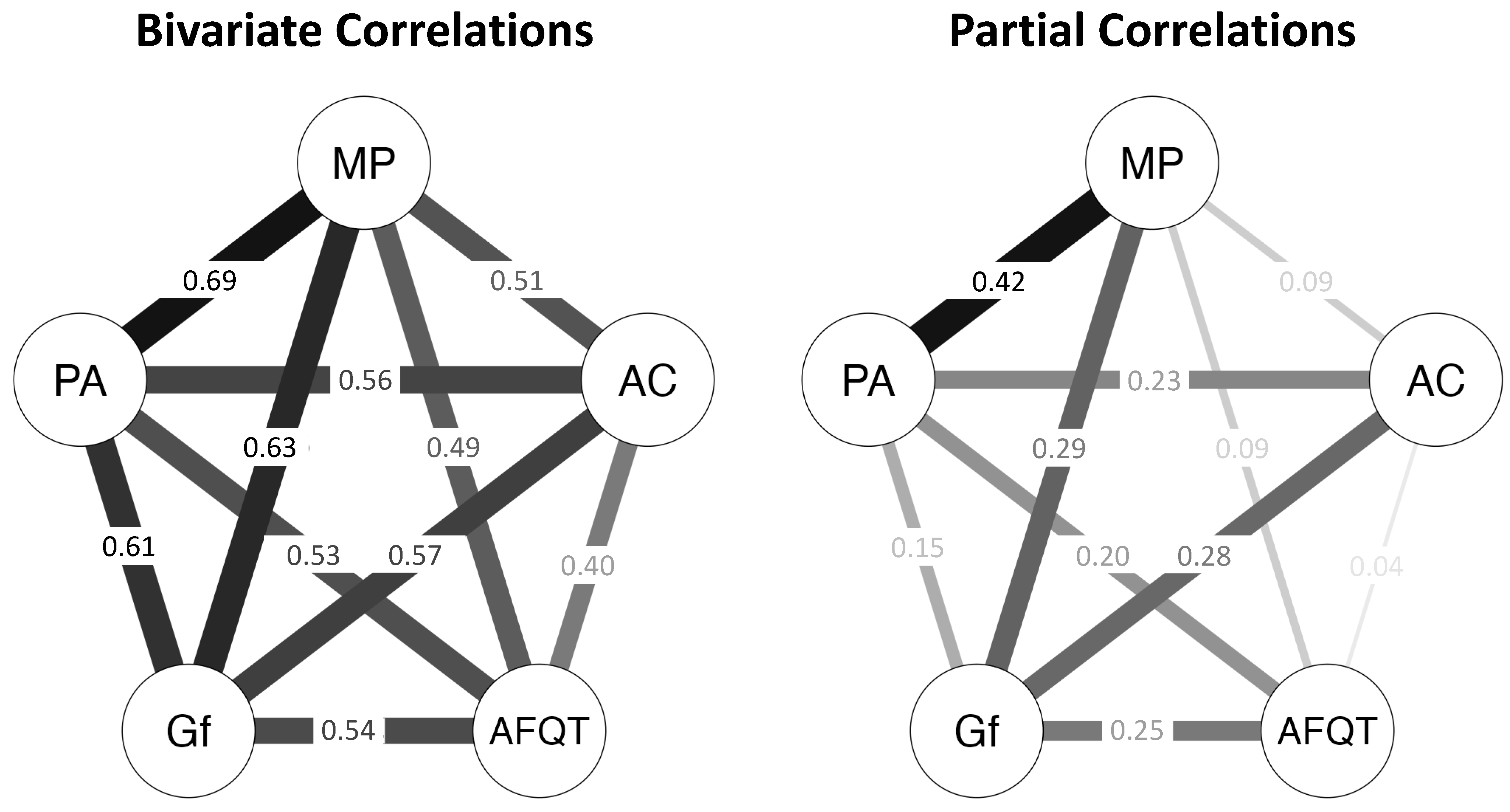
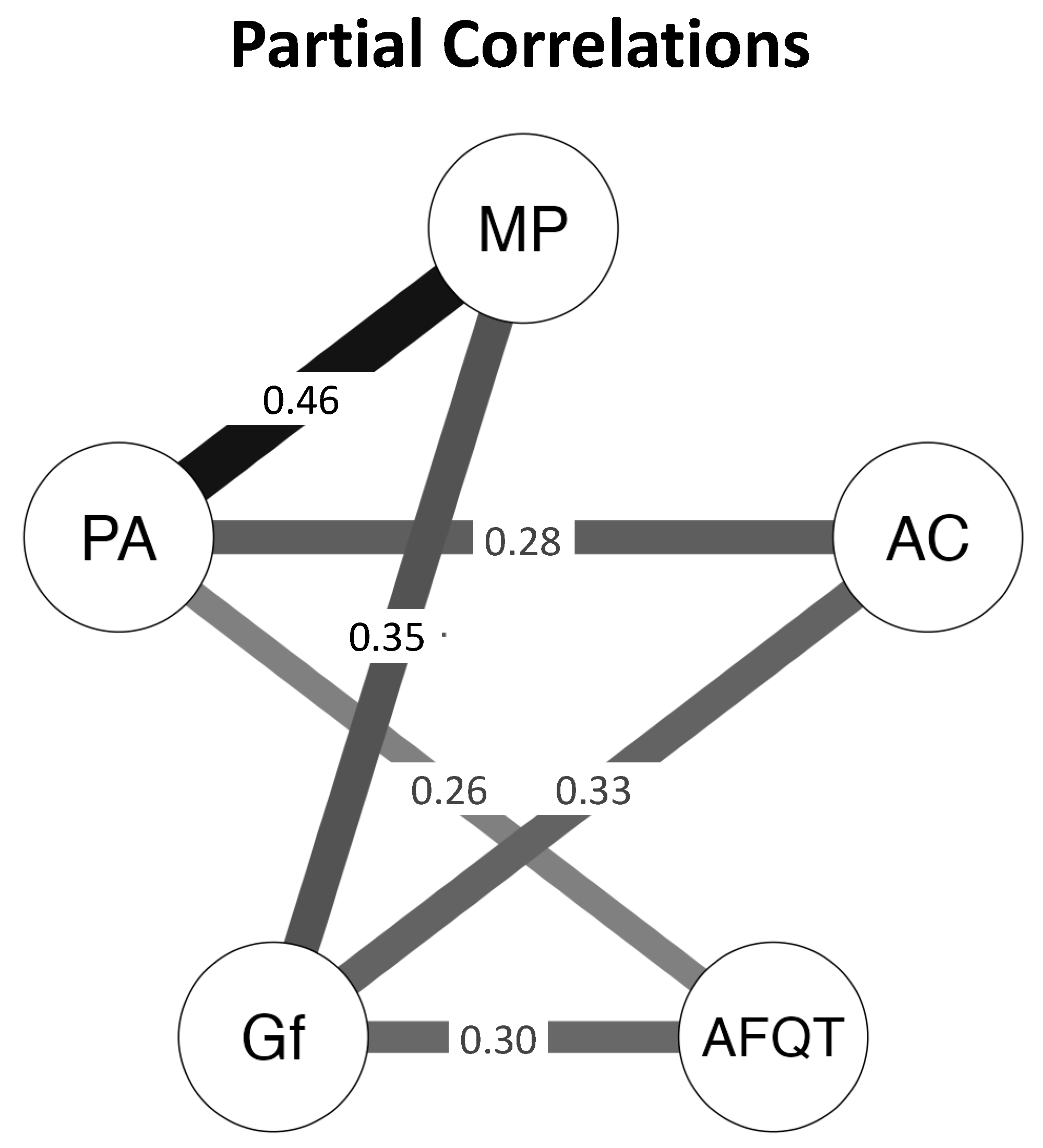
4.1. Psychometric Network Analyses
4.2. Hierarchical Regression Analyses
5. Discussion
6. Limitations
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor Variable | N | M | SD | Min | Max | Sk | Ku | Missing Values | ≤0 | Replaced Values | Outliers |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AFQT | |||||||||||
| Arithmetic Reasoning | 269 | 21.4 | 4.8 | 7 | 30 | −0.54 | −0.32 | 1 | 2 | 3 | 0 |
| Mathematics Knowl | 269 | 17.5 | 3.9 | 8 | 25 | −0.34 | −0.42 | 1 | 2 | 3 | 0 |
| Word Knowl | 269 | 30.5 | 2.9 | 8 | 34 | −2.70 | 15.18 | 1 | 2 | 3 | 2 |
| Paragraph Comp | 269 | 11.6 | 2.2 | 4 | 15 | −0.77 | 0.42 | 1 | 2 | 3 | 0 |
| Fluid Intelligence | |||||||||||
| Raven’s Matrices | 234 | 8.2 | 3.2 | 1 | 16 | −0.01 | −0.57 | 36 | 2 | 38 | 0 |
| Letter Sets | 212 | 9.6 | 2.9 | 3 | 17 | 0.20 | −0.40 | 58 | 0 | 58 | 0 |
| Number Series | 212 | 9.0 | 2.7 | 2 | 15 | −0.13 | −0.33 | 58 | 0 | 58 | 0 |
| Attention Control | |||||||||||
| Antisaccade | 214 | 0.85 | 0.11 | 0.45 | 1.0 | −1.19 | 1.15 | 56 | 0 | 56 | 1 |
| Sustained Attn to Cue | 226 | 0.86 | 0.12 | 0.39 | 1.0 | −1.63 | 2.85 | 44 | 0 | 44 | 3 |
| Flanker Deadline | 210 | 775.1 | 486.2 | 390 | 3750 | 3.71 | 17.13 | 60 | 0 | 60 | 3 |
| Stroop Deadline | 157 | 1320.6 | 638.0 | 570 | 3930 | 2.15 | −5.50 | 113 | 0 | 113 | 4 |
| Selective Visual Arrays | 155 | 0.62 | 0.10 | 0.38 | 0.89 | 0.11 | −0.66 | 115 | 0 | 115 | 0 |
| Placekeeping Ability | |||||||||||
| UNRAVEL | 226 | 0.0 | 1.0 | −3.5 | 1.9 | −0.67 | 0.32 | 44 | 0 | 44 | 1 |
| Letterwheel | 201 | 0.0 | 1.0 | −3.5 | 1.9 | −0.78 | 0.34 | 69 | 0 | 69 | 1 |
| Multitasking Performance | |||||||||||
| Foster Task | 240 | 0.0 | 1.0 | −1.5 | 3.4 | 0.98 | 1.17 | 30 | 11 | 41 | 0 |
| Control Tower | 213 | 0.0 | 1.0 | −3.5 | 1.9 | −0.64 | 0.81 | 57 | 0 | 57 | 1 |
| SynWin | 150 | 0.0 | 1.0 | −2.7 | 2.1 | −0.24 | −0.18 | 120 | 4 | 124 | 0 |
| Mental Counters | 240 | 0.57 | 0.21 | 0.03 | 0.97 | −0.38 | 0.47 | 30 | 3 | 33 | 0 |
| Variable | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1. AFQT | (0.73) | |||||||||||||
| 2. Raven’s Matrices | 0.46 *** | (0.73) | ||||||||||||
| 3. Letter Sets | 0.30 *** | 0.46 *** | (0.74) | |||||||||||
| 4. Number Series | 0.51 *** | 0.37 *** | 0.44 *** | (0.69) | ||||||||||
| 5. Antisaccade | 0.26 *** | 0.28 *** | 0.41 *** | 0.34 *** | (0.91) | |||||||||
| 6. Sustained AC | 0.22 *** | 0.34 *** | 0.23 *** | 0.13 * | 0.39 *** | (0.87) | ||||||||
| 7. Flanker Deadline | 0.34 *** | 0.38 *** | 0.40 *** | 0.35 *** | 0.56 *** | 0.31 *** | - | |||||||
| 8. Stroop Deadline | 0.19 ** | 0.31 *** | 0.24 *** | 0.25 *** | 0.38 *** | 0.27 *** | 0.51 *** | - | ||||||
| 9. Selective VA | 0.45 *** | 0.43 *** | 0.35 *** | 0.40 *** | 0.37 *** | 0.40 *** | 0.37 *** | 0.39 *** | (0.73) | |||||
| 10. UNRAVEL | 0.45 *** | 0.33 *** | 0.39 *** | 0.39 *** | 0.44 *** | 0.26 *** | 0.34 *** | 0.16 ** | 0.31 *** | (0.73) | ||||
| 11. Letterwheel | 0.51 *** | 0.40 *** | 0.54 *** | 0.57 *** | 0.54 *** | 0.34 *** | 0.51 *** | 0.27 *** | 0.44 *** | 0.66 *** | (0.72) | |||
| 12. Foster Task | 0.16 ** | 0.16 ** | 0.33 *** | 0.23 *** | 0.14 * | 0.06 | 0.15 * | 0.17 ** | 0.24 *** | 0.21 *** | 0.32 *** | (0.52) | ||
| 13. Control Tower | 0.44 *** | 0.33 *** | 0.50 *** | 0.52 *** | 0.47 *** | 0.25 *** | 0.43 *** | 0.20 *** | 0.27 *** | 0.54 *** | 0.63 *** | 0.32 *** | (0.58) | |
| 14. SynWin | 0.49 *** | 0.34 *** | 0.42 *** | 0.49 *** | 0.42 *** | 0.22 *** | 0.39 *** | 0.26 *** | 0.45 *** | 0.48 *** | 0.62 *** | 0.23 *** | 0.39 *** | (0.77) |
| Multiple R | 0.69 | 0.63 | 0.67 | 0.69 | 0.69 | 0.54 | 0.70 | 0.58 | 0.66 | 0.70 | 0.83 | 0.44 | 0.73 | 0.69 |
Appendix B
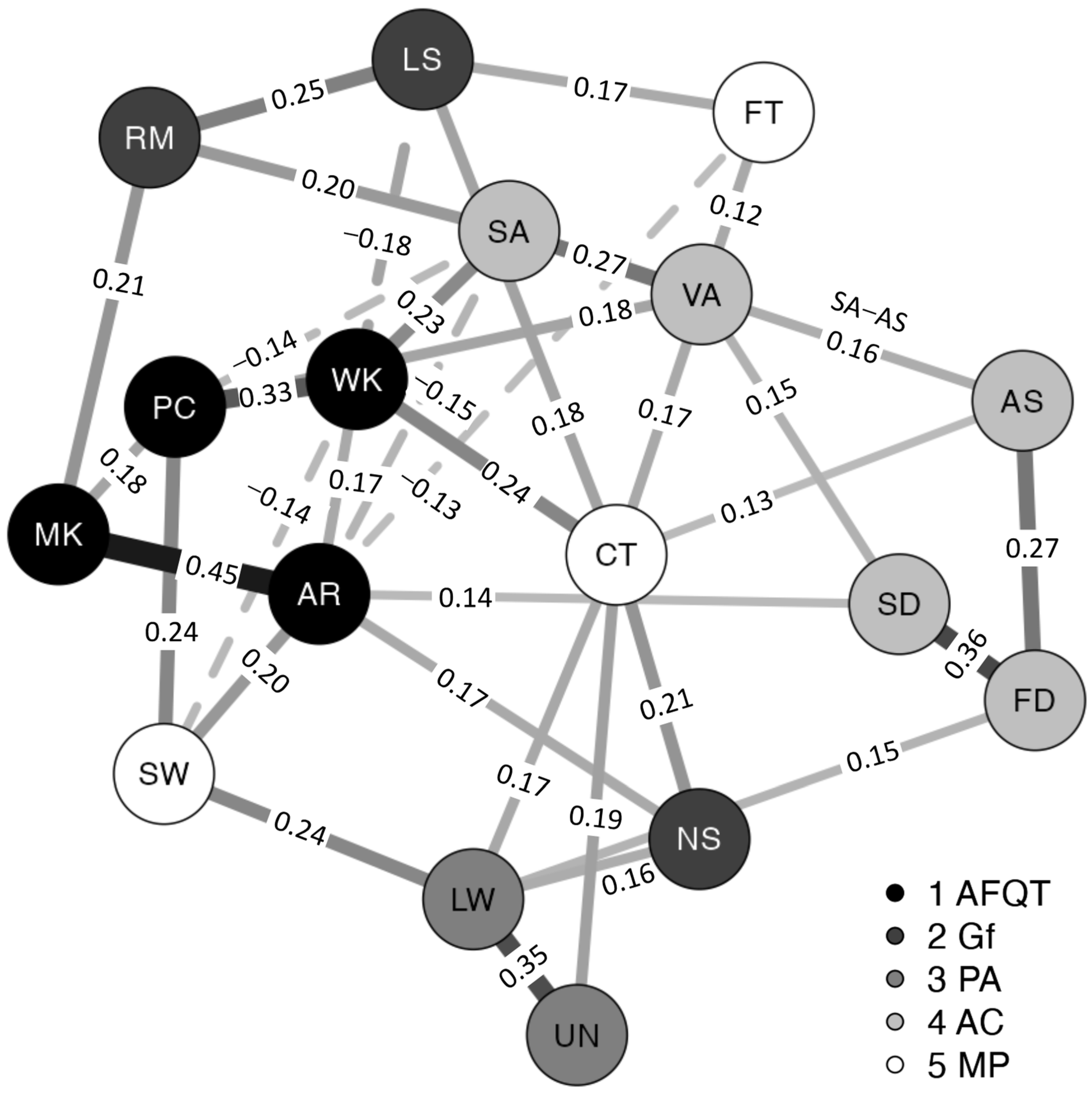
| Network | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Variable | RM | LS | NS | UN | LW | AS | SA | FD | SD | VA | AR | WK | MK | PC | CT | SW | FT |
| RM | 0.000 | 0.249 | 0.021 | 0.054 | −0.053 | −0.071 | 0.201 | 0.089 | 0.069 | 0.091 | 0.063 | 0.010 | 0.209 | 0.070 | −0.009 | −0.040 | −0.038 |
| LS | 0.249 | 0.000 | 0.064 | −0.010 | 0.120 | 0.093 | 0.003 | 0.065 | −0.066 | 0.009 | 0.055 | −0.180 | 0.038 | −0.076 | 0.182 | 0.061 | 0.167 |
| NS | 0.021 | 0.064 | 0.000 | −0.080 | 0.163 | 0.014 | −0.122 | −0.028 | 0.034 | 0.100 | 0.169 | 0.034 | 0.102 | 0.005 | 0.209 | 0.101 | −0.023 |
| UN | 0.054 | −0.010 | −0.080 | 0.000 | 0.348 | 0.116 | 0.001 | −0.072 | −0.039 | −0.022 | −0.028 | 0.053 | 0.078 | 0.059 | 0.186 | 0.100 | −0.037 |
| LW | −0.053 | 0.120 | 0.163 | 0.348 | 0.000 | 0.098 | 0.117 | 0.148 | −0.066 | 0.039 | 0.055 | 0.008 | 0.023 | 0.013 | 0.170 | 0.235 | 0.122 |
| AS | −0.071 | 0.093 | 0.014 | 0.116 | 0.098 | 0.000 | 0.161 | 0.268 | 0.122 | 0.078 | −0.079 | 0.000 | −0.023 | −0.084 | 0.135 | 0.120 | −0.095 |
| SA | 0.201 | 0.003 | −0.122 | 0.001 | 0.117 | 0.161 | 0.000 | −0.014 | 0.085 | 0.268 | −0.147 | 0.230 | 0.003 | −0.138 | 0.005 | 0.022 | −0.079 |
| FD | 0.089 | 0.065 | −0.028 | −0.072 | 0.148 | 0.268 | −0.014 | 0.000 | 0.360 | 0.003 | −0.087 | 0.026 | 0.046 | 0.081 | 0.114 | 0.033 | −0.091 |
| SD | 0.069 | −0.066 | 0.034 | −0.039 | −0.066 | 0.122 | 0.085 | 0.360 | 0.000 | 0.152 | 0.137 | −0.113 | −0.014 | −0.055 | −0.051 | −0.017 | 0.117 |
| VA | 0.091 | 0.009 | 0.100 | −0.022 | 0.039 | 0.078 | 0.268 | 0.003 | 0.152 | 0.000 | 0.090 | −0.059 | 0.055 | 0.177 | −0.114 | 0.078 | 0.123 |
| AR | 0.063 | 0.055 | 0.169 | −0.028 | 0.055 | −0.079 | −0.147 | −0.087 | 0.137 | 0.090 | 0.000 | 0.168 | 0.449 | 0.021 | 0.045 | 0.203 | −0.131 |
| WK | 0.010 | −0.180 | 0.034 | 0.053 | 0.008 | 0.00 | 0.230 | 0.026 | −0.113 | −0.059 | 0.168 | 0.000 | −0.030 | 0.325 | 0.237 | −0.138 | −0.029 |
| MK | 0.209 | 0.038 | 0.102 | 0.078 | 0.023 | −0.023 | 0.003 | 0.046 | −0.014 | 0.055 | 0.449 | −0.030 | 0.000 | 0.179 | 0.005 | −0.068 | 0.077 |
| PC | 0.070 | −0.076 | 0.005 | 0.059 | 0.013 | −0.084 | −0.138 | 0.081 | −0.055 | 0.177 | 0.021 | 0.325 | 0.179 | 0.000 | −0.086 | 0.238 | 0.014 |
| CT | −0.009 | 0.182 | 0.209 | 0.186 | 0.170 | 0.135 | 0.005 | 0.114 | −0.051 | −0.114 | 0.045 | 0.237 | 0.005 | −0.086 | 0.000 | −0.086 | 0.169 |
| SW | −0.040 | 0.061 | 0.101 | 0.100 | 0.235 | 0.120 | 0.022 | 0.033 | −0.017 | 0.078 | 0.203 | −0.138 | −0.068 | 0.238 | −0.086 | 0.000 | 0.040 |
| FT | −0.038 | 0.167 | −0.023 | −0.037 | 0.122 | −0.095 | −0.079 | −0.091 | 0.117 | 0.123 | −0.131 | −0.029 | 0.077 | 0.014 | 0.169 | 0.040 | 0.000 |
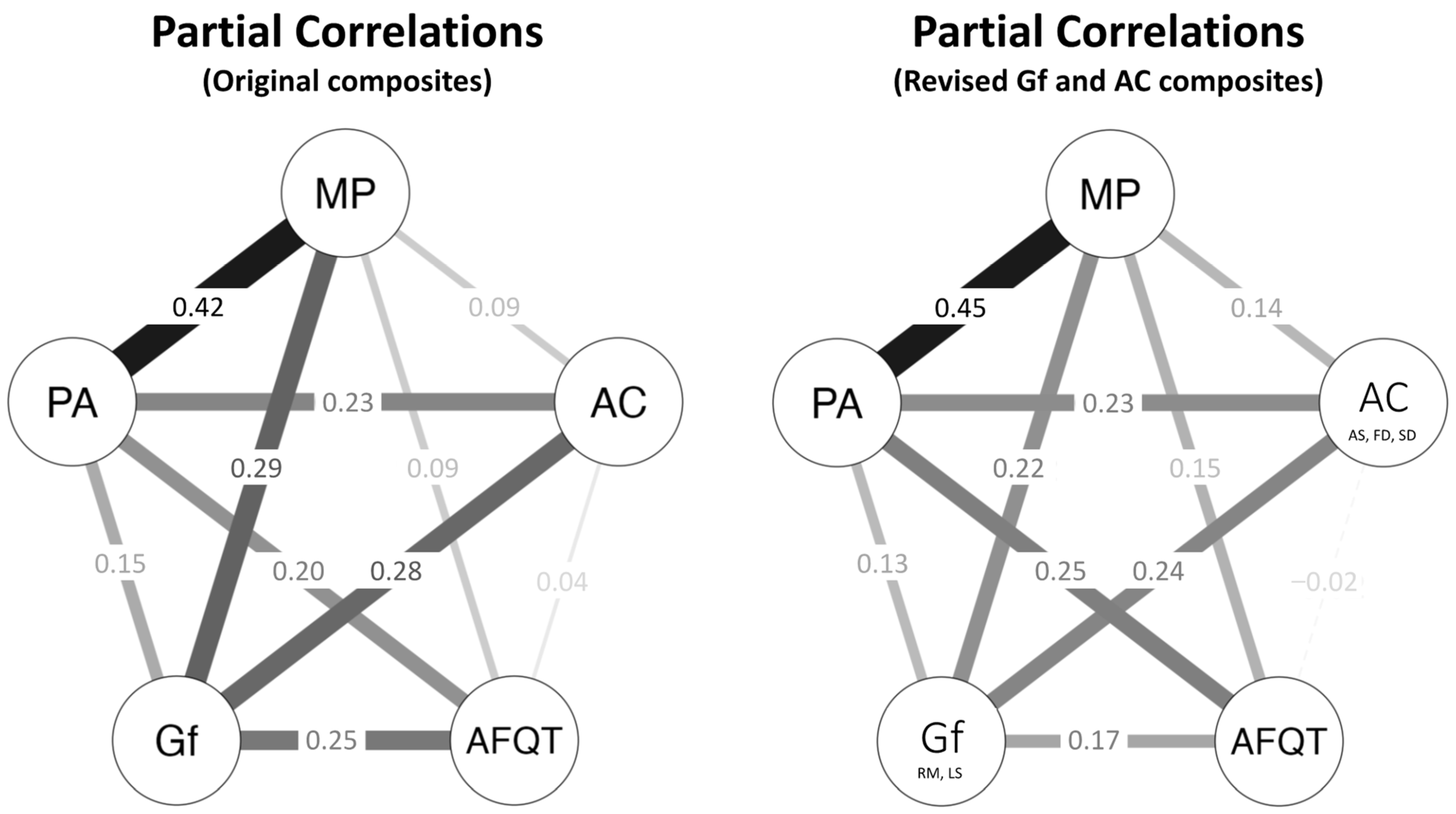
Appendix C
Appendix C.1. Psychometric Network Analyses
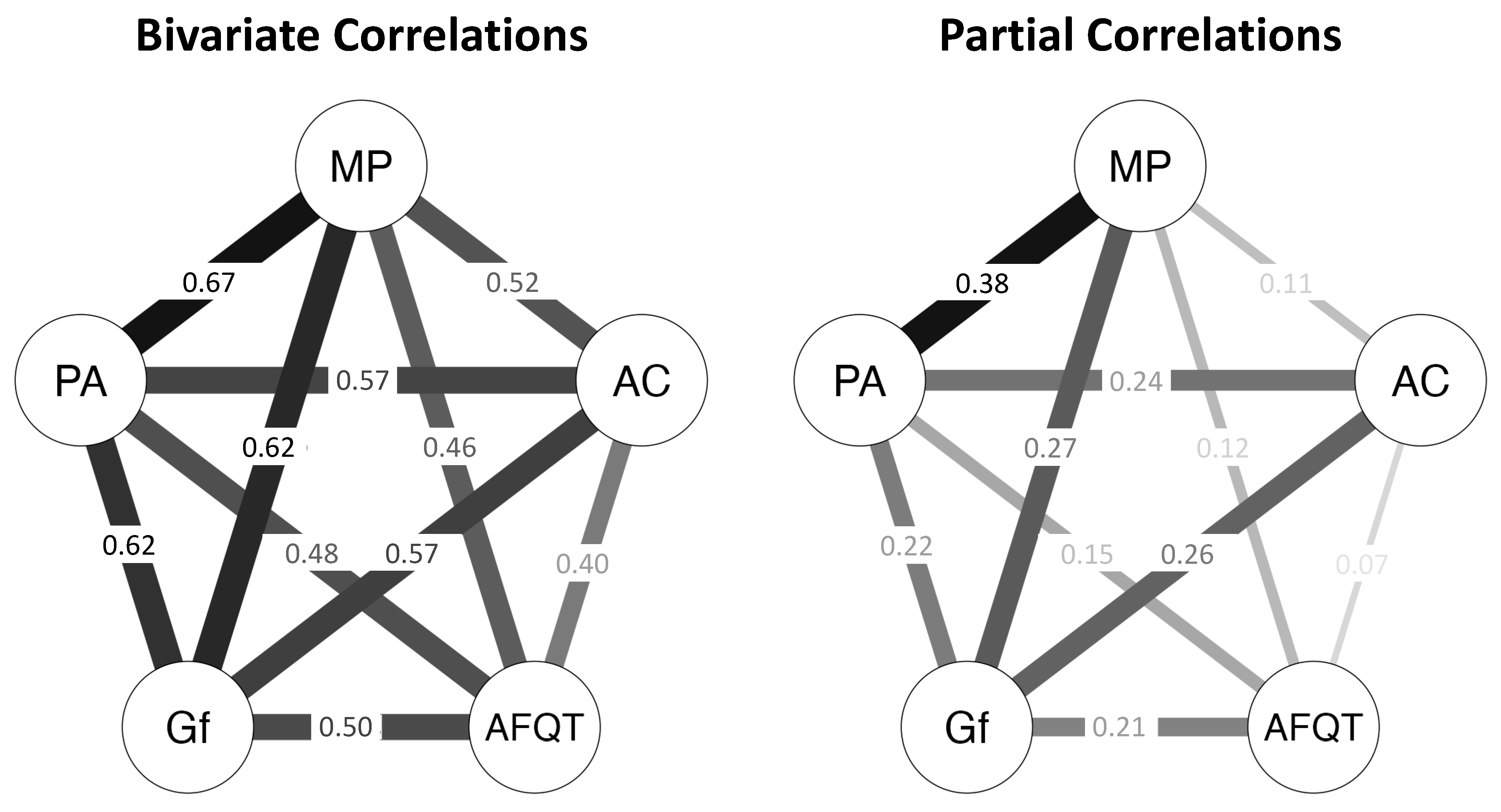
Appendix C.2. Hierarchical Regression Analyses
| Full Sample (N = 270) | All Sessions (n = 158) | ||||
|---|---|---|---|---|---|
| Model | Incremental Validity Test | ΔR2 | ΔF | ΔR2 | ΔF |
| 1A | Gf over AFQT | 0.193 | 91.06 *** | 0.205 | 54.87 *** |
| 1B | PA over AFQT | 0.257 | 136.62 *** | 0.255 | 74.72 *** |
| 1C | AC over AFQT | 0.119 | 49.54 *** | 0.130 | 30.75 *** |
| 2A | Gf over AFQT & PA | 0.055 | 32.46 *** | 0.053 | 17.03 *** |
| 2B | Gf over AFQT & AC | 0.100 | 49.42 *** | 0.103 | 28.91 *** |
| 2C | PA over AFQT & Gf | 0.118 | 70.43 *** | 0.103 | 33.21 *** |
| 2D | PA over AFQT & AC | 0.156 | 85.87 *** | 0.145 | 43.89 *** |
| 2E | AC over AFQT & Gf | 0.026 | 12.84 ** | 0.028 | 7.90 ** |
| 2F | AC over AFQT & PA | 0.018 | 9.95 ** | 0.020 | 6.02 * |
| 3A | Gf over AFQT, PA, & AC | 0.040 | 24.17 *** | 0.053 | 17.03 *** |
| 3B | PA over AFQT, Gf, & AC | 0.096 | 57.59 *** | 0.080 | 26.02 *** |
| 3C | AC over AFQT, Gf, & PA | 0.004 | 2.36 | 0.006 | 1.81 |
Appendix D
Appendix D.1. Psychometric Network Analyses
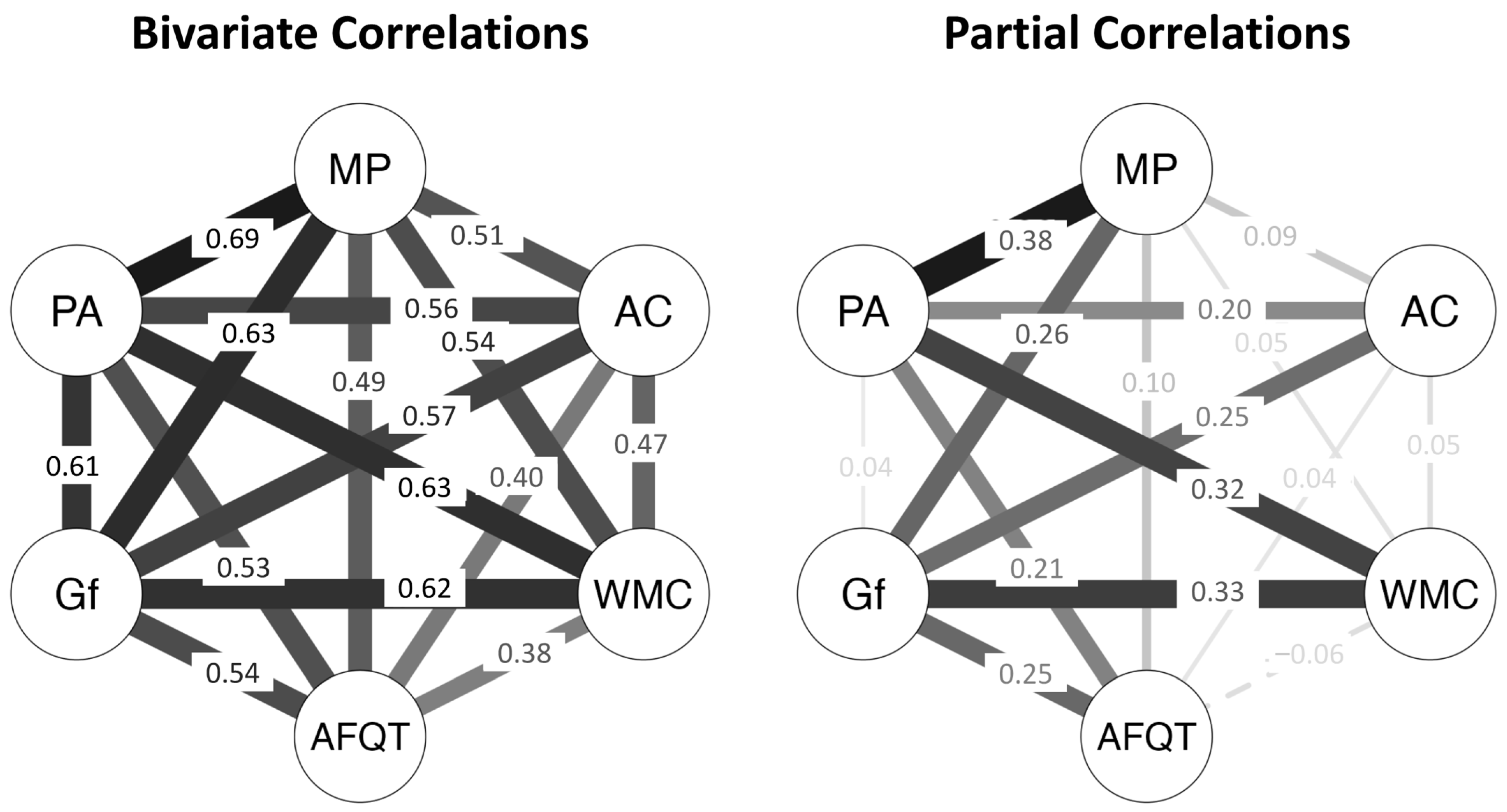
Appendix D.2. Hierarchical Regression Analyses
| ΔR2 | ΔF | df | β [95% CI] | t | |
|---|---|---|---|---|---|
| Model 1 | |||||
| Step 1 | 0.241 | 85.17 *** | 1, 268 | ||
| AFQT | 0.49 [0.39, 0.60] | 9.23 *** | |||
| Step 2 | 0.142 | 61.27 *** | 1, 267 | ||
| MC | 0.41 [0.31, 0.51] | 7.83 *** | |||
| Model 2A | |||||
| Step 1 | 0.434 | 102.42 *** | 2, 267 | ||
| AFQT | 0.21 [0.10, 0.32] | 3.83 *** | |||
| Gf | 0.52 [0.41, 0.63] | 9.54 *** | |||
| Step 2 | 0.028 | 13.98 *** | 1, 266 | ||
| AFQT | 0.20 [0.09, 0.30] | 3.63 *** | |||
| Gf | 0.40 [0.27, 0.52] | 6.28 *** | |||
| MC | 0.22 [0.10, 0.33] | 3.74 *** | |||
| Model 2B | |||||
| Step 1 | 0.498 | 132.44 *** | 2, 267 | ||
| AFQT | 0.18 [0.08, 0.28] | 3.45 *** | |||
| PA | 0.60 [0.50, 0.70] | 11.69 *** | |||
| Step 2 | 0.015 | 8.23 ** | 1, 266 | ||
| AFQT | 0.16 [0.07, 0.26] | 3.25 *** | |||
| PA | 0.50 [0.39, 0.62] | 8.44 *** | |||
| MC | 0.16 [0.05, 0.27] | 2.87 ** | |||
| Model 2C | |||||
| Step 1 | 0.360 | 75.06 *** | 2, 267 | ||
| AFQT | 0.34 [0.23, 0.44] | 6.33 *** | |||
| AC | 0.38 [0.27, 0.48] | 7.04 *** | |||
| Step 2 | 0.072 | 33.62 *** | 1, 266 | ||
| AFQT | 0.27 [0.16, 0.37] | 5.10 *** | |||
| AC | 0.26 [0.15, 0.37] | 4.79 *** | |||
| MC | 0.31 [0.21, 0.42] | 5.80 *** | |||
| Model 3 | |||||
| Step 1 | 0.557 | 83.15 *** | 4, 265 | ||
| AFQT | 0.08 [−0.02, 0.18] | 1.54 | |||
| Gf | 0.28 [0.17, 0.40] | 4.92 *** | |||
| PA | 0.43 [0.32, 0.54] | 7.59 *** | |||
| AC | 0.08 [−0.02, 0.19] | 1.54 | |||
| Step 2 | 0.001 | 0.63 | 1, 264 | ||
| AFQT | 0.08 [−0.02, 0.18] | 1.58 | |||
| Gf | 0.27 [0.15, 0.39] | 4.32 *** | |||
| PA | 0.41 [0.30, 0.53] | 6.78 *** | |||
| AC | 0.08 [−0.03, 0.18] | 1.49 | |||
| MC | 0.05 [−0.07, 0.16] | 0.79 |
Appendix E
| Model | R2 | F | df |
|---|---|---|---|
| 1 predictor | |||
| AFQT | 0.241 | 85.17 | 1, 268 |
| AC | 0.264 | 96.11 | 1, 268 |
| Gf | 0.403 | 180.93 | 1, 268 |
| PA | 0.476 | 243.05 | 1, 268 |
| 2 predictors | |||
| AFQT, AC | 0.360 | 75.06 | 2, 267 |
| AFQT, Gf | 0.434 | 102.42 | 2, 267 |
| Gf, AC | 0.437 | 103.64 | 2, 267 |
| AFQT, PA | 0.498 | 132.44 | 2, 267 |
| PA, AC | 0.500 | 133.52 | 2, 267 |
| Gf, PA | 0.548 | 161.99 | 2, 267 |
| 3 predictors | |||
| AFQT, Gf, AC | 0.460 | 75.59 | 3, 266 |
| AFQT, PA, AC | 0.516 | 94.57 | 3, 266 |
| Gf, PA, AC | 0.533 | 109.50 | 3, 266 |
| AFQT, Gf, PA | 0.553 | 109.51 | 3, 266 |
| 4 predictors | |||
| AFQT, Gf, PA, AC | 0.557 | 83.15 | 4, 265 |
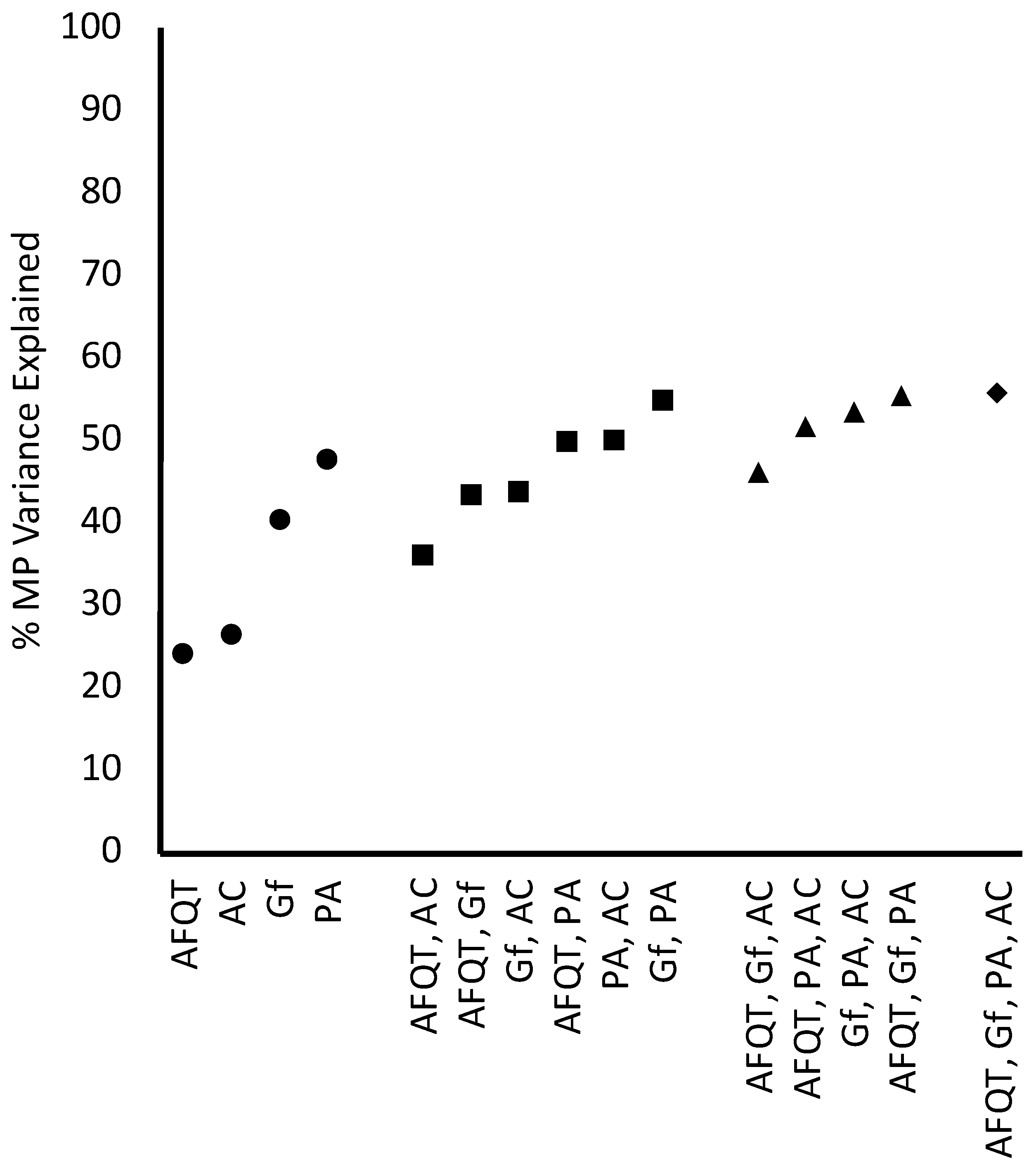
Appendix F



| 1 | In SEM, a latent variable is represented as a circle (or oval) and an observed variable as a square (or rectangle). In psychometric network analysis, a node is represented as a circle, but this may not indicate that the variable is latent. The nodes in the psychometric network analyses we present here are not latent variables, but rather are composites of observed variables. |
| 2 | Our battery included one test of working memory capacity (Mental Counters, administered in Session 2). Because we had only this one indicator of working memory capacity, we did not include it in our main analyses, and instead report a separate analysis including results of this test in Appendix D. We are grateful to Cyrus Foroughi, Ph.D., U.S. Naval Research Lab, for sending us this test and granting us permission to use it. |
| 3 | At present, the minimum AFQT percentile score (with a high school degree) is 30 for the Army, 35 for the Navy, 32 for the Marine Corps, 31 for the Air Force, and 36 for the Coast Guard (https://www.military.com/join-armed-forces/asvab, accessed on 3 December 2023). |
| 4 | We are extremely grateful to Randy Engle for granting us permission to use these attention control tasks in our study and to Jason Tsukahara for sending the tasks to us. |
References
- Ackerman, Philip L., Margaret E. Beier, and Mary O. Boyle. 2005. Working memory and intelligence: The same or different constructs? Psychological Bulletin 131: 30. [Google Scholar] [CrossRef] [PubMed]
- Alluisi, Earl A. 1967. Methodology in the use of synthetic tasks to assess complex performance. Human Factors 9: 375–84. [Google Scholar] [CrossRef] [PubMed]
- Altmann, Erik M., and David Z. Hambrick. 2022. Task independence of placekeeping as a cognitive control construct: Evidence from individual differences and experimental effects. Cognition 229: 105229. [Google Scholar] [CrossRef] [PubMed]
- Altmann, Erik M., J. Gregory Trafton, and David Z. Hambrick. 2014. Momentary interruptions can derail the train of thought. Journal of Experimental Psychology: General 143: 215–26. [Google Scholar] [CrossRef] [PubMed]
- Banich, Marie T. 2009. Executive function: The search for an integrated account. Current Directions in Psychological Science 18: 89–94. [Google Scholar] [CrossRef]
- Borsboom, Denny, Marie K. Deserno, Mijke Rhemtulla, Sacha Epskamp, Eiko I. Fried, Richard J. McNally, Donald J. Robinaugh, Marco Perugini, Jonas Dalege, Giulio Costantini, and et al. 2021. Network analysis of multivariate data in psychological science. Nature Reviews Methods Primers 1: 58. [Google Scholar] [CrossRef]
- Burgoyne, Alexander P., and Randall W. Engle. 2020. Attention control: A cornerstone of higher-order cognition. Current Directions in Psychological Science 29: 624–30. [Google Scholar] [CrossRef]
- Burgoyne, Alexander P., Cody A. Mashburn, and Randall W. Engle. 2021a. Reducing adverse impact in high-stakes testing. Intelligence 87: 101561. [Google Scholar] [CrossRef]
- Burgoyne, Alexander P., David Z. Hambrick, and Erik M. Altmann. 2019. Placekeeping ability as a component of fluid intelligence: Not just working memory capacity. American Journal of Psychology 132: 439–49. [Google Scholar] [CrossRef]
- Burgoyne, Alexander P., David Z. Hambrick, and Erik M. Altmann. 2021b. Incremental validity of placekeeping as a predictor of multitasking. Psychological Research 85: 1515–28. [Google Scholar] [CrossRef]
- Burgoyne, Alexander P., Jason S. Tsukahara, Cody A. Mashburn, Richard Pak, and Randall W. Engle. 2023. Nature and measurement of attention control. Journal of Experimental Psychology: General 152: 2369–402. [Google Scholar] [CrossRef] [PubMed]
- Cattell, Raymond B. 1943. The measurement of adult intelligence. Psychological Bulletin 40: 153–93. [Google Scholar] [CrossRef]
- Cattell, Raymond B. 1987. Abilities: Their Structure, Action, and Growth. Boston: Houghton Mifflin. First published 1971. [Google Scholar]
- Colom, Roberto, Agustín Martínez-Molina, Pei C. Shih, and José Santacreu. 2010. Intelligence, working memory, and multitasking performance. Intelligence 38: 543–51. [Google Scholar] [CrossRef]
- Conway, Andrew R. A., Nelson Cowan, Michael F. Bunting, David J. Therriault, and Scott R. Minkoff. 2002. A latent variable analysis of working memory capacity, short-term memory capacity, processing speed, and general fluid intelligence. Intelligence 30: 163–83. [Google Scholar] [CrossRef]
- Deary, Ian. 2000. Looking Down on Human Intelligence: From Psychometrics to the Brain. Oxford: OUP Oxford, vol. 36. [Google Scholar]
- Draheim, Christopher W., Jason S. Tsukahara, Jessie D. Martin, Cody A. Mashburn, and Randall W. Engle. 2021. A toolbox approach to improving the measurement of attention control. Journal of Experimental Psychology: General 150: 242–75. [Google Scholar] [CrossRef] [PubMed]
- Ekstrom, Ruth B., John W. French, Harry H. Harman, and Diran Dermen. 1976. Kit of Factor-Reference Cognitive Tests. Princeton: Educational Testing Service. [Google Scholar]
- Elsmore, Timothy F. 1994. SYNWORK1: A PC-based tool for assessment of performance in a simulated work environment. Behavior Research Methods, Instruments, & Computers 26: 421–26. [Google Scholar] [CrossRef]
- Hambrick, David Z., Alexander B. Burgoyne, and Frederick L. Oswald. 2023. The validity of general cognitive ability predicting job-specific performance is stable across different levels of job experience. Journal of Applied Psychology. [Google Scholar] [CrossRef]
- Hambrick, David Z., Tara A. Rench, Elizabeth M. Poposki, Emily S. Darowski, Donna Roland, Ronald M. Bearden, Frederick L. Oswald, and Randy Brou. 2011. The relationship between the ASVAB and multitasking in Navy sailors: A process-specific approach. Military Psychology 23: 365–80. [Google Scholar] [CrossRef]
- Hasher, Lynn, Cynthia Lustig, and Rose T. Zacks. 2007. Inhibitory mechanisms and the control of attention. In Models of Working Memory: Mechanisms of Active Maintenance and Executive Function. Edited by Akira Miyake and Priti Shah. Cambridge: Cambridge University Press, pp. 227–49. [Google Scholar]
- Held, Janet D., and John H. Wolfe. 1997. Validities of unit-weighted composites of the ASVAB and the ECAT battery. Military Psychology 9: 77–84. [Google Scholar] [CrossRef]
- Held, Janet D., Sarah A. Hezlett, Jeff W. Johnson, Rodney A. McCloy, Fritz Drasgow, and Eduardo Salas. 2014. Introductory Guide for Conducting ASVAB Validation/Standards Studies in the US Navy. Millington: Navy Personnel Research Studies and Technology. [Google Scholar]
- Hunt, Earl. 2010. Human Intelligence. Cambridge: Cambridge University Press. [Google Scholar] [CrossRef]
- Hunter, John E., and Frank L. Schmidt. 1996. Intelligence and job performance: Economic and social implications. Psychology, Public Policy, and Law 2: 447–72. [Google Scholar] [CrossRef]
- Jastrzębski, Jan, Michal Ociepka, and Adam Chuderski. 2023. Graph Mapping: A novel and simple test to validly assess fluid reasoning. Behavior Research Methods 55: 448–60. [Google Scholar] [CrossRef] [PubMed]
- Kane, Michael J., David Z. Hambrick, Stephen W. Tuholski, Oliver Wilhelm, Tabitha W. Payne, and Randall W. Engle. 2004. The generality of working memory capacity: A latent-variable approach to verbal and visuospatial memory span and reasoning. Journal of Experimental Psychology: General 133: 189–217. [Google Scholar] [CrossRef] [PubMed]
- Koch, Iring, Edita Poljac, Hermann Müller, and Andrea Kiesel. 2018. Cognitive structure, flexibility, and plasticity in human multitasking-An integrative review of dual-task and task-switching research. Psychological Bulletin 144: 557–83. [Google Scholar] [CrossRef] [PubMed]
- Kovacs, Kristof, and Andrew R. A. Conway. 2016. Process overlap theory: A unified account of the general factor of intelligence. Psychological Inquiry 27: 151–77. [Google Scholar] [CrossRef]
- Kyllonen, Patrick C. 1993. Aptitude testing inspired by information processing: A test of the four-sources model. The journal of General Psychology 120: 375–405. [Google Scholar] [CrossRef]
- Kyllonen, Patrick C., and Raymond E. Christal. 1990. Reasoning ability is (little more than) working-memory capacity?! Intelligence 14: 389–433. [Google Scholar] [CrossRef]
- Larson, Gerald E., and David L. Alderton. 1990. Reaction time variability and intelligence: A “worst performance” analysis of individual differences. Intelligence 14: 309–25. [Google Scholar] [CrossRef]
- Larson, Gerald E., and John H. Wolfe. 1995. Validity results for g from an expanded test base. Intelligence 20: 15–25. [Google Scholar] [CrossRef]
- Lee, Michael D., and Eric J. Wagenmakers. 2014. Bayesian Cognitive Modeling: A Practical Course. Cambridge: Cambridge University Press. [Google Scholar]
- Martin, Jessie D., Cody A. Mashburn, and Randall W. Engle. 2020. Improving the validity of the Armed Services Vocational Aptitude Battery with measures of attention control. Journal of Applied Research in Memory and Cognition 9: 323–35. [Google Scholar] [CrossRef]
- Mayberry, Paul W. 1990. Validation of ASVAB against Infantry Job Performance. Alexandria: Center for Naval Analyses, Force Structure and Acquisition Division. [Google Scholar]
- McGrew, Kevin S. 2023. Carroll’s three-stratum (3S) cognitive ability theory at 30 years: Impact, 3S-CHC theory clarification, structural replication, and cognitive–achievement psychometric network analysis extension. Journal of Intelligence 11: 32. [Google Scholar] [CrossRef] [PubMed]
- Morgan, Benjamin B., Jr., and Earl A. Alluisi. 1972. Synthetic work: Methodology for assessment of human performance. Perceptual and Motor Skills 35: 835–45. [Google Scholar] [CrossRef]
- National Center for Education Statistics. 2019. Digest of Education Statistics. Available online: https://nces.ed.gov/programs/digest/d19/tables/dt19_226.40.asp (accessed on 29 June 2023).
- National Center for O*NET Development. 2023. O*NET OnLine. Available online: https://www.onetonline.org/link/summary/53-2021.00 (accessed on 4 February 2023).
- Raven, John, John C. Raven, and John H. Court. 1998. Manual for Raven’s progressive matrices and vocabulary scales: Section 4. In The Advanced Progressive Matrices. San Antonio: Harcourt Assessment. [Google Scholar]
- Redick, Thomas S., Zachary Shipstead, Matthew E. Meier, Janelle J. Montroy, Kenny L. Hicks, Nash Unsworth, Michael J. Kane, David Z. Hambrick, and Randall W. Engle. 2016. Cognitive predictors of a common multitasking ability: Contributions from working memory, attention control, and fluid intelligence. Journal of Experimental Psychology: General 145: 1473–92. [Google Scholar] [CrossRef] [PubMed]
- Ree, Malcolm J., and James A. Earles. 1992. Intelligence is the best predictor of job performance. Current Directions in Psychological Science 1: 86–89. [Google Scholar] [CrossRef]
- Ree, Malcolm J., and Thomas R. Carretta. 2022. Thirty years of research on general and specific abilities: Still not much more than g. Intelligence 91: 101617. [Google Scholar] [CrossRef]
- Ree, Malcolm J., and Toni G. Wegner. 1990. Correcting differences in answer sheets for the 1980 Armed Services Vocational Aptitude Battery reference population. Military Psychology 2: 157–69. [Google Scholar] [CrossRef]
- Ree, Malcolm J., James A. Earles, and Mark S. Teachout. 1994. Predicting job performance: Not much more than g. Journal of Applied Psychology 79: 518–24. [Google Scholar] [CrossRef]
- Reeve, Charlie L., and Silvia Bonaccio. 2011. On the myth and the reality of the temporal validity degradation of general mental ability test scores. Intelligence 39: 255–72. [Google Scholar] [CrossRef]
- Roberts, Richard D., Ginger N. Goff, Fadi Anjoul, Patrick C. Kyllonen, Gerry Pallier, and Lazar Stankov. 2000. The Armed Services Vocational Aptitude Battery (ASVAB): Little more than acculturated learning (Gc)!? Learning and Individual Differences 12: 81–103. [Google Scholar] [CrossRef]
- Schmank, Christopher J., Sara A. Goring, Kristof Kovacs, and Andrew R. A. Conway. 2019. Psychometric network analysis of the Hungarian WAIS. Journal of Intelligence 7: 21. [Google Scholar] [CrossRef]
- Schmidt, Frank L., and John Hunter. 2004. General mental ability in the world of work: Occupational attainment and job performance. Journal of Personality and Social Psychology 86: 162–73. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, Frank L., John E. Hunter, Alice N. Outerbridge, and Stephen Goff. 1988. Joint relation of experience and ability with job performance: Test of three hypotheses. Journal of Applied Psychology 73: 46–57. [Google Scholar] [CrossRef]
- Schmidt, Frank L., John E. Hunter, Robert C. McKenzie, and Tressie W. Muldrow. 1979. Impact of valid selection procedures on work-force productivity. Journal of Applied Psychology 64: 609–26. [Google Scholar] [CrossRef]
- Thurstone, Louis L. 1938. Primary Mental Abilities. Chicago: University of Chicago Press. [Google Scholar]
- Wall, Janet E. 2017. ASVAB Basic Training for the AFQT. New York: McGraw-Hill. [Google Scholar]
- Welsh, John R., Susan K. Kucinkas, and Linda T. Curran. 1990. Armed Services Vocational Battery (ASVAB): Integrative review of validity studies. Available online: https://apps.dtic.mil/sti/pdfs/ADA225074.pdf (accessed on 4 December 2023).
| Subtest | Acronym | Description | Items | Time |
|---|---|---|---|---|
| General Science | GS | Knowledge of physical and biological sciences | 25 | 11 |
| Arithmetic Reasoning * | AR | Ability to solve arithmetic word problems | 30 | 36 |
| Word Knowledge * | WK | Knowledge of and ability to infer word meanings | 35 | 11 |
| Paragraph Comprehension * | PC | Ability to obtain information from written passages | 15 | 13 |
| Mathematics Knowledge * | MK | Knowledge of high school-level mathematics concepts | 25 | 24 |
| Electronics Information | EI | Knowledge of electrical principles and electronic devices | 20 | 9 |
| Automotive and Shop Information | AS | Knowledge of automotive technology, shop terminology | 25 | 11 |
| Mechanical Comprehension | MC | Knowledge of mechanical and physical principles | 25 | 19 |
| Assembling Objects | AO | Ability to imagine how objects look when disassembled | 25 | 15 |
| Session 1 | Session 2 | Session 3 | Session 4 |
|---|---|---|---|
| Consent form Demographic form | Foster Task (MP) | Control Tower (MP) | SynWin (MP) |
| Arithmetic Reasoning (ASVAB) | UNRAVEL (PA) | Letter Sets (Gf) | Stroop Deadline (AC) |
| Word Knowledge (ASVAB) | Mental Counters (WMC) | Antisaccade (AC) | Selective Visual Arrays (AC) |
| Mathematics Knowledge (ASVAB) | Raven’s Matrices (Gf) | Letterwheel (PA) | |
| Paragraph Comprehension (ASVAB) | Sustained Attention to Cue (AC) | Number Series (Gf) | |
| Flanker Deadline (AC) |
| Composite Variable | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1. AFQT | - | 0.25 ** [0.14, 0.36] | 0.04 [−0.10, 0.17] | 0.20 ** [0.05, 0.34] | 0.09 [−0.03, 0.22] |
| 2. Gf | 0.54 *** [0.45, 0.62] | - | 0.28 *** [0.15, 0.40] | 0.15 * [0.02, 0.28] | 0.29 *** [0.18, 0.41] |
| 3. Attention Control | 0.40 *** [0.30, 0.50] | 0.57 *** [0.48, 0.65] | - | 0.23 ** [0.08, 0.38] | 0.09 [−0.05, 0.24] |
| 4. Placekeeping Ability | 0.53 *** [0.44, 0.61] | 0.61 *** [0.53, 0.68] | 0.56 *** [0.47, 0.63] | - | 0.42 *** [0.31, 0.53] |
| 5. Multitasking Performance | 0.49 *** [0.40, 0.58] | 0.63 *** [0.56, 0.70] | 0.51 *** [0.42, 0.60] | 0.69 *** [0.62, 0.75] | - |
| Composite Variable | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1. AFQT | - | 0.00 | 16.67 | 0.00 | 8.33 |
| 2. Gf | ∞ | - | 0.00 | 2.33 | 0.00 |
| 3. Attention Control | 0.06 | ∞ | - | 0.00 | 6.67 |
| 4. Placekeeping Ability | ∞ | 0.43 | ∞ | - | 0.00 |
| 5. Multitasking Performance | 0.12 | ∞ | 0.15 | ∞ | - |
| ΔR2 | ΔF | df | β [95% CI] | t | |
| Model 1A | |||||
| Step 1 | 0.241 | 85.17 *** | 1, 268 | ||
| AFQT | 0.49 [0.39, 0.60] | 9.23 *** | |||
| Step 2 | 0.193 | 91.06 *** | 1, 267 | ||
| AFQT | 0.21 [0.10, 0.32] | 3.83 *** | |||
| Gf | 0.52 [0.41, 0.63] | 9.54 *** | |||
| Model 1B | |||||
| Step 1 | 0.241 | 85.17 *** | 1, 268 | ||
| AFQT | 0.49 [0.39, 0.60] | 9.23 *** | |||
| Step 2 | 0.257 | 136.62 *** | 1, 267 | ||
| AFQT | 0.18 [0.08, 0.28] | 3.45 ** | |||
| PA | 0.60 [0.50, 0.70] | 11.69 *** | |||
| Model 1C | |||||
| Step 1 | 0.241 | 85.17 *** | 1, 268 | ||
| AFQT | 0.49 [0.39, 0.60] | 9.23 *** | |||
| Step 2 | 0.119 | 49.54 *** | 1, 267 | ||
| AFQT | 0.34 [0.23, 0.44] | 6.33 *** | |||
| AC | 0.38 [0.27, 0.48] | 7.04 *** |
| ΔR2 | ΔF | df | β [95% CI] | t | |
|---|---|---|---|---|---|
| Model 2A | |||||
| Step 1 | 0.498 | 132.44 *** | 2, 267 | ||
| AFQT | 0.18 [0.08, 0.28] | 3.45 ** | |||
| PA | 0.60 [0.50, 0.70] | 11.69 *** | |||
| Step 2 | 0.055 | 32.46 *** | 1, 266 | ||
| AFQT | 0.08 [−0.02, 0.18] | 1.62 | |||
| PA | 0.46 [0.35, 0.56] | 8.39 *** | |||
| Gf | 0.31 [0.20, 0.42] | 5.70 *** | |||
| Model 2B | |||||
| Step 1 | 0.360 | 75.06 *** | 2, 267 | ||
| AFQT | 0.34 [0.23, 0.44] | 6.33 *** | |||
| AC | 0.38 [0.27, 0.48] | 7.04 *** | |||
| Step 2 | 0.100 | 49.42 *** | 1, 266 | ||
| AFQT | 0.18 [0.08, 0.29] | 3.38 ** | |||
| AC | 0.20 [0.09, 0.31] | 3.58 *** | |||
| Gf | 0.42 [0.31, 0.54] | 7.03 *** | |||
| Model 2C | |||||
| Step 1 | 0.434 | 102.42 *** | 2, 267 | ||
| AFQT | 0.21 [0.10, 0.32] | 3.83 *** | |||
| Gf | 0.52 [0.41, 0.63] | 9.54 *** | |||
| Step 2 | 0.118 | 70.43 *** | 1, 266 | ||
| AFQT | 0.08 [−0.02, 0.18] | 1.62 | |||
| Gf | 0.31 [0.20, 0.42] | 5.70 *** | |||
| PA | 0.46 [0.35, 0.56] | 8.39 *** | |||
| Model 2D | |||||
| Step 1 | 0.360 | 75.06 *** | 2, 267 | ||
| AFQT | 0.34 [0.23, 0.44] | 6.33 *** | |||
| AC | 0.38 [0.27, 0.48] | 7.04 *** | |||
| Step 2 | 0.156 | 85.87 *** | 1, 266 | ||
| AFQT | 0.15 [0.05, 0.25] | 2.97 ** | |||
| AC | 0.16 [0.06, 0.27] | 3.15 ** | |||
| PA | 0.52 [0.41, 0.63] | 9.27 *** | |||
| Model 2E | |||||
| Step 1 | 0.434 | 102.42 *** | 2, 267 | ||
| AFQT | 0.21 [0.10, 0.32] | 3.83 *** | |||
| Gf | 0.52 [0.41, 0.63] | 9.54 *** | |||
| Step 2 | 0.026 | 12.84 *** | 1, 266 | ||
| AFQT | 0.18 [0.08, 0.29] | 3.38 ** | |||
| Gf | 0.42 [0.31, 0.54] | 7.03 *** | |||
| AC | 0.20 [0.09, 0.31] | 3.58 *** | |||
| Model 2F | |||||
| Step 1 | 0.498 | 132.44 *** | 2, 267 | ||
| AFQT | 0.18 [0.08, 0.28] | 3.45 ** | |||
| PA | 0.60 [0.50, 0.70] | 11.69 *** | |||
| Step 2 | 0.018 | 9.95 *** | 1, 266 | ||
| AFQT | 0.15 [0.05, 0.25] | 2.97 ** | |||
| PA | 0.52 [0.41, 0.63] | 9.27 *** | |||
| AC | 0.16 [0.06, 0.27] | 3.15 ** |
| ΔR2 | ΔF | df | β [95% CI] | t | |
|---|---|---|---|---|---|
| Model 3A | |||||
| Step 1 | 0.516 | 94.57 *** | 3, 266 | ||
| AFQT | 0.15 [0.05, 0.25] | 2.97 ** | |||
| PA | 0.52 [0.41, 0.63] | 9.27 *** | |||
| AC | 0.16 [0.06, 0.27] | 3.15 ** | |||
| Step 2 | 0.040 | 24.17 *** | 1, 265 | ||
| AFQT | 0.08 [−0.02, 0.18] | 1.54 | |||
| PA | 0.43 [0.32, 0.54] | 7.59 *** | |||
| AC | 0.08 [−0.02, 0.19] | 1.54 | |||
| Gf | 0.28 [0.17, 0.40] | 4.92 *** | |||
| Model 3B | |||||
| Step 1 | 0.460 | 75.59 *** | 3, 266 | ||
| AFQT | 0.18 [0.08, 0.29] | 3.38 ** | |||
| Gf | 0.42 [0.31, 0.54] | 7.03 *** | |||
| AC | 0.20 [0.09, 0.31] | 3.58 *** | |||
| Step 2 | 0.096 | 57.59 *** | 1, 265 | ||
| AFQT | 0.08 [−0.02, 0.18] | 1.54 | |||
| Gf | 0.28 [0.17, 0.40] | 4.92 *** | |||
| AC | 0.08 [−0.02, 0.19] | 1.54 | |||
| PA | 0.43 [0.32, 0.54] | 7.59 *** | |||
| Model 3C | |||||
| Step 1 | 0.553 | 109.51 *** | 3, 266 | ||
| AFQT | 0.08 [−0.02, 0.18] | 1.62 | |||
| Gf | 0.31 [0.20, 0.42] | 5.70 *** | |||
| PA | 0.46 [0.35, 0.56] | 8.39 *** | |||
| Step 2 | 0.004 | 2.36 | 1, 265 | ||
| AFQT | 0.08 [−0.02, 0.18] | 1.54 | |||
| Gf | 0.28 [0.17, 0.40] | 4.92 *** | |||
| PA | 0.43 [0.32, 0.54] | 7.59 *** | |||
| AC | 0.08 [−0.02, 0.19] | 1.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hambrick, D.Z.; Burgoyne, A.P.; Altmann, E.M.; Matteson, T.J. Explaining the Validity of the ASVAB for Job-Relevant Multitasking Performance: The Role of Placekeeping Ability. J. Intell. 2023, 11, 225. https://doi.org/10.3390/jintelligence11120225
Hambrick DZ, Burgoyne AP, Altmann EM, Matteson TJ. Explaining the Validity of the ASVAB for Job-Relevant Multitasking Performance: The Role of Placekeeping Ability. Journal of Intelligence. 2023; 11(12):225. https://doi.org/10.3390/jintelligence11120225
Chicago/Turabian StyleHambrick, David Z., Alexander P. Burgoyne, Erik M. Altmann, and Tyler J. Matteson. 2023. "Explaining the Validity of the ASVAB for Job-Relevant Multitasking Performance: The Role of Placekeeping Ability" Journal of Intelligence 11, no. 12: 225. https://doi.org/10.3390/jintelligence11120225
APA StyleHambrick, D. Z., Burgoyne, A. P., Altmann, E. M., & Matteson, T. J. (2023). Explaining the Validity of the ASVAB for Job-Relevant Multitasking Performance: The Role of Placekeeping Ability. Journal of Intelligence, 11(12), 225. https://doi.org/10.3390/jintelligence11120225