Measuring Personality through Images: Validating a Forced-Choice Image-Based Assessment of the Big Five Personality Traits


Abstract
:1. Introduction
1.1. Assessment in Selection
1.2. Game and Image-Based Assessments
2. Materials and Methods
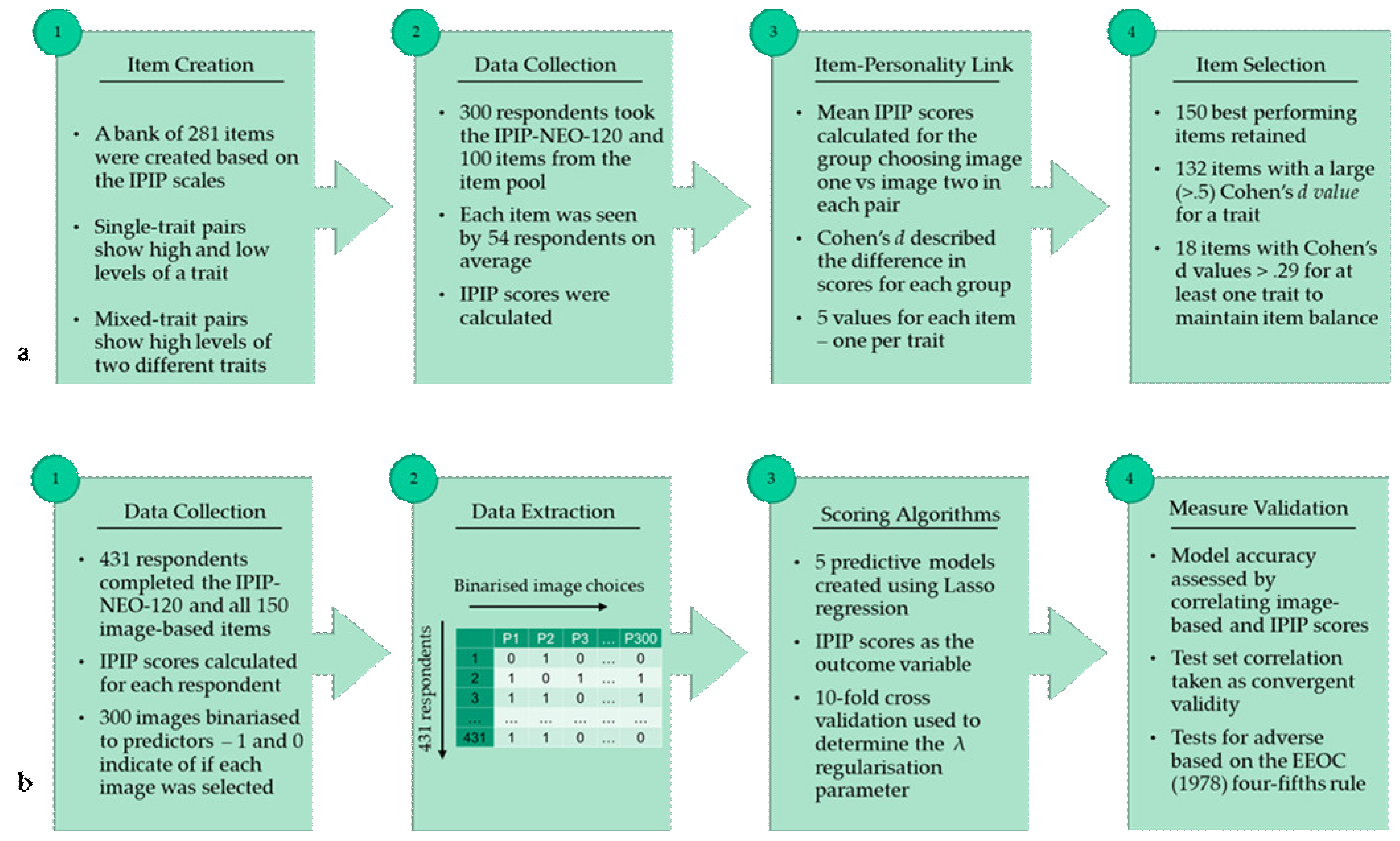
- Study 1—Item Bank Creation: Study 1 describes the creation of an item pool of image pairs, along with the selection of the 150 best-performing items (image pairs), and the mapping of these items to the Big Five traits;
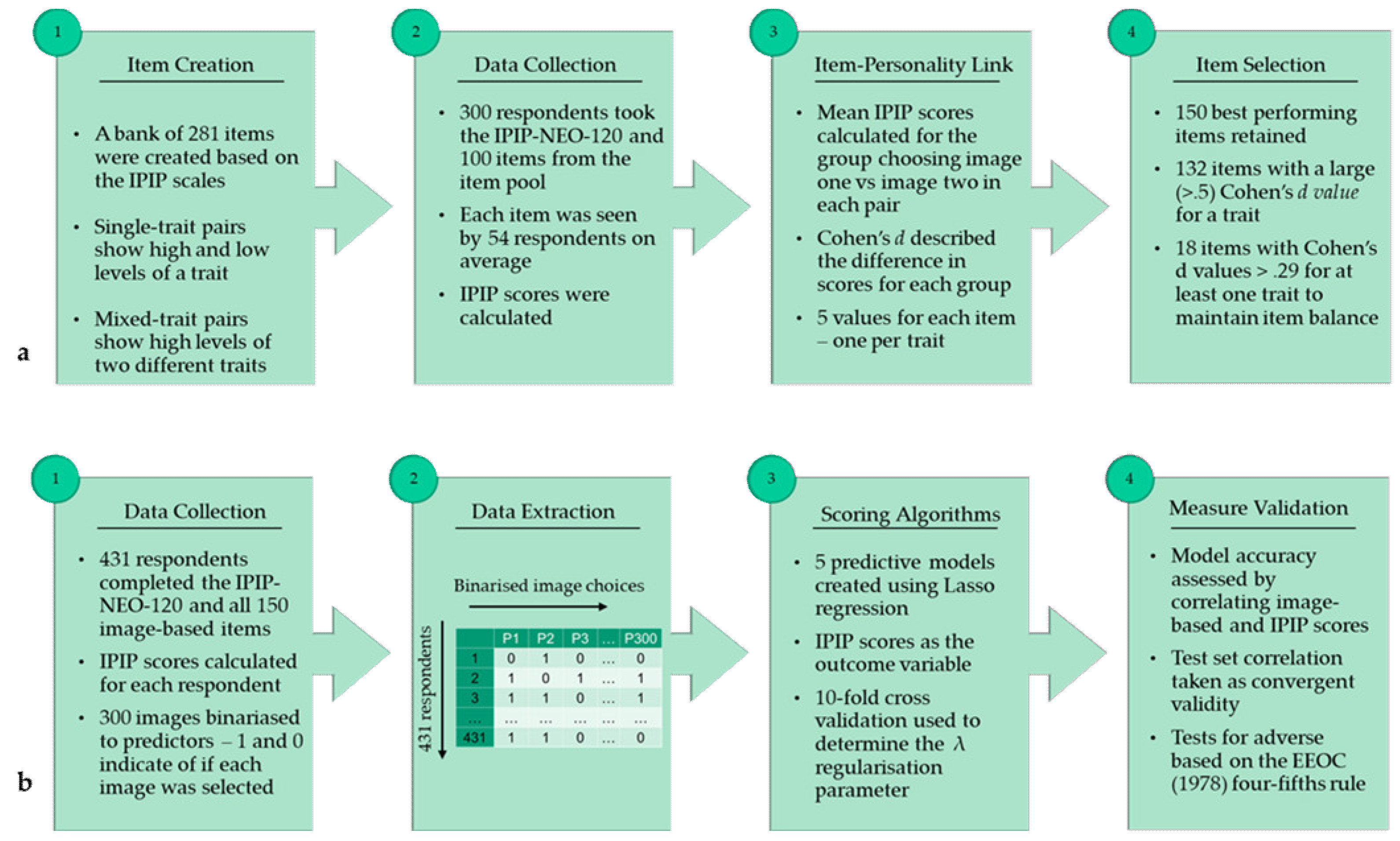
- Study 2—Measure Validation: Study 2 describes the development of predictive machine-learning-based scoring algorithms based on a panel of respondents. This approach, where algorithms are developed that predict outcomes on traditional assessments, is common practice in predictive measures of personality (e.g., Bachrach et al. 2012; Kosinski et al. 2013; Leutner et al. 2017; Schwartz et al. 2013), as they convert binary choices to a more interpretable output that is more reflective of the continuous nature of the Big Five traits. Study 2 also describes the validation of the assessment through measuring convergent and discriminant validity with Johnson’s (2014) questionnaire-based IPIP-NEO-120 and tests for potential adverse impact.
2.1. Study 1: Item Bank Creation
2.1.1. Image-Based Measure
2.1.2. Questionnaire-Based Measure
2.1.3. Participants
2.1.4. Item Selection
2.2. Study 2: Measure Validation
2.2.1. Participants
2.2.2. Analysis
3. Results
3.1. Descriptive Statistics
3.2. Model Performance
3.3. Adverse Impact Analysis
4. Discussion
4.1. Model Performance
4.2. Methodological Considerations
4.3. Future Validation
- User experience: To better understand how respondents engage with the measure, future studies could examine user experience, including how engaging respondents found the measure to be. It could also investigate whether the meaning assigned to the items by the team of designers converges with that of the respondents by asking a sample of respondents to assign their own adjectives to the items. This would allow further refinements to be made to the measure which may strengthen its performance;
- The potential for shorter measures: Since only a small number of predictors were retained by each model and there was some crossover in the predictors retained by the models, future studies should investigate how shorter versions of the assessment could take advantage of this by examining how effective different item combinations are at measuring the traits. This would result in even shorter testing times for candidates, reducing the time it takes to complete the overall battery of selection assessments;
- Bias and transparency: Group differences in scores do not always indicate bias and can instead be reflective of genuine differences in latent levels of traits for different subgroups (Society for Industrial and Organizational Psychology 2018). However, even when group differences in scores are not due to differences in ability, they do not always lead to adverse impact, especially when the analysis is based on a small sample (EEOC et al. 1978). Therefore, further validation is needed with a larger sample to more robustly determine whether the reported group differences could result in adverse impact, particularly since the importance of transparency and fairness in the algorithms used in hiring is increasingly a point of concern (Kazim et al. 2021; Raghavan et al. 2020);
- Mitigating bias: While the potential for adverse impact from this assessment echoes concerns about the fairness of conventional selection assessments (Hough et al. 2001), adverse impact associated with algorithmic recruitment processes can be mitigated by removing the items associated with group differences and updating the algorithms (HireVue 2019; Pymetrics 2021), unlike with traditional assessments that use a standard scoring key. Further research exploring the potential for mitigating group differences in the algorithms used by this assessment is needed, particularly since there is evidence of measurement bias in the questionnaire-based measure used to construct and validate the algorithms. Follow-up studies are, therefore, required to investigate the best way to mitigate this;
- Generalizability: The samples used in this study may be limited if they did not represent a diverse group of respondents. For example, data referring to the occupation of respondents were not collected, meaning the generalizability of the findings could be limited to a particular industry if respondents are from a similar background. To address this, a future study should recruit an additional sample from another source such as MTurk to validate the algorithm in a different population of respondents who are likely to have different attributes to those in the current samples;
- Cultural appropriateness: As only English-speaking respondents were included in this study, a variation in the interpretation of the items was not investigated across multiple cultures or languages. Whilst it is suggested that non-verbal assessments can be applied to any language without redevelopment (Paunonen et al. 1990), it is still important to ascertain whether the images included in this assessment are appropriate in other cultures. The findings of this study indicate that there are potential differences in the interpretation of the images for different subgroups, with convergence being null on some traits for Asian and Black respondents. Therefore, future studies should take a cross-cultural approach to investigate the performance of the measure in different cultures and ethnicities;
- Score inflation: Job application contexts have higher stakes as they can affect career-related opportunities (Stobart and Eggen 2012). Since there is evidence for the inflation of personality scores in high-stakes contexts (Arthur et al. 2010), a future study could investigate score inflation on this novel assessment in a high-stakes context. The forced-choice image-based format might decrease candidates’ ability to fake their responses compared to questionnaire based tests;
- Measure reliability: Respondents only took the measure once, meaning that response stability and consistency (test-retest reliability) could not be examined. Thus, it is not known whether respondents are likely to make the same image choices and therefore have similar personality scores each time they take the assessment. Further validation is needed to determine the test-retest reliability of this assessment;
- Measure validity: Additionally, further investigation is needed into other forms of validity, including internal validity since items mapped to multiple different traits were used in the models to predict each Big Five trait;
- Multitrait-multimethod approach: To better compare this measure to other traditional assessments, a future study using a multitrait-multimethod approach would provide insight into how the measure performs in terms of convergent and divergent validity with multiple other assessments (Dumenci 2000). Such an approach could also investigate whether user experience is greater for the image-based assessment as compared to traditional assessments, as has been previously indicated (Georgiou and Nikolaou 2020; Leutner et al. 2020).
4.4. Implications
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Armstrong, Michael B., Jared Z. Ferrell, Andrew B. Collmus, and Richard N. Landers. 2016a. Correcting misconceptions about gamification of assessment: More than SJTs and badges. Industrial and Organizational Psychology 9: 671–77. [Google Scholar] [CrossRef] [Green Version]
- Armstrong, Michael B., Richard N. Landers, and Andrew B. Collmus. 2016b. Gamifying recruitment, selection, training, and performance management: Game-thinking in human resource management. In Emerging Research and Trends in Gamification. Edited by Harsha Gangadharbatla and Donna Z. Davis. Hershey: IGI Global, pp. 140–65. [Google Scholar] [CrossRef]
- Arthur, Winfred, Ryan M. Glaze, Anton J. Villado, and Jason E. Taylor. 2010. The magnitude and extent of cheating and response distortion effects on unproctored internet-based tests of cognitive ability and personality. International Journal of Selection and Assessment 18: 1–16. [Google Scholar] [CrossRef]
- Atkins, Sharona M., Amber M. Sprenger, Gregory J. H. Colflesh, Timothy L. Briner, Jacob B. Buchanan, Sydnee E. Chavis, Sy-yu Chen, Gregory L. Iannuzzi, Vadim Kashtelyan, Eamon Dowling, and et al. 2014. Measuring working memory is all fun and games. Experimental Psychology 61: 417–38. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bachrach, Yoram, Michal Kosinski, Thore Graepel, Pushmeet Kohli, and David Stillwell. 2012. Personality and patterns of Facebook usage. Paper presented the 4th Annual ACM Web Science Conference, Evanston, IL, USA, June 22–24; pp. 24–32. [Google Scholar] [CrossRef]
- Barrick, Murray R., and Michael. K Mount. 1991. The Big Five personality dimensions and job performance: A meta-analysis. Personnel Psychology 44: 1–26. [Google Scholar] [CrossRef]
- Campbell, Donald T., and Donald W. Fiske. 1959. Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin 56: 81–105. [Google Scholar] [CrossRef] [Green Version]
- Chamorro-Premuzic, Tomas. 2017. The Talent Delusion: Why Data, Not Intuition, Is the Key to Unlocking Human Potential. London: Piatkus. [Google Scholar]
- Chamorro-Premuzic, Tomas, Reece Akhtar, Dave Winsborough, and Ryne A. Sherman. 2017. The datafication of talent: How technology is advancing the science of human potential at work. Current Opinion in Behavioral Sciences 18: 13–16. [Google Scholar] [CrossRef]
- Chang, Luye, Brian S. Connelly, and Alexis A. Geeza. 2012. Separating method factors and higher order traits of the Big Five: A meta-analytic multitrait–multimethod approach. Journal of Personality and Social Psychology 102: 408–26. [Google Scholar] [CrossRef]
- Cohen, Jacob. 1992. A power primer. Psychological Bulletin 112: 155–59. [Google Scholar] [CrossRef]
- Costa, Paul T., and Robert R. McCrae. 2008. The revised NEO personality inventory (NEO-PI-R). In The SAGE Handbook of Personality Theory and Assessment: Volume 2—Personality Measurement and Testing. Edited by G. J. Boyle, G. Matthews and D. H. Saklofske. Southern Oaks: SAGE Publications, pp. 179–98. [Google Scholar] [CrossRef]
- Cronbach, Lee J. 1951. Coefficient alpha and the internal structure of tests. Psychometrika 16: 297–334. [Google Scholar] [CrossRef] [Green Version]
- Cui, Zaixu, and Gaolang Gong. 2018. The effect of machine learning regression algorithms and sample size on individualized behavioral prediction with functional connectivity features. NeuroImage 178: 622–37. [Google Scholar] [CrossRef]
- De Beer, Joost, Josephine Engels, Yvonne Heerkens, and Jac van der Klink. 2014. Factors influencing work participation of adults with developmental dyslexia: A systematic review. BMC Public Health 14: 1–22. [Google Scholar] [CrossRef] [Green Version]
- De Corte, Wilfried, Filip Lievens, and Paul R. Sackett. 2007. Combining predictors to achieve optimal trade-offs between selection quality and adverse impact. Journal of Applied Psychology 92: 1380–93. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Downes-Le Guin, Theo, Reg Baker, Joanne Mechling, and Erica Ruyle. 2012. Myths and realities of respondent engagement in online surveys. International Journal of Market Research 54: 613–33. [Google Scholar] [CrossRef] [Green Version]
- Dumenci, Levent. 2000. Multitrait-multimethod analysis. In Handbook of Applied Multivariate Statistics and Mathematical Modeling. Edited by Howard E. A. Tinsley and Steven D. Brown. Amsterdam: Elsevier, pp. 583–611. [Google Scholar] [CrossRef]
- Equal Employment Opportunity Commission—EEOC, Civil Service Commission, U.S. Department of Labor, and U.S. Department of Justice. 1978. Uniform guidelines on employee selection procedures. Federal Register 43: 38290–309. [Google Scholar]
- Georgiou, Konstantina, and Ioannis Nikolaou. 2020. Are applicants in favor of traditional or gamified assessment methods? Exploring applicant reactions towards a gamified selection method. Computers in Human Behavior 109: 106356. [Google Scholar] [CrossRef]
- Goldberg, Lewis. R. 1992. The development of markers for the Big-Five factor structure. Psychological Assessment 4: 26–42. [Google Scholar] [CrossRef]
- Hausdorf, Peter A., Manon M. Leblanc, and Anuradha Chawla. 2003. Cognitive ability testing and employment selection: Does test content relate to adverse impact? Applied HRM Research 7: 41–48. Available online: http://applyhrm.asp.radford.edu/2002/ms 7_2_ hausdorf.pdf (accessed on 3 February 2022).
- Hausknecht, John P., David V. Day, and Scott C. Thomas. 2004. Applicant reactions to selection procedures: An updated model and meta-analysis. Personnel Psychology 57: 639–83. [Google Scholar] [CrossRef] [Green Version]
- Higgins, Daniel M., Jordan B. Peterson, Robert O. Pihl, and Alice G. Lee. 2007. Prefrontal cognitive ability, intelligence, Big Five personality, and the prediction of advanced academic and workplace performance. Journal of Personality and Social Psychology 93: 298–319. [Google Scholar] [CrossRef]
- HireVue. 2019. Bias, AI Ethics, and the HireVue Approach. Available online: https://www.hirevue.com/why-hirevue/ethical-ai. (accessed on 14 December 2021).
- Hogan, Robert, Joyce Hogan, and Brent W. Roberts. 1996. Personality measurement and employment decisions: Questions and answers. American Psychologist 51: 469–77. [Google Scholar] [CrossRef]
- Hough, Leatta M., Frederick L. Oswald, and Robert E. Ployhart. 2001. Determinants, detection and amelioration of adverse impact in personnel selection procedures: Issues, evidence and lessons learned. International Journal of Selection and Assessment 9: 152–94. [Google Scholar] [CrossRef]
- Jacobucci, Ross, Kevin J. Grimm, and John J. McArdle. 2016. Regularized structural equation modeling. Structural Equation Modeling 23: 555–66. [Google Scholar] [CrossRef]
- Johnson, John. A. 2014. Measuring thirty facets of the Five Factor Model with a 120-item public domain inventory: Development of the IPIP-NEO-120. Journal of Research in Personality 51: 78–89. [Google Scholar] [CrossRef]
- Judge, Timothy A., Chad A. Higgins, Carl J. Thoresen, and Murray R. Barrick. 1999. The big five personality traits, general mental ability, and career success across the life span. Personnel Psychology 52: 621–52. [Google Scholar] [CrossRef]
- Kazim, Emre, Adriano S. Koshiyama, Airlie Hilliard, and Roseline Polle. 2021. Systematizing Audit in Algorithmic Recruitment. Journal of Intelligence 9: 46. [Google Scholar] [CrossRef] [PubMed]
- Kim, Hae-Young. 2013. Statistical notes for clinical researchers: Assessing normal distribution (2) using skewness and kurtosis. Restorative Dentistry & Endodontics 38: 52. [Google Scholar] [CrossRef]
- Kosinski, Michal, David Stillwell, and Thore Graepel. 2013. Private traits and attributes are predictable from digital records of human behavior. Proceedings of the National Academy of Sciences 110: 5802–5. [Google Scholar] [CrossRef] [Green Version]
- Krainikovsky, Stanislav, Mikhail Melnikov, and Roman Samarev. 2019. Estimation of psychometric data based on image preferences. Conference Proceedings for Education and Humanities, WestEastInstitute 2019: 75–82. Available online: https://www.westeastinstitute.com/wp-content/uploads/2019/06/EDU-Vienna-Conference-Proceedings-2019.pdf#page=75 (accessed on 3 February 2022).
- Krosnick, Jon. A. 1991. Response strategies for coping with the cognitive demands of attitude measures in surveys. Applied Cognitive Psychology 5: 213–36. [Google Scholar] [CrossRef]
- Kuncel, Nathan R., Deniz S. Ones, and Paul R. Sackett. 2010. Individual differences as predictors of work, educational, and broad life outcomes. Personality and Individual Differences 49: 331–36. [Google Scholar] [CrossRef]
- Landers, Richard N., Michael B. Armstrong, Andrew B. Collmus, Salih Mujcic, and Jason Blaik. 2021. Theory-driven game-based assessment of general cognitive ability: Design theory, measurement, prediction of performance, and test fairness. Journal of Applied Psychology. Advance online publication. [Google Scholar] [CrossRef]
- Leutner, Franziska, and Tomas Chamorro-Premuzic. 2018. Stronger together: Personality, intelligence and the assessment of career potential. Journal of Intelligence 6: 49. [Google Scholar] [CrossRef] [Green Version]
- Leutner, Franziska, Adam Yearsley, Sonia C. Codreanu, Yossi Borenstein, and Gorkan Ahmetoglu. 2017. From Likert scales to images: Validating a novel creativity measure with image based response scales. Personality and Individual Differences 106: 36–40. [Google Scholar] [CrossRef] [Green Version]
- Leutner, Franziska, Sonia C. Codreanu, Joshua Liff, and Nathan Mondragon. 2020. The potential of game- and video-based assessments for social attributes: Examples from practice. Journal of Managerial Psychology 36: 533–47. [Google Scholar] [CrossRef]
- Lieberoth, Andreas. 2015. Shallow gamification: Testing psychological effects of framing an activity as a game. Games and Culture 10: 229–48. [Google Scholar] [CrossRef]
- Lim, Beng-Chong, and Robert E. Ployhart. 2006. Assessing the convergent and discriminant validity of Goldberg’s international personality item pool: A multitrait-multimethod examination. Organizational Research Methods 9: 29–54. [Google Scholar] [CrossRef]
- Mavridis, Apostolos, and Thrasyvoulos Tsiatsos. 2017. Game-based assessment: Investigating the impact on test anxietyand exam performance. Journal of Computer Assisted Learning 33: 137–50. [Google Scholar] [CrossRef]
- McCrae, Robert R., and Paul T. Costa. 1985. Updating Norman’s “adequate taxonomy”. Intelligence and personality dimensions in natural language and in questionnaires. Journal of Personality and Social Psychology 49: 710–21. [Google Scholar] [CrossRef]
- McNeish, Daniel. M. 2015. Using Lasso for predictor selection and to assuage overfitting: A method long overlooked in behavioral sciences. Multivariate Behavioral Research 50: 471–84. [Google Scholar] [CrossRef]
- Mehrabi, Ninareh, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. 2021. A survey on bias and fairness in machine learning. ACM Computing Surveys (CSUR) 54: 1–35. [Google Scholar] [CrossRef]
- Meissner, Franziska, and Klaus Rothermund. 2015. A thousand words are worth more than a picture? The effects of stimulus modality on the implicit association test. Social Psychological and Personality Science 6: 740–48. [Google Scholar] [CrossRef]
- Morris, Scott B., and Russel E. Lobsenz. 2000. Significance tests and confidence intervals for the adverse impact ratio. Personnel Psychology 53: 89–111. [Google Scholar] [CrossRef]
- Office of Federal Contract Compliance Programs. 1993. Federal Contract Compliance Manual. Washington, DC: Department of Labor, Employment Standards Administration, Office of Federal Contract Compliance Programs (SUDOC# L 36.8: C 76/993). [Google Scholar]
- Paunonen, Sampo V., Douglas N. Jackson, and Mirja Keinonen. 1990. The structured nonverbal assessment of personality. Journal of Personality 58: 481–502. [Google Scholar] [CrossRef]
- Paunonen, Sampo V., Michael C. Ashton, and Douglas N. Jackson. 2001. Nonverbal assessment of the Big Five personality factors. European Journal of Personality 15: 3–18. [Google Scholar] [CrossRef]
- Pymetrics. 2021. Compliance with EEOC Guidelines. Available online: https://go2.pymetrics.ai/l/863702/2021-01-25/2qtp4m/863702/1611601742w7dse2DF/pymetrics_EEOC_UGESP_Compliance__1_.pdf (accessed on 3 February 2022).
- Quiroga, M. Ángeles, Sergio Escorial, Francisco J. Román, Daniel Morillo, Andrea Jarabo, Jesús Privado, Miguel Hernández, Borja Gallego, and Roberto Colom. 2015. Can we reliably measure the general factor of intelligence (g) through commercial video games? Yes, we can! Intelligence 53: 1–7. [Google Scholar] [CrossRef]
- Quiroga, M. Ángeles, Francisco J. Román, Javier De La Fuente, Jesús Privado, and Roberto Colom. 2016. The measurement of intelligence in the XXI Century using video games. The Spanish Journal of Psychology 19: 89. [Google Scholar] [CrossRef] [PubMed]
- Raghavan, Manish, Solon Barocas, Jon Kleinberg, and Karen Levy. 2020. Mitigating bias in algorithmic hiring: Evaluating claims and practices. Paper presented the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, January 27–30. [Google Scholar] [CrossRef]
- Raudys, Sarunas J., and Anil K. Jain. 1991. Small sample size effects in statistical pattern recognition: Recommendations for practitioners. IEEE Transactions on Pattern Analysis and Machine Intelligence 13: 252–64. [Google Scholar] [CrossRef]
- Rothmann, Sebastiaan, and Elize P. Coetzer. 2003. The Big Five personality dimensions and job performance. SA Journal of Industrial Psychology 29: 68–74. [Google Scholar] [CrossRef] [Green Version]
- Ryan, Ann Marie, and Robert E. Ployhart. 2013. A century of selection. Annual Review of Psychology 65: 693–717. [Google Scholar] [CrossRef]
- Schmidt, Frank L., and John E. Hunter. 1998. The validity and utility of selection methods in personnel psychology: Practical and theoretical implications of 85 years of research findings. Psychological Bulletin 124: 262–74. [Google Scholar] [CrossRef]
- Schmidt, Frank L., In-Sue Oh, and Jonathan A. Shaffer. 2016. The Validity and Utility of Selection Methods in Personnel Psychology: Practical and Theoretical Implications of 100 Years. Working Paper. Available online: https://home.ubalt.edu/tmitch/645/session%204/Schmidt%20&%20Oh%20MKUP%20validity%20and%20util%20100%20yrs%20of%20research%20Wk%20PPR%202016.pdf (accessed on 3 February 2022).
- Schmitt, Neal. 2014. Personality and cognitive ability as predictors of effective performance at work. Annual Review of Organizational Psychology and Organizational Behavior 1: 45–65. [Google Scholar] [CrossRef] [Green Version]
- Schwartz, Hansen A., Johannes C. Eichstaedt, Lukasz Dziurzynski, Margaret L. Kern, Eduardo Blanco, Michal Kosinski, David Stillwell, Martin E. P. Seligman, and Lyle H. Ungar. 2013. Toward Personality Insights from Language Exploration in Social Media. AAAI Spring Symposium Series. Available online: https://www.aaai.org/ocs/index.php/SSS/SSS13/paper/view/5764/5915 (accessed on 3 February 2022).
- Smits, Jarka, and Nathalie Charlier. 2011. Game-based assessment and the effect on test anxiety: A case study. Proceedings of the European Conference on Games-Based Learning 2021: 562. Available online: https://www.proquest.com/openview/8842f14611cbdc9b254626fbba1de115/1?pq-origsite=gscholar&cbl=396495 (accessed on 3 February 2022).
- Society for Industrial and Organizational Psychology. 2018. Principles for the Validation and Use of Personnel Selection Procedures, 5th ed. Bowling Green: Society for Industrial Organizational Psychology. [Google Scholar] [CrossRef]
- Stobart, Gordon, and Theo Eggen. 2012. High-stakes testing—Value, fairness and consequences. Assessment in Education: Principles, Policy and Practice 19: 1–6. [Google Scholar] [CrossRef]
- Tay, Louis, Sang E. Woo, Louis Hickman, Brandon Booth, and Sidney DMello ’. 2021. A Conceptual Framework for Investigating and Mitigating Machine Learning Measurement Bias (MLMB) in Psychological Assessment. Available online: https://psyarxiv.com/mjph3/ (accessed on 3 February 2022). [CrossRef]
- Tibshirani, Robert. 1996. Regression shrinkage and selection via the Lasso. Journal of the Royal Statistical Society: Series B (Methodological) 58: 267–88. [Google Scholar] [CrossRef]
- Vabalas, Andrius, Emma Gowen, Ellen Poliakoff, and Alexander J. Casson. 2019. Machine learning algorithm validation with a limited sample size. PLoS ONE 14: e0224365. [Google Scholar] [CrossRef]
- West, Stephen G., John F. Finch, and Patrick J. Curran. 1995. Structural equation models with nonnormal variables: Problems and remedies. In Structural Equation Modeling: Concepts, Issues, and Applications. Edited by R. H. Hoyle. Southern Oaks: SAGE Publications, pp. 56–75. [Google Scholar]
- Winsborough, Dave, and Tomas Chamorro-Premuzic. 2016. Talent identification in the digital world: New talent signals and the future of HR assessment. People and Strategy 39: 28–31. Available online: https://info.hoganassessments.com/hubfs/TalentIdentification.pdf (accessed on 3 February 2022).
- Yan, Ting, Frederick. G Conrad, Roger Tourangeau, and Mick P. Couper. 2011. Should I stay or should I go: The effects of progress feedback, promised task duration, and length of questionnaire on completing web surveys. International Journal of Public Opinion Research 23: 131–47. [Google Scholar] [CrossRef]
- Zhang, Huaiwen, Jiaming Zhang, Jitao Sang, and Changsheng Xu. 2017. A demo for image-based personality test. Lecture Notes in Computer Science: MultiMedia Modelling 2017: 433–37. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Trait | Mean | SD | Min | Max | Range | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|
| Questionnaire-based measure | |||||||
| Openness | 82.84 | 12.02 | 34.00 | 114.00 | 80.00 | −0.32 | −0.32 |
| Conscientiousness | 86.31 | 15.14 | 16.00 | 120.00 | 104.00 | −0.54 | −0.54 |
| Extraversion | 75.98 | 15.12 | 11.00 | 114.00 | 103.00 | −0.30 | −0.30 |
| Agreeableness | 90.32 | 13.64 | 13.00 | 119.00 | 106.00 | −1.11 | −1.11 |
| Emotional stability | 76.10 | 18.69 | 10.00 | 120.00 | 110.00 | −0.27 | −0.27 |
| Image-based measure | |||||||
| Openness | 82.89 | 7.19 | 59.16 | 102.31 | 43.16 | −0.05 | 0.03 |
| Conscientiousness | 86.79 | 10.68 | 52.17 | 110.84 | 58.67 | −0.51 | −0.12 |
| Extraversion | 76.07 | 11.77 | 44.20 | 101.97 | 57.77 | −0.11 | −0.65 |
| Agreeableness | 90.20 | 8.46 | 59.80 | 110.54 | 50.74 | −0.54 | 0.51 |
| Emotional stability | 75.71 | 12.67 | 42.35 | 100.84 | 58.49 | −0.37 | −0.49 |
| Trait | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1. Openness | 0.83 | ||||
| 2. Conscientiousness | 0.12 * | 0.91 | |||
| 3. Extraversion | 0.33 ** | 0.43 ** | 0.90 | ||
| 4. Agreeableness | 0.34 ** | 0.52 ** | 0.24 ** | 0.89 | |
| 5. Emotional stability | 0.09 | 0.61 ** | 0.60 ** | 0.35 ** | 0.93 |
| Trait | Training (n = 323) | Test (n = 108) | ||||
|---|---|---|---|---|---|---|
| r | R2 | MSE | r | R2 | MSE | |
| Openness | 0.77 ** | 0.56 | 65.63 | 0.71 ** | 0.50 | 64.46 |
| Conscientiousness | 0.82 ** | 0.66 | 82.62 | 0.70 ** | 0.47 | 97.26 |
| Extraversion | 0.86 ** | 0.74 | 61.23 | 0.78 ** | 0.61 | 82.28 |
| Agreeableness | 0.77 ** | 0.56 | 84.97 | 0.60 ** | 0.34 | 103.03 |
| Emotional Stability | 0.80 ** | 0.63 | 131.35 | 0.70 ** | 0.47 | 175.29 |
| Trait | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Questionnaire-based | ||||||||||
| 1. Openness | 1.00 | |||||||||
| 2. Conscientiousness | 0.10 | 1.00 | ||||||||
| 3. Extraversion | 0.29 ** | 0.35 ** | 1.00 | |||||||
| 4. Agreeableness | 0.31 ** | 0.50 ** | 0.12 | 1.00 | ||||||
| 5. Emotional stability | 0.01 | 0.63 ** | 0.54 ** | 0.30 ** | 1.00 | |||||
| Image-based | ||||||||||
| 6. Openness | 0.71 ** | 0.05 | 0.39 ** | 0.31 ** | 0.06 | 1.00 | ||||
| 7. Conscientiousness | −0.04 | 0.70 ** | 0.21 * | 0.32 ** | 0.54 ** | 0.00 | 1.00 | |||
| 8. Extraversion | 0.26 ** | 0.30 ** | 0.78 ** | 0.12 | 0.52 ** | 0.48 ** | 0.32 ** | 1.00 | ||
| 9. Agreeableness | 0.18 | 0.42 ** | 0.13 | 0.60 ** | 0.23 * | 0.46 ** | 0.54 ** | 0.22 * | 1.00 | |
| 10. Emotional stability | 0.08 | 0.51 ** | 0.57 ** | 0.21 * | 0.70 ** | 0.19 | 0.69 ** | 0.71 ** | 0.38 ** | 1.00 |
| Demographic | Group Size (N = 431) | Respondents Passing (n) | Respondents Passing (%) | Adverse Impact Ratio | Standard Deviations | Cohen’s d |
|---|---|---|---|---|---|---|
| Openness | ||||||
| Gender | ||||||
| Male | 205 | 79 | 38.54 | 0.68 | −3.67 | 0.36 |
| Female | 222 | 125 | 56.31 | 1.00 | 3.65 | 0.00 |
| Age | ||||||
| 40 or older | 75 | 32 | 42.67 | 1.00 | 0.98 | 0.00 |
| Under 40 | 356 | 174 | 48.88 | 0.87 | −0.98 | 0.12 |
| Ethnicity | ||||||
| White | 209 | 106 | 50.72 | 0.95 | 1.18 | 0.05 |
| Black | 73 | 36 | 49.32 | 0.92 | 0.29 | 0.08 |
| Asian | 66 | 19 | 28.79 | 0.54 | −3.36 | 0.52 |
| Hispanic | 56 | 30 | 53.57 | 1.00 | 0.93 | 0.00 |
| Conscientiousness | ||||||
| Gender | ||||||
| Male | 205 | 102 | 49.76 | 0.83 | −1.89 | 0.20 |
| Female | 222 | 133 | 59.91 | 1.00 | 2.31 | 0.00 |
| Age | ||||||
| 40 or older | 75 | 44 | 58.67 | 0.91 | −0.79 | 0.10 |
| Under 40 | 356 | 191 | 53.65 | 1.00 | 0.79 | 0.00 |
| Ethnicity | ||||||
| White | 209 | 114 | 54.55 | 0.80 | 0.01 | 0.23 |
| Black | 73 | 50 | 68.49 | 1.00 | 2.63 | 0.00 |
| Asian | 66 | 36 | 54.55 | 0.80 | 0.00 | 0.29 |
| Hispanic | 56 | 24 | 42.86 | 0.63 | −1.88 | 0.53 |
| Extraversion | ||||||
| Gender | ||||||
| Male | 205 | 106 | 51.71 | 1.00 | 0.08 | 0.00 |
| Female | 222 | 115 | 51.8 | 1.00 | 0.13 | 0.00 |
| Age | ||||||
| 40 or older | 75 | 40 | 53.33 | 0.96 | −0.35 | 0.04 |
| Under 40 | 356 | 182 | 51.12 | 1.00 | 0.35 | 0.00 |
| Ethnicity | ||||||
| White | 209 | 109 | 52.15 | 0.98 | 0.26 | 0.02 |
| Black | 73 | 39 | 53.42 | 1.00 | 0.36 | 0.00 |
| Asian | 66 | 33 | 50 | 0.94 | −0.27 | 0.07 |
| Hispanic | 56 | 27 | 48.21 | 0.90 | −0.53 | 0.10 |
| Agreeableness | ||||||
| Gender | ||||||
| Male | 205 | 91 | 44.39 | 0.68 | −4.02 | 0.42 |
| Female | 222 | 144 | 64.86 | 1.00 | 4.44 | 0.00 |
| Age | ||||||
| 40 or older | 75 | 45 | 60 | 0.89 | −1.05 | 0.13 |
| Under 40 | 356 | 190 | 53.37 | 1.00 | 1.05 | 0.00 |
| Ethnicity | ||||||
| White | 209 | 124 | 59.33 | 0.98 | 1.94 | 0.02 |
| Black | 73 | 44 | 60.27 | 1.00 | 1.08 | 0.00 |
| Asian | 66 | 29 | 43.94 | 0.73 | −1.88 | 0.33 |
| Hispanic | 56 | 22 | 39.29 | 0.65 | −2.46 | 0.43 |
| Emotional Stability | ||||||
| Gender | ||||||
| Male | 205 | 118 | 57.56 | 1.00 | 1.66 | 0.00 |
| Female | 222 | 111 | 50 | 0.87 | −1.44 | 0.15 |
| Age | ||||||
| 40 or older | 75 | 39 | 52 | 1.00 | 0.26 | 0.00 |
| Under 40 | 356 | 191 | 53.65 | 0.97 | −0.26 | 0.03 |
| Ethnicity | ||||||
| White | 209 | 109 | 52.15 | 0.86 | −0.49 | 0.14 |
| Black | 73 | 42 | 57.53 | 0.95 | 0.78 | 0.06 |
| Asian | 66 | 40 | 60.61 | 1.00 | 1.28 | 0.00 |
| Hispanic | 56 | 27 | 48.21 | 0.80 | −0.83 | 0.25 |
| Demographic | Group Size (N = 431) | Respondents Passing (n) | Respondents Passing (%) | Adverse Impact Ratio | Standard Deviations | Cohen’s d |
|---|---|---|---|---|---|---|
| Openness | ||||||
| Gender | ||||||
| Male | 205 | 93 | 45.37 | 0.77 | −3.54 | 0.27 |
| Female | 222 | 130 | 58.56 | 1.00 | 3.75 | 0.00 |
| Age | ||||||
| 40 or older | 75 | 29 | 38.67 | 0.70 | −1.87 | 0.34 |
| Under 40 | 356 | 197 | 55.34 | 1.00 | 1.87 | 0.00 |
| Ethnicity | ||||||
| White | 209 | 108 | 51.67 | 0.80 | 0.26 | 0.21 |
| Black | 73 | 41 | 56.16 | 0.87 | 0.10 | 0.17 |
| Asian | 66 | 23 | 34.85 | 0.54 | −0.80 | 0.61 |
| Hispanic | 56 | 36 | 64.29 | 1.00 | 0.33 | 0.00 |
| Conscientiousness | ||||||
| Gender | ||||||
| Male | 205 | 95 | 46.34 | 0.80 | −2.23 | 0.24 |
| Female | 222 | 129 | 58.11 | 1.00 | 2.63 | 0.00 |
| Age | ||||||
| 40 or older | 75 | 43 | 57.33 | 1.00 | −1.02 | 0.00 |
| Under 40 | 356 | 181 | 50.84 | 0.89 | 1.02 | 0.13 |
| Ethnicity | ||||||
| White | 209 | 111 | 53.11 | 0.86 | 0.46 | 0.14 |
| Black | 73 | 45 | 61.64 | 1.00 | 1.81 | 0.00 |
| Asian | 66 | 33 | 50.00 | 0.81 | −0.35 | 0.23 |
| Hispanic | 56 | 27 | 48.21 | 0.78 | −0.60 | 0.27 |
| Extraversion | ||||||
| Gender | ||||||
| Male | 205 | 102 | 49.76 | 0.92 | −0.79 | 0.09 |
| Female | 222 | 120 | 54.05 | 1.00 | 0.99 | 0.00 |
| Age | ||||||
| 40 or older | 75 | 39 | 52.00 | 1.00 | −0.05 | 0.00 |
| Under 40 | 356 | 184 | 51.69 | 0.99 | 0.05 | 0.01 |
| Ethnicity | ||||||
| White | 209 | 106 | 50.72 | 0.96 | −0.41 | 0.04 |
| Black | 73 | 38 | 52.05 | 0.98 | 0.06 | 0.02 |
| Asian | 66 | 35 | 53.03 | 1.00 | 0.23 | 0.00 |
| Hispanic | 56 | 28 | 50.00 | 0.94 | −0.28 | 0.06 |
| Agreeableness | ||||||
| Gender | ||||||
| Male | 205 | 93 | 45.37 | 0.70 | −3.82 | 0.40 |
| Female | 222 | 144 | 64.86 | 1.00 | 4.25 | 0.00 |
| Age | ||||||
| 40 or older | 75 | 48 | 64.00 | 1.00 | −1.73 | 0.00 |
| Under 40 | 356 | 189 | 53.09 | 0.83 | 1.73 | 0.22 |
| Ethnicity | ||||||
| White | 209 | 140 | 66.99 | 1.00 | 4.86 | 0.00 |
| Black | 73 | 27 | 36.99 | 0.55 | −3.39 | 0.50 |
| Asian | 66 | 26 | 39.39 | 0.59 | −2.77 | 0.57 |
| Hispanic | 56 | 31 | 55.36 | 0.83 | 0.06 | 0.24 |
| Emotional Stability | ||||||
| Gender | ||||||
| Male | 205 | 125 | 60.98 | 1.00 | 3.75 | 0.00 |
| Female | 222 | 96 | 43.24 | 0.71 | −3.54 | 0.36 |
| Age | ||||||
| 40 or older | 75 | 46 | 61.33 | 1.00 | −1.87 | 0.00 |
| Under 40 | 356 | 176 | 49.44 | 0.81 | 1.87 | 0.24 |
| Ethnicity | ||||||
| White | 209 | 109 | 52.15 | 0.97 | 0.26 | 0.02 |
| Black | 73 | 38 | 52.05 | 0.97 | 0.10 | 0.03 |
| Asian | 66 | 31 | 46.97 | 0.88 | −0.80 | 0.13 |
| Hispanic | 56 | 30 | 53.57 | 1.00 | 0.33 | 0.00 |
| Demographic | O | C | E | A | ES |
|---|---|---|---|---|---|
| Gender | |||||
| Male | 0.65 ** | 0.76 ** | 0.80 ** | 0.69 ** | 0.72 ** |
| Female | 0.76 ** | 0.58 ** | 0.76 ** | 0.42 ** | 0.69 ** |
| Age | |||||
| Under 40 years old | 0.67 ** | 0.68 ** | 0.80 ** | 0.50 ** | 0.68 ** |
| Age 40 or older | 0.78 ** | 0.76 ** | 0.68 ** | 0.86 ** | 0.77 ** |
| Ethnicity | |||||
| White | 0.77 ** | 0.75 ** | 0.83 ** | 0.62 ** | 0.83 ** |
| Black | 0.69 ** | −0.01 | 0.86 ** | 0.05 | 0.73 ** |
| Asian | 0.65 ** | 0.72 ** | 0.85 ** | 0.08 | 0.45 |
| Hispanic | 0.56 ** | 0.72 ** | 0.83 ** | 0.83 ** | 0.57 * |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hilliard, A.; Kazim, E.; Bitsakis, T.; Leutner, F. Measuring Personality through Images: Validating a Forced-Choice Image-Based Assessment of the Big Five Personality Traits. J. Intell. 2022, 10, 12. https://doi.org/10.3390/jintelligence10010012
Hilliard A, Kazim E, Bitsakis T, Leutner F. Measuring Personality through Images: Validating a Forced-Choice Image-Based Assessment of the Big Five Personality Traits. Journal of Intelligence. 2022; 10(1):12. https://doi.org/10.3390/jintelligence10010012
Chicago/Turabian StyleHilliard, Airlie, Emre Kazim, Theodoros Bitsakis, and Franziska Leutner. 2022. "Measuring Personality through Images: Validating a Forced-Choice Image-Based Assessment of the Big Five Personality Traits" Journal of Intelligence 10, no. 1: 12. https://doi.org/10.3390/jintelligence10010012
APA StyleHilliard, A., Kazim, E., Bitsakis, T., & Leutner, F. (2022). Measuring Personality through Images: Validating a Forced-Choice Image-Based Assessment of the Big Five Personality Traits. Journal of Intelligence, 10(1), 12. https://doi.org/10.3390/jintelligence10010012