Developing a New Storage Format and a Warp-Based SpMV Kernel for Configuration Interaction Sparse Matrices on the GPU †


Abstract
1. Introduction
1.1. GPU
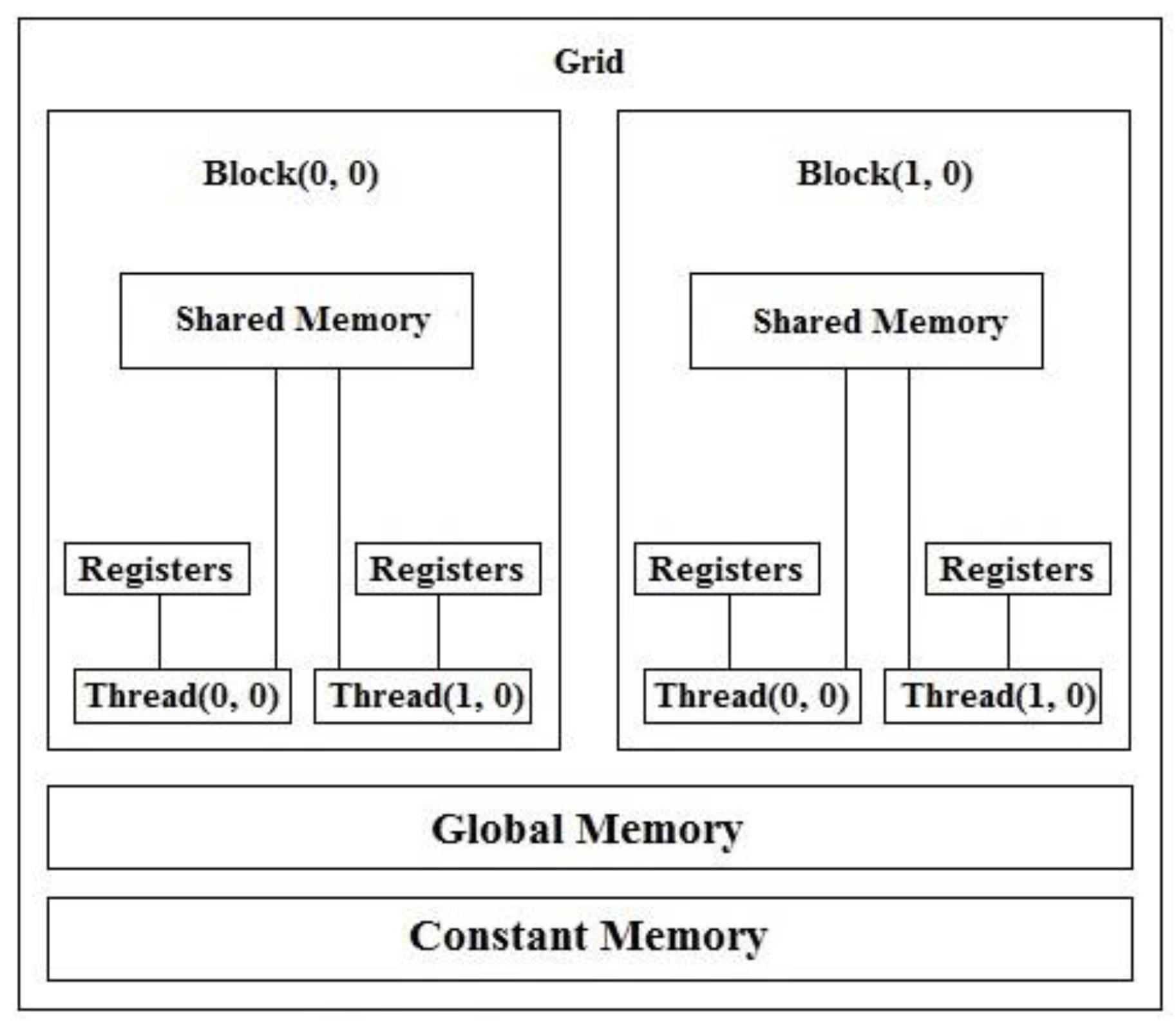
1.2. CUDA
- Faster downloads and readbacks to and from the GPU.
- Scattered reads.
- Unified memory (CUDA 6.0 and above).
- Full support for integer and bitwise operations.
- Unified virtual memory (CUDA 4.0 and above).
- Shared memory—CUDA exposes a fast shared memory region that can be shared among threads.
- The CPU allocates storage on the GPU (using cudaMalloc()).
- The CPU copies input data from the CPU to the GPU (using cudaMemcpy()).
- The CPU launches on the GPU multiple copies of the kernel on parallel threads to process the GPU data. A kernel is a Function (Serial program) that will run on the GPU. The CPU which launch the kernel on parallel threads.
- The CPU copies results back from the GPU to the CPU (using cudaMemcpy()).
- Use or display the output.
__global__ void AddArrays(int *d_Arr1, int *d_Arr2, int *d_sum, unsigned int Length)
{
unsigned int Index = (blockDim.x * blockIdx.x) + threadIdx.x;
if (Index < Length)
{
d_sum[Index] = d_Arr1[Index] + d_Arr2[Index];
}
}
- It takes time to copy data from the CPU to the GPU and vice versa.
- CUDA doesn’t allow all the threads to run simultaneously on the GPU since it depends on the architecture of the GPU.
- Kernel threads access global memory which is implemented in Dynamic Random Access Memory (DRAM) (slow and there is a lookup latency).
1.3. Sparse Matrix-Vector Multiplication (SpMV)
1.4. The Schrödinger Equation
- h: Planck’s constant (6.62607004 × 10−34 J.s).
- = h/2 π.
- m: Mass.
- ∇2: Second Derivative.
- V: Potential Energy.
- ψ: Wavefunction.
- F: Fock operator
- C: Matrix (a wavefunction)
- S: Overlap matrix.
- E: Energy
- Ecorr: Electron Correlation Energy.
- εo: True (exact) ground state energy.
- Eo: HF energy.
2. Configuration Interaction (CI)
2.1. The CI Matrix Elements
2.2. The CI Matrix
- |Φo>: CI wavefunction.
- |Ψo>: Hartree-Fock wavefunction.
- C: Some coefficient that is applied to a Slater Determinant (Ψ).
- |>: All the possible single excitations. An electron is excited from orbital a to orbital r.
- |>: All the possible double excitations.
- …: All the way up to n excitations (excite n electrons).
2.3. The Proposed Work
3. Common Formats
3.1. The CSR (Compressed Sparse Row) or CRS (Compressed Row Storage) Format
- The Value vector: Contains all the non-zero entries.
- The Column vector: Contains column index of each non-zero entry.
- The RowPtr vector: Contains the index of the first non-zero entry of each row in the “Value” vector. We add the number of non-zero entries in the sparse matrix as the last element of the RowPtr vector.
- Value = 1, 2, 3, 4, 5, 6, 7, 8
- Column = 0, 2, 4, 1, 4, 2, 3, 4
- RowPtr = 0, 1, 3, 5, 6, 7, 8
| Algorithm 1 The SpMV kernel for the CSR format. |
| SpMV_CSR(Value, Column, Vector, RowPtr, Result) for i ← 0 to ROWS - 1 do Start ← RowPtr[i] End ← RowPtr[i + 1] for j ← Start to End - 1 do Temp ← Temp + (Value[j] * Vector[Column[j]]) Result[i] ← Temp Temp ← 0.00 |
3.2. The ELLPACK (ELL) Format
- The NonZerosEntries matrix: All the non-zero entries.
- The Column matrix: The column index of each non-zero entry.
| Algorithm 2 The SpMV kernel for the ELLPACK format (thread per row). |
| SpMV_ELLPACK(NonZerosEntries, Column, Vector, Result, MaxNonZeros) for r1 ← 0 to ROWS – 1 do for r2 ← 0 to MaxNonZeros – 1 do if Column[r1][r2] = -1 then exit loop Temp = Temp + (NonZerosEntries[r1][r2] * Vector[Column[r1][r2]]) Result[r1] ← Temp Temp ← 0.00 |
3.3. The ELLPACK-R (ELL-R) Format
| Algorithm 3 The SpMV kernel for the ELLPACK-R format (thread per row). |
| SpMV_ELLPACK_R(NonZerosEntries, Column, Vector, NonZerosCount, Result) for r1 ← 0 to ROWS – 1 do End ← NonZerosCount[r1] for r2 ← 0 to End – 1 do Temp ← Temp + (NonZerosEntries[r1][r2] * Vector[Column[r1][r2]]) Result[r1] ← Temp Temp ← 0.00 |
3.4. The Sliced ELLPACK Format
| Algorithm 4 The SpMV kernel for the Sliced ELLPACK format (thread per row). |
| SpMV_SlicedELLPACK(NonZerosEntries, Column, Vector, Result, Rows, Cols) for r1 ← 0 to Rows – 1 do for r2 ← 0 to Cols – 1 do if Column[r1][r2] = -1 then exit loop Temp ← Temp + (NonZerosEntries[r1][r2] * Vector[Column[r1][r2]]) Result[r1] ← Temp Temp ← 0.00 |
3.5. The Sliced ELLPACK-R Format
| Algorithm 5 The SpMV kernel for the Sliced ELLPACK-R format (thread per row). |
| SpMV_SlicedELLPACK_R(NonZerosEntries, Column, Vector, NonZerosCount, Result, Rows) for r1 ← 0 to Rows – 1 do End ← NonZerosCount[r1] for r2 ← 0 to End – 1 do Temp ← Temp + (NonZerosEntries[r1][r2] * Vector[Column[r1][r2]]) Result[r1] ← Temp Temp ← 0.00 |
3.6. The Compressed Sparse Blocks (CSB) Format
- The Value vector: The Value vector is of length nnz. It stored all the non-zero elements of the sparse matrix.
- The row_idx and col_idx vectors: They track the row index and the column index of each non-zero entry inside the Value vector with regard to the block, not the whole entire matrix. Therefore, row_idx and col_idx range from 0 to z – 1.
- The Block_ptr vector: It stores the index of the first non-zero entry of each block inside the Value vector.
4. The Proposed Model
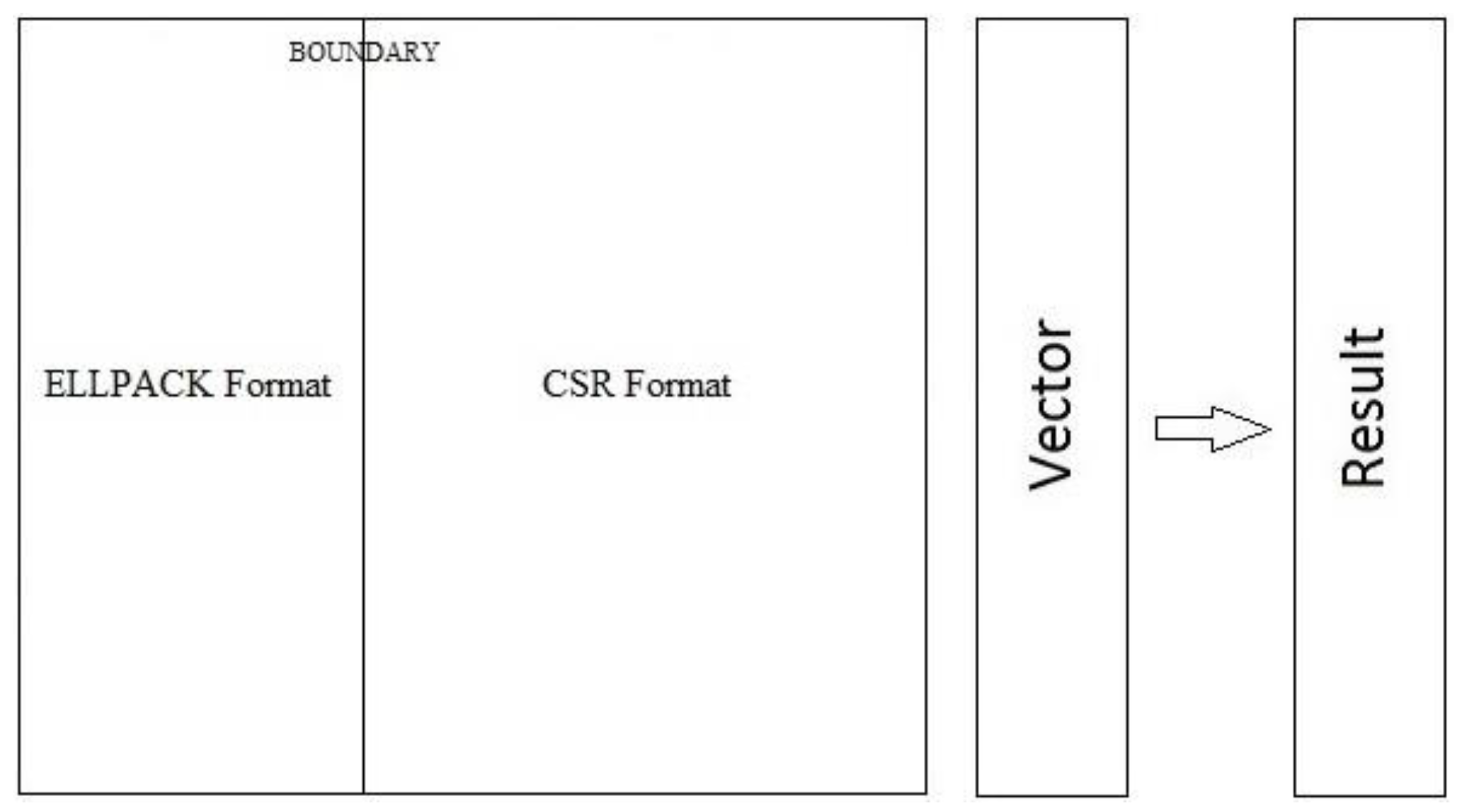
4.1. The Proposed Storage Format
| Algorithm 6 The proposed format. |
| CreateFormat(Mat, NonZerosEntries, ELLPACK_Column, Value, CSR_Column, AllNonZerosCount, StartArr, EndArr) for i ← 0 to ROWS – 1 do c = 0 GotIt = 0 for j ← 0 to COLS – 1 do if Mat[i][j]! = 0.00 then if c < BOUNDARY NonZerosEntries[r][c] = Mat[i][j] ELLPACK_Column[r][c] = j c++ else Value[Index] = Mat[i][j] CSR_Column[Index] = j if GotIt = 0 GotIt = 1 Start = Index Index++ r++ if AllNonZerosCount[i] > BOUNDARY End = Index StartArr[i] = Start EndArr[i] = End |
sizeof(double)) + ROWS × BOUNDARY × sizeof(int)) + (CSRNonZeros ×
sizeof(double)) + (CSRNonZeros × sizeof(unsigned int))
- ROWS: The number of rows in the matrix.
- BOUNDARY: A divider between the Reference region (ELLPACK format) and the Expansion Space region (CSR format). It marks the end of the Reference region and the start of the Expansion Space region.
- CSRNonZeros: The number of non-zero entries in the Expansion Space region.
int)) + ((ROWS + 1) × sizeof(unsigned int))
- AllNonZeros: The number of non-zero entries in the matrix.
- ROWS: The number of rows in the matrix.
MaxNonZeros × sizeof(int))
- ROWS: The number of rows in the matrix.
- MaxNonZeros: The length of the longest non-zero entry row in the matrix.
4.2. The Developed SpMV Kernel
| Algorithm 7 The SpMV kernel for the proposed format. |
| SpMV_Hybrid_ELLPACKandCSR(NonZerosEntries, ELLPACK_Column, Value, CSR_Column, StartArr, EndArr, AllNonZerosCount, Vector, Result) Thread_id ← (blockDim.x × blockIdx.x) + threadIdx.x; Warp_id ← Thread_id/32 Th_Wa_Id ← Thread_id % 32 define ShMem1[32]//Shared Memory define ShMem2[32]//Shared Memory initialize ShMem1 initialize ShMem2 if Warp_id < ROWS then ShMem1[threadIdx.x] = 0.00 for r2 ← 0 + Th_Wa_Id to BOUNDARY – 1 STEP=32 do ShMem1[threadIdx.x] ← ShMem1[threadIdx.x] + (NonZerosEntries[Warp_id][r2] × Vector[ELLPACK_Column[Warp_id][r2]]) //Warp-level reduction for the ELLPACK format: if Th_Wa_Id < 16 ShMem1[threadIdx.x] ←(SynchronousAdd) ShMem1[threadIdx.x] + ShMem1[threadIdx.x + 16] if Th_Wa_Id < 8 ShMem1[threadIdx.x] ←(SynchronousAdd) ShMem1[threadIdx.x] + ShMem1[threadIdx.x + 8] if Th_Wa_Id < 4 ShMem1[threadIdx.x] ←(SynchronousAdd) ShMem1[threadIdx.x] + ShMem1[threadIdx.x + 4] if Th_Wa_Id < 2 ShMem1[threadIdx.x] ←(SynchronousAdd) ShMem1[threadIdx.x] + ShMem1[threadIdx.x + 2] if Th_Wa_Id < 1 ShMem1[threadIdx.x] ←(SynchronousAdd) ShMem1[threadIdx.x] + ShMem1[threadIdx.x + 1] if AllNonZerosCount[Warp_id] > BOUNDARY then Start ← StartArr[Warp_id] End ← EndArr[Warp_id] ShMem2[threadIdx.x] = 0.00 for j ← Start + Th_Wa_Id to End – 1 STEP=32 do ShMem2[threadIdx.x] ← ShMem2[threadIdx.x] + (Value[j] × Vector[CSR_Column[j]]) //Warp-level reduction for the CSR format: if Th_Wa_Id < 16 ShMem2[threadIdx.x] ←(SynchronousAdd) ShMem2[threadIdx.x] + ShMem2[threadIdx.x + 16] if Th_Wa_Id < 8 ShMem2[threadIdx.x] ←(SynchronousAdd) ShMem2[threadIdx.x] + ShMem2[threadIdx.x + 8] if Th_Wa_Id < 4 ShMem2[threadIdx.x] ←(SynchronousAdd) ShMem2[threadIdx.x] + ShMem2[threadIdx.x + 4] if Th_Wa_Id < 2 ShMem2[threadIdx.x] ←(SynchronousAdd) ShMem2[threadIdx.x] + ShMem2[threadIdx.x + 2] if Th_Wa_Id < 1 ShMem2[threadIdx.x] ←(SynchronousAdd) ShMem2[threadIdx.x] + ShMem2[threadIdx.x + 1] if Th_Wa_Id = 0 //Writing the results Result[Warp_id] ← Result[Warp_id] + ShMem1[threadIdx.x] + ShMem2[threadIdx.x] |
5. System Configuration
- NIVIDIA K20m GPU card or Intel® Xeon Phi™ co-processor card.
- 64 GB of memory.
- 150 GB RAID 17.2 K RPM storage hard drives.
- Linux Red Hat operating system RHEL 7.0.
6. The Results
- cudaDeviceProp DeviceProp_var
- cudaGetDeviceProperties(DeviceProp_var, DevNo)
- Print DeviceProp_var.warpSize
7. Conclusions
8. Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Mei, X.; Chu, X. Dissecting GPU Memory Hierarchy through Microbenchmarking. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 72–86. [Google Scholar] [CrossRef]
- Nickolls, J.; Buck, I.; Garland, M.; Skadron, K. Scalable parallel programming with CUDA. In Proceedings of the ACM SIGGRAPH 2008 Classes, Los Angeles, CA, USA, 11–15 August 2008. [Google Scholar]
- NVIDIA Corporation. CUDA®: A General-Purpose Parallel Computing Platform and Programming Model. In NVIDIA CUDA Programming Guide; Version 2.0; NVIDIA: Santa Clara, CA, USA, 2008. [Google Scholar]
- NVidia Developer’s Guide, about CUDA. Available online: https://developer.nvidia.com/about-cuda (accessed on 2 October 2017).
- Kulkarni, M.A.V.; Barde, P.C.R. A Survey on Performance Modelling and Optimization Techniques for SpMV on GPUs. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 7577–7582. [Google Scholar]
- Baskaran, M.M.; Bordawekar, R. Optimizing Sparse Matrix-Vector Multiplication on GPUs. Ninth SIAM Conf. Parallel Process. Sci. Comput. 2009; IBM Research Report no. RC24704. [Google Scholar]
- Bell, N.; Garland, M. Efficient Sparse Matrix-Vector Multiplication on CUDA. In Proceedings of the 2010 2nd International Conference on Education Technology and Computer, Shanghai, China, 22–24 June 2010. [Google Scholar]
- Guo, D.; Gropp, W.; Olson, L.N. A hybrid format for better performance of sparse matrix-vector multiplication on a GPU. Int. J. High Perform. Comput. Appl. 2016, 30, 103–120. [Google Scholar] [CrossRef]
- Echenique, P.; Alonso, J.L. A mathematical and computational review of Hartree-Fock SCF methods in quantum chemistry. Mol. Phys. 2007, 105, 3057–3098. [Google Scholar] [CrossRef]
- Anthony, B.M.; Stevens, J. Virtually going green: The role of quantum computational chemistry in reducing pollution and toxicity in chemistry. Phys. Sci. Rev. 2017, 2. [Google Scholar] [CrossRef]
- Siegbahn, P.E.M. The Configuration Interaction Method. Eur. Summer Sch. Quantum Chem. 2000, 1, 241–284. [Google Scholar]
- Alavi, A. Introduction to Full Configuration Interaction Quantum Monte Carlo with Applications to the Hubbard model Stuttgart. Autumn Sch. Correl. Electrons 2016, 6, 1–14. [Google Scholar]
- Aktulga, H.M.; Buluc, A.; Williams, S.; Yang, C. Optimizing sparse matrix-multiple vectors multiplication for nuclear configuration interaction calculations. In Proceedings of the 2014 IEEE 28th International Parallel and Distributed Processing Symposium, Phoenix, AZ, USA, 19–23 May 2014. [Google Scholar]
- Zardoshti, P.; Khunjush, F.; Sarbazi-Azad, H. Adaptive sparse matrix representation for efficient matrix-vector multiplication. J. Supercomput. 2016, 72, 3366–3386. [Google Scholar] [CrossRef]
- Ren, Z.; Ye, C.; Liu, G. Application and Research of C Language Programming Examination System Based on B/S. In Proceedings of the 2010 Third International Symposium on Information Processing, Qingdao, China, 15–17 October 2010. [Google Scholar]
- Bell, N.; Garland, M. Implementing sparse matrix-vector multiplication on throughput-oriented processors. In Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis, Portland, OR, USA, 14–20 November 2009. [Google Scholar]
- Dziekonski, A.; Lamecki, A.; Mrozowski, M. A memory efficient and fast sparse matrix vector product on a GPU. Prog. Electromagn. Res. 2011, 116, 49–63. [Google Scholar] [CrossRef]
- Ye, F.; Calvin, C.; Petiton, S.G. A study of SpMV implementation using MPI and OpenMP on intel many-core architecture. In VECPAR 2014: High Performance Computing for Computational Science—VECPAR 2014; Lecture Notes in Computer Science Book Series; Springer: Cham, Switzerland, 2015; pp. 43–56. [Google Scholar]
- Maggioni, M.; Berger-Wolf, T. AdELL: An adaptive warp-Balancing ELL format for efficient sparse matrix-Vector multiplication on GPUs. In Proceedings of the 2013 42nd International Conference on Parallel Processing, Lyon, France, 1–4 October 2013. [Google Scholar]
- Eguly, I.R.; Giles, M. Efficient sparse matrix-vector multiplication on cache-based GPUs. In Proceedings of the 2012 Innovative Parallel Computing (InPar), San Jose, CA, USA, 13–14 May 2012. [Google Scholar]
- Buluç, A.; Fineman, J.T.; Frigo, M.; Gilbert, J.R.; Leiserson, C.E. Parallel sparse matrix-vector and matrix-transpose-vector multiplication using compressed sparse blocks. In Proceedings of the Twenty-First Annual Symposium on Parallelism in Algorithms and Architectures, Calgary, AB, Canada, 11–13 August 2009. [Google Scholar]
- Aktulga, H.M.; Afibuzzaman, M.; Williams, S.; Buluç, A.; Shao, M.; Yang, C.; Ng, E.G.; Maris, P.; Vary, J.P. A High Performance Block Eigensolver for Nuclear Configuration Interaction Calculations. IEEE Trans. Parallel Distrib. Syst. 2016, 28, 1550–1563. [Google Scholar] [CrossRef]
- CUDA Toolkit Documentation. nvprof. Available online: https://docs.nvidia.com/cuda/profiler-users-guide/index.html#nvprof-overview (accessed on 19 July 2018).
- CUDA Toolkit Documentation, cuSPARSE. Available online: https://docs.nvidia.com/cuda/cusparse/index.html (accessed on 16 July 2018).
- Liu, W.; Vinter, B. CSR5: An Efficient Storage Format for Cross-Platform Sparse Matrix-Vector Multiplication Categories and Subject Descriptors. In Proceedings of the 29th ACM on International Conference on Supercomputing, Newport Beach, CA, USA, 8–11 June 2015. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Excitation Level (n). | Total Number of CSFs |
|---|---|
| 1 | 71 |
| 2 | 2556 |
| 3 | 42,596 |
| 4 | 391,126 |
| 5 | 2,114,666 |
| 6 | 7,147,876 |
| 7 | 15,836,556 |
| 8 | 24,490,201 |
| 9 | 29,044,751 |
| 10 | 30,046,752 |
| Name | Tesla K20m |
|---|---|
| Major revision number | 3 |
| Minor revision number | 5 |
| Maximum memory pitch | 2,147,483,647 |
| Clock rate | 705,500 |
| Texture alignment | 512 |
| Concurrent copy and execution | Yes |
| Kernel execution timeout enabled | No |
| Number of multiprocessors | 13 |
| The maximum number of threads per multiprocessor | 2048 |
| The maximum number of threads per block | 1024 |
| The maximum sizes of each dimension of a block (x, y, z) | 1024, 1024, 64 |
| The maximum sizes of each dimension of a grid (x, y, z) | 2,147,483,647, 65,535, 65,535 |
| The total number of registers available per block | 65,536 |
| The total amount of shared memory per block (Bytes) | 49,152 |
| The total amount of constant memory (Bytes) | 65,536 |
| The total amount of global memory (Bytes), (Gigabytes) | 4,972,937,216, 4.631409 |
| Warp size (Threads) | 32 |
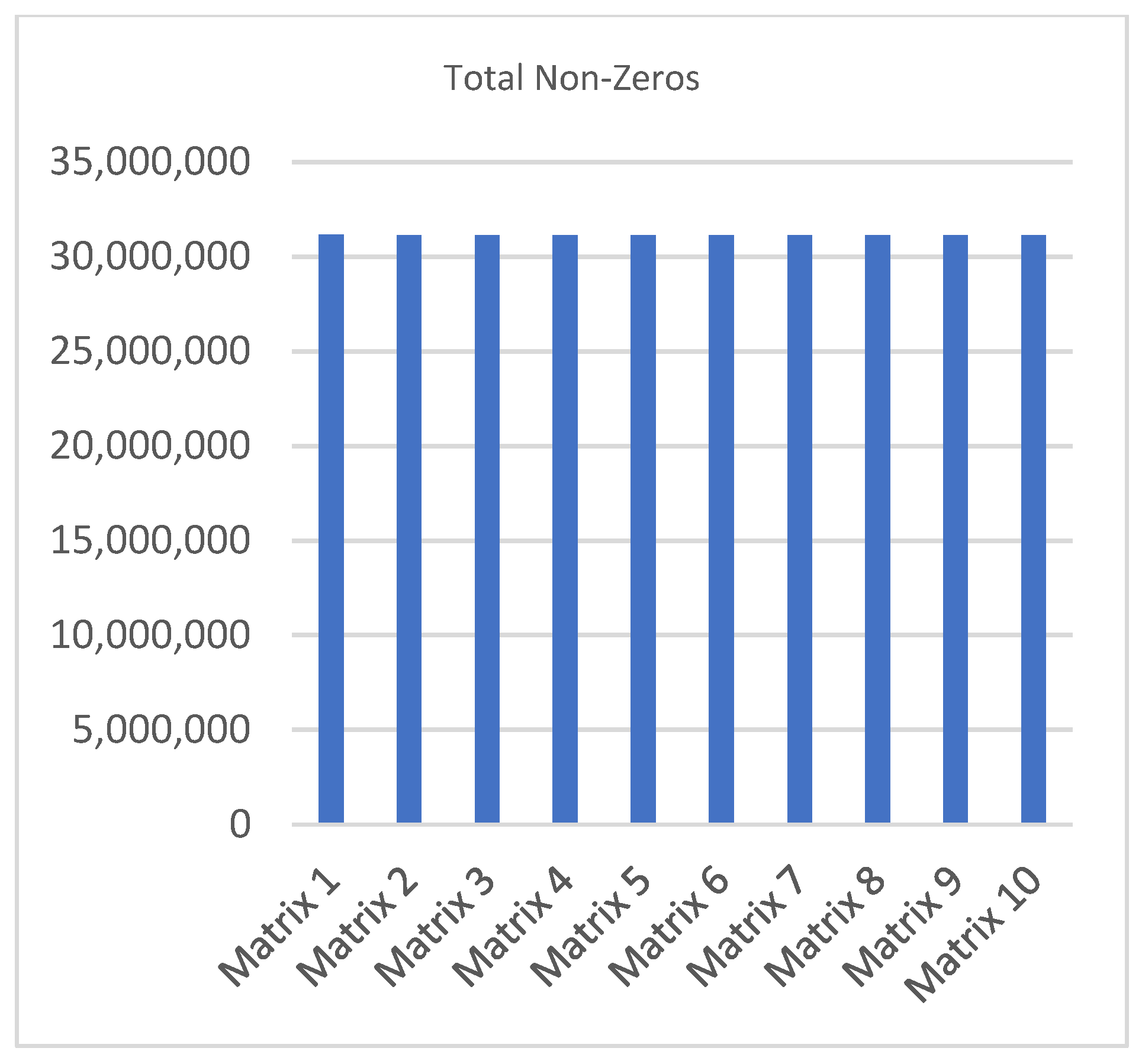
| Ref. Non-Zeros | Exp. Space Non-Zeros | Total Non-Zeros | Length of the Longest Non-Zero Row–Row No. | |
|---|---|---|---|---|
| Matrix 1 | 21,463,040 | 9,678,327 | 31,141,367 | 1074–5314 |
| Matrix 2 | 21,463,040 | 9,673,031 | 31,136,071 | 1069–6144 |
| Matrix 3 | 21,463,040 | 9,666,827 | 31,129,867 | 1078–22,358 |
| Matrix 4 | 21,463,040 | 9,670,529 | 31,133,569 | 1068–21,549 |
| Matrix 5 | 21,463,040 | 9,669,733 | 31,132,773 | 1060–4233 |
| Matrix 6 | 21,463,040 | 9,673,530 | 31,136,570 | 1069–28,394 |
| Matrix 7 | 21,463,040 | 9,666,857 | 31,129,897 | 1079–21,836 |
| Matrix 8 | 21,463,040 | 9,670,234 | 31,133,274 | 1077–20,148 |
| Matrix 9 | 21,463,040 | 9,661,419 | 31,124,459 | 1067–12,787 |
| Matrix 10 | 21,463,040 | 9,670,316 | 31,133,356 | 1064–25,678 |
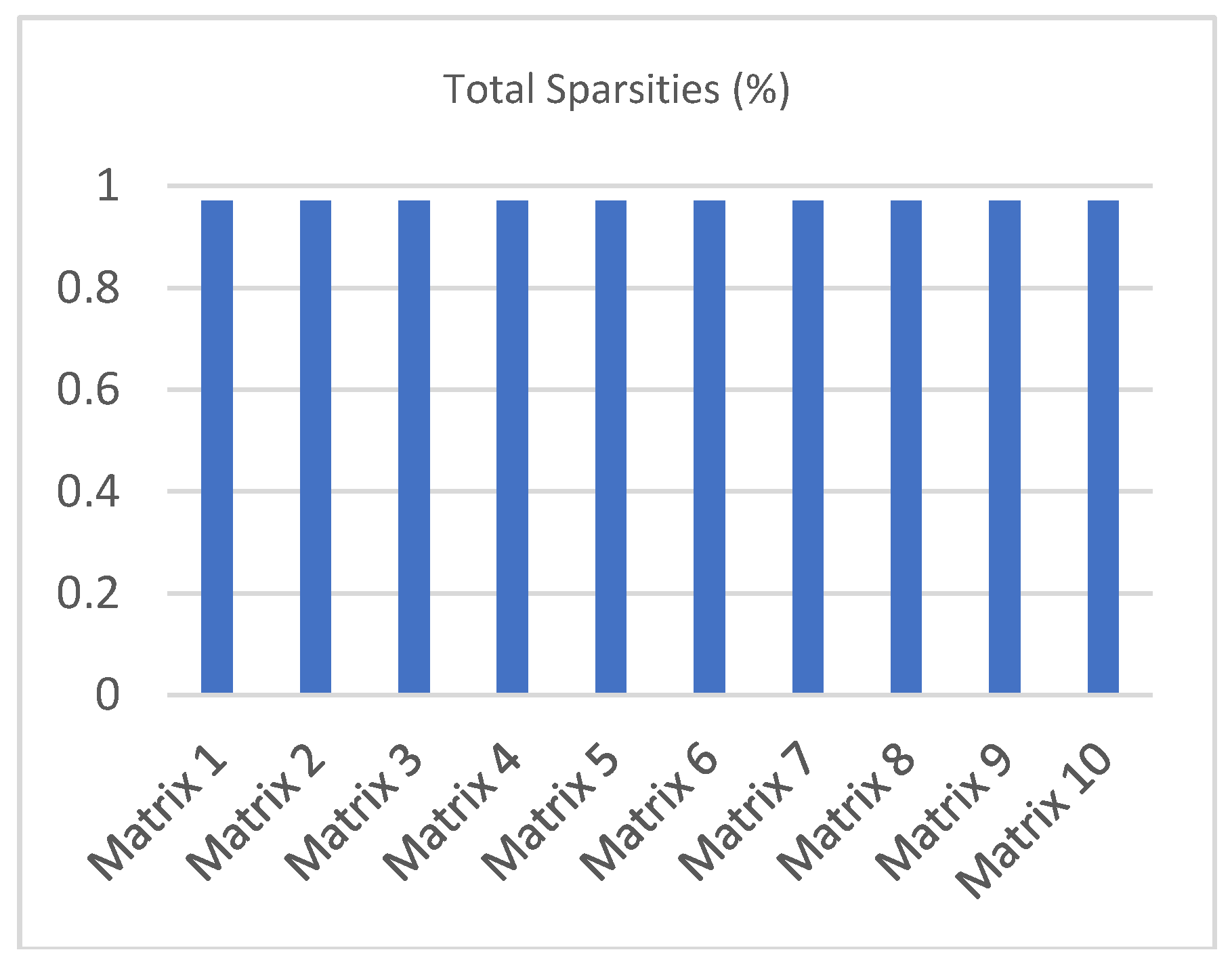
| Ref. Region Spar. (%) | Exp. Space Region Spar. (%) | Total Spar. (%) | |
|---|---|---|---|
| Matrix 1 | 0.800110 | 0.989985 | 0.970997 |
| Matrix 2 | 0.800110 | 0.989990 | 0.971002 |
| Matrix 3 | 0.800110 | 0.989997 | 0.971008 |
| Matrix 4 | 0.800110 | 0.989993 | 0.971005 |
| Matrix 5 | 0.800110 | 0.989994 | 0.971005 |
| Matrix 6 | 0.800110 | 0.989990 | 0.971002 |
| Matrix 7 | 0.800110 | 0.989997 | 0.971008 |
| Matrix 8 | 0.800110 | 0.989993 | 0.971005 |
| Matrix 9 | 0.800110 | 0.990002 | 0.971013 |
| Matrix 10 | 0.800110 | 0.989993 | 0.971005 |
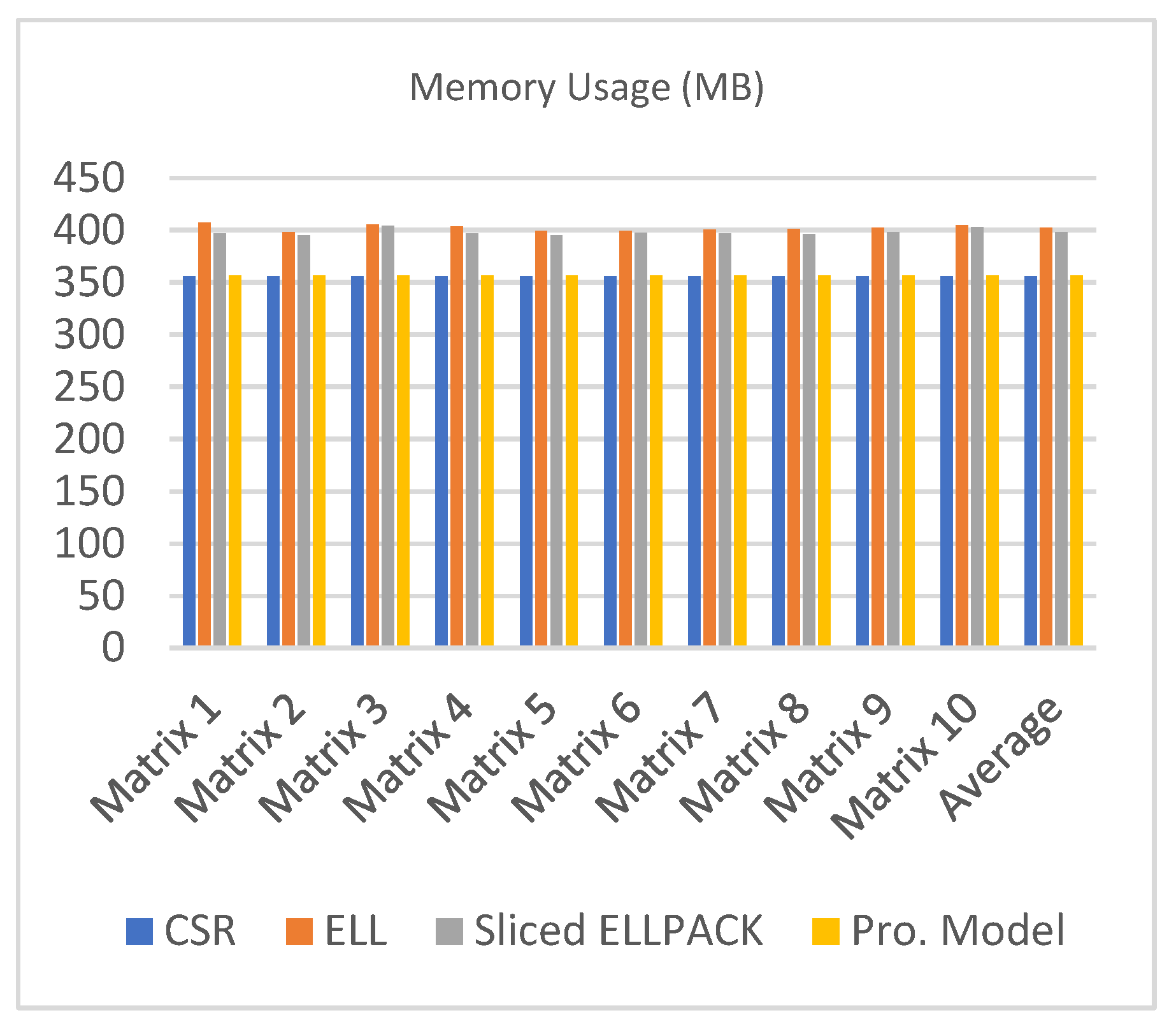
| CSR | ELL | Sliced ELLPACK | Pro. Model | |
|---|---|---|---|---|
| Matrix 1 | 356.44 | 407.25 | 397.13 | 356.76 |
| Matrix 2 | 356.46 | 398.25 | 395.06 | 356.70 |
| Matrix 3 | 356.39 | 405.75 | 404.44 | 356.63 |
| Matrix 4 | 356.49 | 403.88 | 397.03 | 356.67 |
| Matrix 5 | 356.39 | 399.38 | 395.06 | 356.66 |
| Matrix 6 | 356.38 | 399.75 | 397.59 | 356.70 |
| Matrix 7 | 356.45 | 400.88 | 396.94 | 356.63 |
| Matrix 8 | 356.51 | 401.25 | 396.56 | 356.67 |
| Matrix 9 | 356.43 | 402.75 | 398.25 | 356.57 |
| Matrix 10 | 356.44 | 405 | 403.13 | 356.67 |
| Average | 356.44 | 402.41 | 398.12 | 356.67 |
| Block Size | Min | Max | Avg |
|---|---|---|---|
| 16 | 4.8877 ms | 4.8877 ms | 4.8877 ms |
| 16 | 4.8884 ms | 4.8884 ms | 4.8884 ms |
| 16 | 4.8891 ms | 4.8891 ms | 4.8891 ms |
| 16 | 4.8882 ms | 4.8882 ms | 4.8882 ms |
| 16 | 4.8870 ms | 4.8870 ms | 4.8870 ms |
| Average | 4.8881 ms | ||
| Block Size | Min | Max | Avg |
|---|---|---|---|
| 32 | 3.2847 ms | 3.2847 ms | 3.2847 ms |
| 32 | 3.2838 ms | 3.2838 ms | 3.2838 ms |
| 32 | 3.2843 ms | 3.2843 ms | 3.2843 ms |
| 32 | 3.2834 ms | 3.2834 ms | 3.2834 ms |
| 32 | 3.2859 ms | 3.2859 ms | 3.2859 ms |
| Average | 3.2844 ms | ||
| Block Size | Min | Max | Avg |
|---|---|---|---|
| 64 | 3.5451 ms | 3.5451 ms | 3.5451 ms |
| 64 | 3.5424 ms | 3.5424 ms | 3.5424 ms |
| 64 | 3.5437 ms | 3.5437 ms | 3.5437 ms |
| 64 | 3.5410 ms | 3.5410 ms | 3.5410 ms |
| 64 | 3.5448 ms | 3.5448 ms | 3.5448 ms |
| Average | 3.5434 ms | ||
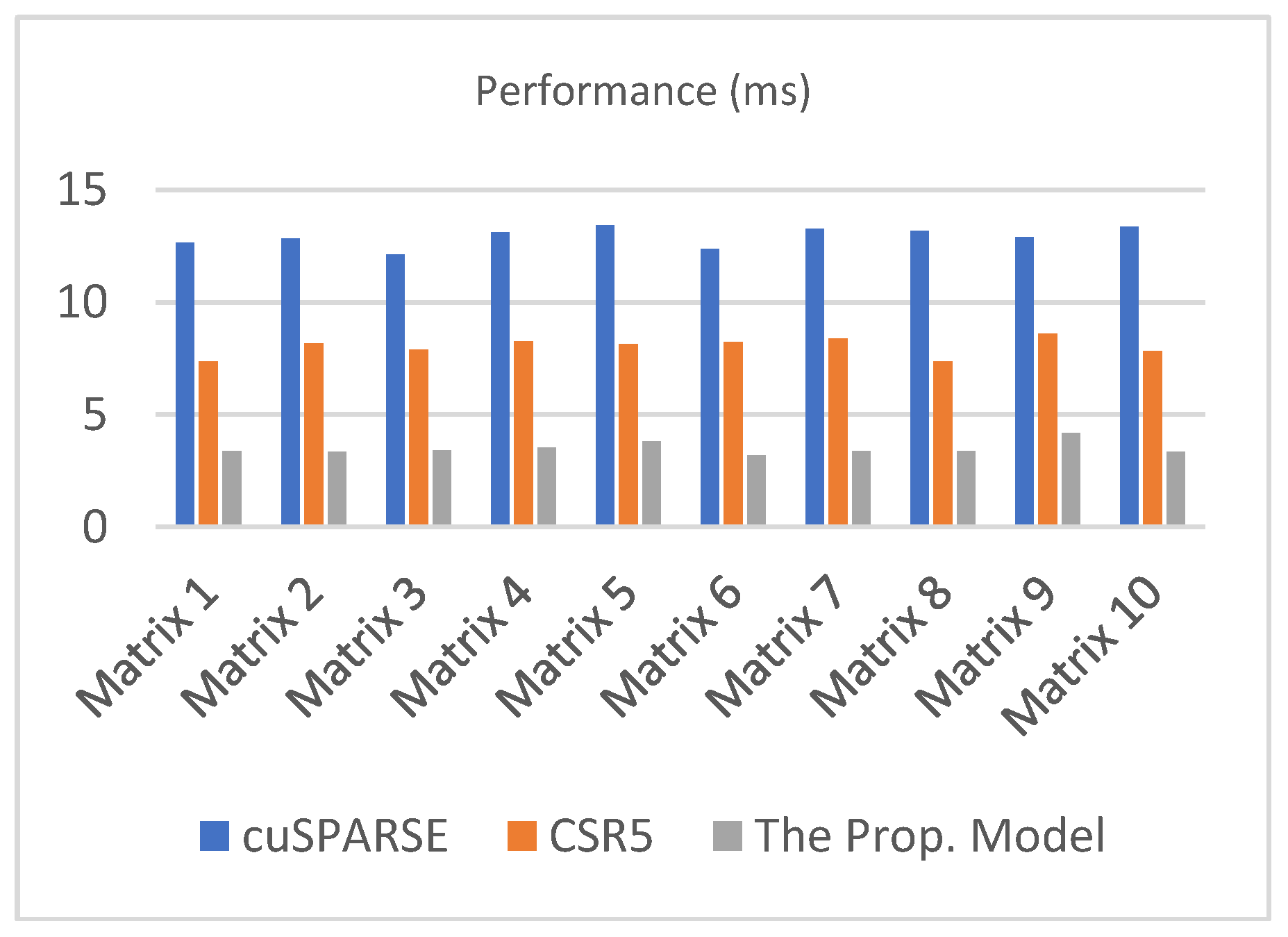
| cuSPARSE | CSR5 | The Prop. Model | |
|---|---|---|---|
| Matrix 1 | 12.6567 | 7.3672 | 3.3661 |
| Matrix 2 | 12.8334 | 8.1694 | 3.3573 |
| Matrix 3 | 12.1227 | 7.8954 | 3.4127 |
| Matrix 4 | 13.1043 | 8.2654 | 3.5434 |
| Matrix 5 | 13.4352 | 8.1489 | 3.8167 |
| Matrix 6 | 12.3672 | 8.2336 | 3.1884 |
| Matrix 7 | 13.2559 | 8.3962 | 3.3655 |
| Matrix 8 | 13.1655 | 7.3672 | 3.3784 |
| Matrix 9 | 12.8985 | 8.5934 | 4.1836 |
| Matrix 10 | 13.3568 | 7.8349 | 3.3471 |
| Average | 12.9196 | 8.0272 | 3.3661 |
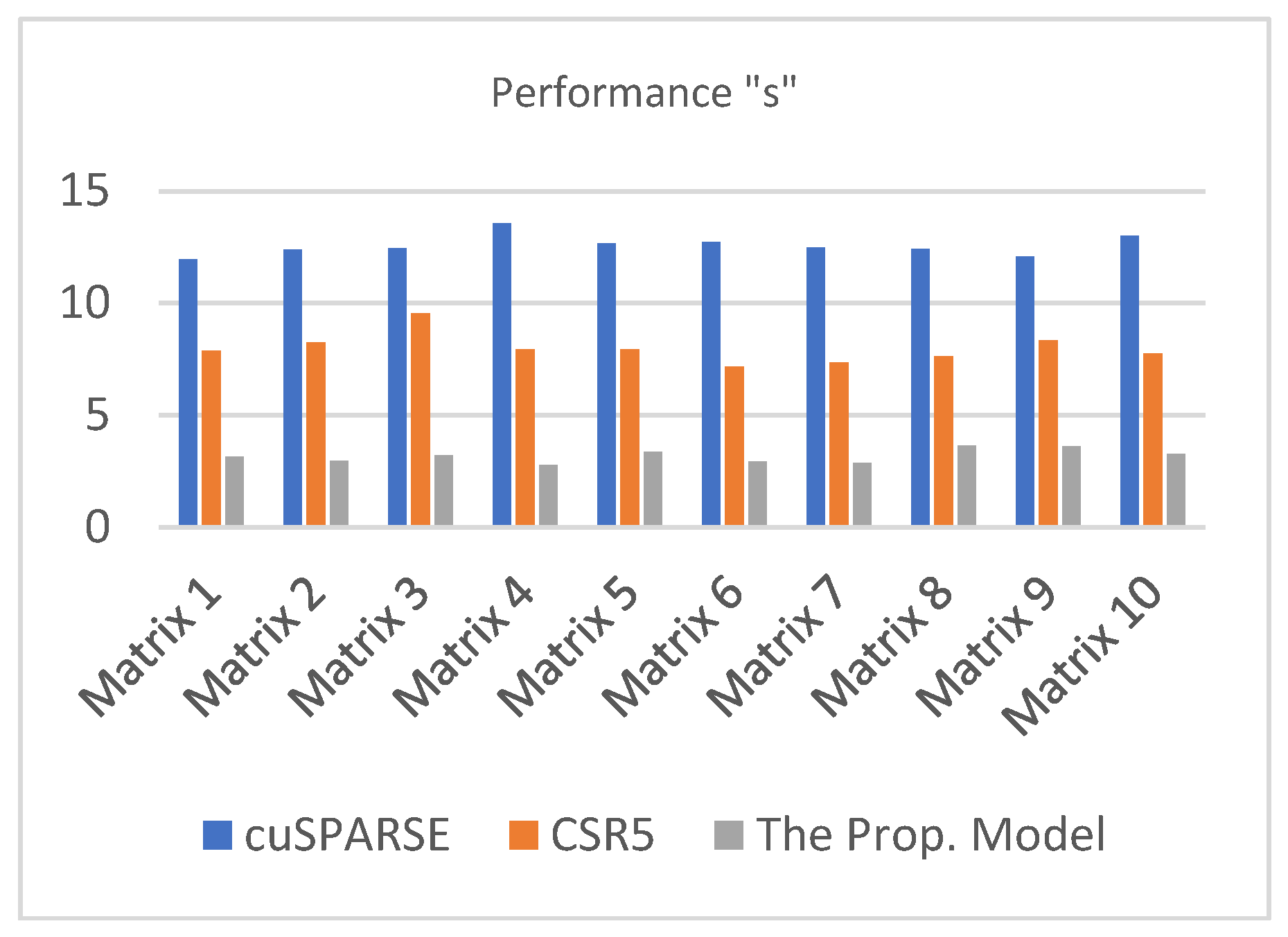
| cuSPARSE | CSR5 | The Prop. Model | |
|---|---|---|---|
| Matrix 1 | 11.9564 | 7.8736 | 3.1583 |
| Matrix 2 | 12.3787 | 8.2376 | 2.9672 |
| Matrix 3 | 12.4513 | 9.5462 | 3.1987 |
| Matrix 4 | 13.5645 | 7.9456 | 2.7761 |
| Matrix 5 | 12.6587 | 7.9348 | 3.3762 |
| Matrix 6 | 12.7457 | 7.1764 | 2.9376 |
| Matrix 7 | 12.4874 | 7.3672 | 2.8729 |
| Matrix 8 | 12.4138 | 7.6327 | 3.6534 |
| Matrix 9 | 12.0845 | 8.3432 | 3.6249 |
| Matrix 10 | 13.0198 | 7.7482 | 3.2653 |
| Average | 12.5761 | 7.9806 | 3.1831 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmoud, M.; Hoffmann, M.; Reza, H. Developing a New Storage Format and a Warp-Based SpMV Kernel for Configuration Interaction Sparse Matrices on the GPU. Computation 2018, 6, 45. https://doi.org/10.3390/computation6030045
Mahmoud M, Hoffmann M, Reza H. Developing a New Storage Format and a Warp-Based SpMV Kernel for Configuration Interaction Sparse Matrices on the GPU. Computation. 2018; 6(3):45. https://doi.org/10.3390/computation6030045
Chicago/Turabian StyleMahmoud, Mohammed, Mark Hoffmann, and Hassan Reza. 2018. "Developing a New Storage Format and a Warp-Based SpMV Kernel for Configuration Interaction Sparse Matrices on the GPU" Computation 6, no. 3: 45. https://doi.org/10.3390/computation6030045
APA StyleMahmoud, M., Hoffmann, M., & Reza, H. (2018). Developing a New Storage Format and a Warp-Based SpMV Kernel for Configuration Interaction Sparse Matrices on the GPU. Computation, 6(3), 45. https://doi.org/10.3390/computation6030045