4.2. Design Philosophy
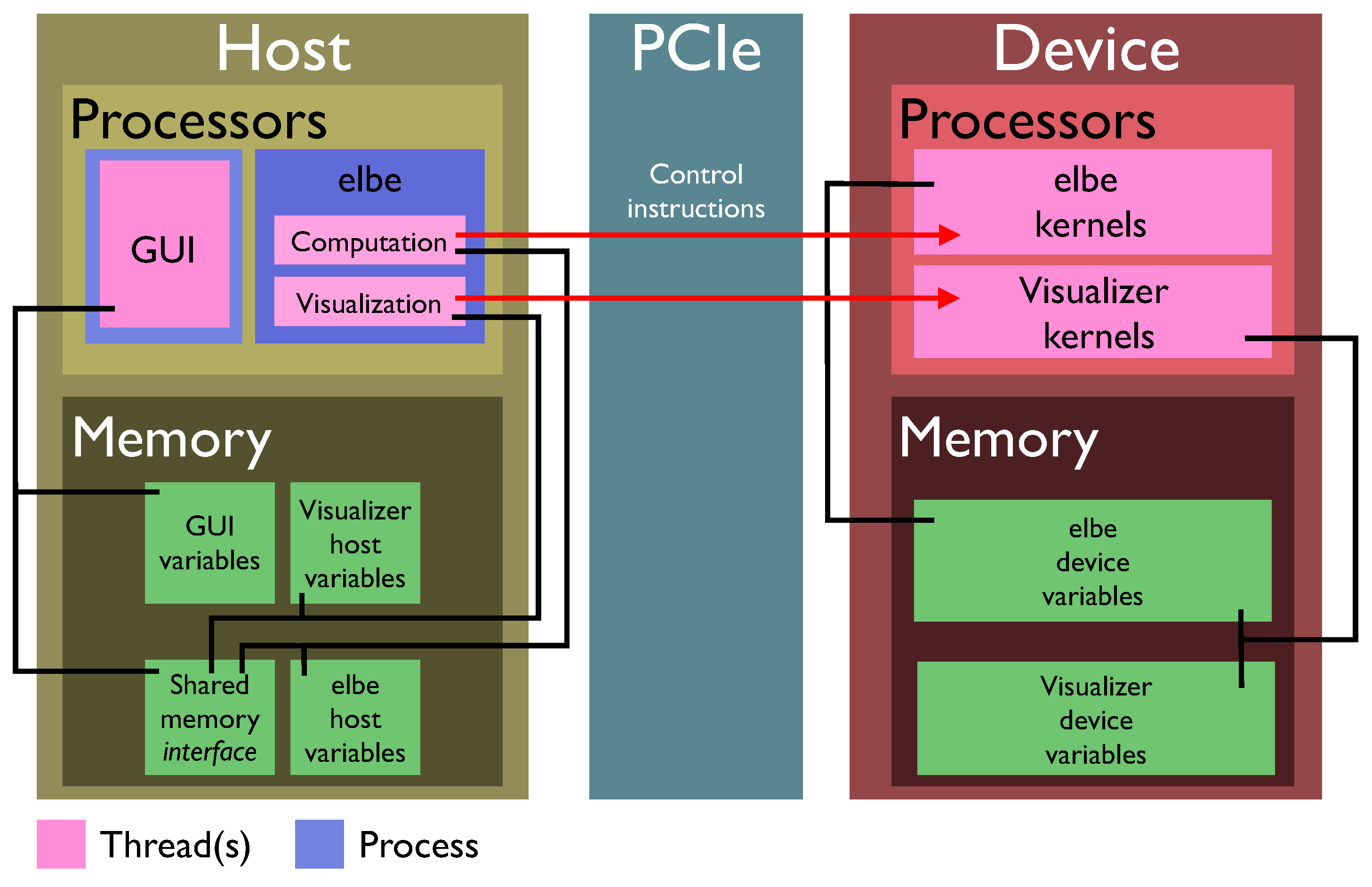
The main concern for the development of an adequate design philosophy was the inherent thread independence of computation and visualization. Generally, depending on the resolution of the simulation, the number of computed time steps per second varies dramatically. For the visualizer, a steady 20 rendered frames per second guarantee responsiveness to user-specified input. The presented design philosophy employs a multi-threaded approach for the instructional loops running on the host processors to control the GPU computation and visualization independently. This allows a constant stream of rendered frames, even under heavy computational load. Assuming that the visualization procedures are executed in an instant, a waiting period of 50 milliseconds results in the targeted 20 frames per second while also guaranteeing a slot in the GPU instruction queue for computational procedures.
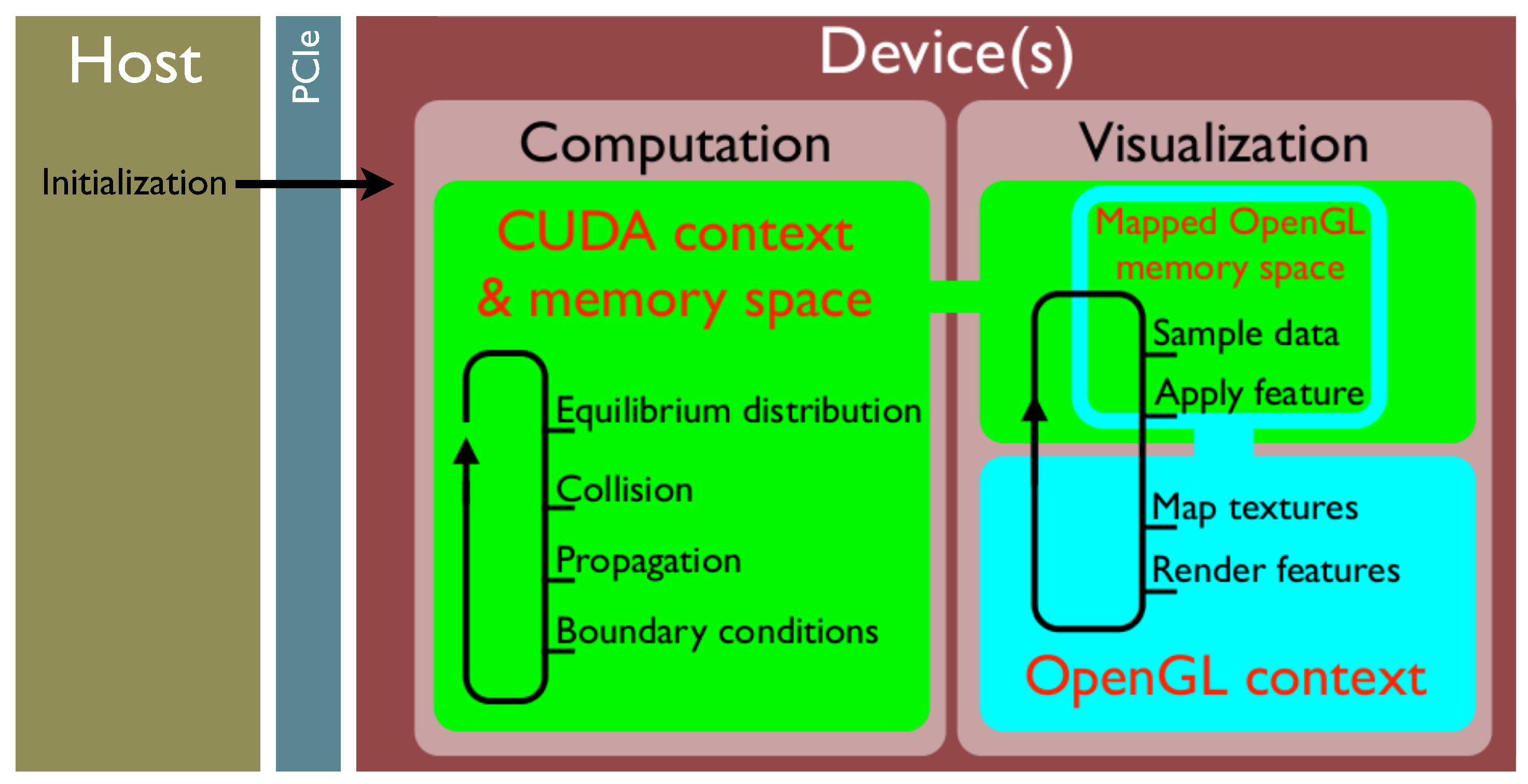
Figure 4.
Outline of the elbevis and graphical user interface instructions and execution, as well as memory handling.
Figure 4.
Outline of the elbevis and graphical user interface instructions and execution, as well as memory handling.
Since the OpenGL buffer objects are mapped to the CUDA memory space, providing the desired pointers, the visualizer can access the computation’s variables at any point in time and render them to the screen in the manner of the applied visualization features. Both computation and visualization are executed in the same
elbevis process, but as independent CPU threads. In order to provide a suitable control environment for the user, a graphical user interface (GUI) has been designed. The GUI is executed as an entirely independent process. To communicate with and instruct the computation/visualization, a shared memory segment is spawned by the
elbevis process upon its start and connected with the GUI on request. The communication interface controls the entirety of the visualizer,
i.e., by enabling the visualizer to toggle in the shared memory segment through the graphical user interface, the visualization thread is initiated. Thus, by turning off the visualizer, all that remains is the computation itself running at full capacity. In this state, the visualizer does not occupy any resources or computation time. Upon request by the GUI, the visualizer thread is spawned and awaits feature instructions read from the shared memory segment.
Figure 4 depicts a schematic overview of the host and device processes/threads and memory organization.
4.2.1. OpenGL-CUDA Interoperability
To explore OpenGL’s capability of rendering data directly from device memory, a buffer object has to be created, registered as a resource with CUDA and mapped to the CUDA address space. A pointer to the mapped buffer can then be used in CUDA kernels to read, write and modify the device data. The mapped OpenGL memory space can be thought of as a pointer that appears to the CUDA context as pointing to a CUDA address, but is actually tunneling to the OpenGL context in which it resides. A buffer object library has been designed in an effort to simplify the extensive use of buffer objects for OpenGL ↔ CUDA interoperability.
Listing 1 provides a basic example of its use.
Listing 1: Basic example of the use of the buffer object library.
1
2
3 main() {
4
5 setup();
6
7 BufferObject *vbo = BufferObject (GL_ARRAY_BUFFER, nElements);
8
9 *dev_ptr = (*) vbo->getDevicePointer();
10
11 cudaKernel<<<blocks, threads>>>(dev_ptr);
12
13 vbo->doneWithDevicePointer();
14
15 vbo->bind();
16
17 drawWithOpenGL();
18
19 vbo->unbind();
20
21 0;
22 }
4.2.2. CPU Multithreading
To decouple visualization and computation, they are executed in two separate threads. The portable operating system interface for UNIX (POSIX) threads, or pthreads, are used to realize the multi-threaded design. The traditional main loop is replaced by a pthread call to start the computation’s main loop in a separate thread. Subsequently, the so-called communicator loop is started, awaiting instructions from the control interface to initiate the visualizer thread. The SDLhandler and Visualizer objects are local variables of the visualizer thread and are allocated and deallocated with the thread’s initiation and termination, respectively. Pthreads’ built-in join functionality is used to guarantee controlled termination of all threads. POSIX is fully portable to the MAC OS X environment, but has very limited portability to Microsoft Windows. An alternative thread management library will have to be utilized to obtain major cross-platform compatibility in future elbevis versions.
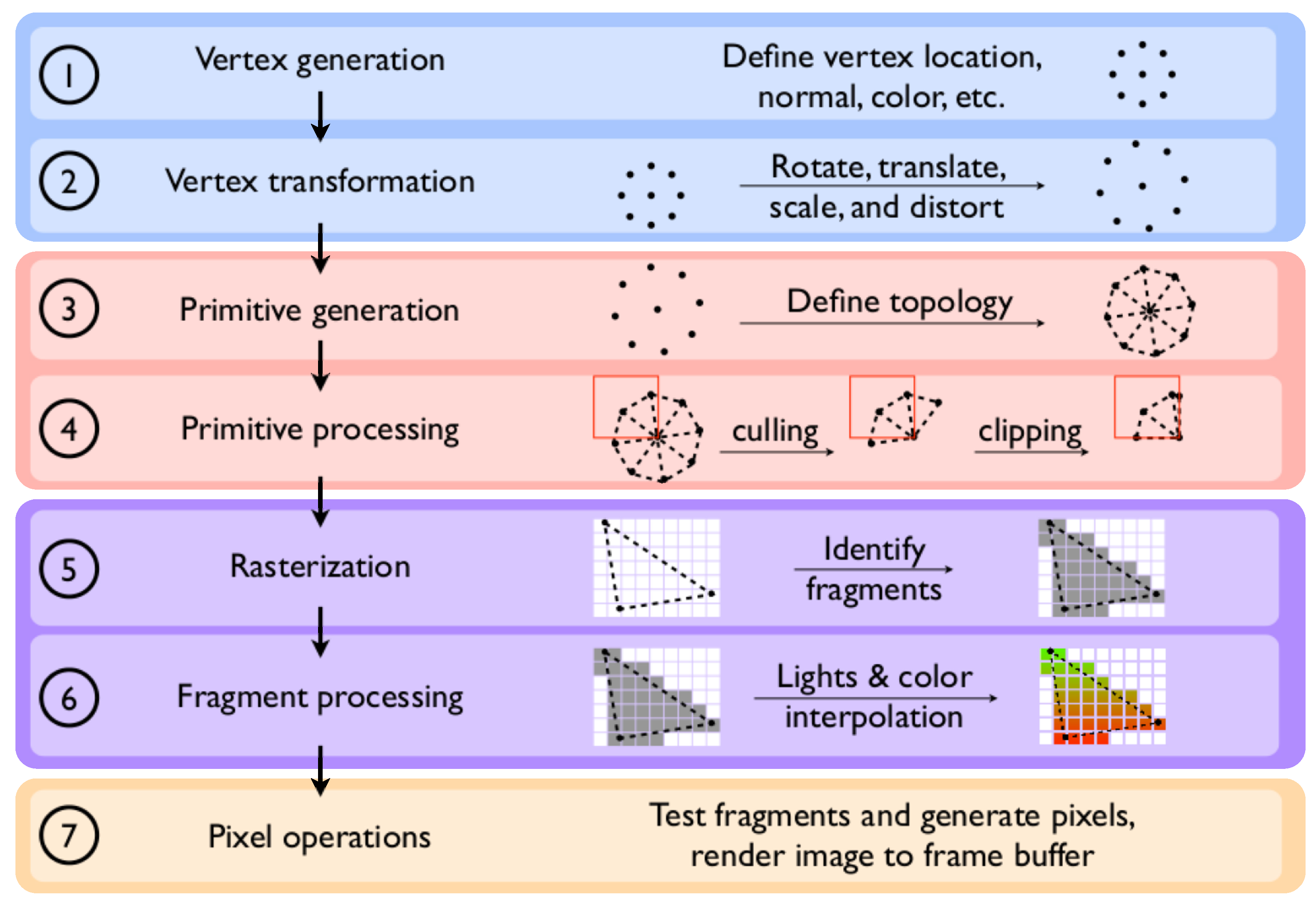
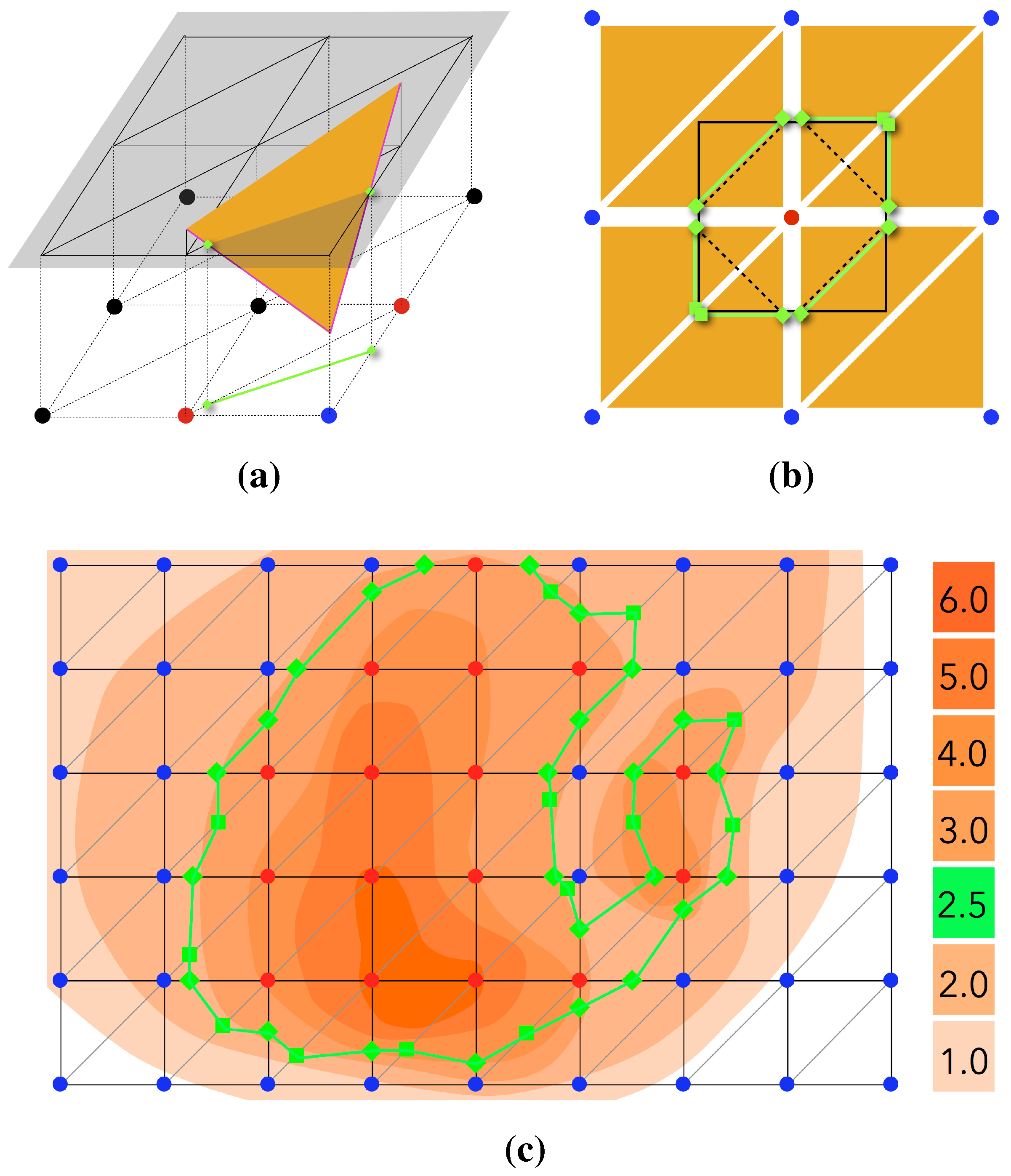
4.3. Data Handling and the Sampling Methodology
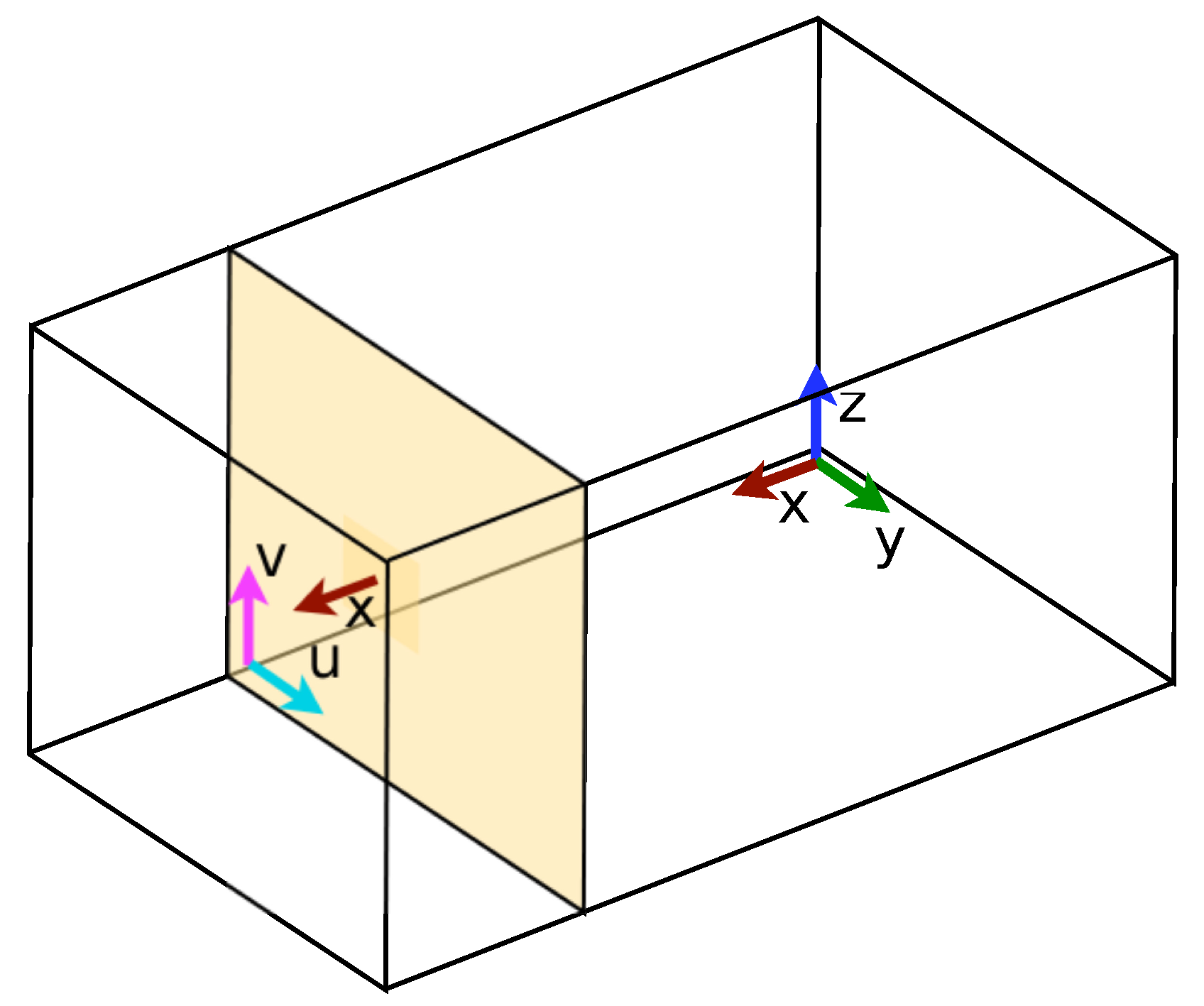
The visualization in the discussed project is based on a sampling method. From the multitude of data available from the computation, a subset is copied to a mapped buffer object. The sampled data can either be written to a texture and then rendered as a quad primitive’s surface or be further processed with CUDA visualization routines before the rendering steps.
Figure 5 depicts the computation and visualization loops and summarizes the mapping and rendering routines.
Figure 5.
A schematic view of the OpenGL rendering process incorporated into the lattice Boltzmann implementation.
Figure 5.
A schematic view of the OpenGL rendering process incorporated into the lattice Boltzmann implementation.
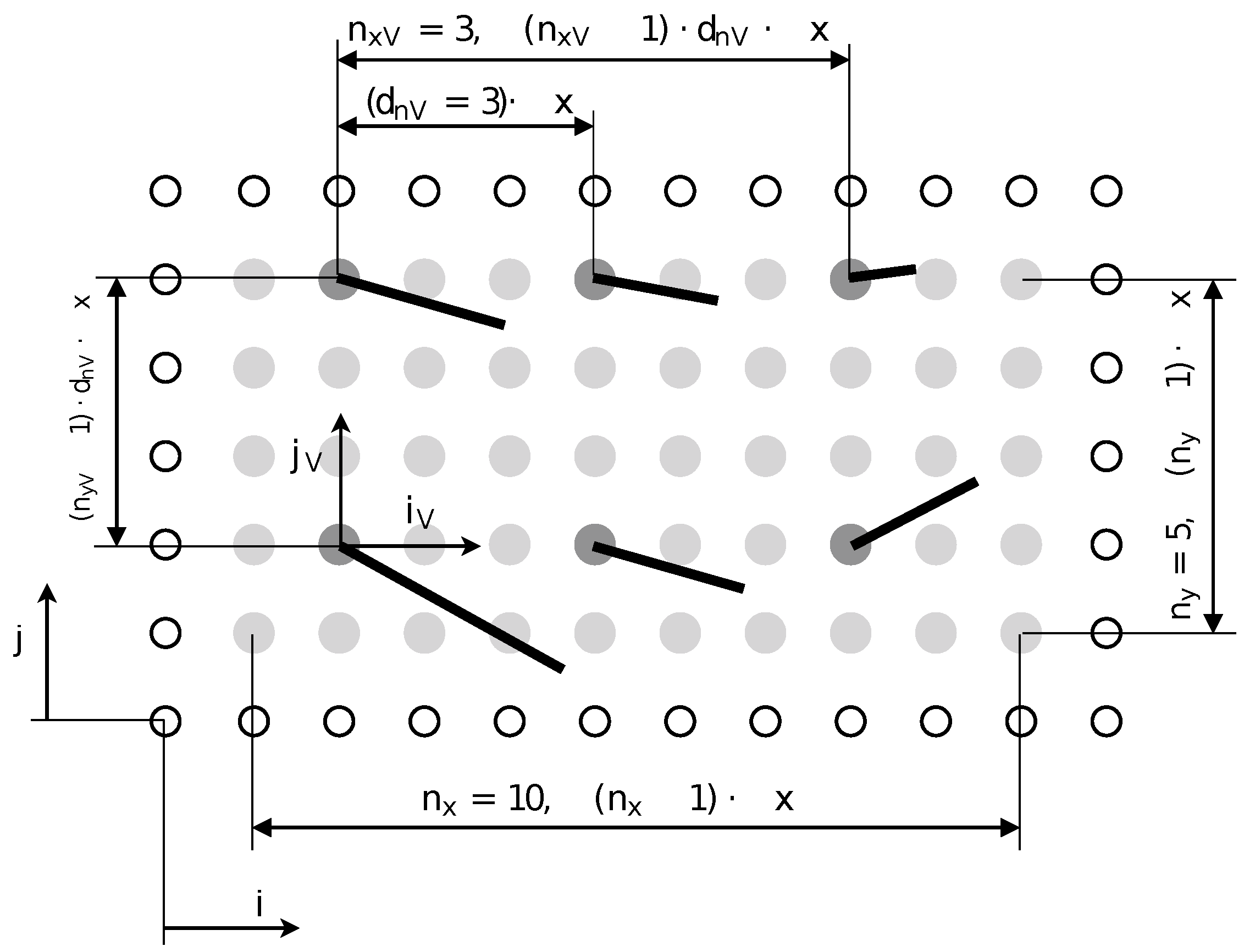
elbe does not support multi-GPU runs in a cluster environment yet. However, as a reference for future work, potential extensions of the proposed visualizer concept and sampling methodology to massively parallel simulations will be briefly discussed here. The primary driver to execute GPU accelerated code on clusters is the very limited amount of on-device DRAM memory, making it necessary to divide the domain of larger simulations into sub-domains, referred to as patches, and to assign these sub-domains to separate GPUs. A GPU cluster consists of two or more graphics devices and one or more hosts . The communication speed between the devices depends on the provided data bus. The data transfer between the hosts is considerably slower than between the devices that share the same host environment, i.e., identical i index. Thus, data transfer limitations greatly incline, and the data transfer has to be limited the more indirect it is with regards to the device.
Real-time visualization on GPU clusters faces several challenges because of the data transfer and memory limitations. If the computation’s data are so large that they do not fit on one device, it is very likely that the data necessary for image processing also exceed the memory limit of the dedicated OpenGL device , i.e., the device with a monitor attached to it. Three alternative visualization approaches are presented and compared to handle the imposed limitations. The approaches are distinguished as dedicated and flexible device methods. For the dedicated device approach, has fixed i and j indices, i.e., the monitor is always connected to the same device. This approach category is most suitable for single host GPU machines. The patch stitching method and the down sampling method are categorized as dedicated device approaches. An example for a flexible device approach where the i and j indices are changing is the patch visiting method.
The visualization work flow involves three essential steps: data sampling, the construction of visualizer features (like isolines) and the rendering of the feature. Depending on the applied visualization method, these steps are performed on one device (the dedicated OpenGL device ) or split up and executed on separate devices.
The patch stitching method is a dedicated device approach. The unique dedicated OpenGL device sequentially samples the data by accessing all computing devices (one at a time) and copying the relevant data subset to a mapped OpenGL vertex or pixel buffer object that is allocated on . It then constructs the visualizer feature for the sampled data and renders the result to the OpenGL device’s frame buffer. This procedure is repeated for each computing device’s data subset. According to the patch’s spatial location, the frame buffer is stitched together. Providing OpenGL pixel and vertex buffer objects for one computing device at a time reduces the memory requirements according to the total number of computing devices. The size of the frame buffer depends on the screen’s resolution and is therefore independent of the cluster size. The reasons for the application of a patch stitching method are the detailed feature construction and the strictly limited memory requirement. The downsides of the stitching method are the significant data transfer because the complete data subset scales with the domain size, the time lag that results while the data is copied and the feature’s patch independence requirement. The time lag is especially considerable if all stitches are supposed to be sampled at the same time step to avoid discontinuities at the reproduced patch borders. The patch independence requirement addresses the feature’s parallelization suitability. Entirely parallelized features, e.g., slice, isolines or vectors, are patch independent and can be constructed for a patch at a time; whereas features integrated in time or space, e.g., streamlines and streaklines, rely on patch communication and are therefore not suitable for a sequential rendering technique like the patch stitching method.
The down sampling method provides a mapped pixel and vertex buffer object of a prescribed size, independent of the domain size (as long as it does not exceed the domain size, in which case an up sampling method would have to be utilized). In accordance to the allocated memory for the buffer objects, a coarse subset of the relevant data subset is sampled from the computing devices, e.g., every fifth node value of a slice is copied to the vertex buffer object. After all of the data are assembled in the buffer objects, the visualizer feature is constructed and rendered to the frame buffer. Sampling all necessary data first and then performing the feature construction for the entire dataset makes this method suitable for all visualizer features. Adjusting the sampling density also changes the time needed for data copying. Therefore, the method is highly adaptable, and scenarios of variable sampling density are possible. For instance, consider a cluster computation of three computing devices and one dedicated OpenGL device. For most of the computation’s simulation time, the sampling density is extremely low, slowing down the main computation by a negligible amount. Upon the user’s request, e.g., holding the mouse button down, the sampling density is increased (almost stalling the main computation), and a high resolution image of the computation is rendered to the screen. With this method, the computation can be controlled throughout the entire simulation while providing detailed information whenever needed.
Patch visiting. The flexible device approach eliminates intra-device and intra-host communication entirely. All devices are computing devices with some memory to spare for visualization. The visualizer is started at the device in question and processes only the local data patch. The image rendered to the screen only visualizes the one patch’s variable field in full resolution. An obvious disadvantage of the patch visiting method is that information is limited to the device with the attached monitor. This method might be considered if a specific region of the domain is of special importance to the user. Consider the simulation of a ship where the pressure distribution on the bulbous bow (possibly limited to only a tenth of the entire domain) is significant for its dynamic shape optimization. In such a case, the visualization can be performed at full resolution and without any costly data transfers.
To conclude, real-time visualization on GPU clusters has to be constrained by either scope or resolution to avoid time-intensive data transfers. This is the case for the down sampling and the patch visiting approaches. The down sampling method should be preferred for cases where the entire domain is of importance, and the patch visiting method is ideal for cases where only a sub-domain is to be visualized. If the time aspect and high update rates are not important, the high resolution patch stitching method can be utilized to generate high resolution images of the entire domain. For now, elbe and elbevis only support simulations in a shared-memory multi-GPU environment with up to four GPUs and support the first preliminary implementations of the down sampling and patch visiting method. However, as multi-GPU simulations are beyond the scope of this work, this is not further investigated here.
4.4. Graphical User Interface
For the graphical user interface, the GTK+toolkit has been used, wrapped for C++ compatibility by the
gtkmm extension package [
32]. Two of the main reasons that lead to the decision of using the GTK+ environment over other GUI development APIs are the (1) unrestricted and comparatively easy portability to other platforms and (2) relative ease of use with the Glade GUI builder.
The layout of the GUI is divided into two main parts. The first is a general controls section applicable to overarching control and visualization features. These include, e.g., the start/stop functionality of the visualizer, displaying computational parameters (time step, grid size, viscosity,
etc.) or pausing the computation. The second part regards the specific visualization features that will be discussed elaborately in
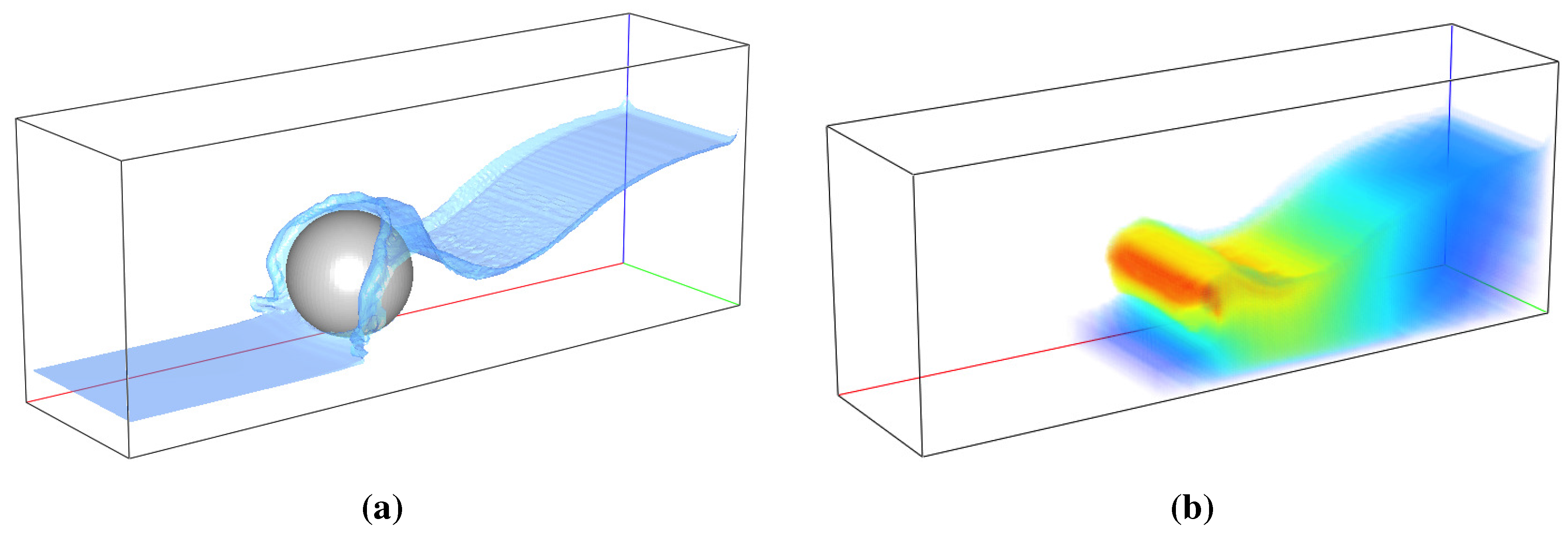
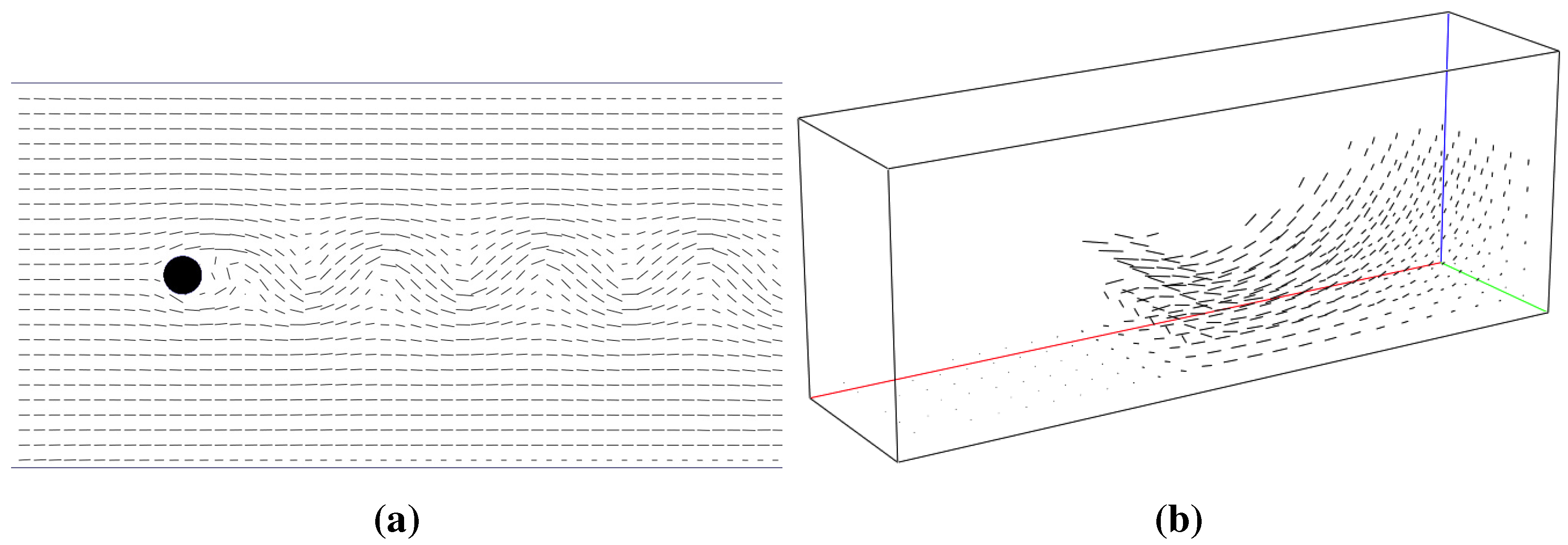
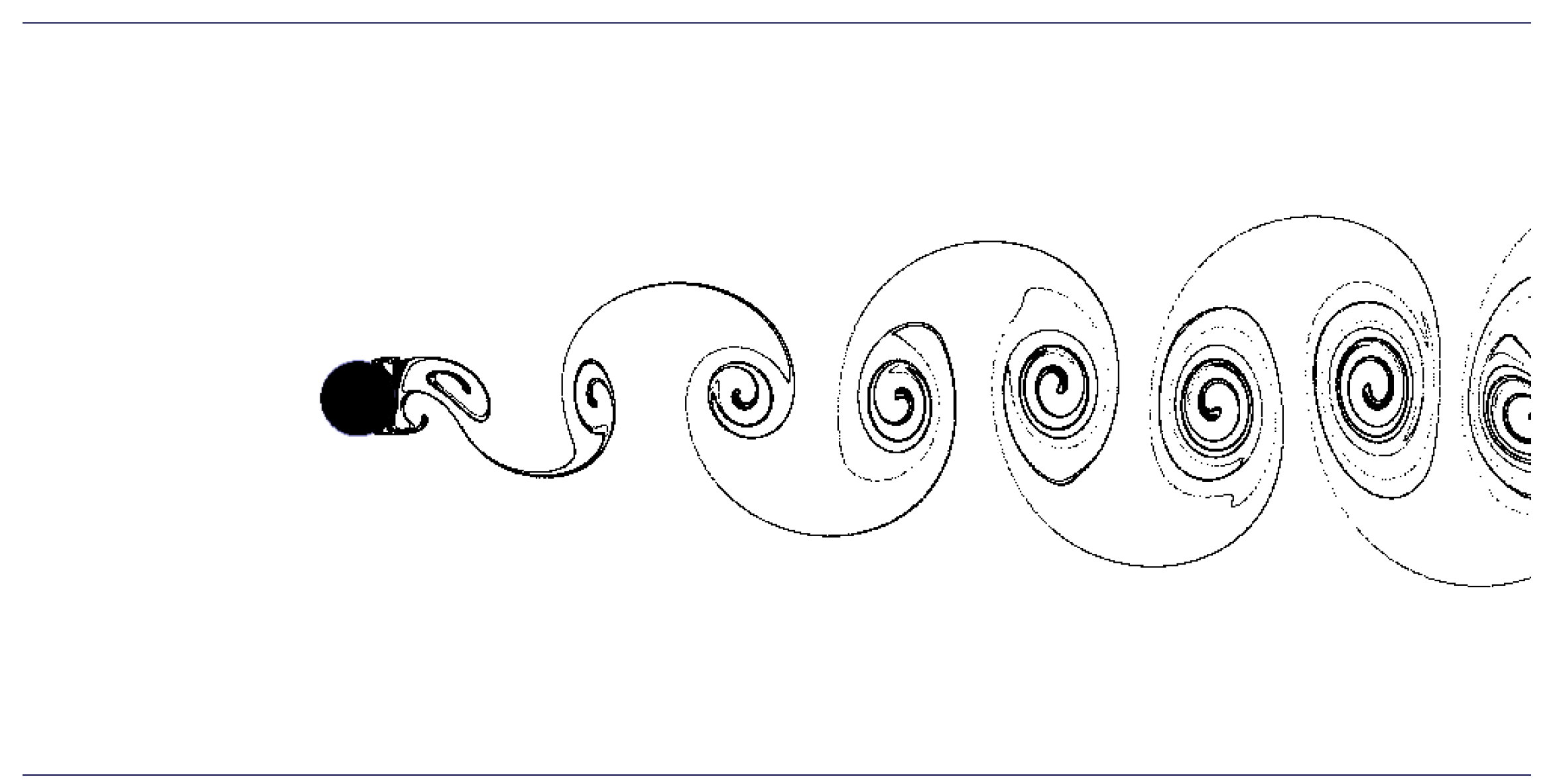
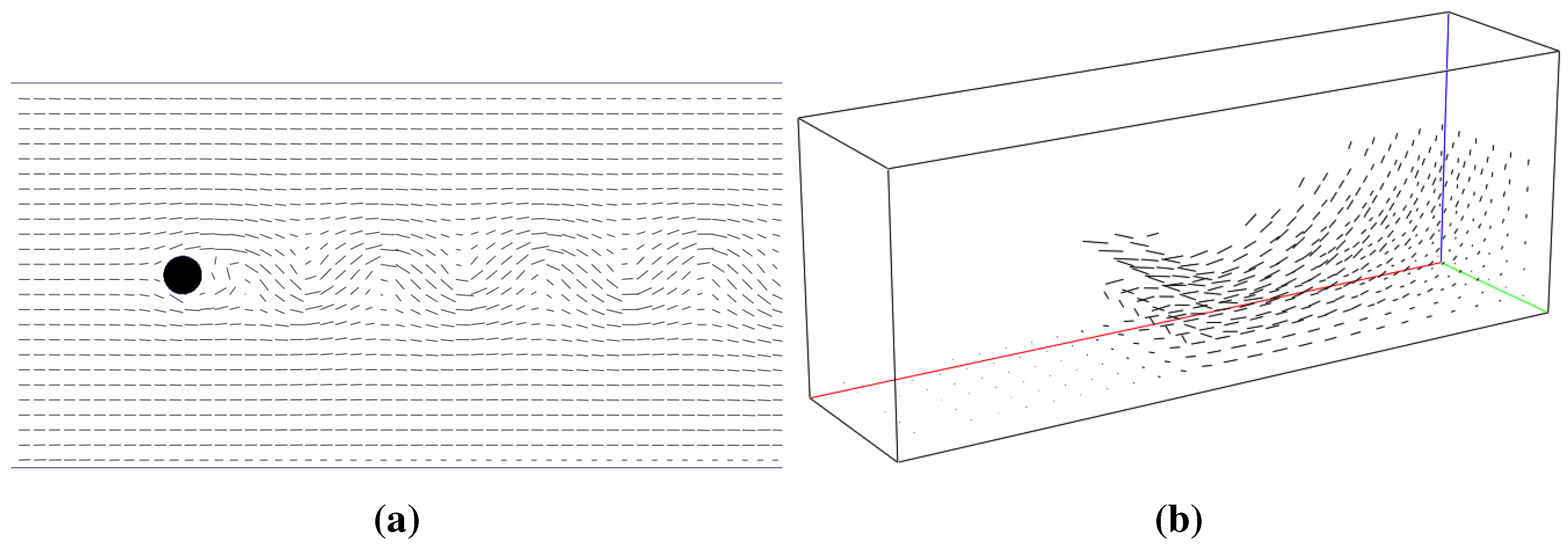
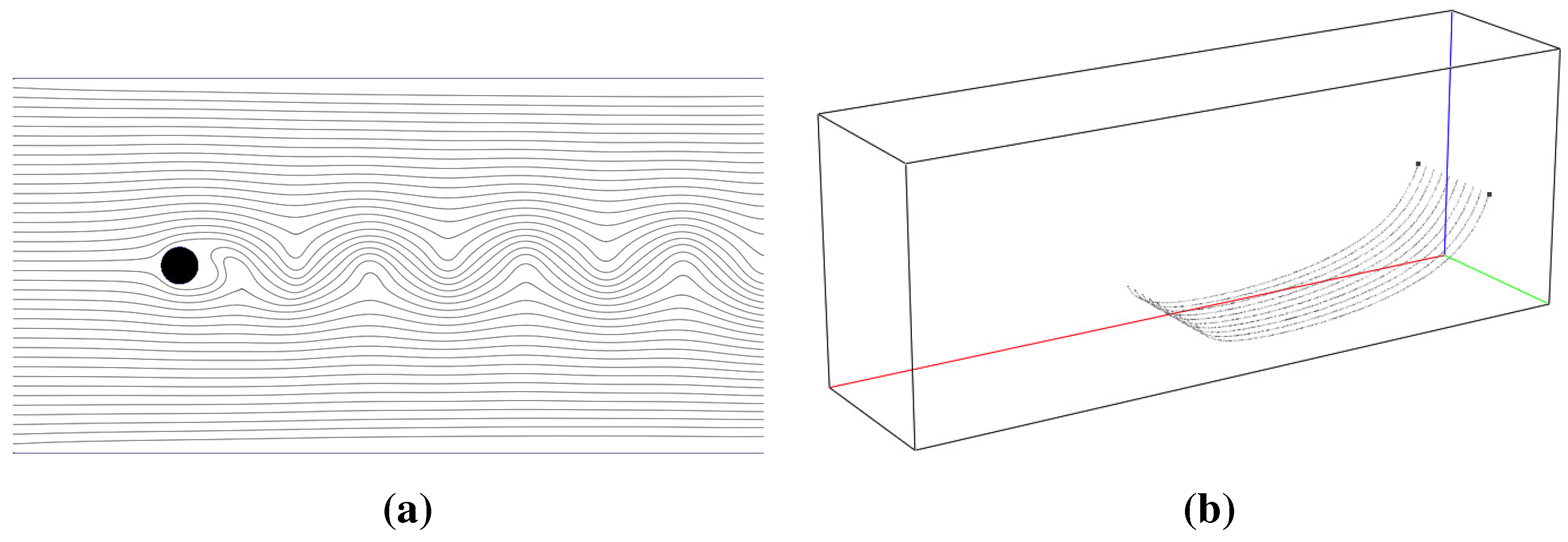
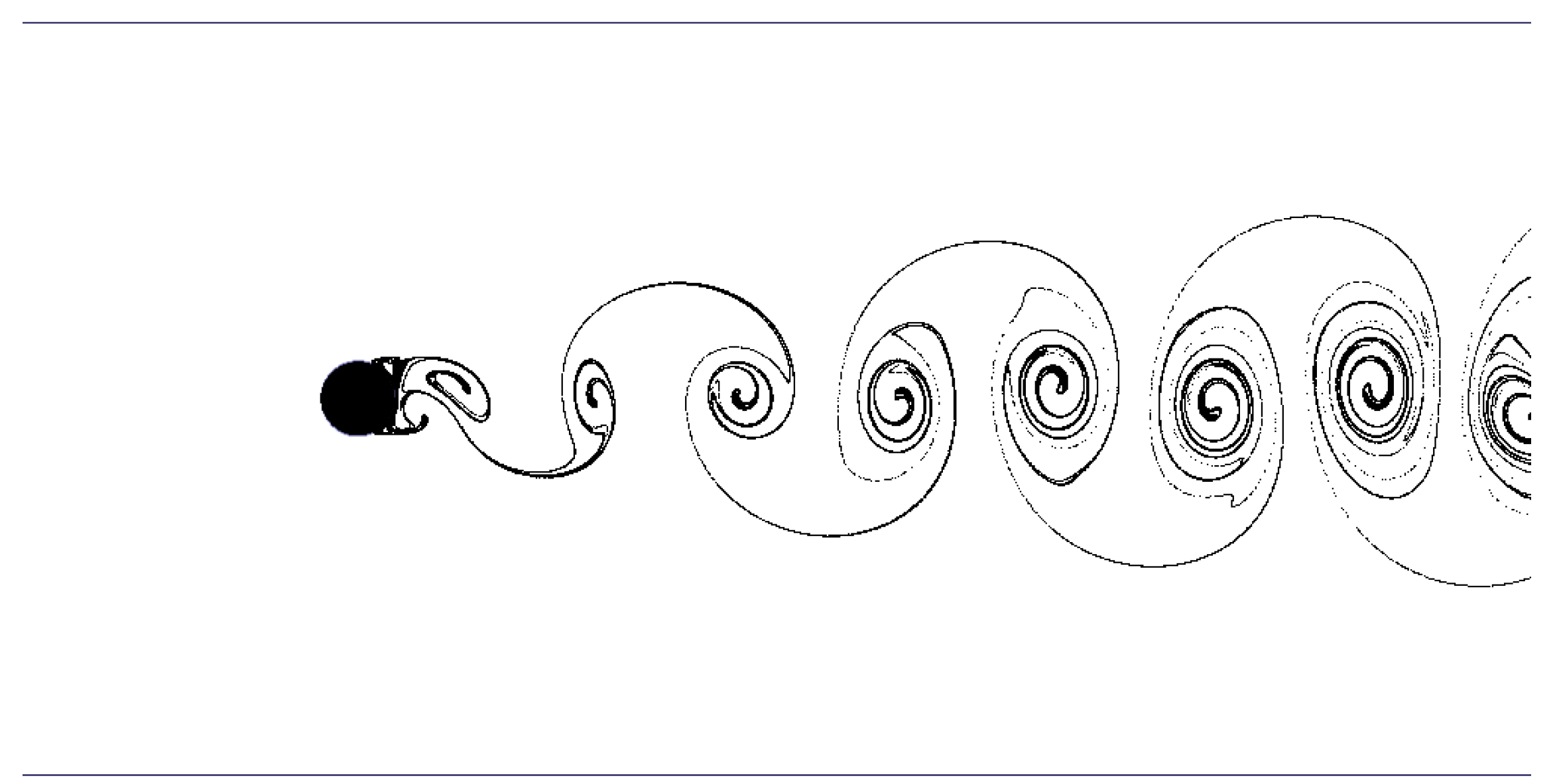
Section 5. The specific features are activated by an on/off toggle button. Upon turning on/off a specific feature, the necessary memory allocation/deallocation is requested by setting the corresponding flag in the shared memory segment. The GTK+ GUI environment allows dynamic reorganization of selectable tree variables. Such variables are used to specify to which of the available and suitable variables the specific visualization feature should be applied. For example, consider the isosurface feature. Variables suitable for isosurface construction are inherently scalar variables or scalars derived from higher order variable fields. This includes such inherently scalar quantities as density or pressure and derived quantities like the velocity magnitude. Since some visualizer features can only be applied to either scalar or vector quantities, different selectable variable trees have to be built for each unique feature.
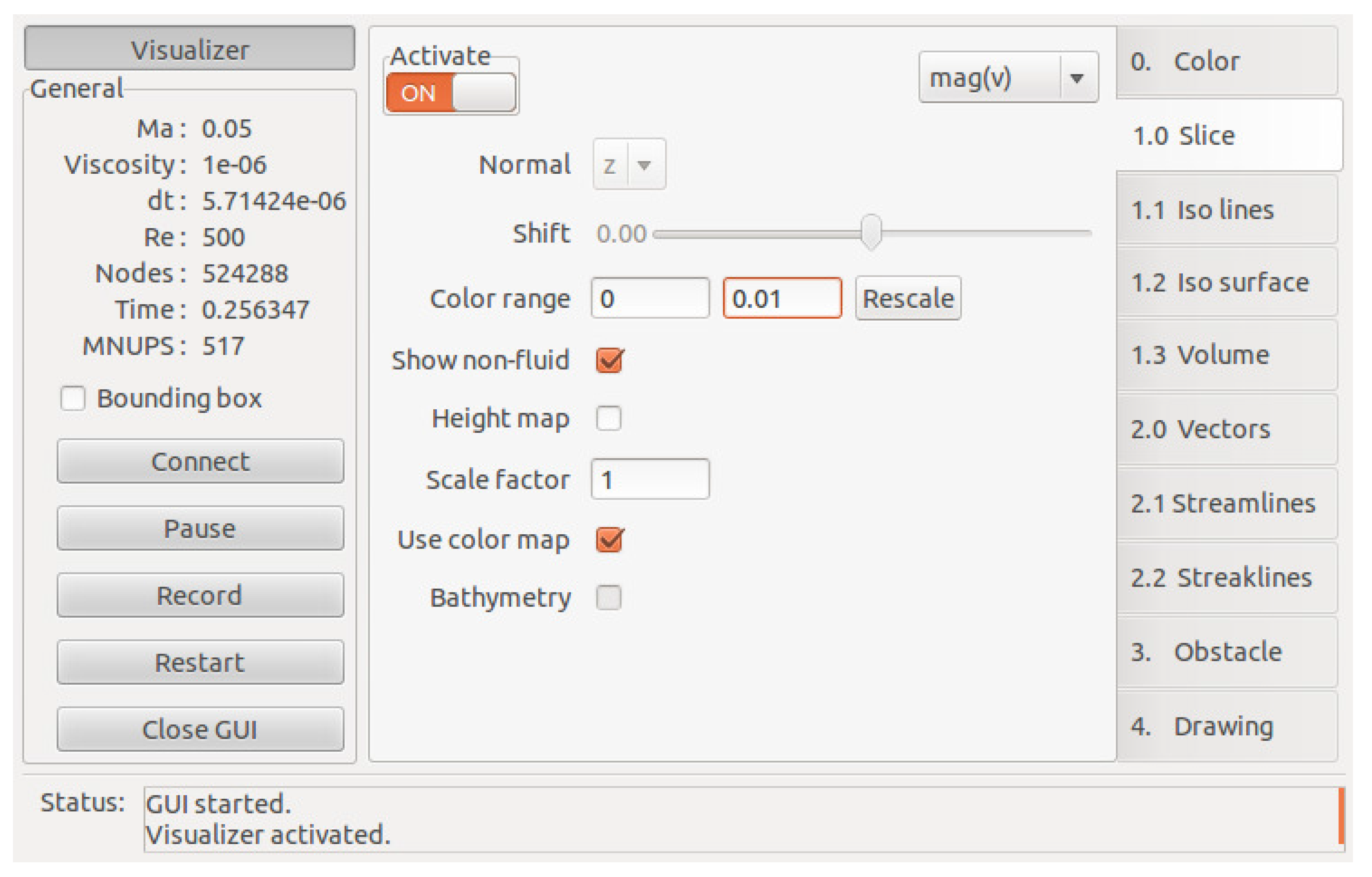
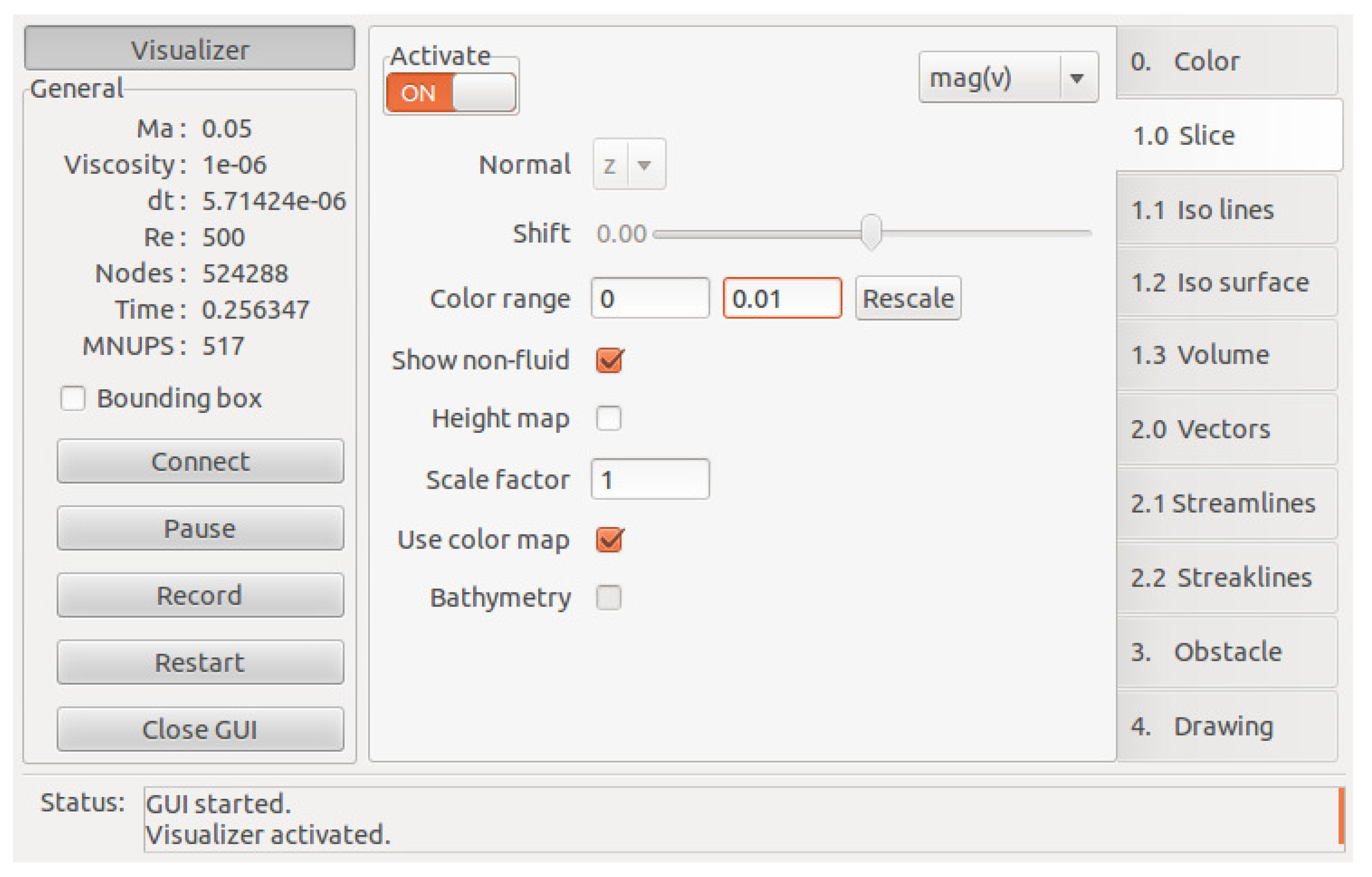
Figure 6 shows the graphical user interface of
elbevis with the active slice page.
Figure 6.
Graphical user interface of the elbevis real-time visualization tool.
Figure 6.
Graphical user interface of the elbevis real-time visualization tool.
4.4.1. Shared Host Memory Control Interface
As stated above, the graphical user interface is not part of the main computational process, thus not having any information about the computation’s variables readily available. The GUI had to be designed in such a way that it can be used for various simulations with a varying set of variables. To this end, basic variable information, like variable symbol (e.g., p for pressure), name, precision (integer, single precision, double precision) and kind (specifying scalar/vector), is stored in the shared memory segment and then used by the GUI to derive the selectable tree structures for each feature. The desired variable for the considered feature is chosen by means of a combo box from the variables available in the tree structure.
The cross-platform compatible boost inter-process library is used to generate, manage and access a shared memory segment in which the control interface is stored. The control interface collects all information necessary for communication between the graphical user interface process and the elbevis process. In the interface, entire variables are stored as opposed to storing pointers to variables, because each process has its own address space. Once a computation is started, a shared memory segment is created. The GUI can then be used to connect to the control interface and change the stored variables according to the user’s input.
The control interface is structured in a simulation and a visualization part. The simulation part stores information like the node number, the origin coordinates or the current simulation time. The visualization part is much more extensive and contains all of the features’ control variables, e.g., flags to activate/deactivate the feature, numeric values for parameters, like the iso value for isosurfaces or lines or each feature’s selected variable ID. The main computation’s field variables are enumerated and can be specified by the variable ID. The control interface’s structure allows easy access to control parameters.
The code snippet in
Listing 2 creates a variable pointer and the control interface and accesses the interface to set the number of nodes in the
x direction and the number of isolines.
Listing 2: Example of how to configure the interface.
1
2
3 Variable velocity (VECTOR, );
4
5
6 velocity.data0D = (*) xVelocityDevicePtr;
7 velocity.data1D = (*) yVelocityDevicePtr;
8 velocity.data2D = (*) zVelocityDevicePtr;
9
10
11 Variable *variablesPtr [1] = &velocity;
12
13
14
15 Interface interface(variablesPtr, numVariables);
16
17
18 interface->sim.nx = numNodesInX;
19 interface->vis.isoLinesNumber = 10;
4.5. User Interaction
User interaction is essential for the generality of the developed real-time visualization tool. A number of different applications require very different analysis tools, point of views and dynamic rearrangement of the applied features. This sort of user interaction is considered interaction with the visualization and is further discussed in
Section 4.5.1. Another kind of user interaction is the direct control of the computation itself,
i.e., changing the actual simulation behavior according to real-time user input; this will be discussed in
Section 4.5.2.
4.5.1. Interactive Monitoring
The most obvious tool for control and interaction with the visualization is the graphical user interface explained in
Section 4.4,
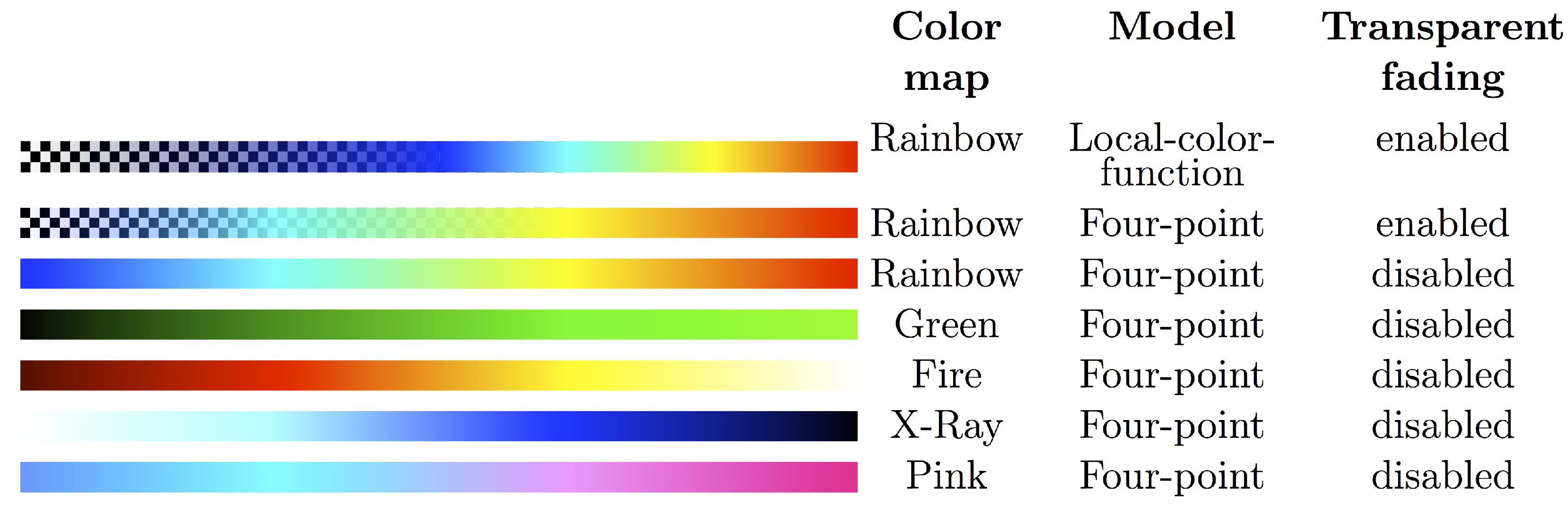
i.e., dynamically changing a slice position, isosurface value, color map,
etc. Additional relevant interaction is realized by mouse or keyboard input. The presented implementation uses the Simple DirectMedia Layer (SDL) development library for low level access to not only the mouse and keyboard, but also the OpenGL setup. The SDL library has been chosen because of its cross-platform compatibility (supporting Windows, MAC OS X and Linux, among others), extended user input device access, and current widespread use and support. Opposed to the OpenGL Utility Toolkit (GLUT) as one of the most widespread alternatives, the SDL framework supports multi-threading and, most importantly for the developed visualizer, is not constrained to a main rendering loop, but can be executed on request. In
elbevis, all SDL functionality is encapsulated in the
SDLHandler library.
Examples for mouse input are panning, orbiting and zooming functionality within the rendered window. Keyboard inputs are used to switch between perspective and parallel projection. By pressing the x, y and z key, the view is aligned along the corresponding axes and parallel projection is activated. Pressing the key again restores the perspective projection and adjusts the zoom factor to fit the viewing spectrum that was obtained through parallel projection.
Scrolling the mouse wheel changes the applied zoom factor. A zooming effect can be acquired by either changing the distance to the shown object or by adjusting the viewing angle. Here, the latter is used. The OpenGL camera system corresponds to a right-handed coordinate system where the view direction is oriented along the z axis, x to the right, and y defines the up direction. Accordingly, the field of view can be defined by an opening angle in the plane. Scrolling the mouse wheel affects the opening angle and updates the perspective projection. By definition of a characteristic angle, the zooming behavior is non-linear for constant angle increments. Thus, for very low viewing angles, the increment is significantly reduced.
Panning and orbiting the displayed scene is implemented by transforming the desired panning vector and the current viewing normal, respectively. The window system has its origin in the upper left-hand corner with the window x-axis pointing to the right and the window y-axis pointing down. The desired window-pan has to be transformed to the simulation’s coordinate system through multiplication with the inverse of the model view matrix’s rotational part (), i.e., . For rotation, the window’s x- and y-axes are transformed to the simulation’s coordinate system with the same procedure, and the entire scene is rotated in two successive rotations around the obtained axes.
4.5.2. Interactive Steering
One of the interactive steering features implemented in elbevis is a drawing feature that can be activated for two-dimensional simulations. It allows the user to draw and remove no-slip walls in the fluid domain using the mouse cursor. This feature is representative for the interaction possibilities that lie within reach. Currently, further interaction with the computation is limited to stalling the simulation with the GUI’s pause button for detailed investigation of a given moment in time. Future interaction features could include drawing in 3D, mouse-controlled movement of objects and the adjustment of simulation parameters, like Mach number, grid spacing, viscosity, etc. Some parameter changes imply reinitialization of the field and reallocation of the memory, i.e., a profound alteration of the computation’s setup, making it difficult to implement.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}