Abstract
Exploring food’s rich composition and nutritional information is crucial for understanding and improving people’s dietary preferences and health habits. However, most existing food recommendation models tend to overlook the impact of food choices on health. Moreover, due to the high sparsity of food-related data, most existing methods fail to effectively leverage the multi-dimensional information of food, resulting in poorly learned node embeddings. Considering these factors, we propose a cross-view contrastive heterogeneous-graph learning method for healthy food recommendation (CGHF). Specifically, CGHF constructs feature relation graphs and heterogeneous information connection graphs by integrating user–food interaction data and multi-dimensional information about food. We then design a cross-view contrastive learning task to learn node embeddings from multiple views collaboratively. Additionally, we introduce a meta-path-based local aggregation mechanism to aggregate node information in local subgraphs, thus allowing for the efficient capturing of users’ dietary preferences. Experimental comparisons with various advanced models demonstrate the effectiveness of the proposed model.
1. Introduction
In recent years, with globalization and shifts in dietary patterns, unhealthy eating habits have become increasingly common. This trend is mainly reflected in the overconsumption of diets high in sugar, fat, and salt, resulting in a notable rise in non-communicable diseases, such as obesity, diabetes, and cardiovascular diseases [1,2,3]. Unhealthy eating behaviors not only have had a profound impact on individual health but also have served as a key factor in the global coexistence of malnutrition and overweight. It is estimated that over 11 million people die annually from diet-related diseases [4], highlighting the urgency and significance of dietary management in global health. However, with the rise in personalized needs, relying solely on traditional, generalized measures is insufficient to address complex customized demands. Therefore, technology-based dietary solutions, especially food recommendation systems, have become a hot topic in research and application [5,6].
Traditional recommendation methods achieve personalized recommendations by mining explicit or implicit interaction data between users and items [6,7]. The most representative methods include collaborative filtering (CF) and content-based recommendation. CF generates recommendations by analyzing users’ historical behavior data to uncover similarities in user interests or correlations between items. However, this method relies on sufficient historical data and faces challenges, such as the cold-start problem and data sparsity [8,9]. Content-based recommendation generates recommendations by matching item attributes (e.g., text descriptions, category labels, or nutritional contents) with user interests, thus mitigating the cold-start problem in CF [10]. However, this method often suffers from a lack of diversity in the recommendation results (i.e., the “filter bubble” phenomenon) and is unable to fully utilize collaborative information between users [11]. Moreover, traditional recommendation methods rely too heavily on domain knowledge, making it challenging to comprehensively model complex user behaviors and item information [12]. Especially in food recommendations, recommendation systems need to integrate multi-dimensional heterogeneous information from both users and foods. Traditional methods show significant short-comings in handling such complex relations. In recent years, graph neural networks (GNNs) have made significant progress in recommendation systems, especially in food recommendation, which requires integrating multi-dimensional heterogeneous information in complex scenarios. Early research focused mainly on recommendation methods for homogeneous graphs [13,14,15], where recommendations were generated by aggregating node features in the user–food interaction graph to model the similarity both between users and between foods. However, these methods have limitations in handling recommendation scenarios that involve multiple types of heterogeneous information and fail to fully represent the heterogeneity between nodes and edges. To address this issue, researchers have begun applying Heterogeneous Information Networks (HINs) to recommendation systems [16,17,18]. Unlike homogeneous graph methods, HINs can flexibly model complex relations between nodes (e.g., users, food, ingredients) and various relations (e.g., user preferences, food components). Additionally, meta-paths are introduced in HIN to capture specific semantic relations in the heterogeneous graph [16], revealing potential connection patterns between nodes by defining specific node-edge sequences. However, meta-path design requires domain knowledge, and different meta-paths have varying importance for node embedding representations. To overcome these challenges, meta-path-based Graph Attention Networks (GATs) have been proposed to dynamically assign weights to meta-paths with different semantics, thereby improving the performance of recommendation systems [19,20].
Despite the significant progress made by GNN-based recommendations, certain disadvantages remain. Firstly, GNN-based methods generally demand substantial labeled data for supervision. However, in the food recommendation scenario, user–food interaction data are typically sparse, especially in the initial phase, where users’ rating and behavior data are limited. This sparsity makes it difficult for the recommendation process to capture the complex relations between user interests and food. On the other hand, meta-path-based GNN methods, which capture heterogeneous node features and semantic information [21], perform well in many scenarios. However, they generally focus only on the direct neighboring nodes of the target user or food, limiting their ability to capture more complex contextual information. For example, the “user–food–user” meta-path can capture the direct relations between the user and the food. However, it overlooks the indirect role of food ingredients and nutrition in the recommendation, thereby limiting the overall effectiveness of the recommendation system.
To address the issues above, we introduce a novel method named Cross-View Contrastive Heterogeneous Graph Attention Network (CGHF) to capture user interests and promote healthy eating recommendations. First, we categorize the user–food recommendation task into two views: the feature relation graph and the heterogeneous information connection graph. In the feature relation graph, we maintain the consistency between food and user in the feature space by propagating node features. The heterogeneous information connection graph propagates node information within the food heterogeneous graph to extract valuable recommendation signals from the global topological structure. Then, we integrate contrastive learning techniques to capture the latent associations between users and foods by differentiating positive and negative sample pairs. Contrastive learning has succeeded in multiple domains by leveraging the similarities and differences between nodes [22,23]. It guides the model to learn more robust feature representations by constructing sample pairs. Based on this, we design positive (healthy foods) and negative (unhealthy foods) sample pairs to differentiate nutritional attributes. This cross-view contrastive learning method optimizes the feature representations between the two views, ensuring that the model retains the accuracy of food recommendation while balancing the goal of promoting healthy eating. Additionally, we integrate the direct interaction relations between users and foods, and integrate the associations between the food–ingredient and food–nutrition. These additional relation types provide multi-level contextual information, enriching the topological structure of the heterogeneous information connection graph. Moreover, we design a local aggregation mechanism for the information aggregation process to more efficiently compute the importance of neighboring nodes while considering the depth of the propagated information. First-order information aggregation focuses on food nodes that match user preferences, eliminating redundant, low-relevance nodes. In higher-order aggregation, we aggregate ingredient and nutritional component nodes related to user preferences to extract deeper information.
The main contributions of this paper can be summarized as follows:
- We propose a combined view pair for a contrastive learning framework that utilizes the graph’s structural information to guide the model in learning embeddings from different views. In this framework, we bring similar features closer and push other nodes away, thereby assisting supervised learning in developing more discriminative node embeddings, especially in the context of limited labeled data.
- We design a local aggregation mechanism in the heterogeneous context of GAT. This mechanism focuses on local nodes that significantly impact the mining results of user preferences and extracts high-order information related to food ingredients and nutrition to capture a user’s dietary preferences.
- We conduct extensive experiments on a real-world food dataset, and the results demonstrate the superiority of our model compared to various state-of-the-art benchmark methods.
2. Related Work
In this section, we review the most relevant work with our method in food recommendation, graph neural networks, and contrastive learning. Table 1 summarizes an overview of recent related research in the application domain of recommender systems.
2.1. Food Recommendation
Food recommendation aims to help users choose foods that suit their preferences, taste, health, and nutrition needs [5,15,24]. Shi et al. [25] proposed a meta-path enhanced food recommendation framework to predict user–food relations for recommendations. Ngo et al. [26] minimized hypoglycemia and hyperglycemia risks by providing risk-averse food recommendations using Bayesian neural networks for type 1 diabetes patients during physical activities. Asani et al. [6] proposed a new method for food recommendation by utilizing user reviews to perceive their dietary preferences. Chen et al. [27] developed a new graph-enhanced recommendation method that generates recommendations by learning the features of interactions between users and item nodes. Sookrah et al. [28] proposed a dietary recommendation system that combines multiple factors to provide personalized recommendations for hypertensive users. Zioutos et al. [29] adjusted dietary recommendations in real-time by analyzing users’ health history. Wang et al. [15] proposed a novel recommendation method that incorporates a word-class interaction mechanism into the model to analyze users’ dietary health and help users find a diet that aligns with their health. As an effective feature representation tool, heterogeneous graphs are widely applied in various research fields [20,30,31]. In food recommendation research, Li et al. [32] proposed a nutrition-oriented dietary recommendation model that optimizes the health exposure of food by defining a health score, thereby improving training effectiveness. Rostami et al. [33] proposed a method that predicts users’ recent dietary preferences by considering food ingredients, categories, and time factors, thereby recommending foods that better align with users’ recent eating habits. Ma et al. [34] introduced a novel nutritional knowledge graph to enhance users’ ability to choose healthy foods. Tang et al. [35] introduced time factors combined with LSTM to dynamically provide healthy dietary recommendations for cancer patients. Additionally, the model uses a cancer knowledge graph to offer diets that help prevent cancer.
2.2. Graph Neural Networks
Graph neural networks (GNNs), as a framework that applies deep learning to graph data, have shown their ability to effectively learn embedded representations of relations between graph nodes [19,36,37,38]. With the increasing diversity of data relation types, GNN-based methods have been widely applied in various fields in recent years. Wang et al. [39] proposed an end-to-end knowledge graph convolutional network (KGCN) for recommendations in movies, music, and books, which iteratively aggregates high-order structural and semantic information. Chen et al. [40] proposed a multi-view attention network to learn embeddings for users and products. Later, Wang et al. [41] utilized graph convolutional networks (GCNs) combined with an attention mechanism for the same domains, which iteratively aggregates neighboring nodes and refines node embeddings. Chang et al. [42] proposed a novel heterogeneous-graph multi-relation recommendation model that mitigates the effects of over-smoothing by reducing negative information propagated through graph convolution layers. Gao et al. [13] utilized multi-modal information in food to perform heterogeneous graph modeling for food recommendation. Ouyang et al. [43] enhanced recipe recommendations by fusing text and image modalities through a multimodal heterogeneous graph neural network. Wang et al. [44] proposed a novel heterogeneous hypergraph learning model that addresses the limitations of static weighting in hypergraph Laplacians by dynamically adjusting weights through convolutional-attention mechanisms. A substantial amount of sparse information exists in food interactions. In this paper, we enhance node embeddings for supervised learning by applying self-supervised learning to sparse node data, leveraging the inherent supervision signal in food data.
2.3. Contrastive Learning
Contrastive learning extracts meaningful representations from unlabeled data by leveraging the similarity and dissimilarity between pairs of nodes [22,23,45]. Yu et al. [46] proposed an integrated triple-training social-aware recommendation model, which builds three graph encoders and iteratively uses two of them to improve the other, thereby enhancing the data views. Wang et al. [47] proposed a new joint contrastive learning mechanism that utilizes two views to collaborate and learn more advanced node embeddings. Wu et al. [48] modified the graph structure in various ways and enhanced node embeddings through self-discrimination, thereby improving robustness to interaction noise. Chen et al. [49] proposed a novel heterogeneous graph contrastive learning mechanism that adaptively fuses multi-view relational semantics with meta-network enhanced knowledge transfer. However, few studies have explored the vast potential of contrastive learning in food recommendation. This paper introduces health scores to distinguish positive and negative food sample pairs, thereby obtaining node embeddings that better align with dietary health (Table 1).

Table 1.
Summary of the recent research methods in recommender systems.
Table 1.
Summary of the recent research methods in recommender systems.
| Authors | Recommendation Approaches | Contributions |
|---|---|---|
| Sun et al. [10] | CF | Establishing user behavior modeling with self-attention mechanisms for benchmark-leading recommendation performance. |
| Ngo et al. [26] | Bayesian Networks | Mitigating glycemic risks through Bayesian neural networks for activity-adaptive food recommendations in diabetes. |
| Gao et al. [14] | GCN | Proposing graph convolutional networks with triple propagation for multi-relational representation learning. |
| Ouyang et al. [43] | GNNs | Enabling precise user–recipe matching through unified feature granularity and graph semantic modeling. |
| Wang et al. [44] | GNNs | Achieving personalized health recipe recommendations via heterogeneous-to-homogeneous conversion. |
| Chen et al. [49] | GNNs, Contrastive learning | Leveraging adaptive contrastive augmentation and personalized knowledge transfer for recommendation. |
3. Methods
This section presents the proposed CGHF model, which is divided into three main modules (Figure 1). Specifically, we build feature relation graphs and heterogeneous information connection graphs using multi-source data from users and foods. Then, we propose a self-supervised framework leveraging cross-view contrastive learning for learning node embeddings. Additionally, we propose an attention mechanism to integrate node features within the heterogeneous information connection graph. Finally, we integrate cross-view contrastive learning with supervised learning to enhance the model’s training effectiveness.
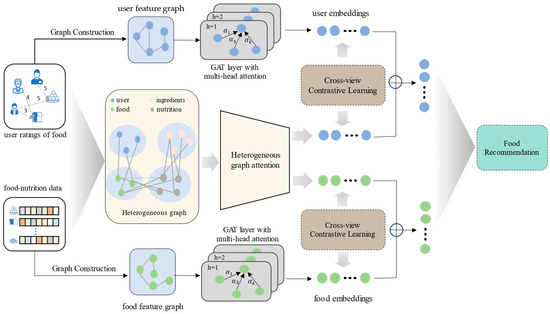
Figure 1.
The framework of the proposed CGHF model’s overall structure.
3.1. Graph Construction
To capture the multi-level associations and contextual information between users and foods, we designed the feature relation graph and the heterogeneous information connection graph. The feature relation graph consists of a user feature relation graph and a food feature relation graph to ensure user–food consistency in the feature space. The heterogeneous information connection graph combines food ingredients and nutritional information to uncover intricate user–food and food–food relations.
3.1.1. Construction of Feature Relation Graph
In order to construct the user feature relation graph, we adopt the embedding generation and clustering method based on metapath2vec [50]. Specifically, we build a relation graph that includes interactions between users and foods, where user nodes represent user IDs, while food nodes represent food IDs. User–food rating relations serve as edges connecting user nodes and food nodes. Then, by defining a user–food–user meta-path, we use a random walk method to generate path sequences, and then extract structural relations of users within the graph, and hence derive user node embeddings. Finally, based on user embedding vectors, we apply the k-nearest neighbors (KNNs) algorithm to cluster the nodes and construct the user feature relation graph [51].
For the food feature relation graph, we construct foods’ nutritional composition and ingredient composition by calculating node feature similarity. Specifically, we first extract the key nutritional features of each food (such as calories, protein, fat, carbohydrates, etc.) and ingredient composition from the food data and represent these features by feature vectors. Next, we standardize the extracted feature vectors to eliminate scale differences between different feature dimensions. Then, we calculate the cosine similarity between any two foods based on their feature vectors, generating a food similarity matrix. Finally, we construct the food feature relation graph based on the similarity matrix.
3.1.2. Construction of Heterogeneous Information Connection Graph
We construct a user–food heterogeneous information network using the Allrecipes dataset for the heterogeneous information connection graph. This network consists of four types of nodes (user, food, ingredient, and nutrition) and three types of edges (user–food, food–ingredient, and food–nutrition). For example, when a user rates a particular food, a link forms between the user’s node and the food’s node. Similarly, if a food is composed of specific ingredients, connections are formed between them. Additionally, food nodes are connected to their corresponding nutritional data nodes. Table 2 summarizes the node types, edge types, and their semantic relations in the heterogeneous information network.
Table 2.
The overview of nodes and edges in the heterogeneous information network.
3.2. Cross-View Contrastive Learning Network
The interaction information between users and foods exhibits heterogeneity and complexity, integrating information from both node features and heterogeneous connections. The key objective of the representation learning component in our framework is to incorporate this information and learn node embeddings that align with user preferences and dietary health. To this end, we propose a cross-view contrastive method to extract embeddings of users and foods from multiple views. Information from different views exhibits divergent characteristics. However, directly merging them without alignment mechanisms may blur the discriminative boundaries. Therefore, we perform node embedding learning separately from the feature structure and the heterogeneous information views. In the feature relation view, we utilize GAT to aggregate the similarity relations of nodes in the feature space from the feature relation graph. In the network topology view, we design a locally aggregated GAT to explore node relations and contextual relations in the heterogeneous information connection graph that align with user preferences. Additionally, we introduce a cross-view contrastive learning task under health standards to jointly optimize the embedding representations of the two views, ensuring consistency and complementarity between their representations. As shown in Figure 1, the CGHF model consists of four core modules: (i) transformation of node features, (ii) node embedding learning in the feature relation view, (iii) contextual representation learning in the heterogeneous information connection graph, and (iv) establishing links between the two views through contrastive learning.
3.2.1. Feature Transformation
In the framework, user, food, ingredient, and nutrition nodes belong to different node categories with varying feature dimensions and distributions in different feature spaces. To enable unified representation learning, we transform the raw features of nodes by mapping various node types into a common latent vector space to support later aggregation operations. Here, we denote the set of nodes of type as . For a node , its original feature is projected through a node-type-specific linear transformation matrix to generate corresponding feature vectors, as expressed by the following equation:
Here, is a learnable linear transformation matrix specific to node type , and represents the original feature vector of node . Through feature transformation, heterogeneous nodes are mapped onto a unified vector space, addressing the inconsistency of features across nodes, establishing a foundation for subsequent feature aggregation and representation learning.
3.2.2. Feature Relation Graph Embedding
GAT achieves superior performance by assigning differentiated attention weights to the neighbors of the target node [52]. Therefore, we use a feature relation graph with node features as input in order to learn the embedding representations of these relational graphs. For example, for the user feature relation graph , the attention score between nodes and node is calculated by the following formula:
Here, represents the activation function. denotes the attention weight between node and node in , the mark represents the aggregation operation, and represents the set of neighbors of node in . To more effectively aggregate information from neighboring nodes, we use node attention combined with a multi-head attention mechanism to generate user node embeddings, denoted as .
In this context, indicates the repetition count of self-attention within the multi-head attention mechanism, while refers to the nonlinear activation function.
3.2.3. Heterogeneous Connection Graph Embedding
In food recommendation systems, heterogeneous information network embeddings integrate various types of nodes (such as users, food items, ingredients, and nutritional information) and their complex relations. However, they often focus on the target node’s direct neighbors and fail to fully leverage the deep contextual information between nodes. Meta-paths, conversely, can define specific sequences of nodes and edges in heterogeneous networks to capture semantic relations and potential connection patterns between different types of nodes. By defining a meta-path that connects user and food , we construct the node context set . For example, based on the meta-path UFIFU (user → food → ingredient → food → user), we can obtain the semantic relation between the user and the food ingredient. In addition, we designed a locally aggregated attention mechanism that focuses only on a limited set of node aggregations. This mechanism prioritizes nodes that are more relevant to user preferences when calculating the importance of neighboring nodes. By aggregating first-order information (such as directly interacted foods) and higher-order information (such as ingredient nodes and nutritional content nodes), node embeddings are learned.
As shown in Figure 2, for a given meta-path , we convert the heterogeneous food connection graph into a subgraph based on the meta-path, and each subgraph would capture specific semantic information. When the starting and ending nodes of the meta-path belong to the same type, an isomorphic subgraph is generated; otherwise, if they belong to different types, a heterogeneous subgraph is generated. Next, we calculate the attention scores of nodes to evaluate the influence of neighboring nodes on the target user or food. Here, the set of neighboring nodes connected based on the meta-path and more closely related to user preferences is denoted as . The formula for calculating the neighbor attention coefficient between node and node is as follows:
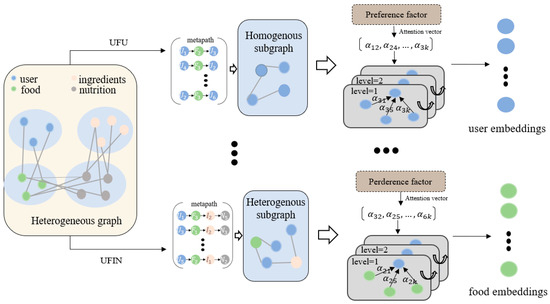
Figure 2.
Heterogeneous information GAT. First, we constructed subgraphs based on various types of meta-paths, such as UFU and UFIN. Then, we incorporated user dietary preferences into the calculation of node attention, ultimately obtaining user embeddings and food embeddings.
Here, represents a trainable weight matrix for , and represents the set of neighbors of node in .
The sequences in the meta-path can reveal deeper semantic relations. Therefore, after aggregating the neighbor nodes, we integrate the embeddings of deeper-layer nodes, and the following formula is used to determine their deep attention scores:
Here, represents the attention weight of food on its nutritional component , and denotes the deeper-layer neighbor set of food . The final node embedding obtained after fusion is defined as follows:
By integrating node information, we can optimize the node loss in the heterogeneous information connection graph, and the loss function is as follows:
It represents the loss between the node , which does not align with user preferences, and the node , which aligns with user preferences, in the heterogeneous information graph.
3.2.4. Nutritional Health Score
To quantify the healthiness of food, we define a Food Nutrition Health Score. This score is based on WHO health standards and evaluates the healthiness of each food by calculating the levels of seven nutrients it contains: protein, carbohydrates, sugar, sodium, saturated fats, and fiber. The calculation method is as follows:
In the above formula, represents the total number of nutrients in the food that meet the standards set by the World Health Organization (WHO) [53,54]. If they meet the criteria, the score is 1, or 0 otherwise, and represents the nutritional content in the food, with a fixed value of 7.
Most foods being sold on the Internet do not meet health standards [54]. Therefore, it is incredibly challenging to find foods where all seven nutrients fully comply with health standards. According to the above definition, we assume that foods with a health score greater than or equal to the threshold value T are considered healthy foods. Otherwise, the food is deemed unhealthy. The set of nutritious foods is shown as follows:
Here, represents the threshold value for healthy foods, and represents the set of foods meeting health standards.
3.2.5. Cross-View Contrastive Learning
Contrastive learning, as a self-supervised learning method, aims to compare positive and negative samples of data from different views, fully leveraging sparse data to improve the performance of recommendation systems [47]. In recent years, this approach has attracted widespread attention in the field of food recommendation. In this paper, we introduce contrastive learning into our recommendation model to learn embedding representations that meet healthy dietary standards from limited interaction information and food characteristics. Specifically, we define two views: the feature relation view between users and foods and the heterogeneous information connection view. We identify positive and negative samples in each of these two views. Taking the food node in the feature relation view as an example, we consider the food node that meets health standards in the heterogeneous information connect graph as positive samples and the food nodes that do not meet health standards as negative samples . Next, by pulling the embedding representations of positive samples closer while pushing those of negative samples farther apart, the contrastive loss function is defined as follows for both positive and negative samples:
In this context, represents the cosine value between vector from the feature relation graph and vector from the heterogeneous information connect graph, while is the fixed temperature parameter. represents the contrastive loss in the food relation graph. Using this cross-view graph contrastive learning method, we ensure that nodes in the feature relation graph are consistent with positive sample nodes in the heterogeneous information connect graph while being distinct from negative sample nodes.
The contrastive losses and , defined in the heterogeneous information connect graph, are similar to . However, for a food node in the heterogeneous information connect graph, the positive samples include the node itself and its direct neighbors in the user feature relation graph or the food feature relation graph. In contrast, negative samples are other nodes in the feature relation graph. Finally, the overall contrastive objective loss is defined as follows:
Through this cross-view contrastive learning method, we are able to establish more robust and discriminative feature representations under sparse data environments.
3.3. Multi-Task Training
Multi-task training can effectively leverage the shared information between user behavior patterns and food features in food recommendation systems, thereby improving recommendation accuracy. This paper’s primary goal is to minimize the loss between users’ preferences for food. Meanwhile, we also need to simultaneously optimize the unsupervised loss, which evaluates the dietary health differences between different food nodes, including the distance between positive samples (healthy foods) and negative samples (unhealthy foods). Our goal is to enhance the performance of supervised learning through self-supervised learning, aiding the model in understanding which foods are close to the user’s preference structure. Therefore, we learn the food recommendation model by minimizing the following joint loss function:
Here, is a hyperparameter, and is a regularization term to prevent overfitting.
4. Experiment
This section includes the dataset, evaluation metrics, comparison with existing methods, and ablation experiments.
4.1. Dataset
The heterogeneous information of users and foods, along with their interaction data, has the potential to reveal the underlying relations between users and foods. Considering that the ingredients and nutritional information of food can accurately reflect users’ dietary preferences and health, we collected the associations between food and ingredients, as well as food and nutritional data from the Allrecipes dataset [13,14,22].
The Allrecipes dataset is the only dataset that fully meets our experimental requirements. This dataset contains 31,518 users, 25,683 food items, 310,830 interaction records, and food composition and nutrition information. Table 3 presents the proportion of users within different rating ranges. It can be observed that most users have rated only a small number of food items, demonstrating the sparsity of the dataset. As shown in Figure 3, we established connections between each user and the food items they rated. Additionally, connections were established between food items and their corresponding ingredient and nutritional data, resulting in a heterogeneous information network with 75,055 nodes and 709,579 edges. Among these, 80% of the dataset was used as training data, while the remaining 20% was used as test data.
Table 3.
User ratings distribution.
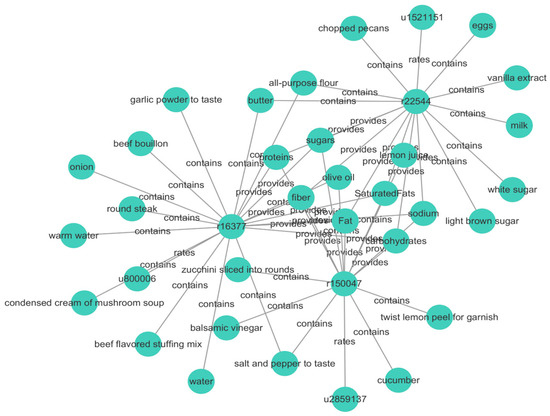
Figure 3.
Heterogeneous information connection graph. The heterogeneous information connection graph is established by connecting the relevant information among users, food, ingredients, and nutrition.
4.2. Experimental Settings
Our model CGHF is implemented in Python 3.8.0 and trained on a machine configured with an NVIDIA GeForce RTX 3090 GPU, 681 GB of RAM, and 24 GB of VRAM. Our training environment is based on PyTorch 2.2.1 and CUDA 12.1.1. CGHF utilizes the Adam optimizer with a learning rate of 0.001, a total of 120 training epochs, and an embedding dimension of 64 for the nodes.
4.3. Evaluation Metrics
To evaluate the performance of our proposed method in food recommendation, we assess the model’s effectiveness on benchmark datasets using precision, recall, normalized discounted cumulative gain (NDCG), and AUC.
AUC (Area Under the Curve) is a metric for evaluating the performance of binary classification models. It represents the area under the Receiver Operating Characteristic (ROC) curve. A value closer to 1 indicates stronger classification ability. Additionally, AUC is unaffected by class imbalance and effectively reflects the model’s predictive performance across all possible thresholds.
NDCG is a metric commonly used in recommendation systems to evaluate the ranking quality of a model. It assesses the model’s performance by measuring the proximity of the recommended ranking to the ideal ranking, where a score typically represents the relevance of each result—the higher the score, the stronger the relevance. Top-ranked recommendations receive larger weights from NDCG to assess their quality. The following is the computation method:
Whereas,
The recommended food list’s length is denoted by L, and indicates the relevance of the recommended food, with values ranging from 0 to 1. A higher value indicates stronger relevance. Additionally, the following is the calculation formula for :
Recall represents the proportion of food items that align with user preferences and are successfully predicted by the recommendation system. The calculation formula is as follows:
Here, represents the number of samples correctly predicted as positive by the model, represents the number of samples incorrectly predicted as negative by the model.
Precision measures the proportion of relevant items in the list of recommendations provided to a user.
Here, represents the number of samples incorrectly predicted as positive by the model.
Health represents the health effects of the top K recommended foods, which takes into account the Nutritional Health Score of the foods. The calculation formula is as follows:
Here, represents the list of the top K recommended foods. is the health score of the recommended food . is the average health score of all the recommended foods. represents the total number of healthy foods. To obtain experimental results for different recommended list sizes, we conducted multiple calculations of various metrics under different values to ensure the reliability of the experiment.
4.4. Comparison with Existing Methods
To demonstrate the effectiveness of our proposed CGHF, we compared it with the following baseline methods on the Allrecipes dataset:
- LDA: This method assumes that each document is composed of a mixture of user-interest topics, treats foods as words in the document, and uses LibRec4 to adjust the number of topics [22,54].
- FM: This method models the interactions between any two features by decomposing interaction parameters. FM takes user ID, food ID, and ingredients as input features and models their latent relations through factorization of feature interactions, which effectively handles sparse data [54,55].
- BPR: This method maximizes the user’s preference for liked items over disliked items, providing high-precision recommendations in sparse data environments [56].
- NGCF: This method constructs a graph structure for users and foods, models users and foods as nodes, and interaction behaviors as edges. It employs graph convolution operations to iteratively aggregate node features, capturing higher-order associations between users and foods [57].
- RGCN: This method constructs a heterogeneous graph to represent entities and their interactions. It uses the information propagation mechanism of graph convolutional networks (GCNs) and multi-layer embedding propagation layers to learn higher-order connectivity between users and foods [58].
- KGAT: This method models the relations between users, foods, and other related entities (e.g., ingredients, attributes) as a collaborative knowledge graph. It introduces an attention mechanism to differentiate the relevance of various neighbors to user preferences [52].
- HAN: This method uses a heterogeneous network model to capture the complex relations between users and items, extracting latent features from heterogeneous information and learning rich embedding representations [20].
- HAFR: This method integrates a hierarchical attention mechanism to capture fine-grained and global preferences by hierarchically modeling the multi-level relations among users, foods, and ingredients [13].
- SCHGCN: This method explicitly models the interactions between ingredients, foods, and users by constructing a heterogeneous graph. It employs an attention mechanism to capture the similarity between the user’s calorie perception and foods for recommendations [22].
- HFRS-DA: This method combines a dual attention network to identify popular and healthy recipes and recommends them to users based on their behavioral information [59].
Table 4 displays the comparative findings on the benchmark dataset, with the bolded values denoting the experiments’ highest performance. From Table 4, we can see that the proposed CGHF achieved optimal performance in terms of AUC and Recall, with an AUC value of 0.7683 and a Recall@10 value of 0.1648. On the benchmark dataset, the performance of CGHF surpasses that of the HFRS-DA method by 0.94% in AUC and 2.11% in Recall@10, suggesting that it effectively recommends foods aligned with user preferences. However, in terms of the NDCG@10 and Precision@10 metrics, our model trails the HFRS-DA model by 1.64% and 4.6%, respectively. This indicates that CGHF has potential for further improvement in optimizing ranking quality. In addition, CGHF outperforms other baselines on Health@10, indicating that the model better recommends foods that align with health and user food preferences.
Table 4.
Performance comparison of competing methods.
Figure 4 further illustrates the NDCG and Recall values for different recommendation list sizes (K). The superior performance of CGHF over other baseline methods is primarily attributed to its ability to learn heterogeneous information in food, information from different meta-paths, and other related data, thereby integrating more prosperous latent relations between users and foods. Notably, the integration of contrastive learning with the food recommendation task enhances the discriminative capability of node embeddings in scenarios with sparse data. Moreover, GNN-based methods outperform traditional recommend-dation approaches, such as HAFR, and our method surpasses conventional methods, such as LDA. This indicates that integrating user and food feature information, as well as the heterogeneous information within food, positively impacts the performance of recommendations. Although the NGCF method incorporates interaction information between users and foods, it overlooks the substantial heterogeneous information contained in food, leading to the worst performance among graph-based recommendation methods. Additionally, the HAFR method performs better by hierarchically modeling the relations among users, food, and ingredients, thereby learning richer node information. However, it neglects users’ preferences for dietary health. Furthermore, though the HFRS-DA method leverages a dual-attention mechanism to learn more comprehensive node embeddings that can perceive user health preferences. However, its performance degrades under sparse data conditions, which further highlights the importance of contrastive learning in optimizing supervised learning. Finally, compared to other baseline methods, our proposed approach achieves the best performance according to 2 metrics, demonstrating its effectiveness and superiority.
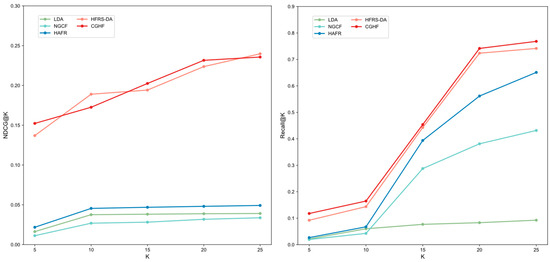
Figure 4.
Comparing CGHF with other models for different recommendation list sizes.
To evaluate food recommendation performance across varying levels of popularity, we grouped foods according to different numbers of ratings (N). Subsequently, we assessed the performance of various methods within four groups using the AUC metric. Figure 5 illustrates the performance of various recommendation methods across different popularity groups. We can observe that the model captures more interaction information between users and foods as N increases, thus enabling a more comprehensive learning of node embeddings. This demonstrates the superiority of our model in capturing comprehensive information.
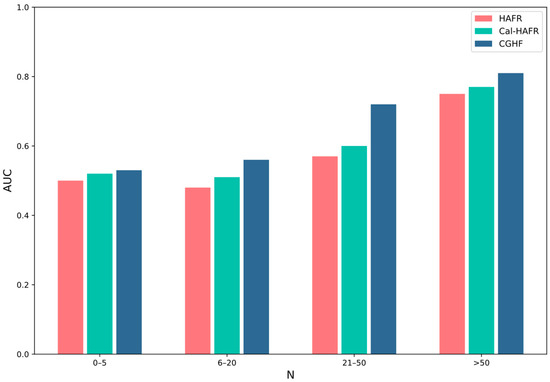
Figure 5.
Comparison of CGHF in the different popularity group sizes based on AUC.
4.5. Ablation Study and Parameter Analysis
To learn more about how various CGHF’s components affect model performance, we constructed multiple variants of the model, each altering only one component of the model. These variants include:
- (1)
- CGHFnoR ignores the food–ingredient and food–nutrient association information in the heterogeneous connection graph, retaining only the user–food association information.
- (2)
- CGHFnoC disregards the contrastive learning task and retains only the supervised learning component to train our model.
- (3)
- CGHFnoP ignores the local aggregation of node-level attention, aggregating all neighbors in the graph generated based on meta-paths.
Table 5 illustrates the performance variations in the proposed CGHF method across different variants. First, the performance of CGHFnoR is significantly inferior to that of CGHF, indicating that the model can capture more complex patterns by integrating the multidimensional relations between users, food, and their features. In addition, the performance of the CGHFnoP variant demonstrates the effectiveness of considering user preference in local node attention aggregation. As shown in Table 5, CGHFnoP performs worse than CGHF, indicating that selectively aggregating local neighbors allows the model to accurately extract key features and enhance overall performance. Most critically, ignoring the contrastive learning task (CGHFnoC) leads to substantial performance degradation across all metrics, with the most notable impact on the Health@10 metric. This strongly validates the crucial role of contrastive learning, not only in enhancing the discriminative power of feature representations but also in effectively distinguishing the health status of nodes.
Table 5.
The performance variations in the CGHF method across different variants.
To validate the hyperparameters’ influence on the model, we tried various values of them, as shown in Figure 6. It can be observed that as the health weight increases, the model focuses more on the healthiness of the recommended food. However, as the health weight continues to increase, the accuracy of the recommendation descends gradually. When it equals 0.1, the model achieves optimal performance, indicating its capability to recommend food by properly balancing user preferences with dietary health.
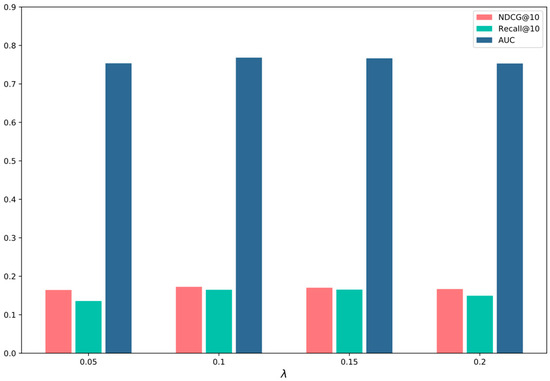
Figure 6.
Hyperparameter analysis with different hyperparameter values.
5. Conclusions
In this study, we propose CGHF, an innovative framework for healthy food recommendation. CGHF introduces a heterogeneous GAT with local aggregation, effectively modeling user–food interactions to more accurately represent user dietary preferences. By decoding topological structures in heterogeneous graphs and aggregating multi-typed features from neighboring nodes, our approach effectively addresses the challenge of insufficiently capturing user dietary preferences. Next, we enhance the model’s ability to distinguish between healthy and unhealthy foods by incorporating nutritional health scores into the contrastive learning framework, thereby strengthening the model’s discriminative capability in modeling health states. The recommended foods not only capture user preferences but also ensure the healthiness of the food. Experimental results validate the effectiveness of our approach in recommending foods that align with both user preferences and health requirements, highlighting its potential to promote healthier dietary patterns.
6. Discussion
Despite the CGHF’s good performance in improving users’ healthy diets, it has notable limitations. First, the model heavily relies on manual meta-path selection, which can be restrictive and inefficient. Second, there are constraints imposed by food health standards, making it challenging to ensure recommendations consistently align with health guidelines. Additionally, the Allrecipes dataset has limited cultural diversity, which could lead to cultural bias in the recommendations. Moreover, the model does not yet leverage multimodal data, such as images and text reviews, which could enhance its accuracy and robustness. Lastly, real-time processing remains a challenge, as the current system may struggle with scalability and low-latency performance.
In future work, we plan to improve the system by addressing several limitations. First, to reduce reliance on manual meta-path selection, we will combine domain knowledge (e.g., nutritional guidelines) with reinforcement learning to create an automated meta-path discovery service that adapts to user needs. Second, we will integrate knowledge graphs and semantic frameworks to ensure recommendations align with health standards and improve model interpretability. We will also expand the dataset to include more diverse recipes and implement bias-mitigation techniques. Additionally, we will explore using multimodal data (e.g., images, reviews) to enhance the recommendation process. Finally, we will focus on real-time processing by deploying the system on cloud platforms and using distributed computing to ensure low latency and scalability.
Author Contributions
Conceptualization, H.Z. and H.C.; methodology, J.W. and Y.W.; software, H.Z.; validation, H.C., J.W., and Y.W.; formal analysis, H.C.; investigation, Y.W.; resources, J.W. and Y.W.; data curation, H.Z.; writing—original draft preparation, H.Z. and H.C.; writing—review and editing, J.W. and Y.W.; visualization, H.C.; supervision, J.W. and Y.W.; project administration, J.W.; funding acquisition, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, Grant Number: 32302241; National Key Research and Development Program of China, grant number: 2024YFF1106705.
Data Availability Statement
The experimental data used in this study were sourced from the Allrecipes dataset (accessible at: https://www.kaggle.com/datasets/elisaxxygao, accessed on 15 October 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ford, N.D.; Patel, S.A.; Narayan, K.V. Obesity in low-and middle-income countries: Burden, drivers, and emerging challenges. Annu. Rev. Public Health 2017, 38, 145–164. [Google Scholar] [CrossRef]
- Lachat, C.; Otchere, S.; Roberfroid, D.; Abdulai, A.; Seret, F.M.A.; Milesevic, J.; Xuereb, G.; Candeias, V.; Kolsteren, P.; Cobiac, L.J. Diet and physical activity for the prevention of noncommunicable diseases in low-and middle-income countries: A systematic policy review. PLoS Med. 2013, 10, e1001465. [Google Scholar] [CrossRef] [PubMed]
- Popkin, B.M. Global nutrition dynamics: The world is shifting rapidly toward a diet linked with noncommunicable diseases. Am. J. Clin. Nutr. 2006, 84, 289–298. [Google Scholar] [CrossRef] [PubMed]
- Afshin, A.; Sur, P.J.; Fay, K.A.; Cornaby, L.; Ferrara, G.; Salama, J.S.; Mullany, E.C.; Abate, K.H.; Abbafati, C.; Abebe, Z.; et al. Health effects of dietary risks in 195 countries, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet 2019, 393, 1958–1972. [Google Scholar] [CrossRef] [PubMed]
- Ge, M.; Elahi, M.; Fernaández-Tobías, I.; Ricci, F.; Massimo, D. Using tags and latent factors in a food recommender system. In Proceedings of the 5th International Conference on Digital Health 2015, Florence, Italy, 18–20 May 2015; pp. 105–112. [Google Scholar]
- Trattner, C.; Elsweiler, D. Food recommender systems: Important contributions, challenges and future research directions. arXiv 2017, arXiv:1711.02760. [Google Scholar] [CrossRef]
- Marcuzzo, M.; Zangari, A.; Albarelli, A.; Gasparetto, A. Recommendation systems: An insight into current development and future research challenges. IEEE Access 2022, 10, 86578–86623. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar]
- Steck, H. Embarrassingly shallow autoencoders for sparse data. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3251–3257. [Google Scholar]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar]
- Gao, X.; Feng, F.; He, X.; Huang, H.; Guan, X.; Feng, C.; Ming, Z.; Chua, T.-S. Hierarchical attention network for visually-aware food recommendation. IEEE Trans. Multimed. 2019, 22, 1647–1659. [Google Scholar] [CrossRef]
- Gao, X.; Feng, F.; Huang, H.; Mao, X.-L.; Lan, T.; Chi, Z. Food recommendation with graph convolutional network. Inf. Sci. 2022, 584, 170–183. [Google Scholar] [CrossRef]
- Wang, W.; Duan, L.-Y.; Jiang, H.; Jing, P.; Song, X.; Nie, L. Market2Dish: Health-aware food recommendation. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–19. [Google Scholar] [CrossRef]
- Fan, S.; Zhu, J.; Han, X.; Shi, C.; Hu, L.; Ma, B.; Li, Y. Metapath-guided heterogeneous graph neural network for intent recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2478–2486. [Google Scholar]
- Fang, Y.; Yang, Y.; Zhang, W.; Lin, X.; Cao, X. Effective and efficient community search over large heterogeneous information networks. Proc. VLDB Endow. 2020, 13, 854–867. [Google Scholar] [CrossRef]
- Forouzandeh, S.; Berahmand, K.; Sheikhpour, R.; Li, Y. A new method for recommendation based on embedding spectral clustering in heterogeneous networks (RESCHet). Expert Syst. Appl. 2023, 231, 120699. [Google Scholar] [CrossRef]
- Li, X.; Sun, L.; Ling, M.; Peng, Y. A survey of graph neural network based recommendation in social networks. Neurocomputing 2023, 549, 126441. [Google Scholar] [CrossRef]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous graph attention network. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2022–2032. [Google Scholar]
- Tan, L.; Gong, D.; Xu, J.; Li, Z.; Liu, F. Meta-path fusion based neural recommendation in heterogeneous information networks. Neurocomputing 2023, 529, 236–248. [Google Scholar] [CrossRef]
- Song, Y.; Yang, X.; Xu, C. Self-supervised calorie-aware heterogeneous graph networks for food recommendation. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–23. [Google Scholar] [CrossRef]
- Yang, Y.; Huang, C.; Xia, L.; Li, C. Knowledge graph contrastive learning for recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1434–1443. [Google Scholar]
- Min, W.; Jiang, S.; Jain, R. Food recommendation: Framework, existing solutions, and challenges. IEEE Trans. Multimed. 2019, 22, 2659–2671. [Google Scholar] [CrossRef]
- Shi, J.; Komamizu, T.; Doman, K.; Kyutoku, H.; Ide, I. RecipeMeta: Metapath-enhanced Recipe Recommendation on Heterogeneous Recipe Network. In Proceedings of the 5th ACM International Conference on Multimedia in Asia, Tainan, China, 6–8 December 2023; pp. 1–7. [Google Scholar]
- Ngo, P.; Tejedor, M.; Tayefi, M.; Chomutare, T.; Godtliebsen, F. Risk-averse food recommendation using bayesian feedforward neural networks for patients with type 1 diabetes doing physical activities. Appl. Sci. 2020, 10, 8037. [Google Scholar] [CrossRef]
- Chen, L.; Xie, T.; Li, J.; Zheng, Z. Graph enhanced neural interaction model for recommendation. Knowl.-Based Syst. 2022, 246, 108616. [Google Scholar] [CrossRef]
- Sookrah, R.; Dhowtal, J.D.; Nagowah, S.D. A DASH diet recommendation system for hypertensive patients using machine learning. In Proceedings of the 2019 7th International Conference on Information and Communication Technology (ICoICT), Kuala Lumpur, Malaysia, 24–26 July 2019; pp. 1–6. [Google Scholar]
- Zioutos, K.; Kondylakis, H.; Stefanidis, K. Healthy Personalized Recipe Recommendations for Weekly Meal Planning. Computers 2023, 13, 1. [Google Scholar] [CrossRef]
- Jia, X.; Jiang, M.; Dong, Y.; Zhu, F.; Lin, H.; Xin, Y.; Chen, H. Multimodal heterogeneous graph attention network. Neural Comput. Appl. 2023, 35, 3357–3372. [Google Scholar] [CrossRef]
- Yang, W.; Li, J.; Tan, S.; Tan, Y.; Lu, X. A heterogeneous graph neural network model for list recommendation. Knowl.-Based Syst. 2023, 277, 110822. [Google Scholar] [CrossRef]
- Li, M.; Li, L.; Tao, X.; Xie, Z.; Xie, Q.; Yuan, J. Boosting healthiness exposure in category-constrained meal recommendation using nutritional standards. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–28. [Google Scholar] [CrossRef]
- Rostami, M.; Farrahi, V.; Ahmadian, S.; Jalali, S.M.J.; Oussalah, M. A novel healthy and time-aware food recommender system using attributed community detection. Expert Syst. Appl. 2023, 221, 119719. [Google Scholar] [CrossRef]
- Ma, W.; Li, M.; Dai, J.; Ding, J.; Chu, Z.; Chen, H. Nutrition-Related Knowledge Graph Neural Network for Food Recommendation. Foods 2024, 13, 2144. [Google Scholar] [CrossRef]
- Tang, J.; Huang, B.; Xie, M. Anticancer Recipe Recommendation Based on Cancer Dietary Knowledge Graph. Eur. J. Cancer Care 2023, 2023, 8816960. [Google Scholar] [CrossRef]
- Hu, B.; Shi, C.; Zhao, W.X.; Yu, P.S. Leveraging meta-path based context for top-n recommendation with a neural co-attention model. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1531–1540. [Google Scholar]
- Jin, J.; Qin, J.; Fang, Y.; Du, K.; Zhang, W.; Yu, Y.; Zhang, Z.; Smola, A.J. An efficient neighborhood-based interaction model for recommendation on heterogeneous graph. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 75–84. [Google Scholar]
- Zhao, H.; Yao, Q.; Li, J.; Song, Y.; Lee, D.L. Meta-graph based recommendation fusion over heterogeneous information networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 635–644. [Google Scholar]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]
- Chen, L.; Cao, J.; Wang, Y.; Liang, W.; Zhu, G. Multi-view graph attention network for travel recommendation. Expert Syst. Appl. 2022, 191, 116234. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.-S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Chang, Y.; Zhou, W.; Wen, J. IHG4MR: Interest-oriented heterogeneous graph for multirelational recommendation. Expert Syst. Appl. 2023, 228, 120321. [Google Scholar] [CrossRef]
- Ouyang, R.; Huang, H.; Ou, W.; Liu, Q. Multimodal Recipe Recommendation with Heterogeneous Graph Neural Networks. Electronics 2024, 13, 3283. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, J.; Aksoy, M.; Sharma, N.; Rahman, A.; Zain, J.M.; Alenazi, M.J.; Aminzadeh, A. Improving healthy food recommender systems through heterogeneous hypergraph learning. Egypt. Inform. J. 2024, 28, 100570. [Google Scholar] [CrossRef]
- Khasahmadi, K.H.A.H. Contrastive multi-view representation learning on graphs. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 13–18 July 2020; pp. 4116–4126. [Google Scholar]
- Yu, J.; Yin, H.; Gao, M.; Xia, X.; Zhang, X.; Hung, N.Q.V. Socially-aware self-supervised tri-training for recommendation. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, Singapore, 14–18 August 2021; pp. 2084–2092. [Google Scholar]
- Wang, X.; Liu, N.; Han, H.; Shi, C. Self-supervised heterogeneous graph neural network with co-contrastive learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, Singapore, 14–18 August 2021; pp. 1726–1736. [Google Scholar]
- Wu, J.; Wang, X.; Feng, F.; He, X.; Chen, L.; Lian, J.; Xie, X. Self-supervised graph learning for recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, 11–15 July 2021; pp. 726–735. [Google Scholar]
- Chen, M.; Huang, C.; Xia, L.; Wei, W.; Xu, Y.; Luo, R. Heterogeneous graph contrastive learning for recommendation. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, Singapore, Singapore, 27 February–3 March 2023; pp. 544–552. [Google Scholar]
- Dong, Y.; Chawla, N.V.; Swami, A. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. Proc. VLDB Endow. 2011, 4, 992–1003. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Nishida, C.; Uauy, R.; Kumanyika, S.; Shetty, P. The joint WHO/FAO expert consultation on diet, nutrition and the prevention of chronic diseases: Process, product and policy implications. Public Health Nutr. 2004, 7, 245–250. [Google Scholar] [CrossRef] [PubMed]
- Trattner, C.; Elsweiler, D. Investigating the healthiness of internet-sourced recipes: Implications for meal planning and recommender systems. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 489–498. [Google Scholar]
- Rendle, S. Factorization machines with libfm. ACM Trans. Intell. Syst. Technol. (TIST) 2012, 3, 1–22. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.-S. Neural graph collaborative filtering. In Proceedings of the 42nd International ACM SIGIR Conference on RESEARCH and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 593–607. [Google Scholar]
- Forouzandeh, S.; Rostami, M.; Berahmand, K.; Sheikhpour, R. Health-aware food recommendation system with dual attention in heterogeneous graphs. Comput. Biol. Med. 2024, 169, 107882. [Google Scholar] [CrossRef] [PubMed]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).