
Deep Learning-Based Short Text Summarization: An Integrated BERT and Transformer Encoder–Decoder Approach


Abstract
1. Introduction
- Developing a robust data cleaning process to remove non-essential elements from tweets, ensuring that the essential that the dataset is free of noise and irrelevant content.
- Implementation of preprocessing techniques, including tokenization, stop word removal, stemming, and lemmatization, specifically designed to optimize input data for short text summarization tasks.
- Proposing a novel framework integrating BERT with a TEDA enhanced with an attention mechanism to effectively summarize short-text content on Twitter.
- Evaluating the framework using key metrics, such as ROUGE scores, across three disaster tweet datasets such as Hagupit, SHShoot, and Hyderabad Blast to assess understanding, coherence, and informativeness.
2. Related Works
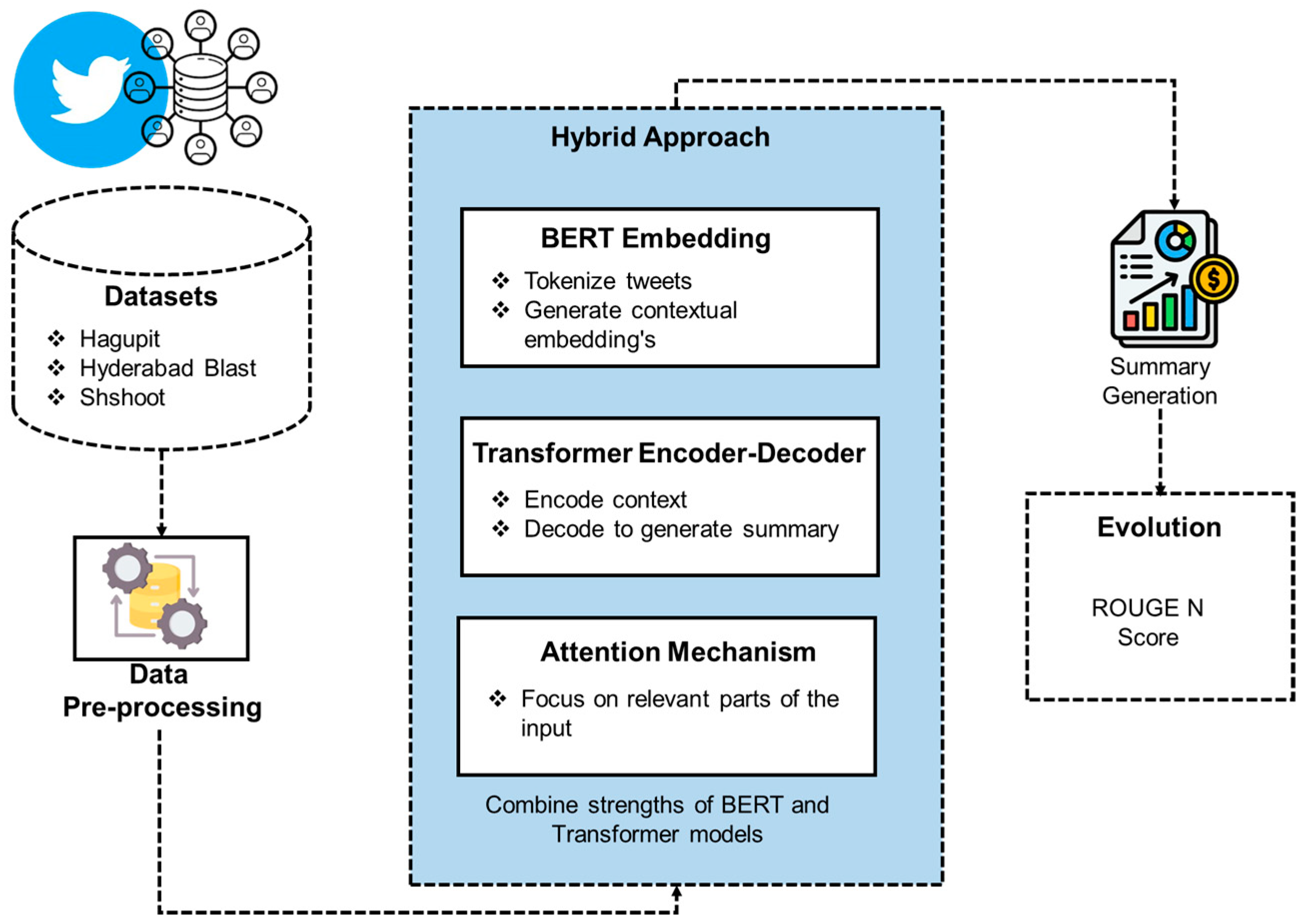
3. Proposed Framework for Short Text Summarization
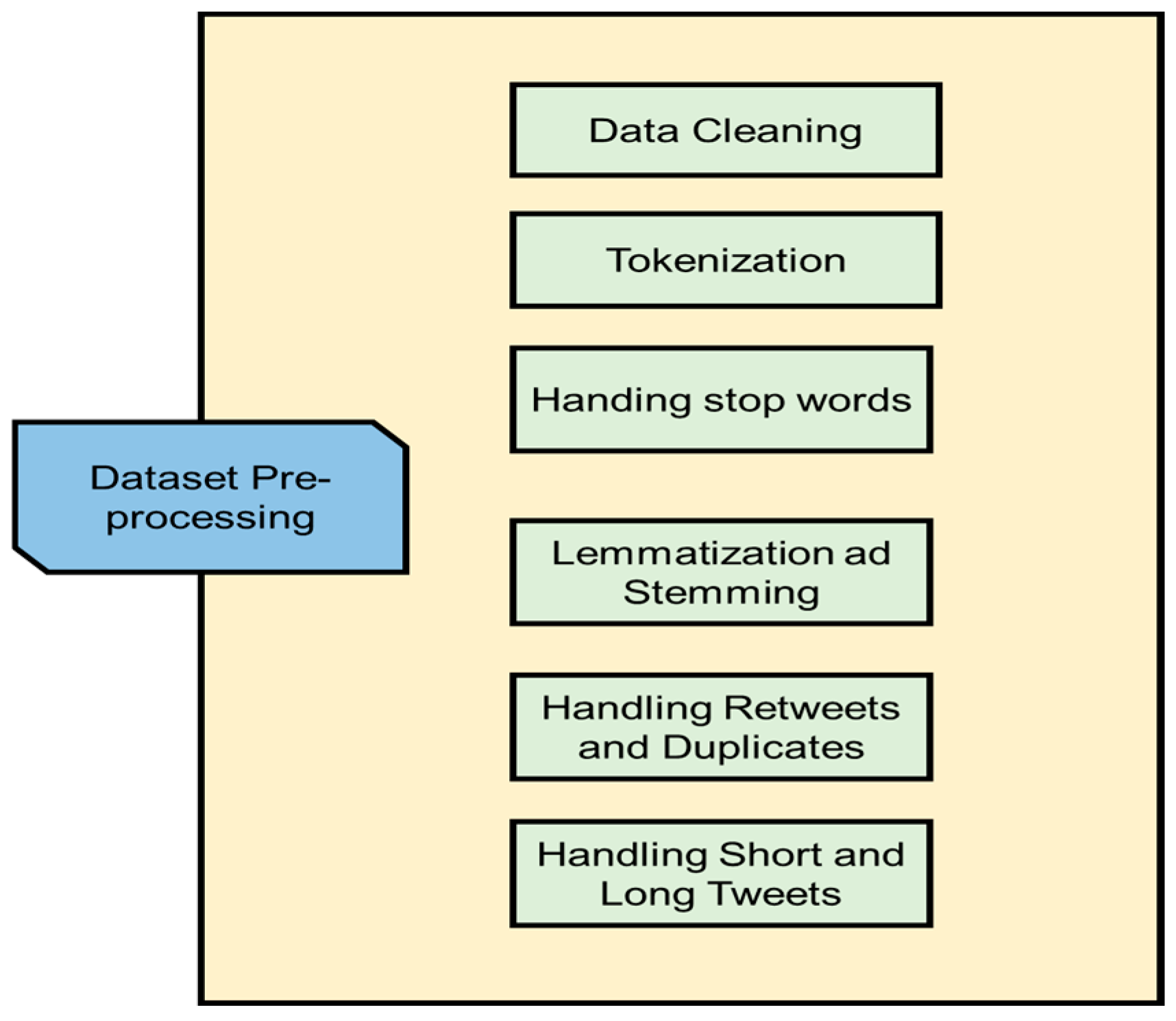
3.1. Data Collection and Preprocessing
- Typhoon Hagupit: A strong cyclone, namely, Typhoon Hagupit, hit the Philippines.
- https://cse.iitkgp.ac.in/~krudra/typhoon_hagupit_dataset.html (accessed on 8 November 2024)
- Sandy Hook Shooting (SHShoot): An assailant killed 20 children and 6 adults at the Sandy Hook Elementary School in Connecticut, USA.
- https://cse.iitkgp.ac.in/~krudra/sandyhook_shoot_dataset.html (accessed on 8 November 2024)
- Hyderabad Blast: Two bomb blasts in Hyderabad city of India.
- https://cse.iitkgp.ac.in/~krudra/hyderabad_blast_dataset.html (accessed on 8 November 2024)
- Data Cleaning:Unnecessary components such as URLs, hashtags, mentions, and special characters are removed, and the text is converted to lowercase for consistency. Emojis and emoticons are either replaced or removed depending on their relevance.
- Tokenization and Subword Representation:BERT’s tokenization process breaks down out-of-vocabulary terms into smaller subunits, while special tokens mark the beginning and end of sequences.
- Handling Stop Words and Lemmatization:Common stop words are removed, and lemmatization is used to reduce words to their base forms, ensuring the preservation of meaning.
- Padding and Truncation:Tweets are padded to meet the input size requirements of BERT, and longer tweets are truncated to ensure they fit within the model’s 512-token limit.
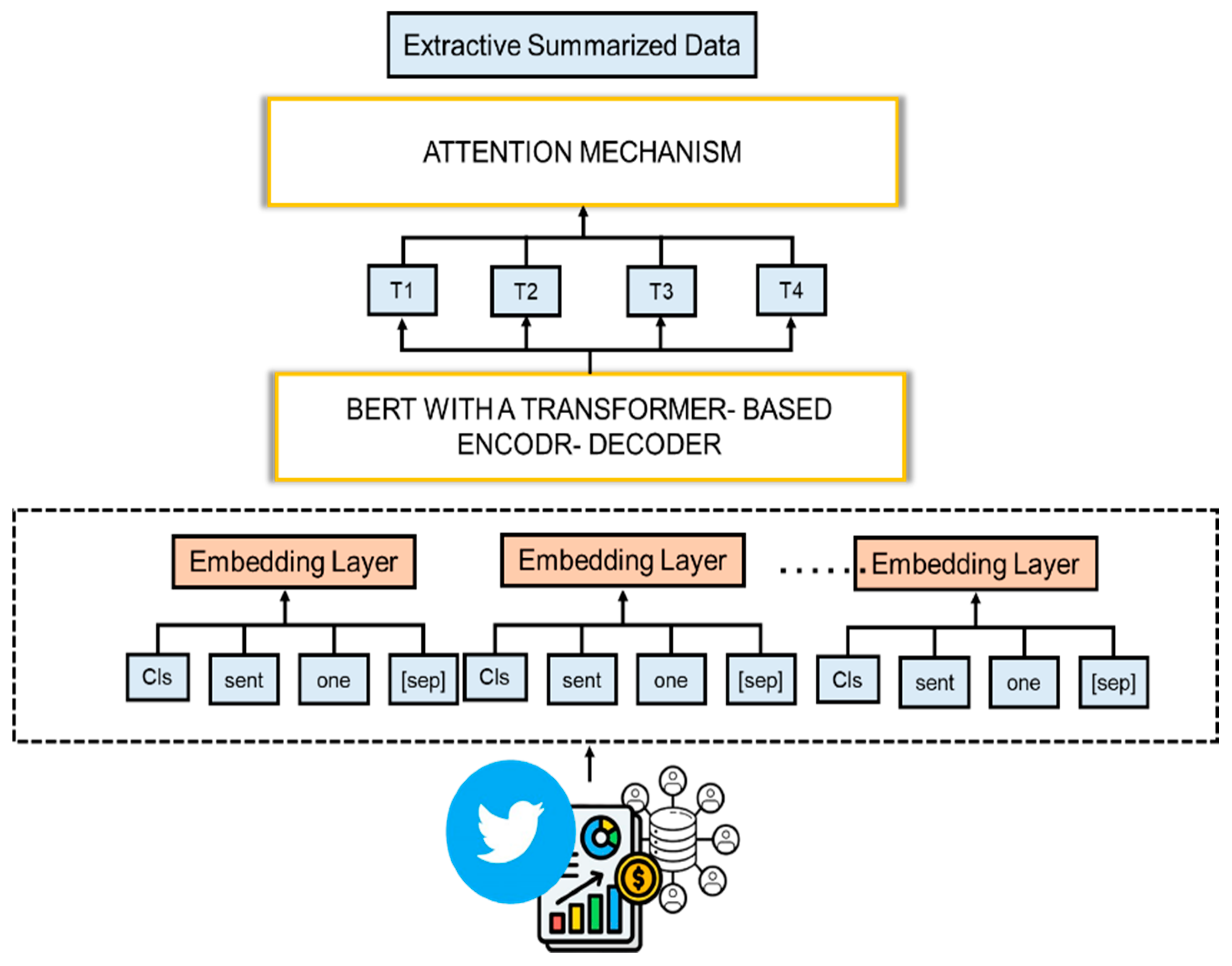
3.2. Hybrid BERT and Transformer Encoder–Decoder Architecture
3.2.1. Contextual Embedding with BERT
- BERT’s tokenizer processes the preprocessed tweets, generating token embeddings that capture the syntactic and semantic relationships within the text. The embeddings are context-aware and represent each token within the broader sentence-level context, ensuring that nuances specific to tweets are preserved [47].
- The embedding for each token, E, is generated by combining the token embedding Et, segment embedding Es, and positional embedding Ep, as represented by Equation (1):
3.2.2. Transformer Encoder–Decoder with Attention
- The transformer encoder processes the embeddings produced by BERT, leveraging its self-attention mechanism to capture long-range dependencies and relationships between tokens [48]. The self-attention mechanism computes the importance of each token pair using Equation (2):
- The encoder’s output is passed to the decoder, which generates summaries by processing the encoded context and iteratively predicting the next tokens in the sequence.
3.2.3. LSTM Integration for Sequential Learning
- LSTM units are incorporated into the architecture to enhance the model’s ability to capture sequential patterns and temporal dependencies. This is especially important for tweets, which often contain time-sensitive information and rely on the sequence of words to convey meaning.
3.2.4. Attention Mechanism for Relevance Focus
- An integrated attention mechanism selectively focuses on the most relevant parts of the input text, enabling the model to prioritize essential information while filtering out redundant or irrelevant details. This ensures that the generated summaries are concise yet highly informative.
3.3. Summary Generation and Evaluation
- ROUGE-1: Measures the overlap of unigrams.
- ROUGE-2: Measures the overlap of bigrams.
- ROUGE-L: Measures the longest common subsequences, reflecting fluency and coherence.
3.4. Advantages of the Proposed Framework
- Contextual Understanding: BERT’s bidirectional transformer effectively captures the nuanced semantics and syntactic structures in tweets, overcoming challenges posed by informal and noisy language.
- Relevance and Focus: The attention mechanism ensures that the summaries prioritize essential information, minimizing the inclusion of irrelevant content.
- Sequential Dependency Modeling: The integration of LSTM units enhances the model’s ability to understand temporal relationships, critical for tweets with event-driven content.
- Adaptability to Twitter Data: The preprocessing pipeline and hybrid architecture are specifically tailored to handle the brevity and diversity of Twitter data, ensuring high-quality summaries that are both concise and informative.
3.5. Pseudocode
4. Result and Discussion
4.1. Baseline Methods
- OntoDSumm [23]: Uses ontology-based techniques to improve summary quality by incorporating domain-specific knowledge.
- OntoRealSumm [51]: Integrates real-world ontologies for more contextually relevant summaries.
- SOM+GSOM [21]: A clustering-based approach that combines self-organizing maps (SOMs) with Generalized SOM (GSOM) to create clusters of text, facilitating the extraction of meaningful content for summaries.
- SOM+SOM [21]: Another variant of SOM. This method uses multiple layers of SOM to better model complex relationships between text segments.
- MOOTweetSumm [22]: A multi-objective extractive summarization approach for tackling the microblog summarization challenge.
- Stream-3GANSumm [26]: Uses multi-view data representations and a triple-generative adversarial network (3GAN) variant for real-time summarization.
- Rel-Cov-Red [52]: A multi-objective pruning approach extracts key concepts from opinionated content, using manifold learning and clustering to optimize relevancy, redundancy, and coverage.
- Rel-Red-Cov [52]: An extension of Rel-Cov-Red, it refines the coverage reduction process by balancing relevance and redundancy.
- ATSumm [29]: It is an abstractive disaster tweet summarization approach that enhances summary quality by integrating auxiliary information.
- IKDSumm [33]: It is an extractive summarization approach for disaster-related tweets, enhancing summary quality by leveraging key phrases and BERT.
4.2. Evaluation of Proposed Framework Performance
4.3. Discussions
4.4. Overall Observations
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ghanem, F.A.; Padma, M.C.; Alkhatib, R. Automatic Short Text Summarization Techniques in Social Media Platforms. Future Internet 2023, 15, 311. [Google Scholar] [CrossRef]
- Supriyono; Wibawa, A.P.; Suyono; Kurniawan, F. A survey of text summarization: Techniques, evaluation and challenges. Nat. Lang. Process. J. 2024, 7, 100070. [Google Scholar] [CrossRef]
- Widyassari, A.P.; Rustad, S.; Shidik, G.F.; Noersasongko, E.; Syukur, A.; Affandy, A.; Setiadi, D.R.I.M. Review of automatic text summarization techniques & methods. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 1029–1046. [Google Scholar] [CrossRef]
- Shakil, H.; Farooq, A.; Kalita, J. Abstractive text summarization: State of the art, challenges, and improvements. Neurocomputing 2024, 603, 128255. [Google Scholar] [CrossRef]
- Yadav, A.K.; Ranvijay; Yadav, R.S.; Maurya, A.K. State-of-the-art approach to extractive text summarization: A comprehensive review. Multimed. Tools Appl. 2023, 82, 29135–29197. [Google Scholar] [CrossRef]
- Baykara, B.; Güngör, T. Abstractive text summarization and new large-scale datasets for agglutinative languages Turkish and Hungarian. Lang. Resour. Eval. 2022, 56, 973–1007. [Google Scholar] [CrossRef]
- Mohiuddin, K.; Alam, M.A.; Alam, M.M.; Welke, P.; Martin, M.; Lehmann, J.; Vahdati, S. Retention is All You Need. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023; ACM: New York, NY, USA, 2023; pp. 4752–4758. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL HLT 2019–2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings of the Conference, Mineapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. Available online: http://arxiv.org/abs/1810.04805 (accessed on 8 November 2024).
- Saleh, M.E.; Wazery, Y.M.; Ali, A.A. A systematic literature review of deep learning-based text summarization: Techniques, input representation, training strategies, mechanisms, datasets, evaluation, and challenges. Expert Syst. Appl. 2024, 252, 124153. [Google Scholar] [CrossRef]
- Liu, Y.; Lapata, M. Text summarization with pretrained encoders. In Proceedings of the EMNLP-IJCNLP 2019–2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Proceedings of the Conference, Hong Kong, China, 10–13 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3730–3740. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. In Proceedings of the ACL 2017 55th Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference (Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; Volume 1, pp. 1073–1083. [Google Scholar] [CrossRef]
- Zhang, H.; Cai, J.; Xu, J.; Wang, J. Pretraining-Based Natural Language Generation for Text Summarization. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), Hong Kong, China, 3–4 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 789–797. [Google Scholar]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Sharma, G.; Sharma, D. Automatic Text Summarization Methods: A Comprehensive Review. SN Comput. Sci. 2022, 4, 33. [Google Scholar] [CrossRef]
- Balaji, N.; Deepa, K.; Bhavatarini, N.; Megha, N.; Sunil, K.P.; Shikah, R.A. Text Summarization using NLP Technique. In Proceedings of the 2022 International Conference on Distributed Computing, VLSI, Electrical Circuits and Robotics (DISCOVER), Shivamogga, Karnataka, India, 14–15 October 2022; pp. 30–35. [Google Scholar]
- Anand, D.; Wagh, R. Effective deep learning approaches for summarization of legal texts. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 2141–2150. [Google Scholar] [CrossRef]
- Jain, A.; Arora, A.; Morato, J.; Yadav, D.; Kumar, K.V. Automatic Text Summarization for Hindi Using Real Coded Genetic Algorithm. Appl. Sci. 2022, 12, 6584. [Google Scholar] [CrossRef]
- Ghanem, F.A.; Padma, M.C.; Abdulwahab, H.M.; Alkhatib, R. Novel Genetic Optimization Techniques for Accurate Social Media Data Summarization and Classification Using Deep Learning Models. Technologies 2024, 12, 199. [Google Scholar] [CrossRef]
- Ramachandran, D.; Ramasubramanian, P. Event detection from Twitter—a survey. Int. J. Web Inf. Syst. 2018, 14, 262–280. [Google Scholar] [CrossRef]
- Panchendrarajan, R.; Hsu, W.; Li Lee, M. Emotion-Aware Event Summarization in Microblogs. In Companion Proceedings of the Web Conference, Ljubljana, Slovenia, 19–23 April 2021; ACM: New York, NY, USA, 2021; pp. 486–494. [Google Scholar]
- Saini, N.; Saha, S.; Mansoori, S.; Bhattacharyya, P. Fusion of self-organizing map and granular self-organizing map for microblog summarization. Soft Comput. 2020, 24, 18699–18711. [Google Scholar] [CrossRef]
- Saini, N.; Saha, S.; Bhattacharyya, P. Multiobjective-Based Approach for Microblog Summarization. IEEE Trans. Comput. Soc. Syst. 2019, 6, 1219–1231. [Google Scholar] [CrossRef]
- Garg, P.K.; Chakraborty, R.; Dandapat, S.K. OntoDSumm: Ontology-Based Tweet Summarization for Disaster Events. IEEE Trans. Comput. Soc. Syst. 2024, 11, 2724–2739. [Google Scholar] [CrossRef]
- Huang, Y.; Shen, C.; Li, T. Event summarization for sports games using twitter streams. World Wide Web 2018, 21, 609–627. [Google Scholar] [CrossRef]
- Goyal, P.; Kaushik, P.; Gupta, P.; Vashisth, D.; Agarwal, S.; Goyal, N. Multilevel Event Detection, Storyline Generation, and Summarization for Tweet Streams. IEEE Trans. Comput. Soc. Syst. 2020, 7, 8–23. [Google Scholar] [CrossRef]
- Paul, D.; Rana, S.; Saha, S.; Mathew, J. Online Summarization of Microblog Data: An Aid in Handling Disaster Situations. IEEE Trans. Comput. Soc. Syst. 2024, 11, 4029–4039. [Google Scholar] [CrossRef]
- Garg, P.K.; Chakraborty, R.; Dandapat, S.K. PORTRAIT: A hybrid aPproach tO cReate extractive ground-TRuth summAry for dIsaster evenT. ACM Trans. Web 2025, 19, 1–36. Available online: http://arxiv.org/abs/2305.11536 (accessed on 4 April 2024). [CrossRef]
- Madichetty, S.; Muthukumarasamy, S. Detection of situational information from Twitter during disaster using deep learning models. Sādhanā 2020, 45, 270. [Google Scholar] [CrossRef]
- Garg, P.K.; Chakraborty, R.; Dandapat, S.K. ATSumm: Auxiliary information enhanced approach for abstractive disaster Tweet Summarization with sparse training data. arXiv 2024, arXiv:2405.06541. [Google Scholar] [CrossRef]
- Lin, C.; Ouyang, Z.; Wang, X.; Li, H.; Huang, Z. Preserve Integrity in Realtime Event Summarization. ACM Trans. Knowl. Discov. Data 2021, 15, 1–29. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Rudra, K. Towards an Interpretable Approach to Classify and Summarize Crisis Events from Microblogs. In Proceedings of the ACM Web Conference, Lyon, France, 25–29 April 2022; ACM: New York, NY, USA, 2022; pp. 3641–3650. [Google Scholar]
- Bansal, D.; Saini, N.; Saha, S. DCBRTS: A Classification-Summarization Approach for Evolving Tweet Streams in Multiobjective Optimization Framework. IEEE Access 2021, 9, 148325–148338. [Google Scholar] [CrossRef]
- Garg, P.K.; Chakraborty, R.; Gupta, S.; Dandapat, S.K. IKDSumm: Incorporating key-phrases into BERT for extractive disaster tweet summarization. Comput. Speech Lang. 2024, 87, 101649. [Google Scholar] [CrossRef]
- Rudra, K.; Goyal, P.; Ganguly, N.; Imran, M.; Mitra, P. Summarizing Situational Tweets in Crisis Scenarios: An Extractive-Abstractive Approach. IEEE Trans. Comput. Soc. Syst. 2019, 6, 981–993. [Google Scholar] [CrossRef]
- Sen, A.; Rudra, K.; Ghosh, S. Extracting situational information from microblogs during disaster events: A classification-summarization approach. In Proceedings of the 2015 7th International Conference on Communication Systems and Networks (COMSNETS), Bangalore, India, 6–10 January 2015; pp. 1–6. [Google Scholar]
- Abdel-Salam, S.; Rafea, A. Performance Study on Extractive Text Summarization Using BERT Models. Information 2022, 13, 67. [Google Scholar] [CrossRef]
- La Quatra, M.; Cagliero, L. BART-IT: An Efficient Sequence-to-Sequence Model for Italian Text Summarization. Future Internet 2022, 15, 15. [Google Scholar] [CrossRef]
- Zhao, Y.; Huang, S.; Zhou, D.; Ding, Z.; Wang, F.; Nian, A. CNsum:Automatic Summarization for Chinese News Text. arXiv 2025, arXiv:2502.19723. [Google Scholar] [CrossRef]
- Divya, S.; Sripriya, N.; Andrew, J.; Mazzara, M. Unified extractive-abstractive summarization: A hybrid approach utilizing BERT and transformer models for enhanced document summarization. PeerJ Comput. Sci. 2024, 10, e2424. [Google Scholar]
- Abadi, V.N.M.; Ghasemian, F. Enhancing Persian text summarization through a three-phase fine-tuning and reinforcement learning approach with the mT5 transformer model. Sci. Rep. 2025, 15, 80. [Google Scholar] [CrossRef] [PubMed]
- Papagiannopoulou, A.; Angeli, C. Encoder-Decoder Transformers for Textual Summaries on Social Media Content. Autom. Control Intell. Syst. 2024, 12, 48–59. [Google Scholar] [CrossRef]
- Kherwa, P.; Arora, J.; Sharma, T.; Gupta, D.; Juneja, S.; Muhammad, G.; Nauman, A. Contextual embedded text summarizer system: A hybrid approach. Expert Syst. 2025, 42, e13733. [Google Scholar] [CrossRef]
- Toprak, A.; Turan, M. Enhanced automatic abstractive document summarization using transformers and sentence grouping. J. Supercomput. 2025, 81, 1–30. [Google Scholar] [CrossRef]
- Murugaraj, K.; Lamsiyah, S.; Schommer, C. Abstractive Summarization of Historical Documents: A New Dataset and Novel Method using a Domain-Specific Pretrained Model. IEEE Access 2025, 13, 10918–10932. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, X.; Zhang, J. SummIt: Iterative Text Summarization via ChatGPT. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 10644–10657. [Google Scholar]
- Ghanem, F.A.; Padma, M.C.; Alkhatib, R. Elevating the Precision of Summarization for Short Text in Social Media using Preprocessing Techniques. In Proceedings of the 2023 IEEE International Conference on High Performance Computing & Communications, Data Science Systems, Smart City & Dependability in Sensor, Cloud & Big Data Systems Application (HPCC/DSS/SmartCity/DependSys), Melbourne, Australia, 17–21 December 2023; pp. 408–416. [Google Scholar]
- Bano, S.; Khalid, S.; Tairan, N.M.; Shah, H.; Khattak, H.A. Summarization of scholarly articles using BERT and BiGRU: Deep learning-based extractive approach. J. King Saud Univ.—Comput. Inf. Sci. 2023, 35, 101739. [Google Scholar] [CrossRef]
- Bano, S.; Khalid, S. BERT-based Extractive Text Summarization of Scholarly Articles: A Novel Architecture. In Proceedings of the 2022 International Conference on Artificial Intelligence of Things (ICAIoT), Istanbul, Turkey, 29–30 December 2022; pp. 1–5. [Google Scholar]
- Bani-Almarjeh, M.; Kurdy, M.-B. Arabic abstractive text summarization using RNN-based and transformer-based architectures. Inf. Process. Manag. 2023, 60, 103227. [Google Scholar] [CrossRef]
- Gray, D.; Bowes, D.; Davey, N.; Sun, Y.; Christianson, B. Further thoughts on precision. IET Semin. Dig. 2011, 2011, 129–133. [Google Scholar] [CrossRef]
- Garg, P.K.; Chakraborty, R.; Dandapat, S.K. OntoRealSumm: Ontology based Real-Time Tweet Summarization. arXiv 2022, arXiv:2201.06545. [Google Scholar] [CrossRef]
- Gudakahriz, S.J.; Moghadam, A.M.E.; Mahmoudi, F. Opinion texts summarization based on texts concepts with multi-objective pruning approach. J. Supercomput. 2023, 79, 5013–5036. [Google Scholar] [CrossRef]
- Lin, C.-Y. ROUGE: A Package for Automatic Evaluation of Summaries Chin-Yew. Text Summ. Branches Out 2004, 74–81. Available online: https://aclanthology.org/W04-1013/ (accessed on 4 April 2024).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Technology Used | Result | Advantages | Limitations |
|---|---|---|---|---|
| Zhang et al. [45] | SummIt with large language models (LLMs). | Improved controllability and faithfulness of summaries with human-like writing by using feedback mechanisms. | Self-evaluation improves the quality and human-likeness of summaries. | Requires extensive human assessment and training to refine models. |
| Paul et al. [26] | GAN-based clustering for disaster data summarization. | AI-based clustering of tweets during disasters, demonstrating GAN’s efficacy on large tweet datasets. | Effectiveness in handling large datasets, especially in crisis situations. | GAN-based method focused on disaster tweets, limiting broader applicability. |
| Garg et al. [29] | Auxiliary pointer generator network (AuxPGN) with key-phrase attention for ATSumm. | Achieved 4–80% improvement in ROUGE-N F1 scores across 13 disaster datasets compared to 10 state-of-the-art approaches. | Effectively addresses data sparsity using key phrases as auxiliary information; superior performance in disaster summarization. | Requires specialized key-phrase extraction process; potentially limited to disaster-related content. |
| Garg et al. [33] | IKDSumm framework for disaster-specific tweet summarization. | Demonstrated an approximate F1 improvement over current techniques across 12 disaster datasets. | Ensures coverage, relevance, and diversity in disaster-related tweet summaries. | Focused specifically on disaster-related tweets, potentially limited in general tweet summarization scenarios. |
| Garg et al. [23] | Ontology-based disaster tweet summarization. | Outperformed six state-of-the-art methods by 2–66% in terms of ROUGE-1 F1 score across 12 disaster datasets | Utilized domain knowledge via ontology for improved tweet categorization and summarization | Requires pre-defined domain-specific ontology; less adaptable to unseen or evolving categories |
| Experimental Setup | Details |
|---|---|
| Model | Hybrid BERT-LSTM with transformer-based encoder–decoder architecture (TEDA) |
| Task | Automatic short text summarization on Twitter |
| Dataset | Hagupit, SHShoot, Hyderabad Blast tweet datasets |
| Hardware | Laptop running Windows 11 |
| Processor | Intel Core i7 Evo 13th Gen |
| RAM | 16 GB |
| Software Environment | Python 3.10.1 |
| Evaluation Metrics | Precision, recall, F1 score, ROUGE score [50] |
| Implementation code | https://github.com/NLPSTS/BERT-and-TEDA- (accessed on 4 April 2024) |
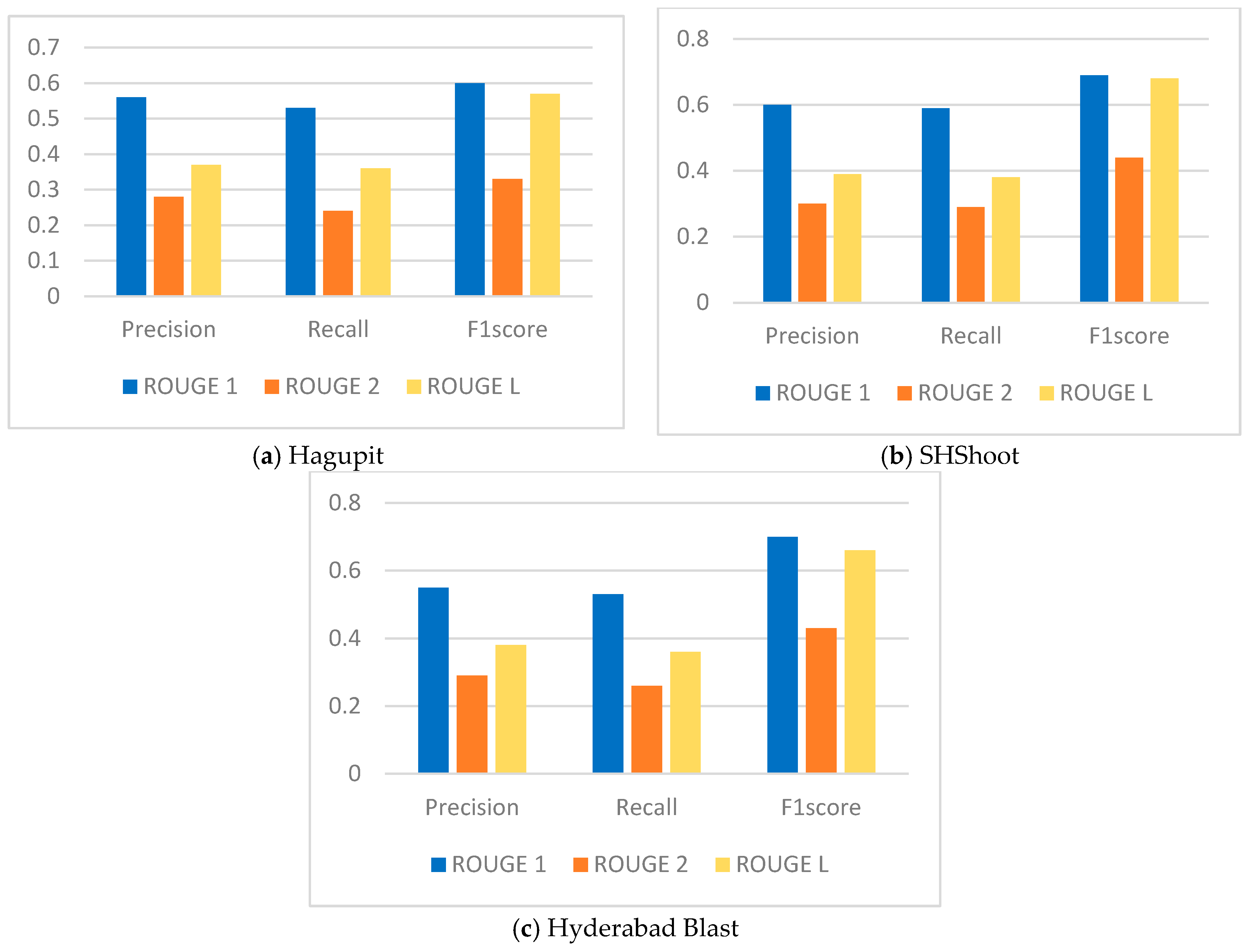
| Dataset | Precision | Recall | F1score | |
|---|---|---|---|---|
| Hagupit | 0.56 | 0.53 | 0.60 | |
| 0.28 | 0.24 | 0.33 | ||
| 0.37 | 0.36 | 0.57 | ||
| SHShoot | 0.60 | 0.59 | 0.69 | |
| 0.30 | 0.29 | 0.44 | ||
| 0.39 | 0.38 | 0.68 | ||
| Hyderabad Blast | 0.55 | 0.53 | 0.70 | |
| 0.29 | 0.26 | 0.43 | ||
| 0.38 | 0.36 | 0.66 |
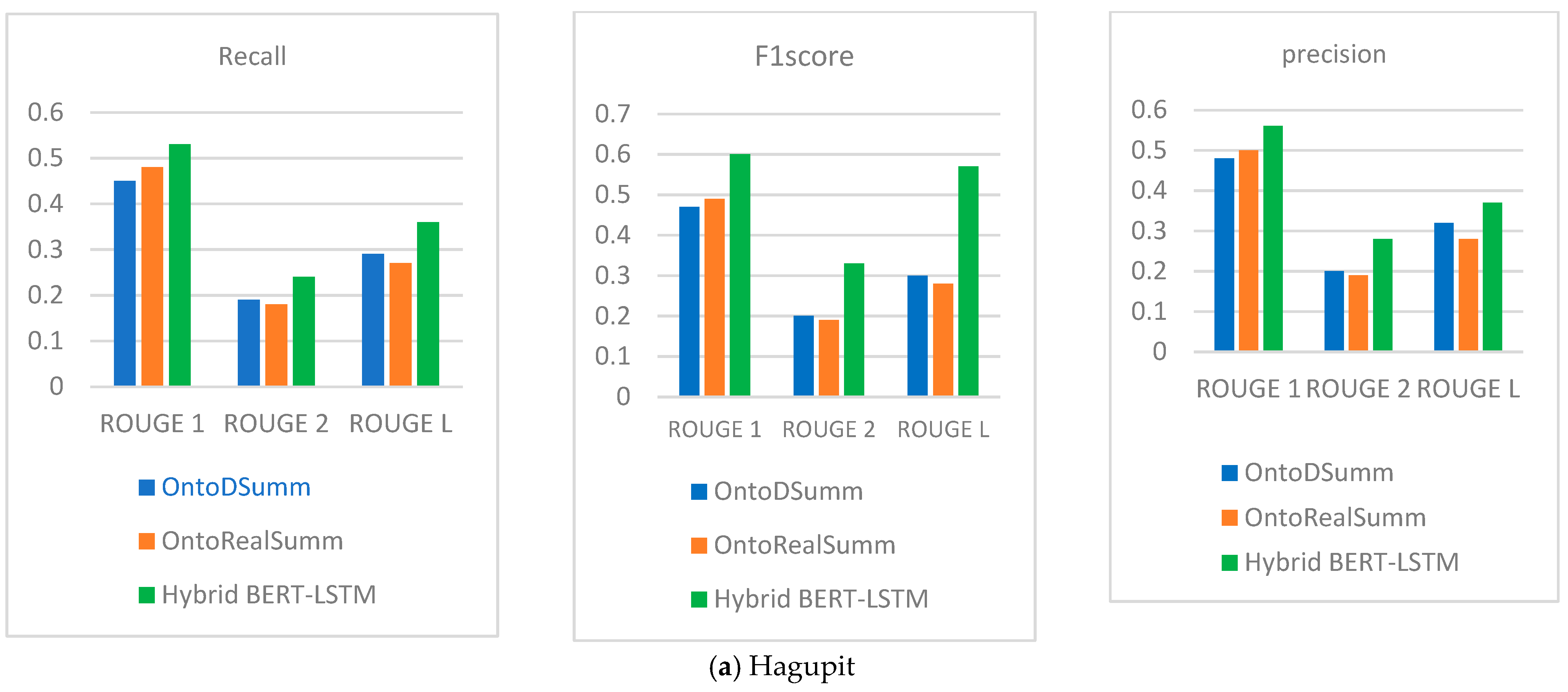
| Dataset | Technique | Measures | ROUGE 1 | ROUGE 2 | ROUGE L |
|---|---|---|---|---|---|
| Hagupit | OntoDSumm [23] | F1 score | 0.47 | 0.20 | 0.30 |
| Recall | 0.45 | 0.19 | 0.29 | ||
| Precision | 0.48 | 0.20 | 0.32 | ||
| OntoRealSumm | F1 score | 0.49 | 0.19 | 0.28 | |
| Recall | 0.48 | 0.18 | 0.27 | ||
| Precision | 0.50 | 0.19 | 0.28 | ||
| Hybrid BERT-LSTM | F1 score | 0.60 | 0.33 | 0.57 | |
| Recall | 0.53 | 0.24 | 0.36 | ||
| Precision | 0.56 | 0.28 | 0.37 | ||
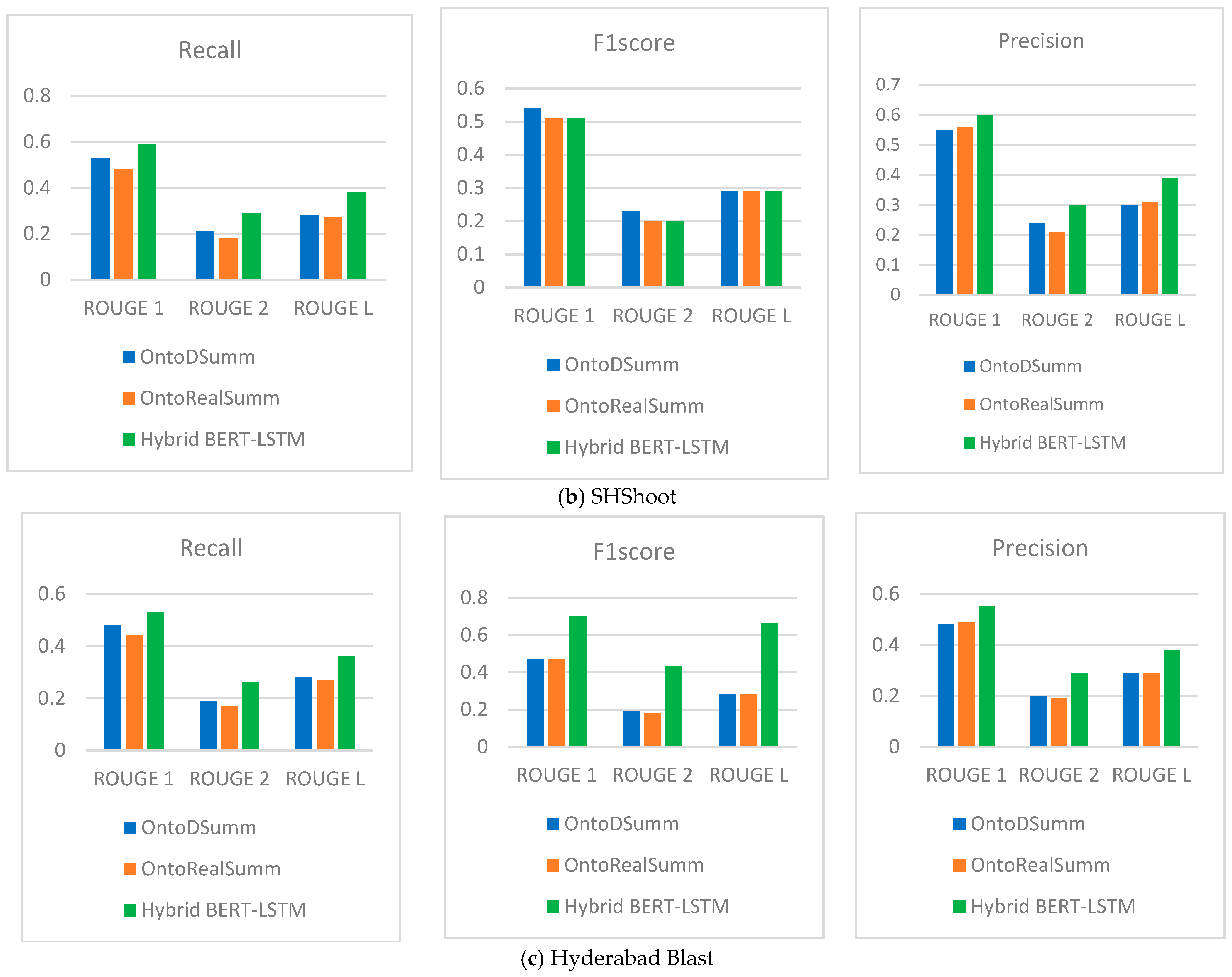
| SHShoot | OntoDSumm | F1 score | 0.54 | 0.23 | 0.29 |
| Recall | 0.53 | 0.21 | 0.28 | ||
| Precision | 0.55 | 0.24 | 0.30 | ||
| OntoRealSumm | F1 score | 0.51 | 0.20 | 0.29 | |
| Recall | 0.48 | 0.18 | 0.27 | ||
| Precision | 0.56 | 0.21 | 0.31 | ||
| Hybrid BERT-LSTM | F1 score | 0.69 | 0.44 | 0.68 | |
| Recall | 0.59 | 0.29 | 0.38 | ||
| Precision | 0.60 | 0.30 | 0.39 | ||
| Hyderabad Blast | OntoDSumm | F1 score | 0.47 | 0.19 | 0.28 |
| Recall | 0.48 | 0.19 | 0.28 | ||
| Precision | 0.48 | 0.20 | 0.29 | ||
| OntoRealSumm | F1 score | 0.47 | 0.18 | 0.28 | |
| Recall | 0.44 | 0.17 | 0.27 | ||
| Precision | 0.49 | 0.19 | 0.29 | ||
| Hybrid BERT-LSTM | F1 score | 0.70 | 0.43 | 0.66 | |
| Recall | 0.53 | 0.26 | 0.36 | ||
| Precision | 0.55 | 0.29 | 0.38 |
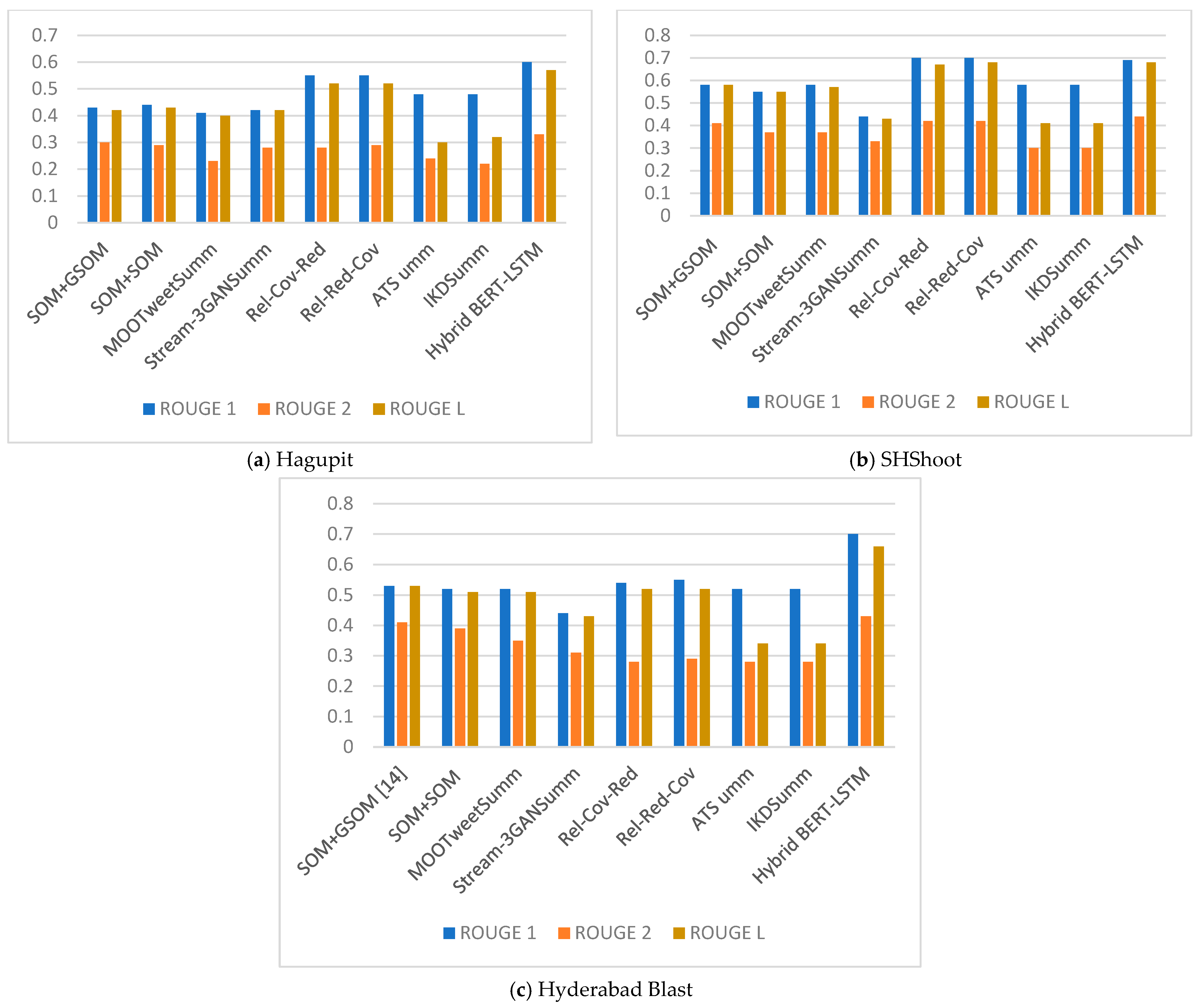
| Dataset | Technique | ROUGE 1 F1 Score | ROUGE 2 F1 Score | ROUGE L F1 Score |
|---|---|---|---|---|
| Hagupit | SOM+GSOM | 0.43 | 0.30 | 0.42 |
| SOM+SOM | 0.44 | 0.29 | 0.43 | |
| MOOTweetSumm | 0.41 | 0.23 | 0.40 | |
| Stream-3GANSumm | 0.42 | 0.28 | 0.42 | |
| Rel-Cov-Red | 0.55 | 0.28 | 0.52 | |
| Rel-Red-Cov | 0.55 | 0.29 | 0.52 | |
| ATSumm | 0.48 | 0.24 | 0.30 | |
| IKDSumm | 0.48 | 0.22 | 0.32 | |
| Hybrid BERT-LSTM | 0.60 | 0.33 | 0.57 | |
| SHShoot | SOM+GSOM | 0.58 | 0.41 | 0.58 |
| SOM+SOM | 0.55 | 0.37 | 0.55 | |
| MOOTweetSumm | 0.58 | 037 | 0.57 | |
| Stream-3GANSumm | 0.44 | 0.33 | 0.43 | |
| Rel-Cov-Red | 0.70 | 0.42 | 0.67 | |
| Rel-Red-Cov | 0.70 | 0.42 | 0.68 | |
| ATSumm | 0.58 | 0.30 | 0.41 | |
| IKDSumm | 0.58 | 0.30 | 0.41 | |
| Hybrid BERT-LSTM | 0.69 | 0.44 | 0.68 | |
| Hyderabad Blast | SOM+GSOM | 0.53 | 0.41 | 0.53 |
| SOM+SOM | 0.52 | 0.39 | 0.51 | |
| MOOTweetSumm | 0.52 | 0.35 | 0.51 | |
| Stream-3GANSumm | 0.44 | 0.31 | 0.43 | |
| Rel-Cov-Red | 0.54 | 0.28 | 0.52 | |
| Rel-Red-Cov | 0.55 | 0.29 | 0.52 | |
| ATS umm | 0.52 | 0.28 | 0.34 | |
| IKDSumm | 0.52 | 0.28 | 0.34 | |
| Hybrid BERT-LSTM | 0.70 | 0.43 | 0.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghanem, F.A.; Padma, M.C.; Abdulwahab, H.M.; Alkhatib, R. Deep Learning-Based Short Text Summarization: An Integrated BERT and Transformer Encoder–Decoder Approach. Computation 2025, 13, 96. https://doi.org/10.3390/computation13040096
Ghanem FA, Padma MC, Abdulwahab HM, Alkhatib R. Deep Learning-Based Short Text Summarization: An Integrated BERT and Transformer Encoder–Decoder Approach. Computation. 2025; 13(4):96. https://doi.org/10.3390/computation13040096
Chicago/Turabian StyleGhanem, Fahd A., M. C. Padma, Hudhaifa M. Abdulwahab, and Ramez Alkhatib. 2025. "Deep Learning-Based Short Text Summarization: An Integrated BERT and Transformer Encoder–Decoder Approach" Computation 13, no. 4: 96. https://doi.org/10.3390/computation13040096
APA StyleGhanem, F. A., Padma, M. C., Abdulwahab, H. M., & Alkhatib, R. (2025). Deep Learning-Based Short Text Summarization: An Integrated BERT and Transformer Encoder–Decoder Approach. Computation, 13(4), 96. https://doi.org/10.3390/computation13040096