Abstract
Background: The single-channel sleep EEG has the advantages of convenient collection, high-cost performance, and easy daily use, and it has been widely used in the classification of sleep stages. Methods: This paper proposes a single-channel sleep EEG classification method based on long short-term memory and a hidden Markov model (LSTM-HMM). First, the single-channel EEG is decomposed using wavelet transform (WT), and multi-domain features are extracted from the component signals to characterize the EEG characteristics fully. Considering the temporal nature of sleep stage changes, this paper uses a multi-step time series as the input for the model. After that, the multi-step time series features are input into the LSTM. Finally, the HMM improves the classification results, and the final prediction results are obtained. Results: A complete experiment was conducted on the Sleep-EDFx dataset. The results show that the proposed method can extract deep information from EEG and make full use of the sleep stage transition rule. The proposed method shows the best performance in single-channel sleep EEG classification; the accuracy, macro average F1 score, and kappa are 82.71%, 0.75, and 0.76, respectively. Conclusions: The proposed method can realize single-channel sleep EEG classification and provide a reference for other EEG classifications.
1. Introduction
Classification of sleep stages is essential for monitoring sleep quality and diagnosing related sleep disorders [1]. The American Academy of Sleep Medicine (AASM) divides sleep stages into five stages, namely wakefulness (W), rapid eye movement (REM), and non-REM (subdivided into N1, N2, and N3) [2]. Experts usually use polysomnography (PSG) to classify sleep stages. PSG includes electroencephalogram (EEG), electrooculogram (EOG), electromyogram (EMG), and electrocardiogram (ECG) [3]. Manual recognition of PSG takes time and effort. In addition, it is not easy to collect PSG, which is not conducive to daily family use [4]. Single-channel EEG signals are easy to collect, convenient for daily family use, and have received more attention in classifying sleep stages [5]. Therefore, proposing an automatic sleep stage classification method based on single-channel sleep EEG is significant.
Feature extraction and classification of single-channel EEG is the key to the automatic classification of sleep stages [6,7,8]. Venkat and colleagues [9] used wavelet packet decomposition to extract five sub-bands from EEG and then extracted Hjorth parameters and feature ratios between different bands from the sub-bands. Finally, K-nearest neighbor (KNN) and SVM were used to classify the sleep stages. Liu and colleagues [10] used ensemble empirical mode decomposition (EEMD) to decompose single-channel sleep EEG and then extracted time-domain features and nonlinear features from each intrinsic modal component (IMF). Jiang and colleagues [11] used empirical mode decomposition (EMD) to decompose single-channel EEG and then extracted multiple time domains, frequency domains, and nonlinear features from the first seven IMFs. Finally, RF was used to realize automatic sleep stage classification. The above studies used signal decomposition for feature extraction, which can fully utilize EEG information. However, the existing studies lacked comparative studies on different signal decomposition methods.
In recent years, more and more studies have shown that deep learning performs well in sleep EEG classification [5,12]. Sharma and colleagues [13] used a wavelet-scattering network to extract EEG features from a single-channel EEG and used a weighted K-nearest neighbor algorithm (WKNN) to classify sleep stages. Phan and colleagues [14] proposed a joint classification and prediction framework based on convolutional neural networks (CNN) and adopted a one-to-many classification strategy to realize automatic sleep EEG classification. Heng and colleagues [15] pointed out that the CNN could extract the time–frequency features of EEG signals, and the gated recurrent unit (GRU) could learn the transition rule of sleep stages. They built an end-to-end network based on CNN and GRU to achieve single-channel sleep EEG classification. Considering the potential regularity of sleep state transition, some studies have begun to use networks with temporal information-learning ability to classify single-channel sleep EEG, including long short-term memory (LSTM) and transformer [16]. LSTM can capture the timing information of signals and excels in processing sequential data with long-term dependencies [16]. The transformer network can learn contextual information, offering advantages in handling short sequences and enabling parallel computation [1]. Nevertheless, most existing studies primarily rely on single-step time data as the input for their models, which hampers the models’ capacity to effectively learn the transition rules between different sleep stages [17,18].
The method based on temporal networks can learn the sleep transition rules during the classification process and improve accuracy. However, due to the classifier’s limited performance, some misclassification is inevitable. According to the previous sleep state, some misidentified sleep states can be well corrected. Ghimatgar and colleagues [19] proposed a single-channel sleep EEG classification method based on the random forest (RF) and hidden Markov model (HMM). First, RF is employed to classify sleep EEG, and then, the HMM is used to learn the sleep transition rules. The experimental results validate the effectiveness of this approach. Networks such as LSTM and Transformer [1,18] are capable of learning sleep stage transition rules during classification, whereas HMM [11] focuses on understanding these transition rules post-classification. Consequently, this paper explores the combination of a temporal network with HMM to learn the sleep transition rules from both perspectives, which has the potential to enhance the classification accuracy of single-channel sleep EEG.
This paper proposed a single-channel sleep EEG classification method based on LSTM and HMM (LSTM-HMM). The contributions of this paper are as follows.
(1) We compared the performances of EMD, VMD, SSA, and WT in the decomposition of single-channel sleep EEG. Further, we analyzed the performance of twenty wavelet functions, which provided a reference for other researchers for EEG decomposition and feature extraction;
(2) The proposed method considered the temporal structure of the sleep stage transition from two perspectives. First, the multi-step time features and LSTM were used to learn the sleep transition rules during the classification. After classification, the HMM was used to find the most likely sleep state transition sequence and automatically corrected the results;
(3) The proposed method was fully verified on the Sleep-EDFx dataset. The results show that WT can extract deep information from EEG. The proposed method can achieve high-precision sleep EEG classification using the sleep stage transition rules and is superior to most existing methods.
2. Method
The single-channel EEG classification method proposed in this paper based on LSTM-HMM is shown in Figure 1. The proposed method can be divided into four stages, namely EEG segmentation, EEG feature extraction, EEG classification, and HMM-based correction. First, the entire night’s sleep EEG signals were segmented into 30 s segments. Then, the EEG was decomposed by WT, and the time domain, frequency domain, and nonlinear feature were extracted. After that, the multi-step time features were input into the LSTM network to realize sleep EEG classification. Finally, the predicted sleep state sequence throughout the night was input into the HMM, and the hidden state sequence with the most significant probability was obtained, which is the final prediction result.
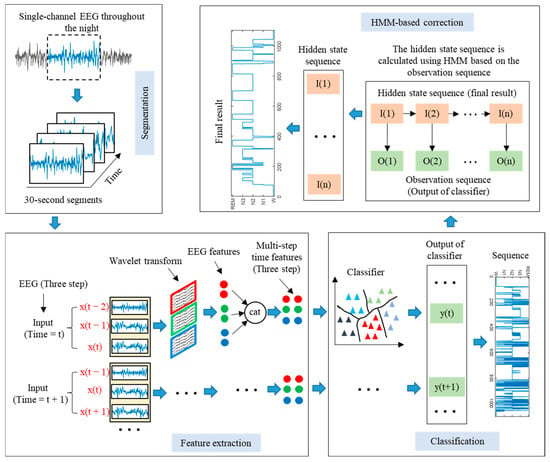
Figure 1.
Framework of proposed method.
2.1. EEG Decomposition Based on Wavelet Transform
The spatial resolution of the single-channel EEG is low, and the information obtained directly is small. Before feature extraction, this paper uses the decomposition method to decompose single-channel EEG signals to extract more hidden information. WT is a time–frequency decomposition positioning technique that decomposes signals through stretched and shifted wavelet functions [20]. Compared with EMD, VMD, and SSA, WT can provide better time–frequency positioning [21]. In addition, the most helpful information in sleep EEG is concentrated in low-frequency components below 30 HZ, and WT has significant advantages in extracting accurate low-frequency data [22]. This paper uses discrete wavelet transform (DWT) to decompose the single-channel EEG signal. The DWT is defined as follows:
where represents the signal and represents the wavelet function. and represent the scale and displacement parameters. Using k-layer DWT to decompose the single-channel EEG , the k + 1 sub-bands are obtained.
where and represent the low-frequency and high-frequency components of the EEG. The EEG is usually divided into five rhythmic waves; the lowest frequency rhythmic wave is delta (0–4 HZ). In order to excavate the hidden information of the EEG as much as possible, avoid excessive decomposition layers to increase the computing load. The signal decomposition is complete when the low-frequency component is in the delta. In this paper, the Sleep-EDFx dataset is used for the experiments. The sampling frequency of the EEG is 100 HZ, so a four-layer DWT is designed to decompose the EEG. The distribution of sub-bands is shown in Figure 2.
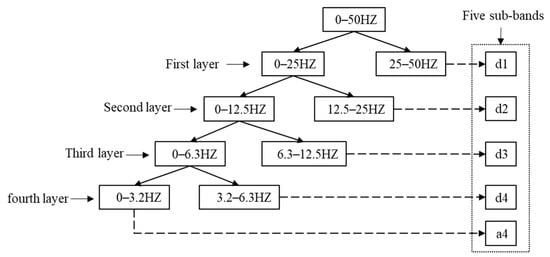
Figure 2.
Sub-band distribution of EEG decomposed with four-layer DWT.
Different wavelet functions (WF) can affect the decomposition results of EEG [21,23]. This paper analyzed the performance of 20 different wavelet functions in EEG decomposition, which can provide a reference for other EEG-related research. The detailed information on the WF is shown in Table 1.

Table 1.
Specific information on wavelet function.
2.2. Time Domain, Frequency Domain, and Nonlinear Feature Extraction
The single-channel EEG signal was decomposed to obtain five sub-bands, as shown in Figure 2. After that, multiple time domains, frequency domains, and nonlinear features are extracted from the five sub-bands to explore the EEG information fully. The EEG features extracted in this paper are shown in Table 2. For an EEG with length , the specific calculation of feature extraction is as follows.
Table 2.
Time domain, frequency domain, and nonlinear features.
2.2.1. Time Domain Features
Time domain features can provide the characteristics of signals in the time domain [9]. The time-domain features extracted in this paper can be divided into statistical and Hjorth parameters. The statistical parameters include the absolute mean value (MA), standard deviation (Std), skewness (Ske), and kurtosis (Kur) of EEG [10].
Hjorth parameters measure the characteristics of signals in the time domain from three aspects, namely activity (HA), mobility (HM), and complexity (HC).
2.2.2. Frequency Domain Features
Frequency domain analysis requires the conversion of the EEG from the time domain to the frequency domain. This paper converts the time domain EEG signal into the frequency domain with the fast Fourier transform [24]. After that, the statistical parameters of the signal in the frequency domain are extracted, namely the mean, standard deviation, skewness, kurtosis, and mean square value. In addition, the power spectral density (PSD) of the signal is calculated, and the average power spectral density (Mpsd) and power (P) are extracted from the PSD [16].
where represents frequency. In addition, the power ratio between five sub-bands is extracted: , , , , , , , , , .
2.2.3. Nonlinear Features
An EEG is a typical nonlinear signal, so the nonlinear features can measure the nonlinearity of EEG [23]. This paper extracted five nonlinear features, namely approximate entropy (AE), differential entropy (DE), Shannon entropy (SE), CO complexity (CC), and fractal dimension (FD) [10].
- (1)
- Approximate entropy (AE)
AE is used to quantify the regularity and unpredictability of signal fluctuations [24]. First, the m-dimension reconstruction of EEG is carried out:
Define the distance between and as:
Given the threshold , count the number of :
Define as:
Finally, the AE of the EEG is obtained:
- (2)
- Shannon entropy (SE)
SE is used to measure the uncertainty ratio of a signal [25]. The greater the SE, the greater the randomness of the signal. SE is defined as:
where represents the probability of the occurrence of a random event .
- (3)
- Differential entropy (DE)
DE is a generalization of Shannon entropy on continuous variables. EEG approximately follows a Gaussian distribution , and its DE is [26]:
- (4)
- CO complexity (CC)
CC is used to measure the degree of irregularity of the signal [27]. First, Fourier transforms the signal and calculates the average value of the power spectrum:
where represents the result of the Fourier transform of EEG. After that, define a new sequence:
Finally, the CO complexity of EEG is obtained:
where represents the inverse Fourier transform result of .
- (5)
- Fractal dimension (FD)
The FD measures the complexity of a signal from the perspective of chaotic dynamics. In this paper, the Higuchi method is used to calculate the FD [11]. First, the signal is converted into sequences:
where . Define the length of each sequence as:
After that, the average of each sequence length is calculated:
Given the interval , calculate the corresponding . and are fitted linearly, and the slope of the linear fitting is the fractal dimension of EEG.
2.3. Classifier
The extracted features are reconstructed into multi-step time features and input into the classifier to realize sleep EEG classification. Ten classifiers are used in this paper, namely radial basis function support vector machine (RBFSVM), linear function support vector machine (LFSVM), random forest (RF), decision tree (DT), naive Bayes (NB), K-nearest neighbor (KNN), convolutional neural network (CNN), long short-term memory (LSTM), bidirectional LSTM (Bi-LSTM), and transformer encoder (TE).
- (1)
- Support vector machine
SVM is a machine-learning method based on statistical learning theory, which performs well for small sample data [28]. The core idea of SVM is to construct an optimal hyperplane in the projection space, separate different types of data, and maximize the distance between the two types of data [23]. Different kernel functions will affect the performance of SVM. This paper uses the radial basis function and linear function as kernel functions:
where represents the bandwidth of the kernel function. The penalty factor and kernel bandwidth of the support vector machine are set to and , respectively.
- (2)
- Random forest
RF is an ensemble-learning model based on the Bagging strategy, which has better robustness to noise, lower complexity, and faster computing speed [22]. There are many classification trees in the RF. Each classification tree classifies the samples during decision-making and determines the sample category according to the voting results [19]. The two cores of RF are sample randomness and feature randomness [12]. Sample randomization refers to sampling some samples randomly from the original dataset to form some sub-datasets. Feature randomization means that, when selecting the optimal feature, only the subset of features selected randomly is considered rather than all of the features. The RF’s tree number and depth are set to 60 and 10, respectively, and the classification tree is constructed using the C4.5 algorithm.
- (3)
- Decision tree
DT is a model that displays decision rules and classification results with a tree-like data structure [23]. The DT consists of a root node and several internal and several leaf nodes. Each internal node represents a test of a feature attribute. Each branch represents the test result, and each leaf node represents the decision result. In this paper, the C4.5 algorithm is used to generate the DT. The C4.5 algorithm uses the information gain ratio to discretize continuous features, thus achieving feature selection [29]. The number depth of the DT is set to 10.
- (4)
- Naive Bayes
NB is a classification method based on Bayes’ theorem and feature independence assumption [30]. The core idea of NB is to use Bayes’ theorem to calculate the conditional probability that a given sample belongs to a class :
where represents the feature of the sample. When is maximum, the corresponding class is the class of the given sample.
- (5)
- K-nearest neighbor
KNN is a distance-based classification method [9]. For a given sample, The KNN first finds K samples closest to the given sample by calculating the distance between the given sample and the known sample, which are called neighbors. Finally, the sample is classified as the class with the most occurrences among K’s nearest neighbors [20]. The nearest neighbor of KNN is set to 5. For two samples and , the Euclidean distance is used to measure the distance between the samples:
- (6)
- Convolutional neural network
CNN is a deep feed-forward neural network with a local connection and weight sharing, which is widely used in EEG classification [2]. CNN usually contains the input, convolutional, activation, pooling, fully connected, and output layers [14]. In this paper, a shallow CNN model is designed for EEG feature classification, and the model structure is shown in Figure 3.
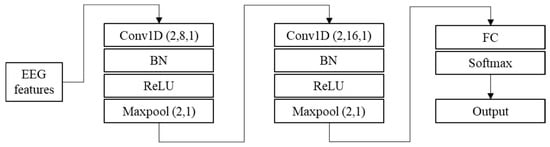
Figure 3.
Structure of CNN.
- (7)
- Long short-term memory
LSTM is a classical recurrent neural network that performs well in sequence data processing [18]. LSTM introduces the forgetting gate, input gate, and output gate based on traditional recurrent neural networks to control the flow of information, which can effectively solve the long-term dependence problem. The model structure is shown in Figure 4. The “hidden-size” and “num-layers” of LSTM in this paper are set to 20 and 1, respectively. The Bi-LSTM network consists of two independent LSTM layers that handle time series’ forward and reverse flow, respectively. The “hidden-size” and “num-layers” of Bi-LSTM in this paper are set to 10 and 1, respectively.
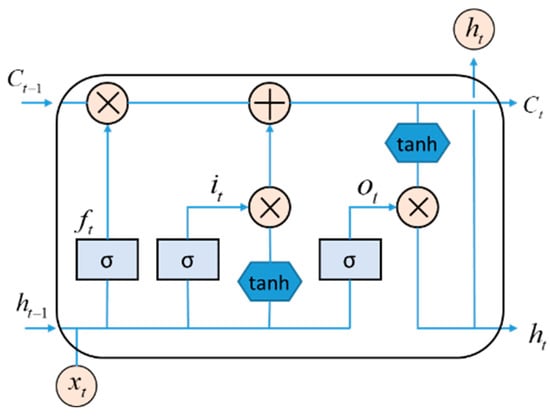
Figure 4.
Structure of LSTM.
- (8)
- Transformer encoder
The transformer is composed of an encoder and decoder and is a sequence model based on the self-attention mechanism [1]. This model is mainly used for various natural language processing tasks, such as translation and text generation, and is also gradually applied to time series prediction. This paper uses the transformer encoder (TE) to classify single-channel sleep EEG. The model structure is shown in Figure 5. The “nhead” and “num-layers” of TE in this paper are set to 3 and 3, respectively.
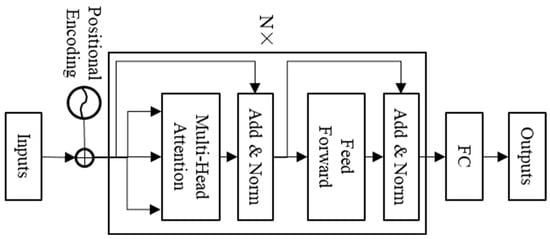
Figure 5.
Structure of transformer encoder model.
2.4. HMM-Based Correction
The transition of sleep states has an apparent time structure. That is, the sleep state of the next stage is related to the sleep state of the previous stage [17]. Therefore, it is possible to correct some of the misclassified sleep states by observing previous sleep states. However, manual recognition of misclassified sleep states is time-consuming and subjective. Some studies have pointed out that HMM can learn the sleep transition rule and realize the adaptive correction of misclassified sleep states. Therefore, HMM is used in this paper to self-correct the prediction results [31]. The structure of the HMM is shown in Figure 6. represents the sequence of hidden states, and the corresponding set is . represents the sequence of observed states, and the corresponding set is . The hidden state sequence is not visible, and the observed state sequence is visible.
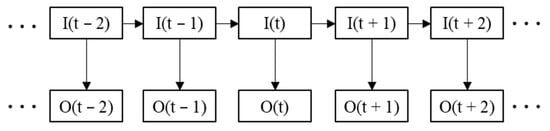
Figure 6.
Structure of the HMM.
The HMM can be represented using a set of parameters [15]. is the hidden state probability matrix, representing the probability of the current hidden state moving to the next hidden state. is the observation probability matrix, representing the probability distribution corresponding to different observation results under the current hidden state. is the initial probability distribution of the hidden states.
The classifier’s output is defined as the observed state sequence of the HMM, and the actual sleep state transition sequence is defined as the hidden state sequence of the HMM. According to the sleep stage division rule, the set of hidden and observed states in this paper is defined as . During the model’s training, the dataset is divided into three parts, namely the training set, the validation set, and the test set. The training set is used to train the classifier model, and then, the trained classifier is used for the validation set. The predicted sequence and the actual sleep state sequence on the validation set are taken as the observed state sequence and hidden state sequence of the HMM. Then, the hidden state transition probability matrix and the observed probability matrix of the HMM are calculated using the maximum likelihood estimation.
where represents the number of times the hidden state sequence transitions from to . represents the number of times the observation state is when the hidden state is . and represent the length of the hidden and observed state sets, respectively, with in this paper. Since the sleep process begins in an awake state, the initial probability distribution is set to . Through the above methods, the HMM is successfully constructed.
In the test phase, the feature of the test set is input into the trained classifier model, and the prediction result is obtained. Currently, the test set’s prediction result is the observed state sequence , and the corresponding hidden state sequence is the final prediction result. Then, for the trained HMM model and the prediction result , the final prediction result is:
In this paper, the Viterbi algorithm [32] is used to solve the most likely hidden state sequence.
3. Sleep EEG Dataset
The Sleep-EDF database expanded (Sleep-EDFX, 2013 version) published on PhysioNet was used for the experiment [33]. The dataset consisted of two subsets, and this paper used the sleep cassette. Twenty healthy subjects (age: 28.65 ± 8.65, 10 males) participated in the experiment. Subject 13 collected the EEG for one night, and the other subjects collected the EEG for two nights, totaling 39 EEG signals for the whole night. The experiment collected EEG signals of Fpz-Cz and Pz-Oz channels, and the sampling frequency was 100 HZ. In this paper, the EEG signal of the Fpz-Cz channel is used for experimental verification. A trained technician manually scores the corresponding sleep EEG (sleep pattern) according to the Rechtschaffen and Kales manuals. Finally, the technician labeled the sleep states at 30 s intervals according to the R&K rules: W, N1, N2, N3, N4, REM, MOVEMENT, and UNKNOWN.
In the data preprocessing stage, a bandpass filter of 0.5–100 HZ is used to reduce the noise of the EEG. According to the AASM modified sleep classification criteria, we discard the MOVEMENT and UNKNOWN tags in the dataset. The N3 and N4 stages were merged into N3, and the sleep state was divided into five stages, namely W, N1, N2, N3, and REM. The EEG was segmented for 30 s, with 3000 sampling points per segment, and mapped to the labeled sleep stages. The 30 s EEG fragments corresponding to different sleep states are shown in Figure 7. Since nearly 24 h of EEGs were collected in the experiment, it was necessary to divide the night sleep time. In this paper, the EEG between staying awake for 30 min before falling asleep and staying awake for 30 min after waking up was intercepted, and the EEG of about 9 h was generally divided. The number of samples corresponding to each sleep stage in the dataset is shown in Table 3.
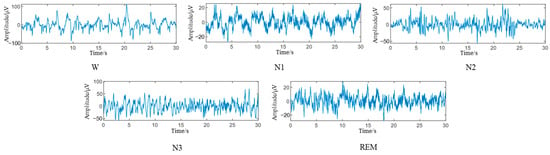
Figure 7.
EEG at different sleep stages.
Table 3.
Number of samples for each sleep stage.
4. Results
4.1. Experimental Setup
In this paper, four-layer wavelet decomposition is designed to extract multi-domain EEG features, and the dimension of single-step time features is 1 × 105. We use the multi-step time feature matrix as the model’s input to enable the network to learn the sleep stage transition rules in the classification process. The dimension of the multi-step time feature matrix is T × 105, where T represents the step length. The time step designed in this paper is 3, so the dimension of the multi-step time feature matrix is 3 × 105. It should be noted that, for the traditional machine-learning model, the multi-step time feature matrix needs to be converted into a one-dimensional vector, so it is difficult for the traditional machine-learning model to learn the sleep transition rules during the classification process.
Ten-fold cross-validation was used for experimental verification. The 39-night EEG data were divided into ten pieces, one of which was taken as the test data each time, and the other nine were taken as the training data. During model training, 20% of the training data was divided into a validation set, which was used to verify model performance and build the HMM. The test set was used to test model performance and was not used during model training. The mean value of cross-validation was used as the model’s evaluation indicator. The accuracy (ACC), macro average F1 score (MF1), and Coenkappa coefficient (kappa) were used as evaluation indicators [19,20,21]. All algorithms were completed on MATLAB 2019 and an Intel(R) Core(TM) i7-9750H CPU, 2.6 GHz.
where , , and represent true positive, false positive, and false negative, respectively. represents the overall accuracy, represents the total number of samples. represents the number of categories, and represents the accidental consistency error.
4.2. Comparison of Different Decomposition Methods
First, the performance of WT, EMD, VMD, and SSA in EEG decomposition is analyzed. The relevant parameters of the algorithm are set as follows. The number of decomposition layers of WT is four, and the wavelet function is db4. The first six intrinsic mode functions (IMFs) in the EMD are selected for calculation in this paper. The number of decomposition layers for VMD and SSA is set to six to ensure that the number of IMFs is the same as that of EMDs.
WT, EMD, VMD, and SSA were used to decompose the first EEG fragment of subject 1, and the results are shown in Figure 8. All four methods can extract the low-frequency and high-frequency components of EEGs. The components of EMD and VMD are more concentrated in the frequency band below 10 HZ, and there is a lack of component information above 10 HZ. The components of WT and SSA are evenly distributed at 0–50 HZ, but the mode aliasing of SSA is severe. The results of signal decomposition show that WT can extract more comprehensive brain frequency band information, and the mode aliasing is not severe.
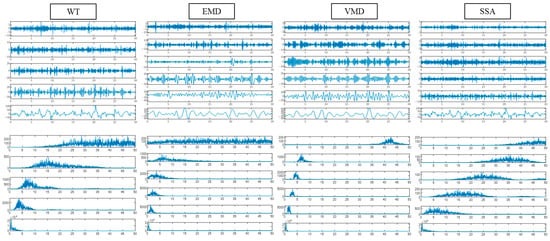
Figure 8.
Component signal and spectral diagram of different signal decompositions.
EEG features were extracted based on WT, EMD, VMD, and SSA, and then, the LSTM was used for EEG classification. The results are shown in Figure 9. It can be seen from the figure that the ACC, MF1, and kappa values of the WT-based method are 81.66%, 0.74, and 0.74, respectively, which are higher than that for other methods. The confidence interval of the WT-based method is lower than that of EMD, VMD, and SSA, indicating that the WT-based method is more stable in single-channel sleep EEG. The results show that WT is suitable for single-channel sleep EEG.
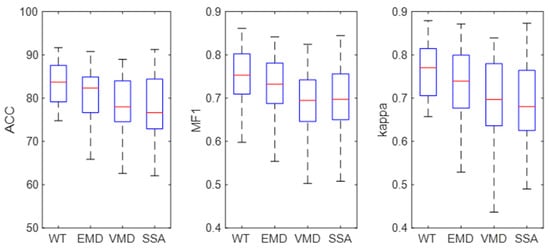
Figure 9.
Classification results of different decomposition methods.
4.3. Classification Results of Different Classifiers
Different classifiers are used to classify the multi-step time features, and the results are shown in Table 4. It can be found from the table that the classification accuracies of LSTM, Bi-LSTM, and TE are higher than 81%, while the classification accuracies of other models are lower than 81%. The results show that, based on the multi-step time feature and timing model, the potential sleep transition rules can be learned during the classification process, which improves the classification accuracy.
Table 4.
Classification accuracy of different classifiers.
Figure 10 shows the ROC curves of the different methods. The area under the ROC curve (AUC) of LSTM, Bi-LSTM, and TE is 0.97, which is higher than that of the other classifiers. The results indicate that the method based on multi-step time features and the time series network can improve single-channel sleep EEG classification accuracy.
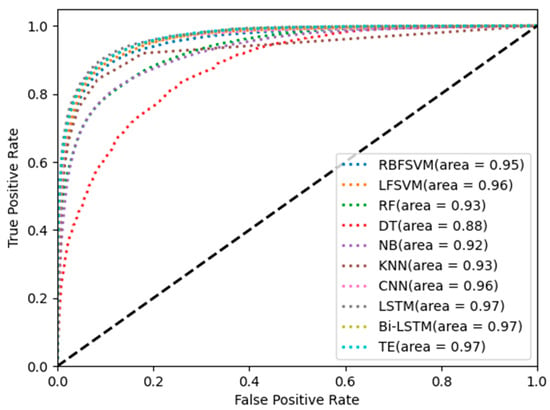
Figure 10.
ROC curves of different methods.
Figure 11 shows the box diagram of the results. It can be found from the figure that the upper and lower limits of DT differ greatly, indicating that DT has poor robustness. The upper and lower limits of the other methods have little difference, which suggests that these methods are robust. The median of accuracy, MF1, and kappa of LSTM are slightly higher than those of the other methods. Meanwhile, the lower limits of accuracy, MF1, and kappa of the LSTM are higher than those of the other methods, which indicates that the performance of the LSTM is superior to other methods.
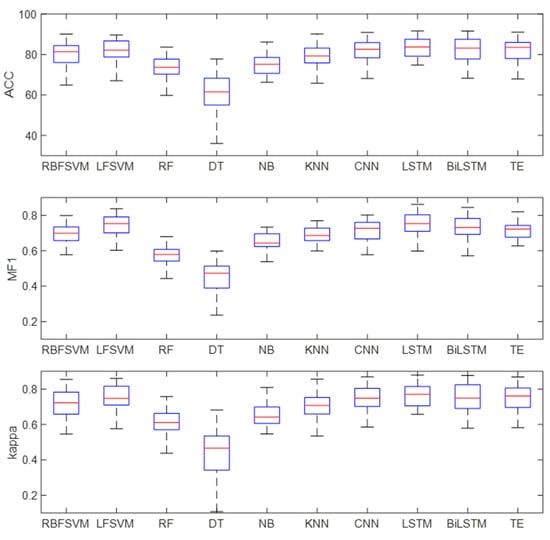
Figure 11.
Classification results of different classifiers.
4.4. Performance Analysis of HMM
After classification, the HMM is used to correct the classification results. To verify the effectiveness of HMM, the EEG classification results were compared before and after HMM processing, as shown in Table 5. It can be seen from the table that the ACC, MF1, and kappa improved after HMM processing. The LSTM performed best among the three classifiers; the classification accuracy, MF1, and kappa are 82.71%, 0.75 and 0.76, respectively. After HMM processing, the classification accuracy, MF1, and kappa of LSTM increased by 1.05%, 0.01, and 0.02, respectively, indicating that HMM can use the sleep transition rules to achieve adaptive correction of the classification results.
Table 5.
Classification results before and after HMM.
Figure 12 shows the box diagram of the classification results. It can be seen from the figure that, after HMM processing, the median values of ACC, MF1, and kappa increased, and the lower limit of MF1 and kappa of the Bi-LSTM and transformer also increased. The results show that the HMM can use sleep transition rules to improve the classification results and that it has good robustness.
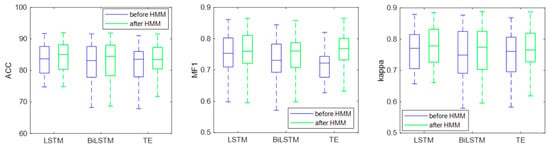
Figure 12.
Classification results before and after HMM.
Figure 13 shows the confusion matrix of the classification results. It can be found from the figure that there exists an imbalance in the data, in which the data number of N1 is about 2000, and the data number of other categories is greater than 5000. The number of correctly identified N1 is less than 50%, and the number of correctly identified remaining categories is more than 80%, which indicates that the classification accuracy of N1 is low. After HMM processing, the number of N1 correctly identified increased, which indicated that HMM was conducive to the classification of N1.
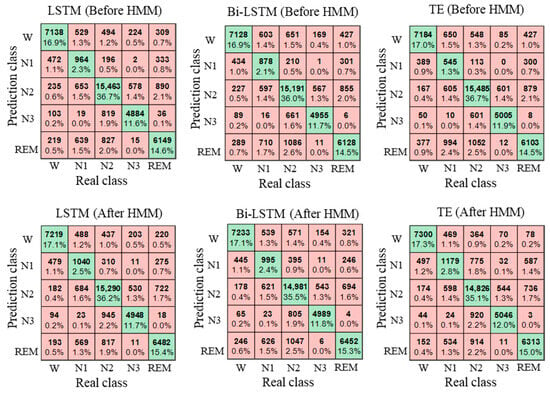
Figure 13.
Confusion matrix of classification results.
4.5. Effect of Wavelet Function on the Method
Figure 14 shows the classification results under different wavelet functions. Horizontal coordinates 1 through 20 represent {‘bior11’, ‘bior22’, ‘bior33’, ‘bior44’, ‘coif1’, ‘coif2’, ‘coif3’, ‘coif4’, ‘db2’, ‘db4’, ‘db6’, ‘db8’, ‘rbio11’, ‘rbio22’, ‘rbio33’, ‘rbio44’, ‘sym2’, ‘sym4’, ‘sym6’, ‘sym8’}. It can be seen from the figure that the LSTM performs better than the Bi-LSTM and transformer encoder on most wavelet functions. When the wavelet function is db4, the LSTM has the best performance, and the classification accuracy, MF1, and kappa are 82.71%, 0.75, and 0.76, respectively. The results show that LSTM can learn the sleep transition rules more accurately and is more helpful for single-channel sleep EEG classification.
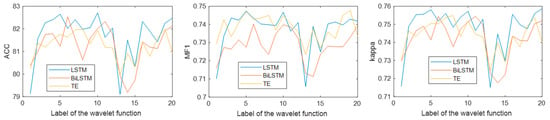
Figure 14.
Classification results under different wavelet functions.
4.6. Effect of the Multi-Step Time Features
Figure 15 shows the classification results of single-step features and multi-step time features. It can be seen that, compared with single-step features, multi-step time features have higher classification accuracy, MF1, and kappa. Compared with the single-step-based method, the accuracy, MF1, and kappa of the multi-step-based method improved by 1.8%, 0.01, and 0.02, respectively. The results show that LSTM can learn the sleep transition rules in the multi-step time features and improve the accuracy of the EEG classification.
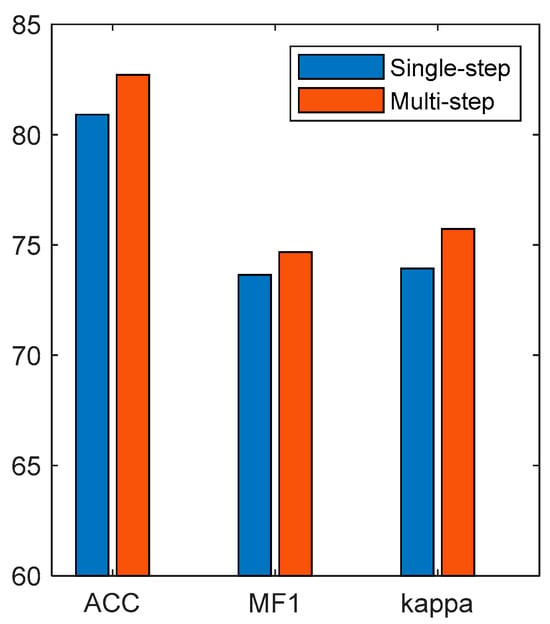
Figure 15.
Classification results of single-step features and multi-step time features.
4.7. Comparison with Existing Research
Table 6 shows the classification results of the proposed method and the existing studies on Sleep-EDFx. Some methods [12,14] used deep networks to extract depth features from the EEG. Although most studies point out that depth features can extract more information than manual features [15], the results of this paper show that manual features are more competitive in the classification of sleep EEG. Some studies [17,19,34] and proposed methods first extract manual features from the EEG and then use machine learning to classify the sleep EEG. The proposed method improves the classification accuracy of sleep EEG from two aspects. First, WT is used to extract the deep information from the EEG. The second is to learn the sleep transition rules to improve classification accuracy. Based on the results, the proposed method is more competitive. The results show that the proposed method can achieve high-precision single-channel sleep EEG classification and is superior to most existing methods.
Table 6.
Results of the proposed method and existing methods on Sleep-EDFx.
5. Discussion
This paper proposed a single-channel sleep EEG classification method based on the LSTM and HMM. First, the proposed method used signal decomposition and multi-domain feature extraction to obtain deep EEG information. Second, the proposed method learned the sleep transition rules in the classification process using multi-step time features and temporal networks. Third, the proposed method used HMM to post-process the classification results and realize the automatic correction of the classification results. A complete experiment was conducted on the Sleep-EDFx dataset. The results show that the proposed method can achieve high-precision single-channel sleep EEG classification and is superior to most existing methods.
The performance of four signal decomposition methods (WT, EMD, VMD, and SSA) in single-channel sleep EEG classification was compared. The results in Figure 8 show that WT achieved the highest accuracy, indicating that WT is more suitable for EEG decomposition. Then, the proposed method was used to classify single-channel sleep EEG, and the performance of 20 different wavelet functions was compared. The results in Figure 14 show that the classification method based on WT-db4 and LSTM had the best performance, and the accuracy, MF1, and kappa were 82.71%, 0.75, and 0.76, respectively. This paper discussed the performances of various signal decomposition methods and wavelet functions in single-channel EEG classification, providing a reference for other EEG analyses.
Table 4 and Figure 10 show the classification results of different classifiers in single-channel sleep EEG. The results show that the classification accuracy of temporal networks (LSTM, Bi-LSTM, and TE) in single-channel sleep EEG was higher than 81%, and the AUC was equal to 0.97, which was higher than that of other classifiers. The sleep state transition had potential regularity, and the temporal network could learn temporal information from temporal features so that the temporal network could improve the EEG classification accuracy. Figure 11 shows the box diagram of the prediction results, and the distribution state of the classification results can be observed. It can be seen from the figure that LSTM, Bi-LSTM, and TE had good robustness, and the minimum accuracy of LSTM was about 70%, indicating that the method had high robustness.
Table 5 and Figure 12 show the EEG classification results before and after HMM processing. Before HMM processing, the classification accuracy, MF1, and kappa of the LSTM were 81.66%, 0.74, and 0.74, respectively. After HMM processing, the classification accuracy, MF1, and kappa of LSTM were 82.71%, 0.75, and 0.76, respectively. The results show that the classification accuracy, MF1, and kappa improved after HMM processing, which indicated that the HMM could modify the classification results by learning the sleep transition rules after the classification was completed. Figure 13 shows the confusion matrix of the classification results, and the specific classification results of different sleep stages can be observed. As can be seen from the figure, the amount of the N1 stage was significantly less than that of the other stages, so the sample imbalance existed in the sleep EEG dataset, which also led to the low classification accuracy of the N1 stage. At the same time, after HMM processing, the number of N1 correctly identified increased, indicating that HMM can improve the sensitivity of the N1 stage.
Finally, we compared the performances of single-step features and multi-step temporal features in EEG classification, and the results are shown in Figure 15. The results show that the performance of the multi-step time features was better than that of the single-step features. The single-step features only used the single-moment EEG features as the model input, so it was difficult for the model to learn the sleep transition rules. The multi-step time features recombined the EEG features of multiple moments into a multi-step time feature matrix to contain the timing information of sleep transition, which was conducive for the timing network to learn the sleep transition rules.
There are also some limitations. First, the proposed method is challenging to directly apply to other EEG classifications of discontinuous states, such as motor-imaging EEG classification. Second, the direct application of the proposed method to the classification of a multi-channel EEG may result in dimensional disaster. Third, the classification accuracy of the proposed method in the N1 stage still needs to improve. Some aspects of the proposed method can be improved in future work so that the proposed method can be used for discontinuous state EEG and multi-channel EEG classification. At the same time, we can pay more attention to the EEG feature-extraction method of the N1 stage in the future.
6. Conclusions
This paper proposed a single-channel EEG classification method based on the LSTM and HMM, and a complete experiment was carried out on the Sleep-EDFx dataset. The performance of EMD, VMD, SSA, and WT in EEG classification was discussed in this paper. The results showed that WT was suitable for EEG decomposition. On this basis, the performance of 20 wavelet functions in EEG classification was discussed, which provided a reference for other EEG-related studies. During classification, the multi-step time features and LSTM were used to learn the sleep transition rules and improve the classification accuracy. After the classification, the proposed method used the HMM to learn the sleep transition rules and realize the adaptive correction of the classification results. The results showed that the proposed method successfully learned the sleep transition rules from two perspectives and significantly improved the classification accuracy of single-channel sleep EEG. The classification accuracy, MF1, and kappa of the proposed method were 82.71%, 0.75, and 0.76, respectively.
Author Contributions
W.C. wrote the paper, conducted experimental verification, and participated in the construction of the model. Y.C. and A.L. proposed the model and revised the manuscript. Y.S. and K.J. collected the data and analyzed the results. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
All data files are available from https://physionet.org/content/sleep-edfx (accessed on 11 October 2023).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Halder, B.; Anjum, T.; Bhuiyan, M.I.H. An attention-based multi-resolution deep learning model for automatic A-phase detection of cyclic alternating pattern in sleep using single-channel EEG. Biomed. Signal Process. Control 2023, 83, 104730. [Google Scholar] [CrossRef]
- Wei, Y. Automatic Sleep Staging Based on Contextual Scalograms and Attention Convolution Neural Network Using Single-channel EEG. IEEE J. Biomed. Health Inform. 2023, 28, 801–811. [Google Scholar] [CrossRef]
- Lu, J.; Yan, C.; Li, J.; Liu, C. Sleep staging based on single-channel EEG and EOG with Tiny U-Net. Comput. Biol. Med. 2023, 163, 107127. [Google Scholar] [CrossRef]
- Chang, S.; Yang, Z.; You, Y.; Guo, X. DSSNet: A Deep Sequential Sleep Network for Self-Supervised Representation Learning Based on Single-Channel EEG. IEEE Signal Process. Lett. 2022, 29, 2143–2147. [Google Scholar] [CrossRef]
- Liao, Y.; Zhang, C.; Zhang, M.; Wang, Z.; Xie, X. LightSleepNet: Design of a Personalized Portable Sleep Staging System Based on Single-Channel EEG. IEEE Trans. Circuits Syst. 2022, 69, 224–228. [Google Scholar] [CrossRef]
- He, Z.; Tang, M.; Wang, P.; Du, L.; Chen, X.; Cheng, G.; Fang, Z. Cross-scenario automatic sleep stage classification using transfer learning and single-channel EEG. Biomed. Signal Process. Control 2023, 81, 104501. [Google Scholar] [CrossRef]
- Zhou, H. SleepNet-Lite: A Novel Lightweight Convolutional Neural Network for Single-Channel EEG-Based Sleep Staging. IEEE Sens. 2023, 7, 7000804. [Google Scholar] [CrossRef]
- Zhang, Y.; Cao, W.; Feng, L.; Wang, M.; Geng, T.; Zhou, J.; Gao, D. SHNN: A single-channel EEG sleep staging model based on semi-supervised learning. Expert Syst. Appl. 2023, 213, 119288. [Google Scholar] [CrossRef]
- Venkat, V. Automatic classification methods for detecting drowsiness using wavelet packet transform extracted time-domain features from single-channel EEG signal. J. Neurosci. Methods 2021, 347, 108927. [Google Scholar]
- Liu, C.; Tan, B.; Fu, M.; Li, J.; Wang, J.; Hou, F.; Yang, A. Automatic sleep staging with a single-channel EEG based on ensemble empirical mode decomposition. Phys. A 2021, 567, 125685. [Google Scholar] [CrossRef]
- Jiang, D.; Lu, Y.-N.; Ma, Y.; Wang, Y. Robust sleep stage classification with single-channel EEG signals using multimodal decomposition and HMM-based refinement. Expert Syst. Appl. 2019, 121, 188–203. [Google Scholar] [CrossRef]
- Zhu, T.; Luo, W.; Yu, F. Convolution- and Attention-Based Neural Network for Automated Sleep Stage Classification. Int. J. Environ. Res. Public Health 2020, 17, 4152. [Google Scholar] [CrossRef] [PubMed]
- Sharma, M.; Anand, D.; Verma, S.; Acharya, U.R. Automated insomnia detection using wavelet scattering network technique with single-channel EEG signals. Eng. Appl. Artif. Intell. 2023, 126, 106903. [Google Scholar] [CrossRef]
- Phan, H.; Andreotti, F.; Cooray, N.; Chen, O.Y.; De Vos, M. Joint Classification and Prediction CNN Framework for Automatic Sleep Stage Classification. IEEE Trans. Biomed. Eng. 2019, 66, 1285–1296. [Google Scholar] [CrossRef] [PubMed]
- Heng, X.; Wang, M.; Wang, Z.; Zhang, J.; He, L.; Fan, L. Leveraging discriminative features for automatic sleep stage classification based on raw single-channel EEG. Biomed. Signal Process. Control 2024, 88, 105631. [Google Scholar] [CrossRef]
- Michielli, N.; Acharya, U.R.; Molinari, F. Cascaded LSTM recurrent neural network for automated sleep stage classification using single-channel EEG signals. Comput. Biol. Med. 2019, 106, 71–81. [Google Scholar] [CrossRef]
- Supratak, A.; Dong, H.; Wu, C.; Guo, Y. DeepSleepNet: A Model for Automatic Sleep Stage Scoring Based on Raw Single-Channel EEG. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 1998–2008. [Google Scholar] [CrossRef]
- Zhao, C.; Li, J.; Guo, Y. SleepContextNet: A temporal context network for automatic sleep staging based single-channel EEG. Comput. Methods Programs Biomed. 2022, 220, 106806. [Google Scholar] [CrossRef]
- Ghimatgar, H.; Kazemi, K.; Helfroush, M.S.; Aarabi, A. An automatic single-channel EEG-based sleep stage scoring method based on hidden Markov Model. J. Neurosci. Methods 2019, 324, 108320. [Google Scholar] [CrossRef]
- Sharma, M. Automated identification of insomnia using optimal bi-orthogonal wavelet transform technique with single-channel EEG signals. Knowl. Based Syst. 2021, 224, 107078. [Google Scholar] [CrossRef]
- Dora, M.; Holcman, D. Adaptive Single-Channel EEG Artifact Removal With Applications to Clinical Monitoring. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 286–295. [Google Scholar] [CrossRef] [PubMed]
- Gao, Q. Automatic sleep staging based on power spectral density and random forest. J. Biomed. Eng. 2023, 40, 280–285+294. [Google Scholar]
- Hussein, R.M.; George, L.E.; Miften, F.S. Accurate method for sleep stages classification using discriminated features and single EEG channel. Biomed. Signal Process. Control 2023, 84, 104688. [Google Scholar]
- Alyoubi, K.H.; Mahato, S.; Khadidos, A.O.; Mohanty, S.N. Computer Aided Detection of Major Depressive Disorder (MDD) Using Electroencephalogram Signals. IEEE Access 2023, 11, 41133–41141. [Google Scholar]
- Mohammed, H.; Diykh, M. Improving EEG major depression disorder classification using FBSE coupled with domain adaptation method based machine learning algorithms. Biomed. Signal Process. Control 2023, 85, 104923. [Google Scholar] [CrossRef]
- Chen, C.; Li, Z.; Wan, F.; Xu, L.; Bezerianos, A.; Wang, H. Fusing Frequency-Domain Features and Brain Connectivity Features for Cross-Subject Emotion Recognition. IEEE Trans. Instrum. Meas. 2022, 71, 2508215. [Google Scholar] [CrossRef]
- Chen, W.; Cai, Y.; Li, A.; Su, Y.; Jiang, K. EEG feature selection method based on maximum information coefficient and quantum particle swarm. Sci. Rep. 2023, 13, 14515. [Google Scholar] [CrossRef]
- Seifpour, S.; Niknazar, H.; Mikaeili, M.; Nasrabadi, A.M. A new automatic sleep staging system based on statistical behavior of local extrema using single channel EEG signal. Expert Syst. Appl. 2018, 104, 277–293. [Google Scholar] [CrossRef]
- Thakare, A.; Anter, A.M.; Abraham, A. Seizure disorders recognition model from EEG signals using new probabilistic particle swarm optimizer and sequential differential evolution. Multidimens. Syst. Signal Process. 2023, 34, 397–421. [Google Scholar] [CrossRef]
- Degirmenci, M.; Yuce, Y.K.; Perc, M.; Isler, Y. Statistically significant features improve binary and multiple Motor Imagery task predictions from EEGs. Front. Hum. Neurosci. 2023, 17, 1223307. [Google Scholar] [CrossRef]
- Su, Y. Research on the precise reconstruction method of robot demonstration trajectory based on feedforward hidden Markov model. Chin. J. Sci. Instrum. 2023, 44, 199–207. [Google Scholar]
- Viterbi, A. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Trans. Inf. Theory 1967, 13, 260–269. [Google Scholar] [CrossRef]
- Kemp, B.; Zwinderman, A.; Tuk, B.; Kamphuisen, H.; Oberye, J. Analysis of a sleep-dependent neuronal feedback loop: The slow-wave microcontinuity of the EEG. IEEE Trans. Biomed. Eng. 2000, 47, 1185–1194. [Google Scholar] [CrossRef]
- Tsinalis, O.; Matthews, P.M.; Guo, Y. Automatic Sleep Stage Scoring Using Time-Frequency Analysis and Stacked Sparse Autoencoders. Ann. Biomed. Eng. 2015, 44, 1587–1597. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).