
Dysarthria Subgroups in Talkers with Huntington’s Disease: Comparison of Two Data-Driven Classification Approaches

 , , and
, , and
Abstract
:1. Introduction
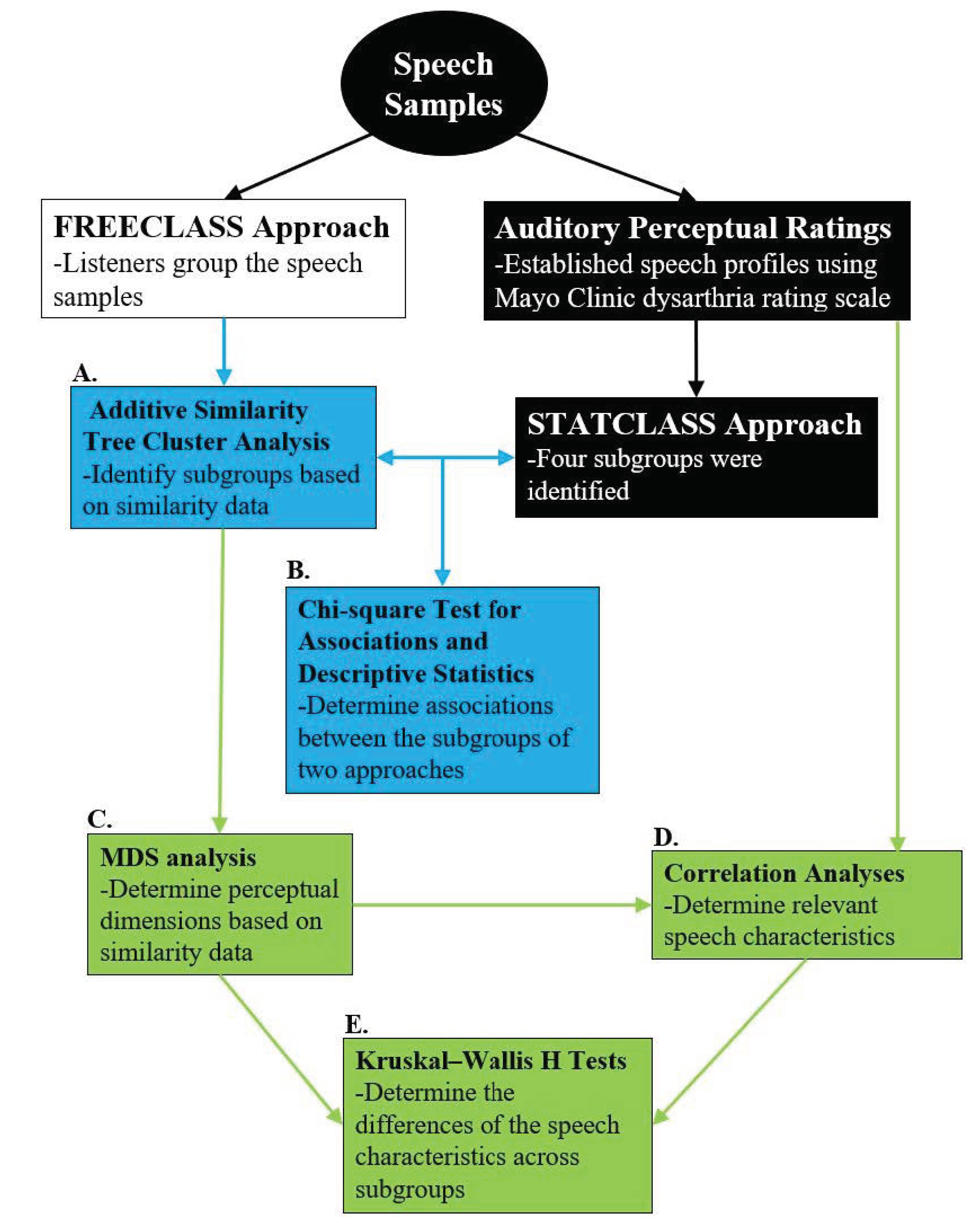
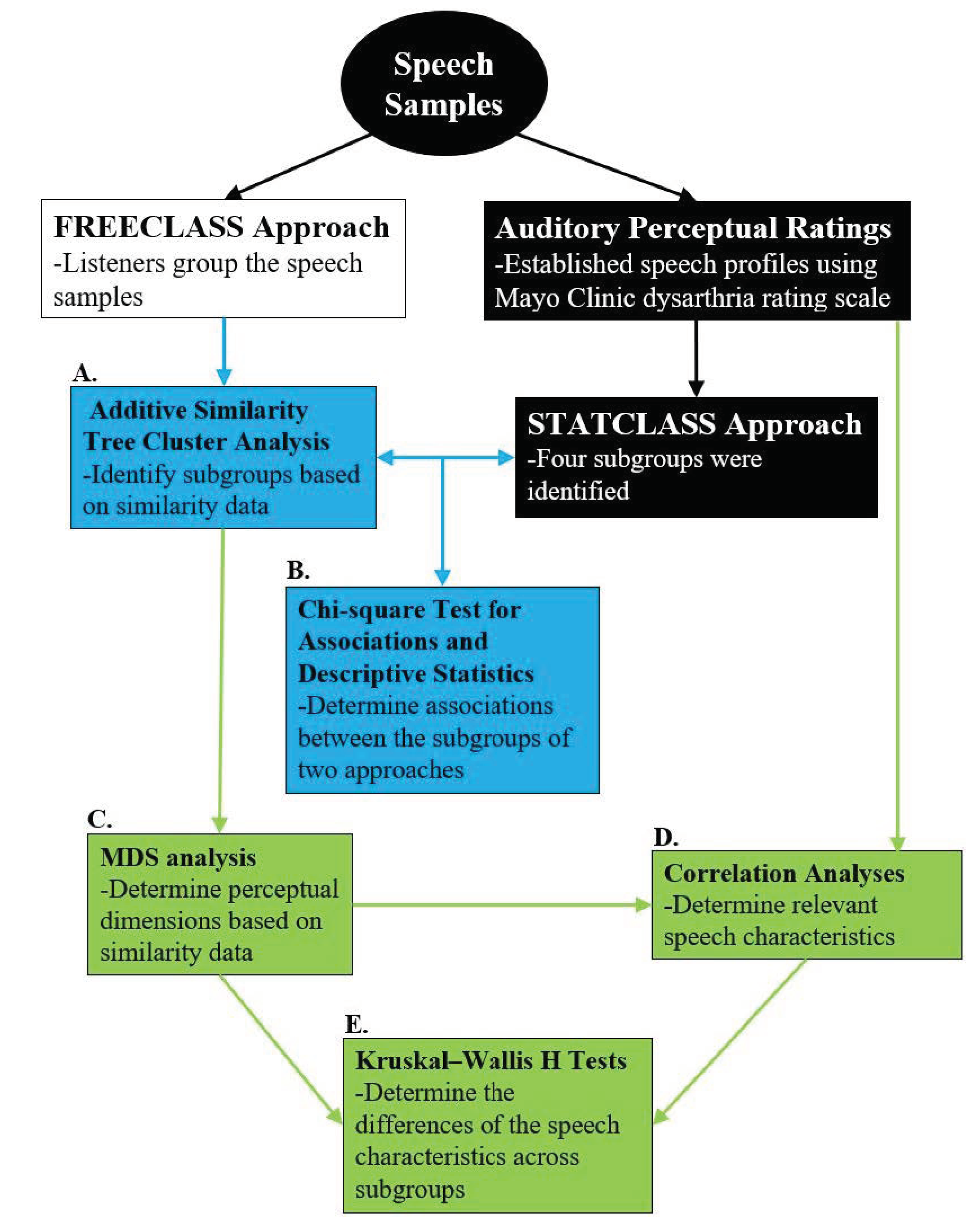
2. Materials and Methods
2.1. Participants (Listeners)
2.2. Talkers and Stimuli
2.3. Rating Each Talker’s Perceptual Speech Characteristics
2.4. The Auditory Free Classification Task
2.5. Data Analysis
3. Results
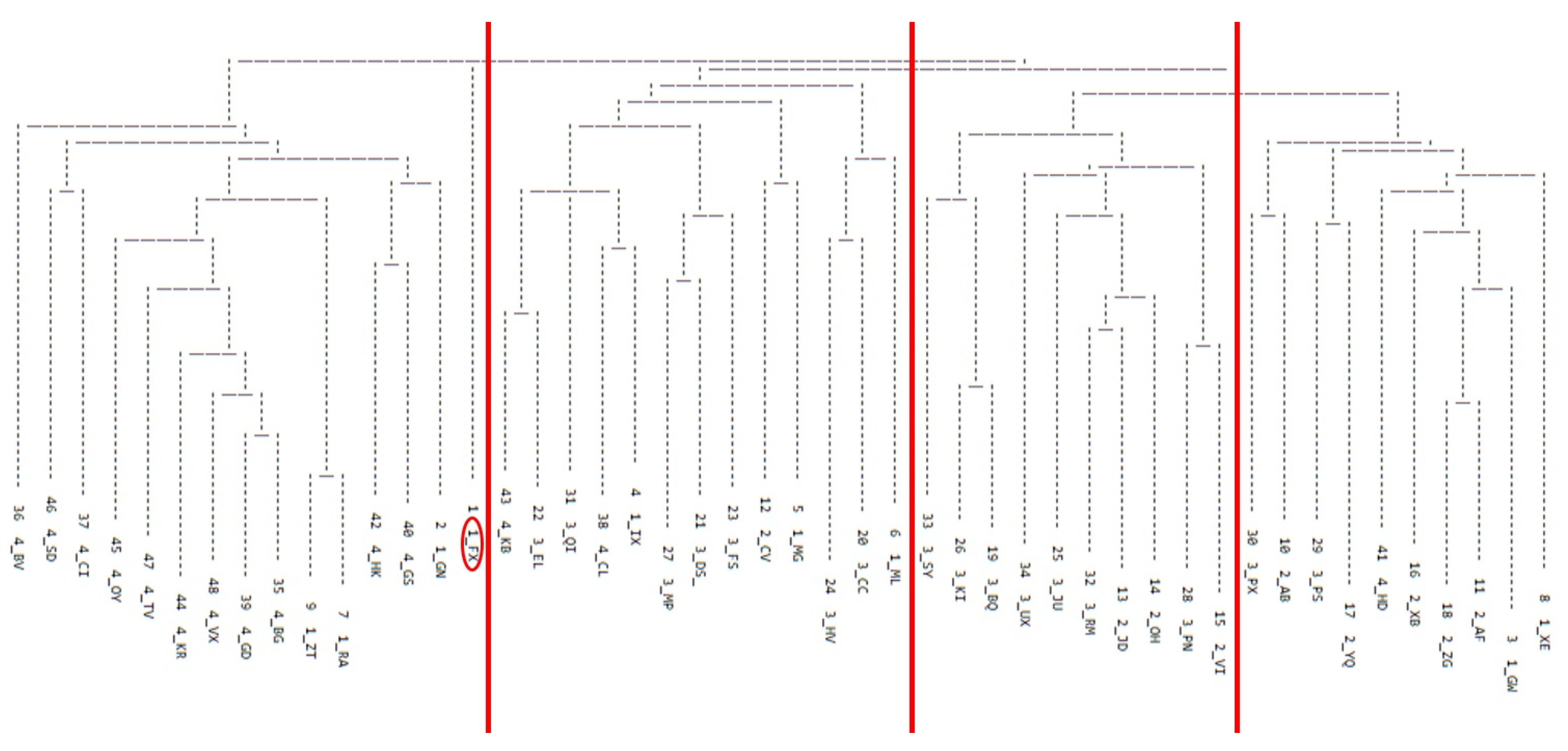
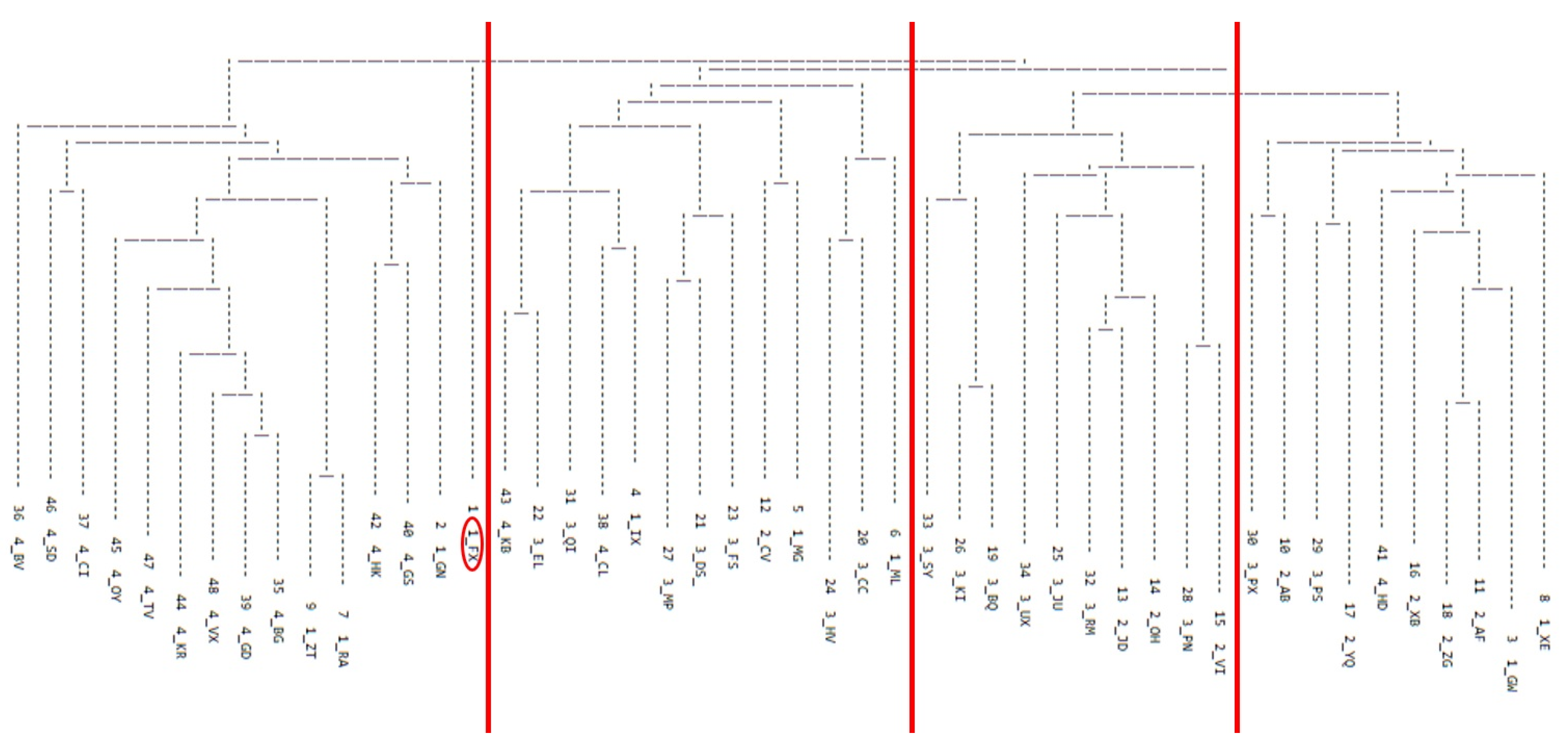
3.1. Determining Numbers of Dysarthria Subgroups among Talkers with HD
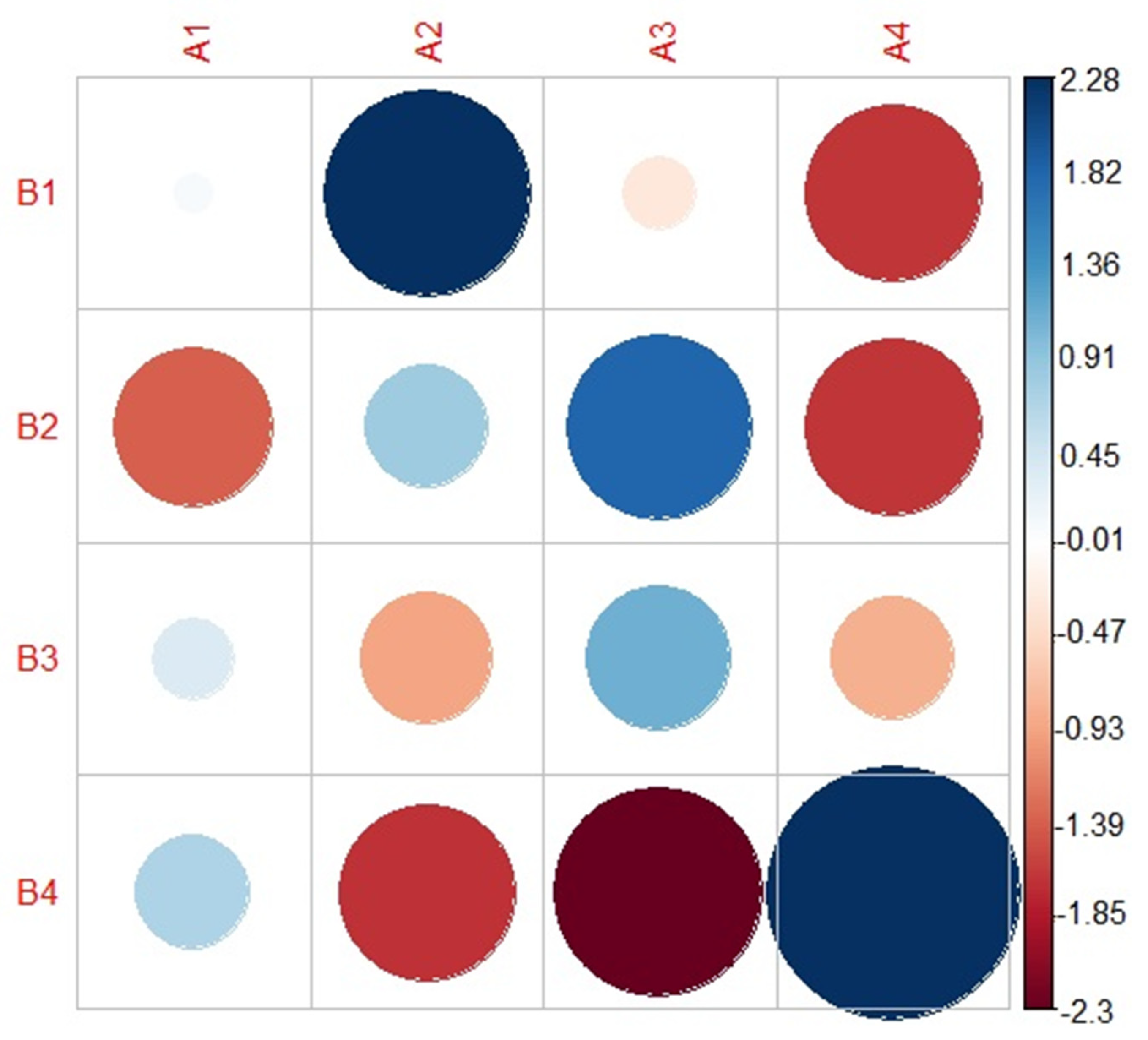
3.2. Extent of Overlap between the FREECLASS and the STATSCLUSTER Approach
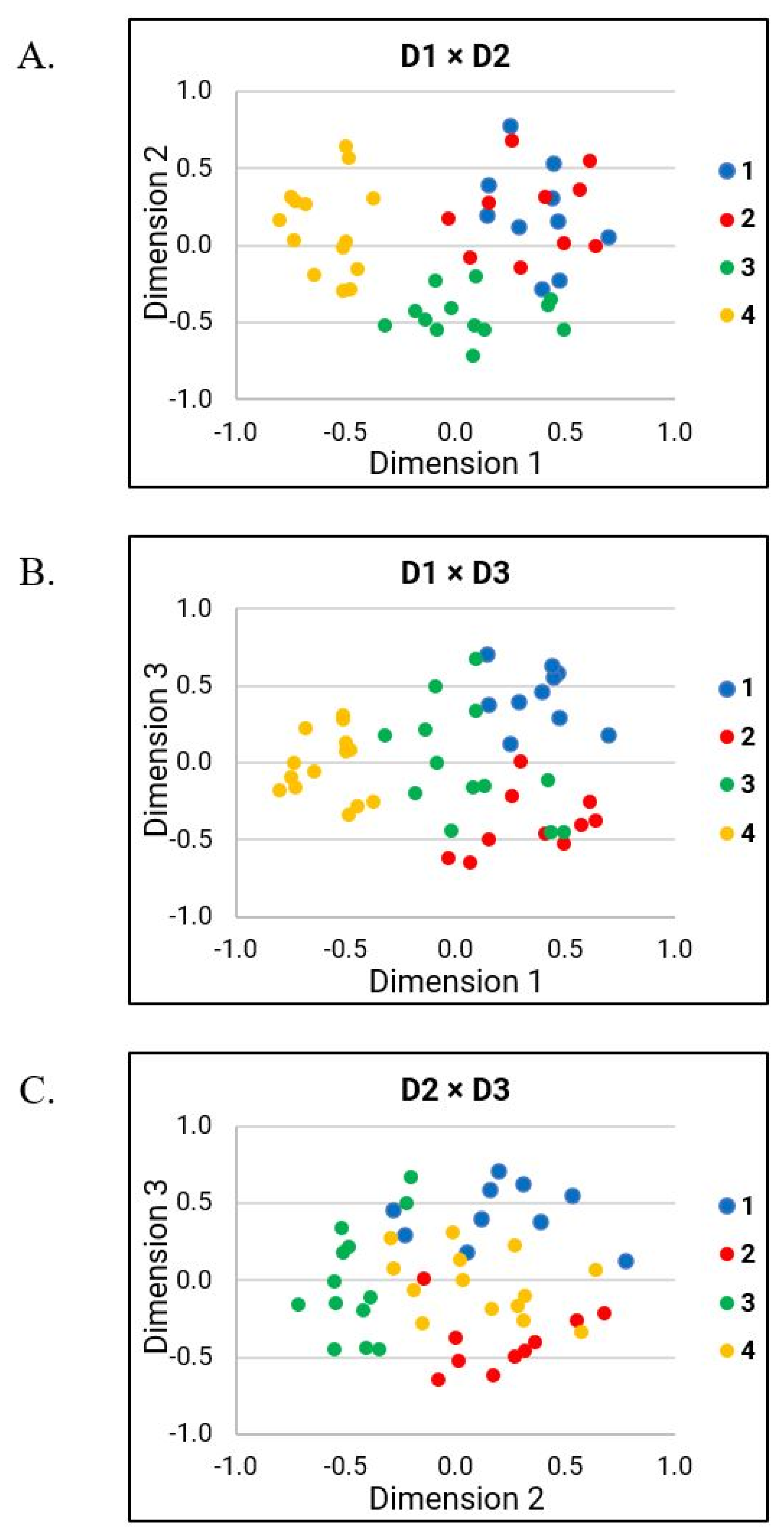
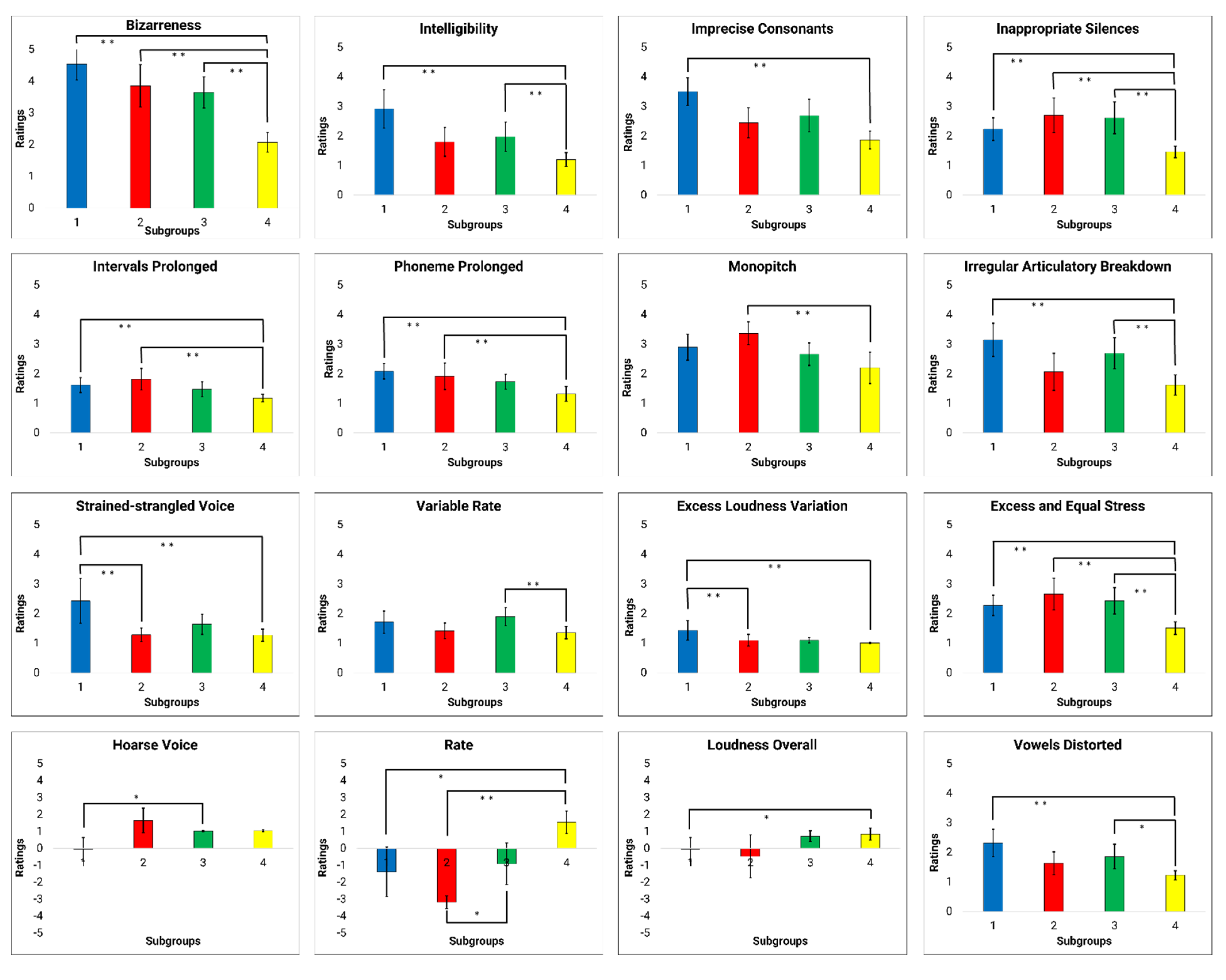
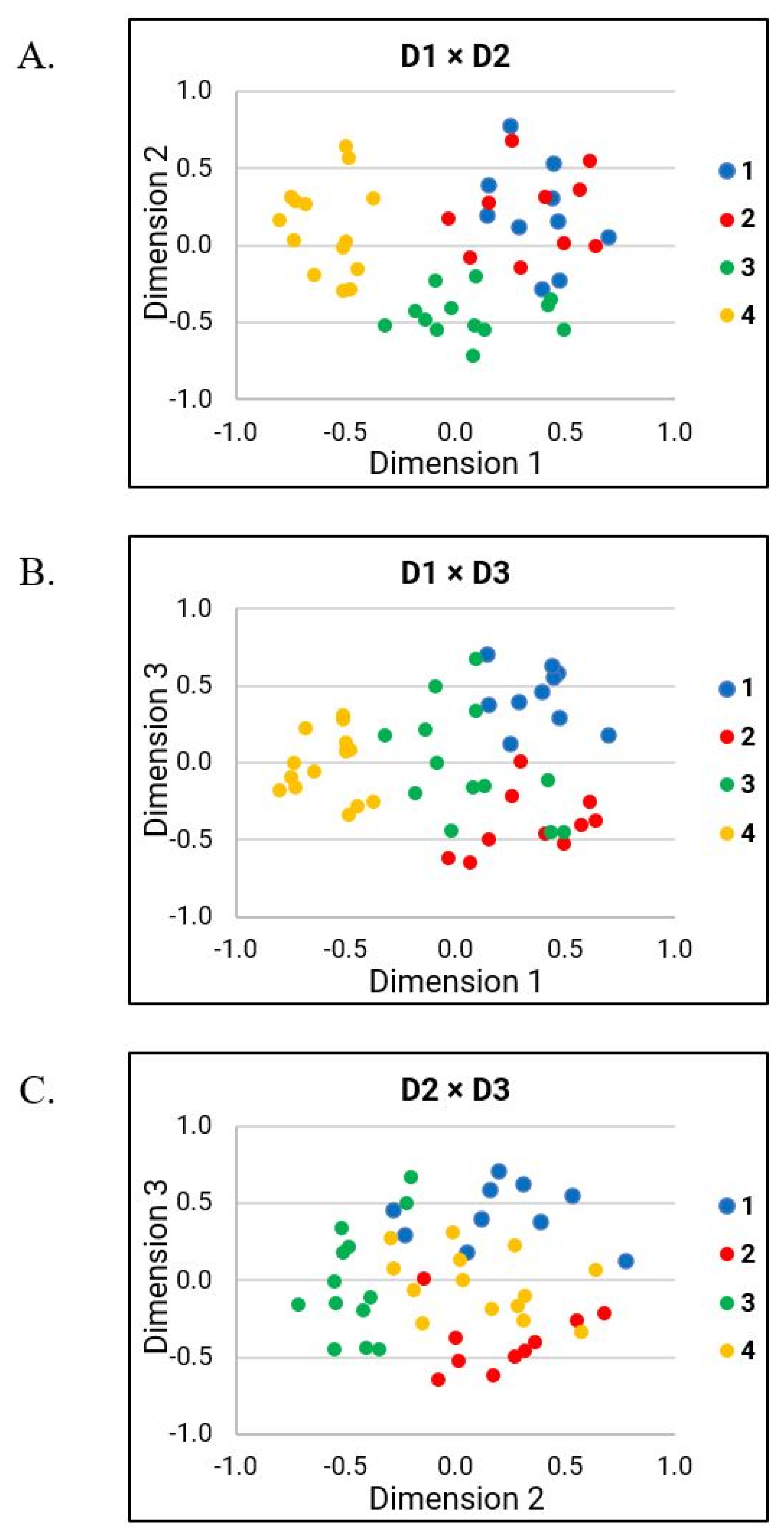
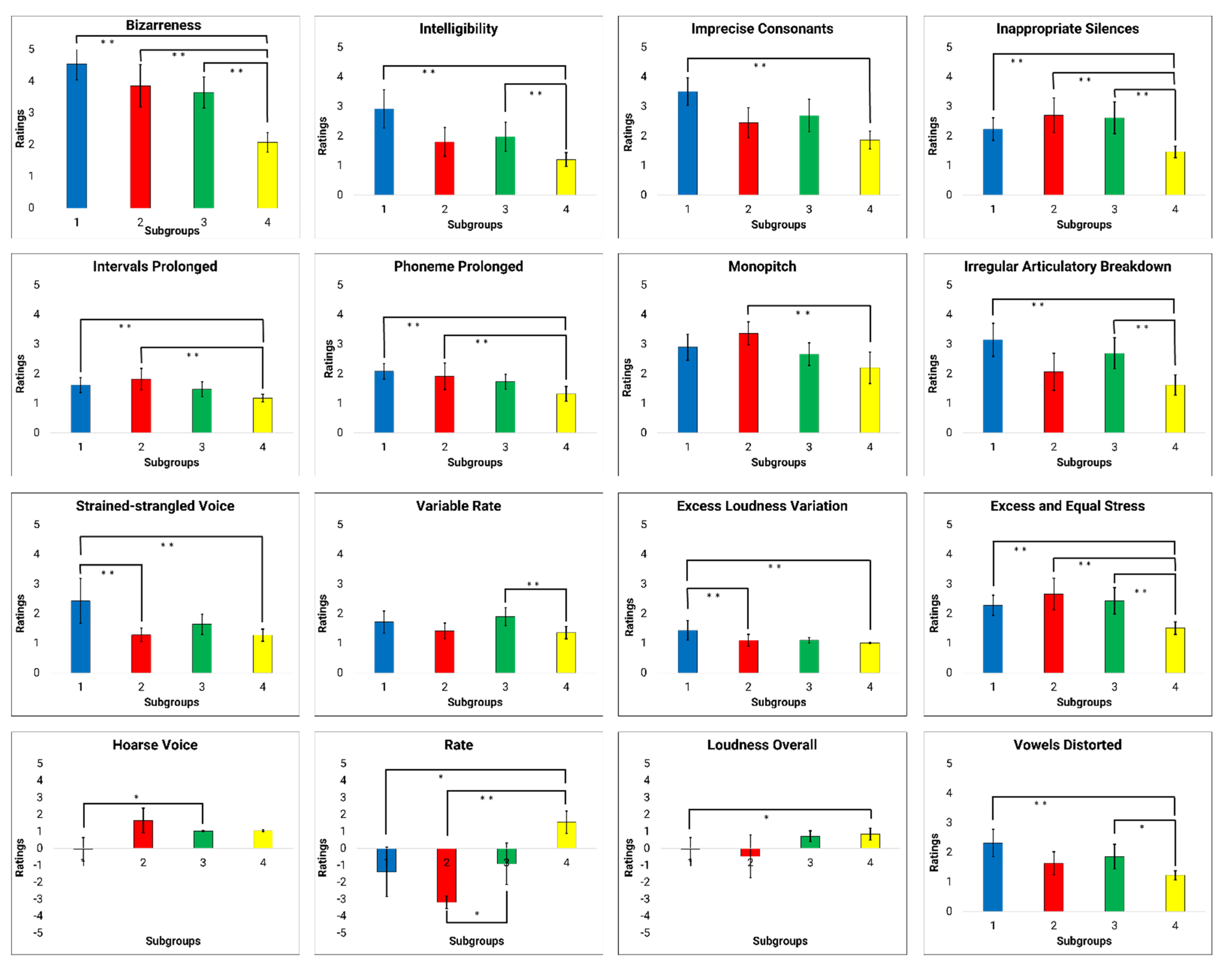
3.3. Determining Distinct Differences between Dysarthria Subgroups of Talkers with HD
3.3.1. Dimension 1
3.3.2. Dimension 2
3.3.3. Dimension 3
4. Discussion
4.1. Overlap between the FREECLASS and the STATCLUSTER Approach
4.2. Perceptual Speech Characteristics Contributing to Subgrouping Decisions
4.2.1. Interpretations of D1
4.2.2. Interpretations of D2
4.2.3. Interpretations of D3
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Duffy, J.R. Motor Speech Disorders-E-Book: Substrates, Differential Diagnosis, and Management; Elsevier Health Sciences: St. Louis, MO, USA, 2013. [Google Scholar]
- Darley, F.L.; Aronson, A.E.; Brown, J.R. Differential diagnostic patterns of dysarthria. J. Speech Hear. Res. 1969, 12, 246–269. [Google Scholar] [CrossRef] [PubMed]
- Darley, F.L.; Aronson, A.E.; Brown, J.R. Clusters of deviant speech dimensions in the dysarthrias. J. Speech Hear. Res. 1969, 12, 462–496. [Google Scholar] [CrossRef] [PubMed]
- Darley, F.L.; Aronson, A.E.; Brown, J.R. Motor Speech Disorders; W. B. Saunders: Philadelphia, PA, USA, 1975. [Google Scholar]
- Rusz, J.; Klempíř, J.; Tykalová, T.; Baborová, E.; Čmejla, R.; Růžička, E.; Roth, J. Characteristics and occurrence of speech impairment in Huntington’s disease: Possible influence of antipsychotic medication. J. Neural Transm. 2014, 121, 1529–1539. [Google Scholar] [CrossRef] [PubMed]
- Lansford, K.L.; Liss, J.M.; Norton, R.E. Free-classification of perceptually similar speakers with dysarthria. J. Speech Lang. Hear. Res. 2014, 57, 2051–2064. [Google Scholar] [CrossRef] [PubMed]
- Simmons, K.C.; Mayo, R. The use of the Mayo Clinic system for differential diagnosis of dysarthria. J. Commun. Disord. 1997, 30, 117–132. [Google Scholar] [CrossRef]
- Allison, K.M.; Hustad, K.C. Data-driven classification of dysarthria profiles in children with cerebral palsy. J. Speech Lang. Hear. Res. 2018, 61, 2837–2853. [Google Scholar] [CrossRef]
- Weismer, G.; Kim, Y. Classification and taxonomy of motor speech disorders: What are the issues? Speech Mot. Control. New Dev. Basic Appl. Res. 2010, 229–241. [Google Scholar]
- Diehl, S.K.; Mefferd, A.S.; Lin, Y.C.; Sellers, J.; McDonell, K.E.; de Riesthal, M.; Claassen, D.O. Motor speech patterns in Huntington disease. Neurology 2019, 93, e2042–e2052. [Google Scholar] [CrossRef]
- Zyski, B.J.; Weisiger, B.E. Identification of dysarthria types based on perceptual analysis. J. Commun. Disord. 1987, 20, 367–378. [Google Scholar] [CrossRef]
- Bunton, K.; Kent, R.D.; Duffy, J.R.; Rosenbek, J.C.; Kent, J.F. Listener Agreement for Auditory-Perceptual Ratings of Dysarthria. J. Speech Lang. Hear. Res. 2007, 50, 1481–1495. [Google Scholar] [CrossRef]
- Shrivastav, R.; Sapienza, C.M.; Nandur, V. Application of Psychometric Theory to the Measurement of Voice Quality Using Rating Scales. J. Speech Lang. Hear. Res. 2005, 48, 323–335. [Google Scholar] [CrossRef]
- Clopper, C.G. Auditory free classification: Methods and analysis. Behav. Res. Methods 2008, 40, 575–581. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Imai, S. Classification of sets of stimuli with different stimulus characteristics and numerical properties. Percept. Psychophys. 1966, 1, 48–54. [Google Scholar] [CrossRef]
- McAdams, S. Recognition of sound sources and events. Think. Sound: Cogn. Psychol. Hum. Audit. 1993, 146, 198. [Google Scholar]
- Clopper, C.G.; Pisoni, D.B. Some acoustic cues for the perceptual categorization of American English regional dialects. J. Phon. 2004, 32, 111–140. [Google Scholar] [CrossRef] [Green Version]
- Blanchet, P.G.; Snyder, G.J. Speech Rate Deficits in Individuals with Parkinson’s disease: A review of the literature. J. Med. Speech-Lang. Pathol. 2009, 17, 1–7. [Google Scholar]
- Metter, E.J.; Hanson, W.R. Clinical and acoustical variability in hypokinetic dysarthria. J. Commun. Disord. 1986, 19, 347–366. [Google Scholar] [CrossRef]
- Yorkston, K.; Beukelman, D.R.; Hakel, M.; Dorsey, M. Sentence Intelligibility Test for Windows; [Software Program]; Institute for Rehabilitation Science and Engineering at Madonna Rehabilitation Hospital: Lincoln, NE, USA, 2007. [Google Scholar]
- Fairbanks, G. The rainbow passage. In Voice and Articulation Drillbook, 2nd ed.; Harper and Row: New York, NY, USA, 1960. [Google Scholar]
- Milenkovic, P. TF32 [Computer software]; University of Wisconsin–Madison: Madison, WI, USA, 2004. [Google Scholar]
- Sevitz, J.S.; Kiefer, B.R.; Huber, J.E.; Troche, M.S. Obtaining objective clinical measures during telehealth evaluations of dysarthria. Am. J. Speech-Lang. Pathol. 2021, 30, 503–516. [Google Scholar] [CrossRef]
- Whitfield, J.A.; Goberman, A.M. Articulatory–acoustic vowel space: Application to clear speech in individuals with Parkinson’s disease. J. Commun. Disord. 2014, 51, 19–28. [Google Scholar] [CrossRef]
- Corter, J.E. An efficient metric combinatorial algorithm for fitting additive trees. Multivar. Behav. Res. 1998, 33, 249–271. [Google Scholar] [CrossRef]
- Luce, R.D. A threshold theory for simple detection experiments. Psychol. Rev. 1963, 70, 61. [Google Scholar] [CrossRef] [PubMed]
- Shepard, R.N. Stimulus and response generalization: A stochastic model relating generalization to distance in psychological space. Psychometrika 1957, 22, 325–345. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Identified Subgroups | Subgroups | # of Overlapped |
|---|---|---|
| (# of Talkers) | (Diehl et al., 2019 [10]) | Talkers (%) |
| Subgroup 1 | Subgroup 1 (n = 9) | 2 (20) |
| (10 talkers; M = 3, F = 7) | Subgroup 2 (n = 9) | 5 (50) |
| Subgroup 3 (n = 16) | 2 (20) | |
| Subgroup 4 (n = 14) | 1 (10) | |
| Subgroup 2 | Subgroup 2 (n = 9) | 3 (30) |
| (10 talkers; M = 6, F = 4) | Subgroup 3 (n = 16) | 7 (70) |
| Subgroup 3 | Subgroup 1 (n = 9) | 3 (23.1) |
| (13 talkers; M = 1, F = 12) | Subgroup 2 (n = 9) | 1 (7.7) |
| Subgroup 3 (n = 16) | 7 (53.8) | |
| Subgroup 4 (n = 14) | 2 (15.4) | |
| Subgroup 4 | Subgroup 1 (n = 9) | 3 (21.4) |
| (14 talkers; M = 5, F = 9) | Subgroup 4 (n = 14) | 11 (78.6) |
| Dimension 1 Variable (Category) | r | Dimension 2 Variable (Category) | r | Dimension 3 Variable (Category) | r |
|---|---|---|---|---|---|
| Bizarreness a b (GI) | 0.835 | Hoarse voice a b (VQ) | 0.422 | Imprecise consonants a b (A) | 0.547 |
| Rate a b (P) | −0.710 | Loudness overall a b (L) | −0.421 | Strained-strangled voice a b (VQ) | 0.539 |
| Excess and equal stress a b (P) | 0.616 | Variable rate a b (P) | −0.414 | Intelligibility a b (GI) | 0.497 |
| Intervals prolonged a b (P) | 0.609 | Breathy voice (VQ) | 0.398 | Irregular articulatory breakdown a b (A) | 0.487 |
| Inappropriate silences a b (P) | 0.597 | Sex | −0.356 | Vowels distorted a b (A) | 0.486 |
| Imprecise consonants a b (A) | 0.583 | Reduced stress (P) | 0.333 | Reduced stress a (P) | 0.412 |
| Phonemes prolonged a b (A) | 0.572 | Harsh voice b (VQ) | 0.302 | Voice stoppages (P) | 0.382 |
| Intelligibility a b (GI) | 0.550 | Voice tremor (PC) | 0.369 | ||
| Vowels distorted a b (A) | 0.536 | Monoloudness b (L) | −0.349 | ||
| Irregular articulatory breakdown a b (A) | 0.521 | Rate b (P) | 0.348 | ||
| Monopitch a b (PC) | 0.460 | Excess and equal stress b (P) | −0.334 | ||
| Excess loudness variation a b (L) | 0.414 | ||||
| Alternating loudness a (L) | 0.410 | ||||
| Monoloudness b (L) | 0.394 | ||||
| Loudness overall b (L) | −0.389 | ||||
| Harsh voice b (VQ) | 0.327 | ||||
| Loudness decay (L) | 0.308 |
| Variable | Kruskal–Wallis Test H | df | Sig. |
|---|---|---|---|
| Alternating loudness | 7.02 | 3 | 0.071 |
| Bizarreness | 27.58 | 3 | <0.001 * |
| Breathy voice | 3.27 | 3 | 0.352 |
| Excess and equal stress | 17.83 | 3 | <0.001 * |
| Excess loudness variation | 16.89 | 3 | 0.001 * |
| Harsh voice | 8.64 | 3 | 0.034 * |
| Hoarse voice | 8.23 | 3 | 0.042 * |
| Imprecise consonants | 17.1 | 3 | 0.001 * |
| Inappropriate silences | 19.47 | 3 | <0.001 * |
| Intelligibility | 21.11 | 3 | <0.001 * |
| Intervals prolonged | 14.46 | 3 | 0.002 * |
| Irregular articulatory breakdown | 16.23 | 3 | 0.001 * |
| Loudness decay | 2.59 | 3 | 0.458 |
| Loudness overall | 8.59 | 3 | 0.035 * |
| Monoloudness | 14.53 | 3 | 0.002 * |
| Monopitch | 10.72 | 3 | 0.013 * |
| Phonemes prolonged | 15.28 | 3 | 0.002 * |
| Rate | 21.39 | 3 | <0.001 * |
| Reduced stress | 7.56 | 3 | 0.056 |
| Sex | NA | NA | NA |
| Strained-strangled voice | 11.62 | 3 | 0.009 * |
| Variable rate | 9.12 | 3 | 0.028 * |
| Voice stoppages | 4.32 | 3 | 0.229 |
| Voice tremor | 7.29 | 3 | 0.063 |
| Vowels distorted | 15.25 | 3 | 0.002 * |
| Variable (Correlated Dimensions) Subgroups | z | p | Variable (Correlated Dimensions) Subgroups | z | p |
|---|---|---|---|---|---|
| Bizarreness | Excess and equal stress | ||||
| (D1) | (D1) | ||||
| 4-3 | 18.5 | 0.003 * | 4-3 | 17.4 | 0.006 * |
| 4-2 | 19.9 | 0.003 * | 4-2 | 20.9 | 0.001 * |
| 4-1 | 27.8 | <0.001 * | 4-1 | 16.1 | 0.027 * |
| Excess loudness | Inappropriate silences | ||||
| variation | (D1) | ||||
| (D1) | 4-3 | 19.7 | 0.001 * | ||
| 4-1 | 18.0 | 0.001 * | 4-2 | 20.7 | 0.002 * |
| 2-1 | 16.5 | 0.007 * | 4-1 | 16.2 | 0.025 * |
| Intervals prolonged | Rate | ||||
| (D1) | (D1) | ||||
| 4-2 | 19.7 | 0.003 * | 4-2 | −25.9 | <0.001 * |
| 4-1 | 15.7 | 0.031 * | 4-1 | −14.5 | 0.064 |
| 3-2 | −14.9 | 0.059 | |||
| Monopitch | Phonemes prolonged | ||||
| (D1) | (D1) | ||||
| 4-2 | 18.2 | 0.008 * | 4-2 | 15.1 | 0.045 * |
| 4-1 | 20.8 | 0.001 * | |||
| Intelligibility | Imprecise Consonants | ||||
| (D1 and D3) | (D1 and D3) | ||||
| 4-3 | 14.1 | 0.040 * | 4-1 | 23.2 | <0.001 * |
| 4-1 | 25.4 | <0.001 * | |||
| Irregular articulatory breakdown | Vowels distorted | ||||
| (D1 and D3) | (D1 and D3) | ||||
| 4-3 | 15.2 | 0.024 * | 4-3 | 13.3 | 0.068 |
| 4-1 | 20.7 | 0.002 * | 4-1 | 21.3 | 0.001 * |
| Hoarse Voice | Variable rate | ||||
| (D2) | (D2) | ||||
| 3-1 | 11.4 | 0.084 | 4-3 | 14.2 | 0.04 * |
| Loudness overall | Strained-strangled voice | ||||
| (D2) | (D3) | ||||
| 4-1 | −13.7 | 0.052 | 4-1 | 16.7 | 0.017 * |
| 2-1 | 7.3 | 0.041 * |
| Variable | Pearson Correlation | Sig. | Correlated Dimensions |
|---|---|---|---|
| Intelligibility | 0.789 | <0.001 * | 1 and 3 |
| Imprecise consonants | 0.764 | <0.001 * | 1 and 3 |
| Irregular articulatory breakdown | 0.730 | <0.001 * | 1 and 3 |
| Vowels distorted | 0.664 | <0.001 * | 1 and 3 |
| Inappropriate silences | 0.619 | <0.001 * | 1 |
| Alternating loudness | 0.520 | <0.001 * | 1 |
| Intervals prolonged | 0.515 | <0.001 * | 1 |
| Excess and equal stress | 0.494 | <0.001 * | 1 and 3 |
| Monopitch | 0.487 | 0.001 * | 1 |
| Rate | −0.474 | 0.001 * | 1 and 3 |
| Reduced stress | 0.449 | 0.002 * | 2 and 3 |
| Excess loudness variation | 0.437 | 0.002 * | 1 |
| Harsh voice | 0.423 | 0.003 * | 1 and 2 |
| Phonemes prolonged | 0.416 | 0.004 * | 1 |
| Strained-strangled voice | 0.415 | 0.004 * | 3 |
| Loudness overall | −0.412 | 0.004 * | 1 and 2 |
| Breathy voice | 0.391 | 0.007 * | 2 |
| Monoloudness | 0.385 | 0.007 * | 1 and 3 |
| Voice stoppages | 0.380 | 0.008 * | 3 |
| Variable rate | 0.368 | <0.001 * | 2 |
| Hoarse voice | 0.284 | 0.053 | 2 |
| Voice tremor | 0.225 | 0.128 | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.; Diehl, S.; de Riesthal, M.; Tjaden, K.; Wilson, S.M.; Claassen, D.O.; Mefferd, A.S. Dysarthria Subgroups in Talkers with Huntington’s Disease: Comparison of Two Data-Driven Classification Approaches. Brain Sci. 2022, 12, 492. https://doi.org/10.3390/brainsci12040492
Kim D, Diehl S, de Riesthal M, Tjaden K, Wilson SM, Claassen DO, Mefferd AS. Dysarthria Subgroups in Talkers with Huntington’s Disease: Comparison of Two Data-Driven Classification Approaches. Brain Sciences. 2022; 12(4):492. https://doi.org/10.3390/brainsci12040492
Chicago/Turabian StyleKim, Daniel, Sarah Diehl, Michael de Riesthal, Kris Tjaden, Stephen M. Wilson, Daniel O. Claassen, and Antje S. Mefferd. 2022. "Dysarthria Subgroups in Talkers with Huntington’s Disease: Comparison of Two Data-Driven Classification Approaches" Brain Sciences 12, no. 4: 492. https://doi.org/10.3390/brainsci12040492
APA StyleKim, D., Diehl, S., de Riesthal, M., Tjaden, K., Wilson, S. M., Claassen, D. O., & Mefferd, A. S. (2022). Dysarthria Subgroups in Talkers with Huntington’s Disease: Comparison of Two Data-Driven Classification Approaches. Brain Sciences, 12(4), 492. https://doi.org/10.3390/brainsci12040492