
Coarse-Grained Neural Network Model of the Basal Ganglia to Simulate Reinforcement Learning Tasks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods and Models
2.1. Fine-Grained Neural Neetwork (FGNN) Model of Basal Ganglia
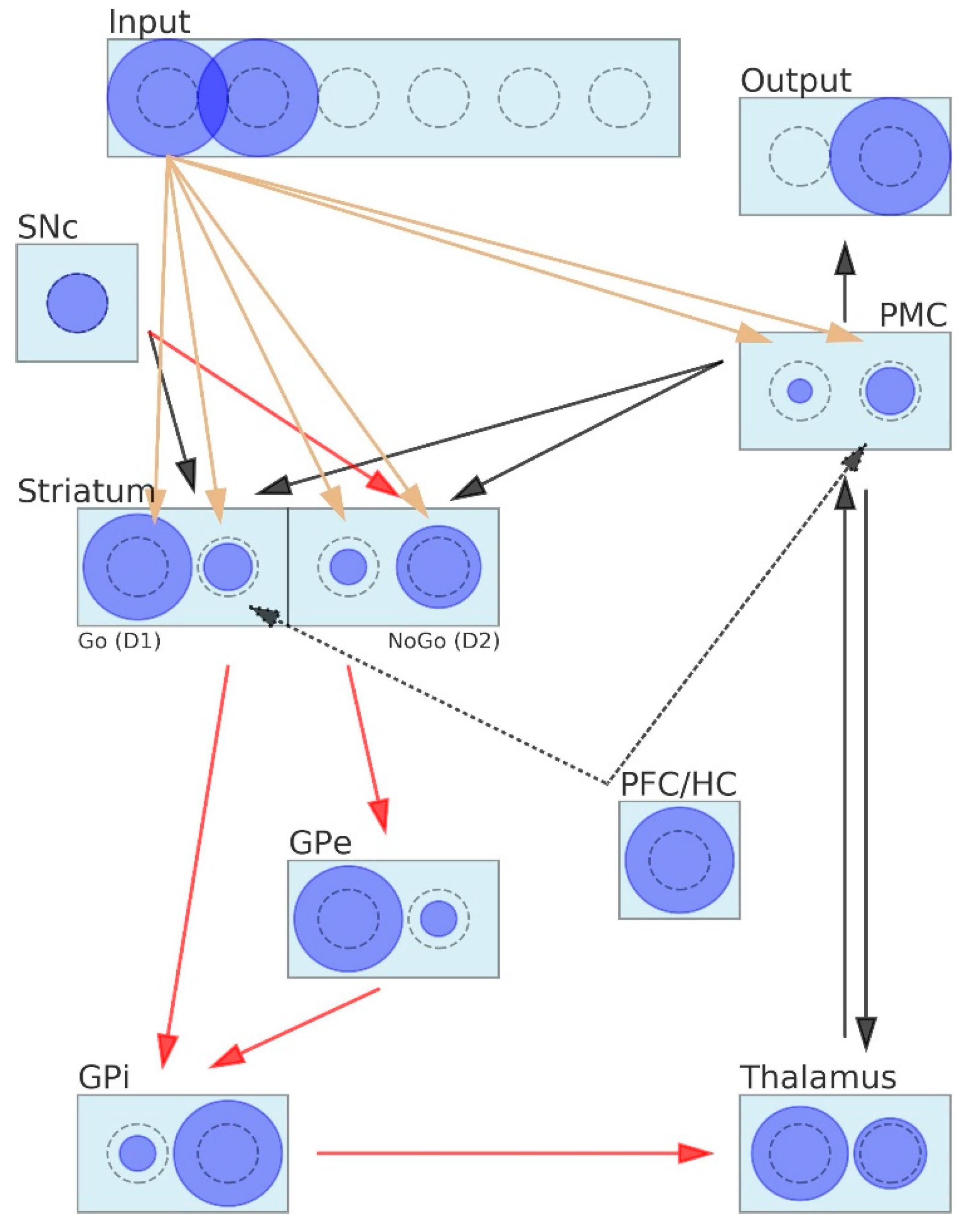
2.2. Coarse-Grained Neural Neetwork (CGNN) Model of Basal Ganglia
2.2.1. Activity of Neurons and Connectivity between Neurons in the CGNN
- The SNc is represented by a single neuron that can return one of the following three values: dopamine dip = 0, tonic dopamine = 0.5 or dopamine burst = 1;
- The input layer encodes stimuli. Each stimulus is represented by one neuron that returns “1” if its stimulus appears on the screen and “0” otherwise;
- Similar rules apply to the output layer, where each decision is encoded by one neuron. Since only one decision may be made at the moment, only one neuron is allowed to return 1, whereas all others are inhibited and return 0;
- The PFC/HC is represented by a single neuron that passes 1 to that neuron of the striatum that is associated with the instructed stimulus. The PFC/HC is active in the instructed probabilistic selection task;
- Neurons belonging to the layers PMC, striatum, GPe, GPi and thalamus may return values belonging to the interval <0,1>;
- The number of neurons included in the layers Input, Output, PMC, GPe, GPi and thalamus is equal to the total number of stimuli in the learning task;
- The striatum layer contains twice as many neurons as the total number of stimuli in the learning task. This layer is composed of two subparts: D1 (including neurons representing Go signals) and D2 (including neurons representing NoGo signals);
- The PFC/HC is connected to those D1 and the PMC neurons that stand for the instructed stimulus;
- The activity of the striatum neurons is evaluated according to the following formula (note that the last term of the equation appears only in the instructed probabilistic task):where is the output of the kth striatum neuron, is a connection weight that equals 1 if the kth neuron stands for a Go signal or equals −1 if it stands for a NoGo signal, is the output of the SNc neuron, is a synaptic weight connecting the kth striatum neuron to the SNC, is the ith input of the network, is a synaptic weight connecting the kth striatum neuron to the ith input of the network, is the output of the PFC/HC, is the synaptic weight connecting the appropriate striatum neuron to the PFC/HC (this weight has a value of 0.3 for all the simulations presented in the article) and is the activation function, which form was chosen experimentally:We used a = 8 for the simulations.
- 10.
- The activity of the GPe neurons is simply:where is the output of the kth GPe neuron, and is the output of the kth neuron of the D2 subsystem.
- 11.
- The following formula describes the activity of the GPi neurons:where is the output of the kth GPi neuron, and ystriaGo is the output of the kth neuron of the D1 subsystem.
- 12.
- The activity of the thalamus neurons is evaluated as:where is the output of the kth neuron of the thalamus layer
- 13.
- The activity of the PMC neurons is calculated in a few steps, due to the bidirectional connections between the PMC and thalamus:where is the synaptic weight of connection between the ith input of the network and kth PMC neuron, and is the synaptic weight of the connection between the PFC/HC, an appropriate neuron of the PMD with the value set to 0.05 for the computer simulations.
- If > 1, then normalization is applied:
- Finally, the activation level of the neurons is evaluated as:where is the output of the kth PMC neuron.
- 14.
- The connection between the PMC and the striatum closes the signal-processing loop in the BG. We assumed that this connection is used to inform the striatum about the decision that was made by the network in order to direct the weight adaptation process that comes next. During the adaptation process, appropriate D1 and D2 neurons are exposed to the SNc stimulation.
- 15.
- The output of the network is the following:
2.2.2. Learning Algorithm in CGNN
2.2.3. Parameters in CGNN
2.3. Reinforcement Learning Tasks
3. Results
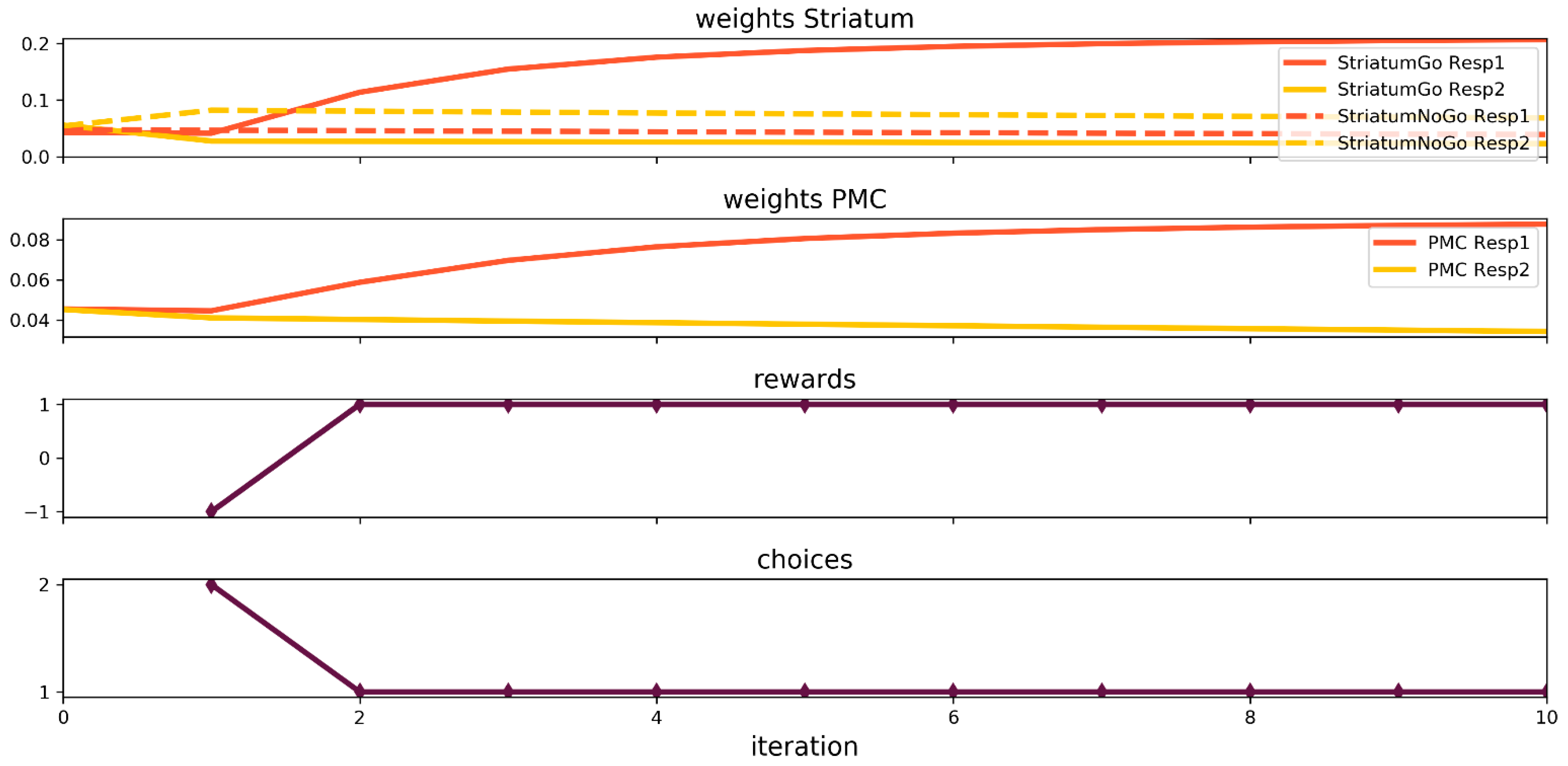
3.1. Simulation of Probabilistic Selection Task
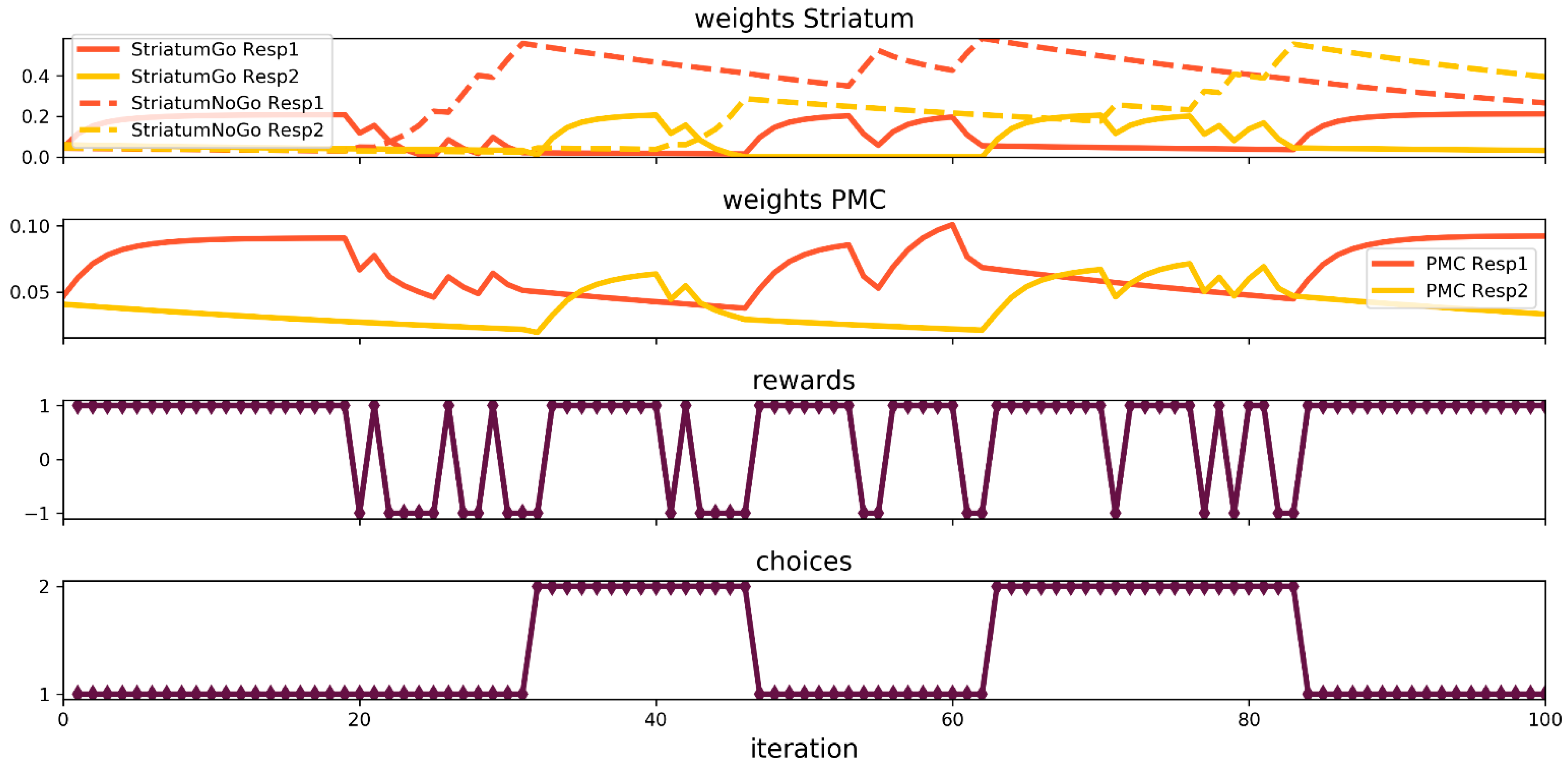
3.2. Simulation of Probabilistic Reversa Learningl Task
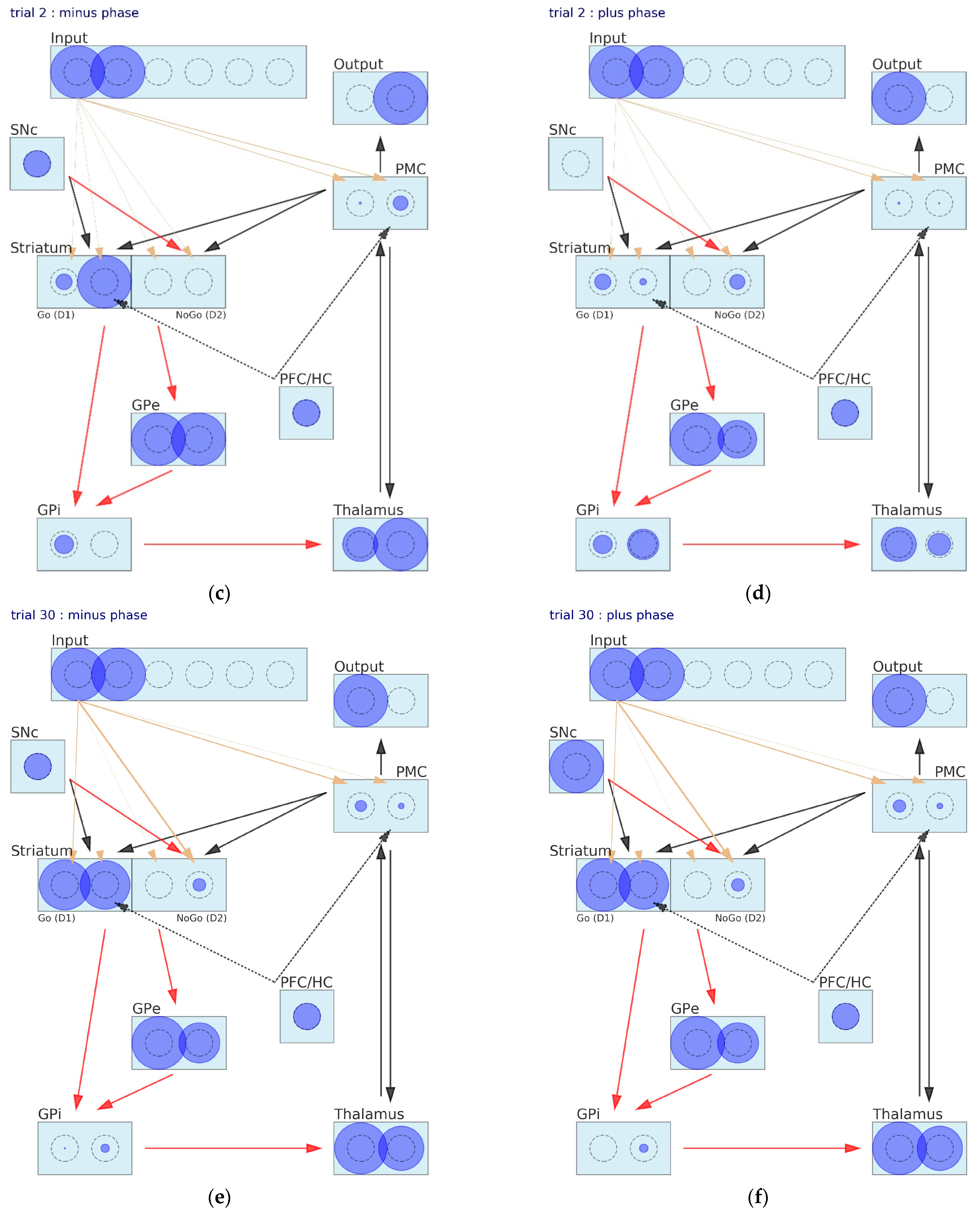
3.3. Simulation of Instructed Probabilistic Selection Task
4. Discussion
5. Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Borgomaneri, S.; Serio, G.; Battaglia, S. Please, don’t do it! Fifteen years of progress of non-invasive brain stimulation in action inhibition. Cortex 2020, 132, 404–422. [Google Scholar] [CrossRef] [PubMed]
- Maia, T.V.; Frank, M.J. From reinforcement learning models to psychiatric and neurological disorders. Nat. Neurosci. 2011, 14, 154–162. [Google Scholar] [CrossRef] [PubMed]
- van Swieten, M.M.H.; Bogacz, R. Modeling the effects of motivation on choice and learning in the basal ganglia. PLoS Comput. Biol. 2020, 16, e1007465. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Yang, T. A neural network model of basal ganglia’s decision-making circuitry. Cogn. Neurodyn. 2021, 15, 17–26. [Google Scholar] [CrossRef]
- Balasubramani, P.P.; Chakravarthy, V.S.; Ravindran, B.; Moustafa, A.A. An extended reinforcement learning model of basal ganglia to understand the contributions of serotonin and dopamine in risk-based decision making, reward prediction, and punishment learning. Front. Comput. Neurosci. 2014, 8, 47. [Google Scholar] [CrossRef] [Green Version]
- Humphries, M.D.; Khamassi, M.; Gurney, K. Dopaminergic Control of the Exploration-Exploitation Trade-Off via the Basal Ganglia. Front. Neurosci. 2012, 6, 9. [Google Scholar] [CrossRef] [Green Version]
- Humphries, M.D.; Stewart, R.D.; Gurney, K.N. A physiologically plausible model of action selection and oscillatory activity in the basal ganglia. J. Neurosci 2006, 26, 12921–12942. [Google Scholar] [CrossRef] [Green Version]
- Schultz, W. Reward signaling by dopamine neurons. Neuroscientist 2001, 7, 293–302. [Google Scholar] [CrossRef]
- Samejima, K.; Ueda, Y.; Doya, K.; Kimura, M. Representation of action-specific reward values in the striatum. Science 2005, 310, 1337–1340. [Google Scholar] [CrossRef] [Green Version]
- Pasupathy, A.; Miller, E.K. Different time courses of learning-related activity in the prefrontal cortex and striatum. Nature 2005, 433, 873–876. [Google Scholar] [CrossRef]
- Wiesendanger, E.; Clarke, S.; Kraftsik, R.; Tardif, E. Topography of cortico-striatal connections in man: Anatomical evidence for parallel organization. Eur. J. Neurosci. 2004, 20, 1915–1922. [Google Scholar] [CrossRef] [PubMed]
- Schultz, W. Getting formal with dopamine and reward. Neuron 2002, 36, 241–263. [Google Scholar] [CrossRef] [Green Version]
- Garofalo, S.; Timmermann, C.; Battaglia, S.; Maier, M.E.; di Pellegrino, G. Mediofrontal Negativity Signals Unexpected Timing of Salient Outcomes. J. Cogn. Neurosci. 2017, 29, 718–727. [Google Scholar] [CrossRef] [PubMed]
- Schultz, W. Multiple dopamine functions at different time courses. Annu. Rev. Neurosci. 2007, 30, 259–288. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schultz, W. Dopamine reward prediction error coding. Dialogues Clin. Neurosci. 2016, 18, 23–32. [Google Scholar]
- Shen, W.; Flajolet, M.; Greengard, P.; Surmeier, D.J. Dichotomous dopaminergic control of striatal synaptic plasticity. Science 2008, 321, 848–851. [Google Scholar] [CrossRef] [Green Version]
- Schroll, H.; Hamker, F.H. Computational models of basal-ganglia pathway functions: Focus on functional neuroanatomy. Front. Syst. Neurosci. 2013, 7, 122. [Google Scholar] [CrossRef] [Green Version]
- Frank, M.J.; Claus, E.D. Anatomy of a decision: Striato-orbitofrontal interactions in reinforcement learning, decision making, and reversal. Psychol. Rev. 2006, 113, 300–326. [Google Scholar] [CrossRef] [Green Version]
- Frank, M.J. Dynamic dopamine modulation in the basal ganglia: A neurocomputational account of cognitive deficits in medicated and nonmedicated Parkinsonism. J. Cogn Neurosci. 2005, 17, 51–72. [Google Scholar] [CrossRef] [Green Version]
- Gurney, K.; Prescott, T.J.; Redgrave, P. A computational model of action selection in the basal ganglia. I. A new functional anatomy. Biol. Cybern. 2001, 84, 401–410. [Google Scholar] [CrossRef]
- Schroll, H.; Vitay, J.; Hamker, F.H. Working memory and response selection: A computational account of interactions among cortico-basalganglio-thalamic loops. Neural Netw. 2012, 26, 59–74. [Google Scholar] [CrossRef] [PubMed]
- Frank, M.J.; Seeberger, L.C.; O’Reilly, R.C. By carrot or by stick: Cognitive reinforcement learning in parkinsonism. Science 2004, 306, 1940–1943. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aisa, B.; Mingus, B.; O’Reilly, R. The emergent neural modeling system. Neural Netw. 2008, 21, 1146–1152. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eliasmith, C. A unified approach to building and controlling spiking attractor networks. Neural Comput. 2005, 17, 1276–1314. [Google Scholar] [CrossRef] [Green Version]
- Gerstner, W. Population dynamics of spiking neurons: Fast transients, asynchronous states, and locking. Neural Comput. 2000, 12, 43–89. [Google Scholar] [CrossRef]
- Baladron, J.; Hamker, F.H. A spiking neural network based on the basal ganglia functional anatomy. Neural Netw. 2015, 67, 1–13. [Google Scholar] [CrossRef]
- Izhikevich, E.M. Simple model of spiking neurons. IEEE Trans. Neural Netw. 2003, 14, 1569–1572. [Google Scholar] [CrossRef] [Green Version]
- Izhikevich, E.M. Which model to use for cor.rtic.c.cal spiking neurons? IEEE Trans. Neural Netw. 2004, 15, 1063–1070. [Google Scholar] [CrossRef]
- Gerstner, W.; Naud, R. Neuroscience. How good are neuron models? Science 2009, 326, 379–380. [Google Scholar] [CrossRef] [Green Version]
- Caporale, N.; Dan, Y. Spike timing-dependent plasticity: A Hebbian learning rule. Annu. Rev. Neurosci. 2008, 31, 25–46. [Google Scholar] [CrossRef] [Green Version]
- Frank, M.J.; Scheres, A.; Sherman, S.J. Understanding decision-making deficits in neurological conditions: Insights from models of natural action selection. Philos Trans. R. Soc. B Biol. Sci. 2007, 362, 1641–1654. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frank, M.J.; Santamaria, A.; O’Reilly, R.C.; Willcutt, E. Testing computational models of dopamine and noradrenaline dysfunction in attention deficit/hyperactivity disorder. Neuropsychopharmacology 2007, 32, 1583–1599. [Google Scholar] [CrossRef] [PubMed]
- Hazy, T.E.; Frank, M.J.; O’Reilly, R.C. Towards an executive without a homunculus: Computational models of the prefrontal cortex/basal ganglia system. Philos. Trans. R Soc. B Biol Sci 2007, 362, 1601–1613. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frank, M.J. Hold your horses: A dynamic computational role for the subthalamic nucleus in decision making. Neural Netw. 2006, 19, 1120–1136. [Google Scholar] [CrossRef] [Green Version]
- Franklin, N.T.; Frank, M.J. A cholinergic feedback circuit to regulate striatal population uncertainty and optimize reinforcement learning. Elife 2015, 4, e12029. [Google Scholar] [CrossRef]
- Girard, B.; Lienard, J.; Gutierrez, C.E.; Delord, B.; Doya, K. A biologically constrained spiking neural network model of the primate basal ganglia with overlapping pathways exhibits action selection. Eur. J. Neurosci. 2021, 53, 2254–2277. [Google Scholar] [CrossRef]
- Hosseini, M.; Powell, M.; Collins, J.; Callahan-Flintoft, C.; Jones, W.; Bowman, H.; Wyble, B. I tried a bunch of things: The dangers of unexpected overfitting in classification of brain data. Neurosci. Biobehav. Rev. 2020, 119, 456–467. [Google Scholar] [CrossRef]
- Vasicek, D.; Lawlor, B. Artificial intelligence and machine learning: Practical aspects of overfitting and regularization. Inf. Serv. Use 2019, 39, 281–289. [Google Scholar] [CrossRef] [Green Version]
- Bejani, M.M.; Ghatee, M. A systematic review on overfitting control in shallow and deep neural networks. Artif. Intell. Rev. 2021, 54, 6391–6438. [Google Scholar] [CrossRef]
- Waltz, J.A.; Frank, M.J.; Robinson, B.M.; Gold, J.M. Selective reinforcement learning deficits in schizophrenia support predictions from computational models of striatal-cortical dysfunction. Biol. Psychiatry 2007, 62, 756–764. [Google Scholar] [CrossRef] [Green Version]
- Frydecka, D.; Misiak, B.; Piotrowski, P.; Bielawski, T.; Pawlak, E.; Kłosińska, E.; Krefft, M.; Al Noaimy, K.; Rymaszewska, J.; Moustafa, A.A.; et al. The Role of Dopaminergic Genes in Probabilistic Reinforcement Learning in Schizophrenia Spectrum Disorders. Brain Sci. 2022, 12, 7. [Google Scholar] [CrossRef] [PubMed]
- Schlagenhauf, F.; Huys, Q.J.; Deserno, L.; Rapp, M.A.; Beck, A.; Heinze, H.J.; Dolan, R.; Heinz, A. Striatal dysfunction during reversal learning in unmedicated schizophrenia patients. Neuroimage 2014, 89, 171–180. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Doll, B.B.; Jacobs, W.J.; Sanfey, A.G.; Frank, M.J. Instructional control of reinforcement learning: A behavioral and neurocomputational investigation. Brain Res. 2009, 1299, 74–94. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frydecka, D.; Piotrowski, P.; Bielawski, T.; Pawlak, E.; Kłosińska, E.; Krefft, M.; Al Noaimy, K.; Rymaszewska, J.; Moustafa, A.A.; Drapała, J.; et al. Confirmation Bias in the Course of Instructed Reinforcement Learning in Schizophrenia-Spectrum Disorders. Brain Sci. 2022, 12, 90. [Google Scholar] [CrossRef]
- Stewart, T.C.; Bekolay, T.; Eliasmith, C. Learning to select actions with spiking neurons in the Basal Ganglia. Front. Neurosci. 2012, 6, 2. [Google Scholar] [CrossRef] [Green Version]
- Baston, C.; Ursino, M. A Biologically Inspired Computational Model of Basal Ganglia in Action Selection. Comput. Intell. Neurosci. 2015, 2015, 187417. [Google Scholar] [CrossRef] [Green Version]
- Salimi-Badr, A.; Ebadzadeh, M.M.; Darlot, C. A system-level mathematical model of Basal Ganglia motor-circuit for kinematic planning of arm movements. Comput. Biol. Med. 2018, 92, 78–89. [Google Scholar] [CrossRef]
- Khaleghi, A.; Mohammadi, M.R.; Shahi, K.; Nasrabadi, A.M. Computational Neuroscience Approach to Psychiatry: A Review on Theory-driven Approaches. Clin. Psychopharmacol. Neurosci. 2022, 20, 26–36. [Google Scholar] [CrossRef]
- Huys, Q.J.M. Advancing Clinical Improvements for Patients Using the Theory-Driven and Data-Driven Branches of Computational Psychiatry. JAMA Psychiatry 2018, 75, 225–226. [Google Scholar] [CrossRef]
- Frank, M.J. Computational models of motivated action selection in corticostriatal circuits. Curr. Opin. Neurobiol. 2011, 21, 381–386. [Google Scholar] [CrossRef]
- Cavanagh, J.F.; Frank, M.J.; Klein, T.J.; Allen, J.J. Frontal theta links prediction errors to behavioral adaptation in reinforcement learning. Neuroimage 2010, 49, 3198–3209. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frank, M.J.; O’Reilly, R.C. A mechanistic account of striatal dopamine function in human cognition: Psychopharmacological studies with cabergoline and haloperidol. Behav. Neurosci. 2006, 120, 497–517. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frank, M.J.; Gagne, C.; Nyhus, E.; Masters, S.; Wiecki, T.V.; Cavanagh, J.F.; Badre, D. fMRI and EEG predictors of dynamic decision parameters during human reinforcement learning. J. Neurosci. 2015, 35, 485–494. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frank, M.J.; Moustafa, A.A.; Haughey, H.M.; Curran, T.; Hutchison, K.E. Genetic triple dissociation reveals multiple roles for dopamine in reinforcement learning. Proc. Natl. Acad. Sci. USA 2007, 104, 16311–16316. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carda, S.; Biasiucci, A.; Maesani, A.; Ionta, S.; Moncharmont, J.; Clarke, S.; Murray, M.M.; Millan, J.D.R. Electrically Assisted Movement Therapy in Chronic Stroke Patients with Severe Upper Limb Paresis: A Pilot, Single-Blind, Randomized Crossover Study. Arch. Phys. Med. Rehabil. 2017, 98, 1628–1635.e1622. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pisotta, I.; Perruchoud, D.; Ionta, S. Hand-in-hand advances in biomedical engineering and sensorimotor restoration. J. Neurosci. Methods 2015, 246, 22–29. [Google Scholar] [CrossRef] [PubMed]
- Perruchoud, D.; Fiorio, M.; Cesari, P.; Ionta, S. Beyond variability: Subjective timing and the neurophysiology of motor cognition. Brain Stimul. 2018, 11, 175–180. [Google Scholar] [CrossRef] [Green Version]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Drapała, J.; Frydecka, D. Coarse-Grained Neural Network Model of the Basal Ganglia to Simulate Reinforcement Learning Tasks. Brain Sci. 2022, 12, 262. https://doi.org/10.3390/brainsci12020262
Drapała J, Frydecka D. Coarse-Grained Neural Network Model of the Basal Ganglia to Simulate Reinforcement Learning Tasks. Brain Sciences. 2022; 12(2):262. https://doi.org/10.3390/brainsci12020262
Chicago/Turabian StyleDrapała, Jarosław, and Dorota Frydecka. 2022. "Coarse-Grained Neural Network Model of the Basal Ganglia to Simulate Reinforcement Learning Tasks" Brain Sciences 12, no. 2: 262. https://doi.org/10.3390/brainsci12020262
APA StyleDrapała, J., & Frydecka, D. (2022). Coarse-Grained Neural Network Model of the Basal Ganglia to Simulate Reinforcement Learning Tasks. Brain Sciences, 12(2), 262. https://doi.org/10.3390/brainsci12020262