
¡Hola! Nice to Meet You: Language Mixing and Biographical Information Processing



Abstract
1. Introduction
2. Materials and Methods
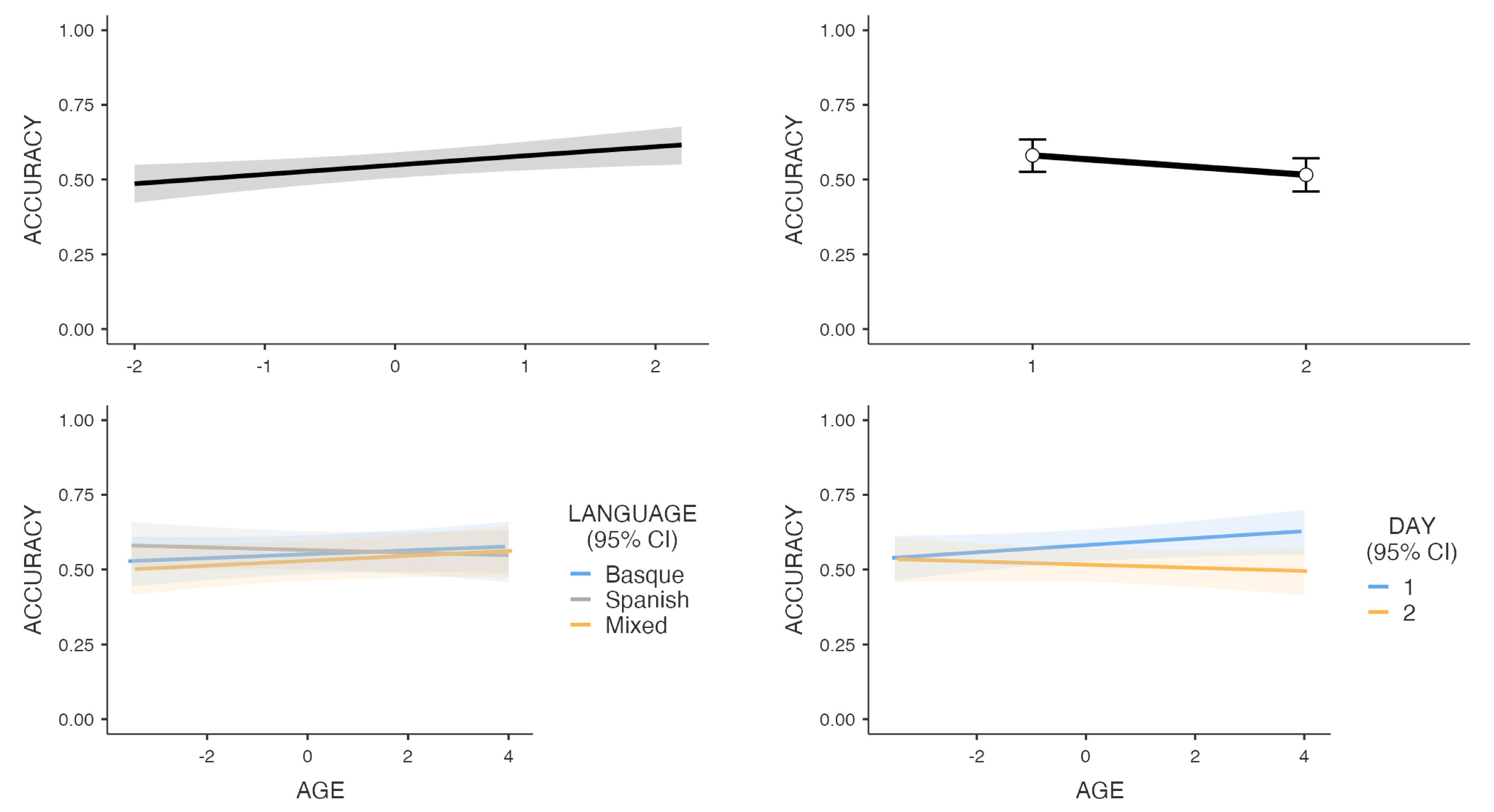
3. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Grosjean, F. Bilingual; Harvard University Press: Cambridge, MA, USA; London, UK, 2010; ISBN 9780674056459. [Google Scholar]
- Crystal, D. The Cambridge Encyclopedia of the English Language; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar]
- Auer, P. Code-Switching in Conversation; Routledge: London, UK; New York, NY, USA, 2013. [Google Scholar]
- Gollan, T.H.; Ferreira, V.S. Should I stay or should I switch? A cost–benefit analysis of voluntary language switching in young and aging bilinguals. J. Exp. Psychol. Learn. Mem. Cogn. 2009, 35, 640–665. [Google Scholar] [CrossRef]
- Milroy, L.; Muysken, P. One Speaker, Two Languages: Cross-Disciplinary Perspectives on Code-Switching; Cambridge University Press: Cambridge, UK, 1995; ISBN 9780521479127. [Google Scholar]
- de Bruin, A.; Samuel, A.G.; Duñabeitia, J.A. Examining bilingual language switching across the lifespan in cued and voluntary switching contexts. J. Exp. Psychol. Hum. Percept. Perform. 2020, 46, 759–788. [Google Scholar] [CrossRef]
- Whorf, B.L. Language, Thought, and Reality: Selected Writings of....; Carroll, J.B., Ed.; Technology Press of MIT: Cambridge, MA, USA, 1956. [Google Scholar]
- Bohnemeyer, J. Linguistic Relativity. In The Wiley Blackwell Companion to Semantics; Wiley: Hoboken, NJ, USA, 2020; pp. 1–33. [Google Scholar]
- Hunt, E.; Agnoli, F. The Whorfian Hypothesis: A Cognitive Psychology Perspective. Psychol. Rev. 1991, 98, 377–389. [Google Scholar] [CrossRef]
- Thierry, G. Neurolinguistic Relativity: How Language Flexes Human Perception and Cognition. Lang. Learn. 2016, 66, 690–713. [Google Scholar] [CrossRef]
- Costa, A.; Foucart, A.; Arnon, I.; Aparici, M.; Apesteguia, J. “Piensa” twice: On the foreign language effect in decision making. Cognition 2014, 130, 236–254. [Google Scholar] [CrossRef]
- Costa, A.; Vives, M.; Corey, J.D. On Language Processing Shaping Decision Making. Curr. Dir. Psychol. Sci. 2017, 26, 146–151. [Google Scholar] [CrossRef]
- Hayakawa, S.; Costa, A.; Foucart, A.; Keysar, B. Using a Foreign Language Changes Our Choices. Trends Cogn. Sci. 2016, 20, 791–793. [Google Scholar] [CrossRef]
- Keysar, B.; Hayakawa, S.L.; An, S.G. The Foreign-Language Effect: Thinking in a Foreign Tongue Reduces Decision Biases. Psychol. Sci. 2012, 23, 661–668. [Google Scholar] [CrossRef]
- Antón, E.; Soleto, N.B.; Duñabeitia, J.A. Recycling in babel: The impact of foreign languages in rule learning. Int. J. Environ. Res. Public Health 2020, 17, 3784. [Google Scholar] [CrossRef] [PubMed]
- Athanasopoulos, P. Cognitive representation of colour in bilinguals: The case of Greek blues. Bilingualism 2009, 12, 83–95. [Google Scholar] [CrossRef]
- Roberson, D.; Davidoff, J.; Davies, I.R.L.; Shapiro, L.R. Color categories: Evidence for the cultural relativity hypothesis. Cogn. Psychol. 2005, 50, 378–411. [Google Scholar] [CrossRef] [PubMed]
- Thierry, G.; Athanasopoulos, P.; Wiggett, A.; Dering, B.; Kuipers, J.R. Unconscious effects of language-specific terminology on preattentive color perception. Proc. Natl. Acad. Sci. USA 2009, 106, 4567–4570. [Google Scholar] [CrossRef]
- Athanasopoulos, P.; Dering, B.; Wiggett, A.; Kuipers, J.R.; Thierry, G. Perceptual shift in bilingualism: Brain potentials reveal plasticity in pre-attentive colour perception. Cognition 2010, 116, 437–443. [Google Scholar] [CrossRef]
- Gilbert, A.L.; Regier, T.; Kay, P.; Ivry, R.B. Support for lateralization of the Whorf effect beyond the realm of color discrimination. Brain Lang. 2008, 105, 91–98. [Google Scholar] [CrossRef]
- Boutonnet, B.; Dering, B.; Viñas-Guasch, N.; Thierry, G. Seeing objects through the language glass. J. Cogn. Neurosci. 2013, 25, 1702–1710. [Google Scholar] [CrossRef]
- Jouravlev, O.; Taikh, A.; Jared, D. Effects of Lexical Ambiguity on Perception: A Test of the Label Feedback Hypothesis Using a Visual Oddball Paradigm. Artic. J. Exp. Psychol. Hum. Percept. Perform. 2018, 44, 1842. [Google Scholar] [CrossRef] [PubMed]
- Gleitman, L.; Papafragou, A. New Perspectives on Language and Thought. In The Oxford Handbook of Thinking and Reasoning; Oxford University Press: Oxford, UK, 2012; ISBN 9780199968718. [Google Scholar]
- Papafragou, A.; Grigoroglou, M. The role of conceptualization during language production: Evidence from event encoding. Lang. Cogn. Neurosci. 2019, 34, 1117–1128. [Google Scholar] [CrossRef]
- Ünal, E.; Papafragou, A. Evidentials, information sources and cognition. In The Oxford Handbook of Evidentiality; Oxford University Press: Oxford, UK, 2018; pp. 175–184. [Google Scholar]
- Sloutsky, V.M. The role of similarity in the development of categorization. Trends Cogn. Sci. 2003, 7, 246–251. [Google Scholar] [CrossRef]
- Hall, G. Perceptual learning in human and nonhuman animals: A search for common ground. In Proceedings of the Learning and Behavior; Springer: New York, NY, USA, 2009; Volume 37, pp. 133–140. [Google Scholar]
- Bornstein, M.H. Perceptual development: Stability and change in feature perception. In Psychological Development from Infancy; Routledge: London, UK, 1979; pp. 37–81. [Google Scholar]
- Bornstein, M.H.; Korda, N.O. Discrimination and matching within and between hues measured by reaction times: Some implications for categorical perception and levels of information processing. Psychol. Res. 1984, 46, 207–222. [Google Scholar] [CrossRef] [PubMed]
- Liberman, A.M.; Harris, K.S.; Hoffman, H.S.; Griffith, B.C. The discrimination of speech sounds within and across phoneme boundaries. J. Exp. Psychol. 1957, 54, 358–368. [Google Scholar] [CrossRef]
- Bodenhausen, G.V.; Kang, S.K.; Peery, D. Social categorization and the perception of social groups. In The SAGE Handbook of Social Cognition; Sage: Thousand Oaks, CA, USA, 2012; pp. 318–336. [Google Scholar]
- Kawakami, K.; Amodio, D.M.; Hugenberg, K. Intergroup Perception and Cognition: An Integrative Framework for Understanding the Causes and Consequences of Social Categorization. In Advances in Experimental Social Psychology; Academic Press Inc.: Cambridge, MA, USA, 2017; Volume 55, pp. 1–80. [Google Scholar]
- Allport, G.W.; Clark, K.; Pettigrew, T. The Nature of Prejudice; Addison-Wesley: New York, NY, USA, 1954. [Google Scholar]
- Meissner, C.A.; Brigham, J.C. Thirty Years of Investigating the Own-Race Bias in Memory for Faces: A Meta-Analytic Review. Psychol. Public Policy Law 2001, 7, 3–35. [Google Scholar] [CrossRef]
- Hills, P.J. A developmental study of the own-age face recognition bias in children. Dev. Psychol. 2012, 48, 499–508. [Google Scholar] [CrossRef]
- Palmer, M.A.; Brewer, N.; Horry, R. Understanding gender bias in face recognition: Effects of divided attention at encoding. Acta Psychol. 2013, 142, 362–369. [Google Scholar] [CrossRef]
- Rhodes, M.G.; Anastasi, J.S. The own-age bias in face recognition: A meta-analytic and theoretical review. Psychol. Bull. 2012, 138, 146–174. [Google Scholar] [CrossRef] [PubMed]
- Wright, D.B.; Sladden, B. An own gender bias and the importance of hair in face recognition. Acta Psychol. 2003, 114, 101–114. [Google Scholar] [CrossRef]
- Kinzler, K.D.; Dupoux, E.; Spelke, E.S. The native language of social cognition. Proc. Natl. Acad. Sci. USA 2007, 104, 12577–12580. [Google Scholar] [CrossRef]
- Pietraszewski, D.; Schwartz, A. Evidence that accent is a dedicated dimension of social categorization, not a byproduct of coalitional categorization. Evol. Hum. Behav. 2014, 35, 51–57. [Google Scholar] [CrossRef]
- Rakić, T.; Steffens, M.C.; Sazegar, A. Do People Remember What Is Prototypical? The Role of Accent–Religion Intersectionality for Individual and Category Memory. J. Lang. Soc. Psychol. 2020, 39, 476–494. [Google Scholar] [CrossRef]
- Blanco-Elorrieta, E.; Pylkkänen, L. Brain bases of language selection: MEG evidence from Arabic-English bilingual language production. Front. Hum. Neurosci. 2015, 9, 27. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Molnar, M.; Ibáñez-Molina, A.; Carreiras, M. Interlocutor identity affects language activation in bilinguals. J. Mem. Lang. 2015, 81, 91–104. [Google Scholar] [CrossRef]
- Hartsuiker, R.J. Visual cues for language selection in bilinguals. In Attention and Vision in Language Processing; Springer: New Delhi, India, 2015; pp. 129–145. ISBN 9788132224433. [Google Scholar]
- Woumans, E.; Martin, C.D.; Vanden Bulcke, C.; Van Assche, E.; Costa, A.; Hartsuiker, R.J.; Duyck, W. Can faces prime a language? Psychol. Sci. 2015, 26, 1343–1352. [Google Scholar] [CrossRef]
- Martin, C.D.; Molnar, M.; Carreiras, M. The proactive bilingual brain: Using interlocutor identity to generate predictions for language processing. Sci. Rep. 2016, 6, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Hayes, B.K.; Heit, E.; Rotello, C.M. Memory, reasoning, and categorization: Parallels and common mechanisms. Front. Psychol. 2014, 5, 529. [Google Scholar] [CrossRef]
- Nosofsky, R.M.; Little, D.R.; James, T.W. Activation in the neural network responsible for categorization and recognition reflects parameter changes. Proc. Natl. Acad. Sci. USA 2012, 109, 333–338. [Google Scholar] [CrossRef]
- Lewandowsky, S. Working Memory Capacity and Categorization: Individual Differences and Modeling. J. Exp. Psychol. Learn. Mem. Cogn. 2011, 37, 720–738. [Google Scholar] [CrossRef] [PubMed]
- Craig, S.; Lewandowsky, S. Whichever way you choose to categorize, working memory helps you learn. Q. J. Exp. Psychol. 2012, 65, 439–464. [Google Scholar] [CrossRef]
- Erten, I.H.; Tekin, M. Effects on vocabulary acquisition of presenting new words in semantic sets versus semantically unrelated sets. System 2008, 36, 407–422. [Google Scholar] [CrossRef]
- Finkbeiner, M.; Nicol, J. Semantic category effects in second language word learning. Appl. Psycholinguist. 2003, 24, 369–383. [Google Scholar] [CrossRef]
- Alanís, I. A Texas Two-way Bilingual Program: Its Effects on Linguistic and Academic Achievement. Biling. Res. J. 2000, 24, 225–248. [Google Scholar] [CrossRef]
- Ferré, P.; Comesaña, M.; Guasch, M. Emotional content and source memory for language: Impairment in an incidental encoding task. Front. Psychol. 2019, 10, 65. [Google Scholar] [CrossRef]
- Marian, V.; Fausey, C.M. Language-dependent memory in bilingual learning. Appl. Cogn. Psychol. 2006, 20, 1025–1047. [Google Scholar] [CrossRef]
- Schroeder, S.R.; Marian, V. Bilingual episodic memory: How speaking two languages influences remembering. In Foundations of Bilingual Memory; Springer: New York, NY, USA, 2014; pp. 113–132. ISBN 9781461492184. [Google Scholar]
- Antón, E.; Thierry, G.; Goborov, A.; Anasagasti, J.; Duñabeitia, J.A. Testing Bilingual Educational Methods: A Plea to End the Language-Mixing Taboo. Lang. Learn. 2016, 66, 29–50. [Google Scholar] [CrossRef]
- Antón, E.; Thierry, G.; Duñabeitia, J.A. Mixing languages during learning? Testing the one subject-one language rule. PLoS ONE 2015, 10, e0130069. [Google Scholar] [CrossRef]
- Antón, E.; Thierry, G.; Dimitropoulou, M.; Duñabeitia, J.A. Similar Conceptual Mapping of Novel Objects in Mixed- and Single-Language Contexts in Fluent Basque-Spanish Bilinguals. Lang. Learn. 2020, 70, 150–170. [Google Scholar] [CrossRef]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. arXiv 2014, arXiv:1406.5823. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing. 2020. Available online: http://www.r-project.org/index.html/ (accessed on 25 May 2021).
- Fox, J.; Weisberg, S. An R Companion to Applied Regression; Sage Publications: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Lenth, R.V. Emmeans: Estimated Marginal Means, aka Least-Squares Means. 2021. Available online: https://cran.r-project.org/web/packages/emmeans/index.html/ (accessed on 25 May 2021).
- Barr, D.J.; Levy, R.; Scheepers, C.; Tily, H.J. Random effects structure for confirmatory hypothesis testing: Keep it maximal. J. Mem. Lang. 2013, 68, 255–278. [Google Scholar] [CrossRef] [PubMed]
- Barton, K. MuMIn: Multi-Model Inference. 2020. Available online: https://cran.r-project.org/web/packages/MuMIn/index.html/ (accessed on 25 May 2021).
- Project, T.J. jamovi. (Version 1.6) [Computer Software]. Available online: https://www.jamovi.org/ (accessed on 29 April 2021).
- Gallucci, M. GAMLj: General Analyses for the Linear Model in Jamovi. Available online: https://gamlj.github.io/ (accessed on 29 April 2021).
- Knippenberg, A.; Twuyver, M.; Pepels, J. Factors affecting social categorization processes in memory. Br. J. Soc. Psychol. 1994, 33, 419–431. [Google Scholar] [CrossRef]
- de Bruin, A.; Samuel, A.G.; Duñabeitia, J.A. Voluntary language switching: When and why do bilinguals switch between their languages? J. Mem. Lang. 2018, 103, 28–43. [Google Scholar] [CrossRef]
- Grosjean, F. The bilingual’s language modes. In The Bilingualism Reader; Routledge: London, UK; New York, NY, USA, 2020; pp. 428–449. [Google Scholar]
- Grosjean, F. Studying bilinguals: Methodological and conceptual issues. Biling. Lang. Cogn. 1998, 1, 131–149. [Google Scholar] [CrossRef]
- Cummins, J. A proposal for action: Strategies for recognizing heritage language competence as a learning resource within the mainstream classroom. Mod. Lang. J. 2005, 585–592. [Google Scholar]
- Lin, A. Classroom code-switching: Three decades of research. Appl. Linguist. Rev. 2013, 4, 195–218. [Google Scholar] [CrossRef]
- Fernandez, C.B.; Litcofsky, K.A.; Van Hell, J.G. Neural correlates of intra-sentential code-switching in the auditory modality. J. Neuroling. 2018, 51, 17–41. [Google Scholar] [CrossRef]
- Pérez, A.; Duñabeitia, J.A. Speech perception in bilingual contexts: Neuropsychological impact of mixing languages at the inter-sentential level. J. Neuroling. 2019, 51, 258–267. [Google Scholar] [CrossRef]
- Thomas, M.S.; Allport, A. Language Switching Costs in Bilingual Visual Word Recognition. J. Mem. Lang. 2000, 43, 44–66. [Google Scholar] [CrossRef]
- Gullifer, J.W.; Kroll, J.F.; Dussias, P.E. When language switching has no apparent cost: Lexical access in sentence context. Front. Psychol. 2013, 4, 278. [Google Scholar] [CrossRef] [PubMed]
- Hartanto, A.; Yang, H. Disparate bilingual experiences modulate task-switching advantages: A diffusion-model analysis of the effects of interactional context on switch costs. Cognition 2016, 150, 10–19. [Google Scholar] [CrossRef]
- Baker, C. Foundations of Bilingual Education and Bilingualism; Multilingual Matters: Bristol, UK, 2011. [Google Scholar]
- Baker, D.L.; Park, Y.; Baker, S.K.; Basaraba, D.L.; Kame’Enui, E.J.; Beck, C.T. Effects of a paired bilingual reading program and an English-only program on the reading performance of English learners in Grades 1–3. J. Sch. Psychol. 2012, 50, 737–758. [Google Scholar] [CrossRef] [PubMed]
- García, O.; Wei, L. Language, bilingualism and education. In Translanguaging: Language, Bilingualism and Education; Palgrave Pivot: London, UK, 2014; pp. 46–62. [Google Scholar]
- García, O. Bilingual Education in the 21st Century: A Global Perspective; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Canagarajah, S. Codemeshing in Academic Writing: Identifying Teachable Strategies of Translanguaging. Mod. Lang. J. 2011, 95, 401–417. [Google Scholar] [CrossRef]
- Cenoz, J.; Gorter, D. Minority languages and sustainable translanguaging: Threat or opportunity? J. Multiling. Multicult. Dev. 2017, 38, 901–912. [Google Scholar] [CrossRef]
- López, L. Bilingual Grammar; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Duñabeitia, J.A.; Dimitropoulou, M.; Uribe-Etxebarria, O.; Laka, I.; Carreiras, M. Electrophysiological correlates of the masked translation priming effect with highly proficient simultaneous bilinguals. Brain Res. 2010, 1359, 142–154. [Google Scholar] [CrossRef] [PubMed]
- Duñabeitia, J.A.; Perea, M.; Carreiras, M. Masked translation priming effects with highly proficient simultaneous bilinguals. Exp. Psychol. 2010, 57, 98–107. [Google Scholar] [CrossRef] [PubMed]
- Badiola, L.; Delgado, R.; Sande, A.; Stefanich, S. Code-switching attitudes and their effects on acceptability judgment tasks. Linguist. Approach. Biling. 2018, 8, 5–24. [Google Scholar] [CrossRef]
- Stefanich, S.; Cabrelli, J.; Hilderman, D.; Archibald, J. The Morphophonology of Intraword Codeswitching: Representation and Processing. Front. Commun. 2019, 4, 54. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Male1 | Male2 | Male3 | Female1 | Female2 | Female3 | |
|---|---|---|---|---|---|---|
| Name | Aimar | Markel | Iker | Ane | Irati | June |
| Age | 18 | 22 | 26 | 19 | 23 | 27 |
| Favorite Food | Chicken | Apple | Fish | Bread | Egg | Cheese |
| Favorite Animal | Dog | Bear | Bird | Horse | Rabbit | Frog |
| Profession | Dancer | Cook | Photographer | Fire-fighter | Teacher | Athlete |
| Language | Task | Day | Accuracy (% Hits) | |
|---|---|---|---|---|
| Basque | Recall | 1 | 0.549 | (0.498) |
| 2 | 0.502 | (0.500) | ||
| Recognition | 1 | 0.554 | (0.497) | |
| 2 | 0.515 | (0.500) | ||
| Mixed | Recall | 1 | 0.556 | (0.497) |
| 2 | 0.477 | (0.500) | ||
| Recognition | 1 | 0.536 | (0.499) | |
| 2 | 0.490 | (0.500) | ||
| Spanish | Recall | 1 | 0.582 | (0.493) |
| 2 | 0.493 | (0.500) | ||
| Recognition | 1 | 0.559 | (0.497) | |
| 2 | 0.533 | (0.499) | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Antón, E.; Duñabeitia, J.A. ¡Hola! Nice to Meet You: Language Mixing and Biographical Information Processing. Brain Sci. 2021, 11, 703. https://doi.org/10.3390/brainsci11060703
Antón E, Duñabeitia JA. ¡Hola! Nice to Meet You: Language Mixing and Biographical Information Processing. Brain Sciences. 2021; 11(6):703. https://doi.org/10.3390/brainsci11060703
Chicago/Turabian StyleAntón, Eneko, and Jon Andoni Duñabeitia. 2021. "¡Hola! Nice to Meet You: Language Mixing and Biographical Information Processing" Brain Sciences 11, no. 6: 703. https://doi.org/10.3390/brainsci11060703
APA StyleAntón, E., & Duñabeitia, J. A. (2021). ¡Hola! Nice to Meet You: Language Mixing and Biographical Information Processing. Brain Sciences, 11(6), 703. https://doi.org/10.3390/brainsci11060703