
Perspectives on Generative Sound Design: A Generative Soundscapes Showcase


Abstract
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
1.1. Transformers in Media Generation
1.2. Historical Context
1.2.1. The Beginnings of Generative Music
1.2.2. Stochastic Soundscapes Origins
1.2.3. Analogue Electronics for Generative Sound
1.2.4. Digital Electronics for Generative Sound
1.2.5. Transformers for Generative Sound Design
2. Related Work
2.1. A Definition of Soundscape
2.2. Generative Soundscapes
2.3. Generative Audio Transformers
2.4. Generative Audio for Video
2.5. Ethical Discourse
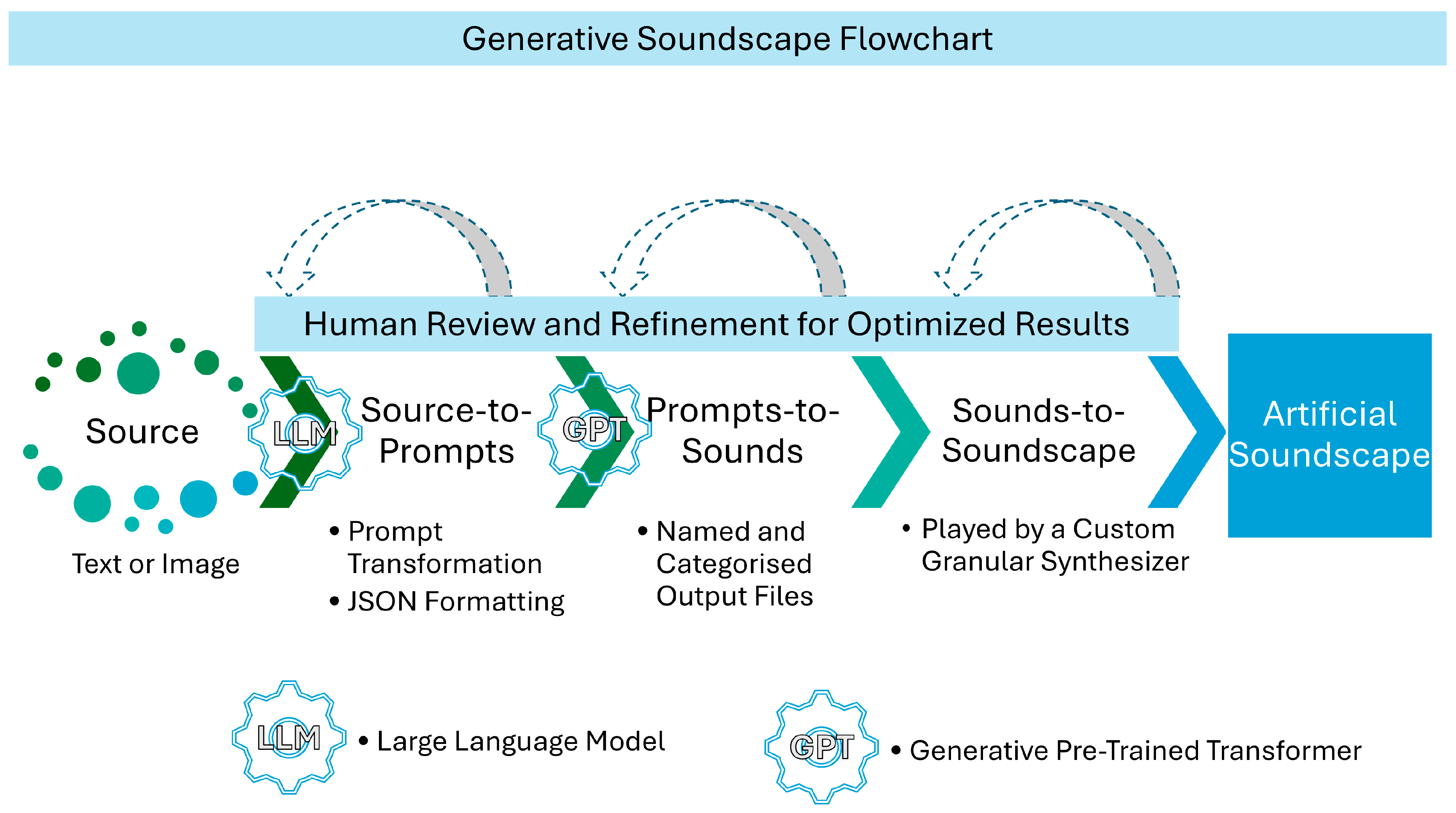
3. Methodology
3.1. Main Assumptions
- Direct Translation: A sound is directly mapped to a concept, where its meaning aligns literally with the source (e.g., forest sounds generated from text or images depicting a forest).
- Free Interpretation: Sounds represent a concept indirectly using illustrative elements (e.g., fatigue expressed through rhythmic breathing, yawning, or the ticking of a clock).
3.2. GPT Feedback
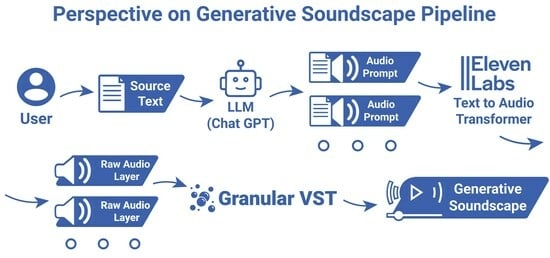
4. Pipeline Implementation
4.1. The Pipeline Concept
4.2. Applied Technologies
- Eleven Labs API: A sound effects generator that enables users to create sound by providing descriptive prompts. This API uses natural language understanding to interpret user input and produce high-quality, context-specific sound effects (Eleven Labs 2024b).
- OpenAI ChatGPT: A multimodal large language model (LLM) capable of handling both text and image inputs. The implementation utilized the gpt-4o-mini (18 July 2024) version, with additional testing conducted using gpt-4o (6 August 2024). (OpenAI 2024).
4.3. The Source-to-Sound-Prompt Module
- Prompt: A descriptive text specifying the auditory characteristics of the sound layer.
- Category: A folder structure categorizing sound layers based on general characteristics and specific concepts (e.g., “General_Tag\Concept_Name”).
- Filename: A descriptive identifier for each sound layer formatted as “snake_case”.
- Duration: Length of the audio segment for each sound layer.
- Num_generations: Number of versions of the sound layer to be generated.
- Prompt_influence: A value that determines the extent to which the descriptive prompt influences the generated sound. This allows for fine-tuning the balance between creative and literal adherence to the prompt.
4.4. Custom Instruction
- Decomposing the concept into distinct sound elements (e.g., natural sounds, ambiance, and human activity).
- Generating 5–8 sound layers, each accompanied by a detailed description.
- Populating metadata for each sound layer
4.5. Data Supplementary Materials and Code
5. Preliminary Testing and Empirical Research
5.1. Highlights
5.2. Limitations
5.2.1. Overlapping Frequencies
5.2.2. Abrupt Endings Without Proper Attenuation
5.2.3. Unintended Sound Artifacts
5.2.4. Misinterpreting Prompt Focusing on Key Words
5.2.5. Generating Random Musical Elements
5.3. Possible Improvements
5.4. The Necessity of Human Verification and Refinement
6. The Development of a Complementary Solution
6.1. Limitations of Generative Samples
6.2. The Granular Synthesizer as a Solution
6.3. Prototype Design and Implementation
6.3.1. User-Adjustable Parameters
- Grain Size defines the duration of each grain extracted from the audio files.
- Overlap determines the degree of overlap between consecutive grains.
- Fade Duration sets the fade-in and fade-out times for each grain, ensuring smooth transitions.
- Simultaneous Grains specifies the number of grains played simultaneously.
- Duration Deviation introduces variability in the duration of each grain to prevent repetitive patterns.
6.3.2. Support for Multiple Instances
- Atmospheric/ambient layers: Parameters can be adjusted to favor longer grain sizes, increased overlap, and softer fade durations to create smooth, continuous soundscapes (Schafer’s keynotes).
- One-shot effects: Parameters can be configured for shorter grain sizes, minimal overlap, and precise fade settings, focusing on the clarity and impact of isolated sound elements (Schafer signals).
7. Conclusions
7.1. Overview
7.2. Challenges
7.3. Complementary Solution
7.4. Future Research
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Agostinelli, Andrea, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, and et al. 2023. MusicLM: Generating Music from Text. arXiv arXiv:2301.11325. [Google Scholar]
- Ashvala, Vinay, and Alexander Lerch. 2022. Evaluating Generative Audio Systems and Their Metrics. Paper presented at International Society for Music Information Retrieval Conference, Bengaluru, India, December 4–8. [Google Scholar]
- Barnett, Julie. 2023. The Ethical Implications of Generative Audio Models: A Systematic Literature Review. Paper presented at AAAI/ACM Conference on AI, Ethics, and Society, Montreal, QC, Canada, August 8–10. [Google Scholar]
- Birchfield, David, Nahla Mattar, and Hari Sundaram. 2005. Design of a Generative Model for Soundscape Creation. Paper presented at International Conference on Mathematics and Computing, January; Available online: https://www.researchgate.net/profile/Nahla-Mattar/publication/252768176_DESIGN_OF_A_GENERATIVE_MODEL_FOR_SOUNDSCAPE_CREATION/links/5d958e8392851c2f70e55d17/DESIGN-OF-A-GENERATIVE-MODEL-FOR-SOUNDSCAPE-CREATION.pdf (accessed on 30 November 2024).
- Blesser, Barry, and Linda-Ruth Salter. 2007. Spaces Speak, Are You Listening? Experiencing Aural Architecture. Cambridge, MA: MIT Press. [Google Scholar]
- Bubeck, Sébastien, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, and et al. 2023. Sparks of Artificial General Intelligence: Early Experiments with GPT-4. arXiv arXiv:2303.12712. [Google Scholar]
- Chen, Sanyuan, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, and et al. 2021. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing. IEEE Journal on Selected Topics in Signal Processing 16: 1505–18. [Google Scholar] [CrossRef]
- Chen, Zhehuai, Yu Zhang, Andrew E. Rosenberg, Bhuvana Ramabhadran, Pedro R. Moreno, Ankur Bapna, and Heiga Zen. 2022. MAESTRO: Matched Speech Text Representations through Modality Matching. arXiv arXiv:2204.03409. [Google Scholar]
- Copet, Jade, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. 2023. Simple and Controllable Music Generation. arXiv arXiv:2306.05284. [Google Scholar]
- Edwards, Justin, Allison Perrone, and Philip R. Doyle. 2020. Transparency in Language Generation: Levels of Automation. Paper presented at 2nd Conference on Conversational User Interfaces, Bilbao, Spain, June 22–24. [Google Scholar]
- Eigenfeldt, Arne, and Philippe Pasquier. 2011. Negotiated Content: Generative Soundscape Composition by Autonomous Musical Agents in Coming Together: Freesound. Paper presented at International Conference on Innovative Computing and Cloud Computing, Mexico City, Mexico, April 27–29; pp. 27–32. Available online: https://computationalcreativity.net/iccc2011/proceedings/the_social/eigenfeldt_iccc11.pdf (accessed on 30 November 2024).
- Eleven Labs. 2024a. Examples for Sound Effects. GitHub. Available online: https://github.com/elevenlabs/elevenlabs-examples/tree/main/examples/sound-effects/video-to-sfx (accessed on 30 November 2024).
- Eleven Labs. 2024b. Sound Effects. Eleven Labs. Available online: https://elevenlabs.io/sound-effects (accessed on 30 November 2024).
- Evans, Zach, Julian D. Parker, C. J. Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons. 2024. Stable Audio Open. arXiv arXiv:2407.14358. [Google Scholar]
- Griffiths, Paul. 2010. Modern Music and After, 3rd ed. New York: Oxford University Press. [Google Scholar]
- Holmes, Thom. 2020. Electronic and Experimental Music: Technology, Music, and Culture. New York: Routledge. Available online: http://archive.org/details/electronicexperi0000holm_3rded (accessed on 30 November 2024).
- Huang, Qingqing, Daniel S. Park, Tao Wang, Timo I. Denk, Andy Ly, Nanxin Chen, Zhengdong Zhang, Zhishuai Zhang, Jiahui Yu, Christian Frank, and et al. 2023a. Noise2Music: Text-Conditioned Music Generation with Diffusion Models. arXiv arXiv:2302.03917. [Google Scholar]
- Huang, Rongjie, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, and et al. 2023b. AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head. arXiv arXiv:2304.12995. [Google Scholar]
- Ji, Shulei, Jing Luo, and Xinyu Yang. 2020. A Comprehensive Survey on Deep Music Generation: Multi-Level Representations, Algorithms, Evaluations, and Future Directions. arXiv arXiv:2011.06801. [Google Scholar]
- Koutini, Khaled, Jan Schlüter, Hamid Eghbalzadeh, and Gerhard Widmer. 2021. Efficient Training of Audio Transformers with Patchout. arXiv arXiv:2110.05069. [Google Scholar] [CrossRef]
- Koutsomichalis, Marinos, and Andrea Valle. 2014. SoundScapeGenerator: Soundscape Modelling and Simulation. Paper presented at XX CIM, Rome, Italy, October 20–22; pp. 65–70. Available online: https://iris.unito.it/retrieve/handle/2318/152887/27120/soundscapeModelling.pdf (accessed on 30 November 2024).
- Kreuk, Felix, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. 2023. AudioGen: Textually Guided Audio Generation. arXiv arXiv:2209.15352. [Google Scholar]
- Le, Matthew, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sarı, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, and et al. 2023. Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale. Neural Information Processing Systems 36: 14005–34. [Google Scholar] [CrossRef]
- Li, Yizhi, Ruibin Yuan, Ge Zhang, Yinghao Ma, Xingran Chen, Hanzhi Yin, Chenghao Xiao, Chenghua Lin, Anton Ragni, Emmanouil Benetos, and et al. 2024. MERT: Acoustic Music Understanding Model with Large-Scale Self-Supervised Training. arXiv arXiv:2306.00107. [Google Scholar]
- Liang, Jinhua, Huan Zhang, Haohe Liu, Yin Cao, Qiuqiang Kong, Xubo Liu, Wenwu Wang, Mark D. Plumbley, Huy Phan, and Emmanouil Benetos. 2024. WavCraft: Audio Editing and Generation with Large Language Models. arXiv arXiv:2403.09527. [Google Scholar]
- Liu, Haohe, Zehua Chen, Zhen Yuan, Xinhao Mei, Xubo Liu, Danilo P. Mandic, Wenwu Wang, and Mark D. Plumbley. 2023a. AudioLDM: Text-to-Audio Generation with Latent Diffusion Models. arXiv arXiv:2301.12503. [Google Scholar] [CrossRef]
- Liu, Xubo, Zhongkai Zhu, Haohe Liu, Yi Yuan, Meng Cui, Qiushi Huang, Jinhua Liang, Yin Cao, Qiuqiang Kong, Mark D. Plumbley, and et al. 2023b. WavJourney: Compositional Audio Creation with Large Language Models. arXiv arXiv:2307.14335. [Google Scholar] [CrossRef]
- Marrinan, Thomas, Pakeeza Akram, Oli Gurmessa, and Anthony Shishkin. 2024. Leveraging AI to Generate Audio for User-Generated Content in Video Games. arXiv arXiv:2404.17018. [Google Scholar]
- Midjourney. 2024. Midjourney Documentation: No Parameter. Midjourney. Available online: https://docs.midjourney.com/docs/no (accessed on 30 November 2024).
- Oh, Sangshin, Minsung Kang, Hyeongi Moon, Keunwoo Choi, and Ben Sangbae Chon. 2023. A Demand-Driven Perspective on Generative Audio AI. arXiv arXiv:2307.04292. [Google Scholar]
- OpenAI. 2024. Models Documentation. OpenAI. Available online: https://platform.openai.com/docs/models (accessed on 30 November 2024).
- Open Science Framework. 2024a. Generative Soundscape Pipeline. Available online: https://osf.io/qjm4a/?view_only=9ffac3ce06994e38bad5a81f3f16d82c (accessed on 7 December 2024).
- Open Science Framework. 2024b. Granular Audio Player. Available online: https://osf.io/yf5qd/?view_only=60029d17660b42a5923408c883835a8e (accessed on 7 December 2024).
- Ouyang, Long, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and et al. 2022. Training Language Models to Follow Instructions with Human Feedback. Neural Information Processing Systems 35: 27730–44. [Google Scholar] [CrossRef]
- Pinch, Trevor J., and Frank Trocco. 2009. Analog Days: The Invention and Impact of the Moog Synthesizer. Cambridge, MA: Harvard University Press. [Google Scholar]
- Porter, Brian, and Edouard Machery. 2024. AI-Generated Poetry Is Indistinguishable from Human-Written Poetry and Is Rated More Favorably. Scientific Reports 14: 26133. [Google Scholar] [CrossRef]
- Qingqing, Huang, Aren Jansen, Joonseok Lee, Ravi Ganti, Judith Yue Li, and Daniel P. W. Ellis. 2022. MuLan: A Joint Embedding of Music Audio and Natural Language. Paper presented at International Society for Music Information Retrieval Conference, Bengaluru, India, December 4–8. [Google Scholar]
- Ray, Partha Pratim. 2023. ChatGPT: A Comprehensive Review on Background, Applications, Key Challenges, Bias, Ethics, Limitations and Future Scope. Internet of Things and Cyber-Physical Systems 3: 121–54. [Google Scholar] [CrossRef]
- Rouard, Simon, Yossi Adi, Jade Copet, Axel Roebel, and Alexandre Défossez. 2024. Audio Conditioning for Music Generation via Discrete Bottleneck Features. arXiv arXiv:2407.12563. [Google Scholar]
- Rubenstein, Paul K., Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, and et al. 2023. AudioPaLM: A Large Language Model that Can Speak and Listen. arXiv arXiv:2306.12925. [Google Scholar]
- Samson, Grzegorz. 2024. Procedurally Generated AI Compound Media for Expanding Audial Creations, Broadening Immersion and Perception Experience. International Journal of Electronics and Telecommunications 70: 341–48. [Google Scholar] [CrossRef]
- Schafer, R. Murray. 1993. The Soundscape: Our Sonic Environment and the Tuning of the World. Rochester: Inner Traditions/Bear. Available online: https://books.google.pl/books?id=_N56QgAACAAJ (accessed on 30 November 2024).
- Stamać, Ivan. 2005. Acoustical and Musical Solution to Wave-Driven Sea Organ in Zadar. Paper presented at 2nd Congress of Alps-Adria Acoustics Association and 1st Congress of Acoustical Society of Croatia, Opatija, Croatia, June 23–24; pp. 203–6. [Google Scholar]
- Taruskin, Richard, and Christopher H. Gibbs. 2013. The Oxford History of Western Music, College ed. New York: Oxford University Press. [Google Scholar]
- Toop, David. 1995. Ocean of Sound: Aether Talk, Ambient Sound and Imaginary Worlds. London: Serpent’s Tail. [Google Scholar]
- Tur, Ada. 2024. Deep Learning for Style Transfer and Experimentation with Audio Effects and Music Creation. Paper presented at AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, February 20–27. [Google Scholar]
- van den Oord, Aäron, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alexander Graves, Nal Kalchbrenner, Andrew W. Senior, and Koray Kavukcuoglu. 2016. WaveNet: A Generative Model for Raw Audio. arXiv arXiv:1609.03499. [Google Scholar]
- Verma, Prateek, and Chris Chafe. 2021. A Generative Model for Raw Audio Using Transformer Architectures. arXiv arXiv:2106.16036. [Google Scholar]
- Verma, Prateek, and Jonathan Berger. 2021. Audio Transformers: Transformer Architectures for Large Scale Audio Understanding. Adieu Convolutions. arXiv arXiv:2105.00335. [Google Scholar]
- Vyas, Apoorv, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, and et al. 2023. Audiobox: Unified Audio Generation with Natural Language Prompts. arXiv arXiv:2312.15821. [Google Scholar]
- Wayne, Kevin. 2023. Mozart Musical Dice Game. Paper presented at 54th SIGCSE Technical Symposium on Computer Science Education, Toronto, ON, Canada, March 15–18. [Google Scholar]
- Xenakis, Iannis, and Sharon Kanach. 1992. Formalized Music: Thought and Mathematics in Composition. Hillsdale: Pendragon Press. Available online: https://books.google.pl/books?id=fDAJAQAAMAAJ (accessed on 30 November 2024).
- Yu, Jiaxing, Songruoyao Wu, Guanting Lu, Zijin Li, Li Zhou, and Kejun Zhang. 2024. Suno: Potential, Prospects, and Trends. Frontiers of Information Technology & Electronic Engineering 25: 1025–30. [Google Scholar] [CrossRef]
- Zhang, Chenshuang, Chaoning Zhang, Shusen Zheng, Mengchun Zhang, Maryam Qamar, Sung-Ho Bae, and In So Kweon. 2023. A Survey on Audio Diffusion Models: Text to Speech Synthesis and Enhancement in Generative AI. arXiv arXiv:303.13336. [Google Scholar]
- Zhuang, Yonggai, Yuhao Kang, Teng Fei, Meng Bian, and Yunyan Du. 2024. From Hearing to Seeing: Linking Auditory and Visual Place Perceptions with Soundscape-to-Image Generative Artificial Intelligence. Computers, Environment and Urban Systems 110: 102122. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samson, G. Perspectives on Generative Sound Design: A Generative Soundscapes Showcase. Arts 2025, 14, 67. https://doi.org/10.3390/arts14030067
Samson G. Perspectives on Generative Sound Design: A Generative Soundscapes Showcase. Arts. 2025; 14(3):67. https://doi.org/10.3390/arts14030067
Chicago/Turabian StyleSamson, Grzegorz. 2025. "Perspectives on Generative Sound Design: A Generative Soundscapes Showcase" Arts 14, no. 3: 67. https://doi.org/10.3390/arts14030067
APA StyleSamson, G. (2025). Perspectives on Generative Sound Design: A Generative Soundscapes Showcase. Arts, 14(3), 67. https://doi.org/10.3390/arts14030067