The Scavenger Hunt for Quasar Samples to Be Used as Cosmological Tools

 , , and
, , and 
Abstract
1. Introduction
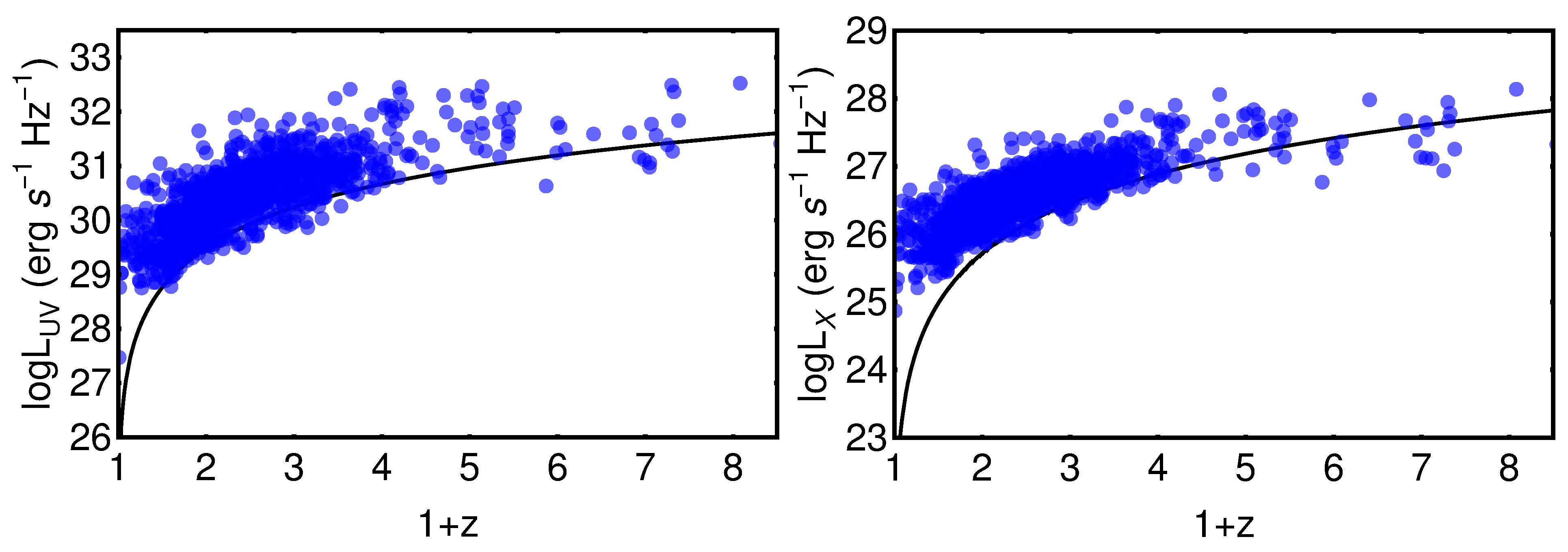
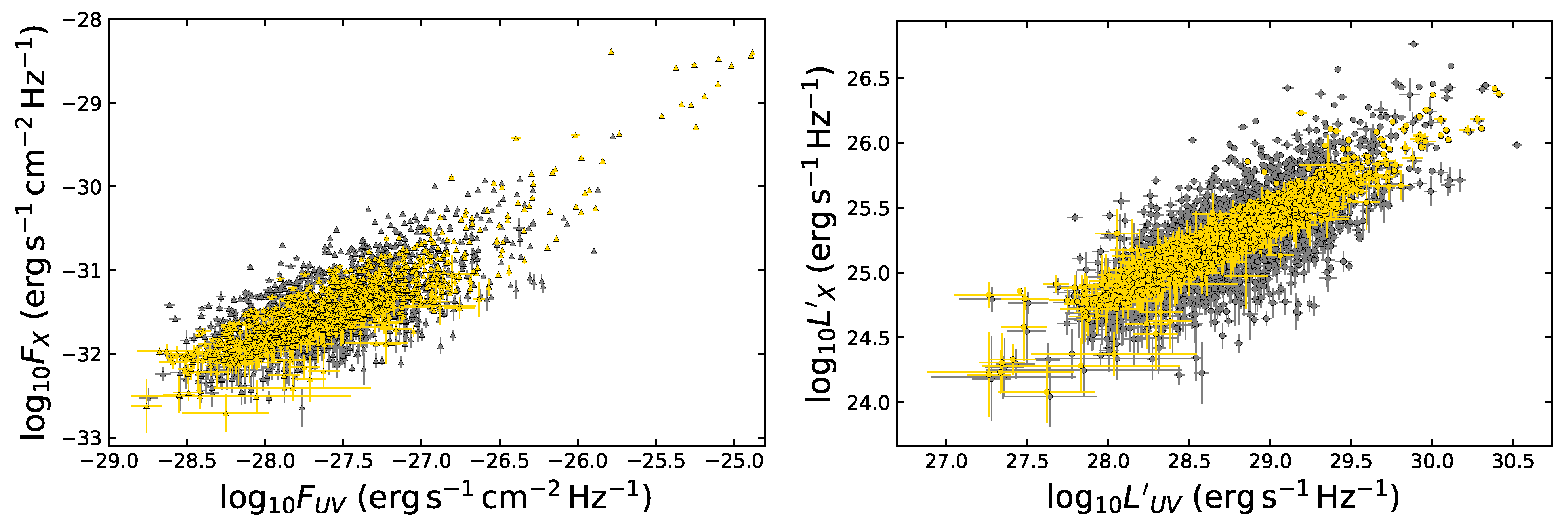
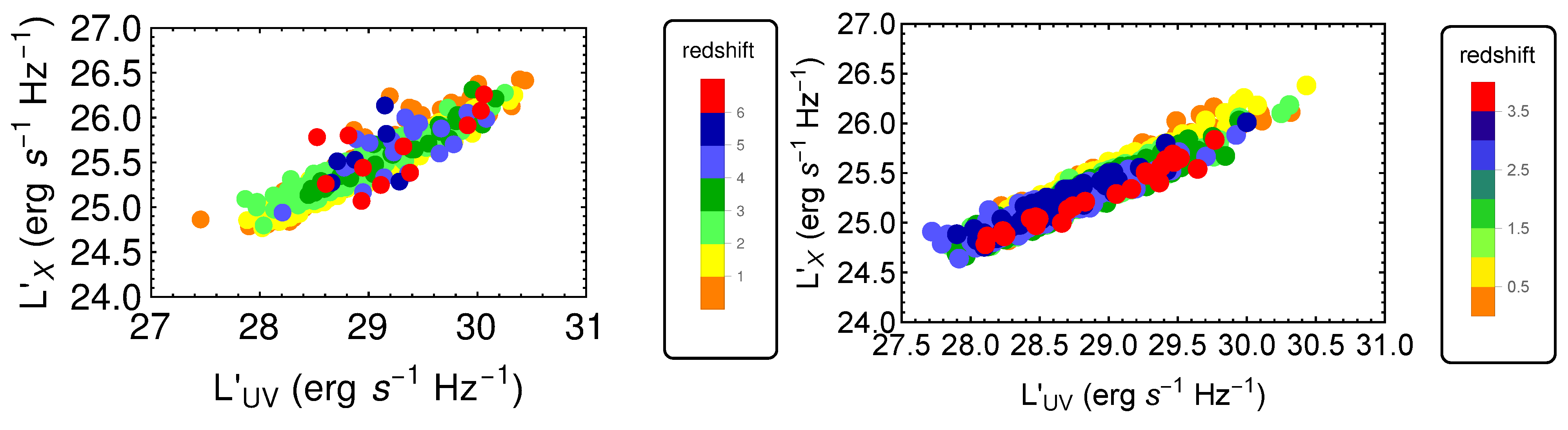
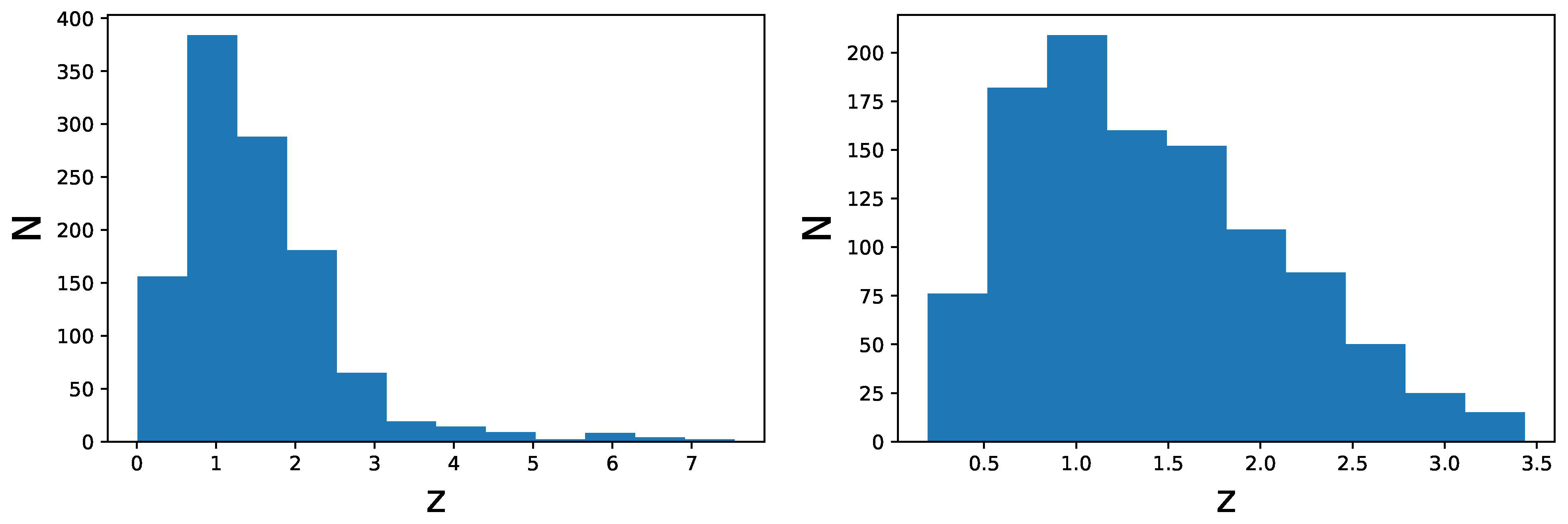
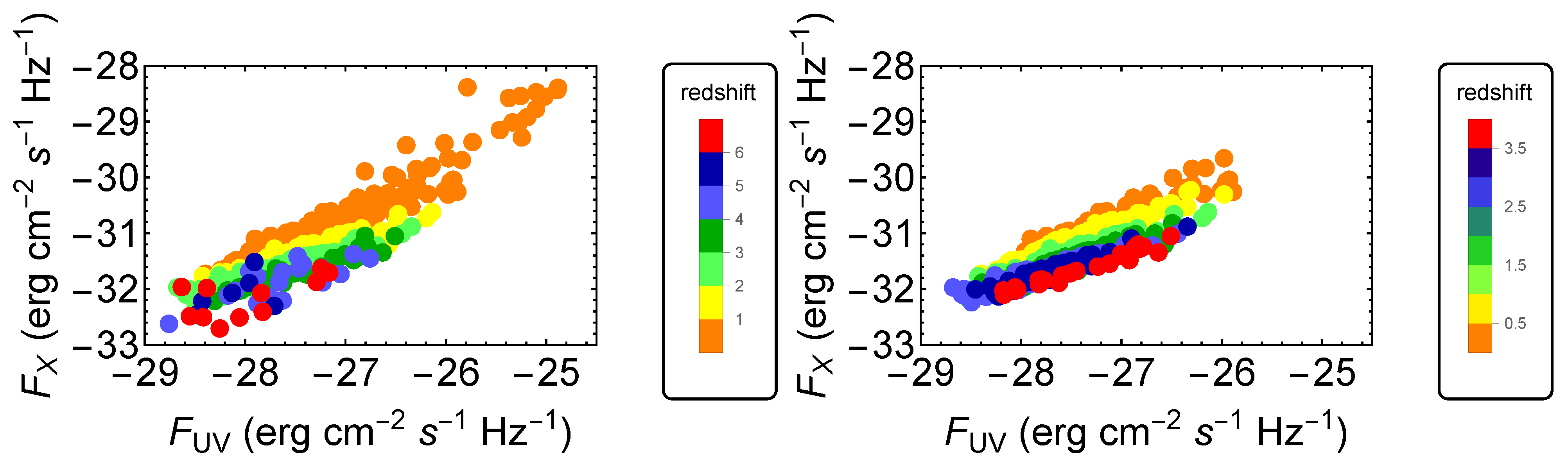
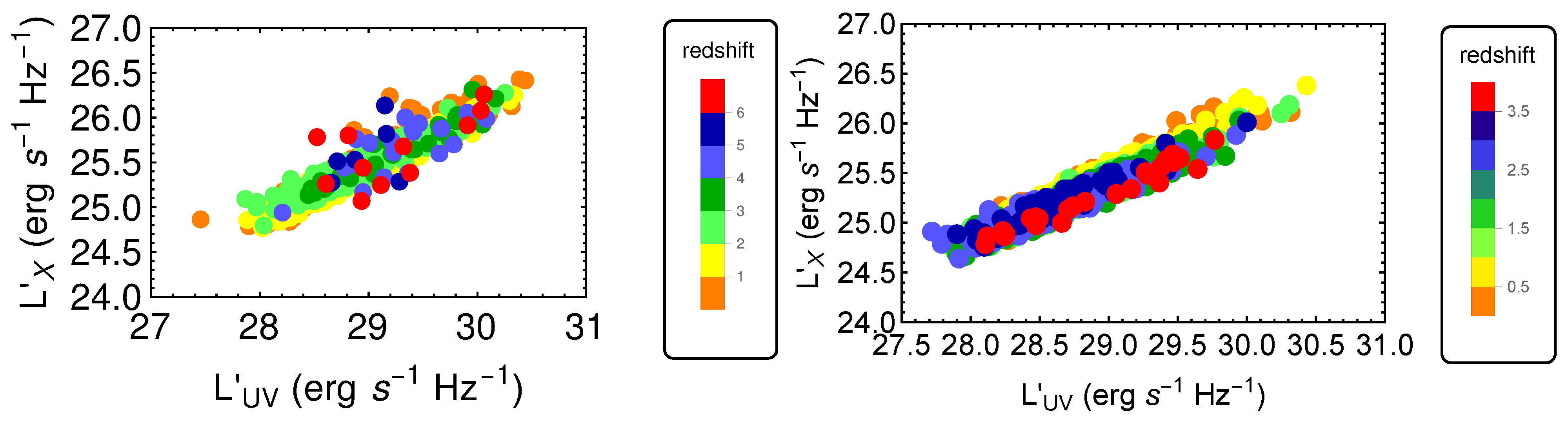
2. The Data Sample
3. Methods
3.1. Selection of the QSO Final Samples
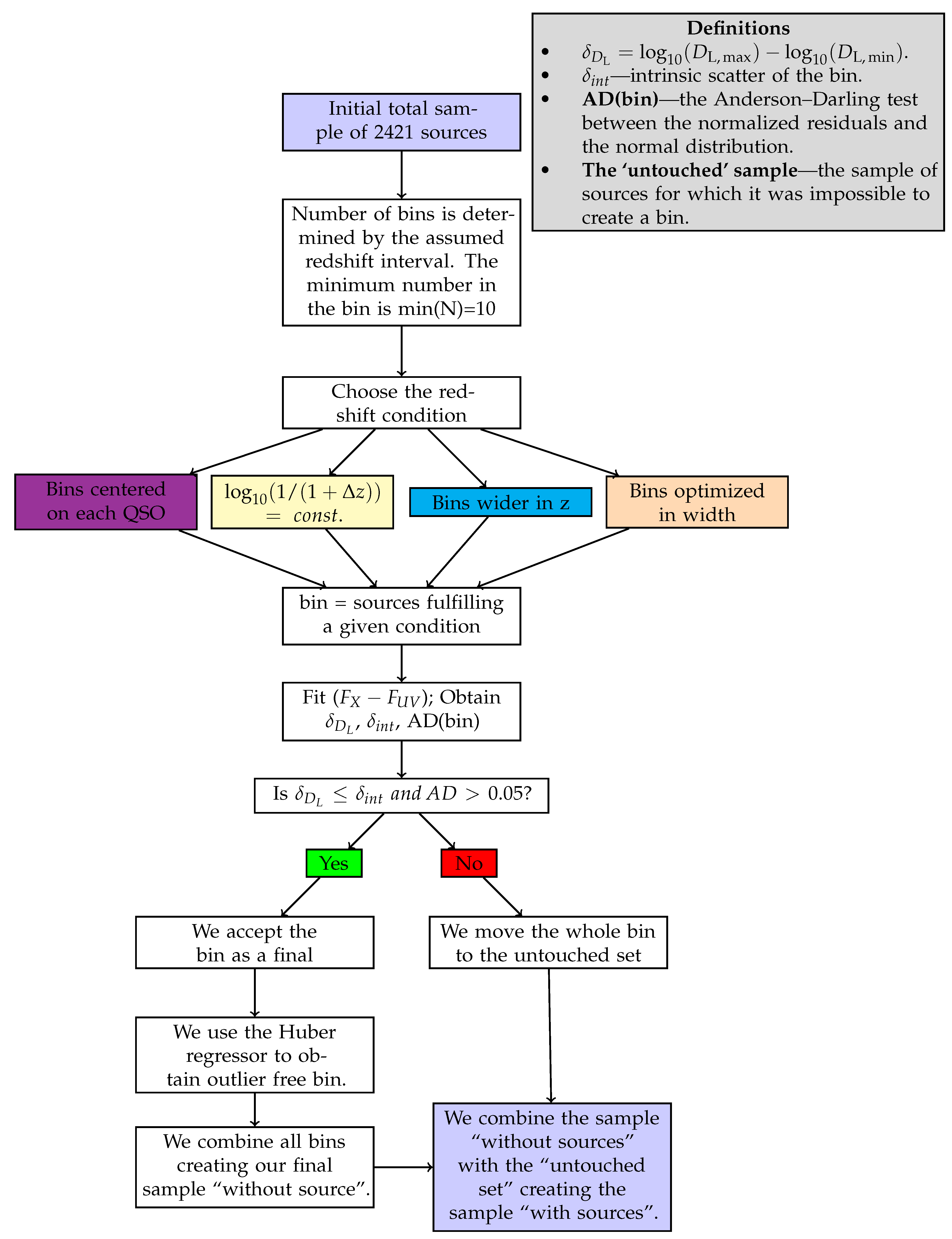
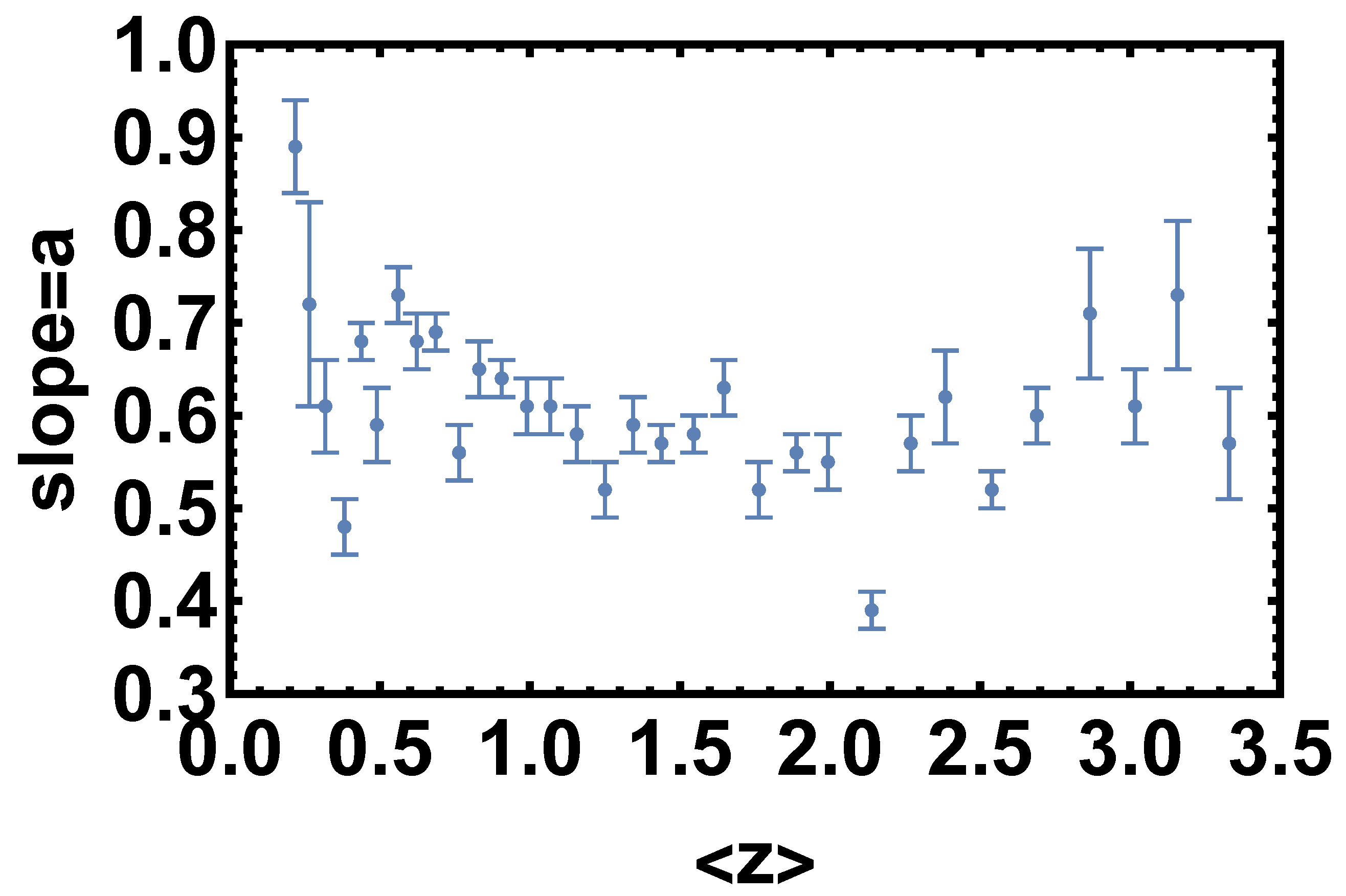
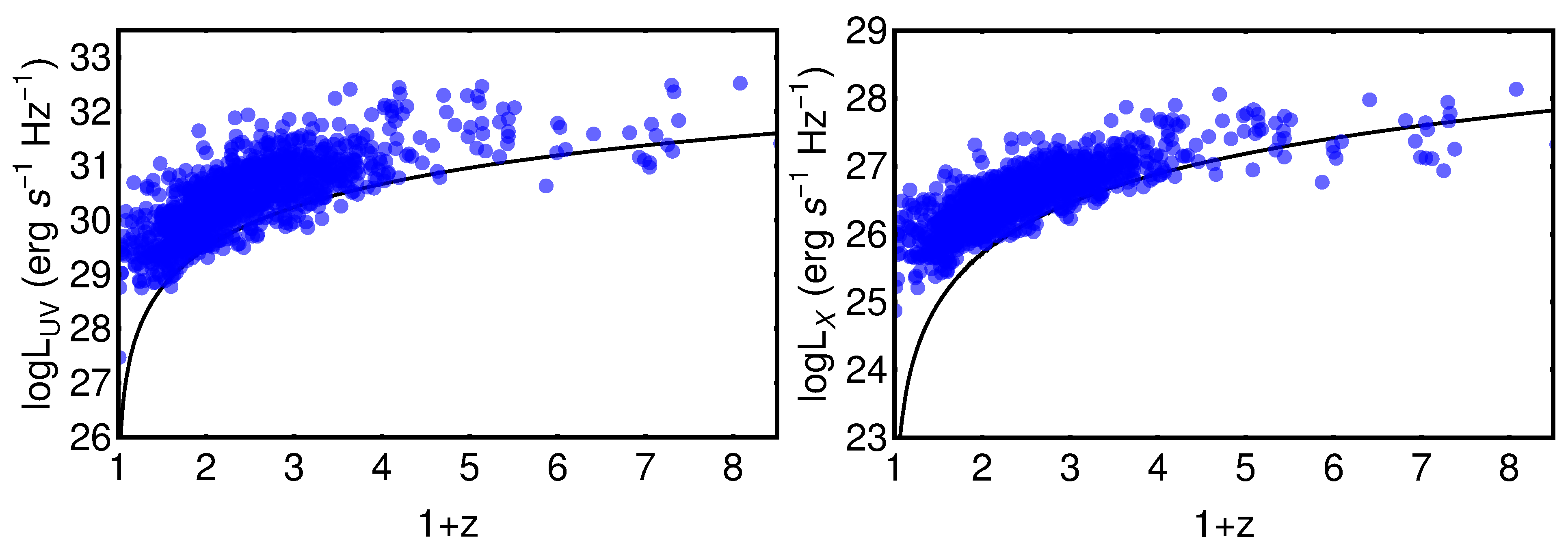
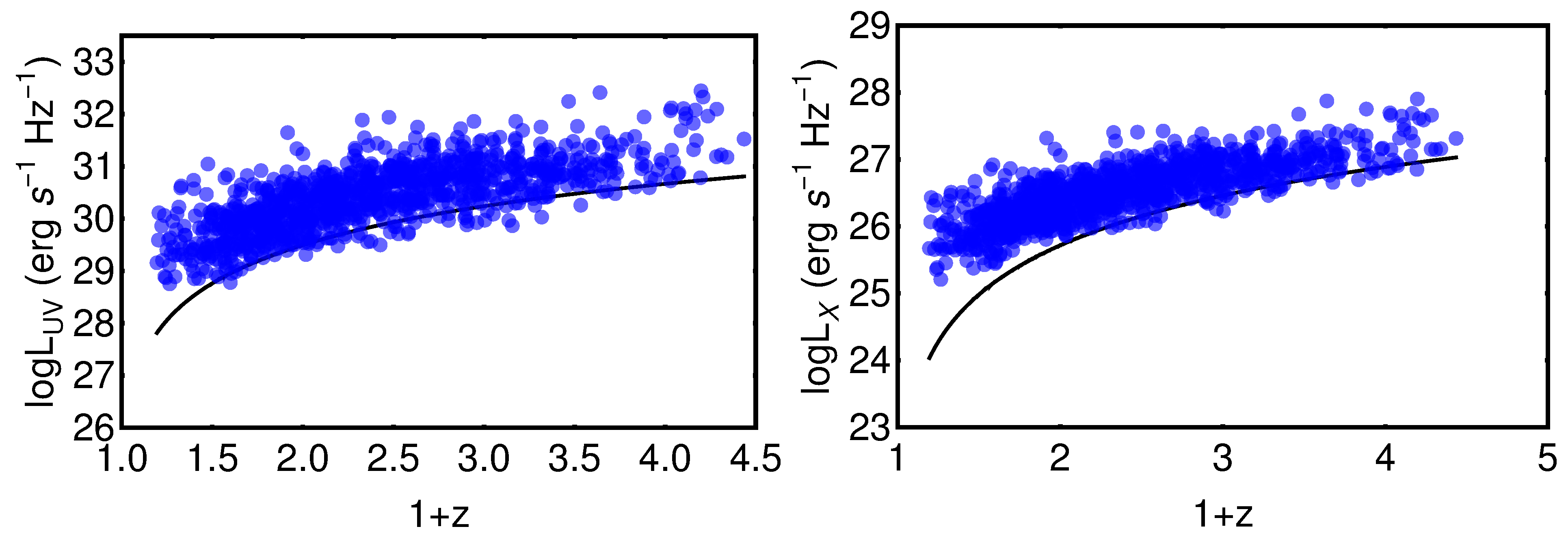
- We have first divided the initial QSO sample into bins of redshift to fit a linear relation between the logarithms of fluxes in each redshift bin. The binning must be chosen to verify a specific condition that can be derived from the RL relation [17,35,36,40]. The RL relation, , can be written in terms of fluxes aswhere a is the notation we use to refer to the slope in the flux–flux plane, and is the luminosity distance in units of cm. Equation (1) can be approximated as a linear relation between and only if the contribution of is negligible compared to the other terms in Equation (1). Thus, in this case, the linear relation in fluxes represents a proxy of the RL relation in luminosities, with a different intercept, in the form and with intrinsic dispersion . More specifically, if we consider Equation (1) in a redshift bin, the contribution of the distance is negligible if the range of values of within the chosen redshift interval is smaller than the intrinsic dispersion of the relation in the same bin. This is the condition that must be fulfilled when choosing how to divide the QSO sample into redshift bins. Nevertheless, in addition to this requirement, we need to fine-tune our choice to ensure enough sources (we require a minimum of 10), at least in the majority of bins, to reliably perform the fit in each of them. The specific choice of 10 sources is arbitrary. Indeed, we could apply a different threshold, which allows sufficient statistics to perform the fit. We have actually performed our analysis also changing the minimum number to 4, 5, 6, and 10, without any change in our results. We here also notice that to reduce the scatter of the relation in each bin, the condition of narrow redshift bins is very relevant, as the smaller the bins, the smaller the difference in is. Hence, we can reduce the intrinsic dispersion up to the limit imposed by . Following all these prescriptions, we have defined our optimal division into redshift bins in terms of with (see the yellow box in Figure 1). We have adopted the division as , which is a natural choice for the division into redshift since it would retain the same division in volume. This way, we can keep the bin constant, and we do not need to derive arbitrary bins. This is an improvement of the method of bin division in [40]. With this division in redshift, we obtain 32 bins with at least 10 sources (see Table 1), which is the threshold we require to guarantee sufficient statistics for the fit.We hereby stress that binning the data into redshift intervals is necessary to use fluxes instead of luminosities. This is a crucial point as it enables us to perform a circularity-free analysis. Indeed, fluxes are measured quantities that do not require any cosmological assumption, unlike luminosities. As a consequence, the use of fluxes in the selection of the sample guarantees that our cosmological results are not induced by any a priori cosmological assumption. It is true that binning leads to the reduction of the sample size (in each bin compared to the total sample size), and therefore, the estimates in each bin might be less accurate. However, in our case, the binning shows that the slope of the flux–flux RL correlation in each bin remains unchanged (see Figure 2), and is compatible with the slope reported in [40]. In addition, binning is often used when it is necessary to highlight features that would otherwise be concealed when noisy data are combined altogether. In this analysis, the binning of the adopted to avoid the circularity problem (see also [58] for a discussion on the importance and reliability of the binning method). This is because the approximate RL correlation for fluxes, which does not depend on the cosmological parameters, holds only within bins of a limited length of redshift and hence of the distance luminosity. This relation within each bin allows us to highlight which QSO sources should be removed. Moreover, we have detailed in Section 5 that our analysis with the binning gives compatible results with the unbinned data (see [59] for comparison). We also further investigate different choices for the division into bins of the initial sample in Section 3.1.2, Section 3.1.3 and Section 3.1.4 and their impact on the cosmological results in Appendix A.
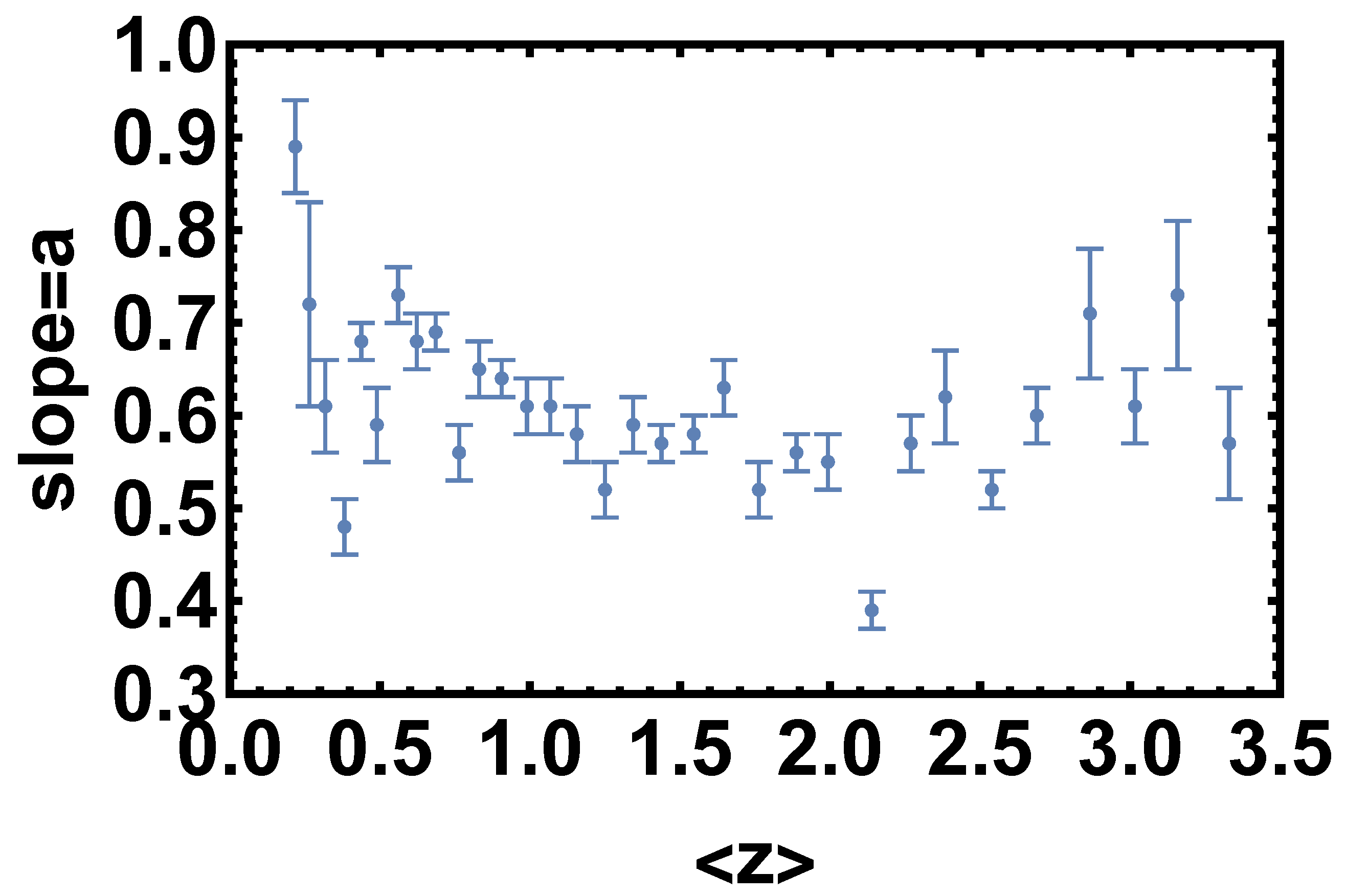
- Once we have divided the redshift bins, we fit in each bin that presents at least 10 sources a linear relation between and . This fit is performed using the Kelly method [60], which accounts for the uncertainties in both quantities and also for the intrinsic dispersion of the correlation. We have also imposed uniform priors in a wide range of values for the free parameters of the fit: the slope, the intercept, and the intrinsic dispersion. To verify that the condition described at Point (1) is satisfied, the best-fit value obtained with the Kelly method for the intrinsic dispersion is compared to the maximum difference of for the sources in the investigated redshift bin. This difference is computed by assuming a flat CDM model. We here notice that the assumption of a specific cosmological model for this computation does not affect the result since we are considering a difference between two luminosity distances. We have retained unmodified sources in the redshift bins that do not provide enough statistics (less than 10 QSOs) to perform a reliable fit. From now on, we denote these sources with the notation “untouched”. Also, we have distinguished two cases, one in which we do not include these sources and another one in which we have added them to the final selected sample obtained after Point (3). The strategy here is to balance and compromise among the smallest bin so that , but still sufficiently large so that the number of sources is at least 10 or more.
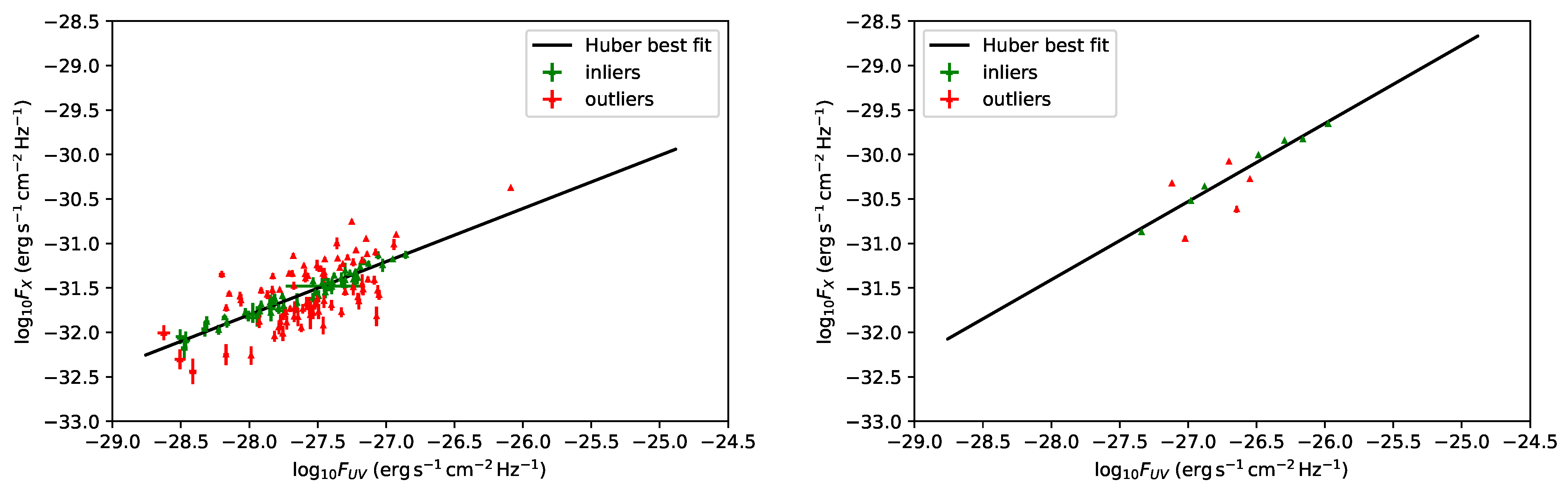
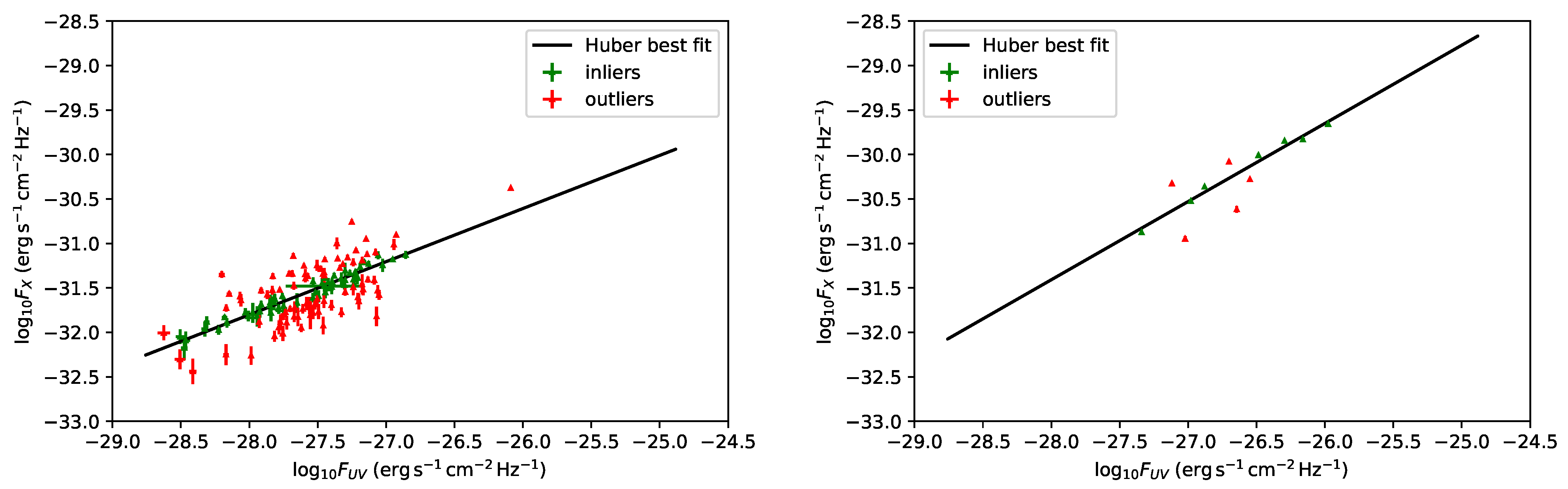
- At this stage, as the presence of outliers can decrease the performance and accuracy of least-squared-loss error-based regression, we have employed the consolidated statistical technique of the Huber algorithm [61,62,63] to reduce the intrinsic dispersion in each bin considered. The Huber regressor is indeed a method for estimating the parameters of a model, in this case the relation, to detect the outliers and weigh them less in the evaluation of the best-fit parameters of the fitted model. We are indeed aware that sources more scattered around this relation hamper significantly the finding of the most suitable sample with the smallest intrinsic dispersion. Thus, compared to traditional fitting procedures, such as the D’Agostini [64] or the Kelly [60] methods, the Huber regression identifies outliers, which can be caused, for example, by errors or problems in the measurements, and recognizes the actual best-fit based on the inliers. For these reasons, this technique is widely applied for robust regression problems. The Huber regressor has the advantage of not being heavily influenced by the outliers, while not completely ignoring them. This allows us to estimate the actual slope and intercept of the relation, not altered by outliers, and contemporaneously to identify the sources that are outliers of the model. Hence, we discard these sources from the QSO sample in each redshift bin. In order to quantitatively evaluate the Huber algorithm’s numerical gain against the traditional fitting one, we have also compared the results obtained with the Huber regressor with those derived from the traditional sigma-clipping selection technique. This comparison is detailed in Section 4.3.After this selection, we have also checked in each bin the following criteria: the null hypothesis that the populations of both UV and X-ray fluxes are drawn from the initial ones in the bin considered must not be rejected with p-value > 5% according to the Anderson two-sample test and if the distribution of the residuals about the best-fit line is Gaussian according to the Anderson–Darling normality test with an acceptance significance level of 5% (see, e.g., [65] for the Gaussianity discussion). The Anderson–Darling test for normality determines whether a data sample is drawn from the Gaussian distribution, and it is commonly applied in the literature (e.g., [43] in astrophysics and [66,67] in statistics). An important property of this test is that it can identify any small deviation from normality. We refer to [68] for a detailed description of the features of this test and its application to cosmological likelihoods. The Anderson–Darling two-sample test instead allows us to verify if the selected sample is still drawn from the original one. This guarantees that we are neither introducing biases nor significantly changing the physical properties of the initial sample when selecting the final sample. We here also stress that the Anderson two-sample test is always fulfilled at a statistical level >25%. Table 1 reports the mean value of z () for each redshift bin with at least 10 initial sources, the number of sources retained, and the corresponding best-fit values for the slope and the intrinsic scatter of the linear relation. A visual representation of the trend of the best-fit values of the slope with the average redshift of each bin is also provided in Figure 2. To showcase the Huber regressor’s advantage in each bin and how effectively it removes the outliers, in Figure 3, we present in green the selected sample and in red the sources identified as outliers. The two bins investigated on the left and right panels of this figure are the second most populated one and the second least populated one, respectively.
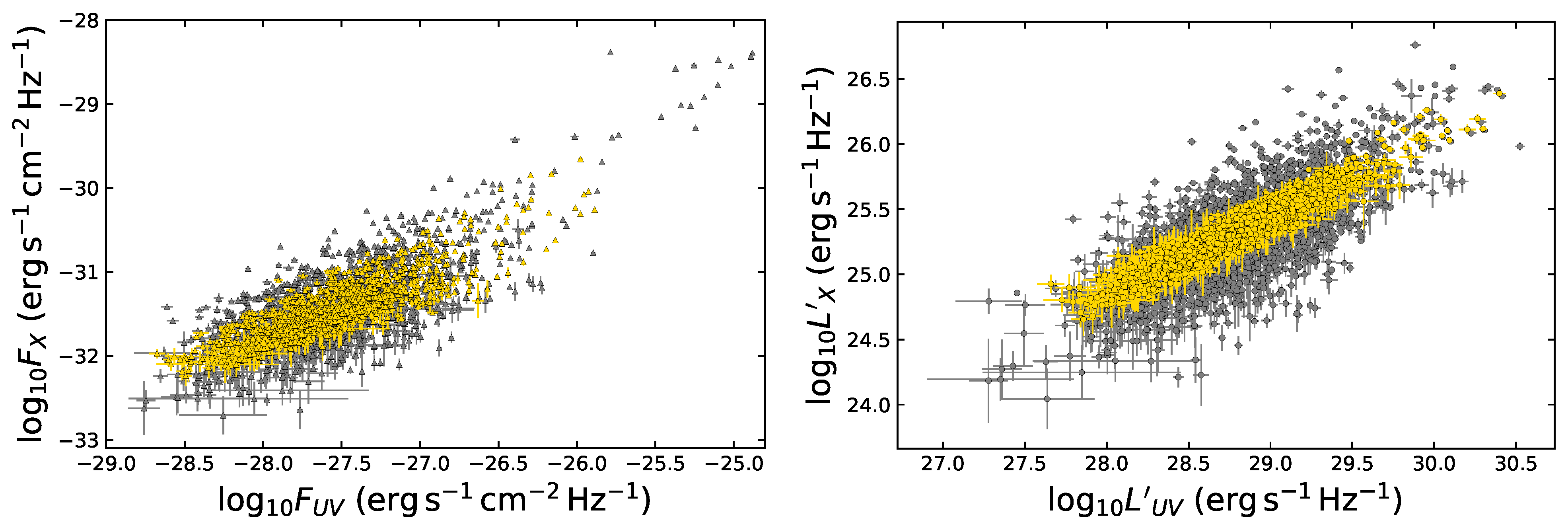
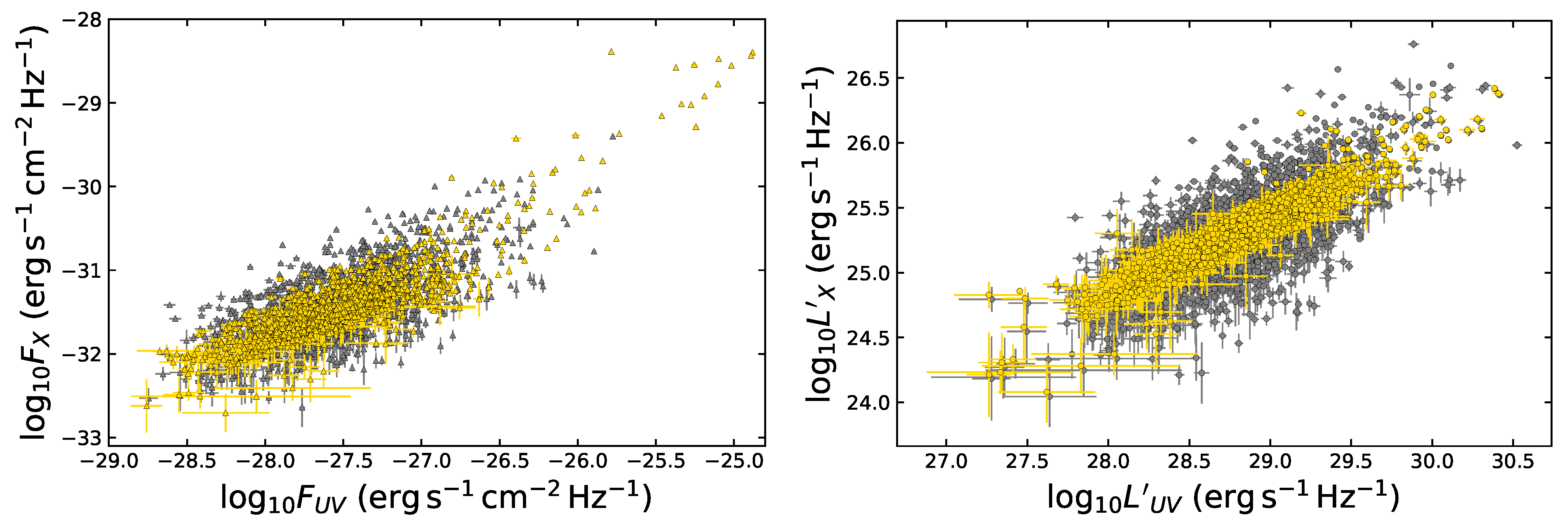
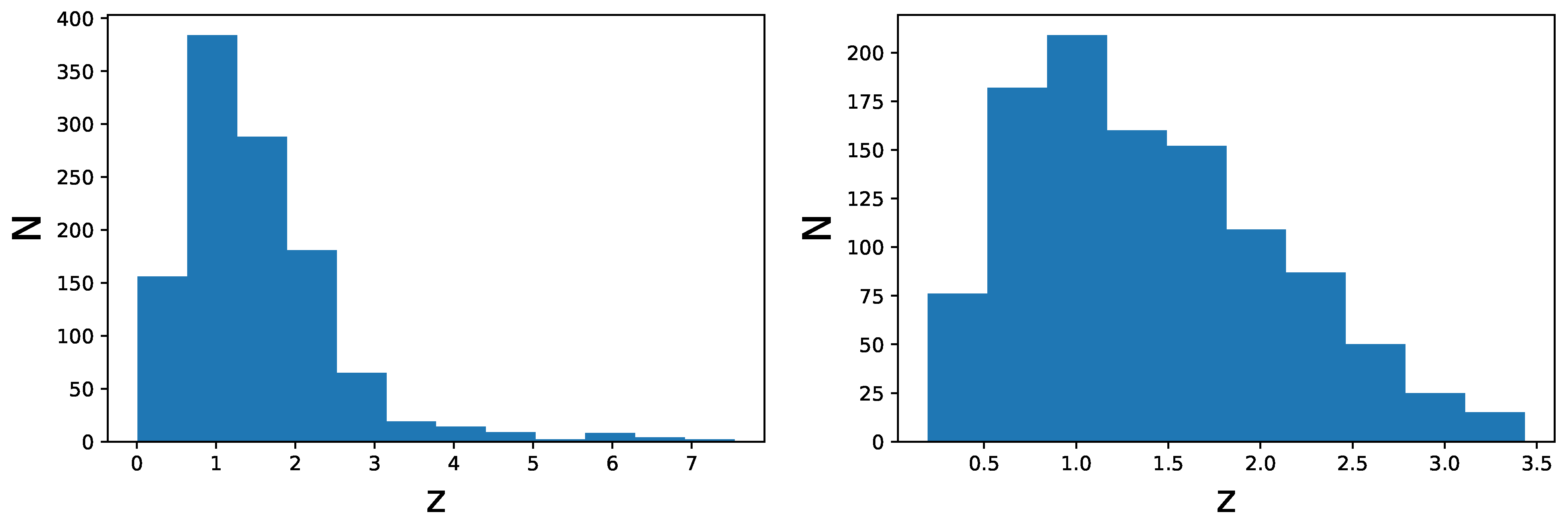
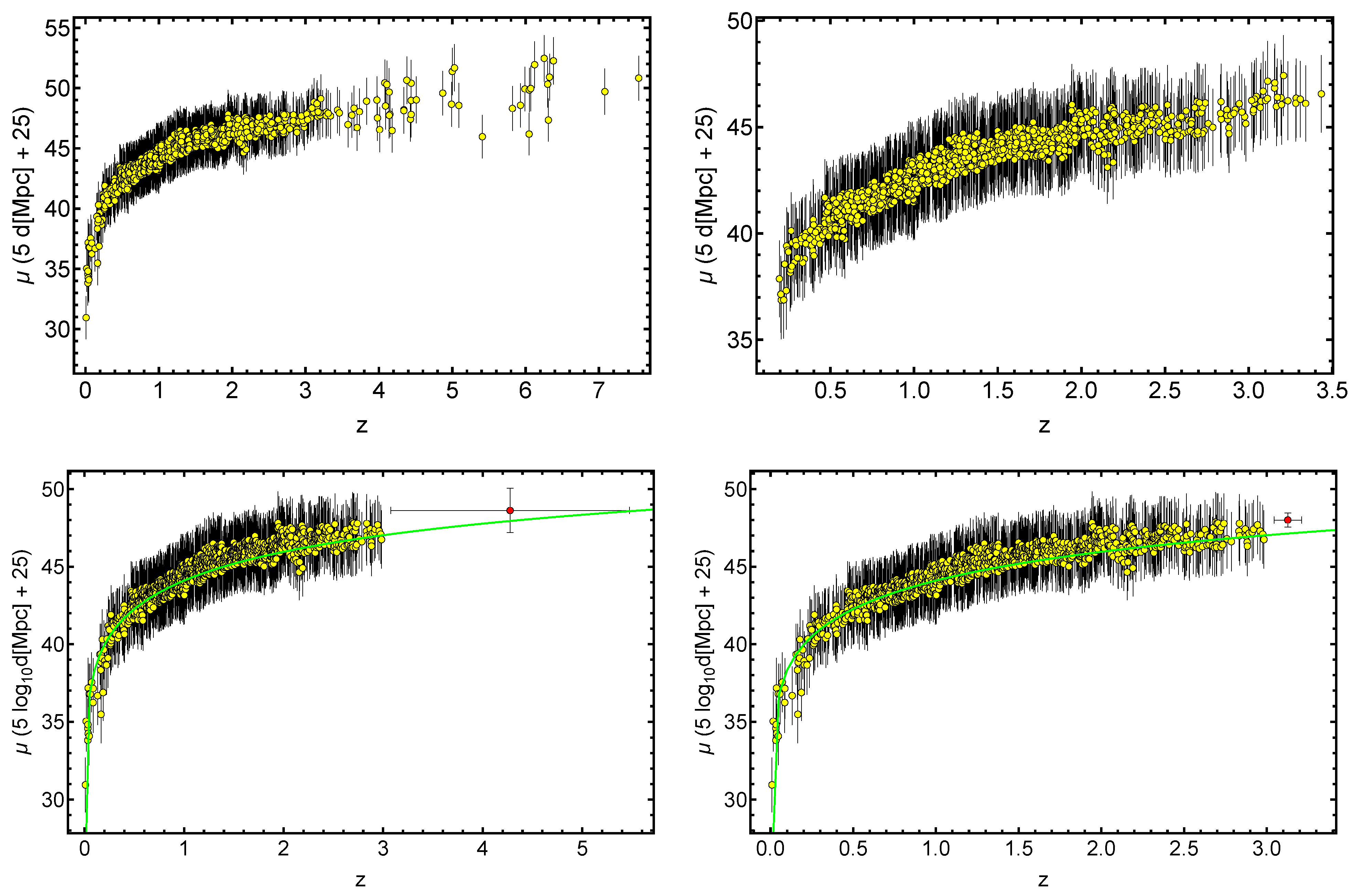
- As anticipated, we have finally defined two ultimate samples: one with only the sources retained through the steps detailed above and another obtained by combining the sources retained in each bin with the unmodified sources of the bins without enough statistics. This way, we have generated the final selected QSO samples composed of 1065 and 1132 sources, respectively. We here anticipate that, among all the binning approaches investigated in this work, we choose as the best one the one that leads to the best precision on for both samples, with and without untouched sources. The sample obtained with this best method is the one referred to as the “gold sample”.
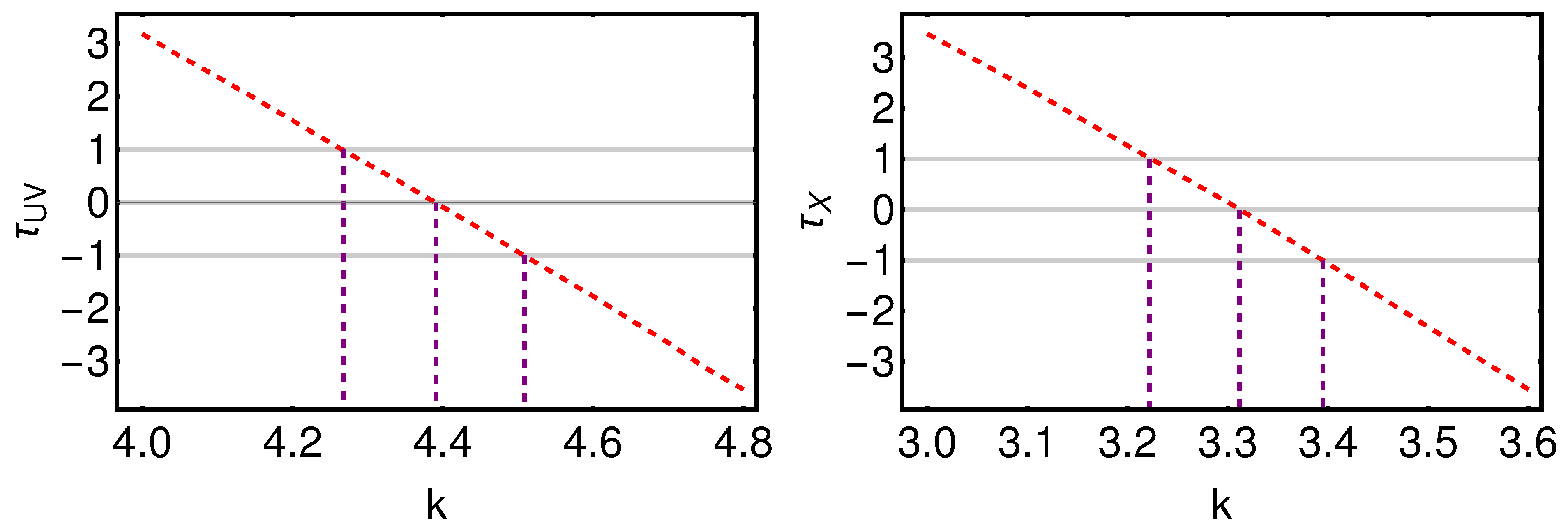
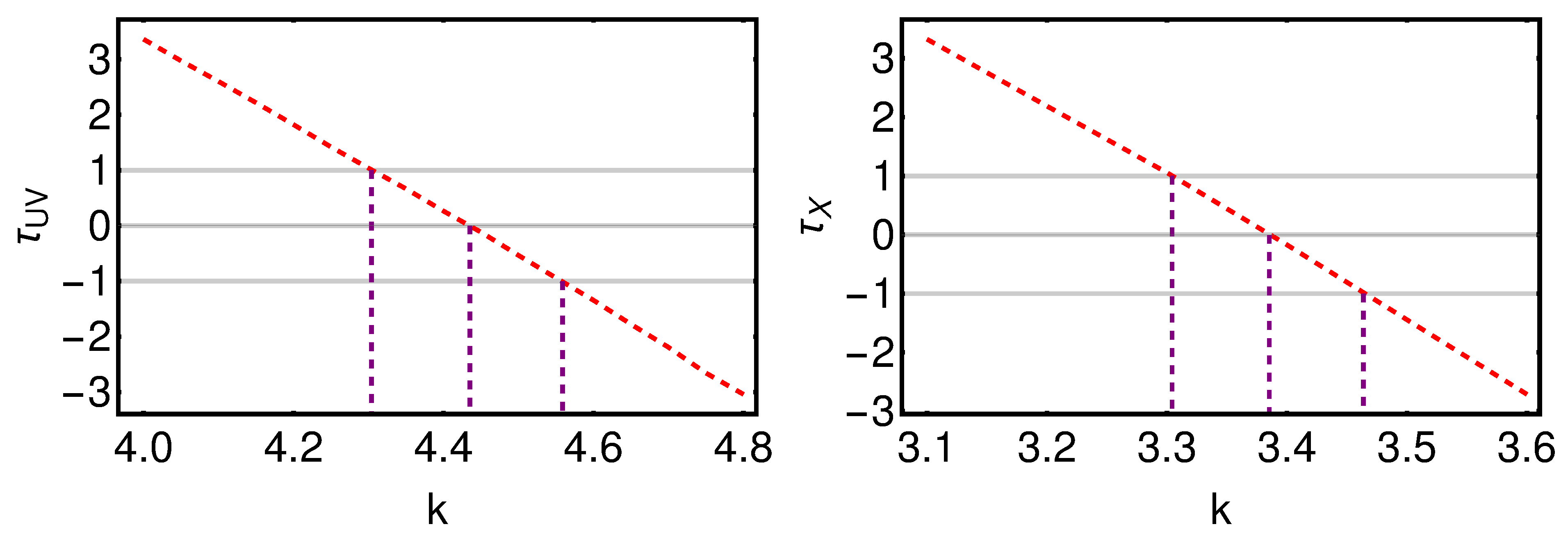
3.1.1. The Parameter in the Huber Procedure
3.1.2. The Impact of the Binning on the Data Analysis: Bins Wider in Redshift
3.1.3. The Impact of the Binning on the Data Analysis: Optimization of the Width of Bins
3.1.4. The Impact of the Binning on the Data Analysis: A Bin Centered on Each Source
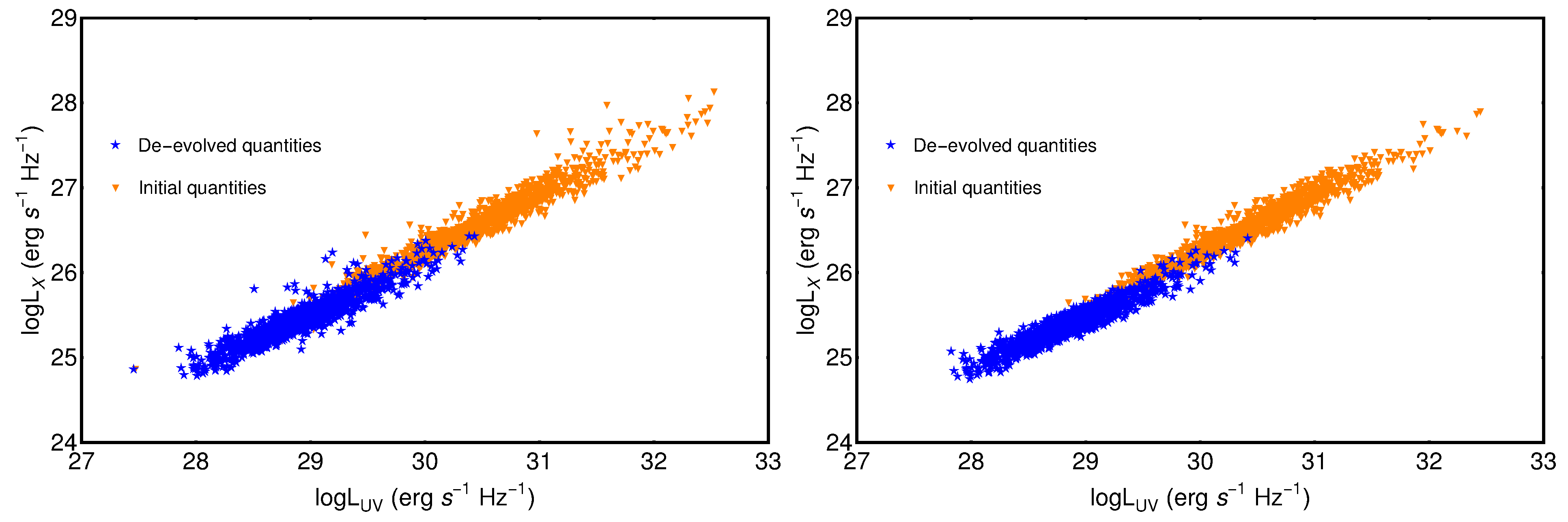
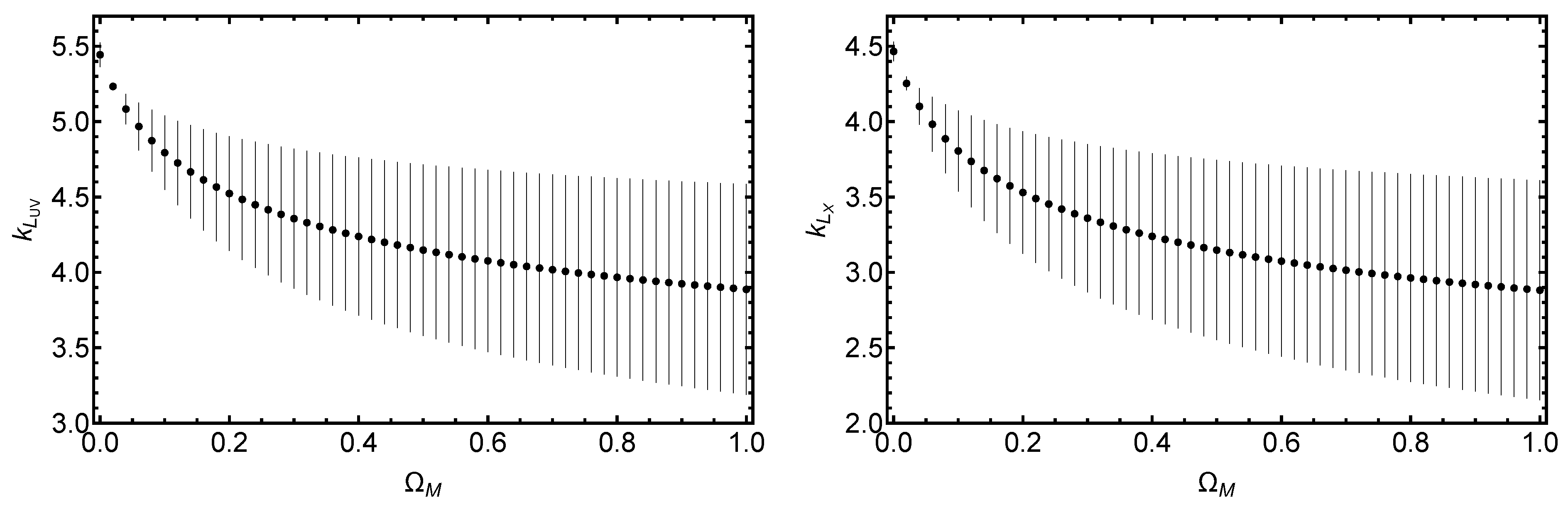
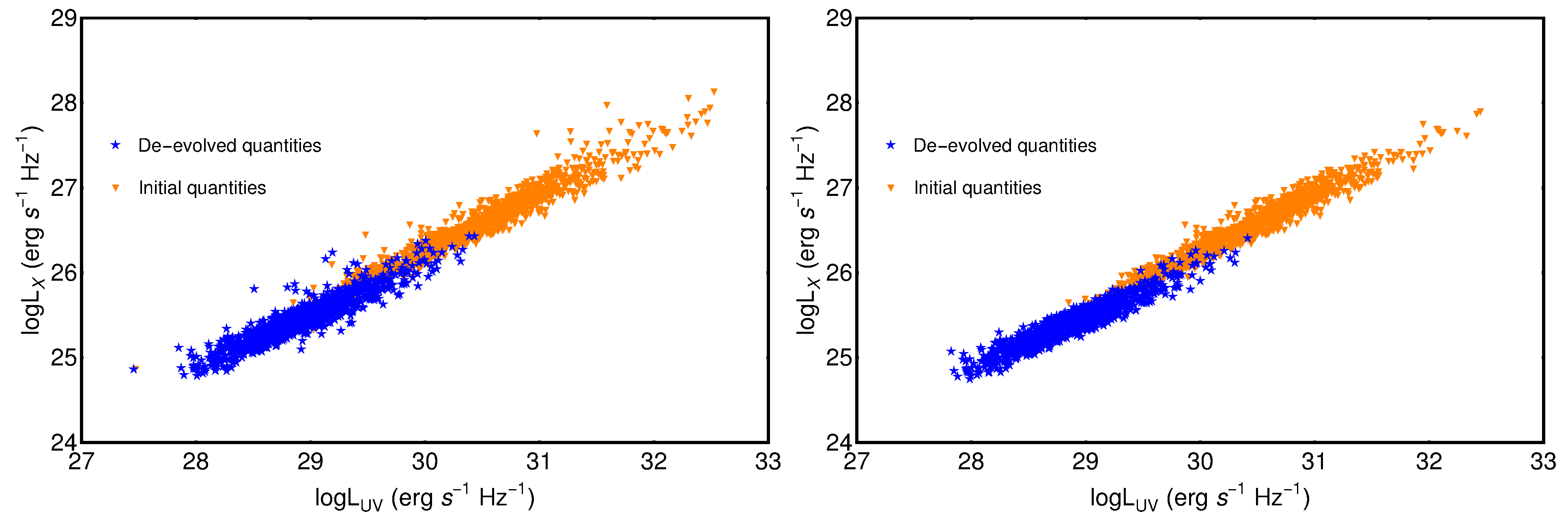
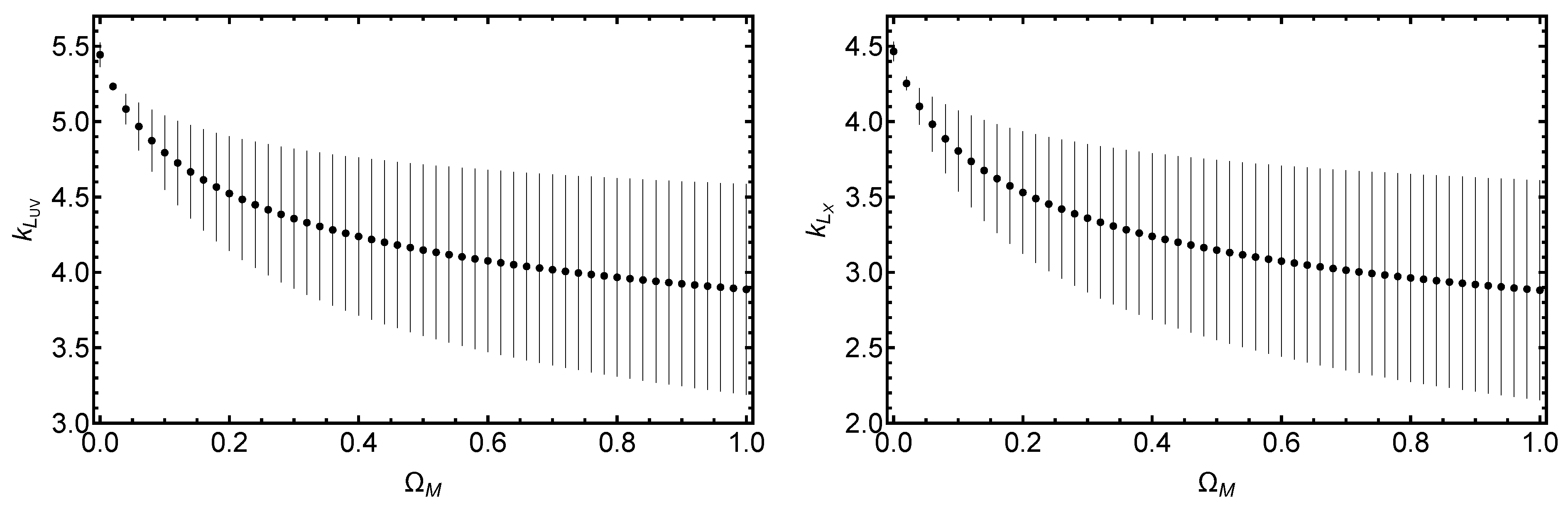
3.2. Treatment of Redshift Evolution and Selection Biases
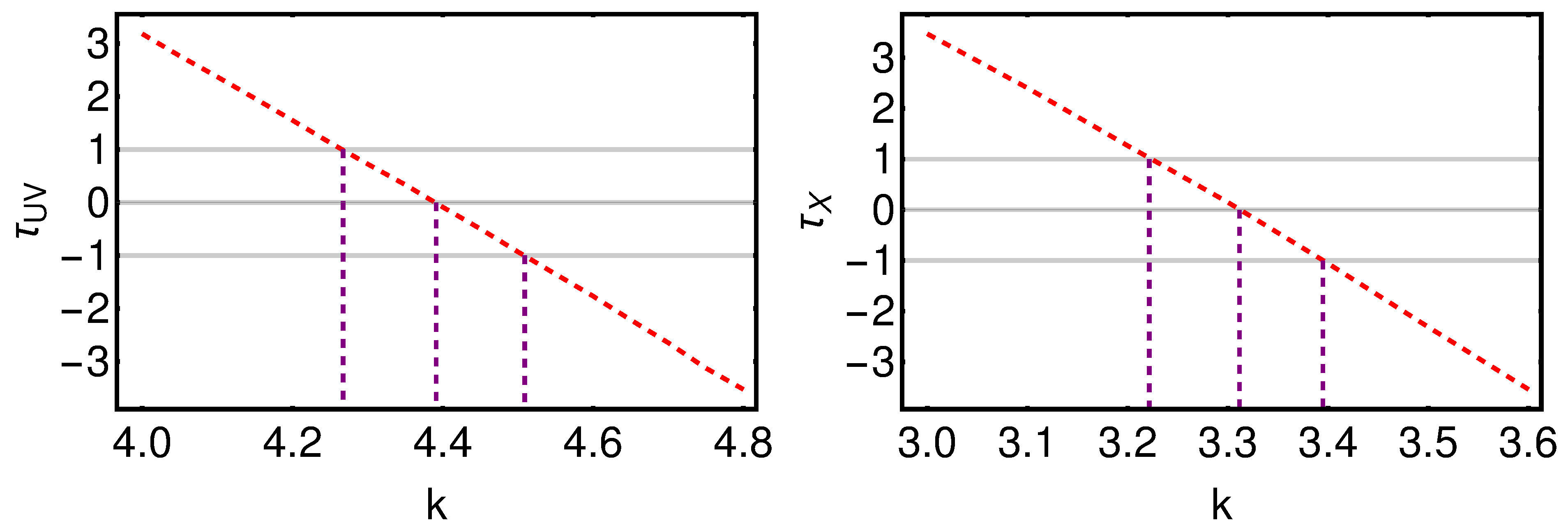
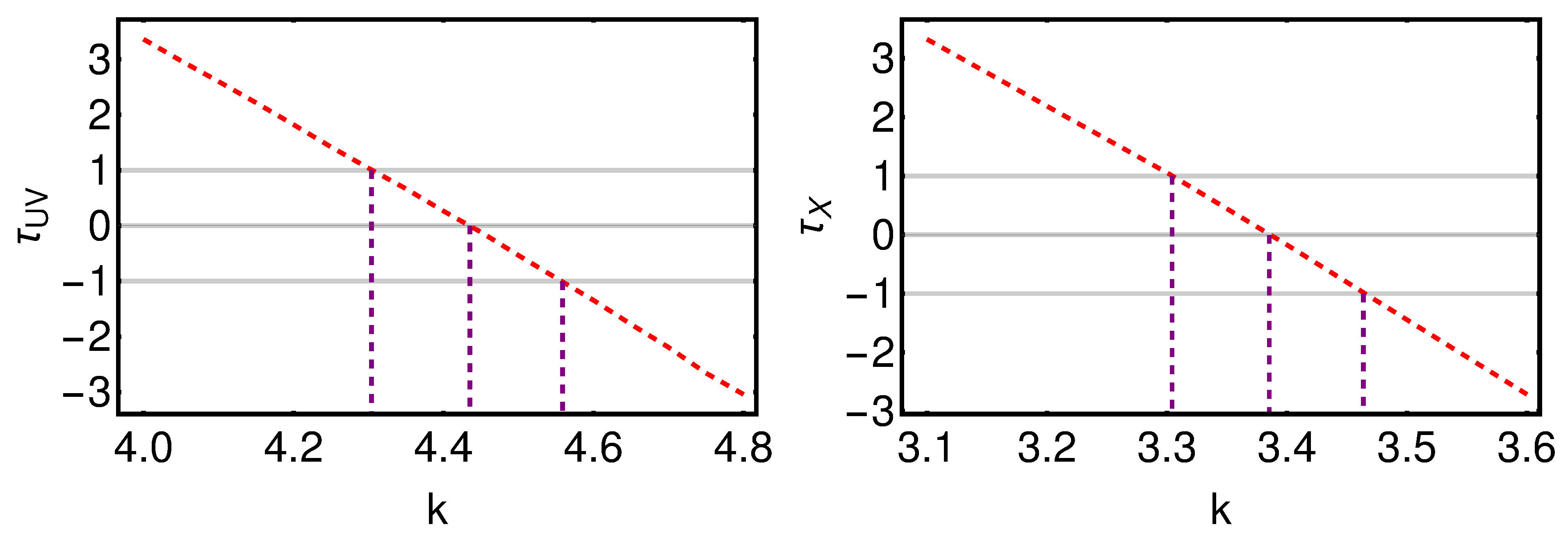
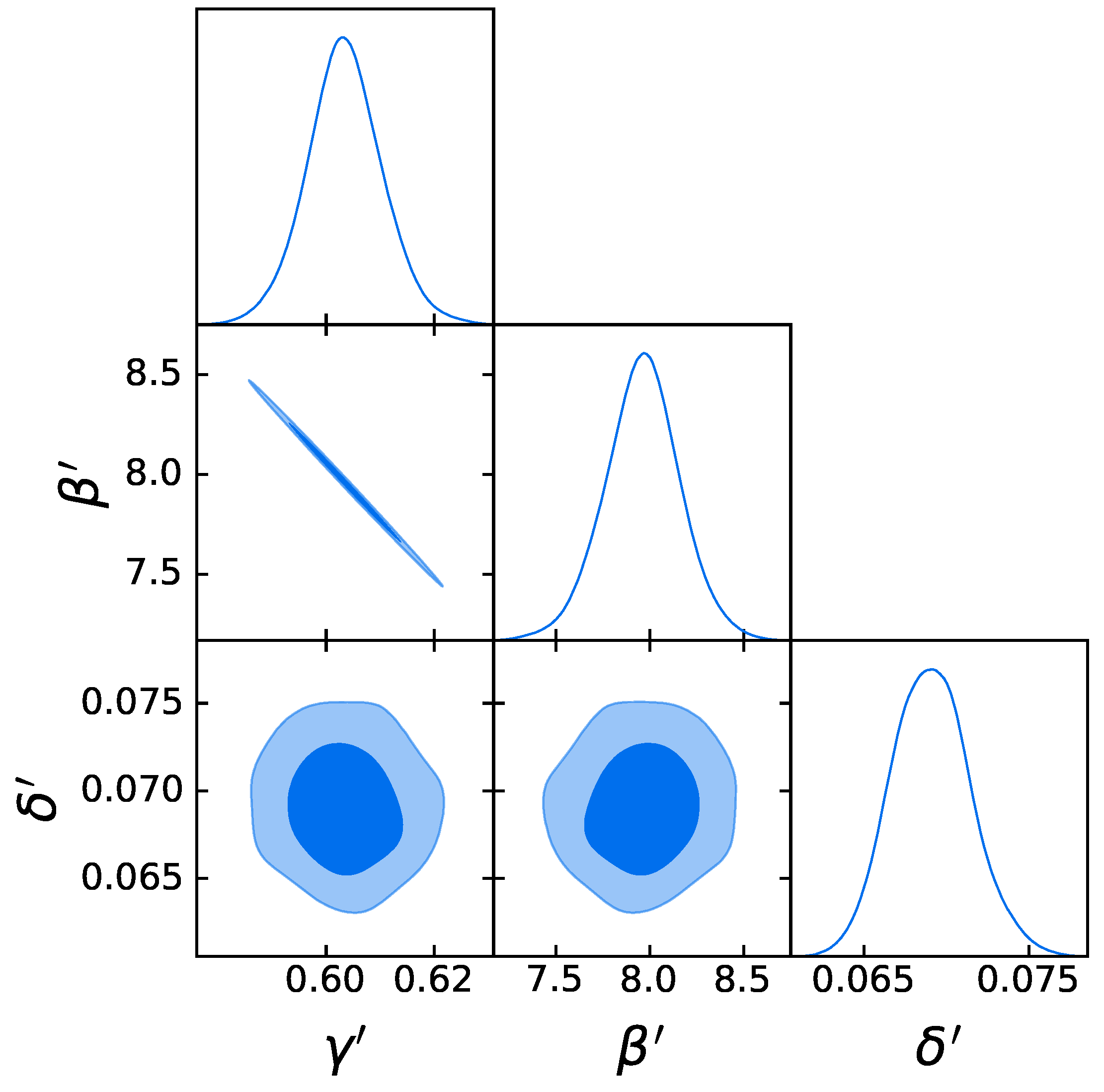
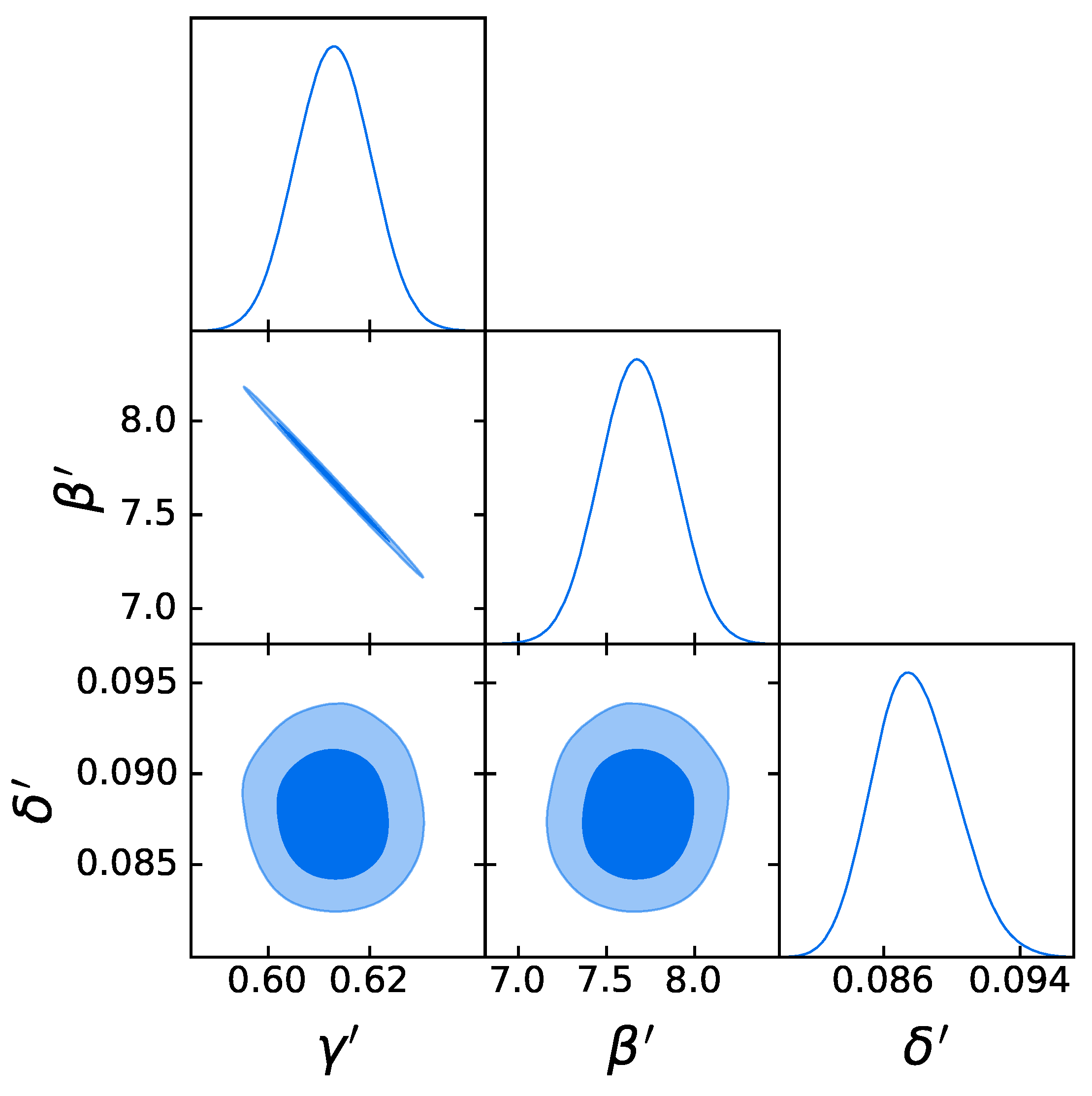
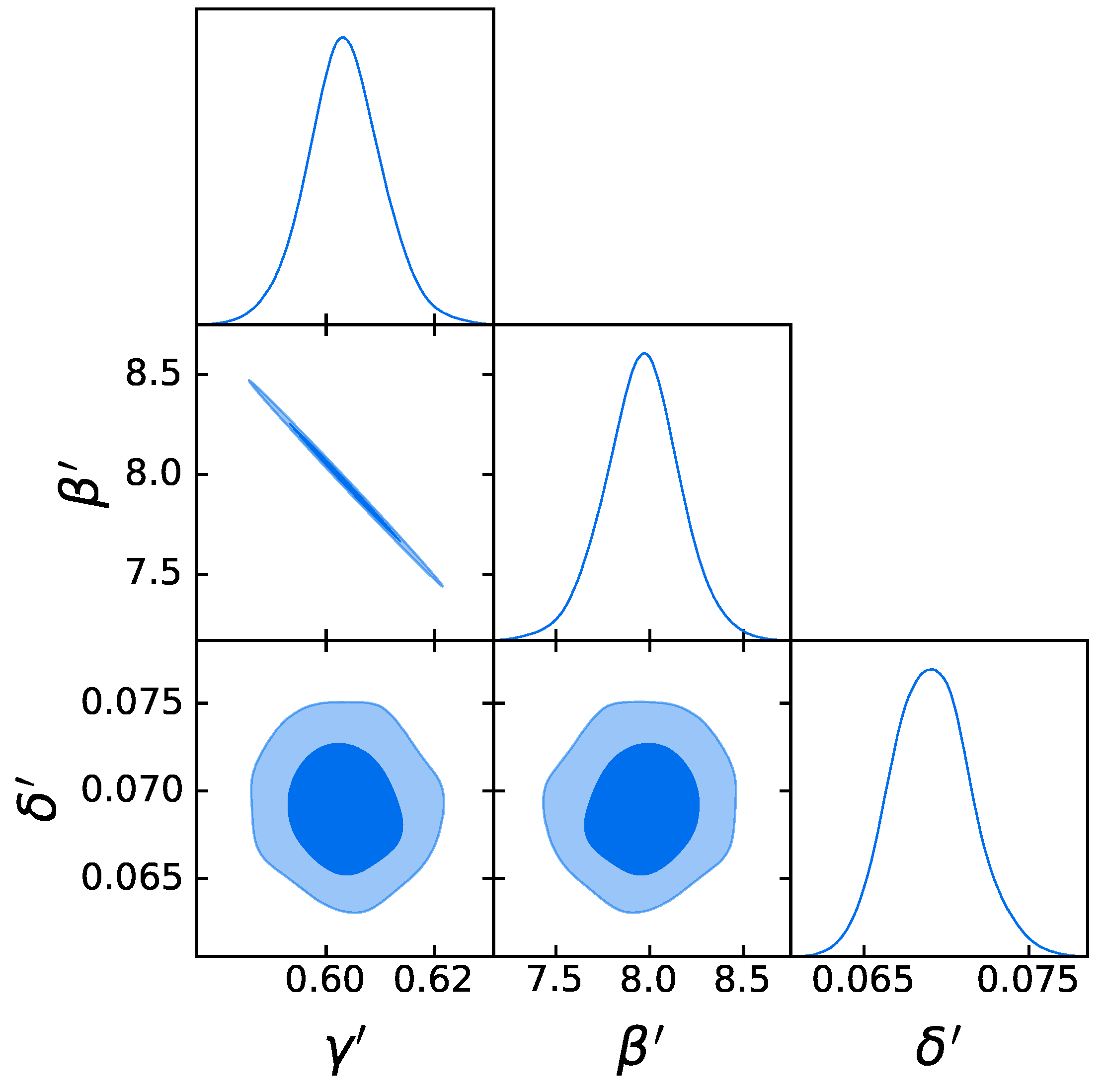
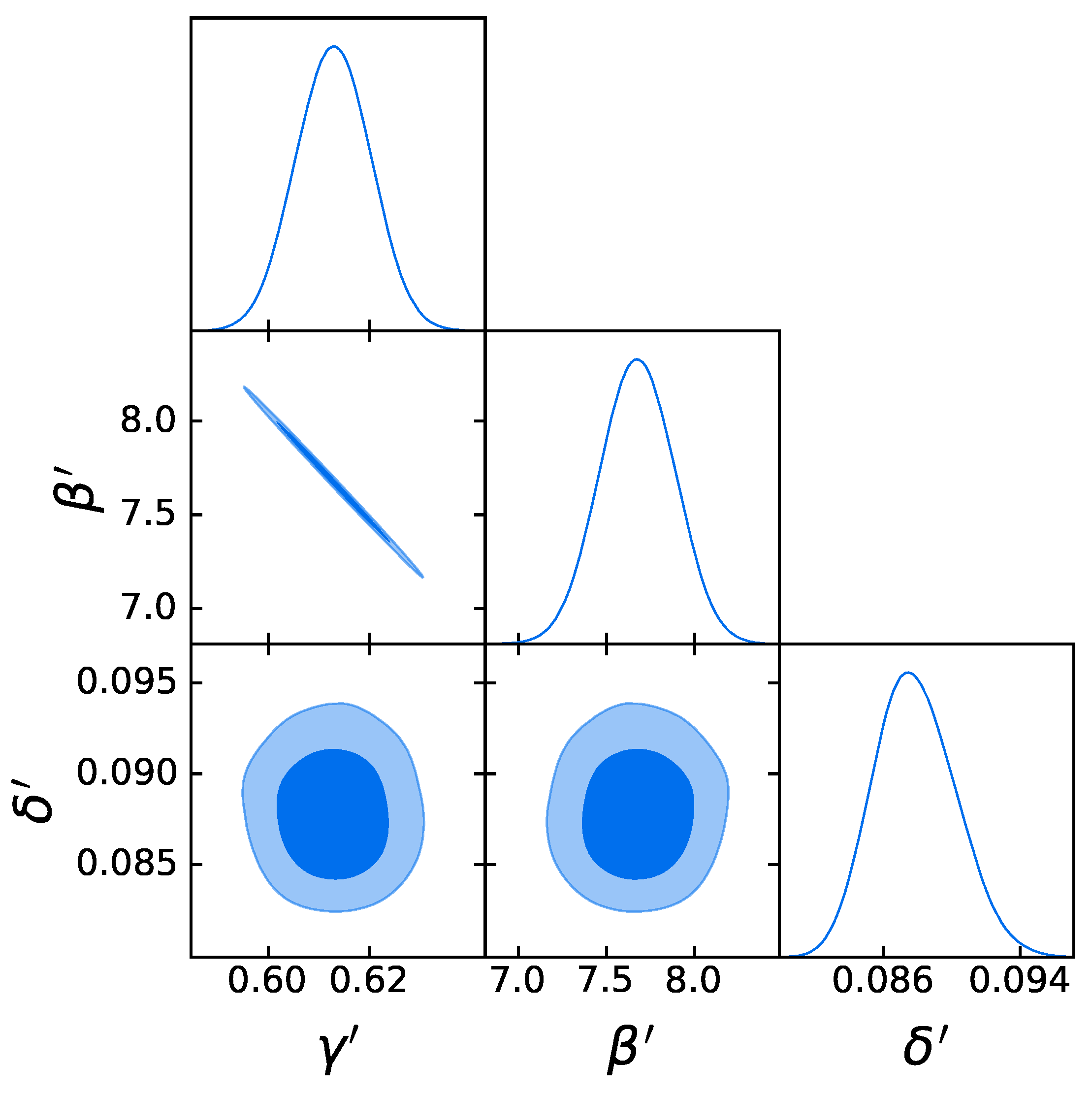
3.3. Cosmological Fit
4. Results
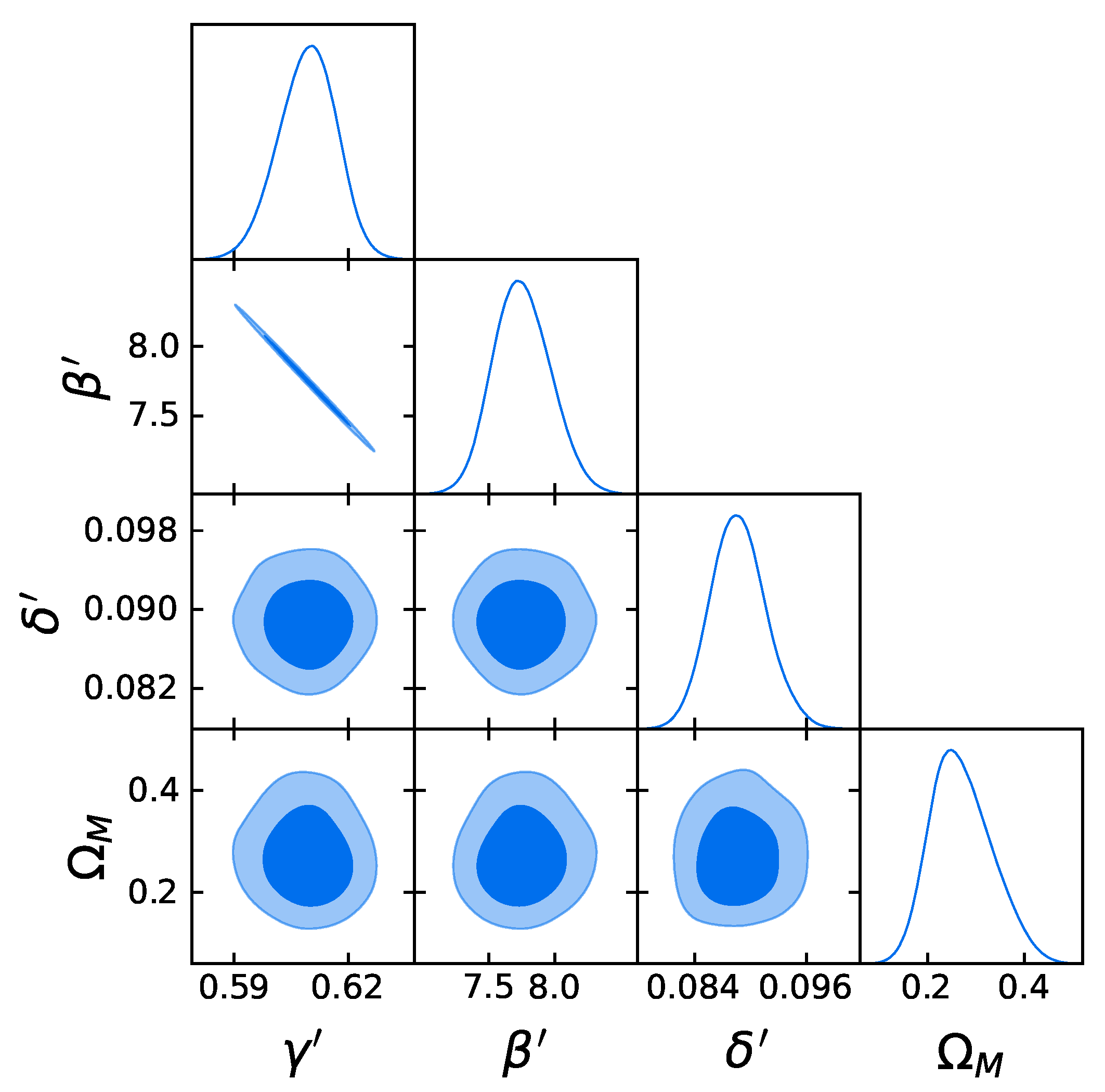
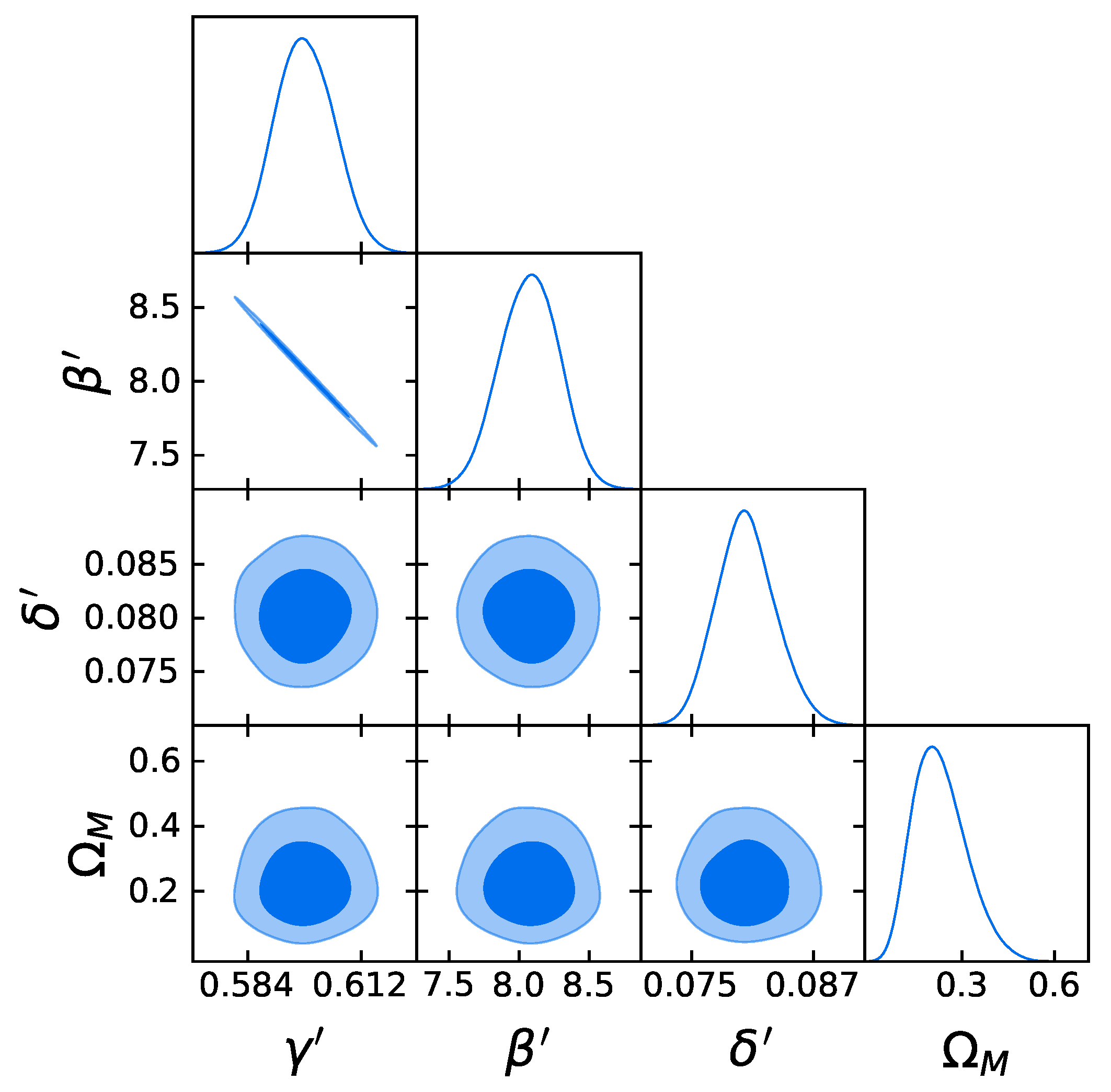
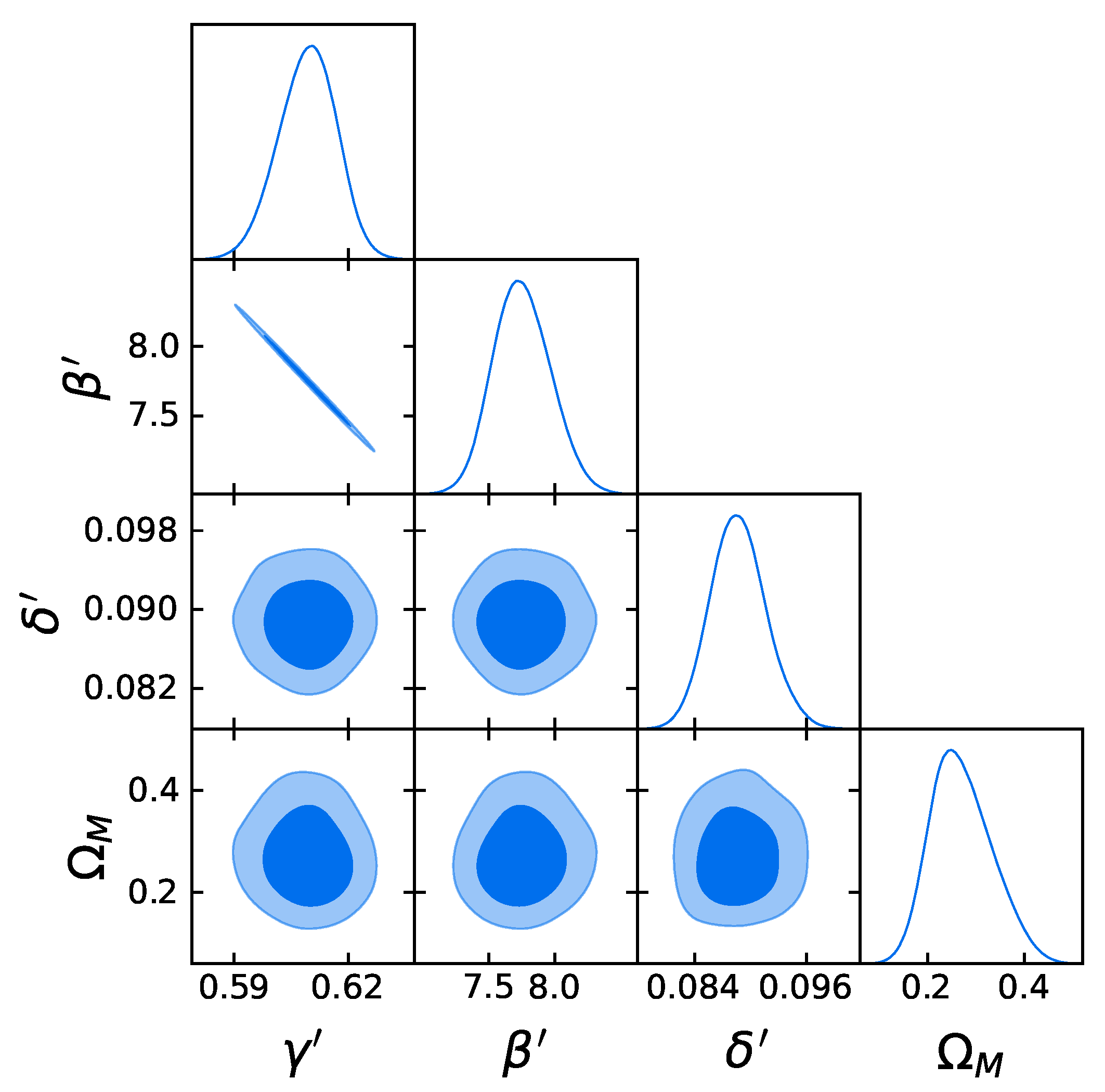
4.1. The Gold Sample of 1132 QSOs
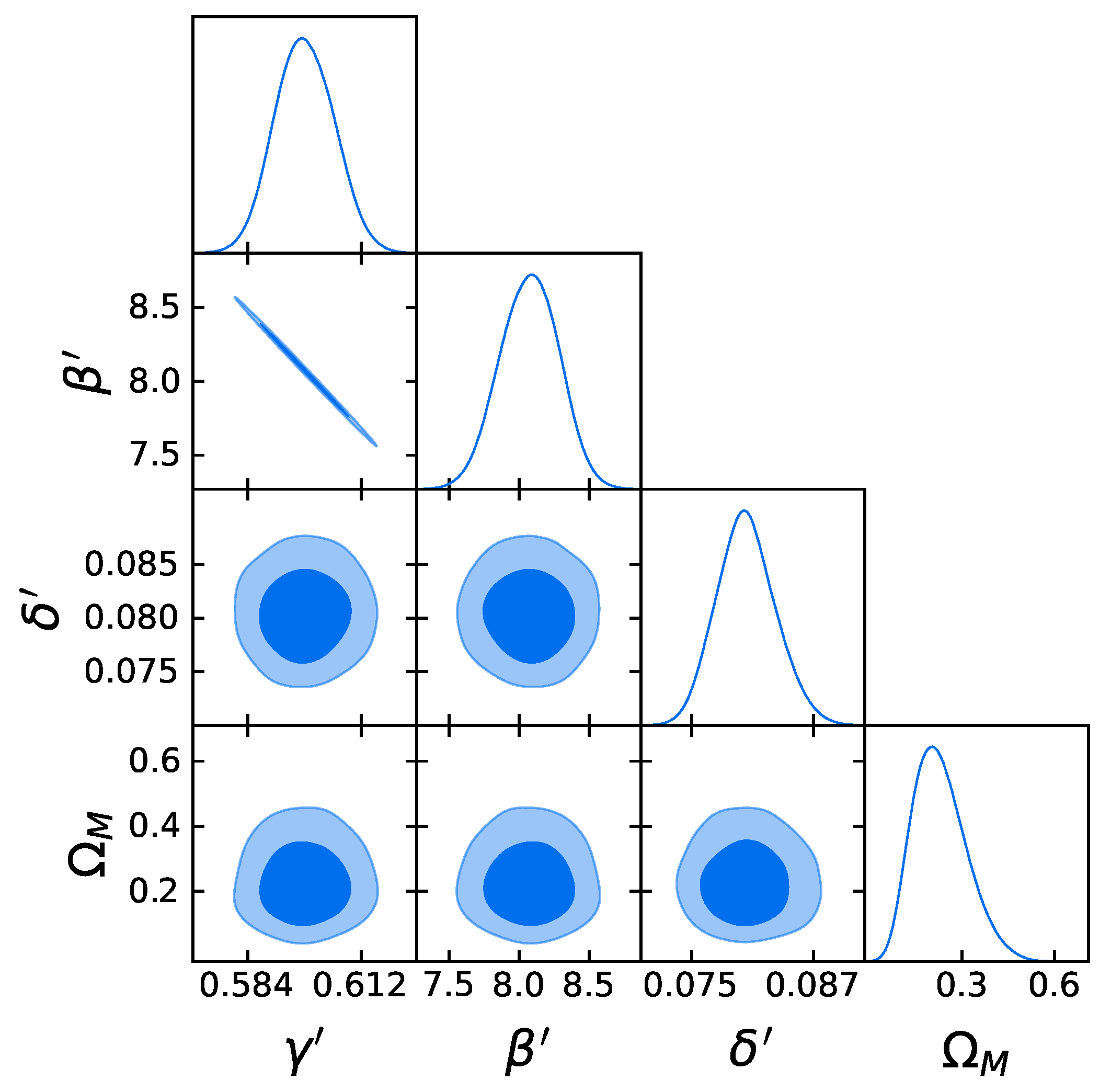
4.2. The Comparison of the Two Final QSO Samples
4.3. The Advantage of Using the Huber Regression Technique versus the Standard Fitting Methods
4.4. The Comparison of These New Gold Samples (with and without the Untouched Sources) with the RL Relation for the Total Initial Sample
4.5. The Need for This Analysis and the Interpretation of Results from a Physical Point of View
5. Summary, Discussion, and Conclusions
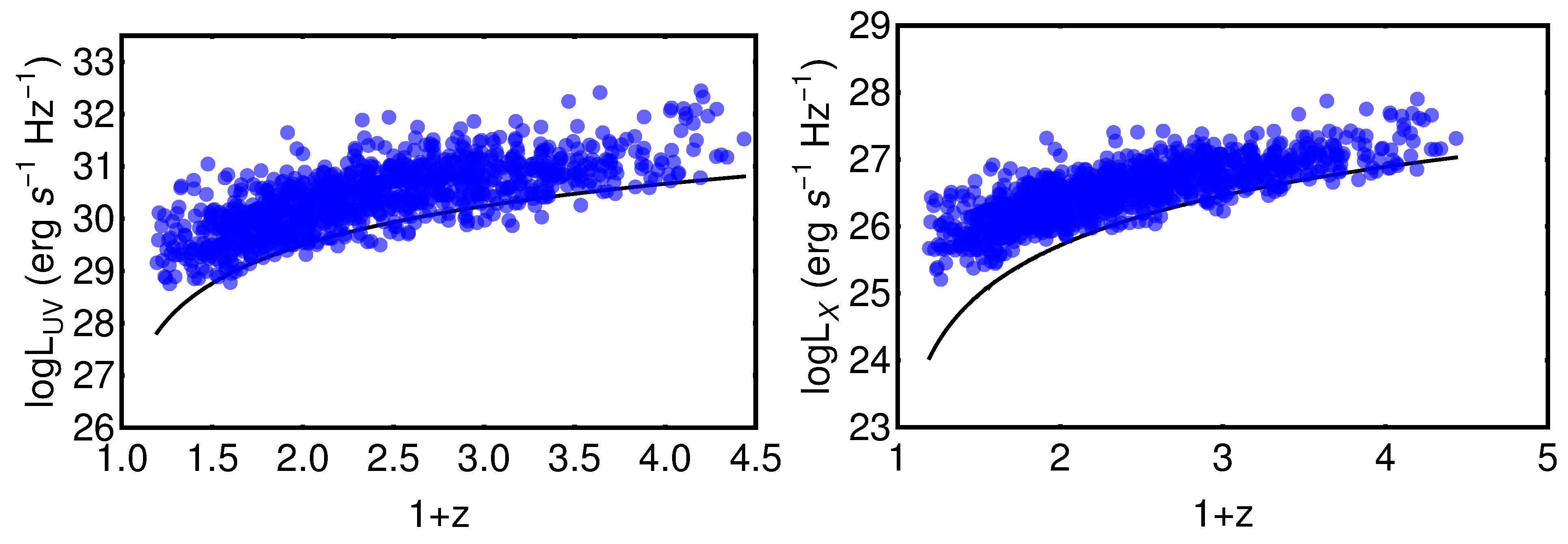
- The strategy in the selection of the QSO gold sample. Since our main challenge is to constrain cosmological parameters, such as , we strive not only to reach the smallest dispersion of the relation but also to keep a statistically sufficient number of sources in each redshift bin. This guarantees that the fitting is still possible from a statistical point of view. Hence, we have found a compromise between these two factors which are antagonistic. The optimal number of sources found is 1132 since these sources fulfill all the following required criteria: the minimum number of sources (i.e., 10 in our case), the Anderson–Darling two-sample tests in each bin, and the requirement on the distance luminosity that should be negligible compared to the dispersion of the relation in flux in each bin. This sample of 1132 QSOs presents and still covers the whole redshift range of the original sample, from to . The intrinsic dispersion of the flux relation can be even reduced if we discard the sources belonging to redshift bins with not enough statistics (i.e., <10), the “untouched” sources, to perform the Huber regression. By applying this choice, we have defined a QSO sample with 1065 sources with reduced redshift coverage between and and intrinsic dispersion of the flux relation .
- Comparison with the original RL relation and cosmological results. We have proven that the RL relation is still verified by our two final samples, once accounted for the redshift evolution. We have also used the obtained QSO gold samples for cosmological application to derive by fitting a flat CDM model leaving contemporaneously free both and the RL relation parameters, , , and , while fixing . We have performed this fit by using the best-fit proper likelihoods for the samples, which proved to be a logistic one for the sub-sample of 1132 QSOs and a Gaussian one for the 1065 sources. We have also performed the fit by applying the correction for the redshift evolution as a function of . The gold sample of 1132 QSOs has provided , whereas the sample with 1065 sources has led to . Hence, we have reached a precision improvement of 58% compared to the one obtained with the whole QSO sample (i.e., 0.210, see [12]). Moreover, these values are compatible with the current value of [71], and hence in agreement with the expected value of the current matter density. Additionally, the obtained values of are compatible in with the one reported in [59], in which a non-binned analysis, independent from the one here presented, is performed to select the QSO sample and constrain . We here point out that our analysis is not biased or induced by any circular reasoning. The sample is trimmed by reducing the uncertainties in the flux–flux relationship, which does not depend on the cosmological parameters once we bin the data (see Section 3.1), but rather on the intrinsic scatter of this relation. Our results show that, after restricting our attention to the probes for which the intrinsic scatter is small, we obtain a substantially improved precision of the estimated cosmological parameter.
- The impact of bin division on cosmology. The above-detailed results have been obtained by trimming the initial QSO sample in bins of , as described in Section 3.1, since this is the approach that leads to the best cosmological results. Nevertheless, to further investigate the impact of this choice for the division into bins and to free our analysis from the arbitrariness and possible issues of the binning procedure, we have also performed our study by applying the three different selection methodologies outlined in Section 3.1.2, Section 3.1.3 and Section 3.1.4. We have thus proved that our results do not depend on the specific methodology employed to select the QSO sample. Indeed, as detailed in Appendix A and Table 2, the values of obtained in all the cases investigated are compatible within and they are also consistent with reported in [71]. This compatibility with the most recent value of measured from SNe Ia ensures that our analyses recover the expected cosmology independently of the binning approach considered. Moreover, the comparison among the results obtained from different procedures has also shown that larger sample sizes shift towards values of , as expected from [12]. Additionally, this extended analysis has also suggested that the low-z QSOs tend to lower the value of . Finally, the employment of these several independent approaches to select the final QSO samples has led to an extensive knowledge of the QSO selection and trimming procedure. Furthermore, leveraging the advantages of the methods investigated, we have avoided our analyses and results being biased or distorted by the arbitrary choice of a fixed binning. The outcomes of all these approaches have established the validity of our results and the robustness of our analysis.
- The need for a larger sample and a physical interpretation. Based on all these considerations, we here point out that we would need a much larger sample with these properties to reach the current value of precision obtained with SNe Ia, which is . This situation is similar to the one occurring for GRBs [45] where the precision of SNe Ia in [85] is reachable now, while for an improved precision as the one the SNe Ia have today, we would need to wait for two other decades. Nevertheless, if a common emission mechanism or properties in this sample will be driven by fundamental physics the waiting time for reaching this precision would be considerably improved. We here point out a parallel case for GRBs: if the plateau emission in the Platinum sample is driven by the magnetar, a given sample of GRBs with peculiar magnetic fields and spin period can drive the standard set. Here, the gold QSOs can help to reveal the physical meaning of these properties. Indeed, the current paper can allow us to identify a QSO sample, highlighted by our statistical procedure, that is driven by fundamental physics. However, this investigation goes beyond the scope of the current paper and will be analyed in a forthcoming paper.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. The Impact of Different Binning Approaches on Cosmology
Appendix B. The Varying Evolution Method
References
- Riess, A.G.; Filippenko, A.V.; Challis, P.; Clocchiatti, A.; Diercks, A.; Garnavich, P.M.; Gilliland, R.L.; Hogan, C.J.; Jha, S.; Kirshner, R.P.; et al. Observational Evidence from Supernovae for an Accelerating Universe and a Cosmological Constant. Astrophys. J. 1998, 116, 1009–1038. [Google Scholar] [CrossRef]
- Perlmutter, S.; Aldering, G.; Goldhaber, G.; Knop, R.A.; Nugent, P.; Castro, P.G.; Deustua, S.; Fabbro, S.; Goobar, A.; Groom, D.E.; et al. Measurements of Ω and Λ from 42 High-Redshift Supernovae. Astrophys. J. 1999, 517, 565–586. [Google Scholar] [CrossRef]
- Planck Collaboration; Aghanim, N.; Akrami, Y.; Ashdown, M.; Aumont, J.; Baccigalupi, C.; Ballardini, M.; Banday, A.J.; Barreiro, R.B.; Bartolo, N.; et al. Planck 2018 results. VI. Cosmological parameters. Astron. Astrophys. 2020, 641, A6. [Google Scholar] [CrossRef]
- Weinberg, S. The cosmological constant problem. Rev. Mod. Phys. 1989, 61, 1–23. [Google Scholar] [CrossRef]
- Riess, A.G.; Yuan, W.; Macri, L.M.; Scolnic, D.; Brout, D.; Casertano, S.; Jones, D.O.; Murakami, Y.; Anand, G.S.; Breuval, L.; et al. A Comprehensive Measurement of the Local Value of the Hubble Constant with 1 km s−1 Mpc−1 Uncertainty from the Hubble Space Telescope and the SH0ES Team. Astrophys. J. Lett. 2022, 934, L7. [Google Scholar] [CrossRef]
- Riess, A.G.; Casertano, S.; Yuan, W.; Macri, L.M.; Scolnic, D. Large Magellanic Cloud Cepheid Standards Provide a 1% Foundation for the Determination of the Hubble Constant and Stronger Evidence for Physics beyond ΛCDM. Astrophys. J. 2019, 876, 85. [Google Scholar] [CrossRef]
- Camarena, D.; Marra, V. Local determination of the Hubble constant and the deceleration parameter. Phys. Rev. Res. 2020, 2, 013028. [Google Scholar] [CrossRef]
- Wong, K.C.; Suyu, S.H.; Chen, G.C.F.; Rusu, C.E.; Millon, M.; Sluse, D.; Bonvin, V.; Fassnacht, C.D.; Taubenberger, S.; Auger, M.W.; et al. H0LiCOW—XIII. A 2.4 per cent measurement of H0 from lensed quasars: 5.3σ tension between early- and late-Universe probes. Mon. Not. R. Astron. Soc. 2020, 498, 1420–1439. [Google Scholar] [CrossRef]
- Rodney, S.A.; Riess, A.G.; Scolnic, D.M.; Jones, D.O.; Hemmati, S.; Molino, A.; McCully, C.; Mobasher, B.; Strolger, L.G.; Graur, O.; et al. Two SNe Ia at Redshift ∼2: Improved Classification and Redshift Determination with Medium-band Infrared Imaging. Astrophys. J. 2015, 150, 156. [Google Scholar] [CrossRef]
- Gómez-Valent, A.; Amendola, L. H0 from cosmic chronometers and Type Ia supernovae, with Gaussian Processes and the novel Weighted Polynomial Regression method. J. Cosmol. Astropart. Phys. 2018, 2018, 051. [Google Scholar] [CrossRef]
- Liao, K.; Shafieloo, A.; Keeley, R.E.; Linder, E.V. A Model-independent Determination of the Hubble Constant from Lensed Quasars and Supernovae Using Gaussian Process Regression. Astrophys. J. 2019, 886, L23. [Google Scholar] [CrossRef]
- Lenart, A.Ł.; Bargiacchi, G.; Dainotti, M.G.; Nagataki, S.; Capozziello, S. A Bias-free Cosmological Analysis with Quasars Alleviating H 0 Tension. Astrophys. J. Suppl. Ser. 2023, 264, 46. [Google Scholar] [CrossRef]
- Freedman, W.L. Measurements of the Hubble Constant: Tensions in Perspective. Astrophys. J. 2021, 919, 16. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Lenart, A.L.; Chraya, A.; Sarracino, G.; Nagataki, S.; Fraija, N.; Capozziello, S.; Bogdan, M. The Gamma-ray Bursts Fundamental Plane correlation as a cosmological tool. Mon. Not. R. Astron. Soc. 2022, 18, 2201–2240. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Sarracino, G.; Capozziello, S. Gamma-ray bursts, supernovae Ia, and baryon acoustic oscillations: A binned cosmological analysis. Publ. Astron. Soc. Jpn. 2022, 74, 1095–1113. [Google Scholar] [CrossRef]
- Roy, S.; Datta, D.; Ghosh, J.; Roy, M.; Kafatos, M. Non-Parametric Tests for Quasar Data and Hubble Diagram. In Modelling and Simulation in Science, Proceedings of the 6th International Workshop on Data Analysis in Astronomy “Livio Scarsi”, Erice, Italy, 15–22 April 2007; di Gesù, V., Lo Bosco, G., Maccarone, M.C., Eds.; The Science and Culture Series-Astrophysics; World Scientific: Singapore, 2008; p. 99. [Google Scholar]
- Risaliti, G.; Lusso, E. Cosmological constraints from the Hubble diagram of quasars at high redshifts. Nat. Astron. 2019, 3, 272–277. [Google Scholar] [CrossRef]
- Khadka, N.; Ratra, B. Using quasar X-ray and UV flux measurements to constrain cosmological model parameters. Mon. Not. R. Astron. Soc. 2020, 497, 263–278. [Google Scholar] [CrossRef]
- Bargiacchi, G.; Benetti, M.; Capozziello, S.; Lusso, E.; Risaliti, G.; Signorini, M. Quasar cosmology: Dark energy evolution and spatial curvature. Mon. Not. R. Astron. Soc. 2022, 515, 1795–1806. [Google Scholar] [CrossRef]
- Wang, B.; Liu, Y.; Yuan, Z.; Liang, N.; Yu, H.; Wu, P. Redshift-evolutionary X-ray and UV luminosity relation of quasars from Gaussian copula. arXiv 2022, arXiv:2210.14432. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Bargiacchi, G.; Lenart, A.Ł.; Capozziello, S.; Ó Colgáin, E.; Solomon, R.; Stojkovic, D.; Sheikh-Jabbari, M.M. Quasar Standardization: Overcoming Selection Biases and Redshift Evolution. Astrophys. J. 2022, 931, 106. [Google Scholar] [CrossRef]
- Li, Z.; Huang, L.; Wang, J. Redshift evolution and non-universal dispersion of quasar luminosity correlation. Mon. Not. R. Astron. Soc. 2022, 517, 1901–1906. [Google Scholar] [CrossRef]
- Pourojaghi, S.; Zabihi, N.F.; Malekjani, M. Can high-redshift Hubble diagrams rule out the standard model of cosmology in the context of cosmography? Phys. Rev. D 2022, 106, 123523. [Google Scholar] [CrossRef]
- Bargiacchi, G.; Dainotti, M.G.; Nagataki, S.; Capozziello, S. Gamma-ray bursts, quasars, baryonic acoustic oscillations, and supernovae Ia: New statistical insights and cosmological constraints. Mon. Not. R. Astron. Soc. 2023, 521, 3909–3924. [Google Scholar] [CrossRef]
- Wang, F.; Yang, J.; Fan, X.; Hennawi, J.F.; Barth, A.J.; Banados, E.; Bian, F.; Boutsia, K.; Connor, T.; Davies, F.B.; et al. A Luminous Quasar at Redshift 7.642. Astrophys. J. Lett. 2021, 907, L1. [Google Scholar] [CrossRef]
- Tananbaum, H.; Avni, Y.; Branduardi, G.; Elvis, M.; Fabbiano, G.; Feigelson, E.; Giacconi, R.; Henry, J.P.; Pye, J.P.; Soltan, A.; et al. X-ray studies of quasars with the Einstein Observatory. Astrophys. J. 1979, 234, L9–L13. [Google Scholar] [CrossRef]
- Zamorani, G.; Henry, J.P.; Maccacaro, T.; Tananbaum, H.; Soltan, A.; Avni, Y.; Liebert, J.; Stocke, J.; Strittmatter, P.A.; Weymann, R.J.; et al. X-ray studies of quasars with the Einstein Observatory II. Astrophys. J. 1981, 245, 357–374. [Google Scholar] [CrossRef]
- Avni, Y.; Tananbaum, H. On the cosmological evolution of the X-ray emission from quasars. Astrophys. J. 1982, 262, L17–L21. [Google Scholar] [CrossRef]
- Avni, Y.; Tananbaum, H. X-ray Properties of Optically Selected QSOs. Astrophys. J. 1986, 305, 83. [Google Scholar] [CrossRef]
- Steffen, A.T.; Strateva, I.; Brandt, W.N.; Alexander, D.M.; Koekemoer, A.M.; Lehmer, B.D.; Schneider, D.P.; Vignali, C. The X-ray-to-Optical Properties of Optically Selected Active Galaxies over Wide Luminosity and Redshift Ranges. Astrophys. J. 2006, 131, 2826–2842. [Google Scholar] [CrossRef]
- Just, D.W.; Brandt, W.N.; Shemmer, O.; Steffen, A.T.; Schneider, D.P.; Chartas, G.; Garmire, G.P. The X-ray Properties of the Most Luminous Quasars from the Sloan Digital Sky Survey. Astrophys. J. 2007, 665, 1004–1022. [Google Scholar] [CrossRef]
- Young, M.; Elvis, M.; Risaliti, G. The X-ray Energy Dependence of the Relation Between Optical and X-ray Emission in Quasars. Astrophys. J. 2010, 708, 1388–1397. [Google Scholar] [CrossRef]
- Lusso, E.; Comastri, A.; Vignali, C.; Zamorani, G.; Brusa, M.; Gilli, R.; Iwasawa, K.; Salvato, M.; Civano, F.; Elvis, M.; et al. The X-ray to optical-UV luminosity ratio of X-ray selected type 1 AGN in XMM-COSMOS. Astron. Astrophys. 2010, 512, A34. [Google Scholar] [CrossRef]
- Lusso, E.; Risaliti, G. The Tight Relation between X-ray and Ultraviolet Luminosity of Quasars. Astrophys. J. 2016, 819, 154. [Google Scholar] [CrossRef]
- Bisogni, S.; Lusso, E.; Civano, F.; Nardini, E.; Risaliti, G.; Elvis, M.; Fabbiano, G. The Chandra view of the relation between X-ray and UV emission in quasars. Astron. Astrophys. 2021, 655, A109. [Google Scholar] [CrossRef]
- Risaliti, G.; Lusso, E. A Hubble Diagram for Quasars. Astrophys. J. 2015, 815, 33. [Google Scholar] [CrossRef]
- Lusso, E.; Risaliti, G. Quasars as standard candles. I. The physical relation between disc and coronal emission. Astron. Astrophys. 2017, 602, A79. [Google Scholar] [CrossRef]
- Nardini, E.; Lusso, E.; Risaliti, G.; Bisogni, S.; Civano, F.; Elvis, M.; Fabbiano, G.; Gilli, R.; Marconi, A.; Salvestrini, F.; et al. The most luminous blue quasars at 3.0 < z < 3.3. I. A tale of two X-ray populations. Astron. Astrophys. 2019, 632, A109. [Google Scholar] [CrossRef]
- Lusso, E.; Piedipalumbo, E.; Risaliti, G.; Paolillo, M.; Bisogni, S.; Nardini, E.; Amati, L. Tension with the flat ΛCDM model from a high-redshift Hubble diagram of supernovae, quasars, and gamma-ray bursts. Astron. Astrophys. 2019, 628, L4. [Google Scholar] [CrossRef]
- Lusso, E.; Risaliti, G.; Nardini, E.; Bargiacchi, G.; Benetti, M.; Bisogni, S.; Capozziello, S.; Civano, F.; Eggleston, L.; Elvis, M.; et al. Quasars as standard candles. III. Validation of a new sample for cosmological studies. Astron. Astrophys. 2020, 642, A150. [Google Scholar] [CrossRef]
- Bisogni, S. The relation between X-ray and UV emission in quasars. arXiv 2023, arXiv:2312.16562. [Google Scholar]
- Dainotti, M.; Petrosian, V.; Willingale, R.; O’Brien, P.; Ostrowski, M.; Nagataki, S. Luminosity-time and luminosity-luminosity correlations for GRB prompt and afterglow plateau emissions. Mon. Not. R. Astron. Soc. 2015, 451, 3898–3908. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Young, S.; Li, L.; Levine, D.; Kalinowski, K.K.; Kann, D.A.; Tran, B.; Zambrano-Tapia, L.; Zambrano-Tapia, A.; Cenko, S.B.; et al. The Optical Two- and Three-dimensional Fundamental Plane Correlations for Nearly 180 Gamma-Ray Burst Afterglows with Swift/UVOT, RATIR, and the Subaru Telescope. Astrophys. J. Suppl. Ser. 2022, 261, 25. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Lenart, A.Ł.; Fraija, N.; Nagataki, S.; Warren, D.C.; De Simone, B.; Srinivasaragavan, G.; Mata, A. Closure relations during the plateau emission of Swift GRBs and the fundamental plane. Publ. Astron. Soc. Jpn. 2021, 73, 970–1000. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Nielson, V.; Sarracino, G.; Rinaldi, E.; Nagataki, S.; Capozziello, S.; Gnedin, O.Y.; Bargiacchi, G. Optical and X-ray GRB Fundamental Planes as cosmological distance indicators. Mon. Not. R. Astron. Soc. 2022, 514, 1828–1856. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Postnikov, S.; Hernandez, X.; Ostrowski, M. A Fundamental Plane for Long Gamma-Ray Bursts with X-ray Plateaus. Astrophys. J. 2016, 825, L20. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Hernandez, X.; Postnikov, S.; Nagataki, S.; O’brien, P.; Willingale, R.; Striegel, S. A Study of the Gamma-Ray Burst Fundamental Plane. Astrophys. J. 2017, 848, 88. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Lenart, A.Ł.; Sarracino, G.; Nagataki, S.; Capozziello, S.; Fraija, N. The X-ray Fundamental Plane of the Platinum Sample, the Kilonovae, and the SNe Ib/c Associated with GRBs. Astrophys. J. 2020, 904, 97. [Google Scholar] [CrossRef]
- Bañados, E.; Venemans, B.P.; Mazzucchelli, C.; Farina, E.P.; Walter, F.; Wang, F.; Decarli, R.; Stern, D.; Fan, X.; Davies, F.B.; et al. An 800-million-solar-mass black hole in a significantly neutral Universe at a redshift of 7.5. Nature 2018, 553, 473–476. [Google Scholar] [CrossRef]
- Salvestrini, F.; Risaliti, G.; Bisogni, S.; Lusso, E.; Vignali, C. Quasars as standard candles II. The non-linear relation between UV and X-ray emission at high redshifts. Astron. Astrophys. 2019, 631, A120. [Google Scholar] [CrossRef]
- Vito, F.; Brandt, W.N.; Bauer, F.E.; Calura, F.; Gilli, R.; Luo, B.; Shemmer, O.; Vignali, C.; Zamorani, G.; Brusa, M.; et al. The X-ray properties of z > 6 quasars: No evident evolution of accretion physics in the first Gyr of the Universe. Astron. Astrophys. 2019, 630, A118. [Google Scholar] [CrossRef]
- Menzel, M.L.; Merloni, A.; Georgakakis, A.; Salvato, M.; Aubourg, E.; Brandt, W.N.; Brusa, M.; Buchner, J.; Dwelly, T.; Nandra, K.; et al. Northern XMM-XXL Field AGN Catalog (Menzel+, 2016). Vizier Online Data Cat. J/MNRAS/457/110. 2016. Available online: http://cdsarc.u-strasbg.fr/viz-bin/cat/J/A+A/642/A150 (accessed on 13 October 2020).
- Pâris, I.; Petitjean, P.; Aubourg, É.; Myers, A.D.; Streblyanska, A.; Lyke, B.W.; Anderson, S.F.; Armengaud, É.; Bautista, J.; Blanton, M.R.; et al. The Sloan Digital Sky Survey Quasar Catalog: Fourteenth data release. Astron. Astrophys. 2018, 613, A51. [Google Scholar] [CrossRef]
- Webb, N.A.; Coriat, M.; Traulsen, I.; Ballet, J.; Motch, C.; Carrera, F.J.; Koliopanos, F.; Authier, J.; de la Calle, I.; Ceballos, M.T.; et al. The XMM-Newton serendipitous survey. IX. The fourth XMM-Newton serendipitous source catalogue. Astron. Astrophys. 2020, 641, A136. [Google Scholar] [CrossRef]
- Evans, I.N.; Primini, F.A.; Glotfelty, K.J.; Anderson, C.S.; Bonaventura, N.R.; Chen, J.C.; Davis, J.E.; Doe, S.M.; Evans, J.D.; Fabbiano, G.; et al. The Chandra Source Catalog. Astrophys. J. Suppl. Ser. 2010, 189, 37–82. [Google Scholar] [CrossRef]
- Watson, M.G.; Auguères, J.L.; Ballet, J.; Barcons, X.; Barret, D.; Boer, M.; Boller, T.; Bromage, G.E.; Brunner, H.; Carrera, F.J.; et al. The XMM-Newton Serendipitous Survey. I. The role of XMM-Newton Survey Science Centre. Astron. Astrophys. 2001, 365, L51–L59. [Google Scholar] [CrossRef]
- Signorini, M.; Risaliti, G.; Lusso, E.; Nardini, E.; Bargiacchi, G.; Sacchi, A.; Trefoloni, B. Quasars as Standard Candles V. Evaluation of a ≤ 0.06 dex intrinsic dispersion in the LX-LUV relation. arXiv, 2023; arXiv:2312.08448. [Google Scholar] [CrossRef]
- Khadka, N.; Zajaček, M.; Prince, R.; Panda, S.; Czerny, B.; Martínez-Aldama, M.L.; Jaiswal, V.K.; Ratra, B. Quasar UV/X-ray relation luminosity distances are shorter than reverberation-measured radius-luminosity relation luminosity distances. Mon. Not. R. Astron. Soc. 2023, 522, 1247–1264. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Bargiacchi, G.; Łukasz Lenart, A.; Nagataki, S.; Capozziello, S. Quasars: Standard candles up to z = 7.5 with the precision of Supernovae Ia. Astrophys. J. 2023, 950, 45. [Google Scholar] [CrossRef]
- Kelly, B.C. Some Aspects of Measurement Error in Linear Regression of Astronomical Data. Astrophys. J. 2007, 665, 1489–1506. [Google Scholar] [CrossRef]
- Huber, P.J. Robust estimation of a location parameter. In Breakthroughs in Statistics: Methodology and Distribution; Springer: New York, NY, USA, 1992; pp. 492–518. [Google Scholar]
- Owen, A.B. A robust hybrid of lasso and ridge regression. Contemp. Math. 2007, 443, 59–72. [Google Scholar]
- Ronchetti, E.M.; Huber, P.J. Robust Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- D’Agostini, G. Fits, and especially linear fits, with errors on both axes, extra variance of the data points and other complications. arXiv, 2005; arXiv:physics/0511182. [Google Scholar]
- Li, X.; Keeley, R.E.; Shafieloo, A.; Zheng, X.; Cao, S.; Biesiada, M.; Zhu, Z.H. Hubble diagram at higher redshifts: Model independent calibration of quasars. Mon. Not. R. Astron. Soc. 2021, 507, 919–926. [Google Scholar] [CrossRef]
- Stephens, M.A. EDF statistics for goodness of fit and some comparisons. J. Am. Stat. Assoc. 1974, 69, 730–737. [Google Scholar] [CrossRef]
- Razali, N.M.; Wah, Y.B. Power comparisons of shapiro-wilk, kolmogorov-smirnov, lilliefors and anderson-darling tests. J. Stat. Model. Anal. 2011, 2, 21–33. [Google Scholar]
- Dainotti, M.G.; Bargiacchi, G.; Bogdan, M.; Capozziello, S.; Salvatore Nagataki, S. On the statistical assumption on the distance moduli of Supernovae Ia and its impact on the determination of cosmological parameters. J. High Energy Astrophys. Accept. 2024, 41, 30–41. [Google Scholar] [CrossRef]
- Lenart, A.Ł.; Dainotti, M.G.; Bargiacchi, G. Selection Biases and Redshift Evolution in Relation to Cosmology. 2023. Available online: https://notebookarchive.org/2023-05-8b2lbrh (accessed on 18 May 2023).
- Colgáin, E.Ó.; Sheikh-Jabbari, M.M.; Solomon, R. High Redshift ΛCDM Cosmology: To Bin or not to Bin? arXiv 2022, arXiv:2211.02129. [Google Scholar] [CrossRef]
- Brout, D.; Scolnic, D.; Popovic, B.; Riess, A.G.; Carr, A.; Zuntz, J.; Kessler, R.; Davis, T.M.; Hinton, S.; Jones, D.; et al. The Pantheon+ Analysis: Cosmological Constraints. Astrophys. J. 2022, 938, 110. [Google Scholar] [CrossRef]
- Dainotti, M.; Lenart, A.; Yengejeh, M.; Chakraborty, S.; Fraija, N.; Di Valentino, E.; Montani, G. A New Binning Method to Choose a Standard Set of Quasars. 2024; submitted. [Google Scholar]
- Terzian, Y.; Weedman, D.; Khachikian, E. The Evolution and Luminosity Function of Quasars.
- Dainotti, M.G.; Cardone, V.F.; Piedipalumbo, E.; Capozziello, S. Slope evolution of GRB correlations and cosmology. Mon. Not. R. Astron. Soc. 2013, 436, 82–88. [Google Scholar] [CrossRef]
- Efron, B.; Petrosian, V. A Simple Test of Independence for Truncated Data with Applications to Redshift Surveys. Astrophys. J. 1992, 399, 345–352. [Google Scholar] [CrossRef]
- Green, R.F.; Khachikian, E.Y.; Sanders, D.B. AGN Surveys: IAU Colloquium 184. In Proceedings of the International Astronomical Union Colloquium, Byurakan, Armenia, 18–22 June 2001; Astronomical Society of the Pacific Conference Series. Astronomical Society of the Pacific: San Francisco, CA, USA, 2002; Volume 284. [Google Scholar]
- Ying, Z.; Yu, W.; Zhao, Z.; Zheng, M. Regression analysis of doubly truncated data. J. Am. Stat. Assoc. 2019, 115, 810–821. [Google Scholar] [CrossRef]
- Dainotti, M.; Levine, D.; Fraija, N.; Chandra, P. Accounting for Selection Bias and Redshift Evolution in GRB Radio Afterglow Data. Galaxies 2021, 9, 95. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Bargiacchi, G.; Bogdan, M.; Łukasz Lenart, A.; Iwasaki, K.; Capozziello, S.; Zhang, B.; Fraija, N. Reducing the uncertainty on the Hubble constant up to 35% with an improved statistical analysis: Different best-fit likelihoods for Supernovae Ia, Baryon Acoustic Oscillations, Quasars, and Gamma-Ray Bursts. arXiv 2023, arXiv:2305.10030. [Google Scholar] [CrossRef]
- Singal, J.; Petrosian, V.; Lawrence, A.; Stawarz, Ł. On the Radio and Optical Luminosity Evolution of Quasars. Astrophys. J. 2011, 743, 104. [Google Scholar] [CrossRef]
- Dainotti, M.G.; Petrosian, V.; Bowden, L. Cosmological Evolution of the Formation Rate of Short Gamma-Ray Bursts with and without Extended Emission. Astrophys. J. 2021, 914, L40. [Google Scholar] [CrossRef]
- Levine, D.; Dainotti, M.; Zvonarek, K.J.; Fraija, N.; Warren, D.C.; Chandra, P.; Lloyd-Ronning, N. Examining Two-dimensional Luminosity-Time Correlations for Gamma-Ray Burst Radio Afterglows with VLA and ALMA. Astrophys. J. 2022, 925, 15. [Google Scholar] [CrossRef]
- Singal, J.; Petrosian, V.; Stawarz, Ł.; Lawrence, A. The Radio and Optical Luminosity Evolution of Quasars. II. The SDSS Sample. Astrophys. J. 2013, 764, 43. [Google Scholar] [CrossRef]
- Scolnic, D.M.; Jones, D.O.; Rest, A.; Pan, Y.C.; Chornock, R.; Foley, R.J.; Huber, M.E.; Kessler, R.; Narayan, G.; Riess, A.G.; et al. The Complete Light-curve Sample of Spectroscopically Confirmed SNe Ia from Pan-STARRS1 and Cosmological Constraints from the Combined Pantheon Sample. Astrophys. J. 2018, 859, 101. [Google Scholar] [CrossRef]
- Conley, A.; Guy, J.; Sullivan, M.; Regnault, N.; Astier, P.; Balland, C.; Basa, S.; Carlberg, R.G.; Fouchez, D.; Hardin, D.; et al. Supernova Constraints and Systematic Uncertainties from the First Three Years of the Supernova Legacy Survey. Astrophys. J. Suppl. Ser. 2011, 192, 1. [Google Scholar] [CrossRef]
- Trefoloni, B.; Lusso, E.; Nardini, E.; Risaliti, G.; Bargiacchi, G.; Bisogni, S.; Civano, F.M.; Elvis, M.; Fabbiano, G.; Gilli, R.; et al. The most luminous blue quasars at 3.0 < z < 3.3. III. LBT spectra and accretion parameters. Astron. Astrophys. 2023, 677, A111. [Google Scholar] [CrossRef]
- Rałowski, M.; Hryniewicz, K.; Pollo, A.; Stawarz, Ł. Covering factor in AGNs: Evolution versus selection. arXiv, 2023; arXiv:2311.00072. [Google Scholar] [CrossRef]
- Marziani, P.; Sulentic, J.W.; Negrete, C.A.; Dultzin, D.; Zamfir, S.; Bachev, R. Broad-line region physical conditions along the quasar eigenvector 1 sequence. Mon. Not. R. Astron. Soc. 2010, 409, 1033–1048. [Google Scholar] [CrossRef]
- Shen, Y.; Ho, L.C. The diversity of quasars unified by accretion and orientation. Nature 2014, 513, 210–213. [Google Scholar] [CrossRef]
- Negrete, C.A.; Dultzin, D.; Marziani, P.; Esparza, D.; Sulentic, J.W.; del Olmo, A.; Martínez-Aldama, M.L.; García López, A.; D’Onofrio, M.; Bon, N.; et al. Highly accreting quasars: The SDSS low-redshift catalog. Astron. Astrophys. 2018, 620, A118. [Google Scholar] [CrossRef]
- Dultzin, D.; Marziani, P.; de Diego, J.A.; Negrete, C.A.; Del Olmo, A.; Martínez-Aldama, M.L.; D’Onofrio, M.; Bon, E.; Bon, N.; Stirpe, G.M. Extreme quasars as distance indicators in cosmology. Front. Astron. Space Sci. 2020, 6, 80. [Google Scholar] [CrossRef]
- Bon, N.; Marziani, P.; Bon, E.; Negrete, C.A.; Dultzin, D.; del Olmo, A.; D’Onofrio, M.; Martínez-Aldama, M.L. Selection of highly-accreting quasars. Spectral properties of Fe IIopt emitters not belonging to extreme Population A. Astron. Astrophys. 2020, 635, A151. [Google Scholar] [CrossRef]
- Sacchi, A.; Risaliti, G.; Signorini, M.; Lusso, E.; Nardini, E.; Bargiacchi, G.; Bisogni, S.; Civano, F.; Elvis, M.; Fabbiano, G.; et al. Quasars as high-redshift standard candles. Astron. Astrophys. 2022, 663, L7. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | |||
|---|---|---|---|
| 0.218 | 7 | ||
| 0.265 | 9 | ||
| 0.318 | 12 | ||
| 0.382 | 13 | ||
| 0.438 | 13 | ||
| 0.490 | 24 | ||
| 0.561 | 33 | ||
| 0.623 | 33 | ||
| 0.686 | 39 | ||
| 0.764 | 46 | ||
| 0.831 | 48 | ||
| 0.906 | 48 | ||
| 0.990 | 55 | ||
| 1.068 | 44 | ||
| 1.156 | 64 | ||
| 1.250 | 46 | ||
| 1.344 | 48 | ||
| 1.438 | 46 | ||
| 1.546 | 58 | ||
| 1.646 | 49 | ||
| 1.763 | 46 | ||
| 1.888 | 46 | ||
| 1.993 | 45 | ||
| 2.139 | 36 | ||
| 2.269 | 35 | ||
| 2.384 | 32 | ||
| 2.539 | 27 | ||
| 2.689 | 22 | ||
| 2.866 | 12 | ||
| 3.016 | 12 | ||
| 3.158 | 12 | ||
| 3.330 | 5 |
| Method | Sample | N | |||
|---|---|---|---|---|---|
| Bins in | Without sources | 1065 | |||
| With sources | 1132 | ||||
| Bins wider in z | Without sources | 1084 | |||
| With sources | 1125 | 0 | |||
| Bins optimized in width from highest z | Without sources | 1843 | |||
| With sources | 1858 | ||||
| Bins optimized in width from lowest z | Without sources | 1965 | |||
| With sources | 1980 | ||||
| Bins centered on each QSO | Without sources | 811 | * | ||
| With sources | 825 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dainotti, M.G.; Bargiacchi, G.; Lenart, A.Ł.; Capozziello, S. The Scavenger Hunt for Quasar Samples to Be Used as Cosmological Tools. Galaxies 2024, 12, 4. https://doi.org/10.3390/galaxies12010004
Dainotti MG, Bargiacchi G, Lenart AŁ, Capozziello S. The Scavenger Hunt for Quasar Samples to Be Used as Cosmological Tools. Galaxies. 2024; 12(1):4. https://doi.org/10.3390/galaxies12010004
Chicago/Turabian StyleDainotti, Maria Giovanna, Giada Bargiacchi, Aleksander Łukasz Lenart, and Salvatore Capozziello. 2024. "The Scavenger Hunt for Quasar Samples to Be Used as Cosmological Tools" Galaxies 12, no. 1: 4. https://doi.org/10.3390/galaxies12010004
APA StyleDainotti, M. G., Bargiacchi, G., Lenart, A. Ł., & Capozziello, S. (2024). The Scavenger Hunt for Quasar Samples to Be Used as Cosmological Tools. Galaxies, 12(1), 4. https://doi.org/10.3390/galaxies12010004