1. Introduction
Internationally, health sector constantly has a high demand for clinical care; there are many reasons that influence the overload in the quality of medical care and also cause a saturation of patients. The factors that generate a clinical saturation are diminished personnel, insufficient or well-qualified medical personnel, deficient infrastructure, ventilators, delay in medical diagnosis, hospitalization time, lack of medicines, among others [
1,
2,
3,
4,
5]. Nowadays, an example of saturation of the health sector worldwide is the Coronavirus pandemic (COVID-19), which has caused an overflow in the quality and capacity of medical care in many of the clinical centers. This situation is also caused due to the high number of infected patients with COVID-19, until 17 April 2022, over 500 million confirmed cases and over 6 million deaths have been reported globally [
6,
7]. These numbers continue to increase and cause problems in clinical demand. Another problem consists in the difficulty to give an accurate diagnosis in a short time, without forgetting that this diagnosis can be somewhat subjective. There are several factors that influence to achieve a correct medical assessment, such as the professional capacity and specialty of the staff, degree of studies, own judgment, stress, assessment of the patient, fatigue of personnel, among others [
8,
9,
10,
11].
Coronavirus pandemic has led to the demand for the application of various modern techniques and technologies such as artificial intelligence (AI) tools, which has multiple applications in fields of science such as medicine, meteorology, astronomical exploration, including applications in financial systems, among others [
12,
13,
14,
15]. In this sense, IA makes it possible to design schemes in order to speed up medical diagnoses, reduce the saturation of clinical centers, increase the quality of medical care, obtain better medical assessment and solve various other problems [
12,
13,
14,
15,
16,
17,
18,
19]. Thus, novel models need to be developed to support medical personnel, allowing them to be an aid in diagnosing more efficiently health status of a COVID-19 infected patient.
Accordingly, IA models can use risk factors associated with the death as guideline and predict the probabilities that a patient will die or recover (health status diagnosis) from this new Coronavirus. Risk probability results are helpful in making better quality clinical decisions in a limited time environment and with limited resources, obtaining more detailed and accurate clinical diagnoses. Consequently, health risk factors plays an important role, increasing the chances of developing a serious COVID-19 infection (suffering complications) and causing death, or at least increasing its chances. In addition, these factors can originate complications, and therefore be taken to an intensive care unit (ICU) [
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34]. A logistic study with several variables indicated that factors such as chills, body temperature, initial chest X-ray findings and diabetes were valued as elements that cause the aggravation of the health status of patients with COVID-19. This is probably because some of these factors cause hyperglycemic conditions that generate immune dysfunction, as well as impaired neutrophil function, humoral immunity and antioxidant system function [
35]. In other previous studies, age was reported to be the most important predictor of death in COVID-19 patients. In this sense, infected older people often suffer severe complications, mainly due to age-dependent functional defects in immune cells that lead to poor suppression of viral replication [
35,
36].
Another risk factor to consider in modeling these IA schemes is cardiac injury, where the mortality rate is higher among patients with this disease in relation to those who do not have it. COVID-19 patients with cardiac injury experienced greater severity, evidenced by abnormal radiographic and laboratory results, among which are: NT-proBNP, elevated levels of C-reactive protein and creatinine levels, as well as more multiple mottling and opacity in ground glass; where a higher proportion required non-invasive or invasive ventilation [
37]. Severe pneumonia was also independently associated with admission to intensive care unit, mechanical ventilation, or death in the competitive-risk multivariate model due to the cause of more severe respiratory problems [
38]. Besides, regarding recent information, obesity is a factor that originates the aggravation of the disease, causing people to require hospitalization and ventilation mechanisms. In this way, obesity induces alterations in the microbiota and physiological and immune responses, which are related to deficient viral responses [
39].
Taking into account this information, there are several types of AI applications based on various variables in the COVID-19 pandemic, in addition to abundant and diverse works for each type of application [
16,
17]. For example, the early detection and diagnosis of infection, which aims to analyze irregular symptoms and other “warning flags”, and thus help make decisions faster. Another application lies in reducing the workload of healthcare staff, assisting in the early diagnosis of the virus and providing medication in a timely manner using some kind of data analysis process [
40]. Also this supplies opportunities to improve abilities of medical workers with respect to the new challenges of the disease [
12,
16,
18].
Regarding the projection of COVID-19 cases and mortality, the aim is to foretell the number of sick and unrecovered people in a specific country; furthermore, it can help recognize which type of people is vulnerable. Likewise, there is a great variety of studies of this type despite the short time that has elapsed since the pandemic began [
16,
41]. We can find research around the world about this topic employing IA techniques such as random forest models [
17,
42,
43,
44,
45], deep learning [
46,
47,
48,
49,
50,
51,
52,
53], decision trees [
43,
54], support vector machine (SVM) [
49,
55] and logistic regression procedures [
49,
56]; which are intended to predict the health status (mortality risk or disease severity) of a COVID-19 infected patient employing factors such as the patients age, weight, gender, physiological conditions, demographic data, travel data, computed tomography, vital signs, symptoms, smoking history, radiological features, clinical features, genetic variants, platelets, laboratory test, D-dimer test, chronic comorbidities and general health information. Meantime, other studies [
57] create models using data analysis techniques with the aim of predicting the need of oxygen therapy in a timely manner in COVID-19 patients; which employed variables like shortness of breath, cough, age and fever. We can also find related works intended to design CNN-based models with the purpose of detecting positive cases of COVID-19 using chest X-ray images [
58].
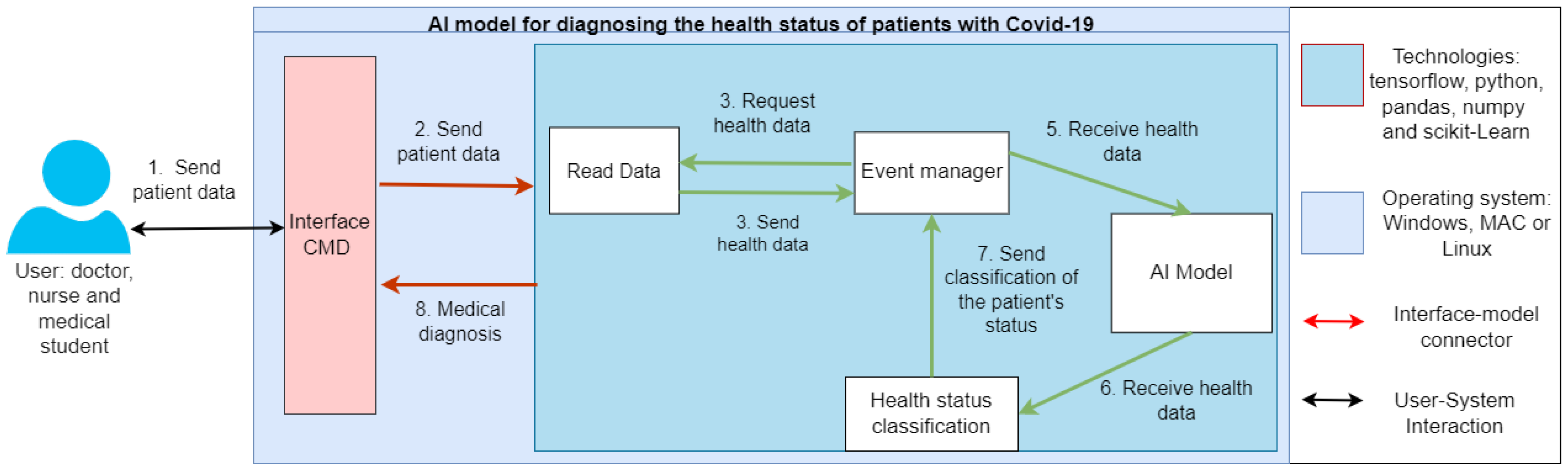
This research defines AI models taking into account risk factors to predict the health status (chances of recovering or not recovering) of patients infected by COVID-19 in Mexico. Thus, this proposal can support medical workers to evaluate patients more quickly and accurately due to overload in hospitals; likewise, they can also provide better quality care based on priorities for risk of severity or death. To accomplish the task, various machine learning and learning mathematical models are implemented and compared for prediction and classification, such as logistic regression, KNN, decision trees, neural networks and random forests. To the best of our knowledge, there is no AI-based model in the state-of-the-art review that considers the same predictive variables, thus making it an alternative support approach. In this sense, the implementation of the algorithms is carried out by performing the search for squares and cross validation to fit the models, which is applied on a open dataset provided by the Secretary of Health of Mexico. This corpus of data collects information on different risk factor variables (16 risk factors and other variables), which are associated with death in patients with COVID-19. This dataset contains the accumulated information (epidemiological study) of all suspected and confirmed cases of the viral disease COVID-19 in Mexico; furthermore, these cases are found within different units of the Mexican Health Sector [
59]. With these proposal, ANN was the suggested model to predict the health status (risk probability of dying) that patients with COVID-19 have, obtaining an accuracy of 90.02%, a precision of 92.60% and F1 score of 89.64%; while for the recall a 86.87% was obtained. The suggested results do not present high variance problems, but high bias problems. The results showed that the variables (risk factors) with the greatest importance or influence on death caused by COVID-19 are intubation requirement with 47%, pneumonia with 34% and age with 14%.
Due to the similar objective of other existing works, it is worth mentioning that this study is under other conditions and has been carried out in different country or region. Each site has its own circumstances and may differ from place to place (causing a different pattern in the statistics) in terms of the quality of medical care (hospital infrastructure, quality of care, professional training). In addition, other factors are involved, such as population with obesity, eating habits, average age of population, quality of health (diseases suffered by age), number of infected by age, general habits of population like smoking, among others. For this reason, the main contributions of this paper are emphasized:
A mortality predictor model based on risk factors for COVID-19 is presented, which is trained with data from the open dataset “COVID-19 databases in Mexico” provided by the Secretary of Health of Mexico. The proposed scheme uses different data and predictor variables regarding the state-of-the-art, while being applied in different region and circumstances.
An analysis of the relationship of variables used and their interpretation is carried out.
This work proposes an AI model to identify risk factors with the greatest influence on death from COVID-19 in Mexico.
This work applies the grid search technique in a nested way with cross validation to improve performance and evaluate the proposed algorithms.
This analysis will allow researchers to continue working on the development of new models to predict the health status of patients, and will allow to identify new variables with influence on death caused by COVID-19, especially in Mexico.
The rest of the paper is organized as follows.
Section 2 presents the proposal of this work, which describes the statistical analysis carried out and the basic idea behind the proposed models. The evaluation and results of the models as well as their comparisons are shown in
Section 3. A discussion of the results and their corresponding comparison is described in
Section 4. Finally,
Section 5 concludes the paper with a brief analysis and future work.
4. Discussion
Early identification of patients at risk of die has several predictable benefits including better allocation of critical care staff and supplies, the ability to contact people who are not currently admitted to the hospital and ensure they are thoroughly evaluated; and the ability to relocate inpatients to a facility capable of providing a higher level of care. Our designs aim to be trained first to identify the most relevant characteristics and then predict patient mortality. Initially, simple linear models were built working with the 16 or 8 parameters of the epidemiological study, but in some models or cases we sought to simplify the model through excluding features, to increase its performance and reduce underfitting.
The benefits of this research is the identification and assessment of new features for prediction models of health status. And given the results, it can be seen good indications showing that it is possible to achieve alternative models that are alike efficient based on quick diagnoses. Our predictive model differs from others in several ways, first of all, this makes it possible to predict the health status of a patient from a simple and faster medical diagnosis in the point of view of users (by using the mobile app, for instance). By not analyzing variables such as vital signs, patient region, blood oxygen, among others, this way allows faster medical assessments to identify patients with more susceptibility to die. Second, it proposes a model taken to a higher level of abstraction with a performance similar to other existing models, which is independent of specific cases where the region of the patient is taken into account; this is achieved by considering different variables of prediction. Finally, this analysis uses a large amount of data from different regions of a single country (Mexico). Another strength is the use and validation of widely used prediction models in different circumstances. Also the application and comparison of different methods allows to identify the appropriate techniques in the prognosis of the health status of patients infected. In addition, this research allows the identification of new techniques that could be useful; the identification of existing variables that have not been applied until now (as far as is known) in predicting SARS-COV-2 mortality.
This study has several considerations, for example, it is a retrospective study carried out in a single country in different health institutions. This work is a first step towards AI-assisted clinical prediction. Our predictive model needs to be externally validated using multi-institutional data and/or prospective studies from other countries before clinical application can be made. If our tool is externally validated in due course, then we imagine that this predictive model can be used by frontline people to more effectively diagnose COVID-19 patients. The validation of these mortality predictors in future prospective studies could be useful to identify and stratify the risk groups, as well as to provide the necessary health services.
In addition, this study is under different circumstances and has been carried out in different regions of Mexico. These circumstances may differ from place to place, causing a different pattern in the statistics from one place to another. They may differ in terms of the quality of medical care in the country (hospital infrastructure, quality of care, professional training, among others), in addition to factors such as obese population, the quality of their diet, the average age, the quality of health (diseases suffered by age), the number of people infected by age, the population’s habits (smoking), to mention a few. In this sense, we only analyzed clinical variables at patient admission (risk factors). A final comment can be aimed at emphasizing that the circumstances in which COVID-19 occurs are unusual and are constantly changing. Thus, the number of hospitalized patient and their flow in ICU, as well as the mortality factor may depend on the region load and the available resources of individual hospitals, which also differ between countries, as well as other patterns and behaviors in habits and characteristics of health in the population by region.
5. Conclusions and Future Work
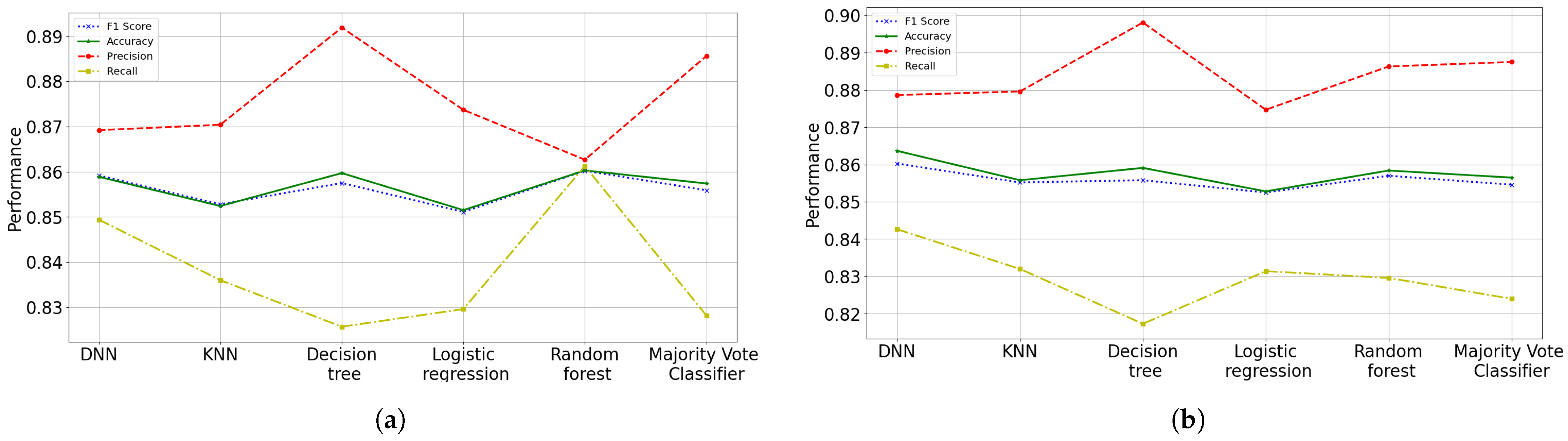
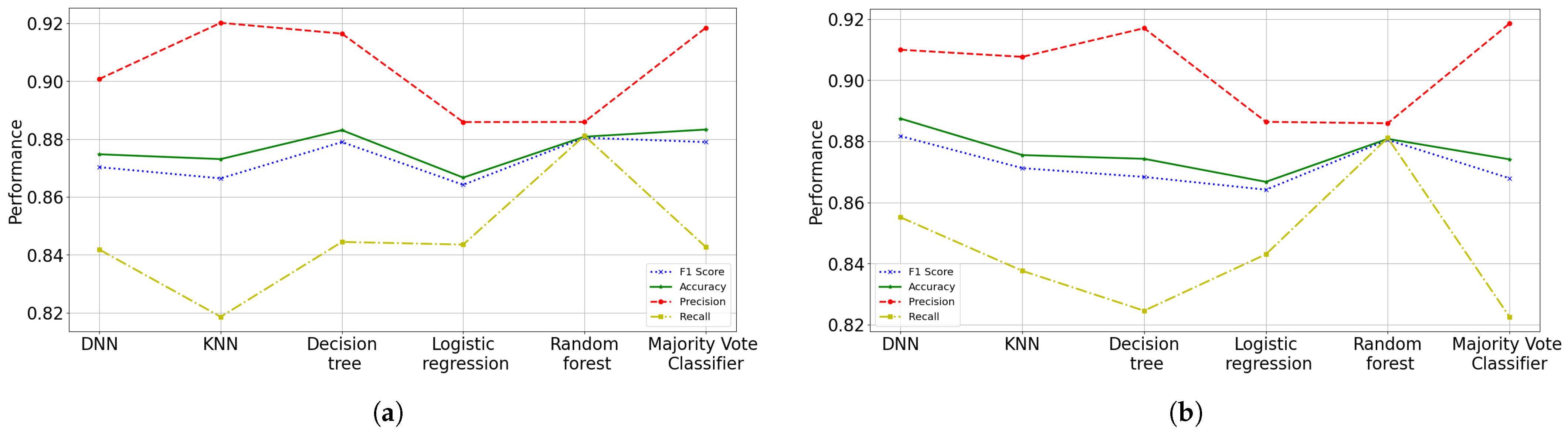
The current application of data analysis techniques around world is more and more necessary today in order to propose models to process patient data seeking to define efficient treatment strategies. In this work, a comparison of machine learning techniques was made with the aim of determining the probability that a person infected by COVID-19 can recover. We presented different prediction models, where the ANN scheme has been chosen as the most accurate framework, because not only we can obtain the patient’s classification, because also it can be obtained in terms of probabilities. Although the different proposed and implemented prediction models do not present an overfitting problem, they do present a slight underfitting problem. These models present a low variance, but a high bias, and the models underfit the data since they do not achieve a high level of abstraction of them. Since the parameters in all the models were adjusted and regularized as best as possible by means of grid searching and among other techniques, it is possible that more features may need to be built or collected to improve the accuracy of the models. Although a process of determining the features importance was done, like many models, selecting more features gave better results.
As a solution to improve the accuracy and precision of performance and reduce the under-adjustment of the algorithms, it is suggested to collect more characteristics, since there may be more related risk factors (not considered) in determining the mortality of patients infected with COVID-19. Due to that, there may be other different and important factors (with high influence and relationship) to determine more accurately whether a patient infected can survive or die. Such factors can be type of viral strain, seriousness and professional capacity of the medical staff (experience, physical exhaustion, preparation); besides, some symptoms or vital signs can be included, e.g., the amount of oxygen in the patient’s blood.
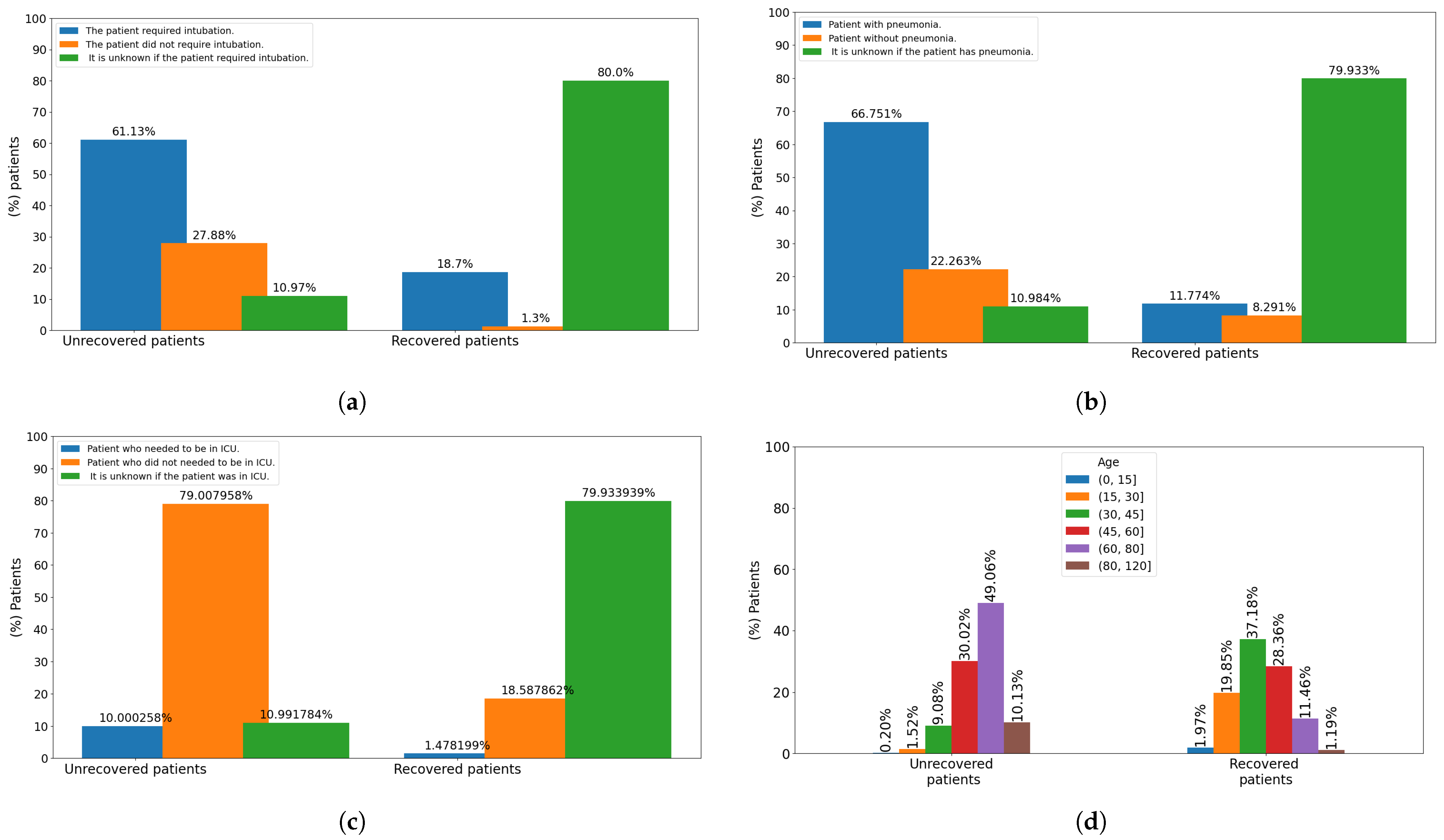
Otherwise, the data analyzed in this study have revealed that the rates (probabilities) of mortality were higher if the patients presented the following main risk factors: requiring intubation, having pneumonia, advanced age, diabetes and hypertension. For the selection of these characteristics, a random forest model was implemented to identify the features importance, obtaining an accuracy of 89.40% with a F1 metric of 89.37% in testing phase. It was also found in this research that people with pneumonia and advanced age are not only have more possibilities to die, but also to have more complications (be intubated or entering the ICU) due to COVID-19. Finally, at an older age there is a higher risk of suffering from risk factors associated with death. Therefore, the performance error of the different implemented algorithms is around 14% or less. ANN was the proposed model to predict the risk probability of death or healing of patients with COVID-19, obtaining an accuracy of 89.8%, a precision of 92.3%, a recall of 86.8% and F1 score of 89.5%. For this work, an open data set “COVID-19 databases in Mexico” provided by the Secretary of Health of Mexico was used, which was filtered to be adapted to the requirements.
In a future work, the construction of a new more robust dataset for the training of these models is suggested. A more representative and robust dataset will reduce the under-adjustment in the algorithms, finding in a more precise way the importance of risk factors. In addition, the improvement of the employed techniques and the implementation of new schemes and models are suggested.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}