Abstract
This study proposes a novel approach that utilizes Convolutional Neural Networks (CNNs) and Support Vector Machines (SVMs) to tackle a critical challenge: detecting defects in wrapped film products. With their delicate and reflective film wound around a core material, these products present formidable hurdles for conventional visual inspection systems. The complex task of identifying defects, such as unwound or protruding areas, remains a daunting endeavor. Despite the power of commercial image recognition systems, they struggle to capture anomalies within wrap film products. Our research methodology achieved a 90% defect detection accuracy, establishing its practical significance compared with existing methods. We introduce a pioneering methodology centered on covariance vectors extracted from latent variables, a product of a Variational Autoencoder (VAE). These covariance vectors serve as feature vectors for training a specialized One-Class SVM (OCSVM), a key component of our approach. Unlike conventional practices, our OCSVM does not require images containing defects for training; it uses defect-free images, thus circumventing the challenge of acquiring sufficient defect samples. We compare our methodology against feature vectors derived from the fully connected layers of established CNN models, AlexNet and VGG19, offering a comprehensive benchmarking perspective. Our research represents a significant advancement in defect detection technology. By harnessing the latent variable covariance vectors from a VAE encoder, our approach provides a unique solution to the challenges faced by commercial image recognition systems. These advancements in our study have the potential to revolutionize quality control mechanisms within manufacturing industries, offering a brighter future for product integrity and customer satisfaction.
1. Introduction
The manufacturing industry, especially that of wrap film products, contends with unique challenges in maintaining quality control. The delicate and reflective properties of these products present significant obstacles for traditional visual inspection systems, underscoring the need to develop more sophisticated and accurate defect detection methods.
Accurate and effective anomaly detection techniques are fundamental to industry safety and efficiency. Recent advancements in machine learning offer promising solutions to these challenges. Our study introduces a novel approach that combines Convolutional Neural Networks (CNNs) and One-Class Support Vector Machines (OCSVMs), particularly the use of covariance vectors derived from Variational Autoencoder (VAE) latent variables. This approach addresses specific challenges in film defect detection, such as the detection of micro-defects and handling variations in film texture and thickness, representing a significant leap over traditional methods. This has generated considerable interest and anticipation for its potential to revolutionize defect detection in wrap film products.
Emerging hybrid methodologies, blending machine learning with advanced feature extraction, have shown promise in enhancing anomaly detection [1,2]. Convolutional Neural Networks (CNNs) have demonstrated exceptional capabilities in image analysis and classification tasks [3]. Our research capitalizes on these capabilities by exploring the synergy between CNNs and OCSVMs, particularly in the demanding environment of wrap film product manufacturing. This research holds particular significance in the packaging industry, where quality control is not just a priority but a real necessity.
However, since these techniques are applied in practical applications, evaluating their thorough performance and identifying potential avenues to enhance their performance becomes crucial. This paper focuses on defect detection in wrap film products, a critical process in the packaging industry. The objective is to design and assess OCSVM models that utilize the encoder part of a Variational Autoencoder (VAE) and various CNNs as feature extractors. The proposed models aim to differentiate between normal and defective wrap film images, addressing the specific challenges of detecting micro-defects and handling variations in film texture and thickness. Models such as STMask R-CNN have been developed for automatic visual inspection [4]. Furthermore, image augmentation techniques with CNNs have contributed to ongoing innovation in anomaly detection technologies [5]. The exploration of three-dimensional CNNs for complex manufacturing environments [6] and transformer networks with multi-stage CNN backbones [7] illustrate the dynamic evolution of CNN applications in defect detection. The integration of CNNs and image augmentation for defect detection in processes like seat foaming [8] illustrates the hybridization of methodologies for improved results.
Pimentel et al. reviewed novelty detection methods and highlighted the importance of considering previously unseen patterns in anomaly detection [9]. Schölkopf et al. introduced their work on estimating the support of high-dimensional distributions using SVMs, laying the theoretical foundation for constructing decision boundaries around a standard reference representing a norm in anomaly detection tasks [10]. Liu et al. surveyed real-time surface defect inspection methods and provided insights into approaches that can be employed for anomaly detection [11]. These references highlight the diverse methods and practices developed and tested for anomaly detection.
Recent studies in anomaly detection have explored various advanced methodologies that complement the use of OCSVMs. He et al. proposed a two-stage dense representation learning model for the image anomaly localization (IAL) task. The learned representations were compatible with the dense IAL task and showed strong transferability to new datasets. However, the model’s discriminative ability on subtle defects remains challenging [12]. Similarly, Wang et al. introduced a multi-feature reconstruction network named MFRNet, based on crossed-mask restoration for unsupervised anomaly detection. This method can detect anomalies accurately using only anomaly-free images. Nonetheless, it requires a masking operation and faces challenges related to the effectiveness of the masking strategy, detection accuracy, and inference speed [13].
Building upon this foundational understanding, this paper explores unique methodologies, detailing the integration of OCSVMs, VAEs, and CNNs in addressing the challenges of defect detection in wrap film products. The primary objective of this study is to develop and validate OCSVM models utilizing VAEs and CNNs to enhance defect detection accuracy in wrap film products. This paper combines selected feature extractor techniques that include OCSVMs, VAEs, and CNNs to solve specific problems in the film product domain such as detecting micro-defects and managing variations in film texture and thickness. The encoder component of the VAE is employed as a feature extractor, helping to extract latent representations that capture essential characteristics of the input images [14]. Also, CNNs, such as VGG19 [15], are assessed as potential feature extractors because of their ability to learn complex hierarchical features from images [16]. These hybrid combinations facilitate the detection of defects based on extracting features from given images and enable effective anomaly detection.
The proposed models aim to differentiate between normal and defective wrap film images, contributing to improved quality control in the packaging process. This paper combines selected feature extractor techniques, including OCSVMs, VAEs, and CNNs, exploring VGG19, among others, for feature extraction [15,17]. These approaches are inspired by recent surveys and studies highlighting the diverse methods and practices developed for anomaly detection [17,18].
Our approach is not just a response to challenges in film defect detection but a reference offering the following promising solutions to these issues, which are significant in the field:
- Detection of Micro-Defects: Micro-defects, often missed by traditional inspection systems, can significantly impact the quality of wrap film products. The integration of CNNs, particularly AlexNet and VGG19, allows for detailed feature extraction, capturing subtle anomalies critical for identifying micro-defects [19,20]. VAE-derived covariance vectors enhance this capability by robustly representing normal data, making deviations more detectable [21].
- Handling Variations in Film Texture and Thickness: Variations in texture and thickness can introduce noise and inconsistencies in defect detection. Our method leverages CNNs’ adaptability to learn and generalize from these variations, while the OCSVM, trained on normal images, distinguishes true defects from variations. This combination ensures that the system remains sensitive to defects while being robust against benign variations in the film [10].
- Training Without Defect Images: One of the significant advancements of this study is the ability to train OCSVM models using only normal images. This approach addresses the common limitation of requiring defect images for training, which are often scarce and difficult to obtain in sufficient quantities. The use of Sequential Minimal Optimization (SMO), as described by Platt (1998), provides a fast and efficient algorithm for training support vector machines (SVMs), further enhancing the practicality of training OCSVM models in such scenarios [22]. This capability allows for effective anomaly detection even with limited defect data, providing a practical advantage in real-world industrial applications.
These advantages enable our approach to improve detection accuracy and reduce false positives, ensuring a more reliable quality control process in wrap film production. By employing OCSVMs with VAE-derived covariance vectors, our method uniquely overcomes the challenge of requiring defect images for training, a common limitation in traditional methods. This significant innovation allows for effective anomaly detection even with limited defect data.
Our research contributes to the field by evaluating OCSVM models enhanced by VAEs and CNNs for precise defect detection in wrap film products, as evidenced by our experimental findings. Previous works have predominantly relied on conventional machine learning techniques, which often require extensive data labeling and may need help with the complex nature of wrap film surfaces.
This paper introduces a novel approach that integrates Convolutional Neural Networks (CNNs) and One-Class Support Vector Machines (OCSVMs) to address the challenges of defect detection in wrap film products. Our study draws inspiration from recent advancements in applying CNNs and SVMs for defect detection in industrial products [1,2]. Previous surveys such as the one published by Chandola et al. have presented comprehensive reviews of anomaly detection techniques that have contributed to understanding various methods used to detect anomalies [23]. This diverse range of developed approaches and techniques reflects the growing importance of anomaly detection across different domains and industries.
This paper aims to advance defect detection techniques in the packaging industry and inspire further exploration of hybrid machine learning approaches for anomaly detection. It presents a comprehensive overview of the proposed methodology, encompassing the technical details of OCSVMs, VAEs, and CNNs, and outlines the experimental setup, dataset, and performance evaluation metrics. The structure of this paper is as follows: Section 2 presents a review of related work, Section 3 describes the methodology, Section 4 discusses the experimental setup and results, and Section 5 concludes with a discussion of the findings and potential future research directions.
2. Image Dataset and Training
2.1. Image Dataset for Training and Testing
This section provides a comprehensive overview of the image dataset employed for training and testing. The dataset comprises wrap film product images obtained from a manufacturer, focusing explicitly on products with a standardized length of 40 m. This deliberate choice ensures uniformity across the dataset, facilitating consistent analysis. In Figure 1, we present visual samples of the training images, offering readers a tangible glimpse into the nature of the dataset.

Figure 1.
Training image samples without defects.
We utilized a training dataset of 9512 images depicting normal wrap film products to initiate the training process. This dataset forms the foundation for training our models and algorithms, enabling them to distinguish between normal and defective instances effectively. For the testing phase, we curated two distinct sets of images as follows: one containing defect-free wrap film products and another containing wrap film products with specific defects. Notably, these test images are entirely disjoint from the training dataset, ensuring an unbiased assessment of our models’ performance.
The horizontal flipping technique was employed to enhance the diversity of the dataset and effectively account for variations. This augmentation method enabled us to amplify the number of defective images, thus providing a more extensive and representative dataset for thoroughly testing our anomaly detection methods. The choice of 320 images for each test set was made to ensure a balanced evaluation of our models’ performance. This balance allowed for a fair assessment of the model’s ability to detect both normal and defective instances effectively. The specific number was selected to maintain consistency and enable reliable comparisons between the two scenarios, thus enhancing the validity of our results.
2.2. Training of the One-Class SVM
Moving on to the training procedure for our One-Class Support Vector Machines (SVMs), which play a crucial role in identifying anomalies within wrap film products. To facilitate this process, we input images from our dataset into a selection of networks, including the renowned AlexNet and VGG19 and the innovative Variational Autoencoder (VAE). These networks, functioning as feature extractors, precisely capture essential image characteristics that formed the foundation of our subsequent anomaly detection process.
The pre-training phase involving the VAE’s encoder and decoder components is critical. Before its role in feature extraction, the VAE undergoes pre-training using the training dataset. This preparatory step significantly enhances the VAE’s capacity to extract relevant features effectively, which is crucial in aiding the SVM during anomaly detection. Hence, this approach utilizes the latent space representations optimized to depict normal characteristics accurately.
Each selected network plays a distinct role in the anomaly detection process. AlexNet and VGG19 are renowned for their exceptional ability to extract hierarchical features from images. This capability enables them to capture complex patterns and relationships within the data, facilitating the identification of defects and anomalies. The Variational Autoencoder (VAE) focuses on learning latent features from the data distribution. By representing the data in a probabilistic latent space, it enhances the ability to differentiate between normal and abnormal instances, making it well-suited for anomaly detection tasks.
The distinctive strengths of each feature extractor network contribute significantly to the feature extraction process, guiding us to select features that are both convincing and aligned with the task. Consequently, the combined usage of AlexNet, VGG19, and the Variational Autoencoder (VAE) emerged as capable competitors aiming to fulfill the task’s requirements. The appropriate selection and combination arose from the fact that AlexNet and VGG19 excel in extracting hierarchical features from images, while the unique prowess of VAE lies in its capacity to learn probabilistic distributions of latent features. Therefore, employing these feature extractors in combination enables a comprehensive exploration of diverse feature extraction strategies, ultimately leading to a high level of performance in anomaly detection using the OCSVM-based approach.
This alignment of feature extractor networks seamlessly integrates with the dataset’s composition, encompassing wrap film product images that contribute to and support the deep learning process. This synergy is further enhanced by a training set containing 9512 normal images used for model training. Additionally, separate sets of defect-free and defective images are employed for testing, each consisting of 320 images. The dataset’s diversity is augmented through the application of various techniques. The training of OCSVMs is facilitated using feature extraction networks, including AlexNet, VGG19, and the Variational Autoencoder (VAE), with each network offering distinct contributions to the anomaly detection process.
2.3. Combined Strengths of AlexNet, VGG19, and VAE in Feature Extraction
This subsection aims to clarify our approach’s synergistic combination of AlexNet, VGG19, and the Variational Autoencoder (VAE), highlighting how they collectively contribute to an enhanced defect detection process in wrap film products.
2.3.1. Individual Contributions
AlexNet: Known for its capability to identify patterns and detailed features through hierarchical feature extraction, AlexNet forms the base for recognizing standard features in wrap film product images. Its foundational strengths were established in ImageNet Classification with Deep Convolutional Neural Networks by Krizhevsky et al. (2012) [16], and its application in modern contexts can be seen in Kornblith et al. (2019) [24]. In our OCSVM framework, AlexNet is used directly as a feature extractor without additional pretraining or fine-tuning. The model, pre-trained on the ImageNet dataset, provides feature vectors directly utilized by the OCSVM for anomaly detection, bypassing further modification.
VGG19: With its deeper network structure, VGG19 excels in extracting fine details and complex features from images, essential for detecting subtle anomalies in wrap film products. This capability was first introduced by Simonyan and Zisserman (2014) [15] and has been applied recently, as demonstrated by Li and Wang (2019) [25]. Similar to AlexNet, VGG19 is employed in our approach as a pre-trained feature extractor. The model does not undergo further pre-training or fine-tuning on the target dataset, as the OCSVM directly uses the extracted feature vectors to identify anomalies.
Variational Autoencoder (VAE): VAE’s strength lies in modeling normal data distribution and identifying anomalies based on deviations from this norm using its encoder–decoder structure. Kingma and Welling (2013) [14] performed foundational work on this, with recent applications shown by Razavi et al. (2019) [26].
2.3.2. Synergistic Integration
Comprehensive Feature Extraction: The synergetic integration of AlexNet’s pattern recognition with VGG19’s detailed-oriented approach provides a robust feature extraction mechanism. This allows for the identification of a wide spectrum of defects in wrap film products, ranging from easily detectable to minute.
Depth and Detail Enhancement: VGG19 adds depth to the feature extraction process, complementing AlexNet’s broader capabilities and ensuring that no defect, regardless of size, is overlooked.
Cascading Evaluation Process: The three OCSVMs (AlexNet-based, VGG19-based, and VAE-based) operate in a cascading manner. This approach ensures that each image undergoes a thorough evaluation across different levels of feature extraction, with each model specializing in detecting different types of defects. The process begins with the AlexNet-based OCSVM, which filters out images with no apparent defects. The VGG19-based OCSVM then examines the remaining images for more subtle and complex anomalies. Finally, the VAE-based OCSVM evaluates the images for anomalies that deviate from the normal data distribution, ensuring comprehensive defect detection. Only images that pass all three stages are classified as defect-free. We also added a framework diagram to this manuscript (Figure 2) to visually illustrate the cascading evaluation process and how each model contributes to defect detection.
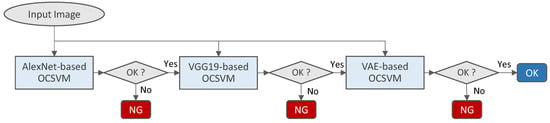
Figure 2.
The proposed cascade-type OCSVMs for classifying images into OK or NG categories, employing AlexNet-based, VGG19-based, and VAE-based OCSVMs.
2.3.3. Role of Covariance Vectors in VAE’s Latent Variables
Efficiency Enhancement: The covariance vectors extracted from the latent variables of VAE play a crucial role in our methodology. These vectors provide a comprehensive understanding of the data’s underlying distribution, enhancing the model’s ability to distinguish between normal and defective instances with higher precision.
Integration with OCSVM: These covariance vectors are feature vectors that train the One-Class SVM (OCSVM). This integration is essential to our approach, allowing the OCSVM to learn and identify anomalies effectively without needing defect-containing images in the training set.
2.3.4. Maximizing Defect Detection Efficiency
Enhanced Anomaly Detection: The combined strengths of AlexNet, VGG19, and VAE, along with the advanced use of covariance vectors, result in a powerful tool for anomaly detection in wrap film products. This approach increases detection accuracy and reduces false positives, making the system more reliable and efficient. Enhanced Micro-Defect Detection: Detecting micro-defects, often missed by traditional inspection systems, is critical to ensuring the quality of wrap film products. To address this challenge, our methodology leverages the fine-grained feature extraction capabilities of VGG19, known for its deep architecture that excels in identifying subtle anomalies. Additionally, AlexNet contributes by providing a broader pattern recognition that complements VGG19’s detailed analysis. Integrating VAE-derived covariance vectors further enhances the system’s ability to model the normal data distribution accurately, making even minute deviations indicative of micro-defects more detectable. This approach ensures that the system can identify micro-defects with higher accuracy, significantly improving the overall defect detection process in wrap film products.
Innovative Approach: This unique combination and utilization of advanced feature extraction techniques and latent variable analysis represent a significant innovation in defect detection, setting a new standard for accuracy and efficiency.
3. One-Class SVMs (OCSVMs)
OCSVMs, as powerful methods for anomaly detection, are uniquely suited for training using solely normal images. However, it is important to recognize a limitation in its ability to control the false negative rate during training. While an OCSVM excels in utilizing only normal data, it needs to improve its sensitivity to anomalies because of the lack of anomaly instances in the training dataset. As a result, optimizing the false negative rate can be complex and potentially affect the model’s performance in scenarios where precise control over false negatives is crucial for its performance in real-world situations.
3.1. Overview of OCSVMs
One-Class Support Vector Machines (OCSVMs) are powerful methods for anomaly detection that can be trained using only normal images. This characteristic makes OCSVMs particularly suitable for our application, as obtaining defect images can be challenging. Our approach leverages an OCSVM to construct a decision boundary that separates normal data from anomalies, significantly enhancing defect detection in wrap film products without requiring defect images during training.
To better understand an OCSVM’s behavior, it is necessary to explore its underlying principles. An OCSVM builds upon the foundation of Support Vector Machines (SVMs), initially developed for binary classification (TCSVM). An OCSVM extends a SVM to unsupervised learning [10]. Using only standard training data, it constructs a hyperplane function that assigns positive values to normal inputs and zeros to anomalies.
A critical consideration in anomaly detection is balancing the false positive and false negative rates. These rates reflect the misclassification of normal as anomalies and vice versa. However, controlling the false negative rate in an OCSVM is complex because of the absence of anomaly samples in training. Indeed, while an OCSVM effectively handles the challenge of training solely on normal data, it presents a limitation in controlling the false negative rate during training. The inherent nature of OCSVM training with only normal cases results in the absence of anomaly instances in the training dataset. This lack of anomaly samples makes adjusting the model’s sensitivity to anomalies challenging, leading to potential difficulties in optimizing the false negative rate. As a result, an OCSVM may exhibit suboptimal performance in scenarios where precise control over the false negative rate is critical.
OCSVMs aim to segregate data from the origin in high-dimensional predictor space, making it suitable for outlier detection. The objective is to minimize the dual expression involving Lagrange multipliers and feature vectors extracted from training images [27,28].
where the value of is an element of the Gram matrix. The Gram matrix of a set of feature vectors is an -by- matrix whose elements are the inner products of the transformed predictions using a kernel function. In Equation (1), the following conditions are satisfied:
where is called the regularization parameter.
Equation (1) represents the objective function L of the One-Class SVM (OCSVM), which aims to minimize the sum of the pairwise products of the Lagrange multipliers (αi) corresponding to the support vectors. This minimization is subject to the constraint that αi must be greater than or equal to zero and less than or equal to one for all i, and the sum of their products with the Gram matrix must be equal to 1/2. The kernel matrix contains the inner products of the transformed predictors using a kernel function computed for all pairs of training instances Xi and Xj [29]. Equation (2) represents a constraint on the sum of the Lagrange multipliers (αi) in the One-Class SVM (OCSVM) formulation. The constraint ensures that the sum of the Lagrange multipliers equals ν, where ν is a parameter that controls the trade-off between maximizing the margin and minimizing the fraction of outliers. The Lagrange multipliers αi range from 0 to 1, indicating the contribution of each training instance to the decision function. By setting ν, practitioners can adjust the expected proportion of outliers in the training set.
In this context, it is essential to highlight that adjusting the regularization parameter impacts the model’s flexibility. A smaller value tightens the decision boundary, potentially leading to under-fitting, whereas a larger value allows more flexibility, risking overfitting. The outlier fraction further fine-tunes the model’s false positive rate, offering a trade-off between adaptability and accuracy. Understanding the influence of the regularization parameter and the outlier fraction on the decision boundary flexibility is crucial. Let us consider an analogy where the decision boundary is analogous to a rubber band. When the parameter is set to a smaller value, like tightening the rubber band, it leads to fewer support vectors and a less flexible boundary. This configuration may result in the model overlooking some complexities in the data, potentially causing under-fitting.
On the contrary, increasing the parameter “loosens” the rubber band, allowing it to conform more closely to the complexities in the training data. Consequently, the decision boundary becomes more flexible, increasing the sensitivity of the model to variations in the dataset. However, if is set too high, the boundary may become excessively flexible and start capturing noise, leading to over-fitting.
Similarly, the outlier fraction offers a mechanism to fine-tune the model’s false positive rate. A lower value restricts the sensitivity of the model to anomalies, minimizing false positives. In contrast, a higher value makes the model more tolerant of anomalies, potentially increasing the false positive rate. Thus, and provide a way to balance model complexity, adaptability, and the trade-off between false positive and false negative rates. In the conducted experiments described in the next subsection, 2700 combinations of the parameters are compared by changing the values of and from 0.01 to 0.9 and from 0.01 to 0.3 in increments of 0.01, respectively.
As described earlier, in the case of this nonlinear OCSVM, the inner products of the feature vectors extracted from training images are also replaced by the corresponding element of the constructed Gram matrix through a dual formulation. This formulation is called the kernel trick. The nonlinear SVM, after training, acts in the transformed predictor space as a separating hyperplane given by
where are the obtained support vectors and the is the number of the support vectors obtained through the training associated with the normal category of training dataset. and are the bias and the Lagrange multipliers, respectively, representing the parameters of SVM estimated from the training process. is the distance from the origin to the hyperplane. is the label set to 1, indicating the one class learning case. represents the signed distance to the decided hyperplane, while is the kernel function given by
where and are the kernel scale and the standardized input vector, respectively, which are calculated by
where ⊘, , , and m represent Hadamrd operators for the elementwise product, power, root, and the number of training images, respectively.
In summary, the false negative rate plays a crucial role in anomaly detection, particularly in real-world applications such as quality control in manufacturing. A high false negative rate can lead to undetected anomalies, potentially resulting in defective products reaching consumers, compromising product quality, and posing safety risks. By understanding the significance of the false negative rate, stakeholders can make informed decisions about model performance metrics, ensuring effective anomaly detection and minimizing the likelihood of quality control issues and customer dissatisfaction.
3.2. Overview of VAEs
Variational Autoencoders (VAEs) are generative models that learn latent variable representations of input data. Our method uses a VAE to derive covariance vectors from the latent variables, which serve as feature vectors for the OCSVM. This novel use of VAE-derived features improves the OCSVM’s ability to detect anomalies by accurately representing normal data distributions and identifying deviations indicative of defects.
The VAE is a neural network-based generative model introduced by Kingma et al. [14]. It consists of the following two main parts: the encoder and the decoder. The encoder compresses the input data into a low-dimensional latent space, capturing the essential features in a simplified form. The decoder then reconstructs the input data from these latent variables, effectively generating new data samples that resemble the original inputs.
The VAE compresses the input data into a latent variable , assuming that the latent variable corresponds to a probability distribution. However, the encoder outputs a mean vector and a covariance vector of the latent variables. The latent variable is then sampled from a multivariate normal distribution. The decoder part outputs restored data from the sampled latent variable . The VAE, consisting of an encoder and a decoder, is trained so that the input and restored data can be well-matched.
In the experiment, a VAE was designed with an input image size of 256 × 256 × 3, whose encoder part consists of six convolutional layers and one fully connected layer. The encoder part output a 1024-dimensional mean vector and a covariance vector , respectively. The mean and covariance vectors, as well as the random vector and the Adamar product , were used to compute the latent variable given by Equation (8),
The decoder reconstructs the image data from the encoder part using the latent variable .
While this section provides a general overview of incorporating the VAE into the OCSVM, we recommend enhancing clarity by investigating the mechanics of using the VAE encoder as a feature extractor more deeply in future work. Additionally, we recommend elaborating on how the covariance vector can be extracted using the encoder in OCSVM training to provide a clearer understanding of the process.
3.3. Training of the VAE
Comprehensive and proper VAE training is crucial for anomaly detection to use a VAE for OCSVM effectively. This training involves utilizing the 9512 normal wrap film images from Section 2.1. Successful image reconstruction validates the proficiency of the VAE in reconstructing normal images, as shown in Figure 3. The VAE reconstruction and anomaly detection is discussed in Section 3.4.3.

Figure 3.
Three reconstructed results in the case of three test images without a defect given to the VAE.
This training involves utilizing the 9512 good wrap film images from Section 2.1. As illustrated in Figure 3, successful image reconstruction validates the proficiency of the VAE in replicating input images. However, as shown in Figure 4, the VAE primarily focuses on reproducing only the defect area, highlighting its potential in wrap film anomaly detection.

Figure 4.
Three reconstructed results given in the case of three test images, including defects.
The results of the VAE training and its limitations in reproducing defect areas, along with potential implications for anomaly detection performance, will be discussed more explicitly.
3.4. An OCSVM Using a VAE as a Feature Extractor
This part explores how we can combine a VAE with an OCSVM for anomaly detection. We use the encoder part of the VAE to extract useful features from the data, which are then used by the OCSVM to detect anomalies. However, this integration comes with its challenges. For example, we need to find the right settings for training the VAE and carefully design the anomaly detection pipeline to exclude the decoder part of the VAE.
Integrating a Variational Autoencoder (VAE) with a One-Class Support Vector Machine (OCSVM) represents a complex yet essential aspect of anomaly detection methodology. This section investigates this integration, detailing the processes involved in using a VAE as a feature extractor for an OCSVM. The training process of the VAE forms the foundation for subsequent anomaly detection tasks. VAEs are neural networks comprising encoder and decoder components tasked with compressing input data into low-dimensional latent variables and reconstructing input data from these variables, respectively. Understanding the interplay between these components and their role in anomaly detection is essential for grasping the significance of VAE integration with OCSVM. The encoder component of the VAE plays a crucial role in extracting meaningful features from input data, which are subsequently utilized by the OCSVM for anomaly detection. However, this integration poses unique challenges and considerations. For instance, determining the optimal parameters for VAE training, such as the learning rate and batch size, can significantly impact the quality of latent representations and, consequently, the performance of the OCSVM. Moreover, excluding the decoder component from SVM training in OCSVM-VAE integration necessitates careful design and evaluation of the anomaly detection pipeline. Understanding the implications of this design choice and its effects on model performance is paramount for achieving robust anomaly detection outcomes.
Incorporating a VAE into an OCSVM involves utilizing the covariance vector from the encoder as training data while excluding the decoder from SVM training. Figure 5 illustrates this approach. As described in Section 3.1, the two parameters and were varied within the ranges from 0.01 to 0.9 and 0.01 to 0.3 in increments of 0.01, resulting in the modeling of 2700 SVMs. Then, the classification performances of these 2700 SVMs, trained under each combination of and , were compared. The results confirmed that the combination of = 0.12 = 0.11 gave the best classification performance for the OCSVM using the VAE as a feature extractor. The exhaustive analysis of these combinations uncovers patterns and informs parameter selection for optimal classification accuracy and a balanced trade-off between false positive and false negative rates. Table 1 shows the classification results.
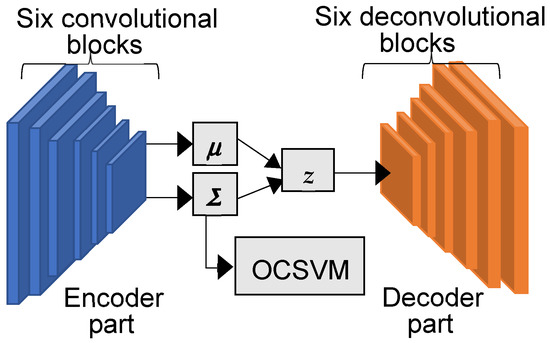
Figure 5.
Configuration of the proposed One-Class learning-based SVM with a VAE for feature extraction.

Table 1.
Confusion matrix of the OCSVM with a VAE for feature extraction (row: true, column: predicted).
3.4.1. Data Distribution and Experimental Setup
The experimental setup involved capturing images of wrap films using high-resolution cameras installed along the production line. The cameras captured images at a frequency of one frame per second, ensuring real-time defect detection. The original resolution of each photo was 640 × 480. The images were cropped to 384 × 384 by template matching, as shown in Figure 5. When the extracted images were given to the input layer of each OCSVM with the backbone based on AlexNet, VGG19, or VAE, the resolution was downsized to 227 × 227, 224 × 224, or 256 × 256, respectively, to fit each input layer. After training, the forward calculation times by the three OCSVMs to predict normal or anomaly from an image was around a few tens of milliseconds, so there was almost no difference in processing time.
The dataset consisted of 9512 images of normal wrap films and varying defective images categorized by defect type. The images were preprocessed using the template matching method to crop the regions of interest. The data were then split into training, validation, and test sets, with a detailed distribution as follows:
- a.
- Training Data: The wrap film manufacturer provided 9512 normal images, which were used to optimize the OCSVM using a solver called sequential minimal optimization (SMO) [19].
- b.
- Test Data: The test data contained 320 normal images and 320 anomaly images. The anomaly images consisted of 160 originals and 160 augmented by horizontal flipping. As shown in Figure 5, the 320 anomaly test images include various defects.
The manufacturing process of wrap films involves several stages, including extrusion, cooling, winding, and packaging. Defects can occur at any stage, caused by improper material handling, mechanical failures, or variations in environmental conditions. Common defects include rolling with a step, wrinkled film, and deviated film. The defect inspection system must be able to detect these defects to maintain high-quality production standards.
3.4.2. Examples of Defects and Image Processing
Figure 6 shows the defects included in images before the template matching process. These defects are seen in the production line of the wrap films. The images for training and testing were cropped using the template matching method, as shown in Figure 1. The test images in Figure 4 include undesirable defects such as rolling with a step, wrinkled film, and deviated film. The defect inspection system required for a wrap film product has to be able to detect these defects. However, it is not easy to realize such a defect inspection system as these defects can be discriminated from normal products, so automation has yet to be achieved.
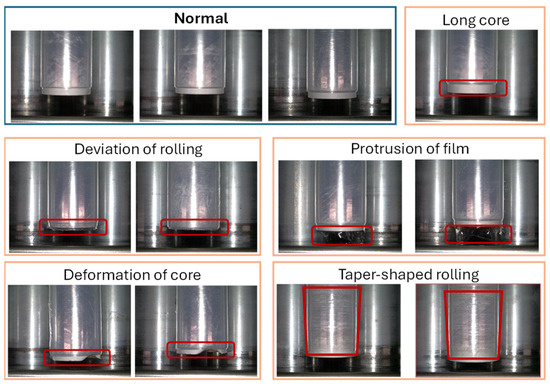
Figure 6.
Original examples of normal and anomaly images before the template matching process.
3.4.3. VAE Reconstruction and Anomaly Detection
Before we can use a VAE encoder for an OCSVM, comprehensive and proper VAE training is essential for detecting anomalies. During training, we used a large set of normal images to teach the VAE how to reconstruct them accurately. The trained VAE could accurately reconstruct the images when normal ones were given, as shown in Figure 3. However, if anomaly images were given, the VAE did not successfully reconstruct them, as shown in Figure 4.
Figure 6 shows examples of normal and anomaly images cropped by the template matching technique, which were used to test the generalization ability of the trained OCSVM. Each test image was classified as normal or anomaly based on the score given by Equation (3), which was used to predict an image. If f(x) > 0 (threshold), the image was predicted as normal, and if f(x) < 0, the image was predicted as an anomaly. Moreover, an OCSVM’s understanding can be checked by observing the difference between input and reconstructed images.
This approach does not require defect images for training because the VAE does not reconstruct anomalies, making them detectable by the OCSVM. This is a significant strength of the VAE in this context, as it allows for effective anomaly detection even without defect data.
3.5. OCSVMs Using AlexNet as Feature Extractor
This section investigates using another type of neural network, AlexNet, for feature extraction in OCSVMs. AlexNet is good at classifying images into different categories. We used a specific part of AlexNet to extract features from our data and then trained the OCSVM to detect anomalies using these features. However, choosing the right settings for an OCSVM is crucial for good performance. AlexNet is a Convolutional Neural Network proposed by Krizhevsky et al.; it was the winner of the 2012 ILSVRC [8]. The model is capable of classifying images into 1000 categories. AlexNet consists of five convolutional layers and three fully connected layers.
In this experiment, AlexNet was used as a feature extractor to train an OCSVM using the 4096-dimensional feature vector output from the second fully connected layer. Feature selection involved choosing relevant features that contribute to the anomaly detection task, while transformation included normalizing the features to a common scale. Feature creation might involve generating new features from the existing ones to improve the model’s performance. Figure 7 shows a conceptual diagram of the OCSVM with AlexNet as the feature extractor. When designing an OCSVM with AlexNet as the feature extractor, the image size was fixed to 227 × 227 × 3 for training and validation.
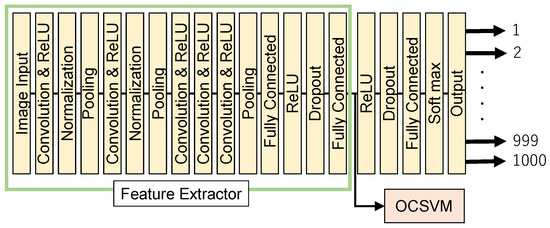
Figure 7.
Configuration of the proposed One-Class SVM with AlexNet for feature extraction.
Parameter tuning and optimization are critical for the performance of and , which were varied within specific ranges to find the optimal values. Specifically, was varied from 0.01 to 0.9 and from 0.01 to 0.3 in increments of 0.01, resulting in the modeling of 2700 SVMs. The classification performances of these 2700 SVMs, trained under each combination of and , were compared to determine the best combination. The OCSVM using AlexNet as the feature extractor showed the lowest misclassification rate when the parameters were set at = 0.02 and = 0.07. The classification results are shown in Table 2.
Table 2.
Confusion matrix of the SVM with AlexNet for feature extraction (row: true, column: predicted).
While the classification results for the OCSVM using AlexNet are presented, providing insights into the significance of the chosen parameters and their implications for model performance would enhance the interpretation.
3.6. OCSVMs Using VGG19 as a Feature Extractor
VGG19 is another Convolutional Neural Network proposed by Simonyan et al.; it was awarded second place in the 2014 ILSVRC [15]. The model can also classify images into 1000 categories. VGG19 consists of 16 convolutional layers and three fully connected layers.
Through our developed user interface, as shown in Figure 8, we applied several powerful CNN models, such as AlexNet, GoogleNet, VGG16, and VGG19, to the backbones of the originally built transfer learning CNNs for defect detection of industrial products and materials. The interface provides a selection function that chooses among these models for designing an SVM. VGG19-based CNN models consistently performed better in classification and detection tasks than the other models in our experiments. Thus, VGG19 was selected as the feature extractor for this study.
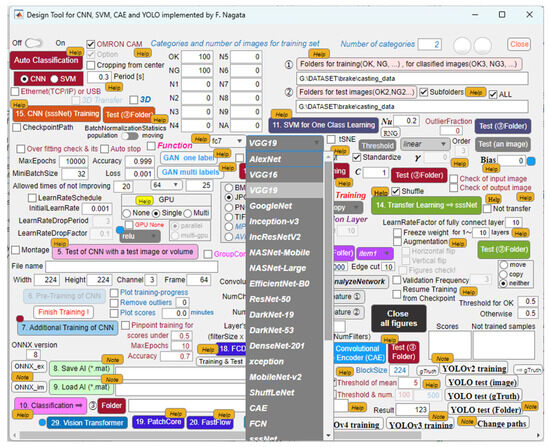
Figure 8.
Our developed application provides a selection function for one of the powerful CNN models to design an SVM.
In this experiment, VGG19 was utilized as a feature extractor to train 2700 OCSVMs using the 4096-dimensional feature vector output from the second fully connected layer. Figure 9 illustrates a conceptual diagram of the OCSVM with VGG19 as the feature extractor. When configuring the OCSVM with VGG19 as the feature extractor, the image size was fixed at 224 × 224 × 3 for training and validation purposes.
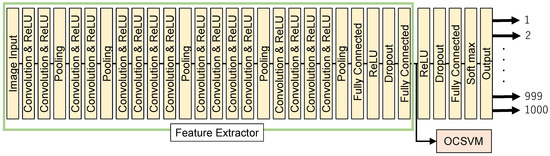
Figure 9.
Configuration of the proposed One-Class SVM with VGG19 for feature extraction.
The OCSVM trained with ν = 0.24 and o = 0.11 demonstrated the lowest misclassification rate, as depicted in Table 3. While the classification results for OCSVM using VGG19 are provided, for future work, we recommend discussing how parameters ν and o impact model performance to provide valuable insights into the decision-making process.
Table 3.
Confusion matrix of SVM with VGG19 for feature extraction (row: true, column: predicted).
The classification experiments using the OCSVMs revealed that the accuracy of VAE-based, AlexNet-based, and VGG19-based OCSVMs was approximately 87%, 89%, and 90%, respectively. While these results did not meet the target classification accuracy of 95% set by the wrap film manufacturer, they demonstrate significant potential. We anticipate that by optimizing each integrated technique’s parameters and maximizing the synergy between them, this developed approach will achieve and surpass the target accuracy in the next stage, as guided by the suggestions listed in future work.
4. Results and Discussion
The classification experiments using the OCSVMs revealed that the accuracy of the VAE-based, AlexNet-based, and VGG19-based OCSVMs was approximately 87%, 89%, and 90%, respectively. While these results did not meet the target classification accuracy of 95% set by the wrap film manufacturer, they demonstrated significant potential. By optimizing each technique’s parameters and maximizing their synergy, we expect to surpass the target accuracy in future work.
Recent studies have demonstrated the effectiveness of using only normal images for training anomaly detection models. For example, Ruff et al. (2020) used Deep SAD, a semi-supervised anomaly detection method, and achieved robust performance with minimal labeled anomaly data. While specific accuracy percentages for industrial applications were not provided, the method showed promising results in experimental settings [3]. This aligns with our findings and further supports the practicality and significance of our OCSVM approach.
In this paper, we consider a dominant wrap film manufacturer who set the target classification accuracy of 95% using an OCSVM. While CNN models, such as the one in the paper published by the authors and discussed by Nakashima et al. (2021), have achieved the desired accuracy of over 95% for wrap film products, the developed approach requires normal and anomaly images for adequate training [30]. In contrast, the presented OCSVM method is trained using only normal images. This is a significant advantage given the low occurrence rate of defect images in modern wrap film production and the difficulties in collecting a reasonable size of images covering it. This ability to train effectively without defect images is the strength of our approach, as it addresses the challenge of acquiring sufficient defect data and uses it flexibly in a real industrial environment.
Figure 10 shows examples of anomaly images cropped by the template matching technique, which were used to test the generalization ability of trained OCSVM. As stated previously, each test image was classified as normal or anomaly based on the score given by Equation (3). If f(x) > 0 (threshold), the image was predicted as normal, and if f(x) < 0, the image was predicted as an anomaly. The OCSVM’s understanding was checked by observing the difference between input and reconstructed images.

Figure 10.
Examples of anomaly images after the template matching process.
Our study demonstrates that an OCSVM can achieve significant accuracy in defect detection using only normal images (See Table 4). This is particularly advantageous in industrial applications where low defect rates make collecting defect images challenging. The flexibility of using OCSVM in real industrial environments makes it a practical choice for defect detection in wrap film products.
Table 4.
Comparison of different methods for defect detection.
Our future work will focus on optimizing the parameters of each integrated technique and maximizing their synergy to achieve and potentially surpass the target accuracy of 95%. Additionally, exploring the application of this method in other industrial settings with similar challenges could further validate its robustness and effectiveness.
To provide a clearer comparison of the OCSVM performance with different feature extractors, we summarize the outcomes of the confusion matrices from Table 1, Table 2 and Table 3, including accuracy, precision, recall, and the F1 score, in Table 5.
Table 5.
Comparison of OCSVM performance with different feature extractors.
Table 3 highlights the confusion matrix of the OCSVM with VGG19 as the feature extractor. Our experiments, conducted using 2700 parameter combinations, revealed that the combination of ν = 0.24 and o = 0.11 achieved the optimal classification performance. This combination provided the best trade-off between detection accuracy and the balance of false positive and false negative rates.
Compared with other combinations, the combination of OCSVM and VGG19 provided the best results, as evidenced by the intensive experimental testing summarized in Table 3. This testing confirmed that our selected parameters yield the highest classification performance.
In industrial production lines, particularly defect detection systems, minimizing the false negative rate is of paramount importance. A high false negative rate can result in defective products being passed as non-defective, leading to significant quality issues. Our trials indicated that controlling the false negative rate is crucial for the system’s reliability. Therefore, by optimizing the values of ν and o, we can achieve a balance that minimizes false negatives while maintaining a manageable false positive rate, thus enhancing the overall effectiveness of the approach.
5. Conclusions and Future Work
5.1. Summary of Findings
In this study, we proposed anomaly detection models using an OCSVM with both the encoder part of a VAE and trained CNNs for defect detection in wrap film products. The defect detection accuracies were approximately 87% for VAE-based models, 84% for AlexNet-based models, and 90% for VGG19-based models. These results highlight the effectiveness of deep learning-based anomaly detection methods in identifying defects in wrap film products. Notable trends observed include variations in accuracy across different defect types, with VGG19-based models consistently outperforming the other models in detecting subtle anomalies. The achieved accuracies represent significant progress in defect detection methodologies for wrap film products, provide valuable insights, and lay the foundation for future research extensions and enhancements.
5.2. Key Innovations and Advantages
Our approach leverages the strength of OCSVMs in being trained with only normal images, addressing the challenge of acquiring sufficient defect data in industrial settings. Integrating VAE-derived covariance vectors with OCSVMs allows for effective anomaly detection without the need for defect images, a significant advantage in real-world applications where defects are rare. This novel integration sets our research apart, offering a practical solution for defect detection in wrap film products.
5.3. Practical Implications
The proposed models offer a scalable solution for implementing quality control processes in real-world manufacturing. Automating defect detection can improve product quality assurance, reduce waste, and optimize production efficiency, making it a practical choice for manufacturers.
5.4. Comparison to Initial Goals
Although our initial goal was to achieve a defect detection accuracy of 95%, the results still represent significant progress with an accuracy of up to 90%. Several factors, including dataset limitations and model complexity, may have contributed to falling short of the target. Nevertheless, these findings provide a strong foundation for further optimization and enhancement.
5.5. Future Research Directions
Future research should focus on several key areas to address the identified limitations and build upon this study’s findings. These include the following:
- a.
- Enhancing dataset quality and size, encompassing various defect types, lighting conditions, and production stages.
- b.
- Exploring methods like noise reduction, illumination normalization, and data augmentation to improve model robustness.
- c.
- Combining strengths of different models to enhance overall accuracy and minimize individual model weaknesses.
- d.
- Bridging the gap between labeled datasets and real-world anomalies.
- e.
- Implementing strategies that dynamically adjust decision thresholds based on input data characteristics.
- a.
- Investigating attention mechanisms or self-supervised learning to capture finer details and enhance discriminatory power.
- g.
- Evaluating newer CNN architectures such as ResNet, WideResNet, and MobileNet for feature extraction to potentially improve anomaly detection performance by leveraging their advanced design and feature extraction capabilities.
- h.
- Exploring hybrid structures that combine the strengths of multiple architectures to further enhance anomaly detection performance.
In conclusion, this research highlights the efficacy of deep learning-based anomaly detection methods for defect detection in wrap film products. While further research is needed to address limitations and enhance model performance, our findings underscore the potential of these methods to revolutionize quality control processes in the manufacturing industry. Continued advancements in this area are key to improving defect detection methodologies and driving innovation in manufacturing quality assurance.
Author Contributions
Methodology, F.N. and M.K.H.; Software, T.S. and K.A.; Validation, F.N.; Formal analysis, T.S. and F.N.; Investigation, M.K.H., A.O. and K.W.; Resources, K.W.; Writing—original draft, T.S.; Writing—review & editing, M.K.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Nakashima, K.; Nagata, F.; Watanabe, K. Detecting defects in a wrapped roll using convolutional neural networks. In Proceedings of the 36th Fuzzy System Symposium, Virtual, 7–9 September 2020; pp. 111–115. (In Japanese). [Google Scholar]
- Ehara, F.; Muto, Y. Bearing abnormal sound detection system using a one-class support vector machine. Jpn. J. Inst. Ind. Appl. Eng. 2021, 9, 31–37. (In Japanese) [Google Scholar]
- Ulger, F.; Yuksel, S.E.; Yilmaz, A. Anomaly detection for solder joints using β-VAE. IEEE Trans. Compon. Packag. Manuf. Technol. 2021, 11, 2214–2221. [Google Scholar] [CrossRef]
- Tang, H.; Liang, S.; Yao, D.; Qiao, Y. Improved STMask R-CNN-based Defect Detection Model for Automatic Visual Inspection. Appl. Opt. J. 2023, 62, 8869–8881. [Google Scholar] [CrossRef] [PubMed]
- Srilakshmi, V.; Kiran, G.U.; Yashwanth, G.; Gayathri Ch, N.; Raju, A.S. Automatic Visual Inspection—Defects Detection using CNN. In Proceedings of the 6th International Conference of Electronics, Communication and Aerospace Technology (ICECA 2022), Coimbatore, India, 1–3 December 2022. [Google Scholar] [CrossRef]
- Lee, K.-H.; Lee, W.H.; Yun, G.J. A Defect Detection Framework Using Three-Dimensional Convolutional Neural Network (3D-CNN) with in-situ Monitoring Data in Laser Powder Bed Fusion Process. Opt. Laser Technol. 2023, 165, 109571. [Google Scholar] [CrossRef]
- Jiang, X.; Guo, K.; Lu, Y.; Yan, F.; Liu, H.; Cao, J.; Xu, M.; Tao, D. CINFormer: Transformer Network with Multi-Stage CNN Backbones for Defect Detection. Computer Vision and Pattern Recognition. aXiv 2023, arXiv:2309.12639. [Google Scholar]
- Choi, N.-H.; Sohn, J.W.; Oh, J.-S. Defect Detection Model Using CNN and Image Augmentation for Seat Foaming Process. Mathematics 2023, 11, 4894. [Google Scholar] [CrossRef]
- Pimentel MA, F.; Clifton, D.A.; Clifton, L.; Tarassenko, L. A Review of Novelty Detection. Signal Process. 2014, 99, 215–249. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Zhang, C.; Dong, X. A Survey of Real-time Surface Defect Inspection Methods Based on Deep Learning. Artif. Intell. Rev. 2023, 56, 12131–12170. [Google Scholar] [CrossRef]
- He, H.; Erfani, S.; Gong, M.; Ke, Q. Learning Transferable Representations for Image Anomaly Localization Using Dense Pretraining. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 1113–1122. [Google Scholar]
- Wang, J.; Xu, G.; Li, C.; Gao, G.; Cheng, Y. Multi-feature Reconstruction Network using Crossed-mask Restoration for Unsupervised Anomaly Detection. arXiv 2024, arXiv:2404.13273. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding Variational Bayes. The Latest Revised Version is v11, 10 December 2022. Available online: https://arxiv.org/abs/1312.6114v11 (accessed on 20 August 2024).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-scale Image Recognition. International Conference on Learning Representations (ICLR2015). arXiv 2015, arXiv:1409.1556. The revised version is also available (v6, 2015). [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Bhushan Jha, S.; Babiceanu, R.F. Deep CNN-based Visual Defect Detection: Survey of Current Literature. Comput. Ind. 2023, 148, 103911. [Google Scholar] [CrossRef]
- Erik, W.; Seitz, H. A Machine Learning Method for Defect Detection and Visualization in Selective Laser Sintering Based on Convolutional Neural Networks. Addit. Manuf. 2021, 41, 101965. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Platt, J. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines. Technical Report MSR–TR–98–14. 1998, pp. 1–24. Available online: https://www.microsoft.com/en-us/research/uploads/prod/1998/04/sequential-minimal-optimization.pdf (accessed on 20 August 2024).
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. CSUR 2009, 41, 15. [Google Scholar] [CrossRef]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do better ImageNet models transfer better? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2656–2666. [Google Scholar] [CrossRef]
- Li, H.; Wang, Y. Understanding feature learning in Adversarial Settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrucken, Germany, 21–24 March 2016. [Google Scholar] [CrossRef]
- Razavi, A.; van den Oord, A.; Vinyals, O. Generating diverse high-fidelity images with VQ-VAE-2. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar] [CrossRef]
- Mathworks. MATLAB Documentation R2023b, fitcsvm. 2023. Available online: https://jp.mathworks.com/help/stats/fitcsvm.html (accessed on 1 May 2024).
- Mathworks. MATLAB Documentation R2023b, “Statistics and Machine Learning Toolbox”. 2023. Available online: https://jp.mathworks.com/help/stats/classreg.learning.classif.compactclassificationsvm.predict.html (accessed on 1 May 2024).
- Rätsch, G.; Mika, S.; Schölkopf, B.; Müller, K. Constructing Boosting Algorithms from SVMs: An Application to One-Class Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1184–1199. [Google Scholar] [CrossRef]
- Nakashima, K.; Nagata, F.; Otsuka, A.; Watanabe, K.; Habib, M.K. Defect Detection in Wrap Film Product Using Compact Convolutional Neural Network. Artif. Life Robot. 2021, 26, 360–366. [Google Scholar] [CrossRef]
- Ruff, L.; Vandermeulen, R.A.; Binder, A.; Görnitz, N.; Müller, E.; Müller, K.-R.; Kloft, M. Deep Semi-Supervised Anomaly Detection. In Proceedings of the Eighth International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).