
Intelligent Numerical Control Programming System Based on Knowledge Graph

Abstract
1. Introduction
- We propose CAM knowledge unit, which reduces the granularity of knowledge, and construct a CAM knowledge graph using the enterprise’s historical machining resource database, thus achieving the integration of manufacturing information.
- A CAM knowledge graph completion algorithm model based on neighborhood aggregation and semantic enhancement is proposed to address issues such as data sparsity and missing relationships between knowledge within the CAM knowledge graph.
- To improve the accuracy of knowledge graph applications, we define logical rules between entities to align and fuse multi-source descriptive information for the same entity across different knowledge graphs, and we construct a Jena-based reasoning framework to evaluate programming parameters.
- We develop a knowledge graph-based intelligent NC programming system, using actual machining parts from a diesel engine enterprise for experimentation. This system effectively enhances the reuse capability of historical case knowledge and improves the efficiency and intelligence level of NC programming.
2. State of the Art
2.1. Intelligence NC Programming
2.2. Knowledge Graph Application in Intelligent Manufacturing
2.3. Knowledge Graph Completion
- (1)
- Metric Learning-Based Methods: These methods learn a similarity matching function between samples to identify the most similar samples to the reference ones. The GMatching [27] model was the first to define the few-shot knowledge graph completion task, using a neighbor encoder to aggregate one-hop neighbor structural information of entities and learning a metric function to match entity pairs. However, GMatching does not distinguish the importance of different neighbors, so it can introduce noise. To address this, FSRL [28] introduced a static attention mechanism to assign different weights to one-hop neighbors, obtaining richer entity information. Sheng et al. [29] proposed the FAAN model, which dynamically adjusts neighbor information weights based on different tasks, extending the previous methods but increasing task complexity.
- (2)
- Optimization-Based Meta-Learning Methods: These methods focus on learning the most crucial information from the support set to the query set. A typical model is MetaR [30], which defines the most important information in completion tasks through relational meta and gradient meta. Relational meta represents higher-order relations between entities, while gradient meta captures the loss gradients of relational meta information. Niu et al. [31] proposed the GANA model based on meta-learning, combining the Trans series models to aggregate neighbor information and fully considering complex relationships, such as 1-N, N-1, and N-N. Although these methods have made progress in few-shot knowledge graph tasks, they still face limitations, such as rigid or high computational cost in weighting aggregated neighborhood information and high dependency on pre-trained models when dealing with complex relationship types.
2.4. Knowledge Graph Reasoning
- (1)
- Knowledge reasoning based on representation learning: The core idea of reasoning algorithms based on representation learning is to find a mapping function that projects entities, relationships, and attributes in a semantic network into a low-dimensional real-valued vector space to obtain distributed representations. This approach captures implicit associations between entities and relationships. Researchers have proposed numerous reasoning methods based on representation learning, including those based on tensor decomposition [33,34], distance models [19,35], semantic matching [36,37], and multi-information models [38]. Representation learning has developed rapidly and shows great potential in knowledge representation and reasoning within large-scale knowledge graphs. This algorithm addresses the issue of data sparsity that logical rule-based algorithms cannot resolve, offering strong generalization capabilities and achieving reasonable results on large-scale knowledge graphs. However, it also has drawbacks, such as the lack of clear physical meaning in the vector values of entities and relationships, and poor interpretability. Additionally, reasoning based on representation learning only considers the constraints that the facts in the knowledge graph must satisfy, without considering deeper compositional information, thus limiting its reasoning capabilities.
- (2)
- Knowledge reasoning based on logical rules: Early knowledge reasoning primarily relied on logical rule-based reasoning. The fundamental idea is to leverage traditional rule-based reasoning methods and apply simple rules or statistical features to knowledge graphs. It mainly includes logical rule-based reasoning [39,40] and ontology-based reasoning [41]. The advantages of logical rule-based reasoning algorithms are their solid mathematical foundation and strong interpretability. When combined with large-scale parsed corpora and background knowledge, these algorithms can emulate human reasoning and capture hidden semantic information within knowledge graphs, making it possible to leverage prior knowledge to support and enhance reasoning. However, the nodes in knowledge graphs often follow a long-tail distribution, where only a small number of entities and relationships occur frequently, while a majority have low occurrence rates. Consequently, logical rule-based reasoning struggles to address data-sparsity issues, cannot effectively handle multi-hop reasoning, and significantly impacts reasoning performance.
- (3)
- Knowledge reasoning based on neural networks: The construction of deep learning models is partly inspired by the multi-layered biological neural networks structure of the human brain, simulating how the brain combines lower-level features to form more abstract, higher-level features. Neural network-based reasoning possesses stronger generalization and learning capabilities, combining the representation learning methods through multiple nonlinear layers and then representing their deep features for knowledge reasoning. This includes reasoning approaches based on convolutional neural networks [42], recurrent neural networks [43], and reinforcement learning [44]. Neural network-based methods have higher learning, reasoning, and generalization capabilities. They can leverage vast amounts of textual data, addressing the data-explosion problem posed by large-scale knowledge graphs, and directly model fact triples, thereby reducing computational complexity. Furthermore, with appropriate design and the use of auxiliary storage units, these methods can partially simulate the human brain’s process of reasoning and problem-solving. However, the increased complexity of these models also leads to poorer interpretability.
3. Basic Concepts and Overview of Proposed Approach
3.1. Basic Concepts
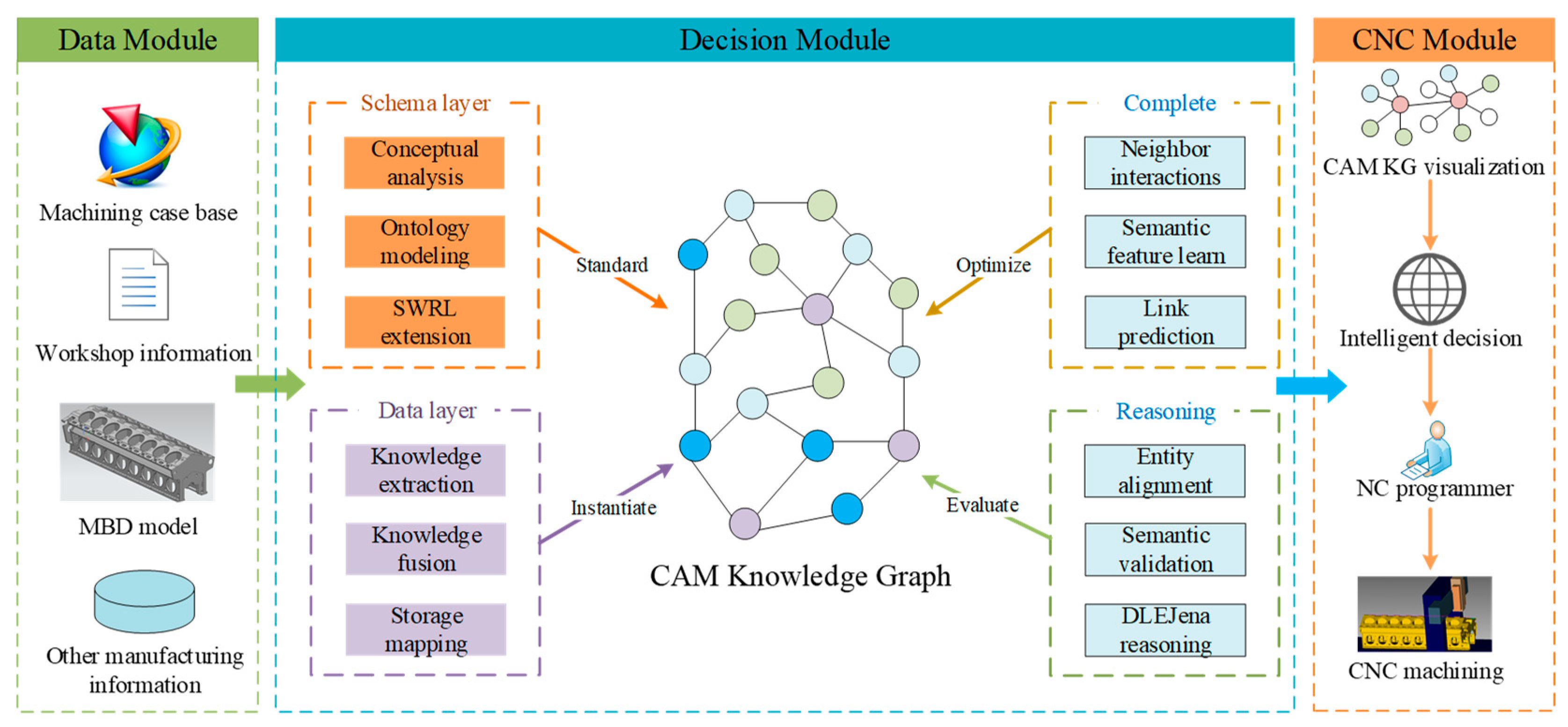
3.2. Overview of Approach
- (1)
- (Data module: To support the knowledge graph decision module, it is essential to collect manufacturing information that influences NC programming decisions, as well as historical NC programming cases generated during manufacturing processes. This includes data such as MBD models (e.g., process planning and geometric features), workshop information (e.g., tooling and machine tool data), and other relevant manufacturing information (e.g., material properties and personnel details).
- (2)
- Decision module: Emulate the decision-making process of NC programming experts to determine optimal programming parameters for machining features. It includes the knowledge graph schema layer and ontology layer construction, and knowledge graph complete and reasoning. The knowledge graph construction module provides semantic and data support for the NC programming system. Knowledge graph complete and reasoning modules ensure the reliability of the generated NC programming parameters.
- (3)
- CNC module: Following evaluation and optimization, the CAM knowledge graph will be mapped to a machining template and visualized in graph format, accompanied by suggestions for further evaluation and optimization. Programmers will review the optimized template in conjunction with the knowledge graph and reasoning recommendations, and then the reviewed template is used for production machining.
4. Methodology
4.1. Knowledge Graph Construction
4.1.1. Ontology Modeling
4.1.2. Semantic Rule Extension
4.1.3. Feature Information Extraction
- Manufacturing semantics: Manufacturing semantics describe the intended meaning of the manufacturing feature, including the material of the part, the type of manufacturing feature, and the basic requirements of the feature. Typically, manufacturing semantic information is defined and stored in the MBD model during the CAD/CAPP stages.
- Geometric elements: Geometric elements encompass the geometric attributes of the manufacturing feature, including the basic dimensions of the feature and its basic positional information.
- Geometric topology: Geometric topology information is used to describe the geometric shape and structure of the feature, including the relative position of features, the basic structure of the feature, and the dependencies between features.
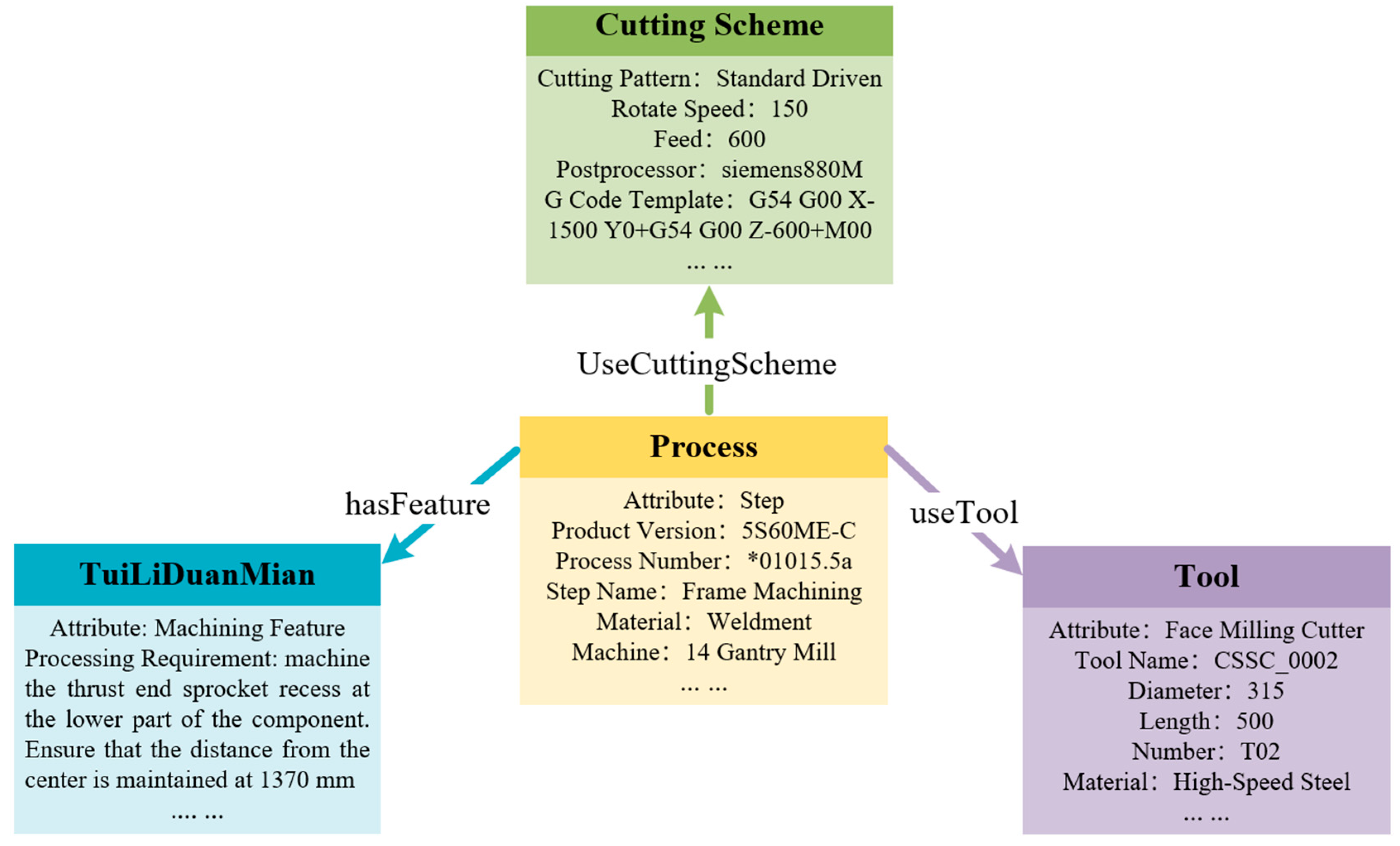
4.1.4. Construction
4.2. Knowledge Reasoning
4.2.1. Entity Alignment
4.2.2. Knowledge Reasoning Based on Semantic Rules
- (1)
- Creating the Pellet reasoner: The ‘PelletReasonerFactory’ class is used in a factory pattern to create a Pellet reasoner. Pellet is a high-performance reasoner that supports SWRL rules, allowing it to conduct semantic reasoning based on strict inference rules. It is capable of quickly handling large-scale and complex reasoning tasks, and it provides an adaptation interface for the Jena framework.
- (2)
- Creating the ontology model: The Pellet reasoner is passed as a parameter to the ‘ModelFactory.Create’ function in the Jena framework, which is used to create the ontology model. Once the ontology model ‘InfoModel’ is obtained, SWRL rules from the schema layer are loaded into the ‘InfoModel’.
- (3)
- Binding the data model: The data model ‘Model’ is then bound, which triggers events. The ontology model ‘InfoModel’ automatically performs rule-based and ontology reasoning as a result of this process [22].
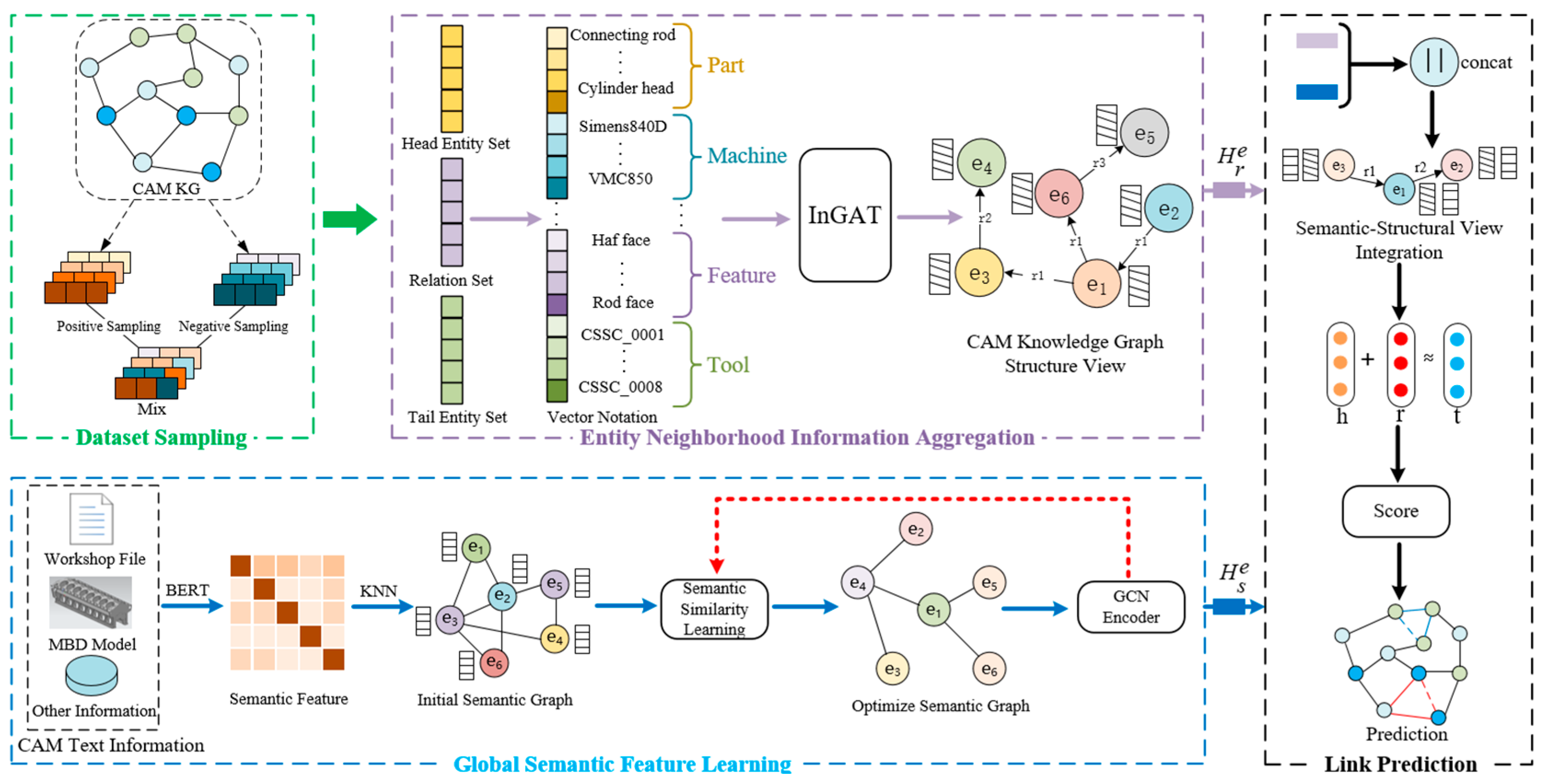
4.3. CAM Knowledge Graph Completion
4.3.1. Dataset Sampling Module
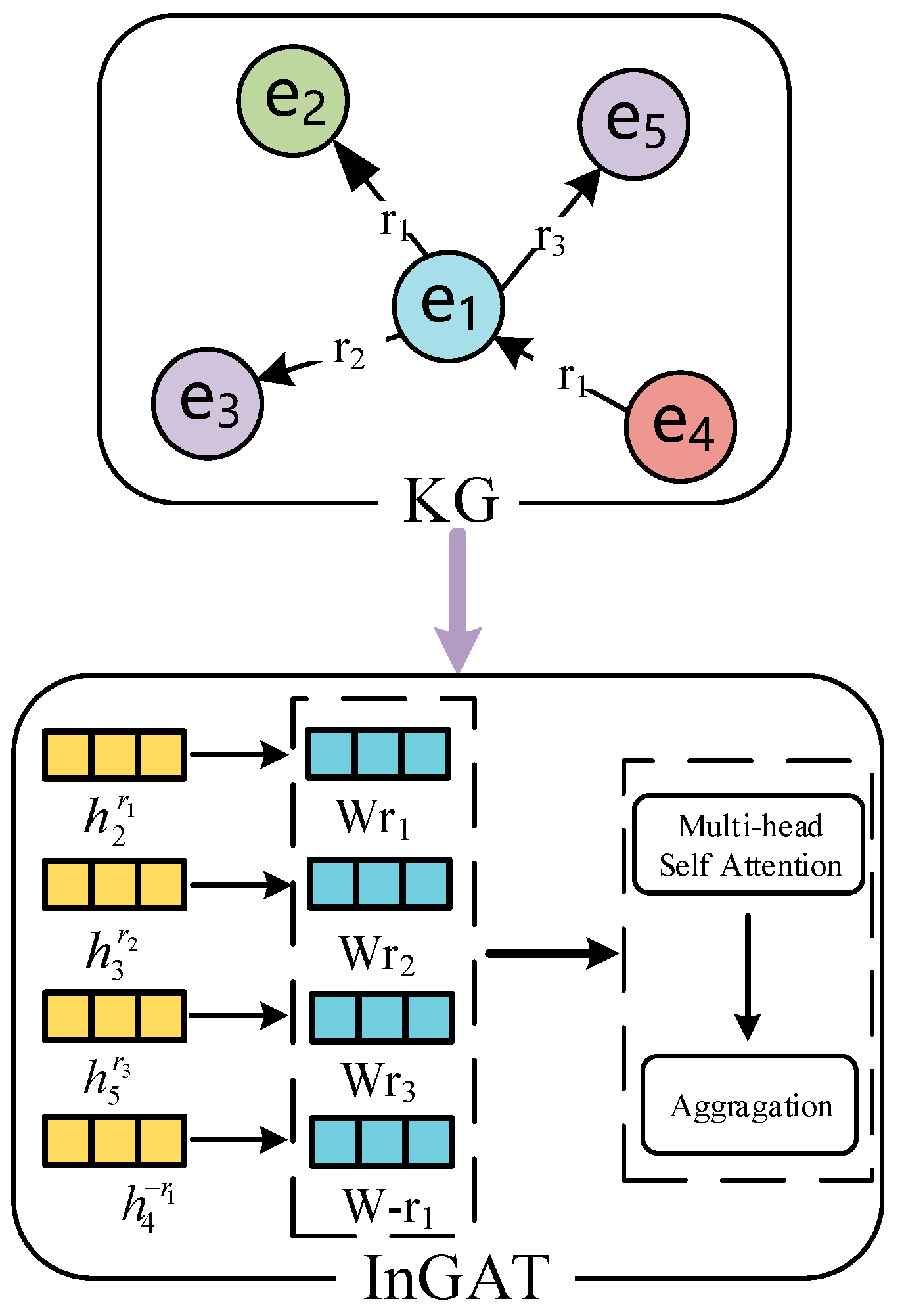
4.3.2. Entity Neighborhood Information Aggregation Module
4.3.3. Global Semantic Feature Learning Module
4.3.4. Link Prediction Module
5. Experiments and Analysis
5.1. Dataset Description
5.2. Baselines Model
5.3. Evaluation Metrics
5.4. Parameter Settings
5.5. Comparative Experimental Results
5.6. Ablation Study
5.7. Discussion and Analysis
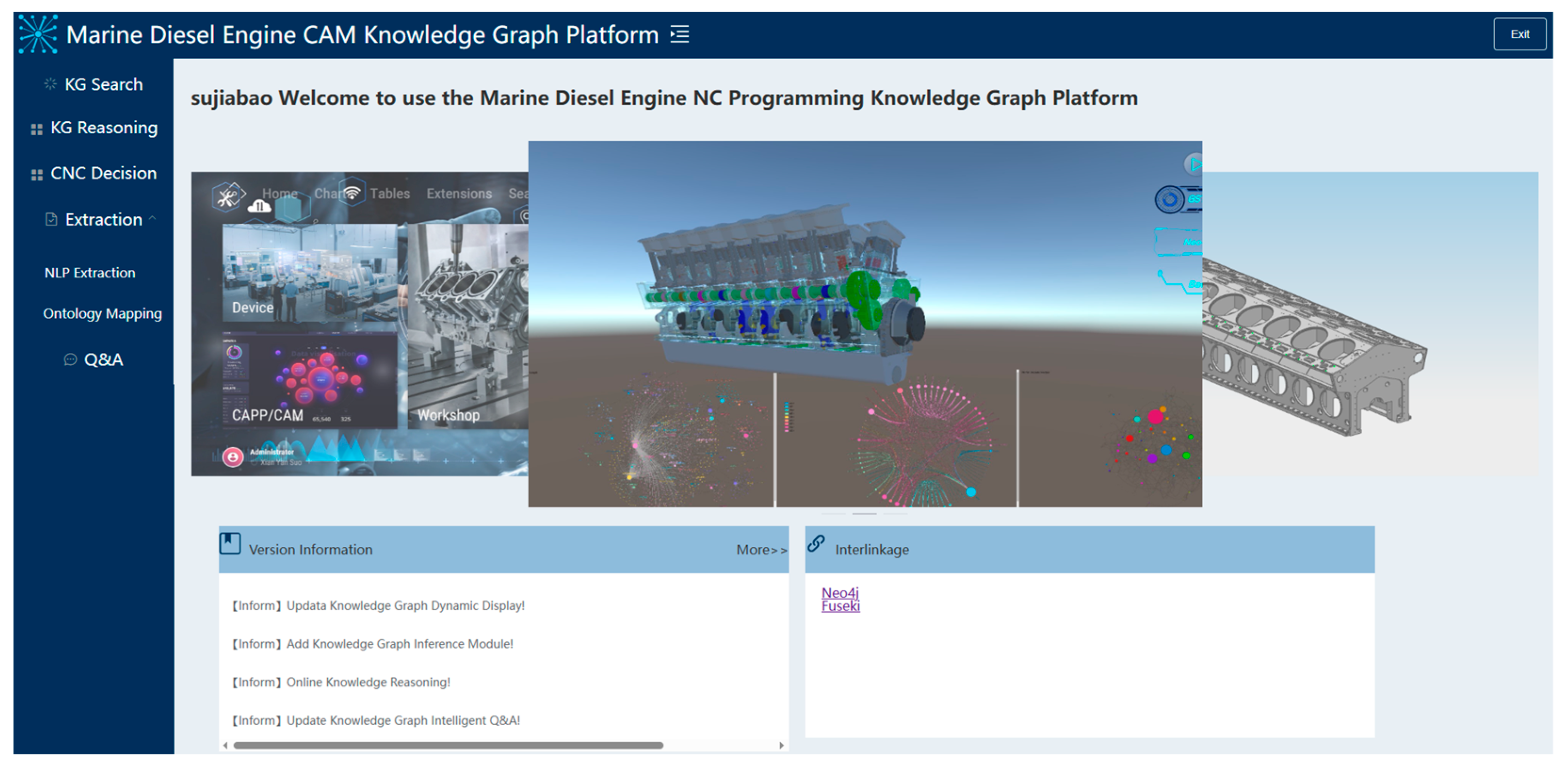
6. Prototype System Development and Application Validation
7. Conclusions and Future Work
- (1)
- A method for constructing a knowledge graph in the CAM field is proposed. First, CAM knowledge elements are developed to reduce the granularity of knowledge reuse. Then, the thinking patterns of experts in the NC programming domain are analyzed to establish the ontology layer and semantic rules of the knowledge graph. Finally, knowledge extraction is performed using the enterprise’s historical machining resource database as the data source, leading to the construction of the CAM knowledge graph data layer.
- (2)
- A knowledge reasoning method for the CAM knowledge graph is proposed. First, rules for entity alignment are defined to integrate multi-source descriptive information of the same entity or concept, addressing issues of information redundancy, disorder, and ambiguity. Then, a reasoning framework based on Jena is designed to facilitate the inference and evaluation of programming parameters, thereby enhancing the accuracy of knowledge graph applications.
- (3)
- We propose a CAM knowledge graph completion algorithm model based on neighborhood aggregation and semantic enhancement. By employing a hybrid sampling method, the training set of the few-shot knowledge graph is expanded. A relationship path-based entity neighborhood information aggregation network is designed, and a multi-head self-attention network is introduced to address the limitations of traditional entity neighborhood aggregation networks. Additionally, a semantic graph is created to fully utilize textual information beyond structural views, combining triplet structural features and semantic characteristics of entities to enhance the performance of link prediction models.
- (4)
- Based on the aforementioned theoretical foundation, an intelligent NC programming system based on knowledge graphs was developed. Using actual machining parts from a diesel engine enterprise as experimental objects, the reliability of the tool paths and NC code generated by the system was validated. This effectively enhanced the reuse capability of historical case knowledge within the enterprise, reduced the workload of programming personnel, and improved the efficiency and intelligence of CAM programming.
- (1)
- In future work, efforts will be made to extract hierarchies from the type of information of entities, while considering the integration of multimodal information, thus further enhancing the performance of knowledge graphs in the field of NC programming.
- (2)
- Additionally, there is a need to expand the application scope and increase the scale of the knowledge graph, further leveraging its powerful reasoning capabilities to achieve greater generality.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bruno, G.; Faveto, A.; Traini, E. An open source framework for the storage and reuse of industrial knowledge through the integrationof PLM and MES. Manag. Prod. Eng. Rev. 2020, 11, 62–73. [Google Scholar] [CrossRef]
- Huang, R.; Fang, Z.; Huang, B.; Jiang, J. An effective NC machining process planning method via integrating grammar knowledge with deep learning. Expert Syst. Appl. 2024, 249, 123872. [Google Scholar] [CrossRef]
- Efthymiou, K.; Sipsas, K.; Mourtzis, D.; Chryssolouris, G. On knowledge reuse for manufacturing systems design and planning: A semantic technology approach. CIRP J. Manuf. Sci. Technol. 2015, 8, 1–11. [Google Scholar] [CrossRef]
- Mourtzis, D.; Doukas, M. Knowledge Capturing and Reuse to Support Manufacturing of Customised Products: A Case Study from the Mould Making Industry. Procedia CIRP 2014, 21, 123–128. [Google Scholar] [CrossRef]
- Huang, B.; He, K.; Huang, R.; Zhang, F.; Zhang, S. Blockchain-based application for NC machining process decision and transaction. Adv. Eng. Inform. 2023, 57, 102037. [Google Scholar] [CrossRef]
- Zhang, J.-C.; Zain, A.M.; Zhou, K.-Q.; Chen, X.; Zhang, R.-M. A review of recommender systems based on knowledge graph embedding. Expert Syst. Appl. 2024, 250, 123876. [Google Scholar] [CrossRef]
- Bao, Q.; Zheng, P.; Dai, S. Hierarchical construction and application of machining domain knowledge graph based on as-fabricated information model. Adv. Eng. Inform. 2024, 62, 102638. [Google Scholar] [CrossRef]
- Wan, Y.; Liu, Y.; Chen, Z.; Chen, C.; Li, X.; Hu, F.; Packianather, M. Making knowledge graphs work for smart manufacturing: Research topics, applications and prospects. J. Manuf. Syst. 2024, 76, 103–132. [Google Scholar] [CrossRef]
- Xiao, W.; Zheng, L.; Huan, J.; Lei, P. A complete CAD/CAM/CNC solution for STEP-compliant manufacturing. Robot. Comput.-Integr. Manuf. 2015, 31, 1–10. [Google Scholar] [CrossRef]
- Ferreira, J.C.E.; Benavente, J.C.T.; Inoue, P.H.S. A web-based CAD/CAPP/CAM system compliant with the STEP-NC standard to manufacture parts with general surfaces. J. Braz. Soc. Mech. Sci. Eng. 2016, 39, 155–176. [Google Scholar] [CrossRef]
- Asghar, E.; Ratti, A.; Tolio, T. An automated approach to reuse machining knowledge through 3D—CNN based classification of voxelized geometric features. Procedia Comput. Sci. 2023, 217, 1209–1216. [Google Scholar] [CrossRef]
- Deng, T.; Li, Y.; Liu, X. An inexact subgraph matching algorithm for subpart retrieval in NC process reuse. J. Manuf. Syst. 2023, 67, 410–423. [Google Scholar] [CrossRef]
- Wen, P.; Ma, Y.; Wang, R. Systematic knowledge modeling and extraction methods for manufacturing process planning based on knowledge graph. Adv. Eng. Inform. 2023, 58, 102172. [Google Scholar] [CrossRef]
- Li, X.; Zhang, S.; Huang, R.; Huang, B.; Xu, C.; Kuang, B. Structured modeling of heterogeneous CAM model based on process knowledge graph. Int. J. Adv. Manuf. Technol. 2018, 96, 4173–4193. [Google Scholar] [CrossRef]
- Hedberg, T.D.; Manas, B., Jr.; Camelio, J.A. Using graphs to link data across the product lifecycle for enabling smart manufacturing digital threads. J. Comput. Inf. Sci. Eng. 2020, 20, 011011. [Google Scholar] [CrossRef]
- Guo, L.; Yan, F.; Li, T.; Yang, T.; Lu, Y. An automatic method for constructing machining process knowledge base from knowledge graph. Robot. Comput.-Integr. Manuf. 2022, 73, 102222. [Google Scholar] [CrossRef]
- Shen, T.; Zhang, F.; Cheng, J. A comprehensive overview of knowledge graph completion. Knowl.-Based Syst. 2022, 255, 109597. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge Graph Embedding via Dynamic Mapping Matrix. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Beijing, China, 26–31 July 2015. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D Knowledge Graph Embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Jiang, X.; Wang, Q.; Wang, B. Adaptive Convolution for Multi-Relational Learning. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Nguyen, D.Q.; Vu, T.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D. A Capsule Network-based Embedding Model for Knowledge Graph Completion and Search Personalization. arXiv 2018, arXiv:1808.04122. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D.Q. A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Ma, R.; Wu, H.; Wang, X.; Wang, W.; Ma, Y.; Zhao, L. Multi-view semantic enhancement model for few-shot knowledge graph completion. Expert Syst. Appl. 2023, 238, 122086. [Google Scholar] [CrossRef]
- Xiong, W.; Yu, M.; Chang, S.; Guo, X.; Wang, W.Y. One-Shot Relational Learning for Knowledge Graphs. arXiv 2018, arXiv:1808.09040. [Google Scholar] [CrossRef]
- Zhang, C.; Yao, H.; Huang, C.; Jiang, M.; Li, Z.J.; Chawla, N. Few-Shot Knowledge Graph Completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Sheng, J.; Guo, S.; Chen, Z.; Yue, J.; Wang, L.; Liu, T.; Xu, H. Adaptive Attentional Network for Few-Shot Knowledge Graph Completion. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020. [Google Scholar]
- Chen, M.; Zhang, W.; Zhang, W.; Chen, Q.; Chen, H. Meta Relational Learning for Few-Shot Link Prediction in Knowledge Graphs. arXiv 2019, arXiv:1909.01515. [Google Scholar] [CrossRef]
- Niu, G.; Li, Y.; Tang, C.; Geng, R.; Dai, J.; Liu, Q.; Wang, H.; Sun, J.; Huang, F.; Si, L.; et al. Relational Learning with Gated and Attentive Neighbor Aggregator for Few-Shot Knowledge Graph Completion. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021. [Google Scholar]
- Liu, X.; Mao, T.; Shi, Y.; Ren, Y. Overview of knowledge reasoning for knowledge graph. Neurocomputing 2024, 585, 127571. [Google Scholar] [CrossRef]
- Wu, Y.; Zhu, D.; Liao, X.; Zhang, D.; Lin, K. Knowledge graph reasoning based on paths of tensor factorization. Pattern Recognit. Artif. Intell. 2017, 30, 473–480. [Google Scholar]
- Jain, P.; Murty, S.; Chakrabarti, S. Joint Matrix-Tensor Factorization for Knowledge Base Inference. arXiv 2017, arXiv:1706.00637. [Google Scholar] [CrossRef]
- Lin, Y.; Liu, Z.; Luan, H.; Sun, M.; Rao, S.; Liu, S. Modeling Relation Paths for Representation Learning of Knowledge Bases. arXiv 2015, arXiv:1506.00379. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Weston, J.; Bengio, Y. A semantic matching energy function for learning with multi-relational data. Mach. Learn. 2013, 94, 233–259. [Google Scholar]
- Yang, B.; Yih, W.T.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Qu, M.; Tang, J. Probabilistic Logic Neural Networks for Reasoning. arXiv 2019, arXiv:1906.08495. [Google Scholar]
- Richardson, M.; Domingos, P. Markov logic networks. Mach. Learn. 2006, 62, 107–136. [Google Scholar] [CrossRef]
- Mitchell, T.M.; Cohen, W.W.; Hruschka, E.; Talukdar, P.P.; Yang, B.; Betteridge, J.; Carlson, A.; Dalvi, B.; Gardner, M.; Kisiel, B.; et al. Never-Ending Learning. Commun. ACM 2015, 61, 103–115. [Google Scholar] [CrossRef]
- Chen, Y.; Goldberg, S.; Wang, D.Z.; Johri, S. Ontological Pathfinding. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016. [Google Scholar]
- Shaojie, L.; Shudong, C.; Xiaoye, O.; Lichen, G. Joint learning based on multi-shaped filters for knowledge graph completion. High Technol. Lett. 2021, 27, 43–52. [Google Scholar]
- Shen, Y.; Huang, P.-S.; Chang, M.-W.; Gao, J. Traversing Knowledge Graph in Vector Space without Symbolic Space Guidance. arXiv 2016, arXiv:1611.04642. [Google Scholar]
- Wang, Q.; Ji, Y.; Hao, Y.; Cao, J. GRL: Knowledge graph completion with GAN-based reinforcement learning. Knowl.-Based Syst. 2020, 209, 106421. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Ent | #Rel | #Tri | #Splits | #Sem |
|---|---|---|---|---|---|
| FB15k237-One | 14,478 | 237 | 309,621 | 32/5/8 | 89 |
| NELL-One | 68,545 | 358 | 181,109 | 51/5/11 | 278 |
| Model | MRR (%) | Hits@1 (%) | Hits@5 (%) | Hits@10 (%) |
|---|---|---|---|---|
| TransE (2013) | 15.9 | 8.9 | 21.2 | 31.2 |
| ComplEx (2018) | 27.8 | 19.2 | 31.2 | 41.0 |
| GMatching (2018) | 18.9 | 10.1 | 27.4 | 36.0 |
| FSRL (2019) | 22.3 | 10.2 | 36.4 | 48.6 |
| MetaR (2019) | 20.3 | 10.7 | 29.1 | 37.7 |
| FAAN (2020) | 20.9 | 10.7 | 33.4 | 41.8 |
| GANA (2021) | 25.9 | 17.8 | 42.4 | 54.1 |
| Ours | 29.0 | 21.3 | 46.8 | 59.0 |
| Model | MRR (%) | Hits@1 (%) | Hits@5 (%) | Hits@10 (%) |
|---|---|---|---|---|
| TransE (2013) | 13.5 | 8.1 | 16.1 | 26.3 |
| ComplEx (2018) | 17.4 | 11.8 | 29.9 | 29.7 |
| GMatching (2018) | 18.4 | 12.9 | 23.0 | 27.9 |
| FSRL (2019) | 14.2 | 8.8 | 17.5 | 28.4 |
| MetaR (2019) | 22.7 | 16.4 | 28.2 | 34.0 |
| FAAN (2020) | 26.8 | 19.2 | 36.0 | 41.7 |
| GANA (2021) | 30.4 | 19.4 | 43.2 | 51.7 |
| Ours | 34.7 | 23.2 | 48.6 | 57.7 |
| MRR (%) | Hits@1 (%) | Hits@5 (%) | Hits@10 (%) | |
|---|---|---|---|---|
| -DE | 27.5 | 20.1 | 45.5 | 57.9 |
| -NA | 25.0 | 18.5 | 43.1 | 56.2 |
| -SF | 26.2 | 19.2 | 44.1 | 57.0 |
| NS-KGC | 29.0 | 21.3 | 46.8 | 59.0 |
| MRR (%) | Hits@1 (%) | Hits@5 (%) | Hits@10 (%) | |
|---|---|---|---|---|
| -DE | 33.5 | 22.1 | 47.5 | 56.4 |
| -NA | 31.4 | 20.1 | 45.1 | 53.8 |
| -SF | 32.2 | 21.2 | 46.5 | 54.3 |
| NS-KGC | 34.7 | 23.2 | 48.6 | 57.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, X.; Su, J.; Cheng, D. Intelligent Numerical Control Programming System Based on Knowledge Graph. Machines 2024, 12, 851. https://doi.org/10.3390/machines12120851
Fang X, Su J, Cheng D. Intelligent Numerical Control Programming System Based on Knowledge Graph. Machines. 2024; 12(12):851. https://doi.org/10.3390/machines12120851
Chicago/Turabian StyleFang, Xifeng, Jiabao Su, and Dejun Cheng. 2024. "Intelligent Numerical Control Programming System Based on Knowledge Graph" Machines 12, no. 12: 851. https://doi.org/10.3390/machines12120851
APA StyleFang, X., Su, J., & Cheng, D. (2024). Intelligent Numerical Control Programming System Based on Knowledge Graph. Machines, 12(12), 851. https://doi.org/10.3390/machines12120851