
Research on a Fault Diagnosis Method for the Braking Control System of an Electric Multiple Unit Based on Deep Learning Integration


Abstract
1. Introduction
- (1)
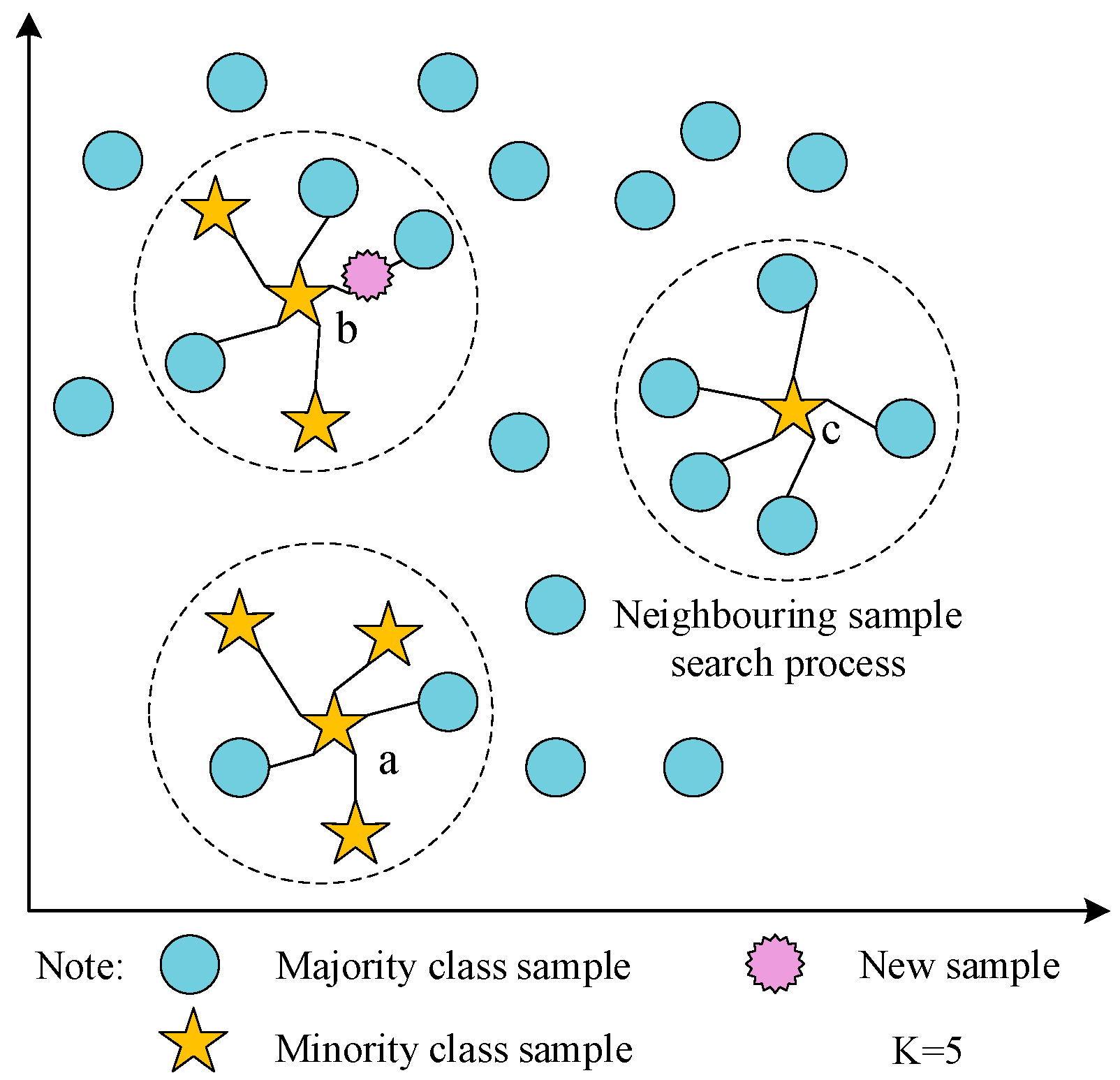
- This study proposes an imbalance optimization method for fault data in the braking control system of EMUs, utilizing the B-SMOTE algorithm. The B-SMOTE algorithm is employed to generate minority class samples at the boundaries. Subsequently, the data distribution is optimized, effectively reducing the probability of misdiagnosis in the minority class samples.
- (2)
- This study presents a deep learning-based ensemble model for fault diagnosis in the braking control system of EMUs. The model incorporates deep-level feature extraction of the fault data, enabling precise fault classification even with imbalanced samples. Consequently, the fault diagnosis of EMU braking control systems can be effectively achieved. In comparison with conventional fault diagnosis models, the proposed approach significantly enhances the accuracy and robustness of fault diagnosis for the braking control system of EMUs.
- (3)
- This study proposes a fault classifier for the braking control system of EMUs based on LightGBM. LightGBM significantly reduces the time and computational complexity of fault classification through the utilization of the histogram algorithm and the gradient-based one-side sampling algorithm. Moreover, LightGBM accelerates model training by employing optimized feature and data parallelism methods, thereby effectively improving the fault diagnosis accuracy of the braking control system.
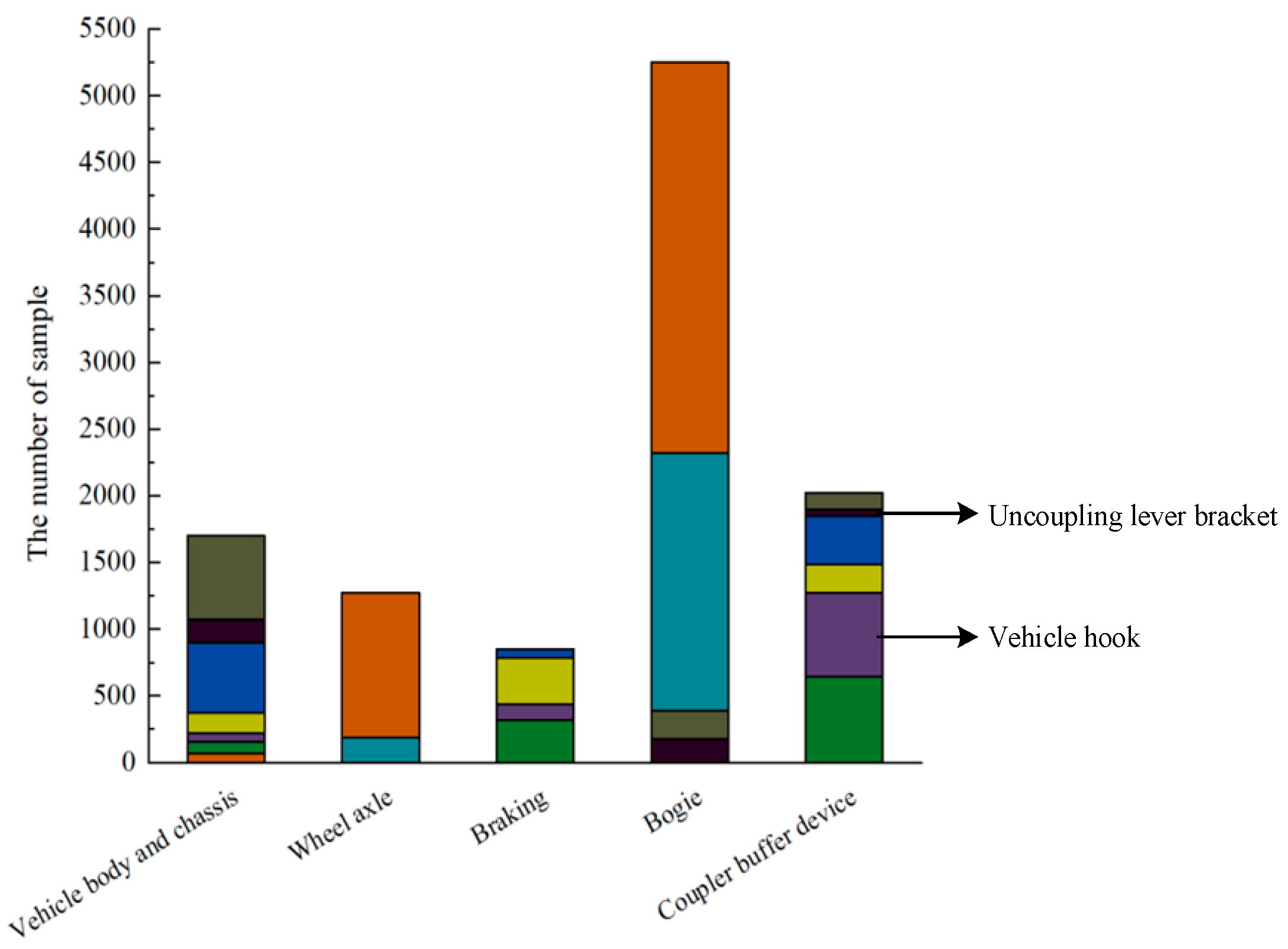
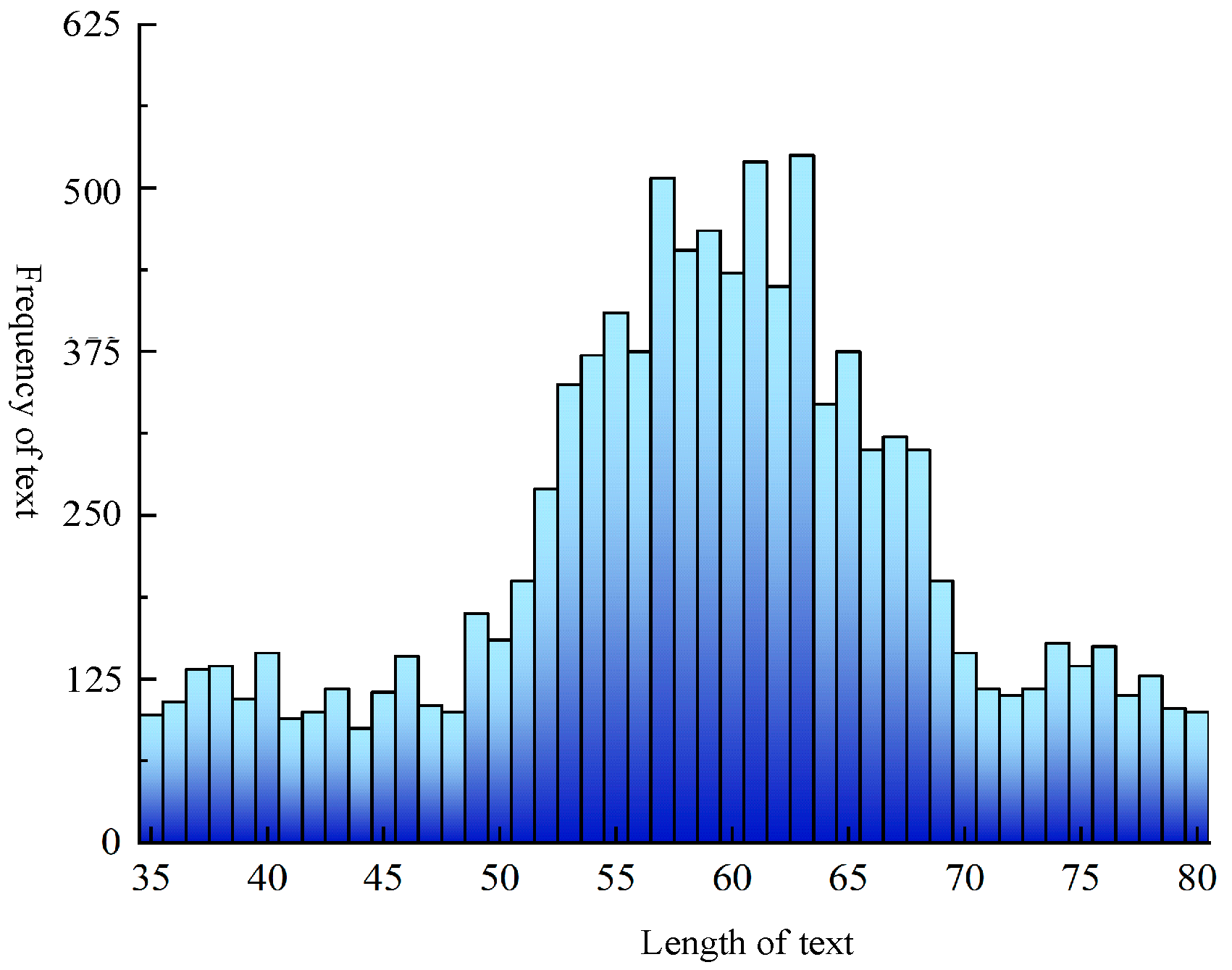
2. Data Source and Data Characteristics
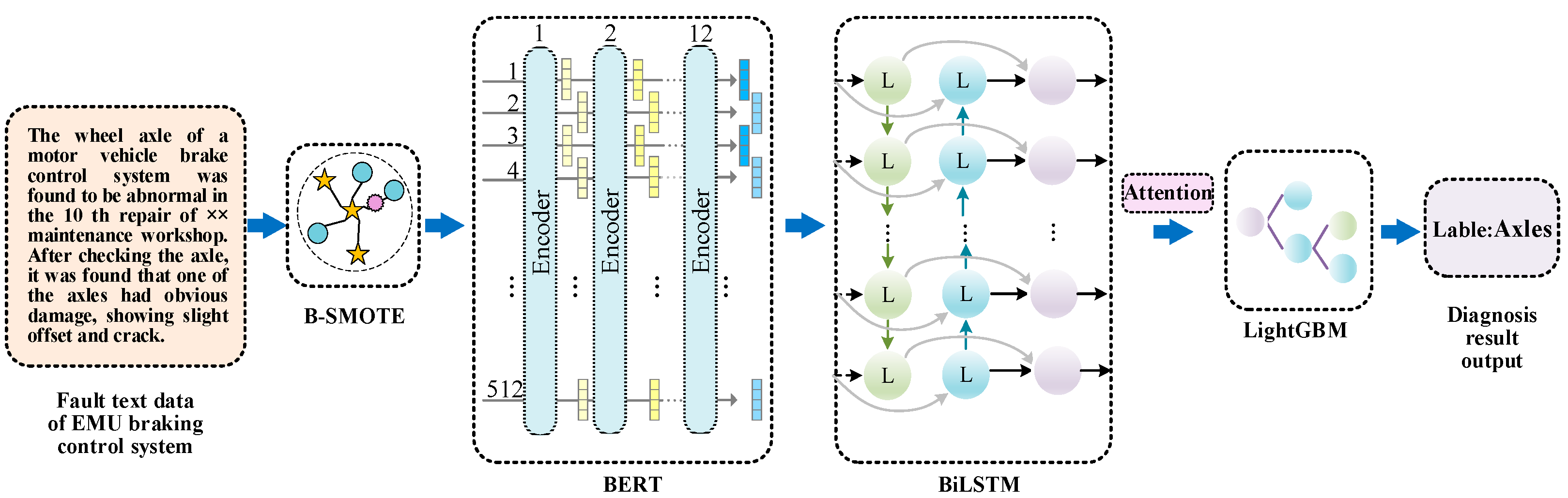
3. Research Framework
3.1. Optimization of Text Data Distribution
3.2. BERT
3.3. BiLSTM
3.4. Attention Mechanism
3.5. LightGBM
4. Experimental Analysis
4.1. Experimental Dataset and Evaluation Index
4.2. Setup of the Experimental Environment
4.3. B-SMOTE-Generated Minority Class Samples for Experimentation
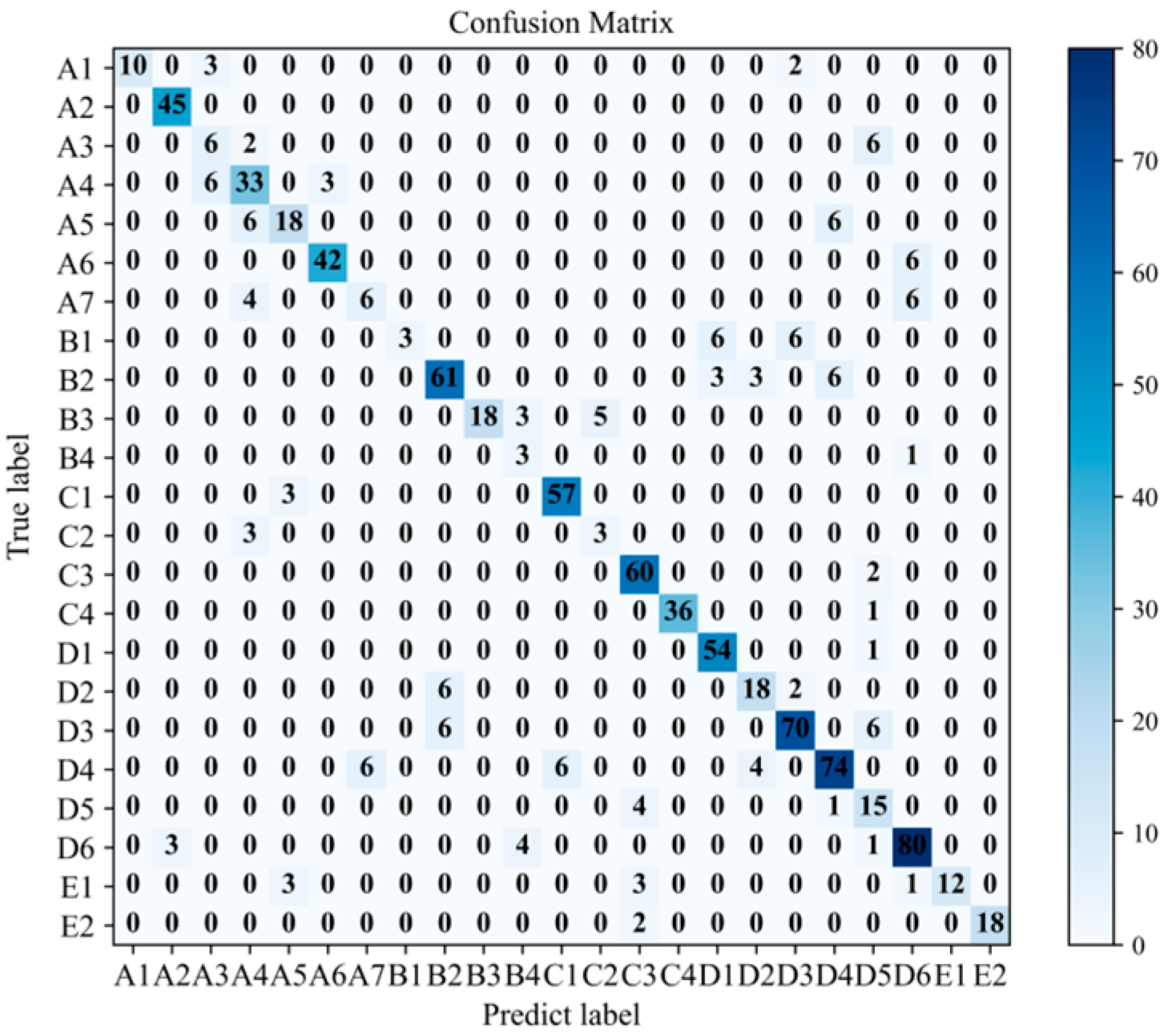
4.4. Experimental Analysis
- (1)
- The BiLSTM-Attention model, which is based on the BiLSTM model, utilizes the attention mechanism to enable the model to focus on identifying input information that is highly relevant to the current classification. Consequently, when compared with the BiLSTM model, the BiLSTM-Attention model demonstrates improvements in both accuracy and F1 score of 1.87% and 4.19%, respectively. These results indicate that the attention mechanism effectively enhances the efficiency of feature extraction for key vectors.
- (2)
- Then, the BiLSTM-Attention and CNN models are separately combined with Word2vec, and the word embedding BERT is introduced for comparison. The results demonstrate that both word embedding methods improve the model’s performance. However, as a dynamic word embedding method, BERT specifically enhances the representation of text features, enabling it to achieve optimal results when dealing with complex texts in the railway field. Consequently, compared to Word2vec, the BERT model exhibits a classification effect that is 1.73% and 0.74% higher than the Word2vec-CNN and Word2vec-BiLSTM-Attention models, respectively. Furthermore, the classification accuracy of the BERT-BiLSTM-Attention model surpasses that of the BERT model by 1.14%, with a corresponding 0.69% increase in the F1 value. This indicates that the combined model of BERT and BiLSTM-Attention overcomes the limitations of a single BERT model in text feature extraction and weight distribution.
- (3)
- In order to improve the practicality of the method for engineering applications, we incorporate LightGBM as the classifier. The experimental results indicate that under the same experimental conditions, the proposed model outperforms the BERT-BiLSTM-Attention model, achieving a 4.73% improvement in comprehensive evaluation metrics. Furthermore, to examine the influence of LightGBM on model performance, a comparison is conducted among different control models based on their training and testing times, as depicted in Table 3. In contrast, the BERT-BiLSTM-Attention model, configured using the parameters specified in Table 2, requires 24.8 min to train the dataset, whereas our model requires only 16.4 min. These results suggest that the LightGBM model enables parallel analysis, effectively reducing model complexity and thus enhancing efficiency of analysis. Therefore, the proposed model enhances the efficiency of fault diagnosis in the braking control system of the EMU to a certain degree, thereby increasing the practicality of the method in engineering applications.
5. Conclusions
- (1)
- To mitigate the problem of inadequate model generalization and diagnostic accuracy, which are caused by imbalanced sample distribution, in diagnosing EMU braking control system faults, we employed the B-SMOTE algorithm to generate minority class samples and optimize the distribution of fault textual data. The experimental results demonstrate that the application of the B-SMOTE algorithm improved the diagnostic accuracy of minority class samples in our model while maintaining the diagnostic accuracy of majority class samples. This model effectively handles imbalanced datasets. However, its performance may be affected by hyperparameter settings, and it may not be suitable for all types of datasets. In future research, we will investigate adaptive parameter adjustment methods based on dataset characteristics to enhance the flexibility and adaptability of B-SMOTE, thus reducing reliance on hyperparameter settings.
- (2)
- In order to provide additional evidence regarding the efficacy of the deep learning integration model in diagnosing faults within the EMU braking control system, we conducted comparative experiments utilizing authentic fault data and alternative models. The outcomes clearly demonstrate that the proposed model surpasses other models in terms of accuracy, recall rate, and F1 score, achieving values of 94.34%, 92.32%, and 92.72%, respectively.
- (3)
- In order to enhance the practicality of the method in engineering applications, we employed the LightGBM classifier to classify the extracted semantic features. A comparative analysis between the proposed model and the original BERT-BiLSTM-Attention model illustrates a 4.73% improvement in overall evaluation metrics, accompanied by a reduction in training time of 8.4 min. These findings indicate that LightGBM has the ability to decrease model complexity and expedite runtime, effectively addressing the time-consuming challenges encountered by traditional algorithms when dealing with large-scale sample data. Ultimately, this approach significantly enhances the accuracy and robustness of the model.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Awad, F.A.; Graham, D.J.; Singh, R.; AitBihiOuali, L. Predicting urban rail transit safety via artificial neural networks. Saf. Sci. 2023, 167, 106282. [Google Scholar] [CrossRef]
- Shrestha, S.; Spiryagin, M.; Wu, Q. Friction condition characterization for rail vehicle advanced braking system. Mech. Syst. Signal Process. 2019, 134, 106324. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, Z.; Mo, J.; Zhou, Z. Modelling and stability analysis of a high-speed train braking system. Int. J. Mech. Sci. 2023, 250, 108315. [Google Scholar] [CrossRef]
- Gültekin, Ö.; Cinar, E.; Özkan, K.; Yazici, A. Multisensory data fusion-based deep learning approach for fault diagnosis of an industrial autonomous transfer vehicle. Expert Syst. Appl. 2022, 200, 117055. [Google Scholar] [CrossRef]
- Velasco-Gallego, C.; De Maya, B.N.; Molina, C.M.; Lazakis, I.; Mateo, N.C. Recent advancements in data-driven methodologies for the fault diagnosis and prognosis of marine systems: A systematic review. Ocean. Eng. 2023, 284, 115277. [Google Scholar] [CrossRef]
- Zuo, B.; Zhang, Z.; Cheng, J.; Huo, W.; Zhong, Z.; Wang, M. Data-driven flooding fault diagnosis method for proton-exchange membrane fuel cells using deep learning technologies. Energy Convers. Manag. 2022, 251, 115004. [Google Scholar] [CrossRef]
- Yang, D.; Karimi, H.R.; Gelman, L. An explainable intelligence fault diagnosis framework for rotating machinery. Neurocomputing 2023, 541, 126257. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, H.; Zhou, Y.; Li, M.; Sun, G. Efficient visual fault detection for freight train braking system via heterogeneous self distillation in the wild. Adv. Eng. Inform. 2023, 57, 102091. [Google Scholar] [CrossRef]
- Zhang, Y.C. Real-time monitoring and fault diagnosis expert system for locomotive braking system. Comput. Meas. Control 2013, 21, 2615–2617, 2620. [Google Scholar]
- Atamuradov, V.; Camci, F.; Baskan, S.; Sevkli, M. Failure diagnostics for railway point machines using expert systems. In Proceedings of the 2009 IEEE International Symposium on Diagnostics for Electric Machines, Power Electronics and Drives, Cargèse, France, 31 August–3 September 2009; IEEE: New York, NY, USA, 2009; pp. 1–5. [Google Scholar]
- Li, W.X.; Zhang, Y.; Lin, R.W.; Wang, L. Fault Diagnosis and Safety Measures of EMU Braking System. Railw. Locomot. Car 2011, 31, 39–42. [Google Scholar]
- Zhang, T. CCBII brake based on multi-hierarchy fuzzy evaluation. Electr. Eng. 2009, 2009, 61–65. [Google Scholar]
- Soares, N.; de Aguiar, E.P.; Souza, A.C.; Goliatt, L. Unsupervised machine learning techniques to prevent faults in railroad switch machines. Int. J. Crit. Infrastruct. Prot. 2021, 33, 100423. [Google Scholar] [CrossRef]
- Zhou, D.H.; Ji, H.Q.; He, X.; Shang, J. Fault detection and isolation of the brake cylinder system for electric multiple units. IEEE Trans. Control. Syst. Technol. 2018, 26, 1744–1757. [Google Scholar] [CrossRef]
- Seo, B.; Jo, S.H.; Oh, H.; Youn, B.D. Solenoid valve diagnosis for railway braking systems with embedded sensor signals and physical interpretation. In Proceedings of the Annual Conference of the PHM Society, Denver, CO, USA, 2–8 October 2016; p. 8. [Google Scholar]
- Liu, J.; Li, Y.F.; Zio, E. A SVM framework for fault detection of the braking system in a high-speed train. Mech. Syst. Signal Process. 2017, 87, 401–409. [Google Scholar] [CrossRef]
- Liu, J.; Zio, E. A scalable fuzzy support vector machine for fault detection in transportation systems. Expert Syst. Appl. 2018, 102, 36–43. [Google Scholar] [CrossRef]
- Zuo, J.; Ding, J.; Feng, F. Latent leakage fault identification and diagnosis based on multi-source information fusion method for key pneumatic units in Chinese standard electric multiple units (EMU) braking system. Appl. Sci. 2019, 9, 300. [Google Scholar] [CrossRef]
- Liu, H.; Wang, Y.; Zhou, X.; Ye, Y. Question answering system for deterministic fault diagnosis of intelligent railway signal equipment. Smart Resilient Transp. 2021, 3, 202–214. [Google Scholar] [CrossRef]
- Lu, R.J.; Lin, H.X.; Xu, L.; Lu, R.; Zhao, Z.X.; Bai, W.S. Fault diagnosis for on-board equipment of train control system based on CNN and PSO-SVM hybrid model. J. Meas. Sci. Instrum. 2022, 13, 430–438. [Google Scholar]
- Shangguan, W.; Meng, Y.Y.; Yang, J.M.; Cai, B.G. LSTM-BP neural network based fault diagnosis for on-board equipment of Chinese train control. J. Beijing Jiaotong Univ. 2019, 43, 54–62. [Google Scholar]
- Chen, S.; Ding, Y.; Xie, Z.; Liu, S.; Ding, H. Chinese Weibo sentiment analysis based on character embedding with dual-channel convolutional neural network. In Proceedings of the 2018 IEEE 3rd International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 20–22 April 2018; IEEE: New York, NY, USA, 2009; pp. 107–111. [Google Scholar]
- Yang, L.B.; Li, P.; Xue, R.; Ma, X.; Wu, Y.H.; Zou, D.L. Intelligent classification of faults of railway signal equipment based on imbalanced text data mining. J. China Railw. Soc. 2018, 40, 59–66. [Google Scholar]
- Georgios, D.; Fernando, B. Geometric SMOTE a geometrically enhanced drop-in replacement for SMOTE. Inf. Sci. 2019, 501, 118135. [Google Scholar]
- Li, X.Y.; Yang, M.; Quan, R. Unbalanced text classification method based on deep learning. J. Jilin Univ. 2022, 52, 1889–1895. [Google Scholar]
- Deng, J.F.; Cheng, L.L.; Wang, Z.W. Attention-based BiLSTM fused CNN with gating mechanism model for Chinese long text classification. Comput. Speech Lang. 2021, 68, 101182. [Google Scholar] [CrossRef]
- Gao, F.; Li, F.; Wang, Z.F. Research on multilevel classification of high-speed railway signal equipment fault based on text mining. J. Electr. Comput. Eng. 2021, 2021, 7146435. [Google Scholar] [CrossRef]
- Li, W.J.; Qi, F.; Yu, Z.T. Sentiment classification method based on multi-channel features and self-attention. J. Softw. 2021, 32, 2783–2800. [Google Scholar]
- Liriam, E.; Santos, A.R.; Ricardo, M.; Li, W.G.; Geraldo, P. Multi-label legal text classification with BiLSTM and attention. Int. J. Comput. Appl. Technol. 2022, 68, 369–378. [Google Scholar]
- Lin, H.X.; Lu, R.J.; Lu, R. Automatic classification method of railway signal fault based on text mining. J. Yunnan Univ. 2022, 44, 281–289. [Google Scholar]
- Han, G.; Bu, T.; Wang, M.M. Text classification of railway traffic accidents based on dual-channel bidirectional long short term memory network. J. China Railw. Soc. 2021, 43, 71–79. [Google Scholar]
- Alammary, A.S. BERT Models for Arabic Text Classification: A Systematic Review. Appl. Sci. 2022, 12, 5720. [Google Scholar] [CrossRef]
- Shobana, J.; Murali, M. An Improved Self Attention Mechanism Based on Optimized BERT-BiLSTM Model for Accurate Polarity Prediction. Comput. J. 2023, 66, 1279–1294. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
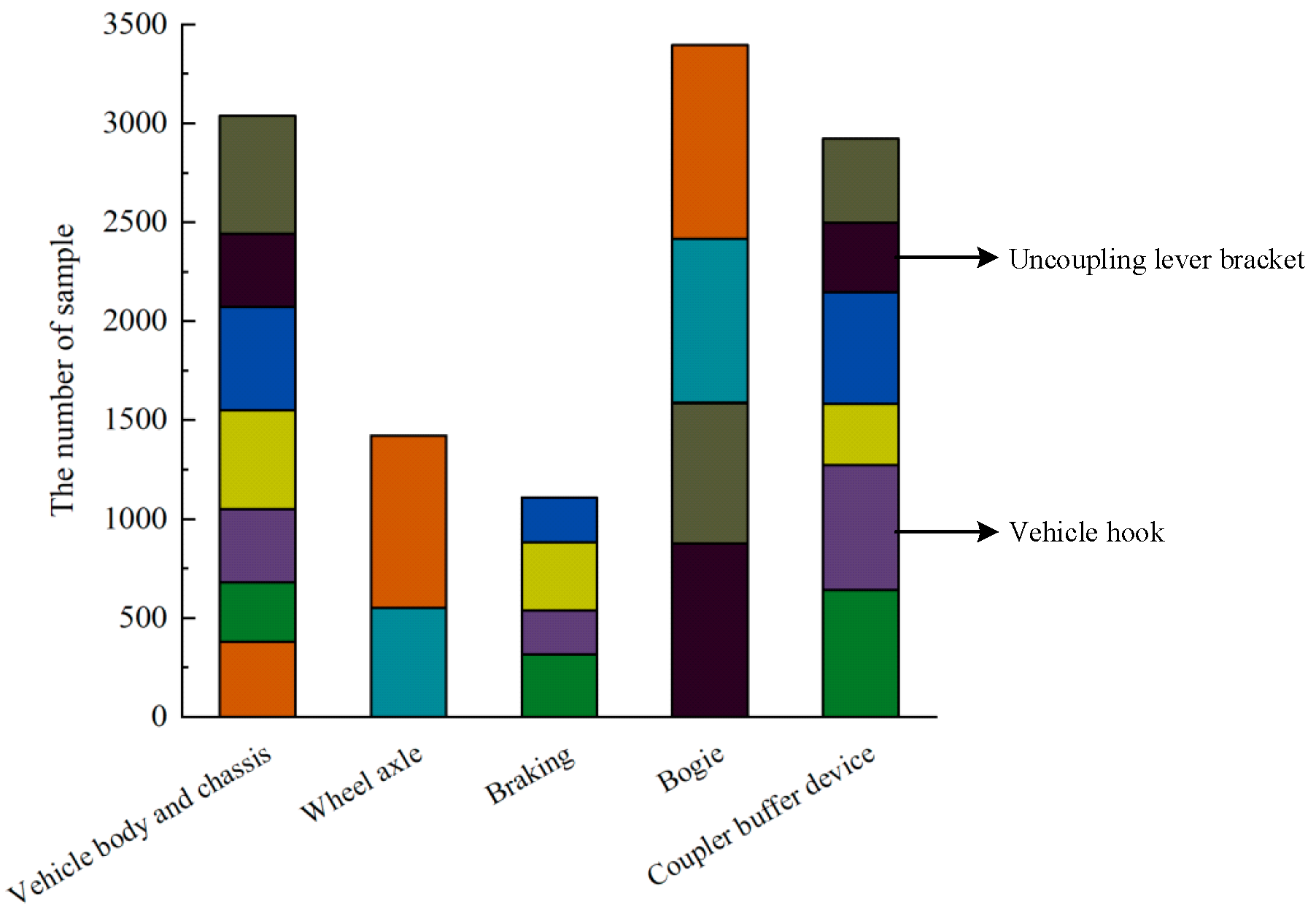
| Primary Fault | Secondary Fault | |
|---|---|---|
| The fault classification of the braking control system of EMU | Vehicle body and chassis | Railway carriage (A1) |
| Wall panels (A2) | ||
| Floor (A3) | ||
| Beam (A4) | ||
| Reservoir (A5) | ||
| Release valve (A6) | ||
| Chassis structure (A7) | ||
| Braking | Brake regulator (B1) | |
| Tube system (B2) | ||
| Brake cylinder (B3) | ||
| Drawbar (B4) | ||
| Bogie | Bolster (C1) | |
| Side frame (C2) | ||
| Crossbar (C3) | ||
| Spring-loaded pallet (C4) | ||
| Coupler buffer device | Vehicle hook (D1) | |
| Hooked tongue (D2) | ||
| Coupler yoke (D3) | ||
| Uncoupling lever bracket (D4) | ||
| Coupling lever (D5) | ||
| Buffers (D6) | ||
| Wheel axle | Rim-spoke plate (E1) | |
| Axles (E2) |
| Hyperparameter Name | Hyperparameter Value |
|---|---|
| Epoch | 25 |
| Learning rate | 0.001 |
| BERT embedding dimension | 300 |
| Maximum sequence length | 128 |
| Number of nodes in the hidden layer of LSTM | 256 |
| Number of LSTM layers | 2 |
| Optimization function | Adam |
| Batch size | 32 |
| Loss | 0.5 |
| Depth | 14 |
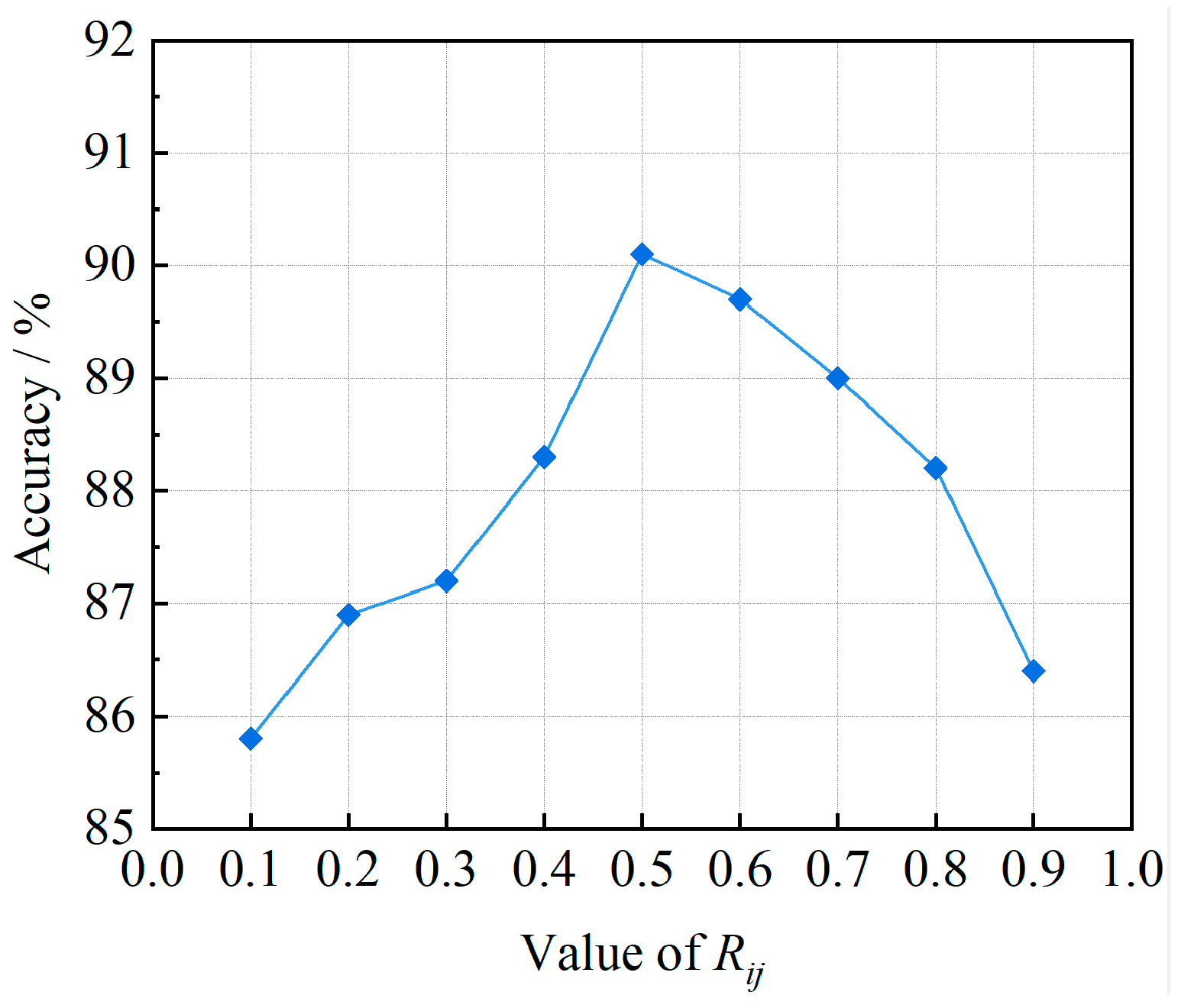
| Rij | 0.5 |
| Padding size | 72 |
| Model | Training Time/min | Testing Time/s |
| BiLSTM | 10.7 | 1.41 |
| BiLSTM-Attention | 12.6 | 1.53 |
| Word2vec-CNN | 10.8 | 1.43 |
| Word2vec-BiLSTM-Attention | 14.5 | 1.78 |
| BERT | 15.6 | 1.95 |
| BERT-BiLSTM-Attention | 24.8 | 2.12 |
| Proposed method | 16.4 | 2.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Lin, H.; Li, D.; Bao, J.; Hu, N. Research on a Fault Diagnosis Method for the Braking Control System of an Electric Multiple Unit Based on Deep Learning Integration. Machines 2024, 12, 70. https://doi.org/10.3390/machines12010070
Wang Y, Lin H, Li D, Bao J, Hu N. Research on a Fault Diagnosis Method for the Braking Control System of an Electric Multiple Unit Based on Deep Learning Integration. Machines. 2024; 12(1):70. https://doi.org/10.3390/machines12010070
Chicago/Turabian StyleWang, Yueheng, Haixiang Lin, Dong Li, Jijin Bao, and Nana Hu. 2024. "Research on a Fault Diagnosis Method for the Braking Control System of an Electric Multiple Unit Based on Deep Learning Integration" Machines 12, no. 1: 70. https://doi.org/10.3390/machines12010070
APA StyleWang, Y., Lin, H., Li, D., Bao, J., & Hu, N. (2024). Research on a Fault Diagnosis Method for the Braking Control System of an Electric Multiple Unit Based on Deep Learning Integration. Machines, 12(1), 70. https://doi.org/10.3390/machines12010070