

LSTM for Modeling of Cylinder Pressure in HCCI Engines at Different Intake Temperatures via Time-Series Prediction

 ,
,
Abstract
:1. Introduction
2. Setup & Methodology
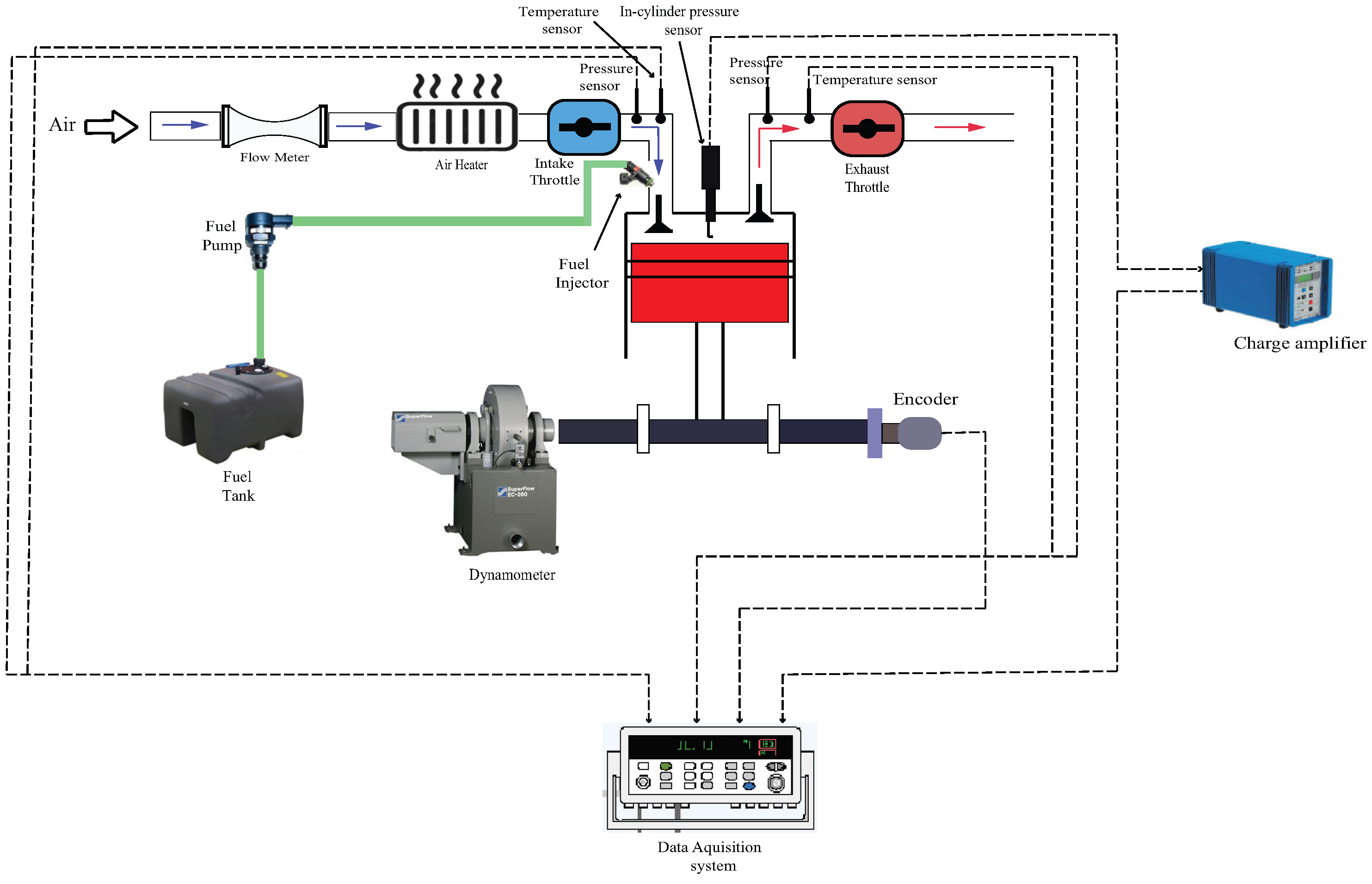
2.1. Experimental Setup
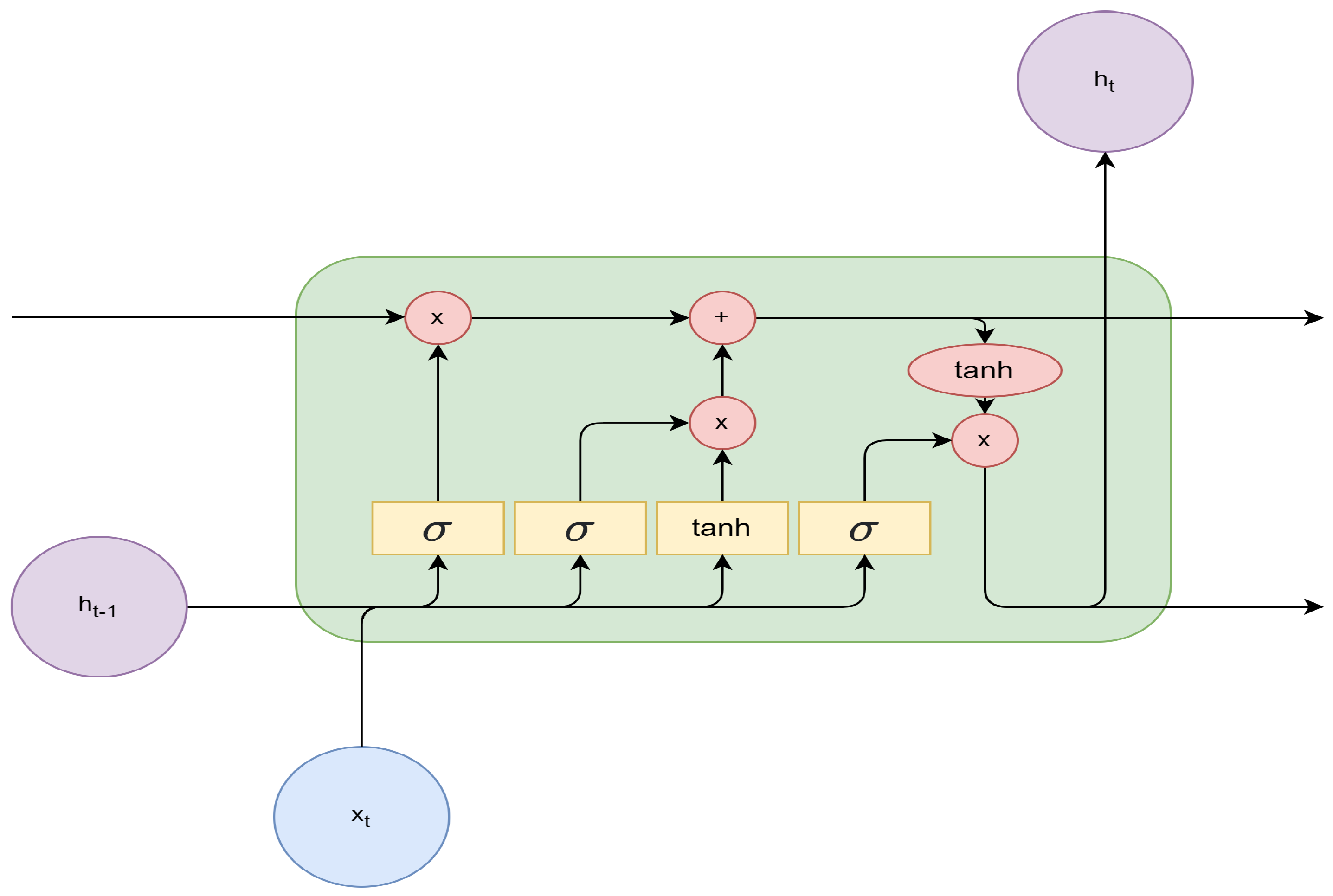
2.2. Long Short-Term Memory (LSTM)
3. Results & Discussion
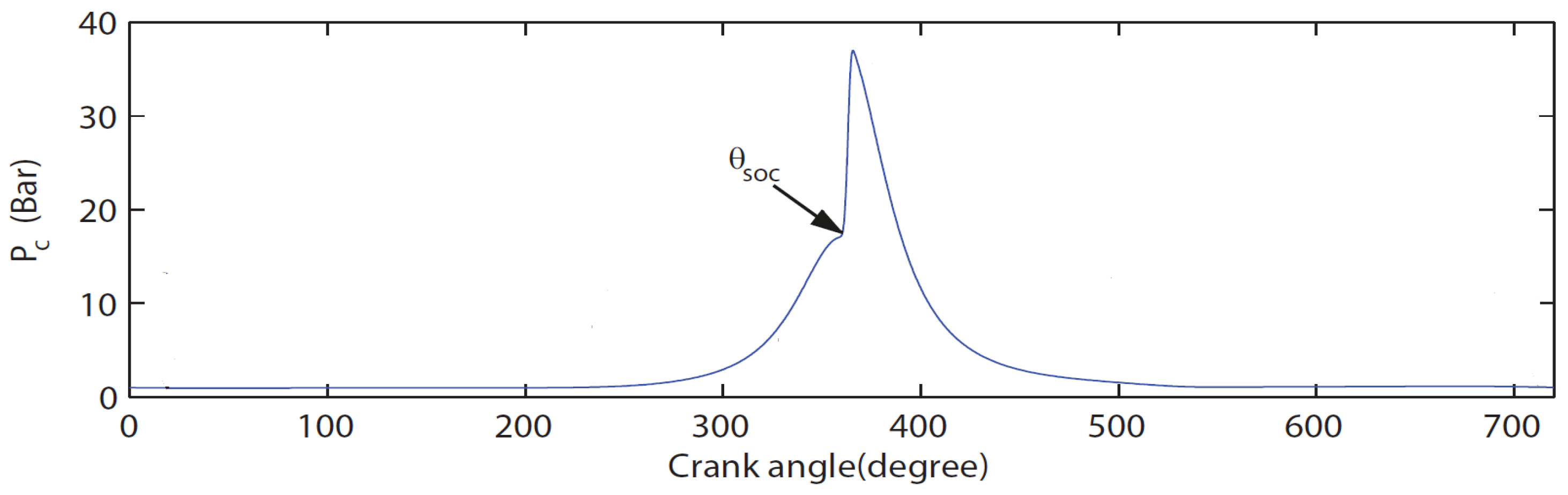
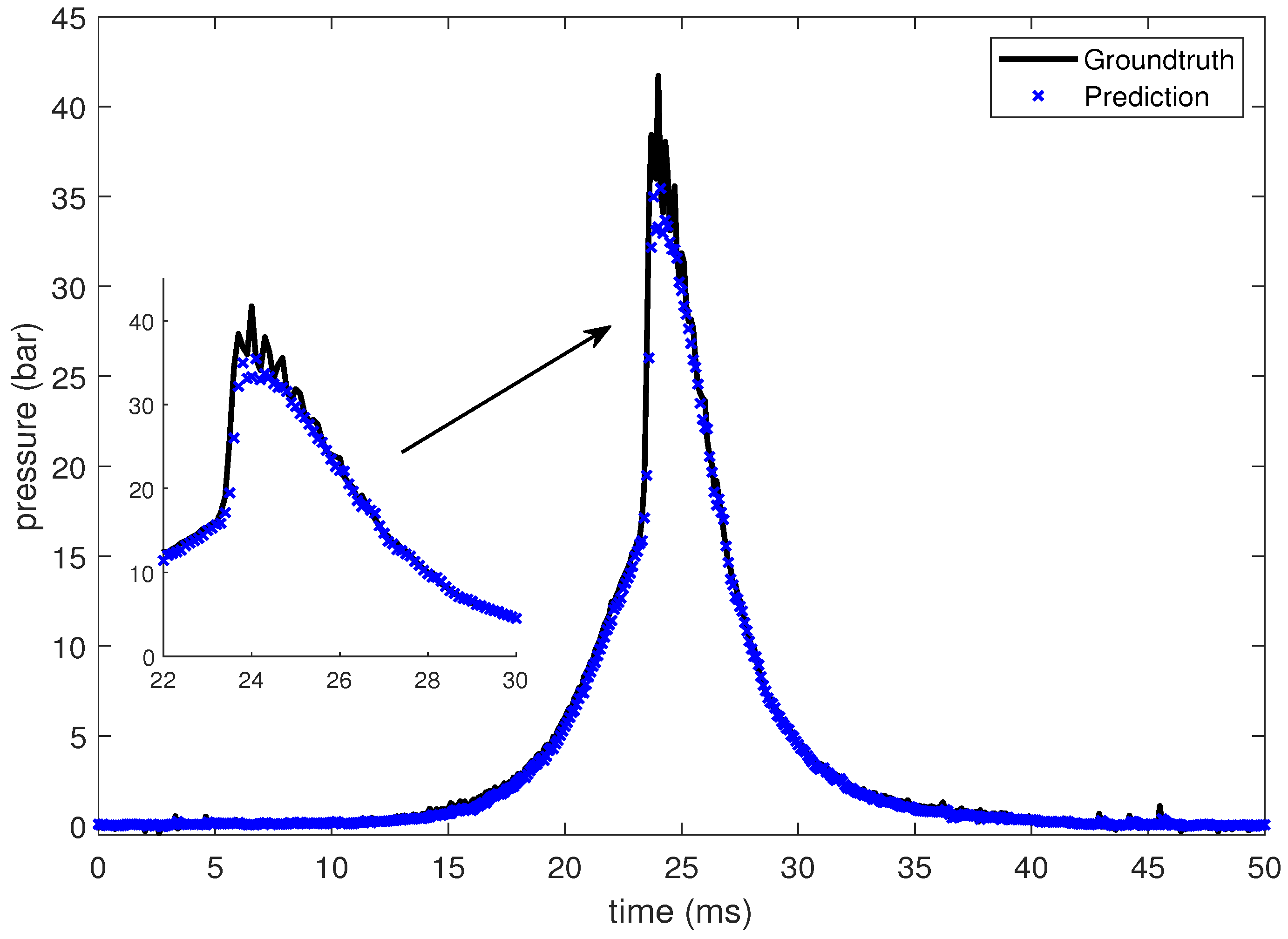
3.1. LSTM for Pressure Time-Series Prediction
- (a)
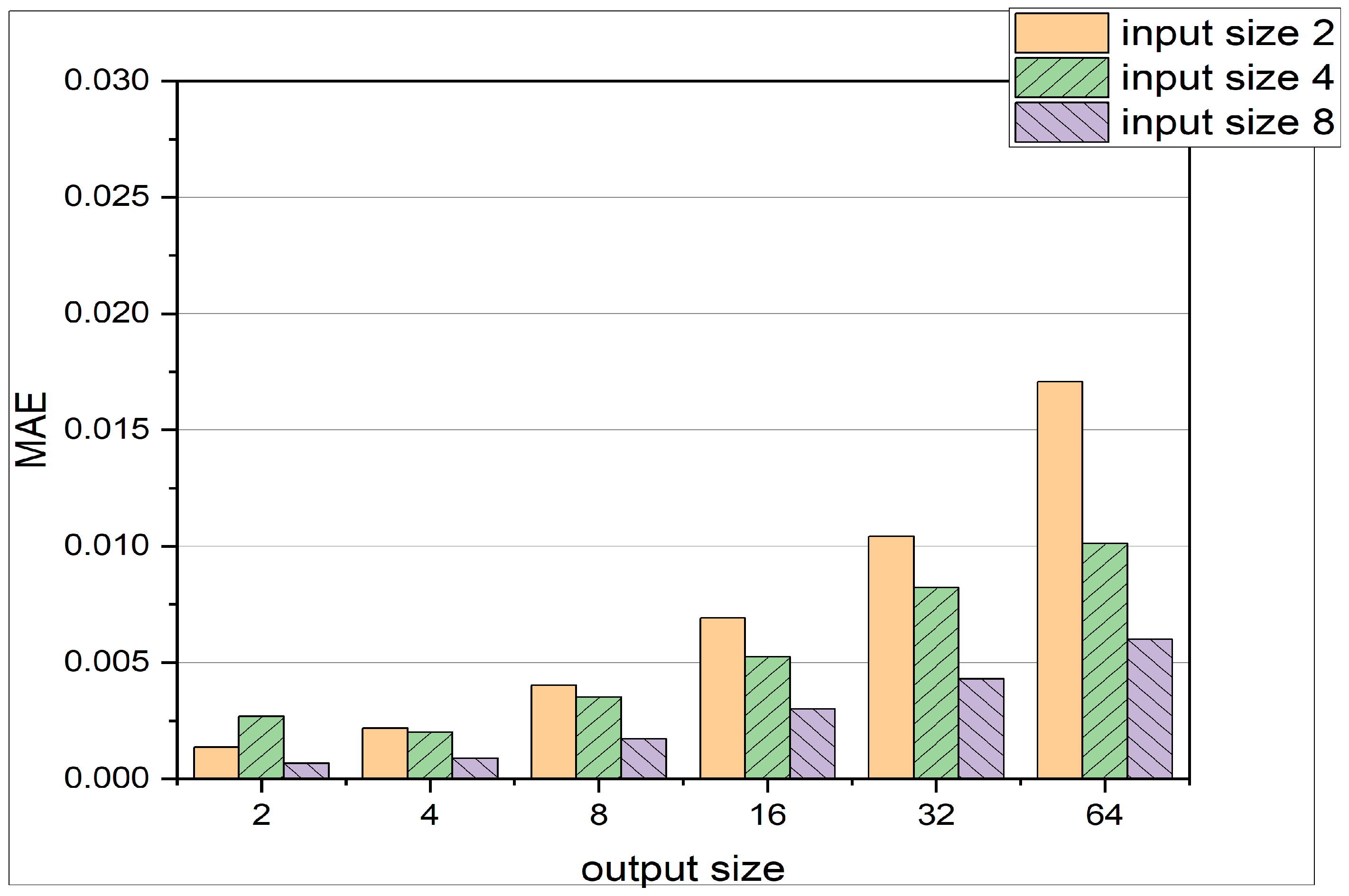
- As the input size increases, the MAE and MSE values generally decrease. This trend can be attributed to the fact that a larger input size provides more information to the LSTM, enabling it to make better forecasts.
- (b)
- Conversely, as the output size increases, the MAE and MSE values tend to increase. This outcome occurs because a larger output size corresponds to predictions that are further away from the current time step. For example, when the output size is 64, the LSTM predicts pressure states more than 64 time steps away from the input pressure states. Predicting these distant pressure states accurately becomes more challenging due to the cycle-to-cycle variation of cylinder pressure data.
- (c)
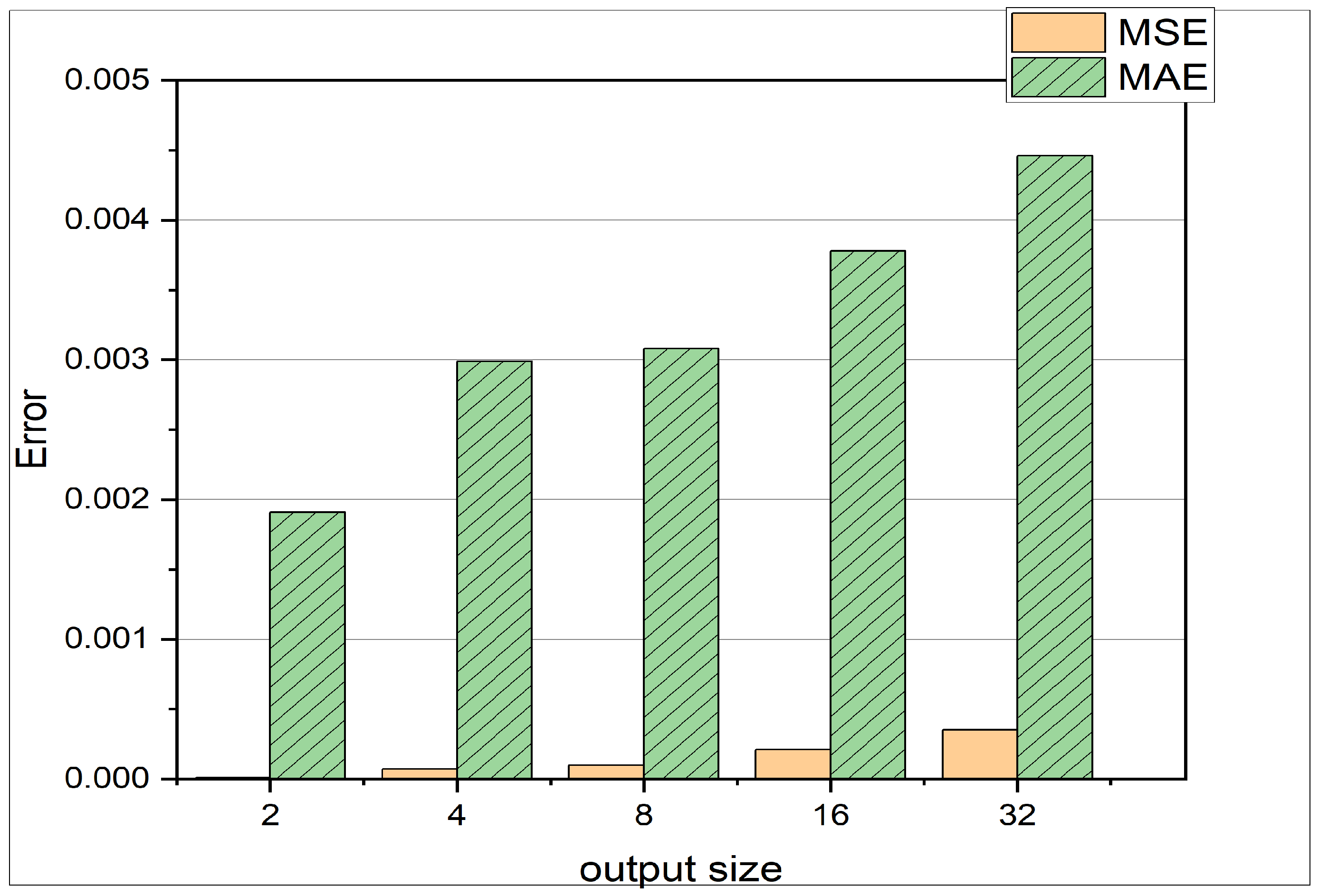
- A comparison of MAE and MSE loss in Figure 6 reveals that the MSE is much smaller than the MAE. This observation indicates that most of the predictions are very close to the actual results, and there are not many outliers. This is due to the fact, that the MSE loss carries a square term, as can be seen in Equation (10). Therefore the MSE loss punishes outliers [39].
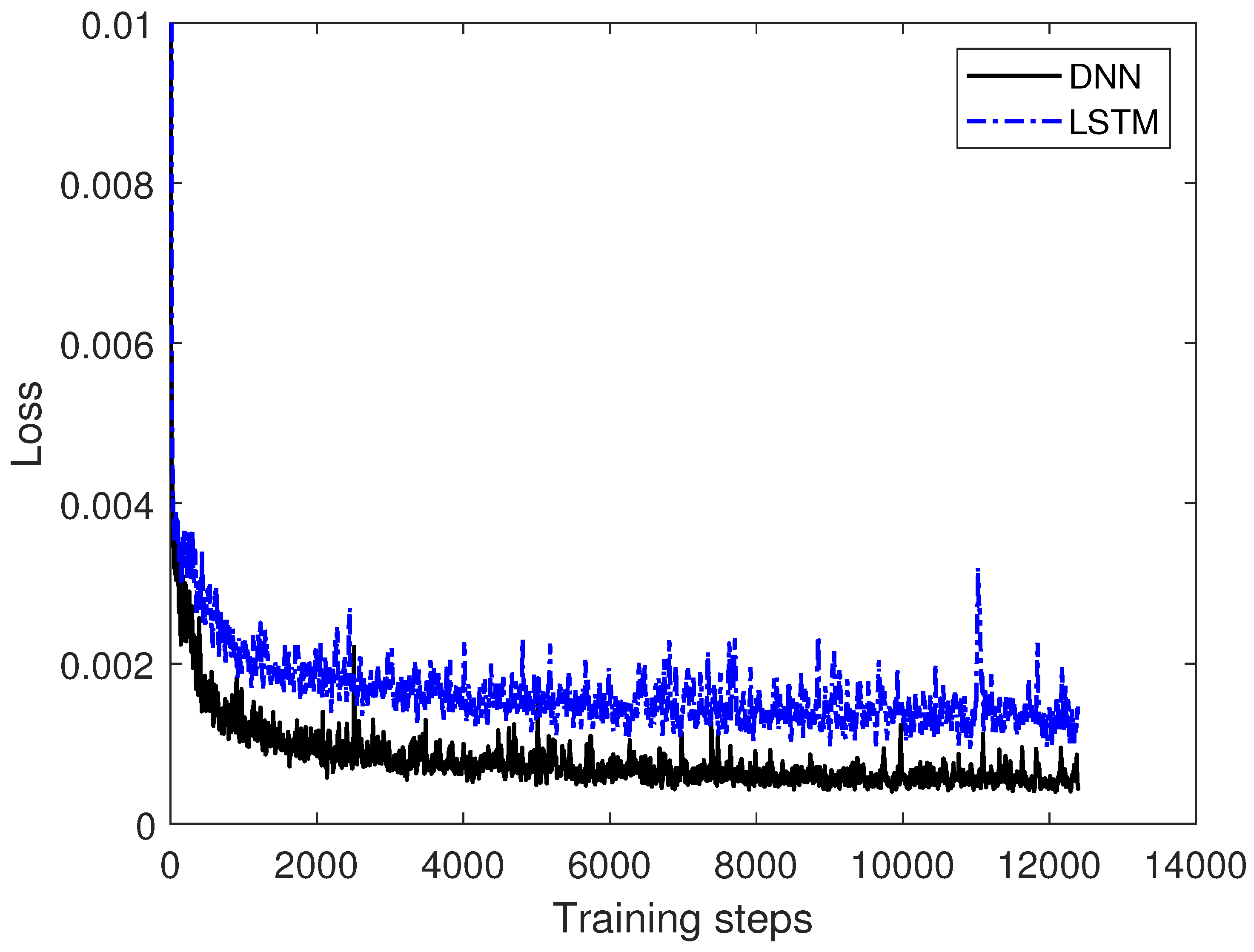
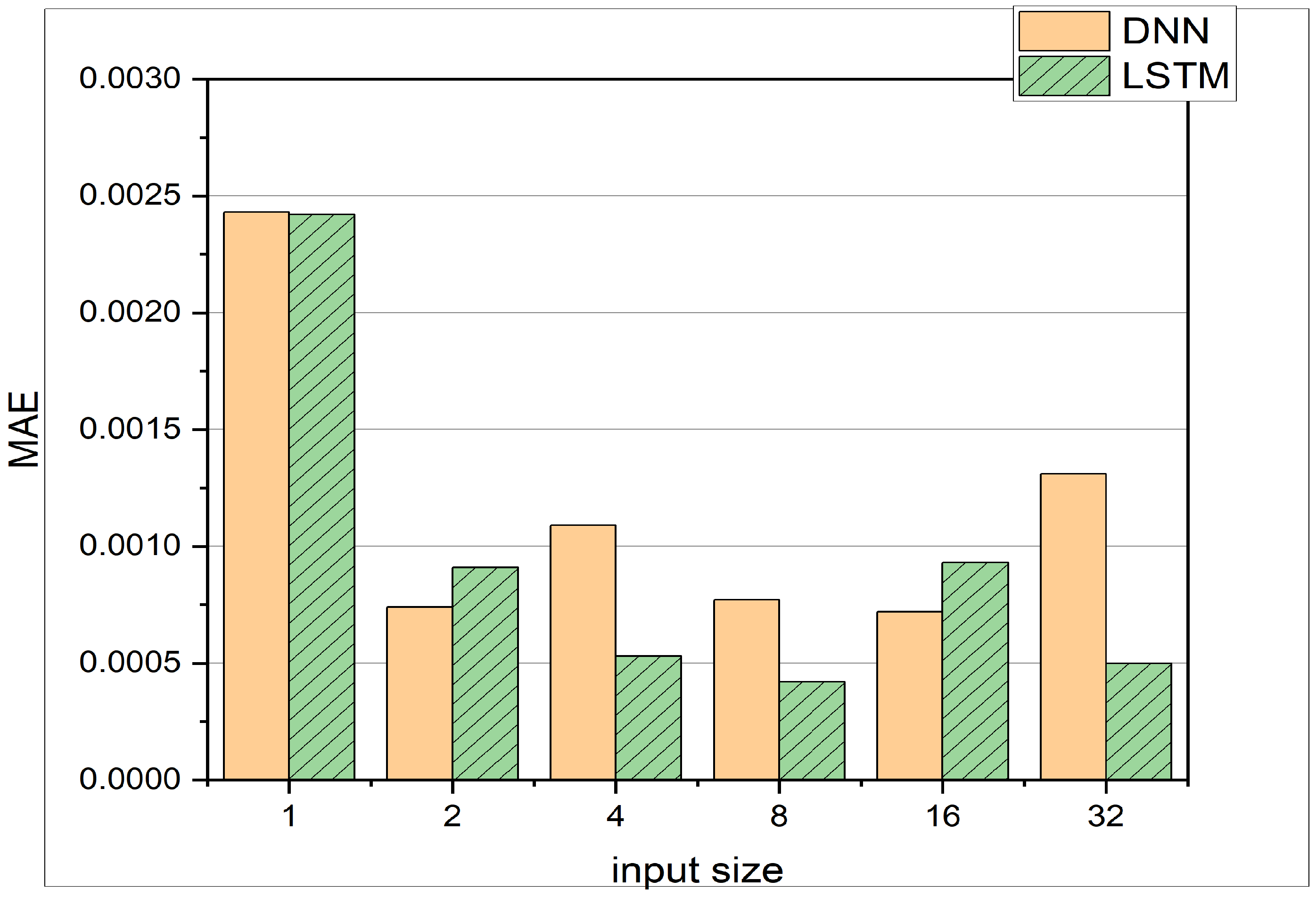
3.2. Comparison between LSTM and DNN
3.3. Intake Temperature
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LSTM | Long short term memory |
| SOC | start of combustion |
| HCCI | homogeneous charge compression ignition |
| ANN | artificial neural network |
| SVR | support vector regression |
| RF | random forest |
| GBRT | gradient boosted regression trees |
| WNN | wavelet neural network |
| SGA | stochastic gradient algorithm |
| NARX | non-linear autoregressive with exogenous input |
| KNN | K-nearest neighbors |
| SVM | support vector machines |
| IMEP | indicated mean effective pressure |
| MAE | mean average error |
| MSE | mean squared error |
| DNN | deep neural network |
References
- Fathi, M.; Jahanian, O.; Shahbakhti, M. Modeling and controller design architecture for cycle-by-cycle combustion control of homogeneous charge compression ignition (HCCI) engines—A comprehensive review. Energy Convers. Manag. 2017, 139, 1–19. [Google Scholar] [CrossRef]
- Chiang, C.J.; Singh, A.K.; Wu, J.W. Physics-based modeling of homogeneous charge compression ignition engines with exhaust throttling. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2022, 237, 1093–1112. [Google Scholar] [CrossRef]
- Yoon, Y.; Sun, Z.; Zhang, S.; Zhu, G.G. A control-oriented two-zone charge mixing model for HCCI engines with experimental validation using an optical engine. J. Dyn. Syst. Meas. Control 2014, 136, 041015. [Google Scholar] [CrossRef]
- Zeng, X.; Wang, J. A physics-based time-varying transport delay oxygen concentration model for dual-loop exhaust gas recirculation (EGR) engine air-paths. Appl. Energy 2014, 125, 300–307. [Google Scholar] [CrossRef]
- Souder, J.S.; Mehresh, P.; Hedrick, J.K.; Dibble, R.W. A multi-cylinder HCCI engine model for control. In Proceedings of the ASME International Mechanical Engineering Congress and Exposition, Anaheim, CA, USA, 13–19 November 2004; Volume 47063, pp. 307–316. [Google Scholar]
- Hikita, T.; Mizuno, S.; Fujii, T.; Yamasaki, Y.; Hayashi, T.; Kaneko, S. Study on model-based control for HCCI engine. IFAC-PapersOnLine 2018, 51, 290–296. [Google Scholar] [CrossRef]
- Chiang, C.J.; Stefanopoulou, A.G.; Jankovic, M. Nonlinear observer-based control of load transitions in homogeneous charge compression ignition engines. IEEE Trans. Control. Syst. Technol. 2007, 15, 438–448. [Google Scholar] [CrossRef]
- Su, Y.H.; Kuo, T.F. CFD-assisted analysis of the characteristics of stratified-charge combustion inside a wall-guided gasoline direct injection engine. Energy 2019, 175, 151–164. [Google Scholar] [CrossRef]
- Ramesh, N.; Mallikarjuna, J. Evaluation of in-cylinder mixture homogeneity in a diesel HCCI engine—A CFD analysis. Eng. Sci. Technol. Int. J. 2016, 19, 917–925. [Google Scholar] [CrossRef]
- Yaşar, H.; Çağıl, G.; Torkul, O.; Şişci, M. Cylinder pressure prediction of an HCCI engine using deep learning. Chin. J. Mech. Eng. 2021, 34, 7. [Google Scholar] [CrossRef]
- Maass, B.; Deng, J.; Stobart, R. In-Cylinder Pressure Modelling with Artificial Neural Networks; Technical Report, SAE Technical Paper; SAE International: Warrendale, PA, USA, 2011. [Google Scholar]
- Erikstad, S.O. Design patterns for digital twin solutions in marine systems design and operations. In Proceedings of the 17th International Conference Computer and IT Applications in the Maritime Industries COMPIT’18, Pavone, Italy, 14–16 May 2018; pp. 354–363. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Wei, L.; Ding, Y.; Su, R.; Tang, J.; Zou, Q. Prediction of human protein subcellular localization using deep learning. J. Parallel Distrib. Comput. 2018, 117, 212–217. [Google Scholar] [CrossRef]
- Martín, A.; Lara-Cabrera, R.; Fuentes-Hurtado, F.; Naranjo, V.; Camacho, D. Evodeep: A new evolutionary approach for automatic deep neural networks parametrisation. J. Parallel Distrib. Comput. 2018, 117, 180–191. [Google Scholar] [CrossRef]
- Mohammad, A.; Rezaei, R.; Hayduk, C.; Delebinski, T.; Shahpouri, S.; Shahbakhti, M. Physical-oriented and machine learning-based emission modeling in a diesel compression ignition engine: Dimensionality reduction and regression. Int. J. Engine Res. 2022, 24, 904–918. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, J. Machine learning assisted analysis of an ammonia engine performance. J. Energy Resour. Technol. 2022, 144, 112307. [Google Scholar] [CrossRef]
- Jafarmadar, S.; Khalilaria, S.; Saraee, H.S. Prediction of the performance and exhaust emissions of a compression ignition engine using a wavelet neural network with a stochastic gradient algorithm. Energy 2018, 142, 1128–1138. [Google Scholar]
- Gharehghani, A.; Abbasi, H.R.; Alizadeh, P. Application of machine learning tools for constrained multi-objective optimization of an HCCI engine. Energy 2021, 233, 121106. [Google Scholar] [CrossRef]
- Namar, M.M.; Jahanian, O.; Koten, H. The Start of Combustion Prediction for Methane-Fueled HCCI Engines: Traditional vs. Machine Learning Methods. Math. Probl. Eng. 2022, 2022, 4589160. [Google Scholar] [CrossRef]
- Shamsudheen, F.A.; Yalamanchi, K.; Yoo, K.H.; Voice, A.; Boehman, A.; Sarathy, M. Machine Learning Techniques for Classification of Combustion Events under Homogeneous Charge Compression Ignition (HCCI) Conditions; Technical Report, SAE Technical Paper; AE International: Warrendale, PA, USA, 2020. [Google Scholar]
- Janakiraman, V.M.; Nguyen, X.; Assanis, D. Nonlinear identification of a gasoline HCCI engine using neural networks coupled with principal component analysis. Appl. Soft Comput. 2013, 13, 2375–2389. [Google Scholar] [CrossRef]
- Mishra, C.; Subbarao, P. Machine learning integration with combustion physics to develop a composite predictive model for reactivity controlled compression ignition engine. J. Energy Resour. Technol. 2022, 144, 042302. [Google Scholar] [CrossRef]
- Zheng, Z.; Lin, X.; Yang, M.; He, Z.; Bao, E.; Zhang, H.; Tian, Z. Progress in the application of machine learning in combustion studies. ES Energy Environ. 2020, 9, 1–14. [Google Scholar] [CrossRef]
- Luján, J.M.; Climent, H.; García-Cuevas, L.M.; Moratal, A. Volumetric efficiency modelling of internal combustion engines based on a novel adaptive learning algorithm of artificial neural networks. Appl. Therm. Eng. 2017, 123, 625–634. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Gers, F.A.; Schraudolph, N.N.; Schmidhuber, J. Learning precise timing with LSTM recurrent networks. J. Mach. Learn. Res. 2002, 3, 115–143. [Google Scholar]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef]
- Chen, K.; Zhou, Y.; Dai, F. A LSTM-based method for stock returns prediction: A case study of China stock market. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2823–2824. [Google Scholar]
- Aydin, O.; Guldamlasioglu, S. Using LSTM networks to predict engine condition on large scale data processing framework. In Proceedings of the 2017 4th International Conference on Electrical and Electronic Engineering (ICEEE), Ankara, Turkey, 8–10 April 2017; pp. 281–285. [Google Scholar]
- Yuan, M.; Wu, Y.; Lin, L. Fault diagnosis and remaining useful life estimation of aero engine using LSTM neural network. In Proceedings of the 2016 IEEE International Conference on Aircraft Utility Systems (AUS), Beijing, China, 10–12 October 2016; pp. 135–140. [Google Scholar]
- Shi, Z.; Chehade, A. A dual-LSTM framework combining change point detection and remaining useful life prediction. Reliab. Eng. Syst. Saf. 2021, 205, 107257. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Lindemann, B.; Müller, T.; Vietz, H.; Jazdi, N.; Weyrich, M. A survey on long short-term memory networks for time series prediction. Procedia CIRP 2021, 99, 650–655. [Google Scholar] [CrossRef]
- Chui, K.T.; Gupta, B.B.; Vasant, P. A genetic algorithm optimized RNN-LSTM model for remaining useful life prediction of turbofan engine. Electronics 2021, 10, 285. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Körding, K.P.; Wolpert, D.M. The loss function of sensorimotor learning. Proc. Natl. Acad. Sci. USA 2004, 101, 9839–9842. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value | Unit |
|---|---|---|
| Bore | 9 | |
| Stroke | 9.8 | |
| Crankshaft length | 3.9 | |
| Compression ratio | 13 | - |
| Connecting rod length | 12.6 | |
| Intake valve open | 5 | |
| Intake valve close | 58 | |
| Exhaust valve open | 47 | |
| Exhaust valve close | 11 |
| Dataset | Temperature |
|---|---|
| data 1 | 235 |
| data 2 | 245 |
| data 3 | 255 |
| data 4 | 265 |
| data 5 | 235, 245, 255, 265 |
| Input Size | Output Size | LSTM | |
|---|---|---|---|
| MAE | MSE | ||
| 2 | 2 | 0.00136 | 1 × |
| 4 | 2 | 0.00268 | 1 × |
| 8 | 2 | 6.7 × | 1 × |
| 2 | 4 | 0.00218 | 7 × |
| 4 | 4 | 0.002 | 1 × |
| 8 | 4 | 8.8 × | 6 × |
| 2 | 8 | 0.00403 | 0.0001 |
| 4 | 8 | 0.00351 | 0.00017 |
| 8 | 8 | 0.00172 | 0.00017 |
| 2 | 16 | 0.00691 | 0.00021 |
| 4 | 16 | 0.00525 | 0.00025 |
| 8 | 16 | 0.003 | 0.00024 |
| 2 | 32 | 0.01043 | 0.00035 |
| 4 | 32 | 0.00822 | 0.00035 |
| 8 | 32 | 0.00429 | 0.00032 |
| 2 | 64 | 0.01708 | 0.00042 |
| 4 | 64 | 0.01012 | 0.00044 |
| 8 | 64 | 0.006 | 0.00037 |
| Hidden Layer Size | Criteria | |
|---|---|---|
| MAE | MSE | |
| 1 | 0.00664 | 0.00044 |
| 2 | 0.00597 | 0.00041 |
| 4 | 0.00551 | 0.0004 |
| 8 | 0.00644 | 0.00041 |
| 16 | 0.00566 | 0.00039 |
| 32 | 0.00543 | 0.00039 |
| 64 | 0.00612 | 0.0042 |
| No. | Window Size | DNN | LSTM | ||
|---|---|---|---|---|---|
| Train | Test | Train | Test | ||
| 1 | 1 | 0.00339 | 0.00243 | 0.00242 | 0.00242 |
| 2 | 2 | 0.00085 | 0.00074 | 0.00096 | 0.00091 |
| 3 | 4 | 0.00082 | 0.00109 | 0.0006 | 0.00053 |
| 4 | 8 | 0.00086 | 0.00077 | 0.00053 | 0.00042 |
| 5 | 16 | 0.00103 | 0.00072 | 0.00043 | 0.00093 |
| 6 | 32 | 0.00119 | 0.00131 | 0.00038 | 0.0005 |
| No. | Dataset | DNN | LSTM | ||
|---|---|---|---|---|---|
| MAE | MSE | MAE | MSE | ||
| 1 | data 1 | 0.02604 | 0.00477 | 0.025 | 0.00583 |
| 2 | data 2 | 0.00962 | 0.00065 | 0.00914 | 0.00078 |
| 3 | data 3 | 0.0096 | 0.00091 | 0.00779 | 0.00074 |
| 4 | data 4 | 0.02707 | 0.01103 | 0.04769 | 0.02539 |
| No. | Input | Dataset | DNN | LSTM | ||
|---|---|---|---|---|---|---|
| MAE | MSE | MAE | MSE | |||
| 1 | P, CA | data 5 | 0.46 | 0.29 | 0.37 | 0.20 |
| 2 | P, CA, T | data 5 | 0.46 | 0.29 | 0.45 | 0.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sontheimer, M.; Singh, A.-K.; Verma, P.; Chou, S.-Y.; Kuo, Y.-L. LSTM for Modeling of Cylinder Pressure in HCCI Engines at Different Intake Temperatures via Time-Series Prediction. Machines 2023, 11, 924. https://doi.org/10.3390/machines11100924
Sontheimer M, Singh A-K, Verma P, Chou S-Y, Kuo Y-L. LSTM for Modeling of Cylinder Pressure in HCCI Engines at Different Intake Temperatures via Time-Series Prediction. Machines. 2023; 11(10):924. https://doi.org/10.3390/machines11100924
Chicago/Turabian StyleSontheimer, Moritz, Anshul-Kumar Singh, Prateek Verma, Shuo-Yan Chou, and Yu-Lin Kuo. 2023. "LSTM for Modeling of Cylinder Pressure in HCCI Engines at Different Intake Temperatures via Time-Series Prediction" Machines 11, no. 10: 924. https://doi.org/10.3390/machines11100924
APA StyleSontheimer, M., Singh, A.-K., Verma, P., Chou, S.-Y., & Kuo, Y.-L. (2023). LSTM for Modeling of Cylinder Pressure in HCCI Engines at Different Intake Temperatures via Time-Series Prediction. Machines, 11(10), 924. https://doi.org/10.3390/machines11100924