1. Introduction
Recently, prognostics and health management (PHM) has played a crucial role in the complex and sophisticated modern industrial system, which helps to improve the reliability of equipment [
1,
2,
3], reduce the maintenance cost of industrial systems, and even avoid severe safety accidents. Remaining useful life (RUL) prediction is important part of PHM. RUL is defined as the time that the monitored equipment can work before it fails completely [
4]. The goal of RUL prediction is to model the degradation process and predict the RUL of the system accurately, thus some measures can be taken before the equipment fails completely. RUL prediction has attracted more and more attention from researchers since it helps in improving the intelligent level of operation and maintenance of industrial systems.
Generally, RUL prediction methods can be roughly classified into model-based methods, data-driven methods, and hybrid methods. Model-based methods build a physical model based on the failure mechanism of the system, which describes the degradation process. Thereby the RUL of the system can be predicted. Paris-Erdogan (PE) model is the most widely used physical model in industrial RUL prediction, which is built to describe the crack propagation process of a component [
5]. However, as modern industrial systems become more complex, it becomes more and more difficult to build accurate physical models, and the researchers pay more attention to data-driven RUL prediction methods. Data-driven RUL prediction aims to utilize machine learning methods to model the degradation process of the system and extract informative degradation features from the multi-source data, thus predicting the RUL of the system from the monitoring signals. Hybrid methods try to integrate the advantages of both data-driven and model-based approaches, however, they still face difficulties because still require physical knowledge to model the system, so this approach covers the least publications in past research.
In recent years, thanks to the cheap and high-performance sensors and the development of big data analysis technology, a large amount of monitoring data have become cheap and easy to obtain. These informative monitoring data provide the possibility to construct data-driven RUL prediction methods. Thereby, the data-driven RUL prediction methods have become the most promising RUL prediction method, and attracted many researchers’ focus on this field. Data-driven approaches attempt to use machine learning techniques to learn the degradation patterns of machines from monitoring data [
6]. Researchers have proposed many data-driven RUL prediction methods including some typical methods such as SVR-based methods [
7], hidden Markov model (HMM) methods [
8], convolutional neural network (CNN) [
9] based methods [
10,
11], recurrent neural network (RNN) and long short-term memory (LSTM) [
12] based methods [
13], etc. Deep learning-based methods are currently a popular data-driven RUL prediction method. Deep learning techniques can extract deep features from data without any manually operations. The auto extracted features can be more specific to the task and loss less information, therefore it usually performs well on RUL prediction. For example, in [
10] the researchers proposed a novel deep convolutional neural network-bootstrap-based integrated prognostic approach for RUL prediction, which utilized a deep convolutional neural network–multilayer perceptron (i.e., DCNN–MLP) dual network to simultaneously extract informative representations hidden in both time series-based and image-based features and to predict the RUL. Despite some shortcomings of deep learning technology, such as poor interpretability and high requirements on data and computing resources, it is still been widely studied.
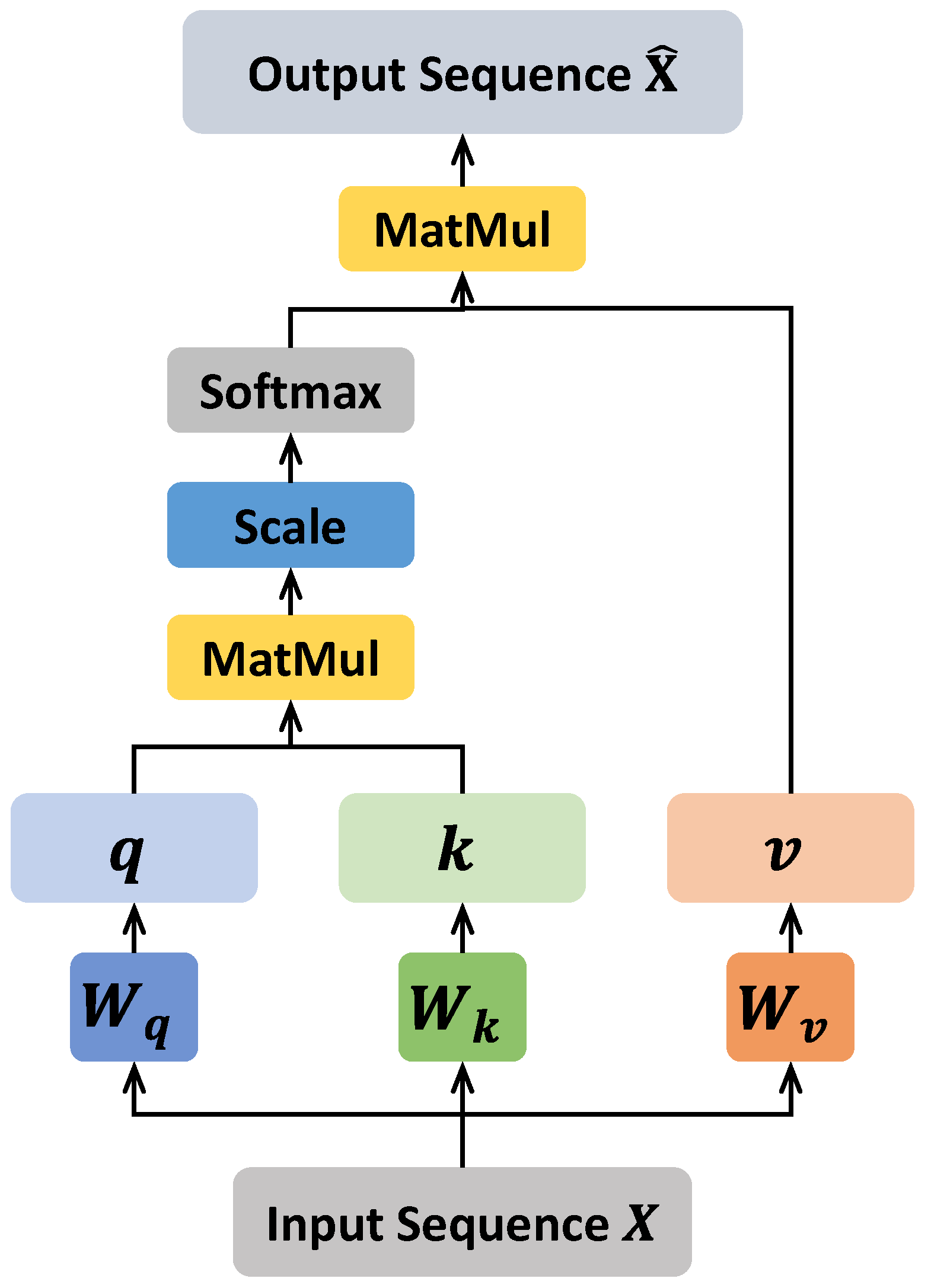
Transformer [
14] is a popular model which has made excellent progress in both natural language processing (NLP) [
15] and computer vision (CV) [
16], where self-attention mechanism is the crucial part of it. The self-attention mechanism can model the global correlation of sequence data or image data, it has a larger receptive field and generalization than CNN-based and RNN-based methods, which is the reason why the self-attention mechanism performs well in both CV and NLP. Due to the outstanding performance of the self-attention mechanism and its naturally suitable for modeling sequence data, many researchers try to apply transformer and self-attention mechanism in RUL prediction [
17,
18,
19,
20,
21]. In [
18], the author proposed a two-stage RUL prediction method based on transformer. Specifically, in the first stage, a feature pre-extraction mechanism is designed to replace manual feature extraction and selection, which will retain more detailed information. In the second stage, an adaptive transformer (AT) model is proposed to achieve RUL prediction from low-level features which combines the advantages of the recurrent model and the novel attention mechanism, which can adaptively and accurately model the complex relationship between high-dimensional features and RUL compared to traditional recurrent models. To overcome the shortcomings of CNN and RNN-based traditional methods, ref. [
20] proposed a full self-attention RUL prediction model without any CNN or RNN module. This model consists of an encoder and decoder, the encoder utilized two paralleled self-attention modules to explore the data from time and sensor aspects and adaptively fuses the feature maps of the two aspects, and the fused feature map is sent to the decoder for RUL prediction.
Although the above mentioned methods provide new ideas and perspectives for RUL prediction, there are still some shortcomings. The problem of corruption data is a common problem in industrial applications. In practice, the common used measure is to directly discard samples with corrupted values and then perform RUL prediction, but this will lead to few-shot problem in the training process. Simply filling the missing values is another way to deal with this problem, such as mean value filling, last value filling, clustering-based missing value filling etc. But these methods often lead to filling errors and are not quite effective in the following prediction task. To deal with this problem, some researchers have proposed a few studies [
22,
23,
24]. For example, in [
22], the author proposed an integrated imputation and prediction scheme based on extreme learning machines. First, missing value imputation is performed using single imputation and multiple imputation. Next, the imputed data is used for RUL prediction using various prediction modules. In [
23], multivariate functional principal component analysis (MFPCA) is used for missing value imputation and multi-sensor feature fusion, and the fused metrics are used in log-location-scale regression for RUL prediction. The above methods are essentially two-stage methods, which include two stages: first performing the missing values imputation, and then use the filled data for RUL prediction. There are some drawbacks in these methods: the missing value imputation stage does not fully exploit the effective information in the available data, which will lead to filling error, and this will lead to poorly RUL prediction performance. What’s more, the goals of the two stages of these methods are inconsistent, that is, the goal of the data imputation stage is inconsistent with the goal of the RUL prediction stage, which will cause the model to fail to achieve optimal.
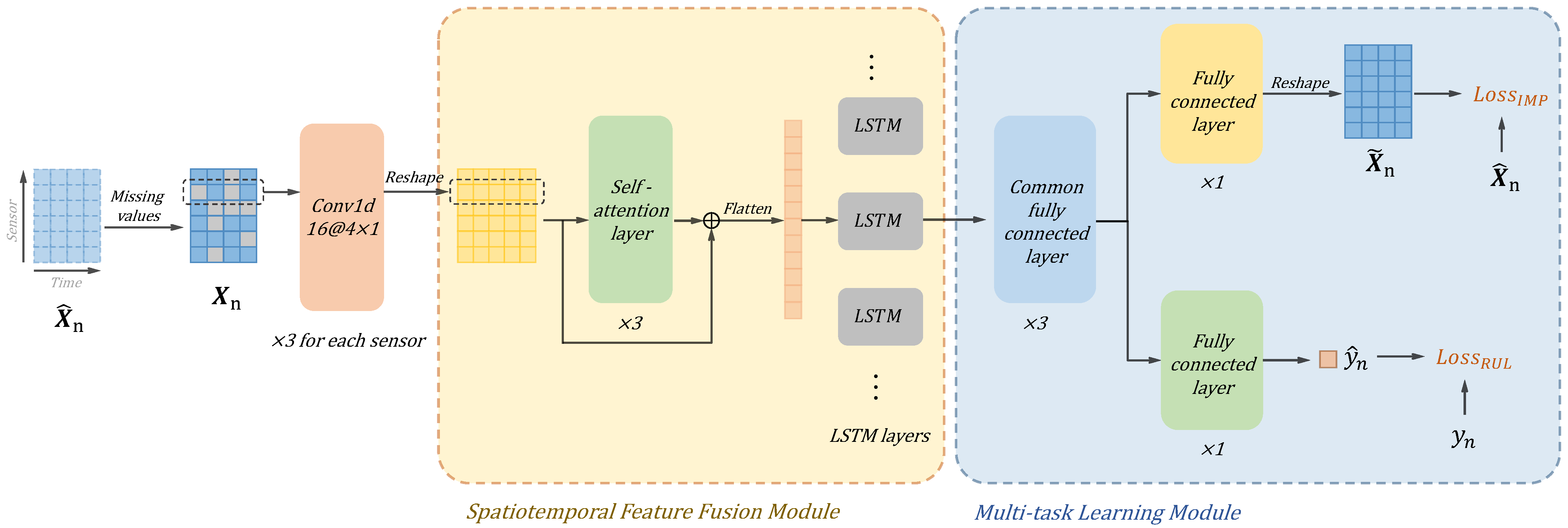
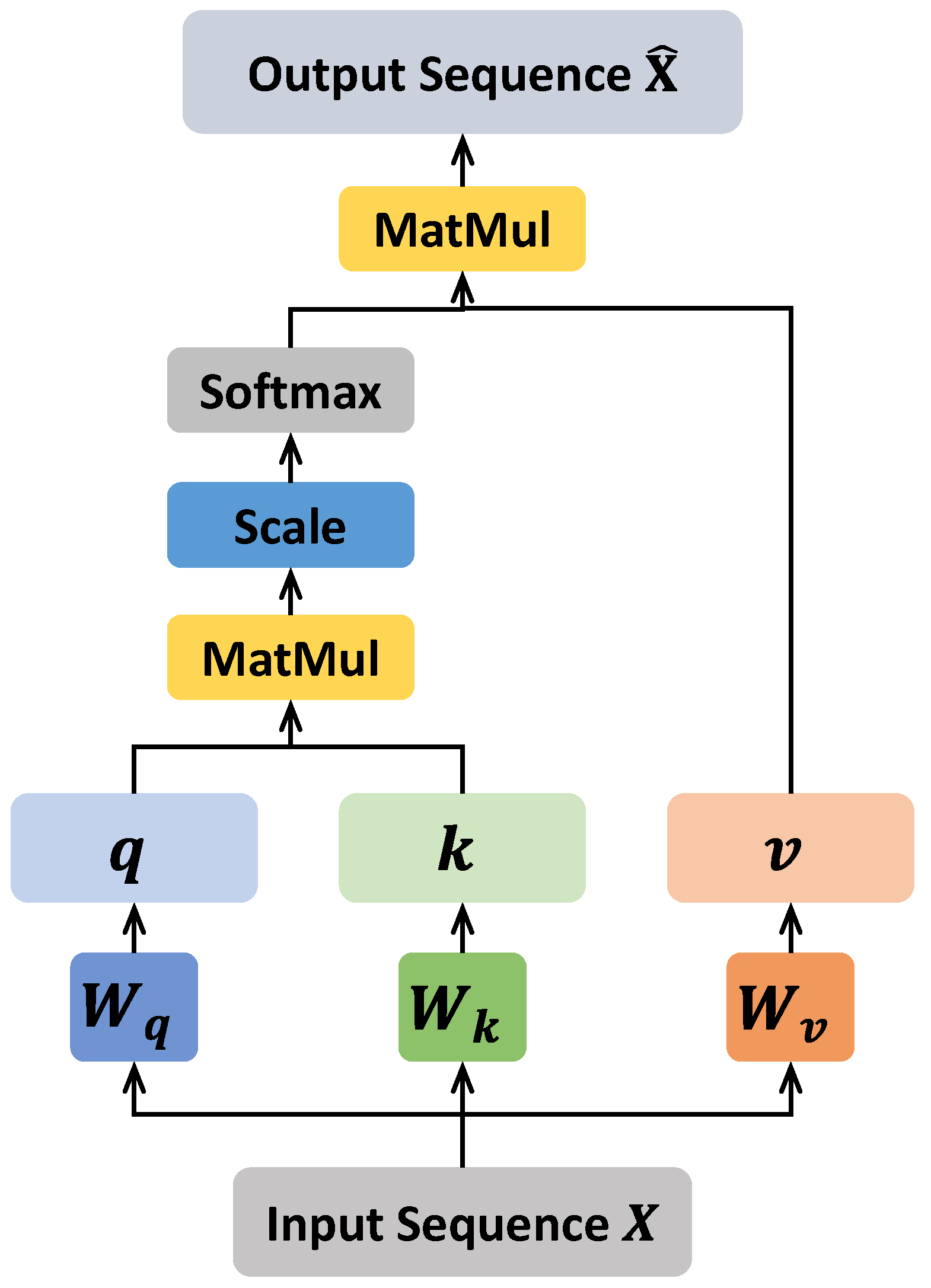
To handle the problems mentioned above, a novel deep learning model is proposed in this work, which is named self-attention-based multi-task network (SMTN). There are two main modules in SMTN to deal with the missing values problem, namely the spatiotemporal feature fusion module and the multi-task learning module. The former module aims at fully exploiting the deep information in the available data, and the latter one tries to recover the complete representation for better RUL prediction. The novelty of this work lies in proposing a novel multi-task deep learning framework dealing with missing values in RUL prediction. The object of the proposed method is to predict the RUL accurately with missing values in the input data, which is common in real world applications. Specifically, in order to accurately predict RUL when there are missing values in the input data, the missing value imputation task is implemented to extract features containing complete degradation information, and such features are utilized for RUL prediction. In order to fully exploit the information in incomplete data, a spatiotemporal feature fusion mechanism combining self-attention mechanism and LSTM is proposed, which can effectively fully extract information from complete and incomplete data. In general, the novelty of the work is to propose a new paradigm that helps a lot in RUL prediction under missing values. The contributions of this work are summarized as follows:
A novel self-attention-based deep learning model is proposed which can effectively handle the missing values problem in RUL prediction.
Two mechanisms are designed in the proposed SMTN to deal with the missing values in different ways, namely the spatiotemporal feature fusion module and multi-task learning module.
Extensive experimental studies verified the effectiveness of the proposed method.
The rest is organized as follows: the details of the proposed method are described in
Section 2,
Section 3 shows the experimental studies and the results, and finally,
Section 4 concludes this work.
3. Experimental Study
To comprehensively verify the performance of the proposed method, we conduct experimental studies, including comparative experiments, ablation studies, and parameter sensitivity analysis. A detailed description will be given in the following sections.
3.1. Data Description and Preprocessing
The dataset used in our experimental study is the simulated aero-engine degradation data [
27] created by NASA, which is also named C-MAPSS. Four sub-datasets are included in the C-MAPSS dataset, namely FD001, FD002, FD003, and FD004 which consists of training set and testing set in each of them. Each training set contains a sets of multi-sensor degradation signals corresponding to different engines under different fault modes and operation conditions, and the same is true for the test set. The difference is that the signal in the training set is collected from minor initial fault until it fails completely, while the signal in the testing set are ended at some time point before it fails completely. The real RUL is provided in all training and testing samples, and we applied piece-wise RUL as the target RUL according to [
28]. The details of C-MAPSS are shown in
Table 1.
As the previous studies [
21,
30], we performed sensor selection on this dataset which means removing the meaningless sensor data that has no degradation information.
The max-min normalization is utilized after sensor selection, which is a commonly used method in previous studies. The purpose of normalization is to map the features in different scales to the same scale, thereby the model can be well trained instead of failure due to pay too much attention on the large scale features and ignore the small scale features. Here, we map the features to
using the following formula:
where
i and
j stands for the number of sensor and data point,
and
denotes the raw data and normalized data,
and
are the maximum and minimum values of sensor
i, respectively.
In the proposed method, both the data with missing values and the corresponding ground-truth of the complete data are required, which is determined by the proposed method since missing value imputation is a supervised task. Or simply put, the complete values corresponding to the missing values are needed in calculating the loss function of missing values imputation task. Thus, the dataset with real world missing values are not applicable in the proposed method, since there are no complete values corresponding to the missing values can be obtained as the label in missing values imputation task, as a result we perform artificial missing value simulation on the complete data to construct the dataset we need. To some extent, the simulation of missing values is part of the proposed method, not only for experimental studies.
A variety of datasets with different overall missing rates are constructed, where the missing rates range from 0 to 0.8. There is a assumption that the missing values can be detected, and the missing values are simply set to 0. In order to improve the robustness of the model, instead of simply removing values randomly, we perform different degrees of value missing according to the sensor importance given in the literature [
31]. That is, the more important the sensor is, the higher the missing rate is set. By recovering the important sensor data, the model can learn to capture the important information.
After normalization and missing values simulation, we implement sliding window processing with step size 1 to slice the time series signals to a series of samples. That is, each sample is a matrix , where w is the length of the sliding window and S is the number of sensors, and there are overlapping time points between adjacent samples. In our experiments, w and S are set to 30 and 14, respectively.
3.2. Experimental Settings and Metrics
In our experiments, there are several hyperparameters in the proposed method to be selected, we performed the grid searching method to select the proper value. Specifically, the number of the self-attention layers is 3, the number of LSTM layers is 2, and the hidden size in the LSTM is 512. In the objective function, the α is set to be 0.35. We used the Adam optimizer to perform the model training, and the learning rate, batch size, and epochs are 0.001, 128, and 300, respectively. The model is initialized with the Xavier uniform initializer [
32]. In the selected comparison methods in
Section 3.4, the support vector regression (SVR) and multi layer perceptron (MLP) are implemented using the classic machine learning library
with default values of the training parameters. For the deep long-short term memory (DLSTM) [
33], we implement it according to the paper and adapt it to our data dimension. For the feature-attention based bidirectional gated recurrent unit CNN model (AGCNN) [
29] and deep convolution neural network (DCNN) [
34], we constructed the models with the given parameters in the paper, then applied them to our datasets. All experiments are performed on a server with 64-bit Ubuntu 18.04, which has a GeForce RTX 2080 Ti GPU with 12 GB memory. All the reported results are an average of five times.
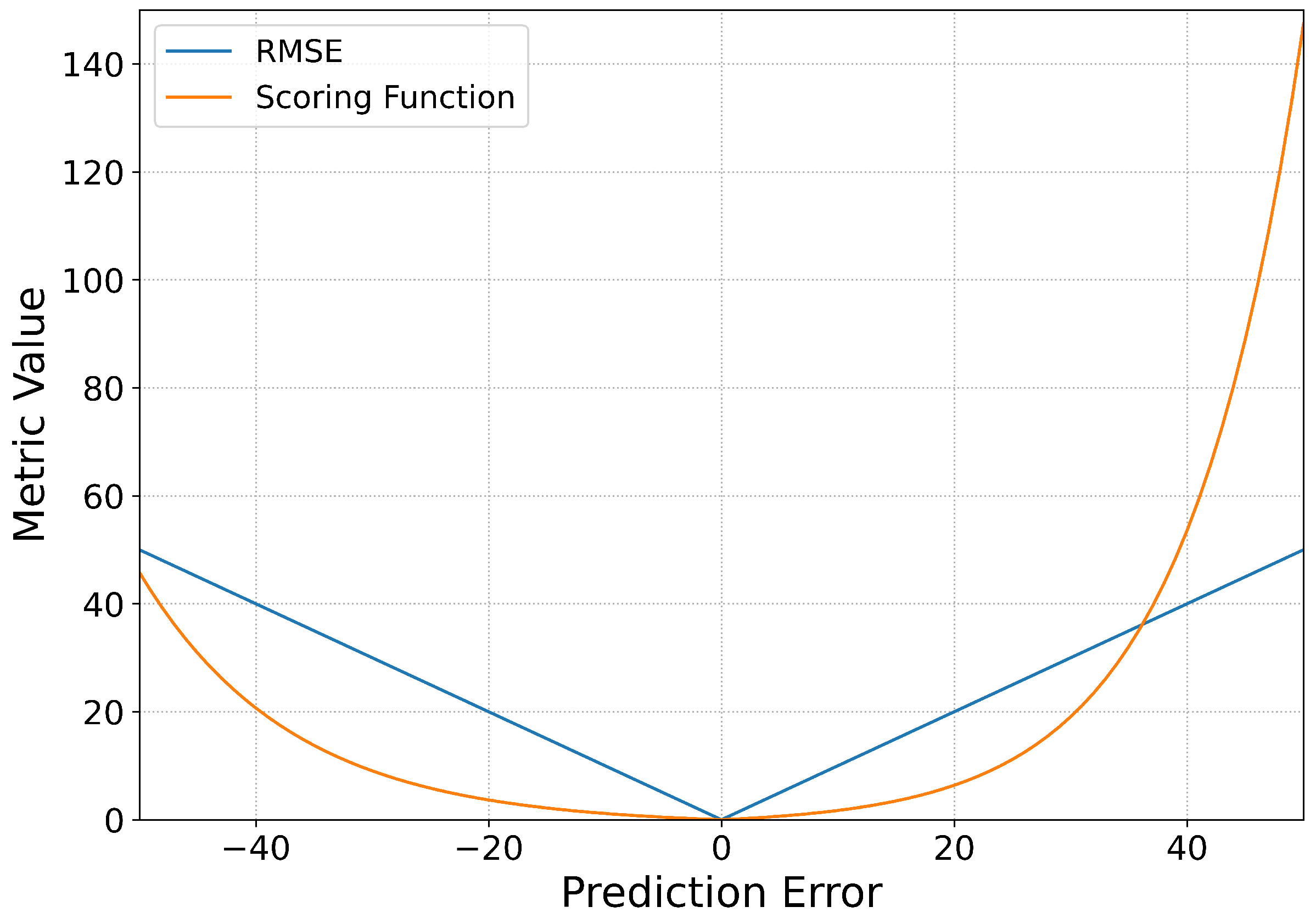
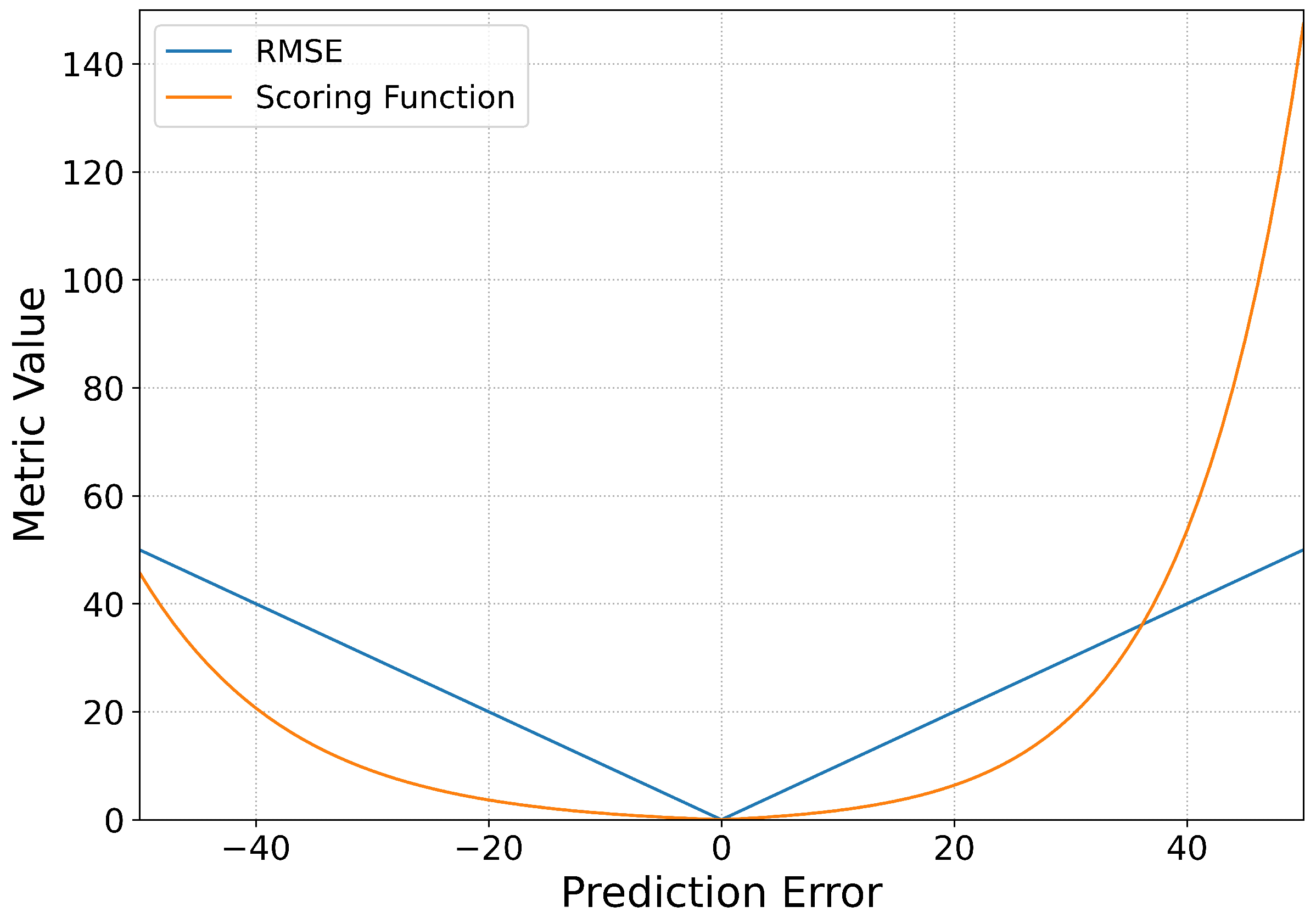
To evaluate and compare the performance of the proposed model, two metrics are used here which are root mean square error (RMSE) and the scoring function in [
27]. RMSE is widely used to evaluate the performance of regression task, and the scoring function is a specially designed metric for RUL prediction task. The RMSE is calculated with
where
N means the number of samples,
and
denote the predicted value and the target RUL of sample
n, respectively.
The scoring function is designed to overcome the shortcomings of RMSE, which can penalize the earlier and later prediction in different degrees, this is important in real industrial applications. The scoring function is defined as
where
E denotes the total number of testing engines,
and
denote the predicted RUL and the target RUL of the last sample of engine
e, respectively. As it defined, the scoring function penalizes more severe on late prediction. RMSE and the scoring function are visualized in
Figure 3.
Intuitively, it can be seen on the positive axis of prediction error in
Figure 3 that when the predicted RUL is larger than the actual RUL, which means late prediction and usually leads to severe accidents, the scoring function imposes a larger penalty on the error. While under the situation of earlier prediction on the negative axis of prediction error, the scoring function penalizes less than the former case. However, the RMSE is symmetrical about 0 which means paying equal attention to the earlier and later prediction cases that lead to different degrees of harm.
3.3. Ablation Study
To deal with the RUL prediction problem under missing values, there are two main measures in SMTN: spatiotemporal feature fusion based on self-attention mechanism and multi-task learning. To verify the effectiveness of these designs, we conduct ablation studies on FD003 subset. Specifically, first we validate the role of the spatiotemporal feature fusion module in RUL prediction. By removing the spatiotemporal fusion module from SMTN, which is named SMTN
, we directly input the features extracted by the CNN into the multi-task learning module and compare the prediction performance under different missing rates with the standard version SMTN. Next, to study the effectiveness of the multi-task learning module, we implement the ablation study by setting the hyperparameter alpha to 0, which is named SMTN
. That is, the missing value imputation module is not optimized, which is equivalent to using only the RUL prediction module. The performance is also compared with the standard version. The experimental results of the above two cases are shown in
Table 2 and
Table 3, respectively.
Note that the
is defined as
where
denotes the RMSE of the two ablated models, namely SMTN
and SMTN
in
Table 2 and
Table 3, respectively, and
stands for the RMSE of standard version model, namely
.
The results in
Table 2 show that the RUL prediction performance under missing values of SMTN
is much lower than that of the standard version. In terms of RMSE, even though there are no missing values in the data, the standard version SMTN is improved by about 20% compared with SMTN
. As the increase of the missing rate, the improvement of the RMSE value remains at about 20%, until the missing rate reaches more than 0.6, the improvement ratio is reduced to about 10%. The reason lies in that the spatiotemporal fusion module can effectively fully explore and fuse the available information in the input data from both the time and space dimensions, and this is critical to RUL prediction both under and no under missing values. However, without the mechanism of effective fusion of spatiotemporal features, the RUL prediction accuracy of the model is greatly reduced. Thus, the results fully demonstrate that the spatiotemporal module is crucial in the proposed model.
Table 3 compared the RUL prediction performance under different missing rates using multi-task learning and not using multi-task learning. In general, the performance of SMTN that using multi-task learning improves a lot than SMTN
that not using it, but the improvement is not significant when the missing rate is too low or too high. For the former case, there are less information losing in the data and the general method is sufficient for dealing with this problem, multi-task learning cannot give full play to its advantages. When the missing rate is too high, the excessive information loss makes multi-task learning unable to obtain better prediction performance because it cannot recover the missing values with few available data. In general, the multi-task learning can achieve better RUL prediction when the missing rate is not too high or too low, because multi-task learning can obtain a hidden representation containing complete information by recovering the missing values with the available data, and this representation can lead to better RUL prediction performance.
3.4. Comparative Experiment
To investigate the performance of the proposed method for RUL prediction in values missing scenarios, comparative experiments are conducted between the proposed method and some typical methods. We selected a variety of typical comparison methods including SVR, MLP, DLSTM, DCNN, and AGCNN, and reproduced the results reported in the paper as much as possible, and then applied them to our dataset. The comparison results using RMSE and the score are shown in
Table 4.
It can be seen that the proposed method comprehensively outperforms the compared methods. Generally, the classical SVR and MLP methods perform far less well than relatively advanced methods, especially when encountering the missing values. The reason is that they cannot effectively exploit the abstract deep features in the data. The typical deep learning methods such as DCNN and AGCNN are basically the same as the proposed method when there are no missing values, but when encountering a lot of missing values in the data, the proposed method surpasses other compared methods. The reason is that there are various designed mechanisms for values missing problem in the proposed method.
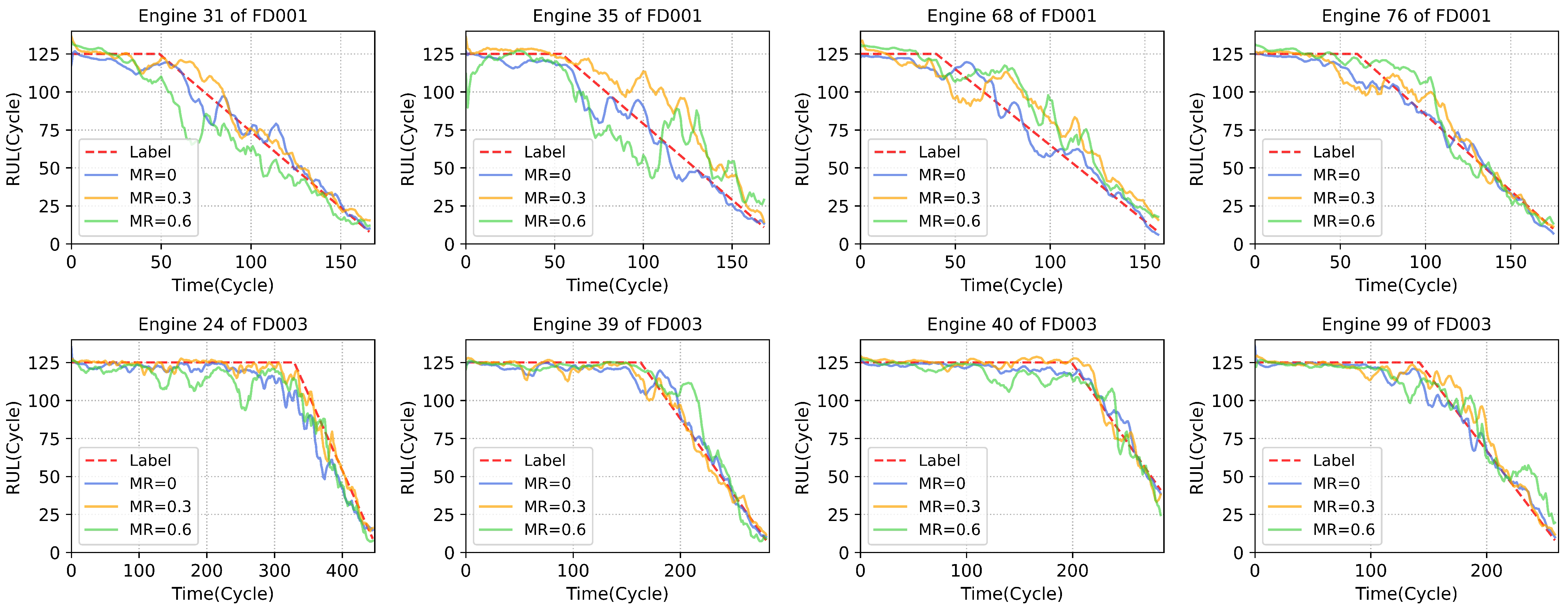
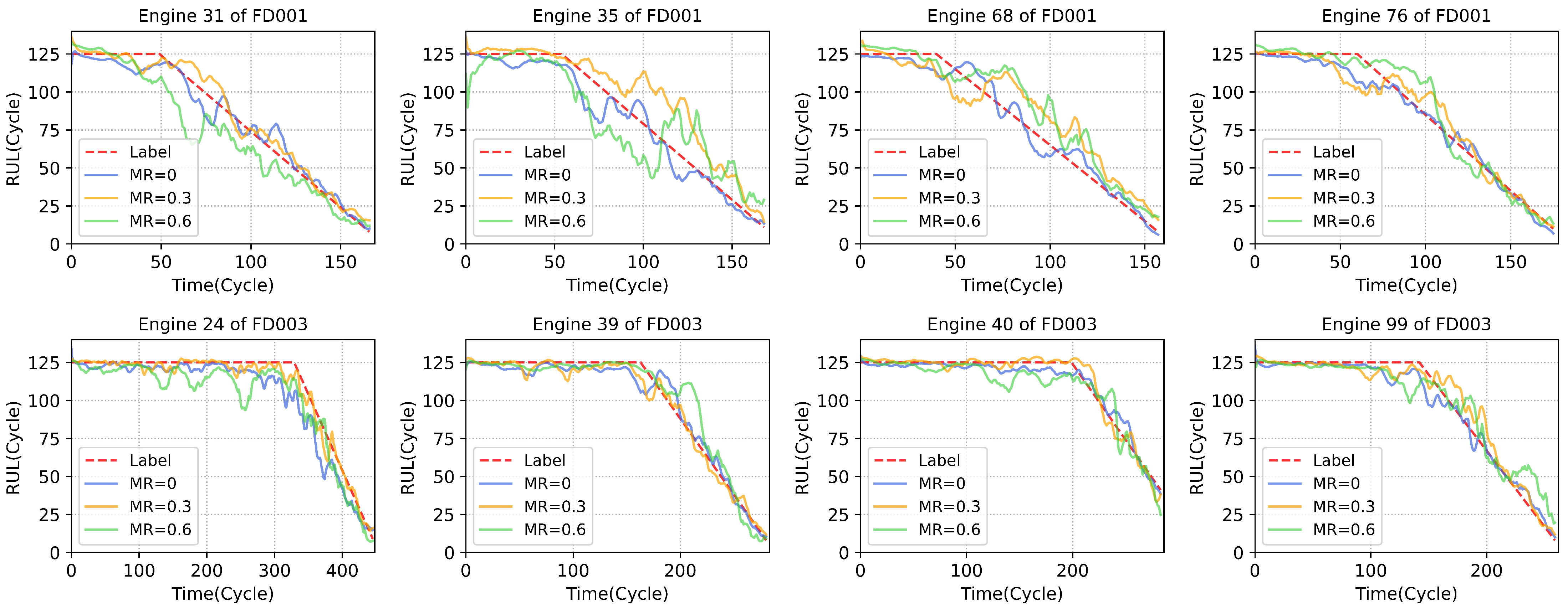
Firstly, the spatiotemporal feature extracting and fusion module can effectively exploit and integrate the information in the available data, which provides the guarantee for high-performance RUL prediction under values missing. The effectiveness is guaranteed by the ability of the self-attention mechanism to model the correlations between different sensors, which contains the spatial information, and the LSTM layers can fuse the features along time steps in the output representations which utilizes the history information of degradation. The multi-task learning further improves the performance under missing values. The missing value imputation task can recover the missing values, thus with the assistance of the missing values imputation task, the representations containing complete information can be effectively extracted by the model, which is not available in the compared methods. To demonstrate the RUL prediction performance of the proposed method intuitively, we select some typical samples to show the prediction performance of SMTN in
Figure 4.
3.5. Parameter Sensitivity Analysis
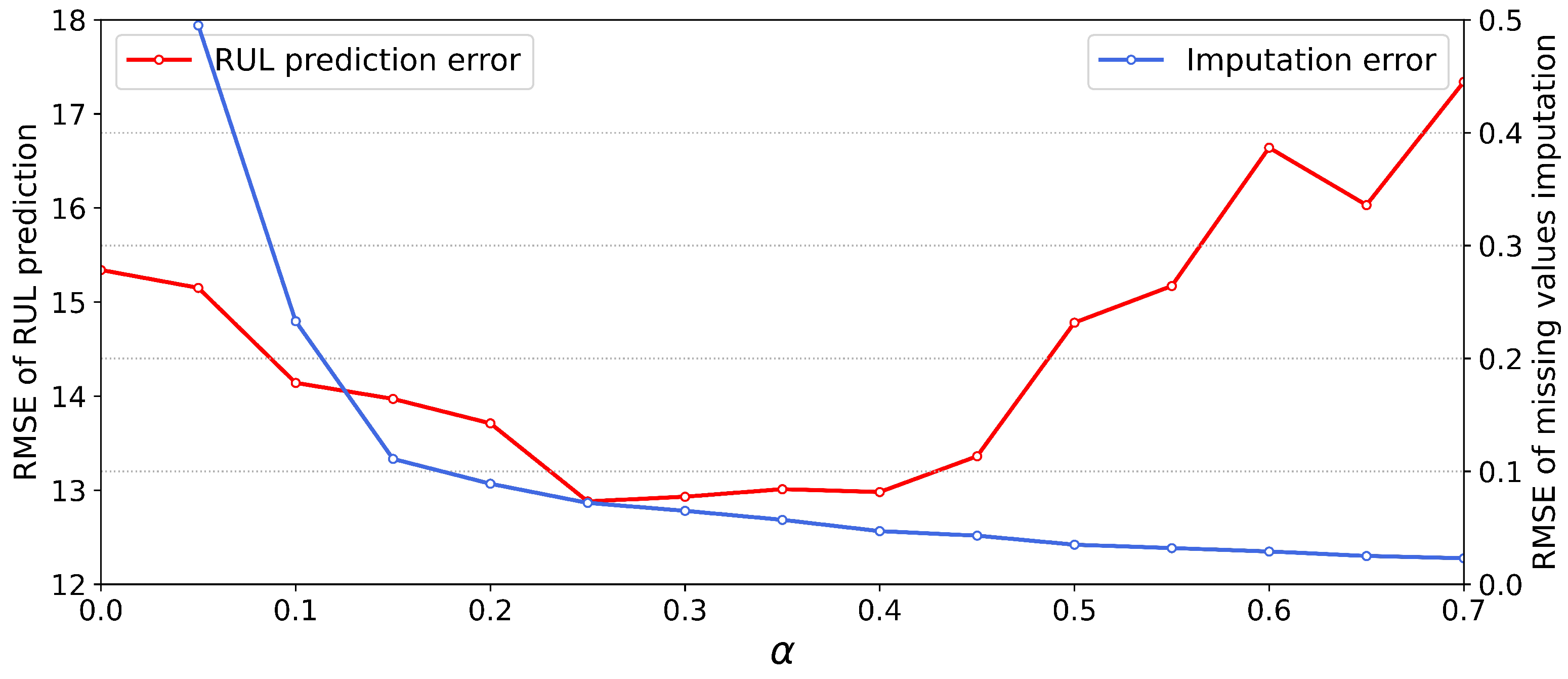
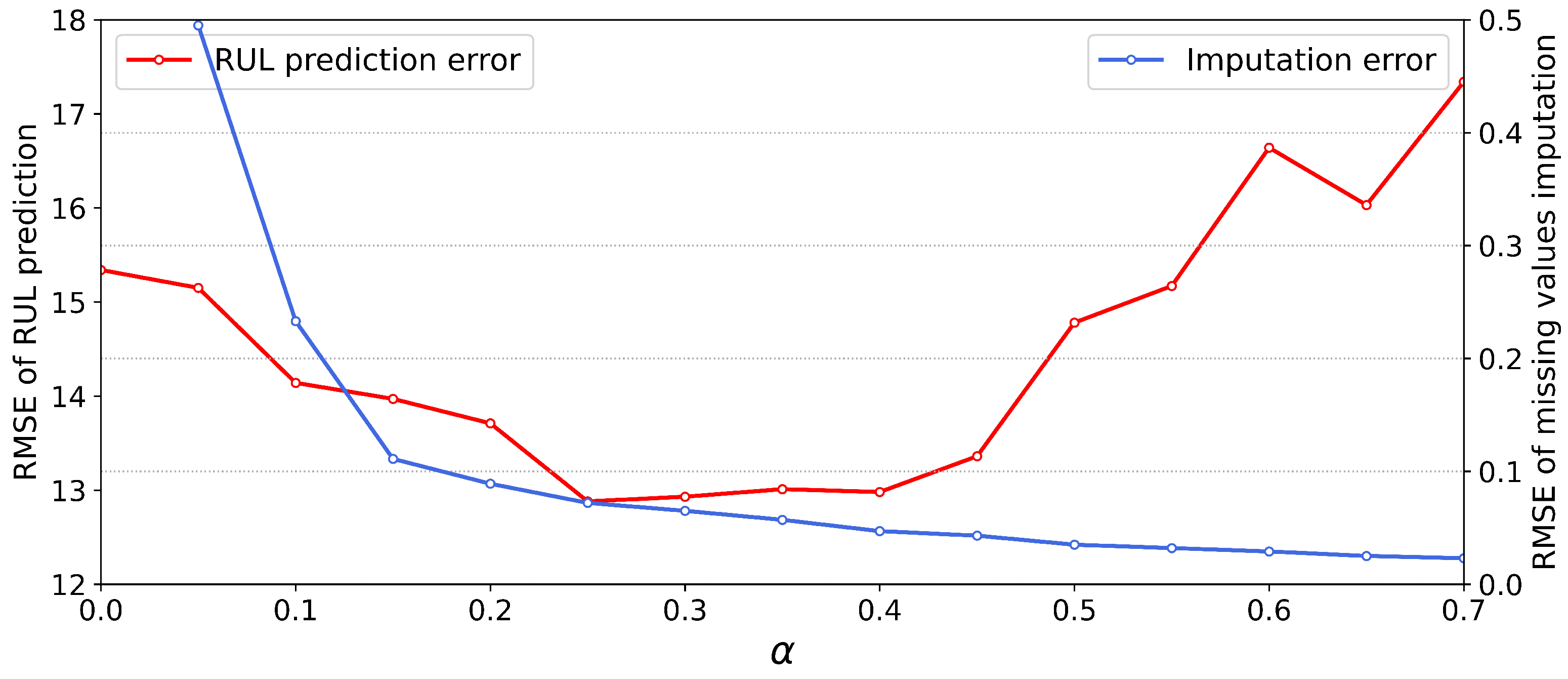
In our multi-task approach, the contribution of the two tasks to the model optimization process is controlled by the hyper-parameter alpha, which determines the proportion of loss in the objective function for the missing values imputation task and the RUL prediction task. The inappropriate parameters will lead to the degradation of the performance of the model because there need a trade-off between two tasks. In order to investigate the impact of the choice of
on the model performance, we conducted experiments on the FD003 dataset under missing rate of 0.4. We set different
and then training and testing the model, the RUL prediction error and missing values imputation error are shown in
Figure 5.
The blue and red line represents the RMSE value of missing values imputation task and RUL prediction task, respectively. When which means the missing values imputation module is not trained, the output by the missing values imputation module is equivalent to a random value, and the RMSE is very large and meaningless. When , the imputation error is significantly reduced, and the RUL prediction performance is slightly improved. This indicates that the missing value imputation module is effectively optimized and recovers the missing values to a certain degree. When is further increased, the performance of the model is also improved accordingly and reaches its peak until , and the missing value imputation error tends to stabilize. When is further increased, it can be seen that the error of missing value imputation is still slowly decreasing, but the performance of RUL prediction becomes worse. This is because an excessively large alpha value makes the model pay too much attention to the accuracy of missing value imputation, which leads to overfitting of the missing value imputation module. Thus, the hidden representation of the middle layer contains too much noise information that is useless for RUL prediction, which leads to the deterioration of RUL prediction performance. Note that the results we show were obtained with a certain missing rate of 0.4 for FD003, and in fact we have experimented with a variety of missing rates and the results show that the optimal value of is close under different missing rates, and the best is set to 0.25 accordingly.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}