

A Lightweight Aerial Power Line Segmentation Algorithm Based on Attention Mechanism


Abstract
:1. Introduction
- (1)
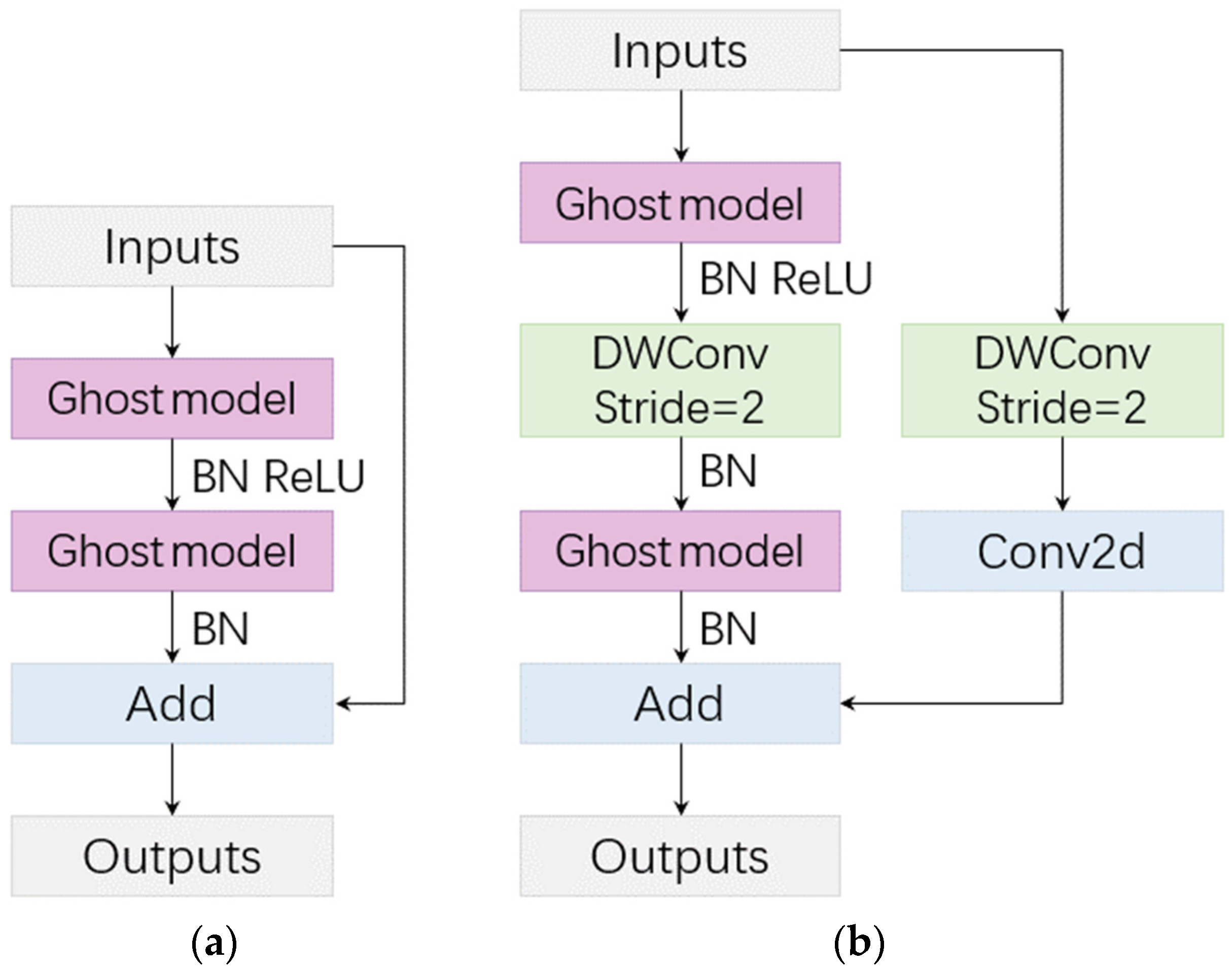
- GhostNet [17] proposed by Han et al. is an efficient lightweight network whose main component is the Ghost bottleneck. Therefore, we proposed using a lightweight structure combining traditional convolution with the Ghost bottleneck as the encoder of the model G-UNets to extract power line features. At the same time, in the encoder stage of G-UNets, a multi-scale input fusion strategy was adopted to reduce the loss of context information, which significantly reduces the amount of Y-UNet parameters while ensuring segmentation accuracy.
- (2)
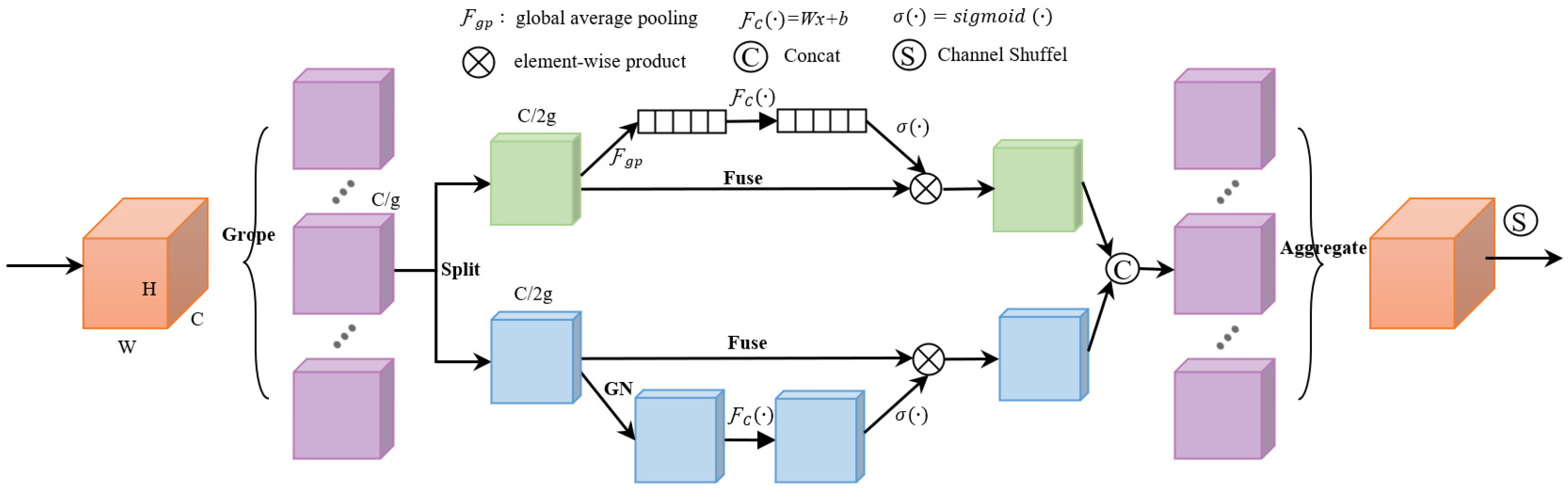
- The spatial attention module in the upsampling process of Y-UNet was replaced by permutation attention that effectively combines spatial and channel attention, and the feature map was enhanced from the channel and space dimensions to improve the model segmentation accuracy.
- (3)
2. Basic Principle of Y-UNet
3. G-UNets
3.1. Overall Structure of G-UNets
3.2. Encoder Structure
3.3. Shuffle Attention
3.4. Loss Function
4. Experiment and Result Analysis
4.1. Experimental Environment Configuration and Data
4.2. Evaluation Indicators
4.3. G-UNets Model Training
4.4. Exploring the Effectiveness of G-UNets
- (1)
- Comparing the experimental results of Y-UNet and Y-UNet_L, the F1-Score and IoU of Y-UNet_L using the weighted mixed loss function are improved by 1.12% and 1.31%, respectively.
- (2)
- Compared with Y-UNet_L, after improvement 1 selects a lightweight structure to extract power line features in the coding stage, its F1-Score and IoU are only slightly reduced, but the amount of network parameters is greatly reduced. This is due to the use of depthwise separable convolutions in the Ghost bottleneck structure, which can trade a small loss of accuracy for a large memory reduction.
- (3)
- Compared with Y-UNet, the improved methods 1–3 proposed have a certain improvement in F1-Score and IoU evaluation indicators, and compared with the Y-UNet parameter amount reduced by about 73%, indicating that the lightweight feature extraction method combined with the traditional convolution module and Ghost bottleneck, the multi-scale input fusion strategy, the replacement of the attention replacement AM module, and the weighted hybrid loss function is effective in this paper. The proposed improvement method can improve the network. The segmentation accuracy greatly reduces the number of network parameters.
- (4)
- From the perspective of F1-Score and IoU evaluation indicators, compared with Y-UNet, the improved method and the DeeplabV3+ network, the G-UNets proposed in this paper are the best in both F1-Score and IoU indicators. They reach 89.24% and 82.98%, respectively, which are 2.19% and 2.85% higher than Y-UNet, and far surpass the DeeplabV3+ network. In terms of parameter quantity, G-Unets is 6.808M, which is about 26.55% of Y-UNet and is only slightly larger than the DeeplabV3+ network. To test the model segmentation speed on the power line test set, G-UNets saves about 25% of the time to segment a graph compared to Y-UNet. It can be seen that while improving the accuracy of the model, G-UNets further improves the speed of segmentation, and can efficiently segment power lines in aerial images.
4.5. Comparison of Power Line Splitting Effects
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, H.; Wu, L.; Chen, Y.; Chen, R.; Kong, S.; Wang, Y.; Hu, J.; Wu, J. Attention-guided multitask convolutional neural network for power line parts detection. IEEE Trans. Instrum. Meas. 2022, 71, 5008213. [Google Scholar] [CrossRef]
- Liu, Z.; Miao, X.; Chen, J.; Jiang, H. Review of visible image intelligent processing for transmission line inspection. Power Syst. Technol. 2020, 44, 1057–1069. [Google Scholar]
- Chen, M.; Wang, Y.; Dai, Y.; Yan, Y.; Qi, D. Small and strong: Power line segmentation network in real time based on self-supervised learning. Proc. CSEE 2022, 42, 1365–1375. [Google Scholar]
- Xu, C.; Li, Q.; Zhou, Q.; Zhang, S.; Yu, D.; Ma, Y. Power line-guided automatic electric transmission line inspection system. IEEE Trans. Instrum. Meas. 2022, 71, 3512118. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Tong, L.; Cao, Y.; Xue, Z. Automatic power line extraction from high resolution remote sensing imagery based on an improved Radon transform. Pattern Recognit. 2016, 49, 174–186. [Google Scholar]
- Tian, F.; Wang, Y.; Zhu, L. Power line recognition and tracking method for UAVs inspection. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015. [Google Scholar]
- Zhao, L.; Wang, X.; Dai, D.; Long, J.; Tian, M.; Zhu, G. Automatic extraction algorithm of power line in complex background. High Volt. Eng. 2019, 45, 218–227. [Google Scholar]
- Zhang, Y.; Wang, W.; Zhao, S.; Zhao, S. Research on automatic extraction of railway catenary power lines under complex background based on RBCT algorithm. High Volt. Eng. 2022, 48, 2234–2243. [Google Scholar]
- Yetgin, O.E.; Benligiray, B.; Gerek, O.N. Power line recognition from aerial images with deep learning. IEEE Trans. Aerosp. Electron. Syst. 2019, 55, 2241–2252. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, X.; Yao, H.; Tian, M.; Jian, Z. Power line extraction from aerial images using object-based Markov random field with anisotropic weighted penalty. IEEE Access 2019, 7, 125333–125356. [Google Scholar] [CrossRef]
- Choi, H.; Koo, G.; Kim, B.J.; Kim, S.W. Weakly supervised power line detection algorithm using a recursive noisy label update with refined broken line segments. Expert. Syst. Appl. 2021, 165, 113895. [Google Scholar] [CrossRef]
- Chen, X.; Xia, J.; Du, K. Overhead transmission line detection based on multiple linear-feature enhanced detector. J. Zhejiang Univ. Eng. Sci. 2021, 55, 2382–2389. [Google Scholar]
- Xu, G.; Li, G. Research on lightweight neural network of aerial powerline image segmentation. J. Image Graph. 2021, 26, 2605–2618. [Google Scholar]
- Liu, J.; Li, Y.; Gong, Z.; Liu, X.; Zhou, Y. Power line recognition method via fully convolutional network. J. Image Graph. 2020, 25, 956–966. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention(MICCAI), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Yang, L.; Fan, J.; Xu, S.; Li, E.; Liu, Y. Vision-Based Power Line Segmentation With an Attention Fusion Network. IEEE Sens. J. 2022, 22, 8196–8205. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghost net: More features from cheap operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 5 August 2020. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Milletari, F.; Navab, N.; Ahmadi, S. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Yang, Z.; Wang, S.; Zhao, Y.; Liao, M.; Zeng, Y. Automatic Liver Tumor Segmentation Based on Cascaded Dense-UNet and Graph Cuts. J. Electron. Inf. Technol. 2022, 44, 1683–1693. [Google Scholar]
- Yuan, H.; Liu, Z.; Shao, Y.; Liu, M. ResD-UNet Research and Application for Pulmonary Artery Segmentation. IEEE Access 2021, 9, 67504–67511. [Google Scholar] [CrossRef]
- Wu, Z.; Zhao, L.; Zhang, H. MR-UNet Commodity Semantic Segmentation Based on Transfer Learning. IEEE Access 2021, 9, 159447–159456. [Google Scholar] [CrossRef]
- Cui, B.; Chen, X.; Lu, Y. Semantic segmentation of remote sensing images using transfer learning and deep convolutional neural network with dense connection. IEEE Access 2020, 8, 116744–116755. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. 2019, 8, 2011–2023. [Google Scholar]
- Zhang, Q.; Yang, Y. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. In Proceedings of the ICASSP 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of Localization Confidence for Accurate Object Detection. ECCV 2018, 11218, 816–832. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 2018 European Conference on Computer Vision(ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | Expansion | Output | SE | Stride |
|---|---|---|---|---|---|
| 5122 × 3 | Conv2d-M | - | 5122 × 8 | - | 1 |
| 5122 × 3 | Conv2d-M | - | 2562 × 16 | - | 2 |
| 5122 × 3 | Conv2d-M | - | 1282 × 24 | - | 4 |
| 5122 × 3 | Conv2d-M | - | 642 × 40 | - | 8 |
| 5122 × 8 | Conv2d-M | - | 5122 × 16 | - | 2 |
| 2562 × 16 | G-bneck | 16 | 2562 × 16 | - | 1 |
| 2562 × 16 | Add | - | 2562 × 16 | - | - |
| 2562 × 16 | |||||
| 2562 × 16 | G-bneck | 48 | 2562 × 24 | - | 2 |
| 1282 × 24 | G-bneck | 72 | 1282 × 24 | - | 1 |
| 1282 × 24 | Add | - | 1282 × 24 | - | - |
| 1282 × 24 | |||||
| 1282 × 24 | G-bneck | 72 | 1282 × 40 | 1 | 2 |
| 642 × 40 | G-bneck | 120 | 642 × 40 | 1 | 1 |
| 642 × 40 | Add | - | 642 × 40 | - | - |
| 642 × 40 | |||||
| 642 × 40 | G-bneck | 240 | 642 × 80 | - | 2 |
| 322 × 80 | G-bneck | 200 | 322 × 80 | - | 1 |
| 322 × 80 | G-bneck | 184 | 322 × 80 | - | 1 |
| 322 × 80 | G-bneck | 184 | 322 × 80 | - | 1 |
| 322 × 80 | G-bneck | 480 | 322 × 112 | 1 | 1 |
| 322 × 112 | G-bneck | 672 | 322 × 112 | 1 | 1 |
| Method | Conv2d-M & G-Bneck | Multi-In | AM | SA | WH-Loss | F1-Score (%) | IoU (%) | Params (M) | Speed (s) |
|---|---|---|---|---|---|---|---|---|---|
| Y-UNet | √ | 87.05 | 80.13 | 25.638 | 3.9726 | ||||
| Y-UNet_L | √ | √ | 88.17 | 81.44 | 25.638 | 3.9287 | |||
| Improvement 1 | √ | √ | √ | 88.12 | 81.33 | 6.796 | 3.0625 | ||
| Improvement 2 | √ | √ | √ | 88.51 | 81.87 | 6.808 | 3.1838 | ||
| Improvement 3 | √ | √ | √ | 88.73 | 82.28 | 6.796 | 3.0550 | ||
| DeeplabV3+ [27] | 56.41 | 53.04 | 5.831 | 0.0167 | |||||
| G-UNets | √ | √ | √ | √ | 89.24 | 82.98 | 6.808 | 2.9983 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, G.; Zhang, M.; Li, Q.; Liu, X.; Li, T.; Zhao, L.; Liu, K.; Qin, L. A Lightweight Aerial Power Line Segmentation Algorithm Based on Attention Mechanism. Machines 2022, 10, 881. https://doi.org/10.3390/machines10100881
Han G, Zhang M, Li Q, Liu X, Li T, Zhao L, Liu K, Qin L. A Lightweight Aerial Power Line Segmentation Algorithm Based on Attention Mechanism. Machines. 2022; 10(10):881. https://doi.org/10.3390/machines10100881
Chicago/Turabian StyleHan, Gujing, Min Zhang, Qiang Li, Xia Liu, Tao Li, Liu Zhao, Kaipei Liu, and Liang Qin. 2022. "A Lightweight Aerial Power Line Segmentation Algorithm Based on Attention Mechanism" Machines 10, no. 10: 881. https://doi.org/10.3390/machines10100881
APA StyleHan, G., Zhang, M., Li, Q., Liu, X., Li, T., Zhao, L., Liu, K., & Qin, L. (2022). A Lightweight Aerial Power Line Segmentation Algorithm Based on Attention Mechanism. Machines, 10(10), 881. https://doi.org/10.3390/machines10100881