2.1. Modeling the Sensorium
Consider the basic scale invariant non-exact (the barred symbol,
, is used to stress the anholonomic nature of the one-forms) one-forms:
in which
are Cartesian coordinates. From an operational point of view, one could regard these as locally adaptive measurement rods, with the help of which, one may assign a numeric value to a vector depending on the base point to which it is attached. More precisely, if
is such a vector, “living” at base point
and expressed relative to globally-defined Cartesian unit vectors
and
, then:
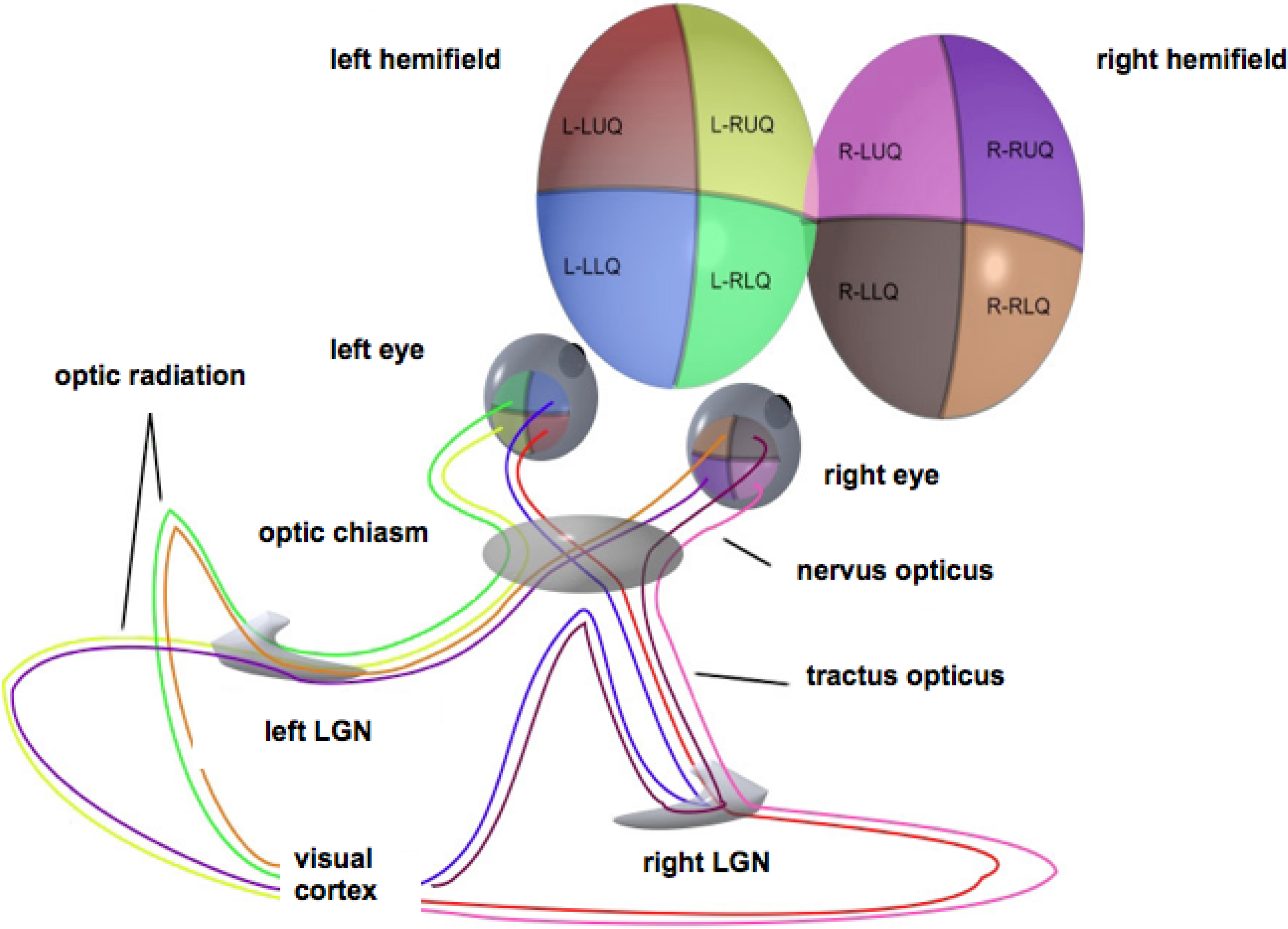
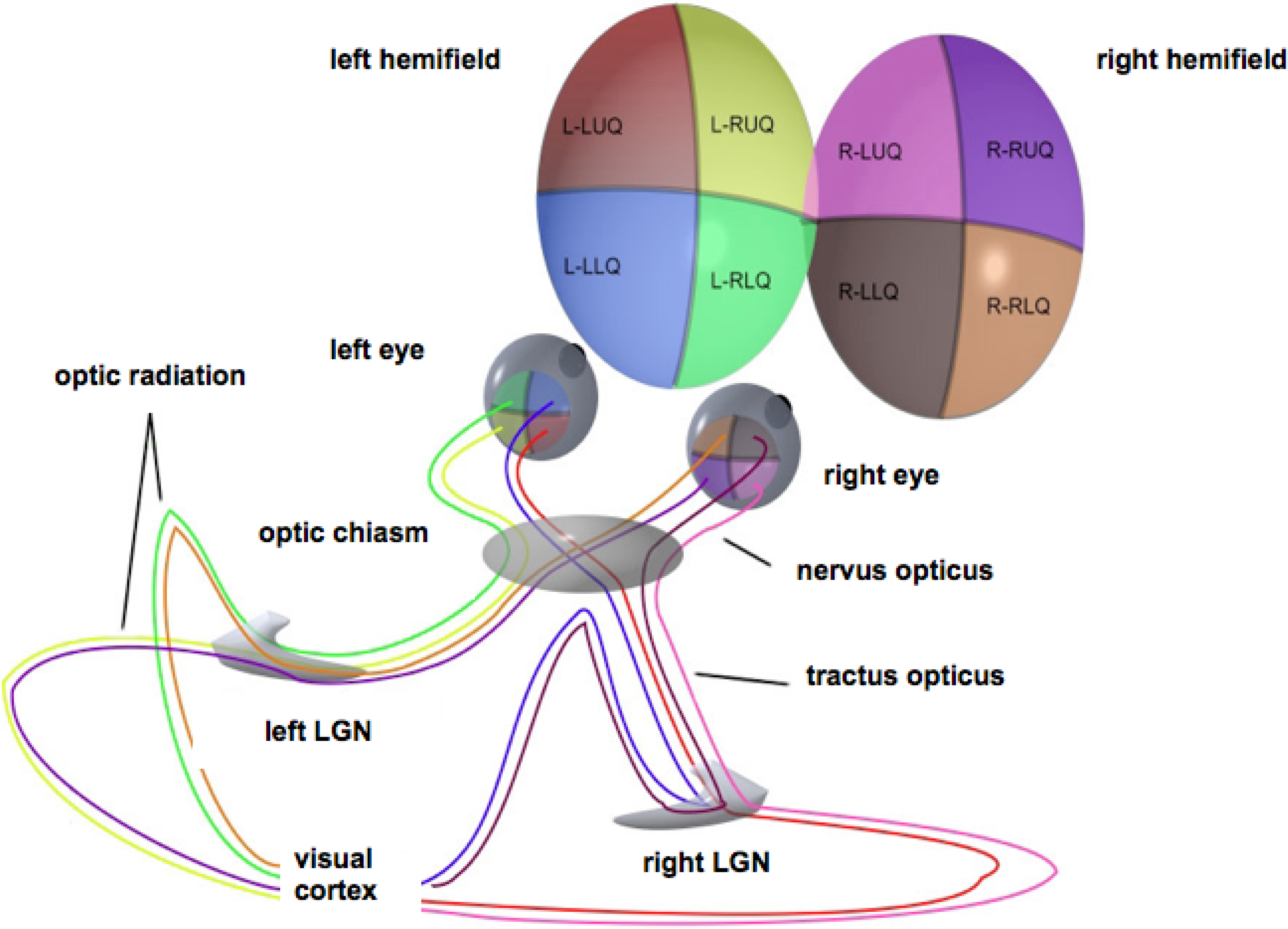
Figure 1.
Schematic representation of the optic pathways from each of the four quadrants of view for both eyes. Adapted from Wikimedia Commons, original illustration by Ratznium. LGN, lateral geniculate nucleus.
Figure 1.
Schematic representation of the optic pathways from each of the four quadrants of view for both eyes. Adapted from Wikimedia Commons, original illustration by Ratznium. LGN, lateral geniculate nucleus.
These numeric values could be interpreted to represent the “visual significance” of the respective Cartesian vector components depending on the position in the visual field. Clearly, in order to be equally significant, the components of a vector at some peripheral location (large ) will need to be larger than those of a more central one (small ). The reason for this is to geometrically express the roughly linear increase of typical receptive field size (with a concomitant linear decrease of spatial resolving power) as a function of eccentricity . The (small) physical size parameter is needed to avoid a non-physical singularity at the center. Its visual significance will become apparent below.
We will confine the region of interest to a disk of radius R, which represents the radius of the geometric retina(). The parameter, a, represents a transient radius separating the geometric foveola(the geometric foveola is a construct of our model, to be distinguished from the biological foveolain the mammalian retina; terminology betrays a modest amount of foresight) () from its periphery().
The one-forms of Equation (
1) induce a scale invariant area two-form, geometrically representing a spatially-weighted area of support (regardless of shape) of a Euclidean sensory element,
, at position
relative to the foveal center:
in which:
is the square root of the metric determinant associated with the two-dimensional spatial metric:
Again, the number in Equation (
4) reflects the fact that a peripheral receptive field will need to have a larger area of support in order to be treated on par with a similar one closer to the foveal center.
As an aside, recall that the every two-dimensional Riemannian manifold is conformally flat and that the Ricci curvature tensor,
, is always proportional to the metric tensor,
viz.:
in which
and
are the components of
and G, respectively. For the case at hand, Equation (
5), the space-variant Ricci scalar (equal to twice the Gaussian curvature) equals:
This curvature scalar assumes appreciable values within the fovea centralis. The point of departure in previous work [
14] was based on the assumption that
for all
. Combined with the aforementioned symmetries and applied to a conformally flat metric, this requirement admits a family of metrics, of which Equation (
5) is a particular member, only if
, leaving a spurious singularity at the origin. It is clearly not compatible with our regularized metric with
.
2.2. Modeling Retino-Cortical Magnification
Consider the area (measured by the Riemannian metric of Equation (
5)) of an infinitesimally narrow ring
around the fovea:
Geometrically, the quantity:
measures the (Riemannian) perimeter of a the circle of radius
ρ around the fovea. It is easy to see that there exists a maximal circle, with perimeter
, demarcating the transition
between the geometric foveola and periphery (whether this transient circle has a distinguished functional role in mammalian vision is not clear, but anatomical evidence does show a fairly sharp demarcation of the biological foveola [
13]).
If we normalize
, such that
, and introduce the dimensionless quantities:
and:
with
, and:
then:
This
integrated retino-cortical magnificationmeasures the relative capacity dedicated to the central region inside a foveal disk of radius
relative to that of the full retina. Limiting cases are clearly
and
. For the foveola, we have
;
cf.
Figure 2 for an illustration.
To verify the biological plausibility of our model, consider the case of a peripheral ring with the same processing capacity as the enclosed foveal disk,
i.e., Equation (
13) with
equipartitioning radius defined, such that:
A straightforward computation yields:
in which the approximation reflects the phenomenological case,
. In other words, under this assumption, the theoretical equipartitioning radius approximately equals the geometric mean of the radii of the geometric foveola and geometric retina:
Generalizing Equations (
14)–(
16), we may define the
α-partitioning radii
, via:
yielding (the approximations hold for not too small
α,
i.e., well outside the geometric foveola):
or, in terms of physical length scales,
This prediction likewise admits experimental verification once consistent values of a and R are at hand.
Vice versa, we may use Equations (
16)–(
19) to
definethe constant,
a, given empirical data for
R and, say,
. For instance, in the case of humans, it is known that about half of the striate cortex is devoted to the portion of the retina that lies within
–
of the fovea [
13]. Assuming that the striate cortex has a homogeneous distribution of similar visual cells, the fractional size within it occupied by the retinotopically-mapped central portion of the visual field will be tantamount to its fractional processing capacity. A typical retina measures [
18]
;
of visual angle corresponds to approximately
. The monocular visual field covers approximately
(
[
19]), or roughly
in eccentricity when approximated by an isotropic figure for our purposes (Hartridge [
20] reports a functional limit on visual field eccentricity of
). With these figures, we have (for the biological counterparts of the quantities involved)
, from which one deduces with the help of Equations (
12) and (
15) that
. The phenomenological value
used in
Figure 2 justifies our assumption,
, and the predicted size of the geometric foveola happens to agree remarkably well with that of the human foveola (Rodieck ([
13], Chapter 9) reports a value of
), which gives us a biological interpretation of the constant,
a, and, at the same time, justifies the name “geometric foveola”;
cf.
Figure 3.
In the next section, we consider the modification of the log-polar map by taking into account the physical resolution limitation of the fovea centralis and show how the log-polar map emerges asymptotically.
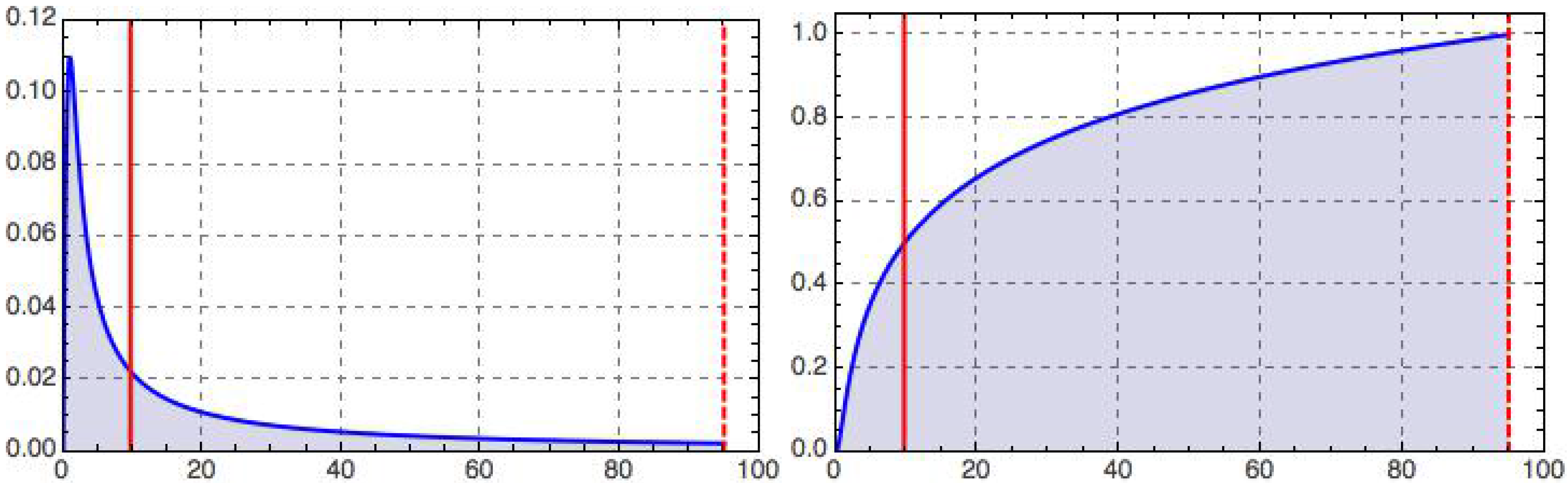
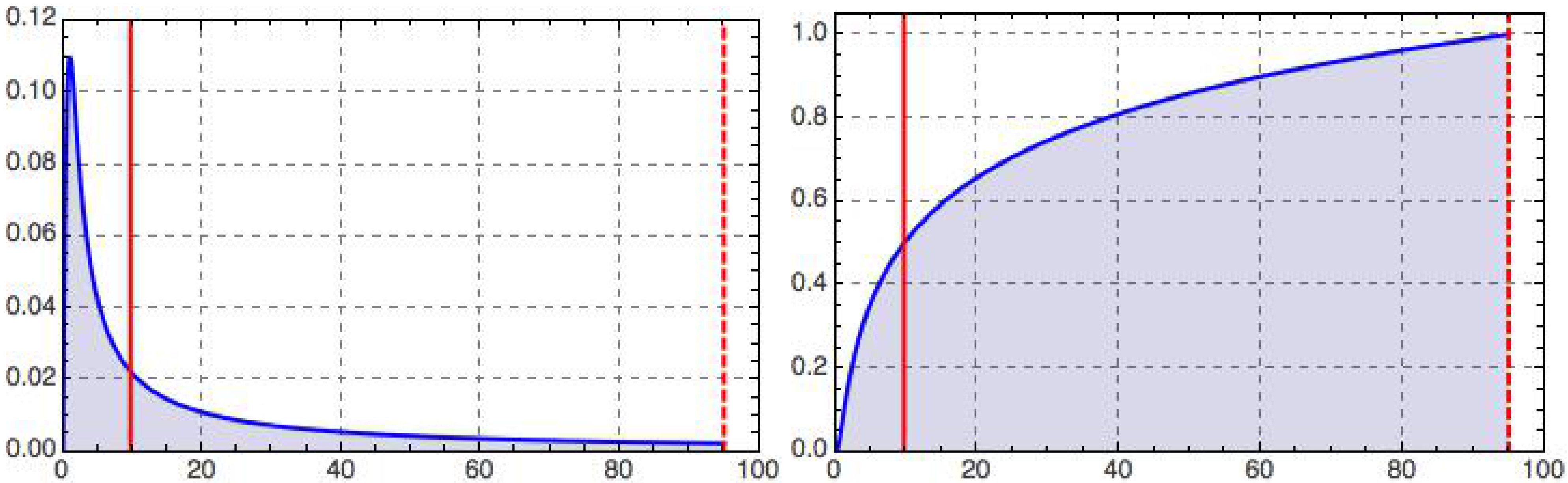
Figure 2.
Retino-cortical magnification,
(
left), and its integral,
(
right), as a function of dimensionless eccentricity,
t, illustrated for the case
(dashed vertical line); recall Equations (
12)–(
15). The peak on the left occurs at
and marks the border
of the geometric foveola. The half maximum on the right is reached at
, corresponding to the geometric equipartitioning radius (left vertical line),
. With our choice of parameters (motivated in the text), the tiny geometric foveola has a relative processing capacity
; recall Equation (
13).
Figure 2.
Retino-cortical magnification,
(
left), and its integral,
(
right), as a function of dimensionless eccentricity,
t, illustrated for the case
(dashed vertical line); recall Equations (
12)–(
15). The peak on the left occurs at
and marks the border
of the geometric foveola. The half maximum on the right is reached at
, corresponding to the geometric equipartitioning radius (left vertical line),
. With our choice of parameters (motivated in the text), the tiny geometric foveola has a relative processing capacity
; recall Equation (
13).
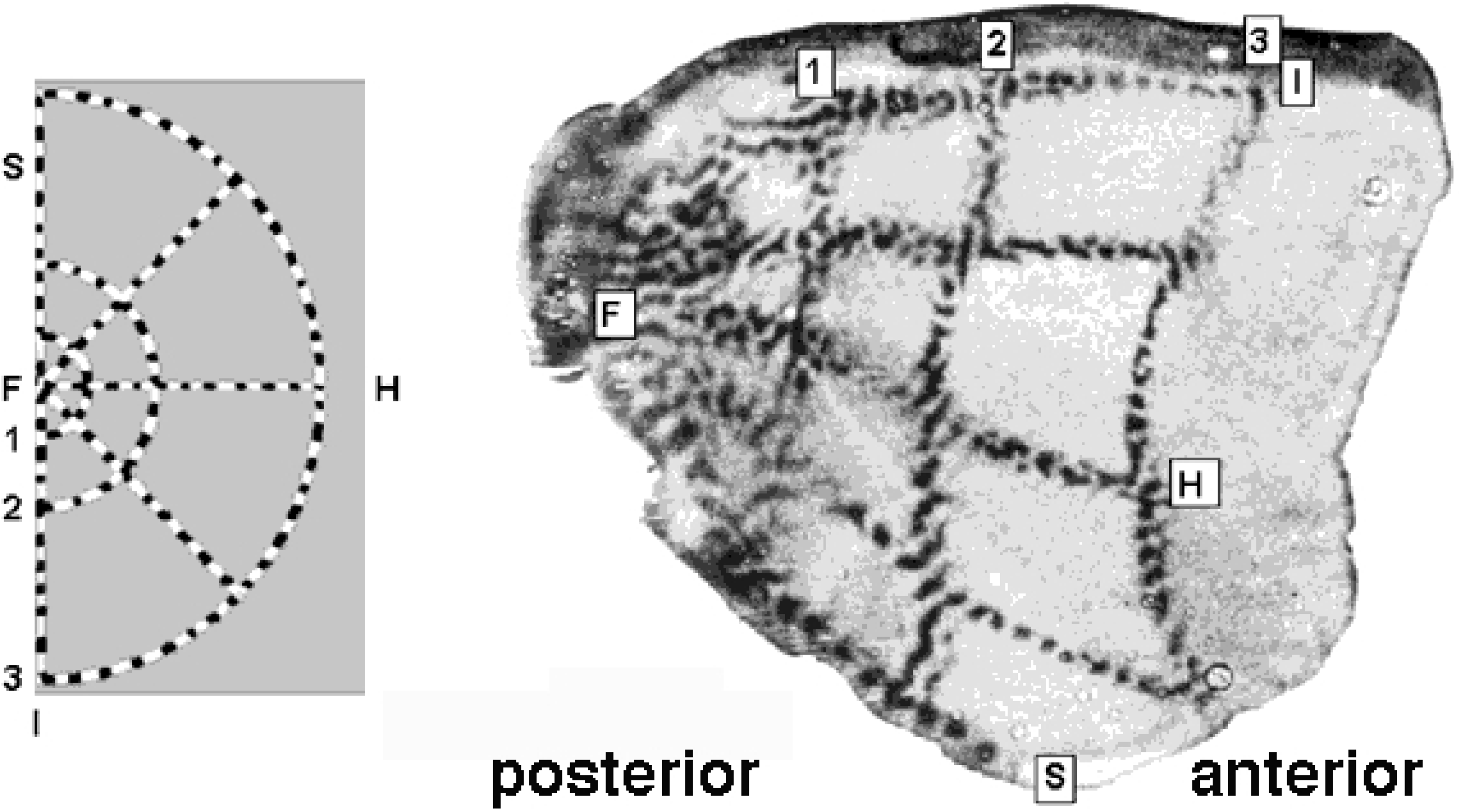
Figure 3.
Retino-cortical mapping of macaque monkey. (
Left) Retina with spoke-wheel stimulus. (
Right) Stimulus image retinotopically mapped onto the posterior part of (hemifield) striate cortex, a.k.a. calcarine sulcus. Source: Tootell
et al. [
21].
Figure 3.
Retino-cortical mapping of macaque monkey. (
Left) Retina with spoke-wheel stimulus. (
Right) Stimulus image retinotopically mapped onto the posterior part of (hemifield) striate cortex, a.k.a. calcarine sulcus. Source: Tootell
et al. [
21].
2.3. Canonical Coordinates
Retino-cortical magnification can be conveniently described in terms of
canonical coordinates(recall that the primary visual cortex on one side of the brain represents a hemifield, hence the bounds on
ϕ):
Using these canonical coordinates, it follows that the basic area two-form (recall Equation (
3)) can be expressed as the wedge product of holonomic one-forms, warranting the attribute “canonical”:
Note that near the foveal point, we have:
In the periphery, we reobtain the familiar log-polar coordinates (up to an irrelevant offset):
The physical part of the
-domain is reminiscent of the actually observed shape of the cortical surface of V1; compare
Figure 3 and
Figure 4.
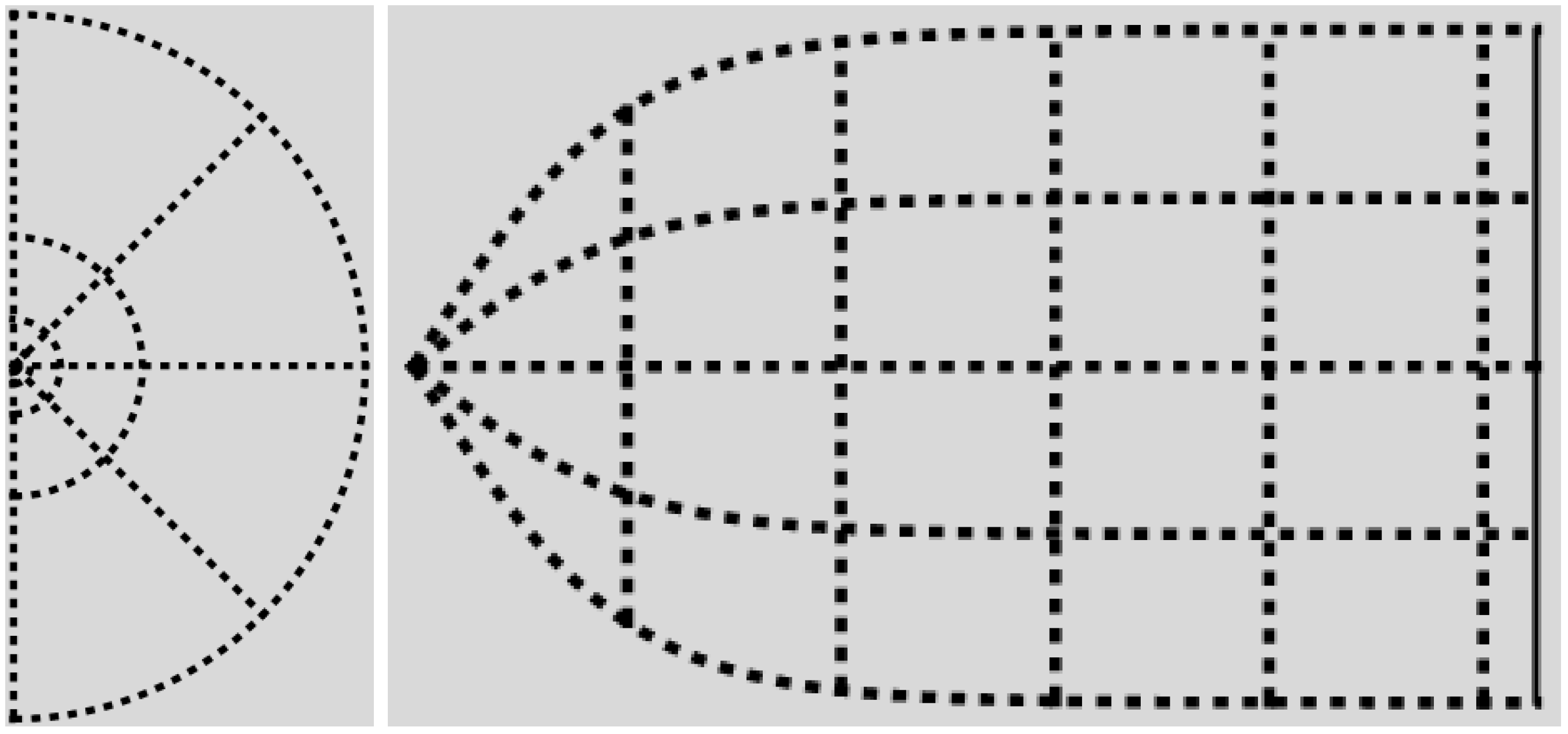
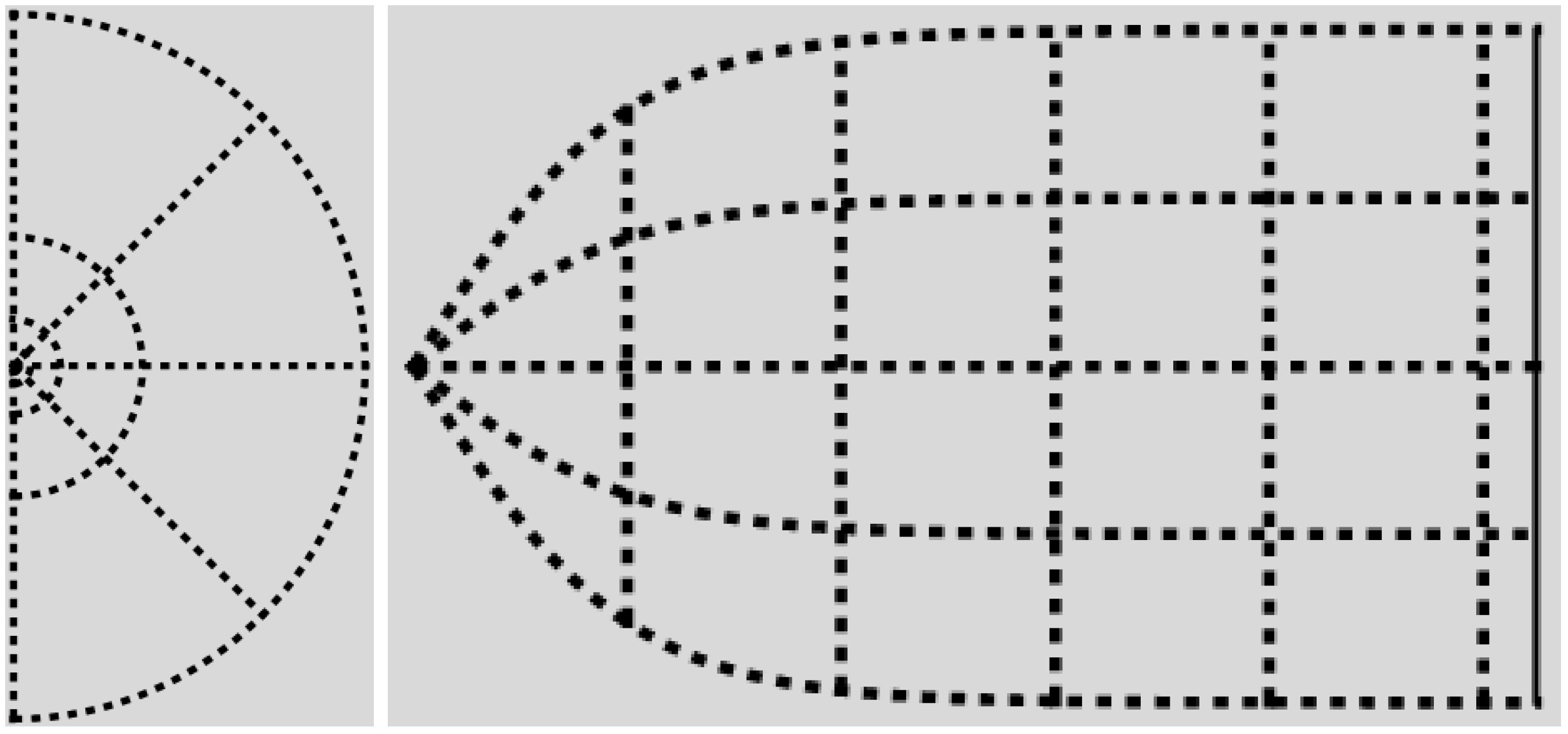
Figure 4.
The canonical
-domain is the region between the graphs of
and the lines
and
. On the
left,
are dimensionless radial and azimuthal coordinates. On the
right, the canonical
-coordinates are plotted as Cartesian coordinates, with
p on the horizontal axis. Recall Equation (
28), and compare with
Figure 3.
Figure 4.
The canonical
-domain is the region between the graphs of
and the lines
and
. On the
left,
are dimensionless radial and azimuthal coordinates. On the
right, the canonical
-coordinates are plotted as Cartesian coordinates, with
p on the horizontal axis. Recall Equation (
28), and compare with
Figure 3.
Expressed in canonical coordinates, the retino-cortical metric, Equation (
5), looks rather more cumbersome:
It is evident that the
-coordinate lines do not intersect perpendicularly, unlike with log-polar coordinates;
cf.
Figure 4. For the angle of intersection,
α, at a fiducial point
, we have:
For peripheral points, this is close to zero:
For central points, on the other hand, we have:
independent of eccentricity, revealing the non-orthogonal intersection of canonical coordinate lines away from the horizon (
). The deviation from orthogonality remains nonetheless fairly small almost everywhere, reaching its maximum at the foveal point, with an intersection angle still close to
. Typical measurements, such as
Figure 3, lack resolving power to delineate foveal details in the most posterior part of the striate cortex and, thus, remain indecisive.
Let
denote the full retinal domain. In
-space this is the area in-between the graphs of:
and the lines
and
(to see this, express
q as a function of
p and parameter
ϕ using Equation (
20), and consider the boundary values
). By the same token, if
denotes the fraction of the retinal domain on the left of the line
, then a straightforward computation yields:
reproducing Equation (
13) as expected. This confirms that the
-coordinates of Equation (
20) are indeed more natural than the commonly used log-polar coordinates. The latter arise in the limit of vanishing
a. As such, log-polar coordinates fail to describe both foveal, as well as transient behavior, and are suited only for the peripheral field. Although the periphery represents by far the largest part of the visual field, it is much less significant in the visual brain.
As a final remark, note that, by construction, -space is most naturally discretized by a uniform sampling (with grid constants and of fixed aspect ratio). Biologically, one expects this to be reflected in a uniform spatial layout and the functional similarity of cortical receptive fields in the entire primary visual cortex.

{kind=link}
{kind=link}
{kind=link}
{kind=link}