Abstract
The quadratic regularization technique is widely used in the literature for constructing efficient algorithms, particularly for solving nonsmooth optimization problems. We propose an inexact nonsmooth quadratic regularization algorithm for solving large-scale optimization, which involves a large-scale smooth separable item and a nonsmooth one. The main difference between our algorithm and the (exact) quadratic regularization algorithm is that it employs inexact gradients instead of the full gradients of the smooth item. Also, a slightly different update rule for the regularization parameters is adopted for easier implementation. Under certain assumptions, it is proved that the algorithm achieves a first-order approximate critical point of the problem, and the iteration complexity of the algorithm is . In the end, we apply the algorithm to solve LASSO problems. The numerical results show that the inexact algorithm is more efficient than the corresponding exact one in large-scale cases.
Keywords:
nonsmooth optimization; separable function; inexact quadratic regularization; proximal mapping; proximal boundedness; iteration complexity MSC:
49J52; 65K10; 90C53
1. Introduction
Consider the following nonsmooth optimization problem:
where is a continuously differentiable function and is a lower semi-continuous proper function (both f and h can be nonconvex). When , the problem reduces to a smooth optimization. The trust-region-based algorithm is one of the classical methods for solving the problem, and it has attracted great attention in the literature since it was introduced. Comprehensive and systematical introductions can be found, for example, in book [1] and two novel variants in [2], which include regularization versions of the algorithm. By introducing a second-order nonlinear step-size control for the algorithm, Grapiglia et al. [3] proved the iteration complexity of the trust-region algorithm is . Bergou et al. [4] used the scaled norms for the trust-region algorithm and a cubic adaptive regularization algorithm, and by introducing line-search into the algorithm, the iteration complexity of the algorithm was improved to . In cases where in problem (1), the nonsmooth trust-region algorithm and the nonsmooth regularization methods (based on general directional derivatives) have also been proposed and studied; see details, e.g., [5,6,7]. For more smooth/nonsmooth methods for solving these two kinds of optimizations, the readers are referred to [8,9,10] and references therein. In the composite case of problem (1) when f and h are convex, Lee et al. [11] proposed a proximal Newton method for solving the problem and established the global convergence of the algorithm. Kim et al. [12] introduced a nonsmooth trust-region algorithm for the problem, which employs the full gradients of f in each subproblem. For a more general case when , where g is convex and c is continuously differentiable, Cartis et al. [13] proposed both the nonsmooth trust-region algorithm and the quadratic regularization variants for solving the problem. The iteration complexities of these algorithms were proven to . For more generalized and improved nonsmooth trust-region-based algorithms for solving such problems, see, e.g., [14,15,16]. It is worth mentioning that the proximal gradient method is also a commonly used class of algorithms for solving this problem. They have been extensively studied and applied to problems such as (group) sparse optimization and constrained optimization. For more details, refer to [17,18,19,20,21] and their references.
We focus on the more general composite problem (1) (where both f and h can be nonconvex). Li et al. [22] proposed a monotone proximal gradient algorithm for solving the problem. Its sublinear convergence properties are established under the Kurdyka-Łojasiewicz condition. In particular, we note the work by Aravkin et al. [23], where the nonsmooth trust-region algorithm and the nonsmooth quadratic regularization algorithms were proposed and studied. Under certain conditions, they proved that the iteration complexities of both algorithms are . It should be noted that some of the aforementioned works related to the smooth term f all use the full gradients of f. To solve the following large-scale optimizations, we shall propose an algorithm that uses the inexact gradients of f instead of the full gradients. Specifically, we consider the following large-scale separable nonsmooth optimization problem:
where each component function is continuously differentiable (), is a proper and lower semi-continuous function, and (i.e., n is very large). Such large-scale problems have broad applications in areas like machine learning, signal processing, image analysis and restoration, etc.; see, e.g., [24,25,26,27]. To reduce the computational complexity and memory usage in each iteration, some inexact techniques are applied in the algorithm design. For example, the incremental algorithms compute by processing data incrementally, typically one sample or a small batch at a time; see, e.g., [24]. Stochastic algorithms update estimates sequentially using stochastic batches of data; see, e.g., [25,26,27] and references therein. For solving problem (2), we propose an inexact nonsmooth quadratic regularization algorithm, which employs inexact gradients of f in the subproblems and also an account for nonsmooth function h (note that the inexact gradient of f includes sub-sampled gradient
of f as a special case, where is a sample collection from ; see Remark 4 for more details). The algorithm is actually an inexact version of the algorithm in ([23], Algorithm 6.1). The main difference between our algorithm and ([23], Algorithm 6.1) is that we employ inexact gradients of f, while the latter uses full gradients of f. Moreover, we adopt a different stopping criteria and slightly different update rules for the regularization parameters; see details in Remarks 1 and 2. Under certain conditions, we show that the iteration complexity of the algorithm is , which is similar to the result about the exact algorithm established in [23]. Finally, the algorithm is applied to solve LASSO problems, and numerical experiments show that in large-scale cases, the inexact algorithm is generally more efficient than the corresponding exact one.
The paper is organized as follows. The next section provides some necessary notions, notation and results. The main results are presented in Section 3, including the inexact nonsmooth quadratic regularization algorithm and the convergence analysis. Some numerical comparisons are illustrated in Section 4 for solving LASSO problems. The conclusion is given afterwards.
In addition, some useful notations are displayed in Table 1.

Table 1.
Notations and descriptions.
2. Preliminaries
We gather some notation, notions, and results which will be used in this paper. For more details, the readers are referred to [1,23,28].
Let R denote the set of all real numbers and N denote the set of all non-negative integers. Let and denote the -norm and the inner product in Euclidean space , respectively. The closed ball centered at 0 with radius is denoted by ; that is, . Let , and let be a nonempty subset. The distance from x to A is denoted by , which is defined by . Let be a lower semi-continuous proper function. As usual, stands for the domain of h, that is,
The function h is said to be convex if the following inequality holds for any
Furthermore, h is said to be strongly convex with modulus if there exists a constant such that for any , the following holds:
For , we use to stand for the -level set of h, that is,
If is bounded for any , then h is said to be level-bounded. In the case when a lower semi-continuous proper function h is level-bounded, then the set is nonempty and compact; see, e.g., ([28], Theorem 1.9).
The following concepts of the Moreau envelope and the proximal mapping of h can be found in ([23], Definition 2.1).
Definition 1 (Moreau Envelope and Proximal Mapping).
Let , and . The Moreau envelope and the proximal mapping of the function h at x are, respectively, defined by
and
For a general lower semi-continuous proper function h, the set can be empty or contain multiple elements. The range of parameter values for which the Moreau envelope of h admits a finite value is given by the following definition, which is taken from ([28], Definition 1.23).
Definition 2 (Prox-boundedness).
The function h is said to be prox-bounded if there exists a parameter and at least one point such that . The threshold of prox-boundedness of h is the supremum of all such .
It can be shown that the threshold of prox-boundedness of h is independent of the point x in the definition. In the special case when h is level-bounded, we see that . A prox-bounded function exhibits the following properties ([28], Theorem 1.25).
Proposition 1.
Let be a prox-bounded function with proximal boundedness threshold . Then, for any and , the following properties hold:
(i) is a nonempty and compact set;
(ii) the function is continuous, and as λ monotonically decreases to 0, monotonically increases to .
We end this section with some optimality conditions for the nonsmooth optimization
where is a lower semi-continuous proper function, which can be found in [23] or [28]. To this end, we first recall the following notions of the subgradient and subdifferential.
Definition 3 (Subgradient and Subdifferential).
Let . A vector is said to be a regular subgradient of ϕ at the point if
The set of all regular subgradients of ϕ at is denoted by , which is called the Fréchet subdifferential of ϕ at . Moreover, if there exist sequences and satisfying , and , then the vector v is called a general subgradient of ϕ at . The set of all general subgradients of ϕ at is denoted by , which is called the limiting subdifferential of ϕ at .
It is clear that for any . In the case when is convex, the Fréchet and limiting subdifferentials coincide with the subdifferential of convex analysis. Let , where is a continuously differentiable function, and let . Then, . The following necessary optimality condition for (5) is well known.
Proposition 2.
Let be a local minimizer of ϕ. Then, . If ϕ is convex, then is a global minimizer of ϕ.
A point is called a critical point of if . In the next iteration complexity analysis, we need the following definition of approximate critical points, where is the distance associated with .
Definition 4.
Let . A point is said to be a ε-approximate critical point of ϕ if .
3. Inexact Nonsmooth Quadratic Regularization Algorithm
We consider the following large-scale separable nonsmooth optimization problem:
where (n is very large), each component function is continuously differentiable , and is a lower semi-continuous proper function. Since n is very large, the computational cost of the (full) gradient of f becomes prohibitively expensive. To reduce the computational cost per iteration, we shall propose an inexact nonsmooth quadratic regularization algorithm (i.e., Algorithm 1) for solving problem (6), which employs approximate gradients of f instead of the full gradients in subproblems. The algorithm is actually an inexact version of the (exact) quadratic regularization algorithm proposed in ([23], Algorithm 6.1), for solving nonsmooth optimizations. In the k-th iteration, we construct an approximate model for at the iterate and then solve a quadratic regularization subproblem:
where is the regularization parameter.
We always make the following blanket assumption on the model.
Assumption 1 (Model Assumption).
For any ,
(i) is a linear function, which is defined by
where ;
(ii) is a lower semi-continuous proper function, and it satisfies and . Furthermore, is uniformly prox-bounded; that is, such that for any .
Remark 1.
We note that Assumption 1 is similar to the corresponding one made in [23] for the (exact) nonsmooth quadratic regularization algorithm ([23], Algorithm 6.1), except the latter uses the full gradient of f in (8), that is, in (8). This means that both our algorithm (see Algorithm 1 below) and ([23], Algorithm 6.1) adopt a linear approximation φ of f in the quadratic regularization subproblem. The main difference lies in
- The first-order term of φ: Algorithm 1 uses the inexact gradient g as stated in (8), while ([23], Algorithm 6.1) uses the full gradient , that is,We adopt a different tolerance that is easier to verify, which in turn requires a slightly modified update rule for the regularization parameters in Algorithm 1. These are specified as follows; see more explanations in Remark 2.
- Different stopping criterion: the stopping criterion of Algorithm 1 is (see Step 5 of Algorithm 1), while the stopping criterion of ([23], Algorithm 6.1) is
- Different update rule for : Algorithm 1 uses parameter to ensure that all regularization parameters have a positive lower bound, while ([23], Algorithm 6.1) does not use such a bound.
Below, we show that one can use proximal mappings to solve the quadratic regularization subproblems of Algorithm 1. To proceed, let . Noting the definition of subproblem (7) in the k-th iteration, we set
In view of (7) and (8), we can write
Recalling (3) and (4), it holds from (9) and (10) that
and
Noting that is a linear function, it is easy to verify that is also the threshold of the prox-boundedness of . Thus, the following result is immediate from Proposition 1(i).
Proposition 3.
Let and . Then, is a nonempty and compact set.
By Assumption 1 and (13), the following decrease is guaranteed by the proximal gradient method.
Lemma 1.
Let and . Then, we have
Below, we present the inexact nonsmooth quadratic regularization algorithm for solving problem (6), where the parameter .
| Algorithm 1 Inexact Nonsmooth Quadratic Regularization Algorithm |
|
Remark 2.
Compared to ([23], Algorithm 6.1), we adopt a slightly different update rule for the regularization parameters at very successful iterations. This is because we use a different tolerance in Algorithm 1, which is easier to be verified than the tolerance used in [23]. This leads to the necessity of the update rule when we study the iteration complexity of Algorithm 1 in what follows. In addition, we note that just like ([23], Algorithm 6.1), there may be iterations of Algorithm 1 where . At such iterations, is increased, and then after a finite number of such increases, there holds that .
Similar to the (exact) quadratic regularization algorithm in ([23], Algorithm 6.1), we always make the following step assumption.
Assumption 2 (Step Assumption).
There exists such that for all k,
Remark 3.
Let , and let be defined as . If is Lipschitz continuous with constant and there exist constants such that for any ,
then Assumption 2 is satisfied. In fact, in this case,
By the mean value theorem, there exists on the line segment connecting and such that
From the definition of φ and (16), we have
Thus, Assumption 2 holds with . Additionally, when , where has a Lipschitz continuous Jacobian and is Lipschitz continuous, the above condition can be replaced by , and Assumption 2 is still satisfied.
Regarding the sequence of regularization parameters , the following important property holds, where
Lemma 2.
If Algorithm 1 does not terminate at the k-th iteration and the regularization parameter satisfies , then the k-th iteration is very successful, and .
Proof of Lemma 2.
Let , and let and be the corresponding iteration point and direction, respectively. Since Algorithm 1 does not terminate in finite steps, we have . Combining Assumption 2 and (14), we obtain
From the definition of and , we have . Noting that and , it follows that . By the definition of Algorithm 1, the k-th iteration is very successful, and . □
Lemma 2 and the definition of Algorithm 1 indicate that the regularization parameters generated by the algorithm have positive lower and upper bounds, i.e.,
where . Next, we show the iteration complexity of Algorithm 1. To this end, let represent the number of iterations such that the termination condition is satisfied. Define the sets of all successful iterations and all unsuccessful iterations as
Let stand for the cardinality of the index subset . The following lemma gives estimates about the cardinalities of and , respectively. We note that the estimation method is similar to the complexity analysis of the classical regularization algorithm by Cartis et al. [13] or that of the nonsmooth quadratic regularization algorithm in [23].
Lemma 3.
Suppose that for all . Then, the following estimates hold:
and
Proof of Lemma 3.
Let . By the definition of Algorithm 1 and (14), there holds that
Summing up the above inequalities over all , we get that
Noting that the sequence is decreasing and bounded from below by , it follows that
which implies (18). Note that each unsuccessful iteration increases the regularization parameter by at least a factor of , while each successful iteration reduces the regularization parameter by at most a factor of (). Therefore, we have
and so
Thus, (19) is valid, completing the proof. □
The following iteration complexity for Algorithm 1 is immediate from the above lemma.
Theorem 1.
Under the assumptions made in Lemma 3, we have .
The following proposition provides some conditions to ensure that Algorithm 1 terminates at an approximate stationary point.
Proposition 4.
Suppose that Algorithm 1 terminates at the k-th iteration, that is, . Suppose further that is Lipschitz continuous with constant , , and
holds with some . Then, is a -approximate critical point of .
Proof of Proposition 4.
By assumption and the definition of , we have
Thus,
Noting that
and
we get that
By definition, this implies that is a -approximate critical point of . The proof is complete. □
Remark 4.
Noting that is separable, one can adopt sub-sampled inexact gradient , where is a sample collection with or without replacement from . There are some methods to provide sufficient sample sizes to guarantee that the sub-sampled inexact gradient g approximates in a probabilistic way; for more details, the readers are referred to, for example, ([29], Lemma 3). In the next section, we always adopt sub-sampled inexact gradients in implementing Algorithm 1.
4. Implementation and Numerical Results
We consider the following LASSO problem:
where is a given design matrix, , is the -norm in Euclidean space , is the i-th row vector of matrix A, and is the observed noisy data. This model aims to recover sparse coefficient x, which is a popular model used in high-dimensional data analysis, sparse feature selection, and dimensionality reduction, etc.; see, e.g., for example [23,30]. All numerical experiments are implemented in Python 3.11.7 and on a Lenovo 90M2CTO1WW PC (Intel(R) Core(TM) i5-9500, 3.00 GHz, 8.00 GB (2667 MHz) RAM).
In particular, we generate a sparse vector which contains mostly zeros and 10 values of , where both the index of the nonzero entry and are randomly generated. We generate the matrix using i.i.d. (independent and identically distributed) random entries, where each entry is sampled from the standard normal distribution , and , where . The parameter of problem (21) is set by .
We apply Algorithm 1 to solve problem (21), where the subproblem (7) is set as
(). Two versions of Algorithm 1 are considered as follows.
- (1)
- Algorithm 1 employs inexact gradients, which are referred to as IG-QR for short. That is, in the subproblem (11) in the k-th iteration, where is an index subset randomly sampled from I without replacement. The sampling technique is referred to the stochastic gradient algorithm, for example [25,26,31]. More specifically, we set the sampling ratio at .
- (2)
- Algorithm 1 employs full gradients, which are referred to as FG-QR for short. That is, in the subproblem (11) in the k-th iteration.
In all implementations, the initial points are drawn from a standard normal distribution, which is denoted as . The parameter values are set as follows: , , , , , , and .
Table 2 reports the numerical results of FG-QR and IG-QR across various dimensions. For the special case when , , we performed 20 independent trials. In each trail, we regenerate a sparse vector , data pairs and initial points . As illustrated in Figure 1, we compare the objective function values of FG-QR and IG-QR versus CPUtime across 20 independent trials. Meanwhile, Figure 2 shows alongside the recovered coefficients obtained by FG-QR and IG-QR. We observe from the numerical results that FG-QR and IG-QR achieve comparable accuracy in recovering . Notably, although IG-QR requires more iterations, it outperforms FG-QR in terms of less CPUtime. This observation shows the superiority of IG-QR especially when dealing with high-dimensional problems.
Table 2.
Numerical results across various dimensions, where O-v = , R-e = , I-k is the number of iterations, and T-s is the CPU time (in seconds).
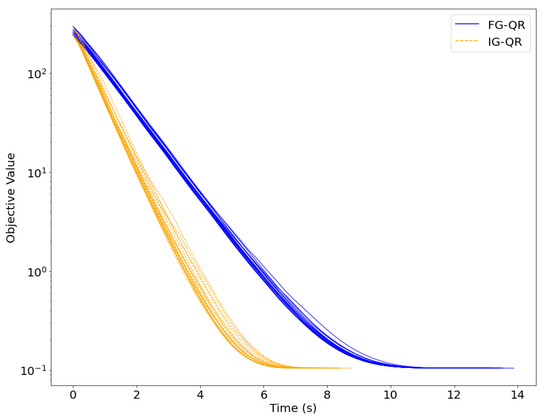
Figure 1.
Numerical performance of FG-QR and IG-QR, when , , was evaluated across 20 independent trials.
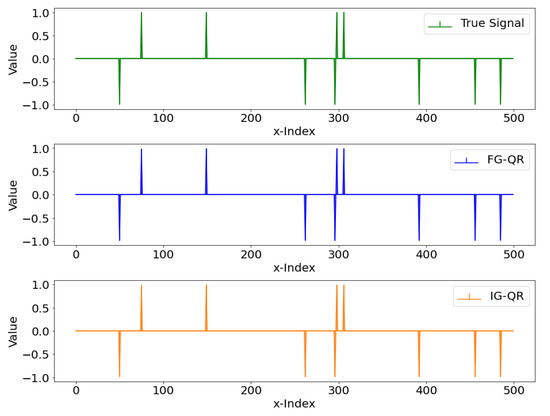
Figure 2.
alongside the recovered coefficients obtained by FG-QR and IG-QR in a trial.
5. Conclusions
This paper proposes an inexact nonsmooth quadratic regularization algorithm based on approximate gradients. The primary objective is to reduce the computational cost per iteration when dealing with large-scale problems. We have shown that the iteration complexity of this algorithm is comparable to that of the corresponding algorithm using full gradients. When the approximate gradient meets certain conditions, an approximate first-order stationary point of the original problem can be achieved. To verify the efficiency of the algorithm in practical applications, we apply it to solve large-scale LASSO problems. Numerical results indicate that Algorithm 1 outperforms the exact algorithm using full gradients, especially when dealing high-dimensional LASSO problems. Note that in general, it is difficult to get an exact solution of the subproblem. Our future work will consider algorithms for the inexact solutions of subproblems as well as some specific computational issues. Additionally, we will consider cubic regularization methods and more general nonlinear step-size control approaches.
Author Contributions
Conceptualization, A.W. and X.W.; methodology, A.W. and X.W.; software, A.W. and C.L.; validation, A.W. and C.L.; formal analysis, A.W. and X.W.; investigation, A.W. and C.L.; resources, A.W.; data curation, A.W.; writing—original draft preparation, A.W.; writing—review and editing, X.W. and C.L.; visualization, X.W.; supervision, X.W. and C.L.; project administration, A.W., X.W. and C.L.; funding acquisition, X.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (grant number: 12161017), Guizhou Provincial Science and Technology Projects (grant number: ZK[2022]110). The APC was funded by X.W.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Acknowledgments
The authors are indebted to the handling editor and the referees.
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- Conn, A.R.; Gould, N.I.M.; Toint, P.L. Trust Region Methods, 1st ed.; SIAM: Philadelphia, PA, USA, 2000; pp. 113–434. ISBN 978-0-89871-985-7. [Google Scholar]
- Toint, P.L. Nonlinear stepsize control, trust regions and regularizations for unconstrained optimization. Optim. Method Softw. 2013, 28, 82–95. [Google Scholar] [CrossRef][Green Version]
- Grapiglia, G.N.; Yuan, J.Y.; Yuan, Y.X. Nonlinear stepsize control algorithms: Complexity bounds for first- and second-order optimality. J. Optim. Theory Appl. 2016, 171, 980–997. [Google Scholar] [CrossRef]
- Bergou, E.H.; Diouane, Y.; Gratton, S. A line-search algorithm inspired by the adaptive cubic regularization framework and complexity analysis. J. Optim. Theory Appl. 2018, 178, 885–913. [Google Scholar] [CrossRef]
- Dennis, J.E., Jr.; Li, S.B.B.; Tapia, R.A. A unified approach to global convergence of trust region methods for nonsmooth optimization. Math. Program. 1995, 68, 319–346. [Google Scholar] [CrossRef][Green Version]
- Qi, L.Q.; Sun, J. A trust region algorithm for minimization of locally Lipschitzian functions. Math. Program. 1994, 66, 25–43. [Google Scholar] [CrossRef]
- Mashreghi, Z.; Nasri, M. Bregman distance regularization for nonsmooth and nonconvex optimization. Can. Math. Bul.-Bul. Can. Math. 2024, 67, 415–424. [Google Scholar] [CrossRef]
- Wang, X.M. Subgradient algorithms on Riemannian manifolds of lower bounded curvatures. Optimization 2018, 67, 179–194. [Google Scholar] [CrossRef]
- Wang, J.H.; Wang, X.M.; Li, C.; Yao, J.C. Convergence analysis of gradient algorithms on Riemannian manifolds without curvature constraints and application to Riemannian Mass. SIAM J. Optim. 2021, 31, 172–199. [Google Scholar] [CrossRef]
- Sun, W.M.; Liu, H.W.; Liu, Z.X. A regularized limited memory subspace minimization conjugate gradient method for unconstrained optimization. Numer. Algorithms 2023, 94, 1919–1948. [Google Scholar] [CrossRef]
- Lee, J.D.; Sun, Y.K.; Saunders, M.A. Proximal Newton-type methods for minimizing composite functions. SIAM J. Optim. 2014, 24, 1420–1443. [Google Scholar] [CrossRef]
- Kim, D.; Sra, S.; Dhillon, I. A scalable trust-region algorithm with application to mixed-norm regression. In Proceedings of the 27th International Conference on Machine Learning (ICML 2010), Haifa, Israel, 21–24 June 2010; pp. 519–526. [Google Scholar]
- Cartis, C.; Gould, N.I.M.; Toint, P.L. On the evaluation complexity of composite function minimization with applications to nonconvex nonlinear programming. SIAM J. Optim. 2011, 21, 1721–1739. [Google Scholar] [CrossRef]
- Chen, Z.A.; Milzarek, A.; Wen, Z.W. A trust-region method for nonsmooth nonconvex optimization. J. Comput. Math. 2023, 41, 683–716. [Google Scholar] [CrossRef]
- Liu, R.Y.; Pan, S.H.; Wu, Y.Q.; Yang, X.Q. An inexact regularized proximal Newton method for nonconvex and nonsmooth optimization. Comput. Optim. Appl. 2024, 88, 603–641. [Google Scholar] [CrossRef]
- Bolte, J.; Sabach, S.; Teboulle, M. Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Program. 2014, 146, 459–494. [Google Scholar] [CrossRef]
- Fukushima, M.; Mine, H. A generalized proximal point algorithm for certain non-convex minimization problems. Int. J. Syst. Sci. 1981, 12, 989–1000. [Google Scholar] [CrossRef]
- Tseng, P. On accelerated proximal gradient methods for convex-concave optimization. SIAM J. Optim. 2008, 2, 1–20. [Google Scholar]
- Tseng, P.; Yun, S. Block-coordinate gradient descent method for linearly constrained nonsmooth separable optimization. J. Optim. Theory Appl. 2009, 140, 513–535. [Google Scholar] [CrossRef]
- Nesterov, Y. Gradient methods for minimizing composite functions. Math. Program. 2013, 140, 125–161. [Google Scholar] [CrossRef]
- Wu, Q.Q.; Peng, D.T.; Zhang, X. Continuous exact relaxation and alternating proximal gradient algorithm for partial sparse and partial group sparse optimization problems. J. Sci. Comput. 2024, 100, 20. [Google Scholar] [CrossRef]
- Li, H.; Lin, Z.C. Accelerated proximal gradient methods for nonconvex programming. In Proceedings of the 29th International Conference on Neural Information Processing Systems (NIPS’15), Montreal, QC, Canada, 7–12 December 2015; pp. 379–387. [Google Scholar]
- Aravkin, A.Y.; Baraldi, R.; Orban, D. A proximal quasi-Newton trust-region method for nonsmooth regularized optimization. SIAM J. Optim. 2022, 32, 900–929. [Google Scholar] [CrossRef]
- Yang, D.; Wang, X.M. Incremental subgradient algorithms with dynamic step sizes for separable convex optimizations. Math. Meth. Appl. Sci. 2023, 46, 7108–7124. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Statist. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Franchini, G.; Porta, F.; Ruggiero, V.; Trombini, I.; Zanni, L. A stochastic gradient method with variance control and variable learning rate for Deep Learning. J. Comput. Appl. Math. 2024, 451, 116083. [Google Scholar] [CrossRef]
- Johnson, R.; Zhang, T. Accelerating stochastic gradient descent using predictive variance reduction. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS’13), Lake Tahoe, NV, USA, 5–10 December 2013; pp. 315–323. [Google Scholar]
- Rockafellar, R.T.; Wets, R.J.B. Variational Analysis, 3rd ed.; Springer Science & Business Media: Berlin, Germany, 2009; pp. 1–74. ISBN 978-3-642-02431-3. [Google Scholar]
- Roosta-Khorasani, F.; Mahoney, M.W. Sub-sampled Newton methods. Math. Program. 2019, 174, 293–326. [Google Scholar] [CrossRef]
- Shen, H.L.; Peng, D.T.; Zhang, X. Smoothing composite proximal gradient algorithm for sparse group Lasso problems with nonsmooth loss functions. J. Appl. Math. Comput. 2024, 70, 1887–1913. [Google Scholar] [CrossRef]
- Yang, J.D.; Song, H.M.; Li, X.X.; Hou, D. Block Mirror Stochastic Gradient Method For Stochastic Optimization. J. Sci. Comput. 2023, 94, 69. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).