
RegCGAN: Resampling with Regularized CGAN for Imbalanced Big Data Problem


Abstract
1. Introduction
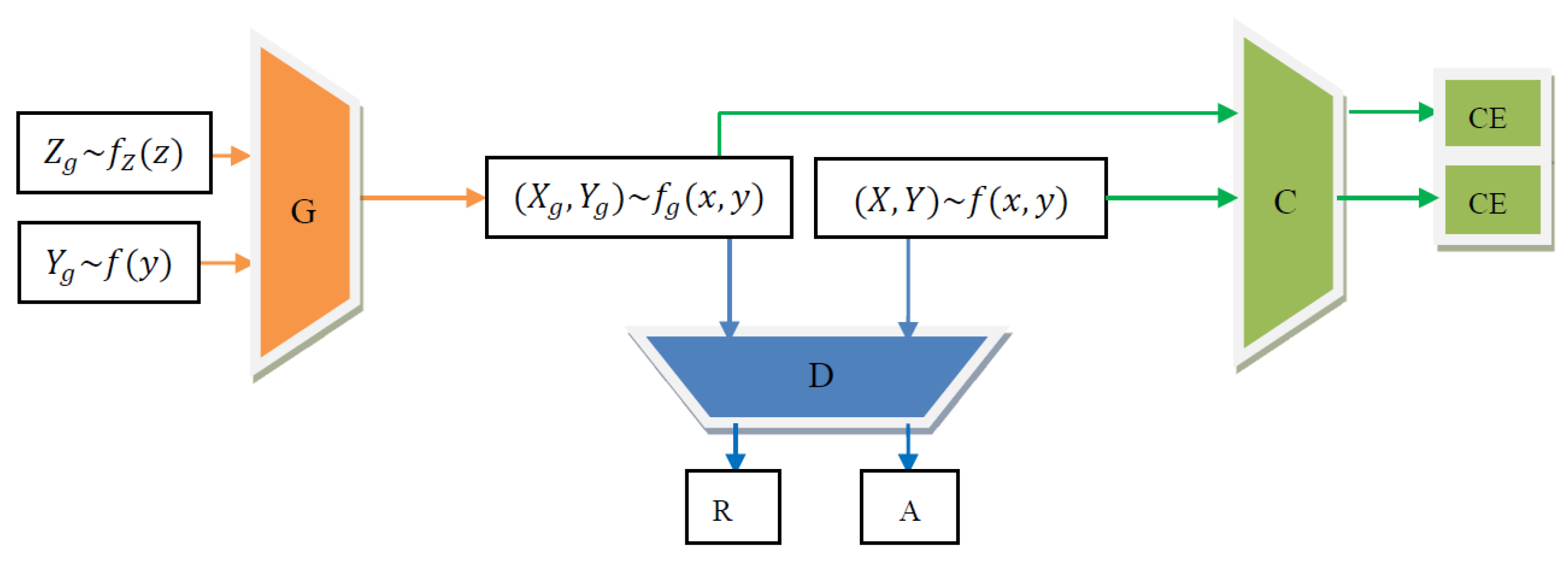
2. Methodology
2.1. Resampling Model for Imbalanced Data
- The equilibrium point in RegCGAN is demonstrated to exist and be unique;
- The minority class prediction capability of RegCGAN: specifically, we study whether the generator can accurately produce resampled data that follow the minority class distribution, and whether the classifier—trained using the utility function in Equation (2)—can, with the aid of the generator, effectively improve the prediction accuracy for the minority class while making full use of the information contained in the entire dataset.
2.2. Theoretical Analysis
2.3. Optimization
| Algorithm 1 Minibatch Minibatch SGD training of RegCGAN. |
|
3. Related Work
- Supervised Learning: The majority of existing research addresses class imbalance within the supervised learning framework. These approaches are generally grouped into three categories: Sampling-based data-level methods mitigate class imbalance by modifying the training dataset. These are considered external strategies [38,39,40,41,42]. Algorithm-level strategies adapt or redesign learning algorithms to emphasize the minority class, making them internal methods that integrate imbalance awareness directly into the learning process [43,44,45]. Cost-sensitive methods assign higher penalties to errors involving minority class instances. These techniques can be applied at the data level, algorithm level, or both, with the goal of reducing high-cost misclassifications [46,47,48,49,50]. However, none of these approaches can be directly applied to unsupervised scenarios, as they inherently depend on class labels or prediction outputs tied to labels. Recent studies have also revealed that the feature extractor (backbone) and the classifier can be trained separately [51,52], inspiring new strategies such as imbalance-aware pre-training and later fine-tuning for target tasks.
- Self-Supervised Learning: The exploration of self-supervised learning on naturally imbalanced datasets was initiated by [53]. Their findings suggest that pre-training with self-supervised tasks, such as image rotation [54] or contrastive learning methods like MoCo [55], consistently improves performance over direct end-to-end training. This implies a regularizing effect that leads to a more balanced feature representation. Subsequent studies [56,57] further validate the advantage of contrastive learning in mitigating data imbalance while also pointing out that it does not completely resolve the issue.
- Active Learning: In conventional machine learning, active learning has been widely studied as an effective approach to data-efficient sampling, with techniques including information-theoretic approaches [58], ensemble-based strategies [59,60], and uncertainty sampling [61,62]. A recent study [63] addressed the challenge of imbalanced seed data in active learning by introducing a model-aware K-center sampling strategy, a unified sampling framework designed to enhance learning efficiency in such settings.
4. Application
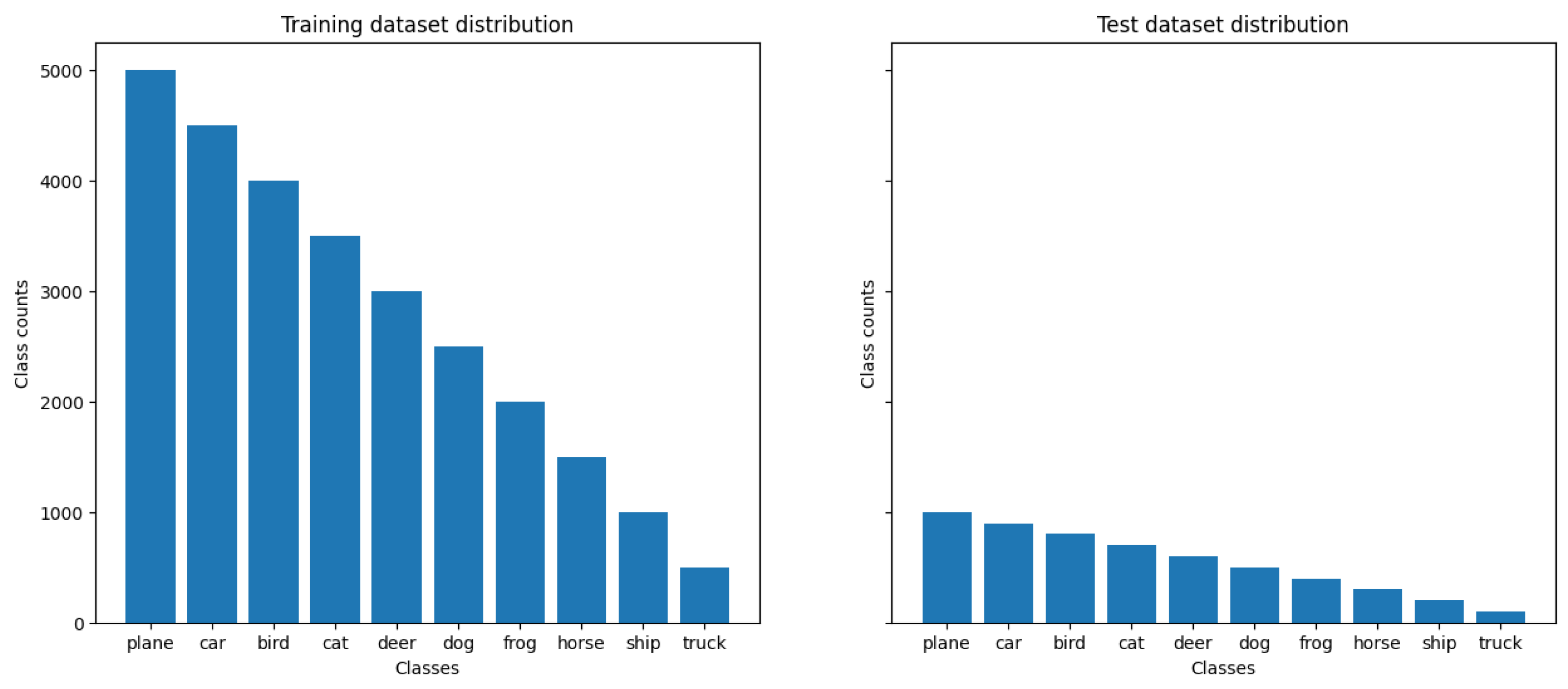
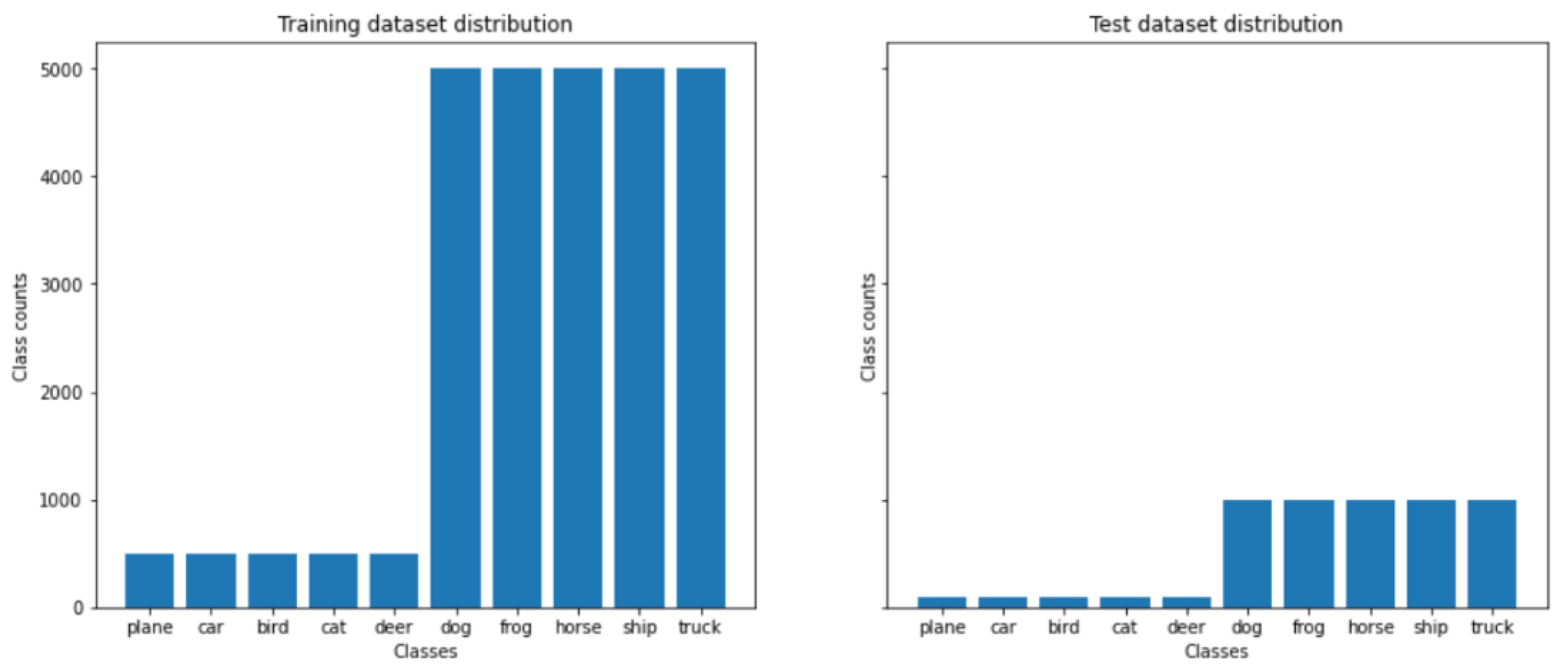
4.1. Setting
4.2. Experimental Results
4.3. Empirical Results
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| GAN | Generative adversarial network |
| CGAN | Conditional generative adversarial network |
| RegCGAN | Regularized conditional generative adversarial network |
| SSL | Semi-supervised learning |
| FEM | Finite element method |
References
- Fernández, A.; López, V.; Galar, M.; Del Jesus, M.J.; Herrera, F. Analysing the classification of imbalanced data-sets with multiple classes: Binarization techniques and ad-hoc approaches. Knowl. Based Syst. 2013, 42, 97–110. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially learned inference. arXiv 2016, arXiv:1606.00704. [Google Scholar]
- Donahue, J.; Simonyan, K. Large scale adversarial representation learning. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1–9. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, J.; Reed, S.E.; Yang, M.H.; Lee, H. Weakly-supervised disentangling with recurrent transformations for 3d view synthesis. Adv. Neural Inf. Process. Syst. 2015, 28, 1099–1107. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. Adv. Neural Inf. Process. Syst. 2016, 29, 2180–2188. [Google Scholar]
- Li, C.; Welling, M.; Zhu, J.; Zhang, B. Graphical generative adversarial networks. Adv. Neural Inf. Process. Syst. 2018, 31, 1–12. [Google Scholar]
- Li, C.; Zhu, J.; Shi, T.; Zhang, B. Max-margin deep generative models. Adv. Neural Inf. Process. Syst. 2015, 28, 1837–1845. [Google Scholar]
- Locatello, F.; Bauer, S.; Lucic, M.; Raetsch, G.; Gelly, S.; Schölkopf, B.; Bachem, O. Challenging common assumptions in the unsupervised learning of disentangled representations. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 4114–4124. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Springenberg, J.T. Unsupervised and semi-supervised learning with categorical generative adversarial networks. arXiv 2015, arXiv:1511.06390. [Google Scholar]
- Odena, A. Semi-supervised learning with generative adversarial networks. arXiv 2016, arXiv:1606.01583. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. Adv. Neural Inf. Process. Syst. 2016, 29, 2234–2242. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, F.; Cohen, W.W.; Salakhutdinov, R.R. Good semi-supervised learning that requires a bad gan. Adv. Neural Inf. Process. Syst. 2017, 30, 6513–6523. [Google Scholar]
- Zhang, X.; Wang, Z.; Liu, D.; Ling, Q. Dada: Deep adversarial data augmentation for extremely low data regime classification. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2807–2811. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from simulated and unsupervised images through adversarial training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Douzas, G.; Bacao, F. Effective data generation for imbalanced learning using conditional generative adversarial networks. Expert Syst. Appl. 2018, 91, 464–471. [Google Scholar] [CrossRef]
- Li, C.; Xu, T.; Zhu, J.; Zhang, B. Triple generative adversarial nets. Adv. Neural Inf. Process. Syst. 2017, 30, 4091–4101. [Google Scholar]
- Weiss, G.M. Mining with rarity: A unifying framework. Acm Sigkdd Explor. Newsl. 2004, 6, 7–19. [Google Scholar] [CrossRef]
- Weiss, G.M.; Tian, Y. Maximizing classifier utility when there are data acquisition and modeling costs. Data Min. Knowl. Discov. 2008, 17, 253–282. [Google Scholar] [CrossRef]
- Sun, Y.; Wong, A.K.; Kamel, M.S. CLASSIFICATION OF IMBALANCED DATA: A REVIEW. Int. J. Pattern Recognit. Artif. Intell. 2009, 23, 687–719. [Google Scholar] [CrossRef]
- Soda, P. A multi-objective optimisation approach for class imbalance learning. Pattern Recognit. 2011, 44, 1801–1810. [Google Scholar] [CrossRef]
- Khoshgoftaar, T.M.; Hulse, J.V.; Napolitano, A. Comparing Boosting and Bagging Techniques With Noisy and Imbalanced Data. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2011, 41, 552–568. [Google Scholar] [CrossRef]
- Galar, M. A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Fernandez, A.; Garcia, S.; Jesus, M.J.D.; Herrera, F. A study of the behaviour of linguistic fuzzy rule based classification systems in the framework of imbalanced data-sets. Fuzzy Sets Syst. 2008, 159, 2378–2398. [Google Scholar] [CrossRef]
- Garcia, S.; Derrac, J.; Triguero, I.; Carmona, C.J.; Herrera, F. Evolutionary-based selection of generalized instances for imbalanced classification. Knowl. Based Syst. 2012, 25, 3–12. [Google Scholar] [CrossRef]
- Tahir, M.A.; Kittler, J.; Yan, F. Inverse random under sampling for class imbalance problem and its application to multi-label classification. Pattern Recognit. 2012, 45, 3738–3750. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, Y.Q.; Chawla, N.V.; Krasser, S. SVMs Modeling for Highly Imbalanced Classification. IEEE Trans. Cybern. 2009, 39, 281–288. [Google Scholar] [CrossRef]
- Barandela, R.; Sánchez, J.S.; Garcıa, V.; Rangel, E. Strategies for learning in class imbalance problems. Pattern Recognit. 2003, 36, 849–851. [Google Scholar] [CrossRef]
- Cieslak, D.A.; Hoens, T.R.; Chawla, N.V.; Kegelmeyer, W.P. Hellinger distance decision trees are robust and skew-insensitive. Data Min. Knowl. Discov. 2012, 24, 136–158. [Google Scholar] [CrossRef]
- García-Pedrajas, N.; Pérez-Rodríguez, J.; García-Pedrajas, M.; Ortiz-Boyer, D.; Fyfe, C. Class imbalance methods for translation initiation site recognition in DNA sequences. Knowl. Based Syst. 2010, 25, 22–34. [Google Scholar] [CrossRef]
- Domingos, P. MetaCost: A General Method for Making Classifiers Cost-Sensitive. In Proceedings of the Acm Sigkdd International Conference on Knowledge Discovery & Data Mining, San Diego, CA, USA, 15–18 August 1999. [Google Scholar]
- Sun, Y.; Kamel, M.S.; Wong, A.K.C.; Wang, Y. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit. 2007, 40, 3358–3378. [Google Scholar] [CrossRef]
- Ting, K.M. An instance-weighting method to induce cost-sensitive trees. IEEE Trans. Knowl. Data Eng. 2002, 14, 659–665. [Google Scholar] [CrossRef]
- Zhao, H. Instance weighting versus threshold adjusting for cost-sensitive classification. Knowl. Inf. Syst. 2008, 15, 321–334. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Liu, X.Y. ON MULTI-CLASS COST-SENSITIVE LEARNING. Comput. Intell. 2010, 26, P.232–257. [Google Scholar] [CrossRef]
- Kang, B.; Xie, S.; Rohrbach, M.; Yan, Z.; Gordo, A.; Feng, J.; Kalantidis, Y. Decoupling Representation and Classifier for Long-Tailed Recognition. arXiv 2019, arXiv:1910.09217. [Google Scholar]
- Zhang, J.; Liu, L.; Wang, P.; Shen, C. To Balance or Not to Balance: A Simple-yet-Effective Approach for Learning with Long-Tailed Distributions. arXiv 2019, arXiv:1912.04486. [Google Scholar]
- Yang, Y.; Xu, Z. Rethinking the Value of Labels for Improving Class-Imbalanced Learning. arXiv 2020, arXiv:2006.07529. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised Representation Learning by Predicting Image Rotations. arXiv 2018, arXiv:1803.07728. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Kang, B.; Li, Y.; Yuan, Z.; Feng, J. FEATURE S PACES FOR R EP-RESENTATION L EARNING. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Jiang, Z.; Chen, T.; Mortazavi, B.; Wang, Z. Self-Damaging Contrastive Learning. In Proceedings of the International Conference on Machine Learning, Shenzhen, China, 26 February–1 March 2021. [Google Scholar]
- MacKay, D.J. Information-based objective functions for active data selection. Neural Comput. 1992, 4, 590–604. [Google Scholar] [CrossRef]
- McCallumzy, A.K.; Nigamy, K. Employing em and pool-based active learning for text classification. In Proceedings of the International Conference on Machine Learning, Madison, WI, USA, 24–27 July 1998; pp. 359–367. [Google Scholar]
- Yoav Freund, H.; Sebastian Seung, E.S.; Tishby, N. Selective sampling using the query by committee algorithm. Mach. Learn. 1997, 28, 133–168. [Google Scholar] [CrossRef]
- Tong, S.; Koller, D. Support vector machine active learning with applications to text classification. J. Mach. Learn. Res. 2001, 2, 45–66. [Google Scholar]
- Li, X.; Guo, Y. Adaptive active learning for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 859–866. [Google Scholar]
- Jiang, Z.; Chen, T.; Chen, T.; Wang, Z. Improving contrastive learning on imbalanced data via open-world sampling. Adv. Neural Inf. Process. Syst. 2021, 34, 5997–6009. [Google Scholar]
- Versaci, M.; Laganà, F.; Morabito, F.C.; Palumbo, A.; Angiulli, G. Adaptation of an Eddy Current Model for Characterizing Subsurface Defects in CFRP Plates Using FEM Analysis Based on Energy Functional. Mathematics 2024, 12, 2854. [Google Scholar] [CrossRef]
- Versaci, M.; Angiulli, G.; Crucitti, P.; De Carlo, D.; Laganà, F.; Pellicanò, D.; Palumbo, A. A fuzzy similarity-based approach to classify numerically simulated and experimentally detected carbon fiber-reinforced polymer plate defects. Sensors 2022, 22, 4232. [Google Scholar] [CrossRef]
- Versaci, M.; Angiulli, G.; La Foresta, F.; Laganà, F.; Palumbo, A. Intuitionistic fuzzy divergence for evaluating the mechanical stress state of steel plates subject to bi-axial loads. Integr. Comput. Aided Eng. 2024, 31, 363–379. [Google Scholar] [CrossRef]
- Cao, K.; Wei, C.; Gaidon, A.; Arechiga, N.; Ma, T. Learning imbalanced datasets with label-distribution-aware margin loss. Adv. Neural Inf. Process. Syst. 2019, 32, 1567–1578. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 16 December 2011; Volume 2011, p. 4. [Google Scholar]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The balanced accuracy and its posterior distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar]
- Kingma, D.P.; Mohamed, S.; Jimenez Rezende, D.; Welling, M. Semi-supervised learning with deep generative models. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Zhu, X.; Anguelov, D.; Ramanan, D. Capturing long-tail distributions of object subcategories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 915–922. [Google Scholar]
- Feldman, V. Does learning require memorization? A short tale about a long tail. In Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, Chicago, IL, USA, 22–26 June 2020; pp. 954–959. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Balanced Data | Long-Tailed Data | Step Data |
|---|---|---|---|
| CNN | 71.75 | 69.80 | 71.13 |
| RegCGAN | 80.93 | 81.60 | 86.38 |
| Model | CNN | Resnet34 | RegCGAN |
|---|---|---|---|
| accuracy | 89.30 | 90.68 | 92.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, L.; Wang, X. RegCGAN: Resampling with Regularized CGAN for Imbalanced Big Data Problem. Axioms 2025, 14, 485. https://doi.org/10.3390/axioms14070485
Xu L, Wang X. RegCGAN: Resampling with Regularized CGAN for Imbalanced Big Data Problem. Axioms. 2025; 14(7):485. https://doi.org/10.3390/axioms14070485
Chicago/Turabian StyleXu, Liwen, and Ximeng Wang. 2025. "RegCGAN: Resampling with Regularized CGAN for Imbalanced Big Data Problem" Axioms 14, no. 7: 485. https://doi.org/10.3390/axioms14070485
APA StyleXu, L., & Wang, X. (2025). RegCGAN: Resampling with Regularized CGAN for Imbalanced Big Data Problem. Axioms, 14(7), 485. https://doi.org/10.3390/axioms14070485